基础课8——中文分词
中文分词指的是将一个汉字序列切分成一个一个单独的词。分词就是将连续的字序列按照一定的规范重新组合成词序列的过程。在英文的行文中,单词之间是以空格作为自然分界符的,而中文只是字、句和段能通过明显的分界符来简单划界,唯独词没有一个形式上的分界符,虽然英文也同样存在短语的划分问题,不过在词这一层上,中文比之英文要复杂的多、困难的多。
例如,对于句子“我爱北京天安门”,中文分词的任务是将这句话切分成一个一个单独的词。根据中文分词的规则,这句话可以被切分成“我”、“爱”、“北京”、“天安门”四个词。
1.英文分词
英文分词是将英文文本切分成一个个单独的单词。英文单词之间通常以空格作为自然分界符,因此英文分词相对比较简单。常用的英文分词工具包括NLTK、spaCy等。以下是一个简单的例子:
import nltk text = "Hello, how are you? I'm fine, thank you."
tokens = nltk.word_tokenize(text)
print(tokens)输出结果:
['Hello', ',', 'how', 'are', 'you', '?', 'I', "'m", 'fine', ',', 'thank', 'you', '.']在这个例子中,我们使用了NLTK库的word_tokenize函数对文本进行分词。分词结果以列表的形式返回,每个单词作为一个独立的元素。

2.中文分词
中文分词的标准存在不同的版本和依据。
- 意义标准:最早可追溯到马建忠的《马氏文通》,其分词标准是以意义为依据,将词语根据其词汇意义进行划分。
- 形态标准:在中文语法学中,传统分词方法是按照词的意义划分词类,并照搬印欧语的词类划分方法。这种分词方法简单地将汉语的词类与句子成分对应起来,认为汉语中作主语、宾语的是名词,作定语的是形容词,作谓语的是动词,作状语的是副词。
- 功能标准:词的语法功能主要表现一方面是组合能力,主要包括实词与实词的组合能力、实词与虚词的组合能力。不同词类之间是否能够组合、以什么方式组合、组合后发生什么样的语法关系等。另外一方面是词在句子中充当句法结构成分的能力,实词都能充当句子成分,例如名词的显著特点就是可以作主语和宾语,形容词的显著特点是可以作谓语、定语等。

3.分词方法
分词方法主要有以下几种:
- 基于规则的分词方法:基于规则的分词方法通常采用一组预定义的规则或模式,对文本进行分词。这些规则可以基于词法、语法、语义等语言学特征,也可以基于特定的领域知识和应用需求。例如,基于正则表达式的分词方法可以根据预定义的规则将文本切分成符合特定模式的词序列。
- 基于统计的分词方法:基于统计的分词方法通常利用机器学习或自然语言处理技术,对大量的语料库进行训练和学习,从而自动地进行分词。这些方法通常会根据词频、语境等信息,对文本中的词汇进行概率计算和预测,从而自动地将文本切分成符合语言规则的词序列。例如,最大匹配法、HMM模型、CRF模型等都是基于统计的分词方法。
- 基于深度学习的分词方法:基于深度学习的分词方法通常利用神经网络模型,对大量的语料库进行训练和学习,从而自动地进行分词。这些方法通常会采用循环神经网络(RNN)、长短时记忆网络(LSTM)、卷积神经网络(CNN)等模型,对文本进行逐字的编码和解码,从而自动地将文本切分成符合语言规则的词序列。例如,基于Bi-LSTM的分词方法就是一种基于深度学习的分词方法。
实践证明,基于规则的分词系统效果比不上基于统计学习的分词系统。未登录词造成的分词精度失落至少比分词歧义大5倍以上,基于字的标注系统能够大幅度提高未登录词的识别能力。
3.1基于词典的分词方法
基于词典的分词方法是基于规则的分词方法中的一种,它通常使用一个包含常见词汇的词典,并根据词典中的词汇对文本进行分词。
基于词典的分词方法的基本原理是将待分词文本与词典进行匹配,根据匹配结果进行分词。其分词过程包括以下步骤:
- 构建词典:建立一个包含常见词汇的词典,词典中的每个词汇都是一个基本的语义单位。
- 匹配过程:将待分词的文本与词典中的词汇逐个进行匹配。匹配时可以采用正向最大匹配、逆向最大匹配或双向最大匹配等方法。
- 确定分词结果:根据匹配的结果确定分词的位置,并将分词结果输出。
基于词典的分词方法具有以下特点:
- 简单高效:基于词典的分词方法不需要依赖大量的语料库,只需要一个词典即可进行分词。因此,它的分词速度较快,适用于对实时性要求较高的场景。
- 准确性高:由于基于词典的分词方法是根据词典进行匹配,因此可以保证分词的准确性。同时,词典可以不断更新,以适应新词汇的出现。
- 存在歧义:基于词典的分词方法存在一定的歧义问题。当待分词文本中的词汇不在词典中时,就无法进行匹配,导致分词失败。此外,一些词汇具有多种含义,可能会导致歧义的出现。
常用的基于词典的分词方法包括正向最大匹配法(Maximum Matching)、逆向最大匹配法(Reverse Maximum Matching)、双向最大匹配法(Bi-directional Maximum Matching)等。这些方法根据不同的匹配方向和匹配长度优先级来进行分词,具有较高的准确性和效率。
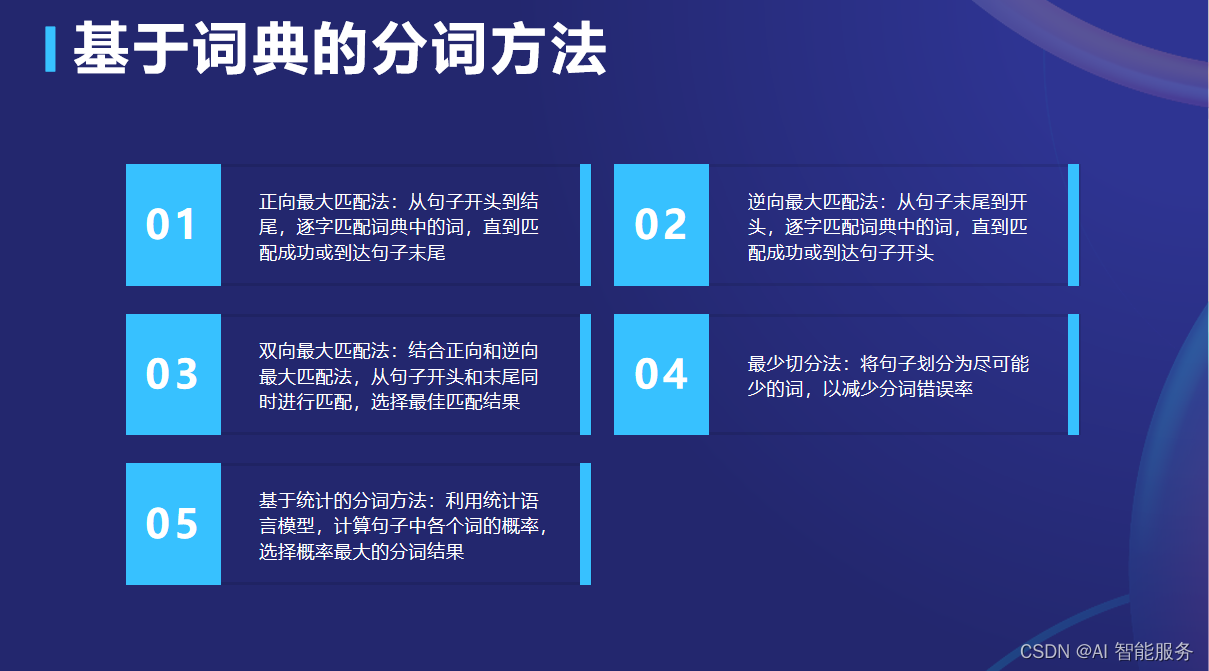
3.1.1正向最大匹配法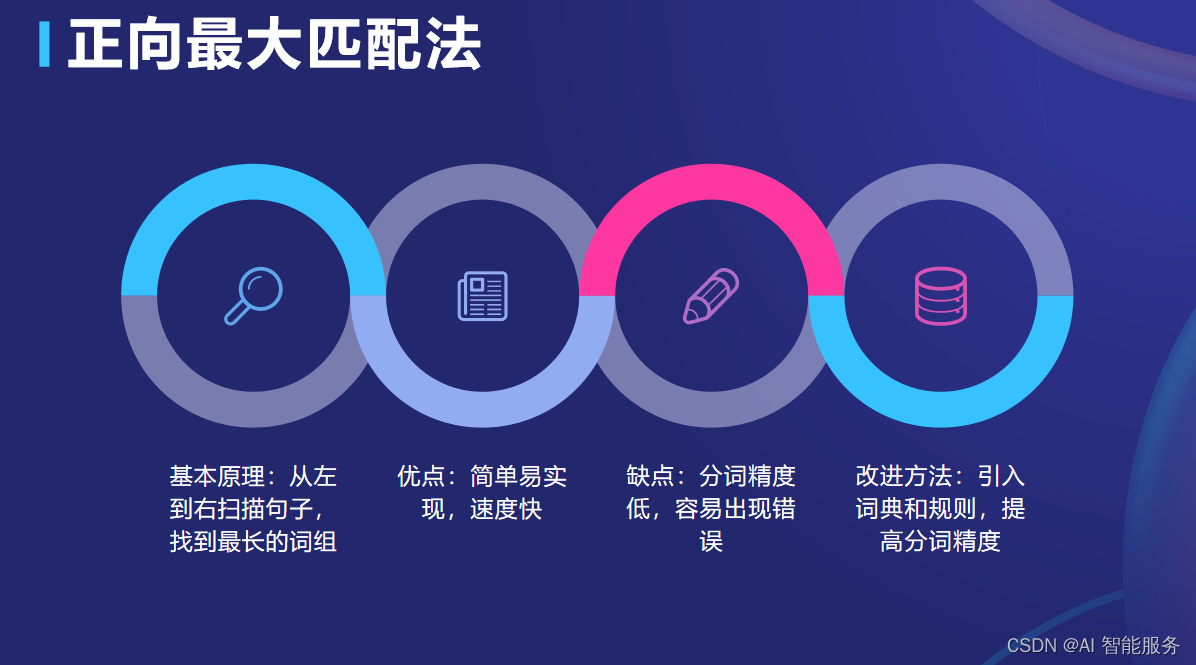
3.1.2逆向最大匹配法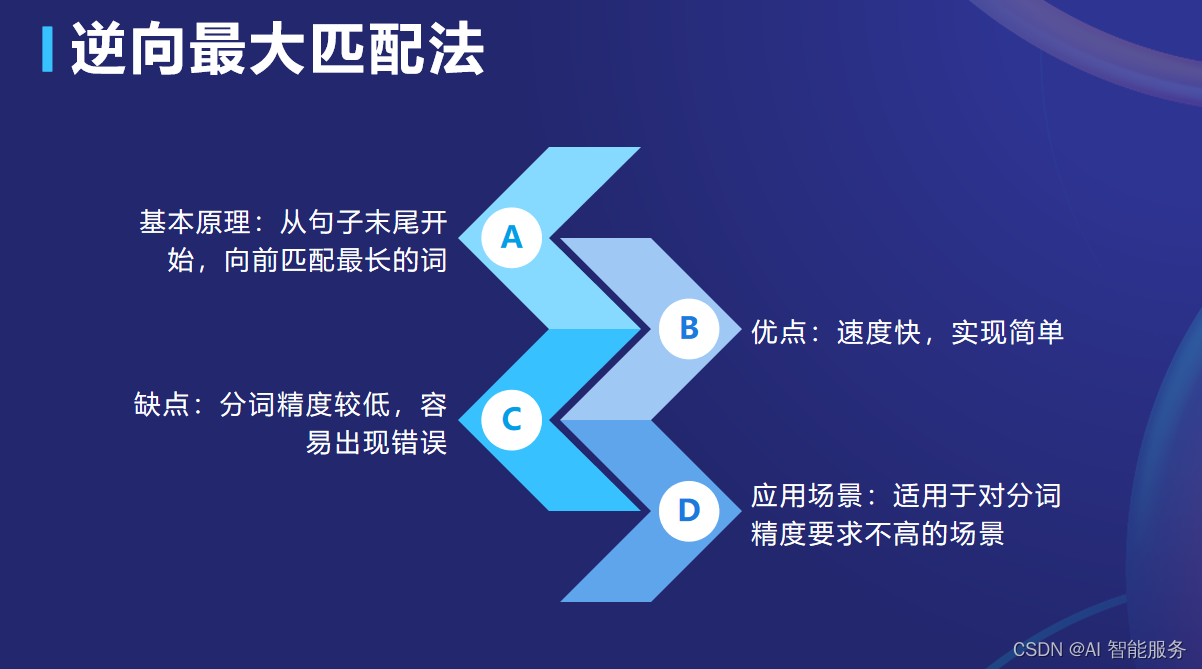
3.1.3双向匹配分词法
3.2基于统计的分词方法
基于统计的分词方法是基于统计模型的分词方法,利用训练文本中的统计信息进行分词。其基本原理是根据上下文出现的频率来计算词汇之间的概率,然后根据这些概率来切分词语。
基于统计的分词方法通常采用隐马尔可夫模型(HMM)或条件随机场(CRF)等模型,通过一定的优化方法来进行分词。
基于统计的分词方法具有以下特点:
- 准确性较高:基于统计的分词方法利用了大量的文本数据,可以较为准确地切分出词汇。
- 适用于不同领域:基于统计的分词方法可以适用于不同的领域和语言,只要具备足够的训练数据就可以进行分词。
- 模型复杂度高:基于统计的分词方法需要建立复杂的统计模型,计算量大,需要较高的计算资源。
- 需要大量训练数据:基于统计的分词方法需要大量的训练数据来训练模型,才能取得较好的分词效果。
案例说明:
假设我们有一段文本:“我爱北京天安门”,我们希望将其分词为“我”、“爱”、“北京”、“天安门”。
首先,我们需要对文本进行预处理,将其转换为词频统计结果。对于“我爱北京天安门”这句话,统计结果如下:
| 词 | 出现次数 |
|---|---|
| 我 | 1 |
| 爱 | 1 |
| 北京 | 1 |
| 天安门 | 1 |
接下来,我们可以利用HMM模型进行分词。首先,我们需要确定模型中的状态和转移概率。在这个例子中,我们的状态就是上述的四个词,转移概率可以通过训练文本进行学习。具体来说,我们可以利用Baum-Welch算法来估计HMM模型的参数,包括转移概率和发射概率。
假设我们已经得到了转移概率矩阵和发射概率矩阵,接下来就可以利用Viterbi算法来计算最可能的分词结果。根据计算,最可能的分词结果为“我”、“爱”、“北京”、“天安门”。
具体来说,Viterbi算法是一种动态规划算法,用于在HMM模型中寻找最可能的状态序列。在我们的例子中,Viterbi算法的过程如下:
- 初始化:对于每个状态Si(i=1,2,3,4),设置一个初始概率P(Si),表示在当前位置为Si的概率。对于所有的状态,设置一个初始概率P(S0),表示在当前位置开始出现Si的概率。根据这些初始概率,我们可以得到一个初始的路径概率P(S0)。
- 递推:对于每个时间t(t=1,2,3,4),遍历所有的状态Si,计算在时刻t,以Si为当前状态时的最大路径概率P(Si)。在计算路径概率时,我们需要考虑当前状态Si的发射概率和从上一个时刻转移到当前时刻的转移概率。
- 终止:在最后一个时刻,选择路径概率最大的状态作为最终的状态。在我们的例子中,最终的状态就是“天安门”。
- 回溯:从最终的状态开始,根据转移概率矩阵回溯到起始状态,得到最可能的分词结果。
最后,我们输出最可能的分词结果“我”、“爱”、“北京”、“天安门”。
实际的分词任务可能需要更复杂的模型和算法,以及更多的训练数据。由于语言模型的复杂性和数据的不充分性,基于统计的分词方法也存在一定的误差率和挑战。
4.举例
4.1科大讯飞的分词方法
科大讯飞公司采用基于大数据和用户行为进行分词。其分词系统具备多种功能,包括分词、词性标注和命名实体识别等,旨在全面支撑机器对基础文本的理解与分析。
在分词方面,科大讯飞公司的分词系统可以切分成词序列。对于汉语中的词,它是承载语义的最基本的单元。分词是信息检索、文本分类、情感分析等多项中文自然语言处理任务的基础。
例如,原文:科大讯飞是一家专注于智能语音和人工智能领域的公司。
分词结果:科大/讯飞/是/一家/专注于/智能/语音/和/人工智能/领域/的/公司。
词性标注结果:科大/ORG讯飞/ORG是/v一家/m专注于/v智能/n语音/n和/c人工智能/n领域/n的/u公司/n。
其中,“科大”和“讯飞”是公司名,“是”是动词,“一家”是数量词,“专注于”是动词,“智能”和“语音”是名词,“和”是连词,“人工智能”是名词,“领域”是名词,“的”是助词,“公司”是名词。
此外,科大讯飞公司的分词系统还具备词性标注和命名实体识别等功能。词性标注是指为自然语言文本中的每个词汇赋予一个词性的过程,例如动词、名词、形容词等。命名实体识别则是指在句子的词序列中定位并识别人名、地名、机构名等实体。
这些功能可以帮助机器更好地理解文本,并进行更准确的分析和处理。科大讯飞公司的分词系统基于大数据和用户行为进行训练和优化,以提高其分词的准确性和效率。
4.2代码实战
举个例子,我们可以使用jieba分词库来进行中文分词。jieba分词库是一个基于Python的中文分词工具,支持三种分词模式:精确模式、全模式和搜索引擎模式。
下面是一个使用jieba分词库进行中文分词的例子:
import jiebatext = "我爱自然语言处理技术"
seg_list = jieba.cut(text, cut_all=False)
print(" / ".join(seg_list))输出结果为:
我爱 / 自然语言 / 处理 / 技术详细代码:
import jieba
import jieba.analyse
from tkinter import * # 预处理数据
def pre_process(text): # 去除停用词 stopwords = ["的", "了", "在", "是", "我", "有", "和", "就", "不", "人", "都", "一", "一个", "上", "也", "很", "到", "说", "要", "去", "你", "会", "着", "没有"] text = [word for word in text if word not in stopwords] return text # 训练模型
def train_model(text): # 使用jieba库训练模型 jieba.analyse.set_stop_words(stopwords) jieba.analyse.set_idf_path("idf.txt") seg_list = jieba.cut(text) return seg_list # 实现分词算法
def segment(text): # 预处理数据 text = pre_process(text) # 训练模型 seg_list = train_model(text) # 对新文本进行分词 new_seg_list = jieba.cut(text) return new_seg_list # 可视化界面
def visualize(): root = Tk() root.title("中文分词工具") label = Label(root, text="请输入待分词的文本:") label.pack() entry = Entry(root) entry.pack() button = Button(root, text="分词", command=lambda: segment(entry.get())) button.pack() label2 = Label(root, text="分词结果:") label2.pack() result = Text(root) result.pack() root.mainloop() # 调用可视化界面进行分词处理
visualize()该示例代码包括预处理、训练、实现分词算法和可视化界面的实现。其中,预处理函数pre_process用于去除停用词,训练函数train_model使用jieba库训练模型,实现分词算法函数segment对新的文本进行分词处理,可视化界面函数visualize使用Python的GUI库Tkinter创建一个简单的界面,用户可以输入待分词的文本,并显示分词结果。
相关文章:
基础课8——中文分词
中文分词指的是将一个汉字序列切分成一个一个单独的词。分词就是将连续的字序列按照一定的规范重新组合成词序列的过程。在英文的行文中,单词之间是以空格作为自然分界符的,而中文只是字、句和段能通过明显的分界符来简单划界,唯独词没有一个…...

OpenHarmony应用开发入门教程(一、开篇)
前言 华为正式宣布2024年发布的华为鸿蒙OS Next版将不再兼容安卓系统。这一重大改变,预示着华为鸿蒙OS即将进入一个全新的阶段。 都说科技无国界,这是骗人的鬼话。谷歌的安卓12.0系统早已发布,但是自从受到美影响,谷歌就拒绝再向…...

vue侦听器详解及代码
在 Vue 中,我们可以使用侦听器(watcher)来监听数据的变化,并在数据发生变化时执行相应的操作。Vue 提供了 watch 选项来定义侦听器,并可以使用 vm.$watch 方法来创建侦听器。 下面是一个简单的示例,我们监…...

Python爬虫的七个常用技巧总结,这些你一定得知道!
文章目录 前言1、基本抓取网页2、使用代理IP3、Cookies处理4、伪装成浏览器5、验证码的处理6、gzip压缩7、多线程并发抓取关于Python技术储备一、Python所有方向的学习路线二、Python基础学习视频三、精品Python学习书籍四、Python工具包项目源码合集①Python工具包②Python实战…...
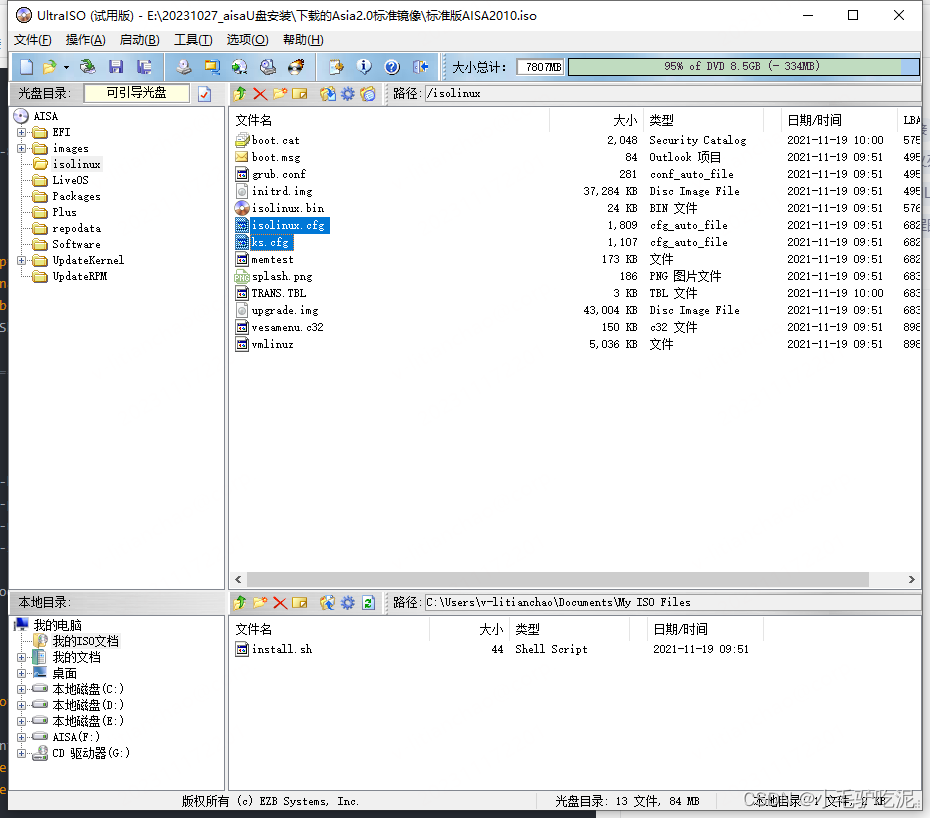
【Linux】U盘安装的cfg引导文件配置
isolinux.cfg文件 default vesamenu.c32 timeout 600display boot.msg# Clear the screen when exiting the menu, instead of leaving the menu displayed. # For vesamenu, this means the graphical background is still displayed without # the menu itself for as long …...
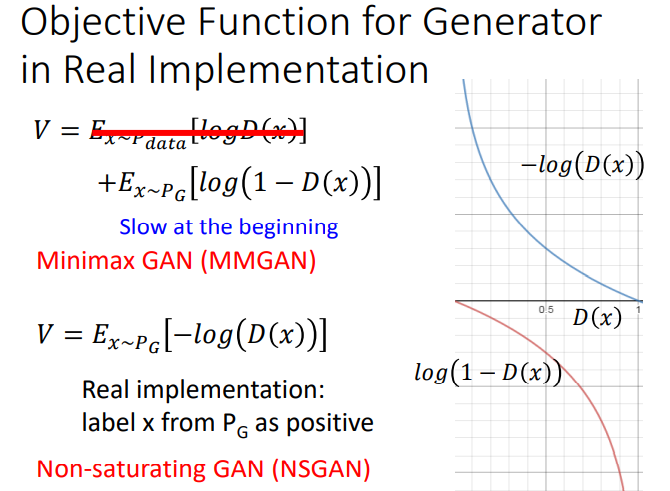
Theory behind GAN
假如要生成一些人脸图,实际上就是想要找到一个分布,从这个分布内sample出来的图片像是人脸,分布之外生成的就不像人脸。而GAN要做的就是找到这个distribution。 在GAN之前用的是Maximum Likelihood Estimation。 Maximum Likelihood Estimat…...

《Deep learning for fine-grained image analysis: A survey》阅读笔记
论文标题 《Deep learning for fine-grained image analysis: A survey》 作者 魏秀参,旷世研究院 初读 摘要 细粒度图像分析(FGIA)的任务是分析从属类别的视觉对象。 细粒度性质引起的类间小变化和类内大变化使其成为一个具有挑战性的…...

节点导纳矩阵
节点导纳矩阵(Node Admittance Matrix)是电力系统分析中的关键工具,它用于描述电力系统中不同节点之间的电导和电纳参数。这个矩阵为电力工程师提供了深入了解电力系统运行和分析所需的数学工具。 节点导纳矩阵是一个复数矩阵,通常…...

小米真无线耳机 Air 2s产品蓝牙配对ubuntu20.04 笔记本电脑
小米真无线耳机 Air 2s产品蓝牙配对ubuntu20.04 笔记本电脑 1.我的笔记本是 22款联想拯救者y9000k,安装了双系统,ubuntu20.04。 2.打开耳机,按压侧面按钮2秒,指示灯显示白色闪烁。 3.打开ubunru20.04 系统右上角wifi的位置&…...

Python爬虫批量下载图片
一、思路: 1. 分析URL,图片的URL内嵌于base_url的返回当中 2. 下载图片 二、代码 import time import requests import os from lxml import etreeclass DownloadImg():爬虫进行美女图片下载def __init__(self):self.url http://xxxxxx/4kmeinv/self…...
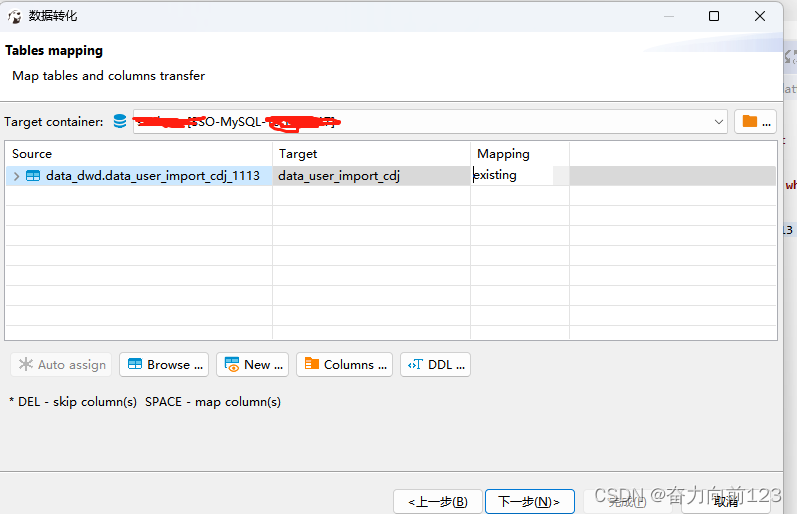
java入门,从CK导一部分数据到mysql
一、需求 需要从生产环境ck数据库导数据到mysql,数据量大约100w条记录。 二、处理步骤 1、这里的关键词是生产库,第二就是100w条记录。所以处理数据的时候就要遵守一定的规范。首先将原数据库表进行备份,或者将需要导出的数据建一张新的表了…...
表白墙/留言墙 —— 中级SpringBoot项目,MyBatis技术栈MySQL数据库开发,练手项目前后端开发(带完整源码) 全方位全步骤手把手教学
🧸欢迎来到dream_ready的博客,📜相信你对这篇博客也感兴趣o (ˉ▽ˉ;) 📜表白墙/留言墙初级Spring Boot项目(此篇博客的简略版,不带MyBatis数据库开发) 目录 1、项目前端页面及项目…...

Stable Diffusion - StableDiffusion WebUI 软件升级与扩展兼容
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://spike.blog.csdn.net/article/details/134463035 目前,StableDiffusion WebUI 的版本是 1.6.0,同步更新 controlnet、tagcomplete、roop、easy-prompt-selector等…...

git创建新分支将项目挂载到新分支操作
1.如果是本地项目,没有关联过git // 在git创建仓库(默认master分支) // 复制克隆链接(默认下载下来的是master仓库,克隆指定分支如下所示) git clone -b 分支名 克隆地址 // 将某分支克隆下来后,直接将项目放到新文件夹内(执行以下命令提交即可) git add . git commit -m 备注…...
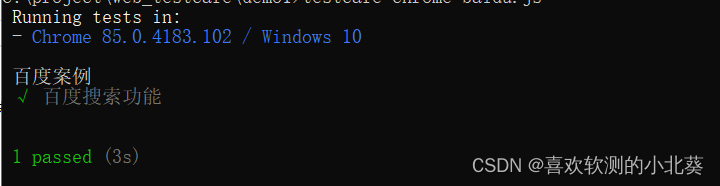
WEB 自动化神器 TestCafe(一)—安装和入门篇
今天小编给大家带来WEB 自动化神器 TestCafe(一) —安装和入门篇 一、TestCafe 介绍: TestCafe 是一款基于 Node.js 的端到端 Web 自动化测试框架,支持 TypeScript 或 JavaScript 来编写测试用例,运行用例,并生成自动化测试报告。…...
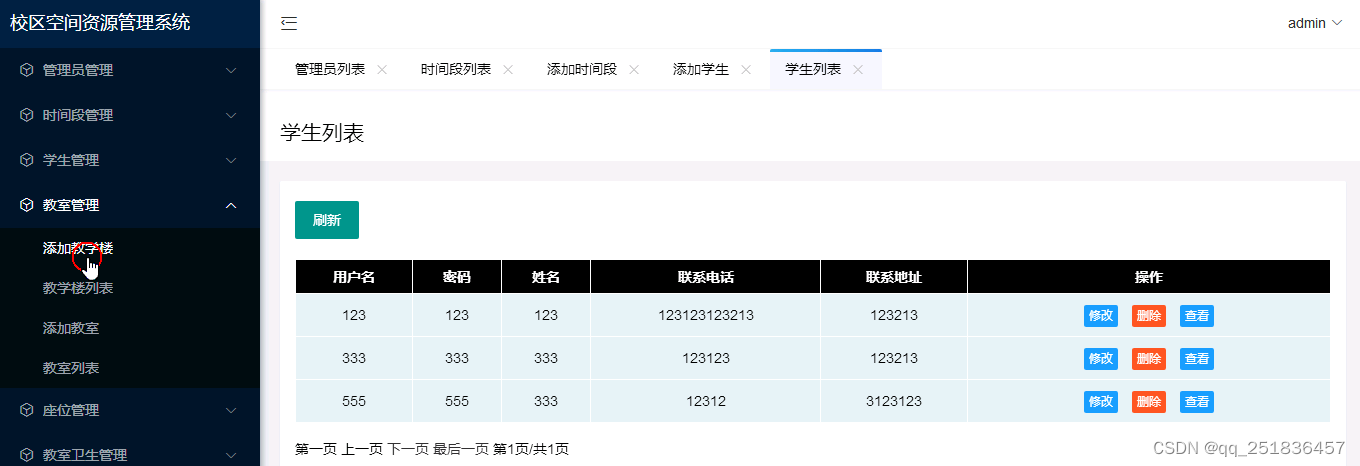
asp.net 学校资源信息管理系统VS开发sqlserver数据库web结构c#编程计算机网页项目
一、源码特点 asp.net 学校资源信息管理系统 是一套完善的web设计管理系统,系统具有完整的源代码和数据库,系统主要采用B/S模式开发。 asp.net学校资源管理系统 二、功能介绍 本系统使用Microsoft Visual Studio 2019为开发工具,SQL …...
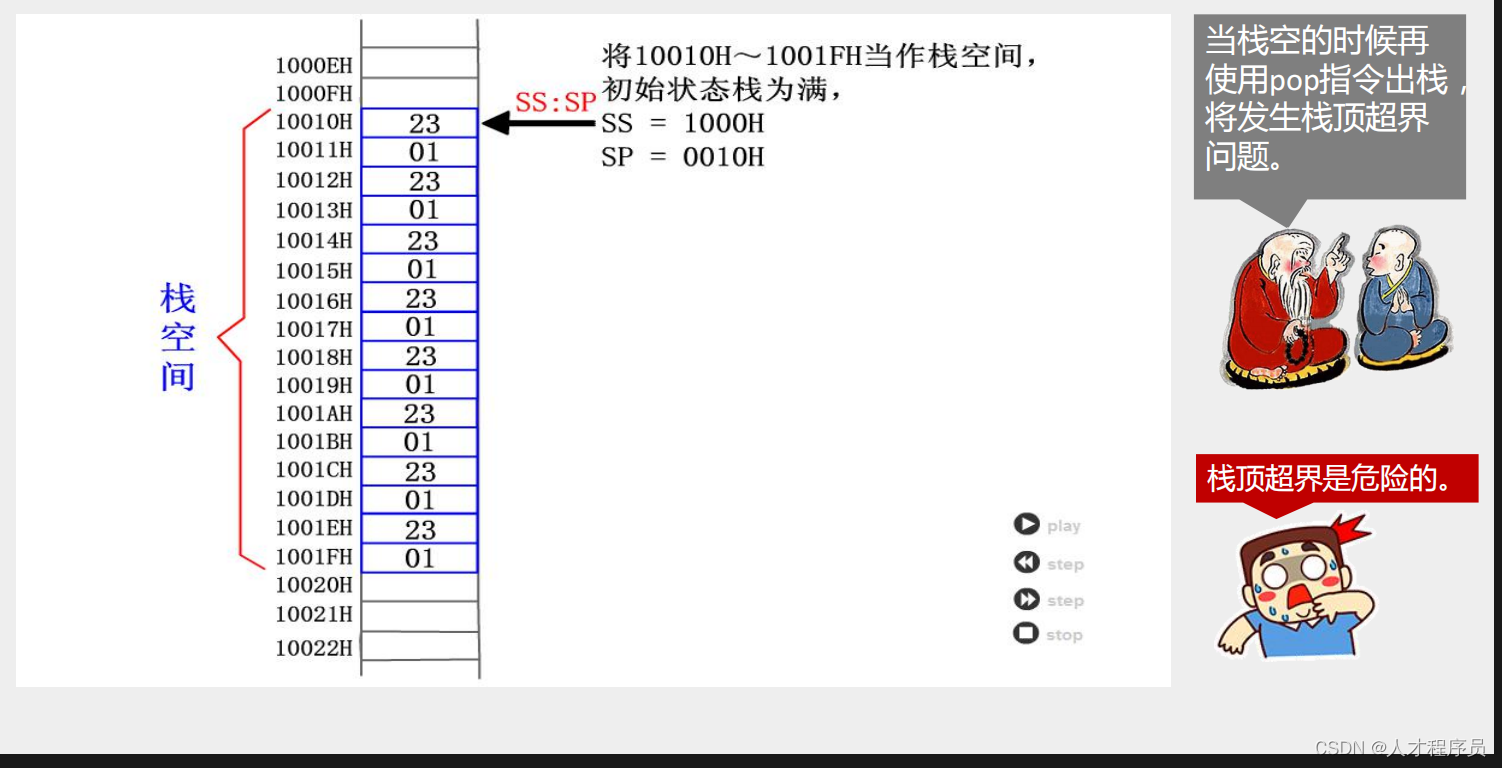
【汇编】栈及栈操作的实现
文章目录 前言一、栈是什么?二、栈的特点三、栈操作四、8086cpu操作栈4.1 汇编指令4.2 汇编代码讲解问题:回答: 4.3 栈的操作4.3 push 指令和pop指令的执行过程执行入栈(push)时,栈顶超出栈空间执行出栈(pop)时,栈顶超…...
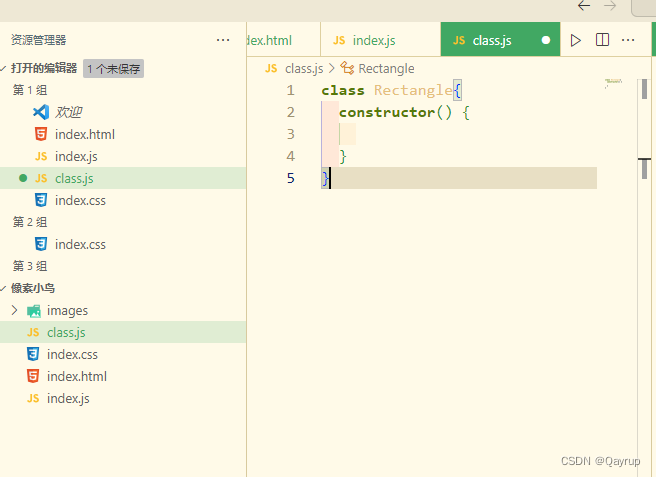
前段-用面向对象的方式开发一个水管小鸟的游戏
首先准备好各类空文件 index.js css html 和图片 图片是下面这些,如果没有的可在这里下载 2 开发开始 好了,基础准备工作完毕,开发开始, 首先,先把天空,大地,小鸟的盒子准备好,并…...

Java中利用OpenCV进行人脸识别
OpenCV 概述 OpenCV(Open Source Computer Vision Library)是一个开源计算机视觉库,它提供了丰富的工具和算法,用于处理图像和视频数据。该库由一系列高效的计算机视觉算法组成,涵盖了许多领域,包括目…...
23111708[含文档+PPT+源码等]计算机毕业设计基于javaweb的旅游网站前台与后台旅景点
文章目录 **论文截图:****实现:****代码片段:** 编程技术交流、源码分享、模板分享、网课教程 🐧裙:776871563 下面是系统运行起来后的部分截图: 论文截图: 实现: 代码片段…...

Docker 离线安装指南
参考文章 1、确认操作系统类型及内核版本 Docker依赖于Linux内核的一些特性,不同版本的Docker对内核版本有不同要求。例如,Docker 17.06及之后的版本通常需要Linux内核3.10及以上版本,Docker17.09及更高版本对应Linux内核4.9.x及更高版本。…...

FFmpeg 低延迟同屏方案
引言 在实时互动需求激增的当下,无论是在线教育中的师生同屏演示、远程办公的屏幕共享协作,还是游戏直播的画面实时传输,低延迟同屏已成为保障用户体验的核心指标。FFmpeg 作为一款功能强大的多媒体框架,凭借其灵活的编解码、数据…...

Vue2 第一节_Vue2上手_插值表达式{{}}_访问数据和修改数据_Vue开发者工具
文章目录 1.Vue2上手-如何创建一个Vue实例,进行初始化渲染2. 插值表达式{{}}3. 访问数据和修改数据4. vue响应式5. Vue开发者工具--方便调试 1.Vue2上手-如何创建一个Vue实例,进行初始化渲染 准备容器引包创建Vue实例 new Vue()指定配置项 ->渲染数据 准备一个容器,例如: …...

MySQL 8.0 OCP 英文题库解析(十三)
Oracle 为庆祝 MySQL 30 周年,截止到 2025.07.31 之前。所有人均可以免费考取原价245美元的MySQL OCP 认证。 从今天开始,将英文题库免费公布出来,并进行解析,帮助大家在一个月之内轻松通过OCP认证。 本期公布试题111~120 试题1…...

全志A40i android7.1 调试信息打印串口由uart0改为uart3
一,概述 1. 目的 将调试信息打印串口由uart0改为uart3。 2. 版本信息 Uboot版本:2014.07; Kernel版本:Linux-3.10; 二,Uboot 1. sys_config.fex改动 使能uart3(TX:PH00 RX:PH01),并让boo…...

OPENCV形态学基础之二腐蚀
一.腐蚀的原理 (图1) 数学表达式:dst(x,y) erode(src(x,y)) min(x,y)src(xx,yy) 腐蚀也是图像形态学的基本功能之一,腐蚀跟膨胀属于反向操作,膨胀是把图像图像变大,而腐蚀就是把图像变小。腐蚀后的图像变小变暗淡。 腐蚀…...

#Uniapp篇:chrome调试unapp适配
chrome调试设备----使用Android模拟机开发调试移动端页面 Chrome://inspect/#devices MuMu模拟器Edge浏览器:Android原生APP嵌入的H5页面元素定位 chrome://inspect/#devices uniapp单位适配 根路径下 postcss.config.js 需要装这些插件 “postcss”: “^8.5.…...

uniapp手机号一键登录保姆级教程(包含前端和后端)
目录 前置条件创建uniapp项目并关联uniClound云空间开启一键登录模块并开通一键登录服务编写云函数并上传部署获取手机号流程(第一种) 前端直接调用云函数获取手机号(第三种)后台调用云函数获取手机号 错误码常见问题 前置条件 手机安装有sim卡手机开启…...

Golang——6、指针和结构体
指针和结构体 1、指针1.1、指针地址和指针类型1.2、指针取值1.3、new和make 2、结构体2.1、type关键字的使用2.2、结构体的定义和初始化2.3、结构体方法和接收者2.4、给任意类型添加方法2.5、结构体的匿名字段2.6、嵌套结构体2.7、嵌套匿名结构体2.8、结构体的继承 3、结构体与…...

逻辑回归暴力训练预测金融欺诈
简述 「使用逻辑回归暴力预测金融欺诈,并不断增加特征维度持续测试」的做法,体现了一种逐步建模与迭代验证的实验思路,在金融欺诈检测中非常有价值,本文作为一篇回顾性记录了早年间公司给某行做反欺诈预测用到的技术和思路。百度…...