ubuntu22.04下hadoop3.3.6+hbase2.5.6+phoenix5.1.3开发环境搭建
一、涉及软件包资源清单
1、java 这里使用的是openjdk
2、hadoop-3.3.6.tar.gz
3、hbase-2.5.6-hadoop3-bin.tar.gz
4、phoenix-hbase-2.5-5.13-bin.tar.gz
5、apache-zookeeper-3.8.3-bin.tar.gz
6、openssl-3.0.12.tar.gz
二、安装
1、操作系统环境准备
- 换源
sudo vim /etc/apt/sources.list 打开资源列表文件进行查看,将内容修改为如下(如果是国内源不管是清华的阿里的都可以,就不用更改。):
deb http://mirrors.aliyun.com/ubuntu/ jammy main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ jammy-backports main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ jammy-security main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ jammy-updates main restricted universe multiverse
sudo apt-get update- 主机名配置
sudo vim /etc/hostname在这里写下你喜欢的主机名,规则:好记、识别度高、不与其它系统名称冲突,别太简单也别太复杂。写完了把它记住一会还要用。保存->退出。
sudo vim /etc/hosts在这里将你机器的IP地址和刚起好的主机名一并写在一行里,如下图蓝字部分。
127.0.0.1 localhost
172.22.10.250 xxx-ytA8000t-01
保存->退出->重启系统。
- ssh免密
首先查看系统是否安装了openssh服务
service sshd status● ssh.service - OpenBSD Secure Shell server
Loaded: loaded (/lib/systemd/system/ssh.service; enabled; vendor preset: enabled)
Active: active (running) since Wed 2023-11-15 11:14:32 CST; 2h 53min ago
Docs: man:sshd(8)
man:sshd_config(5)
Process: 1099 ExecStartPre=/usr/sbin/sshd -t (code=exited, status=0/SUCCESS)
Main PID: 1147 (sshd)
Tasks: 1 (limit: 18911)
Memory: 7.9M
CPU: 236ms
CGroup: /system.slice/ssh.service
└─1147 "sshd: /usr/sbin/sshd -D [listener] 0 of 10-100 startups"
如果提示不是这样,请查明原因,提示没有安装可以使用如下命令安装,-y参数的作用是在安装软件包的过程中自动回答“yes”,而不需要用户手动确认。
sudo apt install -y openssh-server安装完成后使用上面的状态查看命令查看服务的状态,直到状态正常为止。 修改配置文件允许root用户登录,允许公钥登录
sudo vim /etc/ssh/sshd_configPermitRootLogin yes
PubkeyAuthentication yes
去掉以上两项前面的注释 ,退出保存,重启ssh服务
service sshd restart实际过程中不太灵光,直接大招儿 sudo reboot ,有点夸张但却真香。这东西是自启动,重启后使用以下命令生成公钥:
ssh-keygen因为系统默认会使用rsa加密算法,所以这里就不费力的指定了(至于RSA和DSA算法的详细内容请自行查阅)。因为是开发环境所以输入命令后三次回车全部采用默认即可,不用输入任何内容。然后将公钥复制到authorized_keys中去,命令如下:
cd ~/.ssh
ssh-copy-id -i id_rsa.pub authorized_keysssh登录本机试试
ssh localhost第一次登录会问是否把此机器放到已知机器中去,回答 yes 然后回车,后面它就不问了。 这里直到搞到输入命令后什么也不问就给进系统为此,不成功的话查检自己的配置文件中配置的内容是否正确,打开 authorized_key和id_rsa.pub进行比较看两个key是否相同。
- openssl安装
首先查看openssl的版本
openssl versionOpenSSL 3.0.2 15 Mar 2022 (Library: OpenSSL 3.0.2 15 Mar 2022)
切换到你下载openssl源码包的目录,解压后进入到源码包,执行如下三个命令:
./Configure配置的参数说明可以在它的github上找到,这里就不复制了,有需要的自行去查看。链接
makesudo make install*注意这最后一句,这里要加入sudo,因为没有root权限/usr/local目录不允许写入。整个过程当中如果有依赖包缺失它会给出提示,根据提示安装就行。安装完成后再次查看版本
OpenSSL 3.1.0 14 Mar 2023 (Library: OpenSSL 3.1.0 14 Mar 2023)
- 禁用IPv6
默认情况下hbase启动后会跑在ipv6协议下,为了方便这里把ipv6禁用掉,全部使用ipv4协议。
sudo vim /etc/default/grub将如下 两行的内容部分换成下面经字部分 ,设置会在重启系统后生效。
GRUB_CMDLINE_LINUX_DEFAULT="quiet splash ipv6.disable=1"
GRUB_CMDLINE_LINUX="ipv6.disable=1"
sudo update-grubsudo reboot至此环境准备完毕。
2、java环境配置
因为hadoop3支持java11,所以这里使用openjdk11进行配置。使用命令
sudo apt install openjdk-11-jdk安装完成使用命令: java -version 查看是否安装成功
openjdk version "11.0.20.1" 2023-08-24
OpenJDK Runtime Environment (build 11.0.20.1+1-post-Ubuntu-0ubuntu122.04)
OpenJDK 64-Bit Server VM (build 11.0.20.1+1-post-Ubuntu-0ubuntu122.04, mixed mode, sharing)
java的默认安装路径在/usr/lib/jvm下,跳转到此目录下找到以amd64结尾的文件夹就是java的根目录了。将这个根目录添加到系统的profile中去。
sudo vim /etc/profileexport JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
export PATH=$PATH:$JAVA_HOME/bin
source /etc/profile3、zookeeper部署
跳转到zookeeper 下载目录,执行解压
tar -zxvf apache-zookeeper-3.8.3-bin.tar.gz -C /opt/cd /opt/apache-zookeeper-3.8.3/conf
cp zoo_sample.cfg zoo.cfg
sudo vim zoo.cfg在配置文件里指定数据存放目录,不要用默认的/tmp
dataDir=/opt/apache-zookeeper-3.8.3/data
这里的data目录是要自己建的
mkdir data添加全局配置
sudo vim /etc/profileexport ZOOKEEPER_HOME=/opt/apache-zookeeper-3.8.3
export PATH=$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin:$PATH
使配置生效并启动服务
source /etc/profile
zkServer.sh startjps2359 QuorumPeerMain 这就是zookeeper的进程
27098 Jps
4、hadoop部署
跳转到你hadoop下载目录,执行解压
tar -zxvf hadoop-3.3.6.tar.gz -C /opt/cd /opt/hadoop-3.3.6将配置文件目录映射到系统中去,这里使用软链接(这东西的好处是一处更改随处可用)
ln -s /opt/hadoop-3.3.6/etc/hadoop /etc/hadoop修改hdfs-site.xml和core-site.xml两个配置文件
sudo vim /etc/hadoop/hdfs-site.xml<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
sudo vim /etc/hadoop/core-site.xml<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://你在上面步骤中起的主机名:9000(hadoop3和hadoop2这里的端口不一样)</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>指定到你的数据盘中去(就是空间最大的那个地儿)</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>你当前进系统的用户名(不配置的话你在web管理界面建文件夹传文件时报错)</value>
</property>
</configuration>
将hadoop配置进系统的环境变量里
sudo vim /etc/profileexport JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
export ZOOKEEPER_HOME=/opt/apache-zookeeper-3.8.3
export HADOOP_HOME=/opt/hadoop-3.3.6
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native
export PATH=$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$PATH
source /etc/profile以当前用户启动hadoop服务,不要加sudo,那是以root启动的,会很麻烦。
start-all.shjps3394 NodeManager
2359 QuorumPeerMain
3015 SecondaryNameNode
2793 DataNode
3244 ResourceManager
2588 NameNode
26847 Jps
初始化
hadoop namenode -format打开浏览器输入服务器ip + 端口9870查看状态 http://172.22.10.250:9870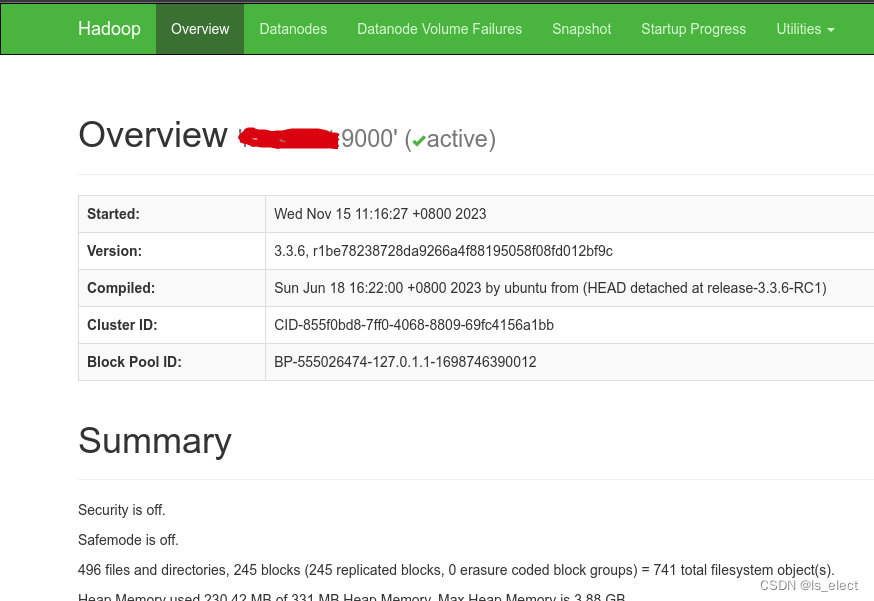
检查hadoop native状态
hadoop checknative -a2023-11-15 16:52:38,350 INFO bzip2.Bzip2Factory: Successfully loaded & initialized native-bzip2 library system-native
2023-11-15 16:52:38,352 INFO zlib.ZlibFactory: Successfully loaded & initialized native-zlib library
2023-11-15 16:52:38,385 INFO nativeio.NativeIO: The native code was built without PMDK support.
Native library checking:
hadoop: true /opt/hadoop-3.3.6/lib/native/libhadoop.so.1.0.0
zlib: true /lib/x86_64-linux-gnu/libz.so.1
zstd : true /lib/x86_64-linux-gnu/libzstd.so.1
bzip2: true /lib/x86_64-linux-gnu/libbz2.so.1
openssl: false EVP_CIPHER_CTX_block_size 这里就是为什么上面要编译安装openssl的原因,不编译安装它会报找不到库的错,这里的false是因为版本不对应引起的。
ISA-L: true /lib/libisal.so.2 这个也要自己去下源码来编译安装才能通过
PMDK: false The native code was built without PMDK support.
PMDK 的全称是 Persistent Memory Development Kit,它包含了 Intel 开发的一系列旨在 方便非易失性内在的应用开发的函数库和工具,是为了存储加速的,这里只是开发环境,所以不用理会。
5、hbase部署
跳转到hbase下载目录,执行解压
tar -zxvf hbase-2.5.6-hadoop3-bin.tar.gz -C /opt/把名改短些
cd /opt
mv hbase-2.5.6-hadoop3-bin hbase-2.5.6修改配置文件,主要有三处,分别是hbase-env.sh、hbase-site.xml、regionservers
sudo vim /opt/hbase-2.5.6/conf/hbase-env.shexport JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
export HBASE_PID_DIR=/opt/hbase-2.5.6/pids
export HBASE_MANAGES_ZK=false
export HBASE_DISABLE_HADOOP_CLASSPATH_LOOKUP="true"
sudo vim /opt/hbase-2.5.6/conf/hbase-site.xml<property>
<name>hbase.cluster.distributed</name>
<value>true</value>配置为true启用伪公布式
</property>
<property>
<name>hbase.tmp.dir</name>
<value>.</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
<property>
<name>hbase.rootdir</name>
<value>hdfs://上面步骤配置的主机名:9000/hbase</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>上面步骤配置的主机名</value>
</property><property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property><!--开启二次索引-->
<property>
<name>hbase.regionserver.wal.codec</name>
<value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value>
</property>
sudo vim /opt/hbase-2.5.6/conf/regionservers172.22.10.250 *这里把默认的localhost改成本机ip,这是其它机器可以访问环境的关键配置,不然只有本机可以访问。
配置系统环境变量
sudo vim /etc/profileexport JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
export HBASE_HOME=/opt/hbase-2.5.6
export HADOOP_HOME=/opt/hadoop-3.3.6
export ZOOKEEPER_HOME=/opt/apache-zookeeper-3.8.3
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$HBASE_HOME/bin:$ZOOKEEPER_HOME/bin:$PHOENIX_HOME/bin:$PATH
source /etc/profile启动服务,先启动regionserver,后启动master
hbase-daemon.sh start regionserverstart-hbase.shjps3394 NodeManager
2359 QuorumPeerMain
27911 Jps
3015 SecondaryNameNode
4231 HMaster
2793 DataNode
3244 ResourceManager
2588 NameNode
3900 HRegionServer
为了验证regionserver的配置是否正确,使用如下命令
netstat -anp |grep 16000tcp 0 0 172.22.10.250:16000 0.0.0.0:* LISTEN 4233/java
tcp 0 0 172.22.10.250:16000 172.22.10.250:35455 ESTABLISHED 4233/java
tcp 0 0 172.22.10.250:35455 172.22.10.250:16000 ESTABLISHED 3887/java
结果中红字部分已不再是127.0.0.1,所以现在它可以被外部访问了。
6、phoenix部署
跳转到phoenix下载目录,执行解压
tar -zxvf phoenix-hbase-2.5-5.1.3-bin.tar.gz -C /opt/cd /optmv phoenix-hbase-2.5-5.1.3-bin phoenix将server文件复制到hbase的lib目录下
cd /opt/phoenixcp phoenix-server-hbase-2.5-5.1.3.jar /opt/hbase-2.5.6/lib/cp phoenix-pherf-5.1.3.jar /opt/hbase-2.5.6/lib/将hadoop的配置文件、hbase的配置文件作软链接到bin目录下
cd /opt/phoenix/binln -s /opt/hadoop-3.3.6/etc/hadoop/hdfs-site.xml /opt/phoenix/bin/hdfs-site.xml
ln -s /opt/hadoop-3.3.6/etc/hadoop/core-site.xml /opt/phoenix/bin/core-site.xml
ln -s /opt/hbase-2.5.6/conf/hbase-site.xml /opt/phoenix/bin/hbase-site.xmlls -l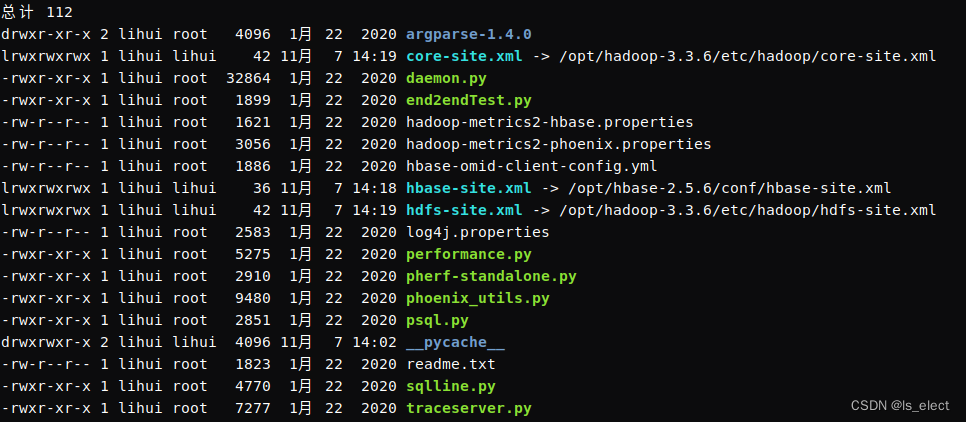
修改hbase-site.xml文件,在里面增加以下三项属性内容
sudo vim /opt/hbase-2.5.6/conf/hbase-site.xml<!-- 开启phoenix命名空间的自动映射 -->
<!-- 使用schema和Namespace对应的配置 -->
<!-- 开启用户自定义函数 -->
<property>
<name>phoenix.schema.isNamespaceMappingEnabled</name>
<value>true</value>
</property>
<property>
<name>phoenix.schema.mapSystemTablesToNamespace</name>
<value>true</value>
</property><property>
<name>phoenix.functions.allowUserDefinedFunctions</name>
<value>true</value>
</property>
配置环境变量
sudo vim /etc/profileexport JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
export HBASE_HOME=/opt/hbase-2.5.6
export HADOOP_HOME=/opt/hadoop-3.3.6
export ZOOKEEPER_HOME=/opt/apache-zookeeper-3.8.3
export PHOENIX_HOME=/opt/phoenix
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$HBASE_HOME/bin:$ZOOKEEPER_HOME/bin:$PHOENIX_HOME/bin:$PATH
source /etc/profile启动sqlline.py查检环境配置结果,正确登录后输入命令 !table查看表信息,能出如图所示结果说明系统正常启动。这一步要求机器上有python环境,一般情况下ubuntu自带phthon3。
sqlline.py localhost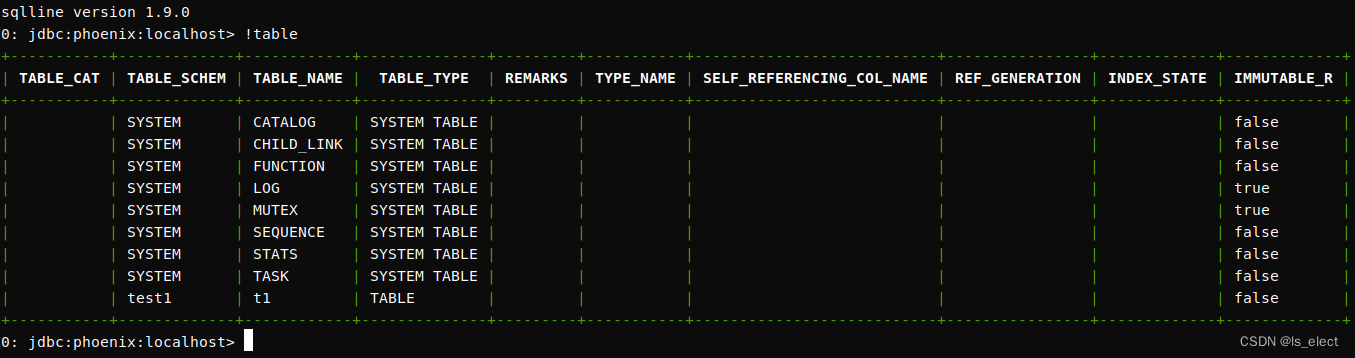
这里会出现的问题是,执行sqlline.py后长时间卡住不动的现象,一般是因为之前的hbase配置不正确造成的,解决的办法就是先停止hbase服务,然后去zookeeper中清除hbase信息,到hdfs中清除hbase的文件。
stop-hbase.sh如果一直画点点,就ctrl+c终止后,使用jps查到H开头的那两个进程,直接 kill -9 进程号强行终止服务。
zkCli.shdeleteall /hbasehadoop fs -rm -r -skipTrash /hbase然后重新启动hbase即可。
至此所有的配置均已完成,可以进行正常的开发工作了。
三、DBeaver连接phoenix
将phoenix安装目录下的client包复制一份备用,然后把hbase配置文件、hadoop配置文件复制到这个备用的jar包里(怎么打包就不说了,自己作吧)。然后把这个合成的jar包复制到想用的机器上的DBeaver的安装目录下的plugins目录下(纯个人喜好,实际放哪儿都行),然后启动dbeaver添加phoenix连接,在出来的配置界面中选择驱动,把这个包添加进去,就可以正常使用了。

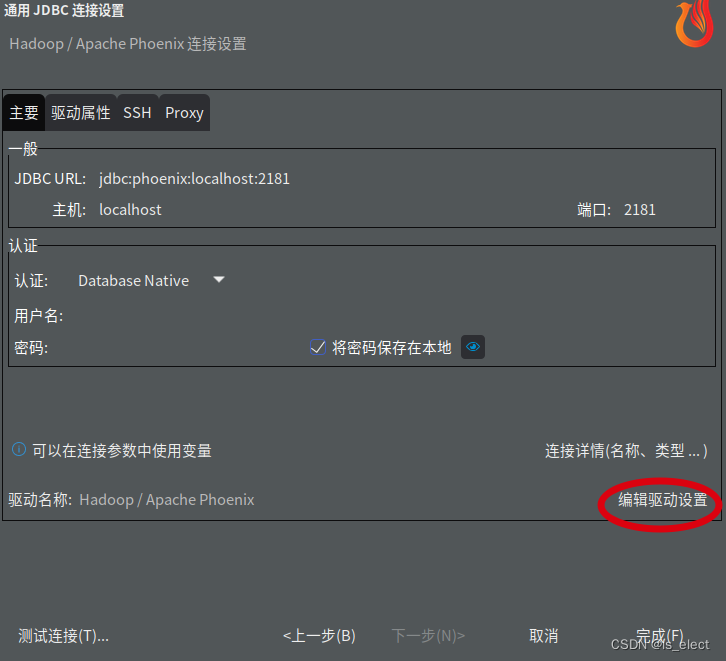
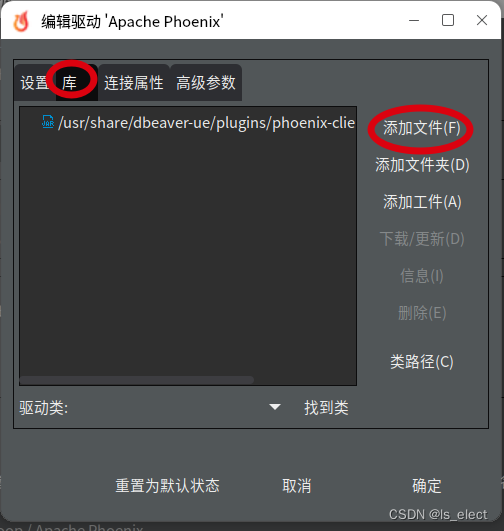
这一步有个重点要把原来自带的那个给它删除了,不然添加了后也认不出新的库文件来。选择好了包后,点击下面的“找到类”按钮,把驱动类找到,点选上它,然后点击页面右下方的“确定”按钮,完成驱动添加。
回到“通用jdbc连接设置”界面,点击驱动属性选项卡添加配置参数

然后回到主要选项卡,将主机地址填写到你服务所在的主机的IP,点击“完成”就可以了。
*如果出现访问不到服务器的问题,需要修改当前机器的hosts文件,在里面把上面配置中服务器里配置hosts的那一条添加到当前主机的hosts配置文件里。
相关文章:
ubuntu22.04下hadoop3.3.6+hbase2.5.6+phoenix5.1.3开发环境搭建
一、涉及软件包资源清单 1、java 这里使用的是openjdk 2、hadoop-3.3.6.tar.gz 3、hbase-2.5.6-hadoop3-bin.tar.gz 4、phoenix-hbase-2.5-5.13-bin.tar.gz 5、apache-zookeeper-3.8.3-bin.tar.gz 6、openssl-3.0.12.tar.gz 二、安装 1、操作系统环境准备 换源 sudo vim /et…...

【随手记】python语言的else语句在for、while等循环语句中的运用
在Python中,else语句可以与if语句一起使用,用于处理条件不成立时的情况。但是,else语句也可以与循环结构(如for循环、while循环)一起使用,用于处理循环正常结束时的情况,即循环没有被break语句中…...

RK3568 + YT 9215交换机芯片,MAC TO MAC 调试记录
前言 原来的方案是rk3568 gmac 直接接phy,phy 接 switch 芯片,只是把交换芯片当交换用,驱动方面基本不用开发,但是要做vlan 那么必须涉及交换芯片的开发。 选择裕太微有两个方面的原因:1.国产化替代2.可获得原厂技术支持3.目前已经完成 两个gmac 口交换芯片的配置,实现v…...
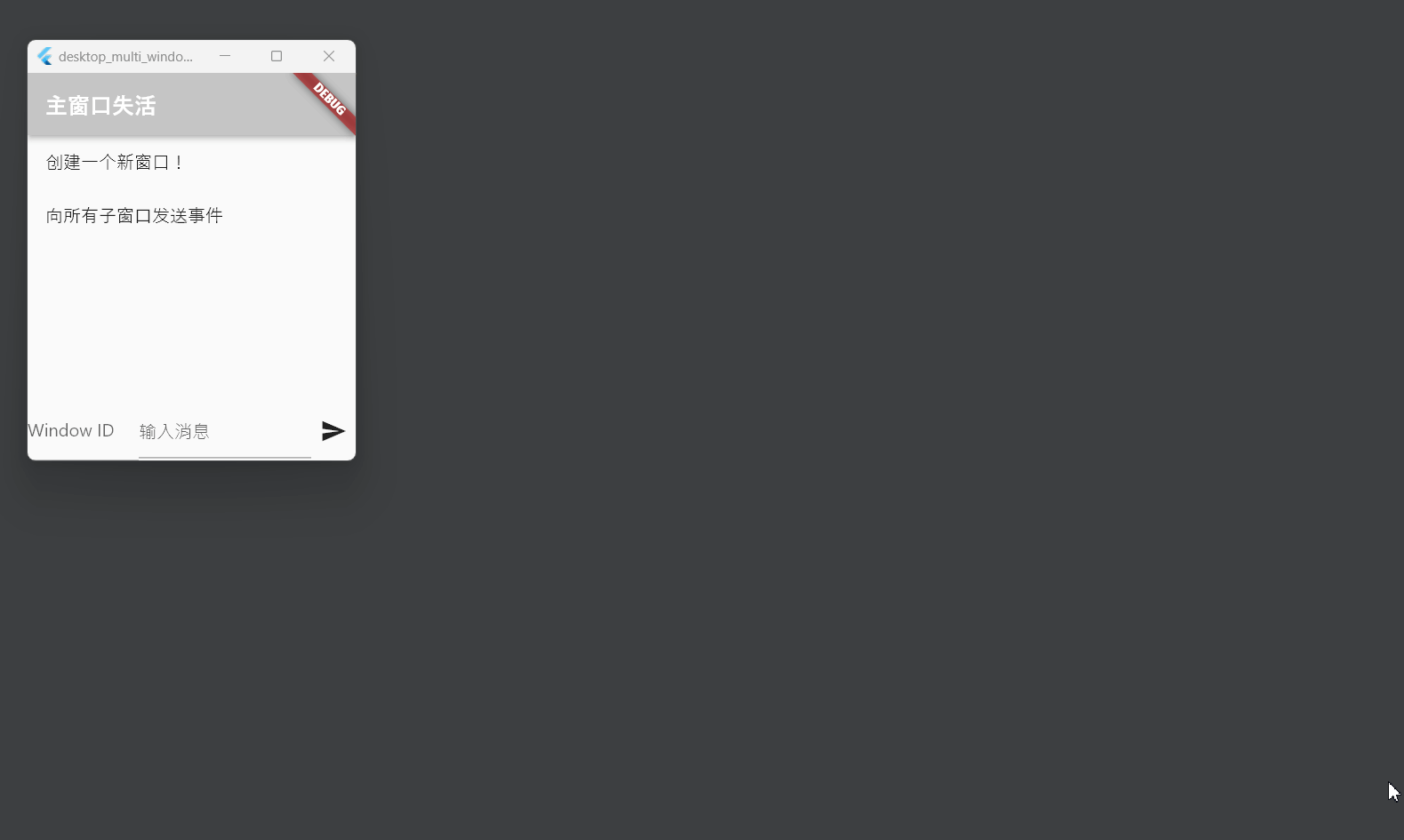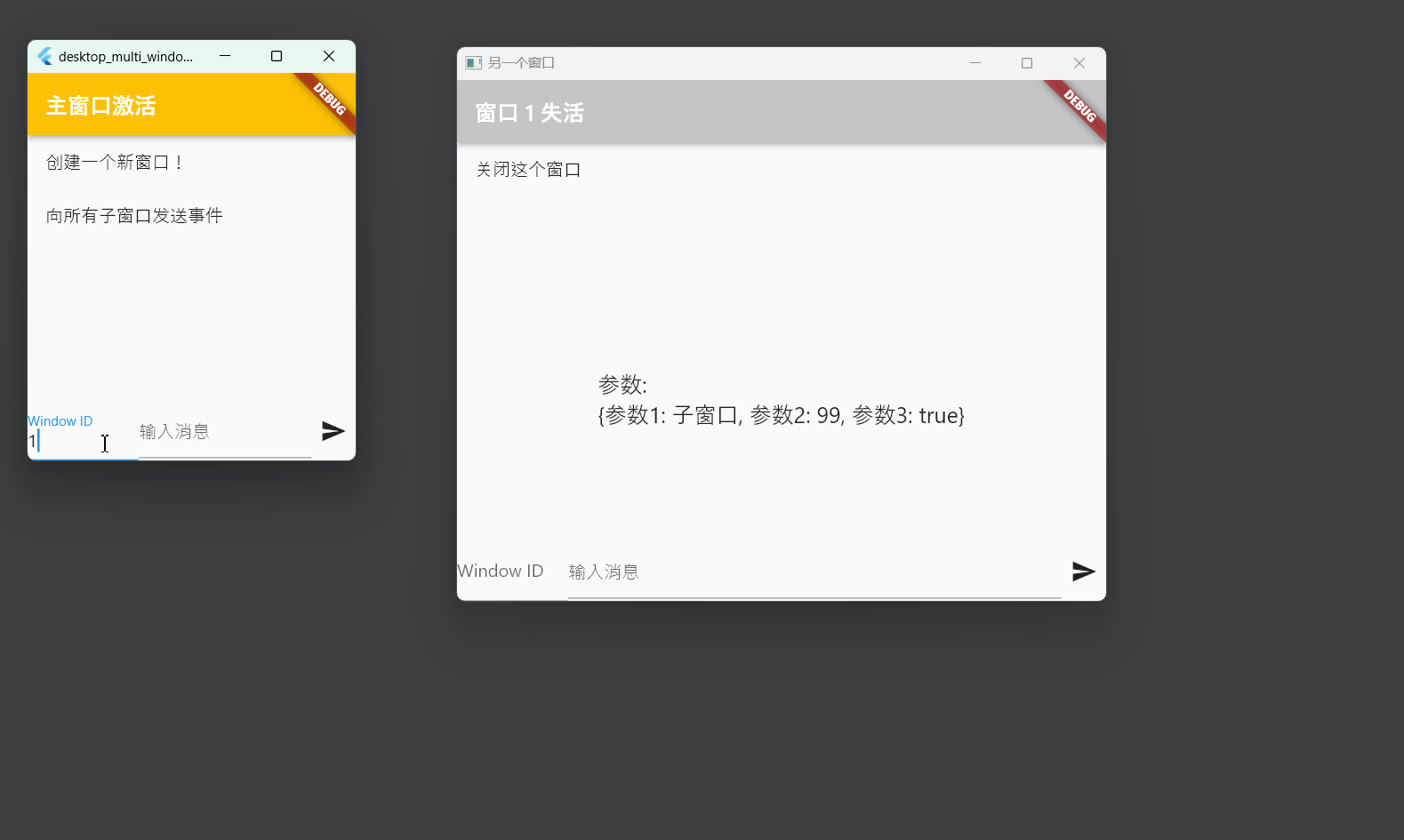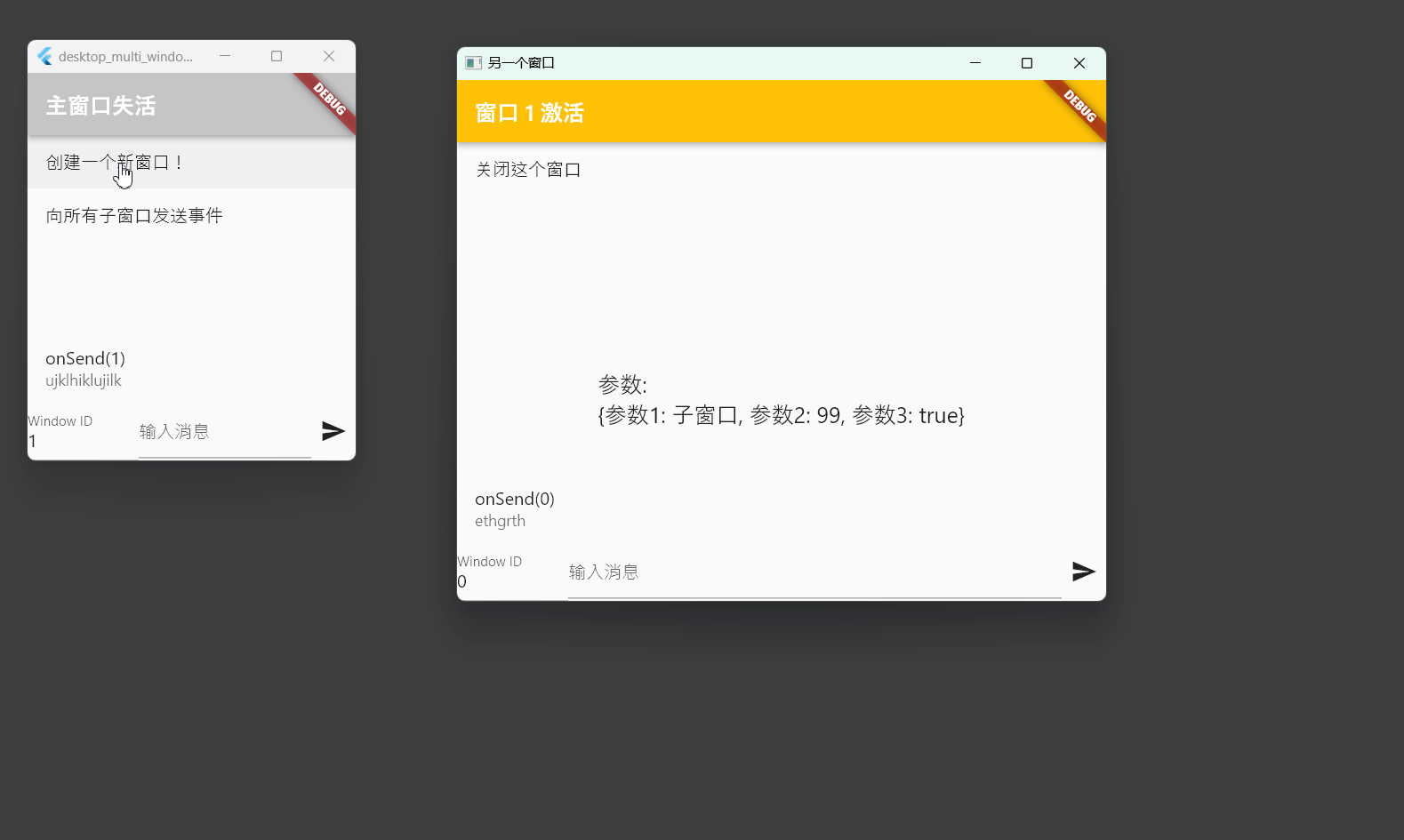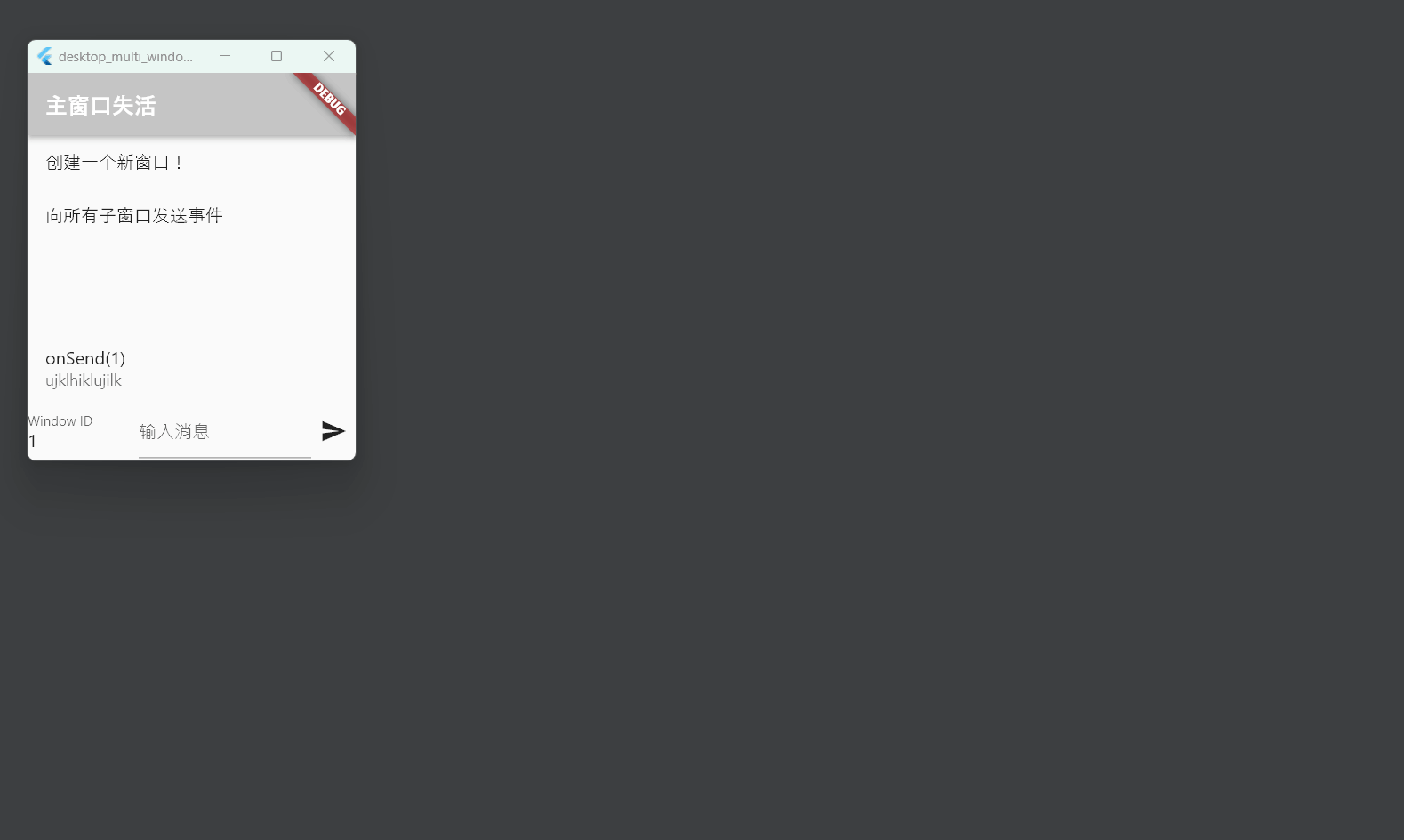
Flutter笔记:桌面端应用多窗口管理方案
Flutter笔记 桌面端应用多窗口管理方案 作者:李俊才 (jcLee95):https://blog.csdn.net/qq_28550263 邮箱 :291148484163.com 本文地址:https://blog.csdn.net/qq_28550263/article/details/134468587 【简介…...
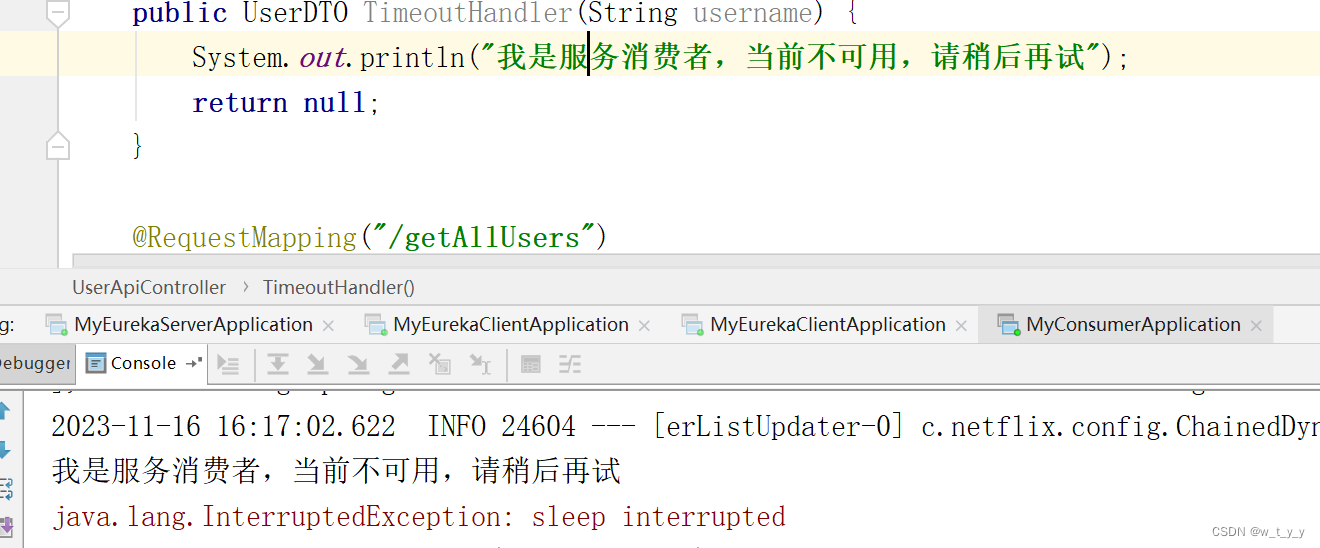
demo(三)eurekaribbonhystrix----服务降级熔断
一、介绍: 1、雪崩: 多个微服务之间调用的时候,假如微服务A调用微服务B和微服务C,微服务B和微服务C又调用其他的微服务,这就是所谓的"扇出"。如果扇出的链路上某个微服务的调用响应的时间过长或者不可用&am…...
相机突然断电,保存的DAT视频文件如何修复
3-7 本文主要解决因相机突然断电导致拍摄的视频文件损坏的问题。 在平常使用相机拍摄视频,比如用单反相机、无人机拍摄视频的时候,如果电池突然断电,或者突然炸机了,就非常有可能会得到一个损坏的视频文件,比如会产生…...

【数据结构与算法篇】顺序栈的C++实现
如何用C实现一个顺序栈 数据结构 -- 栈的简介顺序栈 - 结构体的定义顺序栈的初始化顺序栈的销毁入栈出栈获取栈顶元素判断顺序栈是否为空返回顺序栈中元素的个数 数据结构 – 栈的简介 栈是插入和删除遵循先进后出原则的一种容器。 也是一种线性表对象存放在栈, 可以…...

阿里云ESSD云盘、高效云盘和SSD云盘介绍和IOPS性能参数表
阿里云服务器系统盘或数据盘支持多种云盘类型,如高效云盘、ESSD Entry云盘、SSD云盘、ESSD云盘、ESSD PL-X云盘及ESSD AutoPL云盘等,阿里云服务器网aliyunfuwuqi.com详细介绍不同云盘说明及单盘容量、最大/最小IOPS、最大/最小吞吐量、单路随机写平均时延…...

VSG-001
VulkanSceneGraph (VSG), is a modern, cross platform, high performance scene graph library built upon Vulkan VSG 是一个基于vulkan的现代的、跨平台的高性能场景管理库 VSg特性: 使用C17作为c规范编码,支持 CppCoreGuidelines支持 FOSS Best P…...
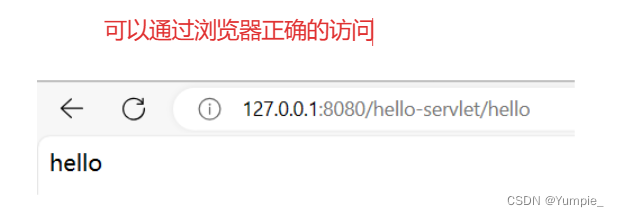
Smart Tomcat的使用
文章目录 Smart Tomcat的作用Smart Tomcat的安装Smart Tomcat的配置Smart Tomcat的启动 Smart Tomcat的作用 我们知道使用Servlet来完成一个项目一共需要七个步骤,即创建maven项目、添加依赖、创建目录结构、编写代码、打包程序、部署程序、验证程序。这样的确是完…...

vue3 TS数据处理常见错误分析:列表变为对象的错误如何处理
注意点1: return 语句无法跳出foreach()循环;return语句可以跳出For()循环。 注意点2:预防 [ ]变为object 后端前端之间传值如果为空的时候,数组会被变成空对象,如何解决呢? 描述:父传子 att…...

Hive效率优化记录
Hive是工作中常用的数据仓库工具,提供存储在HDFS文件系统,将结构化数据映射为一张张表以及提供查询和分析功能。 Hive可以存储大规模数据,但是在运行效率上不如传统数据库,这时需要懂得常见场景下提升存储或查询效率的方法&#x…...

⑩③【MySQL】详解SQL优化
个人简介:Java领域新星创作者;阿里云技术博主、星级博主、专家博主;正在Java学习的路上摸爬滚打,记录学习的过程~ 个人主页:.29.的博客 学习社区:进去逛一逛~ SQL优化 ⑩③【MySQL】了解并掌握SQL优化1. 插…...

SQL 的 AND、OR 和 NOT 运算符:条件筛选的高级用法
AND 运算符 SQL的AND运算符用于根据多个条件筛选记录,确保所有条件都为TRUE才返回记录。下面是AND运算符的基本语法: SELECT column1, column2, ... FROM table_name WHERE condition1 AND condition2 AND condition3 ...;column1, column2,等是您要选…...
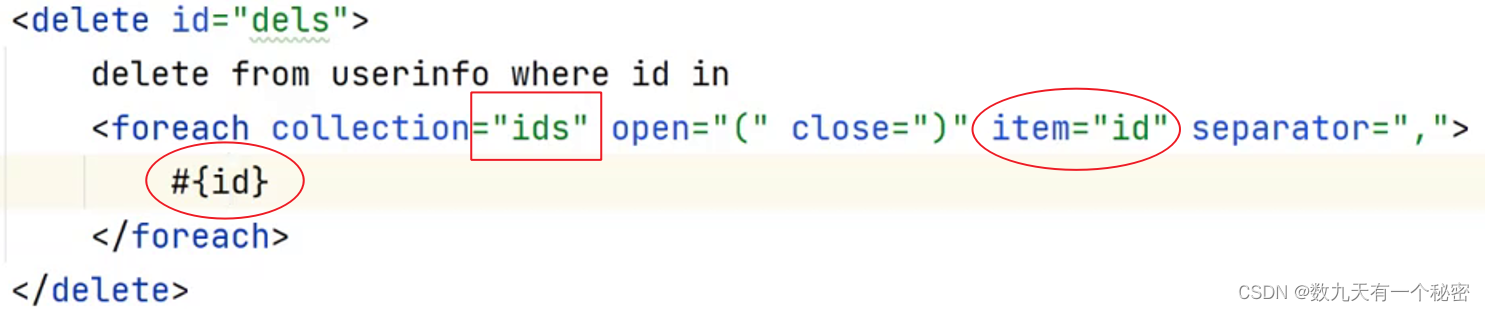
11.5MyBatis(进阶)
一.${}和#{} 1.$是直接替换,#是预处理(使用占位符,替换成?).前者不安全(SQL注入), 后者安全. 2.$的使用场景: 如果传递的值是sql的关键字,只能使用$,不能使用#(asc,desc). 二.SQL注入 注意: 如果使用${}进行传参,一定要是可以穷举的,并且要进行安全性验证(例如排序,只能传a…...

CentOS挂载:解锁文件系统的力量
目录 引言1 挂载简介2 挂载本地分区3 挂载网络共享文件系统4 使用CIFS挂载结论 引言 在CentOS(一种基于Linux的操作系统)上挂载文件系统是一项常见而重要的任务,无论是将新的磁盘驱动器添加到系统,还是挂载网络共享资源ÿ…...

修身养性 - 阿纳托利: 健身指导
欢迎来到我的力量建设培训计划。这是一个介绍性视频,我会对训练项目、技巧和计划进行解释。我每天都在练习英语,但还不够好,所以下面使用了自动翻译。带来不便请原谅。 Welcome to my power building training program. Its an introduction video where I explained about …...

pip anaconda 设置 国内镜像源
一、pip设置国内(清华)镜像源和升级pip 使用下面的命令直接使用清华镜像源 pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simplepython -m pip install --upgrade pip #备选 清华:https://pypi.tuna.tsinghua.edu.cn/simple 阿里云&am…...

三江城115m²3室2厅2卫,现代简约不单是居所更是对生活的向往。福州中宅装饰,福州装修
【前言】 简洁有力,静默无声。 以简约精致的方式,展现现代都市生活; 经典不因潮流褪色,不为悦人只为悦己。 项目信息 项目名称 | 三江城 设计地址 | 福建福州 项目面积 | 115㎡ 项目户型 | 3室2厅 设计风格 | 现代简约 全…...

Hangfire.Pro 3.0 Crack
Hangfire.Pro 有限的存储支持 Hangfire Pro 是一组扩展包,允许使用批处理创建复杂的后台作业工作流程,并提供对超快速Redis作为作业存储的支持 请注意,仅在使用Hangfire.SqlServer、Hangfire.Pro.Redis或Hangfire.InMemory包作为作业存储时才…...

测试微信模版消息推送
进入“开发接口管理”--“公众平台测试账号”,无需申请公众账号、可在测试账号中体验并测试微信公众平台所有高级接口。 获取access_token: 自定义模版消息: 关注测试号:扫二维码关注测试号。 发送模版消息: import requests da…...

微信小程序 - 手机震动
一、界面 <button type"primary" bindtap"shortVibrate">短震动</button> <button type"primary" bindtap"longVibrate">长震动</button> 二、js逻辑代码 注:文档 https://developers.weixin.qq…...

Ascend NPU上适配Step-Audio模型
1 概述 1.1 简述 Step-Audio 是业界首个集语音理解与生成控制一体化的产品级开源实时语音对话系统,支持多语言对话(如 中文,英文,日语),语音情感(如 开心,悲伤)&#x…...

HTML前端开发:JavaScript 常用事件详解
作为前端开发的核心,JavaScript 事件是用户与网页交互的基础。以下是常见事件的详细说明和用法示例: 1. onclick - 点击事件 当元素被单击时触发(左键点击) button.onclick function() {alert("按钮被点击了!&…...
中的KV缓存压缩与动态稀疏注意力机制设计)
大语言模型(LLM)中的KV缓存压缩与动态稀疏注意力机制设计
随着大语言模型(LLM)参数规模的增长,推理阶段的内存占用和计算复杂度成为核心挑战。传统注意力机制的计算复杂度随序列长度呈二次方增长,而KV缓存的内存消耗可能高达数十GB(例如Llama2-7B处理100K token时需50GB内存&a…...

AI病理诊断七剑下天山,医疗未来触手可及
一、病理诊断困局:刀尖上的医学艺术 1.1 金标准背后的隐痛 病理诊断被誉为"诊断的诊断",医生需通过显微镜观察组织切片,在细胞迷宫中捕捉癌变信号。某省病理质控报告显示,基层医院误诊率达12%-15%,专家会诊…...

Python Ovito统计金刚石结构数量
大家好,我是小马老师。 本文介绍python ovito方法统计金刚石结构的方法。 Ovito Identify diamond structure命令可以识别和统计金刚石结构,但是无法直接输出结构的变化情况。 本文使用python调用ovito包的方法,可以持续统计各步的金刚石结构,具体代码如下: from ovito…...

深度学习水论文:mamba+图像增强
🧀当前视觉领域对高效长序列建模需求激增,对Mamba图像增强这方向的研究自然也逐渐火热。原因在于其高效长程建模,以及动态计算优势,在图像质量提升和细节恢复方面有难以替代的作用。 🧀因此短时间内,就有不…...

iview框架主题色的应用
1.下载 less要使用3.0.0以下的版本 npm install less2.7.3 npm install less-loader4.0.52./src/config/theme.js文件 module.exports {yellow: {theme-color: #FDCE04},blue: {theme-color: #547CE7} }在sass中使用theme配置的颜色主题,无需引入,直接可…...

LabVIEW双光子成像系统技术
双光子成像技术的核心特性 双光子成像通过双低能量光子协同激发机制,展现出显著的技术优势: 深层组织穿透能力:适用于活体组织深度成像 高分辨率观测性能:满足微观结构的精细研究需求 低光毒性特点:减少对样本的损伤…...