贝叶斯AB测试
AB测试是用来评估变更效果的有效方法,但很多时候会运行大量AB测试,如果能够在测试中复用之前测试的结果,将有效提升AB测试的效率和有效性。原文: Bayesian AB Testing[1]

随机实验,又称AB测试,是行业中评估因果效应的既定标准。将新方法(新产品、功能、UI等)随机分配给人群中的特定子集(用户、患者、客户等),从而确保平均来说,结果的差异(收入、访问量、点击量等)可以归因于不同的方法。像Booking.com[2]这样的老牌公司报告说,他们会同时运行数千个AB测试。而多邻国(Duolingo)[3]等新兴公司的成功很大程度上要归功于他们的大规模实验文化。
做了这么多实验,自然而然出现了一个问题: 在某个具体实验中,能不能利用以前的测试信息?如何利用?在这篇文章中,我们将尝试通过介绍AB测试的贝叶斯方法来回答这些问题。贝叶斯框架很适合这种类型的任务,允许使用新数据更新现有(先验)知识。然而,该方法对函数形式假设特别敏感,模型选择(如先验分布的偏度)的微小区别可以造成非常不同的估算结果。
搜索和无限滚动
在本文其余部分,我们将使用一个玩具示例,该示例受到Azavedo等人(2019)[4]的启发: 搜索引擎希望在不牺牲搜索质量的情况下增加广告收入。我们是一家拥有成熟实验文化的公司,不断测试如何改进登录页面的新想法。假设我们想出了一个绝妙的新想法: 无限滚动[5]!如果用户想看到更多结果,他们可以继续向下滚动,而不是显示离散的页面序列。

我们通过AB测试了解无限滚动是否有效: 我们将用户随机分为测试组和对照组,只对测试组用户实施无限滚动。我们从```src.dgp```[6]导入数据,生成dgp_infinite_scroll()。对于以前的文章,我们生成了新的DGP父类,处理随机化和数据生成,其子类包含了具体用例。我们还从```src.utils```[7]中导入了绘图函数和库。为了不仅包含代码,还包括数据和表格,我们使用Deepnote[8],一个类似于Jupyter的网络协作笔记本环境。
from src.utils import *
from src.dgp import DGP, dgp_infinite_scroll
dgp = dgp_infinite_scroll(n=10_000)
df = dgp.generate_data(true_effect=0.14)
df.head()
| past_revenue | infinite_scroll | ad_revenue | |
|---|---|---|---|
| 0 | 3.76 | 1 | 3.70 |
| 1 | 2.40 | 1 | 1.71 |
| 2 | 2.98 | 1 | 4.85 |
| 3 | 4.24 | 1 | 4.57 |
| 4 | 3.87 | 0 | 3.69 |
我们有1万名网站访问者信息,观察他们每月产生的ad_revenue,考虑是否被分配到测试组并使用infinite_scroll,以及每月平均past_revenue。
随机测试分配使得均数差(difference-in-means) 估算器没有偏差[9]。我们期望测试组和对照组平均来看具有可比性,因此可以将观察到的平均结果差异归因于测试效果,然后用线性回归估计测试效果,从而可以将测试效果解释为infinite_scroll的作用。
smf.ols('ad_revenue ~ infinite_scroll', df).fit().summary().tables[1]

看起来infinite_scroll确实是个好主意,增加了0.1524美元的月平均收益。此外,在1%的置信水平下,该效应显著高于零。
我们可以通过在回归中控制past_revenue来进一步提高估算器精度。我们不期望估算系数有明显变化,但精度应该会提高(如果想了解更多关于控制变量的信息,请查看关于CUPED[10]和DAG[11]的其他文章)。
reg = smf.ols('ad_revenue ~ infinite_scroll + past_revenue', df).fit()
reg.summary().tables[1]
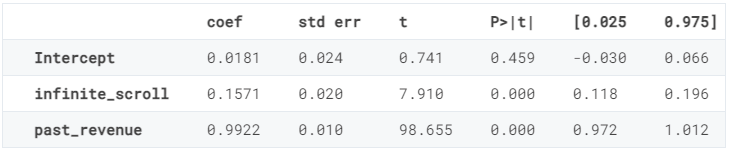
事实上,past_revenue可以准确预测当前ad_revenue,而infinite_scroll估算系数的精度降低了三分之一。
到目前为止,一切都很正常。然而,正如开头所说,假设这不是我们为改进浏览器(并最终提高广告收入)而进行的唯一实验,无限滚动只是我们过去测试过的数千个想法中的一个,有没有一种方法可以有效利用这些额外信息?
贝叶斯统计
贝叶斯统计相对于频率论方法(frequentist approach)的主要优势之一是可以比较容易的将额外信息合并到模型中,该想法来源于贝叶斯统计背后的贝叶斯定理(Bayes Theorem)[12],贝叶斯定理允许我们通过反转推理问题对模型进行推理: 从给定数据的模型的概率,到给定模型的数据的概率,从而使该对象更容易被处理。

可以把贝叶斯定理的右边分成两个部分: 先验(prior) 和可能性(likelihood) ,可能性来自数据关于模型的信息,先验则是关于模型的任何附加信息。
首先,我们把贝叶斯定理映射到环境中,明确数据是什么、模型是什么、我们感兴趣的对象是什么。
-
数据(data) 包括结果变量 ad_revenue(表示为 y),测试变更infinite_scroll(表示为 D和其他变量),past_revenue和常量共同表示为 X -
模型(model) 是在给定 past_revenue和infinite_scroll特性的条件下,ad_revenue的分布,表示为 y|D,X -
感兴趣的对象是得到的 Pr(model|data) ,特别是 ad_revenue和infinite_scroll之间的关系
X = sm.add_constant(df[['past_revenue']].values)
D = df['infinite_scroll'].values
y = df['ad_revenue'].values
如何在AB测试上下文中使用可能包含了额外协变量的先验信息?
贝叶斯回归
我们用线性模型来直接与频率论方法进行比较:
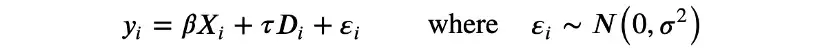
这是一个参数模型,有两组参数: 线性系数β和τ,以及残差方差σ。等价但更符合贝叶斯模型的写法是:
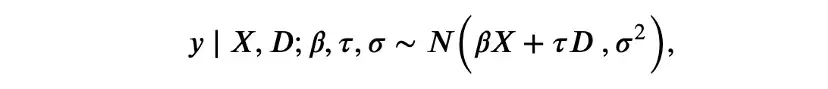
其中半列将数据与模型参数分开。与频率论方法不同,在贝叶斯回归中,不依赖中心极限定理[13]来近似y的条件分布,而是直接假设它是正态分布。
我们感兴趣的是对模型参数β、τ和σ进行推理。频率方法和贝叶斯方法的另一个核心区别是,前者假设模型参数是固定、未知的,而后者允许参数是随机变量。
这个假设有非常实际的含义: 可以很容易的以先验分布的形式合并关于模型参数的先验信息。顾名思义,先验包含了查看数据之前的可用信息。这就引出了贝叶斯统计中最重要的一个相关问题: 如何选择先验信息?
先验信息
选择先验信息时,一个有吸引力的限制是确定先验分布,使得后验信息属于同一家族,这叫做共轭先验(conjugate priors) 。例如,在看到数据之前,假设测试效果是正态分布的,在结合数据中包含的信息后,我们希望它也是正态分布的。
在贝叶斯线性回归的情况下,β、τ和σ的共轭先验是正态分布和逆伽玛分布,我们选择从标准正态和逆伽马分布开始。
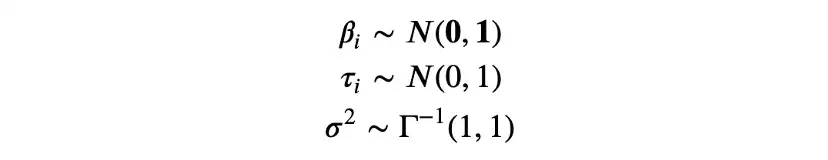
我们用概率编程包PyMC[14]进行推理。首先,需要指定模型: 不同参数的先验分布和数据的可能性。
import pymc as pm
with pm.Model() as baseline_model:
# Priors
beta = pm.MvNormal('beta', mu=np.ones(2), cov=np.eye(2))
tau = pm.Normal('tau', mu=0, sigma=1)
sigma = pm.InverseGamma('sigma', mu=1, sigma=1, initval=1)
# Likelihood
Ylikelihood = pm.Normal('y', mu=(X@beta + D@tau).flatten(), sigma=sigma, observed=y)
PyMC有一个非常好的函数model_to_graphviz,允许我们将模型可视化为图形。
pm.model_to_graphviz(baseline_model)
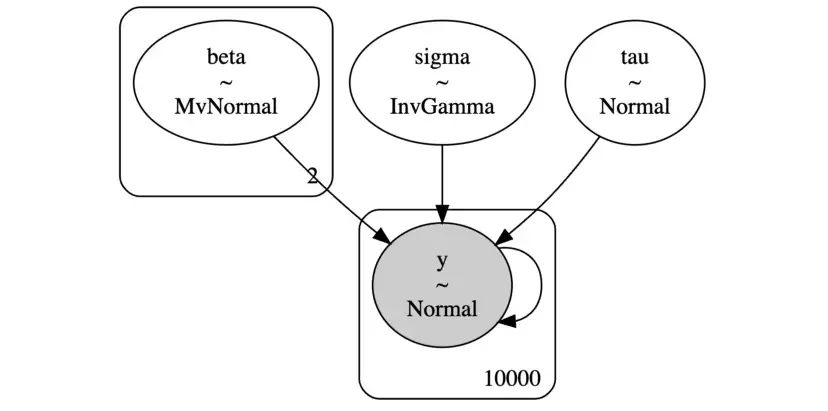
从图中可以看到各种模型组件、分布,以及如何相互作用。
现在准备计算模型的后验。我们对模型参数的实现进行抽样,计算给定值的数据的可能性,并推导出相应的后验。
idata = pm.sample(model=baseline_model, draws=1000)
贝叶斯推理需要抽样,这在历史上一直是贝叶斯统计的主要瓶颈之一,因为它比频率论方法要慢得多。然而,随着计算机模型计算能力的增强,这已不再是问题。
现在准备检查结果。首先,使用summary()方法,可以打印与用于线性回归的```statmodels```[15]包生成的模型摘要非常相似的模型摘要。
pm.summary(idata, hdi_prob=0.95).round(4)
| mean | sd | hdi_2.5% | hdi_97.5% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| beta[0] | 0.019 | 0.025 | -0.031 | 0.068 | 0.001 | 0.0 | 1943.0 | 1866.0 | 1.0 |
| beta[1] | 0.992 | 0.010 | 0.970 | 1.011 | 0.000 | 0.0 | 2239.0 | 1721.0 | 1.0 |
| tau | 0.157 | 0.021 | 0.117 | 0.197 | 0.000 | 0.0 | 2770.0 | 2248.0 | 1.0 |
| sigma | 0.993 | 0.007 | 0.980 | 1.007 | 0.000 | 0.0 | 3473.0 | 2525.0 | 1.0 |
估算的参数与频率论方法得到的参数非常接近,infinite_scroll的估算效果等于0.157。
如果取样的缺点是速度慢,那么优点是非常透明,可以直接画出后验的分布。我们来计算一下测试效应τ,PyMC函数plot_posterior绘制后验分布,黑色条表示贝叶斯等价的95%置信区间。
pm.plot_posterior(idata, kind="hist", var_names=('tau'), hdi_prob=0.95, figsize=(6, 3), bins=30);
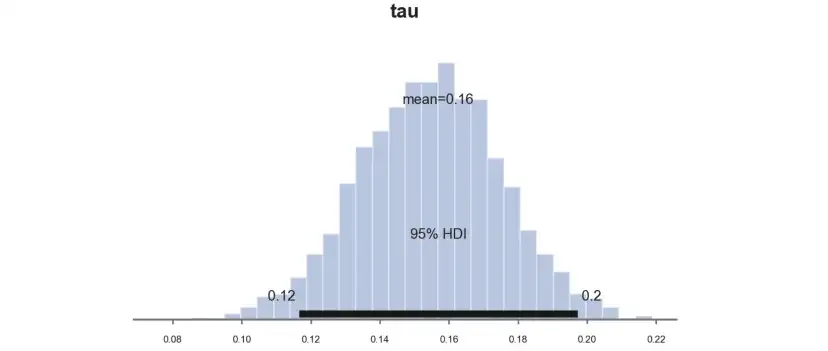
和预期一样,由于我们选择了共轭先验,后验分布看起来是高斯分布。
目前为止,我们并没有对选择先验施加太多指导。然而,假设我们可以查阅过去的实验,如何整合这些特定信息?
过去的实验
假设无限滚动的想法只是我们过去尝试和测试过的众多想法中的一个,对于每个想法,都有相应的实验数据,以及相应的估算系数。
past_experiments = [dgp.generate_data(seed_data=i) for i in range(1000)]
taus = [smf.ols('ad_revenue ~ infinite_scroll + past_revenue', pe).fit().params.values for pe in past_experiments]
我们从过去实验中得出了1000个估算值,那如何使用这些额外的信息呢?
常态先验
第一个想法可能是校准先验,以反映过去的数据分布。我们维持正态假设,使用过去实验估算的平均值和标准差。
taus_mean = np.mean(taus, axis=0)[1]
taus_mean计算结果为0.0009094486420266667,意味着平均而言,对ad_revenue几乎没有影响,平均影响为0.0009。
taus_std = np.sqrt(np.cov(taus, rowvar=0)[1,1])
taus_std计算结果为0.029014447772168384,意味着各实验之间存在明显的变化,标准偏差为0.029。
重写模型,使用过去估算τ的先验分布均值和标准差。
with pm.Model() as model_normal_prior:
# Priors
beta = pm.MvNormal('beta', mu=np.ones(2), cov=np.eye(2))
tau = pm.Normal('tau', mu=taus_mean, sigma=taus_std)
sigma = pm.InverseGamma('sigma', mu=1, sigma=1, initval=1)
# Likelihood
Ylikelihood = pm.Normal('y', mu=(X@beta + D@tau).flatten(), sigma=sigma, observed=y)
从模型中取样:
idata_normal_prior = pm.sample(model=model_normal_prior, draws=1000)
并绘制参数τ的样本后验分布处理效果图。
pm.plot_posterior(idata_normal_prior, kind="hist", var_names=('tau'), hdi_prob=0.95, figsize=(6, 3), bins=30);
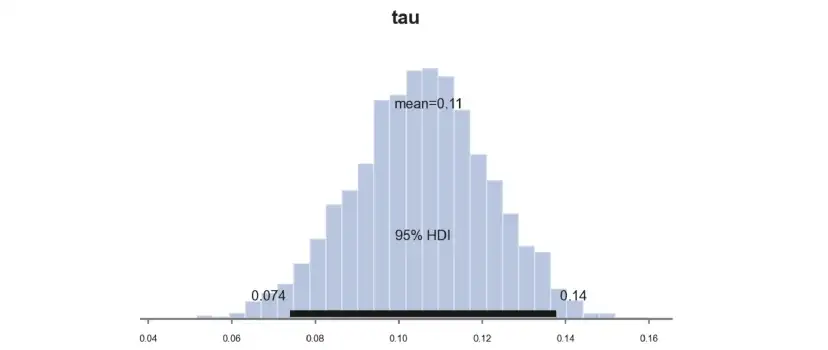
估算系数明显较小,为0.11,而不是先前估算的0.16。为什么会这样呢?
事实是,考虑到我们的先验,之前的系数0.16是极不可能的。在给定先验条件下,可以计算得到相同或更极端值的概率。
1 - sp.stats.norm(taus_mean, taus_std).cdf(0.16)
计算结果为2.0532795019789774e-08,概率几乎为零。因此,估算系数已经向先前的平均值0.0009移动。
T先验(Student-t Prior)
目前为止,我们假设所有线性系数都是正态分布。这样合适吗?让我们从截距系数(intercept coefficient) 开始直观检查。
sns.histplot([tau[0] for tau in taus]).set(title=r'Distribution of $\hat{\beta}_0$ in past experiments');
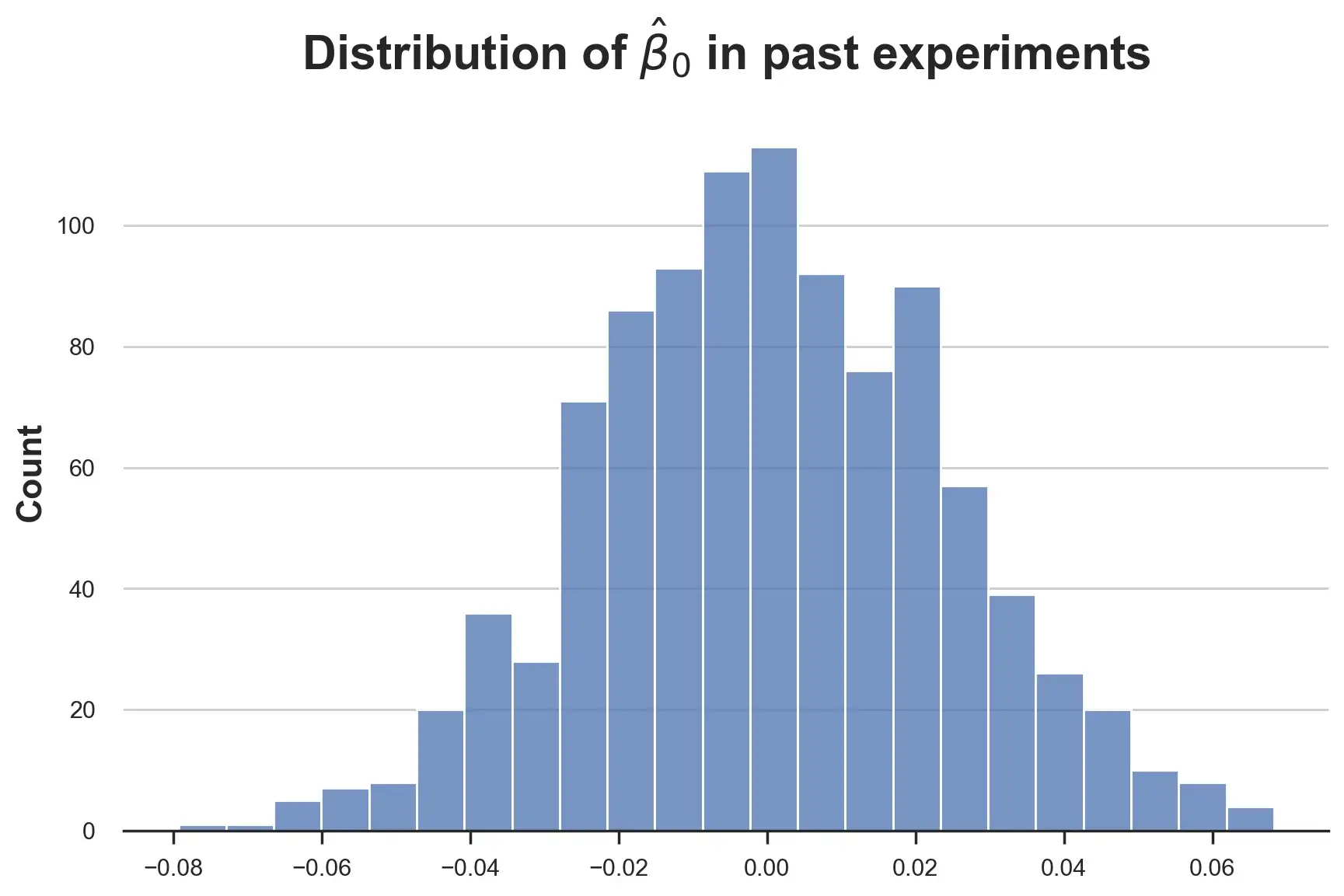
分布似乎很正常,那么效果参数τ呢?
fig, ax = plt.subplots()
sns.histplot([tau[1] for tau in taus], label='past experiments');
ax.axvline(reg.params['infinite_scroll'], lw=2, c='C3', ls='--', label='current experiment')
plt.legend();
plt.title(r'Distribution of $\hat{\tau}$ in past experiments');
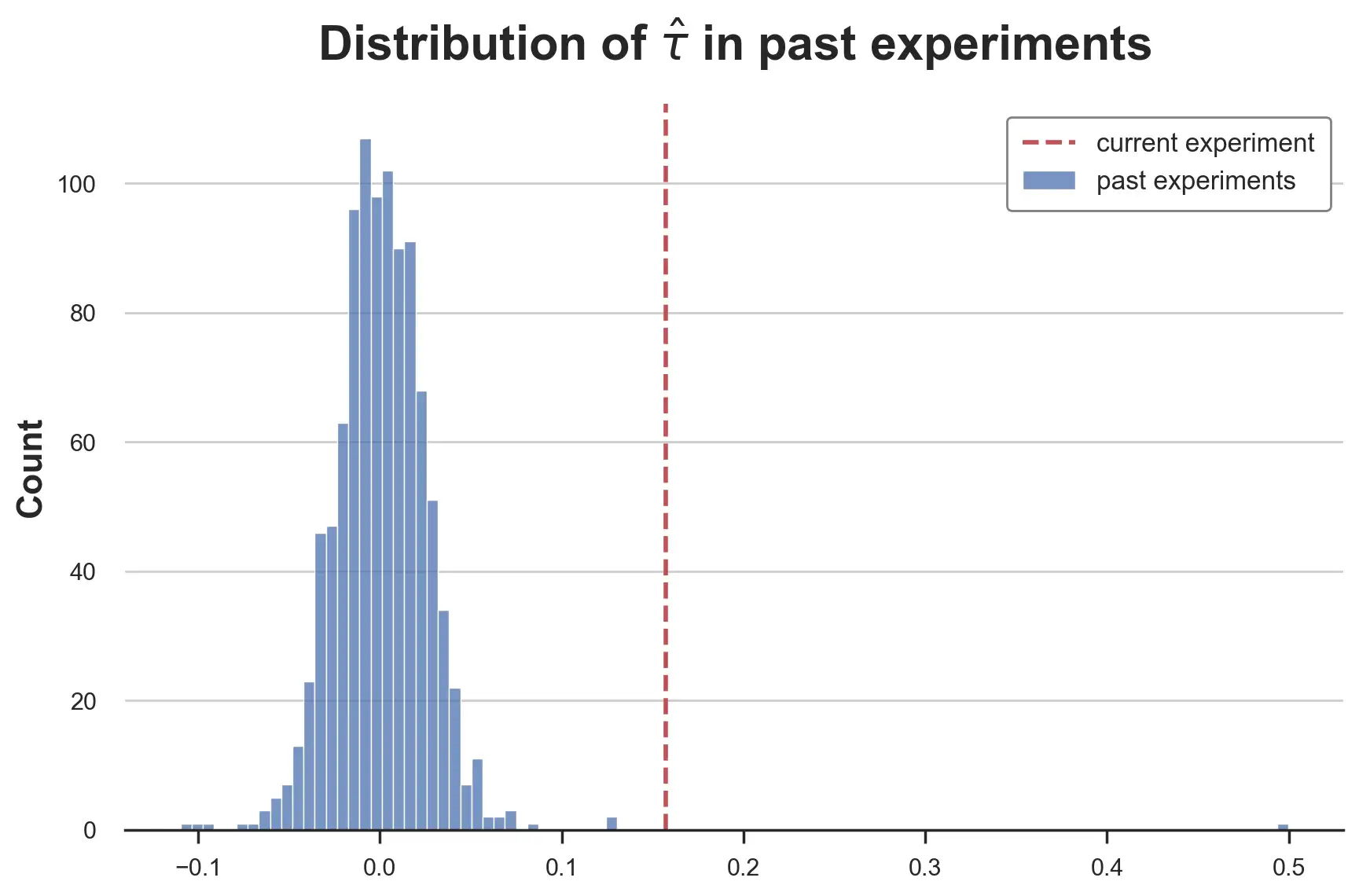
这是一个非常肥尾(heavy-tailed) 的分布,在中心看起来像正态分布,尾部更"胖",有两个非常极端的值。排除测量误差,这是行业中经常发生的情况,大多数想法的影响都非常小或为零,很少有想法是突破性的。
模拟这种分布的一种方法是T分布(student-t)[16]。我们用均值为0.0009,方差为0.003,自由度为1.3的T分布来匹配过去估算的经验分布矩阵。
with pm.Model() as model_studentt_prior:
# Priors
beta = pm.MvNormal('beta', mu=np.ones(2), cov=np.eye(2))
tau = pm.StudentT('tau', mu=taus_mean, sigma=0.003, nu=1.3)
sigma = pm.InverseGamma('sigma', mu=1, sigma=1, initval=1)
# Likelihood
Ylikelihood = pm.Normal('y', mu=(X@beta + D@tau).flatten(), sigma=sigma, observed=y)
从模型中取样。
idata_studentt_priors = pm.sample(model=model_studentt_prior, draws=1000)
并绘制参数τ的样本后验分布处理效果图。
pm.plot_posterior(idata_studentt_priors, kind="hist", var_names=('tau'), hdi_prob=0.95, figsize=(6, 3), bins=30);
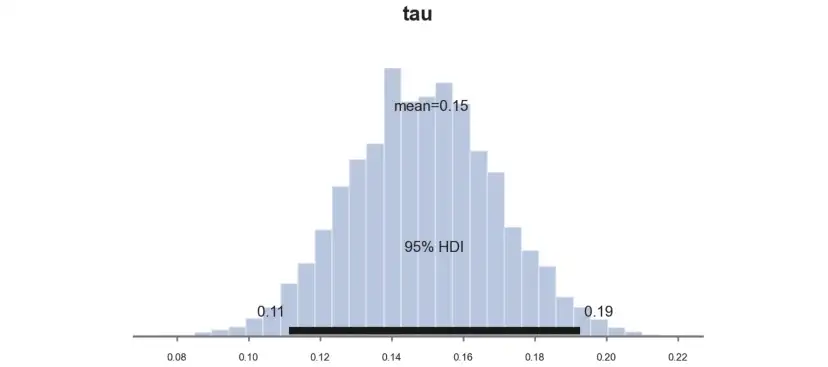
估算系数类似于用标准先验得到的系数0.11,然而由于置信区间从[0.077,0.016]缩小到[0.065,0.015],估算更加精确。
发生了什么?
收缩
答案在于所用的不同先验分布形态:
-
标准正态,N(0,1) -
正态矩匹配,N(0,0.03) -
T型匹配矩阵, (0, 0.003)
t_hats = np.linspace(-0.3, 0.3, 1_000)
distributions = {
'N(0,1)': sp.stats.norm(0, 1).pdf(t_hats),
'N(0, 0.03)': sp.stats.norm(0, 0.03).pdf(t_hats),
'$t_{1.3}$(0, 0.003)': sp.stats.t(df=1.3).pdf(t_hats / 0.003)*300,
}
画在一起看看。
for i, (label, y) in enumerate(distributions.items()):
sns.lineplot(x=t_hats, y=y, color=f'C{i}', label=label);
plt.xlim(-0.15, 0.15);
plt.legend();
plt.title('Prior Distributions');
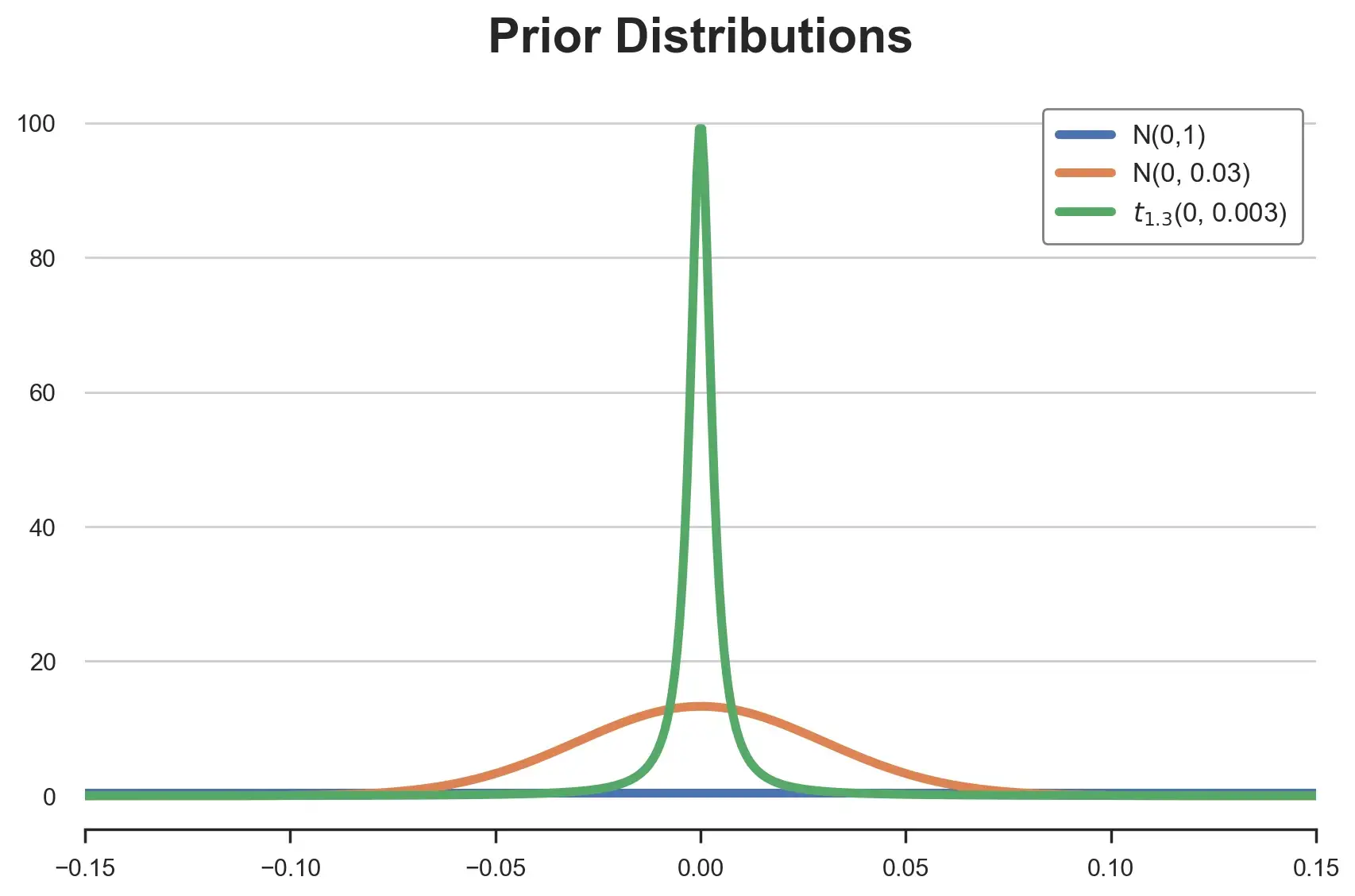
正如我们所看到的,所有分布都以0为中心,但形状非常不同。标准正态分布在[-0.15,0.15]区间内基本上是平坦的,每个值的概率基本相同。而后两个尽管有相同的均值和方差,但形态非常不同。
这如何转化为我们的估算?对每个先验分布,可以画出不同估算的隐含后验。
fig, ax = plt.subplots(figsize=(7,6))
ax.axvline(reg.params['infinite_scroll'], lw=2, ls='--', c='darkgray');
for i, (label, y) in enumerate(distributions.items()):
sns.lineplot(x=t_hats, y=[compute_posterior(t, y) for t in t_hats] , color=f'C{i}', label=label);
plt.legend();
ax.set_xlabel('Experiment Estimate');
ax.set_ylabel('Posterior');
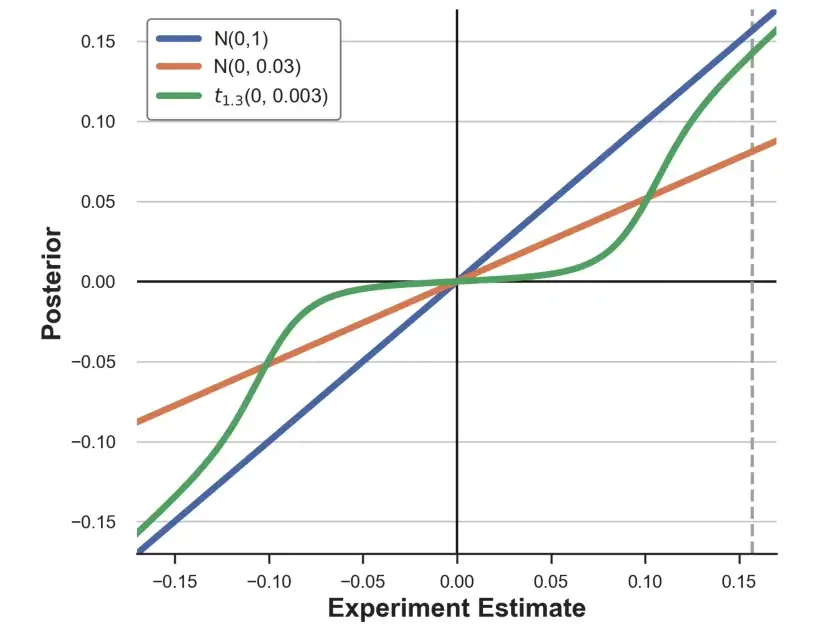
正如我们所看到的,不同的先验以非常不同的方式改变实验估算。标准正态先验基本上对[-0.15,0.15]区间内的估算没有影响。具有匹配矩阵的正常先验反而使每个估算值缩小约2/3。T先验的影响是非线性的: 将小估算缩小到零,而保持大估算不变。灰色虚线标记了不同先验对实验估算τ的影响。

结论
通过本文,我们了解了如何扩展AB测试的分析,以合并来自过去实验的信息。我们特别介绍了AB测试的贝叶斯方法,看到选择先验分布的重要性。在相同均值和方差下,假设存在"肥尾"(非常偏斜)的先验分布,意味着小效应的收缩更强,而大效应的收缩更少。
直觉上,带有"肥尾"的先验分布相当于假设突破性想法是罕见的,但不是不可能。正如我们在这篇文章中所看到的,这在实验后有实际意义,但在实验前也有意义。事实上,正如Azevedo等人(2020)[17]所报告的那样,如果你认为想法的效果分布比较"正常",那么最好是进行少量但大型的实验,以便能够发现较小的效果。相反,如果你认为想法是"要么是突破性的,要么毫无意义",即效果是肥尾的,那么运行小而多的实验更有意义,因为不需要大规模实验来检测大的效果。
代码
本文所有代码都在Jupyter Notebook上: https://github.com/matteocourthoud/Blog-Posts/blob/main/notebooks/bayes_ab.ipynb。
你好,我是俞凡,在Motorola做过研发,现在在Mavenir做技术工作,对通信、网络、后端架构、云原生、DevOps、CICD、区块链、AI等技术始终保持着浓厚的兴趣,平时喜欢阅读、思考,相信持续学习、终身成长,欢迎一起交流学习。
微信公众号:DeepNoMind
参考资料
Bayesian AB Testing: https://towardsdatascience.com/bayesian-ab-testing-ed45cc8c964d
[2]The role of experimentation at Booking.com: https://partner.booking.com/en-gb/click-magazine/industry-perspectives/role-experimentation-bookingcom
[3]Improving Duolingo, one experiment at a time: https://blog.duolingo.com/improving-duolingo-one-experiment-at-a-time
[4]Empirical Bayes Estimation of Treatment Effects with Many A/B Tests: An Overview: https://www.aeaweb.org/articles?id=10.1257/pandp.20191003
[5]Continuous scrolling comes to Search on mobile: https://blog.google/products/search/continuous-scrolling-mobile
[6]src.dgp: https://github.com/matteocourthoud/Blog-Posts/blob/main/notebooks/src/dgp.py
src.utils: https://github.com/matteocourthoud/Blog-Posts/blob/main/notebooks/src/utils.py
Deepnote: https://deepnote.com
[9]Bias of an estimator: https://en.wikipedia.org/wiki/Bias_of_an_estimator
[10]Understanding CUPED: https://towardsdatascience.com/understanding-cuped-a822523641af
[11]DAGs and Control Variables: https://towardsdatascience.com/controls-b63dc69e3d8c
[12]贝叶斯定理(Bayes Theorem): https://en.wikipedia.org/wiki/Bayes'_theorem
[13]中心极限定理: https://en.wikipedia.org/wiki/Central_limit_theorem
[14]PyMC: https://www.pymc.io/projects/docs/en/stable/learn.html
[15]statmodels: https://www.statsmodels.org/dev/index.html
T分布(student-t): https://en.wikipedia.org/wiki/Student%27s_t-distribution
[17]A/B Testing with Fat Tails: https://www.journals.uchicago.edu/doi/full/10.1086/710607
本文由 mdnice 多平台发布
相关文章:
贝叶斯AB测试
AB测试是用来评估变更效果的有效方法,但很多时候会运行大量AB测试,如果能够在测试中复用之前测试的结果,将有效提升AB测试的效率和有效性。原文: Bayesian AB Testing[1] 随机实验,又称AB测试,是行业中评估因果效应的既…...

信息检索与数据挖掘 | 【实验】检索评价指标MAP、MRR、NDCG
文章目录 📚实验内容📚知识梳理📚实验步骤🐇前情提要🐇MAP评价指标函数🐇MRR 评价指标函数🐇NDCG评价指标函数🐇调试结果 📚实验内容 实现以下指标评价,并对…...

读书笔记:彼得·德鲁克《认识管理》第24章 管理岗位的设计与内容
一、章节内容概述 管理岗位应该始终基于必要的任务,应该是一份实实在在的工作,为企业的整体目标做出可见的(如果不是可衡量的话)贡献,还应该具有尽可能广泛的权威和范围。管理者应该接受绩效目标而不是上级领导 的指导和控制。在设计管理岗位…...
某60区块链安全之51%攻击实战学习记录
区块链安全 文章目录 区块链安全51%攻击实战实验目的实验环境实验工具实验原理攻击过程 51%攻击实战 实验目的 1.理解并掌握区块链基本概念及区块链原理 2.理解区块链分又问题 3.理解掌握区块链51%算力攻击原理与利用 4.找到题目漏洞进行分析并形成利用 实验环境 1.Ubuntu1…...
为什么原生IP可以降低Google play账号关联风险?企业号解决8.3/10.3账号关联问题?
在Google paly应用上架的过程中,相信大多数开发者都遇到过开发者账号因为关联问题,导致应用包被拒审和封号的情况。 而众所周知,开发者账号注册或登录的IP地址及设备是造成账号关联的重要因素之一。酷鸟云最新上线的原生IP能有效降低账号因I…...
和A(n,m)理解及代码实现)
排列组合C(n,m)和A(n,m)理解及代码实现
排列组合C(n,m)和A(n,m)理解及代码实现-CSDN博客...

EasyExcel导入从第几行开始
//获得工作簿 read EasyExcel.read(inputStream, Student.class, listener); //获得工作表 又两种形形式可以通过下标也可以通过名字2003Excel不支持名字 ExcelReaderSheetBuilder sheet read.sheet(); sheet.headRowNumber(2);...

均匀光源积分球的应用领域有哪些
均匀光源积分球的主要作用是收集光线,并将其用作一个散射光源或用于测量。它可以将光线经过积分球内部的均匀分布后射出,因此积分球也可以当作一个光强衰减器。同时,积分球可以实现均匀的朗伯体漫散射光源输出,整个输出口表面的亮…...
【LeetCode】每日一题 2023_11_18 数位和相等数对的最大和(模拟/哈希)
文章目录 刷题前唠嗑题目:数位和相等数对的最大和题目描述代码与解题思路思考解法偷看大佬题解结语 刷题前唠嗑 LeetCode? 启动!!! 本月已经过半了,每日一题的全勤近在咫尺~ 题目:数位和相等数对的最大和…...

【喵叔闲扯】--迪米特法则
迪米特法则,也称为最少知识原则(Law of Demeter),是面向对象设计中的一个原则,旨在降低对象之间的耦合性,提高系统的可维护性和可扩展性。该原则强调一个类不应该直接与其它不相关的类相互交互,…...
企业视频数字人有哪些应用场景
来做个数字人吧,帮我干点活吧。 国内的一些数字人: 腾讯智影 腾讯智影数字人是一种基于人工智能技术的数字人物形象,具有逼真的外观、语音和行为表现,可以应用于各种场景,如新闻播报、文娱推介、营销、教育等。 幻…...
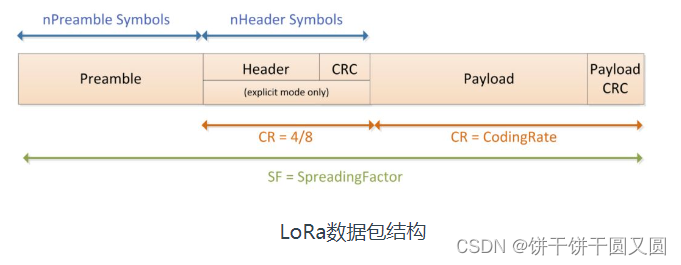
LoRa模块空中唤醒功能原理和物联网应用
LoRa模块是一种广泛应用于物联网领域的无线通信模块,支持低功耗、远距离和低成本的无线通信。 其空中唤醒功能是一项重要的应用,可以实现设备的自动唤醒,从而在没有人工干预的情况下实现设备的远程监控和控制。 LoRa模块空中唤醒功能的原理…...
spring中的DI
【知识要点】 控制反转(IOC)将对象的创建权限交给第三方模块完成,第三方模块需要将创建好的对象,以某种合适的方式交给引用对象去使用,这个过程称为依赖注入(DI)。如:A对象如果需要…...
gpt-4-vision-preview 识图
这些图片都是流行动画角色的插图。 第一张图片中的角色是一块穿着棕色方形裤子、红领带和白色衬衫的海绵,它站立着并露出开心的笑容。该角色在一个蓝色的背景前,显得非常兴奋和活泼。 第二张图片展示的是一只灰色的小老鼠,表情开心…...

Spring Framework 6.1 正式发布
Spring Framework 6.1.0 现已从 Maven Central 正式发布!6.1 一代有几个关键主题: 拥抱 JDK 21 LTS虚拟线程(Project Loom)JVM 检查点恢复(项目 CRaC)重新审视资源生命周期管理重新审视数据绑定和验证新的…...
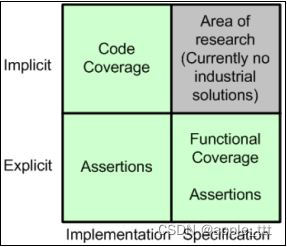
SystemVerilog学习 (11)——覆盖率
目录 一、概述 二、覆盖率的种类 1、概述 2、分类 三、代码覆盖率 四、功能覆盖率 五、从功能描述到覆盖率 一、概述 “验证如果没有量化,那么就意味着没有尽头。” 伴随着复杂SoC系统的验证难度系数成倍增加,无论是定向测试还是随机测试ÿ…...

jQuery,解决命名冲突的问题
使用noConflict(true),把$和jQuery名字都给别人 <body><script>var $ zanvar jQuery lan</script><script src"./jquery.js"></script><script>console.log(jQuery, 11111); // 打印jquery函数console.log($, 222…...
为什么C++标准库中atomic shared_ptr不是lockfree实现?
为什么C标准库中atomic shared_ptr不是lockfree实现? 把 shared_ptr 做成 lock_free,应该是没有技术上的可行性。shared_ptr 比一个指针要大不少:最近很多小伙伴找我,说想要一些C的资料,然后我根据自己从业十年经验&am…...
)
Python基础入门例程58-NP58 找到HR(循环语句)
最近的博文: Python基础入门例程57-NP57 格式化清单(循环语句)-CSDN博客 Python基础入门例程56-NP56 列表解析(循环语句)-CSDN博客 Python基础入门例程55-NP55 2的次方数(循环语句)-CSDN博客 目录 最近的博文: 描述...
航天联志Aisino-AISINO26081R服务器通过调BIOS用U盘重新做系统(windows系统通用)
产品名称:航天联志Aisino系列服务器 产品型号:AISINO26081R CPU架构:Intel 的CPU,所以支持Windows Server all 和Linux系统(重装完系统可以用某60驱动管家更新所有硬件驱动) 操作系统:本次我安装的服务器系统为Serv…...

【入坑系列】TiDB 强制索引在不同库下不生效问题
文章目录 背景SQL 优化情况线上SQL运行情况分析怀疑1:执行计划绑定问题?尝试:SHOW WARNINGS 查看警告探索 TiDB 的 USE_INDEX 写法Hint 不生效问题排查解决参考背景 项目中使用 TiDB 数据库,并对 SQL 进行优化了,添加了强制索引。 UAT 环境已经生效,但 PROD 环境强制索…...

django filter 统计数量 按属性去重
在Django中,如果你想要根据某个属性对查询集进行去重并统计数量,你可以使用values()方法配合annotate()方法来实现。这里有两种常见的方法来完成这个需求: 方法1:使用annotate()和Count 假设你有一个模型Item,并且你想…...

NFT模式:数字资产确权与链游经济系统构建
NFT模式:数字资产确权与链游经济系统构建 ——从技术架构到可持续生态的范式革命 一、确权技术革新:构建可信数字资产基石 1. 区块链底层架构的进化 跨链互操作协议:基于LayerZero协议实现以太坊、Solana等公链资产互通,通过零知…...

PAN/FPN
import torch import torch.nn as nn import torch.nn.functional as F import mathclass LowResQueryHighResKVAttention(nn.Module):"""方案 1: 低分辨率特征 (Query) 查询高分辨率特征 (Key, Value).输出分辨率与低分辨率输入相同。"""def __…...

Golang——6、指针和结构体
指针和结构体 1、指针1.1、指针地址和指针类型1.2、指针取值1.3、new和make 2、结构体2.1、type关键字的使用2.2、结构体的定义和初始化2.3、结构体方法和接收者2.4、给任意类型添加方法2.5、结构体的匿名字段2.6、嵌套结构体2.7、嵌套匿名结构体2.8、结构体的继承 3、结构体与…...

多模态图像修复系统:基于深度学习的图片修复实现
多模态图像修复系统:基于深度学习的图片修复实现 1. 系统概述 本系统使用多模态大模型(Stable Diffusion Inpainting)实现图像修复功能,结合文本描述和图片输入,对指定区域进行内容修复。系统包含完整的数据处理、模型训练、推理部署流程。 import torch import numpy …...

BLEU评分:机器翻译质量评估的黄金标准
BLEU评分:机器翻译质量评估的黄金标准 1. 引言 在自然语言处理(NLP)领域,衡量一个机器翻译模型的性能至关重要。BLEU (Bilingual Evaluation Understudy) 作为一种自动化评估指标,自2002年由IBM的Kishore Papineni等人提出以来,…...

MySQL 索引底层结构揭秘:B-Tree 与 B+Tree 的区别与应用
文章目录 一、背景知识:什么是 B-Tree 和 BTree? B-Tree(平衡多路查找树) BTree(B-Tree 的变种) 二、结构对比:一张图看懂 三、为什么 MySQL InnoDB 选择 BTree? 1. 范围查询更快 2…...
AI语音助手的Python实现
引言 语音助手(如小爱同学、Siri)通过语音识别、自然语言处理(NLP)和语音合成技术,为用户提供直观、高效的交互体验。随着人工智能的普及,Python开发者可以利用开源库和AI模型,快速构建自定义语音助手。本文由浅入深,详细介绍如何使用Python开发AI语音助手,涵盖基础功…...

vue3 daterange正则踩坑
<el-form-item label"空置时间" prop"vacantTime"> <el-date-picker v-model"form.vacantTime" type"daterange" start-placeholder"开始日期" end-placeholder"结束日期" clearable :editable"fal…...