大数据算法重点
1 大数据亚线性空间算法
场景:用二进制存储一个数字N,需要log(N)的空间
问题:如果N特别大而且这样的N又特别的多,该怎么办呢?
思路:减少一些准确性,从而节省更多的空间。
解决办法:使用近似计数算法,每一个数字的存储只需要loglog(N)loglog(N)loglog(N)的空间复杂度就行了。
1.1 流模型的计数问题
问题定义
定义一个数据流<ai>,i∈[1,m],ai∈[1,n]<ai>,i∈[1,m],a_i∈[1,n]<ai>,i∈[1,m],ai∈[1,n],频率向量<fi>,i∈[1,n],fi∈[1,m]<fi>,i∈[1,n],f_i∈[1,m]<fi>,i∈[1,n],fi∈[1,m]。
要求设计空间复杂度为loglog(N)loglog(N)loglog(N)的算法,记录其中出现了几个aia_iai
morris算法
-
将X初始化为0
-
循环:如果aia_iai出现一次,就以1/(2X)1/(2^X)1/(2X)的概率将X增加1
-
返回f^=(2X−1)\hat{f}=(2^X-1)f^=(2X−1)
利用切比雪夫不等式P[∣X−μ∣≥ϵ]⩽σ2/ϵ2P[|X−μ|≥ϵ]⩽σ^2/ϵ^2P[∣X−μ∣≥ϵ]⩽σ2/ϵ2证明
期望E[2XN−1]=NE[2^{X_N}−1]=NE[2XN−1]=N
方差var[2XN−1]=12N2−12Nvar[2^{X_N}−1] = \frac{1}{2}N^2−\frac{1}{2}Nvar[2XN−1]=21N2−21N
令切比雪夫不等式中的X=Y=2XN−1X=Y=2^{X_N}−1X=Y=2XN−1。
最终得到公式 P[∣Y−N∣≥ϵ]⩽N2−N2ϵ2P[|Y−N|≥ϵ]⩽\frac{N^2−N}{2ϵ^2}P[∣Y−N∣≥ϵ]⩽2ϵ2N2−N。
morris+算法
- 运行 k 次 morris 算法
- 记录记录结果(X1,...,Xk)(X_1,...,X_k)(X1,...,Xk)
- 返回γ=1k∑i=1k(2Xi−1)\gamma=\frac{1}{k}\sum^k_{i=1}(2^{X_i}-1)γ=k1∑i=1k(2Xi−1)
证明
E[γ]=NE[γ]=NE[γ]=N
D[γ]=N2−N2kD[γ]=\frac{N^2−N}{2k}D[γ]=2kN2−N。
P[∣γ−N∣≥ϵ]⩽N2−N2kϵ2P[|γ−N|≥ϵ]⩽\frac{N^2−N}{2kϵ^2}P[∣γ−N∣≥ϵ]⩽2kϵ2N2−N
morris++算法
- 重复morris+算法m=O(log(1δ))m=O(log(\frac{1}{δ}))m=O(log(δ1))次
- 取mmm个结果的中位数
证明
E[Xi]=0.9E[X_i]=0.9E[Xi]=0.9
μ=0.9mμ=0.9mμ=0.9m
P[∑Xi<0.5m]<δP[∑X_i<0.5m]<δP[∑Xi<0.5m]<δ
1.2 不重复元素数
问题定义
定义一个数据流<ai>,i∈[1,m],ai∈[1,n]<a_i>,i∈[1,m],a_i∈[1,n]<ai>,i∈[1,m],ai∈[1,n],频率向量<fi>,i∈[1,n],fi∈[1,m]<f_i>,i∈[1,n],f_i∈[1,m]<fi>,i∈[1,n],fi∈[1,m]。计算不等于0并且不重复的元素个数
FM算法
-
随机选取一个哈希函数([0,1][0,1][0,1]上的均匀分布)
h:[n]↦[0,1]h:[n]↦[0,1]h:[n]↦[0,1] -
z=1z=1z=1
-
当一个数字 i 出现的时候:z=min{z,h(i)}z=min\{z,h(i)\}z=min{z,h(i)}
-
返回1z−1\frac{1}{z}-1z1−1
证明
期望E[z]=1d+1E[z]=\frac{1}{d+1}E[z]=d+11
var[z]⩽2(d+1)(d+2)<2(d+1)(d+1)var[z]⩽\frac{2}{(d+1)(d+2)}<\frac{2}{(d+1)(d+1)}var[z]⩽(d+1)(d+2)2<(d+1)(d+1)2
P[∣z−1d+1∣>ϵ1d+1]<var[z]ϵd+12<2ϵ2P[|z−\frac{1}{d+1}|>ϵ\frac{1}{d+1}]<\frac{var[z]}{\frac{ϵ}{d+1}^2}<\frac{2}{ϵ^2}P[∣z−d+11∣>ϵd+11]<d+1ϵ2var[z]<ϵ22
FM+算法
- 总共运行 q 次FM算法
- 为每一次的运行随机选取一个哈希函数
hj:[n]↦[0,1]h_j:[n]↦[0,1]hj:[n]↦[0,1] - 初始化zj=1z_j=1zj=1
- 开始计数:每当 i 出现,更新zj=min(zj,hj(i))z_j=min(z_j,h_j(i))zj=min(zj,hj(i))
- Z=1q∑j=1qzjZ=\frac{1}{q}∑_{j=1}^qz_jZ=q1∑j=1qzj
- 返回1Z−1\frac{1}{Z}-1Z1−1
证明
E[Z]=1d+1E[Z]=\frac{1}{d+1}E[Z]=d+11
var[Z]⩽2(d+1)(d+2)1q<2(d+1)(d+1)1qvar[Z]⩽\frac{2}{(d+1)(d+2)}\frac{1}{q}<\frac{2}{(d+1)(d+1)}\frac{1}{q}var[Z]⩽(d+1)(d+2)2q1<(d+1)(d+1)2q1
P[∣X−d∣>ϵ′d]<2q(2ϵ′+1)2P[|X−d|>ϵ'd]<\frac{2}{q}(\frac{2}{ϵ'}+1)^2P[∣X−d∣>ϵ′d]<q2(ϵ′2+1)2
计算代价缩小为O(1ϵ2log1δ)O(\frac{1}{ {\epsilon}^2}log\frac{1}{\delta})O(ϵ21logδ1)

FM′+算法
- 随机选取一个哈希函数
h:[n]↦[0,1]h:[n]↦[0,1]h:[n]↦[0,1] - (z1,z2,...,zk)=1(z_1,z_2,...,z_k)=1(z1,z2,...,zk)=1也就是所有的z的初值都设置为1
- 维护当前看到的最小的k个哈希值
- 返回kzk\frac{k}{z_k}zkk
证明
P[∣kzk−d∣>ϵd]=P[k(1+ϵ)d>zk]+P[k(1−ϵ)d<zk]P[|\frac{k}{z_k}−d|>ϵd]=P[\frac{k}{(1+ϵ)d}>z_k]+P[\frac{k}{(1−ϵ)d}<z_k]P[∣zkk−d∣>ϵd]=P[(1+ϵ)dk>zk]+P[(1−ϵ)dk<zk]
P<2ϵ2kP < \frac{2}{ {\epsilon}^2k}P<ϵ2k2
PracticalFM算法 和 BJKST算法的准备知识
若我们无法存储实数,则采用PracticalFM算法 和 BJKST算法
若∀j1,...,jk∈[b],∀j1,...,jk∈[a],p[h(i1)=j1∧...∧h(ik)=jk]=1bk则:一个从[a]映射到[b]的哈希函数是k−wise的若\forall j_{1},...,j_{k} \in [b], \forall j_{1},...,j_{k} \in [a],\\ p[h(i_{1}) = j_{1} \wedge ...\wedge h(i_{k}) = j_{k}] = \frac{1}{b^k}\\ 则:一个从[a]映射到[b]的哈希函数是k-wise的 若∀j1,...,jk∈[b],∀j1,...,jk∈[a],p[h(i1)=j1∧...∧h(ik)=jk]=bk1则:一个从[a]映射到[b]的哈希函数是k−wise的
zeros(h(j))=max(i:p%2i=0)也就是展开成二进制后末尾0的个数,比如8对应的二进制是1000,则zeros(8)=3。zeros(h(j)) = max(i:p \% 2^{i} = 0)\\ 也就是展开成二进制后末尾0的个数,\\ 比如8对应的二进制是1000,则zeros(8) = 3。 zeros(h(j))=max(i:p%2i=0)也就是展开成二进制后末尾0的个数,比如8对应的二进制是1000,则zeros(8)=3。
PracticalFM算法
-
从2−wiseindependent2-wise\ independent2−wise independent哈希函数族中随机选取 h:[n]↦[n]h:[n]↦[n]h:[n]↦[n]
-
z=0z=0z=0
-
如果zeros(h(j))>zzeros(h(j))>zzeros(h(j))>z
z=zeros(h(j))z=zeros(h(j))z=zeros(h(j))
-
返回d^=2z+12\hat{d}=2^{z+\frac{1}{2}}d^=2z+21
算法解释
1−22C1 - \frac{2\sqrt{2} }{C}1−C22概率满足d/C≤d^≤Cdd / C \leq \hat{d} \leq Cdd/C≤d^≤Cd。
证明
E[Yr]=d2rE[Y_{r}] = \frac{d}{2 ^ r}E[Yr]=2rd
var[Yr]≤d2rvar[Y_{r}] \leq \frac{d}{2^r}var[Yr]≤2rd。
最终正确的概率应该大于1−22C1 - \frac{2\sqrt{2} }{C}1−C22。
BJKST算法
-
随机选择2−wiseindependent2-wise~ independent2−wise independent哈希函数 h:[n]→[n]h:[n]→[n]h:[n]→[n]
-
随机选择2−wiseindependent2-wise~independent2−wise independent哈希函数 g:[n]→[bϵ−4log2n]g:[n]→[bϵ−4log2n]g:[n]→[bϵ−4log2n]
-
z=0,B=∅z=0,B=∅z=0,B=∅
若zeros(h(j))>zzeros(h(j))>zzeros(h(j))>z
- B=B∪(g(j),zeros(h(j)))B=B∪(g(j),zeros(h(j)))B=B∪(g(j),zeros(h(j)))
- 若∣B∣>cϵ2|B| > \frac{c}{\epsilon^2}∣B∣>ϵ2c
- z=z+1z=z+1z=z+1
- 从B中删除(α,β)(α,β)(α,β),其中β<zβ<zβ<z
-
return d^=∣B∣2z\hat{d}=|B|2^zd^=∣B∣2z
算法解释
要想清楚地解释这个算法,只需要清楚两点即可。
- 当出现的一个新的元素时
- 如果zeros(h(j))>zzeros(h(j))>zzeros(h(j))>z
- 则将相应的二元组插入到B中;
- 如果B中的元素数量超过了某个大小:
- z的值相应的就增加1
- 就将其中第二项小于z的元素从中删除。
- 如果zeros(h(j))>zzeros(h(j))>zzeros(h(j))>z
证明
该算法可以实现至少2/3概率保证(1+ϵ)近似。
E[Yr]=d2rE[Y_{r}] = \frac{d}{2 ^ r}E[Yr]=2rd
var[Yr]≤d2rvar[Y_{r}] \leq \frac{d}{2^r}var[Yr]≤2rd
最终P[FAIL]<1/6P[FAIL]<1/6P[FAIL]<1/6。
再加上之前出去算法假设造成的错误概率,最终总的错误概率在1/3之内。
评价
空间复杂度为O(logn+1ϵ2(log1ϵ+loglogn))O(logn + \frac{1}{\epsilon ^ 2}(log\frac{1}{\epsilon} + loglogn))O(logn+ϵ21(logϵ1+loglogn))。
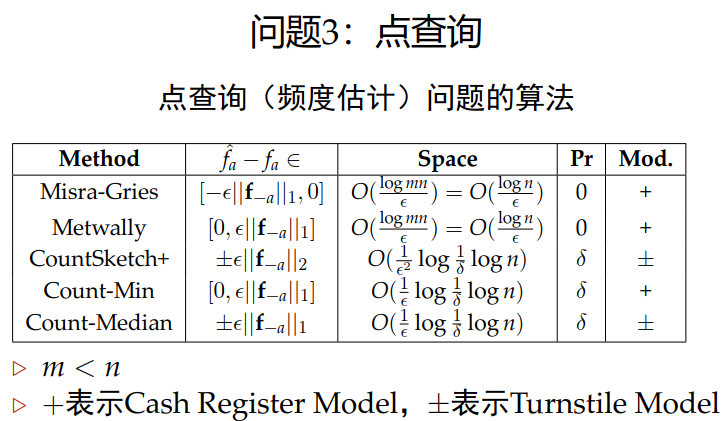
1.3 点查询
问题定义
定义一个数据流<ai>,i∈[1,m],ai∈[1,n]<ai>,i∈[1,m],a_i∈[1,n]<ai>,i∈[1,m],ai∈[1,n],频率向量<fi>,i∈[1,n],fi∈[1,m]<fi>,i∈[1,n],f_i∈[1,m]<fi>,i∈[1,n],fi∈[1,m]。计算流中所有的元素出现次数
知识准备
- 范数:lp=∥x∥p=(∑i∣xi∣p)1pl_{p} = \left \| x \right \|_{p} = {(\sum_{i}{|x_{i}|^p})}^{\frac{1}{p} }lp=∥x∥p=(∑i∣xi∣p)p1
- lpl_plp点查询(频度估计)
给定数据流σσσ和aia_iai输出fi^\hat{f_i}fi^满足fi^=fi±ϵ∣∣f∣∣p\hat{f_{i} } = f_{i} \pm \epsilon \left|| \textbf{f} \right||_{p}fi^=fi±ϵ∣∣f∣∣p
∣∣x∣∣1≥∣∣x∣∣2≥...≥∣∣x∣∣∞\left|| x \right||_{1} \geq \left|| x \right||_{2} \geq ... \geq \left|| x \right||_{\infty}∣∣x∣∣1≥∣∣x∣∣2≥...≥∣∣x∣∣∞,p越大,估计越准确
‖x‖0‖x‖_0‖x‖0是不同元素的数目
‖x‖1‖x‖_1‖x‖1是流的长度
‖x‖∞‖x‖_∞‖x‖∞是最大频度
Misra_Gries算法
维护一个集合A,其中的元素是(i,fi^)(i,\hat{f_{i} })(i,fi^)
-
A←∅A←∅A←∅
-
对每一个数据流中的元素e
if e∈A,令(e,fe^)→(e,fe^+1)(e,\hat{f_{e} }) \rightarrow (e,\hat{f_{e} } + 1)(e,fe^)→(e,fe^+1)
else if ∣A∣<1ϵ|A| < \frac{1}{\epsilon}∣A∣<ϵ1:将(e,1)插入A
else
- 将所有A中计数减 1
- if fj^=0\hat{f_{j} } = 0fj^=0:从A中删除(j,0)
-
对于查询 i,如果i∈Ai∈Ai∈A,返回fi^\hat{f_{i} }fi^,否则返回 0
证明
对任意的查询 i,返回 fi^\hat{f_{i} }fi^ 满足fi−ϵm≤fi^≤fif_{i} - \epsilon m \leq \hat{f_{i} } \leq f_{i}fi−ϵm≤fi^≤fi。
证明
结合算法过程,总共有两种情况。
如果不发生减1的情况,那么fi^=fi\hat{f_{i} } = f_{i}fi^=fi
如果发生了减1的情况,有fi^<fi\hat{f_{i} } < f_{i}fi^<fi
假设发生了c次减1的情况,总数减少cϵ≤m\frac{c}{\epsilon} \leq mϵc≤m,每个计数至多减少c,fi^≥fi−c≥fi−ϵm\hat{f_{i} } \geq f_{i} - c \geq f_{i} - \epsilon mfi^≥fi−c≥fi−ϵm。
算法的空间代价是O(ϵ−1logn)O(\epsilon^{-1}logn)O(ϵ−1logn)
Metwally算法
维护一个集合A,集合中的元素是(i,fi^)(i,\hat{f_i})(i,fi^)
- A←∅
- 对每一个数据流中的元素e
- if e∈A:令(e,fi^)←(e,fi^+1)(e,\hat{f_i})←(e,\hat{f_i}+1)(e,fi^)←(e,fi^+1)
- else if ∣A∣<1ϵ|A| < \frac{1}{\epsilon}∣A∣<ϵ1:将(e,1)插入A
- else 将(e,MIN+1)插入A,并删除一个满足fe^=MIN\hat{f_{e} } = MINfe^=MIN
- 查询 i,如果i∈Ai∈Ai∈A,返回fi^\hat{f_i}fi^,否则返回MIN
证明的目标
对任意的查询 i,返回fi≤fi^≤fi+ϵmf_{i} \leq \hat{f_{i} } \leq f_{i} + \epsilon mfi≤fi^≤fi+ϵm
证明
① 如果不发生删除的情况,那么fi^=fi\hat{f_{i} } = f_{i}fi^=fi。
② 如果删除,计数一定不大于删除后的MIN,有fi^≥fi\hat{f_{i} } \geq f_{i}fi^≥fi,A中元素总是m,MIN1ϵ≤m⇒MIN≤ϵmMIN \frac{1}{\epsilon} \leq m \Rightarrow MIN \leq \epsilon mMINϵ1≤m⇒MIN≤ϵm,每个元素至多超出真实值MIN,fi^≤fi+ϵm\hat{f_{i} } \leq f_{i} + \epsilon mfi^≤fi+ϵm。
算法的空间代价是O(ϵ−1logn)O(\epsilon^{-1}logn)O(ϵ−1logn)


新的定义
Sketch
定义在数据流σ上的数据结构DS(σ)是一个Sketch
如果存在一个Space−Efficient的合并算法COMB使得COMB(DS(σ1),DS(σ2))=DS(σ1∘σ2)COMB(DS(\sigma_{1}),DS(\sigma_{2})) = DS(\sigma_{1} \circ \sigma_{2})COMB(DS(σ1),DS(σ2))=DS(σ1∘σ2),其中∘是数据流的连接操作。
Linear Sketch
定义在[n]上的数据流σ上的sketching输出sk(σ),如果sk(σ)取值为维度l=l(n)的向量,并且是f(σ)的线性函数,那么sk(σ)是一个Linear Sketch,l是这个sketch的维度。
Count-Min算法
-
C[1...t][1...k]←0,k=2ϵ,t=⌈log1δ⌉C[1...t][1...k] \leftarrow \textbf{0},k = \frac{2}{\epsilon},t = \left \lceil log\frac{1}{\delta} \right \rceilC[1...t][1...k]←0,k=ϵ2,t=⌈logδ1⌉
-
随机选择 t 个2−wise独立哈希函数 hi:[n]→[k]h_i:[n]→[k]hi:[n]→[k]
-
对每一个出现的更新(j,c)进行如下操作
for i=1 to t
C[i][hi(j)]=C[i][hi(j)]+cC[i][h_{i}(j)] = C[i][h_{i}(j)] + cC[i][hi(j)]=C[i][hi(j)]+c
-
针对对于a的查询,返回 fa^=min1≤i≤tC[i][hi(a)]\hat{f_{a} } = \min_{1 \leq i \leq t}{C[i][h_{i}(a)]}fa^=min1≤i≤tC[i][hi(a)]
算法解释
在算法开始时,构造一个 t 行 k 列 的空数组,可以认为每一行是独立的,算法在运行时同时记录了t个这样的数组。在每出现一个流数据的时候,对每一个数组进行一次更新,注意元素的第二个下标用的是数据的哈希值。
算法在运行的过程中可能产生冲突,也就是两个不同的流数据的哈希值可能相同,这个时候就会导致结果偏大,但是因为有相当于t次的重复计算,通过取最小值的方法来进行一些弥补
证明
该算法以1−δ概率给出l1l_{1}l1点查询问题的(1+ϵ)近似
评价
算法的空间代价为O(1ϵlog1δ(logn+logm))O(\frac{1}{\epsilon}log\frac{1}{\delta}(logn + logm))O(ϵ1logδ1(logn+logm))
Count-Median算法
-
C[1...t][1...k]←0,k=2ϵ,t=⌈log1δ⌉C[1...t][1...k] \leftarrow \textbf{0},k = \frac{2}{\epsilon},t = \left \lceil log\frac{1}{\delta} \right \rceilC[1...t][1...k]←0,k=ϵ2,t=⌈logδ1⌉
-
随机选择t个2−wise独立哈希函数hi:[n]→[k]h_i:[n]→[k]hi:[n]→[k]
-
对每一个出现的更新(j,c)进行如下操作
for i=1 to t
C[i][hi(j)]=C[i][hi(j)]+cC[i][h_{i}(j)] = C[i][h_{i}(j)] + cC[i][hi(j)]=C[i][hi(j)]+c
-
针对对于a的查询,令∣C[x][hx(a)]∣=median1≤i≤t∣C[i][hi(a)]∣|C[x][h_x(a)]| = median_{1 \leq i \leq t}{|C[i][h_{i}(a)]|}∣C[x][hx(a)]∣=median1≤i≤t∣C[i][hi(a)]∣
-
返回fa^=∣C[x][hx(a)]∣\hat{f_a} = |C[x][h_x(a)]|fa^=∣C[x][hx(a)]∣
算法解释
与Count−MinSketch算法的计数方法完全一致,差别就在返回值的获取上,返回的是所有t个数组值的绝对值的中位数对应的原始值。
Count Sketch算法
-
C[1...k]←0,k=3ϵ2C[1...k] \leftarrow 0,k = \frac{3}{\epsilon^2}C[1...k]←0,k=ϵ23
-
随机选择1个2−wise独立哈希函数h:[n]→[k]h:[n]→[k]h:[n]→[k]
-
随机选择1个2−wise独立哈希函数g:[n]→−1,1g:[n]→{−1,1}g:[n]→−1,1
-
对于每一个更新(j,c)
C[h(j)]=C[h(j)]+c∗g(j)C[h(j)] = C[h(j)] + c * g(j)C[h(j)]=C[h(j)]+c∗g(j)
-
针对查询a,返回f^=g(a)∗C[h(j)]\hat{f} = g(a) * C[h(j)]f^=g(a)∗C[h(j)]
Count Sketch+算法
-
C[1...t][1...k]←0,k=3ϵ2,t=O(log1δ)C[1...t][1...k] \leftarrow \textbf{0},k = \frac{3}{\epsilon^2},t = O(log\frac{1}{\delta})C[1...t][1...k]←0,k=ϵ23,t=O(logδ1)
-
随机选择1个2−wise独立哈希函数 hi:[n]→[k]h_i:[n]→[k]hi:[n]→[k]
-
随机选择1个2−wise独立哈希函数 gi:[n]→{−1,1}g_i:[n] \rightarrow \{-1,1\}gi:[n]→{−1,1}
对于每一个更新(j,c)
对于i:1→ti:1→ti:1→t
C[hi(j)]=C[hi(j)]+c∗gi(j)C[h_i(j)] = C[h_i(j)] + c * g_i(j)C[hi(j)]=C[hi(j)]+c∗gi(j)
-
返回f^=median1≤i≤tgi(a)C[i][hi(a)]\hat f=median~1≤i≤tgi(a)C[i][h_i(a)]f^=median 1≤i≤tgi(a)C[i][hi(a)]
算法解释
相当于是将Count Sketch算法运行了t次,最后取了中值。利用齐尔诺夫不等式可以解决,令Xi=1⇔第i次运行成功,成功概率是2/3,最后只要成功的个数超过一半即可。最终是通过t控制了δ。
1.4 频度矩估计
Basic AMS算法
- (m,r,a)←(0,0,0)(m,r,a)←(0,0,0)(m,r,a)←(0,0,0)
- 对于每一个更新 j
- m←m+1m←m+1m←m+1
- β←randombitwithP[β=1]=1mβ ← random~bit ~with~ P[β = 1] = \frac{1}{m}β←random bit with P[β=1]=m1
- if β==1: a=j,r=0
- if j==a: r←r+1r←r+1r←r+1
- 返回X=m(rk−(r−1)k)X = m(r^k - (r - 1)^k)X=m(rk−(r−1)k)
算法分析
E[X]=FkE[X] = F_kE[X]=Fk
Var[X]≤kn1−1kFk2Var[X] \leq kn^{1 - \frac{1}{k} }F_k^2Var[X]≤kn1−k1Fk2
利用切比雪夫不等式对结果进行检验P[∣X−E[x]∣>ϵE[X]]<kn1−1kϵ2P[|X - E[x]| > \epsilon E[X]]<\frac{kn^{1 - \frac{1}{k} } }{\epsilon^2}P[∣X−E[x]∣>ϵE[X]]<ϵ2kn1−k1
评价
存储 m 和 r 需要 log n 位
存储 a 需要 log m 位
算法的方差太大,需要进一步的改进,但是其相应的存储代价为O(logm+logn)O(logm+logn)O(logm+logn)
Final AMS 算法
- 利用Median‑of‑Mean技术调用Basic AMS算法;
- 计算t=clog1δt = clog\frac{1}{\delta}t=clogδ1个平均值,每个平均值是r=3kϵ2n1−1kr = \frac{3k}{\epsilon ^ 2}n^{1 - \frac{1}{k} }r=ϵ23kn1−k1次调用的平均值
- 返回t个数值的中间值
证明
记{Xij}i∈[t],j∈[r]\{X_{ij}\}_{i \in [t],j \in [r]}{Xij}i∈[t],j∈[r]是与X独立同部分的随机变量集合。
Yi=1r∑j=1rXijY_i = \frac{1}{r}\sum_{j = 1}^{r}X_{ij}Yi=r1∑j=1rXij
Z=∑i=1tYiZ = \sum_{i = 1}^{t}Y_iZ=∑i=1tYi
计算E[Yi]=E[X],Var[Yi]=Var[X]kE[Y_i] = E[X],Var[Y_i] = \frac{Var[X]}{k}E[Yi]=E[X],Var[Yi]=kVar[X]
根据切比雪夫不等式有P[∣Yi−E[Yi]∣≥ϵE[Yi]]≤Var[X]kϵ2E[X]2P[|Y_i - E[Y_i]| \geq \epsilon E[Y_i]] \leq \frac{Var[X]}{k\epsilon^2E[X]^2}P[∣Yi−E[Yi]∣≥ϵE[Yi]]≤kϵ2E[X]2Var[X]
取值r=3Var[X]kϵ2E[X]2r = \frac{3Var[X]}{k\epsilon^2E[X]^2}r=kϵ2E[X]23Var[X],将期望和方差带入可以计算得到算法中给出的结果
现在P[∣Yi−E[Yi]∣≥ϵE[Yi]]≤13P[|Y_i - E[Y_i]| \geq \epsilon E[Y_i]] \leq \frac{1}{3}P[∣Yi−E[Yi]∣≥ϵE[Yi]]≤31
最后利用Median技术进行处理即可。
评价
算法的空间代价为O(1ϵ2log1δkn1−1k(logm+logn))O(\frac{1}{\epsilon^2}log\frac{1}{\delta}kn^{1 - \frac{1}{k} }(logm + logn))O(ϵ21logδ1kn1−k1(logm+logn)),当k≥2时代价过大。
Basic F2 AMS 算法
-
随机选择4−wise独立的哈希函数 h:[n]→−1,1h:[n]→{−1,1}h:[n]→−1,1
-
x←0
-
对于每一个更新(j,c)
x←x+c∗h(j)x \leftarrow x + c * h(j)x←x+c∗h(j)
-
返回x2x^2x2
分析
这个算法本身并没有什么比较好的效果,但是用过median−of−mean技术的优化,可以得到一个(ϵ,δ)的算法。所以在这里的证明中,只计算出结果的期望和方差就行了。
证明
记Yj=h(j),j∈[1,n],X=∑j=1nfjYjY_j = h(j),j \in [1,n],X = \sum_{j = 1}^{n}f_jY_jYj=h(j),j∈[1,n],X=∑j=1nfjYj
E[X2]=∑i=1nfiYi×∑j=1nfjYjE[X^2] = \sum_{i = 1}^{n}f_iY_i \times \sum_{j = 1}^{n}f_jY_jE[X2]=∑i=1nfiYi×∑j=1nfjYj
Var[X2]=E[X4]−E[X2]2Var[X^2] = E[X^4] - E[X^2]^2Var[X2]=E[X4]−E[X2]2
评价
算法的空间代价是O(logm+logn),下面先使用mean将犯错概率限制在1/3,再使用median技术对结果进行优化。
1.5 固定大小采样
水库抽样算法
- m←0
- 使用数据流的前s个元素对抽样数组进行初始化
A[1,...,s],m←sA[1,...,s],m\leftarrow sA[1,...,s],m←s - 对于每一个更新x
- x以sm+1\frac{s}{m + 1}m+1s概率随机替换A中的一个元素
- m++
证明
假定已经流过的数据量为n,采样池大小为s
考虑最普通的情况,第j个元素进了采样池,之后再也没有被选出去,那么在第n个元素流过之后,这个元素还在采样池中的概率是s/n
计算方法:被选进去的概率是s/j,为保证不被选出去,两种情况:新的元素没有选进来,新的元素选进来了但是该元素没有被替换掉。这两种情况对应着(1−sj+1)+sj+1∗s−1s=jj+1(1 - \frac{s}{j + 1}) + \frac{s}{j + 1}*\frac{s - 1}{s} = \frac{j}{j + 1}(1−j+1s)+j+1s∗ss−1=j+1j。依次类推最终可以计算得到结果s/n。
1.6 Bloom Filter
给定一个数据集U,从中抽取一个子集S,给定一个数q∈U,判定q∈S是否成立。
近似哈希的方法
- 令H是一族通用哈希函数:[U]→[m],m=nδ[U]→[m],m = \frac{n}{\delta}[U]→[m],m=δn
- 随机选择 h∈H,并维护数组A[m],S的大小是n
- 对每一个 i∈S,A[h(i)]=1A[h(i)]=1A[h(i)]=1
- 给定查询q,返回yes当且仅当A[h(i)]=1A[h(i)]=1A[h(i)]=1
证明
如果q∈S,返回的就是yes,如果q∉S,那么本应该返回no,但是有一定的概率返回yes,这就是错误的情况,元素本来不在S中,但是它的哈希值却与其中的某个元素的哈希值相同。∑j∈SP[h(q)=h(j)]≤nm=δ\sum_{j \in S}P[h(q) = h(j)] \leq \frac{n}{m} = \delta∑j∈SP[h(q)=h(j)]≤mn=δ,这样就计算除了m的值,并解决了近似问题。
Bloom Filter方法
-
令H是一族独立的理想哈希函数:[U]→[m]
-
随机选取h1,...,hd∈Hh_1,...,h_d \in Hh1,...,hd∈H,并维护数组A[m]
-
对于每一个i∈S
对于每一个j∈[1,d]
A[hj(i)]=1A[h_j(i)] = 1A[hj(i)]=1
-
给定查询q,返回yes当且仅当∀j∈[d],A[hj(q)]=1\forall j \in [d],A[h_j(q)] = 1∀j∈[d],A[hj(q)]=1
证明
失败的概率为P≤(nm)d=δP \leq (\frac{n}{m})^d = \deltaP≤(mn)d=δ,所以最终的代价就是m=O(nlog1δ)m = O(nlog\frac{1}{\delta})m=O(nlogδ1)
2 大数据亚线性时间算法
2.1 计算图的平均度算法Vertex Cover一
定义
已知:G=(V,E)G=(V,E)G=(V,E)
求:平均度dˉ=∑u∈Vd(u)n\bar{d} = \frac{\sum_{u\in V}d(u)}{n}dˉ=n∑u∈Vd(u)
假设:G是简单图,没有平行边和自环
分析
将具有相似或者相同度数的节点分组,然后估算每个分组的平均度数。
首先将所有的点进行分桶,分成t个桶,第i个桶里的点集合为Bi={v∣(1+β)(i−1)<d(v)<(1+β)i},0<i≤t−1B_i=\{v|(1+\beta)^{(i-1)} < d(v) < (1+\beta)^{i}\},0<i\leq t-1Bi={v∣(1+β)(i−1)<d(v)<(1+β)i},0<i≤t−1,其中β是超参数。
于是BiB_iBi中的点的总度数有上下界如公式所示:(1+β)(i−1)∣Bi∣<d(Bi)<(1+β)i∣Bi∣(1+\beta)^{(i-1)}|B_i| < d(B_i) < (1+\beta)^{i}|B_i|(1+β)(i−1)∣Bi∣<d(Bi)<(1+β)i∣Bi∣
进一步的G的总度数可以表示为:∑i=0t−1(1+β)(i−1)∣Bi∣<∑u∈Vd(u)<∑i=0t−1(1+β)i∣Bi∣\sum_{i=0}^{t-1}(1+\beta)^{(i-1)}|B_i| < \sum_{u\in V}d(u) < \sum_{i=0}^{t-1}(1+\beta)^{i}|B_i|∑i=0t−1(1+β)(i−1)∣Bi∣<∑u∈Vd(u)<∑i=0t−1(1+β)i∣Bi∣
于是我们可以得到:∑i=0t−1(1+β)(i−1)∣Bi∣n<dˉ<∑i=0t−1(1+β)i∣Bi∣n\frac{\sum_{i=0}^{t-1}(1+\beta)^{(i-1)}|B_i|}{n} < \bar{d} < \frac{\sum_{i=0}^{t-1}(1+\beta)^{i}|B_i|}{n}n∑i=0t−1(1+β)(i−1)∣Bi∣<dˉ<n∑i=0t−1(1+β)i∣Bi∣
于是将问题转化成了对Bin\frac{B_i}{n}nBi的估计
算法
- 从V取出样本集合S
- Si←S∩BiS_i \gets S \cap B_iSi←S∩Bi
- ρi←SiS\rho_i \gets \frac{S_i}{S}ρi←SSi
- 返回 dˉ^=∑i=0t−1ρi(1+β)i\hat{\bar{d} } = \sum_{i=0}^{t-1}\rho_i(1+\beta)^{i}dˉ^=∑i=0t−1ρi(1+β)i
算法的思想其实很简单,将Bin\frac{B_i}{n}nBi理解为一种概率,就是随机选一个点,这个点属于Bi的概率,这样理解算法就很简单了。
评价
算法的思想和计算都很简单,只是进行了一个非常巧妙的转化,但是这个算法仍然是有问题的
2.2 计算图的平均度算法二
改进算法
对于较小的桶的ρi\rho_iρi,假定一个dˉ\bar{d}dˉ的一个下阶α\alphaα。
- 从V中抽取样本S
- Si←S∩BiS_i \gets S \cap B_iSi←S∩Bi
- fori∈{0,…,t−1}do\boldsymbol{for}\ i \in \{0,\dots,t-1\}\ \boldsymbol{do}for i∈{0,…,t−1} do
- if∣Si∣≥θρthen\boldsymbol{if}\ |S_i| \geq \theta_\rho\ \boldsymbol{then}if ∣Si∣≥θρ then
- ρi←∣Si∣∣S∣\rho_i \gets \frac{|S_i|}{|S|}ρi←∣S∣∣Si∣
- else\boldsymbol{else}else
- ρi←0\rho_i\gets 0ρi←0
- returndˉ^=∑i=0t−1ρi(1+β)i\boldsymbol{return}\ \hat{\bar{d} } = \sum_{i=0}^{t-1}\rho_i(1+\beta)^{i}return dˉ^=∑i=0t−1ρi(1+β)i
我们将算法的结果调整为以2/3的概率有(0.5−ϵ)dˉ<dˉ^<(1+ϵ)dˉ(0.5-\epsilon)\bar{d} < \hat{\bar{d} } < (1 + \epsilon)\bar{d}(0.5−ϵ)dˉ<dˉ^<(1+ϵ)dˉ。
这里给出一组参数,使得能够满足上述结果:
- β=ϵ4\beta = \frac{\epsilon}{4}β=4ϵ
- ∣S∣=Θ(nα⋅poly(logn,1/ϵ))|S| = \Theta(\sqrt{\frac{n}{\alpha} }\cdot poly(log\ n,1/\epsilon))∣S∣=Θ(αn⋅poly(log n,1/ϵ))
- t=⌈log(1+β)n⌉+1t = \left \lceil log_{(1+\beta)}n \right \rceil + 1t=⌈log(1+β)n⌉+1
- θρ=1t38⋅ϵαn∣S∣\theta_{\rho} = \frac{1}{t}\sqrt{\frac{3}{8}\cdot\frac{\epsilon\alpha}{n} }|S|θρ=t183⋅nϵα∣S∣
2.3 计算图的平均度算法三
算法改进的思想
我们将算法出现的误差归结到边上,让我们来看看究竟是哪些边导致了这样的错误。将节点分为U,V/U两部分,其中U是度数较小的节点,V/U是度数较大的节点,E(U,V/U)表示连接两个集合的边的集合。于是,我们断言出现误差就是因为E(U,V/U)中的边我们只计算了一次,关于这一点我们回忆一下之前举的例子就很好理解了。于是我们只要找到每次抽样的时候这部分的边的比例就可以了。
改进算法
利用E[Δi]E[\Delta_i]E[Δi]的1+ϵ1+\epsilon1+ϵ估计,可以得到Δiρi(1+β)i\Delta_i\rho_i(1+\beta)^iΔiρi(1+β)i是Tin的(1+ϵ)(1+β)\frac{T_i}{n}的(1+\epsilon)(1+\beta)nTi的(1+ϵ)(1+β)估计。于是乎,经过改造的算法如下所示:
- 从V中抽取样本S,∣S∣=O~(Lρϵ2),L=poly(lognϵ),ρ=1tϵ4⋅αn|S| = \tilde{O}(\frac{L}{\rho\epsilon^2}),L=poly(\frac{log\ n}{\epsilon}),\rho = \frac{1}{t}\sqrt{\frac{\epsilon}{4}\cdot \frac{\alpha}{n} }∣S∣=O~(ρϵ2L),L=poly(ϵlog n),ρ=t14ϵ⋅nα
- Si←S∩BiS_i \gets S \cap B_iSi←S∩Bi
- fori∈{0,…,t−1}do\boldsymbol{for}\ i \in \{0,\dots,t-1\}\ \boldsymbol{do}for i∈{0,…,t−1} do
- if∣Si∣≥θρthen\boldsymbol{if}\ |S_i| \geq \theta_\rho\ \boldsymbol{then}if ∣Si∣≥θρ then
- ρi←∣Si∣∣S∣\rho_i \gets \frac{|S_i|}{|S|}ρi←∣S∣∣Si∣
- estimateΔiestimate\ \Delta_iestimate Δi
- else\boldsymbol{else}else
- ρi←0\rho_i\gets 0ρi←0
- if∣Si∣≥θρthen\boldsymbol{if}\ |S_i| \geq \theta_\rho\ \boldsymbol{then}if ∣Si∣≥θρ then
- returndˉ^=∑i=0t−1(1+Δi)ρi(1+β)i\boldsymbol{return}\ \hat{\bar{d} } = \sum_{i=0}^{t-1}(1+\Delta_i)\rho_i(1+\beta)^{i}return dˉ^=∑i=0t−1(1+Δi)ρi(1+β)i
2.4 计算图的平均度算法四
Alg III
利用E[Δi]E[\Delta_i]E[Δi]的1+ϵ1+\epsilon1+ϵ估计,可以得到Δiρi(1+β)i\Delta_i\rho_i(1+\beta)^iΔiρi(1+β)i是Tin的(1+ϵ)(1+β)\frac{T_i}{n}的(1+\epsilon)(1+\beta)nTi的(1+ϵ)(1+β)估计。于是乎,经过改造的算法如下所示:
- 从V中抽取样本S,∣S∣=O~(Lρϵ2),L=poly(lognϵ),ρ=1tϵ4⋅αn|S| = \tilde{O}(\frac{L}{\rho\epsilon^2}),L=poly(\frac{log\ n}{\epsilon}),\rho = \frac{1}{t}\sqrt{\frac{\epsilon}{4}\cdot \frac{\alpha}{n} }∣S∣=O~(ρϵ2L),L=poly(ϵlog n),ρ=t14ϵ⋅nα
- Si←S∩BiS_i \gets S \cap B_iSi←S∩Bi
- fori∈{0,…,t−1}do\boldsymbol{for}\ i \in \{0,\dots,t-1\}\ \boldsymbol{do}for i∈{0,…,t−1} do
- if∣Si∣≥θρthen\boldsymbol{if}\ |S_i| \geq \theta_\rho\ \boldsymbol{then}if ∣Si∣≥θρ then
- ρi←∣Si∣∣S∣\rho_i \gets \frac{|S_i|}{|S|}ρi←∣S∣∣Si∣
- estimateΔiestimate\ \Delta_iestimate Δi
- else\boldsymbol{else}else
- ρi←0\rho_i\gets 0ρi←0
- if∣Si∣≥θρthen\boldsymbol{if}\ |S_i| \geq \theta_\rho\ \boldsymbol{then}if ∣Si∣≥θρ then
- returndˉ^=∑i=0t−1(1+Δi)ρi(1+β)i\boldsymbol{return}\ \hat{\bar{d} } = \sum_{i=0}^{t-1}(1+\Delta_i)\rho_i(1+\beta)^{i}return dˉ^=∑i=0t−1(1+Δi)ρi(1+β)i
Alg IV
- α←n\alpha \gets nα←n
- dˉ^<−∞\hat{\bar{d} } < -\inftydˉ^<−∞
- whiledˉ^<αdo\boldsymbol{while}\ \hat{\bar{d} } < \alpha\ \boldsymbol{do}while dˉ^<α do
- α←α/2\alpha \gets \alpha/2α←α/2
- ifα<1nthen\boldsymbol{if}\ \alpha < \frac{1}{n}\ \boldsymbol{then}if α<n1 then
- return0;\boldsymbol{return}\ 0;return 0;
- dˉ^←AlgIII∼α\hat{\bar{d} } \gets AlgIII_{\sim \alpha}dˉ^←AlgIII∼α
- returndˉ^\boldsymbol{return}\ \hat{\bar{d} }return dˉ^
算法相关指标
近似比:(1+ϵ)(1 + \epsilon)(1+ϵ)
运行时间:O~(n)⋅poly(ϵ−1logn)n/dˉ\tilde{O}(\sqrt{n})\cdot poly(\epsilon^{-1}log\ n)\sqrt{n/\bar{d} }O~(n)⋅poly(ϵ−1log n)n/dˉ
2.5 近似最小支撑树
定义
已知:G=(V,E),ϵ,d=deg(G)G=(V,E),ϵ,d=deg(G)G=(V,E),ϵ,d=deg(G),边(u,v)的权重是wuv∈{1,2,…,w}∪{∞}w_{uv}∈\{1,2,…,w\}∪\{∞\}wuv∈{1,2,…,w}∪{∞}
求:M^\hat{M}M^满足(1−ϵ)M≤M^≤(1+ϵ)M(1−ϵ)M≤\hat{M}≤(1+ϵ)M(1−ϵ)M≤M^≤(1+ϵ)M,令M为minTspansGW(T)min_{TspansG}{W(T)}minTspansGW(T)
分析
定义:
G的子图G(i)=(V,E(i))G^{(i)}=(V,E^{(i)})G(i)=(V,E(i))
E(i)={(u,v)∣wuv≤i}E(i)=\{(u,v)|w_{uv}≤i\}E(i)={(u,v)∣wuv≤i}
连通分量的个数为C(i)
定理:若M为所有这样的子图的连通分量的数目的和,M=n−w+∑i=1w−1C(i)M=n-w+\sum_{i=1}^{w-1}{C^{(i)} }M=n−w+∑i=1w−1C(i)
证明:设图G的一个最小生成树为MST=(V,E′)MST=(V,E')MST=(V,E′),MST的子图MST(i)=(V′,E′(i)),V′=V,E′(i)={(u,v)∣(u,v)∈E(i)&(u,v)∈E′}MST^{(i)} = (V',E'^{(i)}),V'=V,E'^{(i)}=\{(u,v)|(u,v) \in E^{(i)} \And (u,v) \in E'\}MST(i)=(V′,E′(i)),V′=V,E′(i)={(u,v)∣(u,v)∈E(i)&(u,v)∈E′}
设αiα_iαi为MST 中权重为i的边的数目
∑i>1αi\sum_{i>1}{\alpha_i}∑i>1αi表示MST中所有边权大于1的边的个数,这个数值加1,应该就是在MST中将这些边从MST中去掉之后得到的MST(l)MST^{(l)}MST(l)中的连通分量的个数
MST(l)MST^{(l)}MST(l)的连通分量的个数应该与G(i)是一致的,于是我们得到了下面的式子:∑i>1αi=C(l)−1\sum_{i>1}{\alpha_i}=C^{(l)}-1∑i>1αi=C(l)−1。
于是我们就可以用如下的方法计算M了:
M=∑i=1wi⋅αi=∑i=1wαi+∑i=2wαi+⋯+∑i=wwαi=C(0)−1+C(1)−1+⋯+C(w−1)−1=n−1+C(1)−1+⋯+C(w−1)−1=n−w+∑i=1w−1C(i)\begin{align*} M &= \sum_{i=1}^{w}{i \cdot \alpha_i}=\sum_{i=1}^{w}{\alpha_i} + \sum_{i=2}^{w}{\alpha_i} + \dots + \sum_{i=w}^{w}{\alpha_i}\\ &= C^{(0)}-1 + C^{(1)}-1 + \dots + C^{(w-1)}-1\\ &= n-1+C^{(1)}-1 + \dots + C^{(w-1)}-1\\ &= n-w+\sum_{i=1}^{w-1}{C^{(i)} } \end{align*} M=i=1∑wi⋅αi=i=1∑wαi+i=2∑wαi+⋯+i=w∑wαi=C(0)−1+C(1)−1+⋯+C(w−1)−1=n−1+C(1)−1+⋯+C(w−1)−1=n−w+i=1∑w−1C(i)
时间复杂度
运行w次求解连通分量个数的时间复杂度:w⋅O(d/ϵ3)=O(dw4/ϵ′3)w\cdot O(d/\epsilon^3)=O(dw^4/\epsilon'^3)w⋅O(d/ϵ3)=O(dw4/ϵ′3)。
2.6 求点集合的直径
定义:
已知:有m个点,点与点之间的距离使用邻接矩阵表示,则Dij表示点i到点j的距离,D是一个对称矩阵,并且满足三角不等式Dij≤Dik+DkjD_{ij} \leq D_{ik} + D_{kj}Dij≤Dik+Dkj。
求出:点对(i,j)使得Dij是最大的,则Dij是这m个点的集合的直径。
求解算法:The Indyk’s Algorithm
- 任选k∈[1,m]k∈[1,m]k∈[1,m]
- 选出lll,使得∀i,Dki≤Dkl\forall i,D_{ki} \leq D_{kl}∀i,Dki≤Dkl
- 返回(k,l),Dkl(k,l),D_{kl}(k,l),Dkl
算法分析之近似比分析
最优解记为 opt,是点 i 和点 j 之间的距离
则有opt2≤Dkl≤opt\frac{opt}{2} \leq D_{kl} \leq opt2opt≤Dkl≤opt
算法分析之近似比证明不等式
关于不等式的右侧易证,左侧的证明如下所示:
opt=Dij≤Dik+Dkj≤Dkl+Dkl≤2Dkl\begin{align*} opt = &D_{ij}\\ \leq &D_{ik} + D_{kj}\\ \leq &D_{kl} + D_{kl}\\ \leq &2D_{kl} \end{align*} opt=≤≤≤DijDik+DkjDkl+Dkl2Dkl
算法评价
算法的时间复杂度为O(m)=O(n)O(m) = O(\sqrt{n})O(m)=O(n)。
2.7 求连通分量的数目
定义
已知:G=(V,E),ϵ,d=deg(G)G = (V,E),\epsilon,d = deg(G)G=(V,E),ϵ,d=deg(G),图G用邻接表表示,其中d表示所有节点中度最大的节点的度,∣V∣=n,∣E∣=m≤d⋅n|V| = n,|E| = m \leq d\cdot n∣V∣=n,∣E∣=m≤d⋅n
求出:一个y,使得C−ϵ⋅n≤y≤C+ϵ⋅nC - \epsilon \cdot n \leq y \leq C + \epsilon \cdot nC−ϵ⋅n≤y≤C+ϵ⋅n,其中C为使用线性算法求解得到的标准解
问题分析
记顶点v所属的连通分量中的节点数目为nvn_vnv,A∈V是一个连通分量的点集合,则存在如下等式关系:∑u∈A1nu=∑u∈A1∣A∣=1\sum_{u \in A}{\frac{1}{n_u} } = \sum_{u \in A}{\frac{1}{|A|} } = 1∑u∈Anu1=∑u∈A∣A∣1=1,这个很容易证明,因为同一个连通分量中的每一个点的nvn_vnv是一样的,都是分量中点的个数的倒数。如此,则最终的结果C可以表示为∑u∈V1nu\sum_{u\in V}{\frac{1}{n_u} }∑u∈Vnu1。因此进一步地,对C的估计可以转化为对1nu\frac{1}{n_u}nu1的估计。
求解问题的思想
nun_unu很大,精确计算很难,但是此时1nu\frac{1}{n_u}nu1很小,可以用一个很小的常量代替1nu\frac{1}{n_u}nu1(0或者ϵ2\frac{\epsilon}{2}2ϵ),如果我设nu^=min{nu,2ϵ}\hat{n_u} = min\{n_u,\frac{2}{\epsilon}\}nu^=min{nu,ϵ2},则C^=∑u∈V1nu^\hat{C} = \sum_{u \in V}{\frac{1}{\hat{n_u} } }C^=∑u∈Vnu^1,使用C^\hat{C}C^来估计C可以获得很不错的结果。
算法-计算nu^\hat{n_u}nu^
思想很简单,就是一个小型的搜索,如果搜索到的点的个数小于2ϵ\frac{2}{\epsilon}ϵ2就继续搜索,否则直接返回2ϵ\frac{2}{\epsilon}ϵ2。
时间复杂度为O(d⋅1ϵ)O(d\cdot \frac{1}{\epsilon})O(d⋅ϵ1),d越大,用的时间越长,1ϵ\frac{1}{\epsilon}ϵ1越大,用的时间越长。
算法-计算nun_unu
从节点集合中随机选出r=b/ϵ2r = b/{\epsilon}^2r=b/ϵ2个节点构成节点U,对每个节点应用上一个算法,于是最终的C^=nr∑u∈U1nu^\hat{C} = \frac{n}{r} \sum_{u \in U}{\frac{1}{\hat{n_u} } }C^=rn∑u∈Unu^1,时间复杂度为O(d/ϵ3)O(d/{\epsilon}^3)O(d/ϵ3)
3 并行计算算法
3.1 基本问题(一)
MapReduce
使用MR模型进行计算有几个要点:
- 计算分轮次进行,每一轮的输入和输出的数据都是形如<key,value>的
- 每一轮分为:Map、Shuffle、Reduce
- Map:每个数据被
map函数处理,输出一个新的数据集合,也就是改变了<key,value> - Shuffle:对编程人员透明,所有在Map中输出的数据,被按照
key分组,具备相同key的数据被分配到相同的reducer - Reduce:输入<k,v1,v2,…>,输出新的数据集合
- 针对这样的计算框架,我们的设计目标为:更少的轮数、更少的内存、更大的并行度
问题实例
下面我们来看一些具体的问题实例,这些例子都是可以并行的,当然实现的逻辑不止一种,有多种可能性,这里只是给出一种方法。
构建倒排索引
定义:给定一组文档,统计每一个单词出现在哪些文件中
- Map函数:<docID,content>→<word,docID><docID,content> \rightarrow <word,docID><docID,content>→<word,docID>,在map函数处理的时候对content进行拆分,并将分出来的word都转换成word加上对应的docID输出。
- Reduce函数:<word,docID>→<word,listofdocID><word,docID> \rightarrow <word,list\ of\ docID><word,docID>→<word,list of docID>,map函数结束之后,shuffle会自动将key相同的键值对输出到一个机器上,我们直接对这个批次中的数据规整到一起即可。
单词计数
定义: 给定一组文档,统计每一个单词出现的次数
- Map函数:<docID,content>→<word,1>
- Reduce函数:<word,1>→<word,count>
检索
定义:给定行号和相应的文档内容,统计指定单词出现的位置(*行号)
- Map函数:略
- Reduce函数:略
3.2 基本问题(二)
简介
问题实例:矩阵乘法
就是简单的矩阵乘法,我们知道,普通的矩阵乘法的时间复杂度是O(m⋅n⋅d),对于一个m⋅d和d⋅n的矩阵相乘。通过并行计算框架我们极大加速这个过程的执行,具体的两个方法如下面所示
矩阵乘法1
定义:矩阵A和矩阵B,(A,i,j)指向矩阵A的第i行j列的元素,但并不是真实的这个元素,而是表示一种索引,aij表示的则是这个元素。
- Map:
- ((A,i,j),aij)→(j,(A,i,aij))
- ((B,j,k),bjk)→(j,(B,k,bjk))
- Reduce:(j,(A,i,aij)),(j,(B,k,bjk))→((i,k),aij∗bjk)
- Map:nothing(identity)
- Reduce:((i,k),(v1,v2,…))→((i,k),∑vi)
思路剖析:目标矩阵上的每个元素都是由d个中间元素(aij∗bjk)累加得到的,我们先统把这样的所有的元素求出来,然后累加起来即可。对于目标矩阵上的每个元素都是如此。
矩阵乘法2
-
Map函数:
- ((A,i,j),aij)→((i,x),(A,j,aij)) for all x∈[1,n]
- ((B,j,k),bjk)→((y,k),(B,j,bjk)) for all y∈[1,m]
-
Reduce函数:((i,k),(A,j,aij))∧((i,k),(B,j,bjk))→((i,k),∑aij∗bjk)
思路剖析:相对于第一个方法,方法2先不把中间元素求出来,而是把求解每个目标矩阵上要用到的2d个基本元素都放到一起,然后进行点积操作。
3.3 排序算法
问题简介
算法
使用p台处理器,输入<i,A[i]><i,A[i]><i,A[i]>
-
Map:<i,A[i]>→<j,((i,A[i]),y)><i,A[i]> \rightarrow <j,((i,A[i]),y)><i,A[i]>→<j,((i,A[i]),y)>
-
输出<i%p,((i,A[i]),0)><i\%p,((i,A[i]),0)><i%p,((i,A[i]),0)>
-
以概率T/n为所有j∈[0,p−1]j ∈ [0, p − 1]j∈[0,p−1]输出<j,((i,A[i]),1)><j,((i,A[i]),1)><j,((i,A[i]),1)>
否则输出<j,((i,A[i]),0)><j,((i,A[i]),0)><j,((i,A[i]),0)>
-
-
Reduce:
- 将y=1的数据收集为S并排序
- 构造(s1,s2,...,sp−1)(s_1,s_2,...,s_{p−1})(s1,s2,...,sp−1),sks_ksk为S中第k⌈∣S∣p⌉k\left \lceil \frac{|S|}{p} \right \rceilk⌈p∣S∣⌉
- 将y=0的数据收集为D
- (i,x)∈D满足sk<x≤sk+1s_k < x \leq s_{k+1}sk<x≤sk+1,输出<k,(i,x)>
-
Map:nothing(identity)
-
Reduce:$ <j, ((i, A[i]), . . . )>$
- 将所有(i,A[i])(i, A[i])(i,A[i])根据$ A[i]$排序并输出
思路剖析:整体的思路就是先对整个数据进行一个划分,分成不同的小段,段与段之间的数据具有严格的大小关系,这样每个段内部的数据都是一些很接近的数据,如此我们就可以借助一些高效的排序手段对每个段内部的数据集进行排序。然后**解决问题的一个关键就是,我们对数据的划分的好坏,这一点我们可以通过理论来证明有很大概率可以保证划分的效果。**但是也不绝对,出现某个计算节点上基本没有数据,而另一个计算节点上出现超量的数据也是有可能的,当然这是极小概率事件。
3.4 计算最小支撑树(生成树)
问题简介
已知图G=(V,E),其中V,E分别是图的点集合和边集合。图G的一个子图T∗=(V,E′)T^*=(V,E')T∗=(V,E′)被称为最小生成树当且仅当T∗T^∗T∗是连通的并且∑(u,v)∈T∗w(u,v)=minT{∑(u,v)∈Tw(u,v)}\sum_{(u,v)\in T^*}{w(u,v)} = \min_{T}\{\sum_{(u,v)\in T}{w(u,v)}\}∑(u,v)∈T∗w(u,v)=minT{∑(u,v)∈Tw(u,v)}。
在小数据范围内,通常使用Kruskal或Prim算法求解,当图的规模变得较大时,由于这两个算法的复杂度的限制,在有限时间内将无法求解。这时可以借助MapReduce来加速计算。
算法主要思想
利用图划分算法,将图G划分成k个子图,在每个子图中计算最小生成树,具体如下。
- 将节点分成k部分,对每一个(i,j)∈[k]2(i,j)\in [k]^2(i,j)∈[k]2,令Gij=(Vi∪Vj,Eij)G_{ij} = (V_i\cup V_j,E_{ij})Gij=(Vi∪Vj,Eij)为节点Vi∪VjV_i\cup V_jVi∪Vj上的导出子图
- 在每个Gij上分别求解Mij=MSF(Gij)M_{ij}=MSF(G_{ij})Mij=MSF(Gij)
- 令H=∪i,jMijH = \cup_{i,j}M_{ij}H=∪i,jMij,计算M=MST(H)M=MST(H)M=MST(H)
注:MSF指的是最小生成森林,举个例子来说明这个概念,在一个最小生成树中有n−1条边,可以理解为是一个只有一棵树的最小生成森林。同理,在同一个图中也存在有两棵树、三棵树的最小生成森林,只要这个森林是min{∑(u,v)∈Forestw(u,v)}\min\{\sum_{(u,v)\in Forest}w(u,v)\}min{∑(u,v)∈Forestw(u,v)}就可以。
本质上讲,算法的本质就是先在局部算好生成树,然后用剩余的连接这些生成树的边组成一个新的图,并求出这个新的图的最小生成树作为最总的结果。
MR算法
- Map:input:<(u,v),NULL>
- 转化<(h(u),h(v));(u,v)>
- 针对上述转化数据,如果h(u)=h(v),则对所有j∈[1,k],输出<(h(u),j);(u,v)>
- Reduce:input:<(i,j);Eij>
- 令Mij=MSF(Gij)
- 对Mij中的每条边e=(u,v)输出<NULL;(u,v)>
- Map:nothing(identity)
- Reduce:M=MST(H)
其中h是哈希函数,可以用一个取值均匀的随机算法实现(ps:用随机算法生成哈希表,而不是每次运行都随机取值)。
当然在划分时还要考虑各个计算节点的负载均衡问题。
4 外存模型算法
4.1 外存模型
外存模型
到目前为止,按照存储模型,我们学过的算法模型应该分为两种:一种是RAM模型,也就是我们常用的算法的设计模型,另一种是I/O模型,内存比数据量小,外存是无限的。
外存访问与内存访问有一些差异:
- 与外存相比,内存的速度更快
- 外存的连续访问比随机访问代价小,也就是说:以块(block)为单位访问
基于外存模型的基本问题
在I/O模型中,内存的大小为M,页面大小为B,外存大小无限,页面大小为B。
连续读取外存上的N个数据,需要O(N/B)次I/O
如何计算矩阵乘法?
输入两个大小为N×N的矩阵X和Y
- 将矩阵分为大小为M/2×M/2\sqrt{M}/2\times\sqrt{M}/2M/2×M/2的块
- 考虑X×Y矩阵中的每个块,显然共有O((NM)2)O((\frac{N}{\sqrt{M} })^2)O((MN)2)个块需要输出
- 每个块需要扫描NM\frac{N}{\sqrt{M} }MN对输入块
- 每次内存计算需要O(M/B)次I/O
- 共计O((NM)3⋅M/B)O((\frac{N}{\sqrt{M} })^3\cdot M/B)O((MN)3⋅M/B)次I/O
链表
进行三种操作:insert(x,p),remove§,traverse(p,k)
内存模型下各个操作的时间复杂度:updateO(1),traverseO(k)
在外存模型下,将一个链表中连续的元素放在一个大小为B的块中。同时,令每个块大小至少为B/2:
- remove:删除后如果小于B/2,与邻接的块合并,合并后如果大于B,则平均划分
- insert:插入后如果大于B,则平均划分
- traverse:O(2k/B)
搜索结构
进行三种操作:insert(x),remove(x),query(x)
(a,b)−tree:2≤a≤(b+1)/2(a,b)-tree:2\leq a \leq (b+1)/2(a,b)−tree:2≤a≤(b+1)/2
类似二分查找树⇒(p0,k1,...,kc,pc)\Rightarrow (p_0,k_1,...,k_c,p_c)⇒(p0,k1,...,kc,pc)
root节点有0个或者≥2个孩子;除了root,每个非叶子节点的孩子数目∈[a,b]:
- remove:找到对应叶子节点,删除后如果小于a,与邻接的块合并,合并后如果大于b,平均划分,进而在上一层递归删除节点或者调整键值
- insert:找到对应叶子节点,插入后如果大于b,平均划分,递归向上一层插入
- query:O(loga(N/a))query:O(log_a(N/a))query:O(loga(N/a))
4.2 外存排序
外存排序问题
考虑外存排序算法的时候要与外存模型紧密地结合起来。
算法
- 给定N个数据,将其分成大小为O(M)的组
- 每一组数据可以在内存排序
- 将每一组数据从外存读进来需要O(M/B)次I/O
- 对所有分组进行以上操作,于是每个分组内部都是已经排好序的数据
- 对这些排好序的分组进行多路归并排序
- 每次可以归并O(M/B)个分组
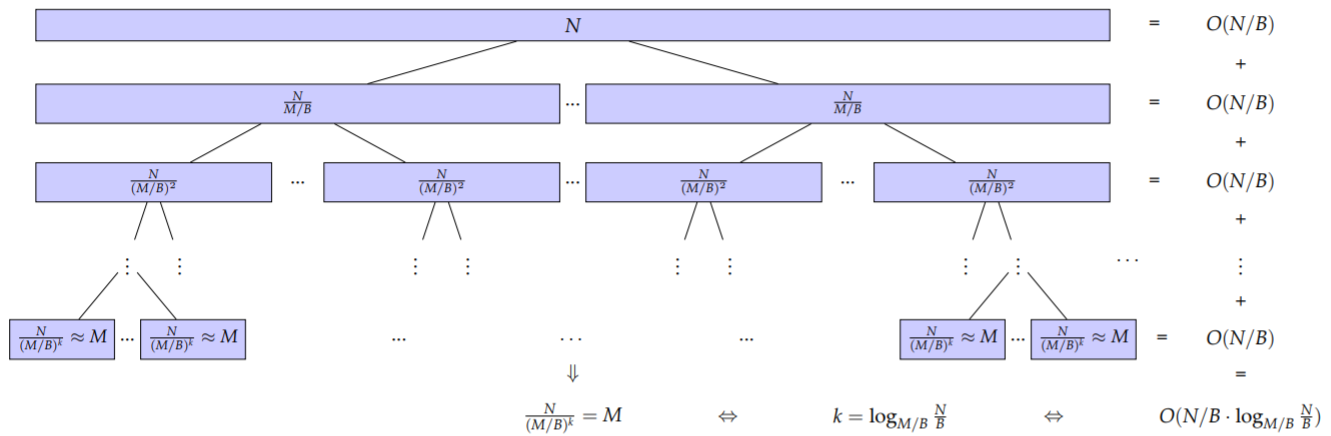
过程解释
首先需要明白的一点是从外存向内存转移数据的时候,一次只能转移B的数据量。于是,要想一次把内存读慢,相应的I/O次数就是O(M/B)。另外进行多路归并排序时,至多可以归并多少分组。从每个分组读出来一个页面,然后进行排序,所以这里跟每个分组的大小没有关系,只跟内存的大小有关,所以是O(M/B)。
图示
评价
时间复杂度分为两个部分,一个是分组内排序,另一个是分组间归并排序。
- 对于分组内排序,只需要将每个分组的数据读入内存即可,这部分对应的时间复杂度为O(N/B)O(N/B)O(N/B)。
- 对于归并排序,相应的时间代价应该是每一趟归并的开销之和,而每一趟归并都需要把所有数据都导入到内存中一次,这个时间代价为O(N/B)O(N/B)O(N/B)。而归并的趟数可以表示为O(logM/BNB)O(log_{M/B}\frac{N}{B})O(logM/BBN)。综上所述:总的时间开销为:O(N/B⋅logM/BNB)O(N/B \cdot log_{M/B}\frac{N}{B})O(N/B⋅logM/BBN)
4.3 List Ranking
List Ranking
定义
[List Ranking Problem]:给定大小为N的邻接链表L,L存储在数组(连续的外存空间)中,计算每个节点的rank(在链表中的序号)。
[General List Ranking Problem]:给定大小为N的邻接链表L,L存储在数组(连续的外存空间)中,L中的每个节点v上存储权重wvw_vwv,计算每个节点v的rank(从头节点到v的权重和)
分析
- 如果合并链表上的子序列为一个节点(也就是页面内部合并,将一个页面当作一个节点),将权重和做为该节点的权重,不影响前后节点的rank 值。
- 如果链表大小至多为M,那么利用O(M/B)次I/O可解决这个问题,也就是将所有的数据都读入内存,使用内存算法解决这个问题。
我们通过一个图片来看一下对这个问题的直观理解,如下图所示,相关数据为:N=10,B=2,M=4。最坏的情况下访问代价为O(N)次I/O 。

算法
输入大小为N的外存链表L
- 寻找L中的一个顶点独立集 X
- 将X中的节点“跳过”,构建新的、更小的外存链表L′
- 递归地求解L′
- 将X中的节点“回填”,根据L′的rank构建L的rank
第1.1.4步骤都可以在O(sort)=O(NBlogMBNB)O(sort) = O(\frac{N}{B}log_{\frac{M}{B} }{\frac{N}{B} })O(sort)=O(BNlogBMBN)次I/O求解,则构建如下递归方程:
T(N)=T((1−α)N)+O(NBlogMBNB)T(N) = T((1-\alpha)N) + O(\frac{N}{B}log_{\frac{M}{B} }{\frac{N}{B} })T(N)=T((1−α)N)+O(BNlogBMBN),解方程得:T(N)=O(NBlogMBNB)T(N) = O(\frac{N}{B}log_{\frac{M}{B} }{\frac{N}{B} })T(N)=O(BNlogBMBN)
step~1
按照节点的ID顺序,分为forward(f)链表和backward(b)链表,将f链表按照red,blue间隔染色,将b链表按照green,blue间隔染色。注意这里的f链表和b链表指的是链表的一个连续段,该段内的数据的ID顺序关系要么全部与内存中的位置一致,要么正好相反。显然,一个链表中有多个f链表和b链表。
这一步的实现只需要进行一个外存排序即可实现,因此时间代价为O(NBlogMBNB)O(\frac{N}{B}log_{\frac{M}{B} }{\frac{N}{B} })O(BNlogBMBN)。
step~2,4
- L~=copy(L)\tilde{L} = copy(L)L~=copy(L)
- 将链表L按照后继节点的地址排序,排序的同时进行如下操作
- 在step~2,将后继节点属于X的节点指针和权重重写
- 在step~4,将后继节点属于X的节点指针和权重重写,将属于X的节点权重重写
存,使用内存算法解决这个问题。
我们通过一个图片来看一下对这个问题的直观理解,如下图所示,相关数据为:N=10,B=2,M=4。最坏的情况下访问代价为O(N)次I/O 。
算法
输入大小为N的外存链表L
- 寻找L中的一个顶点独立集 X
- 将X中的节点“跳过”,构建新的、更小的外存链表L′
- 递归地求解L′
- 将X中的节点“回填”,根据L′的rank构建L的rank
第1.1.4步骤都可以在O(sort)=O(NBlogMBNB)O(sort) = O(\frac{N}{B}log_{\frac{M}{B} }{\frac{N}{B} })O(sort)=O(BNlogBMBN)次I/O求解,则构建如下递归方程:
T(N)=T((1−α)N)+O(NBlogMBNB)T(N) = T((1-\alpha)N) + O(\frac{N}{B}log_{\frac{M}{B} }{\frac{N}{B} })T(N)=T((1−α)N)+O(BNlogBMBN),解方程得:T(N)=O(NBlogMBNB)T(N) = O(\frac{N}{B}log_{\frac{M}{B} }{\frac{N}{B} })T(N)=O(BNlogBMBN)
step~1
按照节点的ID顺序,分为forward(f)链表和backward(b)链表,将f链表按照red,blue间隔染色,将b链表按照green,blue间隔染色。注意这里的f链表和b链表指的是链表的一个连续段,该段内的数据的ID顺序关系要么全部与内存中的位置一致,要么正好相反。显然,一个链表中有多个f链表和b链表。
这一步的实现只需要进行一个外存排序即可实现,因此时间代价为O(NBlogMBNB)O(\frac{N}{B}log_{\frac{M}{B} }{\frac{N}{B} })O(BNlogBMBN)。
step~2,4
- L~=copy(L)\tilde{L} = copy(L)L~=copy(L)
- 将链表L按照后继节点的地址排序,排序的同时进行如下操作
- 在step~2,将后继节点属于X的节点指针和权重重写
- 在step~4,将后继节点属于X的节点指针和权重重写,将属于X的节点权重重写
- 将L重新按照地址排序
相关文章:
大数据算法重点
1 大数据亚线性空间算法 场景:用二进制存储一个数字N,需要log(N)的空间 问题:如果N特别大而且这样的N又特别的多,该怎么办呢? 思路:减少一些准确性,从而节省更多的空间。 解决办法:使…...

【Eclipse】The import xxxx cannot be resolved 问题解决
在Eclipse使用过程中,某一个类明明存在,但是使用import导入时,却总是提示The import xxxx cannot be resolved的错误,解决办法如下: 点击Project->Clean......

LinkWeChat系统Docker版部署注意事项
具体部署手册:https://www.yuque.com/linkwechat/help/ffi7bu注意事项:启动类配置文件路径需要修改,各个模块启动类原配置如下:.properties("spring.config.name:bootstrap", "config/run/bootstrap.yml")各个…...

【高数】不定积分之有理函数的积分
文章目录前言有理函数积分的通用解法有理函数的特殊解法前言 这个专栏开始更新高等数学的解题方法,本专栏没有特别强调概念,主要是让大家熟悉考研中的一些题型以及如何求解 关键步骤用蓝色高亮提示 总结方法用红色高亮提示 注意事项用绿色高亮提示 希望…...
Java——数组
目录 前言 一、数组的定义 二、数组声明和创建 三、三种初始化及内存分析 Java内存分析 三种初始化 静态初始化 动态初始化 数组的默认初始化 数组的四个基本特点 四、下标越界及小结 五、数组的使用 For-Each循环 数组作方法入参 数组作返回值 六、二维数组 七…...

产品分析|虎扑APP
不同于传统的体育新闻门户网站,虎扑以篮球社区起家,在经历了从体育论坛到体育新闻网站的发展后,又逐渐回归社区发展。 目前,虎扑汇聚了大量的男性用户,俨然成为了“互联网直男的自留地”。特立独行的发展方向使得虎扑不断发展壮大,同时也使得虎扑逐渐触碰到了行业天花板。…...

有限差分法-二维泊松方程及其Matlab程序实现
2.2 偏微分方程的差分解法 2.2.1 二维泊松方程 考虑区域 Ω \Omega Ω 上的二维泊松问题: { − ( ∂ 2...
【设计模式】6.代理模式
概述 代理模式:为一个对象提供一个替身,以控制对这个对象的访问。即通过代理访问目标对象 这样做的好处是:可以在目标对象实现的基础上,增强额外的功能操作,即扩展目标对象的功能。 被代理的对象可以是:远程对象、创建开销大的对象或需要安全…...
SRC挖掘之Access验证校验的漏洞挖掘
漏洞已修复,感谢某大佬的知识分享。 任意用户密码重置->可获取全校师生个人mingan信息 开局就是信息收集。 对于挖掘edu的信息收集 1.可尝试谷歌搜索语法,获取学号信息 2. 旁站的渗透获取 3. 学校的贴吧获取(大部分都是本校学生) 当然我就是闲&a…...

GG-21 100V 5A逆功率继电器
1 用途 GG-21逆功率继电器在出现逆功率时,从电网中断开交流发电机。 2 概述 逆功率继电器是基于感应式原理(具有旋转磁场)而工作。 继电器导磁体由两个磁路系统组成:上磁路系统和下磁路系统。电流线圈安装在上磁路系统中,它由接在发电机某相的…...

MyBatis中#{}和${}的区别
目录 前言 1、处理参数的方式不同 2、${}的优点 3、SQL注入问题 4、like查询问题 前言 #{}和${}都可以在MyBatis中用来动态地接收参数,但二者在本质上还是有很大的区别。 1、处理参数的方式不同 ${} :预编译处理 MyBatis在处理#{}时,…...

ElementUi的使用
ElementUi使用说明 element ui安装与配置 npm i element-ui –S项目入口文件main.js 导入 Element-UI 相关资源// 导入组件库 import ElementUI from element-ui; // 导入组件相关样式 import element-ui/lib/theme-chalk/index.css; // 配置 Vue 插件 Vue.use(ElementUI);文档…...
)
termux手机端安装mysql(MariaDB)
目录1 下载MariaDB2 配置MariaDB3 启动MariaDB服务器查看进程pid杀死进程4 登录 Mysqltermux用户登录MySQLroot用户登录MySQL5 配置 MariaDB 远程登录创建一个可远程登录的用户:用户授权:刷新授权:6 停止 MariaDB 服务器7 可选,但…...
)
Python枚举类定义和使用(详解版)
一些具有特殊含义的类,其实例化对象的个数往往是固定的,比如用一个类表示月份,则该类的实例对象最多有 12 个;再比如用一个类表示季节,则该类的实例化对象最多有 4 个。 针对这种特殊的类,Python 3.4 中新…...
京东HBase异地多活调研
京东HBase平台架构 HBase Replication原理 HBase的Replication是基于WAL日志文件的,在主集群中的每个RegionServer上,由ReplicationSource线程来负责推送数据,在备集群的RegionServer上由ReplicationSink线程负责接收数据。ReplicationSourc…...
【LeetCode】剑指 Offer 18. 删除链表的节点(题目一) p119 -- Java Version
题目链接:https://leetcode.cn/problems/shan-chu-lian-biao-de-jie-dian-lcof/ 1. 题目介绍(18. 删除链表的节点) 给定单向链表的头指针和一个要删除的节点的值,定义一个函数删除该节点。 返回删除后的链表的头节点。 注意&…...

SpringMVC异步请求
背景 Tomcat等应用服务器的连接线程池实际上是有限制的;每一个连接请求都会耗掉线程池的一个连接数;如果某些耗时很长的操作,如对大量数据的查询操作、调用外部系统提供的服务以及一些 IO 密集型操作等,会占用连接很长时间&#…...

这七个100%提高Python代码性能的技巧,一定要知道
B站|公众号:啥都会一点的研究生 相关阅读 整理了几个100%会踩的Python细节坑,提前防止脑血栓 整理了十个100%提高效率的Python编程技巧,更上一层楼 Python-列表,从基础到进阶用法大总结,进来查漏补缺 Python-元组&…...

计算机网络笔记、面试八股(五)—— 浏览器输入URL
本章目录5. 从输入URL到浏览器显示页面过程中都发生了什么5.1 URL输入5.2 DNS解析5.2.1 域名的等级5.2.2 DNS解析的流程5.2.3 DNS查询方式5.3 建立TCP连接5.4 发送HTTP/HTTPS请求5.5 服务器处理请求并返回HTTP响应5.6 浏览器解析渲染页面5.7 HTTP请求结束,断开TCP连…...

【速记】快速调通算法项目的环境
1.创建新的conda环境,避免把原有的环境给搞坏。 在CMD中执行,而不是在anaconda的命令行中执行: conda create -n 环境名 --offline python3.8 2.在pycharm中配置conda环境: setting->Project Interpreter->齿轮->add-&g…...

【Oracle APEX开发小技巧12】
有如下需求: 有一个问题反馈页面,要实现在apex页面展示能直观看到反馈时间超过7天未处理的数据,方便管理员及时处理反馈。 我的方法:直接将逻辑写在SQL中,这样可以直接在页面展示 完整代码: SELECTSF.FE…...

ElasticSearch搜索引擎之倒排索引及其底层算法
文章目录 一、搜索引擎1、什么是搜索引擎?2、搜索引擎的分类3、常用的搜索引擎4、搜索引擎的特点二、倒排索引1、简介2、为什么倒排索引不用B+树1.创建时间长,文件大。2.其次,树深,IO次数可怕。3.索引可能会失效。4.精准度差。三. 倒排索引四、算法1、Term Index的算法2、 …...

深入理解Optional:处理空指针异常
1. 使用Optional处理可能为空的集合 在Java开发中,集合判空是一个常见但容易出错的场景。传统方式虽然可行,但存在一些潜在问题: // 传统判空方式 if (!CollectionUtils.isEmpty(userInfoList)) {for (UserInfo userInfo : userInfoList) {…...
协议转换利器,profinet转ethercat网关的两大派系,各有千秋
随着工业以太网的发展,其高效、便捷、协议开放、易于冗余等诸多优点,被越来越多的工业现场所采用。西门子SIMATIC S7-1200/1500系列PLC集成有Profinet接口,具有实时性、开放性,使用TCP/IP和IT标准,符合基于工业以太网的…...
 Module Federation:Webpack.config.js文件中每个属性的含义解释)
MFE(微前端) Module Federation:Webpack.config.js文件中每个属性的含义解释
以Module Federation 插件详为例,Webpack.config.js它可能的配置和含义如下: 前言 Module Federation 的Webpack.config.js核心配置包括: name filename(定义应用标识) remotes(引用远程模块࿰…...
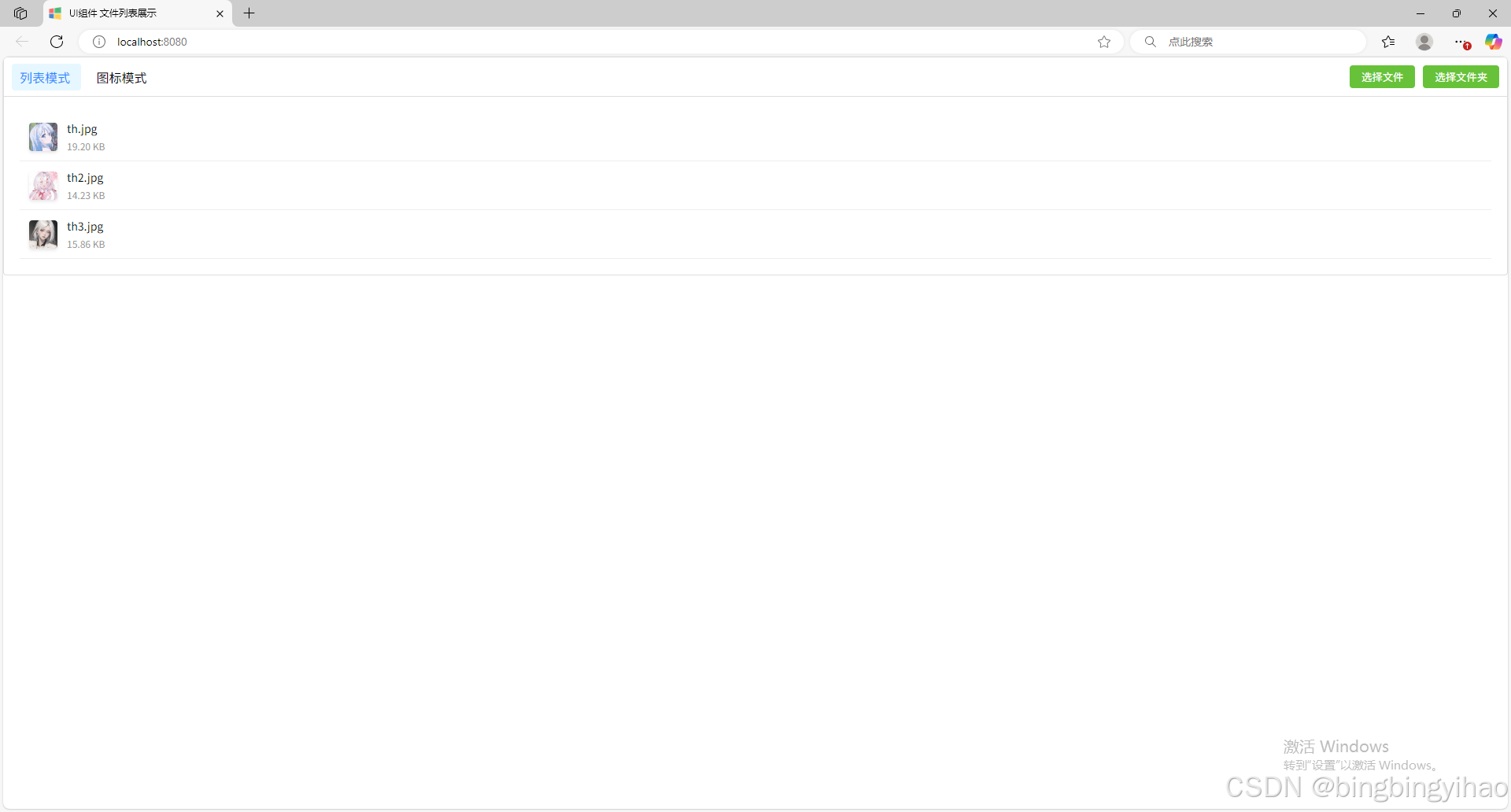
ui框架-文件列表展示
ui框架-文件列表展示 介绍 UI框架的文件列表展示组件,可以展示文件夹,支持列表展示和图标展示模式。组件提供了丰富的功能和可配置选项,适用于文件管理、文件上传等场景。 功能特性 支持列表模式和网格模式的切换展示支持文件和文件夹的层…...
QT开发技术【ffmpeg + QAudioOutput】音乐播放器
一、 介绍 使用ffmpeg 4.2.2 在数字化浪潮席卷全球的当下,音视频内容犹如璀璨繁星,点亮了人们的生活与工作。从短视频平台上令人捧腹的搞笑视频,到在线课堂中知识渊博的专家授课,再到影视平台上扣人心弦的高清大片,音…...
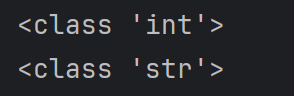
python基础语法Ⅰ
python基础语法Ⅰ 常量和表达式变量是什么变量的语法1.定义变量使用变量 变量的类型1.整数2.浮点数(小数)3.字符串4.布尔5.其他 动态类型特征注释注释是什么注释的语法1.行注释2.文档字符串 注释的规范 常量和表达式 我们可以把python当作一个计算器,来进行一些算术…...

Vuex:Vue.js 应用程序的状态管理模式
什么是Vuex? Vuex 是专门为 Vue.js 应用程序开发的状态管理模式 库。它采用集中式存储管理应用的所有组件的状态,并以相应的规则保证状态以一种可预测的方式发生变化。 在大型单页应用中,当多个组件共享状态时,简单的单向数据流…...

如何让非 TCP/IP 协议驱动屏蔽 IPv4/IPv6 和 ARP 报文?
——从硬件过滤到协议栈隔离的完整指南 引言 在现代网络开发中,许多场景需要定制化网络协议(如工业控制、高性能计算),此时需确保驱动仅处理特定协议,避免被标准协议(如 IPv4/IPv6/ARP)干扰。本文基于 Linux 内核驱动的实现,探讨如何通过硬件过滤、驱动层拦截和协议栈…...