机器学习中的独立和同分布 (IID):假设和影响
一、介绍
在机器学习中,独立和同分布 (IID) 的概念在数据分析、模型训练和评估的各个方面都起着至关重要的作用。IID 假设是确保许多机器学习算法和统计技术的可靠性和有效性的基础。本文探讨了 IID 在机器学习中的重要性、其假设及其对模型开发和性能的影响。
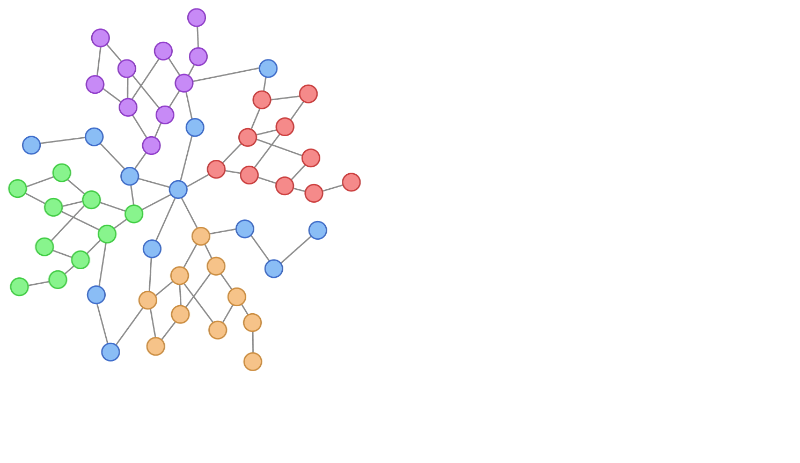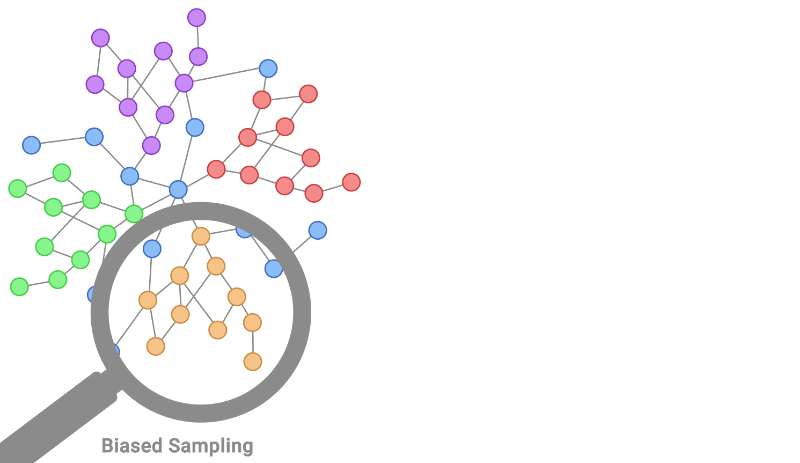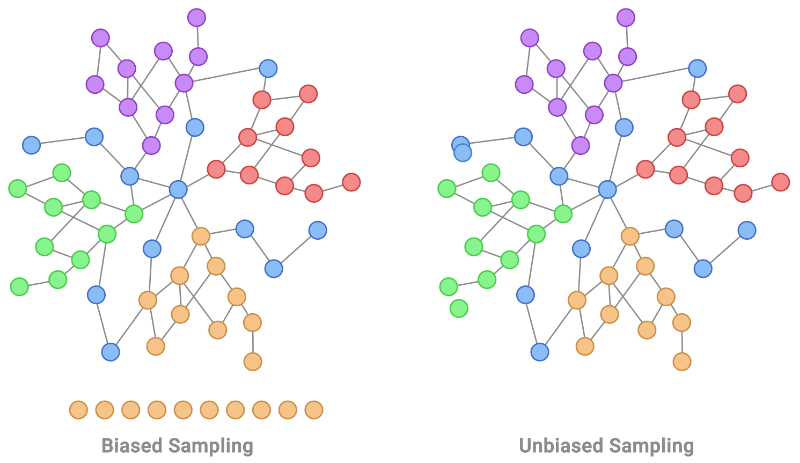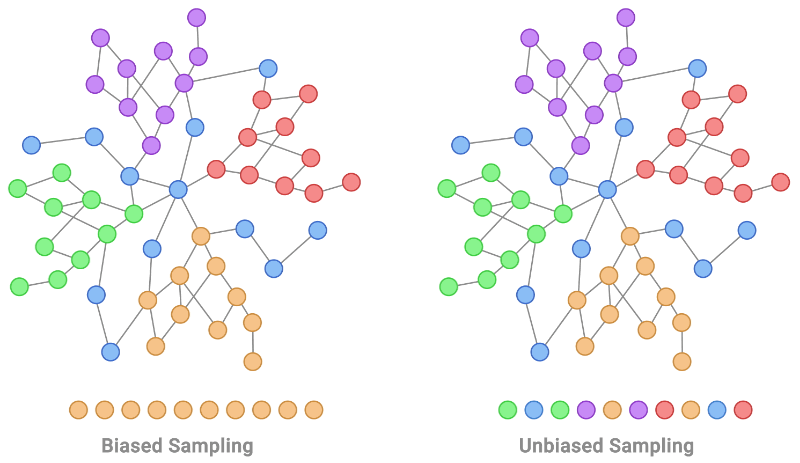
二、了解机器学习中的 IID
在机器学习的上下文中,IID 是指用于构建模型的训练数据是从相同的基础分布中独立随机采样的假设。假定每个数据点都独立于其他数据点,并遵循相同的分布特征。这种假设使得应用强大的统计方法和学习算法成为可能,这些方法和算法依赖于数据中不存在系统依赖性或偏差。
三、IID在机器学习中的假设
- 独立性:独立性假设意味着一个数据点的出现或值不提供有关另一个数据点的出现或值的任何信息。它假设数据点不受彼此影响,并且它们之间没有隐藏的结构或相关性。违反此假设可能会导致模型预测有偏差或不可靠。
- 相同分布:相同分布假设假设数据点来自相同的基础分布。这意味着统计属性(如均值、方差和其他分布特征)在整个数据集中保持一致。偏离此假设可能会引入抽样偏差,导致模型对新的、看不见的数据的泛化能力很差。
四、IID 在机器学习中的影响
- 训练和评估:IID 假设在模型训练和评估过程中至关重要。当训练数据满足IID假设时,机器学习算法可以有效地学习底层模式并做出准确的预测。此外,在模型评估期间,IID 允许使用交叉验证技术和统计测试,确保性能估计值可靠并代表模型的真实性能。
- 特征选择和工程设计:IID 假设会影响特征选择和工程过程。如果违反了独立性假设,则必须正确识别和处理相关或从属特征。特征选择方法可以帮助识别冗余或高度相关的特征,而特征工程技术可以转换或组合特征,以减轻数据中依赖关系的影响。
- 正则化和过拟合:IID 假设与过拟合问题密切相关。当数据违反 IID 假设时,模型可能倾向于记忆或过度拟合训练数据中存在的特定模式,无法很好地泛化到看不见的数据。正则化技术(如 L1 或 L2 正则化)有助于缓解过拟合并提高模型的泛化性能。
- 统计推断和假设检验:IID 假设在机器学习中的统计推断和假设检验中至关重要。统计检验(如 t 检验或卡方检验)假定数据点是独立且相同的分布。违反 IID 假设会导致 p 值不准确,从而影响统计推论和假设检验结果的有效性。
五、挑战和考虑因素
必须认识到,IID 假设可能不适用于所有现实世界场景。真实世界的数据集通常表现出复杂的依赖关系、时间相关性或不平衡的分布。在处理非IID数据时,需要采用专门的技术,如时间序列分析、序列建模或处理不平衡数据的技术,来适当地应对这些挑战。
在机器学习中,模型的训练和评估通常采用独立和同分布 (IID) 的概念。虽然数据可能并不总是严格遵守 IID 假设,但它是许多算法的常见起点。下面是如何使用 Python 创建 IID 数据集并训练简单机器学习模型的示例:
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score# Generate IID dataset
np.random.seed(0)
num_samples = 1000
num_features = 5# Generate independent random features
X = np.random.rand(num_samples, num_features)# Generate independent and identically distributed labels
y = np.random.randint(0, 2, num_samples)# Split the data into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# Train a logistic regression model
model = LogisticRegression()
model.fit(X_train, y_train)# Make predictions on the test set
y_pred = model.predict(X_test)# Calculate accuracy
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)在上面的代码中,我们首先生成一个 IID 数据集。我们使用 np.random.rand 创建独立的随机特征 (X),其中每行代表一个样本,每列代表一个特征。我们还使用 np.random.randint 生成独立且同分布的标签 (y),其中每个标签对应一个样本。 接下来,我们使用 scikit-learn 库中的 train_test_split 将数据分成训练集和测试集。
训练集(X_train和y_train)将用于训练模型,而测试集(X_test和y_test)将用于评估模型的性能。然后,我们使用 scikit-learn 中的 LogisticRegression 初始化逻辑回归模型,并使用 fit 将其拟合到训练数据。训练结束后,我们使用predict对测试集进行预测。最后,我们使用 scikit-learn 中的 precision_score 计算模型预测的准确性并打印结果。
请记住,此示例假定数据为 IID 的简化方案。在实践中,真实世界的数据集通常表现出更复杂的模式、依赖关系或不平衡,需要额外的预处理步骤和专门的技术来处理这种情况。
六、结论
独立和同分布式 (IID) 的概念在机器学习中起着至关重要的作用,它能够开发鲁棒模型和准确预测。独立性和相同分布的假设为统计方法、正则化技术和模型评估程序提供了基础。了解 IID 假设的含义有助于机器学习从业者在数据预处理、算法选择和模型评估方面做出明智的决策,以确保其模型的可靠性和泛化能力。5-28-2
相关文章:
机器学习中的独立和同分布 (IID):假设和影响
一、介绍 在机器学习中,独立和同分布 (IID) 的概念在数据分析、模型训练和评估的各个方面都起着至关重要的作用。IID 假设是确保许多机器学习算法和统计技术的可靠性和有效性的基础。本文探讨了 IID 在机器学习中的重要性、其假设及其对模型开…...

PTP软硬件时间戳
软硬件时间戳 抄袭来源:http://www.bdtime.com.cn/pinlv/4296.html PTP 是一种网络协议,用于在计算机网络中进行时钟校准和时间同步。硬件时间戳和软件时间戳是在实现 PTP 时常见的两种方式,它们在精度、可靠性、实时性以及资源消耗等方面存…...
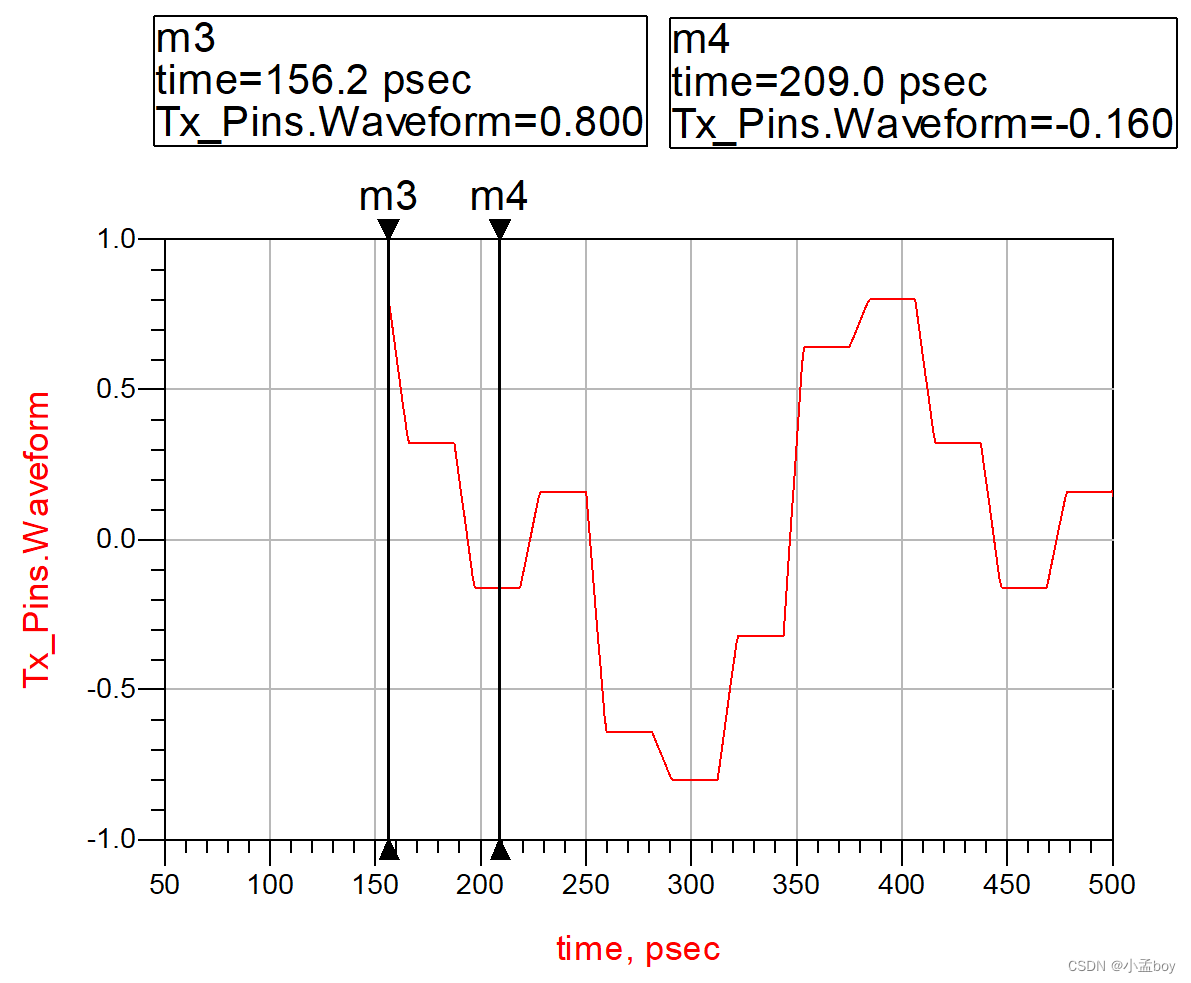
使用ADS进行serdes仿真时,Tx_Diff中EQ的设置对发送端波形的影响。
研究并记录一下ADS仿真中Tx_Diff的EQ设置。原理图如下: 最上面是选择均衡方法Choose equalization method:Specify FIR taps,Specify de-emphasis和none。 当选择Specify de-emphasis选项时,下方可以输入去加重具体的dB值&#x…...
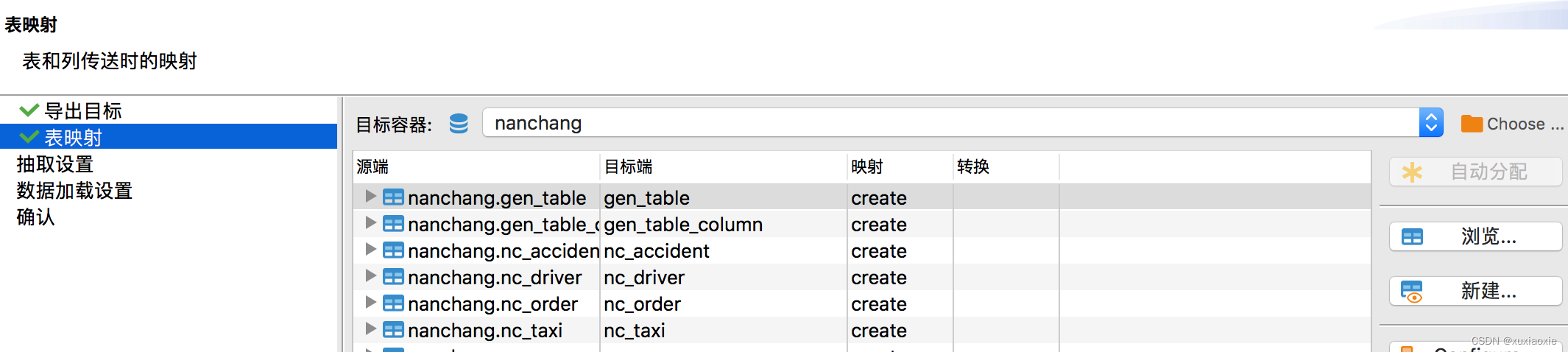
数据库迁移(DBeaver版本)
最近需要做一个数据库迁移, 测试环境开发的差不多了,需要将脚本迁移到生产。 中间了试了一些工具,比如Jetbrain出品的datagrip,这个数据库工具平时还是很好用的,但是数据迁移感觉不是那么好用,所以还是用到…...

【c++STL常见排序算法sort,merge,random_shuffle,reverse】
文章目录 C STL 常见排序算法详解1. sort 算法2. merge 算法3. random_shuffle 算法4. reverse 算法 C STL 常见排序算法详解 1. sort 算法 功能:sort 用于对容器内的元素进行升序排序。示例代码:#include <iostream> #include <algorithm>…...

STM32/N32G455国民科技芯片驱动DS1302时钟---笔记
这次来分享一下DS1302时钟IC,之前听说过这个IC,但是一直没搞过,用了半天时间就明白了原理和驱动,说明还是很简单的。 注:首先来区分一下DS1302和RTC时钟有什么不同,为什么不直接用RTC呢? RTC不…...
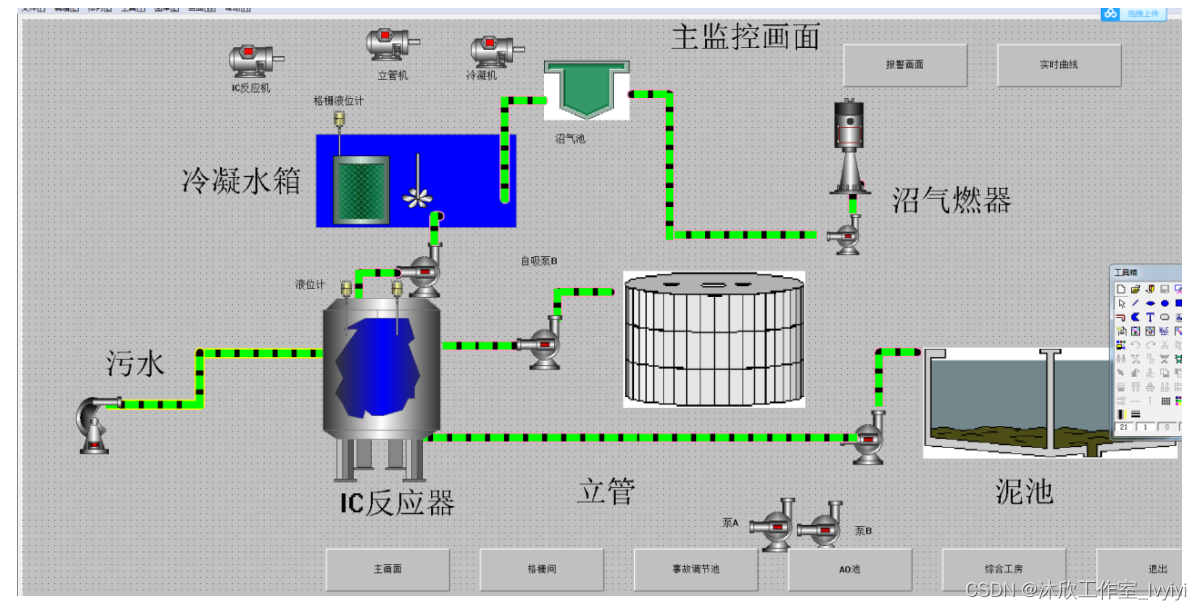
基于PLC的污水厌氧处理控制系统(论文+源码)
1. 系统设计 污水厌氧由进水系统通过粗格栅和清污机进行初步排除大块杂质物体以及漂浮物等,到达除砂池中。在除砂池系统中细格栅进一步净化污水厌氧中的细小颗粒物体,将污水厌氧中的细小沙粒滤除后进入氧化沟反应池。在该氧化沟系统中进行生化处理&…...
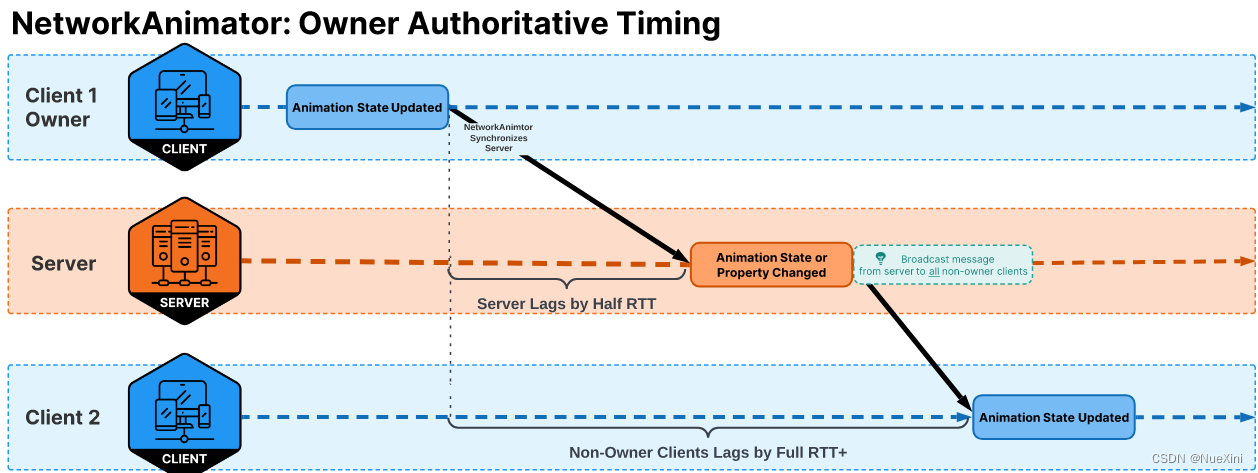
Unity之NetCode多人网络游戏联机对战教程(9)--NetworkAnimator组件
文章目录 前言NetworkAnimatorAnimator的Trigger属性服务器权威模式(Server Authoritative Mode)客户端权威模式 (Owner Authoritative Mode)学习文档 前言 这个组件是NetCode常用的组件之一,NetworkAnimator跟NetworkTransform一样…...

iceoryx之Roudi
目录...
常用转换byte转uint32、byte转float等)
.Net(C#)常用转换byte转uint32、byte转float等
1、byte转String Encoding.ASCII.GetString(byte[]); 2、base64string转byte byte[]Base64Decoder.Decoder.GetDecoded(string); 3、byte转UInt16 方法一 (UInt16)(bytes[0] * 256 bytes[1]) 方法二 (UInt16)((bytes[0] << 8) | bytes[1]); 方法三 字节序要对…...
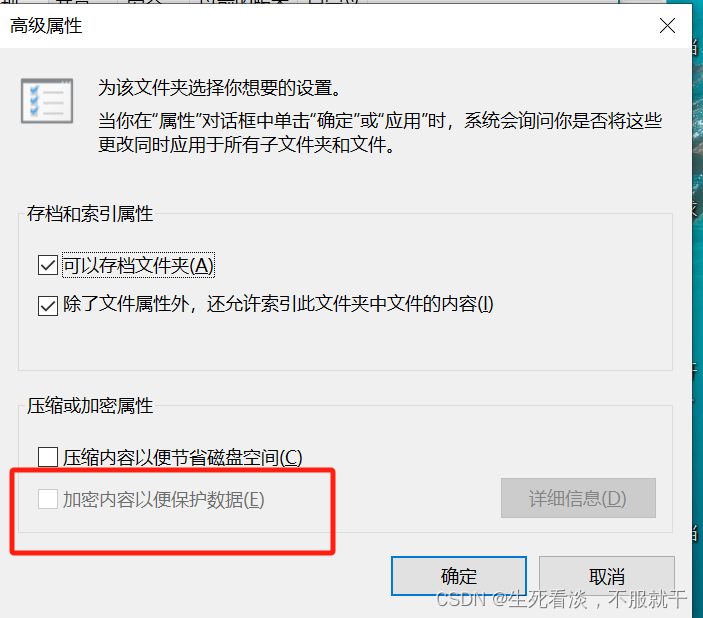
windows快捷方式图标变成空白
今天突然有客户说应用程序快捷方式图标变成了空白,就研究了一下,网上找了一下很多都说是什么图标缓存有问题,试过之后发现并不能解决问题。 然后发现用户的文件上都一把黄色的小锁的标志,查了一下说是文件属性里面设置加密之后就会…...
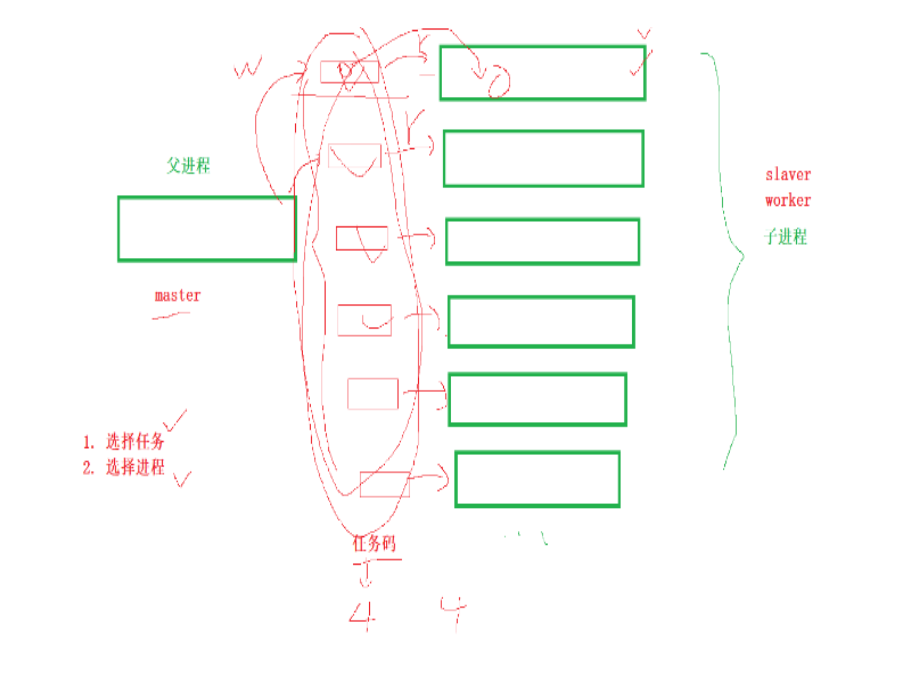
【Linux系统编程十九】:(进程通信)--匿名管道/模拟实现进程池
【Linux系统编程十九】:匿名管道原理/模拟实现进程池 一.进程通信理解二.通信实现原理三.系统接口四.五大特性与四种情况五.应用场景--进程池 一.进程通信理解 什么是通信? 通信其实就是一个进程想把数据给另一个进程,但因为进程具有独立性…...
【全网首发】2023年NOIP真题
目录 前言 真题 结尾 前言 NOIP题目了解一下,后续有可能会出讲解,题目全部来自于洛谷 真题 第一题:词典 第二题:三值逻辑 第三题:双序列扩展 第四题: 天天爱打卡 结尾 大家可以把你的预期分数打在评论…...
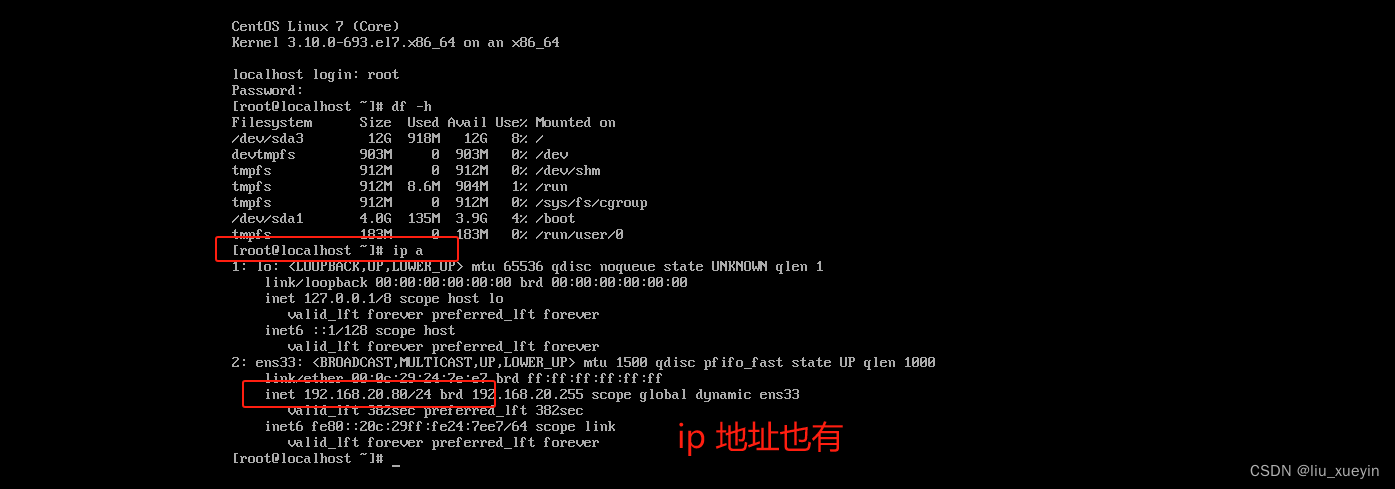
【Linux网络】从原理到实操,感受PXE无人值守自动化高效批量网络安装系统
一、PXE网络批量装机的介绍 1、常见的三种系统安装方式 2、回顾系统安装的过程,了解系统安装的必要条件 3、什么是pxe 4、搭建pxe的原理 5、Linux的光盘镜像中的isolinux中的相关文件学习 二、关于实现PXE无人值守装机的四大文件与五个软件的对应关系详解 5个…...

Pandas+Matplotlib 数据分析
利用可视化探索图表 一、数据可视化与探索图 数据可视化是指用图形或表格的方式来呈现数据。图表能够清楚地呈现数据性质, 以及数据间或属性间的关系,可以轻易地让人看图释义。用户通过探索图(Exploratory Graph)可以了解数据的…...
k8s ingress高级用法一
前面的文章中,我们讲述了ingress的基础应用,接下来继续讲解ingress的一些高级用法 一、ingress限流 在实际的生产环境中,有时间我们需要对服务进行限流,避免单位时间内访问次数过多,常用的一些限流的参数如下&#x…...
C语言--从键盘输入10个数字放在数组中,并输出
用scanf读取数字的时候要注意,可以输入一个数字,按一下回车,输入一个数字,按一下回车,也可以一次性输入完10个数据。(中间可以用空格隔开,系统会自动识别) 输出一:每按下一个数字&am…...

SSL加密
小王学习录 今日摘录前言HTTP + SSL = HTTPSSSL加密1. 对称加密2. 非对称加密 + 对称加密3. 证书今日摘录 但愿四海无尘沙,有人卖酒仍卖花。 前言 SSL表示安全套接层,是一个用于保护计算机网络中数据传输安全的协议。SSL通过加密来防止第三方恶意截取并篡改数据。在实际应用…...
一个美观且功能丰富的 .NET 控制台应用程序开源库
推荐一个美观且功能丰富的 .NET 控制台应用程序开源库,从此告别黑漆漆的界面。 01 项目简介 Spectre.Console 是一个开源的 .NET 库,用于创建美观、功能丰富的控制台(命令行)应用程序。它提供了一组易于使用的 API,…...

DispatcherSynchronizationContext and Dispatcher
https://www.cnblogs.com/liangouyang/archive/2008/11/20/1337907.html SynchronizationContext提供一个自由线程的同步上下文,一个常用的用法是把UI线程的同步上下文保存起来,传给另一个线程,因为UI只能再UI线程中操作,在另外一…...

深度学习在微纳光子学中的应用
深度学习在微纳光子学中的主要应用方向 深度学习与微纳光子学的结合主要集中在以下几个方向: 逆向设计 通过神经网络快速预测微纳结构的光学响应,替代传统耗时的数值模拟方法。例如设计超表面、光子晶体等结构。 特征提取与优化 从复杂的光学数据中自…...

Java如何权衡是使用无序的数组还是有序的数组
在 Java 中,选择有序数组还是无序数组取决于具体场景的性能需求与操作特点。以下是关键权衡因素及决策指南: ⚖️ 核心权衡维度 维度有序数组无序数组查询性能二分查找 O(log n) ✅线性扫描 O(n) ❌插入/删除需移位维护顺序 O(n) ❌直接操作尾部 O(1) ✅内存开销与无序数组相…...

关于nvm与node.js
1 安装nvm 安装过程中手动修改 nvm的安装路径, 以及修改 通过nvm安装node后正在使用的node的存放目录【这句话可能难以理解,但接着往下看你就了然了】 2 修改nvm中settings.txt文件配置 nvm安装成功后,通常在该文件中会出现以下配置&…...

Golang dig框架与GraphQL的完美结合
将 Go 的 Dig 依赖注入框架与 GraphQL 结合使用,可以显著提升应用程序的可维护性、可测试性以及灵活性。 Dig 是一个强大的依赖注入容器,能够帮助开发者更好地管理复杂的依赖关系,而 GraphQL 则是一种用于 API 的查询语言,能够提…...

【决胜公务员考试】求职OMG——见面课测验1
2025最新版!!!6.8截至答题,大家注意呀! 博主码字不易点个关注吧,祝期末顺利~~ 1.单选题(2分) 下列说法错误的是:( B ) A.选调生属于公务员系统 B.公务员属于事业编 C.选调生有基层锻炼的要求 D…...

(转)什么是DockerCompose?它有什么作用?
一、什么是DockerCompose? DockerCompose可以基于Compose文件帮我们快速的部署分布式应用,而无需手动一个个创建和运行容器。 Compose文件是一个文本文件,通过指令定义集群中的每个容器如何运行。 DockerCompose就是把DockerFile转换成指令去运行。 …...

C++使用 new 来创建动态数组
问题: 不能使用变量定义数组大小 原因: 这是因为数组在内存中是连续存储的,编译器需要在编译阶段就确定数组的大小,以便正确地分配内存空间。如果允许使用变量来定义数组的大小,那么编译器就无法在编译时确定数组的大…...

回溯算法学习
一、电话号码的字母组合 import java.util.ArrayList; import java.util.List;import javax.management.loading.PrivateClassLoader;public class letterCombinations {private static final String[] KEYPAD {"", //0"", //1"abc", //2"…...
AxureRP-Pro-Beta-Setup_114413.exe (6.0.0.2887)
Name:3ddown Serial:FiCGEezgdGoYILo8U/2MFyCWj0jZoJc/sziRRj2/ENvtEq7w1RH97k5MWctqVHA 注册用户名:Axure 序列号:8t3Yk/zu4cX601/seX6wBZgYRVj/lkC2PICCdO4sFKCCLx8mcCnccoylVb40lP...

webpack面试题
面试题:webpack介绍和简单使用 一、webpack(模块化打包工具)1. webpack是把项目当作一个整体,通过给定的一个主文件,webpack将从这个主文件开始找到你项目当中的所有依赖文件,使用loaders来处理它们&#x…...