Mybatis学习笔记-映射文件,标签,插件
目录
概述
mybatis做了什么
原生JDBC存在什么问题
MyBatis组成部分
Mybatis工作原理
mybatis和hibernate区别
使用mybatis(springboot)
mybatis核心-sql映射文件
基础标签说明
1.namespace,命名空间
2.select,insert,update,delete为不同类型的sql标签
映射标签的属性说明
1.id
2.parameterType
简单类型
实体类
实体类嵌套
Map
@Param注解
3.resultType
简单类型
实体类
实体类列表
Map
4.resultMap标签
resultMap属性
id,标记这个resultMap,通过id可以使用该resultMap
type,指定映射的实体类
result
association
collection
5.jdbcType的作用
常见类型关系
6.useGeneratedKeys和keyProperty组合
7.statementType
8.useCache&flushCache
mybatis缓存
属性说明
开启缓存后还可以在任意的具体sql中配置缓存的访问控制
select语句
insert,update,delete语句
动态sql标签
1.if test="..."
注意点
判空
判断某个值
嵌套
2.where
3.set
4.choose,when,otherwise
5.isNotEmpty property="xxx"...
6.isEqual property="xxx" compareValue="1"
sql标签
foreach标签
属性说明
注意
如果入参直接传递一个List或者Array
bind标签
selectKey标签
作用
注意
属性
keyProperty
keyColumn
resultType
order
statementType
CDATA
${}和#{}区别
#{value}
${value}
mybatis插件
mybatisX自动生成基础代码
概述
前身是apache开发的iBatis,迁移到goole code后改名为MyBatis,2013年迁移到GitHub
在springboot的背景下,我们不关注原本ssm项目的xml配置,只关注mybatis本身
mybatis做了什么
解决了原生jdbc的弊端,开发者只需要关注sql本身
原生JDBC存在什么问题
1.频繁的获取连接和释放资源
每次需要执行JDBC就会获取连接,执行结束释放资源,浪费系统资源
解决:mybatis使用数据库连接池解决问题
2.将sql语句硬编码,变动sql就要改变java代码
解决:将Sql语句配置在XXXXmapper.xml文件中与java代码分离
3.sql传参麻烦,参数数量可能会变化,而占位符和参数数量要保持一致
解决:mybatis自动映射
4.处理结果也是硬编码,sql变化导致解析结果变化就要改变java代码
解决:mybatis自动映射
MyBatis组成部分
mapper.xml:sql映射文件,配置了操作数据库的sql语句,此类文件需要在SqlMapConfig.xml中加载
SqlSessionFactoryBuilder:SqlSessionFactoryBuilder用于创建SqlSessionFacoty,SqlSessionFacoty是单例,所以一旦创建完成就不再需要SqlSessionFactoryBuilder
SqlSessionFactory:即会话工厂,MyBatis配置完整就可以获取SqlSessionFactory
sqlSession:即会话,由会话工厂SqlSessionFactory创建,操作数据库增删改查需要在会话中进行,通常来说,每个线程创建各自的sqlSession,使用完就close()
Executor:操作数据库,mybatis底层自定义了Executor执行器接口操作数据库,Executor接口有两个实现,一个是基本执行器,一个是缓存执行器
Mapped Statement:Mapped Statement也是mybatis一个底层封装对象,可以简单的理解为一条完整的sql入参,查询,返回就是一个Mapped Statement对象
1.它封装了mybatis配置信息及sql映射信息等,mapper.xml文件中一个sql对应一个Mapped Statement对象,sql的id即是Mapped statement的id
2.它对sql执行输入参数进行定义,包括HashMap、基本类型、pojo,Executor通过Mapped Statement在执行sql前将输入的java对象映射至sql中,输入参数映射就是jdbc编程中对preparedStatement设置参数
3.它对sql执行输出结果进行定义,包括HashMap、基本类型、pojo,Executor通过Mapped Statement在执行sql后将输出结果映射至java对象中,输出结果映射过程相当于jdbc编程中对结果的解析处理过程
Mybatis工作原理
JDK动态代理,Mybatis运行时会使用JDK动态代理为Mapper接口生成代理对象MappedProxy,代理对象会拦截接口方法,根据类的全限定名+方法名,唯一定位到一个MapperStatement并调用执行器执行所代表的sql,然后将sql执行结果返回
mybatis和hibernate区别
1.mybatis是半自动ORM框架,需要程序员编写sql,更灵活,因此更容易满足复杂场景,能更好的控制sql性能
2.mybatis由于要开发者自己编写sql,意味着不同数据库就要学习不同的语法,编写不同的sql,可能增大学习成本和工作量
3.mybatis门槛低,几乎可以说,只要会写sql就等于会用mybatis,而hibernate的配置更繁琐,个人学习成本很高,同时要求团队的所有人都需要精通hibernate,不利于团队开发效率
4.hibernate不需要开发者关注sql,而是集中精力在业务逻辑上,但在处理复杂场景时,更繁琐,甚至可以说繁琐的有些变态,一个动态条件在mybatis中是一个标签两行代码,而hibernate可能需要写几十倍的代码来实现
5.随着mybatis-plus的出现,绝大部分的WEB项目更倾向于选用mybatis
使用mybatis(springboot)
1.在springboot的背景下,不再需要自己配置xml,通过直接导入启动器依赖即可
2.配置Mapped Statement的文件路径,让mybatis知道要执行的sql位置
3.编写mapper接口
4.编写mapper接口对应的Mapped Statement
<dependency><groupId>org.mybatis.spring.boot</groupId><artifactId>mybatis-spring-boot-starter</artifactId><version>2.2.2</version>
</dependency>mybatis:mapper-locations: classpath:mapper/*.xmlconfiguration:log-impl: org.apache.ibatis.logging.stdout.StdOutImpl@Mapper
public interface CustomerMapper {int insert(Customer record);
}<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapperPUBLIC "-//mybatis.org//DTD Mapper 3.0//EN""http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.web.mapper.CustomerMapper"><insert id="insert" keyColumn="id" keyProperty="id" parameterType="com.entity.Customer"useGeneratedKeys="true"></insert>
</mapper>mybatis核心-sql映射文件
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapperPUBLIC "-//mybatis.org//DTD Mapper 3.0//EN""http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.web.mapper.CustomerMapper"><insert id="insert" keyColumn="id" keyProperty="id" parameterType="com.entity.Customer"useGeneratedKeys="true"></insert>
</mapper>基础标签说明
1.namespace,命名空间
指向mapper接口的位置,mapper接口的方法名对应这里sql的id
每个命名空间都是独立的,不同命名空间可以存在相同id的sql
比如TeacherMapper和StudentMapper都可以配置id为queryById的sql
2.select,insert,update,delete为不同类型的sql标签
映射标签的属性说明
1.id
statement的id,可以理解为sql的标识
2.parameterType
输入参数类型,在sql中使用#{value},${value}获取到入参,二者是不同的,后面单独说明
简单类型
比如Integer,String
#{value},${value}的value是接口方法的形参名
select * from student where id = #{value};
实体类
#{value},${value}的value是实体类的属性名
实体类需要有getter,setter方法,否则mybatis无法操作实体类的成员(取值,赋值)
select * from student where name = #{name} and age = #{age};
实体类嵌套
实体类的一个属性是另外一个实体类
包装对象要implements serializable实现序列化接口
使用#{student.name},${student.name}获取属性
Map
#{value},${value}的value为map的key
select * from student where name = #{name} and age = #{age};
@Param注解
低版本的mybatis,只传一个参数时必须在接口上使用@Param声明该参数
高版本的mybatis,只传一个参数时不会报错;传多个参数不使用实体类封装时,每个参数都要用@Param声明
3.resultType
结果映射类型 ,sql查询结果的类型
简单类型
sql结果为简单类型,比如int,String
select count(*) from student;
实体类
sql结果为一条记录,包含多个字段,封装到实体类对象中,比如Student
select * from student where id = #{value};
实体类列表
sql结果为多条记录,包含多个字段,分别封装到实体类中,即对象集合/数组
虽然结果是List,但实际配置的resultType仍然为实体类,即List中所存对象的类型
select * from student;
Map
直接用map接收,会生成List这样的结构
查询结果列名即为map的key,map.get("xxx")可以获取结果的值
可以自定义,指定哪一列映射到key,哪一列映射到value,但这本质上并不是Map,只是看起来像
4.resultMap标签
我们刚刚知道,sql结果可以映射到实体类上,但这样就必须要求sql中的字段名和实体类的属性名相同才行
实际上,往往数据库的字段名和实体类的属性名是不同的,比如,数据库是customer_id,而实体类是customerId,当然我们可以在sql上给字段写别名,就可以让结果映射到实体类上,但这样意味着每条sql都要写一遍这些别名,显然不合理;
要想自动让查询结果映射到实体类,可以使用resultMap标签,resultMap标签可以将查询结果映射到某个给定的实体类上
resultMap属性
id,标记这个resultMap,通过id可以使用该resultMap
type,指定映射的实体类
result
property:实体类字段名,column:表字段名,jdbcType:数据类型
association
主实体类的字段是实体类,一对一关系
property:主实体类的字段名,javaType:子实体类类型,column:关联表的主键
collection
主实体类的字段是实体类,一对多关系
property:主实体类的字段名,ofType:子实体类类型,javaType:集合类型
<resultMap id="StuResultMap" type="com.coolway.bean.Student">
<!--主键--><id property="id" column="ID" jdbcType="VARCHAR"/><result property="name" column="NAME" jdbcType="VARCHAR"/><association property="teacher" javaType="Teacher"column="teacher_id"><id property="id" column="teacher_id"/><result property="teacherName" column="teacher_name"/></association><collection property="subjects" ofType="Subject" javaType="list"><id property="id" column="post_id"/><result property="subject" column="post_subject"/></collection>
</resultMap>
//一个学生对应一个老师,一个学生对应多门课程
<select id="xxxqueryForResultMap" resultMap="StuResultMap">select s.id, s.name stu_name, s.age stu_age, t.id teacher_id, t.name teacher_name, t.age teacher_age,sj.id subject_id, sj.name subject_namefrom student sleft join teacher t on t.id = s.teacher_idleft join subject sj on sj.id = s.subject_id
</select>5.jdbcType的作用
jdbcType会用在#{},中,作用是标记数据库字段的类型
有了给定类型,mybatis就知道拿到入参后应当作为什么类型传递给数据库,拿到数据库结果以后需要处理成什么类型
在入参为空,或者结果为空时,也知道应当给定什么默认值,在这种情况下,显然,我们不能使用基本类型,而是应当使用包装类传递数据,否则值在一些情况下不会是null,而是默认值
常见类型关系
java类型 jdbcType
String VARCHAR
LocalDate DATE
LocalTime TIME
LocalDateTime TIMESTAMP
Byte/Short/Integer/Long/Float/Double/BigDecimal NUMERIC,其中基本类型也有自己对应的类型6.useGeneratedKeys和keyProperty组合
在insert语句中组合使用,可以获取指定字段操作后的值放到入参实体中,显然,通常用来获取自增主键,自生成字段
useGeneratedKeys="true" keyProperty="id"
7.statementType
通常不需要设置,默认即可
用来标记何种方式操作sql
STATEMENT 直接操作sql,不进行预编译,获取数据
PREPARED 预处理,参数,进行预编译,获取数据,默认
CALLABLE 执行存储过程
8.useCache&flushCache
通常不需要设置,默认即可
mybatis缓存
mybatis查询会先查询缓存数据,当存在入参一致的数据时,直接将缓存返回,不再查询数据库
一级缓存是针对sqlSession,每次操作数据库,都会生成sqlSession对象,缓存数据就存在sqlSession中,显然,不同的sqlSession不会互相影响
二级缓存是针对mapper,多个sqlSession操作同一个mapper的sql语句,可以共用这个mapper的二级缓存,显然,二级缓存是跨sqlSession的
sqlSession:理解为JDBC中的Connection,即针对数据库的一次连接
二级缓存需要手动开启
application.yml mybatis: configuration: #开启MyBatis的二级缓存 cache-enabled: true mapper.xml <cache eviction="FIFO" flushInterval="600000" size="4096" readOnly="true"/>
属性说明
eviction:缓存回收策略
LRU:最少使用原则,移除最长时间不使用的对象
FIFO:先进先出原则,按照对象进入缓存顺序进行回收
SOFT:软引用,移除基于垃圾回收器状态和软引用规则的对象
WEAK:弱引用,更积极的移除移除基于垃圾回收器状态和弱引用规则的对象
flushInterval:刷新时间间隔,单位为毫秒,这里配置的100毫秒。如果不配置,那么只有在进行数据库修改操作才会被动刷新缓存区
size:引用额数目,代表缓存最多可以存储的对象个数
readOnly:是否只读,如果为true,则所有相同的sql语句返回的是同一个对象(有助于提高性能,但并发操作同一条数据时,可能不安全),如果设置为false,则相同的sql,后面访问的是cache的clone副本
开启缓存后还可以在任意的具体sql中配置缓存的访问控制
useCache:标记是否启用mybatis缓存,启用缓存后,当入参一样,mybatis将会直接将缓存中的结果返回,而不再查询数据库,每次查询后,会缓存到缓存中
flushCache:标记是否在操作后清空缓存,为了防止读到脏数据,增删改之后,应当清空缓存
select语句
useCache默认为true,即每次查询后,会将结果缓存到缓存中
flushCache默认为false,即每次操作后,不会清空缓存
insert,update,delete语句
没有useCache属性
flushCache默认为true,即每次操作后,清空缓存
动态sql标签
1.if test="..."
<if test="...">
满足if则拼接该段sql,常用于动态条件查询
<select id="queryStudentByMap" parameterType="Map" resultType="com.coolway.bean.Student">select * from student twhere 1=1<if test="name != null and name != ''">AND t.name like '%${name}%'</if><if test="age != null and age!= ''">AND t.age > #{age}</if>
</select>这里有一个where 1=1,这是因为如果第一个if成立,sql就为where and ....,语法错误,如果不想用where 1=1,还要规避这样的问题,那么可以使用<where>标签注意点
判空
对于非String类型的数据,在判空时只需要判断 !=null,如果 !=""会报错
判断某个值
对于String类型,判空需要xxx != null and != '',如果要判断是否等于某个值
嵌套
if标签可以嵌套
如下是错误的
<if test="status!= null and status=='OK'">...
</if>
因为MyBatis是使用的OGNL表达式来进行解析的,要改成
<if test='status!= null and status== "OK" '>...
</if>
或者
<if test="status!= null and status=='OK'.toString()">...
</if>if标签嵌套
<if test="data != null"><if test="data.types !=null and data.types != ''">AND T.TYPES = #{data.types}</if><if test="data.status !=null and data.status != ''">AND T.STATUS = #{data.status}</if>
</if>2.where
<where>
自动添加where关键字,同时去掉sql语句中第一个无关的and关键字
但要注意,and前面不能有注释,否则就没法自动去掉了,这可能是低版本的BUG
3.set
<set>
自动添加set关键字,同时去除末尾的无关逗号
UPDATE T_ABOLISH T
<set><if test="abolishReason != null and abolishReason != ''">T.ABOLISH_REASON = #{abolishReason},</if><if test="abolishUserName != null and abolishUserName != ''">T.ABOLISH_USER_NAME = #{abolishUserName},</if>
</set>4.choose,when,otherwise
<choose> <when> <otherwise>相当于if else
<choose><when test="">//...</when><otherwise>//...</otherwise>
</choose>5.isNotEmpty property="xxx"...
判空
<isEmpty property="xxx">...</isEmpty>
6.isEqual property="xxx" compareValue="1"
判断值
<isNotEqual property="xxx" compareValue="0">...</isNotEqual>
sql标签
表示sql片段
然后在编写sql时,可以通过引用sql片段
select <include refid="studentFields"/> from student
如果引用别的namespace的sql片段,需要在refid的时候加上namespace,但通常不会这么做
<sql id="studentFields">id,name,age,sex
</sql>foreach标签
当传递pojo或者map的属性值为List或者Array时,需要遍历属性值,用foreach
<select...>select * from student<where><foreach collection="ids" item="item" open="id in(" close=")" separator=",">#{item}</foreach></where>
</select>属性说明
collection:遍历的集合,这里是传入pojo/map的属性名
item:遍历时的临时变量,自定义,但是和后面的#{}里面要一致
open:在前面添加的 sql 片段,上面配置的是 id in(
close:在结尾处添加的 sql 片段,上面配置的是 )
separator:指定遍历的元素之间使用的分隔符,上面配置的是,逗号,上面的sql就为 select * from student where id in('xx','xx','xx'...)
注意
如果入参直接传递一个List或者Array
此时collection属性就不能配置为属性名/key了,要为list/array
原因:mybatis处理入参的方式是创建一个map,把入参放入map中,再传给sqlSession执行
对于pojo或者mapper类型,属性名为key,属性值为value
对于Array,属性名为array,属性值为数组的值
对于List,属性名为list,属性值为列表的值
如果必须要用自定义的名称,需要在mapper中给变量增加@Param("xxx")注解
bind标签
使用 OGNL 表达式创建一个变量井将其绑定到上下文中
兼容不同数据库之间的SQL语法差异,对数据库迁移友好
常用于模糊查询,能有效防止sql注入
<bind name = "需要绑定的变量" value = "绑定的最终值" /><if test="customerName != null and customerName != ''"><bind name="customerName" value="'%'+customerName+'%'"/>c.cname like #{customerName,jdbcType=VARCHAR}
</if>selectKey标签
作用
在insert,update语句中,会通过sql处理某些字段的值,通过selectKey可以直接获取某些字段sql运行后的值,而不需要单独查询一次处理后的数据,提高安全性,减少代码冗余
比如针对某个字段要在insert,update操作的前后改变这个字段的值,而且操作后需要知道这个字段变成了什么,比如自增主键,计数字段
有很多博客说selectKey是用来获取自增主键/主键的,实际上并不是,selectKey可以获取任意的字段/表达式的值,但有一定的限制(注意点)
注意
1.只能存在于insert或update的子标签中
2.入参只能是pojo,不能是String等类型
3.返回值并非是selectKey的字段,仍然是update原本的返回值,即被update的记录数
4.我们所需要的selectKey字段实际上是更新到被传入的pojo实例中
属性
keyProperty
结果集映射目标类的属性
若存在多个,则使用逗号分隔
keyColumn
目标类的属性,映射结果集的列名
若存在多个,则使用逗号分割
resultType
设置返回类型
可使用别名
order
设置此selectKey的执行顺序是早于sql语句,还是晚于sql语句
候选值:BEFORE和AFTER;
statementType
设置sql语句的映射类型,默认即可
候选值:STATEMENT,PREPARED,CALLABLE
serviceImpl
NumberDo numberDo = numberMapper.getNumberById(id);
if (numberDo != null) {numberMapper.plusNumberById(numberDo);//注意这里怎么获取更新后的新值return numberDo.getNumber();
}mapper.xml
<update id="plusNumberById" parameterType="com.coolway.testProject.dal.number.NumberDo"><selectKey resultType="java.lang.Integer" keyColumn="INS_NUMBER" keyProperty="insNumber" order="AFTER">SELECT T.INS_NUMBER FROM T_NUMBER T WHERE T.ID = #{id}</selectKey>UPDATE T_NUMBER T<set>T.INS_NUMBER = T.INS_NUMBER + 1</set>WHERE T.ID = #{id}
</update>CDATA
<![CDATA[......]]>
当sql包含<,&符号时,会报错。这是因为<会被xml解析为新元素的开始;&会被xml解析为字符实体的开始
解决方式有两种,虽然>,',"并不会报错,但仍然建议把他们做同样处理
1.使用转义替换
< < 小于
> > 大于
& & 和号
' ' 省略号
" " 引号
select * from student where age < 18;2.使用<![CDATA[......]]>
对于包含大量特殊符号的sql,建议使用
解析器会忽略 CDATA 部分中的所有内容
注意:
CDATA 部分不能包含字符串 "]]>"。也不允许嵌套的 CDATA 部分
标记 CDATA 部分结尾的 "]]>" 不能包含空格或换行
${}和#{}区别
#{value}
sql语句中的占位符,会根据参数类型进行预编译,可以防止sql注入
对于传入的String类型value,占位符#{}会加上单引号,即'value'
select * from student t where t.name like #{name};
select * from student t where t.name like '张三'
而在模糊查询,或者内存中传入一个sql片段,显然#{}不符合要求,所以要用到${value}
select * from student t where t.name like '%#{name}%';
select * from student t where t.name like '%'张三'%'
${value}
用于sql中的字符串拼接,不会预编译,不能防止sql注入
模糊查询的sql注入问题可以通过bind标签解决,也可以通过数据库提供的某些函数解决
select * from student t where t.name like '${value}';
select * from student t where t.name like '张三'
select * from student t where t.name like '%${value}%';
select * from student t where t.name like '%张三%'
mybatis插件
经过上面的学习,我们发现,mybatis上手是很简单,会写sql=会用mybatis,但对于每一张表,或者每一类业务,我们都需要编写resultMap返回值映射,包含所有字段的insert,delete,update,select基础语句,相当于我们要做很多次重复的事情,既麻烦又枯燥
有没有什么办法能够解决这个事情呢,当然有,mybatis提供了逆向工程工具,可以通过数据库表结构,自动生成resultMap返回值映射,包含所有字段的insert,delete,update,select基础语句,但这个逆向工程,需要我们编写一部分代码,而一些mybatis插件,比如mybatisX,mybatisPro等等,可以用图形化操作界面,只需要连接上数据库,配置指定的包路径,就能实现这些基础代码的生成,十分方便快捷,自由度也高
mybatisX自动生成基础代码
1.安装mybatisX插件
2.连接数据库
通过IDEA的database连接数据库
报错:Server returns invalid timezone. Go to ‘Advanced’ tab and set ‘serverTimezone’ property manually
解决:设置时区为当前时区,Advanced->找到serverTimezone,设置为Asia/Shanghai
3.生成mybatis代码
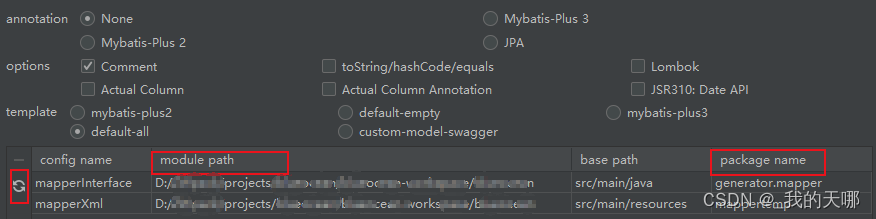
右击表名,选择mybatisX-generator
选择需要生成的类型,如果不使用mybatisplus,选择
annotation:none
template:default-all
点击确认,会发现项目中指定包下,已经生成了实体类,mapper接口,mapper.xml,已经自动生成了resultMap返回值映射,包含所有字段的insert,delete,update,select基础语句

相关文章:
Mybatis学习笔记-映射文件,标签,插件
目录 概述 mybatis做了什么 原生JDBC存在什么问题 MyBatis组成部分 Mybatis工作原理 mybatis和hibernate区别 使用mybatis(springboot) mybatis核心-sql映射文件 基础标签说明 1.namespace,命名空间 2.select,insert&a…...
【C++】模板初阶 【 深入浅出理解 模板 】
模板初阶 前言:泛型编程一、函数模板(一)函数模板概念(二)函数模板格式(三)函数模板的原理(四)函数模板的实例化(五)模板参数的匹配原则 三、类模…...
无需API开发,伯俊科技实现电商与客服系统的无缝集成
伯俊科技的无代码开发实现系统连接 自1999年成立以来,伯俊科技一直致力于为企业提供全渠道一盘货的服务。凭借其24年的深耕零售行业的经验,伯俊科技推出了一种无需API开发的方法,实现电商系统和客服系统的连接与集成。这种无代码开发的方式不…...

Python | 机器学习之逻辑回归
🌈个人主页:Sarapines Programmer🔥 系列专栏:《人工智能奇遇记》🔖少年有梦不应止于心动,更要付诸行动。 目录结构 1. 机器学习之逻辑回归概念 1.1 机器学习 1.2 逻辑回归 2. 逻辑回归 2.1 实验目的…...
手机,蓝牙开发板,TTL/USB模块,电脑四者之间的通讯
一,意图 通过手机蓝牙连接WeMosD1R32开发板,开发板又通过TTL转USB与电脑连接.手机通过蓝牙控制开发板上的LED灯的开,关,闪等动作,在电脑上打开串口监视工具观察其状态.也可以通过电脑上的串口监视工具来控制开发板上LED灯的动作,而在手机蓝牙监测工具中显示灯的状态. 二,原料…...
Springboot更新用户头像
人们通常(为徒省事)把一个包含了修改后userName的完整userInfo对象传给后端,做完整更新。但仔细想想,这种做法感觉有点二,而且浪费带宽。 于是patch诞生,只传一个userName到指定资源去,表示该请求是一个局部更新&#…...
Express.js 与 Nest.js对比
Express.js 与 Nest.js对比 自从 Node.js 发布以来,Javascript 在后端领域的使用有所增加。由于 Node.js 的使用越来越多,每天都会有新的框架和工具发布。Express 和 Nest 是使用 Node.js 创建后端应用程序的最著名的框架之一,在本文中&…...
总结 CNN 模型:将焦点转移到基于注意力的架构
一、说明 在计算机视觉时代,卷积神经网络(CNN)几十年来一直是主导范式。直到 2021 年 Vision Transformers (ViTs) 出现,这个领域才开始发生变化。现在,是时候采用受 Transformer 架构启发的基于注意力的模型了&#x…...
2023.11.16 hivesql高阶函数之开窗函数
目录 1.开窗函数的定义 2.数据准备 3.开窗函数之排序 需求:用三种排序方法查询学生的语文成绩排名,并降序显示 4.开窗函数分组 需求:按照科目来分类,使用三种排序方式来排序学生的成绩 5.聚合函数与分组配合使用 6.聚合函数同时和分组以及排序关键字配合使用 --需求1&…...

QTableWidget常用信号的功能
2023年11月18日,周六上午 itemPressed(QTableWidgetItem *item):当某个项目被按下时发出信号。itemClicked(QTableWidgetItem *item):当某个项目被单击时发出信号。itemDoubleClicked(QTableWidgetItem *item):当某个项目被双击时…...

Vue理解01
项目建立流程 项目文件夹终端vue ui可视化新建项目(需要一些时间)vscode打开项目npm run serve运行 架构理解: 首先打开的页面默认是index.htmlindex.html默认引用main.jsmain.js引用需要的页面,默认App.vue。Vue示例挂载可以在…...
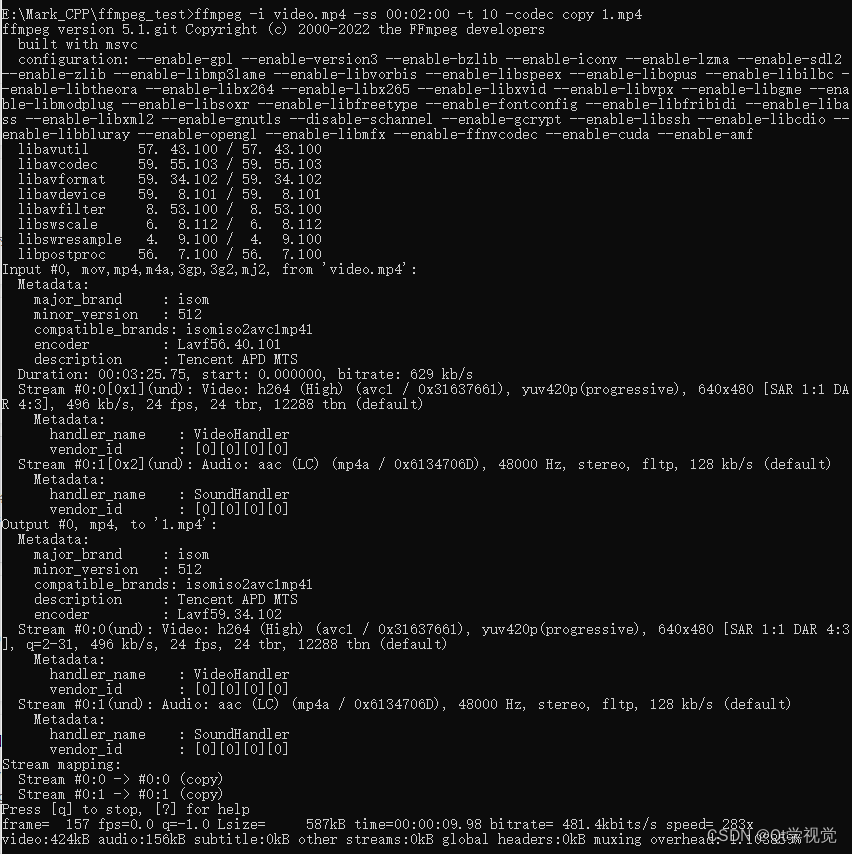
4、FFmpeg命令行操作8
生成测试文件 找三个不同的视频每个视频截取10秒内容 ffmpeg -i 沙海02.mp4 -ss 00:05:00 -t 10 -codec copy 1.mp4 ffmpeg -i 复仇者联盟3.mp4 -ss 00:05:00 -t 10 -codec copy 2.mp4 ffmpeg -i 红海行动.mp4 -ss 00:05:00 -t 10 -codec copy 3.mp4 如果音视…...
【MySQL】索引与事务
作者主页:paper jie_博客 本文作者:大家好,我是paper jie,感谢你阅读本文,欢迎一建三连哦。 本文录入于《MySQL》专栏,本专栏是针对于大学生,编程小白精心打造的。笔者用重金(时间和精力)打造&a…...

切换为root用户后,conda:未找到命令
问题:切换为root用户后,conda:未找到命令 结论详细用户切换配置路径 结论 问题:切换为root用户后,conda:未找到命令 (anaconda) 解决:在~/.bashrc配置里增加conda的路径 详细 用户切换 1 切…...

Qt退出界面
void Dialog::on_pushButton_clicked() {if(ui->lineEdit->text() "admin" && ui->lineEdit_2->text() "123"){accept();//退出} }...

【数据标注】Label Studio用于机器学习标注
原文作者:我辈李想 版权声明:文章原创,转载时请务必加上原文超链接、作者信息和本声明。 文章目录 前言一、使用 Label Studio标注数据1.版本控制 二、Label Studio绑定机器学习后端三、重写机器学习后端四、通过api执行Label Studio动作 前言…...

py字符串转字符串数组
在Python中,你可以使用列表(list)来存储多个字符串。如果你有一个字符串,并且想要将其转换为字符串数组,你可以使用列表推导式(list comprehension)。这是一个简单的例子: # 原始字…...
强化学习各种符号含义解释
:状态 : 动作 : 奖励 : 奖励函数 : 非终结状态 : 全部状态,包括终结状态 : 动作集合 ℛ : 奖励集合 : 转移矩阵 : 离散时间步 : 回合内最终时间步 : 时间t的状态 : 时间t动作 : 时间t的奖励,通常为随机量,且由和决定 : 回报 : n步…...

Axure基础详解二十:中继器随机抽奖效果
效果演示 组件 一、中继器 建立一个“中继器”内部插入一个“正方形”,给“正方形”添加一个【样式效果】>>【选中状态】填充背景为红色,字体白色。在中继器表格中插入两列数据函数:【xuhao】(序号列,按12345……填写&…...

企业信息化与电子商务>供应链信息流
1.供应链信息流概念 供应链信息流是指整个供应链上信息的流动。它是一种虚拟形态,包括了供应链上的供需信息和管理信息,它伴随着物流的运作而不断产生。因此有效的供应链管理作为信息流的管理主要作用在于及时在供应链中传递需求和供给信息,…...

Linux链表操作全解析
Linux C语言链表深度解析与实战技巧 一、链表基础概念与内核链表优势1.1 为什么使用链表?1.2 Linux 内核链表与用户态链表的区别 二、内核链表结构与宏解析常用宏/函数 三、内核链表的优点四、用户态链表示例五、双向循环链表在内核中的实现优势5.1 插入效率5.2 安全…...

江苏艾立泰跨国资源接力:废料变黄金的绿色供应链革命
在华东塑料包装行业面临限塑令深度调整的背景下,江苏艾立泰以一场跨国资源接力的创新实践,重新定义了绿色供应链的边界。 跨国回收网络:废料变黄金的全球棋局 艾立泰在欧洲、东南亚建立再生塑料回收点,将海外废弃包装箱通过标准…...

在WSL2的Ubuntu镜像中安装Docker
Docker官网链接: https://docs.docker.com/engine/install/ubuntu/ 1、运行以下命令卸载所有冲突的软件包: for pkg in docker.io docker-doc docker-compose docker-compose-v2 podman-docker containerd runc; do sudo apt-get remove $pkg; done2、设置Docker…...

Spring是如何解决Bean的循环依赖:三级缓存机制
1、什么是 Bean 的循环依赖 在 Spring框架中,Bean 的循环依赖是指多个 Bean 之间互相持有对方引用,形成闭环依赖关系的现象。 多个 Bean 的依赖关系构成环形链路,例如: 双向依赖:Bean A 依赖 Bean B,同时 Bean B 也依赖 Bean A(A↔B)。链条循环: Bean A → Bean…...

JVM虚拟机:内存结构、垃圾回收、性能优化
1、JVM虚拟机的简介 Java 虚拟机(Java Virtual Machine 简称:JVM)是运行所有 Java 程序的抽象计算机,是 Java 语言的运行环境,实现了 Java 程序的跨平台特性。JVM 屏蔽了与具体操作系统平台相关的信息,使得 Java 程序只需生成在 JVM 上运行的目标代码(字节码),就可以…...

Qemu arm操作系统开发环境
使用qemu虚拟arm硬件比较合适。 步骤如下: 安装qemu apt install qemu-system安装aarch64-none-elf-gcc 需要手动下载,下载地址:https://developer.arm.com/-/media/Files/downloads/gnu/13.2.rel1/binrel/arm-gnu-toolchain-13.2.rel1-x…...

Python 实现 Web 静态服务器(HTTP 协议)
目录 一、在本地启动 HTTP 服务器1. Windows 下安装 node.js1)下载安装包2)配置环境变量3)安装镜像4)node.js 的常用命令 2. 安装 http-server 服务3. 使用 http-server 开启服务1)使用 http-server2)详解 …...

【Veristand】Veristand环境安装教程-Linux RT / Windows
首先声明,此教程是针对Simulink编译模型并导入Veristand中编写的,同时需要注意的是老用户编译可能用的是Veristand Model Framework,那个是历史版本,且NI不会再维护,新版本编译支持为VeriStand Model Generation Suppo…...
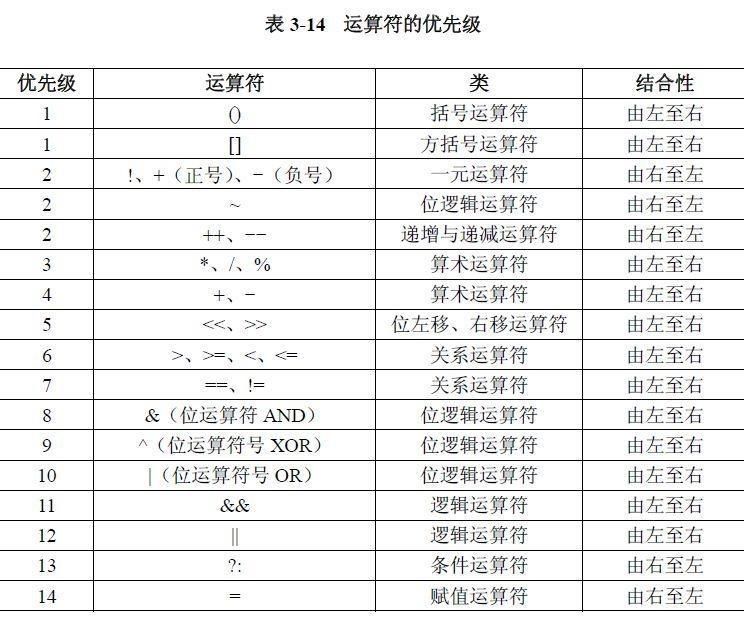
02.运算符
目录 什么是运算符 算术运算符 1.基本四则运算符 2.增量运算符 3.自增/自减运算符 关系运算符 逻辑运算符 &&:逻辑与 ||:逻辑或 !:逻辑非 短路求值 位运算符 按位与&: 按位或 | 按位取反~ …...
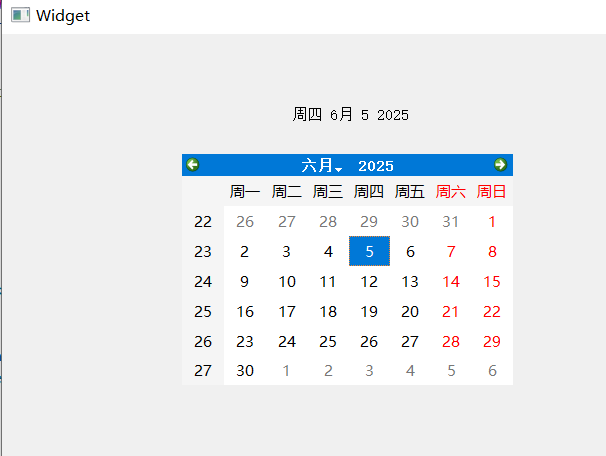
【QT控件】显示类控件
目录 一、Label 二、LCD Number 三、ProgressBar 四、Calendar Widget QT专栏:QT_uyeonashi的博客-CSDN博客 一、Label QLabel 可以用来显示文本和图片. 核心属性如下 代码示例: 显示不同格式的文本 1) 在界面上创建三个 QLabel 尺寸放大一些. objectName 分别…...