总结 CNN 模型:将焦点转移到基于注意力的架构
一、说明
在计算机视觉时代,卷积神经网络(CNN)几十年来一直是主导范式。直到 2021 年 Vision Transformers (ViTs) 出现,这个领域才开始发生变化。现在,是时候采用受 Transformer 架构启发的基于注意力的模型了,使我们能够有效地适应各种数据集变化。
我们需要再次回顾CNN的历史,就像我们回顾过去发生的事情一样,不要重蹈覆辙,也不要改进错误。为了进一步提高基于注意力的模型的性能,学习 CNN 的历史并将其优势应用到这些模型中至关重要。让我们回顾一下 CNN 的影响力时间线,从 LeCun 的 LeNet-1 到广泛使用的 EfficientNet。
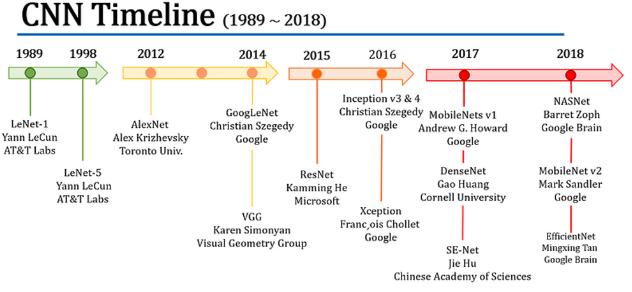
今天,我们探讨了七篇可参考/有意义的关键论文,它们将过渡到基于注意力的模型:[AlexNet、VGG、GoogLeNet、ResNet、DenseNet、SE-Net、EfficientNet]。我们开始吧😃
二、AlexNet:计算机视觉开发的先驱
- 标题:深度卷积神经网络的 ImageNet 分类
- 作者:Alex Krizhevsky、Ilya Sutskever、Geoffrey E. Hinton
- 出版:多伦多大学,2012 年
- :[此处]
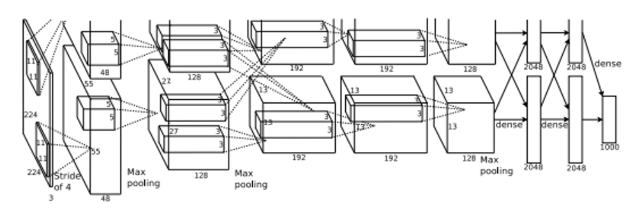
2012 年,大型深度学习模型的特点是计算成本高。人们迫切需要具有成本效益且有效的模型。正是在这段时间,多伦多的研究人员推出了名为 AlexNet 的突破性架构。
AlexNet 最关键的方面之一是其创新的训练环境,它使用两个 3GB GPU。为了优化效率和效果,对架构进行了划分。如上图所示,特征向量在两个 GPU 之间分割,连接位于同一层内。
AlexNet 还解决了臭名昭著的梯度消失问题,即激活输出随着网络加深而减少。与之前通常依赖 Sigmoid 或 tanh 激活函数的模型不同,AlexNet 引入了整流线性单元 (ReLU) 激活函数。AlexNet 引入了修正线性单元 (ReLU) 激活,而不是常用的 Sigmoid 或 tanh。
这一战略选择使得 AlexNet 在大规模视觉识别挑战赛(2012 年的 ILSVRC,ImageNet)中取得了比第二名高出 16% 的准确率,标志着深度学习方法论的重大飞跃。
AlexNet的发布标志着一个转折点,推动了深度学习方法的快速发展。
三、VGG:最大化堆叠 3x3 卷积层的卷积网络的效率。
- 标题:用于大规模图像识别的非常深的卷积网络
- 作者:Karen Simonyan、Andrew Zisserman
- 出版:牛津大学,2014 年
- :[此处]
继 2012 年 AlexNet 取得成功之后,2014 年,谷歌和牛津大学的研究人员推出了两个重要模型,在计算机视觉社区引起了广泛讨论。虽然这些模型有一些相似之处,但人们经常对它们进行比较以评估它们的优势。尽管许多人称赞GoogLeNet 的 1x1 卷积层效率,但值得注意的是 VGG 提出了自己独特的挑战和优点。
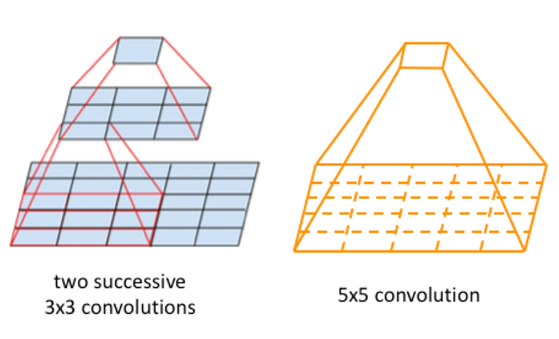
为了说明这一点,让我们考虑一下感受野——计算机视觉中的一个关键方面。左图展示了两个 3x3 卷积层,右图展示了一个 5x5 卷积层。令人惊讶的是,两种设置都提供相同的感受野,这意味着它们可以有效地捕获整个图像的信息。然而,需要注意的是,5x5 卷积层需要 25 倍的计算量,而两个 3x3 层的组合只需要 18 倍的计算量即可产生输出或特征向量。
VGG 通过用多个 3x3 卷积层(在某些情况下甚至是三层)替换较大的卷积层(例如 5x5 或 7x7),在其架构中利用了这种效率。这不仅降低了计算复杂性,而且还为网络增加了非线性,使其能够进行更深入的研究,尽管它依赖于 3x3 卷积层。
在 ILSVRC 挑战中,VGG 获得第二名,落后于 GoogLeNet。然而,更仔细的检查表明,在两种架构之间的直接比较中,VGG 始终优于 GoogLeNet,尽管采用了看似更简单的方法。
四、GoogLeNet:通过不同的卷积实现深度
- 标题:深入了解卷积
- 作者:Christian Szegedy 等人。
- 发布:2014 年 Google Inc
- :[此处]
如果说 VGG 体现了简单性和高性能,那么 GoogLeNet 则展示了卓越的优化过程,旨在利用各种大小的卷积层创建各种模型。尽管如此,VGG 显示,当使用大于 3x3 的卷积层时,计算量会增加,相反,GoogLeNet 引入了一种涉及 1x1 卷积的经济有效的策略,可实现前所未有的模型深度。这使得 GoogLeNet 在保持效率的同时具有令人印象深刻的非线性和强大的性能。
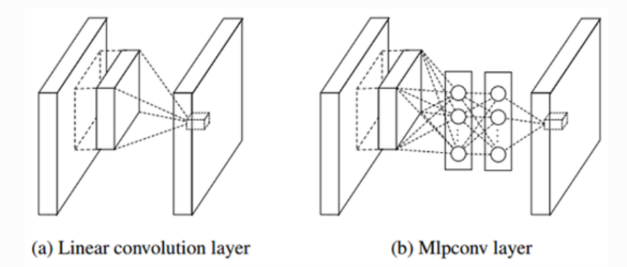
与VGG相比,GoogLeNet还强调了神经网络中非线性的重要性。Google 的方法从 2013 年一篇论文中提出的网络中网络 (NIN) 概念中汲取了灵感。这种创新架构通过采用 1x1 卷积来减少滤波器数量。纵观整个 NIN 结构,网络似乎是嵌套在网络中的。
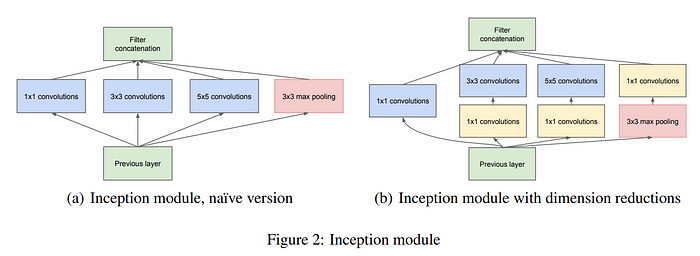
作者承认,更大的模型可以提供更多样化的表达,但它们也带来了挑战,特别是过度拟合和难以优化的风险。为了解决这个问题,他们在网络中引入了稀疏连接——1x1 conv可以实现稀疏连接,旨在在多样性和过度拟合之间取得平衡。然而,值得注意的是,稀疏连接是以计算资源为代价的。
Inception 模块虽然功能强大,但最初面临与成本相关的挑战。为了增强非线性并减轻成本问题,采用 Network in Network 的 1x1 卷积作为战略选择。(图b)
五、ResNet:残差学习重新定义深度学习
- 标题:图像识别的深度残差学习
- 作者:Kamming He 等人。
- 发布:2014 年微软研究团队
- :[此处]
ResNet 已成为该领域最有影响力的论文之一,截至 2023 年 10 月,引用次数超过 180,000 次。它的影响不仅延伸到计算机视觉任务,还延伸到全球范围内的研究挑战。
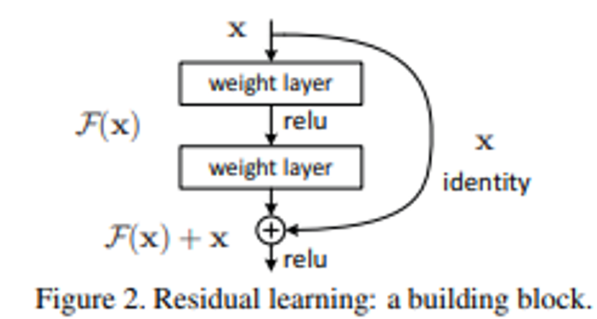
ResNet 引入了一个简单但革命性的概念,称为“残差学习”,它在深度学习领域留下了不可磨灭的印记。该方法的核心是将输入向量添加到网络块的输出。问题出现了:为什么残差学习会产生如此令人印象深刻的结果?
答案就在于这个简单过程的优雅。想象一个场景,我们的模型呈现出狗的图像,其目标是重现相同的狗图像。当这一层被添加到网络中时,它的主要目的是保持输入图像的准确性。因此,模型要么保留输入图像,要么进行最小的更改。这种方法与 VGG 等传统模型明显不同,后者会尝试重建输入图像,从而可能导致结果模糊或扭曲。
这就是为什么 ResNet 的残差学习仍然是一个强大的概念。它允许信息在深层中更无缝地流动,最终有助于其成功。
该残差块最多可以跨越 100 层。这个深度残差块可以成为 2015 年 ILSVRC 挑战赛的获胜者。到目前为止,我们可以看到 ResNet 的许多变体,如 SE-ResNet、ResNext、RegNetY 等。因为它简单且有用。稍后我们将讨论 SE-Net(挤压和激励网络)。在此之前,我们先谈谈 2016 年推出的另一个网络。
六、DenseNet:密集连接层以实现特征多样性
- 标题:密集连接的卷积网络
- 作者:Gao Huang等人
- 发布:Facebook AI 研究团队和康奈尔大学,2017 年
- :[此处]
DenseNet 的架构增强不仅仅考虑输入向量;它确保每个块内的所有层都是互连的。这会提高效率和能力吗?让我们来探索一下。🔥
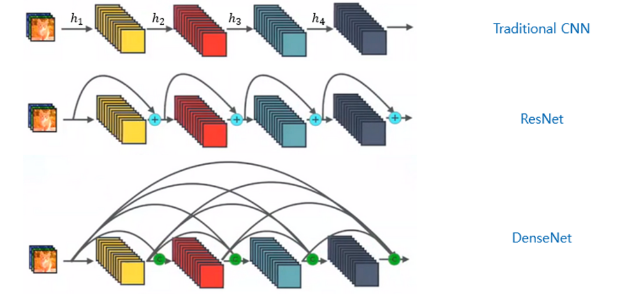
在传统的 CNN 架构中,例如普通 VGG 网络,创建像h_i这样的特征向量,然后传递到后续层,使前一层的动作永久化。同时,ResNet 引入了一项变化,允许层通过将一个密集块的输入添加到另一个密集块的输出来进行连接,形成一种“快捷”连接。现在,仔细观察密集连接的块,我们发现 DenseNet 更进一步。与它的前身不同,DenseNet 确保其块内的所有层都是互连的,形成密集的连接网络。
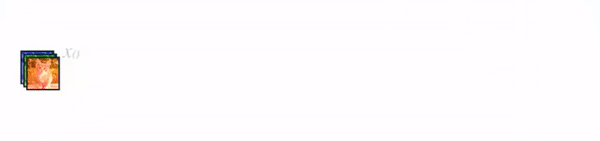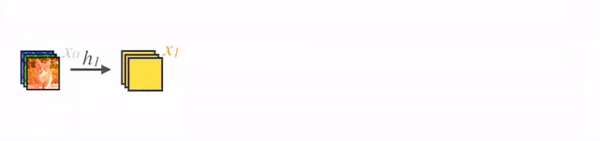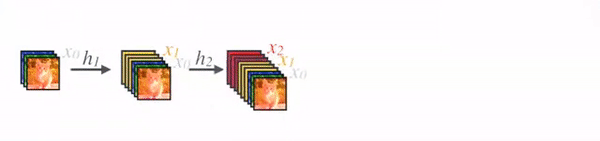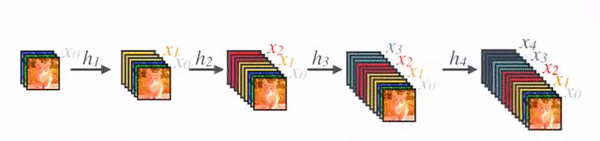
更准确地说,每一层的输出都提供给其后续层。然后,后续层将其自己的输出和从前一层接收到的输出进行集成。
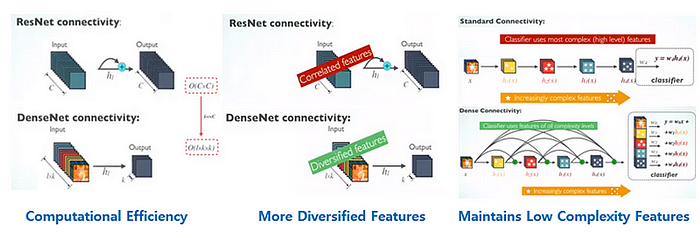
密集互连的层具有三个明显的优势:
1. 计算效率
与 ResNet 的连接相比,DenseNet 的效率更高。ResNet 需要 O(C×C) 的计算成本,而 DenseNet 的运行成本为 O(ℓ×𝓀×𝓀),其中 𝓀 和 ℓ 都明显小于 C。
2. 功能多样化
DenseNet 可以产生比 ResNet 更丰富的特征集。这是因为 DenseNet 层堆叠了前面各层的特征图,比 ResNet 中的相关特征封装了更全面的信息。
3. 多种功能的整合
考虑识别人脸的任务。初始层检测眼睛、耳朵和鼻子等基本特征。然而,更深层次感知更广泛的模式,例如区分男性和女性面孔或识别个人身份。包括 ResNet 在内的传统深度学习模型需要有效压缩输入图像以传递相关信息。然而,由于其密集连接的架构,DenseNet 可以利用大量的特征图,使其异常熟练。
七、SENet:引导注意力以增强学习
- 标题:挤压和激励网络
- 作者:Jie Hu 等人。
- 发布:2017 年中国科学院
- :[此处]
如果我必须选择一种模型架构来促进模型架构,我会选择基于 SE 块的 ResNet。这种方法的美妙之处在于它的简单性和效力。只需添加两个 MLP 层并利用平均池化即可有效提高性能。但更重要的是,其基本思想侧重于区分重要信息和不太重要的渠道。
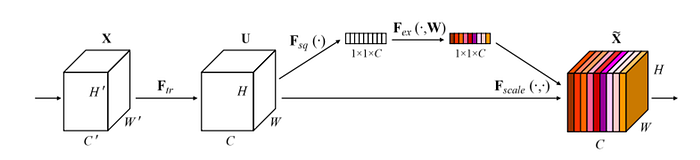
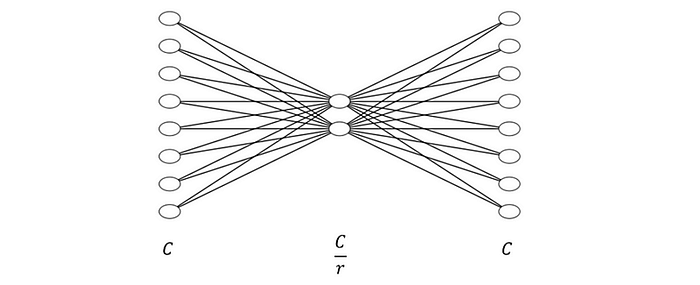
挤压和激励 (SE) 块的工作原理有两个主要步骤
- Squeeze:它使用平均池机制将输入向量压缩到维度 [1×1×C]。
- 激励:这个压缩的 [1×1×C] 向量然后通过两个 MLP 层进行处理,引入非线性。
如图所示,两个 MLP 层引入了非线性,并随后应用 sigmoid 函数 — 确保总和等于 1。这种机制强调了各个特征的重要性。
有趣的是,作者预计 SE 块与 Inception 模块配对将产生显着的改进,这主要是由于能够突出不同的特征。然而,实证结果表明,将其与基于 ResNet 的模型集成比 Inception 模块更有益。
SE 块更具吸引力的是其最小的计算开销。此外,SE 模块复杂地评估渠道间关系,为其赢得了“渠道关注”方法的绰号。
八、EfficientNet:优化模型缩放
- 标题:重新思考卷积神经网络的模型扩展
- 作者:Mingxing Tan 和 Quoc V. Le
- 发布:Google Research,Brain Team 2018 年
- :[此处]
EfficientNet 代表了一种寻求开发紧凑且高性能模型的新颖方法。有效地设计此类架构可能非常具有挑战性。通过一系列实验,EfficientNet 的创建者努力寻找神经网络的最佳平衡点。

EfficientNet 背后的研究人员研究了各种参数:模型的宽度、深度和分辨率。随后,他们制作了一系列模型,从最紧凑的版本到更大的版本。
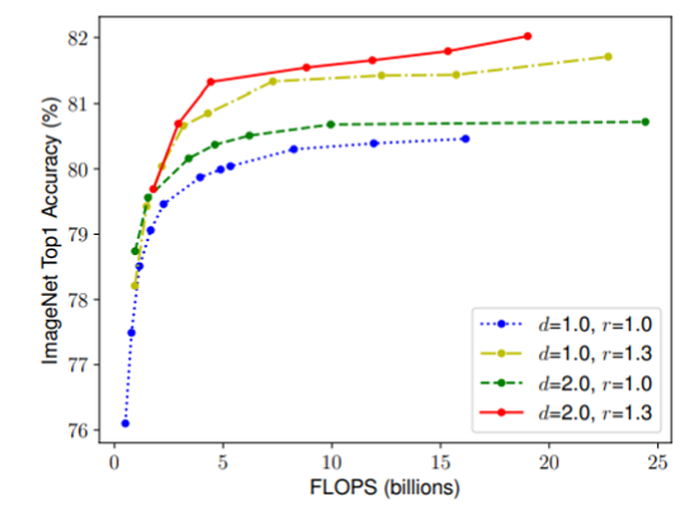
他们的实验证明,分辨率缩放比深度缩放具有更显着的效果,其中“d”表示深度,“r”表示分辨率
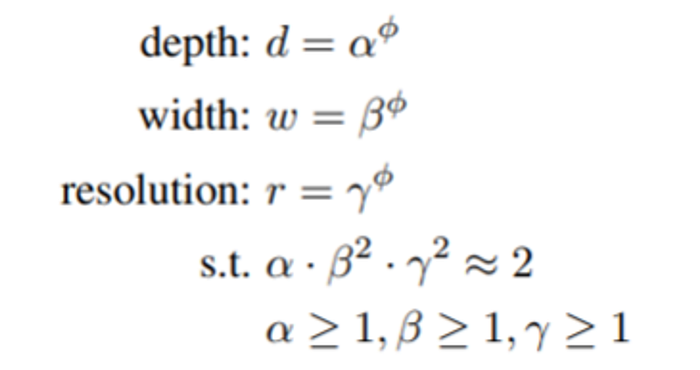
为了扩展模型,EfficientNet 使用phi值。EfficientNet 版本的范围各有不同的 phi 值,在各种模型大小上始终优于竞争对手。此外,与具有相似性能的模型相比,EfficientNet 总是因效率更高而脱颖而出。
九、下一步是什么?
当我们回顾计算机视觉模型的历程时,卷积神经网络 (CNN) 的作用怎么强调都不为过。它们的卷积层和池化机制彻底改变了我们处理视觉数据的方式,推动了图像识别、检测等方面的众多进步。然而,与所有模型一样,CNN 也有其局限性,例如局部感受野以及处理远程依赖性的困难。
输入注意力机制,这是一个新事物,为我们如何建模数据中的依赖关系提供了全新的视角。通过允许模型有选择地处理输入的不同部分,我们打破了固定计算路径的链条,使模型更加灵活和上下文感知。
基于注意力的模型的未来前景广阔。我们或许可以预见:
- 可扩展性:由于注意力机制提供了并行计算的潜力,因此它们非常适合有效处理更大的数据集。回顾 CNN 的演变,很明显后续算法往往变得更加简化和可扩展。
- 可解释性:通过注意力权重的可视化,我们不仅可以深入了解模型认为输入的哪些部分是重要的,而且还可以增强我们对其决策的信任。这与可解释人工智能的更广泛目标相一致,有助于使模型推理更加透明和易于理解。
- 适应性:注意力机制可以与其他架构集成,为利用 CNN 和注意力优势的混合模型铺平道路。
随着研究人员和从业者不断创新,计算机视觉的前景必将不断发展。虽然 CNN 奠定了基础,但基于注意力的模型正在其基础上构建,为我们的探索迈出新的篇章,让我们的模型能够看到和理解。加入这个不断变化的领域是一个激动人心的时刻,我们热切期待未来的奇迹(10-25-2)
相关文章:
总结 CNN 模型:将焦点转移到基于注意力的架构
一、说明 在计算机视觉时代,卷积神经网络(CNN)几十年来一直是主导范式。直到 2021 年 Vision Transformers (ViTs) 出现,这个领域才开始发生变化。现在,是时候采用受 Transformer 架构启发的基于注意力的模型了&#x…...
2023.11.16 hivesql高阶函数之开窗函数
目录 1.开窗函数的定义 2.数据准备 3.开窗函数之排序 需求:用三种排序方法查询学生的语文成绩排名,并降序显示 4.开窗函数分组 需求:按照科目来分类,使用三种排序方式来排序学生的成绩 5.聚合函数与分组配合使用 6.聚合函数同时和分组以及排序关键字配合使用 --需求1&…...

QTableWidget常用信号的功能
2023年11月18日,周六上午 itemPressed(QTableWidgetItem *item):当某个项目被按下时发出信号。itemClicked(QTableWidgetItem *item):当某个项目被单击时发出信号。itemDoubleClicked(QTableWidgetItem *item):当某个项目被双击时…...

Vue理解01
项目建立流程 项目文件夹终端vue ui可视化新建项目(需要一些时间)vscode打开项目npm run serve运行 架构理解: 首先打开的页面默认是index.htmlindex.html默认引用main.jsmain.js引用需要的页面,默认App.vue。Vue示例挂载可以在…...
4、FFmpeg命令行操作8
生成测试文件 找三个不同的视频每个视频截取10秒内容 ffmpeg -i 沙海02.mp4 -ss 00:05:00 -t 10 -codec copy 1.mp4 ffmpeg -i 复仇者联盟3.mp4 -ss 00:05:00 -t 10 -codec copy 2.mp4 ffmpeg -i 红海行动.mp4 -ss 00:05:00 -t 10 -codec copy 3.mp4 如果音视…...
【MySQL】索引与事务
作者主页:paper jie_博客 本文作者:大家好,我是paper jie,感谢你阅读本文,欢迎一建三连哦。 本文录入于《MySQL》专栏,本专栏是针对于大学生,编程小白精心打造的。笔者用重金(时间和精力)打造&a…...

切换为root用户后,conda:未找到命令
问题:切换为root用户后,conda:未找到命令 结论详细用户切换配置路径 结论 问题:切换为root用户后,conda:未找到命令 (anaconda) 解决:在~/.bashrc配置里增加conda的路径 详细 用户切换 1 切…...

Qt退出界面
void Dialog::on_pushButton_clicked() {if(ui->lineEdit->text() "admin" && ui->lineEdit_2->text() "123"){accept();//退出} }...

【数据标注】Label Studio用于机器学习标注
原文作者:我辈李想 版权声明:文章原创,转载时请务必加上原文超链接、作者信息和本声明。 文章目录 前言一、使用 Label Studio标注数据1.版本控制 二、Label Studio绑定机器学习后端三、重写机器学习后端四、通过api执行Label Studio动作 前言…...

py字符串转字符串数组
在Python中,你可以使用列表(list)来存储多个字符串。如果你有一个字符串,并且想要将其转换为字符串数组,你可以使用列表推导式(list comprehension)。这是一个简单的例子: # 原始字…...
强化学习各种符号含义解释
:状态 : 动作 : 奖励 : 奖励函数 : 非终结状态 : 全部状态,包括终结状态 : 动作集合 ℛ : 奖励集合 : 转移矩阵 : 离散时间步 : 回合内最终时间步 : 时间t的状态 : 时间t动作 : 时间t的奖励,通常为随机量,且由和决定 : 回报 : n步…...

Axure基础详解二十:中继器随机抽奖效果
效果演示 组件 一、中继器 建立一个“中继器”内部插入一个“正方形”,给“正方形”添加一个【样式效果】>>【选中状态】填充背景为红色,字体白色。在中继器表格中插入两列数据函数:【xuhao】(序号列,按12345……填写&…...

企业信息化与电子商务>供应链信息流
1.供应链信息流概念 供应链信息流是指整个供应链上信息的流动。它是一种虚拟形态,包括了供应链上的供需信息和管理信息,它伴随着物流的运作而不断产生。因此有效的供应链管理作为信息流的管理主要作用在于及时在供应链中传递需求和供给信息,…...
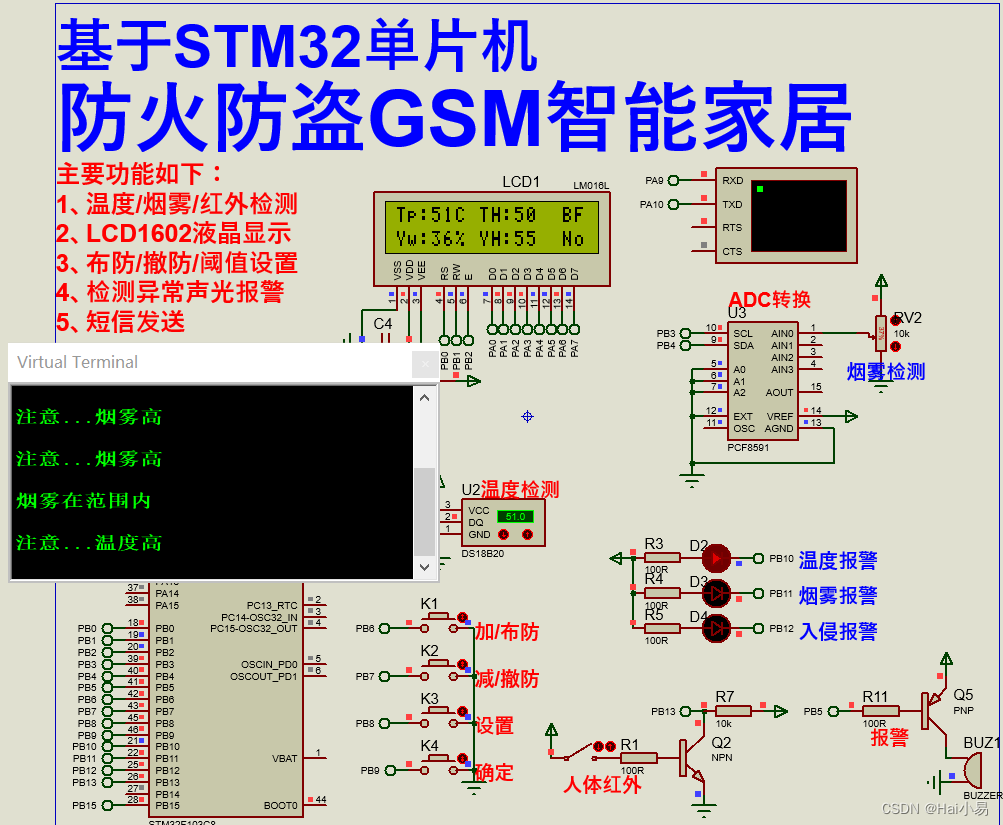
【Proteus仿真】【STM32单片机】防火防盗GSM智能家居设计
文章目录 一、功能简介二、软件设计三、实验现象联系作者 一、功能简介 本项目使用Proteus8仿真STM32单片机控制器,使用声光报警模块、LCD1602显示模块、DS18B20温度、烟雾传感器模块、按键模块、PCF8591 ADC模块、红外检测模块等。 主要功能: 系统运行…...
快速入门ESP32——开发环境配置PlatformIO IDE
相关文章 快速入门ESP32——开发环境配置Arduino IDE 快速入门ESP32——开发环境配置PlatformIO IDE 一、下载安装二、验证 一、下载安装 下载安装 vscode 安装PlatformIO插件 创建工程 二、验证 写一个简单的函数来验证一下功能 void setup() {// put your setup cod…...

Oxygen XML Editor 26版新功能
▲ 搜索“大龙谈智能内容”关注GongZongHao▲ 2023年10月26日,罗马尼亚SyncRO Soft公司发布Oxygen XML Editor、Oxygen Web Author和Oxygen Publish Engine 26版本。 1. Oxygen XML Editor 26新功能简介 AI助手 帮助写作者通过执行重复任务、审查语法、生成结构…...
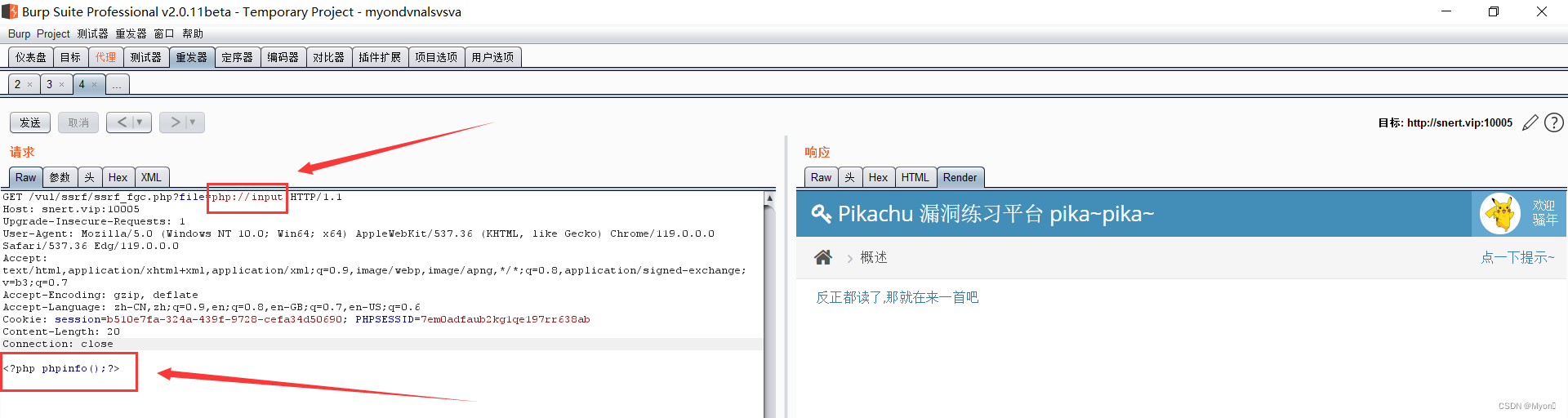
Pikachu漏洞练习平台之SSRF(服务器端请求伪造)
注意区分CSRF和SSRF: CSRF:跨站请求伪造攻击,由客户端发起; SSRF:是服务器端请求伪造,由服务器发起。 SSRF形成的原因大都是由于服务端提供了从其他服务器应用获取数据的功能,但又没有对目标…...

WPF异步编程
在WPF应用程序中进行异步编程是非常重要的,因为这有助于保持用户界面的响应性,特别是当执行长时间运行的操作时,例如访问网络资源、进行大量的数据处理或调用耗时的I/O操作。 WPF的异步编程通常围绕以下几个关键概念: Dispatcher…...

同态加密定义,四大发展阶段总结,FHE系统正式定义-全同态加密
目录 同态加密定义 为什么采用电路模型? 四大发展阶段 总结 FHE系统正式定义...

网上的搜索
Internet中蕴含的信息资源非常丰富,但如何在这浩瀚如海的信息空间内快速找到自己所需要的资源呢?我们需要借助于搜索引擎。在网络上,提供搜索功能的网站非常多,如百度、谷歌、搜狗等,另外有一些门户网站也提供了搜索功能…...

【大模型RAG】拍照搜题技术架构速览:三层管道、两级检索、兜底大模型
摘要 拍照搜题系统采用“三层管道(多模态 OCR → 语义检索 → 答案渲染)、两级检索(倒排 BM25 向量 HNSW)并以大语言模型兜底”的整体框架: 多模态 OCR 层 将题目图片经过超分、去噪、倾斜校正后,分别用…...

【Linux】C语言执行shell指令
在C语言中执行Shell指令 在C语言中,有几种方法可以执行Shell指令: 1. 使用system()函数 这是最简单的方法,包含在stdlib.h头文件中: #include <stdlib.h>int main() {system("ls -l"); // 执行ls -l命令retu…...

2.Vue编写一个app
1.src中重要的组成 1.1main.ts // 引入createApp用于创建应用 import { createApp } from "vue"; // 引用App根组件 import App from ./App.vue;createApp(App).mount(#app)1.2 App.vue 其中要写三种标签 <template> <!--html--> </template>…...

关于 WASM:1. WASM 基础原理
一、WASM 简介 1.1 WebAssembly 是什么? WebAssembly(WASM) 是一种能在现代浏览器中高效运行的二进制指令格式,它不是传统的编程语言,而是一种 低级字节码格式,可由高级语言(如 C、C、Rust&am…...

高防服务器能够抵御哪些网络攻击呢?
高防服务器作为一种有着高度防御能力的服务器,可以帮助网站应对分布式拒绝服务攻击,有效识别和清理一些恶意的网络流量,为用户提供安全且稳定的网络环境,那么,高防服务器一般都可以抵御哪些网络攻击呢?下面…...

Spring数据访问模块设计
前面我们已经完成了IoC和web模块的设计,聪明的码友立马就知道了,该到数据访问模块了,要不就这俩玩个6啊,查库势在必行,至此,它来了。 一、核心设计理念 1、痛点在哪 应用离不开数据(数据库、No…...

【分享】推荐一些办公小工具
1、PDF 在线转换 https://smallpdf.com/cn/pdf-tools 推荐理由:大部分的转换软件需要收费,要么功能不齐全,而开会员又用不了几次浪费钱,借用别人的又不安全。 这个网站它不需要登录或下载安装。而且提供的免费功能就能满足日常…...

人工智能(大型语言模型 LLMs)对不同学科的影响以及由此产生的新学习方式
今天是关于AI如何在教学中增强学生的学习体验,我把重要信息标红了。人文学科的价值被低估了 ⬇️ 转型与必要性 人工智能正在深刻地改变教育,这并非炒作,而是已经发生的巨大变革。教育机构和教育者不能忽视它,试图简单地禁止学生使…...

Python 训练营打卡 Day 47
注意力热力图可视化 在day 46代码的基础上,对比不同卷积层热力图可视化的结果 import torch import torch.nn as nn import torch.optim as optim from torchvision import datasets, transforms from torch.utils.data import DataLoader import matplotlib.pypl…...
ubuntu22.04有线网络无法连接,图标也没了
今天突然无法有线网络无法连接任何设备,并且图标都没了 错误案例 往上一顿搜索,试了很多博客都不行,比如 Ubuntu22.04右上角网络图标消失 最后解决的办法 下载网卡驱动,重新安装 操作步骤 查看自己网卡的型号 lspci | gre…...