MySQL 的执行原理(一)
5.1 单表访问之索引合并
我们前边说过 MySQL 在一般情况下执行一个查询时最多只会用到单个二级
索引,但存在有特殊情况,在这些特殊情况下也可能在一个查询中使用到多个二
级索引,MySQL 中这种使用到多个索引来完成一次查询的执行方法称之为:索引
合并/index merge,具体的索引合并算法有下边三种。
5.1.1. Intersection 合并
Intersection 翻译过来的意思是交集。这里是说某个查询可以使用多个二级
索引,将从多个二级索引中查询到的结果取交集,比方说下边这个查询:
SELECT * FROM order_exp WHERE order_no = 'a' AND expire_time = 'b';
假设这个查询使用 Intersection 合并的方式执行的话,那这个过程就是这样
的:
从 idx_order_no 二级索引对应的 B+树中取出 order_no= 'a’的相关记录。
从 idx_insert_time 二级索引对应的 B+树中取出 insert_time= 'b’的相关记录。
二级索引的记录都是由索引列 + 主键构成的,所以我们可以计算出这两个
结果集中 id 值的交集。
按照上一步生成的 id 值列表进行回表操作,也就是从聚簇索引中把指定 id
值的完整用户记录取出来,返回给用户。
为啥不直接使用 idx_order_no 或者 idx_insert_time 只根据某个搜索条件去读
取一个二级索引,然后回表后再过滤另外一个搜索条件呢?这里要分析一下两种
查询执行方式之间需要的成本代价。
只读取一个二级索引的成本:
按照某个搜索条件读取一个二级索引,根据从该二级索引得到的主键值进行
回表操作,然后再过滤其他的搜索条件
读取多个二级索引之后取交集成本:
按照不同的搜索条件分别读取不同的二级索引,将从多个二级索引得到的主
键值取交集,然后进行回表操作。
虽然读取多个二级索引比读取一个二级索引消耗性能,但是大部分情况下读
取二级索引的操作是顺序 I/O,而回表操作是随机 I/O,所以如果只读取一个二级
索引时需要回表的记录数特别多,而读取多个二级索引之后取交集的记录数非常
少,当节省的因为回表而造成的性能损耗比访问多个二级索引带来的性能损耗更
高时,读取多个二级索引后取交集比只读取一个二级索引的成本更低。
MySQL 在某些特定的情况下才可能会使用到 Intersection 索引合并,哪些情
况呢?
5.1.1.1. 情况一:等值匹配
二级索引列是等值匹配的情况,对于联合索引来说,在联合索引中的每个列
都必须等值匹配,不能出现只匹配部分列的情况。
而下边这两个查询就不能进行 Intersection 索引合并:
SELECT * FROM order_exp WHERE order_no> 'a' AND insert_time = 'a' AND
order_status = 'b' AND expire_time = 'c';
SELECT * FROM order_exp WHERE order_no = 'a' AND insert_time = 'a';
第一个查询是因为对 order_no 进行了范围匹配,第二个查询是因为联合索
引u_idx_day_status中的order_status和expire_time列并没有出现在搜索条件中,
所以这两个查询不能进行 Intersection 索引合并。
5.1.1.2. 情况二:主键列可以是范围匹配
比方说下边这个查询可能用到主键和u_idx_day_status进行Intersection索引
合并的操作:
SELECT * FROM order_exp WHERE id > 100 AND insert_time = 'a';
对于 InnoDB 的二级索引来说,记录先是按照索引列进行排序,
如果该二级索引是一个联合索引,那么会按照联合索引中的各个列依次排序。而二级索引的
用户记录是由索引列 + 主键构成的,二级索引列的值相同的记录可能会有好多
条,这些索引列的值相同的记录又是按照主键的值进行排序的。
所以重点来了,之所以在二级索引列都是等值匹配的情况下才可能使用
Intersection 索引合并,是因为只有在这种情况下根据二级索引查询出的结果集
是按照主键值排序的。
Intersection 索引合并会把从多个二级索引中查询出的主键值求交集,如果
从各个二级索引中查询的到的结果集本身就是已经按照主键排好序的,那么求交
集的过程就很容易。
假设某个查询使用 Intersection 索引合并的方式从 idx_order_no 和
idx_expire_time 这两个二级索引中获取到的主键值分别是:
从 idx_order_no 中获取到已经排好序的主键值:1、3、5
从 idx_expire_time 中获取到已经排好序的主键值:2、3、4
那么求交集的过程就是这样:逐个取出这两个结果集中最小的主键值,如果
两个值相等,则加入最后的交集结果中,否则丢弃当前较小的主键值,再取该丢
弃的主键值所在结果集的后一个主键值来比较,直到某个结果集中的主键值用完
了,时间复杂度是 O(n)。
但是如果从各个二级索引中查询出的结果集并不是按照主键排序的话,那就
要先把结果集中的主键值排序完再来做上边的那个过程,就比较耗时了。
按照有序的主键值去回表取记录有个专有名词,叫:Rowid Ordered Retrieval,
简称 ROR。
另外,不仅是多个二级索引之间可以采用 Intersection 索引合并,索引合并
也可以有聚簇索引参加,也就是我们上边写的情况二:在搜索条件中有主键的范
围匹配的情况下也可以使用 Intersection 索引合并索引合并。为啥主键这就可以
范围匹配了?还是得回到应用场景里:
SELECT * FROM order_exp WHERE id > 100 AND order_no = 'a';
假设这个查询可以采用 Intersection 索引合并,我们理所当然的以为这个查
询会分别按照id > 100这个条件从聚簇索引中获取一些记录,在通过order_no= ‘a’ 这个条件从 idx_order_no 二级索引中获取一些记录,然后再求交集,其实这样就
把问题复杂化了,没必要从聚簇索引中获取一次记录。别忘了二级索引的记录中
都带有主键值的,所以可以在从 idx_order_no 中获取到的主键值上直接运用条件
id > 100 过滤就行了,这样多简单。所以涉及主键的搜索条件只不过是为了从别
的二级索引得到的结果集中过滤记录罢了,是不是等值匹配不重要。
当然,上边说的情况一和情况二只是发生 Intersection 索引合并的必要条件,
不是充分条件。也就是说即使情况一、情况二成立,也不一定发生 Intersection
索引合并,这得看优化器的心情。优化器只有在单独根据搜索条件从某个二级索
引中获取的记录数太多,导致回表开销太大,而通过 Intersection 索引合并后需
要回表的记录数大大减少时才会使用 Intersection 索引合并。
5.1.2. Union 合并
我们在写查询语句时经常想把既符合某个搜索条件的记录取出来,也把符合
另外的某个搜索条件的记录取出来,我们说这些不同的搜索条件之间是 OR 关系。
有时候 OR 关系的不同搜索条件会使用到不同的索引,比方说这样:
SELECT * FROM order_exp WHERE order_no = 'a' OR expire_time = 'b'
Intersection 是交集的意思,这适用于使用不同索引的搜索条件之间使用 AND
连接起来的情况;Union 是并集的意思,适用于使用不同索引的搜索条件之间使
用 OR 连接起来的情况。与 Intersection 索引合并类似,MySQL 在某些特定的情
况下才可能会使用到 Union 索引合并:
5.1.2.1. 情况一:等值匹配
分析同 Intersection 合并
5.1.2.2. 情况二:主键列可以是范围匹配
分析同 Intersection 合并
5.1.2.3. 情况三:使用 Intersection 索引合并的搜索条件
就是搜索条件的某些部分使用 Intersection 索引合并的方式得到的主键集合
和其他方式得到的主键集合取交集,比方说这个查询:
SELECT * FROM order_exp WHERE insert_time = 'a' AND order_status = 'b' AND
expire_time = 'c' OR (order_no = 'a' AND expire_time = 'b');
优化器可能采用这样的方式来执行这个查询:
先按照搜索条件 order_no = ‘a’ AND expire_time = 'b’从索引 idx_order_no 和
idx_expire_time 中使用 Intersection 索引合并的方式得到一个主键集合。
再按照搜索条件 insert_time = ‘a’ AND order_status = ‘b’ AND expire_time = ‘c’ 从联合索引 u_idx_day_status 中得到另一个主键集合。
采用 Union 索引合并的方式把上述两个主键集合取并集,然后进行回表操作,
将结果返回给用户。
当然,查询条件符合了这些情况也不一定就会采用 Union 索引合并,也得看
优化器的心情。优化器只有在单独根据搜索条件从某个二级索引中获取的记录数
比较少,通过 Union 索引合并后进行访问的代价比全表扫描更小时才会使用
Union 索引合并。
5.1.3. Sort-Union 合并
Union 索引合并的使用条件太苛刻,必须保证各个二级索引列在进行等值匹
配的条件下才可能被用到,比方说下边这个查询就无法使用到 Union 索引合并:
SELECT * FROM order_exp WHERE order_no< 'a' OR expire_time> 'z'
这是因为根据 order_no< 'a’从 idx_order_no 索引中获取的二级索引记录的主
键值不是排好序的,根据 expire_time> 'z’从 idx_expire_time 索引中获取的二级索
引记录的主键值也不是排好序的,但是 order_no< 'a’和 expire_time> ‘z’'这两个条
件又特别让我们动心,所以我们可以这样:
- 先根据 order_no< 'a’条件从 idx_order_no 二级索引中获取记录,并按照记录
的主键值进行排序 - 再根据 expire_time> 'z’条件从 idx_expire_time 二级索引中获取记录,并按照
记录的主键值进行排序
因为上述的两个二级索引主键值都是排好序的,剩下的操作和 Union 索引合
并方式就一样了。
上述这种先按照二级索引记录的主键值进行排序,之后按照 Union 索引合并
方式执行的方式称之为 Sort-Union 索引合并,很显然,这种 Sort-Union 索引合并
比单纯的 Union 索引合并多了一步对二级索引记录的主键值排序的过程。
5.1.4. 联合索引替代 Intersection 索引合并
SELECT * FROM order_exp WHERE order_no= 'a' And expire_time= 'z';
这个查询之所以可能使用 Intersection 索引合并的方式执行,还不是因为
idx_order_no 和 idx_expire_time 是两个单独的 B+树索引,要是把这两个列搞一个
联合索引,那直接使用这个联合索引就把事情搞定了,何必用啥索引合并呢,就
像这样:
ALTER TABLE order_exp drop index idx_order_no, idx_expire_time, add index idx_order_no_expire_time(order_no, expire_time);
这样我们把 idx_order_no, idx_expire_time 都干掉,再添加一个联合索引
idx_order_no_expire_time,使用这个联合索引进行查询简直是又快又好,既不用
多读一棵 B+树,也不用合并结果。
5.2. 连接查询
搞数据库一个避不开的概念就是 Join,翻译成中文就是连接。使用的时候常
常陷入下边两种误区:
误区一:业务至上,管他三七二十一,再复杂的查询也用在一个连接语句中
搞定。
误区二:敬而远之,上次慢查询就是因为使用了连接导致的,以后再也不敢
用了。
所以我们来学习一下连接的原理,才能在工作中用好 SQL 连接。
5.2.1. 连接简介
5.2.1.1. 连接的本质
为了方便讲述,我们建立两个简单的演示表并给它们写入数据:
CREATE TABLE e1 (m1 int, n1 char(1));
CREATE TABLE e2 (m2 int, n2 char(1));
INSERT INTO e1 VALUES(1, 'a'), (2, 'b'), (3, 'c');
INSERT INTO e2 VALUES(2, 'b'), (3, 'c'), (4, 'd');
连接的本质就是把各个连接表中的记录都取出来依次匹配的组合加入结果
集并返回给用户。
所以我们把 e1 和 e2 两个表连接起来的过程如下图所示:
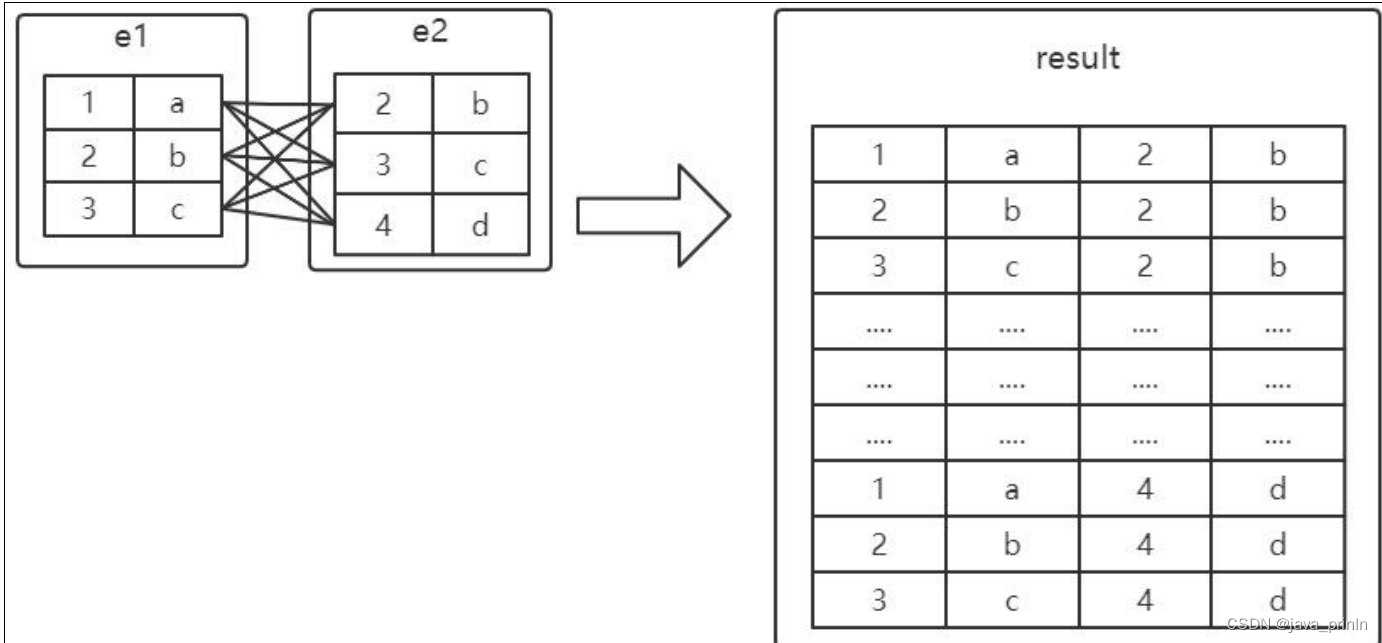
这个过程看起来就是把e1表的记录和e2的记录连起来组成新的更大的记录,
所以这个查询过程称之为连接查询。连接查询的结果集中包含一个表中的每一条
记录与另一个表中的每一条记录相互匹配的组合,像这样的结果集就可以称之为
笛卡尔积。因为表 e1 中有 3 条记录,表 e2 中也有 3 条记录,所以这两个表连接
之后的笛卡尔积就有 3×3=9 行记录。
在 MySQL 中,连接查询的语法很随意,只要在 FROM 语句后边跟多个表名
就好了,比如我们把 e1 表和 e2 表连接起来的查询语句可以写成这样:
SELECT * FROM e1, e2;
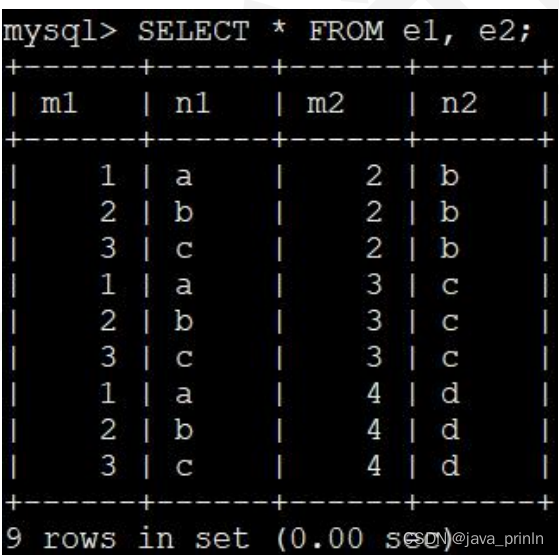
5.2.1.2. 连接过程简介
我们可以连接任意数量张表,但是如果没有任何限制条件的话,这些表连接
起来产生的笛卡尔积可能是非常巨大的。比方说 3 个 100 行记录的表连接起来产
生的笛卡尔积就有 100×100×100=1000000 行数据!所以在连接的时候过滤掉特
定记录组合是有必要的,在连接查询中的过滤条件可以分成两种,比方说下边这
个查询语句:
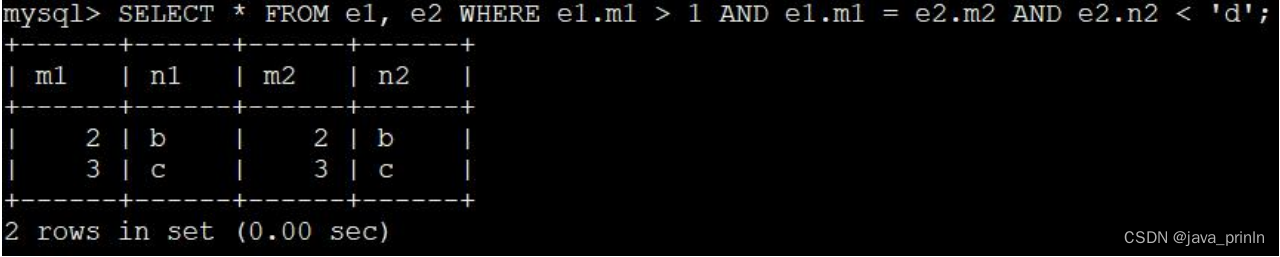
SELECT * FROM e1, e2 WHERE e1.m1 > 1 AND e1.m1 = e2.m2 AND e2.n2 < 'd';
涉及单表的条件
比如 e1.m1 > 1 是只针对 e1 表的过滤条件,e2.n2 < 'd’是只针对 e2 表的过滤
条件。
涉及两表的条件
比如类似 e1.m1 = e2.m2、e1.n1 > e2.n2 等,这些条件中涉及到了两个表。
看一下携带过滤条件的连接查询的大致执行过程在这个查询中我们指明了
这三个过滤条件:
e1.m1 > 1
e1.m1 = e2.m2
e2.n2 < ‘d’ 那么这个连接查询的大致执行过程如下:
步骤一:首先确定第一个需要查询的表,这个表称之为驱动表。单表中执行
查询语句只需要选取代价最小的那种访问方法去执行单表查询语句就好了(就是
说从 const、ref、ref_or_null、range、index、all 等等这些执行方法中选取代价最
小的去执行查询)。
此处假设使用 e1 作为驱动表,那么就需要到 e1 表中找满足 e1.m1 > 1 的记
录,因为表中的数据太少,我们也没在表上建立二级索引,所以此处查询 e1 表
的访问方法就设定为 all,也就是采用全表扫描的方式执行单表查询。
很明显,e1 表中符合 e1.m1 > 1 的记录有两条。
步骤二:针对上一步骤中从驱动表产生的结果集中的每一条记录,分别需要
到 e2 表中查找匹配的记录,所谓匹配的记录,指的是符合过滤条件的记录。因
为是根据 e1 表中的记录去找 e2 表中的记录,所以 e2 表也可以被称之为被驱动
表。上一步骤从驱动表中得到了 2 条记录,所以需要查询 2 次 e2 表。此时涉及
两个表的列的过滤条件 e1.m1 = e2.m2 就派上用场了。
当 e1.m1 = 2 时,过滤条件 e1.m1 = e2.m2 就相当于 e2.m2 = 2,所以此时 e2
表相当于有了 e2.m2 = 2、e2.n2 < 'd’这两个过滤条件,然后到 e2 表中执行单表查
询。
当 e1.m1 = 3 时,过滤条件 e1.m1 = e2.m2 就相当于 e2.m2 = 3,所以此时 e2
表相当于有了 e2.m2 = 3、e2.n2 < 'd’这两个过滤条件,然后到 e2 表中执行单表查
询。
所以整个连接查询的执行过程就如下图所示:
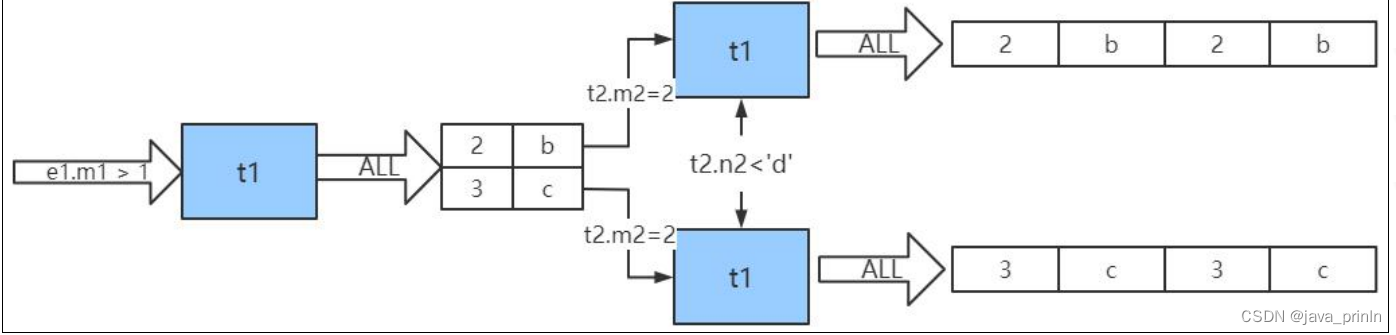
也就是说整个连接查询最后的结果只有两条符合过滤条件的记录:
从上边两个步骤可以看出来,这个两表连接查询共需要查询 1 次 e1 表,2
次 e2 表。当然这是在特定的过滤条件下的结果,如果我们把 e1.m1 > 1 这个条件
去掉,那么从 e1 表中查出的记录就有 3 条,就需要查询 3 次 e2 表了。也就是说
在两表连接查询中,驱动表只需要访问一次,被驱动表可能被访问多次。
5.2.1.3. 内连接和外连接
为了大家更好理解后边内容,我们创建两个有现实意义的表,并插入一些数
据:
CREATE TABLE student (
number INT NOT NULL AUTO_INCREMENT COMMENT '学号',
name VARCHAR(5) COMMENT '姓名',
major VARCHAR(30) COMMENT '专业', PRIMARY KEY (number)
) Engine=InnoDB CHARSET=utf8 COMMENT '客户信息表';CREATE TABLE score (
number INT COMMENT '学号',
subject VARCHAR(30) COMMENT '科目',
score TINYINT COMMENT '成绩', PRIMARY KEY (number, subject)
) Engine=InnoDB CHARSET=utf8 COMMENT '客户成绩表';
SELECT * FROM student; SELECT * FROM score;
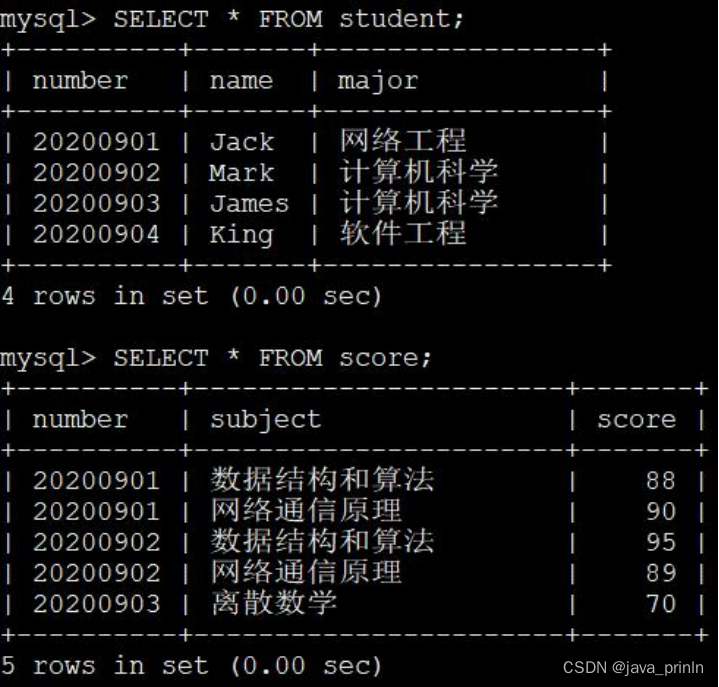
现在我们想把每个学生的考试成绩都查询出来就需要进行两表连接了(因为
score 中没有姓名信息,所以不能单纯只查询 score 表)。连接过程就是从 student
表中取出记录,在 score 表中查找 number 相同的成绩记录,所以过滤条件就是
student.number = socre.number,整个查询语句就是这样:
SELECT s1.number, s1.name, s2.subject, s2.score FROM student AS s1, score
AS s2 WHERE s1.number = s2.number;

从上述查询结果中我们可以看到,各个同学对应的各科成绩就都被查出来了,可
是有个问题,King 同学,也就是学号为 20200904 的同学因为某些原因没有参加
考试,所以在 score 表中没有对应的成绩记录。
如果老师想查看所有同学的考试成绩,即使是缺考的同学也应该展示出来,
但是到目前为止我们介绍的连接查询是无法完成这样的需求的。我们稍微思考一
下这个需求,其本质是想:驱动表中的记录即使在被驱动表中没有匹配的记录,
也仍然需要加入到结果集。为了解决这个问题,就有了内连接和外连接的概念:
对于内连接的两个表,驱动表中的记录在被驱动表中找不到匹配的记录,该
记录不会加入到最后的结果集,我们上边提到的连接都是所谓的内连接。
对于外连接的两个表,驱动表中的记录即使在被驱动表中没有匹配的记录,
也仍然需要加入到结果集。
在 MySQL 中,根据选取驱动表的不同,外连接仍然可以细分为 2 种:
- 左外连接,选取左侧的表为驱动表。
- 右外连接,选取右侧的表为驱动表。
可是这样仍然存在问题,即使对于外连接来说,有时候我们也并不想把驱动
表的全部记录都加入到最后的结果集。
这就犯难了,怎么办?把过滤条件分为两种就可以就解决这个问题了,所以
放在不同地方的过滤条件是有不同语义的:
WHERE 子句中的过滤条件
WHERE 子句中的过滤条件就是我们平时见的那种,不论是内连接还是外连
接,凡是不符合 WHERE 子句中的过滤条件的记录都不会被加入最后的结果集。
ON 子句中的过滤条件
对于外连接的驱动表的记录来说,如果无法在被驱动表中找到匹配 ON 子句
中的过滤条件的记录,那么该记录仍然会被加入到结果集中,对应的被驱动表记
录的各个字段使用 NULL 值填充。
需要注意的是,这个 ON 子句是专门为外连接驱动表中的记录在被驱动表找
不到匹配记录时应不应该把该记录加入结果集这个场景下提出的,所以如果把
ON 子句放到内连接中,MySQL 会把它和 WHERE 子句一样对待,也就是说:内
连接中的 WHERE 子句和 ON 子句是等价的。
一般情况下,我们都把只涉及单表的过滤条件放到 WHERE 子句中,把涉及
两表的过滤条件都放到 ON 子句中,我们也一般把放到 ON 子句中的过滤条件也
称之为连接条件。
左(外)连接的语法
左(外)连接的语法还是挺简单的,比如我们要把 e1 表和 e2 表进行左外连
接查询可以这么写:
SELECT * FROM e1 LEFT [OUTER] JOIN e2 ON 连接条件 [WHERE 普通过滤条
件];
其中中括号里的 OUTER 单词是可以省略的。对于 LEFT JOIN 类型的连接来说,
我们把放在左边的表称之为外表或者驱动表,右边的表称之为内表或者被驱动表。
所以上述例子中 e1 就是外表或者驱动表,e2 就是内表或者被驱动表。需要注意
的是,对于左(外)连接和右(外)连接来说,必须使用 ON 子句来指出连接条
件。了解了左(外)连接的基本语法之后,再次回到我们上边那个现实问题中来,
看看怎样写查询语句才能把所有的客户的成绩信息都查询出来,即使是缺考的考
生也应该被放到结果集中:
SELECT s1.number, s1.name, s2.subject, s2.score FROM student AS s1 LEFT
JOIN score AS s2 ON s1.number = s2.number;
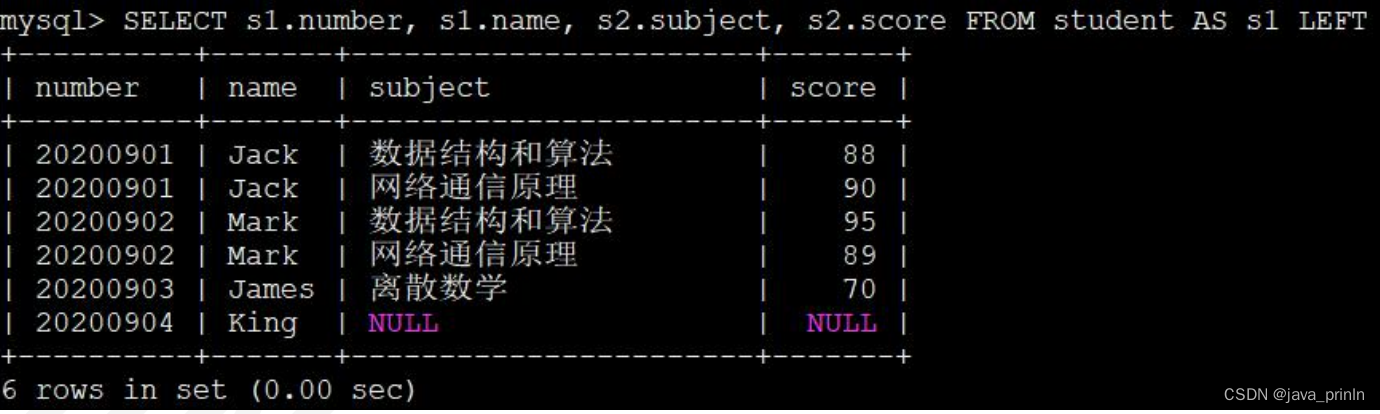
从结果集中可以看出来,虽然 King 并没有对应的成绩记录,但是由于采用
的是连接类型为左(外)连接,所以仍然把她放到了结果集中,只不过在对应的
成绩记录的各列使用 NULL 值填充而已。
右(外)连接的语法
右(外)连接和左(外)连接的原理是一样的,语法也只是把 LEFT 换成 RIGHT
而已:
SELECT * FROM e1 RIGHT [OUTER] JOIN e2 ON 连接条件 [WHERE 普通过滤
条件];
只不过驱动表是右边的表 e2,被驱动表是左边的表 e1。
内连接的语法
内连接和外连接的根本区别就是在驱动表中的记录不符合ON子句中的连接
条件时不会把该记录加入到最后的结果集,一种最简单的内连接语法,就是直接
把需要连接的多个表都放到 FROM 子句后边。其实针对内连接,MySQL 提供了
好多不同的语法:
SELECT * FROM e1 [INNER | CROSS] JOIN e2 [ON 连接条件] [WHERE 普通过滤
条件];
也就是说在 MySQL 中,下边这几种内连接的写法都是等价的:
SELECT * FROM e1 JOIN e2;
SELECT * FROM e1 INNER JOIN e2;
SELECT * FROM e1 CROSS JOIN e2;
上边的这些写法和直接把需要连接的表名放到 FROM 语句之后,用逗号,分
隔开的写法是等价的:
SELECT * FROM e1, e2;
再说一次,由于在内连接中 ON 子句和 WHERE 子句是等价的,所以内连接
中不要求强制写明 ON 子句。
我们前边说过,连接的本质就是把各个连接表中的记录都取出来依次匹配的
组合加入结果集并返回给用户。不论哪个表作为驱动表,两表连接产生的笛卡尔
积肯定是一样的。而对于内连接来说,由于凡是不符合 ON 子句或 WHERE 子句
中的条件的记录都会被过滤掉,其实也就相当于从两表连接的笛卡尔积中把不符
合过滤条件的记录给踢出去,所以对于内连接来说,驱动表和被驱动表是可以互
换的,并不会影响最后的查询结果。
但是对于外连接来说,由于驱动表中的记录即使在被驱动表中找不到符合
ON 子句条件的记录时也要将其加入到结果集,所以此时驱动表和被驱动表的关
系就很重要了,也就是说左外连接和右外连接的驱动表和被驱动表不能轻易互换。
5.2.2. MySQL 对连接的执行
复习了连接、内连接、外连接这些基本概念后,我们需要理解 MySQL 怎么
样来进行表与表之间的连接,才能明白有的连接查询运行的快,有的却慢。
5.2.2.1. 嵌套循环连接(Nested-Loop Join)
我们前边说过,对于两表连接来说,驱动表只会被访问一遍,但被驱动表却
要被访问到好多遍,具体访问几遍取决于对驱动表执行单表查询后的结果集中的
记录条数。
对于内连接来说,选取哪个表为驱动表都没关系,而外连接的驱动表是固定
的,也就是说左(外)连接的驱动表就是左边的那个表,右(外)连接的驱动表
就是右边的那个表。
如果有 3 个表进行连接的话,那么首先两表连接得到的结果集就像是新的驱
动表,然后第三个表就成为了被驱动表,可以用伪代码表示一下这个过程就是这
样:
for each row in e1 { #此处表示遍历满足对 e1 单表查询结果集中的每一条
记录,N 条
for each row in e2 { #此处表示对于某条 e1 表的记录来说,遍历满足
对 e2 单表查询结果集中的每一条记录,M 条
for each row in t3 { #此处表示对于某条 e1 和 e2 表的记录组
合来说,对 t3 表进行单表查询,L 条
if row satisfies join conditions, send to client}}
}
这个过程就像是一个嵌套的循环,所以这种驱动表只访问一次,但被驱动表
却可能被多次访问,访问次数取决于对驱动表执行单表查询后的结果集中的记录
条数的连接执行方式称之为嵌套循环连接(Nested-Loop Join),这是最简单,
也是最笨拙的一种连接查询算法,时间复杂度是 O(NML)。
5.2.2.2. 使用索引加快连接速度
我们知道在嵌套循环连接的步骤 2 中可能需要访问多次被驱动表,如果访问
被驱动表的方式都是全表扫描的话,那酸爽不敢想象!
但是查询 e2 表其实就相当于一次单表查询,我们可以利用索引来加快查询
速度。回顾一下最开始介绍的 e1 表和 e2 表进行内连接的例子:
SELECT * FROM e1, e2 WHERE e1.m1 > 1 AND e1.m1 = e2.m2 AND e2.n2 < 'd';
我们使用的其实是嵌套循环连接算法执行的连接查询,再把上边那个查询执
行过程表回顾一下:
查询驱动表 e1 后的结果集中有两条记录,嵌套循环连接算法需要对被驱动
表查询 2 次:
当 e1.m1 = 2 时,去查询一遍 e2 表,对 e2 表的查询语句相当于:
SELECT * FROM e2 WHERE e2.m2 = 2 AND e2.n2 < 'd';
当 e1.m1 = 3 时,再去查询一遍 e2 表,此时对 e2 表的查询语句相当于:
SELECT * FROM e2 WHERE e2.m2 = 3 AND e2.n2 < 'd';
可以看到,原来的 e1.m1 = e2.m2 这个涉及两个表的过滤条件在针对 e2 表做
查询时关于 e1 表的条件就已经确定了,所以我们只需要单单优化对 e2 表的查询
了,上述两个对 e2 表的查询语句中利用到的列是 m2 和 n2 列,我们可以:
在 m2 列上建立索引,因为对 m2 列的条件是等值查找,比如 e2.m2 = 2、e2.m2
= 3 等,所以可能使用到 ref 的访问方法,假设使用 ref 的访问方法去执行对 e2
表的查询的话,需要回表之后再判断 e2.n2 < d 这个条件是否成立。
这里有一个比较特殊的情况,就是假设 m2 列是 e2 表的主键或者唯一二级
索引列,那么使用 e2.m2 = 常数值这样的条件从 e2 表中查找记录的过程的代价
就是常数级别的。我们知道在单表中使用主键值或者唯一二级索引列的值进行等
值查找的方式称之为 const,而 MySQL 把在连接查询中对被驱动表使用主键值或
者唯一二级索引列的值进行等值查找的查询执行方式称之为:eq_ref。
在 n2 列上建立索引,涉及到的条件是 e2.n2 < ‘d’,可能用到 range 的访问方
法,假设使用 range 的访问方法对 e2 表的查询的话,需要回表之后再判断在 m2
列上的条件是否成立。
假设 m2 和 n2 列上都存在索引的话,那么就需要从这两个里边儿挑一个代
价更低的去执行对 e2 表的查询。当然,建立了索引不一定使用索引,只有在二
级索引 + 回表的代价比全表扫描的代价更低时才会使用索引。
另外,有时候连接查询的查询列表和过滤条件中可能只涉及被驱动表的部分
列,而这些列都是某个索引的一部分,这种情况下即使不能使用 eq_ref、ref、
ref_or_null 或者 range 这些访问方法执行对被驱动表的查询的话,也可以使用索
引扫描,也就是 index(索引覆盖)的访问方法来查询被驱动表。
5.2.2.3. 基于块的嵌套循环连接(Block Nested-Loop Join)
扫描一个表的过程其实是先把这个表从磁盘上加载到内存中,然后从内存中
比较匹配条件是否满足。
现实生活中的表成千上万条记录都是少的,几百万、几千万甚至几亿条记录
的表到处都是。内存里可能并不能完全存放的下表中所有的记录,所以在扫描表
前边记录的时候后边的记录可能还在磁盘上,等扫描到后边记录的时候可能内存
不足,所以需要把前边的记录从内存中释放掉。
而采用嵌套循环连接算法的两表连接过程中,被驱动表可是要被访问好多次
的,如果这个被驱动表中的数据特别多而且不能使用索引进行访问,那就相当于
要从磁盘上读好几次这个表,这个 I/O 代价就非常大了,所以我们得想办法:尽
量减少访问被驱动表的次数。
当被驱动表中的数据非常多时,每次访问被驱动表,被驱动表的记录会被加
载到内存中,在内存中的每一条记录只会和驱动表结果集的一条记录做匹配,之
后就会被从内存中清除掉。然后再从驱动表结果集中拿出另一条记录,再一次把
被驱动表的记录加载到内存中一遍,周而复始,驱动表结果集中有多少条记录,
就得把被驱动表从磁盘上加载到内存中多少次。
所以我们可不可以在把被驱动表的记录加载到内存的时候,一次性和多条驱
动表中的记录做匹配,这样就可以大大减少重复从磁盘上加载被驱动表的代价了。
所以 MySQL 提出了一个 join buffer 的概念,join buffer 就是执行连接查询前申请
的一块固定大小的内存,先把若干条驱动表结果集中的记录装在这个 join buffer
中,然后开始扫描被驱动表,每一条被驱动表的记录一次性和 join buffer 中的多
条驱动表记录做匹配,因为匹配的过程都是在内存中完成的,所以这样可以显著
减少被驱动表的 I/O 代价。使用 join buffer 的过程如下图所示:
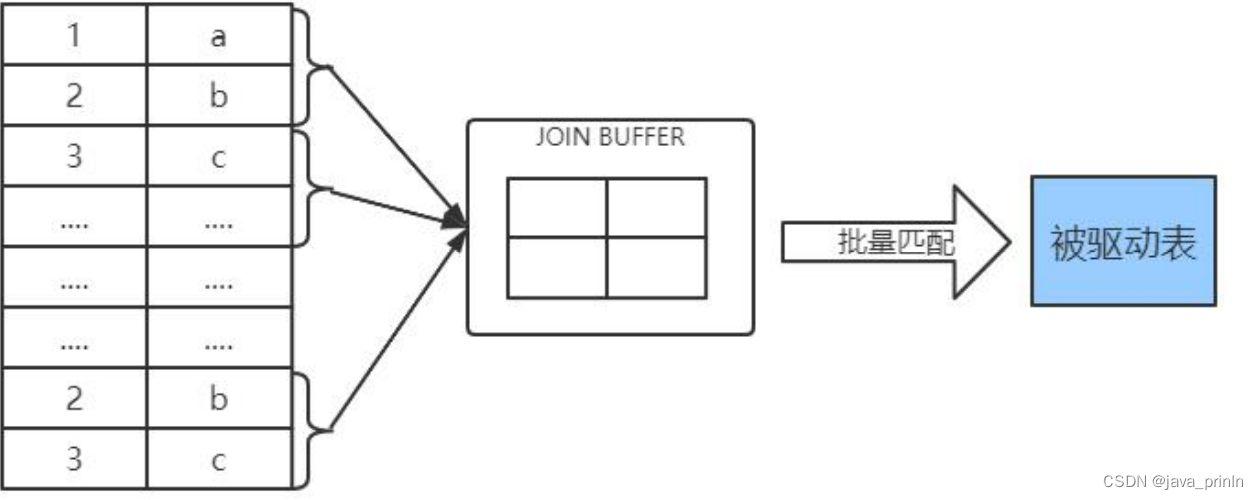
最最好的情况是 join buffer 足够大,能容纳驱动表结果集中的所有记录。
这种加入了 join buffer 的嵌套循环连接算法称之为基于块的嵌套连接(Block
Nested-Loop Join)算法。
这个 join buffer 的大小是可以通过启动参数或者系统变量 join_buffer_size 进
行配置,默认大小为 262144 字节(也就是 256KB),最小可以设置为 128 字节。
show variables like 'join_buffer_size' ;

当然,对于优化被驱动表的查询来说,最好是为被驱动表加上效率高的索引,
如果实在不能使用索引,并且自己的机器的内存也比较大可以尝试调大
join_buffer_size 的值来对连接查询进行优化。
另外需要注意的是,驱动表的记录并不是所有列都会被放到 join buffer 中,
只有查询列表中的列和过滤条件中的列才会被放到 join buffer 中,所以再次提醒
我们,最好不要把*作为查询列表,只需要把我们关心的列放到查询列表就好了,
这样还可以在 join buffer 中放置更多的记录。
相关文章:
MySQL 的执行原理(一)
5.1 单表访问之索引合并 我们前边说过 MySQL 在一般情况下执行一个查询时最多只会用到单个二级 索引,但存在有特殊情况,在这些特殊情况下也可能在一个查询中使用到多个二 级索引,MySQL 中这种使用到多个索引来完成一次查询的执行方法称之为&…...
2023_“数维杯”问题B:棉秸秆热解的催化反应-详细解析含代码
题目翻译: 随着全球对可再生能源需求的不断增加,生物质能作为一种成熟的可再生能源得到了广泛的关注。棉花秸秆作为一种农业废弃物,因其丰富的纤维素、木质素等生物质成分而被视为重要的生物质资源。虽然棉花秸秆的热解可以产生各种形式的可…...

django理解01
接在Vue理解01后 项目创建 pycharm上下载django框架 在需要创建项目的文件夹终端django-admin startproject 项目名终端创建APPpython manage.py startapp app名注册APP,settings.py里INSTALLED_APPS下,增加一项:app名.apps.类名࿰…...
限制Domain Admin登录非域控服务器和用户计算机
限制Domain Admin管理员使用敏感管理员帐户(域或林中管理员组、域管理员组和企业管理员组中的成员帐户)登录到信任度较低的服务器和用户端计算机。 此限制可防止管理员通过登录到信任度较低的计算机来无意中增加凭据被盗的风险。 建议采用的策略 建议使用以下策略限制对信任度…...
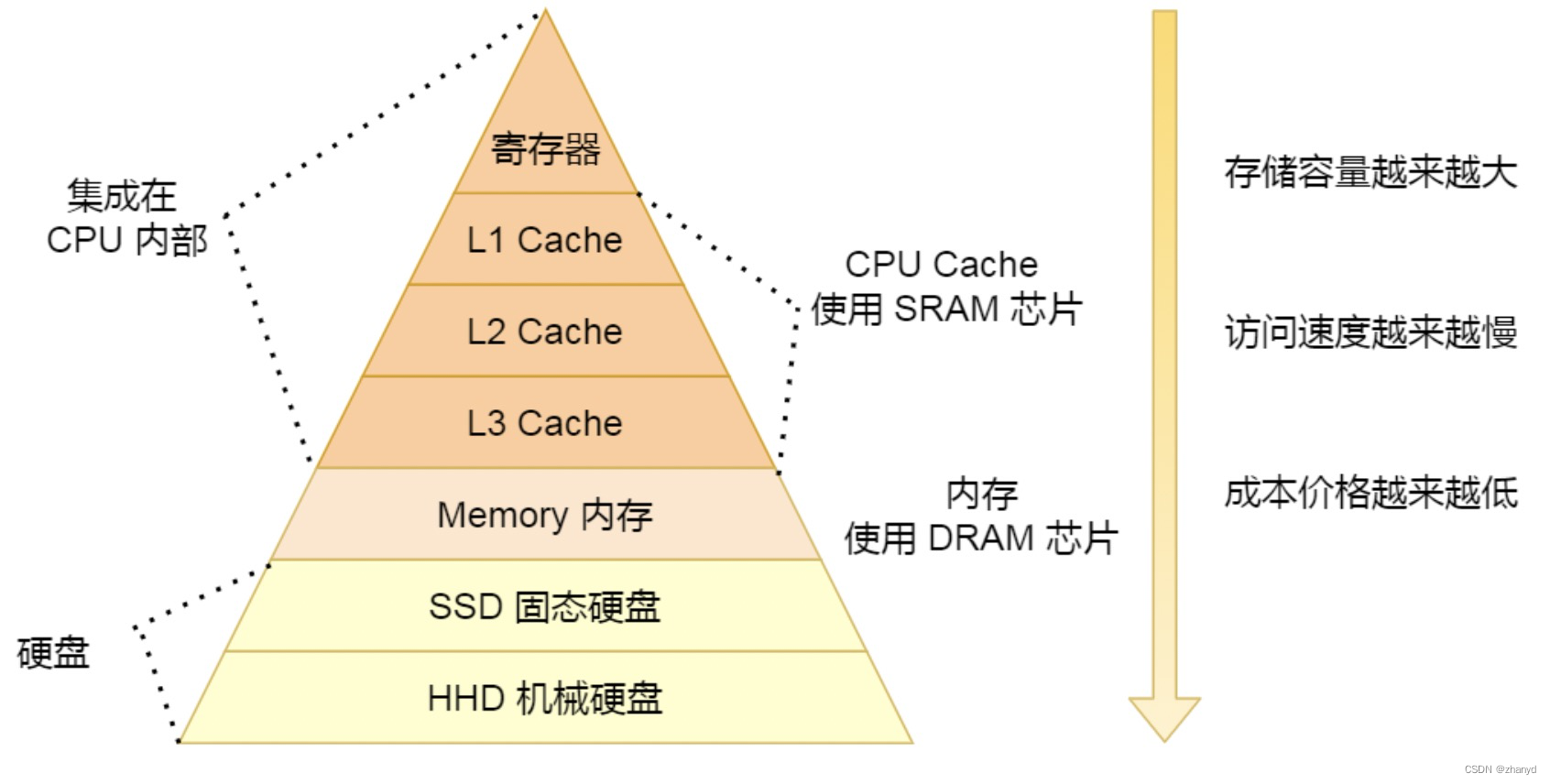
原来机械硬盘比内存慢10万倍
我们都知道机械硬盘的速度很慢,内存的速度很快,那么不同存储器之间的差距到底有多大呢? 我们先来看一幅图: CPU访问寄存器的时间是0.3纳秒,访问L1高速缓存的时间是1纳秒,访问L2高速缓存的时间是4纳秒… 秒…...

ElementUI的Dialog弹窗实现拖拽移动功能
文章目录 1. ElementUI简介2. 弹窗基本使用3. 实现拖拽移动功能4. 拓展与分析 🎉欢迎来到Java学习路线专栏~ElementUI的Dialog弹窗实现拖拽移动功能 ☆* o(≧▽≦)o *☆嗨~我是IT陈寒🍹✨博客主页:IT陈寒的博客🎈该系列文章专栏&a…...
生成式AI模型量化简明教程
在不断发展的人工智能领域,生成式AI无疑已成为创新的基石。 这些先进的模型,无论是用于创作艺术、生成文本还是增强医学成像,都以产生非常逼真和创造性的输出而闻名。 然而,生成式AI的力量是有代价的—模型大小和计算要求。 随着生…...

机器人制作开源方案 | 智能快递付件机器人
一、作品简介 作者:贺沅、聂开发、王兴文、石宇航、盛余庆 单位:黑龙江科技大学 指导老师:邵文冕、苑鹏涛 1. 项目背景 受新冠疫情的影响,大学校园内都采取封闭式管理来降低传染的风险,导致学生不能外出,…...
PostgreSQL技术大讲堂 - 第34讲:调优工具pgBagder部署
PostgreSQL从小白到专家,是从入门逐渐能力提升的一个系列教程,内容包括对PG基础的认知、包括安装使用、包括角色权限、包括维护管理、、等内容,希望对热爱PG、学习PG的同学们有帮助,欢迎持续关注CUUG PG技术大讲堂。 第34讲&#…...

《Python日志新宠——Loguru,轻松记录,笑对Bug!》
嘿,程序媛和程序猿们!👩💻👨💻 你们是不是也曾为日志处理这个“小事”而头疼?别着急,今天我给你们介绍一个简直比拥抱泰迪熊还要温暖的Python库——Loguru!这货不仅强…...

NET8 ORM 使用AOT SqlSugar
.NET AOT8 基本上能够免强使用了, SqlSugar ORM也支持了CRUD 能在AOT下运行了 Nuget安装 SqlSugarCore 具体代码 StaticConfig.EnableAot true;//启用AOT 程序启动执行一次就好了//用SqlSugarClient每次都new,不要用单例模式 var db new SqlSugarClient(new ConnectionC…...

CCRC认证是什么?
什么是CCRC认证? 信息安全服务资质,是信息安全服务机构提供安全服务的一种资格,包括法律地位、资源状况、管理水平、技术能力等方面的要求。 信息安全服务资质(CCRC)是依据国家法律法规、国家标准、行业标准和技术规范…...
)
linux内核面试题(2)
整理了一些网上的linux驱动岗位相关面试题,如果错误,欢迎指正。 工作队列是运行在进程上下文,还是中断上下文?它的回调函数是否允许睡眠? 工作队列是运行在进程上下文的。工作队列的回调函数是允许睡眠的,…...

YOLOV5----修改损失函数-ShuffleAttention
主要修改yolo.py、yolov5s.yaml及添加ShuffleAttention.py 一、ShuffleAttention.py import numpy as np import torch from torch import nn from torch.nn import init from torch.nn.parameter import Parameterclass ShuffleAttention(nn.Module):def...
Kafka(四)消费者消费消息
文章目录 如何确保不重复消费消息?消费者业务逻辑重试消费者提交自定义反序列化类消费者参数配置及其说明重要的参数session.time.ms和heartbeat.interval.ms和group.instance.id增加消费者的吞吐量消费者消费的超时时间和poll()方法的关系 消费者消费逻辑启动消费者…...
Python uiautomation获取微信内容!聊天记录、聊天列表、全都可获取
Python uiautomation 是一个用于自动化 GUI 测试和操作的库,它可以模拟用户操作来执行各种任务。 通过这个库,可以使用Python脚本模拟人工点击,人工操作界面。本文使用 Python uiautomation 进行微信电脑版的操作。 以下是本次实验的版本号。…...

Java通过Lettuce访问Redis主从,哨兵,集群
操作 首先需要maven导入依赖 <dependency><groupId>io.lettuce</groupId><artifactId>lettuce-core</artifactId><version>6.3.0.RELEASE</version> </dependency> 测试连接 public class LettuceDemo {public static voi…...

嵌入式数据库Sqlite
本文主要是介绍如何再Ubuntu下使用sqlite数据库,并且嵌入式QT环境下使用C语言来构建一个sqlite数据库,使用sqlite browser进行数据库的可视化。 1、安装sqlite 在ubuntu系统中的安装需要先下载一个安装包,SQLite Download Page 安装命令&a…...

计算机网络:网络层ARP协议
在实现IP通信时使用了两个地址:IP地址(网络层地址)和MAC地址(数据链路层地址) 问题:已知一个机器(主机或路由器)的IP地址,如何找到相应的MAC地址? 为了解决…...
集成环信IM时常见问题及解决——包括消息、群组、推送
一、消息 环信是不支持空会话的,在插入一个会话,一定要给这个会话再插入一条消息; 发送透传消息也就是cmd消息时,value的em_开头的字段为环信内部消息字段,如果使用会出现收不到消息回调的情况; 如果发送…...

Linux链表操作全解析
Linux C语言链表深度解析与实战技巧 一、链表基础概念与内核链表优势1.1 为什么使用链表?1.2 Linux 内核链表与用户态链表的区别 二、内核链表结构与宏解析常用宏/函数 三、内核链表的优点四、用户态链表示例五、双向循环链表在内核中的实现优势5.1 插入效率5.2 安全…...

剑指offer20_链表中环的入口节点
链表中环的入口节点 给定一个链表,若其中包含环,则输出环的入口节点。 若其中不包含环,则输出null。 数据范围 节点 val 值取值范围 [ 1 , 1000 ] [1,1000] [1,1000]。 节点 val 值各不相同。 链表长度 [ 0 , 500 ] [0,500] [0,500]。 …...

如何将联系人从 iPhone 转移到 Android
从 iPhone 换到 Android 手机时,你可能需要保留重要的数据,例如通讯录。好在,将通讯录从 iPhone 转移到 Android 手机非常简单,你可以从本文中学习 6 种可靠的方法,确保随时保持连接,不错过任何信息。 第 1…...

Axios请求超时重发机制
Axios 超时重新请求实现方案 在 Axios 中实现超时重新请求可以通过以下几种方式: 1. 使用拦截器实现自动重试 import axios from axios;// 创建axios实例 const instance axios.create();// 设置超时时间 instance.defaults.timeout 5000;// 最大重试次数 cons…...
可以参考以下方法:)
根据万维钢·精英日课6的内容,使用AI(2025)可以参考以下方法:
根据万维钢精英日课6的内容,使用AI(2025)可以参考以下方法: 四个洞见 模型已经比人聪明:以ChatGPT o3为代表的AI非常强大,能运用高级理论解释道理、引用最新学术论文,生成对顶尖科学家都有用的…...

HashMap中的put方法执行流程(流程图)
1 put操作整体流程 HashMap 的 put 操作是其最核心的功能之一。在 JDK 1.8 及以后版本中,其主要逻辑封装在 putVal 这个内部方法中。整个过程大致如下: 初始判断与哈希计算: 首先,putVal 方法会检查当前的 table(也就…...

CRMEB 中 PHP 短信扩展开发:涵盖一号通、阿里云、腾讯云、创蓝
目前已有一号通短信、阿里云短信、腾讯云短信扩展 扩展入口文件 文件目录 crmeb\services\sms\Sms.php 默认驱动类型为:一号通 namespace crmeb\services\sms;use crmeb\basic\BaseManager; use crmeb\services\AccessTokenServeService; use crmeb\services\sms\…...

【JavaSE】多线程基础学习笔记
多线程基础 -线程相关概念 程序(Program) 是为完成特定任务、用某种语言编写的一组指令的集合简单的说:就是我们写的代码 进程 进程是指运行中的程序,比如我们使用QQ,就启动了一个进程,操作系统就会为该进程分配内存…...

Spring Security 认证流程——补充
一、认证流程概述 Spring Security 的认证流程基于 过滤器链(Filter Chain),核心组件包括 UsernamePasswordAuthenticationFilter、AuthenticationManager、UserDetailsService 等。整个流程可分为以下步骤: 用户提交登录请求拦…...
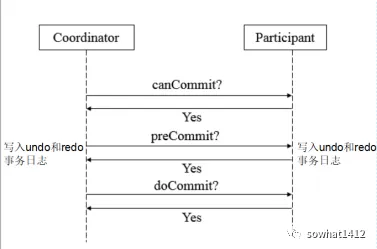
解析两阶段提交与三阶段提交的核心差异及MySQL实现方案
引言 在分布式系统的事务处理中,如何保障跨节点数据操作的一致性始终是核心挑战。经典的两阶段提交协议(2PC)通过准备阶段与提交阶段的协调机制,以同步决策模式确保事务原子性。其改进版本三阶段提交协议(3PC…...