Kafka(四)消费者消费消息
文章目录
- 如何确保不重复消费消息?
- 消费者业务逻辑重试
- 消费者提交
- 自定义反序列化类
- 消费者参数配置及其说明
- 重要的参数session.time.ms和heartbeat.interval.ms和group.instance.id
- 增加消费者的吞吐量
- 消费者消费的超时时间和poll()方法的关系
- 消费者消费逻辑
- 启动消费者
- 关闭消费者
- 配置listener
- 结语
- 示例源码仓库
在 上一篇文章里,对于生产者,发送时失败之后会由定时任务进行重新发送, 并且我们是根据消息的key进行分区的, 所以不管我们重新发送了多少次,对于同一个key,始终会被送到同一个分区。
那么到消费者这里,最重要的问题是如何确保不会重复消费之前因为各种原因被重新发送到某个分区的消息。
如何确保不重复消费消息?
基本思路如下
- 我们在数据库中创建了一个已成功消费的消息表,里面只有一列,消息的key。当消费者消费逻辑成功之后,我们会把其key保存到这张表里 。
- 当消费者拉取新的一批消息时,我们会去数据库的消息表里查是否已经存在该消息的key,存在的话,就跳过实际的消费业务。
- 一批消息里也可能存在相同的key,所以我们处理完一次消费业务,就把该key放到一个set里,消费下一条消息时,则先去set里看一下,存在的话即跳过,不存在则正常执行消费业务。即使前面的消息消费业务失败了,后面相同key的消息也直接跳过,不会再次消费
消费者业务逻辑重试
对于消费者业务逻辑的重试,我们使用failsafe框架进行重试,该框架的使用可参考官方文档,这里不做过多赘述。
消费者提交
这里的方式采用的是Kafka权威指南中消费者一章中提出的方式。 异步+同步。平时使用异步提交,在关闭消费者时,使用同步提交,确保消费者退出之前将当前的offset提交上去。
自定义反序列化类
在生产者端,我们发送自定义的对象时,利用自定义序列化类将其序列化为JSON。在消费者端,我们同样需要自定义反序列类将JSON转为我们之前的对象
public class UserDTODeserializer implements Deserializer<UserDTO> {@Override@SneakyThrowspublic UserDTO deserialize(final String s, final byte[] bytes) {ObjectMapper objectMapper = new ObjectMapper();return objectMapper.readValue(bytes, UserDTO.class);}
}
消费者参数配置及其说明
/*** 以下配置建议搭配 官方文档 + kafka权威指南相关章节 + 实际业务场景需求 自己调整* https://kafka.apache.org/26/documentation/#group.instance.id** 为什么需要group.instance.id?* 假设auto.offset.reset=latest* 1. 如果没有group.instance.id,那么kafka会认为此消费者是dynamic member,在重启期间如果有消息发送到topic,那么重启之后,消费者会【丢失这部分消息】* 假如auto.offset.reset=earliest* 1. 如果没有group.instance.id,那么kafka会认为此消费者是dynamic member,在重启期间如果有消息发送到topic,那么重启之后,消费者会重复消费【全部消息】** 光有group.instance.id还不够,还需要修改heartbeat.interval.ms和session.timeout.ms的值为合理的值* 如果程序部署,重启期间,重启时间超过了session.timeout.ms的值,那么kafka会认为此消费者已经挂了会触发rebalance,在一些大型消息场景,rebalance的过程可能会很慢, 更详细的解释请参考* https://kafka.apache.org/26/documentation/#static_membership* @param groupInstanceId* @return*/public static Properties loadConsumerConfig(int groupInstanceId, String valueDeserializer) {Properties result = new Properties();result.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.0.102:9093");result.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");result.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, valueDeserializer);result.put(ConsumerConfig.GROUP_ID_CONFIG, "test");// 代表此消费者是消费者组的static memberresult.put(ConsumerConfig.GROUP_INSTANCE_ID_CONFIG, "test-" + ++groupInstanceId);// 修改heartbeat.interval.ms和session.timeout.ms的值,和group.instance.id配合使用,避免重启或重启时间过长的时候,触发rebalanceresult.put(ConsumerConfig.HEARTBEAT_INTERVAL_MS_CONFIG, 1000 * 60);result.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, 1000 * 60 * 5);// 关闭自动提交result.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, Boolean.FALSE);// 默认1MB,增加吞吐量,其设置对应的是每个分区,也就是说一个分区返回10MB的数据result.put(ConsumerConfig.MAX_PARTITION_FETCH_BYTES_CONFIG, 1048576 * 10);result.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, 500);// 返回全部数据的大小result.put(ConsumerConfig.FETCH_MAX_BYTES_CONFIG, 1048576 * 100);// 默认5分钟result.put(ConsumerConfig.MAX_POLL_INTERVAL_MS_CONFIG, 1000 * 60 * 5);return result;}
重要的参数session.time.ms和heartbeat.interval.ms和group.instance.id
三者的使用方式见上面代码中的注释。
增加消费者的吞吐量
和上一篇文章一样,由于我们的邮件消息每个大概是20KB,使用默认的消费者参数,吞吐量是上不来的。 所以做了一些优化,除了消费者消费逻辑要尽可能简单之外,为了增加消费者的吞吐量,可以根据实际场景修改倒数第4、3、2个参数。
消费者消费的超时时间和poll()方法的关系
由max.poll.interval.ms参数控制,默认5分钟。如果消费者业务逻辑处理特别耗时,在5分钟之内没有再次调用poll()拉取消息,则Kafka认为消费者已死,根据具体配置会立刻触发rebalance还是等一段时间再触发rebalance。
这里特别强调一下,网上有一部分文章说是要确保消费逻辑在poll(timeUnit)时间内处理完,否则就会触发rebalance。这都是很早之前的Kafka版本了,是因为原来消费者的poll()线程和心跳线程使用的是同一个线程。现在的版本早就把这两个分开了。所以你只需要注意,自己的消费逻辑别超过max.poll.interval.ms即可,如果觉得不够用,也可自己调整。
poll()方法中的时间代表的是多长时间去拉取一次消息。假设你设置的是1分钟,你的消费逻辑处理的很快,可能用了10s。那么在你消费完了之后,消费者会在1分钟之后拉取新消息。
在消费者中使用手动提交。
消费者消费逻辑
这里要注意
- 如果消费逻辑可能抛出异常,则使用try-catch处理,防止因为抛出异常,导致我们错误的关闭了消费者
- 消费者消费逻辑失败时会重试,重试N次之后,我们会将其保存在数据库中,以便和生产者一样,定时处理失败的消息
- 消费逻辑没问题的话,则把该消息的key进行入库处理
@Log
public class MessageConsumerRunner implements Runnable {private final AtomicBoolean closed = new AtomicBoolean(false);private MessageAckConsumesSuccessService messageAckConsumesSuccessService = new MessageAckConsumesSuccessService();private MessageFailedService messageFailedService = new MessageFailedService();private final KafkaConsumer<String, UserDTO> consumer;private final int consumerPollIntervalSecond;public MessageConsumerRunner(KafkaConsumer<String, UserDTO> consumer, int consumerPollIntervalSecond) {this.consumer = consumer;this.consumerPollIntervalSecond = consumerPollIntervalSecond;}/*** 1. 使用https://failsafe.dev/进行重试* 2. 每次消费消息前,判断消息ID是否存在于数据库中和当前Set集合中,避免重复消费,* 我们的消息时根据消息的key进行hash分区的,所以同一个消息即使生产多次,一定会到同一个partition中,partition动态增加引起的特殊情况不在考虑范围之内* 4. 在一次消费消息中重试两次,如果两次都失败,那么将失败原因、消息的JSON字符串插入到message_failed表中,以便后续再次生产或排查问题* 3. 平时异步提交,关闭消费者时使用同步提交*/@Overridepublic void run() {AtomicReference<String> errorMessage = new AtomicReference<>(StringUtils.EMPTY);RetryPolicy<Boolean> retryPolicy = RetryPolicy.<Boolean>builder().handle(Exception.class)// 如果业务逻辑返回false或者抛出异常,则重试.handleResultIf(Boolean.FALSE::equals)// 不包含首次.withMaxRetries(2).withDelay(Duration.ofMillis(200)).onRetry(e -> log.warning("consume message failed, start the {}th retry"+ e.getAttemptCount())).onRetriesExceeded(e -> {Optional.ofNullable(e.getException()).ifPresent(u -> errorMessage.set(u.getMessage()));log.severe("max retries exceeded" + e.getException());}).build();Fallback<Boolean> fallback = Fallback.<Boolean>builder(e -> {// do nothing, suppress exceptions}).build();try {consumer.subscribe(Collections.singletonList("email"));while (!closed.get()) {// get message from kafkaConsumerRecords<String, UserDTO> records = consumer.poll(Duration.ofSeconds(consumerPollIntervalSecond));if (records.isEmpty()) {return;}Set<UserDTO> successConsumed = new HashSet<>();Set<UserDTO> failedConsumed = new HashSet<>();Map<String, String> failedConsumedReason = new HashMap<>();// check message if exist in databaseSet<String> checkingMessageIds = new HashSet<>(records.count());records.iterator().forEachRemaining(item -> checkingMessageIds.add(item.value().getMessageId()));Set<String> hasBeenConsumedMessageIds = messageAckConsumesSuccessService.checkMessageIfExistInDatabase(checkingMessageIds);records.forEach(item -> {if (hasBeenConsumedMessageIds.contains(item.value().getMessageId())) {// if exist, continuereturn;}// 每一批消息中也可能存在同样的消息,所以需要再次判断hasBeenConsumedMessageIds.add(item.value().getMessageId());try {Failsafe.with(fallback, retryPolicy).onSuccess(e -> successConsumed.add(item.value())).onFailure(e -> {failedConsumed.add(item.value());failedConsumedReason.put(item.value().getMessageId(), StringUtils.isNotBlank(errorMessage.get()) ? errorMessage.get() : "no reason, may be check server log");errorMessage.set(StringUtils.EMPTY);}).get(() -> {// 这里是业务逻辑,可以返回true或false,为什么要这样?是因为上面RetryPolicy这里定义的boolean,根据自己实际业务设置相应的类型return true;});// 这里要catch住所有业务异常,防止由业务异常导致消费者线程退出}catch (Exception e) {log.severe("failed to consume email message" + e);failedConsumed.add(item.value());failedConsumedReason.put(item.value().getMessageId(), StringUtils.isNotBlank(e.getMessage()) ? e.getMessage() : e.getCause().toString());}});postConsumed(successConsumed, failedConsumed, failedConsumedReason);// 平时使用异步提交consumer.commitAsync();}}catch (WakeupException e) {if (!closed.get()) {throw e;}} finally {// 消费者退出时使用同步提交try {consumer.commitSync();} catch (Exception e) {log.info("commit sync occur exception: " + e);} finally{try {consumer.close();}catch (Exception e) {log.info("consumer close occur exception: " + e);}log.info( "shutdown kafka consumer complete");}}}/*** 处理成功、成功后的回调、失败* @param successConsumed* @param failedConsumed* @param failedConsumedReason*/private void postConsumed(Set<UserDTO> successConsumed, Set<UserDTO> failedConsumed, Map<String, String> failedConsumedReason) {// 后置处理开启异步线程处理,不阻塞消费者线程// 克隆传进来的集合,而不使用原集合的引用,因为原集合每次消费都会重置Set<UserDTO> cloneSuccessConsumed = new HashSet<>(successConsumed);Set<UserDTO> cloneFailedConsumed = new HashSet<>(failedConsumed);Map<String, String> cloneFailedConsumedReason = new HashMap<>(failedConsumedReason);new Thread( () -> {if (!cloneSuccessConsumed.isEmpty()) {messageAckConsumesSuccessService.insertMessageIds(cloneSuccessConsumed.stream().map(UserDTO::getMessageId).collect(Collectors.toSet()));cloneFailedConsumed.forEach(item -> {if (Objects.nonNull(item.getCallbackMetaData())) {// do callbackCallbackProducer callbackProducer = new CallbackProducer();callbackProducer.sendCallbackMessage(item.getCallbackMetaData(), MessageFailedPhrase.PRODUCER);}});}if (!cloneFailedConsumed.isEmpty()) {ObjectMapper objectMapper = new ObjectMapper();cloneFailedConsumed.forEach(item -> {MessageFailedEntity entity = new MessageFailedEntity();entity.setMessageId(item.getMessageId());entity.setMessageType(MessageType.EMAIL);entity.setMessageFailedPhrase(MessageFailedPhrase.CONSUMER);entity.setFailedReason(cloneFailedConsumedReason.get(item.getMessageId()));try {entity.setMessageContentJsonFormat(objectMapper.writeValueAsString(item));} catch (JsonProcessingException e) {log.info("failed to convert UserDTO message to json string");}messageFailedService.saveOrUpdateMessageFailed(entity);});}}).start();}public void shutdown() {log.info( Thread.currentThread().getName() + " shutdown kafka consumer");closed.set(true);consumer.wakeup();}
}
启动消费者
通过实现ServletContextListener接口对于方法使其在Tomcat启动之后,启动消费者
public class StartUpConsumerListener implements ServletContextListener {/*** 假设开启10个消费者.** 消费者的数量要和partition的数量一致,实际情况下,可以调用AdminClient的方法获取到topic的partition数量,然后根据partition数量来创建消费者.* @param sce*/@Overridepublic void contextInitialized(final ServletContextEvent sce) {ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(10, 10, 30L, TimeUnit.SECONDS, new LinkedBlockingDeque<>(100), new AbortPolicy());for (int i = 0; i < 10; i++) {KafkaConsumer<String, UserDTO> consumer = new KafkaConsumer<>(KafkaConfiguration.loadConsumerConfig(i, UserDTO.class.getName()));MessageConsumerRunner messageConsumerRunner = new MessageConsumerRunner(consumer, 10);// 使用另外一个线程来关闭消费者Thread shutdownHooks = new Thread(messageConsumerRunner::shutdown);KafkaListener.KAFKA_CONSUMERS.add(shutdownHooks);// 启动消费者线程threadPoolExecutor.execute(messageConsumerRunner);}}
}
关闭消费者
public class KafkaListener implements ServletContextListener {public static final Vector<Thread> KAFKA_CONSUMERS = new Vector<>();@Overridepublic void contextInitialized(ServletContextEvent sce) {// do noting}@Overridepublic void contextDestroyed(ServletContextEvent sce) {KAFKA_CONSUMERS.forEach(Thread::run);}
}
配置listener
<?xml version="1.0" encoding="UTF-8" ?>
<web-app xmlns="https://jakarta.ee/xml/ns/jakartaee"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="https://jakarta.ee/xml/ns/jakartaeehttps://jakarta.ee/xml/ns/jakartaee/web-app_6_0.xsd"version="6.0"><display-name>Kafka消息的消费者-消息系统</display-name><!-- listener的contextInitialized顺序按照声明顺序执行, contextDestroyed方法按照声明顺序反向执行--><listener><listener-class>com.message.server.listener.KafkaListener</listener-class></listener><listener><listener-class>com.message.server.listener.StartUpConsumerListener</listener-class></listener>
</web-app>
结语
- 在处理消费者相关逻辑时,我们重点关心如何确保消息不重复消费以及如何增加消费者的吞吐量
- 消费逻辑尽可能保证处理速度快,尽量减少耗时的逻辑
示例源码仓库
- Github地址
- 项目下message-server module代表生产者
- 运行时IDEA配置如下
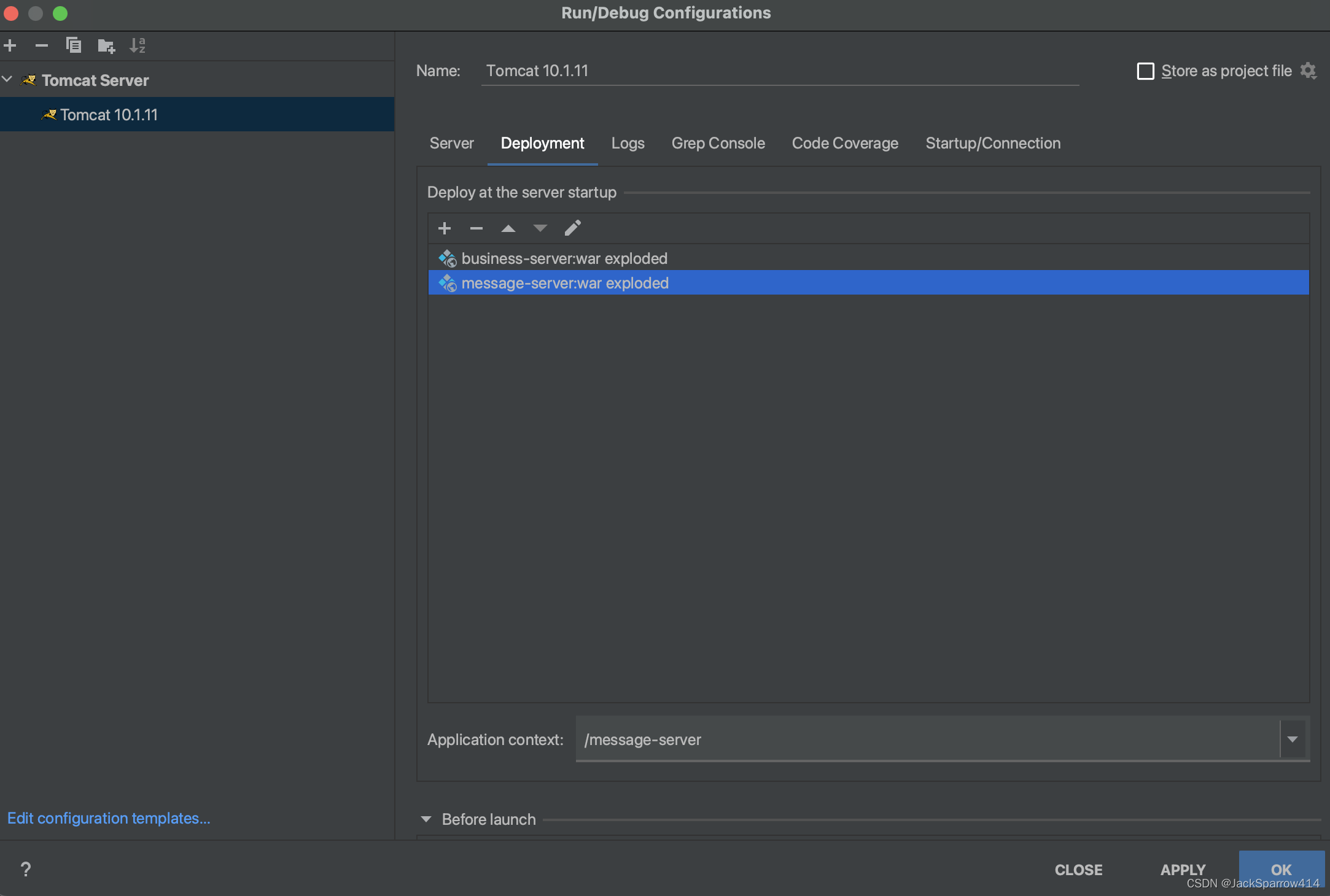
我们生产者和消费者的正常情况都以处理完了,下一篇文章我们将重点处理生产者失败和消费者失败之后重新生产消息和消费消息的逻辑,以及简单说一下Kafka中的rebalance。
相关文章:
Kafka(四)消费者消费消息
文章目录 如何确保不重复消费消息?消费者业务逻辑重试消费者提交自定义反序列化类消费者参数配置及其说明重要的参数session.time.ms和heartbeat.interval.ms和group.instance.id增加消费者的吞吐量消费者消费的超时时间和poll()方法的关系 消费者消费逻辑启动消费者…...
Python uiautomation获取微信内容!聊天记录、聊天列表、全都可获取
Python uiautomation 是一个用于自动化 GUI 测试和操作的库,它可以模拟用户操作来执行各种任务。 通过这个库,可以使用Python脚本模拟人工点击,人工操作界面。本文使用 Python uiautomation 进行微信电脑版的操作。 以下是本次实验的版本号。…...

Java通过Lettuce访问Redis主从,哨兵,集群
操作 首先需要maven导入依赖 <dependency><groupId>io.lettuce</groupId><artifactId>lettuce-core</artifactId><version>6.3.0.RELEASE</version> </dependency> 测试连接 public class LettuceDemo {public static voi…...

嵌入式数据库Sqlite
本文主要是介绍如何再Ubuntu下使用sqlite数据库,并且嵌入式QT环境下使用C语言来构建一个sqlite数据库,使用sqlite browser进行数据库的可视化。 1、安装sqlite 在ubuntu系统中的安装需要先下载一个安装包,SQLite Download Page 安装命令&a…...

计算机网络:网络层ARP协议
在实现IP通信时使用了两个地址:IP地址(网络层地址)和MAC地址(数据链路层地址) 问题:已知一个机器(主机或路由器)的IP地址,如何找到相应的MAC地址? 为了解决…...
集成环信IM时常见问题及解决——包括消息、群组、推送
一、消息 环信是不支持空会话的,在插入一个会话,一定要给这个会话再插入一条消息; 发送透传消息也就是cmd消息时,value的em_开头的字段为环信内部消息字段,如果使用会出现收不到消息回调的情况; 如果发送…...

Selenium自动化测试框架
一.Selenium概述 1.1 什么是框架? 框架(framework)是一个框子——指其约束性,也是一个架子——指其支撑性。是一个基本概念上的 结构用于去解决或者处理复杂的问题。 框架是整个或部分系统的可重用设计,表现为一组抽象构件及…...
C#实现观察者模式
观察者模式是一种软件设计模式,当一个对象的状态发生变化时,其所有依赖者都会自动得到通知。 观察者模式也被称为“发布-订阅”模式,它定义了对象之间的一对多的依赖性,当一个对象状态改变时,所有依赖于它的对象都会得…...

什么是持续部署
管理软件开发和部署有 3 种常见的方法:持续集成、持续交付,然后是持续部署。尽管它们经常被混淆,但它们是明显不同的。 正如您将在本文后面看到的,它们相互融合,并补充彼此的风格。但这篇文章并不是关于他们三个。今天…...
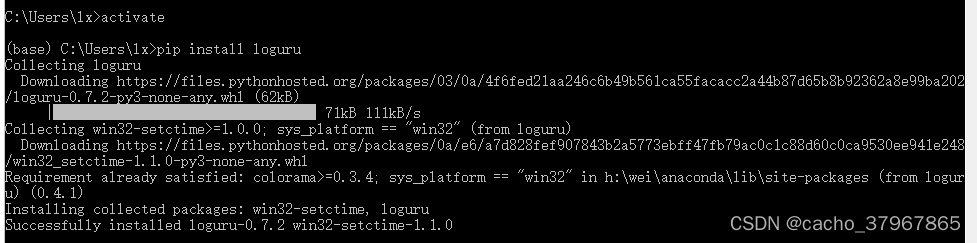
【Python】Loguru模块更简洁的日志记录库
Loguru: 更优雅的日志记录解决方案! loguru 是一个Python 简易且强大的第三方日志记录库,该库旨在通过添加一系列有用的功能来解决标准记录器的注意事项,从而减少 Python 日志记录的痛苦。 使用自带自带的 logging 模块的话,则需要…...

智慧环保:科技驱动下的环境保护新篇章
智慧环保:科技驱动下的环境保护新篇章 环境保护已经成为当今社会的重要议题,而科技的飞速发展为我们开启了智慧环保的新篇章。在这篇文章中,我们将介绍智慧环保所带来的机会和创新,以及科技在环境保护中的重要作用。 智慧环保的理…...
CTF-PWN环境搭建手册
工欲善其事必先利其器,作为一名CTF的pwn手,一定要有自己的专用解题环境。本文将详细记录kali下的pwn解题环境的安装过程,B站也会配备配套视频。 目录 安装前的准备工作 虚拟机环境编辑 VM版本安装教程 1. 下载Kali的VM虚拟机文件 2. 新…...

Nginx安装配置与SSL证书安装部署
一、Nginx Nginx是一款高性能的开源Web服务器和反向代理服务器,被广泛用于构建现代化的Web应用和提供静态内容。 nginx官网 这里下载nginx-1.24.0-zip Nginx是一款高性能的开源Web服务器和反向代理服务器,被广泛用于构建现代化的Web应用和提供静态内…...

高性能面试八股文之编译流程程序调度
1. C的编译流程 C语言程序的编译过程通常包括预处理(Preprocessing)、编译(Compilation)、汇编(Assembly)、链接(Linking)四个主要阶段。下面是这些阶段的详细说明: 1.…...

opencv的MinGW-W64编译
最近使用Qt,需要用到opencv,安装详情参考下面这个网址,写的挺好: opencv的MinGW-W64编译 - 知乎 我电脑安装Qt中自带了MinGW,所以不需要像上面网址中的下载MinGw,只需要将Qt中自带的MinGW添加到环境变量即可,如&…...
在Go编程中调用外部命令的几种场景
1.摘要 在很多场合, 使用Go语言需要调用外部命令来完成一些特定的任务, 例如: 使用Go语言调用Linux命令来获取执行的结果,又或者调用第三方程序执行来完成额外的任务。在go的标准库中, 专门提供了os/exec包来对调用外部程序提供支持, 本文将对调用外部命令的几种使用方法进行总…...

python学习:break用法详解
嗨喽,大家好呀~这里是爱看美女的茜茜呐 在执行while循环或者for循环时,只要循环条件满足,程序会一直执行循环体。 但在某些场景,我们希望在循环结束前就强制结束循环。 Python中有两种强制结束循环的方法: continue语…...

【算法萌新闯力扣】:找到所有数组中消失对数字
力扣热题:找到所有数组中消失对数字 开篇 这两天刚交了蓝桥杯的报名费,刷题的积极性高涨。算上打卡题,今天刷了10道算法题了,题目都比较简单,挑选了一道还不错的题目与大家分享。 题目链接:448.找到所有数组中消失对…...
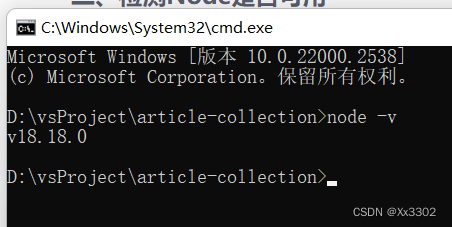
Node.js 安装配置
文章目录 安装检测Node是否可用 安装 首先我们需要从官网下载Node安装包:Node.Js中文网,下载后双击安装没有什么特殊的地方,安装路径默认是C盘,不想安装C盘的话可以选择一下其他的盘符。安装完成以后可以不用配置环境变量,Node安装已经自动给…...
前端JS 使用input完成文件上传操作,并对文件进行类型转换
使用input实现文件上传 // 定义一个用于文件上传的按钮<input type"file" name"upload1" />// accept属性用于定义允许上传的文件类型, onchange用于绑定文件上传之后的相应函数<input type"file" name"upload2"…...

告别繁琐手工操作:工资条生成器使用指南
对于许多财务人员来说,每月制作工资条都是一项让人头疼的工作。 手工制作不仅要花费大量时间,还容易出现各种错误,影响工作效率和准确性。 今天,我们就来详细介绍一款能够彻底改变这种状况的工具——工资条生成器。 工资条生成…...

《WebPages 邮局》
《WebPages 邮局》 引言 在互联网的海洋中,WebPages 邮局犹如一座灯塔,为无数用户指引着信息传递的航向。本文将深入探讨 WebPages 邮局的功能、优势以及其在信息时代的重要地位。 WebPages 邮局的功能 1. 邮件收发 WebPages 邮局的核心功能是邮件收发。用户可以通过 We…...

SMU Debug Tool完全指南:AMD Ryzen硬件调试的终极解决方案
SMU Debug Tool完全指南:AMD Ryzen硬件调试的终极解决方案 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https:…...

Claude Code源码分析之提示词工程
每天免费领 1亿 Token,白嫖DeepSeek、GLM、MiniMax、Kimi等大模型! 在开发大模型应用的时候,管理系统提示词(System Prompt)往往是个让人头大的工程难题。要是只用简单的字符串拼接,随着活儿越接越多&#…...

vscode下载+插件
作为一款轻量又强大的代码编辑器,VSCode 是程序员入门的必备工具,但很多新手第一步就卡在了下载慢、不知怎么下的问题上。这篇指南从官方下载、国内加速下载,到简单的安装注意事项进行讲述。 一、下载 VSCode 的官方下载渠道唯一且安全&…...

不只是投屏:挖掘Scrcpy + ADB在Mac上的高阶玩法,提升开发调试效率
不只是投屏:挖掘Scrcpy ADB在Mac上的高阶玩法,提升开发调试效率 在移动应用开发与测试的日常工作中,效率工具的选择往往决定了生产力水平。Scrcpy作为一款开源的安卓设备投屏工具,其价值远不止于简单的屏幕镜像。当它与ADB&#…...

MATLAB代码:基于源-荷双重不确定性的虚拟电厂/微网日前随机优化调度模型
MATLAB代码:计及源-荷双重不确定性的虚拟电厂/微网日前随机优化调度 关键词:虚拟电厂/微网 随机优化 随机调度 源-荷双重不确定性 虚拟电厂调度 参考文档:《Virtual power plant mid-term dispatch optimization》参考其燃气轮机、以及储…...

如何用ESP32打造你的终极智能网络收音机:YoRadio完全指南
如何用ESP32打造你的终极智能网络收音机:YoRadio完全指南 【免费下载链接】yoradio Web-radio based on ESP32-audioI2S library 项目地址: https://gitcode.com/GitHub_Trending/yo/yoradio ESP32 YoRadio是一款基于ESP32的开源智能网络收音机项目ÿ…...

3个技巧让你轻松掌控暗黑2角色命运:d2s-editor的存档修改艺术
3个技巧让你轻松掌控暗黑2角色命运:d2s-editor的存档修改艺术 【免费下载链接】d2s-editor 项目地址: https://gitcode.com/gh_mirrors/d2/d2s-editor 在《暗黑破坏神2》的冒险旅程中,你是否曾因误加属性点而让精心培养的角色沦为废号࿱…...

BetterJoy终极指南:在Windows电脑上完美使用Switch手柄玩游戏
BetterJoy终极指南:在Windows电脑上完美使用Switch手柄玩游戏 【免费下载链接】BetterJoy Allows the Nintendo Switch Pro Controller, Joycons and SNES controller to be used with CEMU, Citra, Dolphin, Yuzu and as generic XInput 项目地址: https://gitco…...