人工智能-深度学习之文本预处理
文本预处理
对于序列数据处理问题, 这样的数据存在许多种形式,文本是最常见例子之一。 例如,一篇文章可以被简单地看作一串单词序列,甚至是一串字符序列。 本节中,我们将解析文本的常见预处理步骤。 这些步骤通常包括:
-
将文本作为字符串加载到内存中。
-
将字符串拆分为词元(如单词和字符)。
-
建立一个词表,将拆分的词元映射到数字索引。
-
将文本转换为数字索引序列,方便模型操作。
import collections
import re
from d2l import torch as d2l读取数据集
首先,我们从H.G.Well的时光机器中加载文本。 这是一个相当小的语料库,只有30000多个单词,但足够我们小试牛刀, 而现实中的文档集合可能会包含数十亿个单词。 下面的函数将数据集读取到由多条文本行组成的列表中,其中每条文本行都是一个字符串。 为简单起见,我们在这里忽略了标点符号和字母大写。
#@save
d2l.DATA_HUB['time_machine'] = (d2l.DATA_URL + 'timemachine.txt','090b5e7e70c295757f55df93cb0a180b9691891a')def read_time_machine(): #@save"""将时间机器数据集加载到文本行的列表中"""with open(d2l.download('time_machine'), 'r') as f:lines = f.readlines()return [re.sub('[^A-Za-z]+', ' ', line).strip().lower() for line in lines]lines = read_time_machine()
print(f'# 文本总行数: {len(lines)}')
print(lines[0])
print(lines[10])Downloading ../data/timemachine.txt from http://d2l-data.s3-accelerate.amazonaws.com/timemachine.txt... # 文本总行数: 3221 the time machine by h g wells twinkled and his usually pale face was flushed and animated the
词元化
下面的tokenize函数将文本行列表(lines)作为输入, 列表中的每个元素是一个文本序列(如一条文本行)。 每个文本序列又被拆分成一个词元列表,词元(token)是文本的基本单位。 最后,返回一个由词元列表组成的列表,其中的每个词元都是一个字符串(string)。
def tokenize(lines, token='word'): #@save"""将文本行拆分为单词或字符词元"""if token == 'word':return [line.split() for line in lines]elif token == 'char':return [list(line) for line in lines]else:print('错误:未知词元类型:' + token)tokens = tokenize(lines)
for i in range(11):print(tokens[i])['the', 'time', 'machine', 'by', 'h', 'g', 'wells'] [] [] [] [] ['i'] [] [] ['the', 'time', 'traveller', 'for', 'so', 'it', 'will', 'be', 'convenient', 'to', 'speak', 'of', 'him'] ['was', 'expounding', 'a', 'recondite', 'matter', 'to', 'us', 'his', 'grey', 'eyes', 'shone', 'and'] ['twinkled', 'and', 'his', 'usually', 'pale', 'face', 'was', 'flushed', 'and', 'animated', 'the']
词表
词元的类型是字符串,而模型需要的输入是数字,因此这种类型不方便模型使用。 现在,让我们构建一个字典,通常也叫做词表(vocabulary), 用来将字符串类型的词元映射到从0开始的数字索引中。 我们先将训练集中的所有文档合并在一起,对它们的唯一词元进行统计, 得到的统计结果称之为语料(corpus)。 然后根据每个唯一词元的出现频率,为其分配一个数字索引。 很少出现的词元通常被移除,这可以降低复杂性。 另外,语料库中不存在或已删除的任何词元都将映射到一个特定的未知词元“<unk>”。 我们可以选择增加一个列表,用于保存那些被保留的词元, 例如:填充词元(“<pad>”); 序列开始词元(“<bos>”); 序列结束词元(“<eos>”)。
class Vocab: #@save"""文本词表"""def __init__(self, tokens=None, min_freq=0, reserved_tokens=None):if tokens is None:tokens = []if reserved_tokens is None:reserved_tokens = []# 按出现频率排序counter = count_corpus(tokens)self._token_freqs = sorted(counter.items(), key=lambda x: x[1],reverse=True)# 未知词元的索引为0self.idx_to_token = ['<unk>'] + reserved_tokensself.token_to_idx = {token: idxfor idx, token in enumerate(self.idx_to_token)}for token, freq in self._token_freqs:if freq < min_freq:breakif token not in self.token_to_idx:self.idx_to_token.append(token)self.token_to_idx[token] = len(self.idx_to_token) - 1def __len__(self):return len(self.idx_to_token)def __getitem__(self, tokens):if not isinstance(tokens, (list, tuple)):return self.token_to_idx.get(tokens, self.unk)return [self.__getitem__(token) for token in tokens]def to_tokens(self, indices):if not isinstance(indices, (list, tuple)):return self.idx_to_token[indices]return [self.idx_to_token[index] for index in indices]@propertydef unk(self): # 未知词元的索引为0return 0@propertydef token_freqs(self):return self._token_freqsdef count_corpus(tokens): #@save"""统计词元的频率"""# 这里的tokens是1D列表或2D列表if len(tokens) == 0 or isinstance(tokens[0], list):# 将词元列表展平成一个列表tokens = [token for line in tokens for token in line]return collections.Counter(tokens)我们首先使用时光机器数据集作为语料库来构建词表,然后打印前几个高频词元及其索引。
vocab = Vocab(tokens)
print(list(vocab.token_to_idx.items())[:10]) [('<unk>', 0), ('the', 1), ('i', 2), ('and', 3), ('of', 4), ('a', 5), ('to', 6), ('was', 7), ('in', 8), ('that', 9)]
现在,我们可以将每一条文本行转换成一个数字索引列表。
for i in [0, 10]:print('文本:', tokens[i])print('索引:', vocab[tokens[i]])文本: ['the', 'time', 'machine', 'by', 'h', 'g', 'wells'] 索引: [1, 19, 50, 40, 2183, 2184, 400] 文本: ['twinkled', 'and', 'his', 'usually', 'pale', 'face', 'was', 'flushed', 'and', 'animated', 'the'] 索引: [2186, 3, 25, 1044, 362, 113, 7, 1421, 3, 1045, 1]
整合所有功能
在使用上述函数时,我们将所有功能打包到load_corpus_time_machine函数中, 该函数返回corpus(词元索引列表)和vocab(时光机器语料库的词表)。 我们在这里所做的改变是:
-
为了简化后面章节中的训练,我们使用字符(而不是单词)实现文本词元化;
-
时光机器数据集中的每个文本行不一定是一个句子或一个段落,还可能是一个单词,因此返回的
corpus仅处理为单个列表,而不是使用多词元列表构成的一个列表。
def load_corpus_time_machine(max_tokens=-1): #@save"""返回时光机器数据集的词元索引列表和词表"""lines = read_time_machine()tokens = tokenize(lines, 'char')vocab = Vocab(tokens)# 因为时光机器数据集中的每个文本行不一定是一个句子或一个段落,# 所以将所有文本行展平到一个列表中corpus = [vocab[token] for line in tokens for token in line]if max_tokens > 0:corpus = corpus[:max_tokens]return corpus, vocabcorpus, vocab = load_corpus_time_machine()
len(corpus), len(vocab)(170580, 28)
相关文章:

人工智能-深度学习之文本预处理
文本预处理 对于序列数据处理问题, 这样的数据存在许多种形式,文本是最常见例子之一。 例如,一篇文章可以被简单地看作一串单词序列,甚至是一串字符序列。 本节中,我们将解析文本的常见预处理步骤。 这些步骤通常包括…...

【Java 进阶篇】插上翅膀:JQuery 插件机制详解
在前端开发中,JQuery 作为一个广泛应用的 JavaScript 库,为开发者提供了丰富的工具和方法,简化了 DOM 操作、事件处理等繁琐的任务。而在这个庞大的生态系统中,插件机制是 JQuery 的一项重要特性,使得开发者能够轻松地…...

手动编译GDB
手动编译GDB 起因在于使用Clang-14编译C文件并生成调试信息,使用gdb调试时报DWARF相关错误。经检查原因在于虚拟机为Ubuntu 20.04,使用apt下载时官方提供gdb版本为9.2,不支持DWARF5,而Clang-14生成的调试信息是DWARF5版本的。为解决该问题,手…...

竞赛选题 深度学习花卉识别 - python 机器视觉 opencv
文章目录 0 前言1 项目背景2 花卉识别的基本原理3 算法实现3.1 预处理3.2 特征提取和选择3.3 分类器设计和决策3.4 卷积神经网络基本原理 4 算法实现4.1 花卉图像数据4.2 模块组成 5 项目执行结果6 最后 0 前言 🔥 优质竞赛项目系列,今天要分享的是 &a…...

替换SlowFast中Detectron2为Yolov8
一 需求 FaceBookReserch中SlowFast源码中检测框是用Detectron2进行目标检测,本文想实现用yolov8替换detectron2二 实施方案 首先,yolov8 支持有自定义库ultralytics(仅支持yolov8),安装对应库 pip install ultraly…...

轻量化网络--MobileNet V1
文章目录 depth-wise separable convolutions普通卷积depthwise conconvolutionspointwise convolutions网络结构进一步分析网络训练方式两个重要的超参数Width Multiplier: Thinner ModelsResolution Multiplier: Reduced Representation实验结果消融实验细粒度,高分辨率识别…...
gittee启动器
前言 很多小伙伴反馈不是使用gitee,不会寻找好的项目,在拿到一个项目不知道从哪里入手。 鼠鼠我呀就是宠粉,中嘞,老乡。整!!! git的基本指令 在使用gitee的时候呢,我们只需要记住…...

Spark数据倾斜_产生原因及定位处理办法_生产环境
在最近的项目中,历史和实时数据进行关联平滑时出现了数据倾斜,产生了笛卡尔积,具体现象如下:运行内存175GB,核数64,运行代码时,查看SparkUI界面的active jobs ,数据输入是1G…...

2023OceanBase年度发布会后,有感
很荣幸收到了OceanBase邀请,于本周四(11月16日)参加了OceanBase年度发布会并参加了DBA老友会,按照理论应该我昨天(星期五)就回到成都了,最迟今天白天就该把文章写出来了,奈何媳妇儿买…...

ubuntu18.04中代码迁移到20.04报错
一、 PCL库,Eigen库报错,如: /usr/include/pcl-1.10/pcl/point_types.h:903:29: error: ‘enable_if_t’ in namespace ‘std’ does not name a template type; did you mean ‘enable_if’?/usr/include/pcl-1.10/pcl/point_types.h:698:…...

QQ五毛项目记
问题与挑战:某公司为了实现某马总造福全人类,红旗插遍全球的宏伟目标,为应对后续用户激增的问题。特别安排了一次针对全体用户的秒杀活动:于XXXX年XX月XX日XX时XX分XX秒开始的秒杀五毛钱一百个QQ币的活动。每个账户仅限一次&#…...

小程序实现登录持久化
小程序实现登录持久化需要使用到小程序的缓存API,例如wx.getStorageSync()和wx.setStorageSync()等方法。以下是一个简单的代码实现: // App.js App({ // 在全局的App.js中定义全局变量userInfo,用于存放用户信息 globalData: { userInfo: …...

2023年亚太杯数学建模思路 - 案例:ID3-决策树分类算法
文章目录 0 赛题思路1 算法介绍2 FP树表示法3 构建FP树4 实现代码 建模资料 0 赛题思路 (赛题出来以后第一时间在CSDN分享) https://blog.csdn.net/dc_sinor?typeblog 1 算法介绍 FP-Tree算法全称是FrequentPattern Tree算法,就是频繁模…...

C复习-输入输出函数+流
参考: 里科《C和指针》 perror 定义在stdio.h中。当一个库函数失败时,库函数会在一个外部整型变量errno(在errno.h中定义)中保存错误代码,然后传递给用户程序,此时使用perror,会在打印msg后再打…...
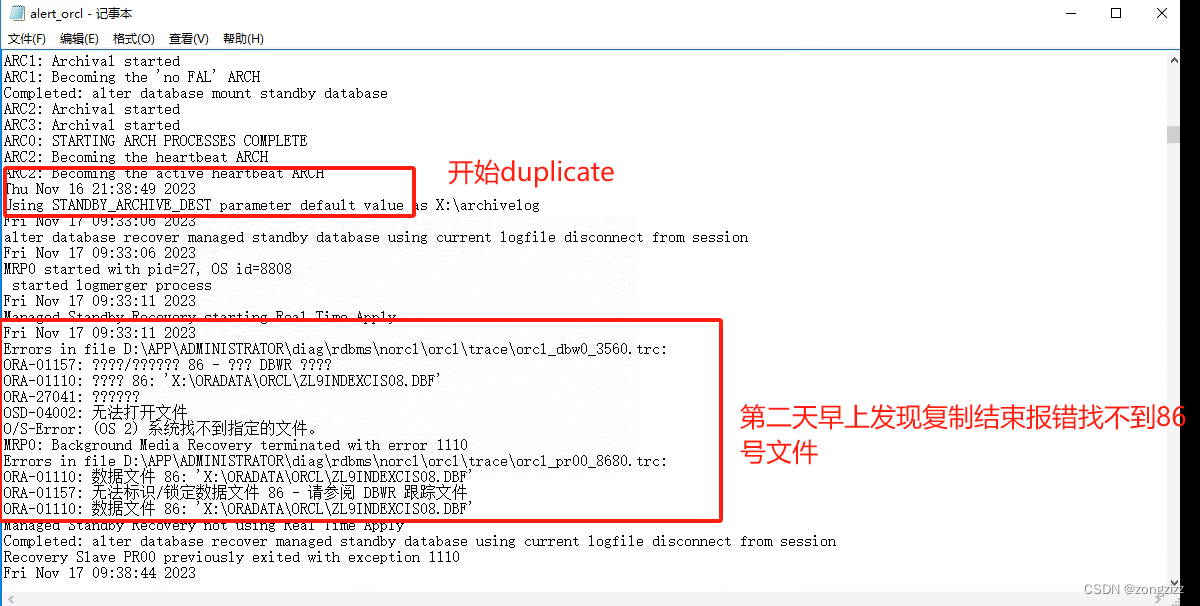
duplicate复制数据库单个数据文件复制失败报错rman-03009 ora-03113
duplicate复制数据库单个数据文件复制失败报错rman-03009 ora-03113 搭建dg过程中,发现有一个数据文件在复制过程中没有复制过来,在备库数据文件目录找不到这个数据文件 处理方法: 第一步:主库备份86#数据文件 C:\Users\Admi…...

golang 解析oracle 数据文件头
package mainimport ("encoding/binary""fmt""io""os" ) // Powered by 黄林杰 15658655447 // Usered for parser oracle datafile header block 1 .... // oracle 数据文件头块解析 // KCBlockStruct represents the structure of t…...

van-popup滑动卡顿并且在有时候在ios上经常性滑动卡顿的情况
解决”pc端页面可以滚动,移动端手势无法滚动“问题的一次经历 - 掘金 <van-popup v-model"studentclassShow" :lock-scroll"false" position"bottom" style"z-index: 3000" :style"{ height: 55% }"><d…...

YOLOv7独家原创改进:最新原创WIoU_NMS改进点,改进有效可以直接当做自己的原创改进点来写,提升网络模型性能精度
💡该教程为属于《芒果书》📚系列,包含大量的原创首发改进方式, 所有文章都是全网首发原创改进内容🚀 💡本篇文章为YOLOv7独家原创改进:独家首发最新原创WIoU_NMS改进点,改进有效可以直接当做自己的原创改进点来写,提升网络模型性能精度。 💡对自己数据集改进有效…...
)
ubuntu20.04中编译zlib1.2.11(源码编译)
1. 安装cmake-gui 2. 下载并解压zlib-1.2.11,在解压得到的文件夹内部创建一个“build”文件夹。 3. 打开cmake-gui,配置zlib1.2.11的configure文件(主要编辑build路径,安装路径,以及其他依赖选项)&#x…...

计算机毕业设计选题推荐-高校后勤报修微信小程序/安卓APP-项目实战
✨作者主页:IT研究室✨ 个人简介:曾从事计算机专业培训教学,擅长Java、Python、微信小程序、Golang、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。 ☑文末获取源码☑ 精彩专栏推荐⬇⬇⬇ Java项目 Python…...

TDengine 快速体验(Docker 镜像方式)
简介 TDengine 可以通过安装包、Docker 镜像 及云服务快速体验 TDengine 的功能,本节首先介绍如何通过 Docker 快速体验 TDengine,然后介绍如何在 Docker 环境下体验 TDengine 的写入和查询功能。如果你不熟悉 Docker,请使用 安装包的方式快…...

【WiFi帧结构】
文章目录 帧结构MAC头部管理帧 帧结构 Wi-Fi的帧分为三部分组成:MAC头部frame bodyFCS,其中MAC是固定格式的,frame body是可变长度。 MAC头部有frame control,duration,address1,address2,addre…...

《用户共鸣指数(E)驱动品牌大模型种草:如何抢占大模型搜索结果情感高地》
在注意力分散、内容高度同质化的时代,情感连接已成为品牌破圈的关键通道。我们在服务大量品牌客户的过程中发现,消费者对内容的“有感”程度,正日益成为影响品牌传播效率与转化率的核心变量。在生成式AI驱动的内容生成与推荐环境中࿰…...

多模态商品数据接口:融合图像、语音与文字的下一代商品详情体验
一、多模态商品数据接口的技术架构 (一)多模态数据融合引擎 跨模态语义对齐 通过Transformer架构实现图像、语音、文字的语义关联。例如,当用户上传一张“蓝色连衣裙”的图片时,接口可自动提取图像中的颜色(RGB值&…...

现代密码学 | 椭圆曲线密码学—附py代码
Elliptic Curve Cryptography 椭圆曲线密码学(ECC)是一种基于有限域上椭圆曲线数学特性的公钥加密技术。其核心原理涉及椭圆曲线的代数性质、离散对数问题以及有限域上的运算。 椭圆曲线密码学是多种数字签名算法的基础,例如椭圆曲线数字签…...

【Zephyr 系列 10】实战项目:打造一个蓝牙传感器终端 + 网关系统(完整架构与全栈实现)
🧠关键词:Zephyr、BLE、终端、网关、广播、连接、传感器、数据采集、低功耗、系统集成 📌目标读者:希望基于 Zephyr 构建 BLE 系统架构、实现终端与网关协作、具备产品交付能力的开发者 📊篇幅字数:约 5200 字 ✨ 项目总览 在物联网实际项目中,**“终端 + 网关”**是…...
)
Java入门学习详细版(一)
大家好,Java 学习是一个系统学习的过程,核心原则就是“理论 实践 坚持”,并且需循序渐进,不可过于着急,本篇文章推出的这份详细入门学习资料将带大家从零基础开始,逐步掌握 Java 的核心概念和编程技能。 …...

Map相关知识
数据结构 二叉树 二叉树,顾名思义,每个节点最多有两个“叉”,也就是两个子节点,分别是左子 节点和右子节点。不过,二叉树并不要求每个节点都有两个子节点,有的节点只 有左子节点,有的节点只有…...

高效线程安全的单例模式:Python 中的懒加载与自定义初始化参数
高效线程安全的单例模式:Python 中的懒加载与自定义初始化参数 在软件开发中,单例模式(Singleton Pattern)是一种常见的设计模式,确保一个类仅有一个实例,并提供一个全局访问点。在多线程环境下,实现单例模式时需要注意线程安全问题,以防止多个线程同时创建实例,导致…...

#Uniapp篇:chrome调试unapp适配
chrome调试设备----使用Android模拟机开发调试移动端页面 Chrome://inspect/#devices MuMu模拟器Edge浏览器:Android原生APP嵌入的H5页面元素定位 chrome://inspect/#devices uniapp单位适配 根路径下 postcss.config.js 需要装这些插件 “postcss”: “^8.5.…...