竞赛 题目:基于深度学习的中文对话问答机器人
文章目录
- 0 简介
- 1 项目架构
- 2 项目的主要过程
- 2.1 数据清洗、预处理
- 2.2 分桶
- 2.3 训练
- 3 项目的整体结构
- 4 重要的API
- 4.1 LSTM cells部分:
- 4.2 损失函数:
- 4.3 搭建seq2seq框架:
- 4.4 测试部分:
- 4.5 评价NLP测试效果:
- 4.6 梯度截断,防止梯度爆炸
- 4.7 模型保存
- 5 重点和难点
- 5.1 函数
- 5.2 变量
- 6 相关参数
- 7 桶机制
- 7.1 处理数据集
- 7.2 词向量处理seq2seq
- 7.3 处理问答及答案权重
- 7.4 训练&保存模型
- 7.5 载入模型&测试
- 8 最后
0 简介
🔥 优质竞赛项目系列,今天要分享的是
基于深度学习的中文对话问答机器人
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
1 项目架构
整个项目分为 数据清洗 和 建立模型两个部分。
(1)主要定义了seq2seq这样一个模型。
首先是一个构造函数,在构造函数中定义了这个模型的参数。
以及构成seq2seq的基本单元的LSTM单元是怎么构建的。
(2)接着在把这个LSTM间单元构建好之后,加入模型的损失函数。
我们这边用的损失函数叫sampled_softmax_loss,这个实际上就是我们的采样损失。做softmax的时候,我们是从这个6000多维里边找512个出来做采样。
损失函数做训练的时候需要,测试的时候不需要。训练的时候,y值是one_hot向量
(3)然后再把你定义好的整个的w[512*6000]、b[6000多维],还有我们的这个cell本身,以及我们的这个损失函数一同代到我们这个seq2seq模型里边。然后呢,这样的话就构成了我们这样一个seq2seq模型。
函数是tf.contrib.legacy_seq2seq.embedding_attention_seq2seq()
(4)最后再将我们传入的实参,也就是三个序列,经过这个桶的筛选。然后放到这个模型去训练啊,那么这个模型就会被训练好。到后面,我们可以把我们这个模型保存在model里面去。模型参数195M。做桶的目的就是节约计算资源。
2 项目的主要过程
前提是一问一答,情景对话,不是多轮对话(比较难,但是热门领域)
整个框架第一步:做语料
先拿到一个文件,命名为.conv(只要不命名那几个特殊的,word等)。输入目录是db,输出目录是bucket_dbs,不存在则新建目录。
测试的时候,先在控制台输入一句话,然后将这句话通过正反向字典Ids化,然后去桶里面找对应的回答的每一个字,然后将输出通过反向字典转化为汉字。
2.1 数据清洗、预处理
读取整个语料库,去掉E、M和空格,还原成原始文本。创建conversion.db,conversion表,两个字段。每取完1000组对话,插入依次数据库,批量提交,通过cursor.commit.
2.2 分桶
从总的conversion.db中分桶,指定输入目录db, 输出目录bucket_dbs.
检测文字有效性,循环遍历,依次记录问题答案,每积累到1000次,就写入数据库。
for ask, answer in tqdm(ret, total=total):if is_valid(ask) and is_valid(answer):for i in range(len(buckets)):encoder_size, decoder_size = buckets[i]if len(ask) <= encoder_size and len(answer) < decoder_size:word_count.update(list(ask))word_count.update(list(answer))wait_insert.append((encoder_size, decoder_size, ask, answer))if len(wait_insert) > 10000000:wait_insert = _insert(wait_insert)break
将字典维度6865未,投影到100维,也就是每个字是由100维的向量组成的。后面的隐藏层的神经元的个数是512,也就是维度。
句子长度超过桶长,就截断或直接丢弃。
四个桶是在read_bucket_dbs()读取的方法中创建的,读桶文件的时候,实例化四个桶对象。
2.3 训练
先读取json字典,加上pad等四个标记。
lstm有两层,attention在解码器的第二层,因为第二层才是lstm的输出,用两层提取到的特征越好。
num_sampled=512, 分批softmax的样本量(
训练和测试差不多,测试只前向传播,不反向更新
3 项目的整体结构
s2s.py:相当于main函数,让代码运行起来
里面有train()、test()、test_bleu()和create_model()四个方法,还有FLAGS成员变量,
相当于静态成员变量 public static final string
decode_conv.py和data_utils.py:是数据处理
s2s_model.py:
里面放的是模型
里面有init()、step()、get_batch_data()和get_batch()四个方法。构造方法传入构造方法的参数,搭建S2SModel框架,然后sampled_loss()和seq2seq_f()两个方法
data_utils.py:
读取数据库中的文件,并且构造正反向字典。把语料分成四个桶,目的是节约计算资源。先转换为db\conversation.db大的桶,再分成四个小的桶。buckets
= [ (5, 15), (10, 20), (15, 25), (20, 30)]
比如buckets[1]指的就是(10, 20),buckets[1][0]指的就是10。
bucket_id指的就是0,1,2,3
dictionary.json:
是所有数字、字母、标点符号、汉字的字典,加上生僻字,以及PAD、EOS、GO、UNK 共6865维度,输入的时候会进行词嵌入word
embedding成512维,输出时,再转化为6865维。
model:
文件夹下装的是训练好的模型。
也就是model3.data-00000-of-00001,这个里面装的就是模型的参数
执行model.saver.restore(sess, os.path.join(FLAGS.model_dir,
FLAGS.model_name))的时候,才是加载目录本地的保存的模型参数的过程,上面建立的模型是个架子,
model = create_model(sess, True),这里加载模型比较耗时,时间复杂度最高
dgk_shooter_min.conv:
是语料,形如: E
M 畹/华/吾/侄/
M 你/接/到/这/封/信/的/时/候/
decode_conv.py: 对语料数据进行预处理
config.json:是配置文件,自动生成的
4 重要的API
4.1 LSTM cells部分:
cell = tf.contrib.rnn.BasicLSTMCell(size)cell = tf.contrib.rnn.DropoutWrapper(cell, output_keep_prob=dropout)cell = tf.contrib.rnn.MultiRNNCell([cell] * num_layers)对上一行的cell去做Dropout的,在外面裹一层DropoutWrapper
构建双层lstm网络,只是一个双层的lstm,不是双层的seq2seq
4.2 损失函数:
tf.nn.sampled_softmax_loss( weights=local_w_t,
b labels=labels, #真实序列值,每次一个
inputs=loiases=local_b,
cal_inputs, #预测出来的值,y^,每次一个
num_sampled=num_samples, #512
num_classes=self.target_vocab_size # 原始字典维度6865)
4.3 搭建seq2seq框架:
tf.contrib.legacy_seq2seq.embedding_attention_seq2seq(encoder_inputs, # tensor of input seq 30decoder_inputs, # tensor of decoder seq 30tmp_cell, #自定义的cell,可以是GRU/LSTM, 设置multilayer等num_encoder_symbols=source_vocab_size,# 编码阶段字典的维度6865num_decoder_symbols=target_vocab_size, # 解码阶段字典的维度 6865embedding_size=size, # embedding 维度,512num_heads=20, #选20个也可以,精确度会高点,num_heads就是attention机制,选一个就是一个head去连,5个就是5个头去连output_projection=output_projection,# 输出层。不设定的话输出维数可能很大(取决于词表大小),设定的话投影到一个低维向量feed_previous=do_decode,# 是否执行的EOS,是否允许输入中间cdtype=dtype)4.4 测试部分:
self.outputs, self.losses = tf.contrib.legacy_seq2seq.model_with_buckets(
self.encoder_inputs,
self.decoder_inputs,
targets,
self.decoder_weights,
buckets,
lambda x, y: seq2seq_f(x, y, True),
softmax_loss_function=softmax_loss_function
)
4.5 评价NLP测试效果:
在nltk包里,有个接口叫bleu,可以评估测试结果,NITK是个框架
from nltk.translate.bleu_score import sentence_bleu
score = sentence_bleu(
references,#y值
list(ret),#y^
weights=(1.0,)#权重为1
)
4.6 梯度截断,防止梯度爆炸
clipped_gradients, norm = tf.clip_by_global_norm(gradients,max_gradient_norm)
tf.clip_by_global_norm(t_list, clip_norm, use_norm=None, name=None)
通过权重梯度的总和的比率来截取多个张量的值。t_list是梯度张量, clip_norm是截取的比率,这个函数返回截取过的梯度张量和一个所有张量的全局范数
4.7 模型保存
tf.train.Saver(tf.global_variables(), write_version=tf.train.SaverDef.V2)
5 重点和难点
5.1 函数
def get_batch_data(self, bucket_dbs, bucket_id):
def get_batch(self, bucket_dbs, bucket_id, data):
def step(self,session,encoder_inputs,decoder_inputs,decoder_weights,bucket_id):
5.2 变量
batch_encoder_inputs, batch_decoder_inputs, batch_weights = [], [], []
6 相关参数
model = s2s_model.S2SModel(data_utils.dim, # 6865,编码器输入的语料长度data_utils.dim, # 6865,解码器输出的语料长度buckets, # buckets就是那四个桶,data_utils.buckets,直接在data_utils写的一个变量,就能直接被点出来FLAGS.size, # 隐层神经元的个数512FLAGS.dropout, # 隐层dropout率,dropout不是lstm中的,lstm的几个门里面不需要dropout,没有那么复杂。是隐层的dropoutFLAGS.num_layers, # lstm的层数,这里写的是2FLAGS.max_gradient_norm, # 5,截断梯度,防止梯度爆炸FLAGS.batch_size, # 64,等下要重新赋值,预测就是1,训练就是64FLAGS.learning_rate, # 0.003FLAGS.num_samples, # 512,用作负采样forward_only, #只传一次dtype){"__author__": "qhduan@memect.co","buckets": [[5, 15],[10, 20],[20, 30],[40, 50]],"size": 512,/*s2s lstm单元出来之后的,连的隐层的number unit是512*/"depth": 4,"dropout": 0.8,"batch_size": 512,/*每次往里面放多少组对话对,这个是比较灵活的。如果找一句话之间的相关性,batch_size就是这句话里面的字有多少个,如果要找上下文之间的对话,batch_size就是多少组对话*/"random_state": 0,"learning_rate": 0.0003,/*总共循环20次*/"epoch": 20,"train_device": "/gpu:0","test_device": "/cpu:0"}7 桶机制
7.1 处理数据集
语料库长度桶结构
(5, 10): 5问题长度,10回答长度
每个桶中对话数量,一问一答为一次完整对话
Analysis
(1) 设定4个桶结构,即将问答分成4个部分,每个同种存放对应的问答数据集[87, 69, 36,
8]四个桶中分别有87组对话,69组对话,36组对话,8组对话;
(2) 训练词数据集符合桶长度则输入对应值,不符合桶长度,则为空;
(3) 对话数量占比:[0.435, 0.78, 0.96, 1.0];
7.2 词向量处理seq2seq
获取问答及答案权重
参数:
- data: 词向量列表,如[[[4,4],[5,6,8]]]
- bucket_id: 桶编号,值取自桶对话占比
步骤:
- 问题和答案的数据量:桶的话数buckets = [(5, 10), (10, 15), (20, 25), (40, 50)]
- 生成问题和答案的存储器
- 从问答数据集中随机选取问答
- 问题末尾添加PAD_ID并反向排序
- 答案添加GO_ID和PAD_ID
- 问题,答案,权重批量数据
- 批量问题
- 批量答案
- 答案权重即Attention机制
- 若答案为PAD则权重设置为0,因为是添加的ID,其他的设置为1
Analysis
-
(1) 对问题和答案的向量重新整理,符合桶尺寸则保持对话尺寸,若不符合桶设定尺寸,则进行填充处理,
问题使用PAD_ID填充,答案使用GO_ID和PAD_ID填充; -
(2) 对问题和答案向量填充整理后,使用Attention机制,对答案进行权重分配,答案中的PAD_ID权重为0,其他对应的为1;
-
(3) get_batch()处理词向量;返回问题、答案、答案权重数据;
返回结果如上结果:encoder_inputs, decoder_inputs, answer_weights.
7.3 处理问答及答案权重
参数:session: tensorflow 会话.encoder_inputs: 问题向量列表decoder_inputs: 回答向量列表answer_weights: 答案权重列表bucket_id: 桶编号which bucket of the model to use.forward_only: 前向或反向运算标志位
返回:一个由梯度范数组成的三重范数(如果不使用反向传播,则为无)。平均困惑度和输出
Analysis
-
(1) 根据输入的问答向量列表,分配语料桶,处理问答向量列表,并生成新的输入字典(dict), input_feed = {};
-
(2) 输出字典(dict), ouput_feed = {},根据是否使用反向传播获得参数,使用反向传播,
output_feed存储更新的梯度范数,损失,不使用反向传播,则只存储损失; -
(3) 最终的输出为分两种情况,使用反向传播,返回梯度范数,损失,如反向传播不使用反向传播,
返回损失和输出的向量(用于加载模型,测试效果),如前向传播;
7.4 训练&保存模型
步骤:
-
检查是否有已存在的训练模型
-
有模型则获取模型轮数,接着训练
-
没有模型则从开始训练
-
一直训练,每过一段时间保存一次模型
-
如果模型没有得到提升,减小learning rate
-
保存模型
-
使用测试数据评估模型
global step: 500, learning rate: 0.5, loss: 2.574068747580052 bucket id: 0, eval ppx: 14176.588030763274 bucket id: 1, eval ppx: 3650.0026667220773 bucket id: 2, eval ppx: 4458.454110999805 bucket id: 3, eval ppx: 5290.083583183104
7.5 载入模型&测试
(1) 该聊天机器人使用bucket桶结构,即指定问答数据的长度,匹配符合的桶,在桶中进行存取数据;
(2) 该seq2seq模型使用Tensorflow时,未能建立独立标识的图结构,在进行后台封装过程中出现图为空的现象;
从main函数进入test()方法。先去内存中加载训练好的模型model,这部分最耗时,改batch_size为1,传入相关的参数。开始输入一个句子,并将它读进来,读进来之后,按照桶将句子分,按照模型输出,然后去查字典。接着在循环中输入上句话,找对应的桶。然后拿到的下句话的每个字,找概率最大的那个字的index的id输出。get_batch_data(),获取data [('天气\n', '')],也就是问答对,但是现在只有问,没有答get_batch()获取encoder_inputs=1*10,decoder_inputs=1*20 decoder_weights=1*20step()获取预测值output_logits,

8 最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
相关文章:
竞赛 题目:基于深度学习的中文对话问答机器人
文章目录 0 简介1 项目架构2 项目的主要过程2.1 数据清洗、预处理2.2 分桶2.3 训练 3 项目的整体结构4 重要的API4.1 LSTM cells部分:4.2 损失函数:4.3 搭建seq2seq框架:4.4 测试部分:4.5 评价NLP测试效果:4.6 梯度截断…...

CCF ChinaSoft 2023 论坛巡礼|软件测试产教研融合论坛
2023年CCF中国软件大会(CCF ChinaSoft 2023)由CCF主办,CCF系统软件专委会、形式化方法专委会、软件工程专委会以及复旦大学联合承办,将于2023年12月1-3日在上海国际会议中心举行。 本次大会主题是“智能化软件创新推动数字经济与社…...
浅谈WPF之控件模板和数据模板
WPF不仅支持传统的Windows Forms编程的用户界面和用户体验设计,同时还推出了以模板为核心的新一代设计理念。在WPF中,通过引入模板,将数据和算法的“内容”和“形式”进行解耦。模板主要分为两大类:数据模板【Data Template】和控…...
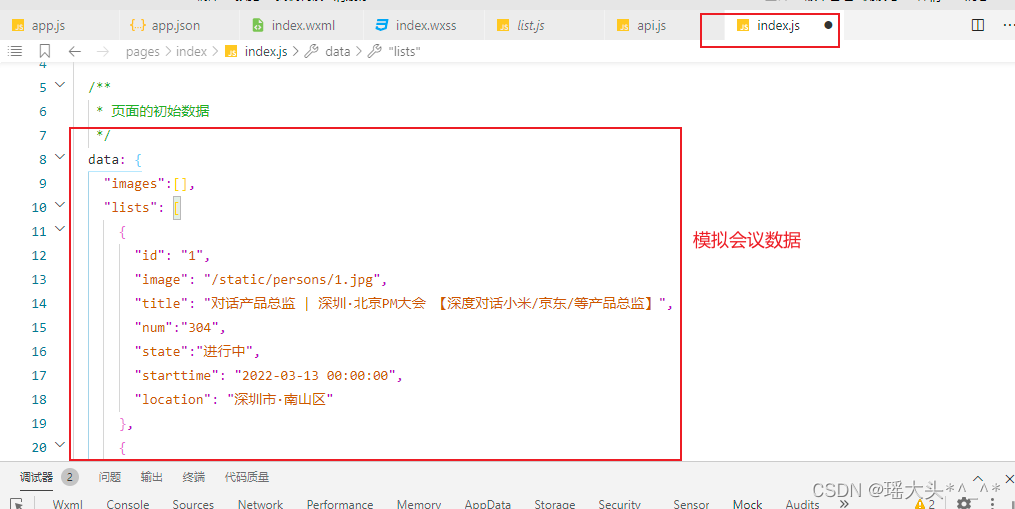
微信小程序会议OA首页-开发说明创建项目关于flex布局关于尺寸单位(rpx)关于WXS轮播图会议信息
目录 1. 创建项目 2. 关于flex布局 3. 关于尺寸单位(rpx) 4. 关于WXS 4. 轮播图 5. 会议信息 1. 创建项目 基于微信原生开发工具,稳定版 Stable Build (1.06.22010310) 创建项目前,请确定有小程序测试账号 使用向导创建一个…...
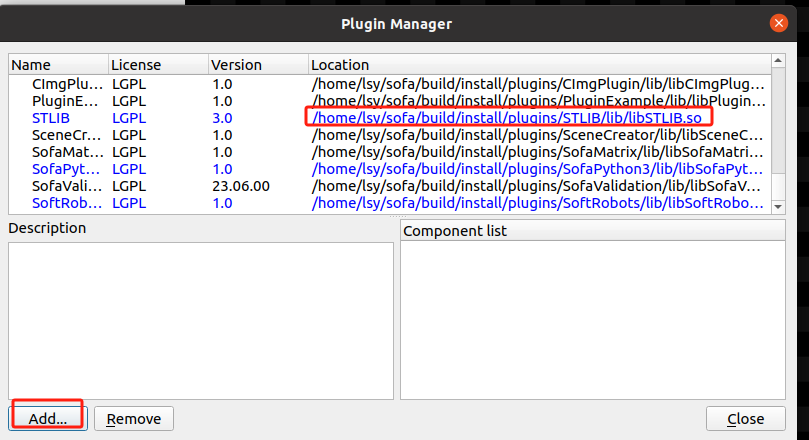
Linux上编译和安装SOFA23.06
前言 你可以直接使用编译安装好的SOFA版本Installing from all-included binaries (v23.06.00): 如果你想自己编译,可以看我下面写的内容,不过绝大多数是从官网来的,如果和官网有出入,建议还是以官网为准。 在Linux下…...

定时任务 Spring Task
一、介绍 Spring Task 是Spring框架提供的任务调度工具,可以按照约定的时间自动执行某个代码逻辑。 定位: 定时任务框架 作用: 定时自动执行某段Java代码 二、cron 表达式 cron表达式在线生成器:https://cron.qqe2.com/ 1、说明…...

golang 上传图片 --chatGPT
问:makeImgUpload(path string) 实现发送发送图片, 发送类型为 multipart/form-data gpt: 下面是一个简单的 makeImgUpload 函数的实现,用于发送图片并以 multipart/form-data 格式进行上传。请注意,此代码假设图片文件路径是正确…...
Android Studio 写一个Java调用c++ 的demo
前提条件: 本地已经配置好了ndk环境,如果没有配置好,建议参考macos 配置ndk环境-CSDN博客 这篇链接。 新建一个Empty Project 比如我这里的Project的名字是HelloJNI,包名是com.example.hellojni 然后在src目录下,右键选择Add C …...

Pandas数据操作_Python数据分析与可视化
Pandas数据操作 排序操作对索引进行排序按行排序按值排序 删除操作算数运算去重duplicated()drop_duplicates() 数据重塑层次化索引索引方式内层选取数据重塑 排序操作 对索引进行排序 Series 用 sort_index() 按索引排序,sort_values() 按值排序; Dat…...

【Debug】查询的数据量比数据库中的数据量还要多
今天前端反馈了一个bug,某个接口返回的数据很多,我到mysql数据库看了一下,查询的表名为trs_risk,其中只有1000多条数据,而页面返回有5000多条数据!! 匪夷所思啊,我定位到Mapper层的…...
nodejs微信小程序-慢性胃炎健康管理系统的设计与实现-安卓-python-PHP-计算机毕业设计
目 录 摘 要 I ABSTRACT II 目 录 II 第1章 绪论 1 1.1背景及意义 1 1.2 国内外研究概况 1 1.3 研究的内容 1 第2章 相关技术 3 2.1 nodejs简介 4 2.2 express框架介绍 6 2.4 MySQL数据库 4 第3章 系统分析 5 3.1 需求分析 5 3.2 系统可行性分析 5 3.2.1技术可行性:…...
二十一、数组(1)
本章概要 数组特性 用于显示数组的实用程序 一等对象返回数组 简单来看,数组需要你去创建和初始化,你可以通过下标对数组元素进行访问,数组的大小不会改变。大多数时候你只需要知道这些,但有时候你必须在数组上进行更复杂的操作…...

react hook 获取setState的新值
利用useRef 存储最新值 let [count,setCount] useState(0)let countRef useRef(count)let handleClick function (){setCount((prev)>{countRef.current prev1return countRef.current})console.info(countRef.current)}利用useRef let [count,setCount] useState(0)le…...
JVM判断对象是否存活之引用计数法、可达性分析
目录 前言 引用计数法 概念 优点 缺点 可达性分析 概念 缺点: 扩展: 1.GC Roots 概念 2.STW (Stop the world) 前言 JVM有两种算法来判断对象是否存活,分别是引用计数法和可达性分析算法,针对可达性分析算法STW时间长、…...

报道 | 2023年12月-2024年2月国际运筹优化会议汇总
2023年12月-2024年2月召开会议汇总: The 16th Annual International Conference on Combinatorial Optimization and Applications (COCOA 2023) Location: Virtual Important dates: Conference: December 11, 2023 (Start) - December 13, 2023 (End) Details…...

【科技素养】蓝桥杯STEMA 科技素养组模拟练习试卷C
单选题 1、A right triangle has a side that is 5cm long, and its hypotenuse is 13cm long.The area of the triangle is (). A、30 cm2 B、60 cm2 C、65 cm2 D、32.5 cm2 答案:A 2、一位旅客安检后走在前往登机口的路上。路途中一部…...

“升级图片管理,优化工作流程——轻松将JPG转为PNG“
在图片时代,无论是工作还是生活,图片管理都显得尤为重要。批量处理图片,将JPG格式轻松转换为PNG格式,能够使您的图片管理更优化,提高工作效率。 首先,我们进入首助编辑高手主页面,会看到有多种…...
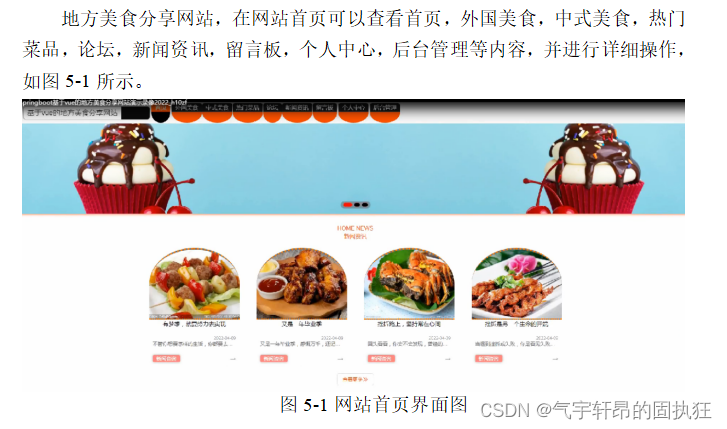
基于Springboot的地方美食分享网站(有报告)。Javaee项目,springboot项目。
演示视频: 基于Springboot的地方美食分享网站(有报告)。Javaee项目,springboot项目。 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。 项目介绍: 采用…...

助力水泥基建裂痕自动化巡检,基于yolov5融合ASPP开发构建多尺度融合目标检测识别系统
道路场景下的自动化智能巡检、洞体场景下的壁体类建筑缺陷自动检测识别等等已经在现实生活中不断地落地应用了,在我们之前的很多博文中也已经有过很多相关的实践项目经历了,本文的核心目的是想要融合多尺度感受野技术到yolov5模型中以期在较低参数量的情…...

rk3588使用vscode远程debug 配置文件
进入调试口,需要本地和远程都装C/C estension 下面是在调mpi_enc_test的launch.json 文件自己make生成的 makefile 没改过 args项是输入参数,配置了相机输入,具体参数看他的demo说明, 记录一下,方便以后拷贝方便 {// …...
结构体的进阶应用)
基于算法竞赛的c++编程(28)结构体的进阶应用
结构体的嵌套与复杂数据组织 在C中,结构体可以嵌套使用,形成更复杂的数据结构。例如,可以通过嵌套结构体描述多层级数据关系: struct Address {string city;string street;int zipCode; };struct Employee {string name;int id;…...

【网络】每天掌握一个Linux命令 - iftop
在Linux系统中,iftop是网络管理的得力助手,能实时监控网络流量、连接情况等,帮助排查网络异常。接下来从多方面详细介绍它。 目录 【网络】每天掌握一个Linux命令 - iftop工具概述安装方式核心功能基础用法进阶操作实战案例面试题场景生产场景…...

<6>-MySQL表的增删查改
目录 一,create(创建表) 二,retrieve(查询表) 1,select列 2,where条件 三,update(更新表) 四,delete(删除表…...

(十)学生端搭建
本次旨在将之前的已完成的部分功能进行拼装到学生端,同时完善学生端的构建。本次工作主要包括: 1.学生端整体界面布局 2.模拟考场与部分个人画像流程的串联 3.整体学生端逻辑 一、学生端 在主界面可以选择自己的用户角色 选择学生则进入学生登录界面…...

相机从app启动流程
一、流程框架图 二、具体流程分析 1、得到cameralist和对应的静态信息 目录如下: 重点代码分析: 启动相机前,先要通过getCameraIdList获取camera的个数以及id,然后可以通过getCameraCharacteristics获取对应id camera的capabilities(静态信息)进行一些openCamera前的…...
)
Java入门学习详细版(一)
大家好,Java 学习是一个系统学习的过程,核心原则就是“理论 实践 坚持”,并且需循序渐进,不可过于着急,本篇文章推出的这份详细入门学习资料将带大家从零基础开始,逐步掌握 Java 的核心概念和编程技能。 …...
)
.Net Framework 4/C# 关键字(非常用,持续更新...)
一、is 关键字 is 关键字用于检查对象是否于给定类型兼容,如果兼容将返回 true,如果不兼容则返回 false,在进行类型转换前,可以先使用 is 关键字判断对象是否与指定类型兼容,如果兼容才进行转换,这样的转换是安全的。 例如有:首先创建一个字符串对象,然后将字符串对象隐…...

python执行测试用例,allure报乱码且未成功生成报告
allure执行测试用例时显示乱码:‘allure’ �����ڲ����ⲿ���Ҳ���ǿ�&am…...

论文笔记——相干体技术在裂缝预测中的应用研究
目录 相关地震知识补充地震数据的认识地震几何属性 相干体算法定义基本原理第一代相干体技术:基于互相关的相干体技术(Correlation)第二代相干体技术:基于相似的相干体技术(Semblance)基于多道相似的相干体…...

网站指纹识别
网站指纹识别 网站的最基本组成:服务器(操作系统)、中间件(web容器)、脚本语言、数据厍 为什么要了解这些?举个例子:发现了一个文件读取漏洞,我们需要读/etc/passwd,如…...