【MySQL之MySQL底层分析篇】系统学习MySQL,从应用SQL语法到底层知识讲解,这将是你见过最完成的知识体系
文章目录
- MySQL体系结构
- MySQL存储结构(以InnoDB为例)
- MySQL执行流程(以InnoDB为例)
- 1. 数据写入原理
- 2. 数据查询原理
- MySQL存储引擎
- 1. 为什么需要不同的存储引擎
- 2. 如何为数据指定不同的存储引擎,数据粒度又是多少
- 3. MySQL支持哪些存储引擎
- 4. MySQL支持的存储引擎各自有什么特性
- 索引
- 1. 索引的概念
- 2. 为什么要使用索引
- a. 没有索引的情况下访问数据
- b. 使用平衡二叉树索引
- 3. InnoDB索引底层为什么选择B+Tree
- a. 二叉树
- b. 二叉平衡树(解决二叉树线性链表的问题)
- c. B树(解决了平衡二叉树的缺点)
- d. B+ Tree
- 4. 什么时候不要用索引,什么时候要用索引
- a. 什么场景不要用索引
- b. 什么场景用索引
- 5. 聚簇索引与非聚簇索引
- 6. 辅助索引
- 7. 全文索引
- 1. 概念
- 2. 实现
- 3. 使用
- 8. 索引失效
- 8.1 最佳左前缀法则
- 8.2 不要再索引列上做任何操作
- 8.3 存储引擎不能使用索引中范围条件右边的列
- 8.4 尽量使用覆盖索引
- 8.5 like以通配符(%)开头的索引会失效变成全表扫描
参考文章:学习Mysql这一篇就够了
参考文章1:MySQL面试题目
参考文章2:MySQL面试题目
参考文章:MySQL数据库学习宝典
参考文章:Mysql存储引擎
参考文章:MySQL 索引底层选择B+Tree
参考文章:全文索引
参考文章1:MyISAM 和 InnoDB介绍
参考文章2:MyISAM 和 InnoDB区别
参考文章:索引失效
参考文章:探索MySQL是否走索引(一)——范围查询一定走索引吗?
工具:提供一个很好用的国外数据结构模拟网站
参考B站视频:总体概括
参考B站视频:详细讲解
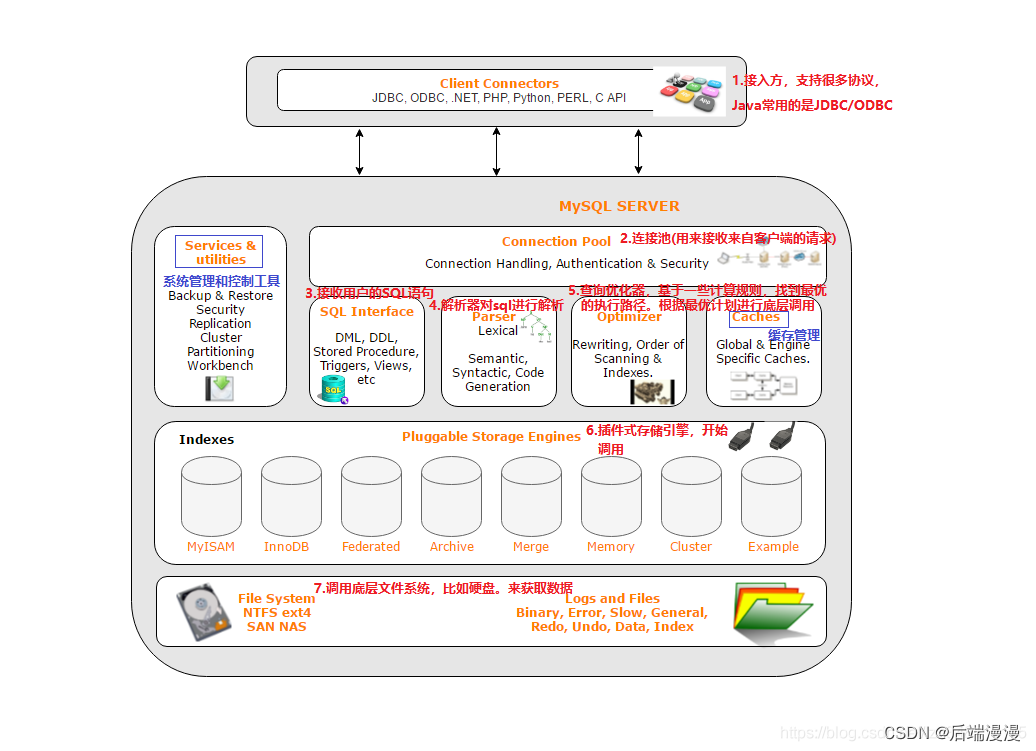
MySQL体系结构
Client Connectors:接入方,程序员通过Client Connectors(JDBC、ODBC)与MySQL打交道
Connection Pool:连接池,管理缓冲用户连接、用户名、密码、权限校验等需要缓存的需求
SQL Interface:SQL接口,接受用户的SQL命令,并且返回用户需要查询的结果
Parser:解析器,验证和解析SQL命令
Optimizer:查询优化器,在查询之前会对SQL语句进行优化
Cache和Buffer:缓存区,如果查询缓存命中,查询语句就可以直接去查询缓存中取数据
pluggable storage Engines:插件式存储引擎,MySQL与文件系统打交道
File System:文件系统,数据、日志(redo,undo)、索引、错误日志、查询记录、慢查询等
MySQL存储结构(以InnoDB为例)
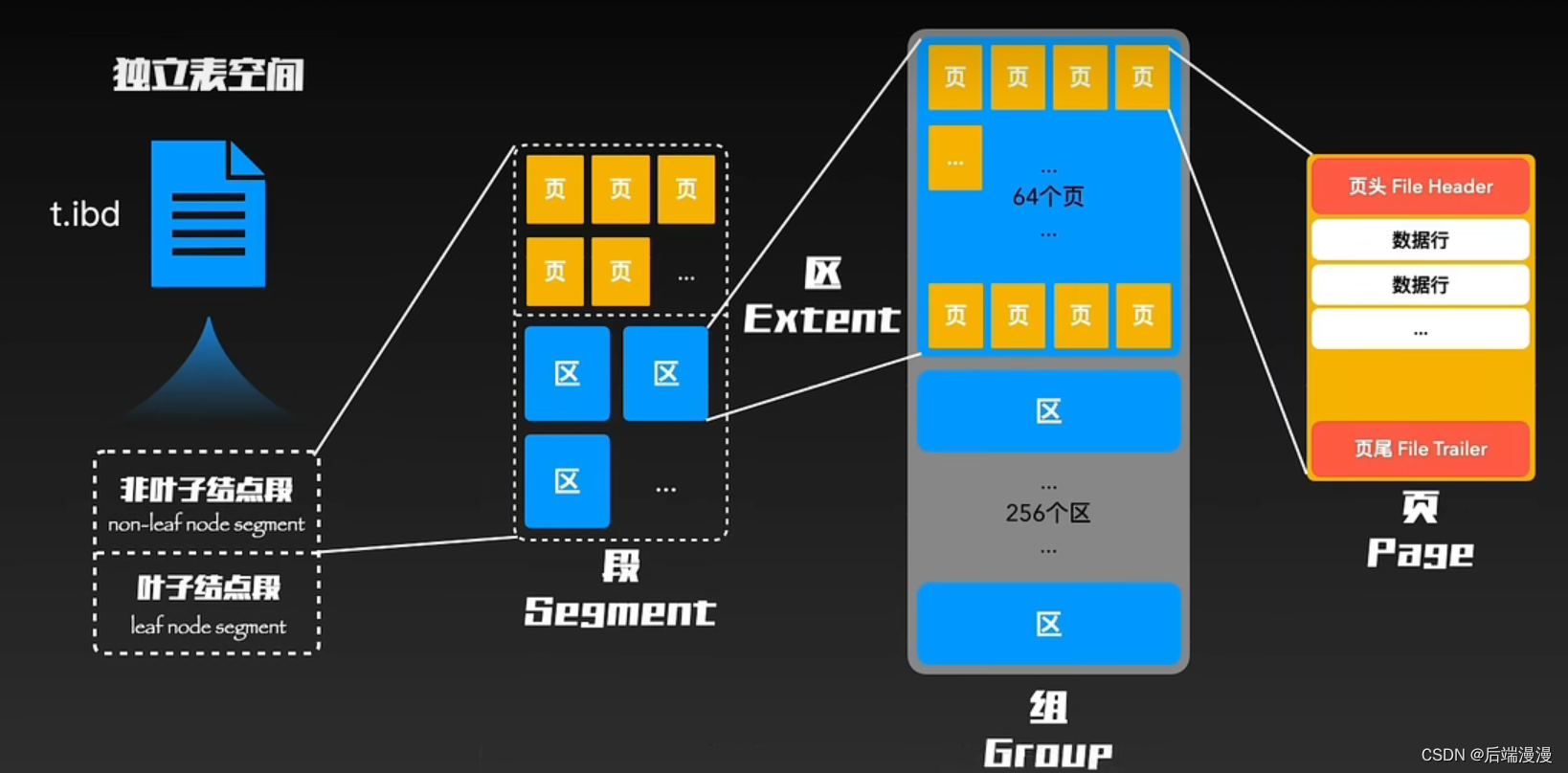
1. InnoDB创建数据表
InnoDB创建数据表,会将数据表分为表结构和表内容存储
- 表结构:存储在.frm文件中
- 表内容:以前存储在系统表空间中,现在默认存储在独立表空间.ibd
2. ibd文件
.ibd文件分为叶子节点段和非叶子节点段和回滚段
- 叶子节点段:B+树的叶子节点
- 非叶子节点段:B+树的非叶子节点
- 回滚段:为存储一些特殊的数据而定义的段
如果没有设置索引,那么所有的节点就不会区分成叶子节点段和非叶子节点段
3. 段
段不对应表空间的某一连续物理区域,而是一个逻辑概念,它是由表空间这个物理空间中的若干个零散页和一系列完整的区组成。
- 叶子节点段:存放在区
- 非叶子节点段:存放在页
4. 区
为什么要有区
- 上面提到页与页之间通过双向链表进行连接,若页与页间隔太远的话,而随机I/O【定义:读写操作时间连续,但访问地址不连续,随机分布在磁盘的地址空间中】是非常慢的。因此为了尽量让链表上相邻的页物理上也相邻,引入了区。
- 一个区在物理位置上就是连续的64个页。数据量大的时候,可一次性分配多个区,不必再按照页为单位进行分配了。消除很多的随机I/O。
碎片区
- 对于数据量太小的表不足以填满整个区的情况,造成空间的浪费。因此针对这种情况,InnoDB提出了碎片区的概念。
- 碎片区中的页并不都是为了存储同一个段而存在的,比如有的页用于段A,有的用于段B,有的页甚至哪个段也不属于。碎片区直属于表空间,并不属于任何一个段。
综上,为段分配的策略是
- 起初向表中插入数据的时候,段是从某个碎片区以单个页面来分配存储空间的。
当某个段已经占用了32个碎片区页面之后,就会申请以完整的区为单位来分配存储空间。
5. 数据页
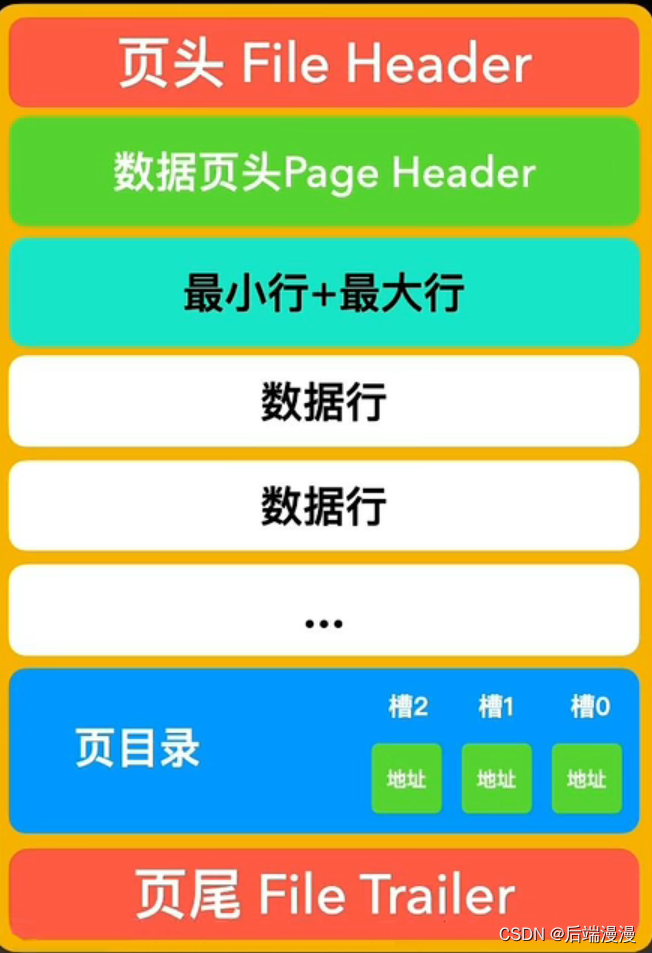
1. 页头File Header
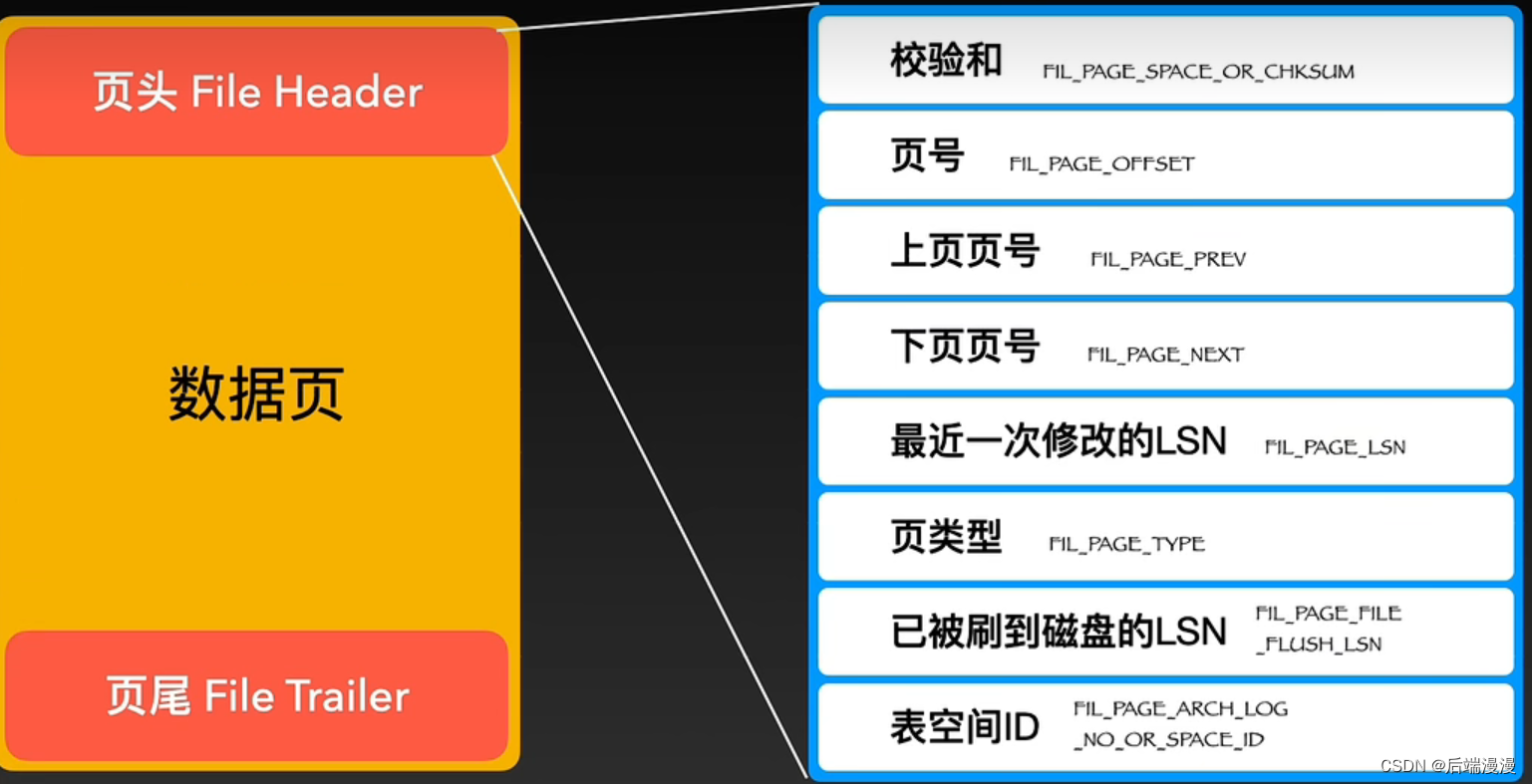
2. 页尾File Trailer
页头和页尾的校验和相对应,由于我们的操作系统传输单元数据块通常是4KB,一个页是4个数据块。如果碰到我断电的情况,那么一些不走运的页,可能只传输了一两个数据块,并没有完整传输,这种不完整就需要用页头和页尾的校验和通过一些验证算法进行验证。默认使用crc32.

3. 数据行

MySQL说:数据行有4种格式:DYNAMIC,REDUNDANT,COMPACT,COMPRESSED,默认为DYNAMIC,可以通过innodb_default_row_format进行查询和变更。
真实数据区
MySQL说:第一个就是主键位置,如果是复合主键,那也会依序排在这里。如果没有主键,就会优先用一个NOT NULL、UNIQUE的列作为主键,如果这个都没有的话,我的innoDB就会构建一个6B的DB_ROW_ID字段存储在这里。
MySQL说:紧接着是6B的事务ID字段DB_TX_ID,7B的回滚指针字段DB_ROLL_PTR
MySQL说:继续向右就记录除了主键和值为null的列之外的真实数据了,因为值为null的列会用其他方法表示,目的就是为了节省空间。
额外信息区
下一行:下一个数据行真实数据的地址。
行类型:0代表普通数据行,1代表索引目录行,2是最小行,3是最大行。
位置:用13bit的heap_no来标记该行在整个页的位置
组行数:如果这个行是分组的最后一行,则在这里标记该组的行数
每层最小:不懂,但是在后面视频有详细讲解
删除标记:在删除数据行时并不会直接移除,而是修改这个标记。同时将这行的next_record指向一个称为垃圾链表的地方,这个链表会用于事务回滚。
NULL值列表:用来记录值为NULL的列,根据列的个数来开辟合适的长度。
可变字段长度列表:记录了数据行里所有变成字段的实际长度。
4. 最大行和最小行
每当我体内创建一个新页,都会自动分配两个行。一个行类型为2的最小行Infimum,固定在0号heap_no位置。一个行类型为3的最大行Supremum,固定在1号heap_no位置。这两个行并不存储真实的信息,而是作为数据行链表的头和尾。
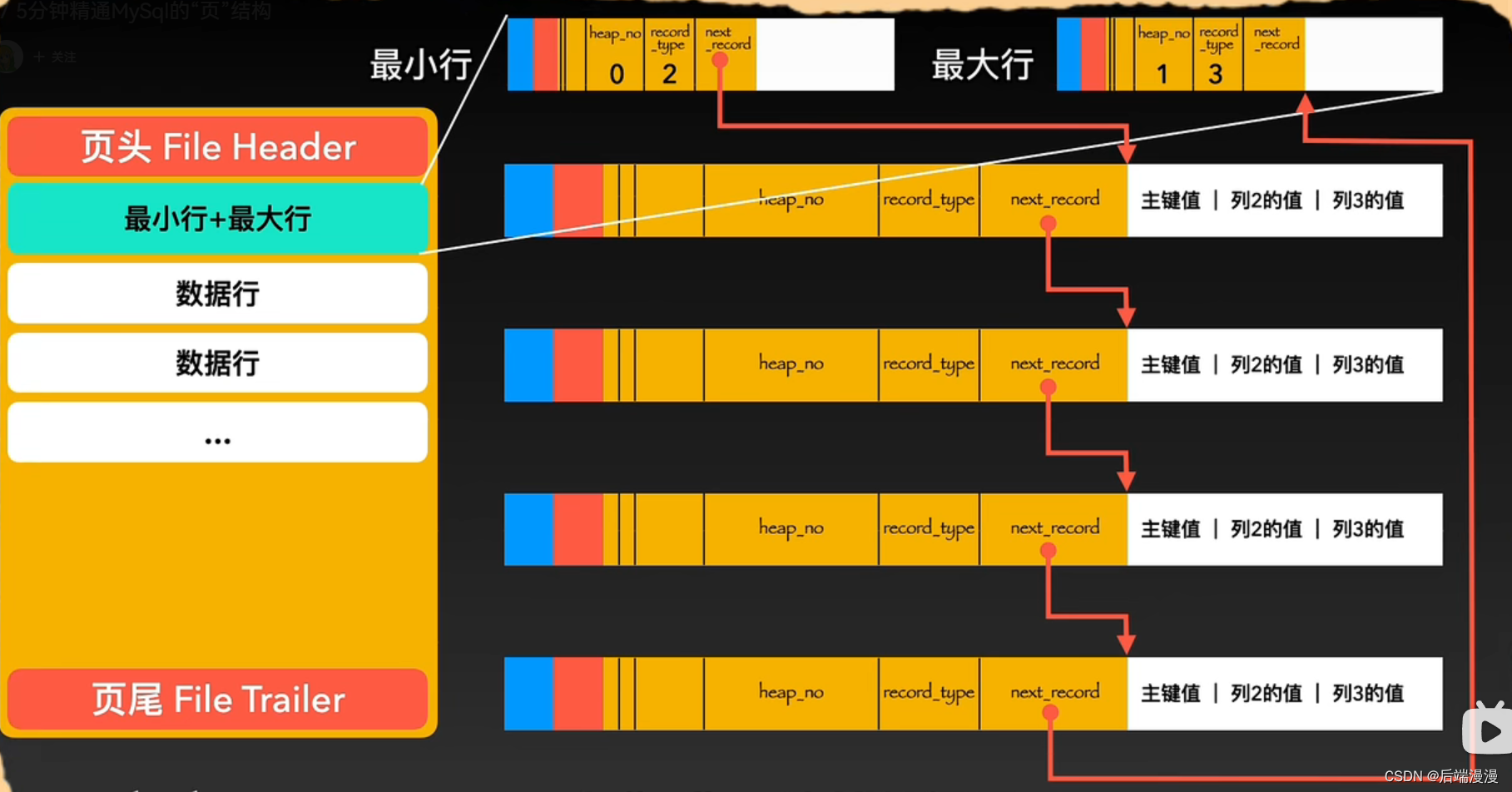
5. 页目录
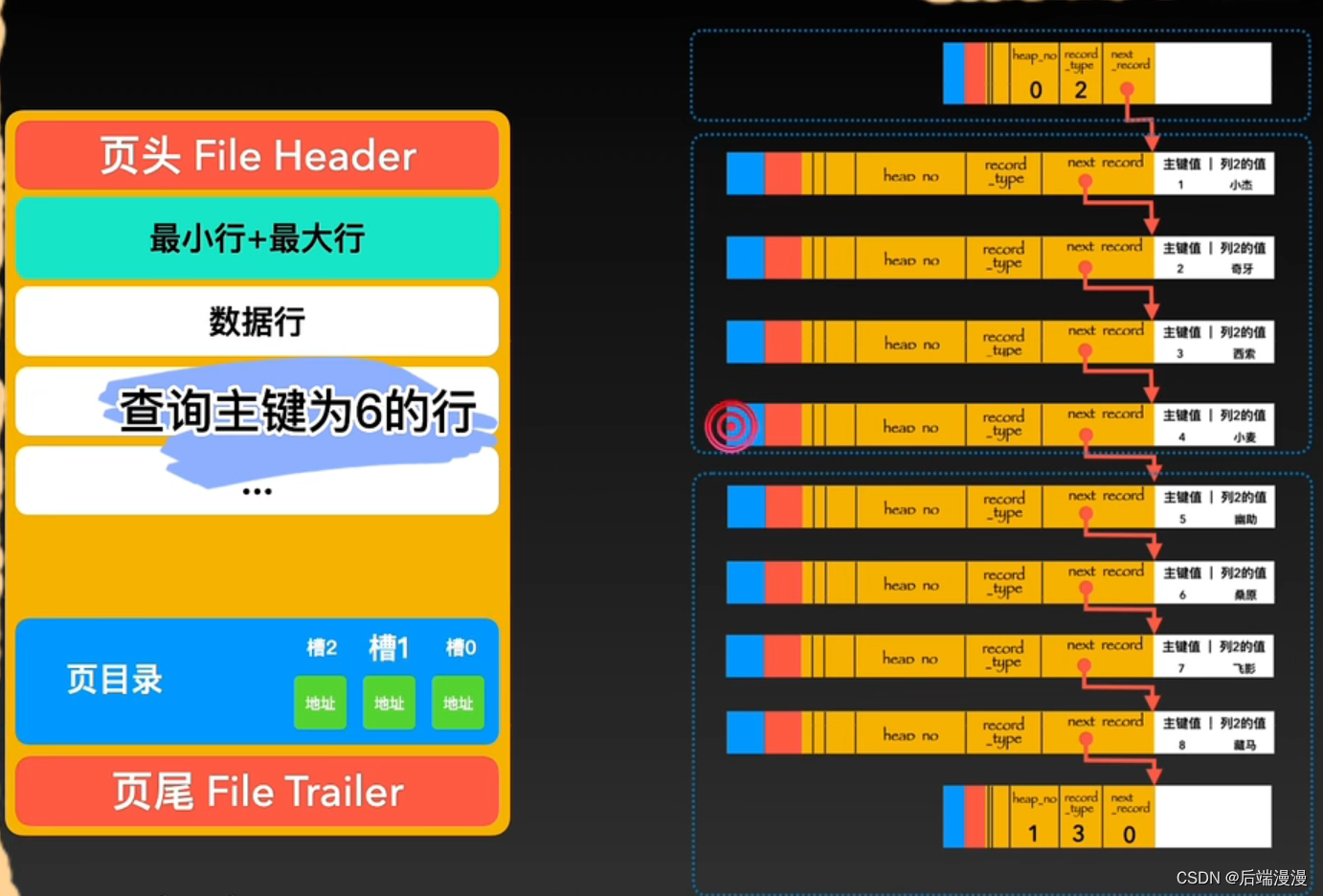
当程序猿大哥想要查询数据时,需要沿着链表顺序一个个比对查找,这样显然是不行的。所以我进化出了一个页目录的器官,它会将页内包括头行、尾行在内的所有行进行分组,约定头行为单独为一组,其他每个组最多有8条数据。同时把每个组最后一个行在页中的地址,按照主键从小到大的顺序记录到页中,这个区域叫做页目录,页目录的每一个位置称为一个槽,每个槽对应一个分组。
在页目录中根据二分法查找到组,再在组里面遍历八个数据行即可找到。
MySQL执行流程(以InnoDB为例)
1. 数据写入原理
省流:
- 执行器执行写入操作,把数据存储在Buffer Pool,把操作信息存储在redo log Buffer
- 并且还把相关信息写入undo log和bin log
- 在一定时间之后,redo log Buffer将操作信息写入redo log
- 再过一段时间之后,Buffer Pool会把数据写入到磁盘文件中
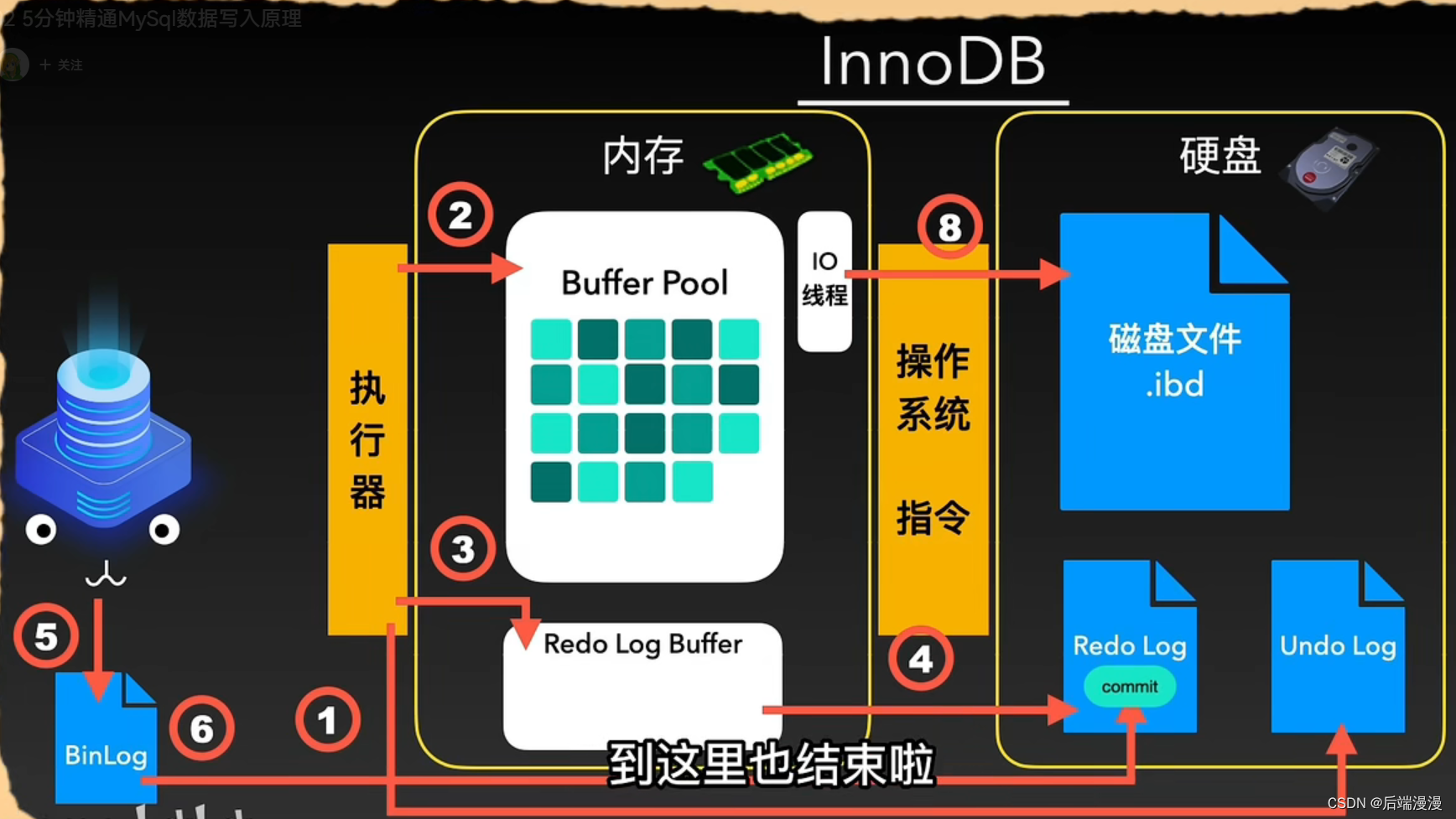
- MySQL深深地知道一切的逻辑处理和写入都只操作内存中的数据,这个内存缓存区被称为
Buffer Pool。InnoDB会把它需要写入的数据插入或更新到Buffer Pool中。- 当然,为了能够让已经写入的数据支持回滚,就需要在这之前将数据的旧值记录到另一个地方,那就是
Undo Log文件。- 将数据写到
Buffer Pool内存之后,InnoDB就会让它的小线程们在一些特定的时机从内存中把需要更新写入的数据读出来,同时写入磁盘。- 一旦MySQL断电或者服务挂掉睡着,那么处在内存区Buffer Pool中的数据就会随着内存失效而永久丢失。为了应对这种突发情况,我的大脑InnoDB研发了一套redo Log体系。这套体系在数据进入Buffer Pool之后会将“更新写入信息”放入内存的另一个区域
Redo Log Buffer,然而光写入内存也无法解决刚才的问题,为了保险起见还是要把它刷到磁盘中。我的InnoDB提供了多种Redo Log的刷盘机制。
# 将“更新写入信息”写入到操作系统Page cache和Redo Log Buffer,并立刻刷新到磁盘中
innoDB_flush_log_at_trx_commit = 1;# 将“更新写入信息”写入到Redo Log Buffer,每隔一秒钟才进行系统内存放入和刷盘操作
innoDB_flush_log_at_trx_commit = 0;# 将“更新写入信息”写入到操作系统Page cache和Redo Log Buffer,每隔一秒钟才进行系统内存放入和刷盘操作
innoDB_flush_log_at_trx_commit = 2;
上述一系列操作都集成在MySQL内存,我的程序猿大哥是不能直接操作的,当我的程序猿大哥执行了错误的SQL语句就不能回复如初的。为了帮程序猿大哥解决这个问题,我进化出了
Bin Log文件。它可以给程序猿大哥提供变更历史查询、数据库备份和恢复、主从复制等功能,我会在Redo日志写入的同时,对Bin Log进行刷盘操作,在Bin Log刷盘成功后,我会告知Redo日志事务“已提交”这个信息,Redo日志也会打入commit标志。这样,一次数据写入的流程就完成啦。
提问:既然为了防止断电,redolog会立刻写入硬盘,那为什么不干脆直接将buffer pool中的数据写入硬盘呢?
一个事务可能包含多个语句,数据不太可能都连续,从bufferpool刷盘就需要大量磁盘io,性能很低。而redolog日志本身不记录真实数据而是一些偏移量、页号之类的很小,刷盘机制也都是顺序io,所以效率高。
2. 数据查询原理
省流:
- 查询缓存,命中则返回结果,不过5.8之后就把缓存撤销了
- 解析器(词法分析、语法分析)
- 优化器
- 多次执行同一个SQL,则提交一次模板,随后只需要多次提交参数
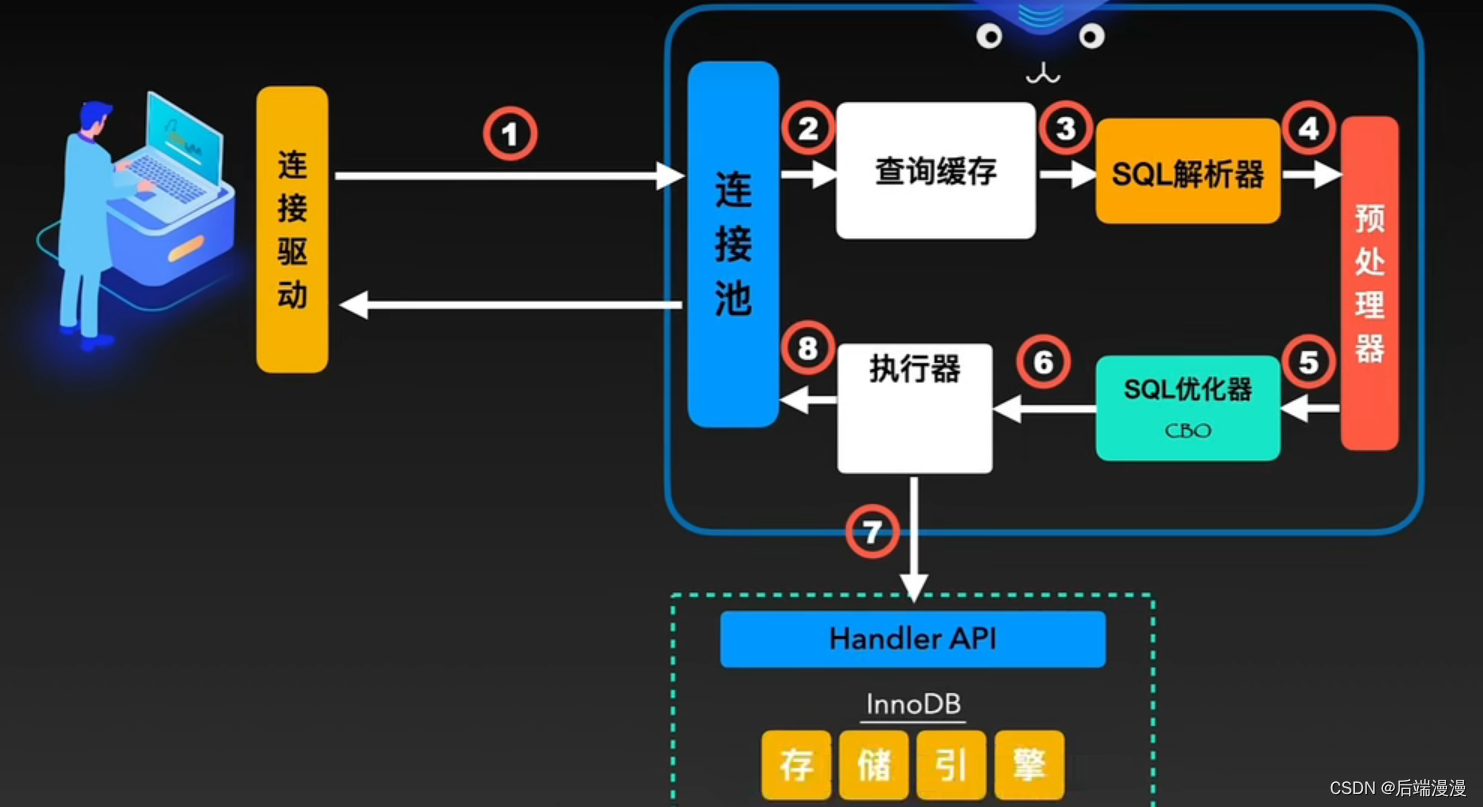
- 查询缓存
查询缓存在5.7版本里是默认关闭的,可以通过query cache type参数查看和设置。到了MySQL8.0,整个缓存都删除了,为什么官方都不建议使用这个看上去还不错的功能呢?首先每次进来查询都要经过查询缓存,加上每次查询条件不同,导致命中率低,那就非常消耗性能了。其次在没有命中缓存,那就要创建新的缓存,也会造成一定的消耗。最后,为了保证数据一致,会添加表级锁,当表内数据更新后需要将这个表对应的缓存均设为失效,又是一波不小的消耗。综上所述,很多情况下“查询缓存”并不能为我们带来实质的效率提升。(最终原因就是缓存命中率低)。
# 查询缓存开关
SHOW VARIABLES LIKE 'query_cache_type';# 设置缓存开关
SET query_cache_type = 0;#query_cache_type=2时,代表按需使用,用SQL_CACHE对某表开启缓存
SELECT SQL_CACHE * FROM test;
- SQL解析器
词法分析:通过sql/sql_lex.cc代码将SQL语句切分为各种Token词,通过其中一个定义了各类关键字、操作符的数组symbols[]进行关键字、非关键字的标记。

语法分析:使用bison这个语法分析器,通过sql/sql_yacc.cc规则代码将语句解析为一个语法树。
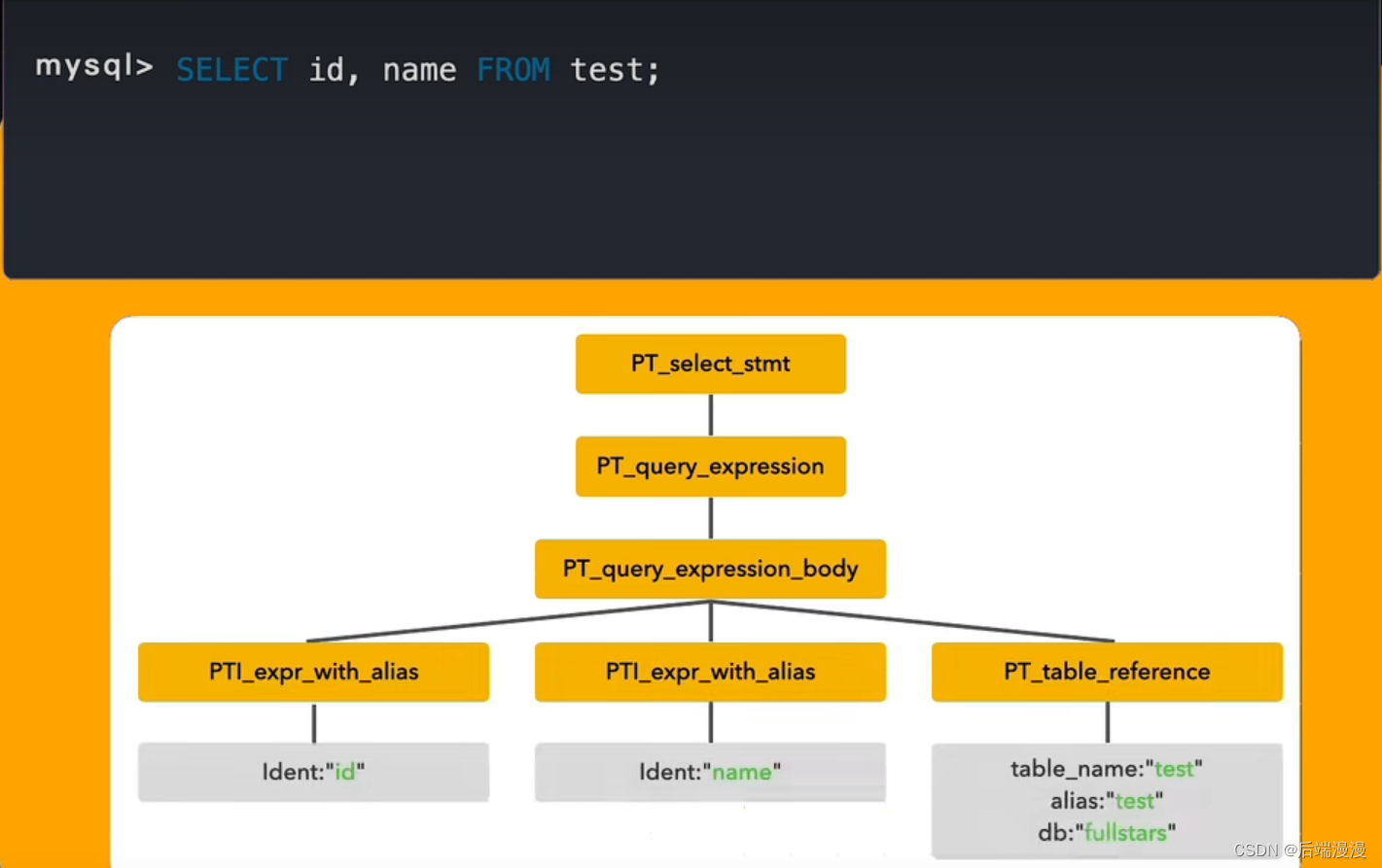
- 预处理器
MySQL说:预处理器将请求进行拆分,先提交SQL模板语句,然后再提交参数并进行执行。通过这种方式,对于重复执行的语句来说,可以提交并处理一次模板即可,然后不断的提交参数就可以实现多次执行,从而提高执行的效率。
MySQL存储引擎
1. 为什么需要不同的存储引擎
关系型数据库,就是用来存储各种数据信息的。根据不同业务场景,比如说:有的表简单,有的表复杂,有的表根本不用来存储任何长期的数据,有的表需要查询非常快。在我们实际的业务开发中,可能需要用到各种各样的表,不同的表也意味着存储不同类型的数据,数据的处理上也就会存在着差异。针对 MySQL 来说,它提供了很多类型的存储引擎来供我们选择,我们可以根据业务需求来选择不同的存储引擎,最大程度的发挥 MySQL 的强大之处。
2. 如何为数据指定不同的存储引擎,数据粒度又是多少
一个库中的每一个表都可以指定选择存储引擎,即数据粒度就是一个数据表
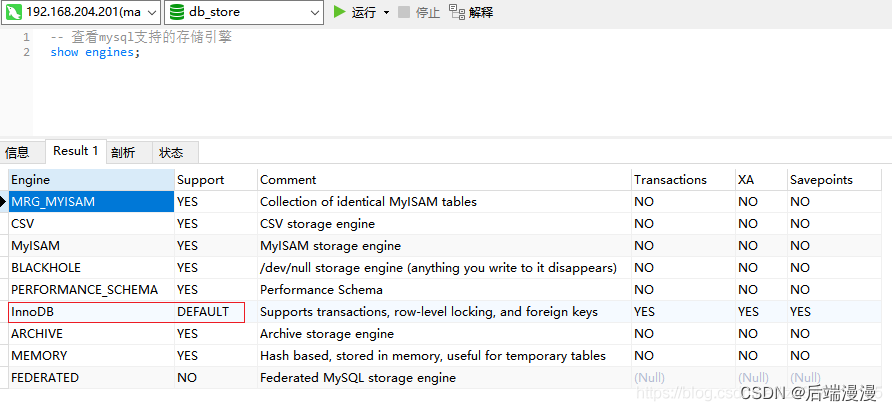
3. MySQL支持哪些存储引擎
我们可以使用命令:show engines;来查看 MySQL 支持哪些存储引擎,如下图所示。我们可以看到 MySQL 默认使用的存储引擎是 InnoDB。
4. MySQL支持的存储引擎各自有什么特性
1. CSV存储引擎
特点:没有索引,没有自增,列必须为NOT NULL
缺点:不适用于大表或者数据查询、排序等处理操作
2. Archive存储引擎
特点:只支持insert 和 select 两种操作、只支持自增ID列建立索引、支持行级锁、不支持事务
缺点:不适用于对数据的处理操作
优点:数据占用磁盘少
3. Memory存储引擎
特点:实际的应用场景中用到的很少,但是它与优化器查询有很大的关系。对于精确查询非常高效、存储在内存、支持Hash索引、B- Tree索引
优点: 数据都是存储在内存中,IO效率比其他引擎高很多
缺点:保证不了持久性,不支持大数据存储类型
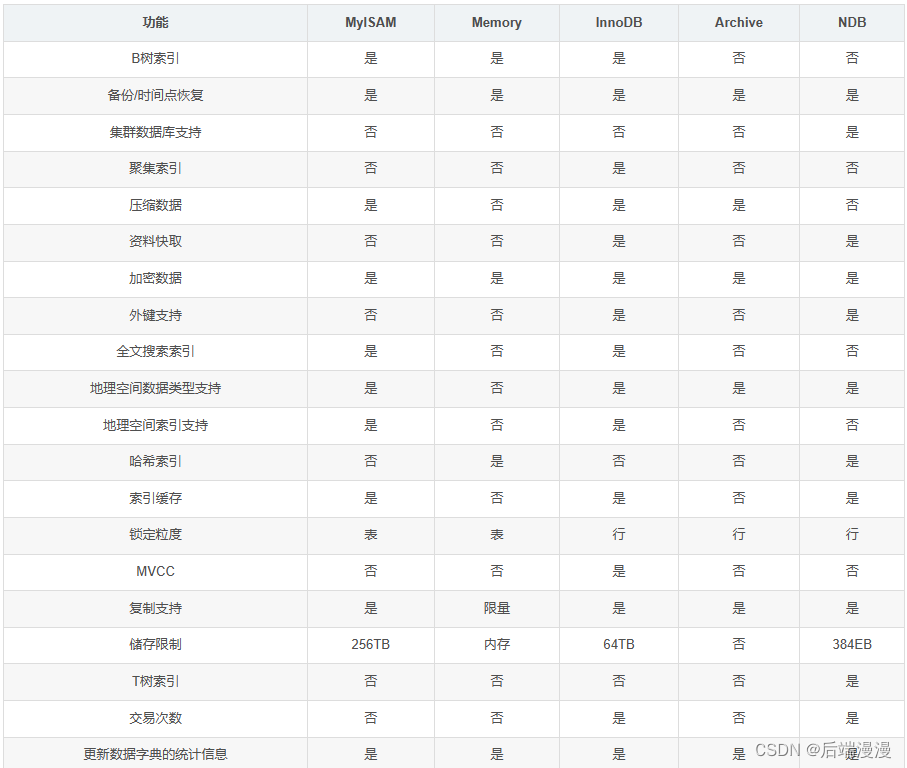
4. InnoDB存储引擎
特点:支持事务、支持外键、支持行级锁、支持表级锁、必须有主键、5.8后支持全文索引、辅助索引和主键索引之间存在层级关系
5. MyISAM存储引擎
特点:不支持事务、不支持外键、不支持行级锁、支持表级锁、主键不是必须的、支持全文索引、MyISAM辅助索引和主键索引则是平级关系
索引
1. 索引的概念
索引是一种利用某种规则的数据结构与实际数据的关系加快数据查找的功能;索引数据节点中有着实际文件的位置,因为索引是根据特定的规则和算法构建的,在查找的时候遵循索引的规则可以快速查找到对应数据的节点,从而达到快速查找数据的效果;说白了,就是把每个数据都放在不同的盒子里,再根据数据结构和算法快速找到指定的盒子。
2. 为什么要使用索引
a. 没有索引的情况下访问数据
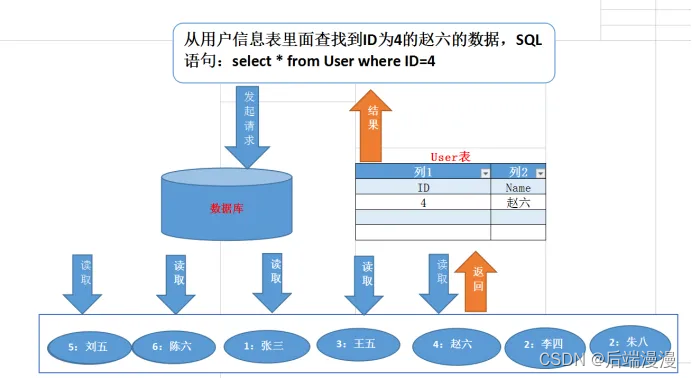
b. 使用平衡二叉树索引
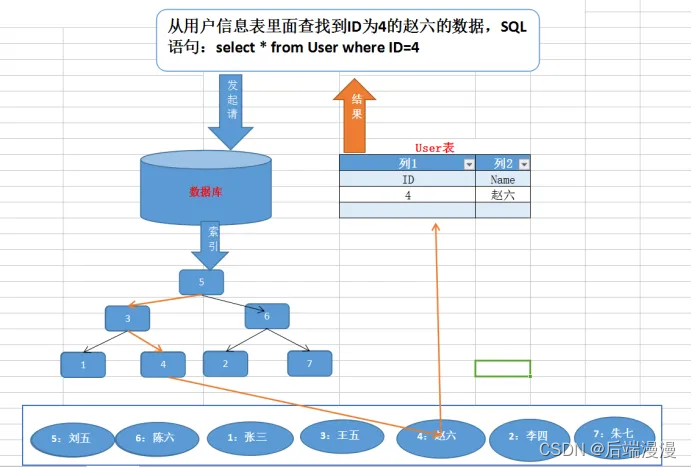
总结:你的数据并不是乱放的,而是根据一定的规则放置的。这样才能按一定的规则快速查找到,无需遍历整个数据表。
3. InnoDB索引底层为什么选择B+Tree
接下来,我们将从 二叉树、平衡二叉树、B-Tree、B+Tree 等方面来分析,了解 MySQL 索引底层为什么会选择 B+Tree 。
a. 二叉树
场景一:可以避免遍历整张数据表
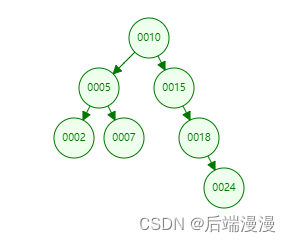
场景二:我们会发现,这种链表样式的二叉树检索和全表扫描没有太大的区别

总结
我们发现二叉树最终的检索效率,其实是取决于数据的分布情况。如果数据分布均匀,还是能提高一定的查询效率的;数据如果分布不均匀,用二叉树来做索引的话,还是存在着一定的不足性。
b. 二叉平衡树(解决二叉树线性链表的问题)
二叉平衡树检索数据的过程
1. 磁盘块分析:一个节点就是一个磁盘块,一个磁盘块保存有如下内容
- 关键字:比如说我们创建 ID 为索引,ID=15,那么15 就是一个关键字。
- 数据区:指向真正数据存储的磁盘位置(内存地址),通过数据区去加载数据。一般情况下,为了节省空间,数据区是不会保存数据的,而是指向磁盘的一个位置,然后去磁盘把内容加载过来,达到快速检索的目的。
- 子节点引用:指向子节点的引用。
2. 检索数据的过程
- 首先将磁盘块1加载到内存中,获取到根节点数据。让 12 和 15 这个关键字进行比对,12<15,会基于 P1 (P1、P2是指向下一个磁盘块的地址),通过顺序 IO 快速的去加载磁盘块 2 中的内容;
- 12 和 10 继续比对,12 > 10,走P2 ,加载磁盘块 5,然后命中 12。命中后,获取到数据区地址,再次加载磁盘中的数据。
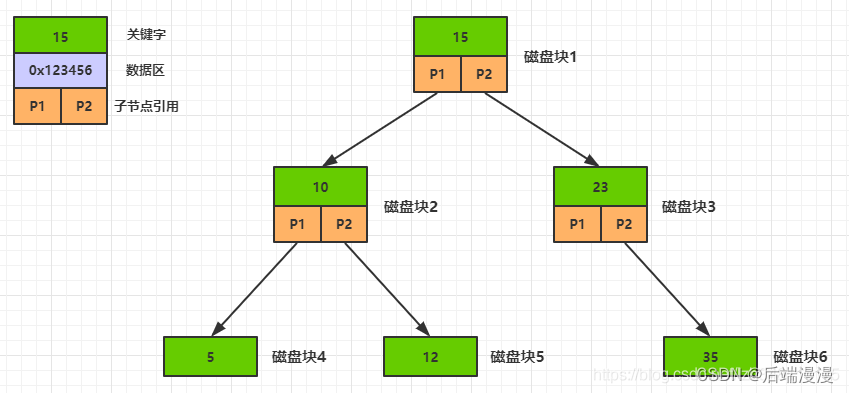
平衡二叉树,还存在哪些缺陷、问题
- 太深了:比如说我们检索 12,需要做 3 次 IO 操作获得数据。(3层高度只能存放 7 个数据)如果我们数据达到亿级别,那么这棵二叉树会有多大,我们无法想象。然而IO 操作是很费时的,显然无法满足条件。
- 太小了:通过N多次 IO 操作后,拿到的数据太少了
- 没能很好的利用数据交换特性
- 没有很好的利用磁盘IO的预读能力
c. B树(解决了平衡二叉树的缺点)
B-Tree相比平衡二叉树,优势在哪?
相比平衡二叉树(共3层能存储7个数据),B-Tree同样是三层,这个存储的数据就很多了,翻倍形式的增长。B-Tree 为多路平衡树,如果我们定成1000路,同样三层 IO 操作,它能检索的数据就更多了。(形象理解:平衡二叉树就是瘦高,B-Tree就是矮胖) 在这种层度上,多路平衡查找树完胜平衡二叉树。
相比平衡二叉树(共3层能存储7个数据),B-Tree同样是三层,这个存储的数据就很多了,翻倍形式的增长。B-Tree 为多路平衡树,如果我们定成1000路,同样三层 IO 操作,它能检索的数据就更多了。(形象理解:平衡二叉树就是瘦高,B-Tree就是矮胖) 在这种层度上,多路平衡查找树完胜平衡二叉树。还记得操作系统是一次性交互 4K 数据,MySQL 一个节点 是 16K。如果我们以 ID 作为索引,一个索引数据(索引数据 4byte + 其他冗余数据大约 4byte(数据区+子类引用等数据))共 8byte (字节)的话,16K 能存放 (16*1024/8=)2048 个索引,那就能存放(2048+1=)2049路。这 2049 路能存放多少数据,就多到数不清了吧。(Tips:加索引时,我们之前只知道数据类型、字段定义越精简越好,为什么呢?因为定义数据类型、字段时,越越精简占用空间越小,一个磁盘块能存放的数据就更多。)
B-Tree如何检索数据
我们以检索 32 为例,流程如下:
首先将磁盘块1加载到内存中,获取到根节点数据。然后让 32 和 17、35进行对比,发现 17 < 32 < 35。此时会基于 P2 (P1、P2、P3是指向下一个磁盘块的地址),通过顺序 IO 快速的去加载磁盘块 3 中的内容;(Tips:检索数据X:X<17 走P1 17<X<35 走P2 X>35 走P3)
32 > 29,走P3,加载磁盘块 10 中的内容,然后命中 32。命中后,获取到数据区地址,再根据地址来加载磁盘中的数据。
B Tree缺点
- B-Tree查询单个值效率并不低,但是如果要搜索大于10小于15这样一个范围,或者要遍历所有数据,那么B树就力不从心了。
- B- Tree中,要查找的数据离根节点近查找的快,离根节点远查找的慢。这样不稳定的搜索时间并不利于我为程序猿大哥们做执行成本的估算。
- B- Tree虽然已经降低了树的高度,但是仍然有下降空间
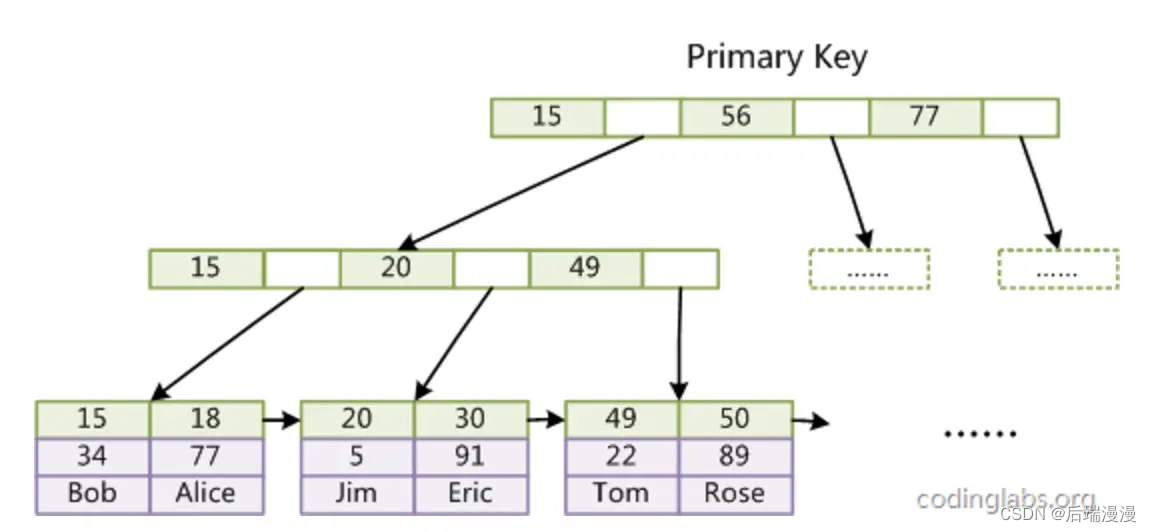
d. B+ Tree
B+树,如何检索数据呢?
根据上图,我们以检索 28 为例,流程如下:
在根节点,我们就发现已经有 28 了。 B树则会直接停止向下检索。B+树则会继续向下检索【因为 B+树枝节点不存储数据,数据都是保存在叶子节点】
然后他会继续向下去检索,直到走到叶子节点,然后命中 28。命中后,它才会获取到数据区地址,再根据地址来加载磁盘中的数据。
MySQL 为什么选择 B+Tree 呢?
- 1.扫库、扫表能力更强:B-Tree 扫库扫表,会扫每一个枝节点,最后再扫子节点,基本都得扫一遍。B+Tree,只扫子节点即可。
- 2.磁盘读写能力更强:B+Tree 枝节点不保存数据,只保存关键字和子节点引用。从理论上来将,能保存的关键字就更多,能加载的关键字就更多。从理论上来讲磁盘的读写能力就更强
- 3.查询效率更加稳定:查询数据:比如使用 B-Tree 第一次查询比较幸运,第二层就出来了并返回,用了0.2s。B树是平衡树,此时如果又新插入一些数据,导致刚刚查询的数据到达了底层,那么此时第二次查询。时间就要大于0.2s了。即:节点数据节点的深度是会变化的,会随着数据的插入、删除而改变,从而导致查询时间有所不稳定数据更多的话,这个时间就会比第一次差距更大了(B+Tree查询,都会去叶子节点查找数据,相对B-Tree来说就更加稳定)
4. 什么时候不要用索引,什么时候要用索引
a. 什么场景不要用索引
-
数据更新性能比查询性能要求要高的情况下不要使用索引,因为数据的更新的同时索引也要进行维护和更新(加了索引查询快但更新就会慢);
-
不要盲目的给表建太多索引,因为索引本身的存储也要占用存储空间,一旦更新操作频繁反而降低新性能;
-
不要给不经常使用的列建索引,不怎么查询还建索引干嘛;
-
不要给高重复值的列建索引,索引本身就是为了提高查询速度,然而数据值高度重复,数据区别性不高,索引起不了效果)(比如说:性别);
-
不要给img,tex.bit数据类型使用索引,因为这种字段一般使用很少,数据量太大;
b. 什么场景用索引
-
经常要用于查询的列 where id=?;
-
经常要用于排序(order by),分组(group by)的列,因为索引已经排好序了;
-
有值唯一性限制的列,比如说主键、用户名;
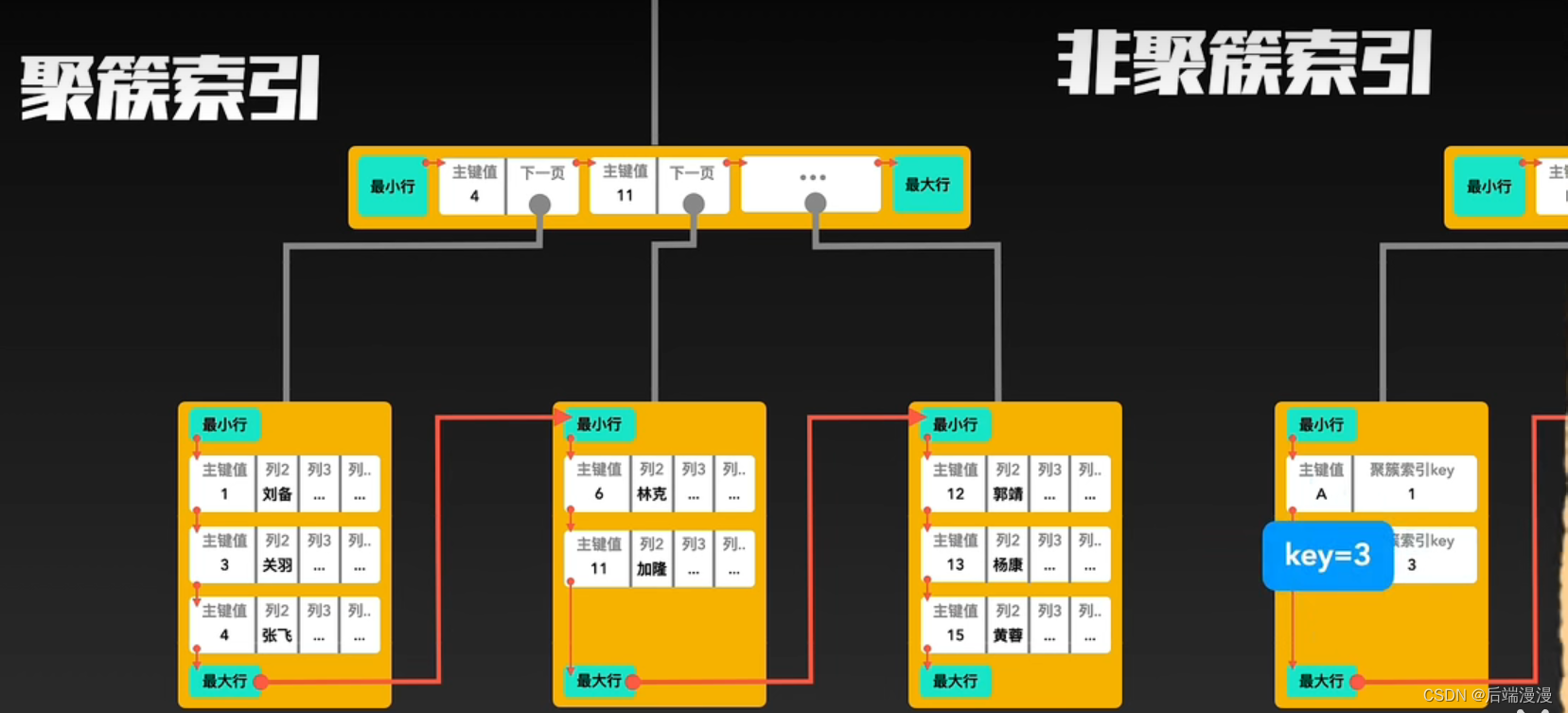
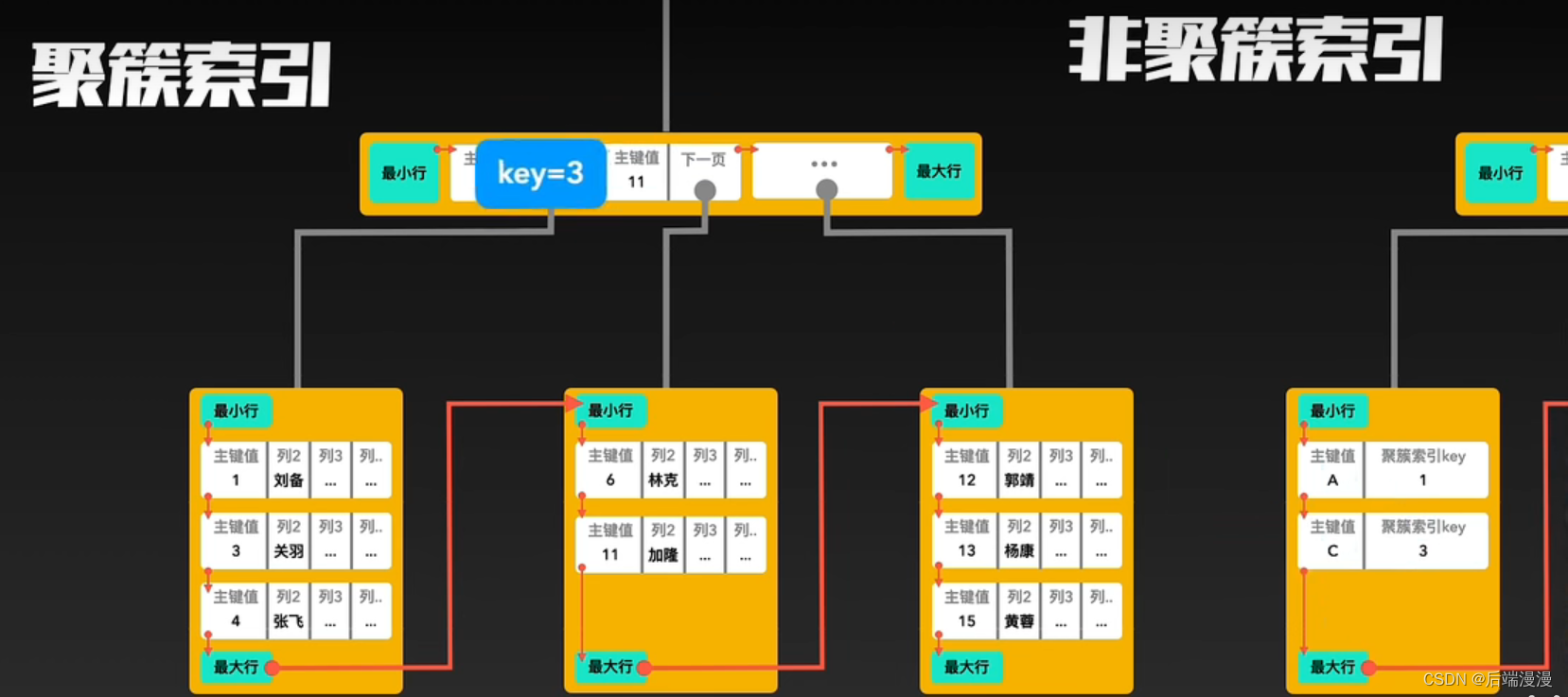
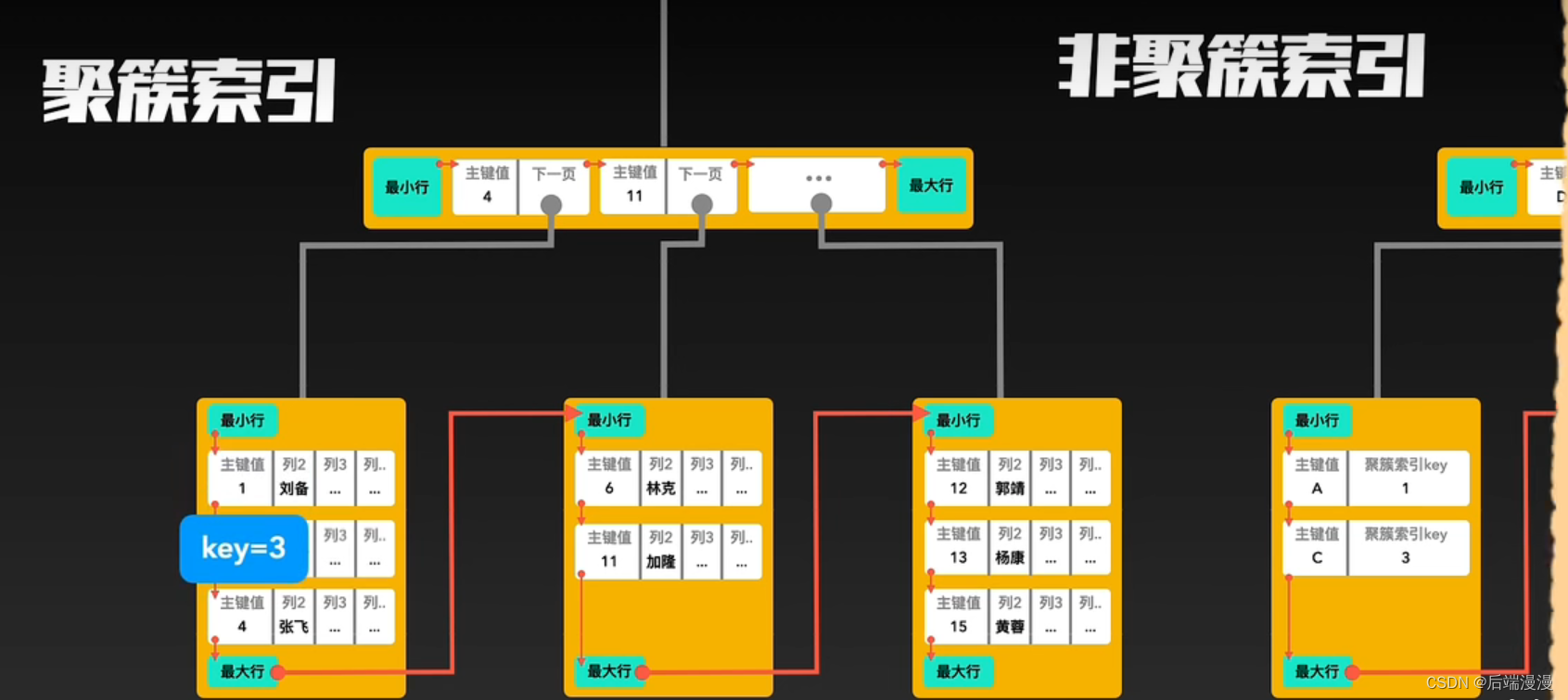
5. 聚簇索引与非聚簇索引
InnoDB使用聚簇索引:索引节点包含数据
MyISAM使用非聚簇索引:索引节点与数据分开
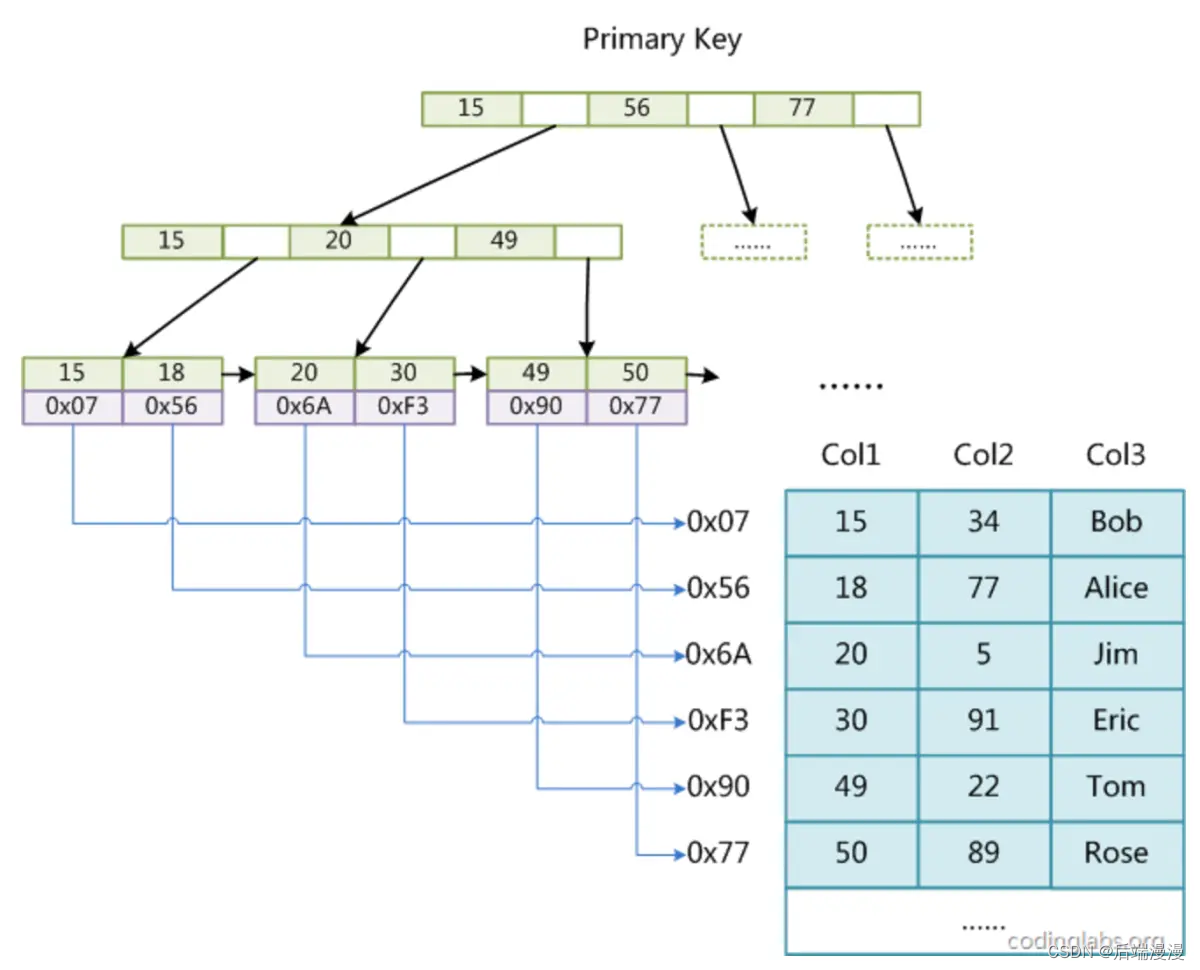
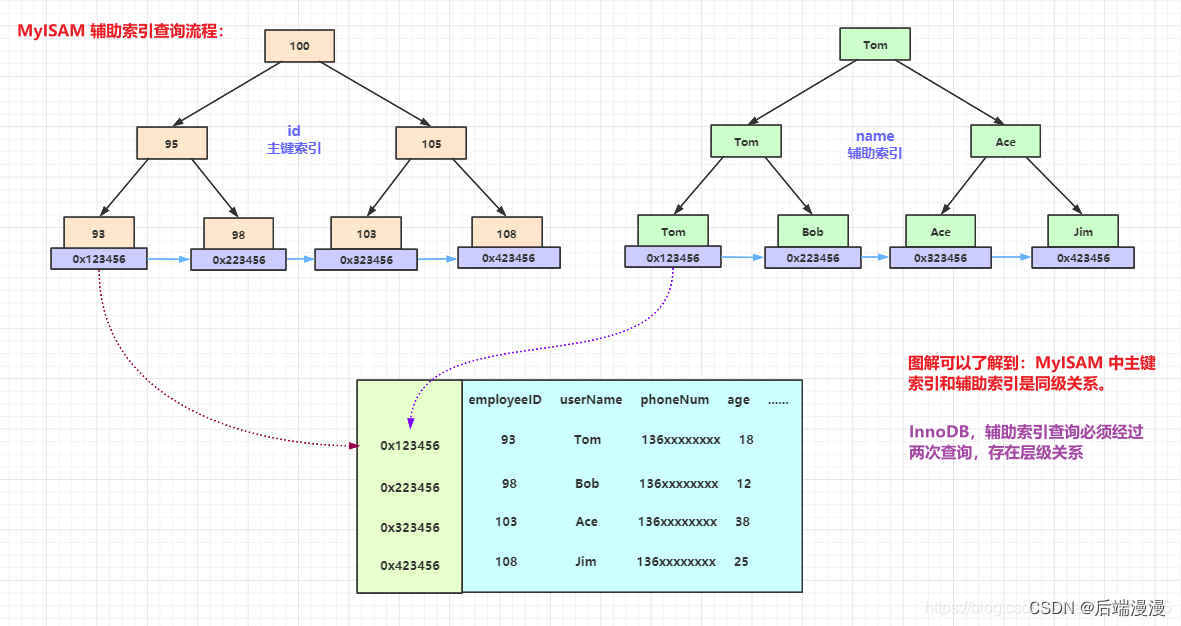
聚簇索引与非聚簇索引的合作查询
如果通过非聚簇索引查询,首先会在这棵“非聚簇索引”树种快速找到叶子结点,叶子结点中有聚簇索引的key,拿着这个key再去聚簇索引中查询一遍,就可以拿到真实数据了。以下是合作查询流程:
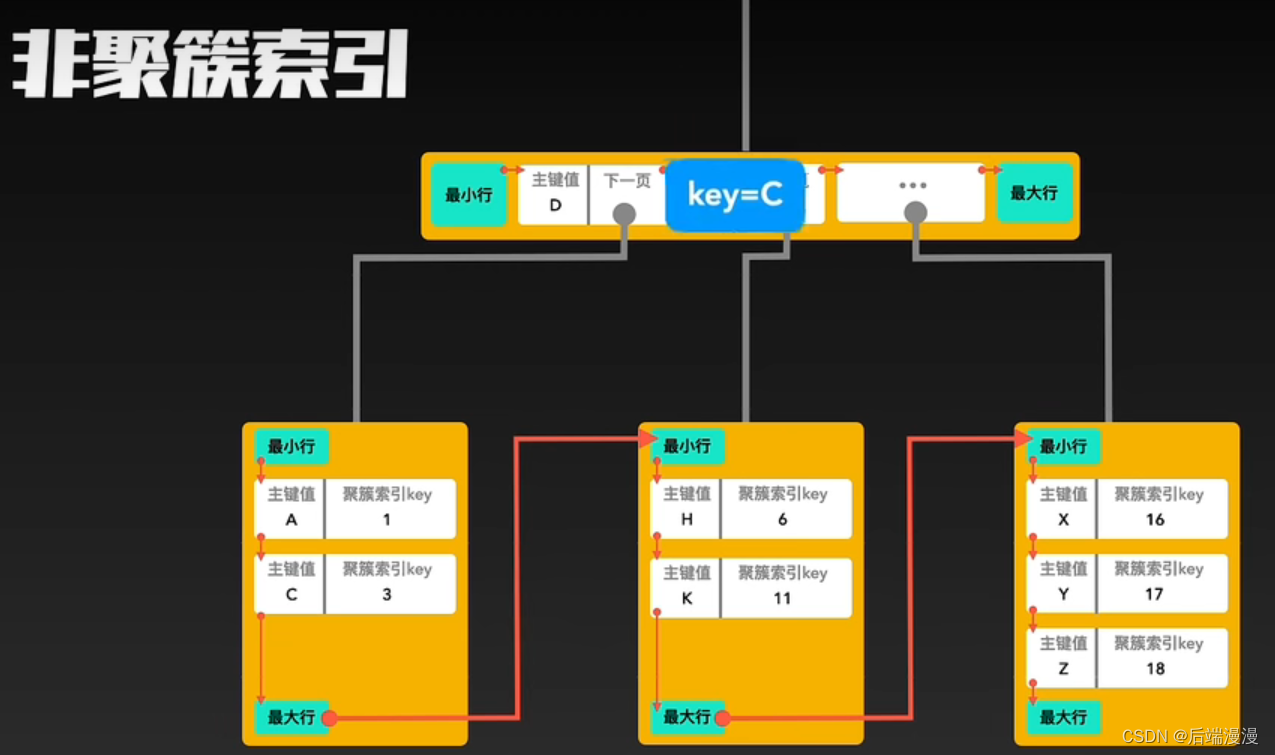
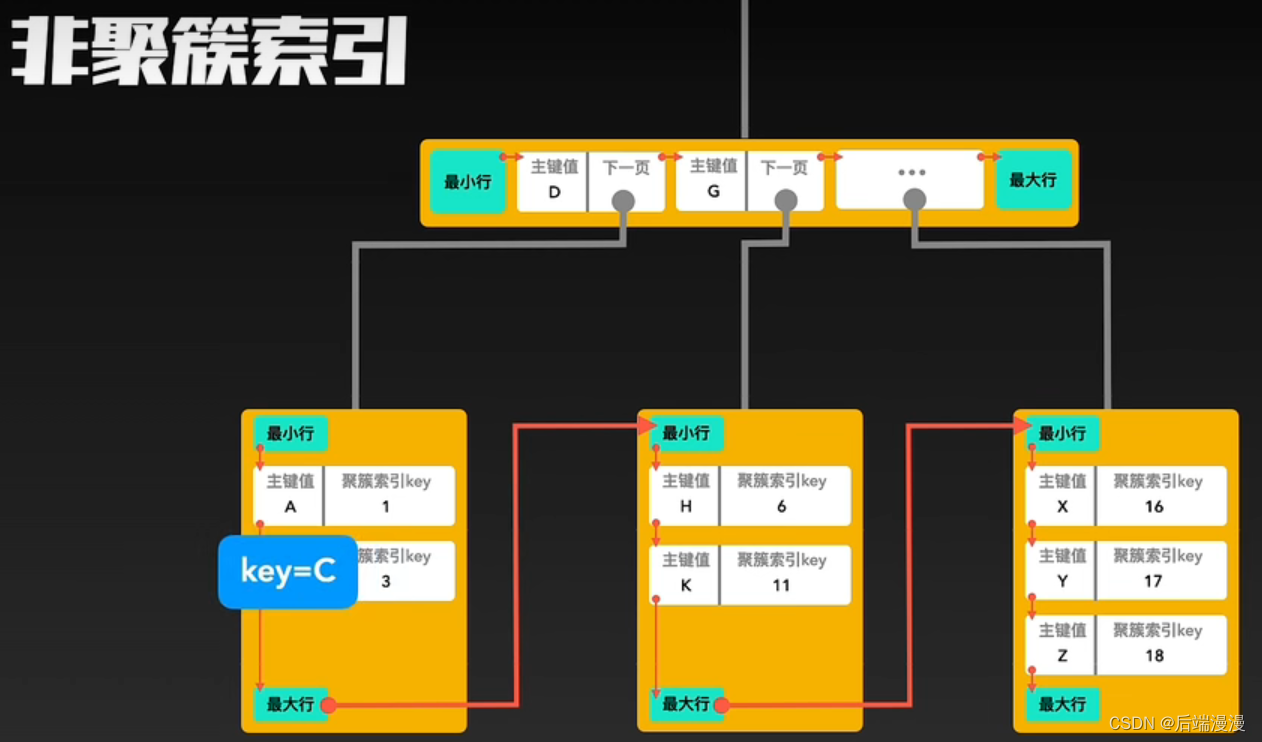
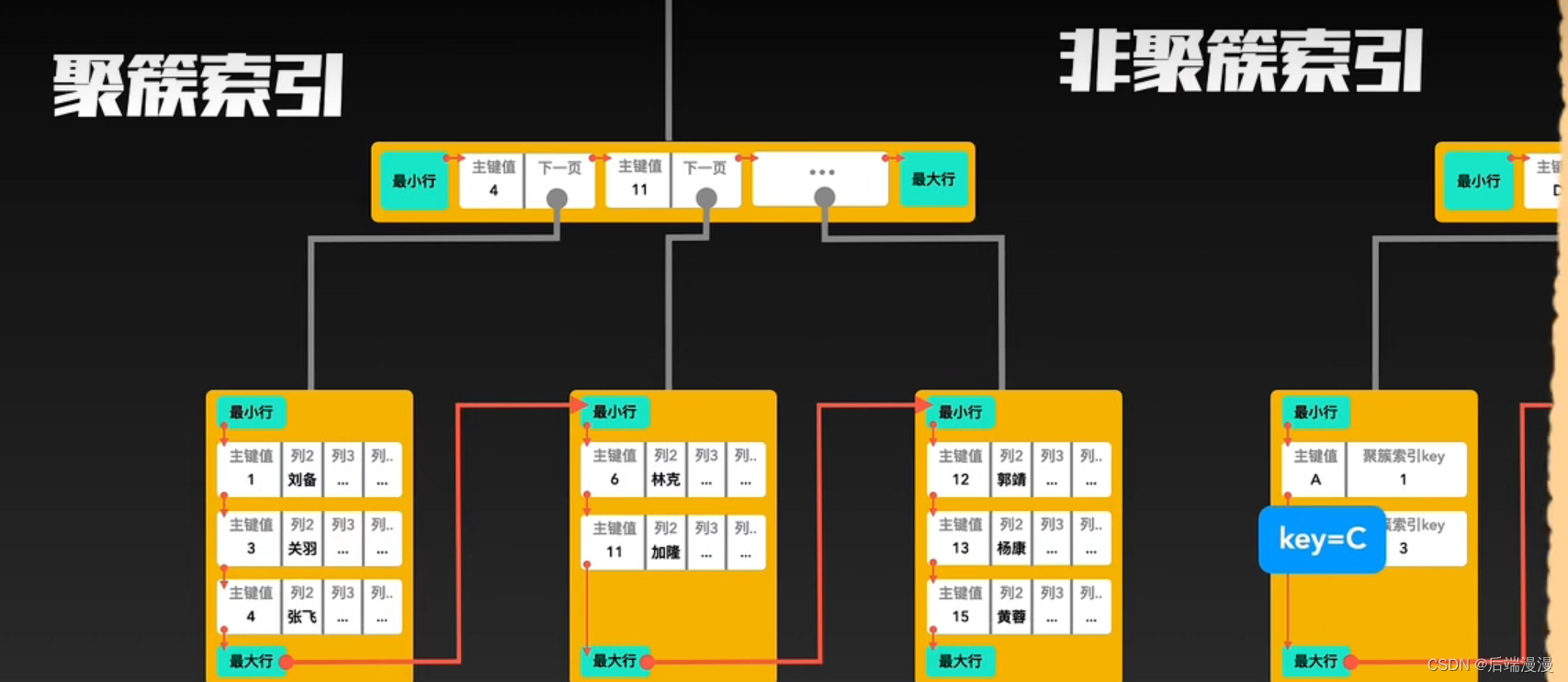
6. 辅助索引
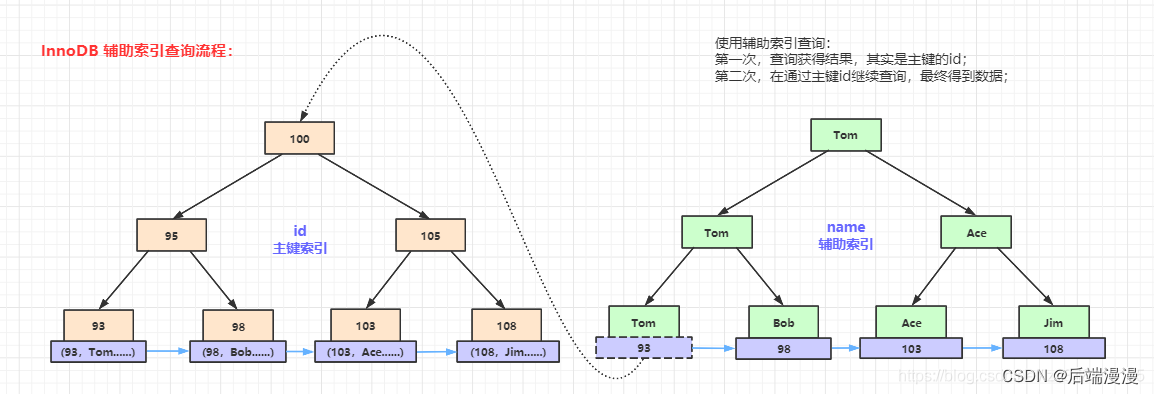
省流:因为数据存放在聚簇索引中,所以辅助索引找到key,再根据key聚簇索引中找到数据
省流:反正非聚簇索引找到key的数据地址也要到其他文件找数据,倒不如辅助索引自己去找数据
7. 全文索引
1. 概念
通过数值比较、范围过滤等就可以完成绝大多数我们需要的查询,但是,如果希望通过关键字的匹配来进行查询过滤,那么就需要基于相似度的查询,而不是原来的精确数值比较。全文索引就是为这种场景设计的。
你可能会说,用 like + % 就可以实现模糊匹配了,为什么还要全文索引?like + % 在文本比较少时是合适的,但是对于大量的文本数据检索,是不可想象的。全文索引在大量的数据面前,能比 like + % 快 N 倍,速度不是一个数量级,但是全文索引可能存在精度问题。
2. 实现
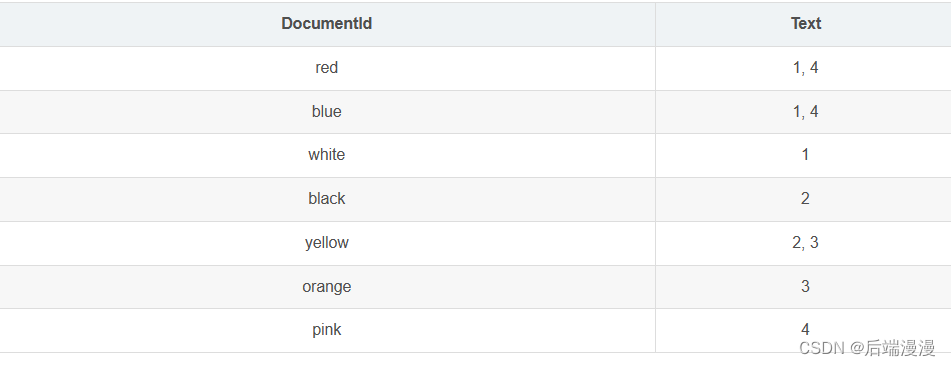
全文索引通常用倒排索引来实现,倒排索引和BTree一样,是一种索引结构,它在辅助表中存储了单词与单词自身在一个或多个文档中所在位置之间的映射,其拥有两种表现形式:
- inverted file idnex:{单词,单词文档所在ID}
- full inverted index:{单词,(单词文档所在ID,具体文档中的位置)}
例如有如下表 A:
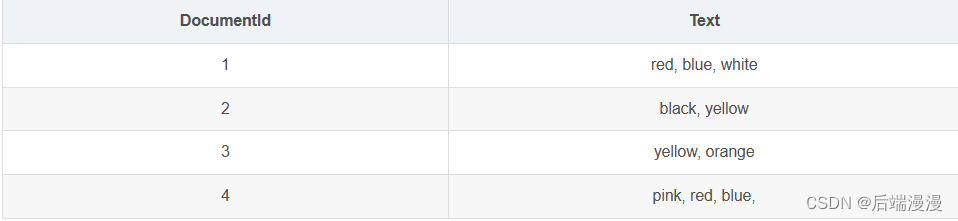
用 inverted file idnex 方式存储内容如下所示:
用 full inverted index 方式存储内容如下所示:
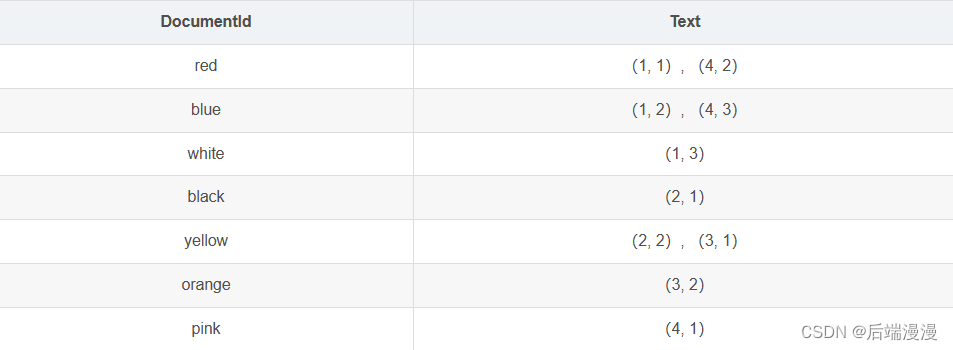
相比之下,full inverted index会占用更多空间,但能更好的定位数据,并扩充其他一些搜索特性。InnoDB全文检索采用full inverted index方式。
3. 使用
3.1 创建全文索引
# 1.创建表时创建全文索引
create table fulltext_test (id int(11) NOT NULL AUTO_INCREMENT,content text NOT NULL,tag varchar(255),PRIMARY KEY (id),FULLTEXT KEY content_tag_fulltext(content,tag) // 创建联合全文索引列
) ENGINE=MyISAM DEFAULT CHARSET=utf8;# 2.在已存在的表上创建全文索引
create fulltext index content_tag_fulltexton fulltext_test(content,tag);# 3.通过 SQL 语句 ALTER TABLE 创建全文索引
alter table fulltext_testadd fulltext index content_tag_fulltext(content,tag);
3.2 删除全文索引
# 1. 直接使用 DROP INDEX 删除全文索引
drop index content_tag_fulltexton fulltext_test;# 2. 通过 SQL 语句 ALTER TABLE 删除全文索引
alter table fulltext_testdrop index content_tag_fulltext;
3.3 使用全文索引
和常用的模糊匹配使用 like + % 不同,全文索引有自己的语法格式,使用 match 和 against 关键字,比如
select * from fulltext_test where match(content,tag) against('xxx xxx');
8. 索引失效
准备
建立员工记录表staffs(id,name,age,pos,add_time),并且给表中name、age、pos字段添加索引(注意三个在字段的顺序)
alter table staff
add index idx_staffs_nameAgePos(name,age,pos)
8.1 最佳左前缀法则
1. 概念
指的是查询从索引的最左前列开始并且不跳过索引中的列
# 情况1:name字段索引一直被使用
SELECT * FROM staffs WHERE NAME = ‘July’;
SELECT * FROM staffs WHERE NAME = ‘July’ and age = 25;
SELECT * FROM staffs WHERE NAME = ‘July’ and age = 25 and pos = 'dev';
SELECT * FROM staffs WHERE NAME = ‘July’ and pos = 'dev' and age = 25;# 情况2:当不查找name而去查找后面age和pos字段时,索引失效
SELECT * FROM staffs WHERE age = 25 and pos = 'dev';# 情况3:查找了name字段和pos字段,而缺少了中间的age字段,字段pos的索引失效,只用到了name字段索引
SELECT * FROM staffs WHERE NAME = ‘July’ and pos = 'dev';
8.2 不要再索引列上做任何操作
不要在索引列上左任何操作(计算,函数,自动or手动类型转换),否则会导致索引失效转换为全表扫描。
下图可以看到,没用left函数之前,是一个正常的索引引用,使用函数之后,索引失效了。
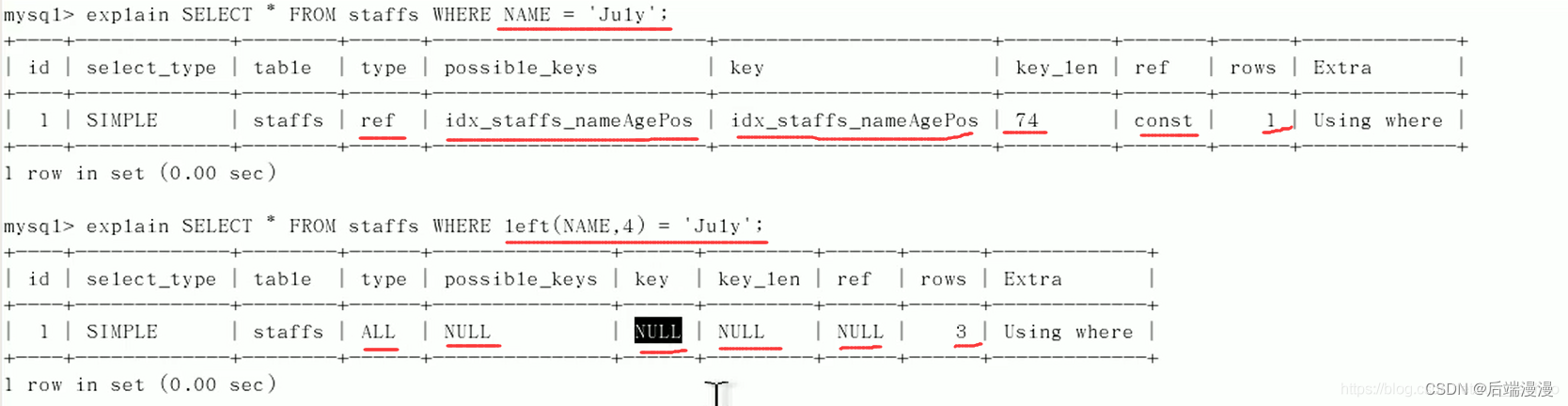
典型问题:字符串不加单引号会导致索引失效
name字段为varchar类型,假设有一行name=‘2000’,这时如果用name=2000条件查找也会有结果
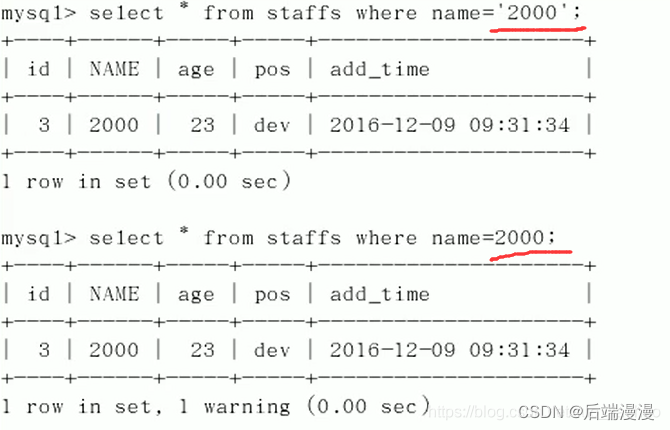
用EXPLAIN分析
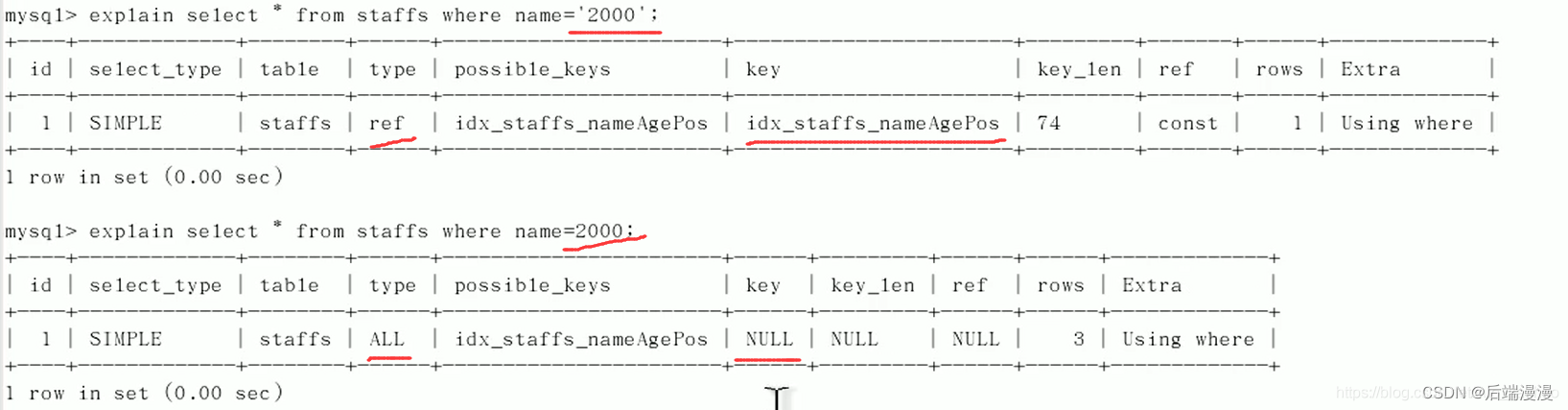
可以看出,用name=2000作为判断条件,不加单引号导致索引失效了,为什么?
因为name=2000也可以查出来是因为MySQL在底层做了一次类型转换,把整形2000转换成了字符串’2000’,所以索引失效。
8.3 存储引擎不能使用索引中范围条件右边的列
省流
并不是给一个列建立了索引,对这个列进行范围查询的时候,就会走索引,他是有一个比例值的。比例值会随着版本、服务器、IO、数据量、数据重复情况而不同。MySQL根据比值来选择索引或全表扫描
提出问题
第一个查询全等值匹配没问题
第二个查询中间使用了范围条件,结果导致manger的索引失效

但实际上,where的范围条件判断后面是否走索引,还需要做其他判断,总的来说,where的范围条件判断后面不一定走索引
范围查询一定走索引吗?
现在就范围查询是否走索引这个问题讨论,后面再总结范围查询后面的字段走不走索引。
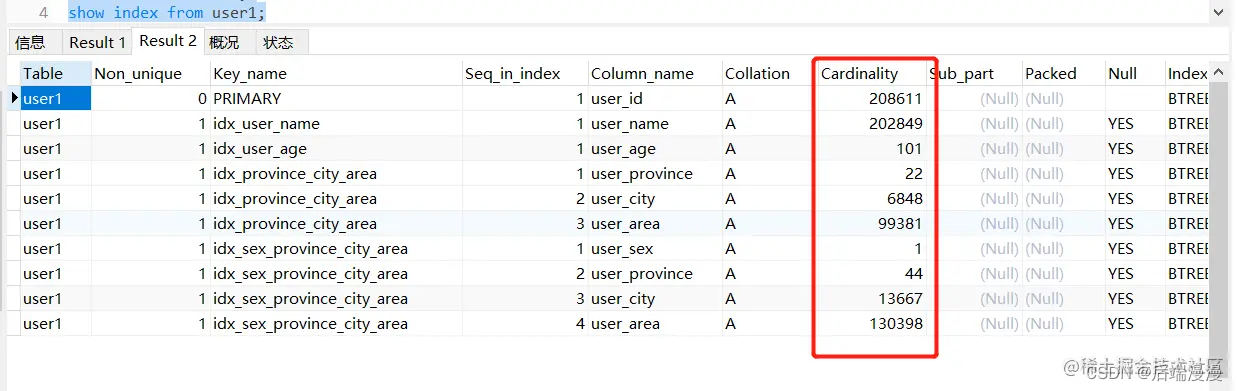
1. MySQL5.5版本
准备数据:
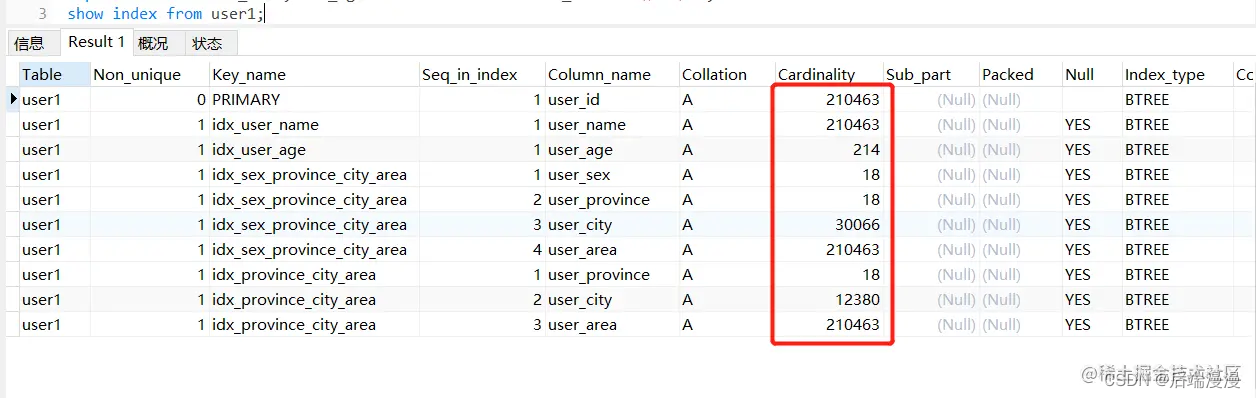
测试数据:


分析数据:
user_age < 8 比值为:35042/210463 = 0.1664(走索引)
user_age <= 8比值为:(35042 + 2221)/210463 = 0.1770(不走索引)
以上可知:比例值<=0.1664可以走索引,比例值>=0.1770优化器认为全表扫描更快,所以就不走索引。
2. MySQL5.6版本
准备数据:
测试数据


分析数据:
user_age < 8 :35042 / 208534 = 0.1680(走索引)
user_age <= 8:(35042+2221)/208534 = 0.1786(不走索引)
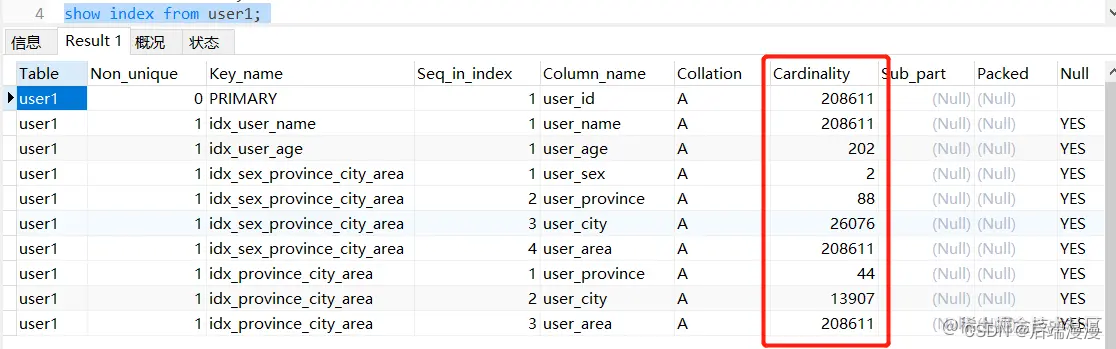
由此可大致推断:5.6版本下,该比例值在 0.1680 ~ 0.1786之间。
3. MySQL5.7版本
准备数据:
测试数据:


分析数据:
user_age < 20:87966 / 208303 = 0.422 (走索引)
user_age <= 20:(87966 + 2093)/208303 = 0.4323(不走索引)
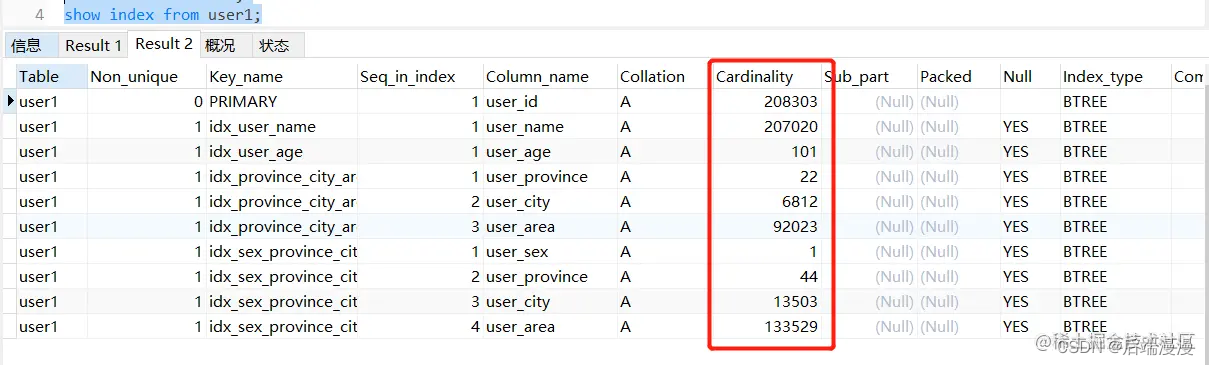
4. MySQL5.8版本
准备数据:
测试数据:


分析数据:
user_age < 12:54798 / 208611 = 0.2626(走索引)
user_age <= 12:(54798 + 2051)/208611 = 0.2725(不走索引)
范围查询后面的字段走不走索引?
其实这个问题比较简单,根据最佳左前缀法则,在联合索引(name,age,pos)中,如果age进行范围查询后都不走索引了,pos还能走索引吗?肯定不能啦。如果age还能走索引,pos自然也能走索引。
8.4 尽量使用覆盖索引
只访问索引列的查询,索引列和查询列一致,避免select *
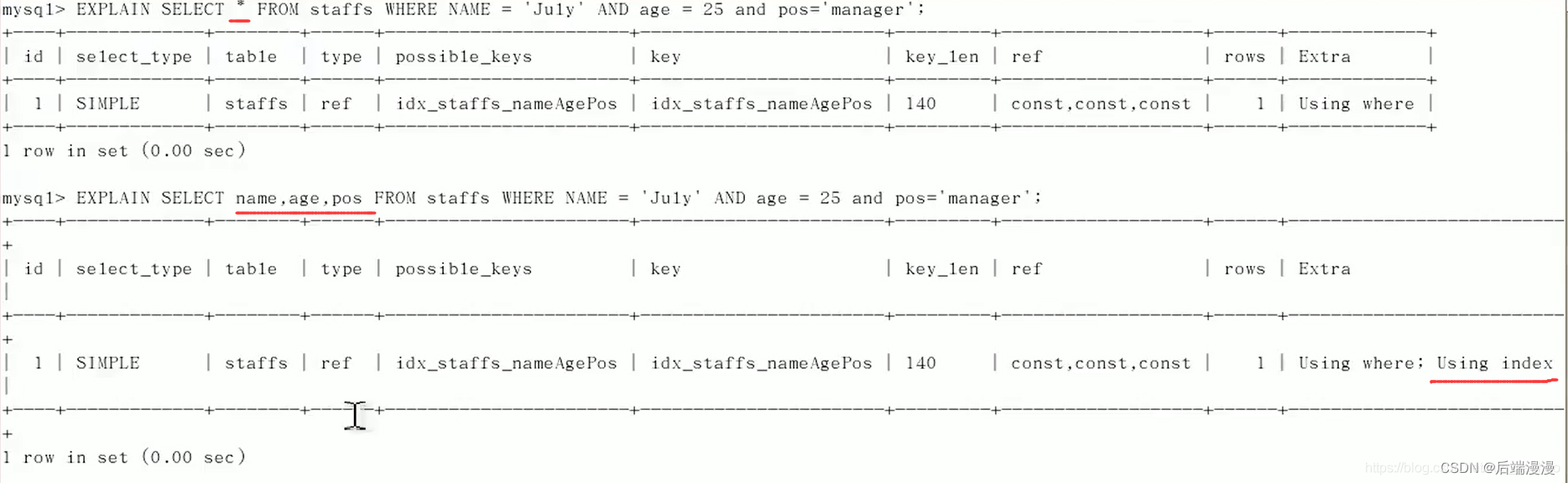
当只访问了索引列后,Extra中出现了Using index,表明是覆盖查询,这是好的
8.5 like以通配符(%)开头的索引会失效变成全表扫描
通配符出现最前面说明所有都适配,所有都要扫描
 不以%开头则不失效
不以%开头则不失效

那我既想要以%作为开头来查询,又想要这个查询是走索引的,怎么办?可以使用覆盖索引
准备数据:tb1_user表中有id,name,age,email四个字段,对name,age字段设置索引,id自动为主键索引。那么查询id,name,age字段都是覆盖索引,都可以使索引生效

但是如果使用explain select * from tb1_user where name like '%aa%'就会索引失效,因为此时不是覆盖索引,不是覆盖索引使用%会失效
相关文章:
【MySQL之MySQL底层分析篇】系统学习MySQL,从应用SQL语法到底层知识讲解,这将是你见过最完成的知识体系
文章目录MySQL体系结构MySQL存储结构(以InnoDB为例)MySQL执行流程(以InnoDB为例)1. 数据写入原理2. 数据查询原理MySQL存储引擎1. 为什么需要不同的存储引擎2. 如何为数据指定不同的存储引擎,数据粒度又是多少3. MySQL…...
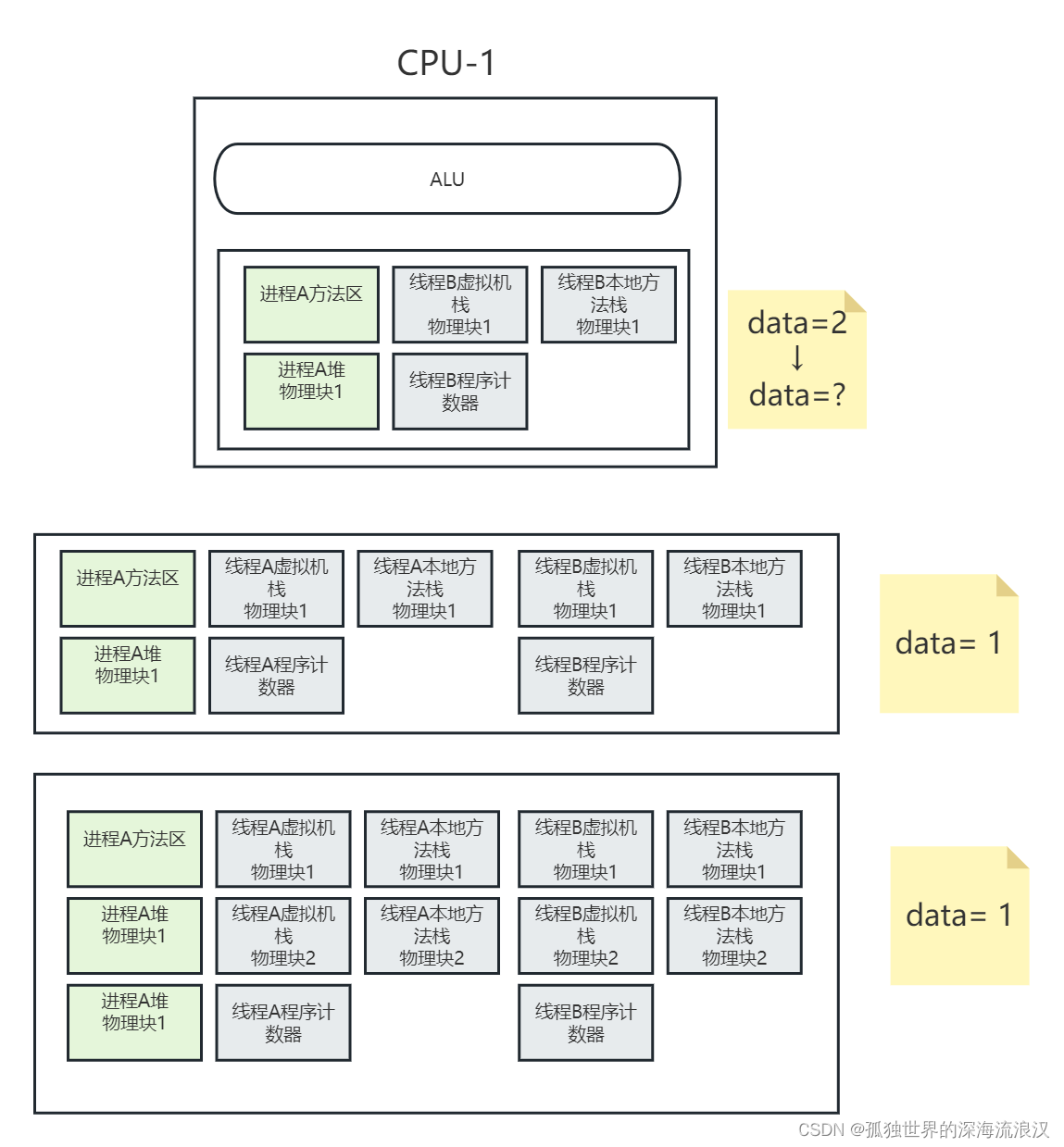
单核CPU是否有线程可见性问题?
本文仅是本人对问题的思考记录,并没有实操验证,有误请大家评论指出。 今天见到了一个经典的问题,单核CPU是否有线程可见性问题,学完操作系统应该可以直接回答,不会有线程安全问题。但如果结合JVM虚拟机来进行分析&…...
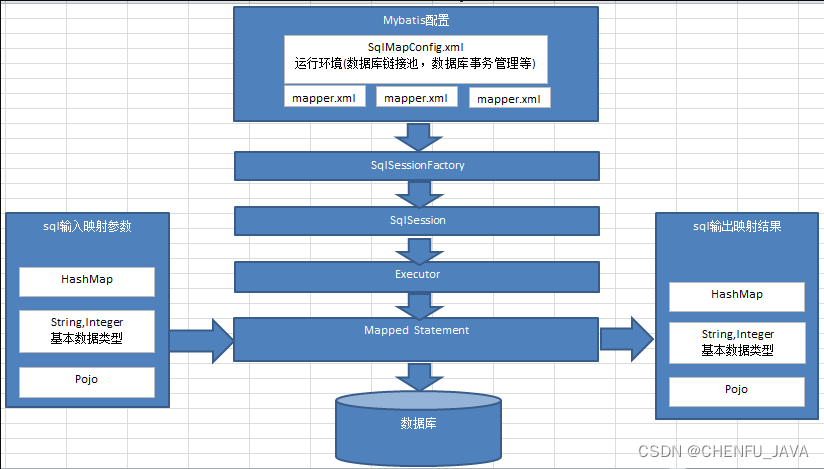
MyBatis 架构介绍
MyBatis 架构介绍MyBatis 架构图MyBatis 所解决的 JDBC 中存在的问题引用MyBatis 架构图 mybatis 配置:mybatis-config.xml,此文件作为 mybatis 的全局配置文件,配置了 mybatis 的运行环境等信息。另一个 mapper.xml 文件即 sql 映射文件,文件…...

加密算法---RSA 非对称加密原理及使用
加密算法---RSA 非对称加密原理及使用一 非对称加密原理介绍二 加密解密测试2.1 加密解密工具类2.2 测试一 非对称加密原理介绍 非对称加密算法中,有两个密钥:公钥和私钥。它们是一对,如果用公钥进行加密,只有用对应的私钥才能解…...

MySQL-查询语句
数据库管理系统的一个最重要的功能就是数据查询,数据查询不应只是简单查询数据库中存储的数据,还应该根据需要对数据进行筛选,以及确定数据以什么样的格式显示。MySQL提供了功能强大、灵活的语句来实现这些操作。下面是通过help帮助查看到的s…...

【算法】【数组与矩阵模块】求数组中需要排序的最短子数组长度
目录前言问题介绍解决方案代码编写java语言版本c语言版本c语言版本思考感悟写在最后前言 当前所有算法都使用测试用例运行过,但是不保证100%的测试用例,如果存在问题务必联系批评指正~ 在此感谢左大神让我对算法有了新的感悟认识! 问题介绍 …...
centos安装Anaconda3
目录一、参考二、Anaconda简介1、用途2、关于anaconda三、下载安装1、下载2、安装anaconda3、配置环境遍历4、测试配置结果5、设置显示前缀一、参考 在centos上安装Anaconda 最新Anaconda3的安装配置及使用教程(附图文) 二、Anaconda简介 一句话&…...

【微信小程序】-- WXML 模板语法 - 列表渲染 -- wx:for wx:key(十二)
💌 所属专栏:【微信小程序开发教程】 😀 作 者:我是夜阑的狗🐶 🚀 个人简介:一个正在努力学技术的CV工程师,专注基础和实战分享 ,欢迎咨询! &…...
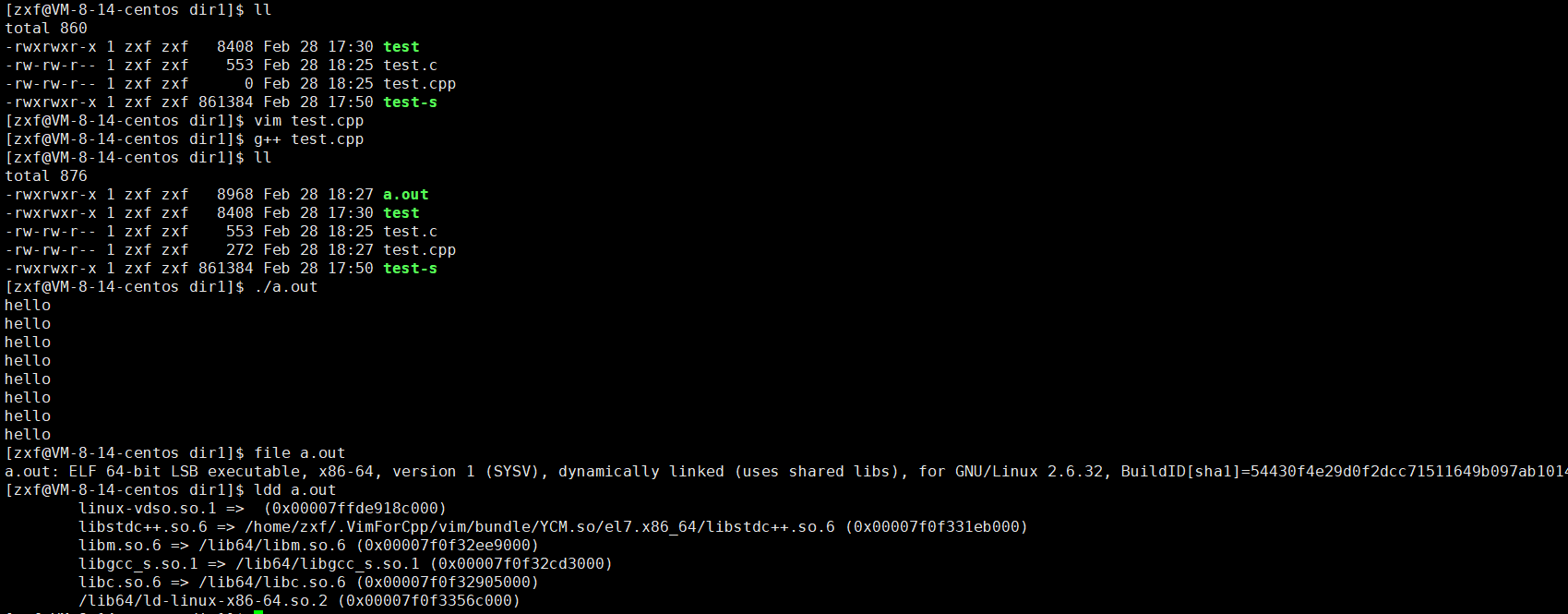
【Linux】Linux中gcc/g++的使用
本期主题:程序的编译过程和gcc/g的使用博客主页:小峰同学分享小编的在Linux中学习到的知识和遇到的问题小编的能力有限,出现错误希望大家不吝赐🍁 1.背景知识 预处理(进行宏替换,去注释,头文件的…...

【Spring Cloud Alibaba】(五)Dubbo启动报错?一直重连报错?你值得学习的是排查问题的方法
系列目录 【Spring Cloud Alibaba】(一)微服务介绍 及 Nacos注册中心实战 【Spring Cloud Alibaba】(二)微服务调用组件Feign原理实战 【Spring Cloud Alibaba】(三)OpenFeign扩展点实战 源码详解 【Spri…...

adb命令的使用
命令 连接机顶盒 adb connect [机顶盒ip]查看已连接设备 adb devices断开某个机顶盒的连接 adb disconnect [机顶盒ip] or adb disconnect [虚拟机名称]断开所有设备连接 adb disconnect获取 root 权限 adb root挂载文件系统 adb remount当想往移动设备端 push 文件时显…...

springBoot自定义参数类型转换器
springBoot允许用户自定义转换器,以处理自定义请求参数协议。 方式一:通过实现接口:WebMvcConfigurer 并重写方法的形式。 Configuration public class BootConfig implements WebMvcConfigurer {/*** 自定义参数转换*/Overridepublic voi…...

OA系统在企业中的应用你知道哪些?
随着人工智能技术的不断发展,企业中的OA系统(Office Automation System)正在逐渐得到广泛应用。OA系统是一种集成了多种功能的信息化工具,能够帮助企业实现办公自动化、信息管理、决策支持等多种功能。本文将从OA系统在企业中的应…...

JAVA中,ArrayList 的扩容机制,含案例
JAVA中,ArrayList 的扩容机制,含案例 在 Java 中,ArrayList 是一个动态数组,它可以根据需要自动增长。当 ArrayList 中的元素数量超过其初始容量时,它会重新分配一个更大的内部数组,然后将现有元素复制到新…...
供应链的有效管理,分析指标有哪些
对于企业而言,供应链是一个很复杂的、体系化的生态系统,从原材料、到供应商、到生产、仓库、物流,最后到达经销商或者最终客户那里,这个链条很长。相关的分析指标也有很多,在这些指标里面也有非常多可以扩展、延申的内…...

嵌入式环境配置—VMware 软件安装和虚拟机的创建
目录 一、VMware软件的安装 二、虚拟机的创建 三、Linux操作系统的安装 VMware软件的安装 为什么要虚拟机? 嵌入式Linux开发需要在Linux系统下进行,我们选择了Ubuntu。 1.双系统安装 有问题,一次只能使用一个系统。Ubuntu基本只做编译用。需求&…...

阿里前端二面经典手写面试题汇总
实现类的继承 实现类的继承-简版 类的继承在几年前是重点内容,有n种继承方式各有优劣,es6普及后越来越不重要,那么多种写法有点『回字有四样写法』的意思,如果还想深入理解的去看红宝书即可,我们目前只实现一种最理想…...

【Eye】Fake News Reading on Social Media: An Eye-tracking Study
Fake News Reading on Social Media: An Eye-tracking Study Abstract 在网上传播假新闻(以及一般的虚假信息)最近被认为是威胁整个社会的一个主要问题。这种传播在很大程度上是由于新的媒体形式,即社交网络和在线媒体网站。研究人员和从业…...

想学计算机,应该学什么专业?
我们在考虑想学计算机,应该学什么专业?这个问题的时候,每个人都应该结合自己的兴趣来确定。有的喜欢编程、有的喜欢设计、有的喜欢做产品跟人打交道……自己有兴趣再加上自己的努力,掌握好专业技能,就一定能进入高薪的…...

Android逆向之旅—反编译利器Apktool使用教程
apktool下载软件首先下载apktool.bat和apktool.jar官网地址:https://ibotpeaches.github.io/Apktool/install/配置环境变量具体的apktool命令自行百度apktool 解包与打包解包: apktool d xxx.apk打包: apktool b xxx1.jadx安装与使用下载exe或…...

【Python】 -- 趣味代码 - 小恐龙游戏
文章目录 文章目录 00 小恐龙游戏程序设计框架代码结构和功能游戏流程总结01 小恐龙游戏程序设计02 百度网盘地址00 小恐龙游戏程序设计框架 这段代码是一个基于 Pygame 的简易跑酷游戏的完整实现,玩家控制一个角色(龙)躲避障碍物(仙人掌和乌鸦)。以下是代码的详细介绍:…...

大型活动交通拥堵治理的视觉算法应用
大型活动下智慧交通的视觉分析应用 一、背景与挑战 大型活动(如演唱会、马拉松赛事、高考中考等)期间,城市交通面临瞬时人流车流激增、传统摄像头模糊、交通拥堵识别滞后等问题。以演唱会为例,暖城商圈曾因观众集中离场导致周边…...
【机器视觉】单目测距——运动结构恢复
ps:图是随便找的,为了凑个封面 前言 在前面对光流法进行进一步改进,希望将2D光流推广至3D场景流时,发现2D转3D过程中存在尺度歧义问题,需要补全摄像头拍摄图像中缺失的深度信息,否则解空间不收敛…...

Python实现prophet 理论及参数优化
文章目录 Prophet理论及模型参数介绍Python代码完整实现prophet 添加外部数据进行模型优化 之前初步学习prophet的时候,写过一篇简单实现,后期随着对该模型的深入研究,本次记录涉及到prophet 的公式以及参数调优,从公式可以更直观…...

第一篇:Agent2Agent (A2A) 协议——协作式人工智能的黎明
AI 领域的快速发展正在催生一个新时代,智能代理(agents)不再是孤立的个体,而是能够像一个数字团队一样协作。然而,当前 AI 生态系统的碎片化阻碍了这一愿景的实现,导致了“AI 巴别塔问题”——不同代理之间…...

linux 下常用变更-8
1、删除普通用户 查询用户初始UID和GIDls -l /home/ ###家目录中查看UID cat /etc/group ###此文件查看GID删除用户1.编辑文件 /etc/passwd 找到对应的行,YW343:x:0:0::/home/YW343:/bin/bash 2.将标红的位置修改为用户对应初始UID和GID: YW3…...

QT: `long long` 类型转换为 `QString` 2025.6.5
在 Qt 中,将 long long 类型转换为 QString 可以通过以下两种常用方法实现: 方法 1:使用 QString::number() 直接调用 QString 的静态方法 number(),将数值转换为字符串: long long value 1234567890123456789LL; …...

网络编程(UDP编程)
思维导图 UDP基础编程(单播) 1.流程图 服务器:短信的接收方 创建套接字 (socket)-----------------------------------------》有手机指定网络信息-----------------------------------------------》有号码绑定套接字 (bind)--------------…...

如何理解 IP 数据报中的 TTL?
目录 前言理解 前言 面试灵魂一问:说说对 IP 数据报中 TTL 的理解?我们都知道,IP 数据报由首部和数据两部分组成,首部又分为两部分:固定部分和可变部分,共占 20 字节,而即将讨论的 TTL 就位于首…...

rnn判断string中第一次出现a的下标
# coding:utf8 import torch import torch.nn as nn import numpy as np import random import json""" 基于pytorch的网络编写 实现一个RNN网络完成多分类任务 判断字符 a 第一次出现在字符串中的位置 """class TorchModel(nn.Module):def __in…...