【Eye】Fake News Reading on Social Media: An Eye-tracking Study
Fake News Reading on Social Media: An Eye-tracking Study
Abstract
在网上传播假新闻(以及一般的虚假信息)最近被认为是威胁整个社会的一个主要问题。这种传播在很大程度上是由于新的媒体形式,即社交网络和在线媒体网站。研究人员和从业者一直试图通过描述假新闻并设计自动检测它们的方法来回答这个问题。到目前为止,这些检测方法的成功程度还很有限,这主要是由于新闻内容和上下文的复杂性,以及缺乏适当的注释数据集。提高自动错误信息检测方法效率的一种可能的方法是模仿人类的检测工作。在更广泛的处理假新闻传播的意义上,了解网络用户的新闻消费行为也很重要。在这篇论文中,我们提出了一项眼球追踪研究,在该研究中,我们让44名参与者随意阅读一个包含新闻文章的社交媒体动态消息。其中一些文章是假的。在第二次测试中,我们要求参与者来决定这些文章的真实性。我们提供了该研究的描述,结果数据集的特征(我们在此发表)和几个发现。
1. Introduction
近年来,假新闻(以及一般的虚假信息)因在网络环境中传播,尤其是通过社交网络传播而臭名昭著。它们对现实世界的人类决策有影响,例如在政治上、在医疗保健领域。
假新闻传播的真正而重大的负面影响促使了密集的研究努力。一些研究都是为了理解假新闻现象(即特征描述),分析了假新闻的属性,他们如何获得读者的信任,假新闻如何传播,以及是什么推动了他们的传播。现有的研究极大地帮助了概念化假新闻。然而,这些研究需要更多的行为研究来调查与(假)新闻互动时的人类判断因素。
基于特征研究的知识,大量的自动假新闻检测方法和平台已经被提出。最流行的趋势是使用机器学习的方法。一些方法分析新闻内容,而一些方法依赖于上下文方面,如源/作者/传播者模型或社交媒体互动。尽管做出了这些努力,但对在线错误信息的可靠检测仍然是一个未解决的问题。虽然普遍缺乏数据集(这将涵盖所有问题的异质性),但新闻内容和上下文的维度却很高。这使得创建通用和可靠的分类模型变得困难。
为了解决上面提到的一些问题,我们提出了一个眼球追踪用户研究,调查了人类在假新闻消费和准确性评估中的行为。在这项研究中,44名参与者首先在类似社交网络的动态动态中随意消费(即消费阶段)的新闻故事。在那之后,他们被要求评估这些故事的真实性(即评估阶段)。这类研究的动机有两个核心原因:
- Understanding the fake news consumption. 人们普遍缺乏对人们如何在社交媒体上消费假新闻现象的理解。通过观察新闻消费行为,我们可能会披露什么吸引新闻读者的注意力在假新闻,多么彻底的消费新闻,之前明确的行动(例如,喜欢或股票)或在什么条件下他们成为“自发”怀疑一篇新闻。
- Learning from human fact-checkers. 通过智能地选择相关特征,可以缓解错误信息检测任务的高维性。观察研究参与者在评估阶段的行为可以为我们指出在线新闻的内容和背景特征,这对真实性验证非常重要。
通过这项工作,我们的目标是填补假新闻消费和检测领域的一个空白。据我们所知,目前还没有对假新闻消费和真实性评估进行过眼球追踪研究。
这项工作有以下贡献:
- The concept of the fake news eye-tracking study. 我们提出的研究概念作为对目前较为SOTA工作的贡献。首先,我们不知道之前在这种情况下做过的任何研究。其次,我们认识到,对社交网络用户行为的详细记录的需求越来越大,因此,我们希望为未来的研究提供一个蓝图。
- The dataset of 44 recorded participants of our study. 通过本文,我们使在本工作中收集的数据集公开。在第4节中,我们提供了对记录的行为数据的描述性分析。我们还报告了一份我们在参与者中发布的问卷的结果,该问卷收集了关于参与者的意见和对新闻中特色主题的兴趣程度的参考信息。
- The findings on consumption and veracity evaluation of social media users. 利用实验消费阶段获得的数据,我们调查并报告了假新闻对社交媒体网站上的用户行为的影响。通过分析在准确性评估过程中记录的数据,我们报告了成功的注释者所采用的策略。
Related Work
据我们所知,目前还没有眼球追踪研究来调查人类在假新闻消费或验证期间的行为。然而,也有几项类似的非眼球追踪研究。我们可以从方法上得出结论,并通过我们的研究来补充他们的发现。
在现有的研究中,与我们的研究最相似的是Flintham等人最近的工作,他调查了社交媒体用户的假新闻阅读行为。首先,他们调查了309名问卷调查者对假新闻的经历及其特征。其次,他们对9名参与者进行了一项定性研究,他们与一个虚假的脸书账户进行了互动,其中包含了使用Rubin等人做的各种类型的真假故事。作者调查了社交媒体用户在多大程度上担心假新闻的传播,以及是什么(内容或背景)特征说服他们相信一个信息是假的。通过基于大声思考方案的定性分析,弗林瑟姆等人确定了新闻读者在真实性评估中使用的三种一般策略。**第一种方法是仅仅根据消息来源的声誉来推断其真实性。第二是评估故事内容,然后用来源声誉来确认假设。第三种策略只依赖于内容。**在分析内容时,参与者主要依赖于合理性评估、标题和写作风格分析。
本文是对弗林瑟姆等人的工作的补充。我们的目标是涉及更大的参与者集(44位而不只是9),并以定量的方式分析他们的行为。我们的研究方案是沉默的(与自声思考相反),因为我们想要模仿更真实的情况。我们还使用了眼球追踪技术来详细跟踪阅读和决策行为。我们研究中的环境更受控制(我们不是在真实的Facebook上创建一个假账户,而是模仿Facebook提要创建了一个完整的应用程序)。此外,由于故事来源(及其声誉)对一些用户来说显然是一个强有力的真实性指标,我们故意省略了用作故事的文章来源。此外,所有的文章(当我们的研究参与者决定完全打开它们时)都以统一的图形方式呈现(因此,原始来源也不能这样推断)。
在另一项研究中,豪伊尔和布莱特调查了影响用户对社交媒体上分享的信任的因素。他们研究的是年轻人,他们是其中一个最受错误信息威胁的群体,因为这个群体主要在网络和社交媒体上访问新闻(根据路透社最近的一项研究表明,18-24岁的用户中有53%报告在社交媒体上访问新闻)。在我们的研究中,我们选择了相同的人口统计学组。然而,与豪雅尔和布莱特相比,我们没有评估新闻来源的可信度,也没有评估其他社交媒体信号,比如点赞或评论的数量(豪雅尔和布莱特没有发现这些信息对用户的评估有显著影响)。
托雷斯、格哈特和内加班提出了一种新闻验证行为模型,他们通过对541名参与者(大学生;64.2%的人年龄在19-24岁)。他们发现,媒体的可信度、用户分享的意图、他们的假新闻意识,以及他们对网络的信任,都是新闻验证行为的相关预测因素。然而,这些发现并没有在实验或用户研究中得到进一步的评估。
一些现有的眼球追踪研究主要集中在新闻阅读行为上。阿拉帕基斯等人研究了读者对在线新闻感兴趣的东西。作者进行了一项眼球追踪研究,他们测量了面向57名参与者的114篇文章的参与度。这些文章在情感和极性方面有不同的属性,这确实影响了他们的吸引力,从而影响了读者的行为。阿拉帕基斯等人的工作对我们的研究也有一定的意义。这些行为应该通过新闻中的多个主题进行调查,因为参与者的个人长期利益可以影响他们的消费和真实性评价行为。参与者的主题兴趣和意见应该通过问卷调查来控制。
最后,已经有一些关于确定可信和非可信新闻指标的工作。我们在本文中提出的研究也旨在通过分析成功用户(即能够高精度检测假新闻的用户)的策略来解决这些问题。Zhang等人提出了一套内容和上下文指标(特性),他们在40篇包含人工注释者的数据集和领域专家上进行了评估。从内容特征来看,点击诱饵标题和逻辑谬误(例如,滑坡)可以很好地预测文章的可信度;从背景因素来看,良好的预测因素是事实核查的结果(文章被标记为虚假)、社交和邮件列表的数量(例如,打电话来分享文章或订阅邮件列表)和广告和社交电话的放置(例如,这些广告有多激进)。然而,对这些特征的自动评估可能是一个问题,作者没有讨论如何克服它。
3. Study Description
为了收集关于社交媒体用户如何感知和消费假新闻的详细数据,我们对44名参与者进行了一项实时的对照研究。我们首先要求参与者在一个类似于社交媒体的订阅源(即消费阶段或第一次通过)的实验性用户界面中浏览(并可选择阅读)类似新闻的故事(帖子)。然后,我们要求他们再次浏览相同的故事(即,评估阶段或第二次通过)。这一次,参与者必须确定(根据他们自己的判断)这些故事的真实性(真实性)。每次传球只有12分钟,上面有50个故事,有些是真实的,有些是捏造的。每个故事都属于这11个相当有争议的话题中的一个。
在整个研究过程中,参与者在社交媒体上的行为都被详细记录下来,包括使用眼球追踪技术。除此之外,我们还发布了一份调查问卷,调查了对这11个主题中的每个主题的参与者的兴趣程度和观点立场。
3.1 Research questions
本研究的动机是基于以下一般的研究问题:
- RQ1: 在社交网络订阅环境中,假新闻消费的行为特征是什么?
- RQ2: 参与者的长期兴趣和观点如何影响消费行为?
- RQ3: 在准确性评估中相对成功的参与者有哪些行为特征?
- RQ4: 是否有一些明显的内容特性,成功的注释者用于其评估(并有可能用于自动检测方法)?
这项研究在很大程度上具有探索性的特征。我们没有预先提出任何假设。
3.2 Participants
该实验共有44名参与者(27名男性,17名女性)参加。参与者的年龄从16岁到20岁不等。
所有的参与者都是高中生。我们选择这一特殊的人口统计学群体有两个原因。第一个原因是要努力减少潜在的混淆因素。当然,试图通过邀请一个有代表性的样本来覆盖整个人口统计范围是有意义的。然而,这将在研究中引入许多不受控制的变量和潜在的混杂因素(如不同人口群体中信息素养的可变性)。因此,我们将研究范围缩小到一个特定的、更同质的群体——高中生。
将范围缩小到一个特定群体的第二个原因是,我们想与一个有点容易受到在线错误信息影响的群体合作。在进行这项研究的斯洛伐克,高中生代表着这一群体。还有其他值得邀请的特定团体。例如,老年人也因容易获得错误信息而闻名。在这种情况下,选择高中生的动机是由于参与者的实用性更好。
尽管使用了特定的人口统计学群体,但我们认为该研究设计也适用于其他群体或一般人群样本。
3.3 Environment and equipment
该研究记录是在位于布拉迪斯拉发的斯洛伐克理工大学的用户体验和交互研究中心2的实验室进行的
该记录是在一个小组眼球追踪实验室中完成的,这意味着有多个参与者参加了研究,并被平行记录。虽然研究设计不需要这种设置,但我们使用它来更快地执行研究。小组眼球追踪研究需要特定的场景调整,对服务人员的要求稍高。它们还需要特殊的基础设施来支持数据的记录和收集。然而,这项投资是值得的:这项研究的记录部分大约4小时(4个1小时的会议,包括管理费用)。如果同样的研究是连续进行的,这将需要超过40个小时。
参与者在带有24英寸显示器(1900x1200)的台式电脑上工作,并安装有Tobii X2-60眼球追踪器。实验使用Tobii Studio软件进行(第一和第二阶段)。调查问卷(第三阶段)通过谷歌表格发布。这些工作站被放置在一个闪电条件稳定的房间里。房间的布局是教室式的,有20个工作站(尽管在一次会议中最多被占用了13个工作站)。在12分钟的过程中,环境是安静的(在过程之前、之后和之间给予口头指示)。
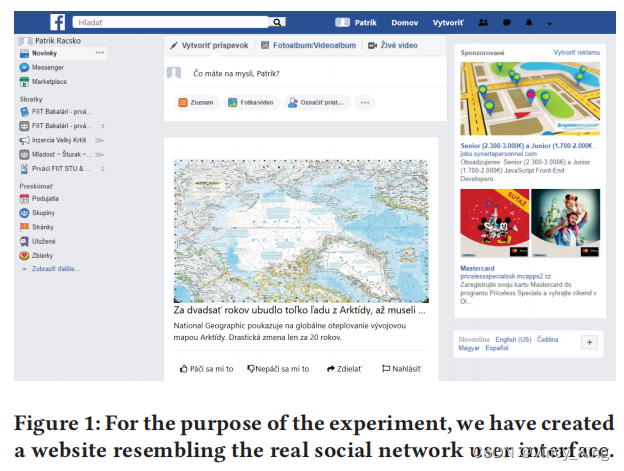
为了本研究的目的,我们创建了一个模拟真实社交网络(Facebook)用户界面的网站。该网站包括一个“后订阅”(见图1),参与者可以通过它滚动,也允许有限的互动选项(例如,在第一阶段分享,在第二阶段进行准确性评估)。参与者也可以通过点击提要文章中的图片、标题或预告片文本来打开全文(见图2)。

3.4 Study scenario (tasks)
每个环节都从参与者到达小组眼球追踪实验室开始。首先,我们向他们介绍了这项研究。接下来,他们被简要介绍了眼球追踪技术的工作原理,并对每个参与者进行了眼动追踪器的校准。
然后,参与者被要求执行以下任务:
- Task 1: News consumption (the first pass). 参与者被要求随意浏览/阅读社交网络动态和文章链接的文章。这项任务持续了12分钟,其目的是记录在类似于休闲社交网络订阅“结账”的情况下的新闻消费行为。说明的关键部分如下:“We will display an imitation of a social network interface to you. For 12 minutes, casually browse the story feed. You may open up the full articles. You may also like, dislike, share or report any story – do so if you feel you would do it in a real situation.”此外,我们将参与者的活动限制在我们的实验应用程序中(我们要求他们不要访问其他网站)。
- Task 2: News veracity evaluation (the second pass). 我们告诉参与者其中的一些文章是假新闻。我们要求他们再次查看提要,并根据他们的内容(或在提要的帖子中或在完整的版本中)来估计文章的准确性。请注意,到目前为止,参与者并没有以任何方式暗示,研究的真正目的是调查假新闻阅读行为(我们小心地不要在任务过程中破坏他们的行为1)。该说明的关键部分内容如下:"您将在类似的环境中再次看到相同的文章。然而,这一次,你的任务将会有所不同。你的目标是确定一篇给定的文章是否正确。提要中的一些文章并不是基于事实的。"我们预计,每一篇文章的准确性评估可能需要一些时间。因此,我们进一步指示参与者:“请按照你自己的节奏评估文章,没有必要评估所有的文章。”这个任务持续了12分钟。参与者使用每个帖子的五个选项中的一个来表示真实性(肯定是真的,相当真的,相当假,肯定是假的,我不知道,见图3)。
- Task 3 - questionnaire. 我们要求参与者填写问卷,以评估人口统计数据、观点立场和对特色话题的兴趣。调查问卷的描述见第3.6节。这项任务没有被眼球追踪。
所有的指示都同时口头给整个组。关于任务的指示总是在任务开始前立即发出。一个任务总是被解释的,我们给参与者一个在任务开始前提问的机会。这种“同步”的研究组织风格被小组眼球追踪设置所暗示。前两个任务有一个固定的时间长度(12 + 12分钟)。在第三个任务中,我们让参与者按照自己的节奏工作。整个会议(其中有4次)耗时了35到40分钟。
3.5 Stimuli (content characteristics)

在第一个和第二个任务中,向参与者显示的提要包含50个帖子。每篇文章代表一篇文章。全文的长度约为350字(所以当全文被打开时,整个文本将适合屏幕,见图2)。每一篇文章都有一个标题,一个说明它的图像,一个引段和文本的其余部分。文章的后表示(在提要中)具有相同的标题和图像以及引导段的开头(如果不符合post界面中分配的两行,则截断),见图3。注意,我们有意省略了文章的来源和作者,也选择了在完整文章视图中统一的可视化设置(即,所有文章在视觉上看起来都是相同的)。
这些文章是用斯洛伐克语写的(所有参与者的母语都是斯洛伐克语)。写作风格类似于新闻或杂志文章,预计参与者很容易理解。
每一篇文章都属于11个主题中的一个,为本研究精心挑选:(content categories), hand-picked for this study: food quality, personal weight reduction, Muslims in the EU, pharmaceutical industry, LGBT rights, right wing extremism, vaccination, extraterrestrial life, global warming, deforestation, migration.
假新闻(一般来说是虚假信息)在每个话题中或多或少是常见的(在斯洛伐克的社会背景下,参与者是从中抽取的)。这11个话题中的每一个话题也都有一定程度的争议。在每一个主题中,都可以找到一个主要的争议维度(即,有两种对立的、普遍的意见立场)。例如,在全球变暖的话题上,我们可以认识到一个否认者和一个危言耸听者的对立立场。对于每个类别,我们收集了4篇文章来填补每一篇文章的真实性和观点立场的组合。这意味着我们总是至少有一篇真实的文章支持每种观点观点,至少有一篇假文章支持每种观点立场。
我们直接从著名的斯洛伐克语新闻网站收集了大多数文章,并从臭名昭著的斯洛伐克语错误信息来源(如果是假新闻)。由于原始文章的长度不同,我们将其中一些文章调整到我们的设置所需的长度。对于一些话题和观点立场的组合,我们不可能找到假新闻的例子。例如,我们没有发现任何支持疫苗接种原因的假新闻文章。在这种情况下,我们自己创建了所需的假新闻文章,通常是通过使用夸张(例如,增加麻疹受害者数量的10倍)、事实改变(例如,改变臭名昭著的主角的名字)和改变形象和标题(所以文章更具启发性)。
我们在实验中总共使用了50篇文章。这意味着,对于一些话题、真实性和观点立场的组合,有不止一个例子。总共发生了6例病例。加入更多文章的原因是,我们有时会遇到多个有趣的例子(通常是假新闻),它们在某种意义上是不同的,我们想记录参与者在其中的行为。
3.6 Questionnaire
调查问卷的主要目的是获取关于这11个主题中的每个主题的参与者的意见立场和兴趣程度的信息。我们将该问卷作为本研究的第三个(也是最后一项)任务发布,以避免对任务1和任务2中参与者的行为产生启动影响。调查问卷的结构如下:
(1) Questions on demographics (gender and age).
(2) Questions on opinion positions. These were organized in 11 sets (one for each topic). Each set contained between 5 to 7 specific questions.
(3) Questions on degree of interest (one question for each topic).
为了在争议的维度内获得(参与者)的意见立场,我们选择了多个具体的问题(而不是问一个一般性的问题来获得这个整体的立场)。我们这样做了,因为我们担心参与者不能直接评估自己
关于意见立场的问题采用了陈述的形式,与会者使用 five-level Likert量表表示同意/不同意。作为一个例子,我们可以以全球变暖的主题为例:
(1) “The global warming is a fabrication and is not really happening.”
(2) “The global warming is a serious threat for our entire planet.”
(3) “People cause the Earth warming.”
(4) “Personally, I do not contribute to the global warming.”
(5) “The global warming has not, and will not have any effect on me.”
可以看出,一个陈述本身总是有它自己的意见极性,并且可以有些暗示性。因此,在每一组问题中,我们都包含了针对两种方式的陈述。在上述例子中,第1、4和5号声明是针对否认者的立场,而第2和3号声明是针对危言耸听的立场。然后将总体意见立场计算为集合中所有陈述的平均答案。然而,在此之前,偏向于其中一个位置(任意选择的)的陈述的贡献被乘以-1。在上面的示例中,我们可以“翻转”语句2和3或语句1、4和5的贡献。
关于兴趣程度的问题,每个主题制定如下:“选择你对以下主题的兴趣程度”。这条指导之后是11个主题,每个主题都有5度的范围,从“我完全不感兴趣”到“我非常感兴趣”。
3.7 Data processing
记录结束后,我们使用Tobii Studio来计算注视注视事件(使用内置的IVT注视过滤器实现)。我们还使用Tobii Studio在提要中的每个文章中定义感兴趣的区域(AOIs):图像、标题、perex(前导段落文本)、动作按钮(如、分享等)。其中一个AOI表示整个帖子(包括所有之前的AOIs)。固定数据(与AOI命中数)被导出,并使用Python脚本进行进一步处理。
4 FINDINGS
4.1 First and second pass statistics
参与者在12分钟中平均浏览12分钟5.1(SD 2)。在第二次阶段,他们平均在12分钟内浏览了5.3分钟(SD 2.6)。剩下的时间都花在了阅读全文上。参与者在第一次平均打开7篇文章(SD 4),第二次平均打开9篇(SD 5)
在实验的第一次阶段,参与者平均看到41个帖子(SD 10)。我们将“看到一个帖子”(印象)定义为一种情况,即我们记录至少10个注视事件击中感兴趣的区域。这通常意味着几秒钟,通过强加这个,我们希望过滤掉快速滚动的提要和其他可能的工件。
其中22名参与者总共执行了122个明确的喜欢、不喜欢、报告和分享行为。对真实文章和虚假文章都进行了相同数量的行为(61次),但对真实文章和虚假文章的行为分布情况不同。类似于行为的意图使用,真实的文章比虚假的文章得到更多的喜欢和分享,虚假的文章比真实的文章更不受欢迎和报道。表1分别显示了真实和虚假文章的显式操作的总数。与我们记录的数千次印象相比,外显行为的总数很低,虽然我们可以在这里看到一个普遍的倾向,但无法从它们中得出有统计数据支持的结论。然而,我们可以在报告行动中看到一些潜力,它更多地用于虚假的文章,而不是真实的文章。

在实验的第二次阶段,参与者在通过饲料时的速度稍慢一些:他们在饲料中平均看到32个帖子(SD 13)。其中,他们平均对29篇文章的准确性进行了评分(SD 16)。表2显示了真实和虚假文章的真实性评级的总数。虚假文章和真实文章的真实性评分分布有统计学上的显著差异(每个参与者和主题评分的非配对t检验结果为p值< 0.001)。在1到5的范围,其中1代表肯定真实真实性评级,真实文章的平均真实性评级为2.5(SD 1)。假文章的平均准确率为3.4(SD 1)。

4.2 Opinion and interest in topics

来自调查的回答使我们能够探索参与者在相关主题中的意见的兴趣、强度和极性(位置)的分布。图4比较了参与者的兴趣强度和意见强度的分布情况。兴趣代表了对调查问卷最后一部分中明确陈述的主题的兴趣。另一方面,意见的力量代表了对意见立场问题的极端答案。
在大多数话题中,意见的强度与参与者的兴趣相匹配(这是一个预期的结果)。然而,在有几个话题中,意见强度的分布相对于兴趣强度的分布更高——例如,右翼极端主义、同性婚姻和疫苗接种。在这些主题中,我们可以看到参与者的意见的极性更加一致,如图5所示。我们不能可靠地解释这一观察结果。一种建议可能是,参与者的意见是由他们的外部环境所塑造的。

我们进一步研究了参与者明确陈述的兴趣和他们在实验第一次(消费阶段)阅读文章时的行为中观察到的隐性兴趣之间的关系。与表示不感兴趣的参与者(相当不感兴趣,完全不感兴趣)相比,表示感兴趣的参与者(相当感兴趣和非常感兴趣)打开了更多的文章,并花更多的时间阅读它们。这一发现表明,参与者在第一次实验时的内隐阅读行为反映了他们明确表示的兴趣,即参与者在实验的消费阶段探索饲料时遵循自己的兴趣。
另一方面,实验第二次时的阅读行为受参与者兴趣的影响较小。与表示不感兴趣的参与者相比,表示感兴趣的参与者在主题中打开的文章仅略多一些。图6显示了在第一次和第二次文章中,对主题的兴趣对文章总可见区域的影响的差异。文章的总可见区域反映了参与者阅读完整文章的深度(记录在注视数据中)。与实验的第一次通过相比,参与者在阅读文章的真实性时,不会更感兴趣。然而,兴趣对第二阶段阅读行为的影响仍然可以在主题的总可见区域的分布中观察到。这与弗林瑟姆等人的研究结果有些不同,相反,他们观察到,参与者不感兴趣的故事“对他们来说“评估他们的真实性并不重要”。

4.3 Correctness of veracity ratings
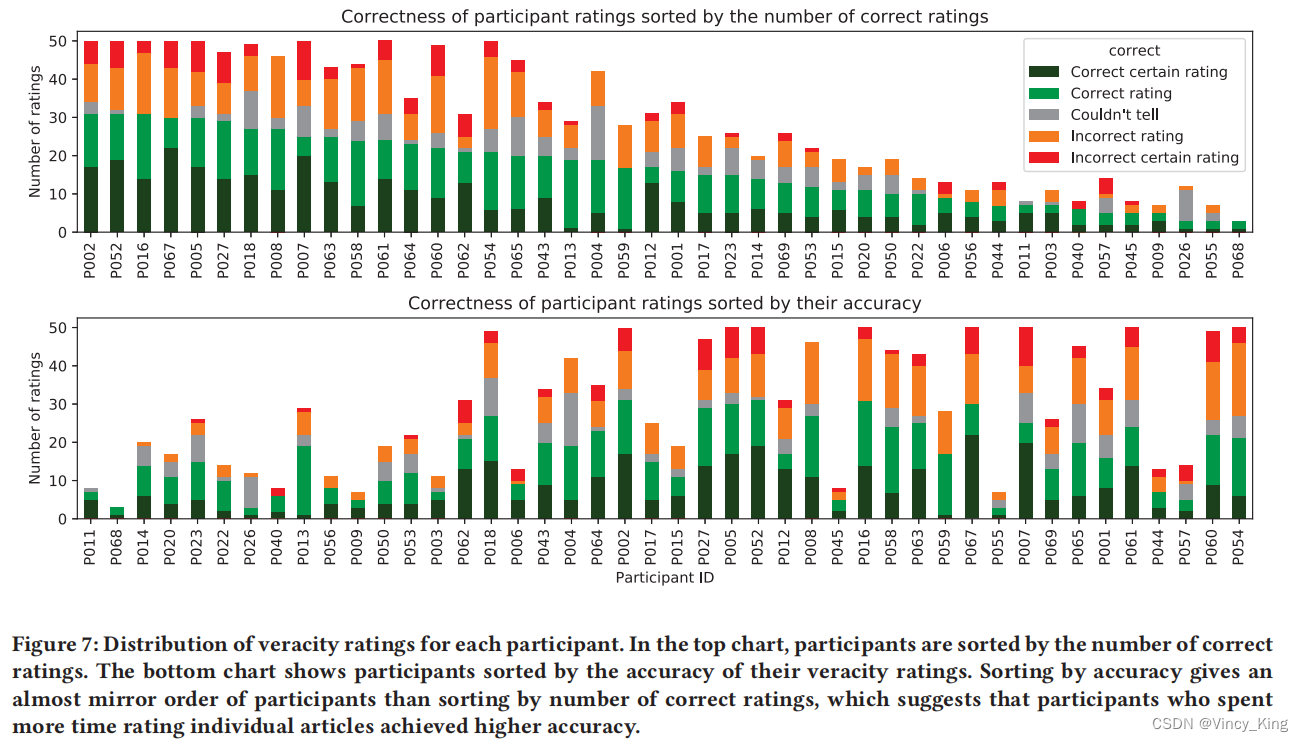
图7显示了每个参与者的准确性评级的分布,按正确评分的数量(顶部)和每个参与者的评级的总体准确性(底部)排序。与根据正确评分的数量对他们进行排序相比,根据准确性对参与者进行排序给出了一个几乎镜像的排序。这表明,那些对较少文章的准确性进行评分,同时花更多时间判断每一篇文章的参与者获得了更高的准确性。为了进一步研究成功和不成功的参与者之间的差异,我们分为两组参与者:成功的组包括25%的参与者,他们的评分准确率最高,不成功的组包括25%的参与者,他们的评分的准确性最低。
在实验的评估阶段,成功组和不成功组之间,查看语料库中帖子标题的平均时间的分布有显著差异(使用非配对t检验的p=0.008)。成功的参与者在语料库中平均花费2秒查看其标题,而不太成功的参与者平均花费2.9秒。在观察提要中帖子的图片或主要段落文本(perex)所花费的时间上没有显著差异。
这表明,与更成功的参与者相比,不成功的参与者更依赖语料库中提供的信息。图8所示的实验第一次和第二次阅读文章的总时间,以及图9所示的提要中查看文章的时间的比较,支持了这一发现。


4.4 Study limitations
在我们进行数据分析的过程中,我们注意到参与者评估个别文章的准确性(即文章难度)的难度。在准备刺激的过程中,我们没有控制文章的难度。尽管大多数文章似乎都相当难以评估,但整个文章集的范围从“几乎不可能”到“非常容易”。图10使用文章准确性评分的准确性直方图说明了文章难度的分布。虽然大多数文章(70%)比随机猜测更好,但有8篇文章(16%)的准确率达到了0.25或更低,这意味着它们不仅很难评估,而且完全欺骗。这种不同的困难可能会影响一些未来的发现和进一步的类似研究,我们建议通过试点来控制困难。

其他的限制来自于在受控的实验室环境中进行的研究,而不是在更自然的真实社交网络环境中进行的研究。在我们的研究中,我们有意地省略了新闻的来源和社交媒体上的信号,如点赞、评论等。以减少(上下文)变量的数量,并关注内容信号。此外,我们的参与者样本仅包括高中生(潜在的大学申请者);然而,我们没有控制他们高中的地理位置或其类型,也没有控制参与者的社会经济背景,这可能是影响他们的观点或批判性思维水平的因素。
Conclusion and future work
我们进行了一项研究,让人类参与者在社交媒体界面上与(假)新闻互动时被盯上他们。本研究的概念回答了相关文献所表达的需求:对假新闻的特征描述和检测的研究可以从人类行为分析中获益。这代表(1)“毫无戒心”的”用户的新闻消费和(2)新闻真实性评估,当用户积极寻找真实性线索时。观察前者有助于对假新闻现象的普遍理解。后者可以指导自动检测方法的创建。在本文中,我们贡献了本研究的设计,所得到的数据集和一些来自数据分析的发现。研究结果包括:
- 与没有考虑这个目标的浏览饲料相比,当参与者负责评估文章的准确性时,参与者的阅读行为受其兴趣的影响较小。
- 明确的行动(例如,喜欢,共享)很少被自发地使用(由于研究的局限性,正如预期的那样)。因此,它们的指示能力(对虚假检测)仍然值得怀疑。例外的是报告操作。在12次中,有10次是假文章。
- 与成功估计文章准确性的参与者相比,不成功的参与者更多地依赖于饲料中提供的信息,而不是实际的完整文章。
- 意见的强度反映了参与者对大多数主题的兴趣的强度。然而,在几个兴趣普遍较低的话题中,参与者有相对较强的观点和共同的极性。这很难解释,但它可能表明,人们经常受到外部环境的影响来形成他们的观点
我们看到了未来工作的多种途径。该研究的概念可以(也应该)用于更多的人口统计学群体。一旦记录的数据池更大,就会出现更多可观察到的稳定行为模式。这将允许在设计中引入更多的自变量。也就是说,更多的信息特性可以添加到当前的(相当于简化的)用户界面中。在当前的设置下,社会互动元素,如评论、赞、分享等。询问用户是如何(如果有的话)在这两个任务中考虑它们的是相关的。此外,文章来源和视觉设计的异质性(这在我们目前的工作中被保留了)也可以被纳入其中
另一个未来的工作途径是让事实核查专家(如记者、活动家、学者)作为类似研究的参与者。类似的,因为邀请这些人作为“毫无戒心”的”参与者参与消费任务没有多大意义(他们会知道他们具体邀请的原因)。然而,邀请专家参加任务2和任务3可以提供关于他们如何处理新闻真实性评估任务的有趣见解。
相关文章:
【Eye】Fake News Reading on Social Media: An Eye-tracking Study
Fake News Reading on Social Media: An Eye-tracking Study Abstract 在网上传播假新闻(以及一般的虚假信息)最近被认为是威胁整个社会的一个主要问题。这种传播在很大程度上是由于新的媒体形式,即社交网络和在线媒体网站。研究人员和从业…...

想学计算机,应该学什么专业?
我们在考虑想学计算机,应该学什么专业?这个问题的时候,每个人都应该结合自己的兴趣来确定。有的喜欢编程、有的喜欢设计、有的喜欢做产品跟人打交道……自己有兴趣再加上自己的努力,掌握好专业技能,就一定能进入高薪的…...

Android逆向之旅—反编译利器Apktool使用教程
apktool下载软件首先下载apktool.bat和apktool.jar官网地址:https://ibotpeaches.github.io/Apktool/install/配置环境变量具体的apktool命令自行百度apktool 解包与打包解包: apktool d xxx.apk打包: apktool b xxx1.jadx安装与使用下载exe或…...

色环电阻的阻值如何识别
这种是色环电阻,其外表有一圈圈不同颜色的色环,现在在一些电器和电源电路中还有使用。下面的两种色环电阻它颜色还不一样,一个蓝色,一个土黄色,其实这个蓝色的属于金属膜色环电阻,外表涂的是一层金属膜&…...
Dataway 让 Spring Boot 不再需要 Controller、Service、DAO、Mapper 简单接口直接开发。
新的sql语法可以先看一下官网,部署起来之后会用到Dataql: DataQL - 数据查询语言https://www.dataql.net/先看一下效果 接下来来实现一下。 1 创建spring boot项目 导入依赖 <!--begin dataWay--><!--hasor-spring 负责 Spring 和 Hasor 框架之…...
C#窗口介绍
窗口就是打开程序我们所面对的一个面板,里面可以添加各种控件,如下图所示,我们可以在属性栏设置其标题名称、图标、大小等。图1 窗口图 图2 设置面板 图3 设置双击标题框,会生成Load函数,也可以到事件里面去找Load函数…...
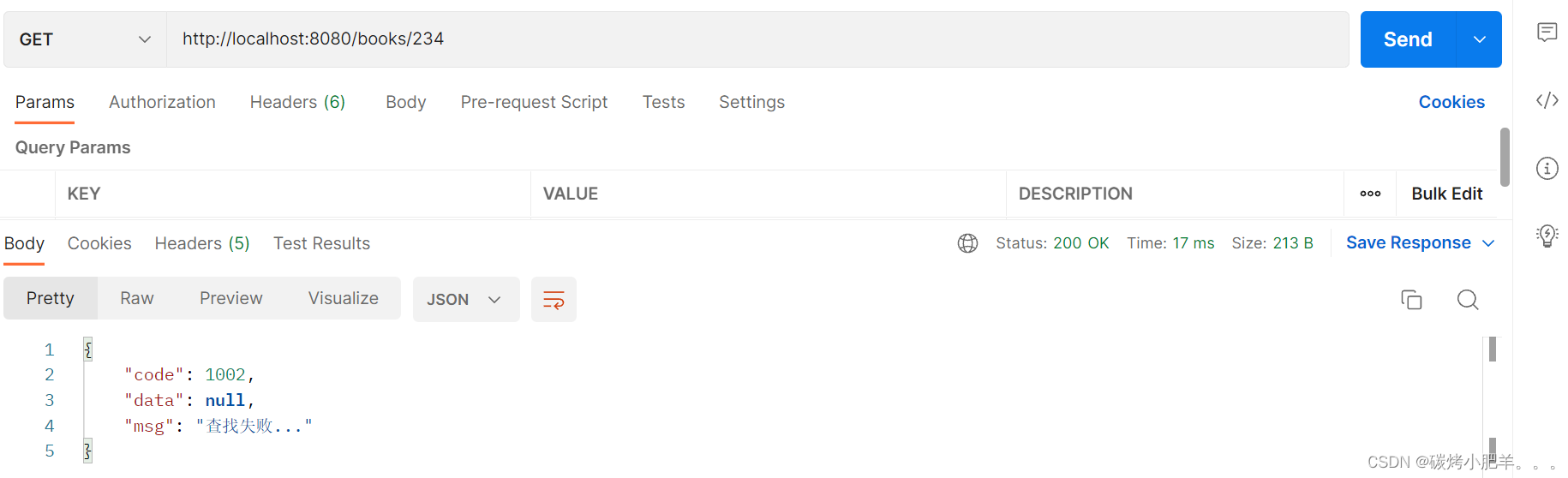
SpringBoot:SpringBoot整合Junit 和 MyBatis(3)
SpringBoot整合Junit 和 MyBatis1. SpringBoot整合Junit2. SpringBoot整合MyBatis2.1 定义SpringBoot项目2.2 定义dao接口2.3 定义service层2.4 定义controller层2.5 配置yml/yaml文件2.6 postman测试1. SpringBoot整合Junit 在com.example.service下创建BookService接口 publ…...

Web自动化测试框架Selenium
作者:霍格沃兹测试开发学社 链接:https://www.zhihu.com/question/59854292/answer/2827875817 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 什么是自动化测试 自动化测试就是࿰…...
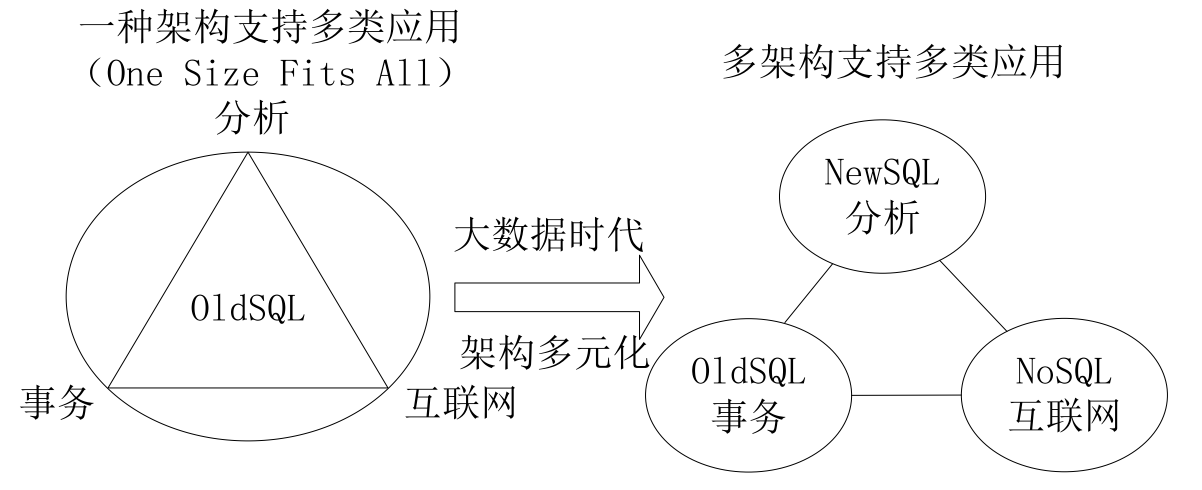
大数据系统自检
第一章 大数据计算系统概述 1.1 大数据计算框架概述 Hadoop Hadoop的运行过程(5个步骤?) split > map > shuffle > reduce > output Hadoop的详细运行过程?(4个大过程,6662) 创建…...
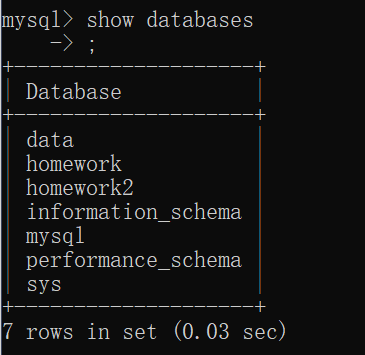
MySQL数据库操作
查看数据库语法show databases——列出所有的数据库 show databases [ like wild ];——列出和字符串wild名字相同的数据库 这里可以配合SQl的 "%" 和 "_" 通配符使用来查找多个数据库在SQL语句中"%"代表任意字符出现任意次数,"_"代表…...
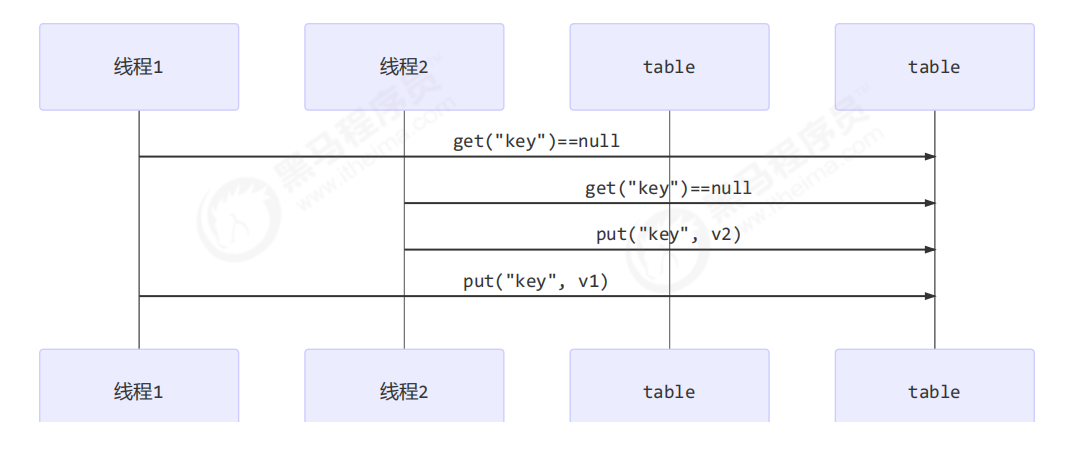
线程安全实例分析
一、变量的线程安全分析 成员变量和静态变量是否线程安全? ● 如果它们没有共享,则线程安全 ● 如果它们被共享了,根据它们的状态是否能够改变,又分两种情况 —— 如果只有读操作,则线程安全 —— 如果有读写操作&am…...
 Catalina初始化)
Tomcat源码分析-启动分析(二) Catalina初始化
Bootstrap Tomcat运行是通过Bootstrap的main方法,在开发工具中,我们只需要运行Bootstrap的main方法,便可以启动tomcat进行代码调试和分析。Bootstrap是tomcat的入口,它会完成初始化ClassLoader,实例化Catalina以及loa…...

基础复习第二十二天 泛型的使用
泛型JDK1.5设计了泛型的概念。泛型即为“类型参数”,这个类型参数在声明它的类、接口或方法中,代表未知的通用的类型。例如:java.lang.Comparable接口和java.util.Comparator接口,是用于对象比较大小的规范接口,这两个…...
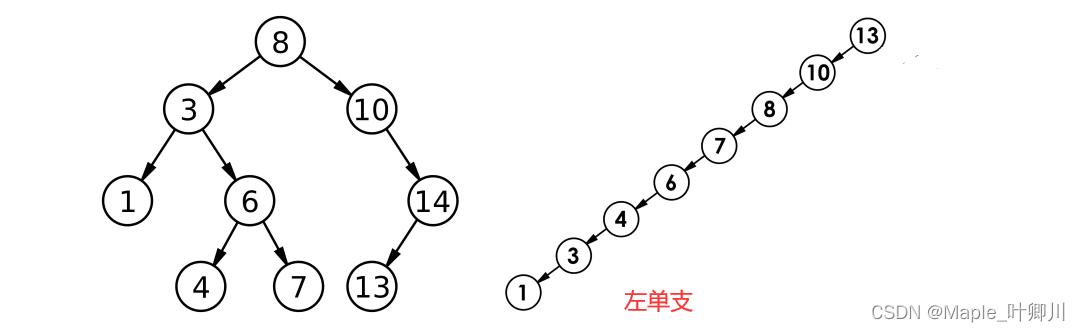
【C++进阶】三、二叉搜索树
目录 一、二叉搜索树 1.1 概念 1.2 二叉搜索树操作 二、二叉搜索树实现 2.1 框架总览 2.2 实现接口总览 2.2.1 构造函数 2.2.2 拷贝构造 2.2.3 赋值重载 2.2.4 析构函数 2.2.5 二叉搜索树的遍历 2.2.6 插入函数 2.2.7 查找函数 2.2.8 删除函数 2.3 二叉搜索数完整…...

电脑系统崩溃怎么修复教程
系统崩溃了怎么办? 如今的软件是越来越复杂、越来越庞大。由系统本身造成的崩溃即使是最简单的操作,比如关闭系统或者是对BIOS进行升级都可能会对PC合操作系统造成一定的影响。下面一起来看看电脑系统崩溃修复方法步骤。 工具/原料: 系统版本…...

语义分割数据标注案例分析
语义分割(Semantic Segmentation)是计算机视觉领域中的一种重要任务,它的目的是将图像中的每个像素分配到对应的语义类别中。简单来说,就是将一张图像分割成多个区域,并为每个像素指定一个标签,标识出它属于…...

回归预测 | MATLAB实现GRU(门控循环单元)多输入单输出(多指标评价)
回归预测 | MATLAB实现GRU(门控循环单元)多输入单输出(多指标评价) 文章目录 回归预测 | MATLAB实现GRU(门控循环单元)多输入单输出(多指标评价)预测效果基本介绍程序设计参考资料预测效果 基本介绍 GRU神经网络是LST...
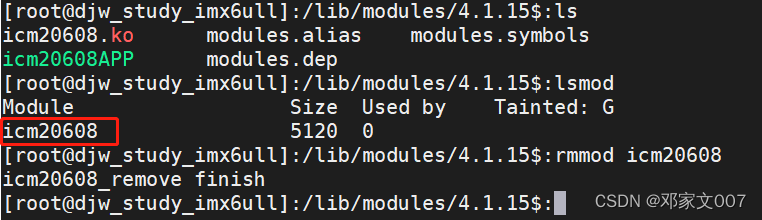
驱动程序开发:Buildroot根文件系统构建并加载驱动文件xxx.ko测试
目录一、buildroot根文件系统简介二、buildroot下载三、buildroot构建根文件系统1、配置 buildroot①配置 Target options②配置 Toolchain③配置 System configuration④配置 Filesystem images⑤禁止编译 Linux 内核和 uboot2、 buildroot 下的 busybox 配置①修改 Makefile&…...

R+VIC模型融合实践技术应用及未来气候变化模型预测
目录 理论专题一:VIC模型的原理及特点 综合案例一:基于QGIS的VIC模型建模 理论专题二:VIC模型率定验证 综合案例二:基于R语言VIC参数率定和优化 理论专题三:遥感技术与未来气候变化 综合案例三:运用V…...

第六章.决策树(Decision Tree)—ID3算法,C4.5算法
第六章.决策树(Decision Tree) 6.1 ID3算法,C4.5算法 1.决策树适用的数据类型 比较适合分析离散数据,如果是连续数据要先转换成离散数据再做分析 2.信息熵 1).概念: 一条信息的信息量大小和它的不确定性有直接的关系,要搞清楚一件非常不确…...

前端倒计时误差!
提示:记录工作中遇到的需求及解决办法 文章目录 前言一、误差从何而来?二、五大解决方案1. 动态校准法(基础版)2. Web Worker 计时3. 服务器时间同步4. Performance API 高精度计时5. 页面可见性API优化三、生产环境最佳实践四、终极解决方案架构前言 前几天听说公司某个项…...

Cilium动手实验室: 精通之旅---20.Isovalent Enterprise for Cilium: Zero Trust Visibility
Cilium动手实验室: 精通之旅---20.Isovalent Enterprise for Cilium: Zero Trust Visibility 1. 实验室环境1.1 实验室环境1.2 小测试 2. The Endor System2.1 部署应用2.2 检查现有策略 3. Cilium 策略实体3.1 创建 allow-all 网络策略3.2 在 Hubble CLI 中验证网络策略源3.3 …...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个医院挂号小程序
一、开发准备 环境搭建: 安装DevEco Studio 3.0或更高版本配置HarmonyOS SDK申请开发者账号 项目创建: File > New > Create Project > Application (选择"Empty Ability") 二、核心功能实现 1. 医院科室展示 /…...

Java 加密常用的各种算法及其选择
在数字化时代,数据安全至关重要,Java 作为广泛应用的编程语言,提供了丰富的加密算法来保障数据的保密性、完整性和真实性。了解这些常用加密算法及其适用场景,有助于开发者在不同的业务需求中做出正确的选择。 一、对称加密算法…...

反射获取方法和属性
Java反射获取方法 在Java中,反射(Reflection)是一种强大的机制,允许程序在运行时访问和操作类的内部属性和方法。通过反射,可以动态地创建对象、调用方法、改变属性值,这在很多Java框架中如Spring和Hiberna…...

【JavaSE】绘图与事件入门学习笔记
-Java绘图坐标体系 坐标体系-介绍 坐标原点位于左上角,以像素为单位。 在Java坐标系中,第一个是x坐标,表示当前位置为水平方向,距离坐标原点x个像素;第二个是y坐标,表示当前位置为垂直方向,距离坐标原点y个像素。 坐标体系-像素 …...

OPenCV CUDA模块图像处理-----对图像执行 均值漂移滤波(Mean Shift Filtering)函数meanShiftFiltering()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 在 GPU 上对图像执行 均值漂移滤波(Mean Shift Filtering),用于图像分割或平滑处理。 该函数将输入图像中的…...
)
Android第十三次面试总结(四大 组件基础)
Activity生命周期和四大启动模式详解 一、Activity 生命周期 Activity 的生命周期由一系列回调方法组成,用于管理其创建、可见性、焦点和销毁过程。以下是核心方法及其调用时机: onCreate() 调用时机:Activity 首次创建时调用。…...

如何更改默认 Crontab 编辑器 ?
在 Linux 领域中,crontab 是您可能经常遇到的一个术语。这个实用程序在类 unix 操作系统上可用,用于调度在预定义时间和间隔自动执行的任务。这对管理员和高级用户非常有益,允许他们自动执行各种系统任务。 编辑 Crontab 文件通常使用文本编…...

OD 算法题 B卷【正整数到Excel编号之间的转换】
文章目录 正整数到Excel编号之间的转换 正整数到Excel编号之间的转换 excel的列编号是这样的:a b c … z aa ab ac… az ba bb bc…yz za zb zc …zz aaa aab aac…; 分别代表以下的编号1 2 3 … 26 27 28 29… 52 53 54 55… 676 677 678 679 … 702 703 704 705;…...