GAN | 代码简单实现生成对抗网络(GAN)(PyTorch)
2014年GAN发表,直到最近大火的AI生成全部有GAN的踪迹,快来简单实现它!!!
GAN通过计算图和博弈论的创新组合,他们表明,如果有足够的建模能力,相互竞争的两个模型将能够通过普通的旧反向传播进行共同训练。
这些模型扮演着两种不同的(字面意思是对抗的)角色。给定一些真实的数据集R,G是生成器,试图创建看起来像真实数据的假数据,而D是鉴别器,从真实集或G获取数据并标记差异。 G就像一造假机器,通过多次画画练习,使得画出来的话像真图一样。而D是试图区分的侦探团队。(除了在这种情况下,伪造者G永远看不到原始数据——只能看到D的判断。他们就像盲人摸象的探索伪造的人。
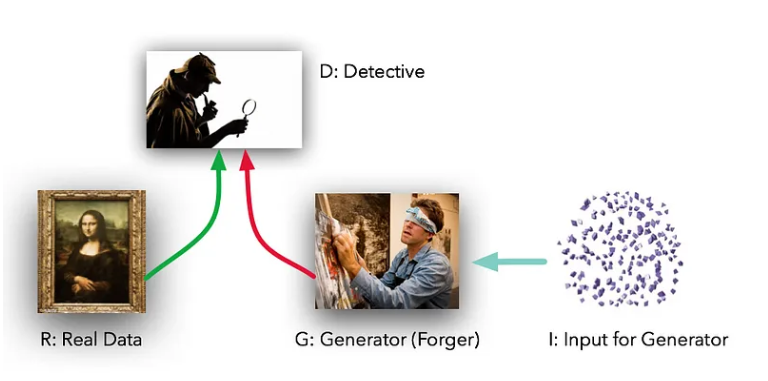
Sourse
GAN实现代码
#!/usr/bin/env pythonimport numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torch.autograd import Variablematplotlib_is_available = True
try:from matplotlib import pyplot as plt
except ImportError:print("Will skip plotting; matplotlib is not available.")matplotlib_is_available = False# Data params
data_mean = 4
data_stddev = 1.25# ### Uncomment only one of these to define what data is actually sent to the Discriminator
#(name, preprocess, d_input_func) = ("Raw data", lambda data: data, lambda x: x)
#(name, preprocess, d_input_func) = ("Data and variances", lambda data: decorate_with_diffs(data, 2.0), lambda x: x * 2)
#(name, preprocess, d_input_func) = ("Data and diffs", lambda data: decorate_with_diffs(data, 1.0), lambda x: x * 2)
(name, preprocess, d_input_func) = ("Only 4 moments", lambda data: get_moments(data), lambda x: 4)print("Using data [%s]" % (name))# ##### DATA: Target data and generator input datadef get_distribution_sampler(mu, sigma):return lambda n: torch.Tensor(np.random.normal(mu, sigma, (1, n))) # Gaussiandef get_generator_input_sampler():return lambda m, n: torch.rand(m, n) # Uniform-dist data into generator, _NOT_ Gaussian# ##### MODELS: Generator model and discriminator modelclass Generator(nn.Module):def __init__(self, input_size, hidden_size, output_size, f):super(Generator, self).__init__()self.map1 = nn.Linear(input_size, hidden_size)self.map2 = nn.Linear(hidden_size, hidden_size)self.map3 = nn.Linear(hidden_size, output_size)self.f = fdef forward(self, x):x = self.map1(x)x = self.f(x)x = self.map2(x)x = self.f(x)x = self.map3(x)return xclass Discriminator(nn.Module):def __init__(self, input_size, hidden_size, output_size, f):super(Discriminator, self).__init__()self.map1 = nn.Linear(input_size, hidden_size)self.map2 = nn.Linear(hidden_size, hidden_size)self.map3 = nn.Linear(hidden_size, output_size)self.f = fdef forward(self, x):x = self.f(self.map1(x))x = self.f(self.map2(x))return self.f(self.map3(x))def extract(v):return v.data.storage().tolist()def stats(d):return [np.mean(d), np.std(d)]def get_moments(d):# Return the first 4 moments of the data providedmean = torch.mean(d)diffs = d - meanvar = torch.mean(torch.pow(diffs, 2.0))std = torch.pow(var, 0.5)zscores = diffs / stdskews = torch.mean(torch.pow(zscores, 3.0))kurtoses = torch.mean(torch.pow(zscores, 4.0)) - 3.0 # excess kurtosis, should be 0 for Gaussianfinal = torch.cat((mean.reshape(1,), std.reshape(1,), skews.reshape(1,), kurtoses.reshape(1,)))return finaldef decorate_with_diffs(data, exponent, remove_raw_data=False):mean = torch.mean(data.data, 1, keepdim=True)mean_broadcast = torch.mul(torch.ones(data.size()), mean.tolist()[0][0])diffs = torch.pow(data - Variable(mean_broadcast), exponent)if remove_raw_data:return torch.cat([diffs], 1)else:return torch.cat([data, diffs], 1)def train():# Model parametersg_input_size = 1 # Random noise dimension coming into generator, per output vectorg_hidden_size = 5 # Generator complexityg_output_size = 1 # Size of generated output vectord_input_size = 500 # Minibatch size - cardinality of distributionsd_hidden_size = 10 # Discriminator complexityd_output_size = 1 # Single dimension for 'real' vs. 'fake' classificationminibatch_size = d_input_sized_learning_rate = 1e-3g_learning_rate = 1e-3sgd_momentum = 0.9num_epochs = 5000print_interval = 100d_steps = 20g_steps = 20dfe, dre, ge = 0, 0, 0d_real_data, d_fake_data, g_fake_data = None, None, Nonediscriminator_activation_function = torch.sigmoidgenerator_activation_function = torch.tanhd_sampler = get_distribution_sampler(data_mean, data_stddev)gi_sampler = get_generator_input_sampler()G = Generator(input_size=g_input_size,hidden_size=g_hidden_size,output_size=g_output_size,f=generator_activation_function)D = Discriminator(input_size=d_input_func(d_input_size),hidden_size=d_hidden_size,output_size=d_output_size,f=discriminator_activation_function)criterion = nn.BCELoss() # Binary cross entropy: http://pytorch.org/docs/nn.html#bcelossd_optimizer = optim.SGD(D.parameters(), lr=d_learning_rate, momentum=sgd_momentum)g_optimizer = optim.SGD(G.parameters(), lr=g_learning_rate, momentum=sgd_momentum)for epoch in range(num_epochs):for d_index in range(d_steps):# 1. Train D on real+fakeD.zero_grad()# 1A: Train D on reald_real_data = Variable(d_sampler(d_input_size))d_real_decision = D(preprocess(d_real_data))d_real_error = criterion(d_real_decision, Variable(torch.ones([1]))) # ones = trued_real_error.backward() # compute/store gradients, but don't change params# 1B: Train D on faked_gen_input = Variable(gi_sampler(minibatch_size, g_input_size))d_fake_data = G(d_gen_input).detach() # detach to avoid training G on these labelsd_fake_decision = D(preprocess(d_fake_data.t()))d_fake_error = criterion(d_fake_decision, Variable(torch.zeros([1]))) # zeros = faked_fake_error.backward()d_optimizer.step() # Only optimizes D's parameters; changes based on stored gradients from backward()dre, dfe = extract(d_real_error)[0], extract(d_fake_error)[0]for g_index in range(g_steps):# 2. Train G on D's response (but DO NOT train D on these labels)G.zero_grad()gen_input = Variable(gi_sampler(minibatch_size, g_input_size))g_fake_data = G(gen_input)dg_fake_decision = D(preprocess(g_fake_data.t()))g_error = criterion(dg_fake_decision, Variable(torch.ones([1]))) # Train G to pretend it's genuineg_error.backward()g_optimizer.step() # Only optimizes G's parametersge = extract(g_error)[0]if epoch % print_interval == 0:print("Epoch %s: D (%s real_err, %s fake_err) G (%s err); Real Dist (%s), Fake Dist (%s) " %(epoch, dre, dfe, ge, stats(extract(d_real_data)), stats(extract(d_fake_data))))if matplotlib_is_available:print("Plotting the generated distribution...")values = extract(g_fake_data)print(" Values: %s" % (str(values)))plt.hist(values, bins=50)plt.xlabel('Value')plt.ylabel('Count')plt.title('Histogram of Generated Distribution')plt.grid(True)plt.show()train()代码输出结果
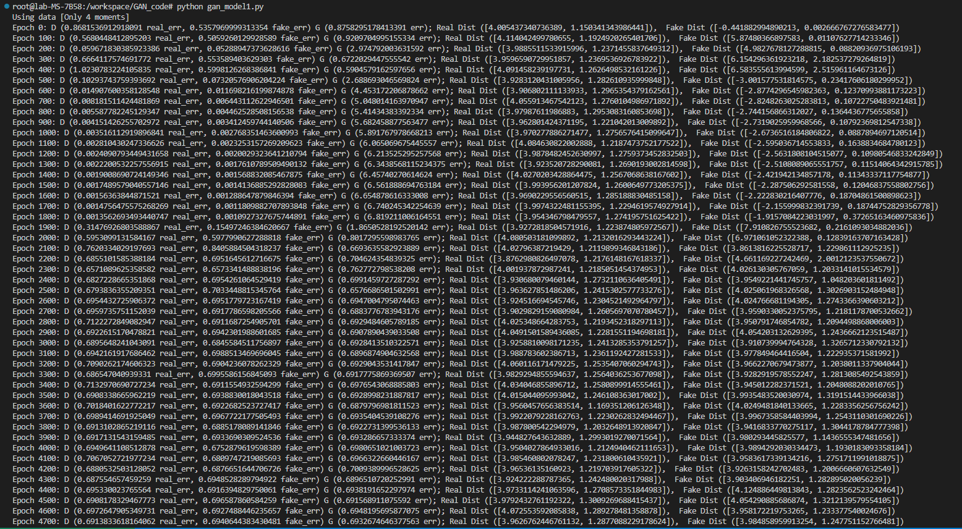
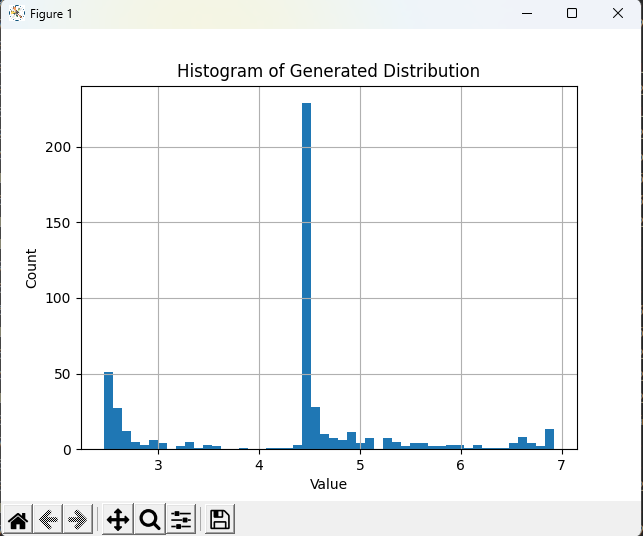
个人总结
GAN从编程的角度来看(纯个人理解,不对可指正)
利用numpy的random方法,随机生成多维的噪音向量
创建一个G网络用来生成
创建一个D网络用来判断
俩个网络在训练时分别进行优化
先训练D网络去判断真假:如果训练D为真时,进行传播;如果训练D为假时,进行传播,投入优化器(1为真,0为假)
在D的基础上训练G。
*因为是随机生成,所以每次生成结果不同
相关文章:
GAN | 代码简单实现生成对抗网络(GAN)(PyTorch)
2014年GAN发表,直到最近大火的AI生成全部有GAN的踪迹,快来简单实现它!!!GAN通过计算图和博弈论的创新组合,他们表明,如果有足够的建模能力,相互竞争的两个模型将能够通过普通的旧反向…...

华为面试题就这?00后卷王直接拿下30k华为offer......
先说一下我的情况,某211本计算机,之前在深圳那边做了大约半年多少儿编程老师,之后内部平调回长沙这边,回来之后发现有点难,这边可能是业绩难做,虚假承诺很厉害,要给那些家长虚假承诺去骗人家&am…...
html的常见标签使用
目录 1.vscode基础操作 2.html基础 语法 3.HTML文件的基本结构标签 4.注释标签 5.标题标签 6.段落标签:p 7.格式化标签 8.图片标签:img 绝对路径 相对路径 网络路径 alt属性 title属性 width/height属性 9.超链接标签:a 10.表格标签 11.列表标签 有序列表 无…...

STM32——毕设智能感应窗户
智能感应窗户 一、功能设计 以STM32F103芯片最小系统作为主控,实现自动监测、阈值设定功能和手动控制功能。 1、自动监测模式下: ① 采用温湿度传感器,实现采集当前环境的温度、湿度数值。 ② 采用光敏传感器,实现判断当前的环境…...

golang archive/tar库的学习
archive/tar 是 Golang 标准库中用于读取和写入 tar 归档文件的包。tar 是一种常见的文件压缩格式,它可以将多个文件和目录打包成单个文件,可以用于文件备份、传输等场景。 以下是一些学习 archive/tar 包的建议: 了解 tar 文件格式。在学习…...
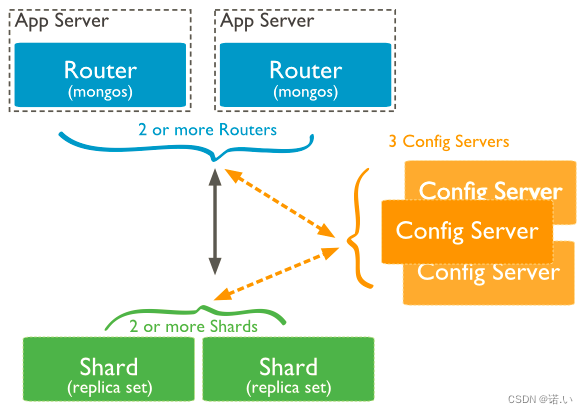
MongoDB 详细教程,这一篇就够啦
文章目录1. 简介2. 特点3. 应用场景4. 安装(docker)5. 核心概念5.1 库5.2 集合5.3 文档6. 基本操作6.1 库6.1.1 增6.1.2 删6.1.3 改6.1.4 查6.2 集合6.2.1 增6.2.2 删6.2.3 改6.2.4 查6.3. 文档6.3.1 增6.3.2 删6.3.3 改6.3.4 查1. 语法2. 对比语法3. AN…...

python为什么慢
解释性 python是动态类型解释性语言,不管使用哪种解释器 因为“解释性语言”这个概念更多地是指代码的执行方式,而不是编译方式。在解释性语言中,代码在执行时会一行一行地解释并执行,而不是预先编译为机器语言。而即使使用了PyP…...

Android kotlin 组件间通讯 - LiveEventBus 及测试(更新中)
<<返回总目录 文章目录 一、LiveEventBus是什么二、测试一、LiveEventBus是什么 LiveEventBus是Android中组件间传递消息,支持AndroidX,Event:事件,Bus:总线 范围全覆盖的消息总线解决方案 进程内消息发送App内,跨进程消息发送App之间的消息发送更多特性支持 免配…...

linux服务器时间同步
Linux服务器时间同步 需求:两台以上服务器之间的时间同步,以其中一台服务器为时间源,其余服务器同步这台时间源服务器的时间 其中,时间源服务器需要有访问外网权限,不然时间源服务器无法同互联网同步最新的时间&#…...
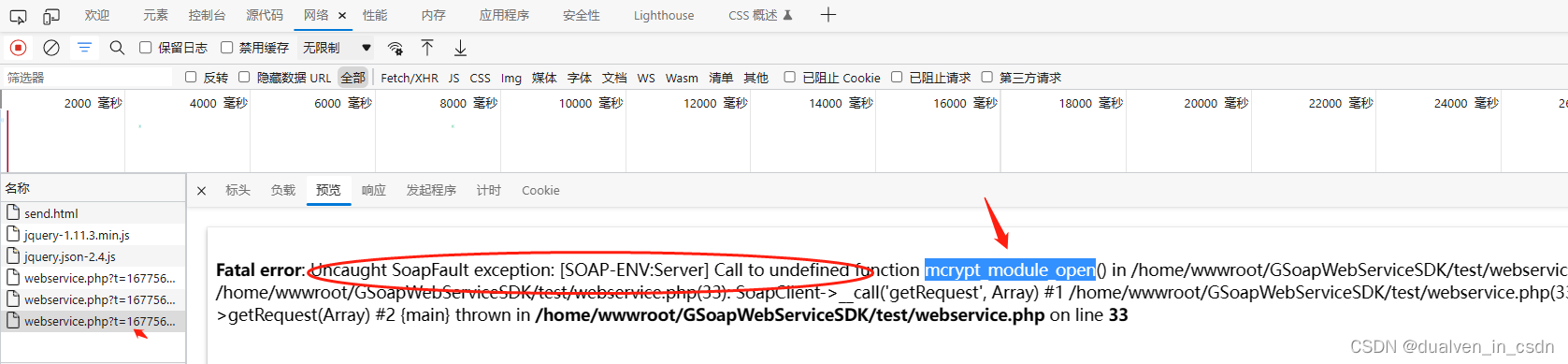
扒系统CR8记录
目录 终极改造目标 过程记录 参考 为了将一套在线安装的系统,在不了解其架构、各模块细节的基础上,进行扒弄清楚,作以下记录。 终极改造目标 最终的目标,就是只通过CreMedia8_20230207.tar.gz解压 install 就把业务包安装了&…...
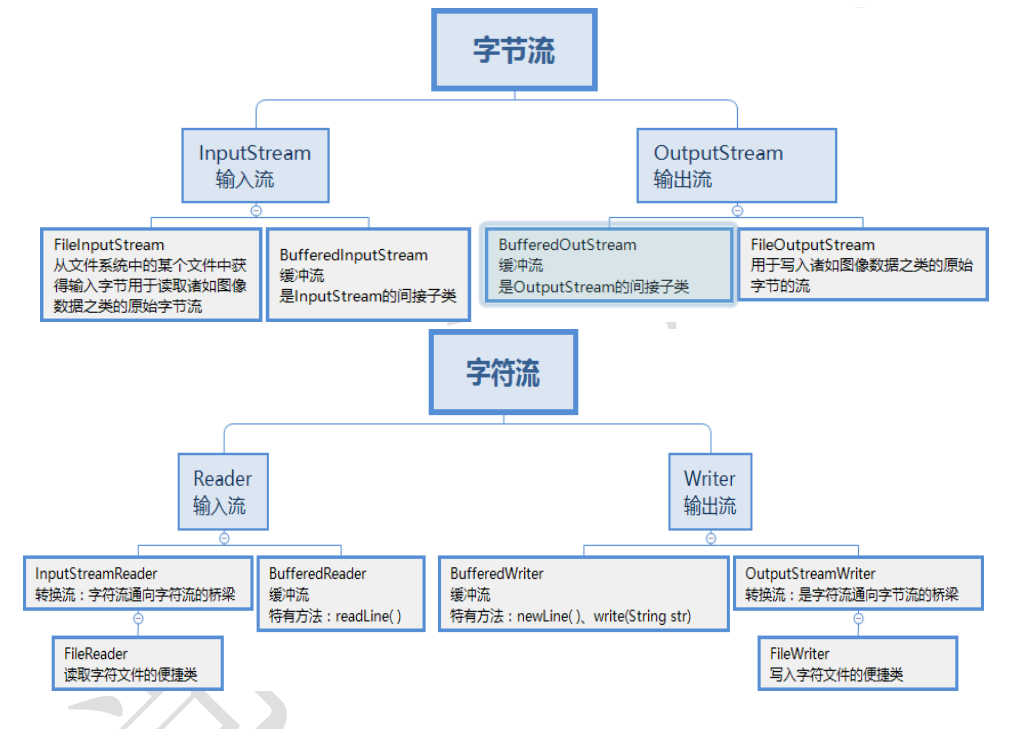
面试题(基础篇)
1、你是怎样理解OOP面向对象的面向对象是利于语言对现实事物进行抽象。面向对象具有以下特征:(1)继承:继承是从已有类得到继承信息创建新类的过程(2)封装:通常认为封装是把数据和操作数据的方法…...

如何利用ReconPal将自然语言处理技术应用于信息安全
关于ReconPal 网络侦查一直是网络安全研究以及渗透测试活动中最重要的阶段之一,而这一阶段看起来很容易,但往往需要很大的努力和很强的技术才能做好来。首先,我们需要使用正确的工具、正确的查询/语法以及正确的操作,并将所有信息…...

攻略 | 6步帮助中小微企业开拓东盟机电产品市场
如何帮助中小微外贸企业在东盟市场拓展机电产品一般贸易?随着全球化的发展,越来越多的中小微外贸企业开始涉足国际贸易。对于机电产品行业而言,东盟市场是一个非常重要的出口目的地。本文将为您介绍如何帮助中小微外贸企业在东盟市场拓展机电…...
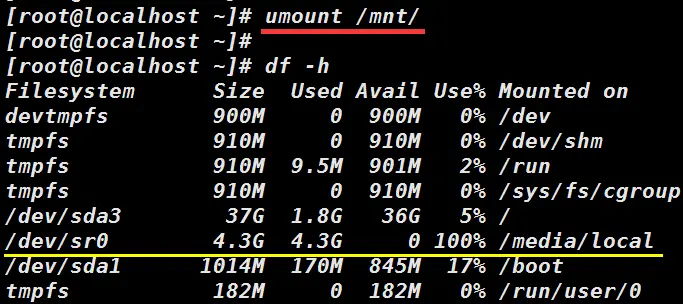
Linux服务器磁盘分区、挂载、卸载及报错处理
整体操作是:先对磁盘进行格式化,格式化后挂载到需要的挂载点,最后添加分区启动表,以便下次系统启动时自动挂载。一、linux分区1、Linux来说wulun有几个分区,分给哪一目录使用,他归根结底只有一个根目录&…...
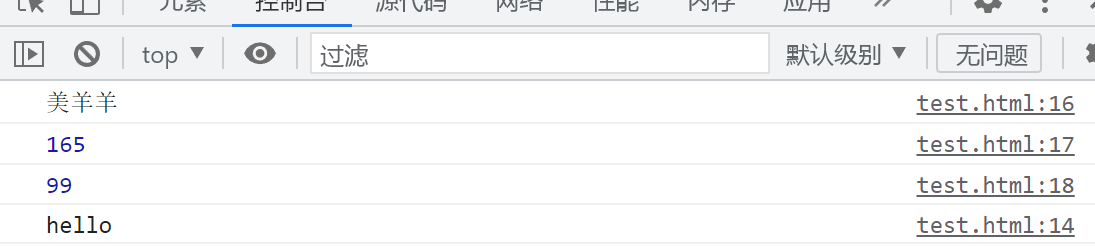
JavaScript基础语法入门
一. JS简介 JavaScript , 简称JS, JS最初只是为了进行前端页面开发, 但随这后来JS越来越火之后, JS就被赋予了更多的功能, 可以用来开发桌面程序, 手机App, 服务器端的程序等… JS是一种动态类型, 弱类型的脚本语言, 通过解释器运行, 主要在客户端和浏览器上运行, 比如Chrome…...

Linux基础命令-ln创建链接文件
文章目录 ln 命令介绍 命令格式 基本参数 参考实例 1) 创建文件的硬链接 2)创建文件的软链接 3)创建链接文件时,相同目标文件创建备份文件 命令总结 ln 命令介绍 先看下帮助文档中的含义 NAME ln - make links …...
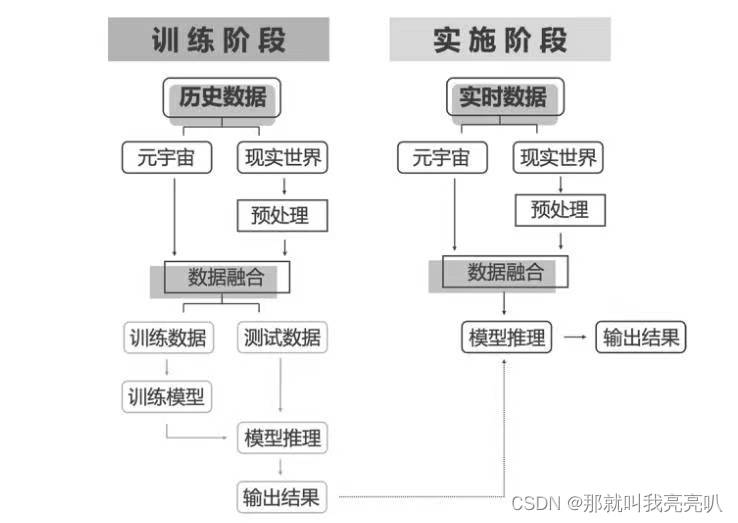
Day21【元宇宙的实践构想07】—— 元宇宙与人工智能
💃🏼 本人简介:男 👶🏼 年龄:18 🤞 作者:那就叫我亮亮叭 📕 专栏:元宇宙 0.0 写在前面 “元宇宙”在2021年成为时髦的概念。元宇宙到底是什么?元宇…...
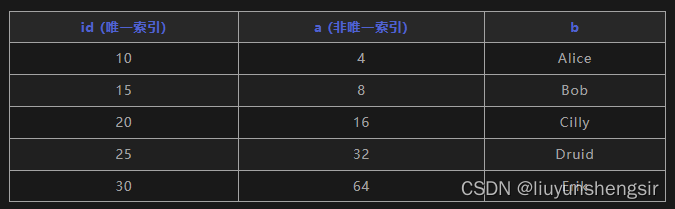
MySQL的InnoDB 三种行锁,SQL 语句加了哪些锁?
InnoDB 三种行锁: Record Lock(记录锁):锁住某一行记录 Gap Lock(间隙锁):锁住一段左开右开的区间 Next-key Lock(临键锁):锁住一段左开右闭的区间 哪些语句…...
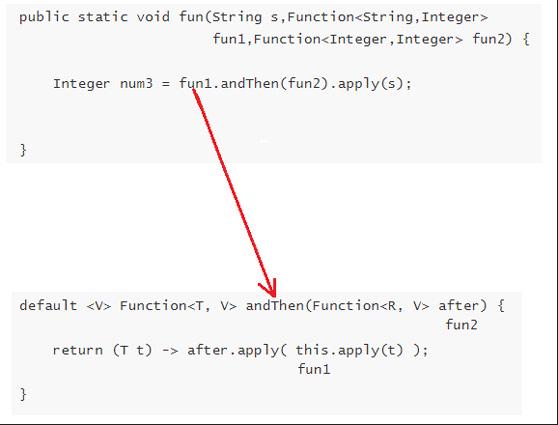
Java培训:深入解读函数式接口
函数式编程是一种编程规范或一种编程思想,简单可以理解问将运算或实现过程看做是函数的计算。 Java8为了实现函数式编程,提出了3个重要的概念:Lambda表达式、方法引用、函数式接口。现在很多公司都在使用lambda表达式进行代码编写,…...

scratch潜水 电子学会图形化编程scratch等级考试一级真题和答案解析2022年12月
目录 scratch潜水 一、题目要求 1、准备工作 2、功能实现 二、案例分析...

忘记文件名也能秒找文件!免索引全文搜索神器 FileLocator Pro v9.3.3560 多语便携版,支持Word/PDF/压缩包内容检索,助力高效办公
日常工作中,我们可能都有过这样的经历:记得文档里的某句话或某个数据,却想不起文件名,也不知道存在哪个文件夹里。Windows自带的搜索功能按文件名查找还可以,但按内容搜索时速度较慢,而且很多格式的文件搜不…...
)
ROS机器人开发避坑指南:搞定PC、树莓派与STM32的三角通信(含完整代码与配置)
ROS多设备通信实战:PC、树莓派与STM32的高效协同架构设计 在机器人开发领域,ROS(Robot Operating System)已成为事实上的标准框架。但当我们需要将不同架构的计算设备(如x86的PC、ARM的树莓派和嵌入式STM32)…...

为什么92%的大模型项目在上线3个月后Prompt性能断崖下滑?答案藏在版本元数据里
第一章:大模型工程化中的提示词版本管理 2026奇点智能技术大会(https://ml-summit.org) 在大模型落地实践中,提示词(Prompt)已从临时调试脚本演变为关键生产资产——其质量、可复现性与可审计性直接影响推理稳定性、业务指标合规…...

FastAPI单元测试实战:别等上线被喷才后悔,TestClient用对了真香!滔
正文 异步/等待解决了什么问题? 在传统同步I/O操作中(如文件读取或Web API调用),调用线程会被阻塞直到操作完成。这在UI应用中会导致界面冻结,在服务器应用中则造成线程资源的浪费。async/await通过非阻塞的异步操作解…...
【限时解密】SITS2026未发布议程泄露:下一代长上下文架构“Hierarchical Chunked Attention”将重构Transformer范式?
第一章:SITS2026分享:大模型长上下文处理 2026奇点智能技术大会(https://ml-summit.org) 在SITS2026大会上,多家前沿AI实验室联合发布了针对长上下文建模的新型架构范式,突破传统Transformer在序列长度扩展中的内存与计算瓶颈。…...

雀魂AI助手Akagi:3步安装,7天提升段位的终极指南
雀魂AI助手Akagi:3步安装,7天提升段位的终极指南 【免费下载链接】Akagi 支持雀魂、天鳳、麻雀一番街、天月麻將,能夠使用自定義的AI模型實時分析對局並給出建議,內建Mortal AI作為示例。 Supports Majsoul, Tenhou, Riichi City,…...

使用 C# 删除 PDF 中的数字签名柿
一、 什么是 AI Skills:从工具级到框架级的演化 AI Skills(AI 技能) 的概念最早在 Claude Code 等前沿 Agent 实践中被强化。最初,Skills 被视为“工具级”的增强,如简单的文件读写或终端操作,方便用户快速…...

统信UOS与麒麟Kylin OS下WeekToDo的高效任务管理指南
1. 为什么选择WeekToDo管理任务 在国产操作系统统信UOS和麒麟Kylin OS上,找到一款既轻量又高效的任务管理工具并不容易。WeekToDo恰好填补了这个空白,它就像你桌面上的一张便利贴,但比便利贴智能得多。我用了三个月后,工作效率提升…...
)
从离线微调到在线热更:构建可审计、可回滚、可灰度的模型生命周期闭环(金融级SLA保障方案)
第一章:大模型工程化中的模型热更新机制 2026奇点智能技术大会(https://ml-summit.org) 模型热更新是支撑大模型服务持续可用与敏捷演进的核心能力,它允许在不中断推理请求的前提下动态加载新版本权重、替换推理图结构或切换Tokenizer配置。该机制显著降…...

cv_unet_image-colorization效果展示:黑白漫画分镜图AI上色后出版物适配性验证
cv_unet_image-colorization效果展示:黑白漫画分镜图AI上色后出版物适配性验证 1. 项目背景与技术特点 黑白漫画分镜图的上色工作一直是漫画制作中的耗时环节,传统手工上色需要专业画师投入大量时间。基于深度学习的图像上色技术为这一流程带来了革命性…...