20- widedeep及函数式构建模型 (TensorFlow系列) (深度学习)
知识要点
- wide&deep: 模型构建中, 卷积后数据和原始数据结合进行输出.
- fetch_california_housing:加利福尼亚的房价数据,总计20640个样本,每个样本8个属性表示,以及房价作为target,所有属性值均为number,详情可调用fetch_california_housing()['DESCR']了解每个属性的具体含义;目标值为连续值
- wide&deep结合: concat = keras.layers.concatenate([input, hidden2]) # 将卷积后的结果和原始的输入值进行结合
- mse: 均方误差
- 多输入wide&deep模型: concat = keras.layers.concatenate([input_wide, hidden2]) # 定义两个输入创建模型, 然后其中一个进行深度卷积, 另一个直接用来结合卷积后的结果. 同时注意需要对输入特征数据进行调整.
- model = keras.models.Model(inputs=[input_wide,input_deep],outputs =[output,output2]) # 多输入输出
- 定义模型回调函数: # log_dir 文件夹目录
callbacks = [keras.callbacks.TensorBoard(log_dir),keras.callbacks.ModelCheckpoint(output_model_file, save_best_only = True),keras.callbacks.EarlyStopping(patience = 5, min_delta = 1e-3)]- 函数式实现wide&deep的方法:
# 子类API的写法, pytch
class WideDeepModel(keras.models.Model):def __init__(self):'''定义模型的层次'''super().__init__()self.hidden1 = keras.layers.Dense(32, activation = 'relu')self.hidden2 = keras.layers.Dense(32, activation = 'relu')self.output_layer = keras.layers.Dense(1)def call(self, input):'''完成模型的正向传播'''hidden1 = self.hidden1(input)hidden2 = self.hidden2(hidden1)# 拼接concat = keras.layers.concatenate([input, hidden2])output = self.output_layer(concat)return output'''定义实例对象'''
model = WideDeepModel()
model.build(input_shape = (None, 8))1 wide and deep模型
1.1 背景
Wide and deep 模型是 TensorFlow 在 2016 年 6 月左右发布的一类用于分类和回归的模型,并应用到了 Google Play 的应用推荐中。wide and deep 模型的核心思想是结合线性模型的记忆能力(memorization)和 DNN 模型的泛化能力(generalization),在训练过程中同时优化 2 个模型的参数,从而达到整体模型的预测能力最优。
记忆(memorization)即从历史数据中发现item或者特征之间的相关性。
泛化(generalization)即相关性的传递,发现在历史数据中很少或者没有出现的新的特征组合。
1.2 网络结构原理
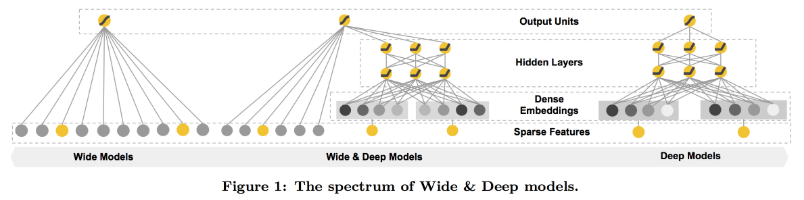
1.3 稀疏特征
离散值特征: 只能从N个值中选择一个
-
比如性别, 只能是男女
-
one-hot编码表示的离散特征, 我们就认为是稀疏特征.
-
Eg: 专业= {计算机, 人文, 其他}, 人文 = [0, 1, 0]
-
Eg: 词表 = {人工智能,深度学习,你, 我, 他 , ..} 他= [0, 0, 0, 0, 1, 0, ...]
-
叉乘 = {(计算机, 人工智能), (计算机, 你)...}
-
叉乘可以用来精确刻画样本, 实现记忆效果.
-
优点:
-
有效, 广泛用于工业界, 比如广告点击率预估(谷歌, 百度的主要业务), 推荐算法.
-
-
缺点:
-
需要人工设计.
-
叉乘过度, 可能过拟合, 所有特征都叉乘, 相当于记住了每一个样本.
-
泛化能力差, 没出现过就不会起效果
-
密集特征
-
向量表达
-
Eg: 词表 = {人工智能, 我们, 他}
-
他 = [0.3, 0.2, 0.6, ...(n维向量)]
-
每个词都可以用一个密集向量表示, 那么词和词之间就可以计算距离.
-
-
Word2vec工具可以方便的将词语转化为向量.
-
男 - 女 = 国王 - 王后
-
-
优点:
-
带有语义信息, 不同向量之间有相关性.
-
兼容没有出现过的特征组合.
-
更少人工参与
-
-
缺点:
-
过度泛化, 比如推荐不怎么相关的产品.
-
1.4 简单神经网络实现回归任务 (加利福尼亚州房价数据)
- concat = keras.layers.concatenate([input, hidden2])
1.4.1 导包
from tensorflow import keras
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from sklearn.model_selection import train_test_split1.4.2 加利福尼亚州房价数据导入
from sklearn.datasets import fetch_california_housing
housing = fetch_california_housing()x_train_all, x_test, y_train_all, y_test = train_test_split(housing.data,housing.target,random_state= 7)
x_train, x_valid, y_train, y_valid = train_test_split(x_train_all, y_train_all,random_state = 11)1.4.3 标准化数据
from sklearn.preprocessing import StandardScaler, MinMaxScaler
scaler =StandardScaler()
x_train_scaled = scaler.fit_transform(x_train)
x_valid_scaled = scaler.transform(x_valid)
x_test_scaled = scaler.transform(x_test)1.4.4 基础神经网络 实现回归任务
# 定义网络
model = keras.models.Sequential([# input_dim是传入数据, input_shape一定要是元组keras.layers.Dense(128, activation = 'relu', input_shape = x_train.shape[1:]),keras.layers.Dense(64, activation = 'tanh'),keras.layers.Dense(1)])
1.4.5 配置和训练模型
# 配置
model.compile(loss = 'mean_squared_error', optimizer = 'sgd', metrics = ['mse'])
# epochs 迭代次数
history = model.fit(x_train_scaled, y_train, validation_data = (x_valid_scaled, y_valid), epochs = 30)
1.4.6 图文显示
# 定义画图函数, 看是否过拟合
def plot_learning_curves(history):pd.DataFrame(history.history).plot(figsize = (8, 5))plt.grid(True)plt.gca().set_ylim(0, 1)plt.show()
plot_learning_curves(history)
1.5 定义回调函数
- 回调函数中添加保存最佳参数的模型
- 定义提前停止的条件 # 连续多少次变化幅度小于某值时停止训练
log_dir = './callback'
if not os.path.exists(log_dir): # 如果没有直接创建os.mkdir(log_dir)# 模型文件保存格式, 一般为h5, 会保存层级
output_model_file = os.path.join(log_dir, 'model.h5') callbacks = [keras.callbacks.TensorBoard(log_dir),keras.callbacks.ModelCheckpoint(output_model_file, save_best_only = True),keras.callbacks.EarlyStopping(patience = 5, min_delta = 1e-3)]
# epochs 迭代次数
history = model.fit(x_train_scaled,y_train,validation_data =(x_valid_scaled,y_valid),epochs = 50, callbacks = callbacks)
2 多输入 wide&deep模型
2.1 wide&deep模型 (内部进行结合)
input = keras.layers.Input(shape = x_train.shape[1:]) # (11610, 8)
hidden1 = keras.layers.Dense(32, activation = 'relu')(input)
hidden2 = keras.layers.Dense(32, activation = 'relu')(hidden1)concat = keras.layers.concatenate([input, hidden2])
output = keras.layers.Dense(1)(concat)
model = keras.models.Model(inputs = [input], outputs = output)
model.compile(loss = 'mean_squared_error', optimizer = 'Adam', metrics= ['mse'])
history = model.fit(x_train_scaled, y_train,validation_data = (x_valid_scaled, y_valid),epochs= 20)
import pandas as pd
def plot_learning_curves(history):pd.DataFrame(history.history).plot(figsize = (8, 5))plt.grid(True)plt.gca().set_ylim(0, 1)plt.show()
plot_learning_curves(history)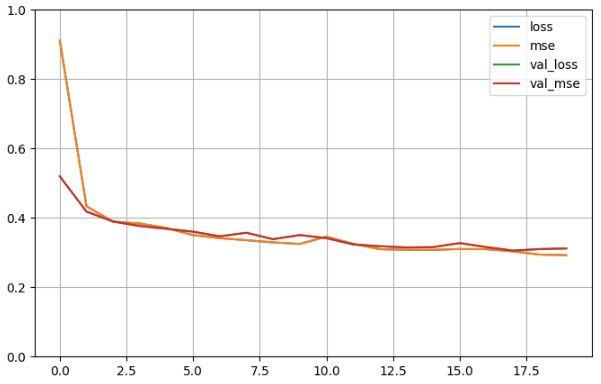
2.2 wide&deep方式二 (多输入)
- 定义两个输入创建模型
# 多输入
# 定义两个输入
input_wide = keras.layers.Input(shape = [5])
input_deep = keras.layers.Input(shape = [6])hidden1 = keras.layers.Dense(30, activation = 'relu')(input_deep)
hidden2 = keras.layers.Dense(30, activation = 'relu')(hidden1)
concat = keras.layers.concatenate([input_wide, hidden2])
output = keras.layers.Dense(1)(concat)model = keras.models.Model(inputs = [input_wide, input_deep], outputs =[output])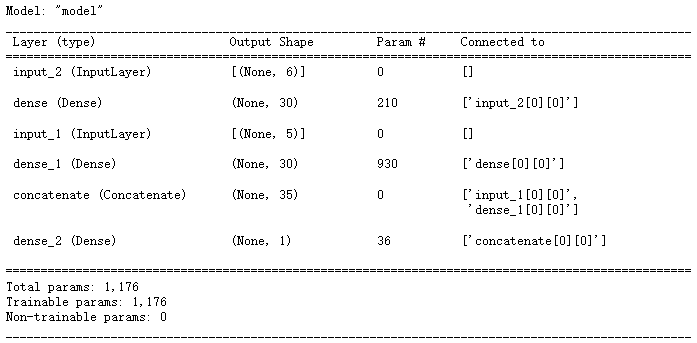
# 对输入数据进行修改
x_train_scaled_wide = x_train_scaled[:, :5]
x_train_scaled_deep = x_train_scaled[:, 2:]x_valid_scaled_wide = x_valid_scaled[:, :5]
x_valid_scaled_deep = x_valid_scaled[:, 2:]x_test_scaled_wide = x_test_scaled[:, :5]
x_test_scaled_deep = x_test_scaled[:, 2:]history = model.fit([x_train_scaled_wide, x_train_scaled_deep],y_train, validation_data = ([x_valid_scaled_wide, x_valid_scaled_deep], y_valid), epochs= 20)
2.3 wide&deep方式三 (多输出)
- 双输入双输出
# 多输出 # 定义两个输入
input_wide = keras.layers.Input(shape = [5])
input_deep = keras.layers.Input(shape = [6])hidden1 = keras.layers.Dense(30, activation = 'relu')(input_deep)
hidden2 = keras.layers.Dense(30, activation = 'relu')(hidden1)
concat = keras.layers.concatenate([input_wide, hidden2])output = keras.layers.Dense(1)(concat)
output2 = keras.layers.Dense(1)(hidden2)model = keras.models.Model(inputs=[input_wide,input_deep],outputs =[output,output2])
# 对输入数据进行修改
x_train_scaled_wide = x_train_scaled[:, :5]
x_train_scaled_deep = x_train_scaled[:, 2:]x_valid_scaled_wide = x_valid_scaled[:, :5]
x_valid_scaled_deep = x_valid_scaled[:, 2:]x_test_scaled_wide = x_test_scaled[:, :5]
x_test_scaled_deep = x_test_scaled[:, 2:]history = model.fit([x_train_scaled_wide, x_train_scaled_deep],[y_train, y_train], validation_data = ([x_valid_scaled_wide, x_valid_scaled_deep], [y_valid, y_valid]), epochs= 20)
- 在该模型的效果一般
3 子类API 实现wide&deep模型
3.1 函数构建模型
- 卷积后的结果结合原始输入进行运算
# 子类API的写法, pytch
class WideDeepModel(keras.models.Model):def __init__(self):'''定义模型的层次'''super().__init__()self.hidden1 = keras.layers.Dense(32, activation = 'relu')self.hidden2 = keras.layers.Dense(32, activation = 'relu')self.output_layer = keras.layers.Dense(1)def call(self, input):'''完成模型的正向传播'''hidden1 = self.hidden1(input)hidden2 = self.hidden2(hidden1)# 拼接concat = keras.layers.concatenate([input, hidden2])output = self.output_layer(concat)return output'''定义实例对象'''
model = WideDeepModel()
model.build(input_shape = (None, 8))
# 配置
model.compile(loss = 'mse', optimizer = 'adam', metrics = ['mse'])
history = model.fit(x_train_scaled, y_train, validation_data = (x_valid_scaled, y_valid), epochs= 20)
相关文章:
20- widedeep及函数式构建模型 (TensorFlow系列) (深度学习)
知识要点 wide&deep: 模型构建中, 卷积后数据和原始数据结合进行输出.fetch_california_housing:加利福尼亚的房价数据,总计20640个样本,每个样本8个属性表示,以及房价作为target,所有属性值均为number࿰…...
大家一起做测试的,凭什么你现在拿20k,我却还只有10k?...
最近我发现一个神奇的事情,我一个97年的朋友居然已经当上了测试项目组长,据我所知他去年还是在深圳的一家创业公司做苦逼的测试狗,短短8个月,到底发生了什么? 于是我立刻私聊他八卦一番。 原来他所在的公司最近正在裁…...

>>数据管理:DAMA简介「考试和续期」
关于DAMA,这里就不再多做描述,可以参考以前写的一些简介或官方介绍。下面就考试再做一些详细介绍。 1 区别 CDGA:数据治理工程师(Certified Data Governance Associate),“DAMA中国”组织的数据治理方面的职业认证考试。 CDGP:数据治理专家(Certified Data Governa…...

React的生命周期详细讲解
什么是生命周期? 所谓的React生命周期,就是指组件从被创建出来,到被使用,最后被销毁的这么一个过程。而在这个过程中,React提供了我们会自动执行的不同的钩子函数,我们称之为生命周期函数。**组件的生命周期…...

蓝蓝算法二期工程day3,一万年太久,只争朝夕
思路: 最好想的是用hashmap,当然用c的话也可以用两个数组,一个数组用于存放字符串,自动对应ACSII码,一个将对应ACSII码的数字对应其下标,当然这也是用的映射的思想。 import java.util.*;public class Cac…...

程序代码的自动化生成方案设计
程序设计就能够适用这种代码自动化生成方法的前提是:PLC 程序代码具有高度重复性,执行的是相同数据处理或者逻辑判断,而相关变量组 是离 散 的,没 有规 律 可循 。以 I/O 变量和中间 变量的地 址 映 射 程序为例 ,程序代码为赋 值 语 句 ,高度重复;IO 变量和与 其 对应 的中间 …...

Go 稀疏数组学习与实现
仍然还是一个数组 基本介绍 一般就是指二维以上的数组 当一个数组中大部分元素是0 ,或者为同一个值的数组时,可以使用系数数组来保存该数组. 稀疏数组的处理方法: 记录数组一共有几行几列,有多少个不同的值把具有不同值的元素的行列及值记录在一个小规模的数组中,从而缩小程…...

MySQL 学习笔记(借鉴黑马程序员MySQL)
MySQL视频课链接 MySQL概述 数据库相关概念 数据库是存储数据的仓库,数据是有组织的进行存储(DataBase) 数据库管理系统是操纵和管理数据库的大型软件(DataBase Management System) SQL是操作关系型数据库的编程语…...

中级工程师职称申报到底需要参加答辩不?
获得中级工程师职称的方式有认定、评审、考试这几种形式。 甘建二老师先来简单说一下关于认定和考试这两种: 1.认定:中级职称认定一般是根据各地职称认定政策,如果你想走认定渠道,首先本人简历条件、业绩、奖项等非常优秀&#…...
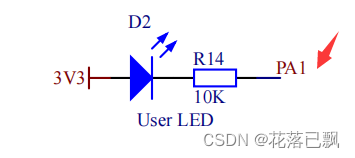
MM32开发教程(LED灯)
文章目录前言一、MM32介绍和STM32的区别二、板载LED灯原理图三、代码编写总结前言 今天将为大家介绍一款性能高体积小的MM32,这款开发板出自百问网团队。他就是灵动的MM32F3273,他体积非常小便于携带。 有128KB的SRAM、512KB的Flash、而且还支持双TypeC…...
win10安装docker
1.win10安装docker,前提必须是要安装WSL2。 现在Docker Desktop默认使用WSL 2来运行,而不是以前的Hyper-V。 WSL2 全称是Windows Subsystem on Linux。意思是,在win10,可以直接启动一个Linux。因为docker依赖Linux内核。 可查看…...
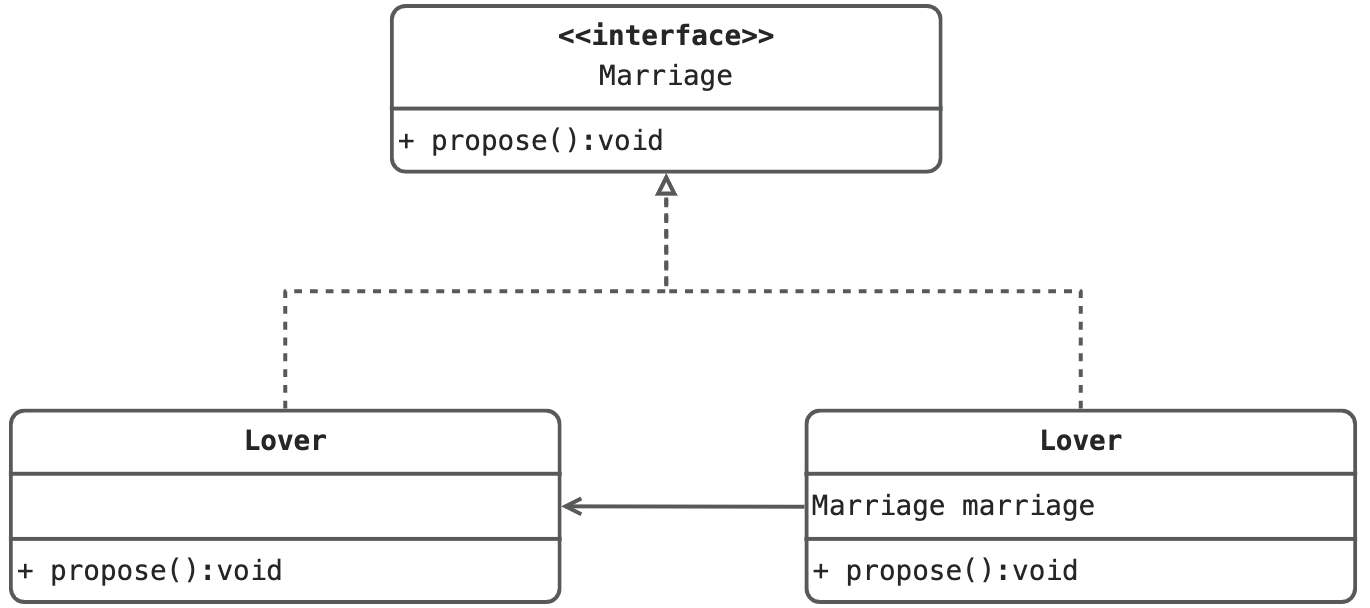
设计模式系列 - 代理模式及动态代理详解
定义 为其他对象提供一种代理以控制对这个对象的访问。在某些情况下,一个对象不适合或者不能直接引用另一个对象,而代理对象可以在客户端和目标对象之间起到中介的作用。 结构 抽象角色:通过接口或抽象类声明真实角色实现的业务方法。 代…...

【分享】订阅集简云畅捷通T+cloud连接器自动同步财务费用单至畅捷通
方案场景 伴随公司发展和数字化水平提高,大量的财务单据需要手动审核和录入,这些重复机械的操作占据大量人力,同时极容易出现数据出错或丢失等情况,严重影响着企业经营效率。 使用集简云提供服务的畅捷通TCloud钉钉连接器完成财…...

GPT的发展历程
GPT是当前最火的人工智能技术之一,自推出以来就广受关注。但大家对这个技术了解多少,又知道它经历了什么? GPT的诞生离不开谷歌在人工智能领域的努力和研究。2004年,谷歌成立了人工智能实验室(现已成为谷歌 AI实验室&…...

iOS开发笔记之九十八——关于Memory Leak总结笔记
*****阅读完此文,大概需要3分钟******关于Memory leak(内存泄漏)的问题,如果是面试被问这个问题以及此类问题,主要涉及下面3个方面:内存泄漏的常见场景有哪些,列举几个常见的例子?开…...
HTML基础语法
一 前端简介构成语言说明结构HTML页面元素和内容表现CSS网页元素的外观和位置等页面样式(美化)行为JavaScript网页模型的定义和页面交互二 HTML1.简介HTML(Hyper Text Markup Language):超文本标记语言。网页结构整体&…...

微软新版必应gpt人工智能体验教程
大家好,我是雄雄,欢迎关注微信公众号:** 雄雄的小课堂 ** 现在是:2023年2月28日18:35:02 前言 前几天,发了一篇文章,主要介绍了如何申请新必应的内测名单,其实一共也就那几步,然后等着就行: 文章连接:new bing如何快速申请内测资格,从而体验人工智能? 今天,终于…...

你问我答|虚拟机、容器和无服务器,怎么选?
在新技术层出不穷的当下,每家企业都希望不断降低成本,并提高运营效率,一个方法就是寻找不同的技术方案来优化运营。 例如,曾经一台服务器只能运行一个应用(裸机);接着,一台服务器的资源可以划分为多个块,从而运行多个应用(虚拟化);再到后来,应用越来越多,为了方便它们…...
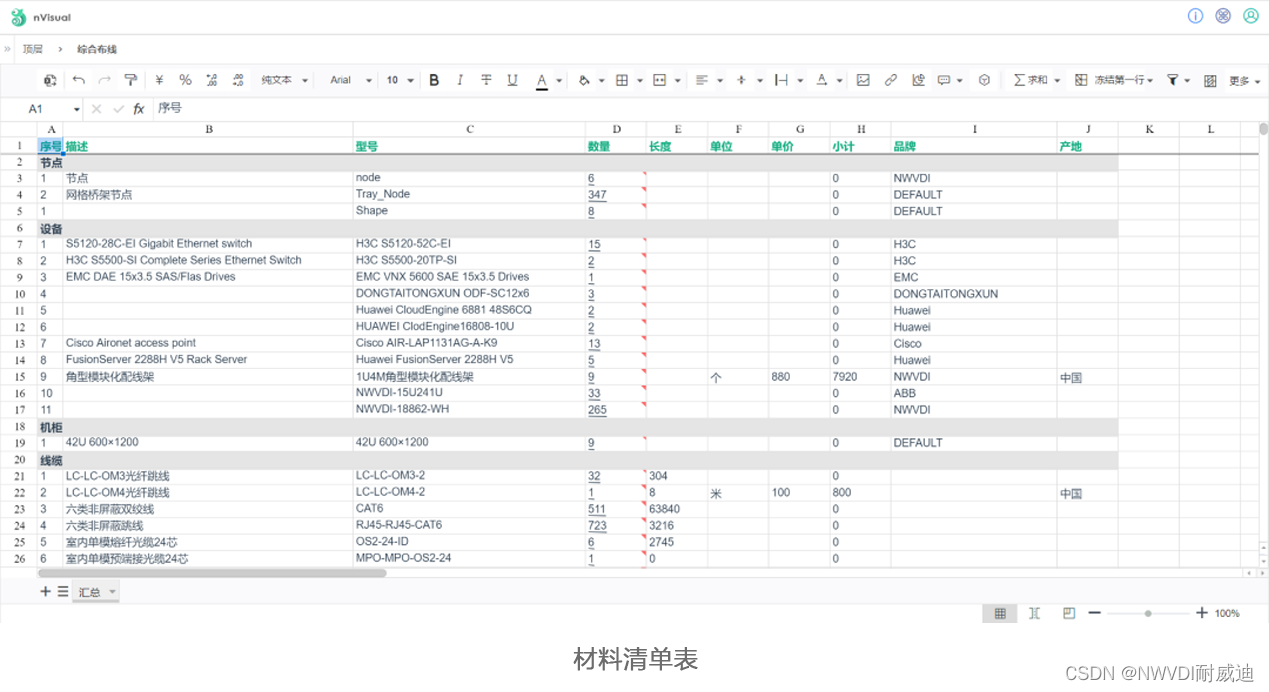
某建筑设计研究院“综合布线管理软件”应用实践
某建筑设计研究院有限公司(简称“某院”)隶属于国务院国资委直属的大型骨干科技型中央企业。“某院”前身为中央直属设计公司,创建于1952年。成立近70年来,始终秉承优良传统,致力于推进国内勘察设计产业的创新发展&…...
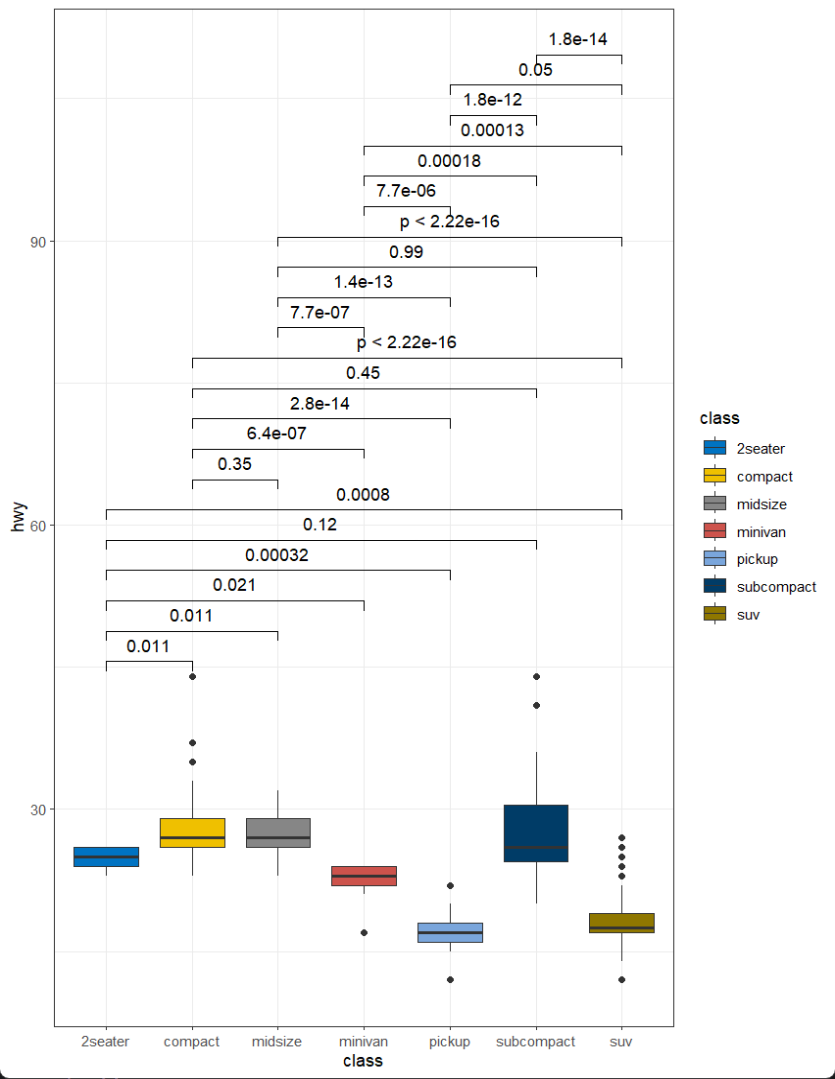
R语言绘制SCI论文中常见的箱线散点图,并自动进行方差分析计算显著性水平
显著性标记箱线散点图 本篇笔记的内容是在R语言中利用ggplot2,ggsignif,ggsci,ggpubr等包制作箱线散点图,并计算指定变量之间的显著性水平,对不同分组进行特异性标记,最终效果如下。 加载R包 library(ggplo…...

Rust 异步编程
Rust 异步编程 引言 Rust 是一种系统编程语言,以其高性能、安全性以及零成本抽象而著称。在多核处理器成为主流的今天,异步编程成为了一种提高应用性能、优化资源利用的有效手段。本文将深入探讨 Rust 异步编程的核心概念、常用库以及最佳实践。 异步编程基础 什么是异步…...

高防服务器能够抵御哪些网络攻击呢?
高防服务器作为一种有着高度防御能力的服务器,可以帮助网站应对分布式拒绝服务攻击,有效识别和清理一些恶意的网络流量,为用户提供安全且稳定的网络环境,那么,高防服务器一般都可以抵御哪些网络攻击呢?下面…...

NXP S32K146 T-Box 携手 SD NAND(贴片式TF卡):驱动汽车智能革新的黄金组合
在汽车智能化的汹涌浪潮中,车辆不再仅仅是传统的交通工具,而是逐步演变为高度智能的移动终端。这一转变的核心支撑,来自于车内关键技术的深度融合与协同创新。车载远程信息处理盒(T-Box)方案:NXP S32K146 与…...

处理vxe-table 表尾数据是单独一个接口,表格tableData数据更新后,需要点击两下,表尾才是正确的
修改bug思路: 分别把 tabledata 和 表尾相关数据 console.log() 发现 更新数据先后顺序不对 settimeout延迟查询表格接口 ——测试可行 升级↑:async await 等接口返回后再开始下一个接口查询 ________________________________________________________…...
详细解析)
Caliper 负载(Workload)详细解析
Caliper 负载(Workload)详细解析 负载(Workload)是 Caliper 性能测试的核心部分,它定义了测试期间要执行的具体合约调用行为和交易模式。下面我将全面深入地讲解负载的各个方面。 一、负载模块基本结构 一个典型的负载模块(如 workload.js)包含以下基本结构: use strict;/…...
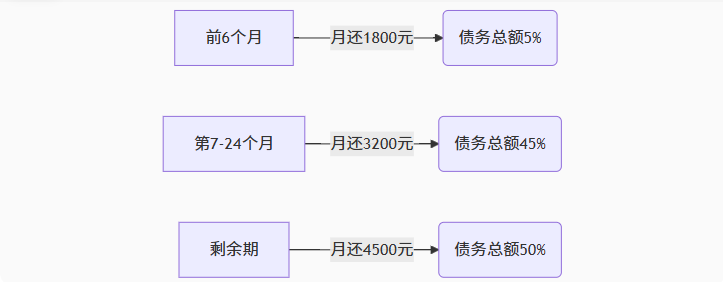
【无标题】湖北理元理律师事务所:债务优化中的生活保障与法律平衡之道
文/法律实务观察组 在债务重组领域,专业机构的核心价值不仅在于减轻债务数字,更在于帮助债务人在履行义务的同时维持基本生活尊严。湖北理元理律师事务所的服务实践表明,合法债务优化需同步实现三重平衡: 法律刚性(债…...
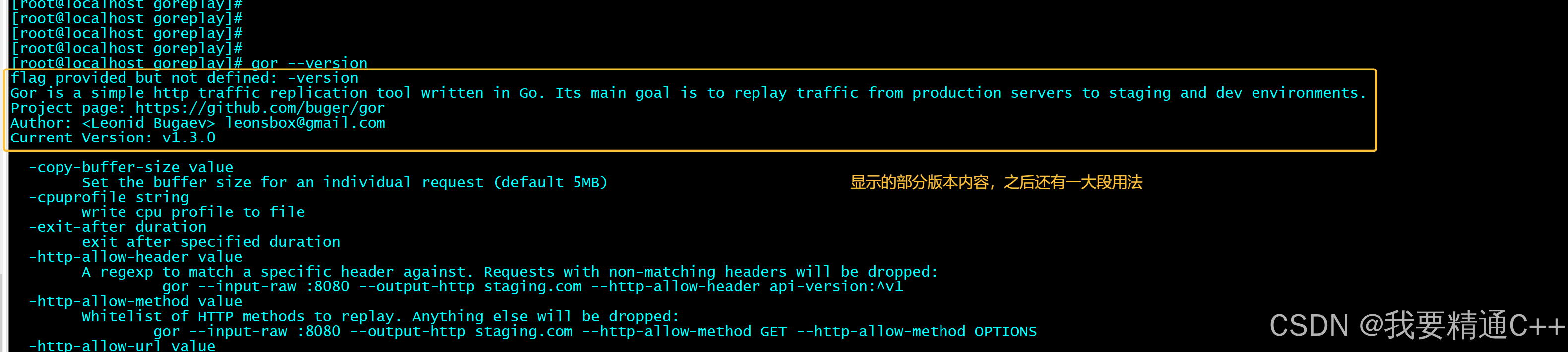
goreplay
1.github地址 https://github.com/buger/goreplay 2.简单介绍 GoReplay 是一个开源的网络监控工具,可以记录用户的实时流量并将其用于镜像、负载测试、监控和详细分析。 3.出现背景 随着应用程序的增长,测试它所需的工作量也会呈指数级增长。GoRepl…...

基于stm32F10x 系列微控制器的智能电子琴(附完整项目源码、详细接线及讲解视频)
注:文章末尾网盘链接中自取成品使用演示视频、项目源码、项目文档 所用硬件:STM32F103C8T6、无源蜂鸣器、44矩阵键盘、flash存储模块、OLED显示屏、RGB三色灯、面包板、杜邦线、usb转ttl串口 stm32f103c8t6 面包板 …...
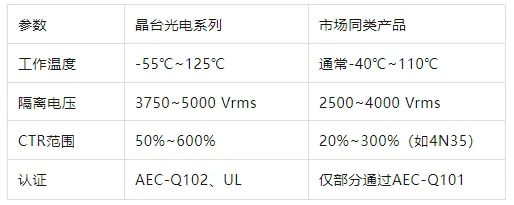
高抗扰度汽车光耦合器的特性
晶台光电推出的125℃光耦合器系列产品(包括KL357NU、KL3H7U和KL817U),专为高温环境下的汽车应用设计,具备以下核心优势和技术特点: 一、技术特性分析 高温稳定性 采用先进的LED技术和优化的IC设计,确保在…...
Springboot 高校报修与互助平台小程序
一、前言 随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱,高校报修与互助平台小程序被用户普遍使用,为…...