Python 之 Pandas merge() 函数、set_index() 函数、drop_duplicates() 函数和 tolist() 函数
文章目录
- 一、merge() 函数
- 1. inner
- 2. left 和 right
- 3. outer
- 二、set_index() 函数
- 三、drop_duplicates() 函数
- 四、tolist() 函数
- 五、视频数据分析案例
- 1. 问题要求
- 2. 解决过程
- 在最开始,我们先导入常规的 numpy 和 pandas 库。
import numpy as np
import pandas as pd
- 为了方便维护,数据在数据库内都是分表存储的,比如用一个表存储所有用户的基本信息,一个表存储用户的消费情况。
- 所以,在日常的数据处理中,经常需要将两张表拼接起来使用,这样的操作对应到 SQL 中是 join,在 Pandas 中则是用 merge 来实现。这篇文章就讲一下 merge 的主要原理。
- 上面的引入部分说到 merge 是用来拼接两张表的,那么拼接时自然就需要将用户信息一一对应地进行拼接,所以进行拼接的两张表需要有一个共同的识别用户的键(key)。
- 总结来说,整个 merge 的过程就是将信息一一对应匹配的过程,下面介绍 merge 的四种类型,分别为 inner、left、right 和 outer。
一、merge() 函数
- merge() 函数的语法格式如下:
pd.merge(left,right,how: str = 'inner',on=None,left_on=None,right_on=None,left_index: bool = False,
right_index: bool = False,sort: bool = False,suffixes=('_x', '_y'),copy: bool = True,indicator: bool = False,validate=None,)
- merge() 函数的参数含义如下:
- left/right 表示两个不同的 DataFrame 对象。
- how 表示要执行的合并类型,从 {‘left’, ‘right’, ‘outer’, ‘inner’} 中取值,默认为 inner 内连接。
- on 表示指定用于连接的键(即列标签的名字),该键必须同时存在于左右两个 DataFrame 中,如果没有指定,并且其他参数也未指定,那么将会以两个 DataFrame 的列名交集做为连接键。
- left_on 表示指定左侧 DataFrame 中作连接键的列名。该参数在左、右列标签名不相同,但表达的含义相同时非常有用。
- right_on 表示指定左侧 DataFrame 中作连接键的列名。
- left_index 为布尔参数,默认为 False。如果为 True 则使用左侧 DataFrame 的行索引作为连接键。
- right_index 为布尔参数,默认为 False。如果为 True 则使用左侧 DataFrame 的行索引作为连接键。
- sort 为布尔参数,默认为 False,则按照 how 给定的参数值进行排序。设置为 True,它会将合并后的数据进行排序。
- suffixes 表示字符串组成的元组。当左右 DataFrame 存在相同列名时,通过该参数可以在相同的列名后附加后缀名,默认为 (‘x’,‘y’)。
- copy 默认为 True,表示对数据进行复制。
- 这里需要注意的是,Pandas 库的 merge() 支持各种内外连接,与其相似的还有 join() 函数(默认为左连接)。
1. inner
- merge() 的 inner 的类型称为内连接,它在拼接的过程中会取两张表的键(key)的交集进行拼接。
- 下面以图解的方式来一步一步拆解。

- 首先我们有以下的数据,左侧和右侧的数据分别代表了用户的基础信息和消费信息,连接两张表的键是 userid。
- 例如,我们先生成 df_1 的初始数据。
df_1 = pd.DataFrame({"userid":['a', 'b', 'c', 'd'], "age":[23, 46, 32, 19]})
df_1
# userid age
#0 a 23
#1 b 46
#2 c 32
#3 d 19
- 我们再生成与 df_1 相连接的数据 df_2。
df_2 = pd.DataFrame({"userid":['a', 'c'],"payment":[2000, 3500]})
df_2
#userid payment
#0 a 2000
#1 c 3500
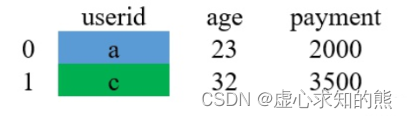
- 使用 merge() 函数对 df_1 和 df_2 进行拼接。由于 df_2 中只有 a 和 c 的参数,因此,合并之后只有 a 和 c。
df_1.merge(df_2,on='userid')
#userid age payment
#0 a 23 2000
#1 c 32 3500
- 还有另一种写法。
pd.merge(df_1, df_2, on='userid')
#userid age payment
#0 a 23 2000
#1 c 32 3500
- 对于上述过程,我们可以采用如下图片进行解释。
- (1) 取两张表的键的交集,这里 df_1 和 df_2 的 userid 的交集是 {a,c}。

- (2) 对应匹配。
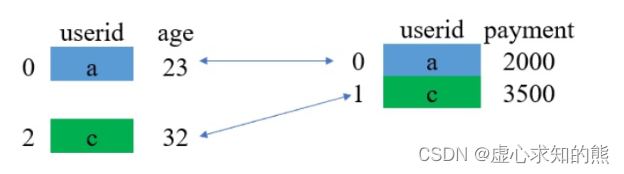
- (3) 结果。
- 相信整个过程并不难理解,上面演示的是同一个键下,两个表对应只有一条数据的情况(一个用户对应一条消费记录)。
- 那么,如果一个用户对应了多条消费记录的话,那又是怎么拼接的呢?
- 假设现在的数据变成了下面这个样子,在 df_2 中,有两条和 a 对应的数据:
- 我们同样用 inner 的方式进行 merge:
df_1 = pd.DataFrame({"userid":['a', 'b', 'c', 'd'], "age":[23, 46, 32, 19]})
df_2 = pd.DataFrame({"userid":['a', 'c','a', 'd'],"payment":[2000, 3500, 500, 1000]})
pd.merge(df_1, df_2, on="userid")
#userid age payment
#0 a 23 2000
#1 a 23 500
#2 c 32 3500
#3 d 19 1000
- 整个过程除了对应匹配阶段,其他和上面基本都是一致的。
2. left 和 right
- left 和 right 的 merge 方式其实是类似的,分别被称为左连接和右连接。这两种方法是可以互相转换的,所以在这里放在一起介绍。
- left 在 merge 时,以左边表格的键为基准进行配对,如果左边表格中的键在右边不存在,则用缺失值 NaN 填充。
- right 在 merge 时,以右边表格的键为基准进行配对,如果右边表格中的键在左边不存在,则用缺失值 NaN 填充。
- 这是什么意思呢?我们用一个例子来具体解释一下,这是演示的数据。

- 现在用 left 的方式进行 merge。
df_1 = pd.DataFrame({"userid":['a', 'b', 'c', 'd'], "age":[23, 46, 32, 19]})
df_2 = pd.DataFrame({"userid":['a', 'c','e'],"payment":[2000, 3500, 600]})
pd.merge(df_1, df_2,how='left', on="userid")
#userid age payment
#0 a 23 2000.0
#1 b 46 NaN
#2 c 32 3500.0
#3 d 19 NaN
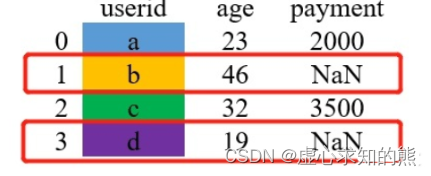
- 其过程可用如下图片进行解释。
- (1) 以左边表格的所有键为基准进行配对。图中,因为右表中的e不在左表中,故不会进行配对。

- (2) 若右表中的 payment 列合并到左表中,对于没有匹配值的用缺失值 NaN 填充。
- 对于 right 类型的 merge 和 left 其实是差不多的,只要把两个表格的位置调换一下,两种方式返回的结果就是一样的,如下:
pd.merge(df_1, df_2,how='right', on="userid")
#userid age payment
#0 a 23.0 2000
#1 c 32.0 3500
#2 e NaN 600
3. outer
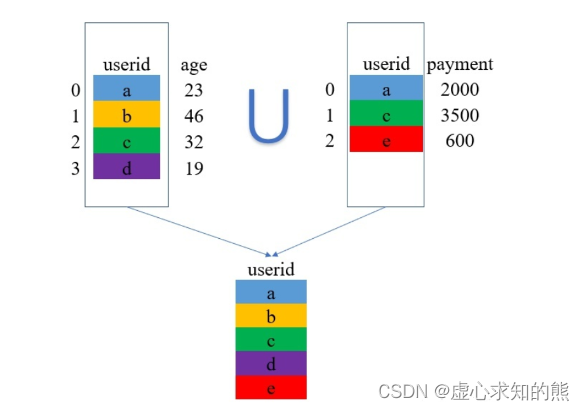
- outer 是外连接,在拼接的过程中它会取两张表的键(key)的并集进行拼接。看文字不够直观,还是上例子吧!
- 还是使用上方用过的演示数据

pd.merge(df_1, df_2,how='outer',on='userid')
#userid age payment
#0 a 23.0 2000.0
#1 b 46.0 NaN
#2 c 32.0 3500.0
#3 d 19.0 NaN
#4 e NaN 600.0
- 其过程可用如下图片进行解释。
- 取两张表键的并集,这里是 {a,b,c,d,e}。
二、set_index() 函数
- 专门用来将某一列设置为 index 的方法。
- 其语法模板如下:
DataFrame.set_index(keys, drop=True, append=False, inplace=False, verify_integrity=False)
- 其参数含义如下:
- keys 表示要设置为索引的列名(如有多个应放在一个列表里)。
- drop 表示将设置为索引的列删除,默认为 True。
- append 表示是否将新的索引追加到原索引后(即是否保留原索引),默认为 False。
- inplace 表示是否在原 DataFrame 上修改,默认为 False。
- verify_integrity 表示是否检查索引有无重复,默认为 False。
- 首先,我们生成初始数据。
df = pd.DataFrame({'month': [1, 4, 7, 10],'year': [2012, 2014, 2013, 2014],'sale': [55, 40, 84, 31]})
df
# month year sale
#0 1 2012 55
#1 4 2014 40
#2 7 2013 84
#3 10 2014 31
- 我们将索引设置为 month 列:
df.set_index('month')year sale
month
#1 2012 55
#4 2014 40
#7 2013 84
#10 2014 31
- 我们将 month 列设置为 index 之后,并保留原来的列。
df.set_index('month',drop=False)
# month year sale
#month
#1 1 2012 55
#4 4 2014 40
#7 7 2013 84
#10 10 2014 31
- 我们保留原来的 index 列。
df.set_index('month', append=True)
df.loc[0]
#month 1
#year 2012
#sale 55
#Name: 0, dtype: int64
- 我们使用 inplace 参数取代原来的对象。
df.set_index('month', inplace=True)
df
# year sale
#month
#1 2012 55
#4 2014 40
#7 2013 84
#10 2014 31
- 我们通过新建 Series 并将其设置为 index。
df.set_index(pd.Series(range(4)))
#year sale
#0 2012 55
#1 2014 40
#2 2013 84
#3 2014 31
三、drop_duplicates() 函数
- 去重通过字面意思不难理解,就是删除重复的数据。
- 在一个数据集中,找出重复的数据删并将其删除,最终只保存一个唯一存在的数据项,这就是数据去重的整个过程。
- 删除重复数据是数据分析中经常会遇到的一个问题。通过数据去重,不仅可以节省内存空间,提高写入性能,还可以提升数据集的精确度,使得数据集不受重复数据的影响。
- Panda DataFrame 对象提供了一个数据去重的函数 drop_duplicates()。
- 其语法模板如下:
DataFrame.drop_duplicates(subset=None, keep='first', inplace=False, ignore_index=False)
- 其部分参数含义如下:
- subset 表示要进去重的列名,默认为 None。
- keep 有三个可选参数,分别是 first、last、False,默认为 first,表示只保留第一次出现的重复项,删除其余重复项,last 表示只保留最后一次出现的重复项,False 则表示删除所有重复项。
- inplace 为布尔值参数,默认为 False 表示删除重复项后返回一个副本,若为 Ture 则表示直接在原数据上删除重复项。
- 我们先生成初始数据,用以后续的观察操作。
df = pd.DataFrame({'brand': ['Yum Yum', 'Yum Yum', 'Indomie', 'Indomie', 'Indomie'],'style': ['cup', 'cup', 'cup', 'pack', 'pack'],'rating': [4, 4, 3.5, 15, 5]
})
df
#brand style rating
#0 Yum Yum cup 4.0
#1 Yum Yum cup 4.0
32 Indomie cup 3.5
#3 Indomie pack 15.0
#4 Indomie pack 5.0
- 在默认情况下,它会基于所有列删除重复的行。
df.drop_duplicates()
#brand style rating
#0 Yum Yum cup 4.0
#2 Indomie cup 3.5
#3 Indomie pack 15.0
#4 Indomie pack 5.0
- 我们删除特定列上的重复项,使用子集。
df.drop_duplicates(subset=['brand'])
#brand style rating
#0 Yum Yum cup 4.0
#2 Indomie cup 3.5
- 我们删除重复项并保留最后出现的项,使用保留。
df.drop_duplicates(subset=['brand', 'style'], keep='last')
#brand style rating
#1 Yum Yum cup 4.0
#2 Indomie cup 3.5
#4 Indomie pack 5.0
四、tolist() 函数
- pandas 的 tolist() 函数用于将一个系列或数据帧中的列转换为列表。
- 首先,我们查看 df 中的 索引取值,他的起始值是 0,终止值是 1,步长是 1。
df.index
#RangeIndex(start=0, stop=5, step=1)
- 我们使用 tolist() 函数将其转化为列表。
df.index.tolist()
#[0, 1, 2, 3, 4]
五、视频数据分析案例
1. 问题要求
- 问题 1:分析出不同导演电影的好评率,并筛选出 TOP20。
- 要求:
- (1) 计算统计出不同导演的好评率。
- (2) 通过多系列柱状图,做图表可视化。
- 提示:
- (1) 好评率 = 好评数 / 评分人数。
- (2) 可自己设定图表风格。
- 问题 2: 统计分析 2001-2016 年每年评影人数总量,求出不同剧的评分人数、好评数总和。
2. 解决过程
- 首先,我们导入 numpy 和 pandas 库,由于要进行图表可视化,因此,我们再导入 matplotlib 库。
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
- 然后,进行文件的读取,并查看文件的信息。
data = pd.read_csv('爱奇艺视频数据.csv',encoding="gbk")
data.info()
#<class 'pandas.core.frame.DataFrame'>
#RangeIndex: 99999 entries, 0 to 99998
#Data columns (total 24 columns):
# # Column Non-Null Count Dtype
#--- ------ -------------- -----
# 0 数据获取日期 99999 non-null object
# 1 演员 97981 non-null object
# 2 视频ID 99999 non-null object
# 3 详细链接 99998 non-null object
# 4 剧名 99999 non-null object
# 5 状态 99158 non-null object
# 6 类型 99999 non-null object
# 7 来源平台 99999 non-null object
# 8 整理后剧名 99999 non-null object
# 9 更新时间 644 non-null object
# 10 上映时间 78755 non-null float64
# 11 语言 85926 non-null object
# 12 评分 99970 non-null float64
# 13 地区 98728 non-null object
# 14 上映年份 78755 non-null float64
# 15 简介 99970 non-null object
# 16 导演 97614 non-null object
# 17 差评数 99970 non-null float64
# 18 评分人数 99970 non-null float64
# 19 播放量 99453 non-null float64
# 20 更新至 1272 non-null float64
# 21 总集数 98871 non-null float64
# 22 第几季 99999 non-null int64
# 23 好评数 99970 non-null float64
#dtypes: float64(9), int64(1), object(14)
#memory usage: 18.3+ MB
- pandas 读取 csv 文件默认是按块读取的,即不一次性全部读取。
- 另外 pandas 对数据的类型是完全靠猜的,所以 pandas 每读取一块数据就对 csv 字段的数据类型进行猜一次,所以有可能 pandas在读取不同块时对同一字段的数据类型猜测结果不一致。
- low_memory=False 参数设置后,pandas 会一次性读取 csv 中的所有数据,然后对字段的数据类型进行唯一的一次猜测。这样就不会导致同一字段的 Mixed types 问题了。
- 但是这种方式真的非常不好,一旦 csv 文件过大,就会内存溢出;所以推荐用第 1 中解决方案。
- (1) 设置 read_csv 的 dtype 参数,指定字段的数据类型。
pd.read_csv(sio, dtype={"user_id": int, "username": object})
- (2) 设置 read_csv的low_memory 参数为 False。
pd.read_csv(sio, low_memory=False})
- 我们可以查看前几条数据。
data.head(3)
- 读取数据的列标签。
data.columns
#Index(['数据获取日期', '演员', '视频ID', '详细链接', '剧名', '状态', '类型', '来源平台', '整理#后剧名',
# '更新时间', '上映时间', '语言', '评分', '地区', '上映年份', '简介', '导演', '差评数', #'评分人数',
# '播放量', '更新至', '总集数', '第几季', '好评数'],
# dtype='object')
- 我们计算统计出不同导演的好评率。
data.groupby('导演')[['好评数','评分人数']].sum()
#好评数 评分人数
#导演
#Exact 375172.0 458543.0
#John Fawcett Steve Dimarco Paul Fox 1477942.0 1729878.0
#Michael Cuesta 527348.0 604104.0
#Michael Dinner 1032245.0 1312847.0
#Michael Engler 47804.0 61844.0
#... ... ...
#龚朝 4634.0 8620.0
#龚朝/杨巧文/王伟仁 676160.0 964912.0
#龚朝晖 4044245.0 5941895.0
#龚艺群 194079.0 290358.0
#龚若飞 29126.0 43151.0
#1196 rows × 2 columns
- 新增好评率。
df_q1 = data.groupby('导演').sum()[['好评数','评分人数']]
df_q1['好评率'] = df_q1['好评数']/df_q1['评分人数']
df_q1
#好评数 评分人数 好评率
#导演
#Exact 375172.0 458543.0 0.818183
#John Fawcett Steve Dimarco Paul Fox 1477942.0 1729878.0 0.854362
#Michael Cuesta 527348.0 604104.0 0.872942
#Michael Dinner 1032245.0 1312847.0 0.786265
#Michael Engler 47804.0 61844.0 0.772977
#... ... ... ...
#龚朝 4634.0 8620.0 0.537587
#龚朝/杨巧文/王伟仁 676160.0 964912.0 0.700748
#龚朝晖 4044245.0 5941895.0 0.680632
#龚艺群 194079.0 290358.0 0.668413
#龚若飞 29126.0 43151.0 0.674979
#1196 rows × 3 columns
- 我们筛选出 TOP20。
result_q1 = df_q1.sort_values('好评率',ascending=False)[:20]
result_q1
- 由于要画图,对图的一些属性进行设置。
# 设置中文:
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
# 中文负号
plt.rcParams['axes.unicode_minus'] = False
# 设置分别率 为100
plt.rcParams['figure.dpi'] = 100
# 设置大小
plt.rcParams['figure.figsize'] = (10,3)
# 绘制图形
plt.bar(result_q1.index,result_q1['好评率'])
# 设置y轴范围
plt.ylim(0.98,1)
# 设置x轴文字倾斜
plt.xticks(rotation=70)
# 设置网格
plt.grid(True, linestyle='--')
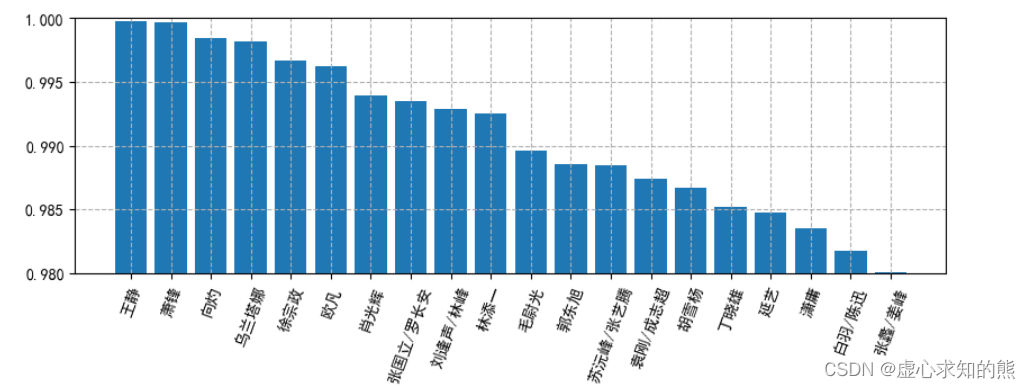
- 绘制柱状图。
result_q1['好评率'].plot(kind='bar',color = 'b',width = 0.8,alpha = 0.4,rot = 45,grid = True,ylim = [0.98,1],figsize = (12,4),title = '不同导演电影的好评率')
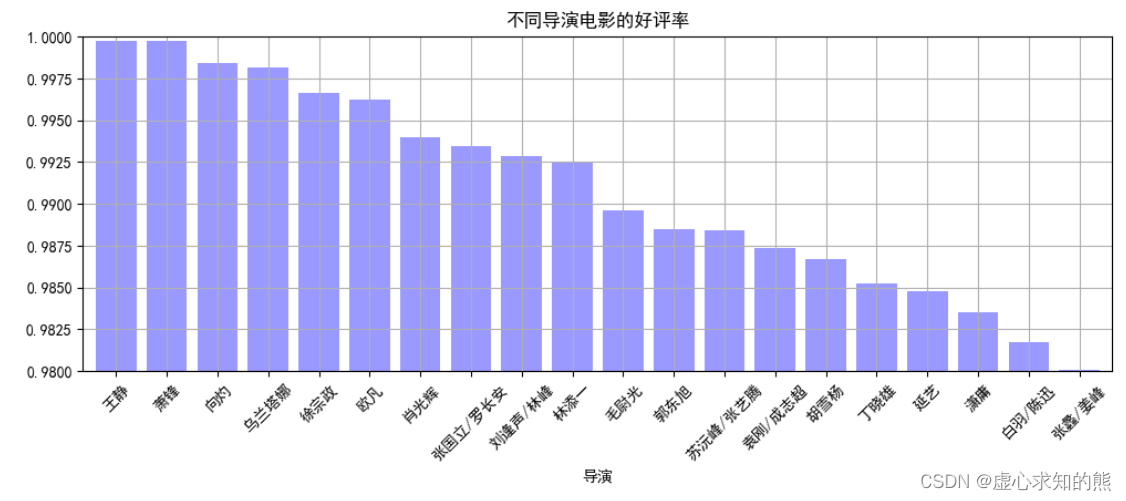
- 至此,我们的问题一就得到了解决,下面进行问题二的计算。
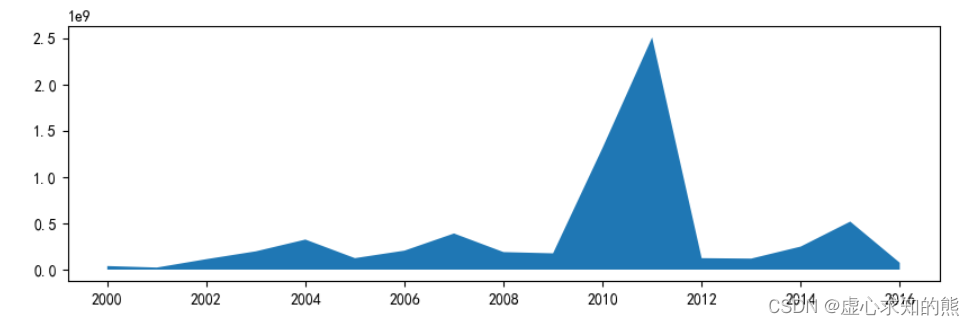
- 我们取出大于 2000 年的数据,并绘制面积图。
movie_year = data.groupby('上映年份')[['评分人数']].sum()
movie_year_2000 = movie_year.loc[2000:]
plt.stackplot(movie_year_2000.index,movie_year_2000['评分人数'])
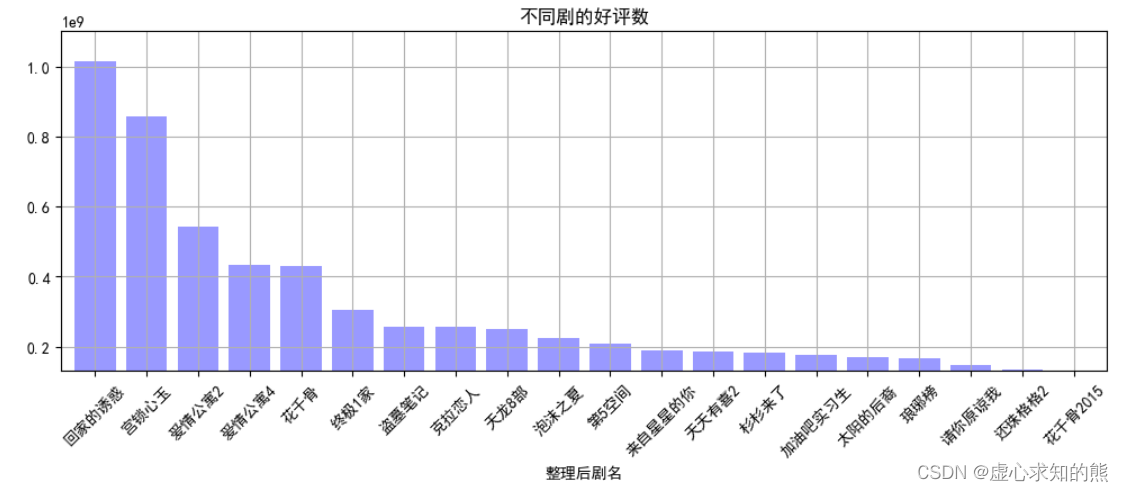
- 然后,我们求出不同剧的评分人数、好评数总和,好评数前 20 绘图。
movie_title_group = data.groupby('整理后剧名')[['评分人数','好评数']].sum()
result_title = movie_title_group.sort_values('好评数',ascending=False)[:20]
result_title
- 并绘制柱状图。
result_title['好评数'].plot(kind='bar',color = 'b',width = 0.8,alpha = 0.4,rot = 45,grid = True,ylim = [1.3e+08,1.1e+09],figsize = (12,4),title = '不同剧的好评数')
相关文章:
Python 之 Pandas merge() 函数、set_index() 函数、drop_duplicates() 函数和 tolist() 函数
文章目录一、merge() 函数1. inner2. left 和 right3. outer二、set_index() 函数三、drop_duplicates() 函数四、tolist() 函数五、视频数据分析案例1. 问题要求2. 解决过程在最开始,我们先导入常规的 numpy 和 pandas 库。 import numpy as np import pandas as …...
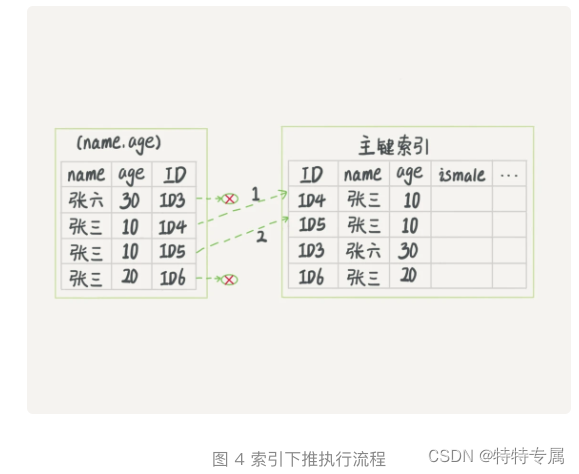
MySQL实战之深入浅出索引(下)
1.前言 在上一篇文章中,我们介绍了InnoDB索引的数据结构模型,今天我们再继续聊一下跟MySQL索引有关的概念。 在介绍之前,我们先看一个问题: 表初始化语句 mysql> create table T ( ID int primary key, k int NOT NULL DEFA…...
leetcode1539. 第 k 个缺失的正整数)
(二分查找)leetcode1539. 第 k 个缺失的正整数
文章目录一、题目1、题目描述2、基础框架3、原题链接二、解题报告1、思路分析2、时间复杂度3、代码详解三、本题小知识一、题目 1、题目描述 给你一个 严格升序排列 的正整数数组 arr 和一个整数 k 。 请你找到这个数组里第 k 个缺失的正整数。 示例 1: 输入&…...

yaml文件格式详解及实例
🍁博主简介 🏅云计算领域优质创作者 🏅华为云开发者社区专家博主 🏅阿里云开发者社区专家博主 💊交流社区:运维交流社区 欢迎大家的加入! 文章目录yaml简介yaml语法规则Yaml语法实例数组…...

AOP在PowerJob中的使用,缓存锁保证并发安全,知识细节全总结
这是一篇简简单单的文章,需要你简简单单看一眼就好,如果有不明白的地方,欢迎留言讨论。 在之前的文章中出现过一次AOP的使用,就是在运行任务之前,需要判断一下,触发该任务执行的server,是不是数…...
对账平台设计
背景 随着公司业务的蓬勃发展,交易履约清结算业务的复杂性也在不断的增高,资金以及各种数据的一致性和准确性也变得越发重要。 以交易链路为例,存在着如下一些潜在的不一致场景: 订单支付成功了,但是订单状态却还是“…...
JavaEE进阶第五课:SpringBoot的创建和使用
上篇文章介绍了Bean 作用域和生命周期,这篇文章我们将会介绍SpringBoot的创建和使用 目录1.为什么要学习StringBoot1.1什么是SpringBoot1.2SpringBoot的优点2.如何用Idea创建SpringBoot项目3.项目目录介绍和运行3.1输入Helloworld结尾1.为什么要学习StringBoot 在前…...

我带过的一名C++实习生——Z同学
刚开始带Z同学,吃饭聊天时,我顺便了解了下他的擅长:linux平台下C、C网络编程。 接下来的实习,主要分为两个阶段:小组公共培训和项目实训。 小组公共培训为期2周,主要学习和了解公司文化制度,讲师…...

面试题13. 机器人的运动范围
面试题13. 机器人的运动范围 难度:middle\color{orange}{middle}middle 题目描述 地上有一个 mmm 行 nnn 列的方格,从坐标 [0,0][0,0][0,0] 到坐标 [m−1,n−1][m-1,n-1][m−1,n−1] 。一个机器人从坐标 [0,0][0, 0][0,0] 的格子开始移动,它…...

LeetCode189_189. 轮转数组
LeetCode189_189. 轮转数组 一、描述 给定一个整数数组 nums,将数组中的元素向右轮转 k 个位置,其中 k 是非负数。 示例 1: 输入: nums [1,2,3,4,5,6,7], k 3 输出: [5,6,7,1,2,3,4] 解释: 向右轮转 1 步: [7,1,2,3,4,5,6] 向右轮转 2 步: [6,7,1,…...

java Files和Paths的使用详解 附有使用demo
前言 Java Files和Paths是Java 7中引入的新API,用于处理文件和目录。Files类提供了许多有用的静态方法来操作文件和目录,而Path类则表示文件系统中的路径。 创建文件和目录 在Java中创建文件和目录非常简单。我们可以使用Files类的createFile()方法和…...

如何使用ApacheTomcatScanner扫描Apache Tomcat服务器漏洞
关于ApacheTomcatScanner ApacheTomcatScanner是一个功能强大的Python脚本,该脚本主要针对Apache Tomcat服务器安全而设计,可以帮助广大研究人员轻松扫描和检测Apache Tomcat服务器中的安全漏洞。 功能介绍 1、支持使用多线程Worker搜索Apache Tomcat服…...
和setInterval())
js中的定时器 setTimeout()和setInterval()
JavaScript 定时器,有时也称为“计时器”,用来在经过指定的时间后执行某些任务,类似于我们生活中的闹钟。 在 JavaScript 中,我们可以利用定时器来延迟执行某些代码,或者以固定的时间间隔重复执行某些代码。例如&…...
【吃透Js】深入学习浅拷贝和深拷贝
一、JavaScript数据类型原始类型对象类型二、原始类型和对象类型的区别1.原始类型2.引用类型3.复制4.比较5.值传递三、浅拷贝概念实现方法四、深拷贝概念五、浅拷贝、深拷贝和赋值的区别浅拷贝和赋值六、小结想要真正搞明白深浅拷贝,你必须要熟练掌握赋值、对象在内…...
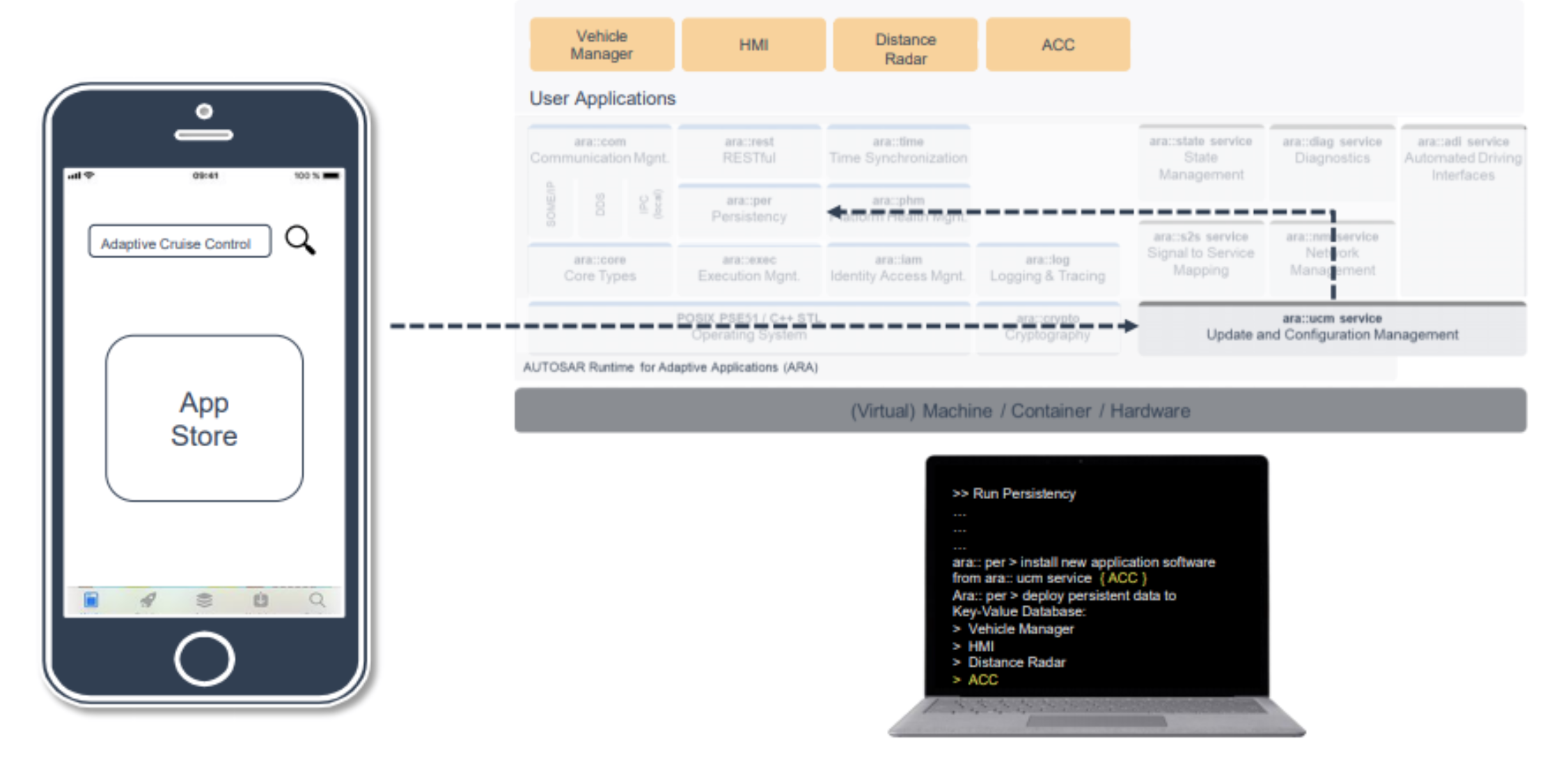
AUTOSAR为啥要开发新的社区商业模式?
总目录链接>> AutoSAR入门和实战系列总目录 文章目录1 自适应平台架构中的集群更新1.1 ara::diag 服务(诊断)更新1.2 信号到服务映射和自动驾驶接口让我们讨论一下信号到服务映射服务:Automated Driving Interface:2 车载应用商店概念本文介绍Re…...

数据结构和算法面试常见题必考以及前端面试题
1.数据结构和算法 1.1 反转单向链表 public class Node {public int value;public Node next; }public Node reverseList(Node head) {Node pre null;Node next null;while (head ! null) {next head.next;head.next pre;pre head;head head.next}return pre; }1.2 在顺…...

一文解决Python所有报错
前言 Python是一种强大的编程语言,但是它也有一些报错,这些报错可能会让你感到困惑。本文将介绍如何解决Python中的常见报错。 首先,让我们来看看Python中最常见的报错:SyntaxError。这种报错表明你的代码中有语法错误,…...
LeetCode 1237. Find Positive Integer Solution for a Given Equation【双指针,二分,交互】
本文属于「征服LeetCode」系列文章之一,这一系列正式开始于2021/08/12。由于LeetCode上部分题目有锁,本系列将至少持续到刷完所有无锁题之日为止;由于LeetCode还在不断地创建新题,本系列的终止日期可能是永远。在这一系列刷题文章…...

【C语言】结构体进阶
一、结构体 1. 结构体的声明 (1) 结构的基础知识 结构是一些值的集合,这些值称为成员变量。结构的每个成员可以是不同类型的变量。(2)结构的声明 struct tag {member-list; }variable-list;例如描述一个学生&#x…...
全志T3+FPGA国产核心板——Pango Design Suite的FPGA程序加载固化
本文主要基于紫光同创Pango Design Suite(PDS)开发软件,演示FPGA程序的加载、固化,以及程序编译等方法。适用的开发环境为Windows 7/10 64bit。 测试板卡为全志T3+Logos FPGA核心板,它是一款基于全志科技T3四核ARM Cortex-A7处理器 + 紫光同创Logos PGL25G/PGL50G FPGA设计…...

【Oracle APEX开发小技巧12】
有如下需求: 有一个问题反馈页面,要实现在apex页面展示能直观看到反馈时间超过7天未处理的数据,方便管理员及时处理反馈。 我的方法:直接将逻辑写在SQL中,这样可以直接在页面展示 完整代码: SELECTSF.FE…...

【JavaEE】-- HTTP
1. HTTP是什么? HTTP(全称为"超文本传输协议")是一种应用非常广泛的应用层协议,HTTP是基于TCP协议的一种应用层协议。 应用层协议:是计算机网络协议栈中最高层的协议,它定义了运行在不同主机上…...

逻辑回归:给不确定性划界的分类大师
想象你是一名医生。面对患者的检查报告(肿瘤大小、血液指标),你需要做出一个**决定性判断**:恶性还是良性?这种“非黑即白”的抉择,正是**逻辑回归(Logistic Regression)** 的战场&a…...

Frozen-Flask :将 Flask 应用“冻结”为静态文件
Frozen-Flask 是一个用于将 Flask 应用“冻结”为静态文件的 Python 扩展。它的核心用途是:将一个 Flask Web 应用生成成纯静态 HTML 文件,从而可以部署到静态网站托管服务上,如 GitHub Pages、Netlify 或任何支持静态文件的网站服务器。 &am…...

屋顶变身“发电站” ,中天合创屋面分布式光伏发电项目顺利并网!
5月28日,中天合创屋面分布式光伏发电项目顺利并网发电,该项目位于内蒙古自治区鄂尔多斯市乌审旗,项目利用中天合创聚乙烯、聚丙烯仓库屋面作为场地建设光伏电站,总装机容量为9.96MWp。 项目投运后,每年可节约标煤3670…...

Fabric V2.5 通用溯源系统——增加图片上传与下载功能
fabric-trace项目在发布一年后,部署量已突破1000次,为支持更多场景,现新增支持图片信息上链,本文对图片上传、下载功能代码进行梳理,包含智能合约、后端、前端部分。 一、智能合约修改 为了增加图片信息上链溯源,需要对底层数据结构进行修改,在此对智能合约中的农产品数…...

Mysql中select查询语句的执行过程
目录 1、介绍 1.1、组件介绍 1.2、Sql执行顺序 2、执行流程 2.1. 连接与认证 2.2. 查询缓存 2.3. 语法解析(Parser) 2.4、执行sql 1. 预处理(Preprocessor) 2. 查询优化器(Optimizer) 3. 执行器…...

安宝特案例丨Vuzix AR智能眼镜集成专业软件,助力卢森堡医院药房转型,赢得辉瑞创新奖
在Vuzix M400 AR智能眼镜的助力下,卢森堡罗伯特舒曼医院(the Robert Schuman Hospitals, HRS)凭借在无菌制剂生产流程中引入增强现实技术(AR)创新项目,荣获了2024年6月7日由卢森堡医院药剂师协会࿰…...

虚拟电厂发展三大趋势:市场化、技术主导、车网互联
市场化:从政策驱动到多元盈利 政策全面赋能 2025年4月,国家发改委、能源局发布《关于加快推进虚拟电厂发展的指导意见》,首次明确虚拟电厂为“独立市场主体”,提出硬性目标:2027年全国调节能力≥2000万千瓦࿰…...

NPOI Excel用OLE对象的形式插入文件附件以及插入图片
static void Main(string[] args) {XlsWithObjData();Console.WriteLine("输出完成"); }static void XlsWithObjData() {// 创建工作簿和单元格,只有HSSFWorkbook,XSSFWorkbook不可以HSSFWorkbook workbook new HSSFWorkbook();HSSFSheet sheet (HSSFSheet)workboo…...