网易一面:select分页要调优100倍,说说你的思路? (内含Mysql的36军规)
背景说明:
Mysql调优,是大家日常常见的调优工作。所以Mysql调优是一个非常、非常核心的面试知识点。
在40岁老架构师 尼恩的读者交流群(50+)中,其相关面试题是一个非常、非常高频的交流话题。
近段时间,有小伙伴面试网易,说遇到一个SQL 深度分页 查询 调优的面试题:
MySQL 百万级数据,怎么做分页查询?说说你的思路?
社群中,还遇到过大概的变种:
形式1:如何解决Mysql深分页问题?
形式2:mysql如何实现高效分页
形式3:后面的变种,应该有很多变种…,会收入 《尼恩Java面试宝典》。
这里尼恩给大家 调优,做一下系统化、体系化的梳理,使得大家可以充分展示一下大家雄厚的 “技术肌肉”,让面试官爱到 “不能自已、口水直流”。
也一并把这个 SQL 深度分页 题目以及参考答案,收入咱们的《尼恩Java面试宝典》,供后面的小伙伴参考,提升大家的 3高 架构、设计、开发水平。
注:本文以 PDF 持续更新,最新尼恩 架构笔记、面试题 的PDF文件,请从这里获取:码云
深挖问题:MySQL分页起点越大查询速度越慢
在数据库开发过程中我们经常会使用分页,核心技术是使用用limit start, count分页语句进行数据的读取。
我们分别看下从10, 1000, 10000, 100000开始分页的执行时间(每页取20条)。
select * from product limit 10, 20 0.002秒
select * from product limit 1000, 20 0.011秒
select * from product limit 10000, 20 0.027秒
select * from product limit 100000, 20 0.057秒
我们已经看出随着起始记录的增加,时间也随着增大,
这说明分页语句limit跟起始页码是有很大关系的,那么我们把起始记录改为100w看下:
select * from product limit 1000000, 20 0.682秒
我们惊讶的发现MySQL在数据量大的情况下分页起点越大,查询速度越慢,
300万条起的查询速度已经需要1.368秒钟。
这是为什么呢?
因为limit 3000000,10的语法实际上是mysql扫描到前3000020条数据, 之后丢弃前面的3000000行,
这个步骤其实是浪费掉的。
select * from product limit 3000000, 20 1.368秒
从中我们也能总结出两件事情:
- limit语句的查询时间与起始记录的位置成正比
- mysql的limit语句是很方便,但是对记录很多的表并不适合直接使用。
基础知识:mysql中limit的用法
语法:
SELECT * FROM 表名 limit m,n;
SELECT * FROM table LIMIT [offset,] rows;
注释:Limit子句可以被用于强制 SELECT 语句返回指定的记录数。
Limit接受一个或两个数字参数,参数必须是一个整数常量。
如果给定两个参数,
- 第一个参数指定第一个返回记录行的偏移量,
- 第二个参数指定返回记录行的最大数目。
1.m代表从m+1条记录行开始检索,n代表取出n条数据。(m可设为0)
如:SELECT * FROM 表名 limit 6,5;
表示:从第7条记录行开始算,取出5条数据
2.值得注意的是,n可以被设置为-1,当n为-1时,表示从m+1行开始检索,直到取出最后一条数据。
如:SELECT * FROM 表名 limit 6,-1;
表示:取出第6条记录行以后的所有数据。
3.若只给出m,则表示从第1条记录行开始算一共取出m条
如:SELECT * FROM 表名 limit 6;
以年龄倒序后取出前3行:
mysql> select * from student order by age desc;
+-----+--------+------+------+
| SNO | SNAME | AGE | SEX |
+-----+--------+------+------+
| 1 | 换换 | 23 | 男 |
| 2 | 刘丽 | 22 | 女 |
| 5 | 张友 | 22 | 男 |
| 6 | 刘力 | 22 | 男 |
| 4 | NULL | 10 | NULL |
+-----+--------+------+------+
5 rows in set (0.00 sec)mysql> select * from student order by age desc limit 3;
+-----+--------+------+------+
| SNO | SNAME | AGE | SEX |
+-----+--------+------+------+
| 1 | 换换 | 23 | 男 |
| 2 | 刘丽 | 22 | 女 |
| 6 | 刘力 | 22 | 男 |
+-----+--------+------+------+
3 rows in set (0.00 sec)
跳过前3行后再2取行.
mysql> select * from student order by age desc limit 3,2;
+-----+--------+------+------+
| SNO | SNAME | AGE | SEX |
+-----+--------+------+------+
| 6 | 刘力 | 22 | 男 |
| 4 | NULL | 10 | NULL |
+-----+--------+------+------+
回到问题:MySQL百万级数据大分页查询优化
我们惊讶的发现MySQL在数据量大的情况下分页起点越大,查询速度越慢,
300万条起的查询速度已经需要1.368秒钟。
那么,该如何优化呢?
方法1: 直接使用数据库提供的SQL语句
语句样式:
MySQL中,可用如下方法:
SELECT * FROM 表名称 LIMIT start, count
功能
Limit限制的是从结果集的start 位置处取出count 条输出,其余抛弃.
原因/缺点:
全表扫描,速度会很慢
而且, 有的数据库结果集返回不稳定(如某次返回1,2,3,另外的一次返回2,1,3).
适应场景:
适用于数据量较少的情况
元祖数量、记录数量级别:百/千级
方法2: 建立主键或唯一索引, 利用索引(假设每页10条)
语句样式:
SELECT * FROM 表名称 WHERE id_pk > (pageNum*10) LIMIT M
除了主键,也可以 利用唯一键索引快速定位部分元组,避免全表扫描
比如: 读第1000到1019行元组(pk是唯一键).
SELECT * FROM 表名称 WHERE pk>=1000 ORDER BY pk ASC LIMIT 0,20
原因 :
索引扫描,速度会很快.
缺点:
如果数据查询出来并不是按照pk_id排序,并且pk_id全部数据都存在没有缺失可以作为序号使用,不然,分页会有漏掉数据,
适应场景 :
- 适用于数据量多的情况(元组数上万)
- id数据没有缺失,可以作为序号使用
方法3: 基于索引再排序
语句样式 :
MySQL中,可用如下方法:
SELECT * FROM 表名称 WHERE id_pk > (pageNum*10) ORDER BY id_pk ASC LIMIT M
适应场景:
适用于数据量多的情况(元组数上万).
最好ORDER BY后的列对象是主键或唯一索引,
id数据没有缺失,可以作为序号使用
使得ORDERBY操作能利用索引被消除但结果集是稳定的
原因:
索引扫描,速度会很快.
但MySQL的排序操作,只有ASC没有DESC
mysql中,索引存储的排序方式是ASC的,没有DESC的索引。
这就能够理解为啥order by 默认是按照ASC来排序的了吧
虽然索引是ASC的,但是也可以反向进行检索,就相当于DESC了
方法4: 基于索引使用prepare
语句样式:MySQL中,可用如下方法:
PREPARE stmt_name FROM SELECT * FROM 表名称 WHERE id_pk > (?*10) ORDER BY id_pk ASC LIMIT M
第一个问号表示pageNum
适应场景:
大数据量
原因:
索引扫描,速度会很快.
prepare语句又比一般的查询语句快一点。
方法5: 利用"子查询+索引"快速定位元组
利用"子查询+索引"快速定位元组的位置,然后再读取元组.
比如(id是主键/唯一键)
利用子查询示例:
SELECT * FROM your_table WHERE id <= (SELECT id FROM your_table ORDER BY id desc LIMIT ($page-1)*$pagesize ORDER BY id desc LIMIT $pagesize
方法6: 利用"连接+索引"快速定位元组的位置,然后再读取元组.
比如(id是主键/唯一键,蓝色字体时变量)
利用连接示例:
SELECT * FROM your_table AS t1 JOIN (SELECT id FROM your_table ORDER BY id desc LIMIT ($page-1)*$pagesize AS t2 WHERE t1.id <= t2.id ORDER BY t1.id desc LIMIT $pagesize;
方法7: 利用表的索引覆盖来调优
我们都知道,利用了索引查询的语句中如果只包含了那个索引列(也就是索引覆盖),那么这种情况会查询很快。
为什么呢?
因为利用索引查找有优化算法,且数据就在查询索引上面,不用再去找相关的数据地址了,这样节省了很多时间。另外Mysql中也有相关的索引缓存,在并发高的时候利用缓存就效果更好了。
在我们的例子中,我们知道id字段是主键,自然就包含了默认的主键索引。现在让我们看看利用覆盖索引的查询效果如何。
这次我们之间查询最后一页的数据(利用覆盖索引,只包含id列),如下:
select id from product limit 866613, 20 0.2秒
如果查询了所有列的37.44秒,这里只要0.2秒,提升了大概100多倍的速度
那么如果我们也要查询所有列,有两种方法,一种是id>=的形式,另一种就是利用join,看下实际情况:
SELECT * FROM product WHERE ID > =(select id from product limit 866613, 1) limit 20
查询时间为0.2秒!
另一种写法
SELECT * FROM product a JOIN (select id from product limit 866613, 20) b ON a.ID = b.id
查询时间也很短!
方法8:利用复合索引进行优化
假设数据表 collect ( id, title ,info ,vtype) 就这4个字段,其中 title 用定长,info 用text, id 是逐渐,vtype是tinyint,vtype是索引。这是一个基本的新闻系统的简单模型。
现在往里面填充数据,填充10万篇新闻。
最后collect 为 10万条记录,数据库表占用硬1.6G。
看下面这条sql语句:
select id,title from collect limit 1000,10;
很快;基本上0.01秒就OK,再看下面的
select id,title from collect limit 90000,10;
从9万条开始分页,结果?
8-9秒完成,my god 哪出问题了?
看下面一条语句:
select id from collect order by id limit 90000,10;
很快,0.04秒就OK。
为什么?
因为用了id主键做索引, 这里实现了索引覆盖(方法7),当然快。
所以,可以按照方法7进行优化,具体如下:
select id,title from collect where id>=(select id from collect order by id limit 90000,1) limit 10;
再看下面的语句,带上where
select id from collect where vtype=1 order by id limit 90000,10;
很慢,用了8-9秒!
注意:vtype 做了索引了啊?怎么会慢呢?vtype做了索引是不错,如果直接对vtype进行过滤,比如
select id from collect where vtype=1 limit 1000,10;
是很快的,基本上0.05秒,可是提高90倍,从9万开始,那就是0.05*90=4.5秒的速度了。
和测试结果8-9秒到了一个数量级。
其实加了where 就不走索引,这样做还是全表扫描,解决的办法是:复合索引!
加一个复合索引, search_index(vtype,id) 这样的索引。
然后测试
select id from collect where vtype=1 limit 90000,10;
非常快!0.04秒完成!再测试:
select id ,title from collect where vtype=1 limit 90000,10;
非常遗憾,8-9秒,没走search_index 复合索引,不是索引覆盖!
综上:
如果对于有where 条件,又想走索引用limit的,
必须设计一个索引,将where 放第一位,limit用到的主键放第2位,而且只能select 主键!
按这样的逻辑,百万级的limit 在0.0x秒就可以分完。完美解决了分页问题了。
看来mysql 语句的优化和索引时非常重要的!
像这种分页最大的页码页显然这种时间是无法忍受的。
40岁老架构师尼恩提示
回答到了这里,已经接近满分了
但是面试,是一个需要120分的活儿
怎么得到120分呢?
可以告诉面试官:如何 提升SQL的性能, 还是要从 表设计、索引设计、SQL设计等全方位解决,具体请看MySQL数据库开发的三十六条军规
接下来,就给面试官介绍一下,MySQL数据库开发的三十六条军规
MySQL数据库开发的三十六条军规
一.核心军规
- 尽量不在数据库做运算,cpu计算的事务必移至业务层;
- 控制表、行、列数量(【控制单张表的数据量 1年/500W条,超出可做分表】,【单库表数据量不超过300张】 、【单张表的字段个数不超过50个,多了拆表】)
- 三大范式没有绝对的要使用,效率优先时可适当牺牲范式
- 拒绝3B(拒绝大sql语句:big sql、拒绝大事物:big transaction、拒绝大批量:big batch);
二.字段类军规
- 用好数值类型(用合适的字段类型节约空间);
如:一个字段注定就只有1跟2 要设计成 int(1) 而不是 int(11) - 字符转化为数字(能转化的最好转化,同样节约空间、提高查询性能);
如,一个字段注定就只有1跟2,要设计成int(1) 而不是char(1) 查询优化如:字段类型是 char(1) 查询应当where xx=‘1’ 而不是 xx=1 会导致效率慢 - 避免使用NULL字段
NULL字段很难查询优化、NULL字段的索引需要额外空间、NULL字段的复合索引无效;
如: 要设计成 `c` int(10) NOT NULL DEFAULT 0
而不是 `c` int(10) NOT NULL;
- 少用text/blob类型(尽量使用varchar代替text字段), 需要请拆表
- 不在数据库存图片,请存图片路径,然后图片文件存在项目文件夹下。
三.索引类军规
- 合理使用索引
改善查询,减慢更新,索引一定不是越多越好;
如:不要给性别创建索引
- 字符字段必须建前缀索引;
`pinyin` varchar(100) DEFAULT NULL COMMENT '小区拼音', KEY `idx_pinyin` (`pinyin`(8)),
- 不在索引做列运算;
如:WHERE to_days(current_date) – to_days(date_col) <= 10
改为:WHERE date_col >= DATE_SUB('2011-10- 22',INTERVAL 10 DAY);
- innodb主键推荐使用自增列
主键建立聚簇索引,主键不应该被修改,字符串不应该做主键
如:用独立于业务的AUTO_INCREMENT
- 不用外键(由程序保证约束);
四.SQL类军规
- sql语句尽可能简单
一条sql只能在一个cpu运算,大语句拆小语句,减少锁时间,一条大sql可以堵死整个库;
- 简单的事务;
- 避免使用trig/func(触发器、函数不用,由客户端程序取而代之);
- 不用select *(消耗cpu,io,内存,带宽,这种程序不具有扩展性);
如:select a ,b,c 会比 select * 好 只取需要列
- OR改写为 IN
如:where a=1 or a=2 改 a in(1,2)
- OR改写为UNION
针对不同字段 where a=1 or b=1
改:select 1 from a where a=1 union select 1 from a where b=1
- 避免负向%;
如:where a like %北京% 改为 where a like '北京%'
- limit高效分页(limit越大,效率越低);
如:Limit 10000,10 改为 where id >xxxx limit 11
- 使用union all替代union(union有去重开销);
- 高并发db少用2个表以上的join;
- 使用group by 去除排序加快效率;
如:group by name 默认是asc排序
改:group by name order by null 提高查询效率
- 请使用同类型比较;
如:where 双精度=双精度 数字=数字 字符=字符 避免转换导致索引丢失
- 打散大批量更新;
如:在凌晨空闲时期更新执行
五.约定类军规
- 隔离线上线下 ,
如:开发用dev库,测试用qa库,模拟用sim库,
线上用线上库,开发无线上库操作权限
- 不在程序端加锁,即外部锁,外部锁不可控,会导致 高并发会炸,极难调试和排查
- 统一字符 UTF-8 校对规则 utf8_general_ci 出现乱码 SET NAMES UTF8
- 统一命名规范,库表名一律小写,索引前缀用
idx_ 库名用缩写(2-7字符),不使用系统关键字保留字命名
40岁老架构师尼恩提示
问题回答到这里,已经20分钟过去了,面试官已经爱到 “不能自已、口水直流” 啦。
参考链接:
https://blog.csdn.net/qq_43518425/article/details/113876287
https://blog.csdn.net/whzhaochao/article/details/49126037
https://blog.csdn.net/wuzhangweiss/article/details/101156910
https://blog.csdn.net/Jerome_s/article/details/44992549
推荐阅读:
《网易二面:CPU狂飙900%,该怎么处理?》
《阿里二面:千万级、亿级数据,如何性能优化? 教科书级 答案来了》
《Linux命令大全:2W多字,一次实现Linux自由》
《峰值21WQps、亿级DAU,小游戏《羊了个羊》是怎么架构的?》
《场景题:假设10W人突访,你的系统如何做到不 雪崩?》
《2个大厂 100亿级 超大流量 红包 架构方案》
《Nginx面试题(史上最全 + 持续更新)》
《K8S面试题(史上最全 + 持续更新)》
《操作系统面试题(史上最全、持续更新)》
《Docker面试题(史上最全 + 持续更新)》
《Springcloud gateway 底层原理、核心实战 (史上最全)》
《Flux、Mono、Reactor 实战(史上最全)》
《sentinel (史上最全)》
《Nacos (史上最全)》
《TCP协议详解 (史上最全)》
《分库分表 Sharding-JDBC 底层原理、核心实战(史上最全)》
《clickhouse 超底层原理 + 高可用实操 (史上最全)》
《nacos高可用(图解+秒懂+史上最全)》
《队列之王: Disruptor 原理、架构、源码 一文穿透》
《环形队列、 条带环形队列 Striped-RingBuffer (史上最全)》
《一文搞定:SpringBoot、SLF4j、Log4j、Logback、Netty之间混乱关系(史上最全)》
《单例模式(史上最全)》
《红黑树( 图解 + 秒懂 + 史上最全)》
《分布式事务 (秒懂)》
《缓存之王:Caffeine 源码、架构、原理(史上最全,10W字 超级长文)》
《缓存之王:Caffeine 的使用(史上最全)》
《Java Agent 探针、字节码增强 ByteBuddy(史上最全)》
《Docker原理(图解+秒懂+史上最全)》
《Redis分布式锁(图解 - 秒懂 - 史上最全)》
《Zookeeper 分布式锁 - 图解 - 秒懂》
《Zookeeper Curator 事件监听 - 10分钟看懂》
《Netty 粘包 拆包 | 史上最全解读》
《Netty 100万级高并发服务器配置》
《Springcloud 高并发 配置 (一文全懂)》## 推荐阅读:
《网易二面:CPU狂飙900%,该怎么处理?》
《阿里二面:千万级、亿级数据,如何性能优化? 教科书级 答案来了》
《峰值21WQps、亿级DAU,小游戏《羊了个羊》是怎么架构的?》
《场景题:假设10W人突访,你的系统如何做到不 雪崩?》
《2个大厂 100亿级 超大流量 红包 架构方案》
《Nginx面试题(史上最全 + 持续更新)》
《K8S面试题(史上最全 + 持续更新)》
《操作系统面试题(史上最全、持续更新)》
《Docker面试题(史上最全 + 持续更新)》
《Springcloud gateway 底层原理、核心实战 (史上最全)》
《Flux、Mono、Reactor 实战(史上最全)》
《sentinel (史上最全)》
《Nacos (史上最全)》
《TCP协议详解 (史上最全)》
《分库分表 Sharding-JDBC 底层原理、核心实战(史上最全)》
《clickhouse 超底层原理 + 高可用实操 (史上最全)》
《nacos高可用(图解+秒懂+史上最全)》
《队列之王: Disruptor 原理、架构、源码 一文穿透》
《环形队列、 条带环形队列 Striped-RingBuffer (史上最全)》
《一文搞定:SpringBoot、SLF4j、Log4j、Logback、Netty之间混乱关系(史上最全)》
《单例模式(史上最全)》
《红黑树( 图解 + 秒懂 + 史上最全)》
《分布式事务 (秒懂)》
《缓存之王:Caffeine 源码、架构、原理(史上最全,10W字 超级长文)》
《缓存之王:Caffeine 的使用(史上最全)》
《Java Agent 探针、字节码增强 ByteBuddy(史上最全)》
《Docker原理(图解+秒懂+史上最全)》
《Redis分布式锁(图解 - 秒懂 - 史上最全)》
《Zookeeper 分布式锁 - 图解 - 秒懂》
《Zookeeper Curator 事件监听 - 10分钟看懂》
《Netty 粘包 拆包 | 史上最全解读》
《Netty 100万级高并发服务器配置》
《Springcloud 高并发 配置 (一文全懂)》
相关文章:
)
网易一面:select分页要调优100倍,说说你的思路? (内含Mysql的36军规)
背景说明: Mysql调优,是大家日常常见的调优工作。所以Mysql调优是一个非常、非常核心的面试知识点。 在40岁老架构师 尼恩的读者交流群(50)中,其相关面试题是一个非常、非常高频的交流话题。 近段时间,有小伙伴面试网易&#x…...
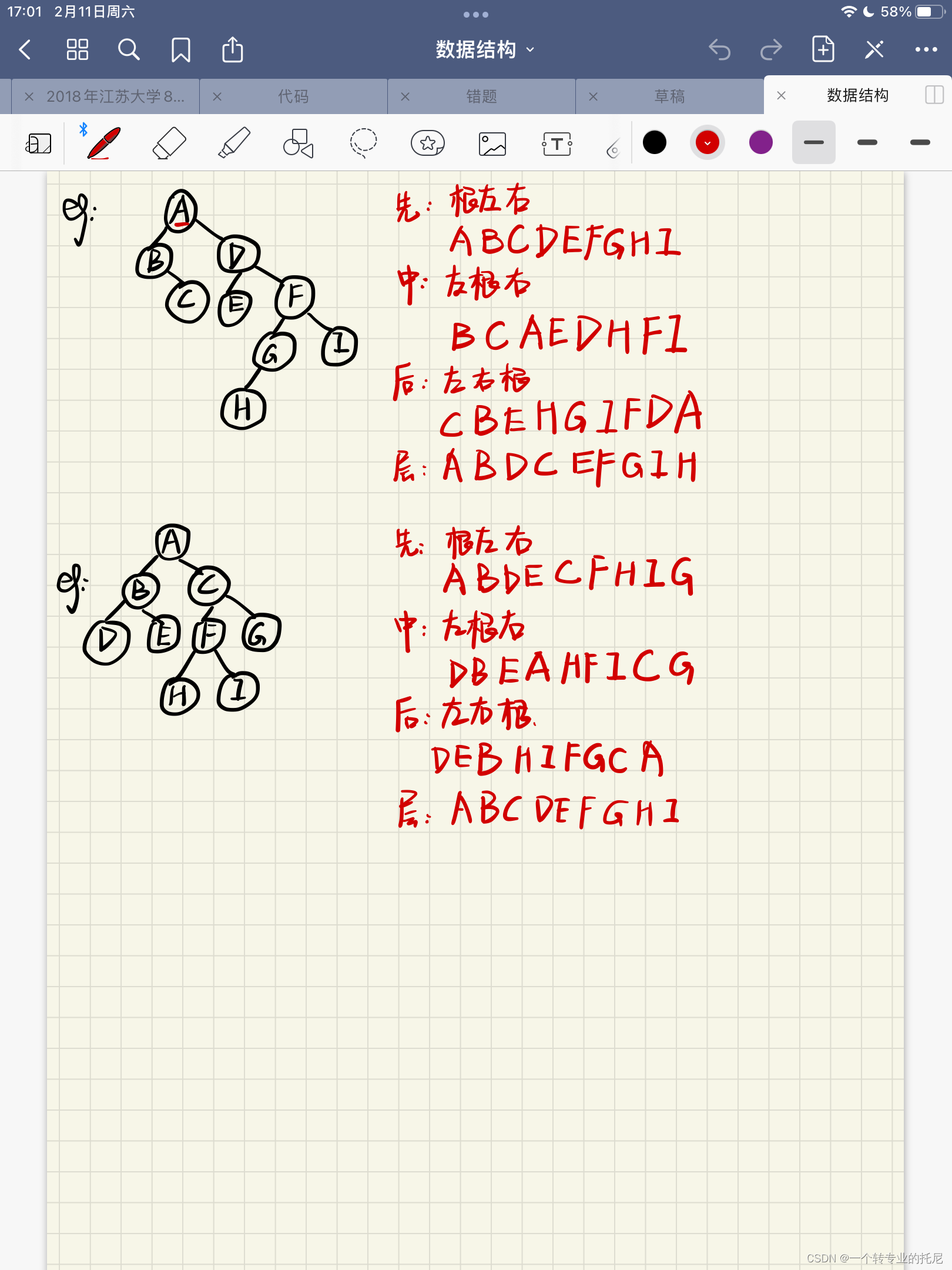
二叉树的遍历 (2023-02-11)
二叉树的遍历 二叉树的遍历分为:先序遍历、中序遍历、后序遍历和层次遍历。 1.先序遍历(根左右) (1)访问根节点 (2)左子树按根左右遍历 (3)右子树按根左右遍历 2.中序…...
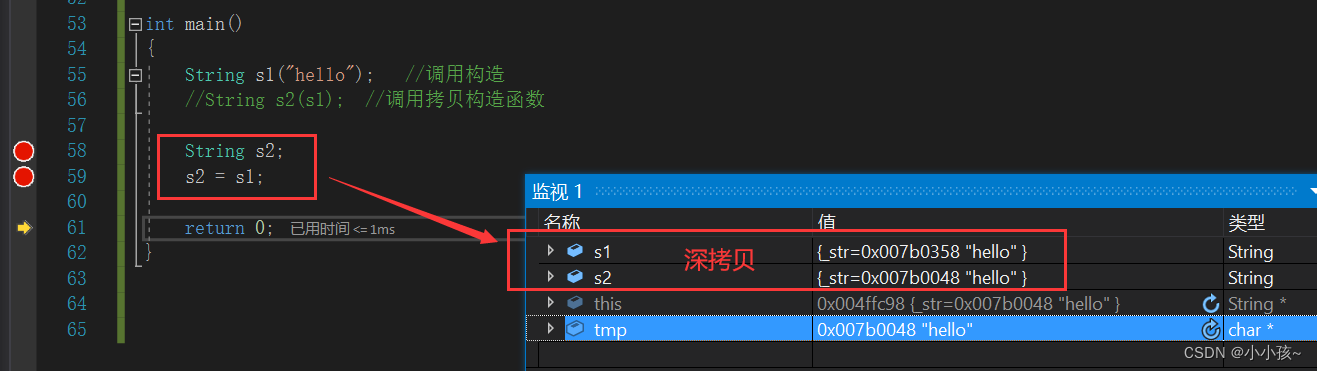
string的深浅拷贝问题
深浅拷贝问题引入浅拷贝深拷贝总结问题引入 对于一个普通的string类: class String { public:String(const char* str ""){//构造函数if (nullptr str)str "";_str new char[strlen(str) 1];strcpy(_str, str);}~String(){//析构函数if …...

C++中的万能头文件
目录一、什么是万能头文件?二、源码三、编译器找不到 bits/stdc.h一、什么是万能头文件? C的万能头文件是: #include <bits/stdc.h>它是一个包含了每一个标准库的头文件。 优点: 在算法竞赛中节约时间;减少了…...

Java 8 Lambda 表达式 Stream
lambda表达式和Stream流是JDK8新增加的新特性,研究本文内容或者运行本文中的demo示例必须安装并使用JDK8以上的JDK版本。demo地址:https://gitee.com/huannzi/bigdataframework/tree/master/src/main/java/com/orkasgb/java 文章目录1、什么是Lambda表达…...
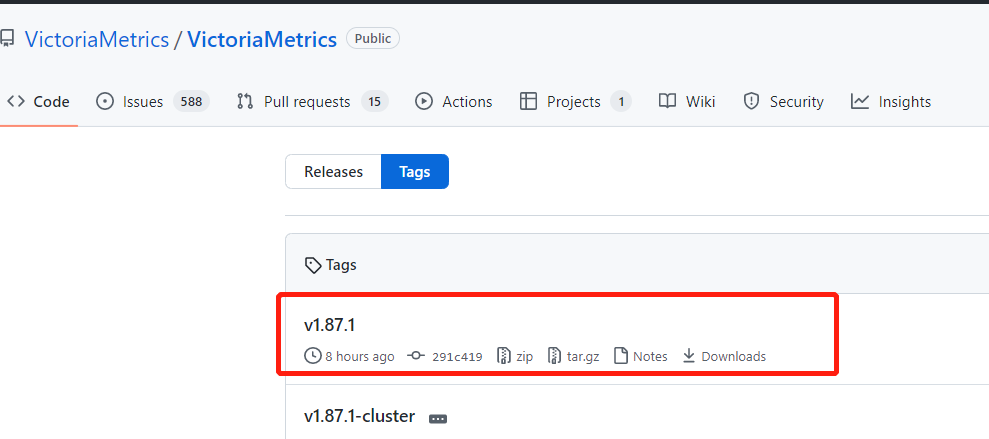
【VictoriaMetrics】VictoriaMetrics单机版部署(二进制版)
1、下载安装包git路径,本文基于1.87.1版本 进入git地址 :https://github.com/VictoriaMetrics/VictoriaMetrics/tags 2、下载其中linux下的 amd64架构...

SCI论文阅读-使用基于图像的机器学习模型对FTIR光谱进行功能组识别
期刊: Analytical Chemistry中科院最新分区(2022年12月最新版):1区(TOP)影响因子(2021-2022):8.008第一作者:Abigail A. Enders通讯作者:Heather C. Allen 原文链接&…...

双11大型互动游戏“喵果总动员” 质量保障方案总结
推荐语:互动游戏是一个系统化工程,在笔者的“喵果总动员”质量方案中,可以看到为保障用户体验,我们在各个难点的解决方案, 例如:用线上压测能力支持业务及时调整各服务容量、通过强化学习覆盖游戏行业的测试…...

剑指Offer专项突击版题解一
1.整数除法 思想:不能用除法、乘法、取余,那么可以用减法完成除法的操作,但是在减去被除数的时候,可以考虑被除数<<1扩大一倍在进行减少,加快减的速率。 2.二进制加法 思想:从末尾向前遍历࿰…...
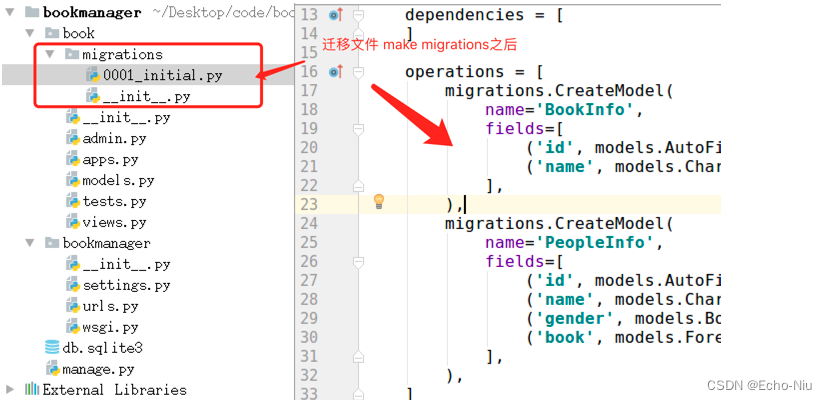
Django框架之模型
模型 当前项目的开发, 都是数据驱动的。 以下为书籍信息管理的数据关系:书籍和人物是 :一对多关系 要先分析出项目中所需要的数据, 然后设计数据库表. 书籍信息表 字段名字段类型字段说明idAutoField主键nameCharField书名 idname1西游记2三国演义…...
OSACN-Net:使用深度学习和Gabor心电图信号谱图进行睡眠呼吸暂停分类
这篇文章在之前读过一次,其主要的思路就是利用Gabor变换,将心电信号转变为光谱图进行识别研究,总体来讲,不同于其他的利用心电信号分类的算法,该论文将心电信号转换为光谱图,在此基础上,分类问题…...
使用开源实时监控系统 HertzBeat 5分钟搞定 Mysql 数据库监控告警
使用开源实时监控系统 HertzBeat 对 Mysql 数据库监控告警实践,5分钟搞定! Mysql 数据库介绍 MySQL是一个开源关系型数据库管理系统,由瑞典MySQL AB 公司开发,属于 Oracle 旗下产品。MySQL 是最流行的开源关系型数据库管理系统之…...

插件 sortablejs:HTML元素可拖动排序
插件 sortablejs 用于可重新排序拖放列表的JavaScript库;关键链接:npm 地址 Github 地址 安装 npm i sortablejs引入 import Sortable from "sortablejs"HTML <ul id"items"><li>item 1</li><li>item …...

libVLC 视频裁剪
作者: 一去、二三里 个人微信号: iwaleon 微信公众号: 高效程序员 裁剪是指去除图像的外部部分,也就是从图像的左,右,顶部和/或底部移除一些东西。通常在视频中,裁剪是一种通过剪切不需要的部分来改变宽高比的特殊方式。 尤其是在做视频墙时,往往需要处理多个 vlc 实例…...

LAMP架构介绍及配置
LAMP架构介绍及配置一、LAMP简介与概述1、LAMP平台概述2、LAMP各组件主要作用3、构建LAMP平台二、编译安装Apache htpd服务1、将所需软件包上传到/opt目录下2、解压以下文件3、移动两个文件并改名4、安装所需工具5、编译安装6、做软连接,使文件可执行7、优化配置文件…...

Android图形显示流程简介
注:本文缩写说明本文代码都是基于Android S一、概述本文将对从App画出一帧画面到这帧画面是如何到达屏幕并最终被人眼看到的这一过程进行简要分析,并将这其中涉及到的各个流程与其在systrace上的体现对应起来,期望最终能够让读者对Android系统…...

4.5.3 ArrayList
文章目录1.特点2. 练习:ArrayList测试3.ArrayList扩容1.特点 存在java.util包中内部是用数组结构存放数据,封装数组的操作,每个对象都有下标内部数组默认的初始容量是10,如果不够会以1.5倍的容量增长查询快,增删数据效率会低 2. 练习:ArrayList测试 package partThree;import…...

十二、Linux文件 - fseek函数讲解
目录 一、fseek函数讲解 二、fseek函数实战 一、fseek函数讲解 重定向文件内部的指针 注:光标 ---- 文件内部的指针 函数原型: int fseek(FILE *stream,long offset,int framewhere) 参数: stream:文件指针offset:…...

Python3.10新特性之match语句示例详解
这篇文章主要为大家介绍了Python3.10新特性之match语句示例详解,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪正文在Python 3.10发布之前,Python是没有类似于其他语言中switch语句的&…...

虎牙盈利能力得到改善,但监管风险对其收入产生负面影响
来源:猛兽财经 作者:猛兽财经 监管风险再次成为焦点 过去一段时间,与中概股相关的监管风险再次引起了投资者的注意,这也是正在考虑投资虎牙(HUYA)的投资者需要注意的问题。 例如,监管机构在2022…...

C++实现分布式网络通信框架RPC(3)--rpc调用端
目录 一、前言 二、UserServiceRpc_Stub 三、 CallMethod方法的重写 头文件 实现 四、rpc调用端的调用 实现 五、 google::protobuf::RpcController *controller 头文件 实现 六、总结 一、前言 在前边的文章中,我们已经大致实现了rpc服务端的各项功能代…...

Java如何权衡是使用无序的数组还是有序的数组
在 Java 中,选择有序数组还是无序数组取决于具体场景的性能需求与操作特点。以下是关键权衡因素及决策指南: ⚖️ 核心权衡维度 维度有序数组无序数组查询性能二分查找 O(log n) ✅线性扫描 O(n) ❌插入/删除需移位维护顺序 O(n) ❌直接操作尾部 O(1) ✅内存开销与无序数组相…...

vscode(仍待补充)
写于2025 6.9 主包将加入vscode这个更权威的圈子 vscode的基本使用 侧边栏 vscode还能连接ssh? debug时使用的launch文件 1.task.json {"tasks": [{"type": "cppbuild","label": "C/C: gcc.exe 生成活动文件"…...

(二)TensorRT-LLM | 模型导出(v0.20.0rc3)
0. 概述 上一节 对安装和使用有个基本介绍。根据这个 issue 的描述,后续 TensorRT-LLM 团队可能更专注于更新和维护 pytorch backend。但 tensorrt backend 作为先前一直开发的工作,其中包含了大量可以学习的地方。本文主要看看它导出模型的部分&#x…...

DAY 47
三、通道注意力 3.1 通道注意力的定义 # 新增:通道注意力模块(SE模块) class ChannelAttention(nn.Module):"""通道注意力模块(Squeeze-and-Excitation)"""def __init__(self, in_channels, reduction_rat…...

在 Nginx Stream 层“改写”MQTT ngx_stream_mqtt_filter_module
1、为什么要修改 CONNECT 报文? 多租户隔离:自动为接入设备追加租户前缀,后端按 ClientID 拆分队列。零代码鉴权:将入站用户名替换为 OAuth Access-Token,后端 Broker 统一校验。灰度发布:根据 IP/地理位写…...

图表类系列各种样式PPT模版分享
图标图表系列PPT模版,柱状图PPT模版,线状图PPT模版,折线图PPT模版,饼状图PPT模版,雷达图PPT模版,树状图PPT模版 图表类系列各种样式PPT模版分享:图表系列PPT模板https://pan.quark.cn/s/20d40aa…...

智能分布式爬虫的数据处理流水线优化:基于深度强化学习的数据质量控制
在数字化浪潮席卷全球的今天,数据已成为企业和研究机构的核心资产。智能分布式爬虫作为高效的数据采集工具,在大规模数据获取中发挥着关键作用。然而,传统的数据处理流水线在面对复杂多变的网络环境和海量异构数据时,常出现数据质…...

力扣-35.搜索插入位置
题目描述 给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。 请必须使用时间复杂度为 O(log n) 的算法。 class Solution {public int searchInsert(int[] nums, …...

JAVA后端开发——多租户
数据隔离是多租户系统中的核心概念,确保一个租户(在这个系统中可能是一个公司或一个独立的客户)的数据对其他租户是不可见的。在 RuoYi 框架(您当前项目所使用的基础框架)中,这通常是通过在数据表中增加一个…...