元数据管理实践数据血缘
- 元数据管理实践&数据血缘
什么是元数据?元数据MetaData狭义的解释是用来描述数据的数据,广义的来看,除了业务逻辑直接读写处理的那些业务数据,所有其它用来维持整个系统运转所需的信息/数据都可以叫作元数据。比如数据表格的Schema信息,任务的血缘关系,用户和脚本/任务的权限映射关系信息等等。
管理这些附加MetaData信息的目的,一方面是为了让用户能够更高效的挖掘和使用数据,另一方面是为了让平台管理人员能更加有效的做好系统的维护管理工作。
出发点很好,但通常这些元数据信息是散落在平台的各个系统,各种流程之中的,而它们的管理也可能或多或少可以通过各种子系统自身的工具,方案或流程逻辑来实现。那么我们所说的元数据管理平台又是用来做什么的?是不是所有的信息都应该或者有必要收集到一个系统中来进行统一管理呢,具体又有哪些数据应该被纳入到元数据管理平台的管理范围之中呢?下面我们就来探讨一下相关的内容。
一、元数据管理平台管什么
数据治理的第一步,就是收集信息,很明显,没有数据就无从分析,也就无法有效的对平台的数据链路进行管理和改进。所以元数据管理平台很重要的一个功能就是信息的收集,至于收集哪些信息,取决于业务的需求和我们需要解决的目标问题。
信息收集再多,如果不能发挥作用,那也就只是浪费存储空间而已。所以元数据管理平台还需要考虑如何以恰当的形式对这些元数据信息进行展示,进一步的,如何将这些元数据信息通过服务的形式提供给周边上下游系统使用,真正帮助大数据平台完成质量管理的闭环工作。
应该收集那些信息,虽然没有绝对的标准,但是对大数据开发平台来说,常见的元数据信息包括:
-
数据的表结构Schema信息
-
数据的空间存储,读写记录,权限归属和其它各类统计信息
-
数据的血缘关系信息
-
数据的业务属性信息
下面我们针对这四项内容再具体展开讨论一下
1.1 数据的表结构Schema信息
数据的表结构信息,这个很容易理解了,狭义的元数据信息通常多半指的就是这部分内容了,它也的确属于元数据信息管理系统中最重要的一块内容。
不过,无论是SQL还是NoSQL的数据存储组件,多半自身都有管理和查询表格Schema的能力,这也很好理解如果没有这些能力的话,这些系统自身就没法良好的运转下去了不是。比如,Hive自身的表结构信息本来就存储在外部DB数据库中,Hive也提供类似 show table,describe table之类的语法对这些信息进行查询。那么我们为什么还要多此一举,再开发一个元数据管理系统对这些信息进行管理呢?
这么做,可能的理由很多,需要集中管理可以是其中一个理由,但更重要的理由,是因为本质上,这些系统自身的元数据信息管理手段通常都是为了满足系统自身的功能运转而设计的。也就是说,它们并不是为了数据质量管理的目的而存在的,由于需求定位不同,所以无论从功能形态还是从交互手段的角度来说,它们通常也就无法直接满足数据质量管理的需求。
举个很简单的例子,比如我想知道表结构的历史变迁记录,很显然多数系统自身是不会设计这样的功能的。而且一些功能就算有,周边上下游的其它业务系统往往也不适合直接从该系统中获取这类信息,因为如果那样做的话,系统的安全性和相互直接的依赖耦合往往都会是个问题。
所以,收集表结构信息,不光是简单的信息汇总,更重要的是从平台管理和业务需求的角度出发来考虑,如何整理和归纳数据,方便系统集成,实现最终的业务价值。
1.2 数据的存储空间,读写记录,权限归属和其它各类统计信息
这类信息,可能包括但不限于:数据占据了多少底层存储空间,最近是否有过修改,都有谁在什么时候使用过这些数据,谁有权限管理和查阅这些数据等等。此外,还可以包括类似昨天新增了多少个表格,删除了多少表格,创建了多少分区之类的统计信息。
在正常的工作流程中,多数人可能不需要也不会去关心这类信息。但是落到数据质量管理这个话题上时,这些信息对于系统和业务的优化,数据的安全管控,问题的排查等工作来说,又往往都是不可或缺的重要信息,所以通常这类信息也可以从Audit审计的角度来归类看待。
与表结构信息类似,对于这类Audit审计类信息的采集和管理,通常具体的底层数据存储管理组件自身的功能也无法直接满足我们的需求,需要通过专门的元数据管理平台中统一进行采集,加工和管理。
1.3 数据的血缘关系信息
血缘信息或者叫做Lineage的血统信息是什么,简单的说就是数据之间的上下游来源去向关系,数据从哪里来到哪里去。知道这个信息有什么用呢?用途很广,举个最简单的例子来说,如果一个数据有问题,你可以根据血缘关系往上游排查,看看到底在哪个环节出了问题。此外我们也可以通过数据的血缘关系,建立起生产这些数据的任务之间的依赖关系,进而辅助调度系统的工作调度,或者用来判断一个失败或错误的任务可能对哪些下游数据造成影响等等。
分析数据的血缘关系看起来简单,但真的要做起来,并不容易,因为数据的来源多种多样,加工数据的手段,所使用的计算框架可能也各不相同,此外也不是所有的系统天生都具备获取相关信息的能力。而针对不同的系统,血缘关系具体能够分析到的粒度可能也不一样,有些能做到表级别,有些甚至可以做到字段级别。
以hive表为例,通过分析hive脚本的执行计划,是可以做到相对精确的定位出字段级别的数据血缘关系的。而如果是一个MapReduce任务生成的数据,从外部来看,可能就只能通过分析MR任务输出的Log日志信息来粗略判断目录级别的读写关系,从而间接推导数据的血缘依赖关系了。
1.4 数据的业务属性信息
前面三类信息,一定程度上都可以通过技术手段从底层系统自身所拥有的信息中获取得到,又或着可以通过一定的流程二次加工分析得到。与之相反,数据的业务属性信息,通常与底层系统自身的运行逻辑无关,多半就需要通过其他手段从外部获取了。
那么,业务属性信息都有哪些呢?最常见的,比如,一张数据表的统计口径信息,这张表干什么用的,各个字段的具体统计方式,业务描述,业务标签,脚本逻辑的历史变迁记录,变迁原因等等,此外,你也可能会关心对应的数据表格是由谁负责开发的,具体数据的业务部门归属等等。
上述信息如果全部需要依靠数据开发者的自觉填写,不是不行,但是显然不太靠谱。毕竟对于多数同学来说,对于完成数据开发工作核心链路以外的工作量,很自然的反应就是能不做就不做,越省事越好。如果没有流程体系的规范,如果没有产生实际的价值,那么相关信息的填写很容易就会成为一个负担或者是流于形式。
所以,尽管这部分信息往往需要通过外部手段人工录入,但是还是需要尽量考虑和流程进行整合,让它们成为业务开发必不可少的环节。比如,一部分信息的采集,可以通过整体数据平台的开发流程规范,嵌入到对应数据的开发过程中进行,例如历史变迁记录可以在修改任务脚本或者表格schema时强制要求填写;业务负责人信息,可以通过当前开发人员的业务线和开发群组归属关系自动进行映射填充;字段统计方式信息,尽可能通过标准的维度指标管理体系进行规范定义。
总体来说,数据的业务属性信息,必然首先是为业务服务的,因此它的采集和展示也就需要尽可能的和业务环境相融合,只有这样才能真正发挥这部分元数据信息的作用。
1.5 元数据分类
- 数据治理:元数据管理 、数据血缘
技术元数据包括:英文字段,字段名称、字段长度、数据库表结构等。
业务元数据包括:中文意思,业务名称、业务定义、业务描述等。
技术元数据为开发和管理数据仓库的IT 人员使用,它描述了与数据仓库开发、管理和维护相关的数据,包括数据源信息、数据转换描述、数据仓库模型、数据清洗与更新规则、数据映射和访问权限等。
业务元数据为管理层和业务分析人员服务,从业务角度描述数据,包括商务术语、数据仓库中有什么数据、数据的位置和数据的可用性等,帮助业务人员更好地理解数据仓库中哪些数据是可用的以及如何使用。
1.5.1 业务元数据
业务元数据主要描述 ”数据”背后的业务含义;从业务角度描述业务领域的相关概念、关系——包括业务术语和业务规则。
业务人员更多关注的是与“客户”、“结算日期”、“销售金额”等相关的内容,这些内容很难从技术元数据中体现出来。
业务元数据使用业务名称、定义、描述等信息表示企业环境中的各种属性和概念,从一定程度上讲,所有数据背后的业务上下文都可以看成是业务元数据。
业务元数据能让用户更好地理解和使用企业环境中的数据,比如用户通过查看业务元数据就可以清晰地理解各指标的含义,指标的计算方法等信息。
业务元数据广泛存在于企业环境中,业务元数据的来源主要有:
-
ERP企业ERP系统中存储着大量的业务元数据,比如说财务计算公式、过程逻辑、业务规则等。
-
报表报表的表头也是一种业务元数据,特别是那些包含合计、平均数等带有总结性质的列,报表中的一些计算公式等。
-
表格与报表类似,EXCEL的表头和公式也是很重要的业务元数据。与报表不同的是,大多数表格中会有单独一列“描述”,有些表格中还会有一列代码和代码描述,这些都是很有用的业务元数据。
-
文件文件中到处都是业务元数据,比如标题、作者、修改时间等,文件内容中的业务元数据的获取相对比较困难,涉及到机器学习等技术。
-
BI工具BI中经常会用到的操作就是“钻取”操作,向上和向下钻取中通常定义了企业的各种分类结构,例如产品等级和组织结构等级等,这些都是很重要的业务元数据。
-
数据仓库数据仓库中也有业务元数据存在,比如说,构建数据仓库之前通常需要做大量调研来研究如何集成多个数据源,这些如数据仓库构建过程相关的文件中存在着大量的业务元数据。
下图是两个具体的例子:
某建筑公司的一张报表,我们可以看到,报表中包含了报表名称、填报时间、制表人和报表表头名称等,这些都是高价值的业务元数据;某公司新员工入职申请表,和报表类似,申请表名称、姓名、性别等申请表各栏名称都是业务元数据。
目前,大部分企业只关注到了技术元数据,忽略了对业务元数据的管理。技术元数据缺少业务含义,很难被技术人员之外的人所理解,比如可能用“rec_temp_fld_a”表示某个字段,用“236IN_TAB”表示数据库中的某张表,在不被理解的情况下很难给企业业务带来收益。业务元数据能代表数据背后的业务含义,企业在对技术元数据管理的同时需要注重业务元数据的管理。
主题定义:每段 ETL、表背后的归属业务主题。
业务描述:每段代码实现的具体业务逻辑。
标准指标:类似于 BI 中的语义层、数仓中的一致性事实;将分析中的指标进行规范化。
标准维度:同标准指标,对分析的各维度定义实现规范化、标准化。
业务元数据,在实际业务中,需要不断的进行维护且与业务方进行沟通确认。
1.5.2 技术元数据
指技术细节相关的概念、关系和规则,包括对数据结构、数据处理方面的描述。以及数据仓库、ETL、前端展现等技术细节的信息。
数据仓库中的技术元数据一般包含以下 4 大系统:数据源元数据;ETL 元数据;数据仓库元数据;BI 元数据。
- 数据源元数据
例如:数据源的 IP、端口、数据库类型;数据获取的方式;数据存储的结构;原数据各列的定义及 key 指对应的值。
- ETL 元数据
根据 ETL 目的的不同,可以分为两类:数据清洗元数据;数据处理元数据。
- 数据清洗元数据
数据清洗,主要目的是为了解决掉脏数据及规范数据格式;
因此此处元数据主要为:各表各列的"正确"数据规则;默认数据类型的"正确"规则。
- 数据处理元数据
数据处理,例如常见的表输入表输出;非结构化数据结构化;特殊字段的拆分等。
源数据到数仓、数据集市层的各类规则。比如内容、清理、数据刷新规则。
- 数据仓库元数据
数据仓库结构的描述,包括仓库模式、视图、维、层次结构及数据集市的位置和内容;
业务系统、数据仓库和数据集市的体系结构和模式等。
- BI 元数据
汇总用的算法、包括各类度量和维度定义算法。数据粒度、主题领域、聚集、汇总、预定义的查询与报告。
1.6 元数据管理
1.元数据自动采集、动态感知,版本差异标记
2.元数据血缘、影响、全链路关系自动探索,图形化展现
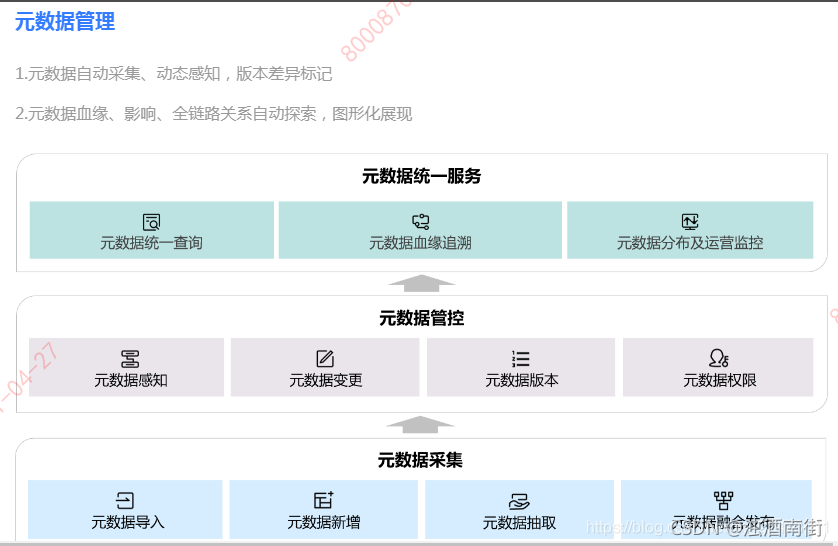
1.7 元数据管理平台架构
元数据管理平台从应用层面,可以分类:元数据采集服务,应用开发支持服务,元数据访问服务、元数据管理服务和元数据分析服务。
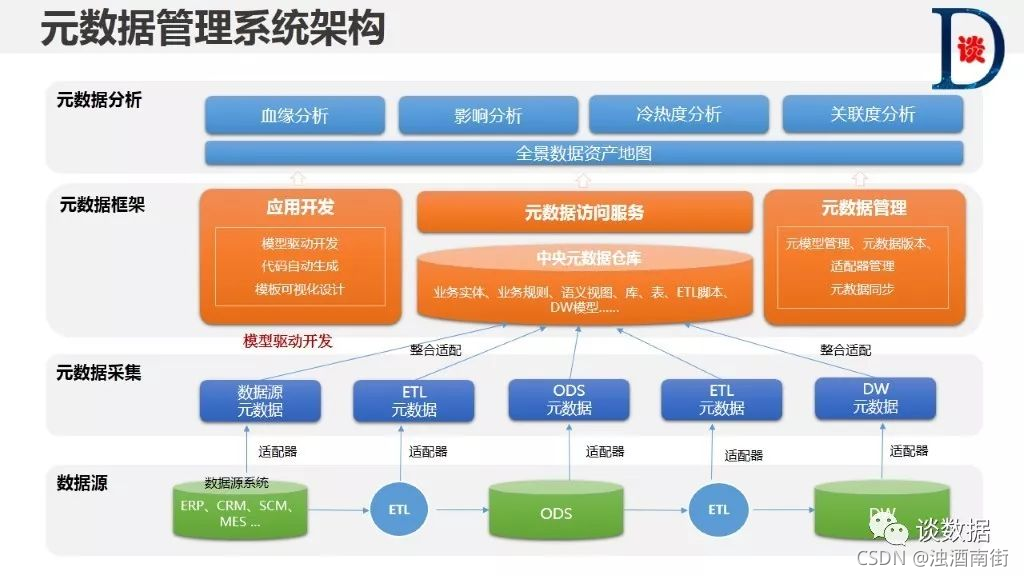
1.7.1 元数据采集服务
在数据治理项目中,通常涉及到的元数据还包括:数据源的元数据,数据加工处理过程的元数据,数据仓库或数据主题库的元数据,数据应用层的元数据,数据接口服务的元数据等等。元数据采集服务提供各类适配器满足以上各类元数据的采集,并将元数据整合处理后统一存储于中央元数据仓库,实现元数据的统一管理。这个过程中,数据采集适配器十分重要,元数据采集要能够适配各种DB、各类ETL、各类DW和Report产品,同时还需要适配各类结构化或半结构化数据源。目前市场上的主流元数据产品还没有哪一家能做到“万能适配”,都需要在实际应用过程中做或多或少的定制化开发。
1.7.2 元模型驱动的设计与开发
通过元数据管理平台实现对应用的逻辑模型、物理模型、UI模型等各类元模型管理,支撑应用的设计和开发。应用开发的元模型有三个状态,分别是:设计态的元数据模型,通常由ERWin、PowerDesigner的等设计工具产生。测试态的元数据模型,通常是关系型数据:Oracle、DB2、Mysql、Teradata等,或非关系型数据库:MongDB、HBase、Hive、Hadoop等。生产态的元模型,本质上与测试态元数据差异不大。通过元数据平台对应用开发三种状态的统一管理和对比分析,能够有效降低元数据变更带来的风险,为下游ODS、DW的数据应用提供支撑。另外,基于元数据的MDD(代码生成服务),可以通过模型(元数据)完成业务对象元数据到UI元数据的关联和转换,自动生成相关代码,表单界面,减少了开发人员的设计和编码量,提升应用和服务的开发效率。

1.7.3 元数据管理服务
市场上主流的元数据管理产品,基本都包括:元数据查询、元模型管理、元数据维护、元数据版本管理、元数据对比分析、元数据适配器、元数据同步管理、元数据生命周期管理等功能。此类功能,各家产品大同小异
1.7.4 元数据访问服务
元数据访问服务是元数据管理软件提供的元数据访问的接口服务,一般支持REST或Webservice等接口协议。通过元数据访问服务支持企业元数据的共享,是企业数据治理的基础。
1.7.5 元数据分析服务,即元数据管理的意义

1、血缘分析:是告诉你数据来自哪里,都经过了哪些加工。其价值在于当发现数据问题时可以通过数据的血缘关系,追根溯源,快速地定位到问题数据的来源和加工过程,减少数据问题排查分析的时间和难度。这个功能常用于数据分析发现数据问题时,快速定位和找到数据问题的原因。
血缘分析是一种技术手段,用于对数据处理过程的全面追踪,从而找到某个数据对象为起点的所有相关元数据对象以及这些元数据对象之间的关系。元数据对象之间的关系特指表示这些元数据对象的数据流输入输出关系。
在元数据管理系统成型后,我们便可以通过血缘分析来对数据仓库中的数据健康、数据分布、集中度、数据热度等进行分析。
2、影响分析:是告诉你数据都去了哪里,经过了哪些加工。其价值在于当发现数据问题时可以通过数据的关联关系,向下追踪,快速找到都哪些应用或数据库使用了这个数据,从而避免或降低数据问题带来的更大的影响。这个功能常用于数据源的元数据变更对下游ETL、ODS、DW等应用应用的影响分析。
在开发中,我们经常会遇到以下问题:如果我要改动某个表、ETL,会造成怎样的影响?
如果没有元数据,那我们可能需要遍历所有的脚本、数据。才能得到想要的答案;而如果有成熟的元数据管理,那我们就可以直接得到答案,节省大量时间。
3、冷热度分析:是告诉你哪些数据是企业常用数据,哪些数据属于“僵死数据”。其价值在于让数据活跃程度可视化,让企业中的业务人员、管理人员都能够清晰的看到数据的活跃程度,以便更好的驾驭数据,激活或处置“僵死数据”,从而为实现数据的自助式分析提供支撑。
4、关联度分析:是告诉你数据和其他数据的关系以及它们的关系是怎样建立的。关联度分析是从某一实体关联的其它实体和其参与的处理过程两个角度来查看具体数据的使用情况,形成一张实体和所参与处理过程的网络,从而进一步了解该实体的重要程度,如:表与ETL 程序、表与分析应用、表与其他表的关联情况等。本功能可以用来支撑需求变更的影响评估。
5、数据资产地图:是告诉你有哪些数据,在哪里可以找到这些数据,能用这些数据干什么。通过元数据可以对企业数据进行完整的梳理、采集和整合,从而形成企业完整的数据资产地图。数据资产地图支持以拓扑图的形式进行可视化展示各类元数据和数据处理过程,通过不同层次的图形展现粒度控制,满足业务上不同应用场景的数据查询和辅助分析需要。
1.7.6 ETL 自动化管理
在数仓中,很大一部分 ETL 都是枯燥重复的步骤。
例如源系统-ODS 层的:表输入——表输出。
又比如 ODS-DW:SQL 输入——数据清洗——数据处理——表输出。
以上的规则其实就属于一部分元数据。
那理论上完全可以实现,写好固定脚本,然后通过前端选择——或 api 接口。
进而对重复的 ETL 实现自动化管理,降低 ETL 开发的时间成本。
1.7.7 数据安全管理
在阿里推崇的数据中台中,一切数据接口指标,都会从数据仓库中出口。因此理论上,我们只需在此处的元数据中对管理元数据的权限进行配置,即可实现全公司的数据安全管理。
二、元数据管理相关系统方案介绍
- 元数据血缘技术调研
2.1 Apache Atlas
社区中开源的元数据管理系统方案,常见的比如Hortonworks主推的Apache Atlas,它的基本架构思想如下图所示
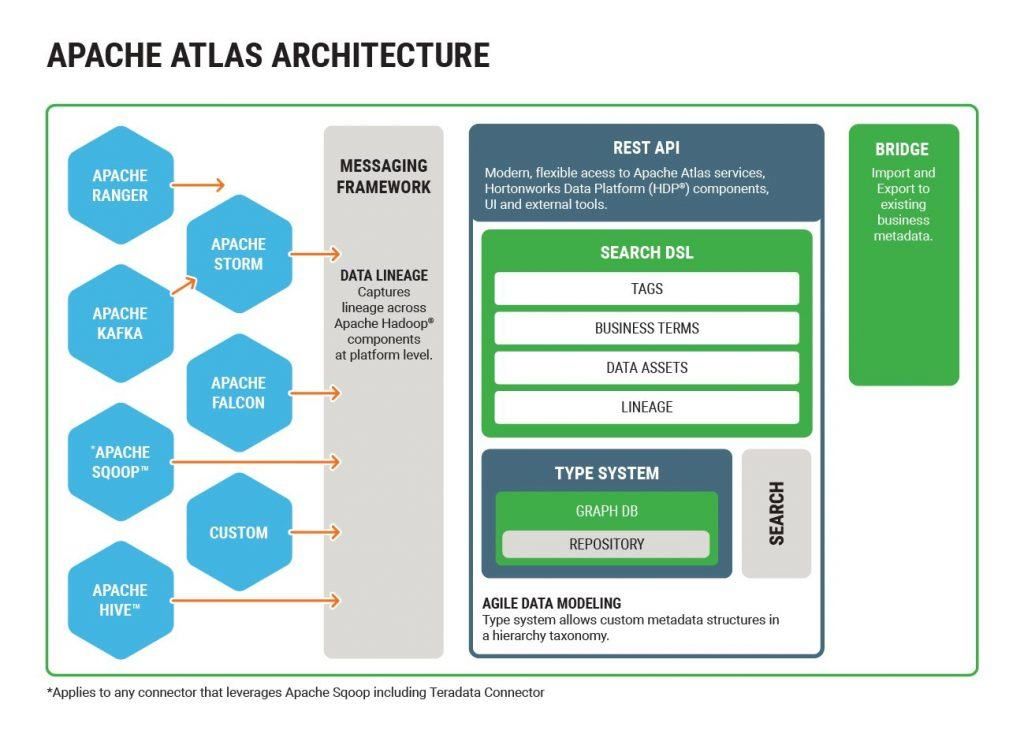
Atlas的架构方案应该说相当典型,基本上这类系统大致都会由元数据的收集,存储和查询展示三部分核心组件组成。此外,还会有一个管理后台对整体元数据的采集流程以及元数据格式定义和服务的部署等各项内容进行配置管理。
对应到Atlas的实现上,Atlas通过各种hook/bridge插件来采集几种数据源的元数据信息,通过一套自定义的Type 体系来定义元数据信息的格式,通过搜索引擎对元数据进行全文索引和条件检索,除了自带的UI控制台意外,Atlas还可以通过Rest API的形式对外提供服务。
Atlas的整体设计侧重于数据血缘关系的采集以及表格维度的基本信息和业务属性信息的管理。为了这个目的,Atlas设计了一套通用的Type体系来描述这些信息。主要的Type基础类型包括DataSet和Process,前者用来描述各种数据源本身,后者用来描述一个数据处理的流程,比如一个ETL任务。
Atlas现有的Bridge实现,从数据源的角度来看,主要覆盖了Hive,HBase,HDFS和Kafka,此外还有适配于Sqoop, Storm和Falcon的Bridge,不过这三者更多的是从Process的角度入手,最后落地的数据源还是上述四种数据源。
具体Bridge的实现多半是通过上述底层存储,计算引擎各自流程中的Hook机制来实现的,比如Hive SQL的Post Execute Hook,HBase的Coprocessor等,而采集到的数据则通过Kafka消息队列传输给Atlas Server或者其它订阅者进行消费。
在业务信息管理方面,Atlas通过用户自定义Type 属性信息的方式,让用户可以实现数据的业务信息填写或者对数据打标签等操作,便于后续对数据进行定向过滤检索。
最后,Atlas可以和Ranger配套使用,允许Ranger通过Atlas中用户自定义的数据标签的形式来对数据进行动态授权管理工作,相对于基于路径或者表名/文件名的形式进行静态授权的方式,这种基于标签的方式,有时候可以更加灵活的处理一些特定场景下的权限管理工作。
总体而言,Atlas的实现,从结构原理的角度来说,还算是比较合理的,但从现阶段来看,Atlas的具体实现还比较粗糙,很多功能也是处于可用但并不完善的状态。此外Atlas在数据审计环节做的工作也不多,与整体数据业务流程的集成应用方面的能力也很有限。Atlas项目本身很长时间也都处于Incubator状态,因此还需要大家一起多努力来帮助它的改进。
2.1.1 表级别的血缘关系
如果只是到表级别,这个实现比较简单,像hive tool就自带了一个工具类可以直接获得:

2.2 DataHub
2.3 整体对比
1、没有哪一款开源产品能直接达到我们的需求,必须得针对或多或少的改造、扩展才行
2、Atlas的UI感觉其实是比较简单的,如果要做二次开发,感觉是最容易的(只用它的数据模型和API,不用它的页面UI)
3、Atlas通过hook的方式,可以实时收集元数据,这是它的优势,但是针对我们的场景,hive表的元数据其实是在动态变化的,用这种方式可能反而不太好
4、Datahub感觉是整体比较完整的一个产品,支持的数据源也很多,设计上是支持自定义扩展的,重点是产品交互设计等能否达到我们的要求,后期又要做多少修改?
2.4 总结和问题
想把整个链路的数据血缘打通,避免不了自己去针对某个链路进行数据解析和采集,所以必须选择一款扩展性强的产品 首先应该搞清楚一个问题,我们究竟想要做成一个怎样的产品?
是一个仅仅供内部使用,主要为了解决日常痛点,交互体验差一点也可以容忍?
还是想做成一个成熟的,可以商业化的产品?
具体的方案设计应该结合产品需求以及研发能力来综合考虑
大概有三种做法:
1、完全自研
能做到最大的灵活性和体验,产品高度适配业务,但是有较高的研发成本,投入要求高
2、使用开源产品,扩展功能
产品体验受限于开源产品本身,有些功能能否实现也主要看开源产品本身是否支持扩展
3、基于开源产品做二次开发
产品设计还是不能和开源产品相差太远,不然就没有太大意义了。
而且对开发的能力要求是比较高的,需要深入了解开源产品的架构设计和编码实现 可以结合1、2、3,比如后端部分使用开源,前端UI交互自己开发
个人觉得比较可行的方案:
1、后端存储选用Atlas,UI完全自己开发,血缘这块交互比较复杂的可以拷贝代码复用,Atlas不支持的元数据和血缘的采集也自己开发扩展
2、前后端都使用datahub,做少量二次开发,不支持的元数据和血缘的采集自己开发扩展
三、数据血缘
- 数据治理(一)自研血缘关系
3.1 数据血缘的作用与表现形式
- 2022数据血缘关系详解
3.1.1 数据血缘的作用
开篇的场景中的案例是数据血缘的两个典型的作用,总结成一句话就是数据血缘可以帮助数据生产者以及消费者更好地对数据进行追根溯源,提升数据运维、数据治理的效率。
(1)提升数据问题排查效率
数据从生产到赋能业务应用经过很多的处理环节,业务端报表或数据应用服务异常时,需要第一时间定位问题,排查修复。
如果靠一层一层的人肉翻代码效率非常低下,一方面数据开发人力花费在排查上,另一方面定位问题时间越长业务影响和损失越大,基于血缘数据加以可视化的展现形式,可以直观地发现数据生产链路,以及各个环节有无异常。
(2)有助于优化数据资产成本
随着业务地发展数据不断增长,任务、数据表只增不减会不断膨胀大数据资源成本。很多时候不是不愿意做数据、服务治理,二是不敢。
也就是不知道对应的服务有哪些业务在使用,缺少治理的依据,与其直接下线带来业务影响,倒不如一直维持现状。构建全面准确的全链路数据血缘,就可以找出数据下游应用方,做好沟通和信息同步,长期没有调用的服务,及时做下线处理,节省数据成本。
(3)提升数据产品及应用体验
数据部门经常被业务Diss数据是不是有问题,长此以往,会降低业务对数据准确度的信任,搞数据的天天被打上数据不准的标签还是很无奈的。
在数据产出任务层面对数据质量的准确性、一致性、及时性、完整性等维度进行监控覆盖,触发报警机制后,利用数据血缘关系,对下游应用进行通知提醒。业务看到后,至少知道数据部门在处理问题了,不会利用错的数据做错误的决策,或者形成每次都是业务先发现问题的认知。
(4)方便确认数据处理逻辑
业务部门在使用数据时,有时候需要确认数据口径和加工逻辑是什么,是否符合自己的需求,通过血缘的可视化展示,可以方便业务部门查看数据的处理过程。
3.1.2 血缘的表现形式
每个数据表、字段、指标都可以认为是一个数据实体,而生产它的上游,以及使用它的下游,都是对应的数据实体之间的关系,因此,在血缘数据的可视化展示时,主要采用可以直观表示数据生产链路的形态,每个节点需要包含以下要素:
当前节点信息:名称、类型、状态
上游:关系、上游名称、类型、状态
下游:关系、上游名称、类型、状态
3.2 字段血缘分析的意义
通过元数据以企业全局视角对企业各业务域的数据资产进行盘点,实现企业数据资源的统一梳理和盘查,有助于发现分布在不同系统、位置或个人电脑的数据,让隐匿的数据显性化。数据地图包括了数据资源的基本信息,存储位置信息、数据结构信息、各数据之间关系信息,数据和人之间的关系信息,数据使用情况信息等,使数据资源信息详细、统一、透明,降低“找数据”的沟通成本,为数据的使用和大数据挖掘提供支撑。
数仓经常会碰到的两类问题:
1、两个数据报表进行对比,结果差异很大,需要人工核对分析指标的维度信息,比如从头分析数据指标从哪里来,处理条件是什么,最后才能分析出问题原因 ——数据回溯问题
2、基础数据表因某种原因需要修改字段,需要评估其对数仓的影响,费时费力,然后在做方案 —— 影响分析问题
- 追根溯源,发现数据问题本质
企业在做数据分析的时候,数据分析结果不正确,原因可能是数据分析过程出现数据问题,也可能是数据源本身就有问题,还可能是数据在加工处理过程中出现了数据问题……。通过元数据血缘分析,能够快速定位数据来源和加工处理过程,能够帮助数据分析人员快速定位数据问题。另外,通过元数据血缘关系分析,可以理解不同数据指标间的关系,分析产生指标的数据源头波动情况带来的影响。
- 模型驱动,敏捷开发
基于元数据模型的数据应用规划、设计和开发是企业数据应用的一个高级阶段。当企业元数据管理达到一定水平(实现自动化管理的时候),企业中各类数据实体模型、数据关系模型、数据服务模型、数据应用模型的元数据统一在元数据平台进行管理,并自动更新数据间的关联关系。基于元数据、可扩展的MDA,才是快速满足企业数据应用个性化定制需求的最好解决方案。通过将大量的业务进行模型抽象,使用元数据进行业务描述,并通过相应的模型驱动引擎在运行时驱动,使用高度抽象的领域业务模型作为构件,完成代码转换,动态生成相关代码,降低开发成本,应对复杂需求变更。
这两类问题都属于数据血缘分析问题,数据血缘分析还有其它的积极意义,比如:
- 问题定位分析
类似于影响分析,当程序运行出错时,可以方便找到问题的节点,并判断出问题的原因以及后续的影响
- 指标波动分析
当某个指标出现较大的波动时,可进行溯源分析,判断是由哪条数据发生变化所导致的
- 数据体检
判定系统和数据的健康情况,是否存在大量的冗余数据、无效数据、无来源数据、重复计算、系统资源浪费等问题
- 数据评估
通过血缘分析和元数据,可以从数据的集中度、分布、冗余度、数据热度、重要性等多角度进行评估分析,从而初步判断数据的价值
3.3 构建血缘的方案
方案一:只收集SQL,事后分析。
当SQL执行结束,收集SQL到DB或者Kafka。
优点:当计算引擎和工具不多的时候,语法相对兼容的时候,用Hive自带的LineageLogger重新解析SQL可以获得表和字段级别的关系。
缺点:重放SQL的时候可能元数据发生改变,比如临时表可能被Drop,没有临时自定义函数UDF,或者SQL解析失败。
方案二:运行时分析SQL并收集。
当SQL执行结束后立即分析Lineage,异步发送到Kafka。
优点:运行时的状态和信息是最准确的,不会有SQL解析语法错误。
缺点:需要针对各个引擎和工具开发解析模块,解析速度需要足够快。
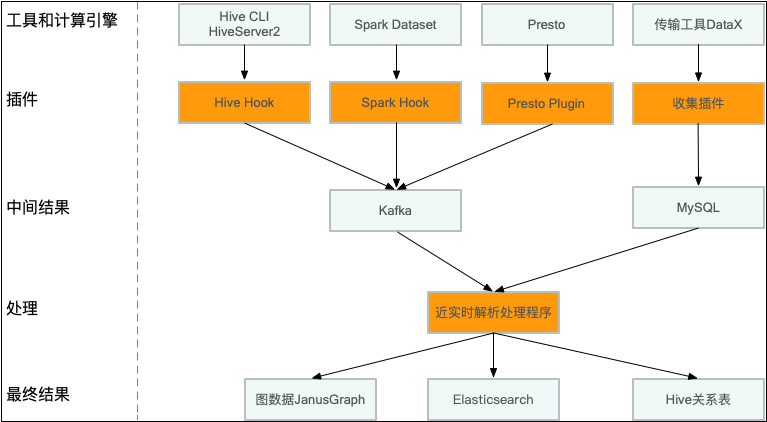
3.4 携程方案
携程采用了方案二,运行时分析SQL并收集分析结果到Kafka。由于开源方案在现阶段不满足需求,则自行开发。
由于当时缺少血缘关系,对数据治理难度较大,表级别的血缘解析难度较低,表的数量远小于字段的数量,早期先快速实现了表级别版本。
在16-17年实现和上线了第一个版本,收集常用的工具和引擎的表级别的血缘关系,T+1构建关系。
在19年迭代了第二个版本,支持解析Hive,Spark,Presto多个查询引擎和DataX传输工具的字段级别血缘关系,近实时构建关系。
3.4.1 第一个版本-表级别血缘关系
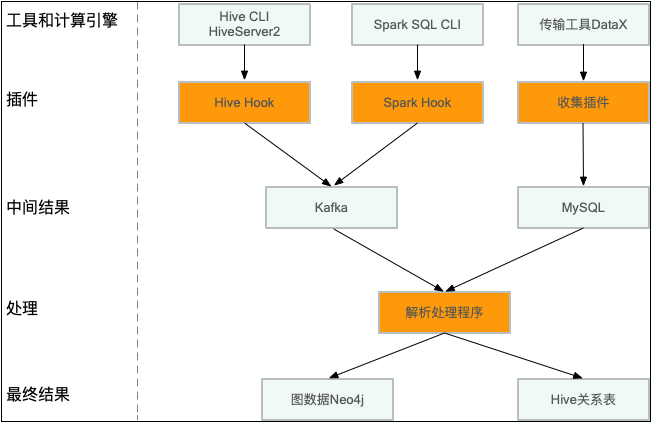
针对Hive引擎开发了一个Hook,实现ExecuteWithHookContext接口,从HookContext可以获得执行计划,输入表,输出表等丰富信息,异步发送到Kafka,部署的时候在hive.exec.post.hooks添加插件即可。
在17年引入Spark2后,大部分Hive作业迁移到Spark引擎上,这时候针对Spark SQL CLI快速开发一个类似Hive Hook机制,收集表级别的血缘关系。
传输工具DataX作为一个异构数据源同步的工具,单独对其开发了收集插件。
在经过解析处理后,将数据写到图数据库Neo4j,提供元数据系统展示和REST API服务,落地成Hive关系表,供用户查询和治理使用。
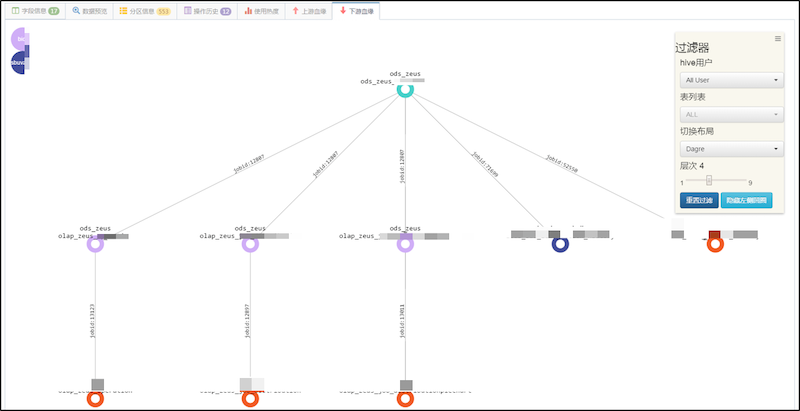
在元数据系统上,可以查看一张表多层级的上下游血缘关系,在关系边上会有任务ID等一些属性。
随着计算引擎的增加,业务的增长,表级别的血缘关系已经不满足需求。
覆盖面不足,缺少Spark ThriftServer , Presto引擎,缺少即席查询平台,报表平台等。
关系不够实时,期望写入表后可以快速查询到关系,用户可以直观查看输入和输出,数据质量系统,调度系统可以根据任务ID查询到输出表,对表执行质量校验任务。
图数据库Neo4j社区版为单机版本,存储数量有限,稳定性欠佳,当时使用的版本较低,对边不能使用索引(3.5支持),这使得想从关系搜索到关联的上下游较为麻烦。
3.4.2 第二版本-字段级别血缘关系
之前实现的第一个版本,对于细粒度的治理和追踪还不够,不仅缺少对字段级别的血缘关系,也不支持采集各个系统的埋点信息和自定义扩展属性,难以追踪完整链路来源,并且关系是T+1,不够实时。
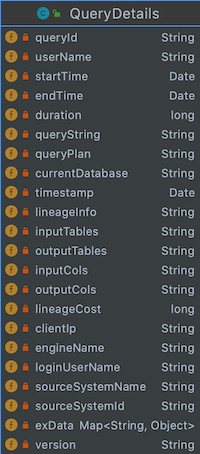
针对各个计算引擎和传输工具DataX开发不同的解析插件,将解析好的血缘数据发送到Kafka,实时消费Kafka,把关系数据写到分布式图数据JanusGraph。
阿里开源的Druid是一个 JDBC 组件库,包含数据库连接池、SQL Parser 等组件。通过重写MySqlASTVisitor、SQLServerASTVisitor来解析MySQL / SQLServer的查询SQL,获得列级别的关系。
计算引擎统一格式,收集输入表、输出表,输入字段、输出字段,流转的表达式等一些信息。
3.5 自研血缘关系
- 数据治理(一)自研血缘关系
数据血缘也称为数据血统或谱系,是来描述数据的来源和派生关系。数据来源是数据科学的关键,也是被公认为数据信任的核心的部分。说白了就是这个数据是怎么来的,经过了哪些过程或阶段,从哪些表,哪些字段计算得来的。
(桑基图是血缘关系的一种表达图表,图表使用ECharts绘制。)
附录A
A.1 数据血缘相关案例
- 携程数据血缘构建及应用
- 搜狐 Hive SQL 血缘关系解析与应用
- 顺丰 基于 Hook 机制实现数据血缘系统
- 字节跳动数据血缘图谱升级方案设计与实现
相关文章:
元数据管理实践数据血缘
元数据管理实践&数据血缘 什么是元数据?元数据MetaData狭义的解释是用来描述数据的数据,广义的来看,除了业务逻辑直接读写处理的那些业务数据,所有其它用来维持整个系统运转所需的信息/数据都可以叫作元数据。比如…...

SQL的优化【面试工作】
SQL的优化 最近看到群友在讨论这块的优化,感觉不管工作和面试,都是用上的,记录下吧!(不然又记不住) 优化点: 处理和优化复杂的 SQL 查询可以有以下几个方向: 1.优化查询语句本身 首先,可以优化 SQL 查询语句本身,尽量让其更加简洁、高效。 …...

Kotlin 40. Dependency Injection 依赖注入以及Hilt在Kotlin中的使用,系列3:Hilt 注释介绍及使用案例
一起来学Kotlin:概念:27. Dependency Injection 依赖注入以及Hilt在Kotlin中的使用,系列3:Hilt 注释介绍及使用案例 此系列博客中,我们将主要介绍: Dependency Injection(依赖注入)…...

1000亿数据、30W级qps如何架构?来一个天花板案例
1000亿级存储、30W级qps系统如何架构?来一个天花板案例 说在前面 在尼恩的(50)读者社群中,经常遇到一个 非常、非常高频的一个架构面试题,类似如下: 千万级数据,如何做系统架构?亿…...
人工智能及其应用(蔡自兴)期末复习
人工智能及其应用(蔡自兴)期末复习 相关资料: 人工智能期末复习 人工智能复习题 人工智能模拟卷 人工智能期末练习题 1 ⭐️绪论 人工智能:人工智能就是用人工的方法在机器(计算机)上实现的智能࿰…...
openpnp - configure - 矫正里程碑
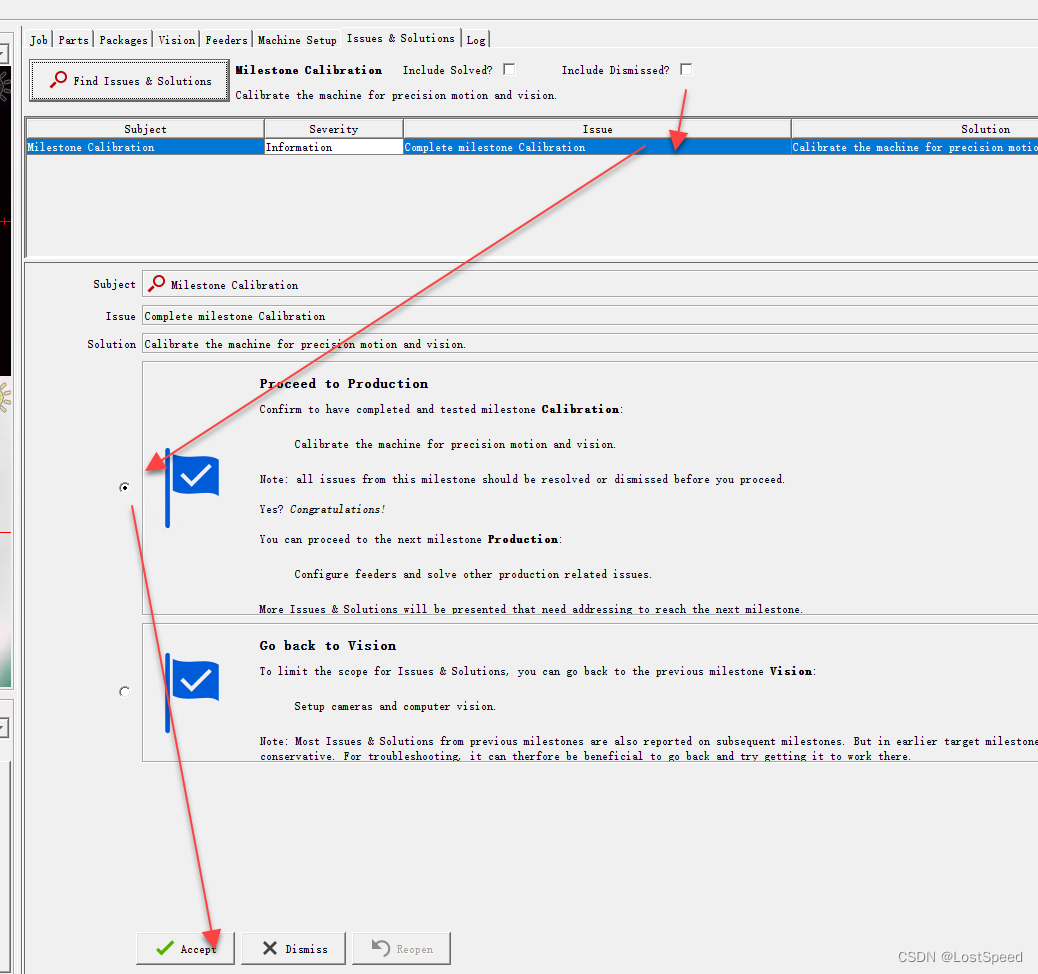
文章目录openpnp - configure - 矫正里程碑概述备注ENDopenpnp - configure - 矫正里程碑 概述 进入矫正里程碑了 查找问题 现在第一个问题是X轴的齿隙矫正 根据提示, 将顶部相机移动到主基准点上, 选择容差(就选用默认的0.025), 开始矫正. 正好开机后, 使能了视觉原点归零. …...
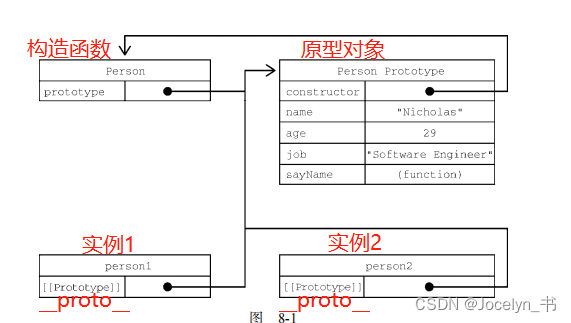
JavaScript高级程序设计读书分享之8章——8.2创建对象
JavaScript高级程序设计(第4版)读书分享笔记记录 适用于刚入门前端的同志 创建Object的实例 let person new Object(); person.name "Nicholas"; person.age 29; person.job "Software Engineer"; person.sayName function() { console.log(this…...

关于Could not build wheels for opencv-python-headless, which is...报错的解决方案
在通过最新版pip在线安装package:opencv-python-headless的时候,会产生报错信息,主要为 ERROR: Failed building wheel for opencv-python-headless ERROR: Could not build wheels for opencv-python-headless, which is required to insta…...
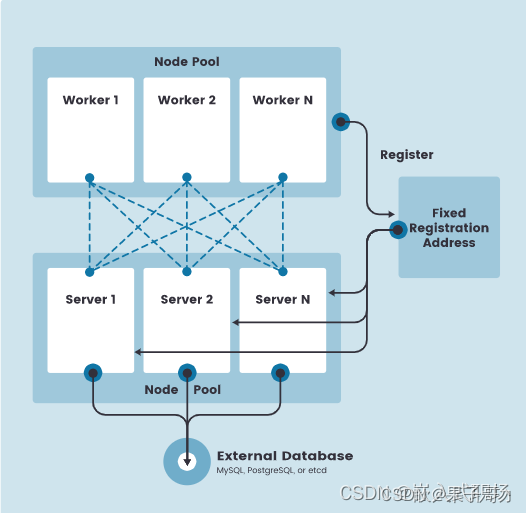
【K3s】第1篇 K3s入门级介绍及架构详解
1、什么是 K3s? K3s 是一个轻量级的 Kubernetes 发行版,它针对边缘计算、物联网等场景进行了高度优化。K3s 有以下增强功能: 打包为单个二进制文件。使用基于 sqlite3 的轻量级存储后端作为默认存储机制。同时支持使用 etcd3、MySQL 和 PostgreSQL 作…...

Java学习--反射
1. 反射 1.1 反射的概述: **专业的解释(了解一下):**是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意属性和方法ÿ…...
)
应用和迭代(名词解释)
应用和迭代是什么意思 应用: ● 一个完整的前端应用,一般用应用脚手架创建,包含路由,页面,状态等 ● 一个应用对应一个代码仓库 ● 应用的分组(业务中心,数据中台等)只用于逻辑分类&…...

HTMLCollection 和 NodeList 区别
Node 和 Element DOM 是一棵树,所有节点都是 NodeNode 是 Element 的基类Element 是其他 HTML 元素的基类,如 HTMLDivElement HTMLCollection 和 NodeList HTMLCollection 是 Element 的集合NodeList 是 Node 的集合 <body><p id"p1&qu…...

fork()出来一个进程,这个进程的父进程是从哪来的?
基本概念fork() creates a new process by duplicating the calling process. The new process is referred to as the child process. The calling process is referred to as the parent process.fork()是一个系统调用,不是一个函数。详细信息可以,man…...

结构体内存对齐
结构体相信大家已经了解过了,现在我们深入讨论一个问题,计算结构体的大小 也是很热门的一个考点:结构体内存对齐 先看看下面结构体的大小 typedef struct Test {char a;char b;char c; }Test; 很容易看出答案为3,结构体的大小位…...
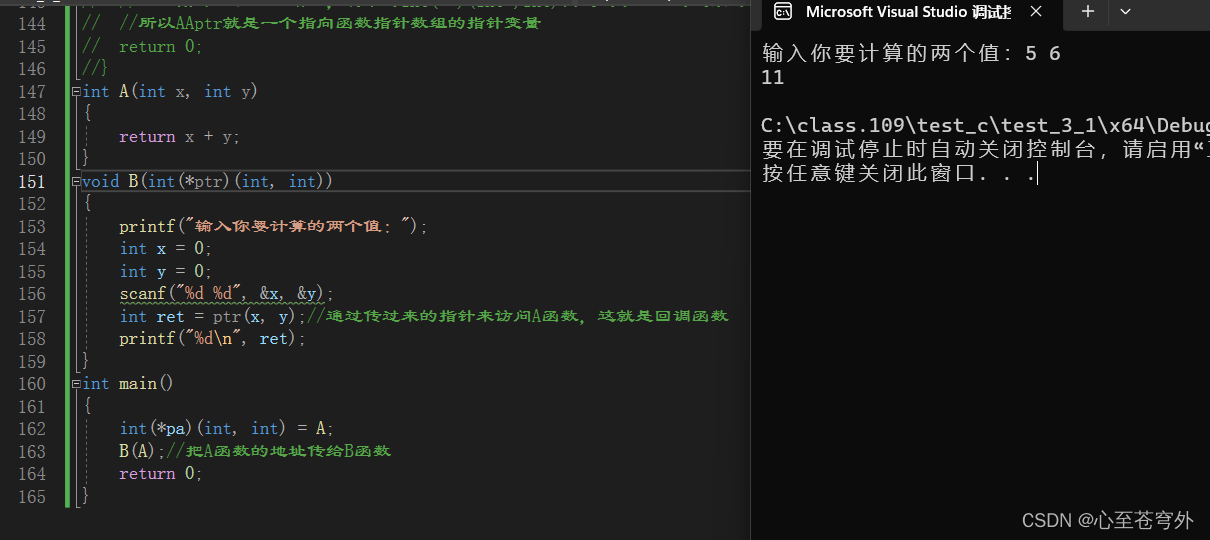
【C语言进阶】指针进阶
今日所做之事勿候明天,自我所做之事勿候他人。 --歌德 目录 指针进阶(更深层次的理解): 一.字符指针 二.指针数组 三.数组指针 1.数组指针的定义: 2.&数组名和数组名: 3.数组指针的使用: 四.数组参数,指针参数 1.一维数组传参:…...

java:Class的isPrimitive方法使用
java:Class的isPrimitive方法使用 1 前言 java中Class类的isPrimitive方法,用于检查类型是否为基本类型。java虚拟机创建了int、byte、short、long、float、double、boolean、char这8种基础信息,以及void,一共9种。为这9种类型时…...
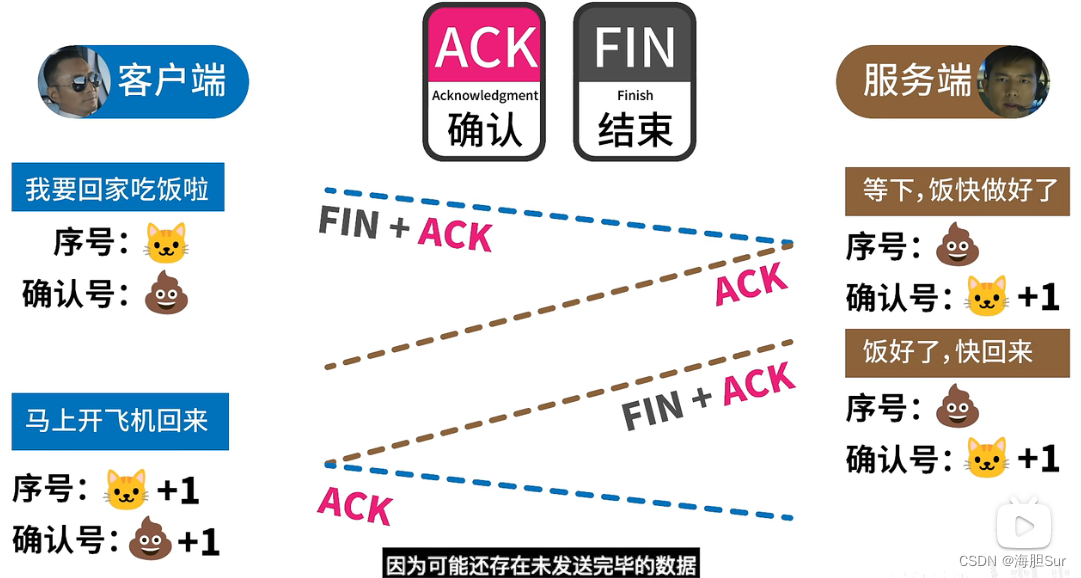
TCP 握手过程 三次 四次
蛋老师视频 SYN 同步 ACK 确认 FIN 结束 核心机制是确定哪些请求或响应需要丢弃 SYN、ACK、FIN 通过 1/0 设置开启/关闭 开启SYN后,报文中会随机生成 Sequence序号 用于校验 (应用可能发起多个会话,可以区分) 服务器的同步序…...
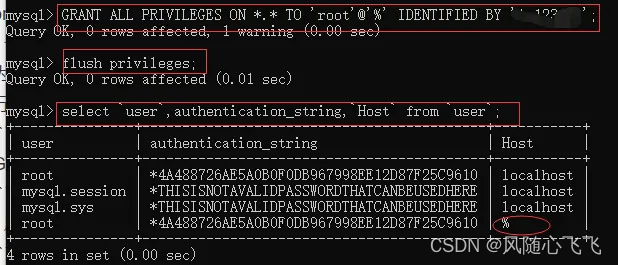
windows 下 安裝mysql 5.7.41 (64位) 超简单方式
文章目录1. 安装包下载2.安装步骤3. 服务卸载方式4. 配上 my.ini 常用配置1. 安装包下载 注意,截至2023年2月23日,MySQL所有版本不提供ARM芯片架构的Windows版本(8.0.12开始支持Red Hat系统的ARM版本),所以ARM架构的Windows无法安装MySQL&am…...
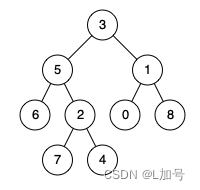
二叉树——二叉树的最近公共祖先
二叉树的最近公共祖先 给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。 百度百科中最近公共祖先的定义为:“对于有根树 T 的两个节点 p、q,最近公共祖先表示为一个节点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一…...
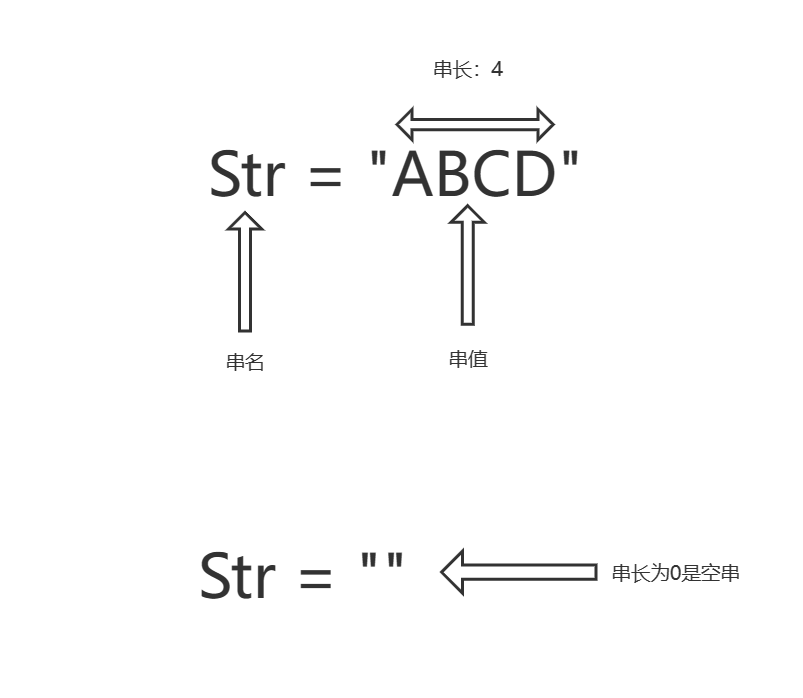
数据结构与算法基础-学习-14-线性表之串
一、串的定义由0-n个字符组成的有限序列。(n>0)二、串的相关术语1、子串串中任意个连续字符组成的子序列成为该串的子串。2、主串包含子串的串成为主串。3、字符位置字符在序列中的序号为该字符在串中的位置。4、子串位置子串第一个字符在主串中的位置…...
Pixel Couplet Gen 惊艳像素春联作品集:AI与传统文化的创意碰撞
Pixel Couplet Gen 惊艳像素春联作品集:AI与传统文化的创意碰撞 1. 开篇:当像素艺术遇上传统春联 春节贴春联是中国人延续千年的传统习俗,而如今人工智能为这一古老文化注入了全新活力。Pixel Couplet Gen模型通过独特的像素艺术风格&#…...
)
30分钟上手开源项目:黑苹果安装实战指南(新手到高手的进阶之路)
30分钟上手开源项目:黑苹果安装实战指南(新手到高手的进阶之路) 【免费下载链接】Hackintosh 国光的黑苹果安装教程:手把手教你配置 OpenCore 项目地址: https://gitcode.com/gh_mirrors/hac/Hackintosh 如何在普通PC上体验…...

支付网关超时、重复扣款、状态不一致,深度解析PHP支付调试中的8大“幽灵Bug”:央行合规日志审计标准实操
第一章:支付网关超时、重复扣款、状态不一致,深度解析PHP支付调试中的8大“幽灵Bug”:央行合规日志审计标准实操支付系统中看似偶发的“幽灵Bug”,往往源于时间窗口、网络抖动与状态机设计的隐性冲突。在PHP支付集成场景下&#x…...
)
用Unity和Game4Automation PRO,在家就能搭建你的第一条虚拟生产线(附PLC连接教程)
用Unity和Game4Automation PRO搭建虚拟生产线的全流程指南 想象一下,你坐在家里的书桌前,却能操控一条完整的自动化生产线——机械臂精准抓取零件,传送带有序运转,PLC控制器实时响应你的指令。这不再是工业巨头的专属能力…...

一次 Nginx 跨域代理的完整排坑实录:从证书错误到 CORS 配置
一次 Nginx 跨域代理的完整排坑实录:从证书错误到 CORS 配置 关键词:Nginx、CORS、跨域、SSL证书、反向代理、预检请求 一、背景与需求 最近在做一个项目,架构如下: 前端域名:https://www.example.com第三方API&…...

中小企业福音:Qwen3-14B私有化部署全流程,轻松搞定智能客服与文档处理
中小企业福音:Qwen3-14B私有化部署全流程,轻松搞定智能客服与文档处理 1. 为什么选择Qwen3-14B 对于中小企业来说,部署AI模型往往面临两难选择:公有云API担心数据安全,自研模型又缺乏技术实力。Qwen3-14B正好填补了这…...

VideoDownloadHelper:一站式网页视频下载神器,告别视频保存烦恼
VideoDownloadHelper:一站式网页视频下载神器,告别视频保存烦恼 【免费下载链接】VideoDownloadHelper Chrome Extension to Help Download Video for Some Video Sites. 项目地址: https://gitcode.com/gh_mirrors/vi/VideoDownloadHelper 还在为…...

如何在Windows电脑上轻松安装安卓应用?APK Installer完整使用指南
如何在Windows电脑上轻松安装安卓应用?APK Installer完整使用指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 还在为无法在电脑上运行手机应用而烦恼吗…...

别再只ping了!用Kali的arpspoof工具,5分钟让你看懂局域网ARP攻击到底怎么断网的
从ARP协议到断网攻击:用Kali的arpspoof工具揭示局域网安全漏洞 你是否遇到过这样的情况——明明Wi-Fi信号满格,却突然无法上网?或者发现网络时断时续,怀疑有人在"搞鬼"?这很可能就是遭遇了ARP欺骗攻击。今天…...

突破显卡性能瓶颈:NVIDIA Profile Inspector高级配置与性能优化指南
突破显卡性能瓶颈:NVIDIA Profile Inspector高级配置与性能优化指南 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector 当你在4K分辨率下运行3A大作时,是否遇到过画面撕裂与输入延迟…...