java集合框架内容整理
主要内容
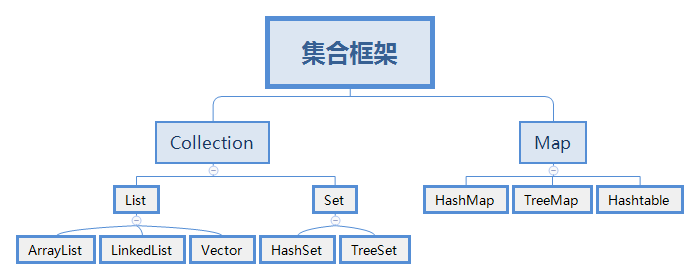
集合框架体系
ArrayList
LinkedList
HashSet
TreeSet
LinkedHashSet
内部比较器和外部比较器
哈希表的原理
List集合
List集合的主要实现类有ArrayList和LinkedList,分别是数据结构中顺序表和链表的实现。另外还包括栈和队列的实现类:Deque和Queue。
• List
• 特点:有序 不唯一(可重复)
• ArrayList
• 在内存中分配连续的空间,实现了长度可变的数组
• 优点:遍历元素和随机访问元素的效率比较高
• 缺点:添加和删除需大量移动元素效率低,按照内容查询效率低
• LinkedList
• 采用双向链表存储方式。
• 缺点:遍历和随机访问元素效率低下
• 优点:插入、删除元素效率比较高(但是前提也是必须先低效率查询才可。如果插入删除发生在头尾可以减少查询次数)
ArrayList
源码分析
ArrayList底层就是一个长度可以动态增长的Object数组;(StringBuilder底层就是一个长度可以动态增长的char数组)
publicclassArrayList<E>extendsAbstractList<E>implements
List<E>, RandomAccess, Cloneable, Serializable{privatestaticfinalintDEFAULT_CAPACITY=10;privatestaticfinalObject[] EMPTY_ELEMENTDATA= {};privatestaticfinalObject[]
DEFAULTCAPACITY_EMPTY_ELEMENTDATA= {};transientObject[] elementData;privateintsize;
}JDK1.7中,使用无参数构造方法创建ArrayList对象时,默认底层数组长度是10。
JDK1.8中,使用无参数构造方法创建ArrayList对象时,默认底层数组长度是0;第一次添加元素,容量不足就要进行扩容了。
publicArrayList() {this.elementData=DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
privatestaticintcalculateCapacity(Object[] elementData, intminCapacity) {if (elementData==DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {returnMath.max(DEFAULT_CAPACITY, minCapacity);}returnminCapacity;
}容量不足时进行扩容,默认扩容50%。如果扩容50%还不足容纳新增元素,就扩容为能容纳新增元素的最小数量。
privatevoidgrow(intminCapacity) {intoldCapacity=elementData.length;intnewCapacity=oldCapacity+ (oldCapacity>>1);if (newCapacity-minCapacity<0)newCapacity=minCapacity;if (newCapacity-MAX_ARRAY_SIZE>0)newCapacity=hugeCapacity(minCapacity); elementData=Arrays.copyOf(elementData, newCapacity);
}ArrayList中提供了一个内部类Itr,实现了Iterator接口,实现对集合元素的遍历
publicIterator<E>iterator() {returnnewItr();
}
privateclassItrimplementsIterator<E> {
}LinkedList
问题1:将ArrayList替换成LinkedList之后,不变的是什么?
² 运算结果没有变
² 执行的功能代码没有变
问题2:将ArrayList替换成LinkedList之后,变化的是什么?
² 底层的结构变了
ArrayList:数组 LinkedList:双向链表
² 具体的执行过程变化了 list.add(2,99)
ArrayList:大量的后移元素
LinkedList:不需要大量的移动元素,修改节点的指向即可
问题3:到底是使用ArrayList还是LinkedList
² 根据使用场合而定
² 大量的根据索引查询的操作,大量的遍历操作(按照索引0--n-1逐个查询一般),建议使用ArrayList
² 如果存在较多的添加、删除操作,建议使用LinkedList
问题4:LinkedList增加了哪些方法
² 增加了对添加、删除、获取首尾元素的方法
² addFirst()、addLast()、removeFirst()、removeLast()、getFirst()、getLast()、
源码分析
底层结构是一个双向链表。
publicclassLinkedList<E>extendsAbstractSequentialList<E>implementsList<E>, Deque<E>, Cloneable, java.io.Serializable{transientintsize=0;//节点的数量transientNode<E>first; //指向第一个节点transientNode<E>last; //指向最后一个节点publicLinkedList() { }}
有一个静态内部类Node,表示双向链表的节点。
privatestaticclassNode<E> {Eitem;//存储节点的数据Node<E>next;//指向后一个节点Node<E>prev; //指向前一个节点Node(Node<E>prev, Eelement, Node<E>next) {this.item=element;this.next=next;this.prev=prev;}
}LinkedList实现了Deque接口,所以除了可以作为线性表来使用外,还可以当做队列和栈来使用
Java中栈和队列的实现类
public class Stack<E> extends Vector<E> Vector过时了,被ArrayList替代了,Stack也就过时了
public interface Queue<E> extends Collection<E> 接口public interface Deque<E> extends Queue<E> 接口
Deque和Queue的实现类
ArrayDeque 顺序栈 数组
LinkedList 链栈 链表
Set集合
• Set
• 特点:无序 唯一(不重复)
实现类:
• HashSet
•采用Hashtable哈希表存储结构(神奇的结构)
•优点:添加速度快 查询速度快 删除速度快
•缺点:无序
• LinkedHashSet
•采用哈希表存储结构,同时使用链表维护次序
•缺点:有序(添加顺序)
• TreeSet
•采用二叉树(红黑树)的存储结构
•优点:有序 查询速度比List快(按照内容查询)
•缺点:查询速度没有HashSet快
HashSet 哈希表 唯一 无序
LinkedHashSet 哈希表+链表 唯一 有序(添加顺序)
TreeSet 红黑树 一种二叉平衡树 唯一 有序(自然顺序)
List针对Collection增加了一些关于索引位置操作的方法 get(i) add(i,elem),remove(i),set(i,elem)
Set是无序的,不可能提供关于索引位置操作的方法,set针对Collection没有增加任何方法
List的遍历方式:for循环、for-each循环、Iterator迭代器、流式编程forEach
lSet的遍历方式: for-each循环、Iterator迭代器、流式编程forEach
HashSet
// TODO: 2022/8/12 HashSet保证唯一性-->equals和hashCode
publicclassSetDemo1 {publicstaticvoidmain(String[] args) {Set<Student>set=newHashSet<>();set.add(newStudent("mark",19));set.add(newStudent("mark",19));System.out.println(set);}
}publicclassStudentimplementsComparable<Student>{privateStringname;privateIntegerid;
@Overridepublicbooleanequals(Objecto) {if (this==o) returntrue;if (o==null||getClass() !=o.getClass()) returnfalse;Studentstudent= (Student) o;returnObjects.equals(name, student.name) &&Objects.equals(id, student.id);}
@OverridepublicinthashCode() {returnObjects.hash(name, id);}
TreeSet
// TODO: 2022/8/12 treeSet保证唯一性-->comparable接口&& compareto外部比较器
public class SetDemo2 {public static void main(String[] args) {Set<Student>set=new TreeSet<>();set.add(new Student("mark",19));set.add(new Student("mayun",49));Set<Teacher>set2=new TreeSet<>(new MyCompareto());set2.add(new Teacher("mark",19));set2.add(new Teacher("mayun",49));}
}public class MyCompareto implements Comparator<Teacher> {@Overridepublic int compare(Teacher o1, Teacher o2) {return o1.getId()-o2.getId();}
}Iterator迭代器
Iterator专门为遍历集合而生,集合并没有提供专门的遍历的方法
Iterator实际是迭代器设计模式的实现
Iterator的常用方法
boolean hasNext(): 判断是否存在另一个可访问的元素
Object next(): 返回要访问的下一个元素
void remove(): 删除上次访问返回的对象。
哪些集合可以使用Iterator遍历
层次1:Collection、List、Set可以、Map不可以
层次2:提供iterator()方法的就可以将元素交给Iterator;
层次3:实现Iterable接口的集合类都可以使用迭代器遍历
for-each循环和Iterator的联系
for-each循环(遍历集合)时,底层使用的是Iterator
凡是可以使用for-each循环(遍历的集合),肯定也可以使用Iterator进行遍历
for-each循环和Iterator的区别
for-each还能遍历数组,Iterator只能遍历集合
使用for-each遍历集合时不能删除元素,会抛出异常ConcurrentModificationException
使用Iterator遍历合时能删除元素
Iterator是一个接口,它的实现类在哪里?
在相应的集合实现类中 ,比如在ArrayList中存在一个内部了Itr implements Iterator
为什么Iterator不设计成一个类,而是一个接口
不同的集合类,底层结构不同,迭代的方式不同,所以提供一个接口,让相应的实现类来实现
Collections工具类
•关于集合操作的工具类,好比Arrays,Math
•唯一的构造方法private,不允许在类的外部创建对象
•提供了大量的static方法,可以通过类名直接调用
Collections简化集合操作
List<Integer>list=new ArrayList<>();Collections.addAll(list,8,1,4,7,1,2,6,4,0);
System.out.println(list);
System.out.println("=========================");
Collections.sort(list);
System.out.println(list);System.out.println("=========================");Collections.sort(list,(t1,t2)->t2-t1);
System.out.println(list);System.out.println("=========================");Integer max = Collections.max(list);
Integer min = Collections.min(list);
System.out.println(max+" "+min);
System.out.println("=========================");
//填充
Collections.fill(list,1);
System.out.println(list);System.out.println("=========================");
List<Integer>list1=new ArrayList<>();
Collections.addAll(list1,6,3,0,3,0,5,1,3,6,99,99);
Collections.copy(list1,list);
System.out.println(list);
System.out.println(list1);System.out.println("=========================");
//变成性能安全
List<Integer> list2 = Collections.synchronizedList(list1);
System.out.println(list2);Stream流
public static void main(String[] args) {List<Integer> list=new ArrayList<>();Collections.addAll(list,8,1,4,7,1,2,6,4,0);System.out.println("===============================");System.out.println(list.stream().max((t1, t2) ->-1 ).get());System.out.println("===============================");list.stream().filter(t->t>2).forEach(t-> System.out.println(t));System.out.println("===============================");List<Integer>list2=new ArrayList<>();list.stream().filter(t->t>5).forEach(t->list2.add(t));System.out.println(list2);
}线程安全类
线程安全集合类可以分为三大类:
遗留的线程安全集合如 Hashtable , Vector
使用 Collections 装饰的线程安全集合,如:
Collections.synchronizedCollection
Collections.synchronizedList
Collections.synchronizedMap
Collections.synchronizedSet
Collections.synchronizedNavigableMap
Collections.synchronizedNavigableSet
Collections.synchronizedSortedMap
Collections.synchronizedSortedSet
java.util.concurrent.*
重点介绍 java.util.concurrent.* 下的线程安全集合类,可以发现它们有规律,里面包含三类关键词:Blocking、CopyOnWrite、Concurrent
Blocking 大部分实现基于锁,并提供用来阻塞的方法
CopyOnWrite 之类的容器修改开销相对较重
Concurrent 类型的容器
内部很多操作使用 cas 优化,一般可以提供较高吞吐量
弱一致性
遍历时弱一致性,例如,当利用迭代器遍历时,如果容器发生修改,迭代器仍然可以继续进行遍历,这时内容是旧的
求大小弱一致性,size 操作未必是 100% 准确
读取弱一致性
遍历时如果发生了修改,对于非安全容器来讲,使用 fail-fast 机制也就是让遍历立刻失败,抛出ConcurrentModificationException,不再继续遍历
HashMap
引入哈希表
哈希表是如何添加数据的
1) 计算哈希 码(调用hashCode(),结果是一个int值,整数的哈希码取自身即可)
2) 计算在哈希表中的存储位置 y=k(x)=x%11
x:哈希码 k(x) 函数y:在哈希表中的存储位置
3) 存入哈希表
n 情况1:一次添加成功
n 情况2:多次添加成功(出现了冲突,调用equals()和对应链表的元素进行比较,比较到最后,结果都是false,创建新节点,存储数据,并加入链表末尾)
n 情况3:不添加(出现了冲突,调用equals()和对应链表的元素进行比较, 经过一次或者多次比较后,结果是true,表明重复,不添加)
结论1:哈希表添加数据快(3步即可,不考虑冲突)
结论2:唯一、无序
hashCode和equals到底有什么神奇的作用
² hashCode():计算哈希码,是一个整数,根据哈希码可以计算出数据在哈希表中的存储位置
² equals():添加时出现了冲突,需要通过equals进行比较,判断是否相同;查询时也需要使用equals进行比较,判断是否相同
如何减少冲突
哈希表的长度和表中的记录数的比例--装填因子:
如果Hash表的空间远远大于最后实际存储的记录个数,则造成了很大的空间浪费, 如果选取小了的话,则容易造成冲突。 在实际情况中,一般需要根据最终记录存储个数和关键字的分布特点来确定Hash表的大小。还有一种情况时可能事先不知道最终需要存储的记录个数,则需要动态维护Hash表的容量,此时可能需要重新计算Hash地址。
装填因子=表中的记录数/哈希表的长度, 4/ 16 =0.25 8/ 16=0.5
如果装填因子越小,表明表中还有很多的空单元,则添加发生冲突的可能性越小;而装填因子越大,则发生冲突的可能性就越大,在查找时所耗费的时间就越多。 有相关文献证明当装填因子在0.5左右时候,Hash性能能够达到最优。
因此,一般情况下,装填因子取经验值0.5。
2)哈希函数的选择
直接定址法 平方取中法 折叠法 除留取余法(y = x%11)
3)处理冲突的方法
链地址法 开放地址法 再散列法 建立一个公共溢出区
JDK1.7 HashMap
•JDK1.7及其之前,HashMap底层是一个table数组+链表实现的哈希表存储结构
•链表的每个节点就是一个Entry,其中包括:键key、值value、键的哈希码hash、执行下一个节点的引用next四部分
static class Entry<K, V> implements Map.Entry<K, V> {final K key; //keyV value;//valueEntry<K, V> next; //指向下一个节点的指针int hash;//哈希码
}JDK1.7中HashMap的主要成员变量及其含义
public class HashMap<K, V> implements Map<K, V> {
//哈希表主数组的默认长度static final int DEFAULT_INITIAL_CAPACITY = 16;
//默认的装填因子static final float DEFAULT_LOAD_FACTOR = 0.75f;
//主数组的引用!!!!transient Entry<K, V>[] table; int threshold;//界限值 阈值final float loadFactor;//装填因子//无参构造public HashMap() {this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);}//有参构造.public HashMap(int initialCapacity, float loadFactor) {this.loadFactor = loadFactor;//0.75threshold = (int) Math.min(capacity * loadFactor,
MAXIMUM_CAPACITY + 1);//16*0.75=12table = new Entry[capacity];....}
}put方法
•调用put方法添加键值对。哈希表三步添加数据原理的具体实现;是计算key的哈希码,和value无关。特别注意:
第一步计算哈希码时,不仅调用了key的hashCode(),还进行了更复杂处理,目的是尽量保证不同的key尽量得到不同的哈希码
第二步根据哈希码计算存储位置时,使用了位运算提高效率。同时也要求主数组长度必须是2的幂)
第三步添加Entry时添加到链表的第一个位置,而不是链表末尾
第三步添加Entry是发现了相同的key已经存在,就使用新的value替代旧的value,并且返回旧的value
public class HashMap {//put方法public V put(K key, V value) {//如果key是null,特殊处理if (key == null) return putForNullKey(value);//1.计算key的哈希码hash int hash = hash(key);//2.将哈希码代入函数,计算出存储位置 y= x%16;int i = indexFor(hash, table.length);//如果已经存在链表,判断是否存在该key,需要用到equals()for (Entry<K,V> e = table[i]; e != null; e = e.next) {Object k;//如找到了,使用新value覆盖旧的value,返回旧valueif (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value;// the United Statese.value = value;//Americae.recordAccess(this);return oldValue;}}//上面循环走完,没有找到这个节点,说明该链表头都没有,添加一个结点addEntry(hash, key, value, i);return null;}
final int hash(Object k) {int h = 0;h ^= k.hashCode();h ^= (h >>> 20) ^ (h >>> 12);return h ^ (h >>> 7) ^ (h >>> 4);
}
static int indexFor(int h, int length) {
//作用就相当于y = x%16,采用了位运算,效率更高return h & (length-1);}
}添加元素时如达到了阈值,需扩容,每次扩容为原来主数组容量的2倍void addEntry(int hash, K key, V value, int bucketIndex) {//如果达到了门槛值,就扩容,容量为原来容量的2位 16---32if ((size >= threshold) && (null != table[bucketIndex])) {resize(2 * table.length);hash = (null != key) ? hash(key) : 0;bucketIndex = indexFor(hash, table.length);}//添加节点createEntry(hash, key, value, bucketIndex);
}扩容时,jdk1.7的链表添加是采用头插法,于是会出现数据的顺序颠倒的情况
void resize(int newCapacity) {//resize(2 * table.length);Entry[] oldTable = table;int oldCapacity = oldTable.length;//得到旧值(主数组长度)if (oldCapacity == MAXIMUM_CAPACITY) {threshold = Integer.MAX_VALUE;return;}Entry[] newTable = new Entry[newCapacity];//新长度为原来的两倍boolean oldAltHashing = useAltHashing;useAltHashing |= sun.misc.VM.isBooted() &&(newCapacity >= Holder.ALTERNATIVE_HASHING_THRESHOLD);boolean rehash = oldAltHashing ^ useAltHashing;transfer(newTable, rehash);//进入transfer方法--->重点 table = newTable;threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}void transfer(Entry[] newTable, boolean rehash) {//将扩容完的主数组传过来int newCapacity = newTable.length;for (Entry<K,V> e : table) {while(null != e) {Entry<K,V> next = e.next;if (rehash) {e.hash = null == e.key ? 0 : hash(e.key);//重新hash}int i = indexFor(e.hash, newCapacity);//计算数组下标//头插开始--------------------------------------e.next = newTable[i];newTable[i] = e;//头插结束--------------------------------------e = next;//接着遍历}}}get方法
•调用get方法根据key获取value。
• 哈希表三步查询数据原理的具体实现
• 其实是根据key找Entry,再从Entry中获取value即可
public V get(Object key) {//根据key找到Entry(Entry中有key和value)Entry<K,V> entry = getEntry(key);//如果entry== null,返回null,否则返回valuereturn null == entry ? null : entry.getValue();
}
final Entry<K,V> getEntry(Object key) {int hash = (key == null) ? 0 : hash(key);for (Entry<K,V> e = table[indexFor(hash, table.length)];e != null;e = e.next) {Object k;if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))return e;}return null;
}JDK1.7死链问题
从transfer方法可以看到,链表插入仍然是采用了头插法。这也就导致了有可能在多线程的情况下发生循环链表的现象。
条件一: 有两个线程,A和B
条件二: 此时在某个链表上面存在两个结点1和2,并且这两个结点经过rehash仍然在同一结点链表上面
条件三: 此时线程A走到tranfer里,并且刚好停留在刚刚拿到Entry e=结点1的代码,同时线程B也在transfer里面,并且它率先完成了扩容!此时链表里面变成了 2 - > 1!!!
条件四: 线程A刚好恢复运行!! 它又把结点1插入新的位置,它将新位置设置成自己的next,但是此时新位置上面放的是结点2!!! 然后让新位置设置成自己!!然后接着遍历,此时next已经是结点2,然而结点2的next却是结点1!!!所以造成了循环链表。
JDK1.8 HashMap
看源码:
HashMap的一些成员变量
public class HashMap<K,V> extends AbstractMap<K,V>implements Map<K,V>, Cloneable, Serializable {private static final long serialVersionUID = 362498820763181265L;static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // 默认容量16static final int MAXIMUM_CAPACITY = 1 << 30; //最大容量2^30static final float DEFAULT_LOAD_FACTOR = 0.75f; //装填因子0.75static final int TREEIFY_THRESHOLD = 8; //是否树化的阈值: 链表长度大于等于8static final int UNTREEIFY_THRESHOLD = 6; //是否退树的阈值: 链表长度小于等于6static final int MIN_TREEIFY_CAPACITY = 64; //最小树化容量: 64// 构造方法:懒惰初始化,仅仅将容量以及阈值赋值,并不真正创建主数组对象。
public HashMap(int initialCapacity) {this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
public HashMap(int initialCapacity, float loadFactor) {//将容量和装填因子填充if (initialCapacity < 0)throw new IllegalArgumentException("Illegal initial capacity: " +initialCapacity);if (initialCapacity > MAXIMUM_CAPACITY)initialCapacity = MAXIMUM_CAPACITY;if (loadFactor <= 0 || Float.isNaN(loadFactor))throw new IllegalArgumentException("Illegal load factor: " +loadFactor);this.loadFactor = loadFactor;this.threshold = tableSizeFor(initialCapacity);
}public HashMap() {this.loadFactor = DEFAULT_LOAD_FACTOR; // 仅仅是赋值装填因子
}public HashMap(Map<? extends K, ? extends V> m) {this.loadFactor = DEFAULT_LOAD_FACTOR;putMapEntries(m, false);
}
node结点的结构:
static class Node<K,V> implements Map.Entry<K,V> {final int hash; //哈希值final K key; //keyV value; //vNode<K,V> next; //下一节点
}put方法
hashMap的put写入数据的具体流程?
首先要通过扰动函数计算出更加散列的hash值
进入到putVal方法,判断当前散列表数组是否为空,如果为空那么就创建散列表,默认数组的长度为16,假如说有指定数组的长度,这个长度会让tableSizeFor给被转化为2的次幂。
用这个哈希值跟数组(散列表数组)的长度-1做与运算&,计算出即将插入散列表的下标值
然后检查这个位置上面是否为空,如果为空直接插入;如果不为空,检查key是否一样,如果一样则直接替换。否则,会判断这个位置是否为红黑树,如果是的话就以红黑树的put插入,否则遍历链表;如果链表中有相同的key,那么直接替换,否则添加到最后(1.7是头插),如果插入之后,长度超过8,那么会进入树化操作,假如说当前散列表数组没有达到树化条件,长度未超过64,那么会直接扩容;否则将链表转化为红黑树。
插入值成功后将modCount自增
最后size自增。检查是否可以扩容,如果可以那么就扩容。
也就是说,我们关注的put操作里面最重要的两个: 扩容与树化发生的时机为:
当链表长度达到一定的阈值(默认为8)时,会进入树化操作。
此时,如果哈希表的size已经达到了64,那么会直接树化。
如果未达到64,那么会进行扩容
最后put成功后,size自增,也会检查是否可以扩容。
源码
public V put(K key, V value) {return putVal(hash(key), key, value, false, true);}final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i;if ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length;//在这里完成第一次主数组的初始化if ((p = tab[i = (n - 1) & hash]) == null)//如果插入位置是头结点tab[i] = newNode(hash, key, value, null);//新建头结点else {//不是头结点-----------------------------//要么就插到链表尾部,要么就是插入红黑树Node<K,V> e; K k;//---------------------------------------整体if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))e = p;//如果进来第一个就是直接拿到这个结点(需要替换)else if (p instanceof TreeNode)//如果当前结点已经是红黑树//放入红黑树,执行红黑树的put结点e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);else {//否则说明在链表里面,需要遍历链表for (int binCount = 0; ; ++binCount) {if ((e = p.next) == null) {p.next = newNode(hash, key, value, null);if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1sttreeifyBin(tab, hash);//如果达到了树化的条件,则转成红黑树break;}if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))break;p = e;}}//---------------------------------------整体if (e != null) { // existing mapping for keyV oldValue = e.value;if (!onlyIfAbsent || oldValue == null)e.value = value;afterNodeAccess(e);return oldValue;}}++modCount;if (++size > threshold)//如果当前数组大小已经超过阈值,那么需要扩容resize();afterNodeInsertion(evict);return null;}红黑树的put结点
final TreeNode<K,V> putTreeVal(HashMap<K,V> map, Node<K,V>[] tab,int h, K k, V v) {Class<?> kc = null;boolean searched = false;TreeNode<K,V> root = (parent != null) ? root() : this;for (TreeNode<K,V> p = root;;) {int dir, ph; K pk;//----------------------------------------------整体if ((ph = p.hash) > h)dir = -1;else if (ph < h)dir = 1;else if ((pk = p.key) == k || (k != null && k.equals(pk)))return p;else if ((kc == null &&(kc = comparableClassFor(k)) == null) ||(dir = compareComparables(kc, k, pk)) == 0) {if (!searched) {TreeNode<K,V> q, ch;searched = true;if (((ch = p.left) != null &&(q = ch.find(h, k, kc)) != null) ||((ch = p.right) != null &&(q = ch.find(h, k, kc)) != null))return q;}dir = tieBreakOrder(k, pk);}//----------------------------------------------整体TreeNode<K,V> xp = p;if ((p = (dir <= 0) ? p.left : p.right) == null) {Node<K,V> xpn = xp.next;TreeNode<K,V> x = map.newTreeNode(h, k, v, xpn);if (dir <= 0)xp.left = x;elsexp.right = x;xp.next = x;x.parent = x.prev = xp;if (xpn != null)((TreeNode<K,V>)xpn).prev = x;moveRootToFront(tab, balanceInsertion(root, x));return null;}}
}树化treeifyBin
final void treeifyBin(Node<K,V>[] tab, int hash) {int n, index; Node<K,V> e;if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)resize();//如果当前表为空或者--》数组的长度未超过64,只扩容不树化else if ((e = tab[index = (n - 1) & hash]) != null) {TreeNode<K,V> hd = null, tl = null;do {TreeNode<K,V> p = replacementTreeNode(e, null);//转化成树结点-----------if (tl == null)hd = p;else {p.prev = tl;tl.next = p;}tl = p;} while ((e = e.next) != null);//拼接成链表(树结点链表)if ((tab[index] = hd) != null)//将树结点链表赋给主数组hd.treeify(tab);//变成红黑树}
}扩容方法resize
final Node<K,V>[] resize() {Node<K,V>[] oldTab = table;int oldCap = (oldTab == null) ? 0 : oldTab.length;int oldThr = threshold;int newCap, newThr = 0;if (oldCap > 0) {if (oldCap >= MAXIMUM_CAPACITY) {threshold = Integer.MAX_VALUE;return oldTab;}else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&oldCap >= DEFAULT_INITIAL_CAPACITY)newThr = oldThr << 1; // double threshold}else if (oldThr > 0) // initial capacity was placed in thresholdnewCap = oldThr;else { // zero initial threshold signifies using defaultsnewCap = DEFAULT_INITIAL_CAPACITY;newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);}if (newThr == 0) {float ft = (float)newCap * loadFactor;newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?(int)ft : Integer.MAX_VALUE);}threshold = newThr;@SuppressWarnings({"rawtypes","unchecked"})Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];table = newTab;if (oldTab != null) {for (int j = 0; j < oldCap; ++j) {Node<K,V> e;if ((e = oldTab[j]) != null) {oldTab[j] = null;if (e.next == null)newTab[e.hash & (newCap - 1)] = e;else if (e instanceof TreeNode)((TreeNode<K,V>)e).split(this, newTab, j, oldCap);else { // preserve orderNode<K,V> loHead = null, loTail = null;Node<K,V> hiHead = null, hiTail = null;Node<K,V> next;do {next = e.next;if ((e.hash & oldCap) == 0) {if (loTail == null)loHead = e;elseloTail.next = e;loTail = e;}else {if (hiTail == null)hiHead = e;elsehiTail.next = e;hiTail = e;}} while ((e = next) != null);if (loTail != null) {loTail.next = null;newTab[j] = loHead;}if (hiTail != null) {hiTail.next = null;newTab[j + oldCap] = hiHead;}}}}}return newTab;
}get方法
public V get(Object key) {Node<K,V> e;return (e = getNode(hash(key), key)) == null ? null : e.value;
}getNode方法
要么就是直接在数组里,要么就是链表,要么就是红黑树。
final Node<K,V> getNode(int hash, Object key) {Node<K,V>[] tab; Node<K,V> first, e; int n; K k;if ((tab = table) != null && (n = tab.length) > 0 &&(first = tab[(n - 1) & hash]) != null) {if (first.hash == hash && // always check first node((k = first.key) == key || (key != null && key.equals(k))))return first;//首结点就是了,不必遍历链表if ((e = first.next) != null) { //要么在链表里面,要么在红黑树里if (first instanceof TreeNode)return ((TreeNode<K,V>)first).getTreeNode(hash, key);do {if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))return e;} while ((e = e.next) != null);}}return null;//否则直接没找到返回空
}TreeMap红黑树
特性
1.二叉搜索树
2.根节点为黑色
3.红子为黑(红结点的孩子只能是黑色结点),则不可能存在连续的红色结点
4.黑高相同(任一结点到叶子结点的路径上黑结点数量一致)
5.null结点和叶子结点为黑色(不保证一定遵循)
总的来说,红黑树是一种特殊的平衡二叉搜索树,它相对平衡树来说没有很频繁地进行平衡,而是通过添加了相应的红黑规则来减少平衡的次数,同时也能达到调整二叉树深度的效果
红黑树插入结点时的情况(默认插入的新结点为红色结点)
当前为根节点,则直接插入
父亲为黑色结点,也可以直接插入
父亲为红色结点
3.叔结点也是为红色结点,那么只需要变色,并且往上递归。
叔结点是黑色结点,需要变色又旋转。分为四种情况
4.新插入的结点和父结点都在右子树,左旋转+变色
5.新插入的结点和父结点都在左子树,右旋转+变色
6.新插入结点在左,父结点在右,右旋+左旋
7.新插入结点在右,父结点在左,左旋+右旋
源码
private final Comparator<? super K> comparator; //外部比较器private transient Entry<K,V> root;//根节点Entry
static final class Entry<K,V> implements Map.Entry<K,V> {K key;V value;Entry<K,V> left;Entry<K,V> right;Entry<K,V> parent;boolean color = BLACK;Entry(K key, V value, Entry<K,V> parent) {this.key = key;this.value = value;this.parent = parent;}public K getKey() {return key;}public V getValue() {return value;}public V setValue(V value) {V oldValue = this.value;this.value = value;return oldValue;}public boolean equals(Object o) {if (!(o instanceof Map.Entry))return false;Map.Entry<?,?> e = (Map.Entry<?,?>)o;return valEquals(key,e.getKey()) && valEquals(value,e.getValue());}public int hashCode() {int keyHash = (key==null ? 0 : key.hashCode());int valueHash = (value==null ? 0 : value.hashCode());return keyHash ^ valueHash;}public String toString() {return key + "=" + value;}
}put方法
public V put(K key, V value) {Entry<K,V> t = root;if (t == null) {compare(key, key); //树的根节点为空,则创建新的根节点root = new Entry<>(key, value, null);size = 1;modCount++;return null;}//-------------------通过红黑树的特性来插入int cmp;Entry<K,V> parent;Comparator<? super K> cpr = comparator;//---------------------------------通过对比大小找出插入结点该放的位置if (cpr != null) {//如果是有自带外部比较器的话就用别人自带的do {parent = t;cmp = cpr.compare(key, t.key);if (cmp < 0)t = t.left;else if (cmp > 0)t = t.right;elsereturn t.setValue(value);} while (t != null);}else {if (key == null)throw new NullPointerException();@SuppressWarnings("unchecked")Comparable<? super K> k = (Comparable<? super K>) key;do {parent = t;cmp = k.compareTo(t.key);if (cmp < 0)t = t.left;else if (cmp > 0)t = t.right;elsereturn t.setValue(value);} while (t != null);}
//---------------------------------通过对比大小找出插入结点该放的位置Entry<K,V> e = new Entry<>(key, value, parent);//创建新的树结点if (cmp < 0)parent.left = e;elseparent.right = e;fixAfterInsertion(e);//这个方法是调整红黑树为合理的红黑树(修复)size++;modCount++;return null;
}修复红黑树
private void fixAfterInsertion(Entry<K,V> x) {x.color = RED;while (x != null && x != root && x.parent.color == RED) {if (parentOf(x) == leftOf(parentOf(parentOf(x)))) {Entry<K,V> y = rightOf(parentOf(parentOf(x)));if (colorOf(y) == RED) {setColor(parentOf(x), BLACK);setColor(y, BLACK);setColor(parentOf(parentOf(x)), RED);x = parentOf(parentOf(x));} else {if (x == rightOf(parentOf(x))) {x = parentOf(x);rotateLeft(x);}setColor(parentOf(x), BLACK);setColor(parentOf(parentOf(x)), RED);rotateRight(parentOf(parentOf(x)));}} else {Entry<K,V> y = leftOf(parentOf(parentOf(x)));if (colorOf(y) == RED) {setColor(parentOf(x), BLACK);setColor(y, BLACK);setColor(parentOf(parentOf(x)), RED);x = parentOf(parentOf(x));} else {if (x == leftOf(parentOf(x))) {x = parentOf(x);rotateRight(x);}setColor(parentOf(x), BLACK);setColor(parentOf(parentOf(x)), RED);rotateLeft(parentOf(parentOf(x)));}}}root.color = BLACK;
}ConcurrentHashMap
解决hashMap留下的线程安全问题——可以使用hashTable,但是由于它大量使用synch,效率不太好。所以要使用并发度更高的concurrentHashMap
jdk1.7的ConcurrentHashMap,引入了分段锁。数据结构使用Segement数组+hashEntry数组+链表。
segement继承reentrantLock,一个segementp[i]就是一把锁,锁的粒度更细,性能更高了。
一个Segement相当于一个锁,它只锁住一个槽位,其他的槽位不受影响。chm将hash表默认分为16个桶,锁的时候只锁住当前需要用到的桶
一开始的hashTable只能一个线程进入,但是现在却可以16个线程同时进入,并发性就得到了大大的提高。
jdk1.8的时候,做出了很大的改变,数据结构采用node数组+链表+红黑树,抛弃了segement分段锁,采用了cas+synch ,锁的粒度更细,只锁住链表头节点(红黑树root节点),不影响其他哈希表数组元素的读写,再次提高了并发度。
相关文章:
java集合框架内容整理
主要内容集合框架体系ArrayListLinkedListHashSetTreeSetLinkedHashSet内部比较器和外部比较器哈希表的原理List集合List集合的主要实现类有ArrayList和LinkedList,分别是数据结构中顺序表和链表的实现。另外还包括栈和队列的实现类:Deque和Queue。• Li…...

win10系统安装Nginx
Nginx是一款自由的、开源的、高性能的HTTP服务器和反向代理服务器,同时也提供了IMAP/POP3/SMTP服务。 Nginx可以进行反向代理、负载均衡、HTTP服务器(动静分离)、正向代理等操作。因为最近在公司使用到了Nginx 第一步:下载Nginx …...

数据库学习笔记(2)——workbench和SQL语言
1、workbench简介: 登录客户端的两种方法 在cmd中,只能通过sql语句控制数据库;workbench其实就是一种图形化数据库管理工具,在workbench中既可以通过sql语句控制数据库,也可以通过图形化界面控制数据库。通过workbenc…...

测量学期末考试之名词解释总结
仅供自己参考,且范围不全面.大地水准面与处于静止平衡状态的平均海水面重合,并延伸通过陆地的水准面高程地面点到大地水准面的铅锤距离水准面处于静止状态的水面就是水准面高差两点的水准面之间的铅锤距离垂直角在铅锤面上,瞄准目标的倾斜视线…...
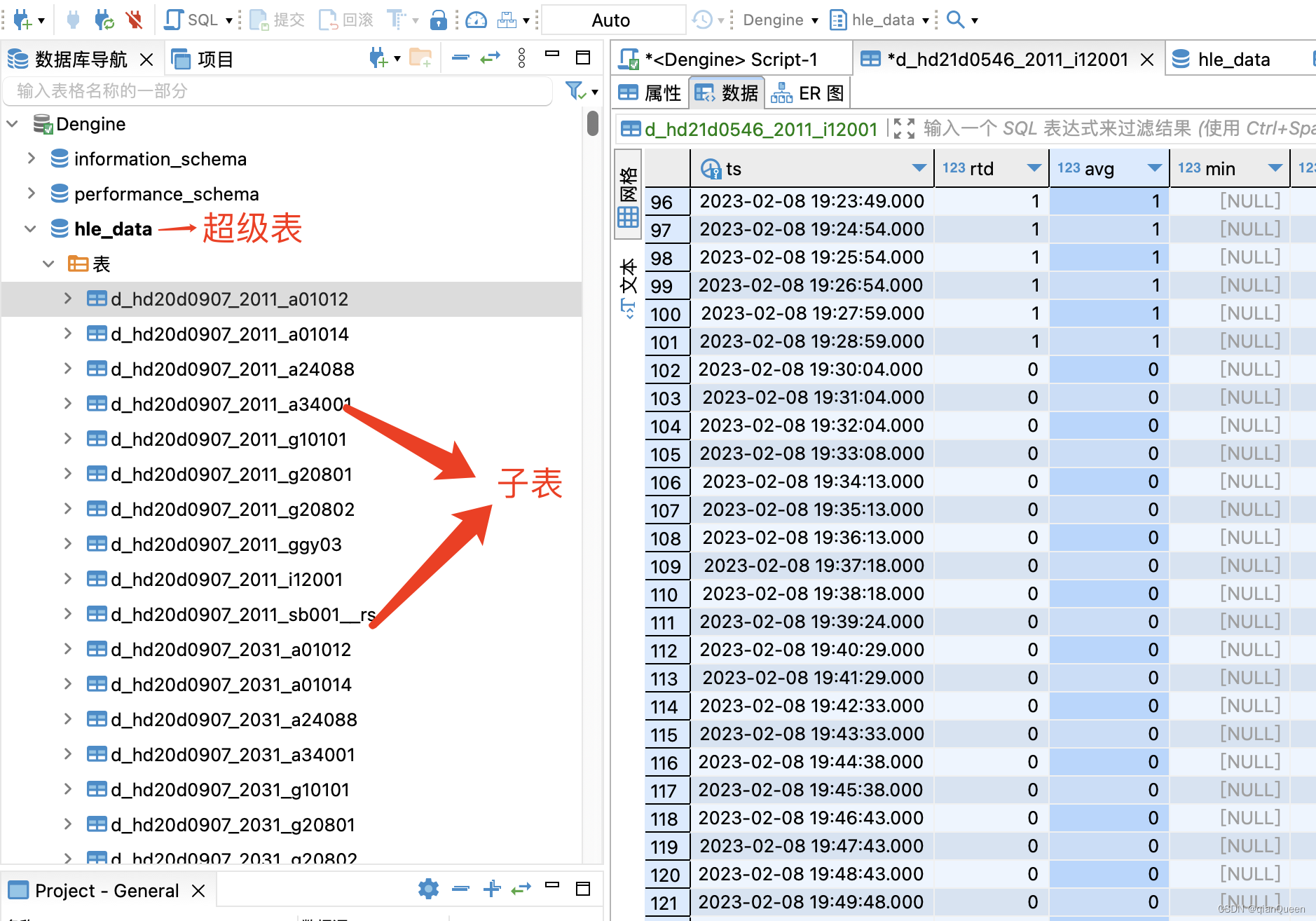
TDengine时序数据库的简单使用
最近学习了TDengine数据库,因为我们公司有硬件设备,设备按照每分钟,每十分钟,每小时上传数据,存入数据库。而这些数据会经过sql查询,统计返回展示到前端。但时间积累后现在数据达到了百万级数据,…...

记录每日LeetCode 2335.装满被子需要的最短总时长 Java实现
题目描述: 现有一台饮水机,可以制备冷水、温水和热水。每秒钟,可以装满 2 杯 不同 类型的水或者 1 杯任意类型的水。 给你一个下标从 0 开始、长度为 3 的整数数组 amount ,其中 amount[0]、amount[1] 和 amount[2] 分别表示需要…...

了解线程池newFixedTheadPool
什么是线程池 操作系统 能够进行运算 调度 的最小单位。线程池是一种多线程处理形式。 为什么引入线程池的概念 解决处理短时间任务时创建和销毁线程代价较大的弊端,可以使用线程池技术。 复用 饭店只有一个服务员和饭店有10个服务员 线程池的种类 newFixedThea…...

IP分片和TCP分段解析--之IP分片
本文目录什么是IP分片为什么会产生IP分片为什么要避免IP分片如何避免IP分片什么是IP分片 IP协议栈将TCP/UDP传输层要求它发送的,但长度大于发送端口MTU的一个数据包,分割成多个IP报文后分多次发送。这些分成多次发送的多个IP报文就是IP分片。 为什么会…...

物联网方向常见通信方式有哪些?
常用的有线通信方式有串口、以太网等。 1、串口 串口通信普及率高、成本低,但是组网能力差,只适合低速率和小数据量的通信 2、以太网接口(网线) 以太网(Ethernet)是目前最普遍的一种局域网 通信技术,它规定了包括 物理层的连线、电子信号和介质访问层协议的内容。 以太…...
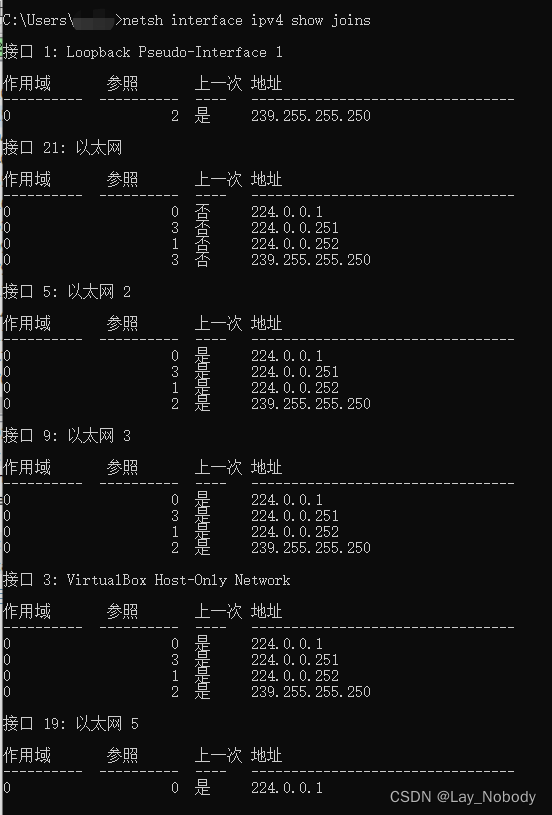
windows wireshark抓到未加入组的组播消息
现象 在Windows上开启wireshark,抓到了大量地址为239.255.255.251的组播包。 同时,根据组播相关命令,调用netsh interface ipv4 show joins,显示当前并没加入 239.255.255.251 组播组。 解决 根据IGMP Snooping,I…...
)
【PTA Advanced】1156 Sexy Primes(C++)
目录 题目 Input Specification: Output Specification: Sample Input 1: Sample Output 1: Sample Input 2: Sample Output 2: 思路 代码 题目 Sexy primes are pairs of primes of the form (p, p6), so-named since "sex" is the Latin word for "…...

项目(今日指数)
一 项目架构1.1 今日指数技术选型【1】前端技术【2】后端技术栈【3】整体概览3.2 核心业务介绍1】业务结构预览【2】业务功能简介1.定时任务调度服务XXL-JOB通过RestTemplate多线程动态拉去股票接口数据,刷入数据库; 2.国内指数服务 3.板块指数服务 4.涨…...
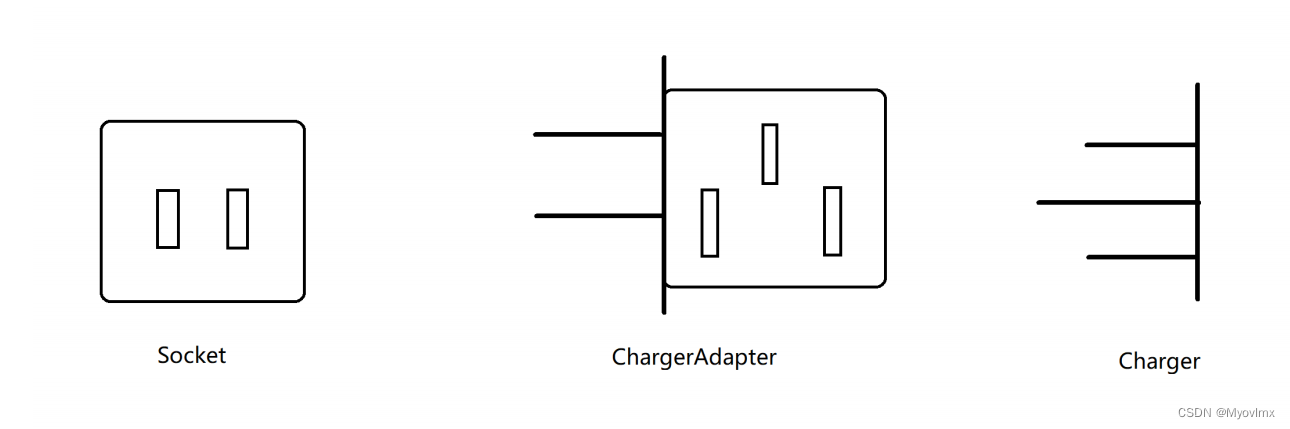
适配器模式(Adapter Pattern)
1.什么是适配器模式? 适配器模式(Adapter Pattern)是作为两个不兼容的接口之间的桥梁。这种类型的设计模式属于结构型模式,它结合了两个独立接口的功能。 这种模式涉及到一个单一的类,该类负责加入独立的或不兼容的接…...
)
网易一面:select分页要调优100倍,说说你的思路? (内含Mysql的36军规)
背景说明: Mysql调优,是大家日常常见的调优工作。所以Mysql调优是一个非常、非常核心的面试知识点。 在40岁老架构师 尼恩的读者交流群(50)中,其相关面试题是一个非常、非常高频的交流话题。 近段时间,有小伙伴面试网易&#x…...
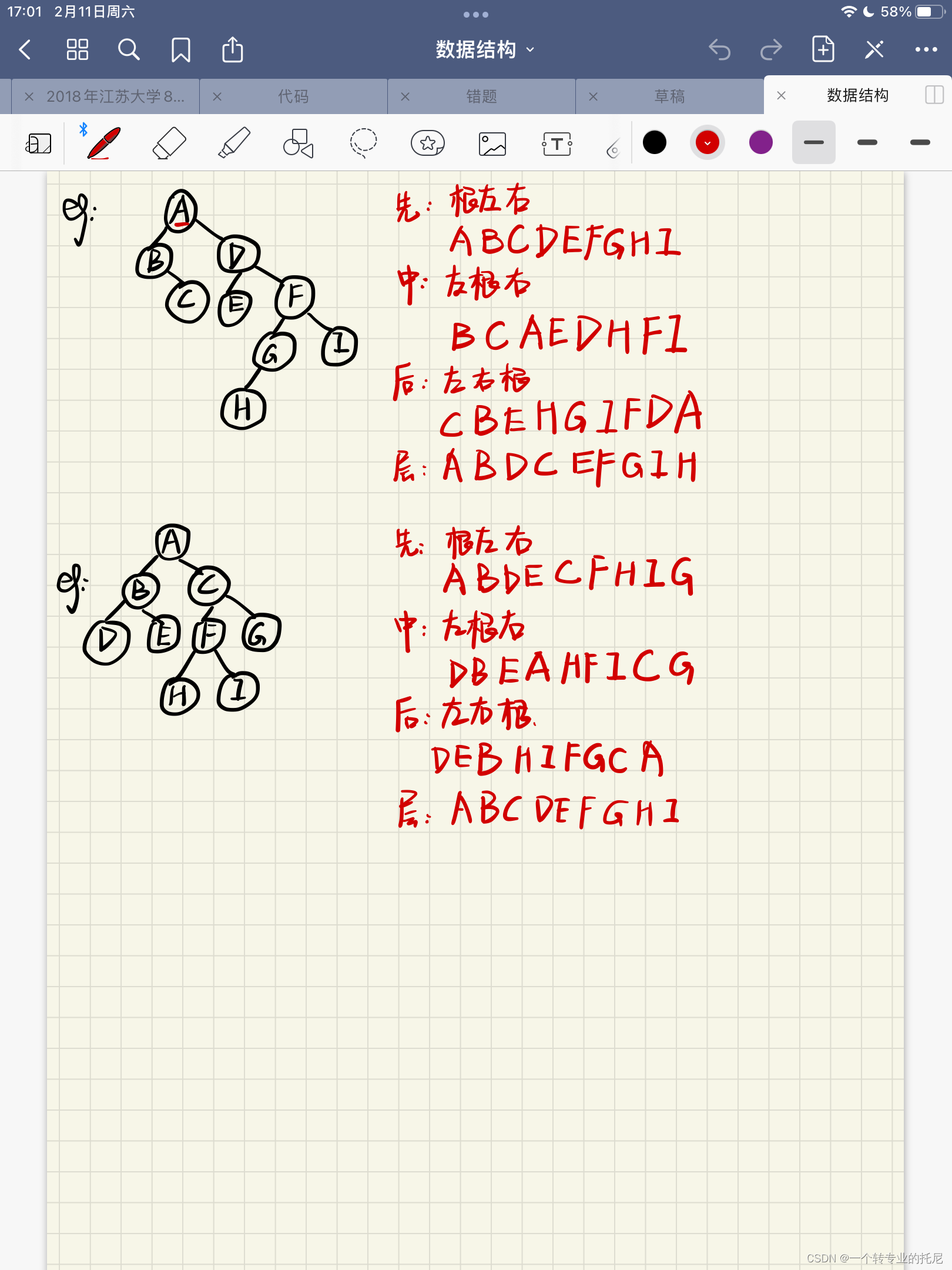
二叉树的遍历 (2023-02-11)
二叉树的遍历 二叉树的遍历分为:先序遍历、中序遍历、后序遍历和层次遍历。 1.先序遍历(根左右) (1)访问根节点 (2)左子树按根左右遍历 (3)右子树按根左右遍历 2.中序…...
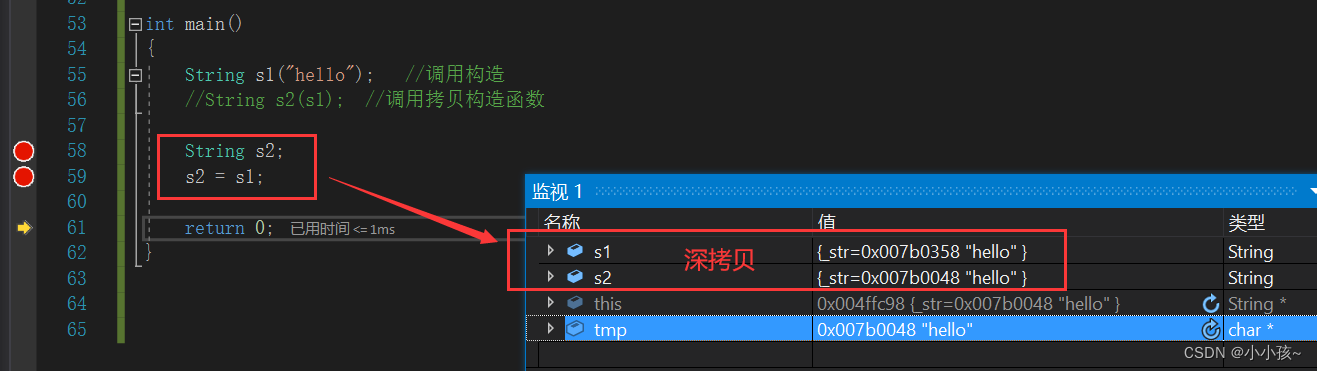
string的深浅拷贝问题
深浅拷贝问题引入浅拷贝深拷贝总结问题引入 对于一个普通的string类: class String { public:String(const char* str ""){//构造函数if (nullptr str)str "";_str new char[strlen(str) 1];strcpy(_str, str);}~String(){//析构函数if …...

C++中的万能头文件
目录一、什么是万能头文件?二、源码三、编译器找不到 bits/stdc.h一、什么是万能头文件? C的万能头文件是: #include <bits/stdc.h>它是一个包含了每一个标准库的头文件。 优点: 在算法竞赛中节约时间;减少了…...

Java 8 Lambda 表达式 Stream
lambda表达式和Stream流是JDK8新增加的新特性,研究本文内容或者运行本文中的demo示例必须安装并使用JDK8以上的JDK版本。demo地址:https://gitee.com/huannzi/bigdataframework/tree/master/src/main/java/com/orkasgb/java 文章目录1、什么是Lambda表达…...
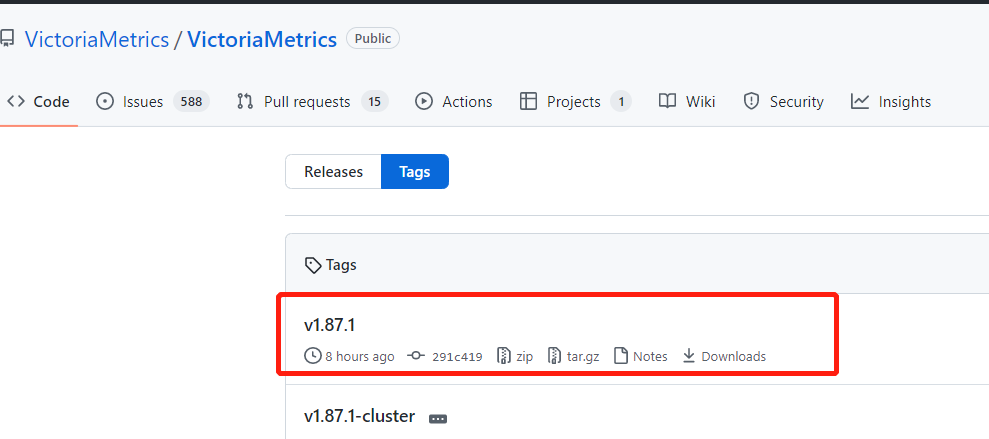
【VictoriaMetrics】VictoriaMetrics单机版部署(二进制版)
1、下载安装包git路径,本文基于1.87.1版本 进入git地址 :https://github.com/VictoriaMetrics/VictoriaMetrics/tags 2、下载其中linux下的 amd64架构...

SCI论文阅读-使用基于图像的机器学习模型对FTIR光谱进行功能组识别
期刊: Analytical Chemistry中科院最新分区(2022年12月最新版):1区(TOP)影响因子(2021-2022):8.008第一作者:Abigail A. Enders通讯作者:Heather C. Allen 原文链接&…...

Chapter03-Authentication vulnerabilities
文章目录 1. 身份验证简介1.1 What is authentication1.2 difference between authentication and authorization1.3 身份验证机制失效的原因1.4 身份验证机制失效的影响 2. 基于登录功能的漏洞2.1 密码爆破2.2 用户名枚举2.3 有缺陷的暴力破解防护2.3.1 如果用户登录尝试失败次…...

基于Uniapp开发HarmonyOS 5.0旅游应用技术实践
一、技术选型背景 1.跨平台优势 Uniapp采用Vue.js框架,支持"一次开发,多端部署",可同步生成HarmonyOS、iOS、Android等多平台应用。 2.鸿蒙特性融合 HarmonyOS 5.0的分布式能力与原子化服务,为旅游应用带来…...

cf2117E
原题链接:https://codeforces.com/contest/2117/problem/E 题目背景: 给定两个数组a,b,可以执行多次以下操作:选择 i (1 < i < n - 1),并设置 或,也可以在执行上述操作前执行一次删除任意 和 。求…...

如何在最短时间内提升打ctf(web)的水平?
刚刚刷完2遍 bugku 的 web 题,前来答题。 每个人对刷题理解是不同,有的人是看了writeup就等于刷了,有的人是收藏了writeup就等于刷了,有的人是跟着writeup做了一遍就等于刷了,还有的人是独立思考做了一遍就等于刷了。…...

Web 架构之 CDN 加速原理与落地实践
文章目录 一、思维导图二、正文内容(一)CDN 基础概念1. 定义2. 组成部分 (二)CDN 加速原理1. 请求路由2. 内容缓存3. 内容更新 (三)CDN 落地实践1. 选择 CDN 服务商2. 配置 CDN3. 集成到 Web 架构 …...

安宝特案例丨Vuzix AR智能眼镜集成专业软件,助力卢森堡医院药房转型,赢得辉瑞创新奖
在Vuzix M400 AR智能眼镜的助力下,卢森堡罗伯特舒曼医院(the Robert Schuman Hospitals, HRS)凭借在无菌制剂生产流程中引入增强现实技术(AR)创新项目,荣获了2024年6月7日由卢森堡医院药剂师协会࿰…...

人工智能(大型语言模型 LLMs)对不同学科的影响以及由此产生的新学习方式
今天是关于AI如何在教学中增强学生的学习体验,我把重要信息标红了。人文学科的价值被低估了 ⬇️ 转型与必要性 人工智能正在深刻地改变教育,这并非炒作,而是已经发生的巨大变革。教育机构和教育者不能忽视它,试图简单地禁止学生使…...

MySQL 知识小结(一)
一、my.cnf配置详解 我们知道安装MySQL有两种方式来安装咱们的MySQL数据库,分别是二进制安装编译数据库或者使用三方yum来进行安装,第三方yum的安装相对于二进制压缩包的安装更快捷,但是文件存放起来数据比较冗余,用二进制能够更好管理咱们M…...

JavaScript 数据类型详解
JavaScript 数据类型详解 JavaScript 数据类型分为 原始类型(Primitive) 和 对象类型(Object) 两大类,共 8 种(ES11): 一、原始类型(7种) 1. undefined 定…...

iview框架主题色的应用
1.下载 less要使用3.0.0以下的版本 npm install less2.7.3 npm install less-loader4.0.52./src/config/theme.js文件 module.exports {yellow: {theme-color: #FDCE04},blue: {theme-color: #547CE7} }在sass中使用theme配置的颜色主题,无需引入,直接可…...