22- estimater使用 (TensorFlow系列) (深度学习)
知识要点
-
estimater 有点没理解透
-
数据集是泰坦尼克号人员幸存数据.
-
读取数据:train_df = pd.read_csv('./data/titanic/train.csv')
-
显示数据特征:train_df.info()
-
显示开头部分数据:train_df.head()
-
提取目标特征:y_train = train_df.pop('survived')
-
显示数据分布:train_df.describe()
-
柱状图显示:train_df.age.hist(bins = 20)
-
横向柱状图: train_df.sex.value_counts().plot(kind = 'barh')
-
pd.concat([train_df, y_train], axis = 1).groupby('sex').survived.mean().plot(kind = 'barh') # 根据幸存率查看各类型的均值
-
提取不同特征的统计: train_df.embark_town.value_counts()
-
提取特征: vocab = train_df[categorical_column].unique()
-
tf.feature_column.indicator_column(tf.feature_column.categorical_column_with_vocabulary_list(categorical_column, vocab)) # one_hot 编码
-
dataset批次设置: dataset = dataset.repeat(epochs).batch(batch_size)
1 导包
from tensorflow import keras
import tensorflow as tf
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt2 数据导入
train_df = pd.read_csv('./data/titanic/train.csv')
eval_df = pd.read_csv('./data/titanic/eval.csv') # eval 评估 # 数据
print(train_df.info())
print(eval_df.info())
train_df.head()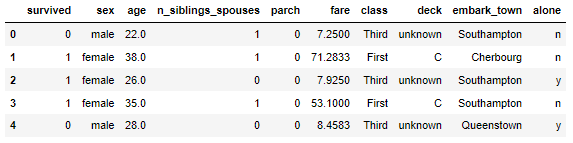
3 目标值获取
y_train = train_df.pop('survived')
y_eval = eval_df.pop('survived')print(train_df.head())
print(eval_df.head())
print(y_train.head())
print(y_eval.head())
4 特征处理
train_df.describe()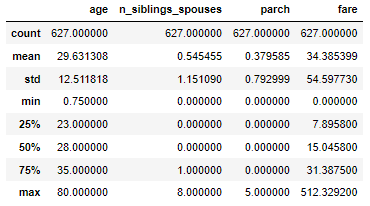
# 观察年龄的数据分布
train_df.age.hist(bins = 20)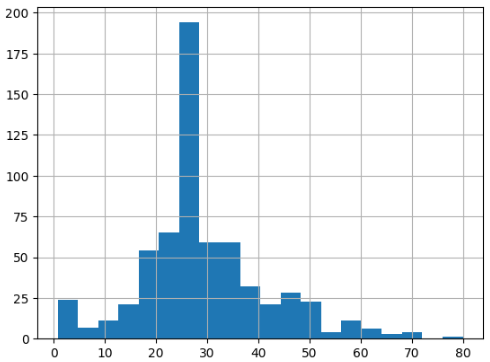
# 观察男女比例, 性别数量对比
train_df.sex.value_counts().plot(kind = 'barh')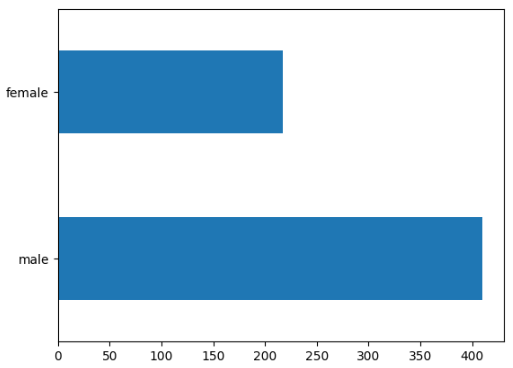
# 仓位对比, 船舱类型
train_df['class'].value_counts().plot(kind = 'barh')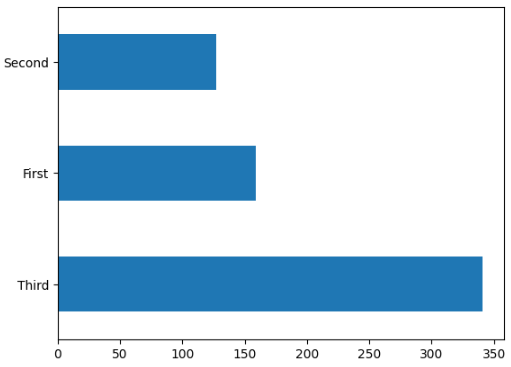
# 看港口人数
train_df['embark_town'].value_counts().plot(kind = 'barh')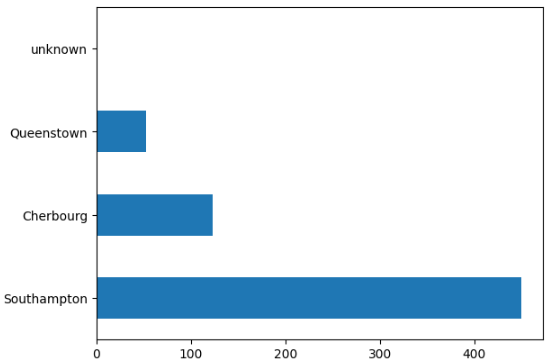
pd.concat([train_df, y_train], axis = 1).groupby('sex').survived.mean().plot(kind = 'barh')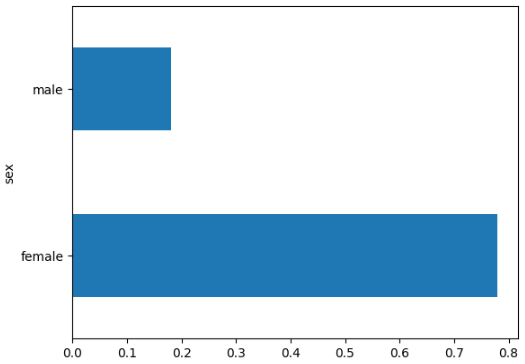
train_df.embark_town.value_counts()
'''Southampton 450
Cherbourg 123
Queenstown 53
unknown 1
Name: embark_town, dtype: int64'''# 区分离散特征和连续特征
categorical_columns = ['sex', 'n_siblings_spouses', 'parch', 'class', 'deck', 'embark_town', 'alone'] # 离散特征
numeric_columns = ['age', 'fare']# 接受特征
feature_columns = []
for categorical_column in categorical_columns:vocab = train_df[categorical_column].unique() # 取出特征值print(vocab)# print(tf.feature_column.categorical_column_with_vocabulary_list(categorical_column, vocab)) # 创建vocabulary 的API# 将离散特征转换为one_hot形式的编码num = tf.feature_column.indicator_column(tf.feature_column.categorical_column_with_vocabulary_list(categorical_column, vocab))feature_columns.append(num)
# 数据类型转换
for numeric_column in numeric_columns:feature_columns.append(tf.feature_column.numeric_column(numeric_column, dtype = tf.float32))5 dataset
# 创建生成dataset的方法
def make_dataset(data_df, label_df, epochs = 10, shuffle = True, batch_size = 32):dataset = tf.data.Dataset.from_tensor_slices((dict(data_df), label_df))if shuffle:dataset = dataset.shuffle(10000) # 打乱, 洗牌dataset = dataset.repeat(epochs).batch(batch_size)return dataset
train_dataset = make_dataset(train_df, y_train, batch_size = 5)# baseline_model
import os
output_dir = 'baseline_model'
if not os.path.exists(output_dir):os.mkdir(output_dir)baseline_estimator = tf.compat.v1.estimator.BaselineClassifier(model_dir = output_dir, n_classes= 2)
# input_fn要求没有输入参数, 要求返回元组(x, y)或者可以返回(x, y)的dataset
baseline_estimator.train(input_fn = lambda : make_dataset(train_df, y_train, epochs = 100))# baseline 是随机参数, 所以结果很差
baseline_estimator.evaluate(input_fn = lambda : make_dataset(eval_df, y_eval, epochs = 1,shuffle = False, batch_size = 20))# linear_model
linear_output_dir = 'linear_model'
if not os.path.exists(linear_output_dir):os.mkdir(linear_output_dir)linear_estimator = tf.estimator.LinearClassifier(feature_columns = feature_columns,model_dir = linear_output_dir)
linear_estimator.train(input_fn = lambda :make_dataset(train_df, y_train, epochs = 100))# baseline 是随机参数, 所以结果很差
linear_estimator.evaluate(input_fn = lambda : make_dataset(eval_df, y_eval, epochs = 1, shuffle = False,batch_size = 20))dnn_output_dir = './dnn_model'
if not os.path.exists(dnn_output_dir):os.mkdir(dnn_output_dir)dnn_estimator = tf.estimator.DNNClassifier(model_dir = dnn_output_dir, # 存储地址n_classes= 2, # 二分类feature_columns = feature_columns, hidden_units = [128, 128], # 隐藏层activation_fn = tf.nn.relu, # 算法optimizer = 'Adam') # 损失函数, 优化:optimizer
# dnn_estimator.train(input_fn = lambda : make_dataset(train_df, y_train, epochs = 100))dnn_estimator.train(input_fn = lambda :make_dataset(train_df, y_train, epochs = 100))dnn_estimator.evaluate(input_fn = lambda : make_dataset(eval_df, y_eval, epochs = 1,shuffle = False, batch_size = 20))相关文章:
22- estimater使用 (TensorFlow系列) (深度学习)
知识要点 estimater 有点没理解透 数据集是泰坦尼克号人员幸存数据. 读取数据:train_df pd.read_csv(./data/titanic/train.csv) 显示数据特征:train_df.info() 显示开头部分数据:train_df.head() 提取目标特征:y_train tr…...

eKuiper 1.8.0 发布:零代码实现图像/视频流的实时 AI 推理
LF Edge eKuiper 是 Golang 实现的轻量级物联网边缘分析、流式处理开源软件,可以运行在各类资源受限的边缘设备上。eKuiper 的主要目标是在边缘端提供一个流媒体软件框架(类似于 Apache Flink )。eKuiper 的规则引擎允许用户提供基于 SQL 或基…...

[Ansible系列]ansible JinJia2过滤器
目录 一. JinJia2简介 二. JinJia2模板使用 2.1 在play中使用jinjia2 2.2 template模块使用 2.3 jinjia2条件语句 2.4 jinjia2循环语句 2.5 jinjia2过滤器 2.5.1 default过滤器 2.5.2 字符串操作相关过滤器 2.5.3 数字操作相关过滤器 2.5.4 列表操作…...

Cookie、Session、Token区分
一开始接触这三个东西,肯定会被绕的不知道都是干什么的。1、为什么要有它们?首先,由于HTTP协议是无状态的,所谓的无状态,其实就是 客户端每次想要与服务端通信,都必须重新与服务端连接,这就意味…...

回暖!“数”说城市烟火气背后
“人间烟火气,最抚凡人心”。在全国各地政策支持以及企业的积极生产运营下,经济、社会、生活各领域正加速回暖,“烟火气”在城市中升腾,信心和希望正在每个人心中燃起。 发展新阶段,高效统筹经济发展和公共安全&#…...

JS逆向-百度翻译sign
前言 本文是该专栏的第36篇,后面会持续分享python爬虫干货知识,记得关注。 有粉丝留言,近期需要做个翻译功能,考虑到百度翻译语言语种比较全面,但是它的参数被逆向加密了,对于这种情况需要怎么处理呢?所以本文以它为例。 废话不多说,跟着笔者直接往下看正文详细内容。…...
Fiddler抓包之Fiddler过滤器(Filters)调试
Filters:过滤器,帮助我们过滤请求。 如果需要过滤掉与测试项目无关的抓包请求,更加精准的展现抓到的请求,而不是杂乱的一堆,那功能强大的 Filters 过滤器能帮到你。 2、Filters界面说明 fiddler中的过滤 说明&#…...

【xib文件的加载过程 Objective-C语言】
一、xib文件的加载过程: 1.xib文件,是不是在这里啊: View这个文件夹里, 然后呢,我们加载xib是怎么加载的呢, 是不是在控制器里,通过我们这个类方法,加载xib: TestAppView *appView = [TestAppView appView]; + (instancetype)appView{NSBundle *rootBundle = [N…...

react setState学习记录
react setState学习记录1.总体看来2.setState的执行是异步的3.函数式setState1.总体看来 (1). setState(stateChange, [callback])------对象式的setState 1.stateChange为状态改变对象(该对象可以体现出状态的更改) 2.callback是可选的回调函数, 它在状态更新完毕、界面也更新…...

Docker容器cpu利用率问题
1.top原理 top 是读的/proc/stat文件 比如cat /proc/PID/stat 进程的总Cpu时间processCpuTime utime stime cutime cstime,该值包括其所有线程的cpu时间 某一进程Cpu使用率的计算 计算方法: 1 采样两个足够短的时间间隔的cpu快照与进程快照&…...

FreeRTOS入门(06):任务通知
文章目录目的基础说明使用演示作为二进制信号量作为计数信号量作为事件组作为队列或邮箱相关函数总结目的 任务通知(TaskNotify)是RTOS中相对常用的用于任务间交互的功能,这篇文章将对相关内容做个介绍。 本文代码测试环境见前面的文章&…...
谷歌seo做的外链怎样更快被semrush识别
本文主要分享做谷歌seo外链如何能让semrush工具快速的记录并能查询到。 本文由光算创作,有可能会被剽窃和修改,我们佛系对待这种行为吧。 谷歌seo做的外链怎样更快被semrush识别? 答案是:多使用semrush搜索目标网站可加速爬虫抓…...

Java | IO 模式之 JavaBIO 应用
文章目录IO模型Java BIOJava NIOJava AIO(NIO.2)BIO、NIO、AIO的使用场景BIO1 BIO 基本介绍2 BIO 的工作机制3 BIO 传统通信实现3.1 业务需求3.2 实现思路3.3 代码实现4 BIO 模式下的多发和多收消息4.1 业务需求4.2 实现思路4.3 代码实现5 BIO 模式下接收…...

C语言学习及复习笔记-【18】C内存管理
18 C内存管理 C 语言为内存的分配和管理提供了几个函数。这些函数可以在 <stdlib.h> 头文件中找到。 序号函数和描述1void *calloc(int num, int size); 在内存中动态地分配 num 个长度为 size 的连续空间,并将每一个字节都初始化为 0。所以它的结果是分配了…...

linux--多线程(一)
文章目录Linux线程的概念线程的优点线程的缺点线程异常线程的控制创建线程线程ID以及进程地址空间终止线程线程等待线程分离线程互斥进程线程间的互斥相关概念互斥量mutex有线程安全问题的售票系统查看ticket--部分的汇编代码互斥量的接口互斥量实现原理探究可重入和线程安全常…...
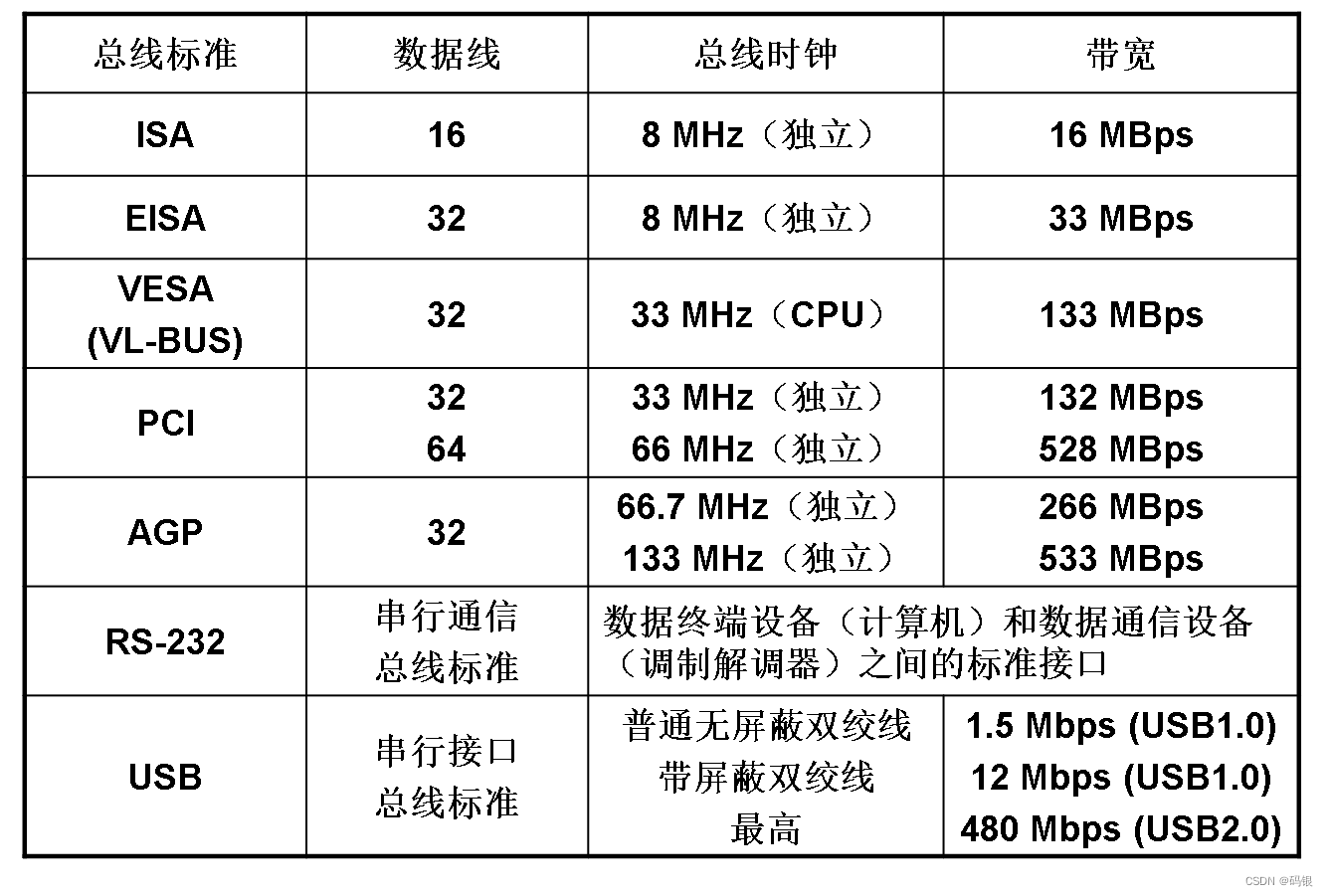
计算机组成原理(2.1)--系统总线
目录 一、总线基本知识 1.总线 2.总线的信息传送 3.分散连接图 4.注 二、总线结构的计算机举例 1.面向 CPU 的双总线结构框图 2.单总线结构框图 3.以存储器为中心的双总线结构框图 三、总线的分类 1.片内总线 2.系统总线 (板级总线或板间总线&#…...

C语言数组【详解】
数组1. 一维数组的创建和初始化1.1 数组的创建1.2 数组的初始化1.3 一维数组的使用1.4 一维数组在内存中的存储2. 二维数组的创建和初始化2.1 二维数组的创建2.2 二维数组的初始化2.3 二维数组的使用2.4 二维数组在内存中的存储3. 数组越界4. 数组作为函数参数4.1 冒泡排序函数…...

并行与体系结构会议
A类会议 USENIX ATC 2022: USENIX Annual Technical Conference(录用率21%) CCF a, CORE a, QUALIS a1 会议截稿日期:2022-01-06 会议通知日期:2022-04-29 会议日期:2022-07-11 会议地点:Carlsbad, Califo…...

【巨人的肩膀】JAVA面试总结(三)
1、💪 目录1、💪1、说说List, Set, Queue, Map 四者的区别1.1、List1.2、Set1.3、Map2、如何选用集合4、线程安全的集合有哪些?线程不安全的呢?3、为什么需要使用集合4、comparable和Comparator的区别5、无序性和不可重复性的含义…...
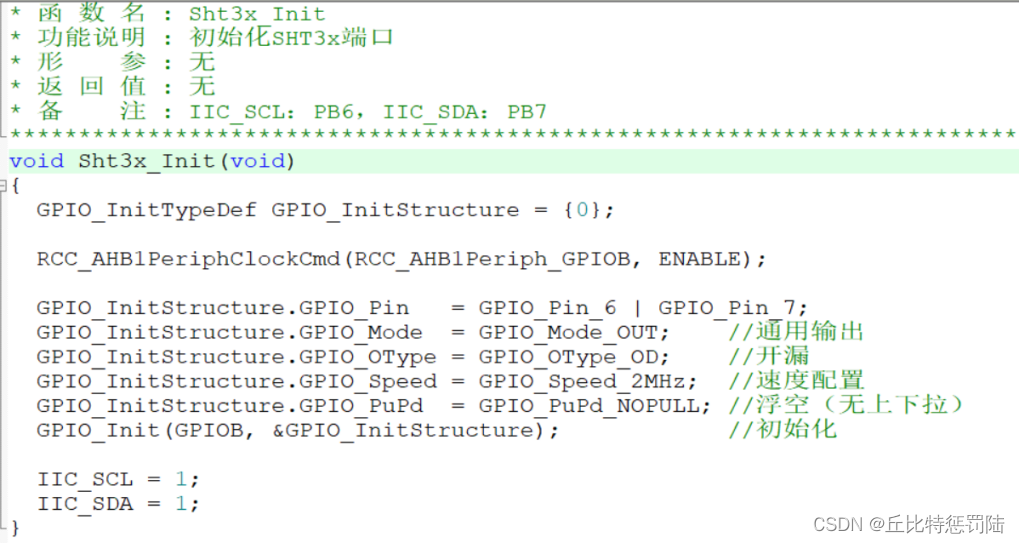
嵌入式 STM32 SHT31温湿度传感器
目录 简介 1、原理图 2、时序说明 数据传输 起始信号 结束信号 3、SHT31读写数据 SHT31指令集 读数据 温湿度转换 4、温湿度转换应用 sht3x初始化 读取温湿度 简介 什么是SHT31? 一主机多从机--通过寻址的方式--每个从机都有唯一的地址&…...

多云管理“拦路虎”:深入解析网络互联、身份同步与成本可视化的技术复杂度
一、引言:多云环境的技术复杂性本质 企业采用多云策略已从技术选型升维至生存刚需。当业务系统分散部署在多个云平台时,基础设施的技术债呈现指数级积累。网络连接、身份认证、成本管理这三大核心挑战相互嵌套:跨云网络构建数据…...

Lombok 的 @Data 注解失效,未生成 getter/setter 方法引发的HTTP 406 错误
HTTP 状态码 406 (Not Acceptable) 和 500 (Internal Server Error) 是两类完全不同的错误,它们的含义、原因和解决方法都有显著区别。以下是详细对比: 1. HTTP 406 (Not Acceptable) 含义: 客户端请求的内容类型与服务器支持的内容类型不匹…...
:OpenBCI_GUI:从环境搭建到数据可视化(下))
脑机新手指南(八):OpenBCI_GUI:从环境搭建到数据可视化(下)
一、数据处理与分析实战 (一)实时滤波与参数调整 基础滤波操作 60Hz 工频滤波:勾选界面右侧 “60Hz” 复选框,可有效抑制电网干扰(适用于北美地区,欧洲用户可调整为 50Hz)。 平滑处理&…...
)
IGP(Interior Gateway Protocol,内部网关协议)
IGP(Interior Gateway Protocol,内部网关协议) 是一种用于在一个自治系统(AS)内部传递路由信息的路由协议,主要用于在一个组织或机构的内部网络中决定数据包的最佳路径。与用于自治系统之间通信的 EGP&…...

Nuxt.js 中的路由配置详解
Nuxt.js 通过其内置的路由系统简化了应用的路由配置,使得开发者可以轻松地管理页面导航和 URL 结构。路由配置主要涉及页面组件的组织、动态路由的设置以及路由元信息的配置。 自动路由生成 Nuxt.js 会根据 pages 目录下的文件结构自动生成路由配置。每个文件都会对…...

MODBUS TCP转CANopen 技术赋能高效协同作业
在现代工业自动化领域,MODBUS TCP和CANopen两种通讯协议因其稳定性和高效性被广泛应用于各种设备和系统中。而随着科技的不断进步,这两种通讯协议也正在被逐步融合,形成了一种新型的通讯方式——开疆智能MODBUS TCP转CANopen网关KJ-TCPC-CANP…...

【git】把本地更改提交远程新分支feature_g
创建并切换新分支 git checkout -b feature_g 添加并提交更改 git add . git commit -m “实现图片上传功能” 推送到远程 git push -u origin feature_g...

【论文阅读28】-CNN-BiLSTM-Attention-(2024)
本文把滑坡位移序列拆开、筛优质因子,再用 CNN-BiLSTM-Attention 来动态预测每个子序列,最后重构出总位移,预测效果超越传统模型。 文章目录 1 引言2 方法2.1 位移时间序列加性模型2.2 变分模态分解 (VMD) 具体步骤2.3.1 样本熵(S…...

OPENCV形态学基础之二腐蚀
一.腐蚀的原理 (图1) 数学表达式:dst(x,y) erode(src(x,y)) min(x,y)src(xx,yy) 腐蚀也是图像形态学的基本功能之一,腐蚀跟膨胀属于反向操作,膨胀是把图像图像变大,而腐蚀就是把图像变小。腐蚀后的图像变小变暗淡。 腐蚀…...

视频行为标注工具BehaviLabel(源码+使用介绍+Windows.Exe版本)
前言: 最近在做行为检测相关的模型,用的是时空图卷积网络(STGCN),但原有kinetic-400数据集数据质量较低,需要进行细粒度的标注,同时粗略搜了下已有开源工具基本都集中于图像分割这块,…...