map和set的使用
文章目录
- 关联式容器
- 树形结构的关联式容器
- set
- insert增减
- erase删除
- multiset
- 修改
- map
- pair<key,value>
- insert
- operator[] 的引入
- insert和operator[]的区别
- multimap
- 小结
- map的使用
- 统计最喜欢吃的前几种水果
- 前K个高频单词,返回单词的频率由高到低,频率相同时,字典序排列
关联式容器
-
序列式容器: vector、list、deque、forward_list(C++11)等,这些容器统称为序列式容器,因为其底层为线性序列的数据结构,里面存储的是元素本身,元素之间无关系,可以随意的插入.
-
关联式容器:map/set… 存储加查找数据,数据之间不能随便插入和删除,有强烈的关联关系.关联式容器也是用来存储数据的,与序列式容器不同的是,其里面存储的是<key, value>结构的键值对,在数据检索时比序列式容器效率更高
-
键值对
用来表示具有一一对应关系的一种结构,该结构中一般只包含两个成员变量key和value,key代表键值,value表示与key对应的信息。比如:现在要建立一个英汉互译的字典,那该字典中必然有英文单词与其对应的中文含义,而且,英文单词与其中文含义是一一对应的关系,即通过该应该单词,在词典中就可以找到与其对应的中文含义.
-
树形结构的关联式容器
set
底层是之前实现过的搜索树的K模型
insert增减
搜索树走得是中序遍历,BS搜索树是底层,自身带有排序+去重的功能。
如果有相同的值就不会进行再次插入的了。
所以有去重的需要可以用set,默认是升序.
erase删除
删除某一个元素,要先进行查找,就是find()
- 删除一个位置和删除一个值的区别:
位置要确保位置的有效,而删除值有就删除没有就没有反馈。
- erase的返回值是已经删除的指定元素的个数
void test_set()
{set<int> st;st.insert(3);st.insert(5);st.insert(4);st.insert(2);st.insert(8);st.insert(9);st.insert(9);//迭代器set<int>::iterator it = st.begin();while (it != st.end()){cout << *it << " ";it++;}cout << endl;//2 3 4 5 8 9set<int>::iterator pos = st.find(3);if (pos != st.end()){st.erase(pos);}//有序说明搜索树走得是中序-排序//去重效果:相同数据插入失败
//范围forfor (auto e : st){cout << e << " ";}cout << endl;
}
multiset
如果只想排序,不想要去重就用:multiset (多样的)
当删除的值有多个的时候,删除的值是哪一个位置的呢?
- find查找到的是中序的第一个,也就是最左节点.
void test_multi_set()
{multiset<int>st;st.insert(3);st.insert(5);st.insert(4);st.insert(2);st.insert(8);st.insert(9);st.insert(9);st.insert(9);st.insert(9);st.insert(9);st.insert(1);multiset<int>::iterator it = st.begin();while (it != st.end()){cout << *it << " ";it++;}cout << endl;auto pos = st.find(9);while (pos != st.end()){cout << *pos << " ";++pos;}//如何将所有重复元素删除//auto pos1 = st.find(9);//while (pos1 != st.end() && *pos1 == 9)//{// st.erase(pos1);// //节点指针被干掉之后是野指针无法++,所以会崩溃// ++pos1;//}cout << st.erase(9) << endl;//把所有9都删了,还返回了删了几个for (auto e : st){cout << e << " ";}cout << endl;
}
修改
运用迭代器进行修改的时候是不允许的,因为改动某一个节点的值之后就可能不是搜索树,因为节点之间存在大小关系.

map
底层是搜索树对应的key-val模型

pair<key,value>

-
pair<>提供构造函数

-
pair<>匿名对象
-
make_pair()函数模板,对匿名对象的一层封装.虽然看起来多一层函数调用,其实可以设置为内联函数直接打开.

pair是一个结构体,两个值都是公有的.
pair并没有重载流插入和流提取运算符,遍历的时候可以通过first和second进行访问.
void test_map()
{map<string,string>m;//pair的构造函数pair<string, string> kv1("sort", "排序");m.insert(kv1);//pair的匿名对象m.insert(pair<string,string>("string","字符串"));//make_pair自动推导类型,简洁m.insert(make_pair("test","测试"));map<string, string>::iterator it = m.begin();while (it != m.end()){//cout << *it << endl;//pair不支持流插入和流提取cout << (*it).first << ":" << (*it).second << endl;cout << it->first << ":" << it->second << endl;++it;}cout << endl;//最好加上&,因为每一次pair中的string都得拷贝给efor (auto& e : m){cout << e.first << ":" << e.second << endl;}cout << endl;
}
map的key不支持修改,但是val是支持修改的.因为搜索树的关系是靠key来维护的.
insert
插入的时候涉及到去重需要先进行查找,由于是搜索树插入的时候为了更合适的位置又进行了一遍查找
为了进行优化,引进了pair(iterator,bool) insert();实现用iterator和bool两个标志来完成对于上面的优化。

void test_map2()
{//了解insert返回值之前string arr[] = {"苹果","苹果", "苹果", "苹果", "苹果", "香蕉","西红柿"};map<string, int> countMap;for (auto& str : arr){auto ret = countMap.find(str);if (ret == countMap.end())countMap.insert(make_pair(str, 1));elseret->second++;}//了解insert返回值之后for (auto& str:arr){auto kv = countMap.insert(make_pair(str,1));if (kv.second == false){kv.first->second++;//返回值的第一个是相同节点的指针}}//[]的引入for (auto& str : arr){countMap[str]++;}for (auto& e : countMap){cout << e.first << ":" << e.second << endl;}cout << endl;
}
operator[] 的引入

迭代器要么指向新插入的节点要么指向相同值的节点.
//map中[]的文档注释
mapped_type& operator[](const key_type& k)
{return *(this->insert(make_pair(k,mapped_type())).first).second;
}
//帮助理解版本
mapped_type&operator[](const key_type& k)
{pair<iterator,bool> ret=insert(make_pair(k,mapped_type()));return ret->first.second;
}

水果第一次出现,插入+修改,insert时考虑的只有key.
水果不是第一次出现,查找+修改,因为&的存在,作用在相同值节点的second上.
insert和operator[]的区别
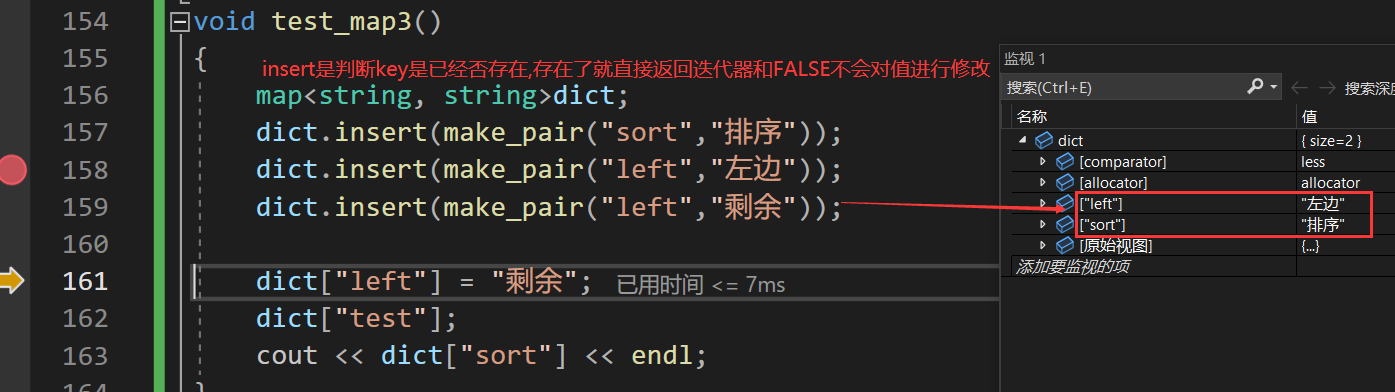

multimap
-
允许key冗余,multimap 类型。无论是否相同都会进行插入.
-
不支持[]的出现根据底层理解,应该返回哪个节点的value值呢?
-
cout<<dict.count(“left”);返回key出现的次数.
小结
前面对map/multimap/set/multiset进行了简单的介绍,在介绍中发现,这几个容器有个共同点是:其底层都是按照二叉搜索树来实现的,但是二叉搜索树有其自身的缺陷,假如往树中插入的元素有序或者接近有序,二叉搜索树就会退化成单支树,时间复杂度会退化成O(N),因此map、set等关联式容器的底层结构是对二叉树进行了平衡处理,即采用平衡树来实现。
map的使用
统计最喜欢吃的前几种水果
# include<algrithm>struct CountVal
{bool operator()(const pair<string ,int>&l,const pair<string,int>&r){//return l.second >r.second;return l.second < r.second;//堆,优先级队列中使用的}
}
struct CountIterator
{bool operator()(const map<string,int>::iterator& l,const map<string,int>::iterator&r){//return l->second>r->second;return l->second< r->second;//优先级队列中使用的,想要建立的是一个大堆}
}
void GetfavoriteFruit(const vector<string>&fruits,size_t k)
{map<string,int>countmap;for(auto &e:countmap){countmap[e]++;}//数据量不大的排序//sort,为了便于进行以次数为依据的排序,需要先将数制拷贝到数组中进行排序。//1. 第一种写法:有很多次对于pair类型的深拷贝放到vector中,如果string很长就是浪费空间vector<pair<string,int>> sortV;for(auto &kv: countmap){sortV.push_back(kv);}sort(sortV.begin(),sortV.end(),CountVal());for(int i=0;i<k;i++){cout<<sortV[i].first<<":"sortV.second<<endl;}cout<<endl;//2. 第二种写法,vector的迭代器支持排序,而map的不支持
//那么就将pair的迭代器拷贝进vector中vector<map<string,int>::iterator> sortV;auto it = countmap.begin();while(it!=countmap.end()){sortV.push_back(it);++it;}sort(sortV.begin(),sortV.end(),CountIterator());for(int i=0;i<k;i++){cout<<sortV[i]->first<<":"<<sortV[i]->second<<endl;//容器当中都是迭代器}cout<<endl;
//3. 使用multimap<>操作
//仿函数默认是升序less,将他设置为greater就改成了降序
//头文件
#include<functional>multimap<int ,string,greater<int>> sortmap;for(auto &kv:countmap){sortmap.insert(make_pair(kv.second,kv.first));//根据value排序}
//4.1 用优先级队列,用的是堆
//#include<queue>priority_queue<pair<string,int>,vector<pair<string,int>>,CountVal> pq;//pq这里类模板传类型CountVal,前两种仿函数是函数模板传对象CountVal()for(auto&kv;countmap){pq.push(kv);}while(k--){cout<<pq.top().first<<" :"<<pq.top().second<<endl;pq.pop();}cout<<endl;//4.2 没有必要将数据也拷贝出来,拷贝迭代器出来就可以找到相应的数据priority_queue<map<string,int>::iterator,vector<map<string,int>::iterator>,CountIterator> pq;auto it=countmap.begin();while(it!=countmap.end()){pq.push(it);++it;}while(k--){cout<<pq.top()->first<<" :"<<pq.top()->second<<endl;pq.pop();}cout<<endl;
}
//pair 是支持比较大小的。- 注意参数(类型,承装类型的容器,仿函数)
- 优先级队列,小于建的是大堆

前K个高频单词,返回单词的频率由高到低,频率相同时,字典序排列
sort的底层是快排,是不稳定的排序。只有稳定的排序才能保证字典序i在L的前面.稳定的排序:stable_sort()
//使用map的特性
vector<string>topKFrequency(vector<int>&words,int k)
{map<string,int> countmap;for(auto& kv : words){countmap[kv]++;}multimap<int ,string,greater<int>> sortMap;for(auto & kv: countmap){sortMap.insert(make_pair(kv.second,kv.first));}vector<string>v;auto it=sortMap.begin();while(k--){v.push_back(it->second);++it;}return v;
}
相关文章:
map和set的使用
文章目录关联式容器树形结构的关联式容器setinsert增减erase删除multiset修改mappair<key,value>insertoperator[] 的引入insert和operator[]的区别multimap小结map的使用统计最喜欢吃的前几种水果前K个高频单词,返回单词的频率由高到低,频率相同时࿰…...

常用正则表达式大全
链接...

注意,摸鱼程序员常用的9个小技巧,早点下班不秃头
9个养生小技巧,祝大家不秃头嗨害大家好鸭! 我是小熊猫~毕竟摸鱼一时爽,一直摸一直爽嘛~一、整理字符串输入二、迭代器切片(Slice)三、跳过可迭代对象的开头四、只包含关键字参数的函数 (kwargs)五、创建支持「with」语…...
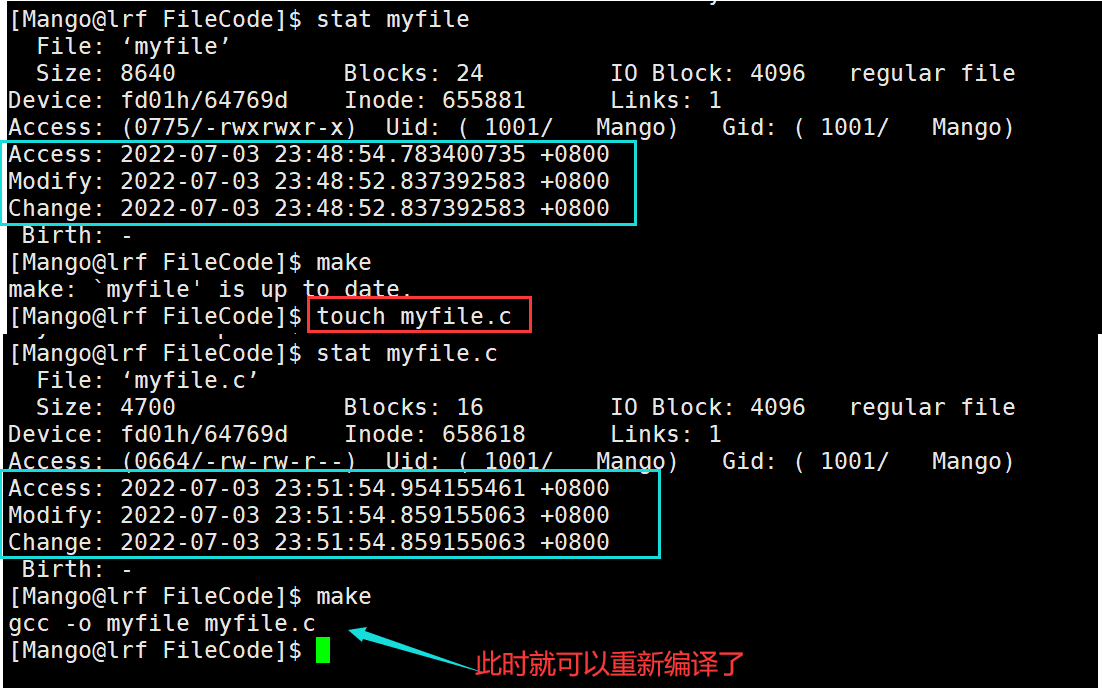
【Linux】文件时间-ACM
文章目录文件时间-acmAccessChangeModify文件时间-acm 我们可以使用stat 文件名的方式查看对应的文件的时间信息 Access 表示文件最近一次被访问的时间 文件的访问 实际也就是文件的读取 实际操作中,文件的Access时间可能没有变化,这是因为在新的Linux内核中,Access时间不…...
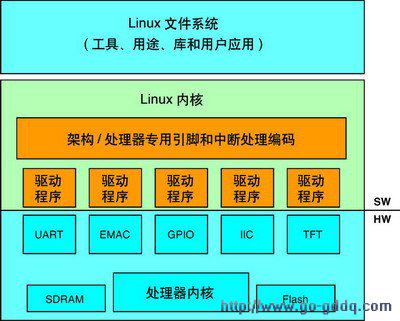
[架构之路-124]-《软考-系统架构设计师》-操作系统-3-操作系统原理 - IO设备、微内核、嵌入式系统
第11章 操作系统第5节 设备管理/文件管理:IO5.1 文件管理5.2 IO设备管理(内存与IO设备之间)数据传输控制是指如何在内存和IO硬件设备之间传输数据,即:设备何时空闲?设备何时完成数据的传输?SPOO…...
【竞赛/TPU】算能TPU编程竞赛总结
如果觉得我的分享有一定帮助,欢迎关注我的微信公众号 “码农的科研笔记”,了解更多我的算法和代码学习总结记录。或者点击链接扫码关注【竞赛/TPU】算能TPU编程竞赛总结 1 基础知识 1.1【Ubuntu】 Ubuntu操作系统中有很多不同的文件夹,每个…...

Substrate 基础教程(Tutorials) -- 模拟网络 添加可信节点
三、模拟网络 本教程基本介绍了如何使用一个私有验证器(validators)的授权集合来启动私有区块链网络。 Substrate节点模板使用授权共识模型(authority consensus model),该模型将块生产限制为授权帐户的旋转列表(rotating list)。授权帐户(…...

SAP 设置无物料号的费用采购
现在还是以外购电来说一下ERP中费用采购单的使用步骤: (1).Tcode:OMSF定义物料组D1,如下图。 (2).到配置路径IMG Path:物料管理->采购->帐户分配(或直接SE16:V_T163K)定义一科目分配类别,默认的K就是费用采购科目分配类型,如果可能可以复制一个,如下图,注意下…...
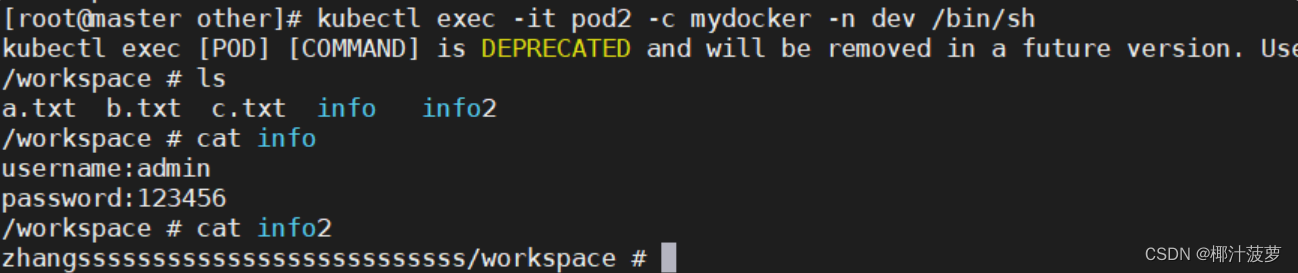
k8s ConfigMap 中 subPath 字段和 items 字段
Kubernetes中什么是subPath 有时,在单个 Pod 中共享卷以供多方使用是很有用的。volumeMounts.subPath 属性可用于指定所引用的卷内的子路径,而不是其根路径。 这句话理解了,基本就懂subPath怎么用了,比如我们要替换nginx.cnf, 挂…...

UML建模
主要记录UML中的相关知识,包括类、对象、接口、方法、用例、活动、状态、组件和部署图,详细介绍类之间关系与类图的绘制 文章目录一、UML介绍二、类图类之间的关系依赖关系继承关系实现关系关联关系组合关系聚合关系正文内容: 一、UML介绍 …...
)
JavaScript常见面试题(更新中)
介绍js的基本数据类型 js一共有五种数据类型 分别是undefined null boolean number string 还有ES6中新增的symbol和ES10的bigInt symbol代表创建后独一无二的不可变的数据类型,他的出现我认为是为了解决可能出现的全局变量冲突的问题 BigInt是一种数字类型的数据 …...
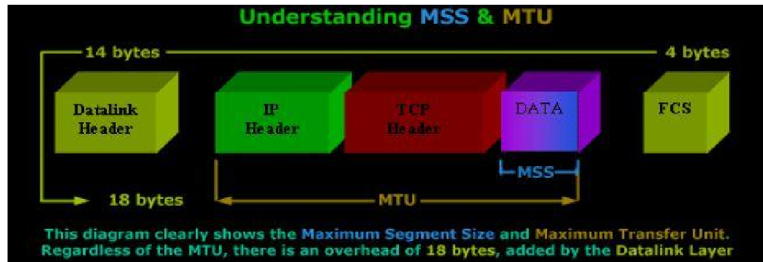
TCP/IP协议
✏️作者:银河罐头 📋系列专栏:JavaEE 🌲“种一棵树最好的时间是十年前,其次是现在” 目录TCP/IP协议应用层协议自定义应用层协议DNS传输层协议端口号UDP协议UDP协议端格式TCP协议TCP协议段格式TCP工作机制确认应答(安…...
Python使用异步线程池实现异步TCP服务器交互
背景: 实现客户端与服务端交互,由于效率原因,要发送与接收异步,提高效率。 需要多线程,本文用线程池管理。 common代码: import pickle import struct import timedef send_msg(conn, data):time.sleep(…...
matplotlib常用操作
文章目录1 matplotlib绘图1.1 绘图步骤2 matplotlib基本元素2.1 matplotlib 画布2.2 设置坐标轴长度和范围2.3 设置图形的线型和颜色2.4 设置图形刻度范围、刻度标签和坐标轴标签等2.4.1 设置刻度范围2.4.2 设置坐标轴刻度2.5 文本标签图例3 matplotlib的ax对象绘图4 绘制子图5…...
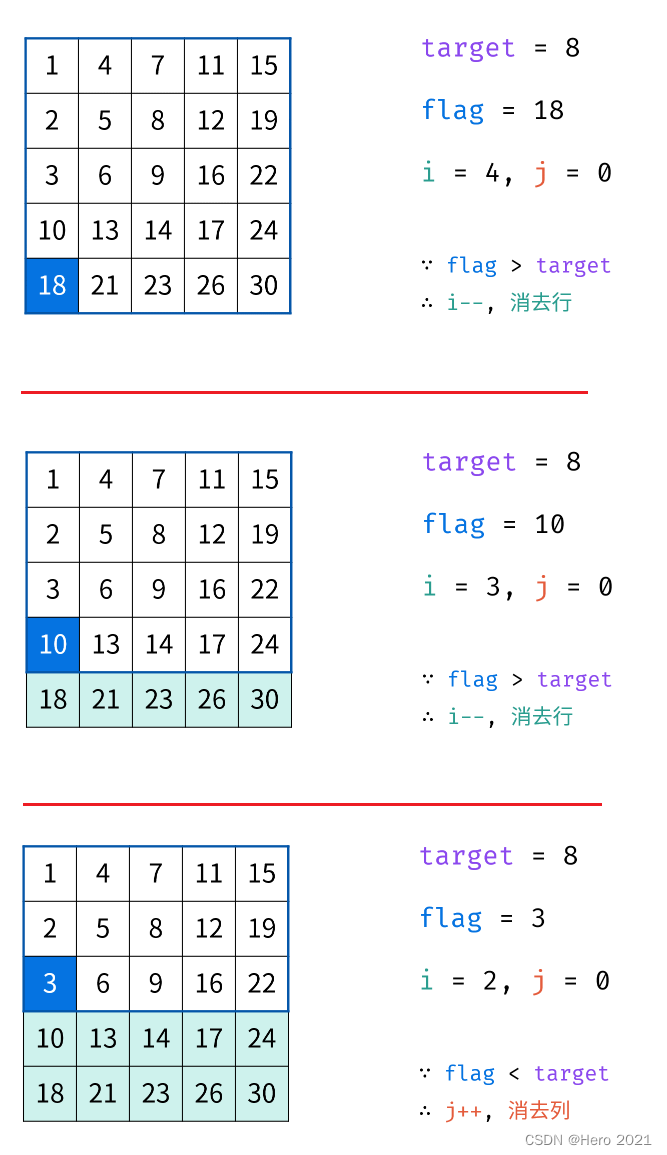
二分算法题
文章目录一、在排序数组中查找数字二、0~n-1中缺失的数字三、旋转数组的最小数字四、二维数组中的查找一、在排序数组中查找数字 题目传送门 法一:暴力解 直接遍历然后计数 法二:二分法求边界 看到关键字排序数组、有序数组,一定要想到二分…...
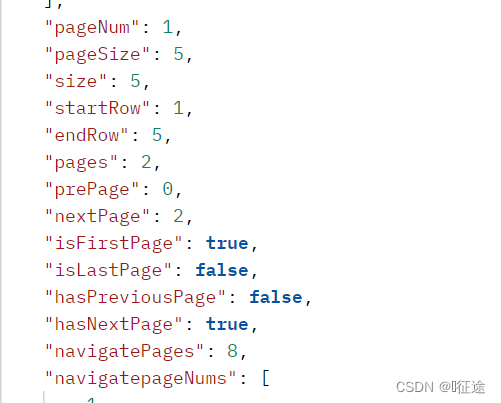
Vue+ElementUI+SpringBoot项目配合分页插件快速实现分页(简单暴力)
首先需要在项目中引入Element-UI的组件库,使用以下命令,不会引入的请自行百度。 npm i element-ui -S Element官网地址:https://element.eleme.cn/#/zh-CN/component/changelog 去Element-UI官网组件库找到合适的分页插件,并把他引…...
)
【回眸】牛客网刷刷刷!嵌入式软件中也会遇到的嵌入式硬件,通讯,通讯协议专题(一)
前言 最近继续刷题,看看嵌入式软件还需要了解一些嵌入式硬件中的通讯协议和常用接口协议 比如说SPI CAN I2C 通讯协议专题 1.波特率 波特率 每秒传送的字符数 * 字符位数。串口的工作模式为1个起始位,7个数据位,1个校验位,1个…...
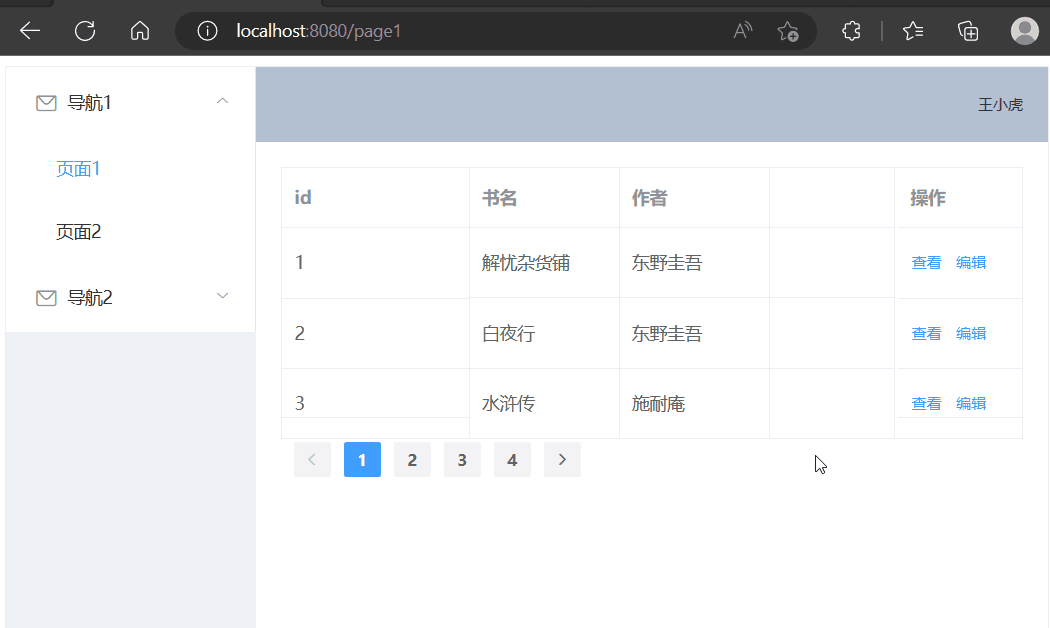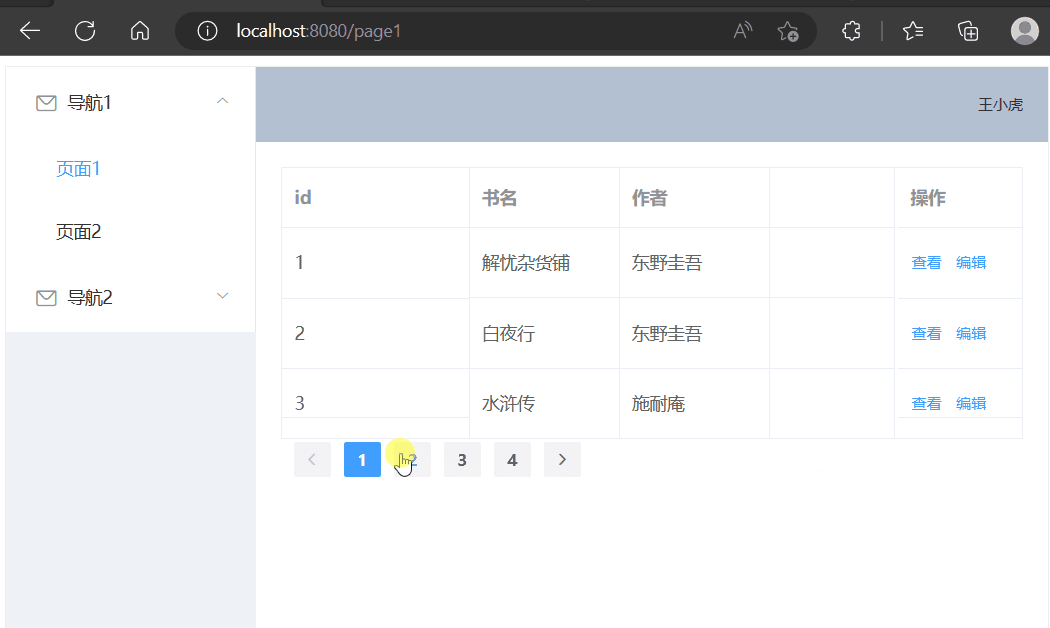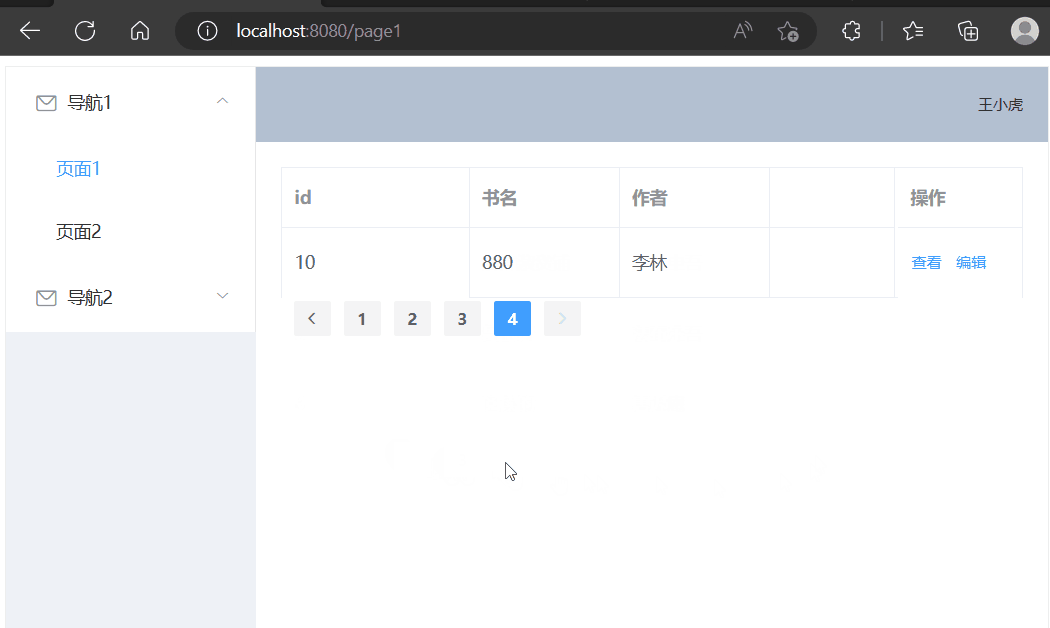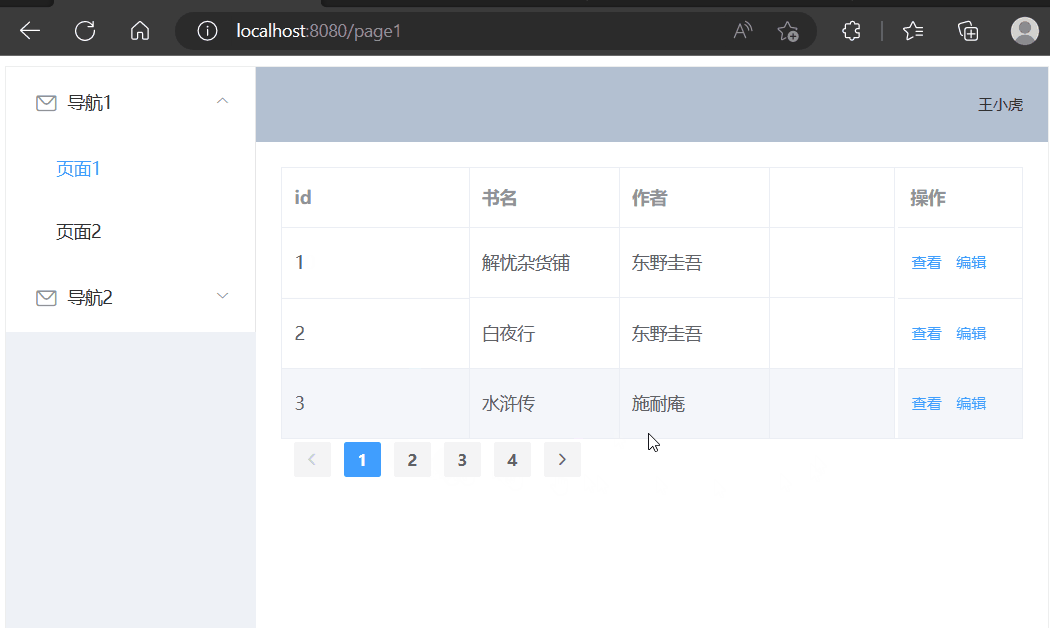
使用Vue展示数据(动态查询)
学习内容来源:视频P4 本篇文章进度接着之前的文章进行续写 精简前后端分离项目搭建 Vue基础容器使用 目录选择组件修改表格组件修改分页组件增加后端接口前端请求数据接口页面初始化请求数据点击页码请求数据选择组件 在官方文档中选择现成的组件,放在页…...

构建数据库测试数据——mysql
建表脚本 -- 建表 CREATE TABLE test_table (id INT(11) NOT NULL AUTO_INCREMENT,varchar_col VARCHAR(50),char_col CHAR(10),text_col TEXT,tinyint_col TINYINT(4),smallint_col SMALLINT(6),mediumint_col MEDIUMINT(9),int_col INT(11),bigint_col BIGINT(20),float_col…...
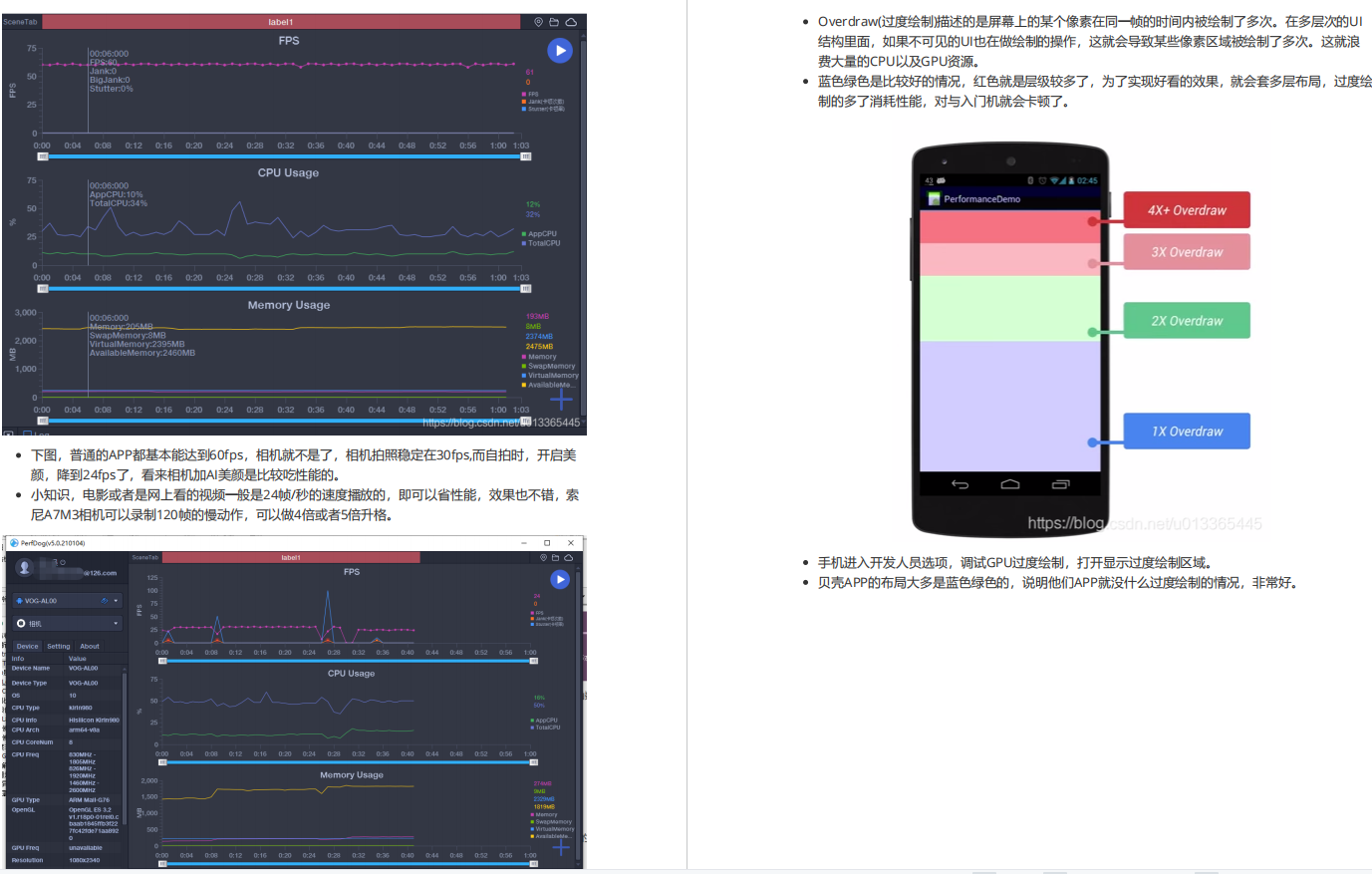
你想要的Android性能优化系列:启动优化 !
App启动优化为什么要做App的启动优化?网页端存在的一个定律叫8秒定律:即指用户访问一个网站时,如果等待打开的时间超过8秒,超过70%的用户将会放弃等待。同样的,移动端也有一个8秒定律:如果一个App的启动时间…...
:手搓截屏和帧率控制)
Python|GIF 解析与构建(5):手搓截屏和帧率控制
目录 Python|GIF 解析与构建(5):手搓截屏和帧率控制 一、引言 二、技术实现:手搓截屏模块 2.1 核心原理 2.2 代码解析:ScreenshotData类 2.2.1 截图函数:capture_screen 三、技术实现&…...

【Linux】C语言执行shell指令
在C语言中执行Shell指令 在C语言中,有几种方法可以执行Shell指令: 1. 使用system()函数 这是最简单的方法,包含在stdlib.h头文件中: #include <stdlib.h>int main() {system("ls -l"); // 执行ls -l命令retu…...

FastAPI 教程:从入门到实践
FastAPI 是一个现代、快速(高性能)的 Web 框架,用于构建 API,支持 Python 3.6。它基于标准 Python 类型提示,易于学习且功能强大。以下是一个完整的 FastAPI 入门教程,涵盖从环境搭建到创建并运行一个简单的…...

使用van-uploader 的UI组件,结合vue2如何实现图片上传组件的封装
以下是基于 vant-ui(适配 Vue2 版本 )实现截图中照片上传预览、删除功能,并封装成可复用组件的完整代码,包含样式和逻辑实现,可直接在 Vue2 项目中使用: 1. 封装的图片上传组件 ImageUploader.vue <te…...

LLM基础1_语言模型如何处理文本
基于GitHub项目:https://github.com/datawhalechina/llms-from-scratch-cn 工具介绍 tiktoken:OpenAI开发的专业"分词器" torch:Facebook开发的强力计算引擎,相当于超级计算器 理解词嵌入:给词语画"…...

如何在最短时间内提升打ctf(web)的水平?
刚刚刷完2遍 bugku 的 web 题,前来答题。 每个人对刷题理解是不同,有的人是看了writeup就等于刷了,有的人是收藏了writeup就等于刷了,有的人是跟着writeup做了一遍就等于刷了,还有的人是独立思考做了一遍就等于刷了。…...

【Oracle】分区表
个人主页:Guiat 归属专栏:Oracle 文章目录 1. 分区表基础概述1.1 分区表的概念与优势1.2 分区类型概览1.3 分区表的工作原理 2. 范围分区 (RANGE Partitioning)2.1 基础范围分区2.1.1 按日期范围分区2.1.2 按数值范围分区 2.2 间隔分区 (INTERVAL Partit…...

OPENCV形态学基础之二腐蚀
一.腐蚀的原理 (图1) 数学表达式:dst(x,y) erode(src(x,y)) min(x,y)src(xx,yy) 腐蚀也是图像形态学的基本功能之一,腐蚀跟膨胀属于反向操作,膨胀是把图像图像变大,而腐蚀就是把图像变小。腐蚀后的图像变小变暗淡。 腐蚀…...
集成 Mybatis-Plus 和 Mybatis-Plus-Join)
纯 Java 项目(非 SpringBoot)集成 Mybatis-Plus 和 Mybatis-Plus-Join
纯 Java 项目(非 SpringBoot)集成 Mybatis-Plus 和 Mybatis-Plus-Join 1、依赖1.1、依赖版本1.2、pom.xml 2、代码2.1、SqlSession 构造器2.2、MybatisPlus代码生成器2.3、获取 config.yml 配置2.3.1、config.yml2.3.2、项目配置类 2.4、ftl 模板2.4.1、…...

【Linux】自动化构建-Make/Makefile
前言 上文我们讲到了Linux中的编译器gcc/g 【Linux】编译器gcc/g及其库的详细介绍-CSDN博客 本来我们将一个对于编译来说很重要的工具:make/makfile 1.背景 在一个工程中源文件不计其数,其按类型、功能、模块分别放在若干个目录中,mak…...