大数据处理技术导论(6) | Datawhale组队学习46期
文章目录
- 1. hive 概述
- 2. hive 与传统关系型数据库的对比
- 3. hive 数据类型
- 4. hive 数据模型
- 5. hive 实战
- 5.1 创建表
- 5.2 修改表
- 5.3 清空表、删除表
- 5.4 其他命令
项目地址 https://github.com/datawhalechina/juicy-bigdata,感谢项目团队的付出。
本次主要学习 hive 相关内容。
1. hive 概述
hive 是建立在 hadoop 之上的数仓工具。它将 hadoop 上存储的结构化、半结构化数据文件映射为表,使得可以通过 HiveQL(HQL)对存储于 hadoop 上的大型数据文件进行访问与分析。
hive 本身并不存储数据,它只是提供了用户与 hadoop 系统文件之前的连接通道。其核心是将 HQL 翻译成 MapReduce 任务,然后提交至 hadoop 集群中进行执行,并给用户返回处理结果。
hive 大幅降低了普通业务人员或者说数据开发(不了解 java 编程)进行大数据分析的门槛。
hive 适合对海量数据进行离线分析,不适合对数据进行实时处理。前边学过的 HBase 适合数据的实时处理。
2. hive 与传统关系型数据库的对比
在使用方面,hive 和传统关系型数据库基本相同,由于其文件系统为 HDFS,hive 与传统关系型数据库还是由不少区别,详见下表对比情况。
| 对比内容 | Hive | 传统关系型数据库 |
|---|---|---|
| 数据存储 | HDFS | 本地文件系统 |
| 索引 | 基本不支持 | 支持复杂索引 |
| 分区 | 支持 | 支持 |
| 执行引擎 | MapReduce、Tez、Spark | 自身的执行引擎 |
| 执行延迟 | 高(T+1) | 低 |
| 扩展性 | 好 | 有限 |
| 数据规模 | 大 | 小 |
3. hive 数据类型
hive 支持以下几种数据类型:
| 大类 | 类型 |
|---|---|
| Integers(整型) | TINYINT:1字节的有符号整数; SMALLINT:2字节的有符号整数; INT:4字节的有符号整数; BIGINT:8字节的有符号整数 |
| Boolean(布尔型) | BOOLEAN:TRUE/FALSE |
| Floating point numbers(浮点型) | FLOAT:单精度浮点型; DOUBLE:双精度浮点型 |
| Fixed point numbers(定点数) | DECIMAL:用户自定义精度定点数,比如 DECIMAL(7,2) |
| String types(字符串) | STRING:指定字符集的字符序列; VARCHAR:具有最大长度限制的字符序列; CHAR:固定长度的字符序列 |
| Date and time types(日期时间类型) | TIMESTAMP:时间戳; TIMESTAMP WITH LOCAL TIME ZONE:本地时区时间戳,纳秒精度; DATE:日期类型 |
| Binary types(二进制类型) | BINARY:字节序列 |
4. hive 数据模型
自上而下,hive 分为库、表、分区、分桶 4种数据模型。
-
库
hive 数据库中,默认的 database 是 default,实际应用中一般不适用 default 数据库而是新建 database。 -
表
hive 本身并不存储数据,hive 表对应的数据都是存储在 HDFS 上,hive 表相关的元数据存储于 hive 内置的Derby(仅支持一个实例,极少使用)或者第三方的MySQL(运行多个实例同时访问)。
hive 表分为内部表和外部表。-
内部表的表创建过程和数据加载过程是分离的,加载数据过程中,数据会被移动至相应的数仓目录下(HDFS 上的 A 位置移动至 HDFS 上的 B 位置),对于 hive 内部表数据的访问都是对数仓目录进行操作。删除 hive 内部表也是真正的删除数据,要慎重哦~
-
外部表的表创建过程和数据加载过程是同一个过程,hive 外部表的创建只是在元数据里添加了映射记录,对于 hive 外部表的访问还是读取 HDFS 上的内容。删除 hive 外部表时,也只是删除了该表的元数据,而并未真正删除数据。
hive 内部表和外部表的差异总结如下:
-
| 对比内容 | 内部表 | 外部表 |
|---|---|---|
| 数据存储位置 | 内部表数据存储的位置由 hive-site.xml 中的hive.Metastore.warehouse.dir参数指定,默认情况下,表的数据存储在 HDFS的/user/hive/warehouse/数据库名.db/表名/目录下 | 外部表数据的存储位置创建表时由Location参数指定 |
| 导入数据 | 在导入数据到内部表,内部表将数据移动到自己的数据仓库目录下, 数据的生命周期由 Hive来进行管理 | 外部表不会将数据移动到自己的数据仓库目录下, 只是在元数据中存储了数据的位置 |
| 删除表 | 删除元数据(metadata)和 HDFS 数据文件 | 只删除元数据(metadata) |
| 安全性 | 低(容易误删数据) | 高 |
- 分区
hive 分区就是将数据存放于不同的目录,查询时命中分区,能避免全表扫描,提高查询效率。 - 分桶
可以在分区的基础上继续进行分桶,所谓分桶,就是将分区内数据以某个字段的hash值进行分组,将数据文件拆分为若干个小文件。优点是优化 join 查询和方便抽样查询,缺点是会生成很多小文件。
5. hive 实战
由于我的 hive 运行环境之前已经部署好了,这里不再赘述,详情可以参考 hive安装部署和管理
好久不用了,试了下,居然报错了
FAILED: HiveException java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient

报错的意思是说无法实例化 hive 元数据客户端,重新初始化之后也是不行。最终通过如下命令解决
cd /opt/module/hive/bin
./hive --service metastore &./hive
该命令的含义是在后台启动了 hive 元数据服务。
5.1 创建表
hive 创建表的语法如下,实际操作时按需选择操作符即可
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name -- 表名[(col_name data_type [COMMENT col_comment],... [constraint_specification])] -- 列名 列数据类型[COMMENT table_comment] -- 表描述[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] -- 分区表分区规则[CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS] -- 分桶表分桶规则[SKEWED BY (col_name, col_name, ...) ON ((col_value, col_value, ...), (col_value, col_value, ...), ...) [STORED AS DIRECTORIES] ] -- 指定倾斜列和值[[ROW FORMAT row_format] [STORED AS file_format]| STORED BY 'storage.handler.class.name' [WITH SERDEPROPERTIES (...)] ] -- 指定行分隔符、存储文件格式或采用自定义存储格式[LOCATION hdfs_path] -- 指定表的存储位置[TBLPROPERTIES (property_name=property_value, ...)] -- 指定表的属性[AS select_statement]; -- 从查询结果创建表
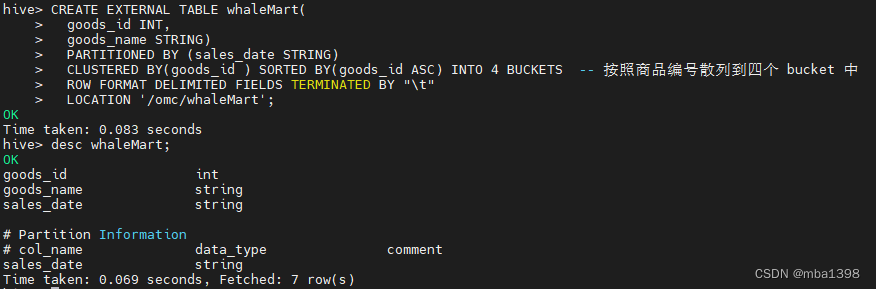
使用 create like 语句可以复制一张表的表结构
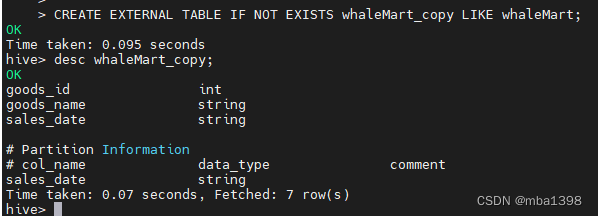
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name -- 创建表的表名LIKE existing_table_or_view_name -- 被复制表的表名[LOCATION hdfs_path]; -- 存储位置
加载 HDFS 路径数据文件到表的命令如下:
-- 加载数据到 emp 表中
load data local inpath "/home/omc/emp.txt" into table emp;
5.2 修改表
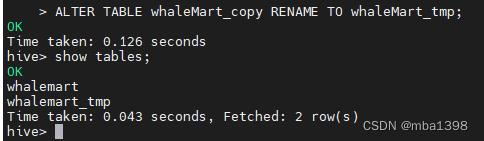
- 修改表名
ALTER TABLE table_name RENAME TO new_table_name;
ALTER TABLE whaleMart_copy RENAME TO whaleMart_tmp;
- 修改列
ALTER TABLE table_name [PARTITION partition_spec] CHANGE [COLUMN] col_old_name col_new_name column_type[COMMENT col_comment] [FIRST|AFTER column_name] [CASCADE|RESTRICT];
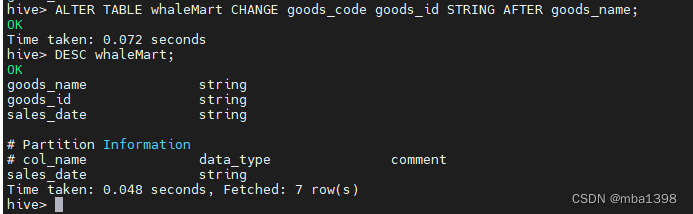
修改 whaleMart 表中的字段属性,命令如下
-- 修改字段名和类型
ALTER TABLE whaleMart CHANGE goods_id goods_code STRING;-- 修改字段 goods_code 的名称并将其放置到 goods_name 字段后
ALTER TABLE whaleMart CHANGE goods_code goods_id STRING AFTER goods_name;-- 为字段增加注释
ALTER TABLE whaleMart CHANGE goods_id goods_id STRING COMMENT '商品编号';
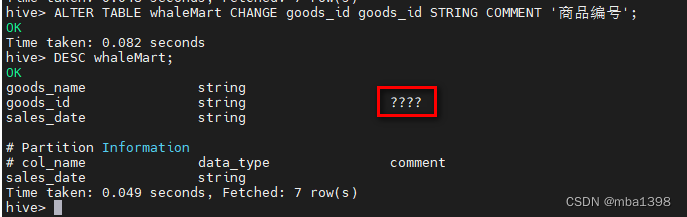
可以看到,添加的中文注释并未正常显示。这是因为 hive 元数据库创建,默认编码是 lanin1,需要登录当前 hive 运行环境的 mysql 数据库,执行如下命令:
//修改字段注释字符集alter table COLUMNS_V2 modify column COMMENT varchar(256) character set utf8;//修改表注释字符集alter table TABLE_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;//修改分区注释字符集alter table PARTITION_KEYS modify column PKEY_COMMENT varchar(4000) character set utf8;5.3 清空表、删除表
- 清空表
-- 清空整个表或表指定分区中的数据
TRUNCATE TABLE table_name [PARTITION (partition_column = partition_col_value, ...)];
需要注意的是:只有内部表才支持 TRUNCATE 命令,对外部表执行 TRUNCATE 操作时会报错。

- 删除表
DROP TABLE [IF EXISTS] table_name [PURGE];
5.4 其他命令
- describe 命令
DESCRIBE|Desc DATABASE [EXTENDED] db_name; -- EXTENDED 是否显示额外属性DESCRIBE|Desc [EXTENDED|FORMATTED] table_name; -- FORMATTED 以友好的展现方式查看表详情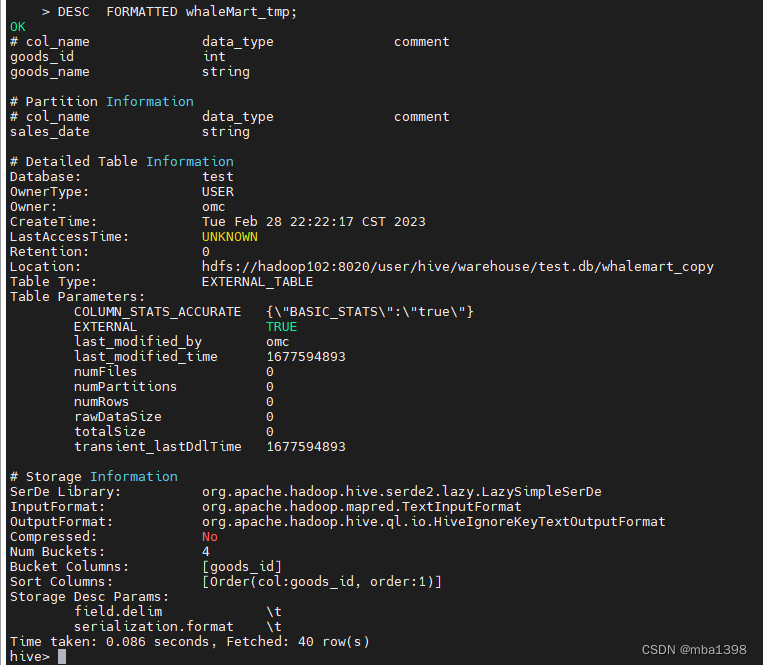
- show
不太常用的命令如下:
-- 查看视图列表
SHOW VIEWS-- 查看表的分区列表
SHOW PARTITIONS table_name;-- 查看表或者视图的创建语句
SHOW CREATE TABLE ([db_name.]table_name|view_name);相关文章:
大数据处理技术导论(6) | Datawhale组队学习46期
文章目录1. hive 概述2. hive 与传统关系型数据库的对比3. hive 数据类型4. hive 数据模型5. hive 实战5.1 创建表5.2 修改表5.3 清空表、删除表5.4 其他命令项目地址 https://github.com/datawhalechina/juicy-bigdata,感谢项目团队的付出。本次主要学习 hive 相关…...

Java——异常
目录 什么是异常 异常处理主要的5个关键字 异常的体系结构 异常语法 异常的分类 异常的处理流程 异常的处理 防御式编程 异常的抛出 throw的注意事项 异常的捕获 异常声明throws try-catch捕获处理 finally 自定义异常类 throw和throws区别 什么是异常 程序在运行时出现错…...
Netty之io.netty.util.concurrent.Promise与io.netty.util.concurrent.Future初解
目录 目标 Netty版本 Netty官方API 三者之间的关系 基本使用方法 java.util.concurrent.Future io.netty.util.concurrent.Future io.netty.util.concurrent.Promise 目标 了解io.netty.util.concurrent.Promise与io.netty.util.concurrent.Future的基本使用方法。了解…...
【正点原子FPGA连载】第二十一章AXI DMA环路测试 摘自【正点原子】DFZU2EG_4EV MPSoC之嵌入式Vitis开发指南
1)实验平台:正点原子MPSoC开发板 2)平台购买地址:https://detail.tmall.com/item.htm?id692450874670 3)全套实验源码手册视频下载地址: http://www.openedv.com/thread-340252-1-1.html 第二十一章AXI D…...

手把手搭建springboot项目06-springboot整合RabbitMQ及其原理和应用场景
目录前言工作流程-灵魂画手名词解释交换机类型一、安装1.1 [RabbitMQ官网安装](https://www.rabbitmq.com/download.html)1.2 Docker安装并启动二、食用教程2.1.导入依赖2.2 添加配置2.3 代码实现2.3.1 直连(Direct)类型2.3.2 引入消息手动确认机制2.3.2…...

如何根据IP地址判断是IPv4还是IPv6
IPv4地址的书写形式为:“192.168.0.1” IPv6地址的书写形式为:“2001:DB8:85A3:8D3:1319:8A2E:370:7344” 给你一个IP地址,它有三种可能:IPv4、IPv6、既不是IPv4也不是IPv6的无效地址。所以,如果用函数ipGetAddressAsNumber,只能判断是不是ipv4,编写如下函数: int R…...

山地车和公路车怎么选
公路车: 只能适应平坦的路面,骑行阻力小,速度快比较适合新手 山地车: 能适应所有路面,更注重操控性和舒适性 怎么选? 1、先决定用途 旅游:旅行车、山地车、 通勤:公路车 2、预…...

Zotero设置毕业论文/中文期刊参考文献格式
大家在使用zotero时很容易遇到的问题: 英文参考文献中有多个作者时出现“等”,而不是用"et al"引文最后面有不需要的DOI号,或者论文链接对于一些期刊分类上会出现OL字样,即[J/OL]作者名为全大写 本文主要解决以上几个…...

【人工智能与深度学习】自动编码器的简介
【人工智能与深度学习】自动编码器的简介 自动编码器的应用图片生成像素空间和潜在空间插值的差异图像超级分辨率图像修补由文字说明转成图片什么是自动编码器?为什么我们用自动编码器?重建损失完成过度降噪自动编码器:Denoising autoencoder压缩式自动编码器定义自动编码器…...
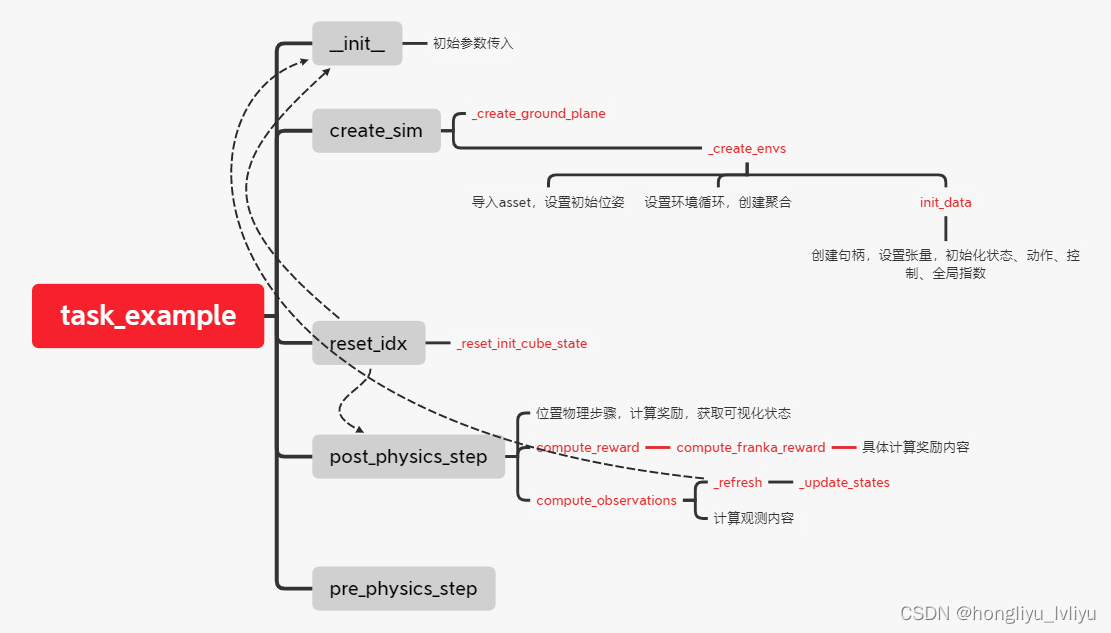
Isaac-gym(9):项目更新、benchmarks框架梳理
一、项目更新 近期重新git clone isaac gym的强化部分(具体见系列第5篇)时发现官方的github库有跟新,git clone下来后发现多了若干个task,在环境配置上也有一定区别。 例如新旧两版工程项目的setup.py区别如下: git …...

Linux 学习笔记(一):终端 和 Shell 的区别和联系
一、Linux 介绍 1、什么是 Linux Linux 就是一个操作系统,全称 GNU/Linux,是一种类 Unix 操作系统Linux 一开始是没有图形界面的,所有操作都靠 命令 完成。如 磁盘操作、文件存取、目录操作、进程管理、文件权限 等等,可以说 Li…...

cycleGAN算法解读
本文参考:https://blog.csdn.net/Mr_health/article/details/112545671 1 CycleGAN概述 CycleGAN:循环生成对抗神经网络,是一种非监督学习模型。 Pix2pix方法适用于成对数据的风格迁移,而大多数情况下对于A风格的图像…...

解读“方差”
其实,从这个标题就可以看出来,方差,这个问题不简单, 先给出定义: 方差其实应该叫,差方差,(差方)差,差的平方的差,与差的平方之间的误差࿰…...
记录面试问题
以下问题不分先后,按照印象深浅排序,可能一次记录不完成,后面想起来会及时补充,如有不对,恳请各位围观大佬多多指教🙏 印象最深的是一道很简单很简单的题目,我结束面试之后赶紧代码敲敲发现答错…...
设计索引的时候,我们一般要考虑哪些因素呢?(上))
(六十四)设计索引的时候,我们一般要考虑哪些因素呢?(上)
本周我们将要讲解一下设计索引的时候,我们通常应该考虑哪些因素,给哪些字段建立索引,如何建立索引,建立好索引之后应该如何使用才是最合适的。 可能有的朋友会希望尽快更新后面的内容,但是因为工作的原因的确非常忙&a…...
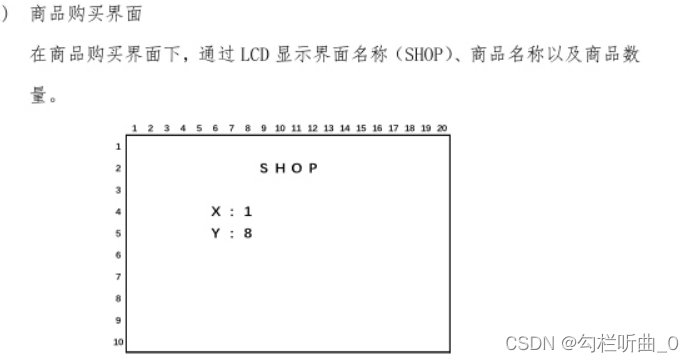
【蓝桥杯嵌入式】LCD屏的原理图解析与代码实现(第十三届省赛为例)——STM32
🎊【蓝桥杯嵌入式】专题正在持续更新中,原理图解析✨,各模块分析✨以及历年真题讲解✨都在这儿哦,欢迎大家前往订阅本专题,获取更多详细信息哦🎏🎏🎏 🪔本系列专栏 - 蓝…...

论文学习——Reproducing Activation Function for Deep Learning
论文学习——Reproducing Activation Function Abstract RAFs将集中基础激活函数进行线性组合,构建出神经元级的、数据驱动的激活函数。使用RAFs为激活函数的神经网络可以重现传统的近似工具,也能相对于传统网络以更少的参数量拟合目标函数。训练过程中,RAFs可以以更好的条…...

【趣味学Python】Python基础语法讲解
目录 编码 标识符 python保留字 注释 实例(Python 3.0) 实例(Python 3.0) 行与缩进 实例(Python 3.0) 实例 多行语句 数字(Number)类型 字符串(String) 实例(Python 3.0) 空行 等待用户输入 实例(Python 3.0) 同一行显示多条语句 实例(Python 3.0) 多个语句构…...
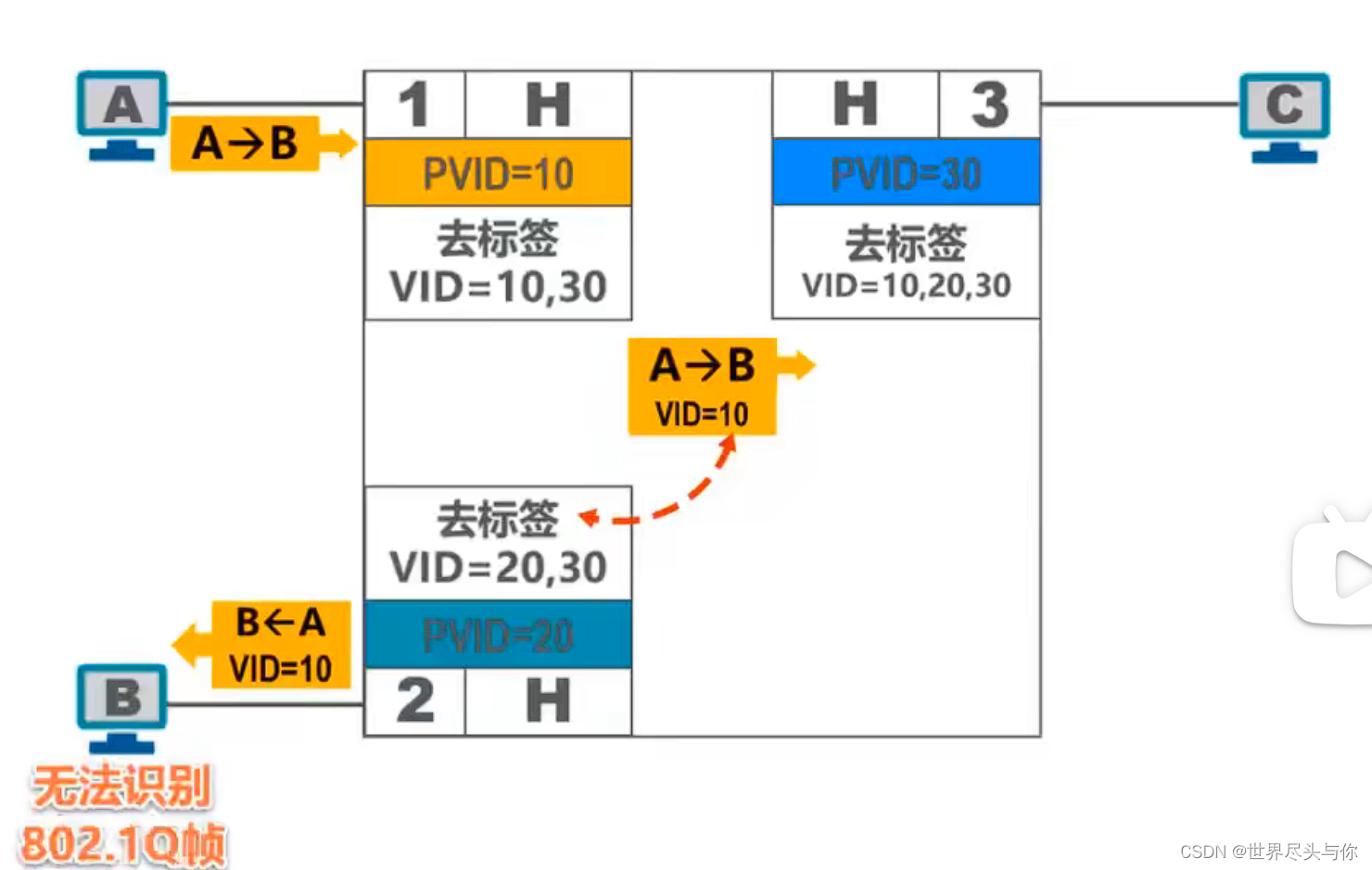
虚拟局域网VLAN的实现机制
虚拟局域网VLAN的实现机制1.IEEE 802.1Q帧2.交换的端口类型AccessTrunkHybrid(华为特有)1.IEEE 802.1Q帧 IEEE802.1Q帧(也称Dot One Q帧)对以太网的MAC帧格式进行了扩展,插入了4字节的VLAN标记。 2.交换的端口类型 A…...
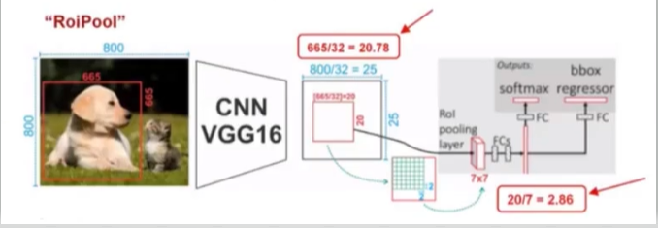
Mask R-CNN 算法学习总结
Mask R-CNN 相关知识点整体框架1.Resnet 深度残差学习1.1 目的1.2 深度学习深度增加带来的问题1.3 Resnet实现思想【添加恒等映射】2.线性插值2.1 目的2.2 线性插值原理2.3 为什么使用线性插值?3.FPN 特征金字塔3.1 FPN介绍3.2 为什么使用FPN?3.3 自下而上层【提取特征】3.4 …...

《从零掌握MIPI CSI-2: 协议精解与FPGA摄像头开发实战》-- CSI-2 协议详细解析 (一)
CSI-2 协议详细解析 (一) 1. CSI-2层定义(CSI-2 Layer Definitions) 分层结构 :CSI-2协议分为6层: 物理层(PHY Layer) : 定义电气特性、时钟机制和传输介质(导线&#…...

React Native在HarmonyOS 5.0阅读类应用开发中的实践
一、技术选型背景 随着HarmonyOS 5.0对Web兼容层的增强,React Native作为跨平台框架可通过重新编译ArkTS组件实现85%以上的代码复用率。阅读类应用具有UI复杂度低、数据流清晰的特点。 二、核心实现方案 1. 环境配置 (1)使用React Native…...
)
【RockeMQ】第2节|RocketMQ快速实战以及核⼼概念详解(二)
升级Dledger高可用集群 一、主从架构的不足与Dledger的定位 主从架构缺陷 数据备份依赖Slave节点,但无自动故障转移能力,Master宕机后需人工切换,期间消息可能无法读取。Slave仅存储数据,无法主动升级为Master响应请求ÿ…...

用机器学习破解新能源领域的“弃风”难题
音乐发烧友深有体会,玩音乐的本质就是玩电网。火电声音偏暖,水电偏冷,风电偏空旷。至于太阳能发的电,则略显朦胧和单薄。 不知你是否有感觉,近两年家里的音响声音越来越冷,听起来越来越单薄? —…...

SiFli 52把Imagie图片,Font字体资源放在指定位置,编译成指定img.bin和font.bin的问题
分区配置 (ptab.json) img 属性介绍: img 属性指定分区存放的 image 名称,指定的 image 名称必须是当前工程生成的 binary 。 如果 binary 有多个文件,则以 proj_name:binary_name 格式指定文件名, proj_name 为工程 名&…...

AI病理诊断七剑下天山,医疗未来触手可及
一、病理诊断困局:刀尖上的医学艺术 1.1 金标准背后的隐痛 病理诊断被誉为"诊断的诊断",医生需通过显微镜观察组织切片,在细胞迷宫中捕捉癌变信号。某省病理质控报告显示,基层医院误诊率达12%-15%,专家会诊…...

三分算法与DeepSeek辅助证明是单峰函数
前置 单峰函数有唯一的最大值,最大值左侧的数值严格单调递增,最大值右侧的数值严格单调递减。 单谷函数有唯一的最小值,最小值左侧的数值严格单调递减,最小值右侧的数值严格单调递增。 三分的本质 三分和二分一样都是通过不断缩…...

MyBatis中关于缓存的理解
MyBatis缓存 MyBatis系统当中默认定义两级缓存:一级缓存、二级缓存 默认情况下,只有一级缓存开启(sqlSession级别的缓存)二级缓存需要手动开启配置,需要局域namespace级别的缓存 一级缓存(本地缓存&#…...
Python训练营-Day26-函数专题1:函数定义与参数
题目1:计算圆的面积 任务: 编写一个名为 calculate_circle_area 的函数,该函数接收圆的半径 radius 作为参数,并返回圆的面积。圆的面积 π * radius (可以使用 math.pi 作为 π 的值)要求:函数接收一个位置参数 radi…...
0609)
书籍“之“字形打印矩阵(8)0609
题目 给定一个矩阵matrix,按照"之"字形的方式打印这个矩阵,例如: 1 2 3 4 5 6 7 8 9 10 11 12 ”之“字形打印的结果为:1,…...