【计算机组成原理】存储器知识
目录
1、存储器分类
1.1、按存储介质分类
1.2、按存取方式分类
1.3、按信息的可改写性分类
1.4、按信息的可保存性分类
1.5、按功能和存取速度分类
2、存储器技术指标
2.1、存储容量
2.2、存取速度
3、存储系统层次结构
4、主存的基本结构
5、主存中数据的存放
5.1、 存储字长与数据字长的概念
5.2、地址访问模式
5.3、大端和小端方式
5.4、数据的边界对齐

1、存储器分类
由于信息载体和电子元器件的不断发展,存储器的功能和结构都发生了很大变化,先后出现了多种类型的存储器,具体可以从以下不同的角度进行分类。
1.1、按存储介质分类
- 磁存储器:磁存储器都以磁性材料作为存储介质,利用磁化单元剩磁的不同磁化方向来存储数据0 和1。它主要包括磁芯、磁盘、磁带存储器等,目前广泛使用的磁盘、磁带中都包含机械装置,所以其体积大、存取速度慢,但磁存储器单位容量成本最低。
- 半导体存储器:用半导体器件组成的存储器称为半导体存储器。目前有两大类:一种是双极型存储器,主要包括TTL 型和ECL 型两种;另一种是金属氧化物半导体存储器,简称MOS 存储器,又可分为静态MOS 存储器(SRAM)和动态MOS 存储器(DRAM)。半导体存储器体积小,存储速度快,但单位容量成本相对较高。
- 光存储器:光存储器利用介质的光学特性读出数据,如CD-ROM、DVD-ROM 均以刻痕的形式将数据存储在盘面上,用激光束照射盘面,靠盘面的不同反射率来读出信息。而磁光盘则利用激光加热辅助磁化的方式写入数据,根据反射光的偏振方向的不同来读出信息。光盘存储器便于携带,成本低廉,适用于电子出版物的发行。
1.2、按存取方式分类
- 随机存储器:随机存储器(Random Access Memory,RAM)可以按照地址随机读写数据存储单元,且存取访问时间与存储单元的位置无关。早期的磁芯存储器和当前大量使用的半导体存储器都是随机存储器。
- 顺序存储器:顺序存储器(Sequential Access Memory,SAM)是指存储单元中的内容只能依地址顺序访问,且访问的速度与存储单元的位置有关的存储器,典型的如磁带存储器。
- 直接存储器:直接存储器(Direct Access Memory,DAM)是指不必经过顺序搜索就能在存储器中直接存取信息的存储器,这类存储器兼有随机存储器和顺序存储器的访问特性,典型的如磁盘存储器。磁盘由于存在机械寻道和旋转延迟,因此数据访问时间和磁头与目标扇区的距离有关系。
1.3、按信息的可改写性分类
既能读出又能写入信息的存储器称为读写存储器。而有些存储器中的内容不允许被改变,只能读出其中的内容,这种存储器称为只读存储器(Read Only Memory,ROM),常见的有半导体只读存储器,也有光盘存储器,如CD-ROM、DVD-ROM 等。
1.4、按信息的可保存性分类
按照信息保存的时间和条件的不同,存储器分为易失性存储器和非易失性存储器。易失性存储器是指断电后,所保存的信息会丢失的存储器,常见的如半导体RAM。非易失性存储器是指断电后,所保存的信息不丢失的存储器,常见的有半导体ROM、闪存、磁盘、光盘存储器等。
1.5、按功能和存取速度分类
- 寄存器存储器:它是由多个寄存器组成的存储器,如CPU 内部的通用寄存器组,一般由几个或几十个寄存器组成,其字长一般与计算机字长相同,主要用来存放地址、数据及运算的中间结果,速度与CPU 匹配,容量很小。
- 高速缓冲存储器:它又称高速缓存cache,是隐藏在寄存器和主存之间的一个高速小容量存储器,用于存放CPU 即将或经常要使用的指令和数据。它一般采用静态RAM 构成,用于缓冲CPU 与慢速主存之间的性能差异,提高存储系统的访问速度。
- 主存储器:主存储器简称主存,是CPU 中除寄存器外唯一能直接访问的存储器,用于存放指令和数据。CPU 通过主存地址直接、随机地读写主存储器。主存一般由半导体存储器构成,但注意主存并不是单一的内存,还包括BIOS、硬件端口等。
- 外存储器:计算机主机外部的存储器称为外存储器,简称外存或辅助存储器。外存容量很大,但存取速度相对较低。目前广泛使用的外存储器包括磁盘、磁带、光盘存储器、磁盘阵列和网络存储系统等。外存用来存放当前暂不参与运行的程序和数据,以及一些需要永久性保存的数据信息。
2、存储器技术指标
存储器的特性由它的技术指标来描述,常见技术指标包括存储容量、存取速度(包括存取时间、存储周期、存储带宽)等。
2.1、存储容量
存储器可以存储的二进制信息总量称为存储容量。存储容量可以采用比特位或者字节来表示。
- 位表示法:以存储器中的存储单元总数与存储字位数的乘积表示,如1K×4 位表示该芯片有1K 个单元(1K = 1024),每个存储单元的长度为4 个二进制位。
- 字节表示法:以存储器中的单元总数表示(一个存储单元由8 个二进制位组成,称为一个字节,用B 表示),如128B 表示该芯片有128 个单元。
2.2、存取速度
- 存取时间:又称为存储器的访问时间,是指启动一次存储器操作(读或写分别对应取与存)到该操作完成所经历的时间,注意读写时间可能不同,DRAM 读慢写快、闪存读快写慢。
- 存取周期:连续启动两次访问操作之间的最短时间间隔;对主存而言,存储周期除包括存取时间外,还包括存储器状态的稳定恢复时间,所以存储周期略大于存取时间。
- 存储器带宽:单位时间内存储器所能传输的信息量,常用的单位包括位/ 秒或字节/秒;带宽是衡量数据传输速率的重要指标,与存取时间的长短和一次传输的数据位的多少有关;一般而言存取时间越短、数据位宽越大,存储带宽越高。
3、存储系统层次结构
当某一种存储器在存储速度、存储容量、价格成本上均被另一种存储器超越时,也就是该存储器被淘汰之时,如传统的软磁盘就被U 盘所替代。人们一直在追求存储速度快、存储容量大、成本低廉的理想存储器,但在现有技术条件下这些性能指标往往是相互矛盾的,还无法使单一存储器同时拥有这些特性,这也是目前同时存在多种不同类型存储器的原因。存储系统层次结构利用程序局部性的原理,从系统级角度将速度、容量、成本各异的存储器有机组合在一起,全方位优化存储系统的各项性能指标。
典型的存储系统层次结构如图4.1 所示。这是一个典型的金字塔结构,从上到下分别是寄存器、高速缓存、主存、磁盘、磁带等。越往上离CPU 越近,访问速度越快,单位容量成本越高;从上到下存储容量越来越大,图中分别给出了不同层级存储设备的大概访问时间延迟和容量量级单位。

由于程序访问存在局部性,因此上层存储器可以为下层存储器做缓冲,将最经常使用数据的副本调度到上层,这样CPU 只需要访问上层快速的小容量存储器即可获得大部分数据。这种方式有效提高了系统访问速度,大大缓解了CPU 与主存、主存与辅存的性能差异,另外使用大容量辅存也大大缓解了主存容量不足的问题。基于这种层次结构,就构成了一个满足应用需求的存储速度快、存储容量大、成本价格低的理想存储系统。
4、主存的基本结构
主存是机器指令直接操作的存储器,采用主存地址进行随机访问,整个主存从空间逻辑上可以看作一个一维数组mem[],每个数组元素存储一个m 位的数据单元,主存地址addr 就是数组的下标索引,数组元素的值mem[addr] 就是主存地址对应的存储内容,在C 语言中学习过的指针本质上就是主存地址。
主存的硬件内部结构如图4.2 所示。它由存储体加上一些外围电路构成。外围电路包括地址译码器、数据寄存器和读写控制电路。
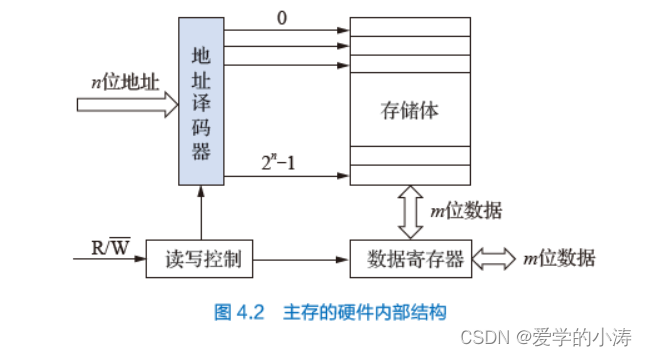
地址译码器接收来自CPU 的n 位地址信号,经译码、驱动后形成2n 根地址译码信号,每一根地址译码信号连接一个存储单元。每给出一个地址,2n 个地址译码信号中只有与地址值对应的那个信号才有效,与之连接的存储单元被选中,输出m 位数据。
数据寄存器暂存CPU 送来的m 位数据,或暂存从存储体中读出的m 位数据。
读写控制电路接收CPU 的读写控制信号后产生存储器内部的控制信号,将指定地址的信息从存储体中读出并送到数据寄存器中供CPU 使用,或将来自CPU 并已存入数据寄存器的信息写入存储体中的指定单元。
CPU 执行某条机器指令时,若需要访问主存,则应首先生成该数据在主存中的地址。该地址经地址译码器后选中存储体中与该地址对应的存储单元,然后由读写控制电路控制读出或写入。读出时,将选中的存储单元所存的数据送入数据寄存器,存储单元中的内容不变。CPU 从数据寄存器中取走该数据,进行指令所要求的处理。写入时,将CPU 送来并已存放于数据寄存器中的数据写入选中的存储单元,存储单元中的原数据被改写。
5、主存中数据的存放
5.1、 存储字长与数据字长的概念
- 存储字长:主存的一个存储单元所存储的二进制位数。
- 数据字长(简称字长):计算机一次能处理的二进制数的位数。存储字长与数据字长不一定相同,如字长为32 位的计算机所采用的存储字长可以是16 位、32 位或64 位。
5.2、地址访问模式
存储字长都是字节的整倍数,主存通常按字节进行编址。以32 位计算机为例,主存既可以按字节访问,也可以按16 位半字访问,还可以按照32 位的字进行访问。按照访问存储单元的大小,主存地址可以分为字节地址、半字地址、字地址。图4.3 所示为不同主存地址访问模式的示意图,图中的主存空间可以按照不同地址进行访问,不同地址访问存储单元的大小不一样。
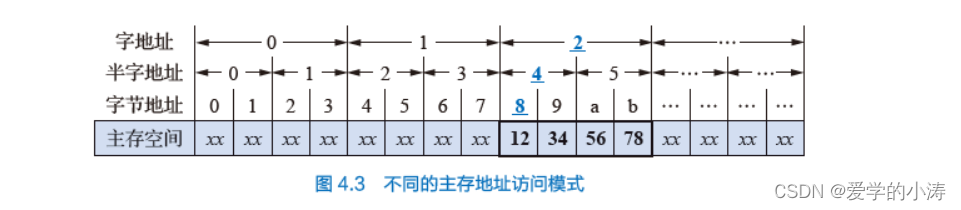
字节地址逻辑右移一位即可得到半字地址,右移两位可得到字地址。图中8 号字节地址对应的半字地址为4,字地址为2,注意这3 个地址在逻辑空间的起始位置都是8 号字节单元,区别只是存储单元的大小不同。以下程序为Intel x86 汇编程序访问不同存储单元的例子,假设数据段寄存器DS 值为0。
5.3、大端和小端方式
- 采用多字节方式访问主存时,主存中的字节顺序非常重要,不同的顺序访问得到的数据完全不一样。当存储器的低字节地址单元中存放的是数据的最低字节时,称这种数据存放方式为小端(Little-Endian)方式;反之,当存储器的低字节地址单元中存放的是数据的最高字节时,称这种数据存放方式为大端(Big-Endian)方式。
- 图4.3 中访问2 号字存储单元时,如果按小端方式访问得到的数据是0x78563412,而如果按照大端方式访问得到的数据则是0x12345678,采用大、小端方式对数据进行存放的主要区别在于字节的存放顺序。采用大端方式进行数据存放符合人类的正常思维,而采用小端方式进行数据存放有利于计算机处理。
- 主流处理器一般都采用小端方式进行数据存放,如Intel x86、IA64 处理器、RISC-V 处理器。有的处理器系统采用了大端方式进行数据存放,如PowerPC 处理器;还有的处理器同时支持大端和小端方式,如ARM、MIPS 处理器。除处理器外,外部设备设计、TCIP/IP 数据传输、音频和视频文件中都存在数据存放方式的选择问题。当计算机中的数据存放方式与其不一致时,就需要进行数据字节顺序的转换。
- 大端与小端方式的差别不仅体现在处理器的寄存器、存储器中,在指令集、系统总线等各个层次中也可能存在大端与小端方式的差别。读者必须深入理解大端和小端方式的上述差别。
5.4、数据的边界对齐
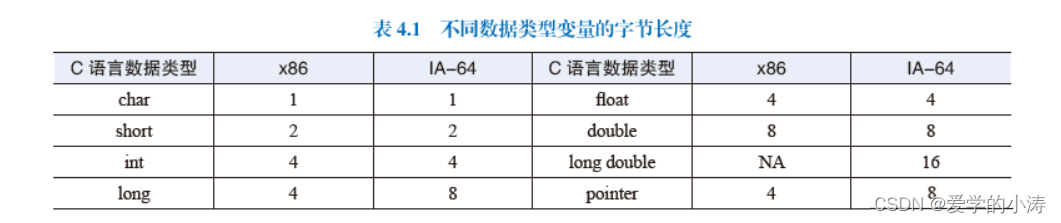
现代计算机中主存空间按照字节编址,而高级语言中不同数据类型的变量对应不同的字节长度,C 语言中不同数据类型变量的字节长度如表4.1 所示。
从表可知,不同数据类型的变量都会包含一个或多个字节单元,这些变量在进行主存地址空间分配时,从理论上讲可以从任何字节地址开始,但当一个多字节变量分布在不同的字存储单元中时,访问该变量就需要多个存储周期。为了提高数据访问效率,通常要考虑数据变量、数据结构在主存空间中的边界对齐问题。
所谓边界对齐就是按照数据类型的大小进行边界对齐,具体规则如下。
- 双字数据起始字节地址的最末3 位为000,地址是8 的整数倍。
- 单字数据起始字节地址的最低两位为00,地址是4 的整数倍。
- 半字数据起始字节地址的最低一位为0,地址是2 的整数倍。
- 单字节数据不存在边界对齐问题(主存按字节编址)。
图4.4 所示为32 位主存中变量未对齐的空间分配模式,这种方式对存储空间的利用率最高,但双精度浮点数x 的8 个字节分布在3 个存储字中,访问该变量需要3 个存储周期;另外最后一个short 变量k 的数据也跨越了两个存储字,会带来访问性能的问题。

图4.5 所示的模式则遵循了边界对齐的规则,变量x、k 都只占用了最少的机器字,访问x只需两个存储周期,访问k 只需要一个存储周期,有效提升了存储速度。但注意这种方式会造成空间的浪费,需要折中考虑。目前主流编译器不仅会对数据变量进行边界对齐,还会对复杂的数据结构进行边界对齐。
推荐:
【计算机网络】(网络层)定长掩码和变长掩码-CSDN博客![]() https://blog.csdn.net/m0_65277261/article/details/134606175?spm=1001.2014.3001.5502【计算机网络】VLAN原理和配置-CSDN博客
https://blog.csdn.net/m0_65277261/article/details/134606175?spm=1001.2014.3001.5502【计算机网络】VLAN原理和配置-CSDN博客![]() https://blog.csdn.net/m0_65277261/article/details/134407790?spm=1001.2014.3001.5502【计算机网络】VRRP协议理论和配置-CSDN博客
https://blog.csdn.net/m0_65277261/article/details/134407790?spm=1001.2014.3001.5502【计算机网络】VRRP协议理论和配置-CSDN博客![]() https://blog.csdn.net/m0_65277261/article/details/134387329?spm=1001.2014.3001.5502
https://blog.csdn.net/m0_65277261/article/details/134387329?spm=1001.2014.3001.5502

相关文章:
【计算机组成原理】存储器知识
目录 1、存储器分类 1.1、按存储介质分类 1.2、按存取方式分类 1.3、按信息的可改写性分类 1.4、按信息的可保存性分类 1.5、按功能和存取速度分类 2、存储器技术指标 2.1、存储容量 2.2、存取速度 3、存储系统层次结构 4、主存的基本结构 5、主存中数据的存放 5.…...

vscode配置代码片段
1.ctrl shift p 然后选择 Snippets:Configure User Snippets (配置用户代码片段) 2.选择vue或者vue.json 3.下面为json内容 { “vue-template”: { “prefix”: “modal-table”, “body”: [ “”, " <a-modal v-model:visible“visible” wi…...
vite脚手架,手写实现配置动态生成路由
参考文档 vite的glob-import vue路由配置基本都是重复的代码,每次都写一遍挺难受,加个页面就带配置下路由 那就利用 vite 的 文件系统处理啊 先看实现效果 1. 考虑怎么约定路由,即一个文件夹下,又有组件,又有页面&am…...

解决浏览器缓存问题
1.index.html文件meta标签添加属性 <meta name"viewport" content"widthdevice-width,initial-scale1.0, maximum-scale1.0, minimum-scale1.0, user-scalableno" viewport-fitcover >2.提前main.html处理逻辑再跳转到index.html页 <script>…...
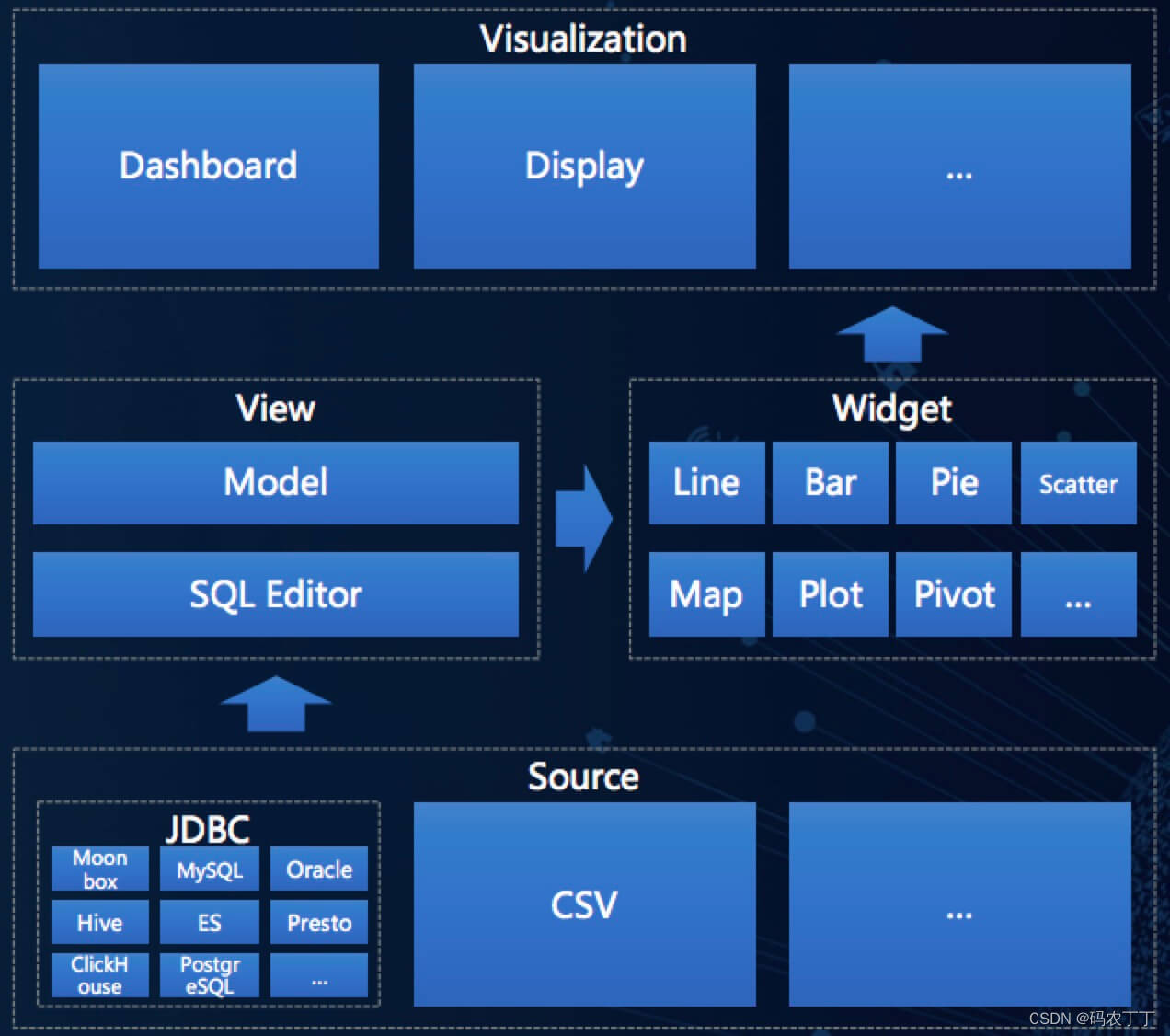
【数据中台】开源项目(2)-Davinci可视应用平台
1 平台介绍 Davinci 是一个 DVaaS(Data Visualization as a Service)平台解决方案,面向业务人员/数据工程师/数据分析师/数据科学家,致力于提供一站式数据可视化解决方案。既可作为公有云/私有云独立部署使用,也可作为…...
Java实现简单飞翔小鸟游戏
一、创建新项目 首先创建一个新的项目,并命名为飞翔的鸟。 其次在飞翔的鸟项目下创建一个名为images的文件夹用来存放游戏相关图片。 用到的图片如下:0~7: bg: column: gameover: ground: st…...

numpy实现神经网络
numpy实现神经网络 首先讲述的是神经网络的参数初始化与训练步骤 随机初始化 任何优化算法都需要一些初始的参数。到目前为止我们都是初始所有参数为0,这样的初始方法对于逻辑回归来说是可行的,但是对于神经网络来说是不可行的。如果我们令所有的初始…...

Bean的加载控制
Bean的加载控制 文章目录 Bean的加载控制编程式注解式ConditionalOn*** 编程式 public class MyImportSelector implements ImportSelector {Overridepublic String[] selectImports(AnnotationMetadata annotationMetadata) {try {Class<?> clazz Class.forName("…...

使用 OpenCV 识别和裁剪黑白图像上的白色矩形--含源码
为了仅获取具有特定边框颜色的矩形,我寻求一种替代识别图像中的轮廓和所有矩形的传统方法。如示例图片所示,我有兴趣使用 opencv 仅获取白色边框矩形的坐标。任何这方面的建议将不胜感激。到目前为止,我的代码已产生如下所示的输出。我的下一个目标是将图像裁剪到大的中心框…...

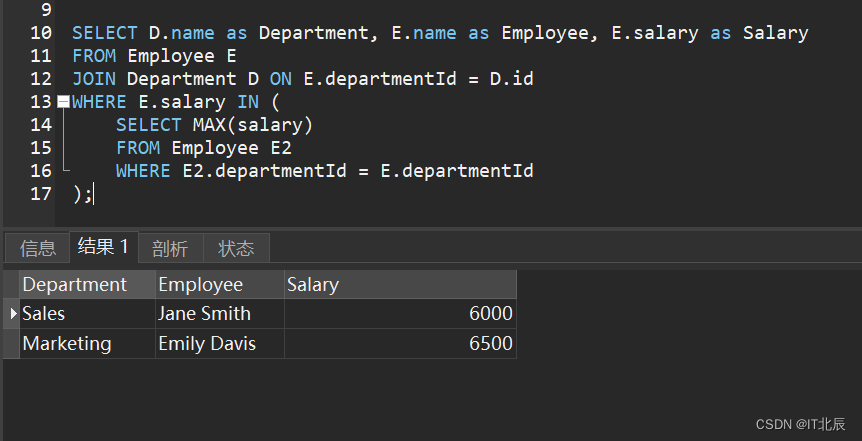
LeetCode 每日一题 Day1
1094. 拼车 车上最初有 capacity 个空座位。车 只能 向一个方向行驶(也就是说,不允许掉头或改变方向) 给定整数 capacity 和一个数组 trips , trip[i] [numPassengersi, fromi, toi] 表示第 i 次旅行有 numPassengersi 乘客,接…...

【hacker送书活动第7期】Python网络爬虫入门到实战
第7期图书推荐 内容简介作者简介大咖推荐图书目录概述参与方式 内容简介 本书介绍了Python3网络爬虫的常见技术。首先介绍了网页的基础知识,然后介绍了urllib、Requests请求库以及XPath、Beautiful Soup等解析库,接着介绍了selenium对动态网站的爬取和S…...

【算法】希尔排序
目录 1. 说明2. 举个例子3. java代码示例4. java示例截图 1. 说明 1.希尔排序是直接插入排序的一种改进,其本质是一种分组插入排序 2.希尔排序采取了分组排序的方式 3.把待排序的数据元素序列按一定间隔进行分组,然后对每个分组进行直接插入排序 4.随着间…...

四、Zookeeper节点类型
目录 1、临时节点 2、永久节点 Znode有两种,分别为临时节点和永久节点。 节点的类型在创建时即被确定,并且不能改变。 1、临时节点 临时节点的生命周期依赖于创建它们的会话。一旦会话结束,临时节点将被自动删除,...
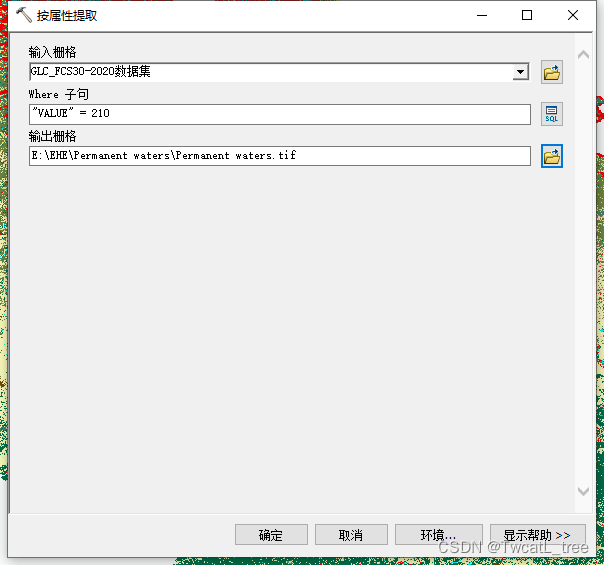
arcgis导出某个属性的栅格
选中栅格特定属性想要导出时,无法选中“所选图形” 【方法】spatial analyst 工具——提取分析——按属性提取...

计算机网络——传输层
传输层的基本单位是报文; 一、传输层的基本概念 传输层提供端到端的服务; 从通信和信息处理的角度看,传输层向上层应用层提供通信服务; (一)端口号 协议作用端口号FTP文件传输协议21连接;2…...

策略设计模式
package com.jmj.pattern.strategy;public interface Strategy {void show(); }package com.jmj.pattern.strategy;public class StrategyA implements Strategy{Overridepublic void show() {System.out.println("买一送一");} }package com.jmj.pattern.strategy;p…...

Golang中rune和Byte,字符和字符串有什么不一样
Rune和Byte,字符和字符串有什么不一样 String Go语言中, string 就是只读的采用 utf8 编码的字节切片(slice) 因此用 len 函数获取到的长度并不是字符个数,而是字节个数。 for循环遍历输出的也是各个字节。 Rune rune 是 int32 …...
实施工程师运维工程师面试题
Linux 1.请使用命令行拉取SFTP服务器/data/20221108/123.csv 文件,到本机一/data/20221108目录中。 使用命令行拉取SFTP服务器文件到本机指定目录,可以使用sftp命令。假设SFTP服务器的IP地址为192.168.1.100,用户名为username,密…...
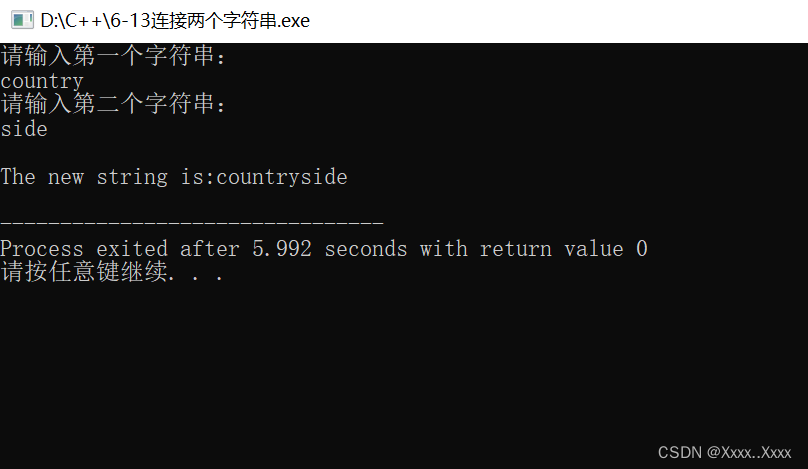
6-13连接两个字符串
#include<stdio.h> int main(){int i0,j0;char s1[222],s2[333];printf("请输入第一个字符串:\n");gets(s1);//scanf("%s",s1);printf("请输入第二个字符串:\n");gets(s2);while(s1[i]!\0)i;while(s2[j]!\0)s1[i]s2…...
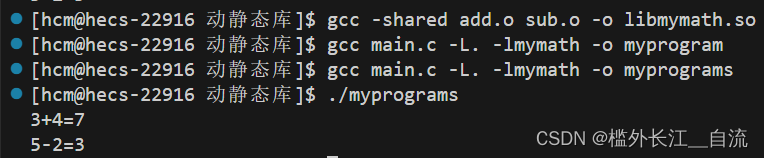
Linux中的文件IO
文章目录 C语言文件操作系统文件I/O接口介绍 open函数返回值文件描述符fd0 & 1 & 2文件描述符的分配规则 重定向使用 dup2 系统调用 FILE理解文件系统理解硬链接软链接acm 动态库和静态库静态库与动态库生成静态库生成动态库: C语言文件操作 先来段代码回顾…...

vue3+vite项目中使用.env文件环境变量方法
vue3vite项目中使用.env文件环境变量方法 .env文件作用命名规则常用的配置项示例使用方法注意事项在vite.config.js文件中读取环境变量方法 .env文件作用 .env 文件用于定义环境变量,这些变量可以在项目中通过 import.meta.env 进行访问。Vite 会自动加载这些环境变…...

企业如何增强终端安全?
在数字化转型加速的今天,企业的业务运行越来越依赖于终端设备。从员工的笔记本电脑、智能手机,到工厂里的物联网设备、智能传感器,这些终端构成了企业与外部世界连接的 “神经末梢”。然而,随着远程办公的常态化和设备接入的爆炸式…...

MySQL:分区的基本使用
目录 一、什么是分区二、有什么作用三、分类四、创建分区五、删除分区 一、什么是分区 MySQL 分区(Partitioning)是一种将单张表的数据逻辑上拆分成多个物理部分的技术。这些物理部分(分区)可以独立存储、管理和优化,…...

【Linux】自动化构建-Make/Makefile
前言 上文我们讲到了Linux中的编译器gcc/g 【Linux】编译器gcc/g及其库的详细介绍-CSDN博客 本来我们将一个对于编译来说很重要的工具:make/makfile 1.背景 在一个工程中源文件不计其数,其按类型、功能、模块分别放在若干个目录中,mak…...

嵌入式常见 CPU 架构
架构类型架构厂商芯片厂商典型芯片特点与应用场景PICRISC (8/16 位)MicrochipMicrochipPIC16F877A、PIC18F4550简化指令集,单周期执行;低功耗、CIP 独立外设;用于家电、小电机控制、安防面板等嵌入式场景8051CISC (8 位)Intel(原始…...
零知开源——STM32F103RBT6驱动 ICM20948 九轴传感器及 vofa + 上位机可视化教程
STM32F1 本教程使用零知标准板(STM32F103RBT6)通过I2C驱动ICM20948九轴传感器,实现姿态解算,并通过串口将数据实时发送至VOFA上位机进行3D可视化。代码基于开源库修改优化,适合嵌入式及物联网开发者。在基础驱动上新增…...
)
uniapp 集成腾讯云 IM 富媒体消息(地理位置/文件)
UniApp 集成腾讯云 IM 富媒体消息全攻略(地理位置/文件) 一、功能实现原理 腾讯云 IM 通过 消息扩展机制 支持富媒体类型,核心实现方式: 标准消息类型:直接使用 SDK 内置类型(文件、图片等)自…...

从物理机到云原生:全面解析计算虚拟化技术的演进与应用
前言:我的虚拟化技术探索之旅 我最早接触"虚拟机"的概念是从Java开始的——JVM(Java Virtual Machine)让"一次编写,到处运行"成为可能。这个软件层面的虚拟化让我着迷,但直到后来接触VMware和Doc…...

【2D与3D SLAM中的扫描匹配算法全面解析】
引言 扫描匹配(Scan Matching)是同步定位与地图构建(SLAM)系统中的核心组件,它通过对齐连续的传感器观测数据来估计机器人的运动。本文将深入探讨2D和3D SLAM中的各种扫描匹配算法,包括数学原理、实现细节以及实际应用中的性能对比,特别关注…...

scan_mode设计原则
scan_mode设计原则 在进行mtp controller设计时,基本功能设计完成后,需要设计scan_mode设计。 1、在进行scan_mode设计时,需要保证mtp处于standby模式,不会有擦写、编程动作。 2、只需要固定mtp datasheet说明的接口即可…...