Redis 数据结构详解
分类 编程技术
Redis 数据类型分为:字符串类型、散列类型、列表类型、集合类型、有序集合类型。
Redis 这么火,它运行有多块?一台普通的笔记本电脑,可以在1秒钟内完成十万次的读写操作。
原子操作:最小的操作单位,不能继续拆分。即最小的执行单位,不会被其他命令插入。高并发下不存在竞态条件。
KEY 的命名:一个良好的建议是 article:1:title 来存储 ID 为 1 的文章的标题。

一、前言
- 1、获取key的列表:KEYS pattern 通配符有 ?*[] 和转义 \。
- 2、key 是否存在: EXISTS key 存在返回 1,不存在返回 0。
- 3、建立 key 和删除 key:SET key 和 DEL key。
- 4、根据 key 获取该键所存储的 redis 数据类型:TYPE key。返回是 string、list、hash、set、zset。下面会对这5种返回的 redis 数据类型逐一讲解。
- 5、rename oldkey newkey:对 key 重命名,如果 newkey 存在则覆盖。
- 6、renamenx oldkey newkey:对 key 重命名,如果 newkey 存在则不覆盖。
- 7、randomkey:随即返回一个 key
- 8、move key db-index:将 key 移动到指定的数据库中,如果 key 不存在或者已经在该数据库中,则返回 0。成功则返回 1。
二、Redis数据类型 Redis数据命令
1、Redis数据类型一字符串类型:这个很好理解,一个key存储一个字符串。如果你要存数据呢?转换成Json或者其他的字符串序列化。
2、Redis数据命令一字符串类型:
- 1)赋值:SET key value。如 set hello world
- 2)取值:GET key。如 get hello。返回是 world
- 3)自增:INCR key。就是 Mysql的AUTO_INCREMENT。每次执行 INCR key时,该key的值都会+1.若key不存在,则先建立一个0,然后+1,返回 1。如果值不是整数则报错。该操作是原子操作。
- 4)自减:DECR key。将指定 key 的值减少 1。 如 DECR num,就是 num-1
- 5)自增 N:INCRBY key increment 用来给指定 key 的值加 increment。如 INCRBY num 5 就是 num+5
- 6)自减 N:DECRBY key increment 用来给指定 key 的值减 increment。如 DECRBY num 5 就是 num-5
- 7)增加浮点数:INCRBYFLOAT key increment。
- 8)向尾部追加:APPEND key value。如set test:key 123、append test:key 456、get test:key 就是 123456
- 9)获取长度:STRLEN key。
- 10)同时给多个 key 赋值:MSET title 这是标题 description 这是描述 content 这是内容。
- 11)同时获取多个 key 的值:MGET title description content
- 12)位操作之获取:GETBIT key offset。如字符 a 在 redis 中的存储为 01100001(ASCII为98),那么 GETBIT key 2 就是 1,GET key 0 就是 0。
- 13)位操作之设置:SETBIT key offset value。如字符 a 在 redis 中的存储为 01100001(ASCII为98),那么 SETBIT key 6 0,SETBIT key 5 1 那么 get key 得到的是 b。因为取出的二进制为 01100010。
- 14)位操作之统计:BITCOUNT key [start] [end]:BITCOUNT key 用来获取 key 的值中二进制是 1 的个数。而 BITCOUNT key start end 则是用来统计key的值中在第 start 和 end 之间的子字符串的二进制是 1 的个数(好绕啊)。
- 15)位操作之位运算:BITOP operation resultKey key1 key2。operation 是位运算的操作,有 AND,OR,XOR,NOT。resultKey 是把运算结构存储在这个 key 中,key1 和 key2 是参与运算的 key,参与运算的 key 可以指定多个。
3、Redis数据类型二散列类型:
Redis 是以字典(关联数组)的形式存储的,一个 key 对应一个 value。在字符串类型中,value 只能是一个字符串。那么在散列类型,也叫哈希类型中,value 对应的也是一个字典(关联数组)。那么就可以理解,Redis 的哈希类型/散列类型中,key 对应的 value 是一个二维数组。但是字段的值只可以是字符串。也就是说只能是二维数组,不能有更多的维度。
4、Redis 数据命令二散列类型:
- 1)赋值:HSET key field value。如 hset user name lane。hset user age 23
- 2)取值:HGET key field。如 hget user name,得到的是 lane。
- 3)同一个key多个字段赋值:HMSET key field1 value1 field2 value2...
- 4)同一个KEY多个字段取值:HMGET key field1 fields2...
- 5)获取KEY的所有字段和所有值:HGETALL key。如 HGETALL user 得到的是 name lane age 23。每个返回都是独立的一行。
- 6)字段是否存在:HEXISTS key field。存在返回 1,不存在返回 0
- 7)当字段不存在时赋值:HSETNX key field value。如果 key 下面的字段 field 不存在,则建立 field 字段,且值为 value。如果 field 字段存在,则不执行任何操作。它的效果等于 HEXISTS + HSET。但是这个命令的优点是原子操作。再高的并发也不会怕怕。
- 8)自增 N:HINCREBY key field increment。同字符串的自增类型,不再阐述。
- 9)删除字段:DEL key field1 field2... 删除指定KEY的一个或多个字段。
- 10)只获取字段名:HKEYS key。与 HGETALL 类似,但是只获取字段名,不获取字段值。
- 11)只获取字段值:HVALS key。与 HGETALL 类似,但是只获取字段值,不获取字段名。
- 12)获取字段数量:HLEN key。
5、Redis 数据类型三列表类型
列表类型存储了一个有序的字符串列表。常用的操作是向两端插入新的元素。时间复杂度为 O(1)。结构为一个链表。记录头和尾的地址。看到这里,Redis 数据类型的列表类型一个重大的作用呼之欲出,那就是队列。新来的请求插入到尾部,新处理过的从头部删除。另外,比如微博的新鲜事。比如日志。列表类型就是一个下标从 0 开始的数组。由于是链表存储,那么越靠近头和尾的元素操作越快,越靠近中间则越慢。
6、Redis 数据命令三列表类型:
- 1)向头部插入:LPUSH key value1 value2...。返回增加后的列表长度。
- 2)向尾部插入:RPUSH key value1 value2...。返回增加后的列表长度。
- 3)从头部弹出:LPOP key。返回被弹出的元素值。该操作先删除key列表的第一个元素,再将它返回。
- 4)从尾部弹出:RPOP key。返回被弹出的元素值。
- 5)列表元素个数:LLEN key。key 不存在返回 0。
- 6)获取列表的子列表:LRANGE start end。返回第 start 个到第 end 个元素的列表。包含 start 和 end。支持负数索引。-1 表示最后一个元素,-2 表示倒数第二个元素。
- 7)删除列表中指定值:LREM key count value。删除 key 这个列表中,所有值为 value 的元素,只删除 count。如果有 count+1 个,那么就保留最后一个。count 不存在或者为 0,则删除所有的。如果 count 大于 0,则删除从头到尾的 count 个,如果 count 小于 0,则删除从尾到头的 count 个。
- 8)获取指定索引值:LINDEX key index。如LINDEX key 0就是列表的第一个元素。index可以是负数。
- 9)设置索引和值:LSET key index value。这个操作只是修改指定 key 且指定 index 的值。如果 index 不存在,则报错。
- 10)保留片段,删除其它:LTRIM key start end。保留 start 到 end 之间的所有元素,含 start 和 end。其他全部删除。
- 11)向列表插入元素:LINSERT key BEFORE/AFTER value1 value2。从列表头开始遍历,发现值为 value1 时停止,将 value2 插入,根据 BEFORE 或者 AFTER 插入到 value1 的前面还是后面。
- 12)把一个列表的一个元素转到另一个列表:RPOPLPUSH list1 list2。将列表 list1 的右边元素删除,并把该与元素插入到列表 list2 的左边。原子操作。
7、Redis 数据类型四集合类型:
集合类型是为了方便对多个集合进行操作和运算。集合中每个元素不同且没有顺序的概念,每个元素都是且只能是一个字符串。常用操作是对集合插入、删除、判断等操作。时间复杂度尾 O(1)。可以进行交集、并集、差集运算。例如文章 1 的有 3 个标签,是一个 Redis 数据类型集合类型存储。文章 2 有 3 个标签,有一个 Redis 数据类型集合类型存储。文章是 1 是 mysql,文章 2 是讲 redis。那么交集是不是就交出了一个数据库?(假设数据库这个tag在两篇文字都有)。集合类型在 redis 中的存储是一个值为空的散列表。
8、Redis 数据命令四集合类型:
- 1)增加:SADD key value。
- 2)删除:SREM key value。
- 3)获取指定集合的所有元素:SMEMBERS key。
- 4)判断某个元素是否存在:SISMEMBER key value。
- 5)差集运算:SDIFF key1 key2...。对多个集合进行差集运算。
- 6)交集运算:SINNER key1 key2...。对多个集合进行交集运算。
- 7)并集运算:SUNION key1 key2...。对多个集合进行并集运算。
- 8)获取集合中元素个数:SCARD key。返回集合中元素的总个数。
- 9)对差集、交集、并集运算的结果存放在一个指定的 key 中:SDIFFSTORE storekey key1 key2。对 key1 和 key2 求差集,结果存放在 key 为 storekey 的集合中。SINNERSTORE 和 SUNIONSTORE 类似。
- 10)获取集合中的随即元素:SRANDMEMBER key [count]。参数 count 可选,如果 count 不存在,则随即一个。count 大于 0,则是不重复的 count 个元素。count 小于 0,则是一共 |count|个 元素,可以重复。
- 11)随即弹出一个元素:SPOP key。随即从集合中弹出一个元素并删除,将该元素的值返回。
9、Redis 数据类型五有序集合类型:
集合类型是无序的,每个元素是唯一的。那么有序集合就是有序的,每个元素是唯一的。有序集合类型和集合类型的差别是,有序集合为每个元素配备了一个属性:分数。有序集合就是根据分数来排序的。有序集合是使用散列表和跳跃表实现的。所以和列表相比,操作中间元素的速度也很快。时间复杂度尾 O(log(N))。Redis 数据类型中的有序集合类型比 Redis 数据类型中的列表类型更加耗费资源。
10、Redis数据命令五有序集合类型
- 1)增加:ZADD key sorce1 value1 sorce2 value2...。
- 2)获取分数:ZSCORE key value。获取key的有序集合中值为 value 的元素的分数。
- 3)获取排名在某个范围内的元素列表:ZRANFGE key start stop [WITHSCORE]。获取排名在 start 和 end 之间的元素列表,包含 start 和 end2 个元素。每个元素一行。如果有WITHSCORE参数,则一行元素值,一行分数。时间复杂度为O(LOGn+m)。如果分数相同,则 0<0
- 4)获取指定分数范围的元素:ZRANGEBYSCORE key min max [WITHSCORE] [LIMIT offset count]。获取分数在 min 和 max 之间的元素列表。含两头。每个元素一行。如果有 WITHSCORE 参数,则一行元素值,一行分数。如果 min 大于 max 则顺序反转。
- 5)为某个元素增加分数:ZINCRBY key increment value。指定的有序集合的值为 value 的元素的分数 +increment。返回值后更改后的分数。
- 6)获取集合中元素的数量:ZCARD key。
- 7)获取指定分数范围内的元素个数:ZCOUNT key min max。
- 8)删除一个或多个元素:ZREM key value1 value2...
- 9)根据排名范围删除元素:ZREMRANGEBYRANK key start end。删除排名在 start 和 end 中的元素。
- 10)按照分数范围删除元素:ZREMRANGEBYSCORE key min max。
- 11)获得元素排名(正序):ZRANK key value。获取 value 在该集合中的从小到大的排名。
- 12)获得元素排名(倒序):ZREVRANK key value。获取 value 在该集合中从大到小的排名。
- 13)有序集合的交集:ZINTERSTORE storekey key1 key2...[WEIGHTS weight [weight..]] [AGGREGATE SUM|MIN|MAX]。用来计算多个集合的交集,结果存储在 storekey中。返回值是 storekey 的元素个数。AGGREGATE 为 SUM 则 storekey 集合的每个元素的分数是参与计算的集合分数和。MIN 是参与计算的分数最小值。MAX 是参与计算分数最大值。WEIGHTS 设置每个集合的权重,如 WEIGHTS 1 0.1。那么集合A的每个元素分数 * 1,集合B的每个元素分数 * 0.1
- 14)有序集合的并集:ZUNIONSTORE storekey key1 kye2...[WEIGHTS weight [weight..]] [AGGREGATE SUM|MIN|MAX]
相关文章:
Redis 数据结构详解
分类 编程技术 Redis 数据类型分为:字符串类型、散列类型、列表类型、集合类型、有序集合类型。 Redis 这么火,它运行有多块?一台普通的笔记本电脑,可以在1秒钟内完成十万次的读写操作。 原子操作:最小的操作单位&a…...

03-IDEA集成Git,初始化本地库,添加远程仓库,提交,拉取,推送,分支的快捷操作
IDEA集成Git 创建Git忽略文件 不同的IDE开发工具有不同的特点文件,这些文件与项目的实际功能无关且不参与服务器上的部署运行, 把它们忽略掉能够屏蔽之间的差异 局部忽略配置文件: 在本地仓库的根目录即项目根目录下直接创建.gitignore文件, 以文件后缀或目录名的方式忽略指定…...
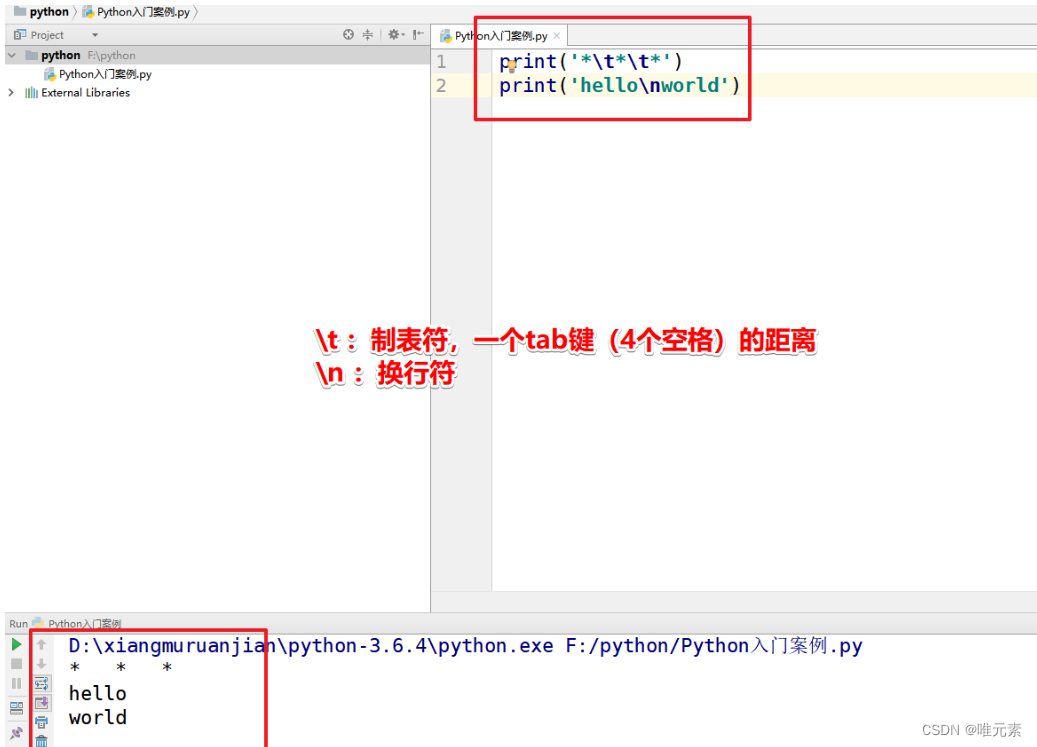
Python---格式化输出与%百分号----涉及转义符 \ 反斜杠的使用
相关链接Python--格式化输出中的转义符号----\t 制表符(空格的)和\n(换行的)_唯元素的博客-CSDN博客 Python---字符串(用单、双引号、 三单/双引号定义。反斜杠 \ 转义,单在双内/双在单内 )-CS…...

大华技术GIS开发工程师24届秋招三场面试Offer面经
本文介绍2024届秋招中,大华技术股份有限公司的GIS开发工程师岗位的3场面试基本情况、提问问题等。 10月投递了大华技术股份有限公司的GIS开发工程师岗位,所在部门为研发中心。目前完成了一面、二面与三面等全部流程,并有幸获得Offerÿ…...
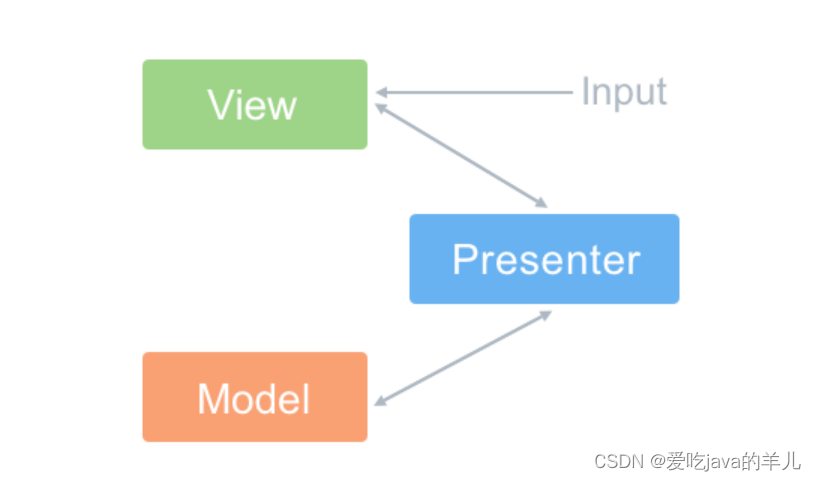
前端三大MV*模式:MVC、mvvm、mvp模式介绍
MVC(同步通信为主):Model、View、Controller MVP(异步通信为主):Model、View、Presenter MVVM(异步通信为主):Model、View、ViewModel mvc模式介绍 MVC(Model–View–Controller)模式是软件…...

分享一些Git的常用命令
常用命令 命令名称作git config —global user.name 用户名设置用户签名git config —global user.email 邮箱设置用户签名git init初始化本地库git status查看本地库状态git add 文件名添加到暂存区git commit -m “日志信息” 文件名提交到本地库git reflog查看历史记录git r…...

C语言第四十二弹---使用多种方法实现字符串左旋转
使用多种方法实现字符串左旋转 一、 左移法 思路:每一次通过移动第一个字符,然后把后面的字符前移,然后再进行移动第一个字符再前移。故需要使用嵌套循环,外层循环控制移动第一个字符的次数,第二个循环进行字符前移 …...
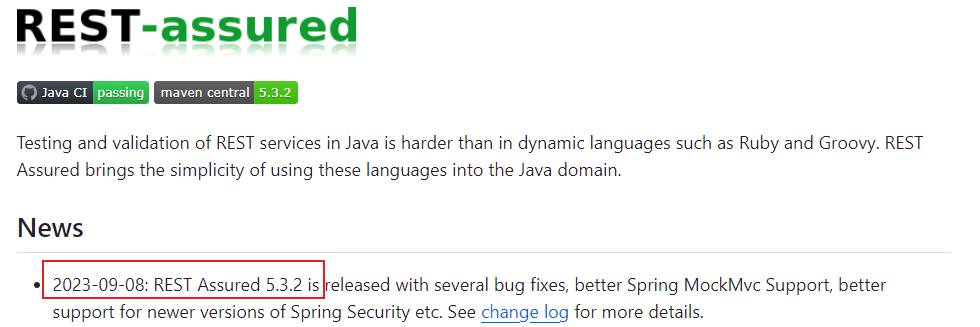
REST-Assured--JAVA REST服务自动化测试的Swiss Army Knife
什么是REST-Assured REST Assured是一套基于 Java 语言实现的开源 REST API 测试框架 Testing and validation of REST services in Java is harder than in dynamic languages such as Ruby and Groovy. REST Assured brings the simplicity of using these languages into t…...

docker中的网络不通问题
前言 有时候在使用docker时,会莫名其妙docker内部与外网网络不通 docker与防火墙 docker内部的网络与宿主机的防火墙有千丝万缕的联系,docker启动的那一刻如果防火墙是启动的,docker内部与外部就会走防火墙转发策略,这个时候&a…...

Android 12.0 修改Android系统的通知自动成组的数量
场景: Android 系统对显示在通知列表中的同一个应用的通知进行分组管理,即相同的packageName中,当通知数量达到系统默认指定的数量时,会自动成一组. Android 12.0 中系统默认的自动成组数如下所示: 核心路径 : frameworks/base/core/res/res/values/config.xml<!-- 来自同…...

Debian12配置ssh服务器
Debian12配置ssh服务器 安装ssh-server sudo apt install openssh-server启动ssh sudo systemctl start ssh启用ssh sudo systemctl enable ssh查看ssh状态 sudo systemctl status ssh可以看到有enabled和running字样 说明ssh启用成功 连接到服务器 # username是你的用…...

飞天使-elk搭建补充
文章目录 es 集群创建密码kibana 配置文件以及和nginx配置pm2 安装定期清理索引以及告警logstash 配置filebeat 配置文件nginx 的日志索引 es 集群创建密码 参考这篇博文进行设置:https://juejin.cn/post/7079955586330132487 最后的效果 #curl -XGET http://127.0…...

YOLOv7+姿态估计Pose+tensort部署加速
YOLOv7-Pose YOLOv7是一种高效的目标检测算法,用于实时物体检测。姿态估计Pose是一种用于识别和跟踪人体关键点的技术。TensorRT是一个针对深度学习推理任务进行加速的高性能推理引擎。 将YOLOv7和姿态估计Pose与TensorRT结合可以实现快速而准确的目标检测和姿态估…...
Java数据结构 之 包装类简单认识泛类
生命不息,奋斗不止 目录 1. 什么是包装类? 1.1 装箱和拆箱 1.2 自动装箱和自动拆箱 2. 什么是泛型 3. 引出泛型 3.1 语法 4 泛型类的使用 4.1 语法 4.2 示例 4.3 类型推导(Type Inference) 5. 裸类型(Raw Type) (了解)…...
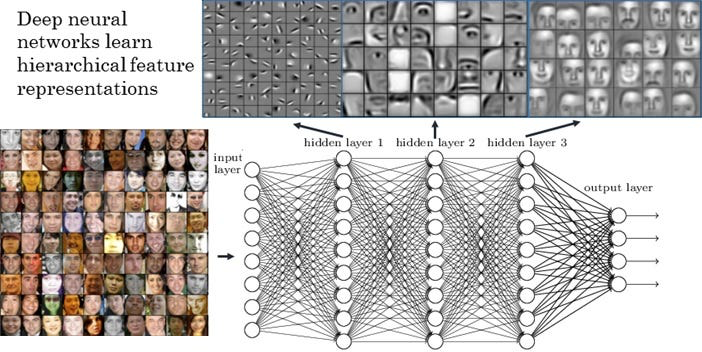
人工智能 - 人脸识别:发展历史、技术全解与实战
目录 一、人脸识别技术的发展历程早期探索:20世纪60至80年代技术价值点: 自动化与算法化:20世纪90年代技术价值点: 深度学习的革命:21世纪初至今技术价值点: 二、几何特征方法详解与实战几何特征方法的原理…...

多元排列熵 Multivariate Permutation Entropy
熵(Entropy) 信息论中熵的概念首次被香农提出,目的是寻找一种高效/无损地编码信息的方法:以编码后数据的平均长度来衡量高效性,平均长度越小越高效;同时还需满足“无损”的条件,即编码后不能有原始信息的丢失。这样&a…...
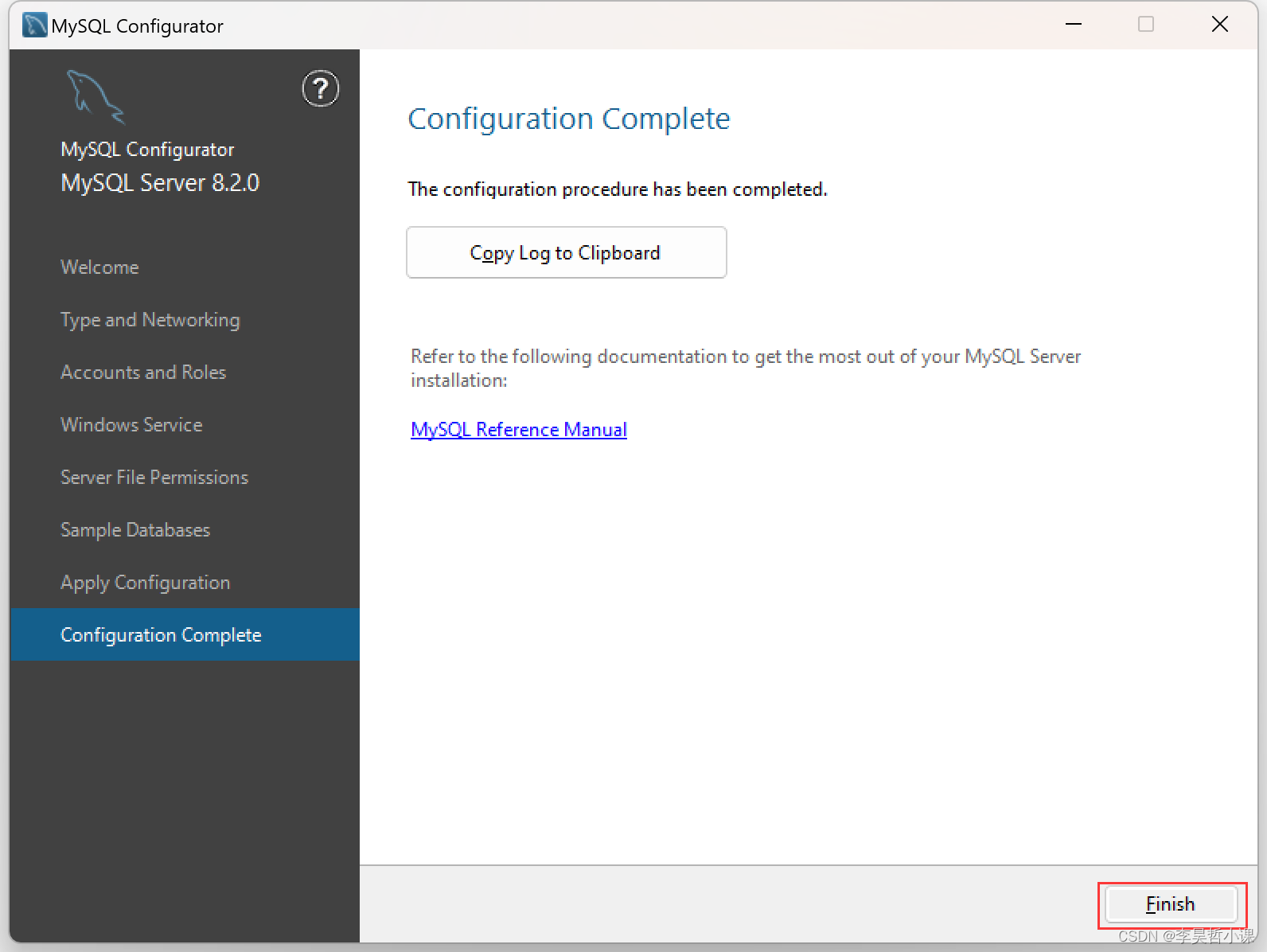
Windows安装MySQL8.2
Windows安装MySQL8.2 三种安装模式 默认自定义完整 本案例选择自定义 选择安装目录 勾选 Run MySQL Configurator 配置MYSQL 默认为开发者模式 在 Config Type 下拉列表中选择数据中心 设置 root 账号密码...
Windows下安全认证机制
NTLM(NT LAN Manager) NTLM协议是在Microsoft环境中使用的一种身份验证协议,它允许用户向服务器证明自己是谁(挑战(Chalenge)/响应(Response)认证机制),以便…...
(学习笔记)Xposed模块编写(一)
前提:需要已经安装Xposed Installer 1. 新建一个AS项目 并把MainActvity和activity_main.xml这两个文件删掉,然后在AndriodManifest.xml中去掉这个Activity的声明 2. 在settings.gralde文件中加上阿里云的仓库地址,否则Xposed依赖无法下载 m…...
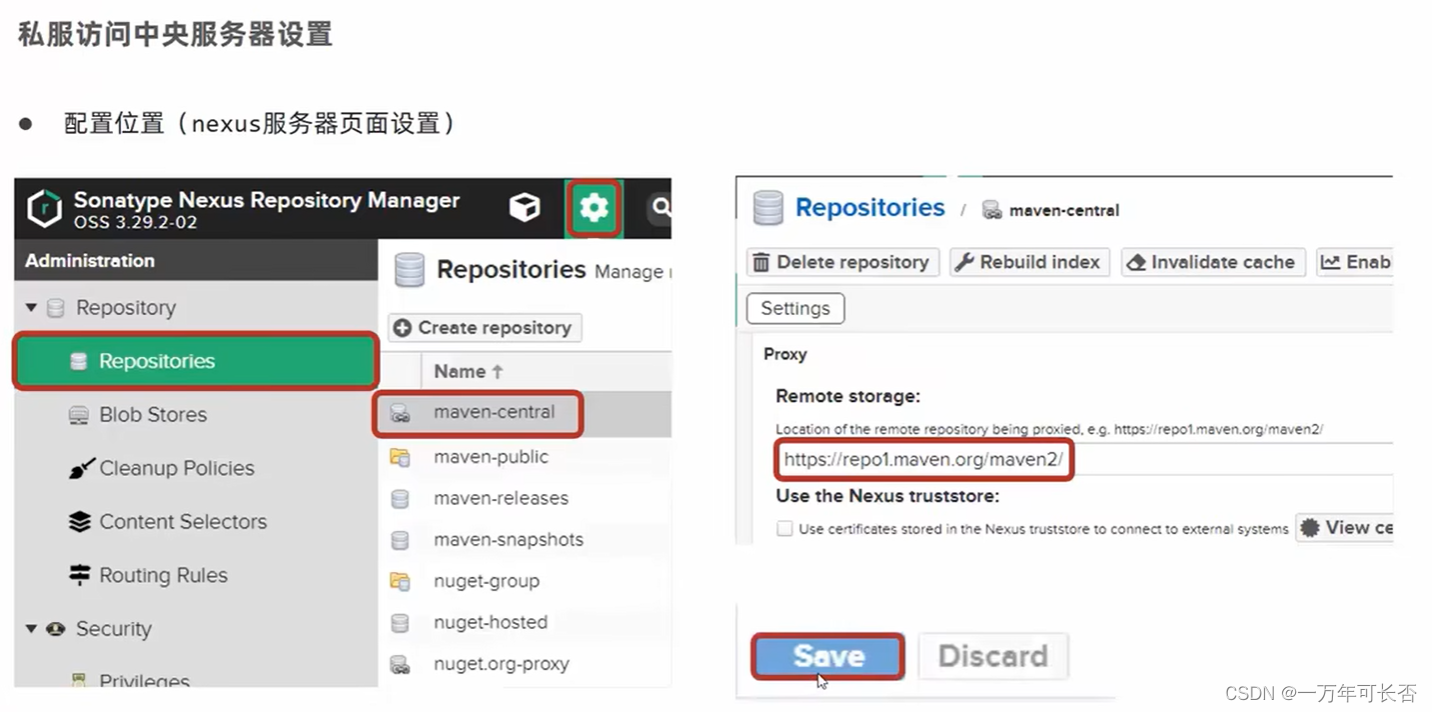
SSM框架(五):Maven进阶
文章目录 一、分模块开发1.1 分模块开发的意义1.2 步骤 二、依赖管理2.1 依赖传递2.2 可选依赖和排除依赖 三、继承与聚合3.1 聚合3.2 继承3.3 聚合和继承区别 四、属性4.1 pom文件的依赖使用属性4.2 资源文件使用属性 五、多环境开发六、跳过测试七、私服7.1 下载与使用7.2 私…...

JavaSec-RCE
简介 RCE(Remote Code Execution),可以分为:命令注入(Command Injection)、代码注入(Code Injection) 代码注入 1.漏洞场景:Groovy代码注入 Groovy是一种基于JVM的动态语言,语法简洁,支持闭包、动态类型和Java互操作性,…...

零门槛NAS搭建:WinNAS如何让普通电脑秒变私有云?
一、核心优势:专为Windows用户设计的极简NAS WinNAS由深圳耘想存储科技开发,是一款收费低廉但功能全面的Windows NAS工具,主打“无学习成本部署” 。与其他NAS软件相比,其优势在于: 无需硬件改造:将任意W…...

Cursor实现用excel数据填充word模版的方法
cursor主页:https://www.cursor.com/ 任务目标:把excel格式的数据里的单元格,按照某一个固定模版填充到word中 文章目录 注意事项逐步生成程序1. 确定格式2. 调试程序 注意事项 直接给一个excel文件和最终呈现的word文件的示例,…...

树莓派超全系列教程文档--(61)树莓派摄像头高级使用方法
树莓派摄像头高级使用方法 配置通过调谐文件来调整相机行为 使用多个摄像头安装 libcam 和 rpicam-apps依赖关系开发包 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 配置 大多数用例自动工作,无需更改相机配置。但是,一…...

2024年赣州旅游投资集团社会招聘笔试真
2024年赣州旅游投资集团社会招聘笔试真 题 ( 满 分 1 0 0 分 时 间 1 2 0 分 钟 ) 一、单选题(每题只有一个正确答案,答错、不答或多答均不得分) 1.纪要的特点不包括()。 A.概括重点 B.指导传达 C. 客观纪实 D.有言必录 【答案】: D 2.1864年,()预言了电磁波的存在,并指出…...

Java - Mysql数据类型对应
Mysql数据类型java数据类型备注整型INT/INTEGERint / java.lang.Integer–BIGINTlong/java.lang.Long–––浮点型FLOATfloat/java.lang.FloatDOUBLEdouble/java.lang.Double–DECIMAL/NUMERICjava.math.BigDecimal字符串型CHARjava.lang.String固定长度字符串VARCHARjava.lang…...

Nginx server_name 配置说明
Nginx 是一个高性能的反向代理和负载均衡服务器,其核心配置之一是 server 块中的 server_name 指令。server_name 决定了 Nginx 如何根据客户端请求的 Host 头匹配对应的虚拟主机(Virtual Host)。 1. 简介 Nginx 使用 server_name 指令来确定…...

鱼香ros docker配置镜像报错:https://registry-1.docker.io/v2/
使用鱼香ros一件安装docker时的https://registry-1.docker.io/v2/问题 一键安装指令 wget http://fishros.com/install -O fishros && . fishros出现问题:docker pull 失败 网络不同,需要使用镜像源 按照如下步骤操作 sudo vi /etc/docker/dae…...

前端开发面试题总结-JavaScript篇(一)
文章目录 JavaScript高频问答一、作用域与闭包1.什么是闭包(Closure)?闭包有什么应用场景和潜在问题?2.解释 JavaScript 的作用域链(Scope Chain) 二、原型与继承3.原型链是什么?如何实现继承&a…...

三分算法与DeepSeek辅助证明是单峰函数
前置 单峰函数有唯一的最大值,最大值左侧的数值严格单调递增,最大值右侧的数值严格单调递减。 单谷函数有唯一的最小值,最小值左侧的数值严格单调递减,最小值右侧的数值严格单调递增。 三分的本质 三分和二分一样都是通过不断缩…...