zookeeper+kafka+ELK+filebeat集群
目录
一、zookeeper概述:
1、zookeeper工作机制:
2、zookeeper主要作用:
3、zookeeper特性:
4、zookeeper的应用场景:
5、领导者和追随者:zookeeper的选举机制
二、zookeeper安装部署:
三、消息队列:kafka
1、消息队列概述:
1.1、消息队列的作用:
1.2、消息队列的模式:
1.3、kafka的工作流程:
四、 Kafka(2.7.0)的安装部署:
五、kafka3.4.1安装部署
六、ELK+filebeat+kafka的安装部署
一、zookeeper概述:
zookeeper:是一个开源的分布式架构。提供协调服务(Apache项目)
1、zookeeper工作机制:
基于观察者模式设计的分布式服务管理架构。
主要职责:存储和管理数据。分布式节点上的服务接收观察者的注册。一旦这些分布式节点上的数据发生变化,由zookeeper来负责通知分布式节点上的服务
总结:zookeeper = 文件系统 + 通知机制。
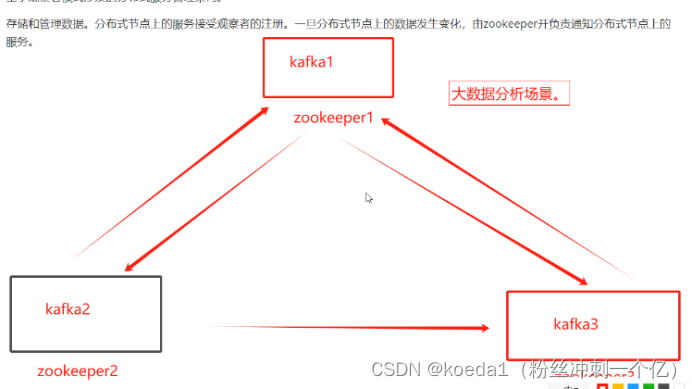
zookeeper分为领导者和被迫者 leader follower 组成的集群
只要有一半以上的集群存活,zookeeper集群就可以正常工作。适用于安装奇数台的服务集群
2、zookeeper主要作用:
全局数据一致,每个zookeeper节点都保存相同的数据。维护监控服务的数据一致
3、zookeeper特性:
- Zookeeper:一个领导者(Leader),多个跟随者(Follower)组成的集群。
- Zookeepe集群中只要有半数以上节点存活,Zookeeper集群就能正常服务。所以Zookeeper适合安装奇数台服务器。
- 全局数据一致:每个Server保存一份相同的数据副本,Client无论连接到哪个Server,数据都是一致的。
- 更新请求顺序执行,来自同一个Client的更新请求按其发送顺序依次执行,即先进先出。
- 数据更新原子性,一次数据更新要么成功,要么失败。
- 实时性,在一定时间范围内,Client能读到最新数据。
4、zookeeper的应用场景:
- 统一命名服务:在分布式的环境下,对所有的应用和服务进行统一命名
- 统一配置管理:配置文件同步,kafka的配置文件被修改,可以快速同步到其他节点
- 统一集群管理:实时掌握所有节点的状态
- 服务器动态上下限
- 负载均衡,把访问的服务器的数据,发送到访问最少的服务器处理客户端的请求
5、领导者和追随者:zookeeper的选举机制
三台服务器:A B C
A先启动,发起第一次选举,投票投给自己,有3台但是自己只有1票,不满足半数,A的状态的looking
B启动,再发起一次选举,A和B分别投自己一票,交换选票信息,A发现B的myid比A大,A的这一票会转而投给B。A0 B2,没有半数以上的结果,A B会进入looking(B有可能成为leader)
C启动,C的myid若最大,A和B都会把票都会投给C 这时A B C都会把票投给C,A0 B0 C3
C的状态变为leader A和B会变成follower
只要leader确定,后续的服务器都是追随者。
只有两种情况会开启选举机制:
- 初始化到达情况下会产生选举
- 服务器之间和leader丢失了连接状态
若leader已存在,建立连接即可
leader不存在
1、服务器ID大的胜出
2、EPOCH大,直接胜出
3、EPOCH相同,事务ID大的胜出
EPOCH是每个leader任期的代号,没有leader,大家的逻辑地位是相同的,没投完一次之后,数据是递增的。
事务ID是用来标识服务器的每一次变更,每变更一次,事务ID变化一次
服务器ID,zookeeper集群中都有一个ID,每台机器不重复,和myid保持一致
service zookeeper restart
service kafka restart
二、zookeeper安装部署:
部署zookeeper集群(三台都安装zookeeper+kafka,最少2核4G)
20.0.0.24
20.0.0.25
20.0.0.26
关闭防火墙和安全机制
升级java环境
yum install -y java-1.8.0-openjdk java-1.8.0-openjdk-devel
安装 Zookeeper
cd /opt
tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz
mv apache-zookeeper-3.5.7-bin /opt/zookeeper
修改配置文件
三台节点上同步操作:
cd /opt/zookeeper/conf/
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
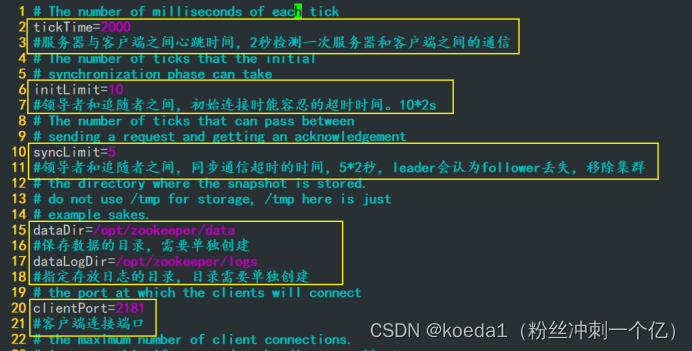
tickTime=2000 #通信心跳时间,Zookeeper服务器与客户端心跳时间,单位毫秒
initLimit=10 #Leader和Follower初始连接时能容忍的最多心跳数(tickTime的数量),这里表示为10*2s
syncLimit=5 #Leader和Follower之间同步通信的超时时间,这里表示如果超过5*2s,Leader认为Follwer死掉,
并从服务器列表中删除Follwer
dataDir=/opt/zookeeper/data ●修改,指定保存Zookeeper中的数据的目录,目录需要单独创建
dataLogDir=/opt/zookeeper/logs ●添加,指定存放日志的目录,目录需要单独创建
clientPort=2181 #客户端连接端口
#最后一行添加集群信息
server.1=20.0.0.24:3188:3288
server.2=20.0.0.25:3188:3288
server.3=20.0.0.26:3188:3288
1:每个zookeeper集群的初始myid
20.0.0.24:服务器的初始地址
3188:领导者和追随者之间交换信息的端口(内部通信的端口)
3288:一旦leader丢失响应,开启选举,3288就是用来执行选举时的服务器之间通信端口。

在每个节点上创建数据目录和日志目录
mkdir /opt/zookeeper/data
mkdir /opt/zookeeper/logs
创建myid文件
在每个节点的dataDir指定的目录下创建一个 myid 的文件,不同节点分配1、2、3
echo 1 > /opt/zookeeper/data/myid
echo 2 > /opt/zookeeper/data/myid
echo 3 > /opt/zookeeper/data/myid
配置 Zookeeper 启动脚本
三台节点全部配置
vim /etc/init.d/zookeeper
#!/bin/bash
#chkconfig:2345 20 90
#description:Zookeeper Service Control Script
ZK_HOME='/opt/zookeeper'
case $1 in
start)
echo "---------- zookeeper 启动 ------------"
$ZK_HOME/bin/zkServer.sh start
;;
stop)
echo "---------- zookeeper 停止 ------------"
$ZK_HOME/bin/zkServer.sh stop
;;
restart)
echo "---------- zookeeper 重启 ------------"
$ZK_HOME/bin/zkServer.sh restart
;;
status)
echo "---------- zookeeper 状态 ------------"
$ZK_HOME/bin/zkServer.sh status
;;
*)
echo "Usage: $0 {start|stop|restart|status}"
esac
设置开机自启
chmod +x /etc/init.d/zookeeper
chkconfig --add zookeeper
分别启动 Zookeeper
service zookeeper start
查看当前状态(leader、follower)
service zookeeper status

三、消息队列:kafka
1、消息队列概述:
为什么要引入消息队列(MQ)
他也是一个中间键。在高并发环境下,同步请求来不及处理。来不及处理的请求会形成阻塞
比方说数据库就会形成行锁或者表锁。请求线程满了,超标了,too many connection,引发整个系统雪崩
1.1、消息队列的作用:
异步处理请求。流量削峰,应用解耦。
解耦:只要通信保证,其他的修改不影响整个集群,每个组件可以独立的扩展,修改,降低组件之间的依赖性。
耦合:在软件系统当中,修改一个组件需要修改所有其他组件,高度耦合
低度耦合:改其中一个对其他组件影响不大,无需修改所有
可恢复性:系统当中有一部分组件消失,不影响整个系统。也就是说在消息队列当中,即使有一个处理消息的进程失败,一旦恢复还可以重新加入到队列当中,继续处理消息
缓冲机制:可以控制和优化数据经过系统的时间和速度。解决生产消息和消费消息处理速度不一致的问题。
峰值的处理能力:消息队列在峰值的情况之下,能够顶住突发的访问压力。避免专门为了突发情况而对系统进行修改
异步通信:允许用户把一个消息放入队列,但是不立即处理,等用户想处理的时候在处理
1.2、消息队列的模式:
点对点 一对一 :消息的生产者发送消息到队列中,消费者从队列中提取消息,消费者提取完之后,队列中被提取的消息将会被移除。后续消费者不能再消费队列中的消息。消息队列可以有多个消费者,但是一个消息,只能由一个消费者提取
RABBITMQ
发布、订阅模式:一对多,观察者模式,消费者提取数据之后,队列当中的消息不会被清除
生产者发布一个消息到主题,所有消费者都是通过主题获取消息
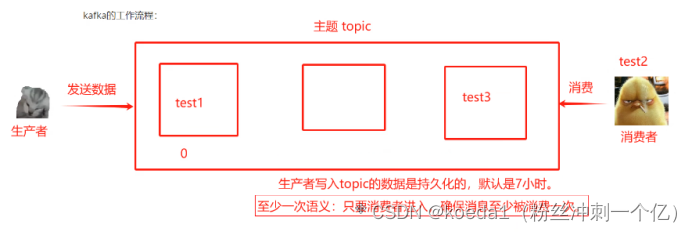
主题:topic topic类似于一个数据流管道,生产者把消息发布到主题,消费者从主题当中订阅数据。每一个主题都可以被分区,每个分区都有自己的偏移量。
分区:partition 每个主题都可以分成多个分区。每个分区是数据的有序子集,分区可以允许kafka进行水平拓展,以处理大量数据。消息在分区中按照偏移量存储,消费者可以独立读取每个分区的数据。
偏移量:是每个消息在分区中的唯一标识。消费者通过偏移量跟踪、获取、已读或者未读消息的位置,也可以通过提交偏移量来记录已处理的信息。

生产者:producer 生产者把数据发送到kafka的主题当中,负责写入消息
消费者:consumer 从主题当中读取数据,消费者可以是一个也可以是多个。每个消费者有一个唯一的消费者组ID,kafka通过消费者实现负载均衡和容错性
经纪人:broker 每个kafka节点都有一个broker,每个broker负责一台服务器,id唯一,存储主题分区中的数据,处理生产和消费者的请求。维护元数据(3.0之前,zookeeper维护。3.0之后自己管理元数据)
zookeeper负责保存元数据,元数据就是topic的相关信息(发布在哪台主机上,指定了多少分区,以及副本数,偏移量)
zookeeper会自建一个主题 __consumer_offsets
3.0之后不依赖zookeeper的核心就是元数据由kafka节点自己管理
1.3、kafka的工作流程:
四、 Kafka(2.7.0)的安装部署:
cd /opt/
tar zxvf kafka_2.13-2.7.0.tgz
mv kafka_2.13-2.7.0 kafka/
修改配置文件
cd /opt/kafka/config
cp server.properties server.properties.bak
vim server.properties
21行
broker的全局唯一编号,每个broker不能重复,因此要在其他机器上配置 broker.id=1、broker.id=2
31行
指定监听的IP和端口,如果修改每个broker的IP需区分开来,也可保持默认配置不用修改
,这里上面broker配置过了

42行
num.network.threads=3
broker 处理网络请求的线程数量,一般情况下不需要去修改
45行
num.io.threads=8
用来处理磁盘IO的线程数量,数值应该大于硬盘数
48行
socket.send.buffer.bytes=102400
发送套接字的缓冲区大小
51行
socket.receive.buffer.bytes=102400
接收套接字的缓冲区大小
54行
socket.request.max.bytes=104857600
请求套接字的缓冲区大小
60行
log.dirs=/var/log/kafka
kafka运行日志存放的路径,也是数据存放的路径
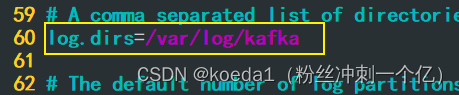
65行
num.partitions=1
topic在当前broker上的默认分区个数,会被topic创建时的指定参数覆盖
69行
num.recovery.threads.per.data.dir=1
用来恢复和清理data下数据的线程数量
103行
log.retention.hours=168
segment文件(数据文件)保留的最长时间,单位为小时,默认为7天,超时将被删除
110行
log.segment.bytes=1073741824
一个segment文件最大的大小,默认为 1G,超出将新建一个新的segment文件
Kafka 以日志文件的形式维护其数据,而这些日志文件被分割成多个日志段。当一个日志段达到指定的大小时,就会创建一个新的日志段。
123行
配置连接Zookeeper集群地址
zookeeper.connect=20.0.0.24:2181,20.0.0.25:2181,20.0.0.26:2181
修改环境变量日志段是主题分区日志文件的一部分。
vim /etc/profile
export KAFKA_HOME=/opt/kafka
export PATH=$PATH:$KAFKA_HOME/bin
source /etc/profile
配置 kafka 启动脚本
vim /etc/init.d/kafka
#!/bin/bash
#chkconfig:2345 22 88
#description:Kafka Service Control Script
KAFKA_HOME='/opt/kafka'
case $1 in
start)
echo "---------- Kafka 启动 ------------"
${KAFKA_HOME}/bin/kafka-server-start.sh -daemon ${KAFKA_HOME}/config/server.properties
;;
stop)
echo "---------- Kafka 停止 ------------"
${KAFKA_HOME}/bin/kafka-server-stop.sh
;;
restart)
$0 stop
$0 start
;;
status)
echo "---------- Kafka 状态 ------------"
count=$(ps -ef | grep kafka | egrep -cv "grep|$$")
if [ "$count" -eq 0 ];then
echo "kafka is not running"
else
echo "kafka is running"
fi
;;
*)
echo "Usage: $0 {start|stop|restart|status}"
esac
设置开机自启
chmod +x /etc/init.d/kafka
chkconfig --add kafka
分别启动 Kafka
service kafka start
做地址映射:
vim /etc/hosts
20.0.0.24 test1
20.0.0.25 test2
20.0.0.26 test3
Kafka 命令行操作
kafka的命令也只能在bin目录下执行
cd /opt/kafka/bin
创建topic(主题):
1、在kafka的bin目录下,是所有的kafka可执行命令文件
2、--zookeeper 指定的是zookeeper的地址和端口,保存kafka的元数据
3、--replication-factor 2 定义每个分区的副本数
4、partitions 3 指定主题的分区数
5、--topic test1 指定主题的名称。
kafka-topics.sh --create --zookeeper 20.0.0.24:2181,20.0.0.25:2181,20.0.0.26:2181 --replication-factor 2 --partitions 3 --topic test1
20.0.0.24:2181:定义集群服务器地址,如果有多个 IP 地址使用逗号分割,一般使用一个 IP 即可
--replication-factor:定义分区副本数,1 代表单副本,建议为 2
--partitions:定义分区数
--topic:定义 topic 名称

查看当前服务器中的所有 topic
kafka-topics.sh --list --zookeeper 20.0.0.24:2181,20.0.0.25:2181,20.0.0.26:2181

查看topic 的详情
kafka-topics.sh --describe --zookeeper 20.0.0.24:2181,20.0.0.25:2181,20.0.0.26:2181
查看某个topic 的详情
kafka-topics.sh --describe --zookeeper 20.0.0.24:2181,20.0.0.25:2181,20.0.0.26:2181 --topic test1
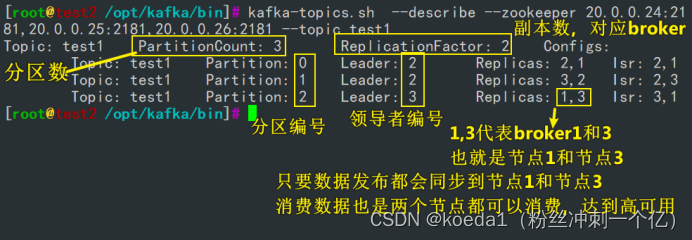
Partition:分区编号
Leader:每个分区都有一个领导者(Leader),领导者负责处理分区的读写操作。
在上述输出中,领导者的编号分别为 3、1、3。
Replicas:每个分区可以有多个副本(Replicas),用于提供冗余和容错性。在上述输出中,Replica 3、1、2 分别对应不同的 Kafka broker。
Isr:ISR(In-Sync Replicas)表示当前与领导者保持同步的副本。
ISR 3、1分别表示与领导者同步的副本。
发布消息
kafka-console-producer.sh --broker-list 20.0.0.24:9092,20.0.0.25:9092,20.0.0.26:9092 --topic test1

消费消息
kafka-console-consumer.sh --bootstrap-server 20.0.0.24:9092,20.0.0.25:9092,20.0.0.26:9092 --topic test1
后接--from-beginning:会把主题中以往所有的数据都读取出来

__consumer_offsets 主题的作用是记录每个消费者组中每个消费者在每个分区上的偏移量。
这样,当消费者组中的消费者重新加入或者新的消费者加入时,它们可以从上次提交的偏移量处继续消费消息,
而不会重复消费或错过消息。
请注意,对于这个主题,配置为 Replication Factor 为 1 可能会对高可用性造成一些影响。
在生产环境中,通常会将 __consumer_offsets 主题的 Replication Factor 设置得更高,
以确保偏移量信息的可靠性。
修改分区数
kafka-topics.sh --zookeeper 20.0.0.24:2181,20.0.0.25:2181,20.0.0.26:2181 --alter --topic test1 --partitions 6

//删除 topic
kafka-topics.sh --delete --zookeeper 20.0.0.24:2181,20.0.0.25:2181,20.0.0.26:2181 --topic test1
"Note: This will have no impact if delete.topic.enable is not set to true."
是关于删除 Kafka 主题的一个重要提示。默认情况下,Kafka 集群禁用了主题删除操作,为了确保不会意外删除数据。
在 Kafka 中,要执行主题删除操作,需要确保 delete.topic.enable 配置项被设置为 true。
这个配置项决定了是否允许删除主题。如果没有设置或设置为 false,即使你执行了删除主题的命令,
实际上也不会删除主题,而只是标记主题为 "marked for deletion"。
在生产环境中,特别谨慎地处理主题删除操作
在配置文件中添加,将彻底删除topic.
delete.topic.enable=true
在zookeeper中查看topic信息:
/zkCli.sh -server 192.168.233.30:2181
ls /brokers/topics
总结:
- zookeeper 主要是分布式,观察者模式,统一各个服务器节点的数据
在kafka当中,收集保存kafka的元数据
- kafka消息队列,订阅发布模式
五、kafka3.4.1安装部署
kafka3.4.1的安装步骤和2.7.1的步骤一模一样
但是命令有些区别,原因是不再依靠zookeeper传输数据了
Kafka 命令行操作
//创建topic
kafka-topics.sh --create --bootstrap-server 192.168.233.10:9092,192.168.233.20:9092,192.168.233.30:9092 --replication-factor 2 --partitions 3 --topic test1
-------------------------------------------------------------------------------------
--bootstrap-server:定义 bootstrap-server 集群服务器地址,如果有多个 IP 地址使用逗号分割,一般使用一个 IP 即可
--replication-factor:定义分区副本数,1 代表单副本,建议为 2
--partitions:定义分区数
--topic:定义 topic 名称
-------------------------------------------------------------------------------------
//查看当前服务器中的所有 topic
kafka-topics.sh --list --bootstrap-server 192.168.233.10:9092,192.168.233.20:9092,192.168.233.30:9092
//查看某个 topic 的详情
[root@test1 efak]# kafka-topics.sh --describe --bootstrap-server 192.168.233.10:9092,192.168.233.20:9092,192.168.233.30:9092
Topic: test1 TopicId: ihBKilk6SNyP7RrVHygCog PartitionCount: 3 ReplicationFactor: 2 Configs: segment.bytes=1073741824
Topic: test1 Partition: 0 Leader: 2 Replicas: 2,1 Isr: 2,1
Topic: test1 Partition: 1 Leader: 1 Replicas: 1,0 Isr: 1,0
Topic: test1 Partition: 2 Leader: 0 Replicas: 0,2 Isr: 0
Leader:每个分区都有一个领导者(Leader),领导者负责处理分区的读写操作。
在上述输出中,领导者的编号分别为 2、1、0。
Replicas:每个分区可以有多个副本(Replicas),用于提供冗余和容错性。
在上述输出中,Replica 0、1、2 分别对应不同的 Kafka broker。
Isr:ISR(In-Sync Replicas)表示当前与领导者保持同步的副本。
ISR 0、1、2 分别表示与领导者同步的副本。
//发布消息
kafka-console-producer.sh --broker-list 192.168.233.10:9092,192.168.233.20:9092,192.168.233.30:9092 --topic test1
//消费消息
kafka-console-consumer.sh --bootstrap-server 192.168.233.10:9092,192.168.233.20:9092,192.168.233.30:9092 --topic test1 --from-beginning
-------------------------------------------------------------------------------------
--from-beginning:会把主题中以往所有的数据都读取出来
-------------------------------------------------------------------------------------
//修改分区数
kafka-topics.sh --bootstrap-server 192.168.233.10:9092,192.168.233.20:9092,192.168.233.30:9092 --alter --topic test1 --partitions 6
//删除 topic
kafka-topics.sh --delete --bootstrap-server 192.168.233.10:9092,192.168.233.20:9092,192.168.233.30:9092 --topic test1
六、ELK+filebeat+kafka的安装部署
工作流程:

部署 Zookeeper+Kafka 集群
zookeeper+kafka节点:
20.0.0.45
20.0.0.46
2.部署 Filebeat
cd /usr/local/filebeat
vim filebeat.yml
filebeat.prospectors:
- type: log
enabled: true
paths:
- /var/log/nginx/access_log
tags: ["access"]
- type: log
enabled: true
paths:
- /var/log/nginx/error_log
tags: ["error"]
#添加输出到 Kafka 的配置
output.kafka:
enabled: true
hosts: ["20.0.0.45:9092,20.0.0.46:9092"]
topic: "nginx"
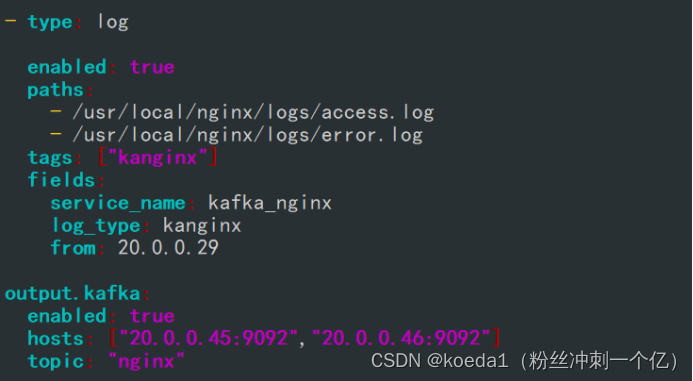
因为不转发到logstash,下面的output全部注释掉
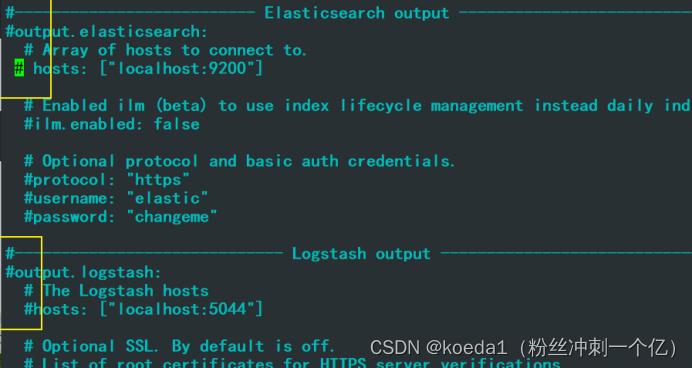
启动 filebeat
nohup ./filebeat -e -c filebeat.yml > filebeat.out &
logstash:
启动logstash:
systemctl start logstash.service
ps -elf | grep logstash
部署 ELK,在 Logstash 组件所在节点上新建一个 Logstash 配置文件
cd /etc/logstash/conf.d/
vim kafka.conf
input {
kafka {
bootstrap_servers => "192.168.233.10:9092,192.168.233.20:9092,192.168.233.30:9092"
#kafka集群地址
topics => "nginx"
#拉取的kafka的指定topic
type => "nginx_kafka"
#指定 type 字段
codec => "json"
#解析json格式的日志数据
auto_offset_reset => "latest"
#拉取最近数据,earliest为从头开始拉取
decorate_events => true
#传递给elasticsearch的数据额外增加kafka的属性数据
}
}
output {
if "nginx_access" in [tags] {
elasticsearch {
hosts => ["192.168.233.12:9200","192.168.233.13:9200"]
index => "nginx_access-%{+YYYY.MM.dd}"
}
}
if "nginx_error" in [tags] {
elasticsearch {
hosts => ["192.168.233.12:9200","192.168.233.13:9200"]
index => "nginx_error-%{+YYYY.MM.dd}"
}
}
stdout { codec => rubydebug }
}
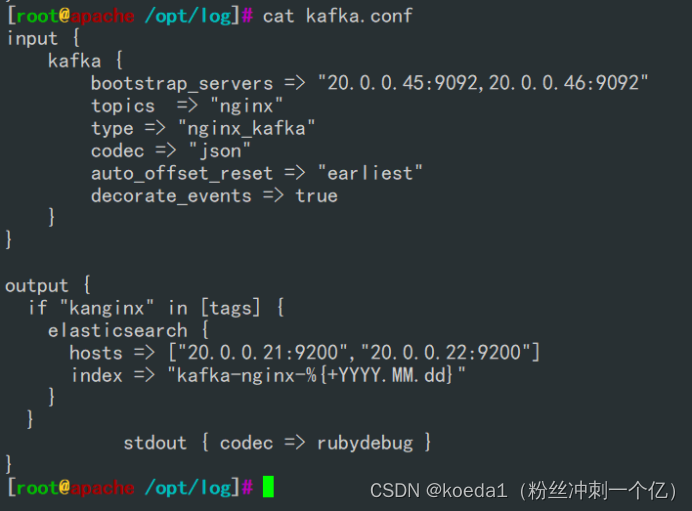
#启动 logstash
logstash -f /opt/log/kafka.conf --path.data /opt/kafka1 &
在此之前要保证ES启动
systemctl restart elasticsearch
cd /opt/elasticsearch-head-master
npm run start &
netstat -natp |grep 9100
netstat -natp |grep 9200
去kafka看有没有创建topic(是filebeat操作的)
kafka-topics.sh --list --bootstrap-server 20.0.0.45:9092,20.0.0.46:9092

消费消息:
kafka-console-consumer.sh --bootstrap-server 20.0.0.45:9092,20.0.0.46:9092 --topic nginx --from-beginning
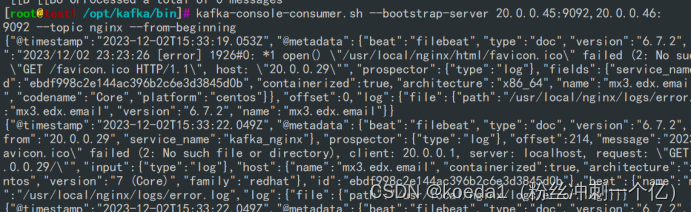
logstash也命中消息

最后去logstash浏览器查看:
索引生成

相关文章:
zookeeper+kafka+ELK+filebeat集群
目录 一、zookeeper概述: 1、zookeeper工作机制: 2、zookeeper主要作用: 3、zookeeper特性: 4、zookeeper的应用场景: 5、领导者和追随者:zookeeper的选举机制 二、zookeeper安装部署: 三…...
-ChatGLM3)
【LangChain实战】开源模型学习(2)-ChatGLM3
介绍 ChatGLM3 是智谱AI和清华大学 KEG 实验室联合发布的新一代对话预训练模型。ChatGLM3-6B 是 ChatGLM3 系列中的开源模型,在保留了前两代模型对话流畅、部署门槛低等众多优秀特性的基础上,ChatGLM3-6B 引入了如下特性: 更强大的基础模型&a…...

Python编程技巧 – 迭代器(Iterator)
Python编程技巧 – 迭代器(Iterator) By JacksonML Iterator(迭代器)是Python语言的核心概念之一。它常常与装饰器和生成器一道被人们提及,也是所有Python书籍需要涉及的部分。 本文简要介绍迭代器的功能以及实际的案例,希望对广大读者和学生有所帮助。…...

C语言练习题
C语言练习题 文章目录 C语言练习题题目一题目二题目三题目四题目五题目六题目八 题目一 #include <stdio.h> //VS2022,默认对齐数为8字节 union Un {short s[7];int n; };int main() {printf("%zd", sizeof(union Un));return 0; }代码运行结果:> 16 sizeo…...

常见的AI安全风险(数据投毒、后门攻击、对抗样本攻击、模型窃取攻击等)
文章目录 数据投毒(Data Poisoning)后门攻击(Backdoor Attacks)对抗样本攻击(Adversarial Examples)模型窃取攻击(Model Extraction Attacks)参考资料 数据投毒(Data Poi…...

flutter开发实战-为ListView去除Android滑动波纹
flutter开发实战-为ListView去除Android滑动波纹 在之前的flutter聊天界面上,由于使用ScrollBehavior时候,当时忘记试试了,今天再试代码发现不对。这里重新记录一下为ListView去除Android滑动波纹的方式。 一、ScrollBehavior ScrollBehav…...
牛客在线编程(SQL大厂面试真题)
1.各个视频的平均完播率_牛客题霸_牛客网 ROP TABLE IF EXISTS tb_user_video_log, tb_video_info; CREATE TABLE tb_user_video_log (id INT PRIMARY KEY AUTO_INCREMENT COMMENT 自增ID,uid INT NOT NULL COMMENT 用户ID,video_id INT NOT NULL COMMENT 视频ID,start_time d…...
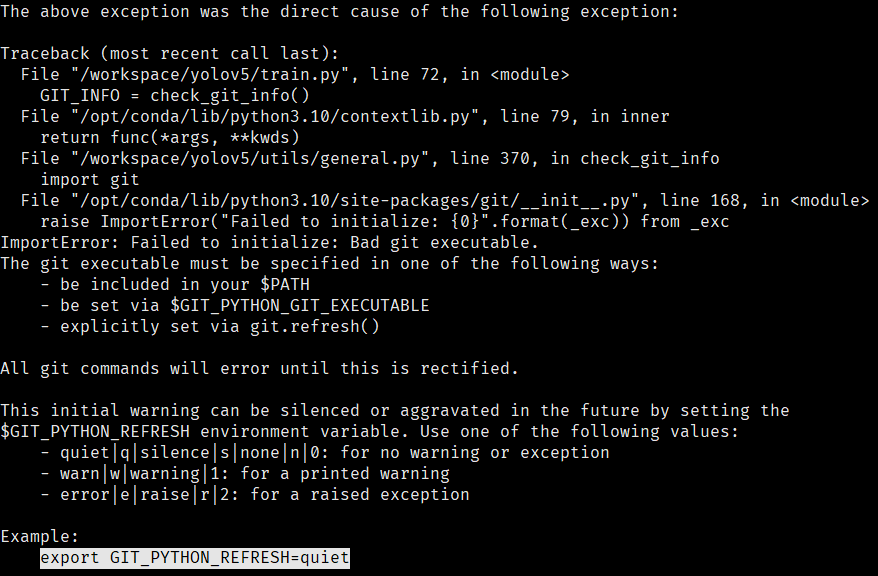
ubuntu下快速搭建docker环境训练yolov5数据集
参考文档 yolov5-github yolov5-github-训练文档 csdn训练博客 一、配置环境 1.1 安装依赖包 前往清华源官方地址 选择适合自己的版本替换自己的源 # 备份源文件 sudo cp /etc/apt/sources.list /etc/apt/sources.list_bak # 修改源文件 # 更新 sudo apt update &&a…...
SpringMVC常用注解和用法总结
目标: 1. 熟悉使用SpringMVC中的常用注解 目录 前言 1. Controller 2. RestController 3. RequestMapping 4. RequestParam 5. PathVariable 6. SessionAttributes 7. CookieValue 前言 SpringMVC是一款用于构建基于Java的Web应用程序的框架,它通…...

webpack如何处理css
一、准备工作 新建目录 添加样式 .word {color: red; } index.js添加dom元素,添加一个css word import ./css/index.css;const div document.createElement("div"); div.innerText "hello word!!!"; div.className "word"; do…...

IELTS学习笔记_grammar_新东方
参考: 新东方 田静 语法 目录: 导学简单句… x.1 导学 学语法以应用为主。 基础为:单词,语法 进阶为:听说读写译,只考听说读写。 words -> chunks -> sentences, chunks(语块的重要…...

【计算机组成原理】存储器知识
目录 1、存储器分类 1.1、按存储介质分类 1.2、按存取方式分类 1.3、按信息的可改写性分类 1.4、按信息的可保存性分类 1.5、按功能和存取速度分类 2、存储器技术指标 2.1、存储容量 2.2、存取速度 3、存储系统层次结构 4、主存的基本结构 5、主存中数据的存放 5.…...

vscode配置代码片段
1.ctrl shift p 然后选择 Snippets:Configure User Snippets (配置用户代码片段) 2.选择vue或者vue.json 3.下面为json内容 { “vue-template”: { “prefix”: “modal-table”, “body”: [ “”, " <a-modal v-model:visible“visible” wi…...
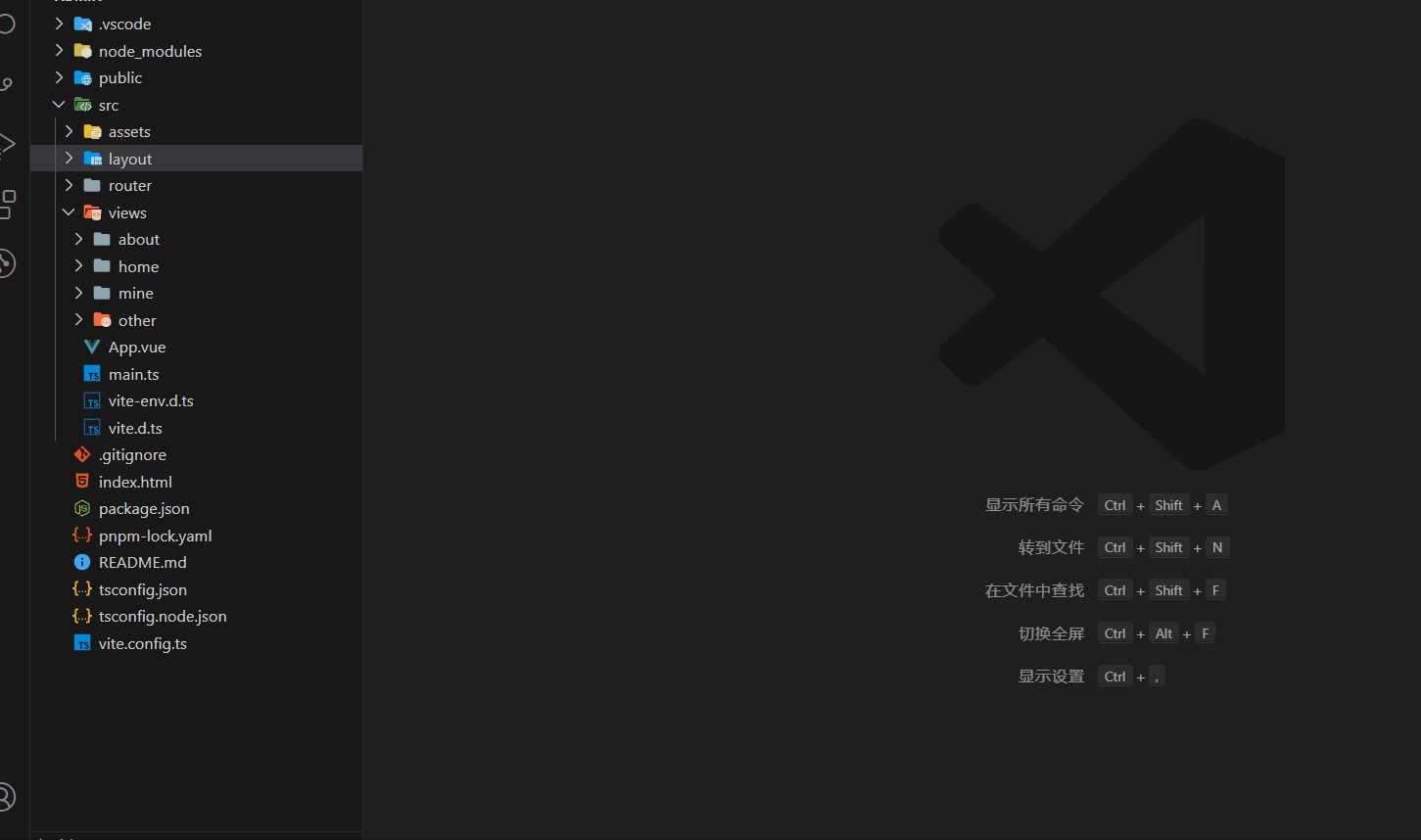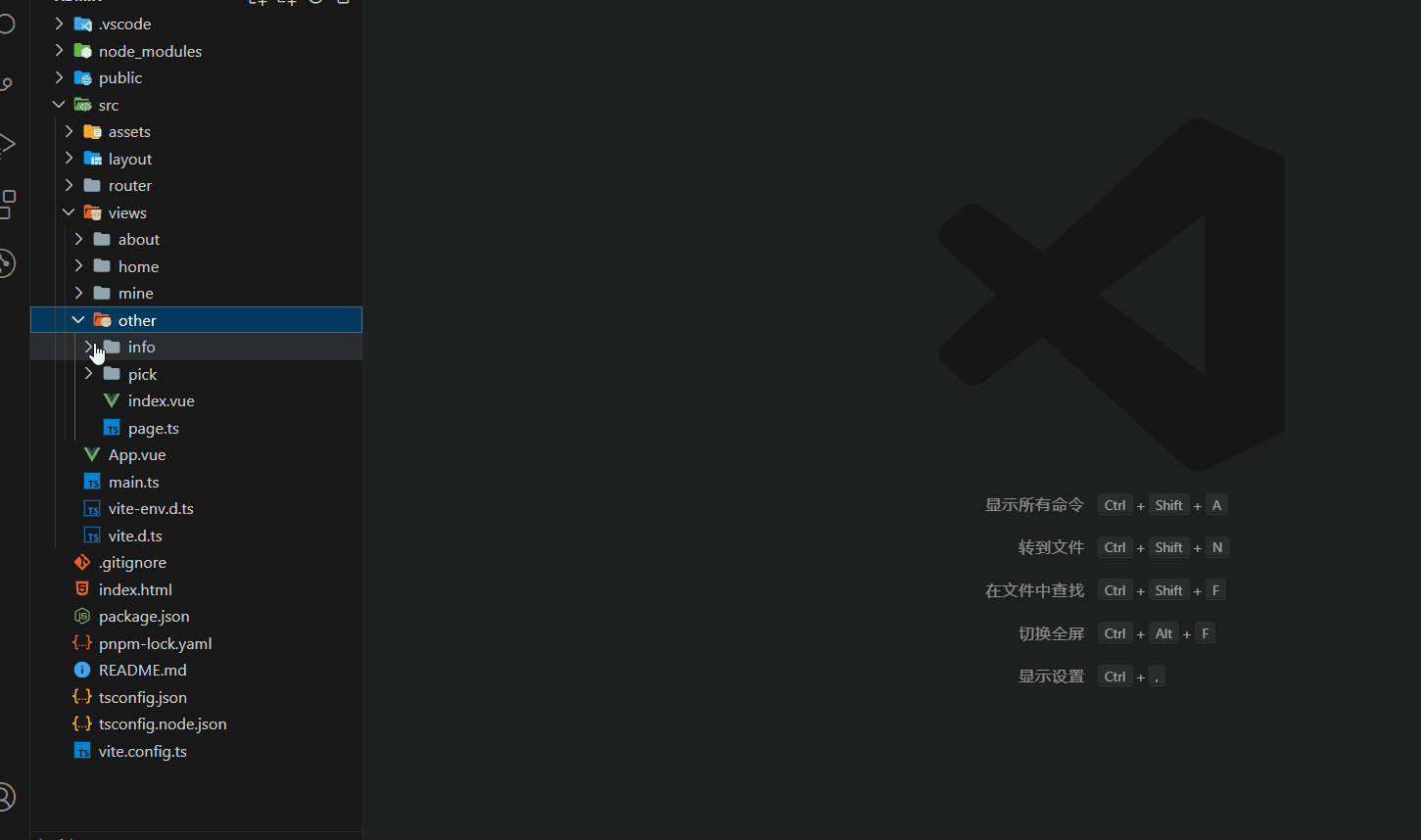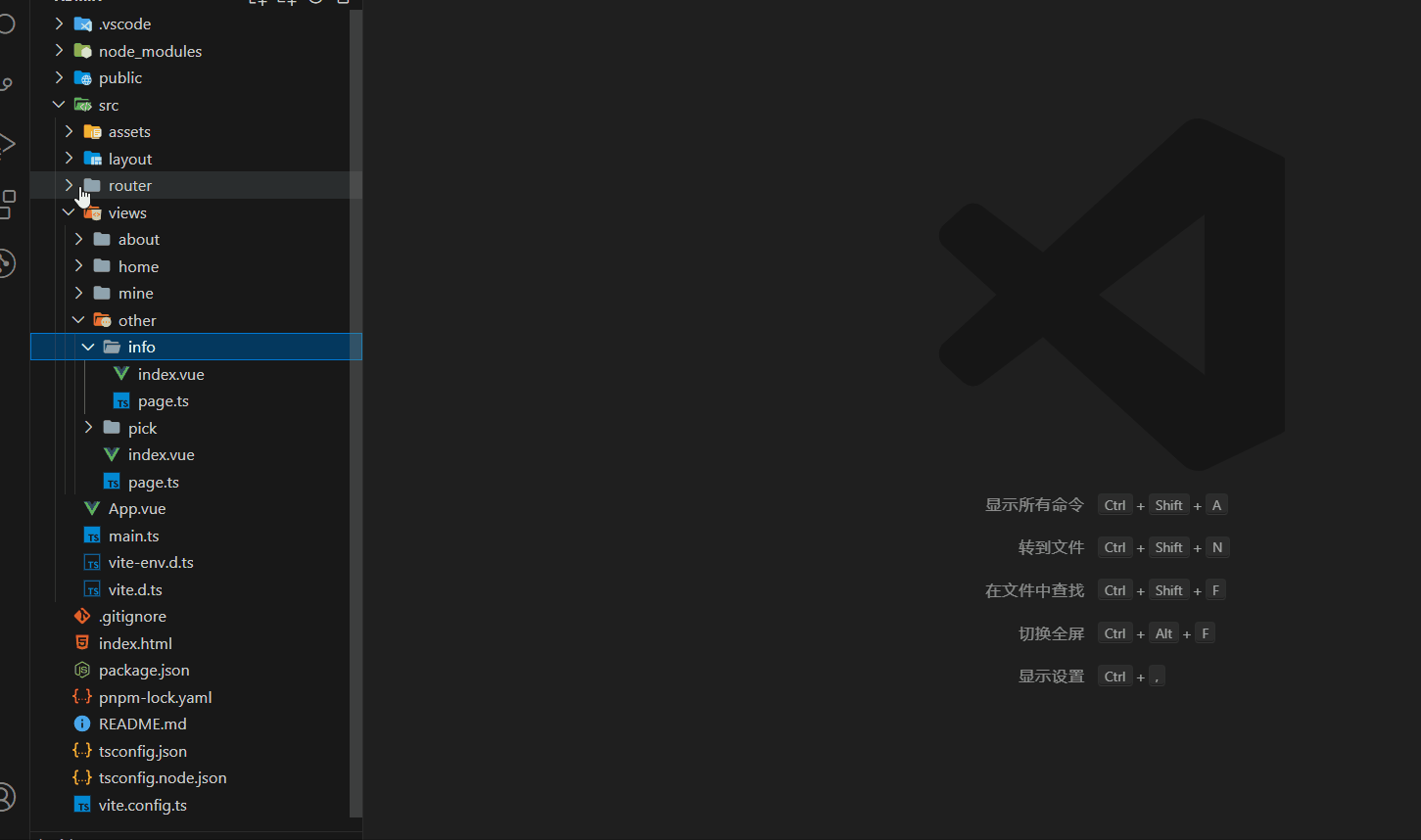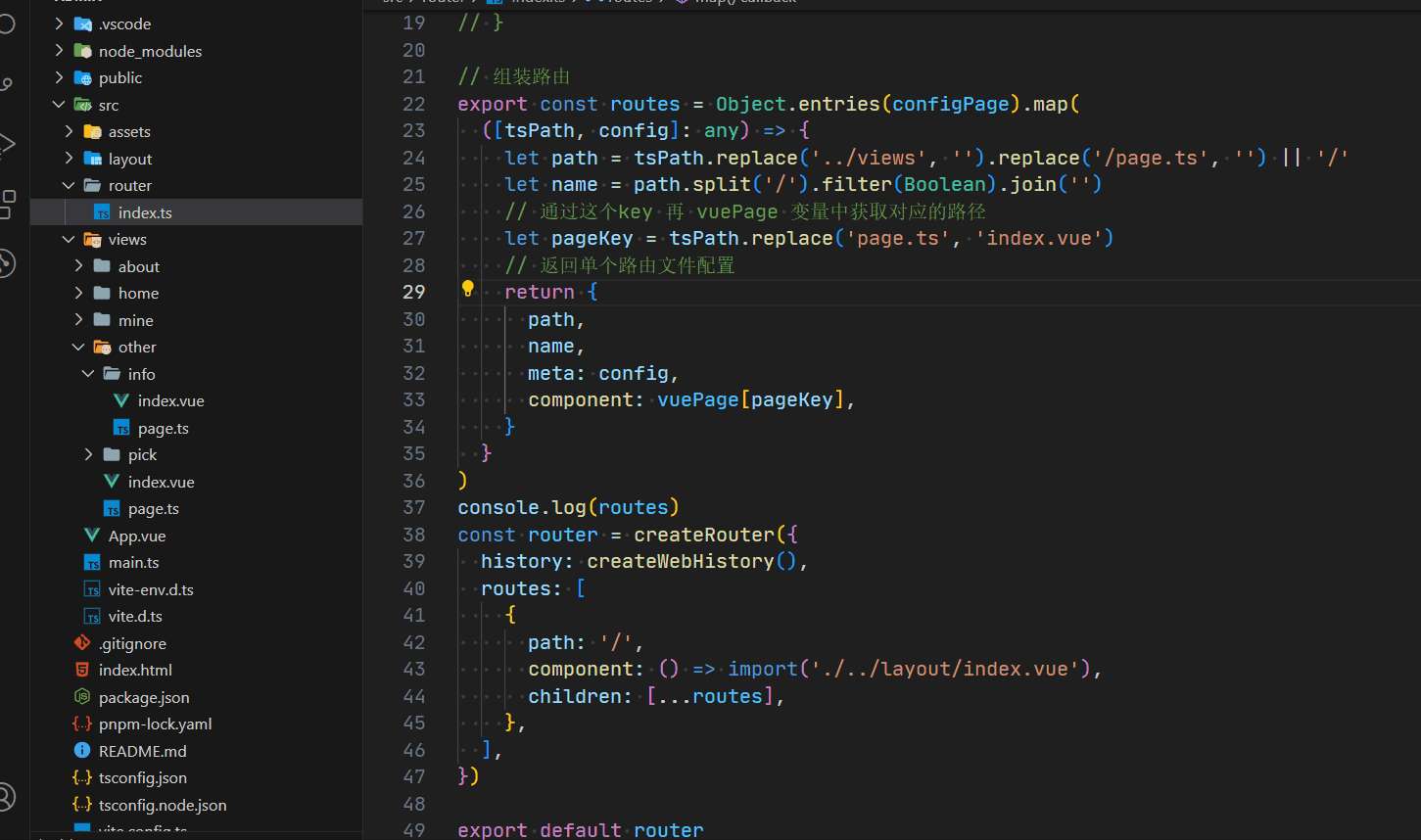
vite脚手架,手写实现配置动态生成路由
参考文档 vite的glob-import vue路由配置基本都是重复的代码,每次都写一遍挺难受,加个页面就带配置下路由 那就利用 vite 的 文件系统处理啊 先看实现效果 1. 考虑怎么约定路由,即一个文件夹下,又有组件,又有页面&am…...

解决浏览器缓存问题
1.index.html文件meta标签添加属性 <meta name"viewport" content"widthdevice-width,initial-scale1.0, maximum-scale1.0, minimum-scale1.0, user-scalableno" viewport-fitcover >2.提前main.html处理逻辑再跳转到index.html页 <script>…...
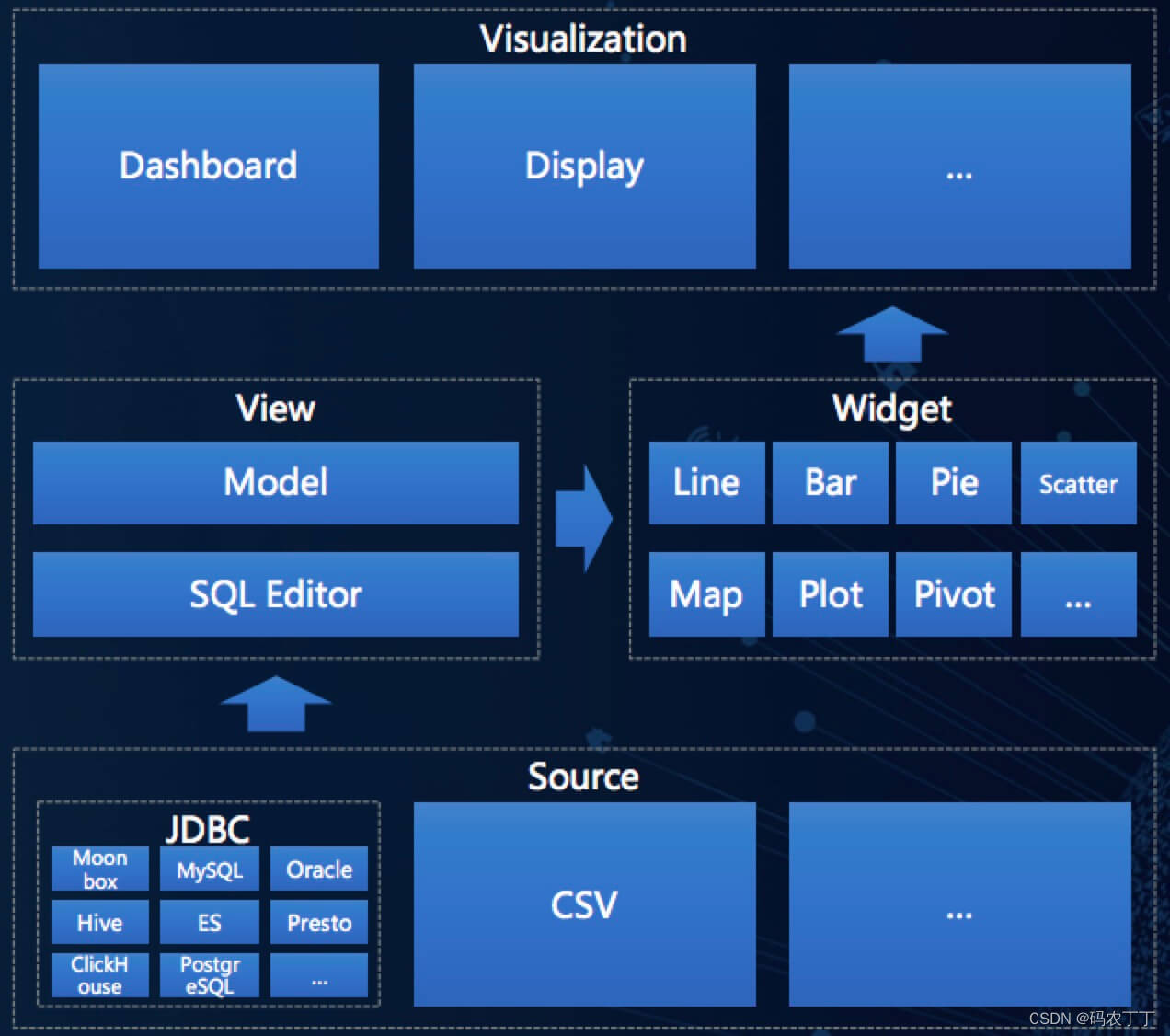
【数据中台】开源项目(2)-Davinci可视应用平台
1 平台介绍 Davinci 是一个 DVaaS(Data Visualization as a Service)平台解决方案,面向业务人员/数据工程师/数据分析师/数据科学家,致力于提供一站式数据可视化解决方案。既可作为公有云/私有云独立部署使用,也可作为…...
Java实现简单飞翔小鸟游戏
一、创建新项目 首先创建一个新的项目,并命名为飞翔的鸟。 其次在飞翔的鸟项目下创建一个名为images的文件夹用来存放游戏相关图片。 用到的图片如下:0~7: bg: column: gameover: ground: st…...

numpy实现神经网络
numpy实现神经网络 首先讲述的是神经网络的参数初始化与训练步骤 随机初始化 任何优化算法都需要一些初始的参数。到目前为止我们都是初始所有参数为0,这样的初始方法对于逻辑回归来说是可行的,但是对于神经网络来说是不可行的。如果我们令所有的初始…...

Bean的加载控制
Bean的加载控制 文章目录 Bean的加载控制编程式注解式ConditionalOn*** 编程式 public class MyImportSelector implements ImportSelector {Overridepublic String[] selectImports(AnnotationMetadata annotationMetadata) {try {Class<?> clazz Class.forName("…...

使用 OpenCV 识别和裁剪黑白图像上的白色矩形--含源码
为了仅获取具有特定边框颜色的矩形,我寻求一种替代识别图像中的轮廓和所有矩形的传统方法。如示例图片所示,我有兴趣使用 opencv 仅获取白色边框矩形的坐标。任何这方面的建议将不胜感激。到目前为止,我的代码已产生如下所示的输出。我的下一个目标是将图像裁剪到大的中心框…...

生成xcframework
打包 XCFramework 的方法 XCFramework 是苹果推出的一种多平台二进制分发格式,可以包含多个架构和平台的代码。打包 XCFramework 通常用于分发库或框架。 使用 Xcode 命令行工具打包 通过 xcodebuild 命令可以打包 XCFramework。确保项目已经配置好需要支持的平台…...

Cilium动手实验室: 精通之旅---20.Isovalent Enterprise for Cilium: Zero Trust Visibility
Cilium动手实验室: 精通之旅---20.Isovalent Enterprise for Cilium: Zero Trust Visibility 1. 实验室环境1.1 实验室环境1.2 小测试 2. The Endor System2.1 部署应用2.2 检查现有策略 3. Cilium 策略实体3.1 创建 allow-all 网络策略3.2 在 Hubble CLI 中验证网络策略源3.3 …...

电脑插入多块移动硬盘后经常出现卡顿和蓝屏
当电脑在插入多块移动硬盘后频繁出现卡顿和蓝屏问题时,可能涉及硬件资源冲突、驱动兼容性、供电不足或系统设置等多方面原因。以下是逐步排查和解决方案: 1. 检查电源供电问题 问题原因:多块移动硬盘同时运行可能导致USB接口供电不足&#x…...

376. Wiggle Subsequence
376. Wiggle Subsequence 代码 class Solution { public:int wiggleMaxLength(vector<int>& nums) {int n nums.size();int res 1;int prediff 0;int curdiff 0;for(int i 0;i < n-1;i){curdiff nums[i1] - nums[i];if( (prediff > 0 && curdif…...

DIY|Mac 搭建 ESP-IDF 开发环境及编译小智 AI
前一阵子在百度 AI 开发者大会上,看到基于小智 AI DIY 玩具的演示,感觉有点意思,想着自己也来试试。 如果只是想烧录现成的固件,乐鑫官方除了提供了 Windows 版本的 Flash 下载工具 之外,还提供了基于网页版的 ESP LA…...
)
GitHub 趋势日报 (2025年06月08日)
📊 由 TrendForge 系统生成 | 🌐 https://trendforge.devlive.org/ 🌐 本日报中的项目描述已自动翻译为中文 📈 今日获星趋势图 今日获星趋势图 884 cognee 566 dify 414 HumanSystemOptimization 414 omni-tools 321 note-gen …...

在Ubuntu24上采用Wine打开SourceInsight
1. 安装wine sudo apt install wine 2. 安装32位库支持,SourceInsight是32位程序 sudo dpkg --add-architecture i386 sudo apt update sudo apt install wine32:i386 3. 验证安装 wine --version 4. 安装必要的字体和库(解决显示问题) sudo apt install fonts-wqy…...

【Go语言基础【13】】函数、闭包、方法
文章目录 零、概述一、函数基础1、函数基础概念2、参数传递机制3、返回值特性3.1. 多返回值3.2. 命名返回值3.3. 错误处理 二、函数类型与高阶函数1. 函数类型定义2. 高阶函数(函数作为参数、返回值) 三、匿名函数与闭包1. 匿名函数(Lambda函…...

AI+无人机如何守护濒危物种?YOLOv8实现95%精准识别
【导读】 野生动物监测在理解和保护生态系统中发挥着至关重要的作用。然而,传统的野生动物观察方法往往耗时耗力、成本高昂且范围有限。无人机的出现为野生动物监测提供了有前景的替代方案,能够实现大范围覆盖并远程采集数据。尽管具备这些优势…...

多模态图像修复系统:基于深度学习的图片修复实现
多模态图像修复系统:基于深度学习的图片修复实现 1. 系统概述 本系统使用多模态大模型(Stable Diffusion Inpainting)实现图像修复功能,结合文本描述和图片输入,对指定区域进行内容修复。系统包含完整的数据处理、模型训练、推理部署流程。 import torch import numpy …...