使用coco数据集进行语义分割(1):数据预处理,制作ground truth
如何coco数据集进行目标检测的介绍已经有很多了,但是关于语义分割几乎没有。本文旨在说明如何处理 stuff_train2017.json stuff_val2017.json panoptic_train2017.json panoptic_val2017.json,将上面那些json中的dict转化为图片的label mask,也就是制作图片像素的标签的ground truth。
首先下载图片和annotation文件(也就是json文件)
2017 Train Images和2017 Val Images解压得到这两个文件夹,里面放着的是所有图片。
annotation下载下来有4个json文件
以及两个压缩包
这两个压缩包里面是panoptic segmentation的mask,用于制作ground truth。
首先说明一下那四个json文件的含义,stuff是语义分割,panoptic是全景分割。二者的区别在与

语义分割只区别种类,全景分割还区分个体。上图中,中间的语义分割将所有的人类视作同一个种类看待,而右边的全景分割还将每一个个体区分出来。
做语义分割,可以使用stuff_train2017.json生成ground truth。但是即便是只做语义分割,不做全景分割,在只看语义分割的情况下,stuff的划分精度不如panoptic,因此建立即使是做语义分割也用panoptic_train2017.json。本文中将两种json都进行说明。
stuff_train2017.json
下面这段代码是处理stuff_train2017.json生成ground truth
from pycocotools.coco import COCO
import os
from PIL import Image
import numpy as np
from matplotlib import pyplot as pltdef convert_coco2mask_show(image_id):print(image_id)img = coco.imgs[image_id]image = np.array(Image.open(os.path.join(img_dir, img['file_name'])))plt.imshow(image, interpolation='nearest')# cat_ids = coco.getCatIds()cat_ids = list(range(183))anns_ids = coco.getAnnIds(imgIds=img['id'], catIds=cat_ids, iscrowd=None)anns = coco.loadAnns(anns_ids)mask = np.zeros((image.shape[0], image.shape[1]))for i in range(len(anns)):tmp = coco.annToMask(anns[i]) * anns[i]["category_id"]mask += tmpprint(np.max(mask), np.min(mask))# 绘制二维数组对应的颜色图plt.figure(figsize=(8, 6))plt.imshow(mask, cmap='viridis', vmin=0, vmax=182)plt.colorbar(ticks=np.linspace(0, 182, 6), label='Colors') # 添加颜色条# plt.savefig(save_dir + str(image_id) + ".jpg")plt.show()if __name__ == '__main__':Dataset_dir = "/home/xxxx/Downloads/coco2017/"coco = COCO("/home/xxxx/Downloads/coco2017/annotations/stuff_train2017.json")# createIndex# coco = COCO("/home/robotics/Downloads/coco2017/annotations/annotations/panoptic_val2017.json")img_dir = os.path.join(Dataset_dir, 'train2017')save_dir = os.path.join(Dataset_dir, "Mask/stuff mask/train")if not os.path.isdir(save_dir):os.makedirs(save_dir)image_id = 9convert_coco2mask_show(image_id)# for keyi, valuei in coco.imgs.items():# image_id = valuei["id"]# convert_coco2mask_show(image_id)
解释一下上面的代码。
coco = COCO("/home/xxxx/Downloads/coco2017/annotations/stuff_train2017.json")从coco的官方库中导入工具,读取json。会得到这样的字典结构
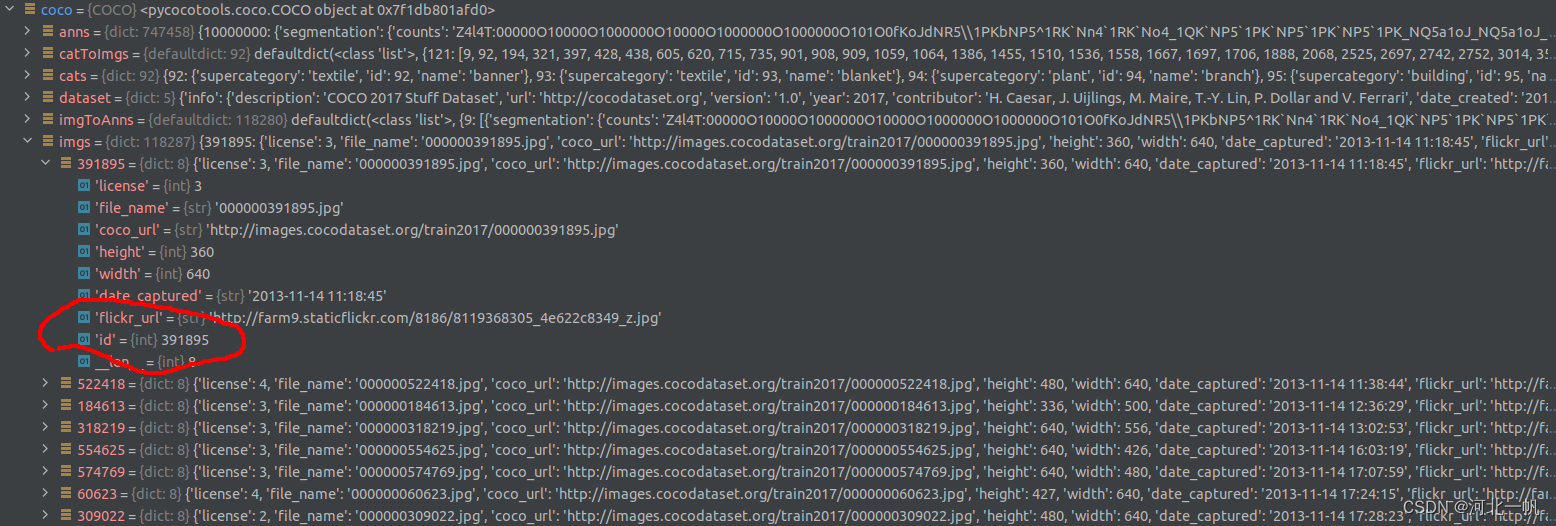
在 coco.imgs ,找到 "id" 对应的value,这个就是每个图片唯一的编号,根据这个编号,到 coco.anns 中去索引 segmentation

注意 coco.imgs 的 id 对应的是 anns 中的 image_id,这个也是 train2017 文件夹中图片的文件名。
# cat_ids = coco.getCatIds()
cat_ids = list(range(183))网上的绝大多数教程都写的是上面我注释的那行代码,那行代码会得到91个类,那个只能用于图像检测,但对于图像分割任务,包括的种类是182个和一个未归类的0类一共183个类。
tmp = coco.annToMask(anns[i]) * anns[i]["category_id"]上面那行代码就是提取每一个类所对应的id,将所有的类都加进一个二维数组,就制作完成了ground truth。
panoptic_train2017.json
上面完成了通过stuff的json文件自作ground truth,那么用panoptic的json文件制作ground truth,是不是只要把
coco = COCO("/home/xxxx/Downloads/coco2017/annotations/stuff_train2017.json")换为
coco = COCO("/home/xxxx/Downloads/coco2017/annotations/annotations/panoptic_val2017.json")就行了呢?
答案是不行!会报错
Traceback (most recent call last):File "/home/xxxx/.local/lib/python3.8/site-packages/IPython/core/interactiveshell.py", line 3508, in run_codeexec(code_obj, self.user_global_ns, self.user_ns)File "<ipython-input-4-66f5c6e7dbe4>", line 1, in <module>coco = COCO("/home/xxxx/Downloads/coco2017/annotations/panoptic_val2017.json")File "/home/robotics/.local/lib/python3.8/site-packages/pycocotools/coco.py", line 86, in __init__self.createIndex()File "/home/xxxx/.local/lib/python3.8/site-packages/pycocotools/coco.py", line 96, in createIndexanns[ann['id']] = ann
KeyError: 'id'用官方的库读官方的json还报错,真是巨坑!关键还没有官方的文档教你怎么用,只能一点点摸索,非常浪费时间精力。
制作panoptic的ground truth,用到了Meta公司的detectron2这个库
# Copyright (c) Facebook, Inc. and its affiliates.
import copy
import json
import osfrom detectron2.data import MetadataCatalog
from detectron2.utils.file_io import PathManagerdef load_coco_panoptic_json(json_file, image_dir, gt_dir, meta):"""Args:image_dir (str): path to the raw dataset. e.g., "~/coco/train2017".gt_dir (str): path to the raw annotations. e.g., "~/coco/panoptic_train2017".json_file (str): path to the json file. e.g., "~/coco/annotations/panoptic_train2017.json".Returns:list[dict]: a list of dicts in Detectron2 standard format. (See`Using Custom Datasets </tutorials/datasets.html>`_ )"""def _convert_category_id(segment_info, meta):if segment_info["category_id"] in meta["thing_dataset_id_to_contiguous_id"]:segment_info["category_id"] = meta["thing_dataset_id_to_contiguous_id"][segment_info["category_id"]]segment_info["isthing"] = Trueelse:segment_info["category_id"] = meta["stuff_dataset_id_to_contiguous_id"][segment_info["category_id"]]segment_info["isthing"] = Falsereturn segment_infowith PathManager.open(json_file) as f:json_info = json.load(f)ret = []for ann in json_info["annotations"]:image_id = int(ann["image_id"])# TODO: currently we assume image and label has the same filename but# different extension, and images have extension ".jpg" for COCO. Need# to make image extension a user-provided argument if we extend this# function to support other COCO-like datasets.image_file = os.path.join(image_dir, os.path.splitext(ann["file_name"])[0] + ".jpg")label_file = os.path.join(gt_dir, ann["file_name"])segments_info = [_convert_category_id(x, meta) for x in ann["segments_info"]]ret.append({"file_name": image_file,"image_id": image_id,"pan_seg_file_name": label_file,"segments_info": segments_info,})assert len(ret), f"No images found in {image_dir}!"assert PathManager.isfile(ret[0]["file_name"]), ret[0]["file_name"]assert PathManager.isfile(ret[0]["pan_seg_file_name"]), ret[0]["pan_seg_file_name"]return retif __name__ == "__main__":from detectron2.utils.logger import setup_loggerfrom detectron2.utils.visualizer import Visualizerimport detectron2.data.datasets # noqa # add pre-defined metadatafrom PIL import Imageimport matplotlib.pyplot as pltimport numpy as nplogger = setup_logger(name=__name__)meta = MetadataCatalog.get("coco_2017_train_panoptic")dicts = load_coco_panoptic_json("/home/xxxx/Downloads/coco2017/annotations/panoptic_train2017.json","/home/xxxx/Downloads/coco2017/train2017","/home/xxxx/Downloads/coco2017/Mask/panoptic mask/panoptic_train2017", meta.as_dict())logger.info("Done loading {} samples.".format(len(dicts)))dirname = "coco-data-vis"os.makedirs(dirname, exist_ok=True)new_dic = {}num_imgs_to_vis = 100for i, d in enumerate(dicts):img = np.array(Image.open(d["file_name"]))visualizer = Visualizer(img, metadata=meta)pan_seg, segments_info = visualizer.draw_dataset_dict(d)seg_cat = {0: 0}for segi in segments_info:seg_cat[segi["id"]] = segi["category_id"]mapped_seg = np.vectorize(seg_cat.get)(pan_seg)# 保存数组为txt文件save_name = "/home/xxxx/Downloads/coco2017/Mask/panoptic label/train/" + str(d["image_id"]) + ".txt"np.savetxt(save_name, mapped_seg, fmt='%i')new_dic[d["image_id"]] = {"image_name": d["file_name"], "label_name": save_name}# # 将numpy数组转换为PIL Image对象# img1 = Image.fromarray(np.uint8(mapped_seg))# # 缩放图片# img_resized = img1.resize((224, 224))# # 将PIL Image对象转换回numpy数组# mapped_seg_resized = np.array(img_resized)# # 创建一个新的图形# plt.figure(figsize=(6, 8))# # 使用imshow函数来显示数组,并使用cmap参数来指定颜色映射# plt.imshow(mapped_seg_resized, cmap='viridis')# # 显示图形# plt.show()# fpath = os.path.join(dirname, os.path.basename(d["file_name"]))# # vis.save(fpath)if i + 1 >= num_imgs_to_vis:# 将字典转换为json字符串json_data = json.dumps(new_dic)# 将json字符串写入文件with open('/home/xxxx/Downloads/coco2017/data_for_train.json', 'w') as f:f.write(json_data)break
dicts = load_coco_panoptic_json("/home/xxxx/Downloads/coco2017/annotations/panoptic_train2017.json","/home/xxxx/Downloads/coco2017/train2017","/home/xxxx/Downloads/coco2017/Mask/panoptic mask/panoptic_train2017", meta.as_dict())load_coco_panoptic_json的第三个参数,就是下载panoptic的annotations时,里面包含的两个压缩包。
上面这段代码,还需要修改一下detectron2库内部的文件
pan_seg, segments_info = visualizer.draw_dataset_dict(d)进入 draw_dataset_dict这个函数内部,将两个中间结果拿出来

603行和604行是我自己加的代码。
这两个中间结果拿出来后,pan_seg是图片每个像素所属的种类,但是这个种类不是coco分类的那183个类
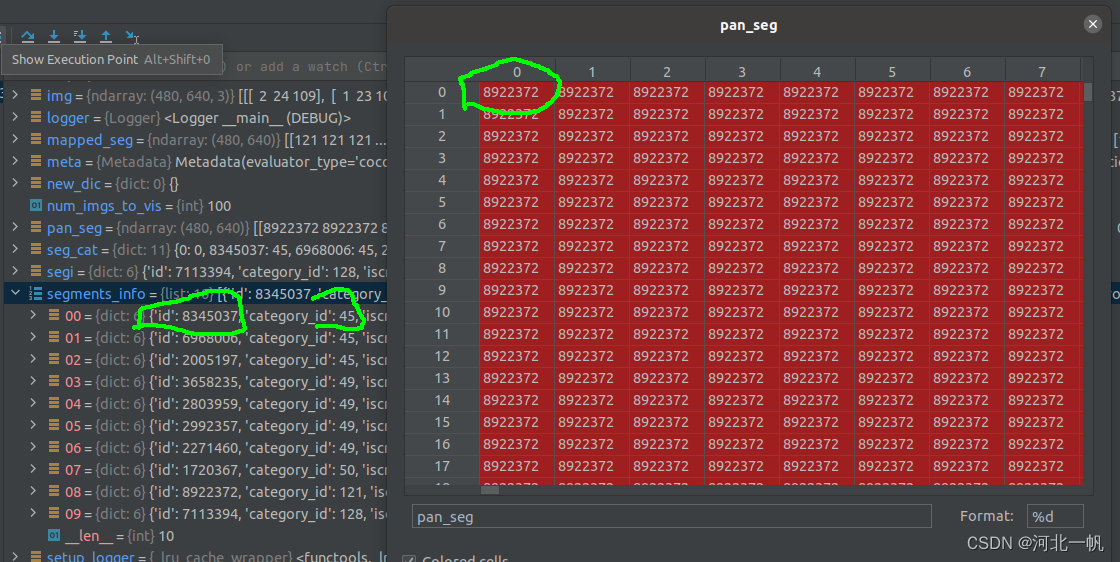
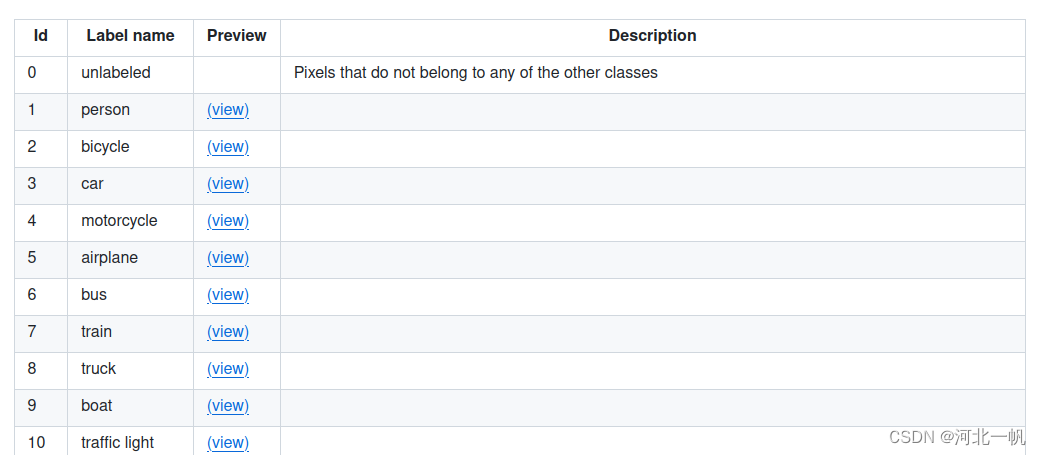
pan_seg中的数,要映射到segments_info中的 category_id,这个才是coco数据集所规定的183个类 。下图节选了183个中的前10个展示
mapped_seg = np.vectorize(seg_cat.get)(pan_seg)上面这行代码就是完成pan_seg中的数,映射到segments_info中的 category_id。不要用两层的for循环,太低效了,numpy中有函数可以完成数组的映射。
这样就得到了语义分割的ground truth,也就是每个像素所属的种类。
相关文章:
使用coco数据集进行语义分割(1):数据预处理,制作ground truth
如何coco数据集进行目标检测的介绍已经有很多了,但是关于语义分割几乎没有。本文旨在说明如何处理 stuff_train2017.json stuff_val2017.json panoptic_train2017.json panoptic_val2017.json,将上面那些json中的dict转化为图片的label mask&am…...

神经网络 模型表示2
神经网络 模型表示2 使用向量化的方法会使得计算更为简便。以上面的神经网络为例,试着计算第二层的值: 我们令 z ( 2 ) θ ( 1 ) x {{z}^{\left( 2 \right)}}{{\theta }^{\left( 1 \right)}}x z(2)θ(1)x,则 a ( 2 ) g ( z ( 2 ) ) {{a}…...

ubuntu使用SSH服务远程登录另一台设备
1、安装openssh-client和openssh-server 查看当前的ubuntu是否安装了ssh-server服务。默认只安装ssh-client服务。 dpkg -l | grep ssh查看有没有openssh-client的相关字眼。 2、安装ssh-server服务(受控制方) sudo apt-get install openssh-server再…...

读书笔记:《Effective Modern C++(C++14)》
Effective Modern C(C14) GitHub - CnTransGroup/EffectiveModernCppChinese: 《Effective Modern C》- 完成翻译 Deducing Types 模版类型推导: 引用,const,volatile被忽略数组名和函数名退化为指针通用引用&#…...

PCL 点云加权均值收缩
文章目录 一、简介二、实现代码三、实现效果参考资料一、简介 受到之前Matlab 加权均值质心计算(WMN)的启发,我们在计算每个点的加权质心时可以很容易的发现,他们这些点会受到周围邻近点密度的影响,最后会收缩到某一个区域,那么这个区域也必定是我们比较感兴趣的一些点,…...

计算机毕业设计 基于协同推荐的白酒销售管理系统的设计与实现 Java实战项目 附源码+文档+视频讲解
博主介绍:✌从事软件开发10年之余,专注于Java技术领域、Python人工智能及数据挖掘、小程序项目开发和Android项目开发等。CSDN、掘金、华为云、InfoQ、阿里云等平台优质作者✌ 🍅文末获取源码联系🍅 👇🏻 精…...
:包含内嵌表单元素的表单)
React-hook-form-mui(五):包含内嵌表单元素的表单
前言 在上一篇文章中,我们介绍了react-hook-form-mui如何与与后端数据联调。在实际项目中,从后端获取的数据可能是复杂的数据对象,本文将介绍,如何通过react-hook-form-mui实现一个包含内嵌表单元素的表单 Demo 以下代码实现了…...
【内网安全】搭建网络拓扑,CS内网横向移动实验
文章目录 搭建网络拓扑 ☁环境CS搭建,木马生成上传一句话,获取WebShellCS上线reGeorg搭建代理,访问内网域控IIS提权信息收集横向移动 实验拓扑结构如下: 搭建网络拓扑 ☁ 环境 **攻击者win10地址:**192.168.8.3 dmz win7地址&…...

1、输入一行字符,分别统计出其中的英文字母、空格、数字和其他字符的个数。
1、输入一行字符,分别统计出其中的英文字母、空格、数字和其他字符的个数。 int main(){char str[N];int letter 0,space 0,digit 0, others 0;printf("请输入一行字符:");gets(str);for(int i0;str[i]!\0;i){if((a<str[i] && …...

戴尔科技推出全新96核Precision 7875塔式工作站
工作站行业一直是快节奏且充满惊喜的。在过去25年中,戴尔Precision一直处于行业前沿,帮助创作者、工程师、建筑师、研究人员等将想法变为现实,并对整个世界产生影响。工作站所发挥的作用至关重要,被视为化不可能为可能的必要工具。如今,人工智能(AI)和生成式AI(GenAI)的浪潮正在…...
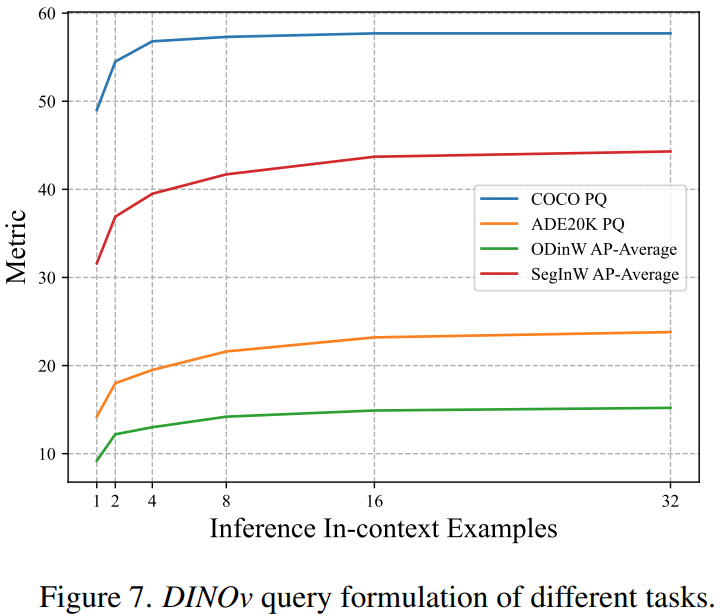
论文阅读——DINOv
首先是关于给了提示然后做分割的一些方法的总结: 左边一列是prompt类型,右边一列是使用各个类型的prompt的模型。这些模型有分为两大类:Generic和Refer,通用分割和参考分割。Generic seg 是分割和提示语义概念一样的所有的物体&am…...

JOSEF电流继电器 DL-33 整定范围0.5-2A 柜内安装板前接线
系列型号: DL-31电流继电器; DL-32电流继电器; DL-33电流继电器; DL-34电流继电器; 一、用途 DL-30系列电流继电器用于电机保护、变压器保护和输电线的过负荷和短路保护线路中,作为起动元件。 二、结构和原理 继电器系电磁式,瞬时动作…...
RCE绕过
1.[SCTF 2021]rceme 总结下获取disabled_funciton的方式 1.phpinfo() 2.var_dump(ini_get(“disable_functions”)); 3.var_dump(get_cfg_var(“disable_functions”)); 其他的 var_dump(get_cfg_var(“open_basedir”)); var_dump(ini_get_all()); <?php if(isset($_POS…...
Qt应用开发--国产工业开发板全志T113-i的部署教程
Qt在工业上的使用场景包括工业自动化、嵌入式系统、汽车行业、航空航天、医疗设备、制造业和物联网应用。Qt被用来开发工业设备的用户界面、控制系统、嵌入式应用和其他工业应用,因其跨平台性和丰富的功能而备受青睐。 Qt能够为工业领域带来什么好处: -…...

css 常用动画效果
css 常用动画效果 文章目录 css 常用动画效果1.上下运动动画2.宽度变化动画 1.上下运动动画 <div class"box"><div class"item"></div> </div>css .box {position: relative; }.item {position: absolute;width: 50px;height: 50…...
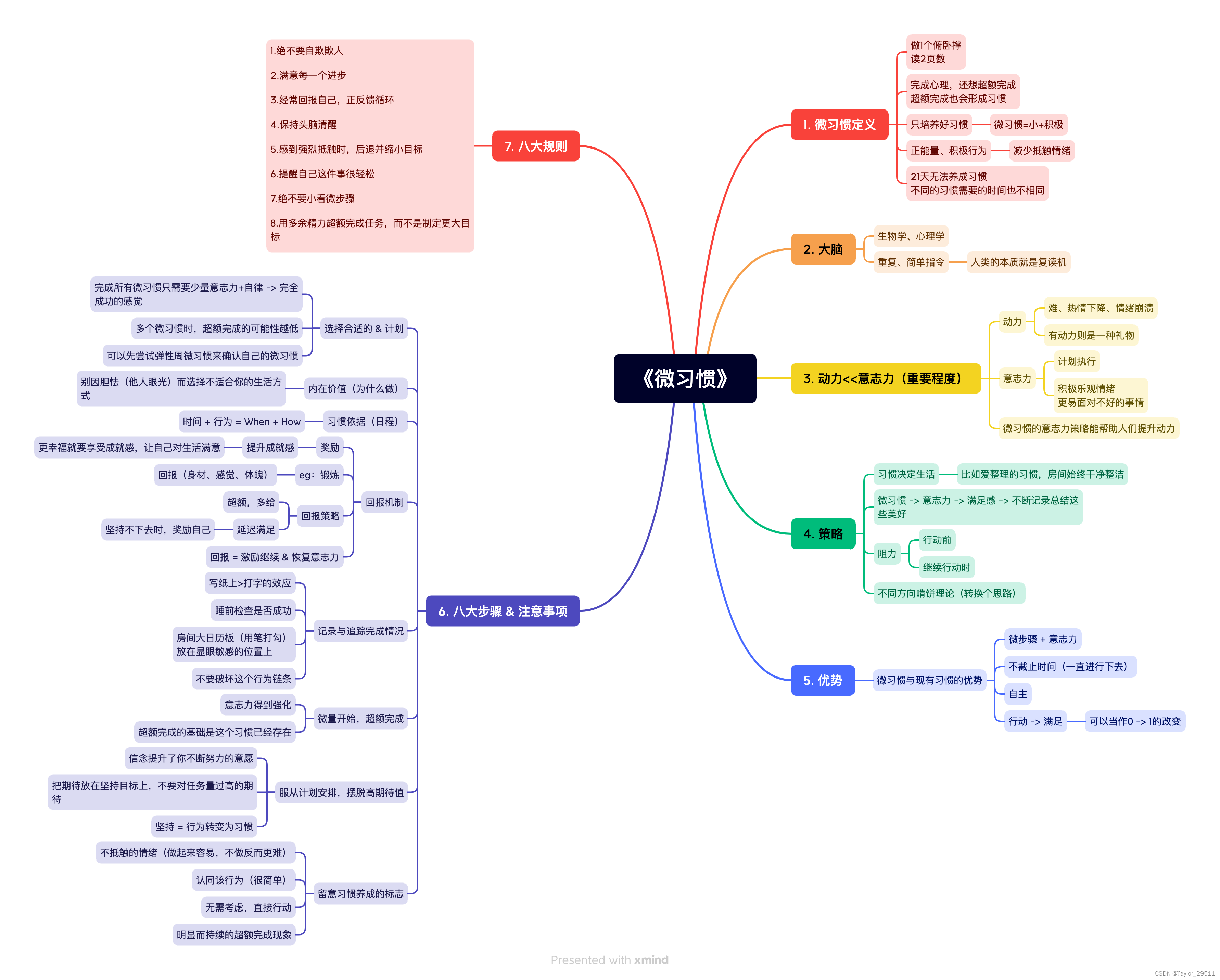
【读书笔记】微习惯
周日晚上尝试速读一本书《微习惯》,共七章看了下目录结构并不复杂,计划每章7-8分钟读完, 从20:15-21:00。读的时候,订下闹钟,催促着自己的进度。边读边记了一些要点和微信读书里面的划线。 第六章实践内容最为丰富&…...

Oracle SQL优化
1、书写顺序和执行顺序 在Oracle SQL中,查询的书写顺序和执行顺序是不同的。 1.1SQL书写顺序如下: SELECTFROMWHEREGROUP BYHAVINGORDER BY 1.2 SQL执行顺序 FROM:数据源被确定,表连接操作也在此步骤完成。 WHERE:对…...

C++实现ATM取款机
C实现ATM取款机 代码:https://mbd.pub/o/bread/ZZeZk5Zp 1.任务描述 要求:设计一个程序,当输入给定的卡号和密码(初始卡号和密码为123456) 时,系统 能登录 ATM 取款机系统,用户可以按照以下规则进行: 查询…...

【数电笔记】11-最小项(逻辑函数的表示方法及其转换)
目录 说明: 逻辑函数的建立 1. 分析逻辑问题,建立逻辑函数的真值表 2. 根据真值表写出逻辑式 3. 画逻辑图 逻辑函数的表示 1. 逻辑表达式的常见表示形式与转换 2. 逻辑函数的标准表达式 (1)最小项的定义 (2&am…...

Gradio库的安装和使用教程
目录 一、Gradio库的安装 二、Gradio的使用 1、导入Gradio库 2、创建Gradio接口 3、添加接口到Gradio应用 4、处理用户输入和模型输出 5、关闭Gradio应用界面 三、Gradio的高级用法 1、多语言支持 2、自定义输入和输出格式 3、模型版本控制 4、集成第三方库和API …...

Linux 文件类型,目录与路径,文件与目录管理
文件类型 后面的字符表示文件类型标志 普通文件:-(纯文本文件,二进制文件,数据格式文件) 如文本文件、图片、程序文件等。 目录文件:d(directory) 用来存放其他文件或子目录。 设备…...

在鸿蒙HarmonyOS 5中实现抖音风格的点赞功能
下面我将详细介绍如何使用HarmonyOS SDK在HarmonyOS 5中实现类似抖音的点赞功能,包括动画效果、数据同步和交互优化。 1. 基础点赞功能实现 1.1 创建数据模型 // VideoModel.ets export class VideoModel {id: string "";title: string ""…...

QMC5883L的驱动
简介 本篇文章的代码已经上传到了github上面,开源代码 作为一个电子罗盘模块,我们可以通过I2C从中获取偏航角yaw,相对于六轴陀螺仪的yaw,qmc5883l几乎不会零飘并且成本较低。 参考资料 QMC5883L磁场传感器驱动 QMC5883L磁力计…...

VTK如何让部分单位不可见
最近遇到一个需求,需要让一个vtkDataSet中的部分单元不可见,查阅了一些资料大概有以下几种方式 1.通过颜色映射表来进行,是最正规的做法 vtkNew<vtkLookupTable> lut; //值为0不显示,主要是最后一个参数,透明度…...

C++八股 —— 单例模式
文章目录 1. 基本概念2. 设计要点3. 实现方式4. 详解懒汉模式 1. 基本概念 线程安全(Thread Safety) 线程安全是指在多线程环境下,某个函数、类或代码片段能够被多个线程同时调用时,仍能保证数据的一致性和逻辑的正确性…...

html css js网页制作成品——HTML+CSS榴莲商城网页设计(4页)附源码
目录 一、👨🎓网站题目 二、✍️网站描述 三、📚网站介绍 四、🌐网站效果 五、🪓 代码实现 🧱HTML 六、🥇 如何让学习不再盲目 七、🎁更多干货 一、👨…...

用机器学习破解新能源领域的“弃风”难题
音乐发烧友深有体会,玩音乐的本质就是玩电网。火电声音偏暖,水电偏冷,风电偏空旷。至于太阳能发的电,则略显朦胧和单薄。 不知你是否有感觉,近两年家里的音响声音越来越冷,听起来越来越单薄? —…...

安宝特方案丨船舶智造的“AR+AI+作业标准化管理解决方案”(装配)
船舶制造装配管理现状:装配工作依赖人工经验,装配工人凭借长期实践积累的操作技巧完成零部件组装。企业通常制定了装配作业指导书,但在实际执行中,工人对指导书的理解和遵循程度参差不齐。 船舶装配过程中的挑战与需求 挑战 (1…...

安全突围:重塑内生安全体系:齐向东在2025年BCS大会的演讲
文章目录 前言第一部分:体系力量是突围之钥第一重困境是体系思想落地不畅。第二重困境是大小体系融合瓶颈。第三重困境是“小体系”运营梗阻。 第二部分:体系矛盾是突围之障一是数据孤岛的障碍。二是投入不足的障碍。三是新旧兼容难的障碍。 第三部分&am…...

LangChain知识库管理后端接口:数据库操作详解—— 构建本地知识库系统的基础《二》
这段 Python 代码是一个完整的 知识库数据库操作模块,用于对本地知识库系统中的知识库进行增删改查(CRUD)操作。它基于 SQLAlchemy ORM 框架 和一个自定义的装饰器 with_session 实现数据库会话管理。 📘 一、整体功能概述 该模块…...