Elasticsearch-Kibana使用教程
1.索引操作
1.1创建索引
PUT /employee
{"settings": {"index": {"refresh_interval": "1s","number_of_shards": 1,"max_result_window": "10000","number_of_replicas": 0}},"mappings": {"properties": {"id": {"type": "long"},"name": {"type": "keyword"},"age": {"type": "integer"},"create_date": {"type": "date","format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"},"address": {"type": "keyword"},"desc": {"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 256}}},"leader": {"type": "object"},"car": {"type": "nested","properties": {"brand": {"type": "keyword","ignore_above": 256},"number": {"type": "keyword","ignore_above": 256},"make": {"type": "keyword","ignore_above": 256}}}}}
} 1.2删除索引
DELETE /employee1.3添加字段
PUT /employee/_mapping
{"properties":{"salary":{"type":"double"}}
}1.4查看表结构
GET /employee/_mapping{
"employee" : {
"mappings" : {
"properties" : {
"address" : {
"type" : "keyword"
},
"age" : {
"type" : "integer"
},
"car" : {
"type" : "nested",
"properties" : {
"brand" : {
"type" : "keyword",
"ignore_above" : 256
},
"make" : {
"type" : "keyword",
"ignore_above" : 256
},
"number" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"create_date" : {
"type" : "date",
"format" : "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
},
"desc" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"id" : {
"type" : "long"
},
"leader" : {
"type" : "object"
},
"name" : {
"type" : "keyword"
},
"salary" : {
"type" : "double"
}
}
}
}
}
2.文档数据CRUD操作
2.1添加文档
PUT /employee/_doc/1
{"id": 1,"name": "张小勇","age": "45","leader": {"name": "马某","age": 40,"depart": "营销部"},"car": [{"brand": "丰田","make": "日本","number": "粤A12345"},{"brand": "奔驰","make": "德国","number": "粤A9999"}],"address": "浙江杭州西湖阿里马巴巴高薪技术开发区110号","desc": "长相不丑,擅长营销...."
}
PUT /employee/_doc/2
{"id": 2,"name": "张某龙","age": "40","leader": {"name": "马x腾","age": 40,"depart": "研发部"},"car": [{"brand": "奔驰","make": "中国北京","number": "粤A8888"},{"brand": "华晨宝马","make": "中国","number": "粤A9999"}],"address": "广东省深圳市南山区某讯大厦1号","desc": "长相帅气,高大威猛,人中龙凤,擅长写代码"
}2.2修改文档
2.2.1PUT覆式修改
PUT /employee/_doc/1
{"id": 1,"address": "浙江杭州西湖阿里马巴巴高薪技术开发区111号"
}2.2.1POST覆盖式和非覆盖修改均支持
覆盖式修改,本质同上,相当于先删除后增加
POST /employee/_doc/1
{"id": 1,"address": "浙江杭州西湖阿里马巴巴高薪技术开发区112号"
}非覆盖式修改,只修改当前字段,其他字段和值保留原样
POST /employee/_update/1
{"doc": {"id": 1,"address": "浙江杭州西湖阿里马巴巴高薪技术开发区110号"}
}2.3查询文档
Query string语法:
q=field:search content语法,默认是_all
+:代表一定要出现,类似must。
-:代表一定不能包含,类似must_not
GET /employee/_search
GET /employee/_search?q=id:1
GET /employee/_search?q=+id:1
GET /employee/_search?q=-id:1
GET /employee/_search?q=-id:1&q=name:赵老哥&sort=id:desc
GET /employee/_search?from=0&size=2
Query DSL写法:略
2.4删除文档
DELETE /employee/_doc/12.分词与分词器
2.1测试分词器
Elasticsearch默认的分词器是标准分词器,即对英文进行单词切割,对中文进行单字切割。
POST /_analyze
{"analyzer": "standard","text": "我是一个中国人"
}
上述分词将分词为:我|是|中|国|人,即单字拆分。
3.文档搜索Query DSL语法
3.1sourcce指定输出字段
GET /employee/_search
{"_source": ["id","name","leader.name","car.*"], "query": {"match_all": {}}
}3.2match查询查询语法
3.2.1match_all查询
不带条件,全部查询
GET /employee/_search
{"query": {"match_all": {}}
}3.2.2match查询
match查询text类型字段
match会被分词,查询text类型的数据,只要match的分词结果和text的分词结果有相同的就匹配
GET /employee/_search
{"_source": ["id","name","desc"], "query": {"match": {"desc": "长相帅气"}}
}查询结果为:
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.5948997,
"hits" : [
{
"_index" : "employee",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.5948997,
"_source" : {
"name" : "张某龙",
"id" : 2,
"desc" : "长相帅气,高大威猛,人中龙凤,擅长写代码"
}
},
{
"_index" : "employee",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.49274418,
"_source" : {
"name" : "张小勇",
"id" : 1,
"desc" : "长相不丑,擅长营销...."
}
}
]
}
}
match查询keyword类型字段
match会被分词,而keyword类型不会被分词,match的需要跟keyword的完全匹配才有结果
GET /employee/_search
{"_source": ["id","name"], "query": {"match": {"name": "张小勇"}}
}查询结果为:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.6931471,
"hits" : [
{
"_index" : "employee",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.6931471,
"_source" : {
"name" : "张小勇",
"id" : 1
}
}
]
}
}
3.2.3match_phrase查询
查询text类型字段,查询用于完整匹配指定短语,按照短语分词顺序匹配
GET /employee/_search
{"_source": ["id","name","desc"], "query": {"match_phrase": {"desc": "长相帅"}}
}查询结果为:
{
"took" : 17,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.9220042,
"hits" : [
{
"_index" : "employee",
"_type" : "_doc",
"_id" : "2",
"_score" : 0.9220042,
"_source" : {
"name" : "张某龙",
"id" : 2,
"desc" : "长相帅气,高大威猛,人中龙凤,擅长写代码"
}
}
]
}
}
查询keyword类型字段,需要完全匹配,原因是keyword类型字段不分词,要完全匹配
GET /employee/_search
{"_source": ["id","name","desc"], "query": {"match_phrase": {"address": "深圳市"}}
}地址里面虽然有广州,但是查询无结果:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 0,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
}
}
3.3fuzzy模糊查询
搜索本身很多时候是不精确的,很多时候我们需要在用户的查询词中有部分错误的情况下也能召回正确的结果,可以理解为模糊匹配
经典莱文斯坦距离(Levenshtein distance):编辑距离的一种,指两个字符串之间,由一个转成另一个所需的最少编辑操作次数
替换一个字符:dog -> dop
插入一个字符:an -> ant
删除一个字符:your -> you
莱文斯坦扩展版(Damerau–Levenshtein distance):莱文斯坦距离的一个扩展版 ,将相邻位置的两个字符的互换当做一次编辑,而在经典的莱文斯坦距离计算中位置互换是2次编辑
参数说明:
fuzziness:代表固定的最大编辑距离,可以是数字0,1,2,默认是0,不开启错误匹配,或者字符串AUTO模式,自动根据字符长度来匹配编辑距离数
prefix_length:控制两个字符串匹配的最小相同的前缀大小,也即是前n个字符不允许编辑,必须与查询词相同,默认是0
max_expansions:匹配最大词项,取每个分片的N个词项,减少召回率,默认值为50
transpositions:将相邻位置字符互换算作一次编辑距离,如 ab -> ba,即使用Damerau–Levenshtein距离算法,默认开启,设置 transpositions=false将使用经典莱文斯坦距离算法
GET /employee/_search
{"query": {"fuzzy": {"desc": {"value": "长相","fuzziness": 1,"prefix_length": 0,"max_expansions": 50,"transpositions": true}}}
}上述查询无结果,是因为fuzzy不会对query分词,标准分词器分词为单字分词
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 0,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
}
}
如果设置编辑距离fuzziness为1,即最大允许分词是错一个字,即:
GET /employee/_search
{"query": {"fuzzy": {"desc": {"value": "长相","fuzziness": 1,"prefix_length": 0,"max_expansions": 50,"transpositions": true}}}
}
查询结果变为:
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 0.0,
"hits" : [
{
"_index" : "employee",
"_type" : "_doc",
"_id" : "2",
"_score" : 0.0,
"_source" : {
"id" : 2,
"name" : "张某龙",
"age" : "40",
"leader" : {
"name" : "马x腾",
"age" : 40,
"depart" : "研发部"
},
"car" : [
{
"brand" : "奔驰",
"make" : "中国北京",
"number" : "粤A8888"
},
{
"brand" : "华晨宝马",
"make" : "中国",
"number" : "粤A9999"
}
],
"address" : "广东省深圳市南山区某讯大厦1号",
"desc" : "长相帅气,高大威猛,人中龙凤,擅长写代码"
}
},
{
"_index" : "employee",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.0,
"_source" : {
"id" : 1,
"name" : "张小勇",
"age" : "45",
"leader" : {
"name" : "马某",
"age" : 40,
"depart" : "营销部"
},
"car" : [
{
"brand" : "丰田",
"make" : "日本",
"number" : "粤A12345"
},
{
"brand" : "奔驰",
"make" : "德国",
"number" : "粤A9999"
}
],
"address" : "浙江杭州西湖阿里马巴巴高薪技术开发区110号",
"desc" : "长相不丑,擅长营销...."
}
}
]
}
}
注意:fuzzy不进行query分词查询,match也可以进行query分词模糊查询
GET /employee/_search
{"query": {"match": {"desc": {"query": "长相","fuzziness": 1}}}
}查询结果:
{
"took" : 5,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 0.49274418,
"hits" : [
{
"_index" : "employee",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.49274418,
"_source" : {
"id" : 1,
"name" : "张小勇",
"age" : "45",
"leader" : {
"name" : "马某",
"age" : 40,
"depart" : "营销部"
},
"car" : [
{
"brand" : "丰田",
"make" : "日本",
"number" : "粤A12345"
},
{
"brand" : "奔驰",
"make" : "德国",
"number" : "粤A9999"
}
],
"address" : "浙江杭州西湖阿里马巴巴高薪技术开发区110号",
"desc" : "长相不丑,擅长营销...."
}
},
{
"_index" : "employee",
"_type" : "_doc",
"_id" : "2",
"_score" : 0.38656068,
"_source" : {
"id" : 2,
"name" : "张某龙",
"age" : "40",
"leader" : {
"name" : "马x腾",
"age" : 40,
"depart" : "研发部"
},
"car" : [
{
"brand" : "奔驰",
"make" : "中国北京",
"number" : "粤A8888"
},
{
"brand" : "华晨宝马",
"make" : "中国",
"number" : "粤A9999"
}
],
"address" : "广东省深圳市南山区某讯大厦1号",
"desc" : "长相帅气,高大威猛,人中龙凤,擅长写代码"
}
}
]
}
}
3.4suggest推荐查询
搜索一般都会要求具有“搜索推荐”或者叫“搜索补全”的功能,即在用户输入搜索的过程中,进行自动补全或者纠错。以此来提高搜索文档的匹配精准度,进而提升用户的搜索体验。
3.4.1TermSuggester
针对单独term的搜索推荐,可以对单个term进行建议或者纠错,不考虑搜索短语中多个term的关系
3.4.2PhraseSuggester
PhraseSuggester即短语建议器,但是phrasesuggester在termsuggester的基础上,考虑多个term之间的关系,比如是否同时出现一个索引原文中,相邻程度以及词频等,但是据说有坑,就是返回的内容不一定是文档中包含的。
3.4.3Completion Suggester
自动补全,自动完成,支持三种查询:前缀查询(prefix)|模糊查询(fuzzy)|正则表达式查询(regex),主要针对的应用场景就是"Auto Completion"。 此场景下用户每输入一个字符的时候,就需要即时发送一次查询请求到后端查找匹配项,在用户输入速度较高的情况下对后端响应速度要求比较苛刻。因此实现上它和前面两个Suggester采用了不同的数据结构,索引并非通过倒排来完成,而是将analyze过的数据编码成FST和索引一起存放。对于一个open状态的索引,FST会被ES整个装载到内存里的,进行前缀查找速度极快。但是FST只能用于前缀查找,这也是Completion Suggester的局限所在。
综上所述,自动推荐补全有以下特点
a.基于内存而非索引,性能强悍。
b.需要结合特定的completion类型
c.只适合前缀推荐
prefix query:基于前缀查询的搜索提示,是最常用的一种搜索推荐查询。
prefix:客户端搜索词
field:建议词字段
size:需要返回的建议词数量(默认5)
skip_duplicates:是否过滤掉重复建议,默认false
fuzzy query:模糊匹配词项
fuzziness:允许的偏移量,默认auto
transpositions:如果设置为true,则换位计为一次更改而不是两次更改,默认为true。
min_length:返回模糊建议之前的最小输入长度,默认 3
prefix_length:输入的最小长度(不检查模糊替代项)默认为 1
unicode_aware:如果为true,则所有度量(如模糊编辑距离,换位和长度)均以Unicode代码点而不是以字节为单位。这比原始字节略慢,因此默认情况下将其设置为false。
regex query:可以用正则表示前缀,不建议使用
重新添加索引,在需要自动补全搜索字段上添加completion子类型,并重新插入数据
PUT /employee
{"settings": {"index": {"refresh_interval": "1s","number_of_shards": 1,"max_result_window": "10000","number_of_replicas": 0}},"mappings": {"properties": {"id": {"type": "long"},"name": {"type": "keyword"},"age": {"type": "integer"},"create_date": {"type": "date","format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"},"address": {"type": "keyword"},"desc": {"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 256},"completion": {"type": "completion"}}},"leader": {"type": "object"},"car": {"type": "nested","properties": {"brand": {"type": "keyword","ignore_above": 256},"number": {"type": "keyword","ignore_above": 256},"make": {"type": "keyword","ignore_above": 256}}}}}
}a.前缀搜索,下面只能搜到以 "长相" 开头的短语
GET employee/_search?pretty
{"_source": ["name","desc"], "suggest": {"descCompletion": {"prefix": "长相","completion": {"field": "desc.completion"}}}
}
返回结果:
{
"took" : 3,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 0,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"suggest" : {
"descCompletion" : [
{
"text" : "长相",
"offset" : 0,
"length" : 2,
"options" : [
{
"text" : "长相不丑,擅长营销....",
"_index" : "employee",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"name" : "张小勇",
"desc" : "长相不丑,擅长营销...."
}
},
{
"text" : "长相帅气,高大威猛,人中龙凤,擅长写代码",
"_index" : "employee",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"name" : "张某龙",
"desc" : "长相帅气,高大威猛,人中龙凤,擅长写代码"
}
}
]
}
]
}
}
b.模糊查询匹配前缀
标准分词器,不好搞,暂时略
GET employee/_search?pretty
{"_source": ["name", "desc"],"suggest": {"descCompletion": {"prefix": "长","completion": {"field": "desc.completion","skip_duplicates": true,"fuzzy": {"fuzziness": 5,"transpositions": false,"min_length": 1,"prefix_length": 1}}}}
}
查询结果
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 0,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"suggest" : {
"descCompletion" : [
{
"text" : "长",
"offset" : 0,
"length" : 1,
"options" : [
{
"text" : "长相不丑,擅长营销....",
"_index" : "employee",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"name" : "张小勇",
"desc" : "长相不丑,擅长营销...."
}
},
{
"text" : "长相帅气,高大威猛,人中龙凤,擅长写代码",
"_index" : "employee",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"name" : "张某龙",
"desc" : "长相帅气,高大威猛,人中龙凤,擅长写代码"
}
}
]
}
]
}
}
c.正则匹配词语前缀,正则搜"长*"有结果,但是搜"长相*"则无结果,因为标准分词器没有"长相"该词项,都是单字
GET employee/_search?pretty
{"suggest": {"descCompletion": {"regex": "长*","completion": {"field": "desc.completion","size": 10}}}
}
搜索结果
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 0,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"suggest" : {
"descCompletion" : [
{
"text" : "长*",
"offset" : 0,
"length" : 2,
"options" : [
{
"text" : "长相不丑,擅长营销....",
"_index" : "employee",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"id" : 1,
"name" : "张小勇",
"age" : "45",
"leader" : {
"name" : "马某",
"age" : 40,
"depart" : "营销部"
},
"car" : [
{
"brand" : "丰田",
"make" : "日本",
"number" : "粤A12345"
},
{
"brand" : "奔驰",
"make" : "德国",
"number" : "粤A9999"
}
],
"address" : "浙江杭州西湖阿里马巴巴高薪技术开发区110号",
"desc" : "长相不丑,擅长营销...."
}
},
{
"text" : "长相帅气,高大威猛,人中龙凤,擅长写代码",
"_index" : "employee",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"id" : 2,
"name" : "张某龙",
"age" : "40",
"leader" : {
"name" : "马x腾",
"age" : 40,
"depart" : "研发部"
},
"car" : [
{
"brand" : "奔驰",
"make" : "中国北京",
"number" : "粤A8888"
},
{
"brand" : "华晨宝马",
"make" : "中国",
"number" : "粤A9999"
}
],
"address" : "广东省深圳市南山区某讯大厦1号",
"desc" : "长相帅气,高大威猛,人中龙凤,擅长写代码"
}
}
]
}
]
}
}
3.4.4ContextSuggester
a.CompletionSuggester的筛选器,通过设置向下文映射来实现
b.在索引和查询启用上下文的完成字段时,必须提供上下文
c.添加上下文映射会增加completion的字段的索引大小。并且这一过程法发生在堆中
相关文章:

Elasticsearch-Kibana使用教程
1.索引操作 1.1创建索引 PUT /employee {"settings": {"index": {"refresh_interval": "1s","number_of_shards": 1,"max_result_window": "10000","number_of_replicas": 0}},"mappi…...
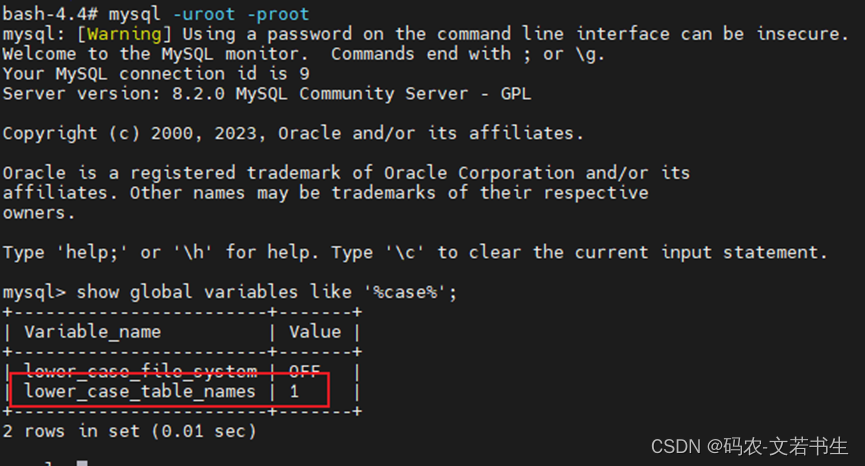
mysql(八)docker版Mysql8.x设置大小写忽略
Mysql 5.7设置大小写忽略可以登录到Docker内部,修改/etc/my.cnf添加lower_case_table_names1,并重启docker使之忽略大小写。但MySQL8.0后不允许这样,官方文档记录: lower_case_table_names can only be configured when initializ…...

KALI LINUX攻击与渗透测试
预计更新 第一章 入门 1.1 什么是Kali Linux? 1.2 安装Kali Linux 1.3 Kali Linux桌面环境介绍 1.4 基本命令和工具 第二章 信息收集 1.1 网络扫描 1.2 端口扫描 1.3 漏洞扫描 1.4 社交工程学 第三章 攻击和渗透测试 1.1 密码破解 1.2 暴力破解 1.3 漏洞利用 1.4 …...
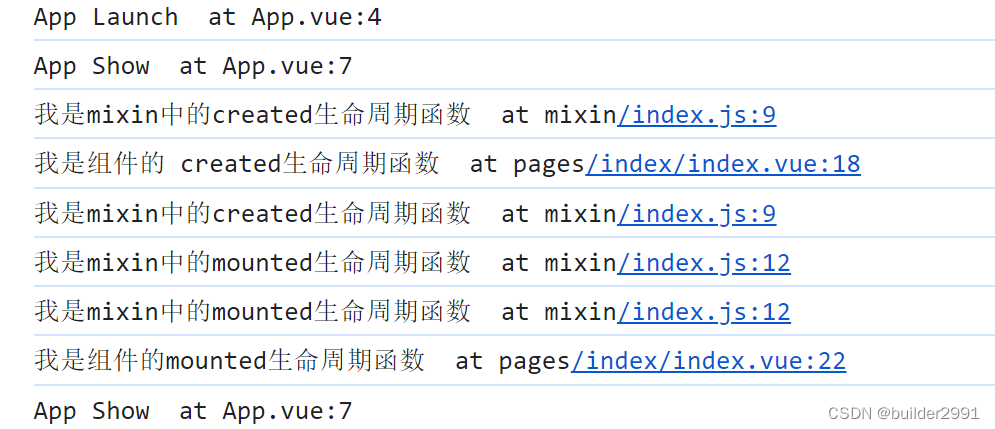
vue之mixin混入
vue之mixin混入 mixin是什么? 官方的解释: 混入 (mixin) 提供了一种非常灵活的方式,来分发 Vue 组件中的可复用功能。一个混入对象可以包含任意组件选项。当组件使用混入对象时,所有混入对象的选项将被“混合”进入该组件本身的…...

[ffmpeg] find 编码器
背景 整理 ffmpeg 中,如何通过名字或者 id 找到对应编码器的。 具体流程 搜索函数 avcodec_find_encoder // 通过 ID 搜索编码器 avcodec_find_encoder_by_name // 通过名字搜索编码器源码分析 ffmpeg 中所有支持的编码器都会注册到 codec_list.c 文件中&…...

Android CardView基础使用
目录 一、CardView 1.1 导入material库 1.2 属性 二、使用(效果) 2.1 圆角卡片效果 2.2 阴影卡片效果 2.3 背景 2.3.1 设置卡片背景(app:cardBackgroundColor) 2.3.2 内嵌布局,给布局设置背景色 2.4 进阶版 2.4.1 带透明度 2.4.2 无透明度 一、CardView 顾名…...

云原生Kubernetes系列 | init container初始化容器的作用
云原生Kubernetes系列 | init container初始化容器的作用 kubernetes 1.3版本引入了init container初始化容器特性。主要用于在启动应用容器(app container)前来启动一个或多个初始化容器,作为应用容器的一个基础。只有init container运行正常后,app container才会正常运行…...

汽车电子芯片介绍之Aurix TC系列
Infineon的AURIX TC系列芯片是专为汽车电子系统设计的,采用了32位TriCore处理器架构。该系列芯片具有高性能、低功耗和丰富的外设接口,适用于广泛的汽车电子应用。以下是AURIX TC系列芯片的主要特性: 1. 高性能处理器 AURIX TC芯片采用了高…...

Linux 设置程序开机自启动的方法
目录 前言开机自启动参考 前言 CentOS Linux release 7.9.2009 (Core) 开机自启动 shell> vim /etc/rc.d/rc.local添加开机后执行的命令 sh /xxx/xxx.sh参考 https://www.cnblogs.com/xlmeng1988/archive/2013/05/22/3092447.html...
java企业财务管理系统springboot+jsp
1、基本内容 (1)搭建基础环境,下载JDK、开发工具eclipse/idea。 (2)通过HTML/CSS/JS搭建前端框架。 (3)下载MySql数据库,设计数据库表,用于存储系统数据。 (4…...

【Windows】如何实现 Windows 上面的C盘默认文件夹的完美迁移
如何实现 Windows 上面的C盘默认文件夹的完美迁移 1. 遇到的问题 在我想迁移C盘的 下载 和 视频 文件夹的时候,遇到了这样的问题,在迁移之后,我显卡录像的视频还是保存到了C盘默认位置里,以及我迁移了 下载 之后下载的盘依然是在…...
kubernetes七层负载Ingress搭建(K8S1.23.5)
首先附上K8S版本及Ingress版本对照 Ingress介绍 NotePort:该方式的缺点是会占用很多集群机器的端口,当集群服务变多时,这个缺点就愈发的明显(srevice变多,需要的端口就需要多) LoadBalancer:该方式的缺点是每个servi…...
二维粒子群算法航线规划
GitHub - gabrielegilardi/PathPlanning: Implementation of particle swarm optimization (PSO) for path planning when the environment is known....

uniapp长按图片识别二维码
引用:https://blog.csdn.net/weixin_48596030/article/details/125405779 <image :src"url" mode"widthFix" click.self"previewImage" show-menu-by-longpress"true" style"width: 350rpx;"></image…...

智能优化算法应用:基于和声算法无线传感器网络(WSN)覆盖优化 - 附代码
智能优化算法应用:基于和声算法无线传感器网络(WSN)覆盖优化 - 附代码 文章目录 智能优化算法应用:基于和声算法无线传感器网络(WSN)覆盖优化 - 附代码1.无线传感网络节点模型2.覆盖数学模型及分析3.和声算法4.实验参数设定5.算法结果6.参考文献7.MATLAB…...
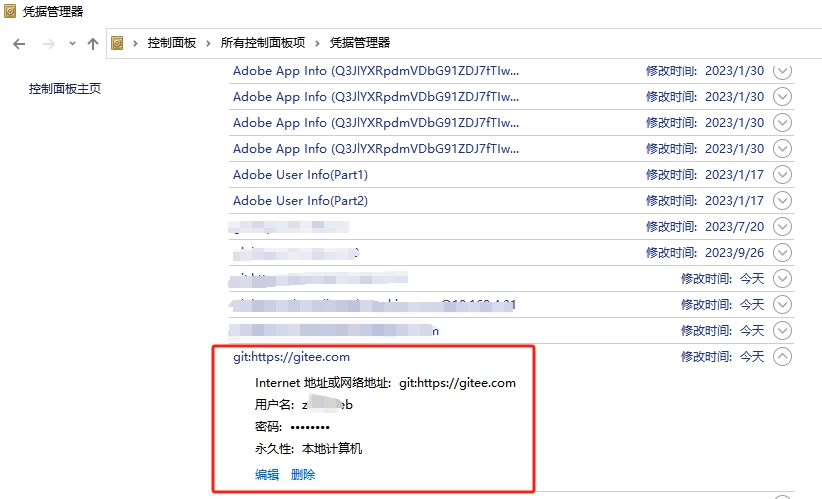
Gitee拉取代码报错You hasn‘t joined this enterprise! fatal unable to access
文章目录 一、问题二、解决2.1、进入**控制面板**2.2、进入**用户账户**2.3、进入**管理Windows凭据**2.4、**普通凭据**2.4.1、添加2.4.2、编辑 2.5、重新拉取|推送代码 三、最后 一、问题 Gitee拉取仓库代码的时候报错You hasnt joined this enterprise! fatal unable to ac…...
算法通关村第十六关-白银挑战滑动窗口经典题目
大家好我是苏麟 , 今天带来滑动窗口经典的一些题目 . 我们继续来研究一些热门的、高频的滑动窗口问题 大纲 最长子串专题无重复字符的最长子串 长度最小的子数组盛最多水的容器 最长子串专题 无重复字符的最长子串 描述 : 给定一个字符串 s ,请你找出其中不含有重…...

springBoot整合task
springBoot整合task 文章目录 springBoot整合task开开关设置任务,并设置执行周期定时任务的相关配置 开开关 设置任务,并设置执行周期 Component public class MyBean {Scheduled(cron "0/1 * * * * ?")public void print(){System.out.prin…...
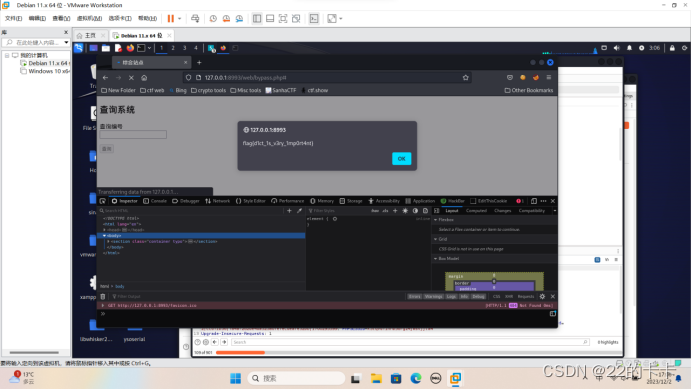
逻辑漏洞测试靶场实验
任务一: 突破功能限制漏洞,要求突破查询按钮disabled限制,获取编号:110010的查询内容(弹框中的flag) 任务二:用户信息泄露漏洞,通过回显信息,以暴力破解法方式猜测系统中…...
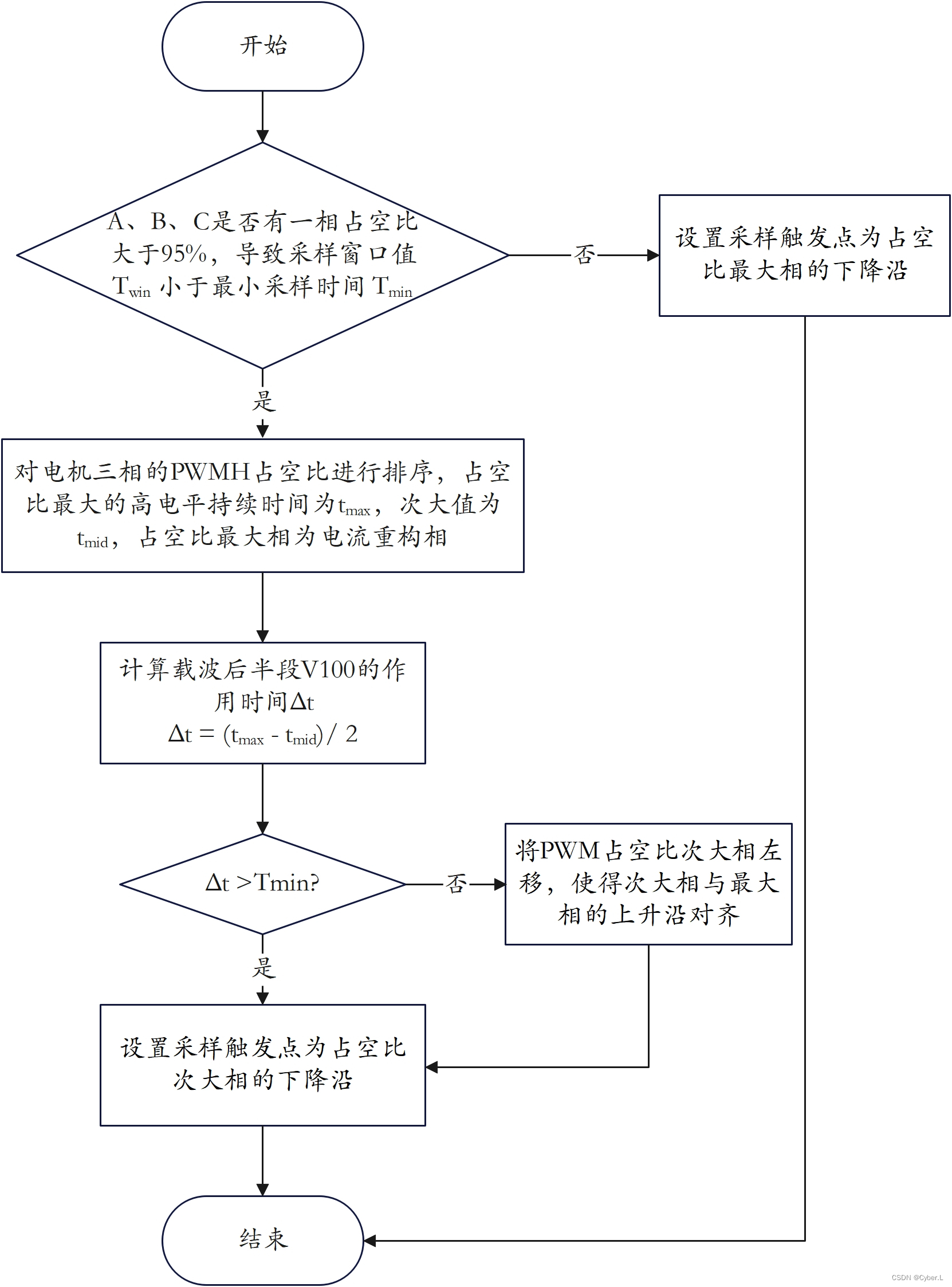
【电机控制】PMSM无感foc控制(六)相电流检测及重构 — 双电阻采样、三电阻采样
0. 前言 目前,永磁同步电机的电流信号采样方法应用较多的是分流电阻采样,包括单电阻、双电阻以及三电阻采样法。其中,单电阻采样上一章节已经讲解,这章讲双电阻以及三电阻电流采样法。 1. 双电阻采样 1.1 双电阻采样原理 双电阻采…...

IDEA运行Tomcat出现乱码问题解决汇总
最近正值期末周,有很多同学在写期末Java web作业时,运行tomcat出现乱码问题,经过多次解决与研究,我做了如下整理: 原因: IDEA本身编码与tomcat的编码与Windows编码不同导致,Windows 系统控制台…...

web vue 项目 Docker化部署
Web 项目 Docker 化部署详细教程 目录 Web 项目 Docker 化部署概述Dockerfile 详解 构建阶段生产阶段 构建和运行 Docker 镜像 1. Web 项目 Docker 化部署概述 Docker 化部署的主要步骤分为以下几个阶段: 构建阶段(Build Stage):…...

突破不可导策略的训练难题:零阶优化与强化学习的深度嵌合
强化学习(Reinforcement Learning, RL)是工业领域智能控制的重要方法。它的基本原理是将最优控制问题建模为马尔可夫决策过程,然后使用强化学习的Actor-Critic机制(中文译作“知行互动”机制),逐步迭代求解…...
)
rknn优化教程(二)
文章目录 1. 前述2. 三方库的封装2.1 xrepo中的库2.2 xrepo之外的库2.2.1 opencv2.2.2 rknnrt2.2.3 spdlog 3. rknn_engine库 1. 前述 OK,开始写第二篇的内容了。这篇博客主要能写一下: 如何给一些三方库按照xmake方式进行封装,供调用如何按…...

【Oracle APEX开发小技巧12】
有如下需求: 有一个问题反馈页面,要实现在apex页面展示能直观看到反馈时间超过7天未处理的数据,方便管理员及时处理反馈。 我的方法:直接将逻辑写在SQL中,这样可以直接在页面展示 完整代码: SELECTSF.FE…...

测试markdown--肇兴
day1: 1、去程:7:04 --11:32高铁 高铁右转上售票大厅2楼,穿过候车厅下一楼,上大巴车 ¥10/人 **2、到达:**12点多到达寨子,买门票,美团/抖音:¥78人 3、中饭&a…...

el-switch文字内置
el-switch文字内置 效果 vue <div style"color:#ffffff;font-size:14px;float:left;margin-bottom:5px;margin-right:5px;">自动加载</div> <el-switch v-model"value" active-color"#3E99FB" inactive-color"#DCDFE6"…...

Cloudflare 从 Nginx 到 Pingora:性能、效率与安全的全面升级
在互联网的快速发展中,高性能、高效率和高安全性的网络服务成为了各大互联网基础设施提供商的核心追求。Cloudflare 作为全球领先的互联网安全和基础设施公司,近期做出了一个重大技术决策:弃用长期使用的 Nginx,转而采用其内部开发…...

令牌桶 滑动窗口->限流 分布式信号量->限并发的原理 lua脚本分析介绍
文章目录 前言限流限制并发的实际理解限流令牌桶代码实现结果分析令牌桶lua的模拟实现原理总结: 滑动窗口代码实现结果分析lua脚本原理解析 限并发分布式信号量代码实现结果分析lua脚本实现原理 双注解去实现限流 并发结果分析: 实际业务去理解体会统一注…...

鱼香ros docker配置镜像报错:https://registry-1.docker.io/v2/
使用鱼香ros一件安装docker时的https://registry-1.docker.io/v2/问题 一键安装指令 wget http://fishros.com/install -O fishros && . fishros出现问题:docker pull 失败 网络不同,需要使用镜像源 按照如下步骤操作 sudo vi /etc/docker/dae…...