算法工程师-机器学习面试题总结(1)
目录
1-1 损失函数是什么,如何定义合理的损失函数?
1-2 回归模型和分类模型常用损失函数有哪些?各有什么优缺点
1-3 什么是结构误差和经验误差?训练模型的时候如何判断已经达到最优?
1-4 模型的“泛化”能力是指?如何提升模型泛化能力?
1-5 如何选择合适的模型评估指标?PR、ROC、AUC、精准度、召回率、F1值都是什么?如何计算?各有什么优缺点?
1-6 如何评判模型是过拟合还是欠拟合?遇到过拟合或欠拟合时,你是如何解决?
1-7 如何理解机器学习的“特征”?
1-8 机器学习中开发特征时候做如何做数据探索,怎样选择有用的特征?
1-9 如何发现数据中的异常值,如何处理异常值?
1-10 标准化和归一化有哪些异同点?哪些算法需要做归一化或标准化?
1-11 GBDT算法需要做归一化吗?xgboost,lightgbm,catboost等算法需要做归一化或者标准化吗?
1-12 你怎样理解组合特征?举个例子,并说明它和单特征有啥区别
1-13 时间类型数据有哪些处理方法
机器学习相关基本概念:
1-1 损失函数是什么,如何定义合理的损失函数?
损失函数是在机器学习和优化算法中使用的一种衡量模型预测结果与真实值之间差异的函数。其目标是最小化模型的预测误差,从而提高模型的性能。
定义合理的损失函数需要考虑以下几个因素:
任务类型:不同的任务(如回归、分类、聚类等)需要选择不同类型的损失函数。比如,在回归问题中,常用的损失函数有均方误差(Mean Squared Error)和平均绝对误差(Mean Absolute Error);在分类问题中,交叉熵损失函数(Cross-Entropy Loss)常被使用。
模型目标:损失函数应该与模型的目标一致。例如,如果模型的目标是最小化错误率,则可以选择0-1损失函数;如果模型的目标是最大化概率似然,则可以选择对数似然损失函数
数据分布:损失函数的选择应该考虑到数据的分布特点。例如,如果数据存在明显的离群点,可以选择鲁棒性较强的损失函数,如Huber损失函数。
可解释性:在某些应用场景下,可解释性对于模型的性能评估很重要。因此,损失函数的定义中可能需要考虑到模型预测的可解释性。
总而言之,定义合理的损失函数需要综合考虑任务类型、模型目标、数据分布和可解释性等因素。这需要针对具体问题进行实践和调试,选择最适合的损失函数来训练和评估模型。
1-2 回归模型和分类模型常用损失函数有哪些?各有什么优缺点
在回归模型和分类模型中,常用的损失函数有一些不同。下面是常见的损失函数及其优缺点:
回归模型常用的损失函数:
均方误差(Mean Squared Error,MSE):MSE是最常见的回归损失函数,计算预测值与真实值之间的平均平方差。优点是MSE的函数曲线光滑、连续,处处可导,便于使用梯度下降算法,是一种常用的损失函数。而且,随着误差的减小,梯度也在减小,这有利于收敛,即使使用固定的学习速率,也能较快的收敛到最小值。缺点是对离群值过于敏感。
平均绝对误差(Mean Absolute Error,MAE):MAE计算目标值与预测值之差绝对值和的均值。相较于MSE,MAE对离群值不敏感,因为MAE计算的是误差(y-f(x))的绝对值,对于任意大小的差值,其惩罚都是固定的。无论对于什么样的输入值,都有着稳定的梯度,不会导致梯度爆炸问题,具有较为稳健性的解。缺点是MAE曲线连续,但是在(y-f(x)=0)处不可导。而且 MAE 大部分情况下梯度都是相等的,这意味着即使对于小的损失值,其梯度也是大的。这不利于函数的收敛和模型的学习。
总之,MAE作为损失函数更稳定,并且对离群值不敏感,但是其导数不连续,求解效率低。另外,在深度学习中,收敛较慢。MSE导数求解速度高,但是其对离群值敏感,不过可以将离群值的导数设为0(导数值大于某个阈值)来避免这种情况。
Huber损失函数:Huber损失函数是一种介于MSE和MAE之间的损失函数,可以平衡对异常值和普通值的敏感程度。
分类模型常用的损失函数:
交叉熵损失函数(Cross-Entropy Loss):交叉熵损失函数常用于分类任务,特别是多类别分类。它通过计算预测概率分布与真实标签之间的交叉熵来衡量模型的预测效果。优点是对于错误分类给予较大的惩罚,缺点是1.容易过拟合,交叉损失函数具有较高的表达能力,但它也容易过拟合,特别是当训练数据稀少或噪声较多时。2.计算和存储开销过大,交叉熵损失函数需要计算和存储每个样本的预测分布和实际分布。
对数似然损失函数(Log-Likelihood Loss):对数似然损失函数通常用于逻辑回归等分类模型。它最大化了观测数据的对数似然,将模型预测的概率与实际标签的概率进行比较。优点是在极大似然估计下可以得到一致性的估计,缺点是对于离群值敏感。
以上仅列举了部分常见的回归和分类模型的损失函数,并介绍了它们的优缺点。在实际应用中,根据具体问题的特点和需求,选择合适的损失函数进行模型训练和评估是非常重要的。
1-3 什么是结构误差和经验误差?训练模型的时候如何判断已经达到最优?
结构误差(也称为泛化误差)和经验误差是在机器学习中用于评估模型性能的两个重要概念。
经验误差:经验误差是指模型在训练集上的误差,即模型对已有训练数据的拟合程度。它可以通过计算模型预测结果与真实标签之间的误差来衡量。通常使用损失函数来表示经验误差,目标是使经验误差尽可能小,以提高模型对训练数据的拟合程度。
结构误差:结构误差是指模型在未知的测试数据上的误差。它反映了模型在现实世界中的泛化能力,即模型对新样本的预测能力。结构误差由于模型的复杂度、训练数据的质量和数量等因素而产生。降低结构误差的目标是使模型具有更好的泛化性能,在面对新样本时能够做出准确的预测。
判断模型达到最优的方法通常包括以下几种:
利用验证集:将数据集分为训练集、验证集和测试集,从训练集中训练模型,在验证集上评估模型的性能。随着模型训练的进行,可以观察验证集上的误差变化情况。当模型在验证集上的误差停止下降或开始增加时,可以认为模型已经达到最优。
使用交叉验证:交叉验证是一种评估模型性能的统计方法,将数据集划分为多个子集,在每个子集上轮流作为验证集,其他子集作为训练集。通过对多个验证集上的评估结果进行平均或加权求和,得到模型的性能评估。当模型在交叉验证中的性能稳定时,可以认为模型已经达到最优。
观察测试集表现:将测试集作为独立的数据集,在模型训练和调参完成后使用测试集来评估模型的泛化能力。如果模型在测试集上的表现令人满意,可以认为模型已经达到最优。
使用正则化技术:正则化技术可以帮助控制模型的复杂度,防止过拟合问题。通过引入正则化项或设置正则化参数,可以在训练过程中平衡经验误差和结构误差。选择适当的正则化策略可以提高模型的泛化能力,从而达到最优。
1-4 模型的“泛化”能力是指?如何提升模型泛化能力?
模型的泛化能力是指模型在面对未见过的数据(测试集或实际应用中的新样本)时的预测准确性和适应能力。一个具有良好泛化能力的模型能够从训练数据中学到普遍规律,并能够对新数据做出准确的预测,而不仅仅是对训练数据的拟合程度。
以下是一些提升模型泛化能力的常见方法:
更多的训练数据:增加训练样本量是提高模型泛化能力最直接有效的方法之一。更多的数据可以帮助模型更好地学习数据的分布和特征,减少对噪声和异常值的敏感性。
数据增强:通过对训练数据进行人工或自动的扩增,可以增加样本的多样性。例如在图像分类任务中,可以进行平移、旋转、裁剪等操作来生成额外的样本,以增加模型对不同变体的鲁棒性。
特征选择与提取:选择合适的特征对模型的泛化能力至关重要。通过特征选择算法或领域知识,筛选出对目标任务有用的特征。另外,使用深度学习等方法进行特征提取也可以帮助模型学习更高层次、更具判别性的特征表示。
模型正则化:正则化是一种通过添加额外约束或惩罚项来控制模型复杂度的技术。常见的正则化方法包括L1正则化(Lasso)和L2正则化(Ridge)。正则化可以避免过拟合,使模型更简单且更具泛化能力。
使用交叉验证:交叉验证可以对模型的泛化性能进行评估,并帮助选择适当的超参数。通过使用K折交叉验证等方法,可以减少因数据集的不同划分而导致的随机性,更准确地估计模型在未见数据上的表现。
集成学习:集成学习通过将多个不同的模型组合起来,可以增强模型的泛化能力。常见的集成方法包括Bagging、Boosting和Stacking,通过综合多个模型的预测结果,可以降低模型的方差,提高模型的稳定性和准确性。
以上方法都可以有助于提升模型的泛化能力。在实际应用中,应根据具体问题和数据的特点,选择和尝试适合的方法,以获得更好的模型性能。
1-5 如何选择合适的模型评估指标?PR、ROC、AUC、精准度、召回率、F1值都是什么?如何计算?各有什么优缺点?
选择合适的模型评估指标取决于具体的问题和任务要求。以下是几个常见的评估指标及其解释:
精确度(Precision):精确度是指预测为正类别的样本中实际为正类别的比例。计算公式为:精确度 = TP / (TP + FP),其中TP表示真阳性(正确预测为正类别的样本数),FP表示假阳性(错误地将负类别样本预测为正类别的样本数)。精确度衡量了模型在预测为正类别时的准确性。
召回率(Recall):召回率是指实际为正类别的样本中被正确预测为正类别的比例。计算公式为:召回率 = TP / (TP + FN),其中TP表示真阳性,FN表示假阴性(错误地将正类别样本预测为负类别的样本数)。召回率衡量了模型对正类别的识别能力。
F1值:F1值是精确度和召回率的调和平均,可以综合考虑模型的准确性和召回能力。计算公式为:F1 = 2 * (精确度 * 召回率) / (精确度 + 召回率)。
PR曲线与AUC:PR曲线是根据不同的分类阈值绘制出的精确度和召回率之间的关系曲线。PR曲线下的面积被称为AUC-PR(Area Under the Precision-Recall Curve)。AUC-PR衡量了模型在不同召回率水平下的整体性能,适用于样本不均衡的问题。
ROC曲线与AUC:ROC曲线是以假阳性率(False Positive Rate)为横轴,真阳性率(True Positive Rate)为纵轴,绘制出的曲线。ROC曲线下的面积被称为AUC-ROC(Area Under the Receiver Operating Characteristic Curve)。AUC-ROC衡量了模型在不同假阳性率下的整体性能,适用于样本均衡或不均衡的问题。
每个评估指标都有其优缺点:
精确度适用于关注模型正确预测为正类别的准确性的情况,但在样本不均衡时可能会受到干扰。
召回率适用于关注模型正确识别正类别的能力的情况,但在样本不均衡时也可能会受到干扰。
F1值是综合考虑精确度和召回率的指标,适用于需要综合考虑准确性和识别能力的情况。
PR曲线和AUC-PR适用于样本不均衡问题,可以通过面积来评估分类器在各种召回率水平下的整体性能。
ROC曲线和AUC-ROC适用于样本均衡或不均衡问题,可以通过面积来评估分类器在各种假阳性率水平下的整体性能。
在选择合适的评估指标时,需要根据具体任务的要求、样本分布以及模型性能的关注点来进行综合考虑。
1-6 如何评判模型是过拟合还是欠拟合?遇到过拟合或欠拟合时,你是如何解决?
评判模型是过拟合还是欠拟合可以通过观察训练集和验证集(或测试集)上的性能表现来进行判断。
1.过拟合:当模型在训练集上表现很好,但在验证集(或测试集)上表现较差时,可能存在过拟合问题。过拟合表示模型在训练数据上过度学习,无法泛化到新数据。常见的迹象包括训练集上准确率高,但验证集上准确率下降、误差增大等。
2.欠拟合:当模型在训练集和验证集上都表现较差时,可能存在欠拟合问题。欠拟合表示模型没有很好地捕捉到数据中的规律和特征,无法适应训练数据和新数据。常见的迹象包括训练集和验证集上准确率都较低、误差较大等。
针对过拟合和欠拟合问题,可以采取以下解决方法:
1.过拟合解决方案:
增加数据量:增加更多的训练数据可以帮助模型更好地学习数据的分布和特征,减少过拟合的风险。
数据增强:通过对训练数据进行扩增,如旋转、缩放、裁剪等操作,可以增加样本的多样性,提升模型的泛化能力。
正则化:通过正则化技术(如L1和L2正则化)来限制模型的复杂度,减少过拟合的风险。正则化可以通过添加额外的约束或惩罚项来控制模型参数的大小。
提前停止:在训练过程中监测验证集上的性能,并在性能不再提升时及时停止训练,避免过度拟合。
2.欠拟合解决方案:
增加模型复杂度:欠拟合可能是由于模型太简单而无法很好地捕捉到数据中的规律。可以尝试增加模型的复杂度,如增加神经网络的层数或神经元的数量,来增强模型的表达能力。
特征工程:尝试引入更多有意义的特征,或者对现有特征进行变换、组合,以提供更丰富的信息给模型。
减小正则化程度:如果使用了正则化方法,可以适当减小正则化的程度,以允许模型更好地拟合训练数据。
调整超参数:尝试调整模型的超参数,如学习率、批次大小等,以获得更好的模型性能。
在解决过拟合或欠拟合问题时,需要根据具体情况和任务需求进行实际调试和优化。可以通过交叉验证、调整模型结构、调整正则化参数等方法来寻找最佳的模型配置。
1-7 如何理解机器学习的“特征”?
在机器学习中,特征是指从数据中提取的有用信息或属性,用于描述数据的某些方面。特征可以是各种各样的数据类型,
例如数字、文本、图像或声音等。特征通常用于对样本进行编码,以便让机器学习算法能够理解和处理数据。
特征的选择和提取是机器学习中的一个重要环节。好的特征应该能够具备以下几个特点:
1. 与预测目标具有相关性:特征应该能够对目标变量或问题有所解释和影响。
2. 区分度高:特征应该能够在不同类别或类别间产生明显的差异。
3. 信息量丰富:特征应该包含足够的信息,能够更好地区分和描述样本。
4. 可解释性:特征应该能够被理解和解释,方便进行模型解释和分析。
特征工程是机器学习中常用的技术之一,它涉及到选择、提取、转换和构建特征的过程。一个好的特征工程可以显著提高机器学习模型的性能和准确度。
1-8 机器学习中开发特征时候做如何做数据探索,怎样选择有用的特征?
在机器学习中,进行数据探索是为了更好地了解数据的特性和结构,从而帮助我们选择有用的特征。以下是一些常用的数据探索方法和特征选择技巧:
1. 数据可视化:通过绘制直方图、散点图、箱线图等可视化手段,探索数据的分布、关联性和异常值等特征。
2. 相关性分析:计算特征之间的相关系数或相关矩阵,通过分析相关系数的大小和符号来判断特征与目标变量之间的关系。
3. 特征重要性:使用特征选择算法(如随机森林、卡方检验等)对特征进行排序或评分,辨别出对目标变量有贡献的重要特征。
4. 领域知识:在选择特征时,充分利用领域专业知识,根据问题的背景和特性,选择与目标变量相关的特征。
5. 过滤式特征选择:根据某种准则(如方差、相关系数等)将特征进行初步筛选,去掉冗余或无关的特征。
6. 包裹式特征选择:通过给定特征集合的子集来训练模型,并评估每个子集的性能,选择性能最好的特征子集。
7. 嵌入式特征选择:在训练模型的过程中,自动选择具有较高权重或重要性的特征,剔除对模型性能贡献较小的特征。
数据探索和特征选择是一个迭代的过程,需要综合考虑数据的特点、问题的需求和机器学习算法的要求,选择最合适的特征。尝试不同的方法和技术,多进行实验和评估,探索最适合问题的特征集合。
1-9 如何发现数据中的异常值,如何处理异常值?
发现数据中的异常值是数据预处理的一个重要步骤,以下是一些常用的方法:
1. 直方图和箱线图:通过绘制数据的直方图和箱线图,可以观察数据的分布和离群点。离群点往往在箱线图中表示为超出上下四分位数的点。
2. 统计方法:使用一些统计方法,如标准差、z-score或箱线图中的IQR方法,可以将与平均值或中位数相差较大的数据点识别为异常值。
3. 数据可视化:使用散点图或其他可视化方法,可以观察数据点之间的关系和模式。异常值通常会在图形中显示为与其他数据点明显不同的点。
处理异常值的方法取决于具体情况和数据的性质。以下是一些处理异常值的常用方法:
1. 删除异常值:如果异常值是由于错误、噪音或异常情况导致的,可以考虑将其从数据集中删除。
2. 替换异常值:对于数值数据,可以用平均值、中位数或其他合适的值来替换异常值。
3. 分箱或离散化:将连续数据转换成具有离散值的数据,可以将异常值放在某个单独的箱子或类别中。
4. 使用异常检测算法:使用机器学习或统计模型来识别和处理异常值,例如聚类方法、离群点检测算法等。
需要注意的是,处理异常值时应该谨慎,并根据具体情况进行决策。处理异常值可能会对数据的分布和模型结果产生影响,因此需要在处理异常值时权衡利弊,并在进行后续分析或建模之前进行评估。
1-10 标准化和归一化有哪些异同点?哪些算法需要做归一化或标准化?
相似点:
1. 目的:都是为了对数据进行缩放,使得数据具有可比性和可解释性。
2. 应用场景:通常应用于机器学习和数据挖掘等领域,以提高模型的性能和准确性。
不同点:
1. 对象:标准化一般针对数据的特征(每一列),而归一化是对数据的样本(每一行)进行操作。
2. 缩放范围:标准化将数据缩放到均值为0,标准差为1的范围内,而归一化将数据缩放到0到1的范围内或其他指定的范围内。
3. 方式:标准化使用的是减去均值再除以标准差的方式,归一化使用的是线性变换的方式。
哪些算法需要进行归一化或标准化?
1. 基于距离的算法:如K近邻算法、支持向量机(SVM)等,它们计算样本之间的距离或相似度,需要对数据进行标准化或归一化,以便消除特征间的量纲影响。
2. 梯度下降优化算法:如线性回归、逻辑回归和神经网络等,它们通常需要对数据进行标准化,以加快算法收敛速度和优化效果。
3. 特征提取算法:如主成分分析(PCA)、因子分析等,它们对数据的协方差矩阵或相关矩阵进行计算,需要对数据进行标准化来保证结果的准确性。
需要注意的是,不是所有算法都需要进行标准化或归一化,有些算法是不受数据缩放影响的。另外,在进行标准化或归一化时,应该根据具体情况和数据的特点进行选择,以保证预处理的效果和结果的可解释性。
1-11 GBDT算法需要做归一化吗?xgboost,lightgbm,catboost等算法需要做归一化或者标准化吗?
GBDT(Gradient Boosting Decision Tree)算法以及其衍生算法XGBoost、LightGBM和CatBoost通常不需要做归一化或标准化。
这些算法使用的是决策树作为基学习器,决策树是根据特征之间的比较进行决策的,而不是依赖特征的绝对值大小。因此,这些算法不受特征的量纲影响,对于特征的缩放和偏移并不敏感。
此外,决策树算法也相对于线性模型而言较为鲁棒,对于异常值和偏差较大的数据也具有一定的容忍度。因此,在使用GBDT、XGBoost、LightGBM和CatBoost等算法时,一般情况下不需要进行归一化或标准化。
然而,在某些情况下,数据的预处理可能仍然对模型的性能产生积极影响。例如,如果特征量纲差异较大,或者存在某些异常值,可以尝试进行归一化或标准化处理以平衡不同特征的重要程度。根据实际问题和实验测试,在使用GBDT、XGBoost、LightGBM和CatBoost等算法时,可以考虑是否进行数据的归一化或标准化处理。
1-12 你怎样理解组合特征?举个例子,并说明它和单特征有啥区别
组合特征是通过将多个单独的特征进行组合、衍生或相互交互来创建新的特征。这些新特征可以包含对原始特征的各种操作,例如求和、乘积、差异、比率、交叉等。组合特征的目的是提取和表达原始数据中的更高层次的特征,并且能够更好地表示数据的复杂关系。
举个例子来说明,假设我们有一个房屋数据集,包含着房屋的面积和卧室数量这两个单特征。我们可以组合这两个特征,创建一个新的特征:总卧室面积。该特征可以通过将面积乘以卧室数量计算得到。这样一来,这个新特征能够更好地捕捉到房屋的卧室空间的信息,而不是仅仅考虑面积和卧室数量两个单独特征的信息。
与单特征相比,组合特征具有以下区别:
1. 表达能力更强:组合特征能够通过结合多个单独特征,更好地表达数据之间的关系和特征的意义。
2. 潜在的非线性关系:通过组合特征,可以捕捉到原始特征之间的非线性关系,从而提供更准确、更全面的特征表示。
3. 提高模型性能:组合特征能够提供更详细的特征信息,有助于提高模型的预测能力和准确性。
4. 增加特征空间:组合特征扩展了特征空间,可能帮助模型发现更多有用的特征组合,提高学习的能力。
需要注意的是,组合特征的创建需要结合具体的领域知识和模型需求,并且在特征工程过程中需要进行特征选择和特征筛选,以避免过度拟合和高维度的问题。
1-13 时间类型数据有哪些处理方法?
时间类型数据在数据处理中常常需要进行一些预处理和转换,下面列举了几种常见的处理方法:
1. 日期解析:将时间类型数据从字符串格式转换为日期对象,以便后续的处理和计算。在Python中,可以使用datetime库或pandas库的to_datetime函数来实现。
2. 特征提取:从时间类型数据中提取出具体的日期、时间、年份、月份、星期几等信息作为新的特征。例如,可以将日期数据提取为"年-月-日"的形式,或提取出季度信息等。
3. 周期性处理:对于涉及到季节性或周期性的时间数据,可以将其转换为相对时间信息,如季度、月份、周数等,以方便模型识别和学习周期性模式。
4. 时间差计算:计算时间数据之间的差值,例如计算时间间隔、时间延迟等。这可以帮助我们了解事件的持续时间或时间间隔的模式。
5. 时间戳转换:将时间数据转换为时间戳(以某一固定时间点为基准的秒数),以便进行时间序列分析、时间索引等操作。
6. 时间划分:将时间数据按照一定的规则进行划分,例如按照年、季度、月份等划分,以便进行时间聚合和分析。
7. 缺失值处理:对于缺失的时间数据,可以根据具体问题和数据集的性质进行适当的处理,例如删除、插值或填充缺失值。
需要根据具体的问题和数据集的特点选择合适的处理方法,并结合领域知识进行处理,以确保对时间类型数据的准确解释和有效使用。
相关文章:
)
算法工程师-机器学习面试题总结(1)
目录 1-1 损失函数是什么,如何定义合理的损失函数? 1-2 回归模型和分类模型常用损失函数有哪些?各有什么优缺点 1-3 什么是结构误差和经验误差?训练模型的时候如何判断已经达到最优? 1-4 模型的“泛化”能力是指&a…...

【蓝桥杯选拔赛真题73】Scratch烟花特效 少儿编程scratch图形化编程 蓝桥杯创意编程选拔赛真题解析
目录 scratch烟花特效 一、题目要求 编程实现 二、案例分析 1、角色分析...

Juniper EX系列交换机端口配置操作
配置物理端口参数 userhost#set interface ge-slot/pic/port decription description #配置端口描述 userhost#set interface ge-slot/pic/port mtu mtu-number #配置端口MTU userhost#set interface ge-slot/pic/port ether-options speed (10m | 100m | 1g) #配置端口速率…...
2.1 Linux C 编程
一、Hello World 1、在用户根目录下创建一个C_Program,并在这里面创建3.1文件夹来保存Hellow World程序; 2、安装最新版nvim ①sudo apt-get install ninja-build gettext cmake unzip curl ②sudo apt install lua5.1 ③git clone https://github.…...
服务器数据恢复—ocfs2文件系统被格式化为其他文件系统如何恢复数据?
服务器故障: 由于工作人员的误操作,将Ext4文件系统误装入到存储中Ocfs2文件系统数据卷上,导致原Ocfs2文件系统被格式化为Ext4文件系统。 由于Ext4文件系统每隔几百兆就会写入文件系统的原始信息,原Ocfs2文件系统数据会遭受一定程度…...
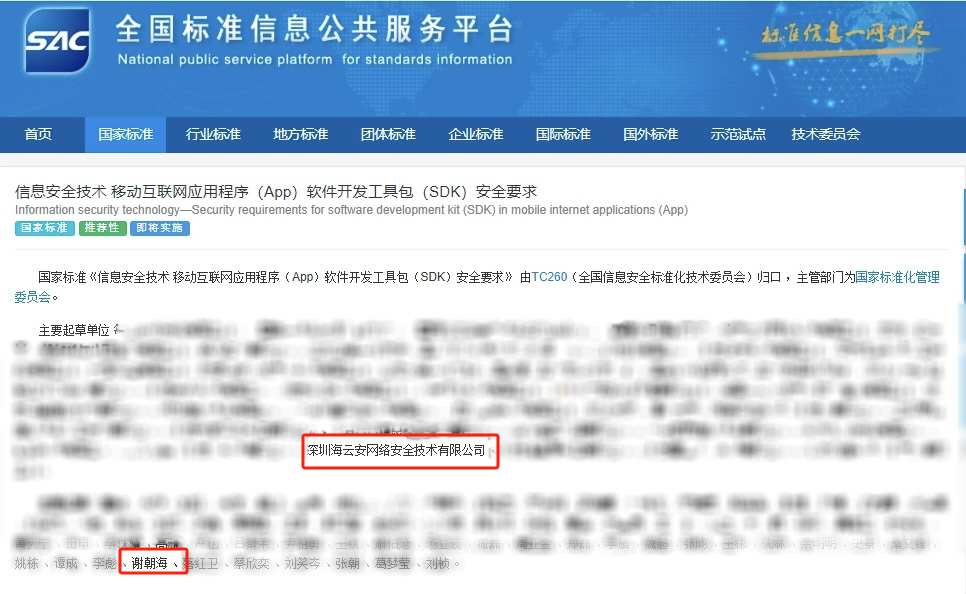
海云安参与制定《信息安全技术 移动互联网应用程序(App)软件开发工具包(SDK)安全要求》标准正式发布
近日,由TC260(全国信息安全标准化技术委员会)归口 ,主管部门为国家标准化管理委员会,深圳海云安网络安全技术有限公司(以下简称“海云安”)等多家相关企事业单位共同参与编制的GB/T 43435-2023《…...
如何调用 API | 学习笔记
开发者学堂课程【阿里云 API 网关使用教程:如何调用 API】学习笔记,与课程紧密联系,让用户快速学习知识。 课程地址:阿里云登录 - 欢迎登录阿里云,安全稳定的云计算服务平台 如何调用 API 调用 API 的三要素 要调用 API 需要三…...

关于云备份项目的HTTP协议字段理解
200状态码 给客户端返回该文件全部内容的响应 304状态码 206状态码 和If-Ranage请求头字段搭配使用,...

掉落的俄罗斯方块
欢迎来到程序小院 掉落的俄罗斯方块 玩法:上键 W↑变换、 左键 A← 左移、右键 D→ 右移、下键S ↓ 加速,两种模式, 可以一个大人玩,也可以两个人一起玩,小鸟经过会撞走方块,快去体验吧^^。开始游戏 html <div idc…...
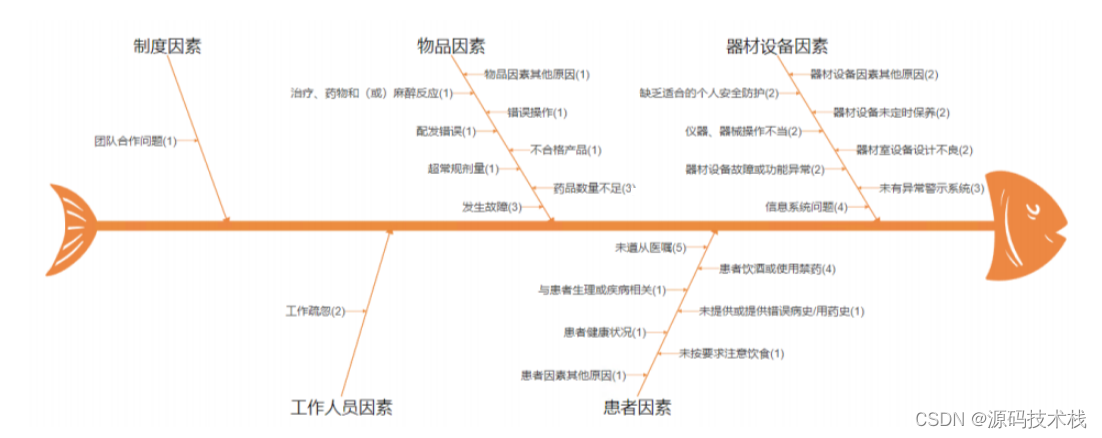
医院不良事件报告系统源码带鱼骨图分析
医院不良事件上报系统通过 “事前的人员知识培训管理和制度落地促进”、“事中的事件上报和跟进处理”、 以及 “事后的原因分析和工作持续优化”,结合预存上百套已正在使用的模板,帮助医院从对护理事件、药品事件、医疗器械事件、医院感染事件、输血事件…...

数据库相关算法题 V3
订单最多的客户 在考虑多个最多订单客户的情况下可以采用dense_rank()函数,最多则由group by customer_number以及order count(*)得到 select customer_number from (select customer_number,dense_rank() over (order by count(*) desc) as rk from Orders group…...
第二证券:本周3只新股申购,大豆蛋白行业领军企业来了!
截至发稿,本周网上发行有2只新股宣布发行价。创业板新股丰茂股份发行价为31.9元,发行市盈率28.27倍,工作最近一个月平均动态市盈率25.76倍。沪主板新股索宝蛋白发行价为21.29元,发行市盈率26.74倍,工作最近一个月平均动…...

【go语言开发】loglus日志框架的使用
本文将简单介绍loglus框架的基本使用,并给出demo 文章目录 前言Loglus常见用法自定义日志级别使用字段钩子输出到多个位置使用钩子实现自定义日志处理demo 前言 Logrus 是一个用于 Go 语言的结构化日志框架,它提供了丰富的日志级别、钩子和格式化选项。…...
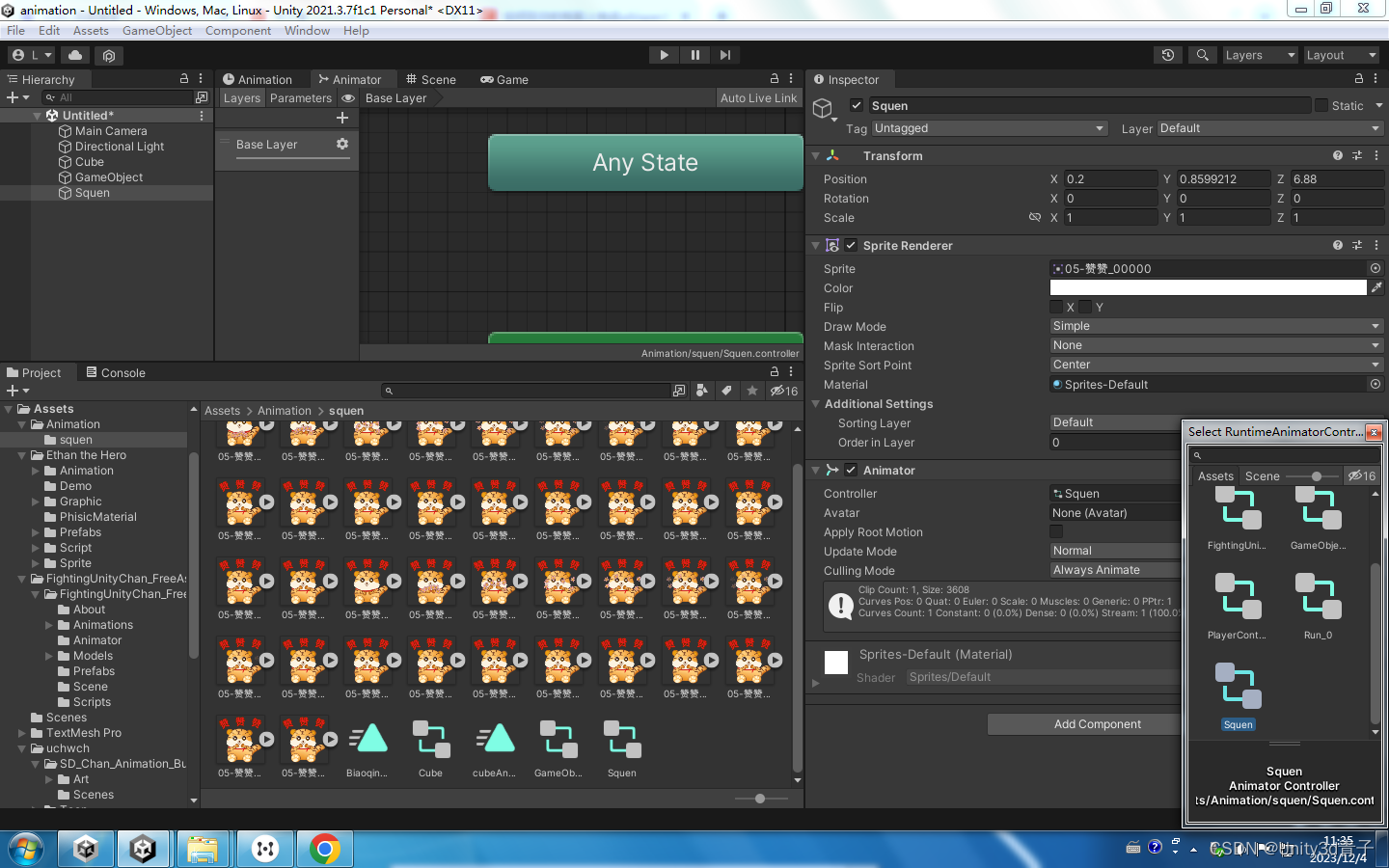
【Unity动画】Unity 动画播放的流程
本文以2D为案例,讲解Unity 播放动画的流程 准备和导入2D动画资源 外部导入序列帧生成的 Unity内部制作的 外部导入的3D动画 2.创建动画过程 打开时间轴Ctrl6 选中场景中的一个未来需要播放动画的物体 回到时间轴点击Create一个新动画片段 拖动2D动画资源放入…...

深度学习——第3章 Python程序设计语言(3.2 Python程序流程控制)
3.2 Python程序流程控制 目录 1.布尔数据类型及相关运算 2.顺序结构 3.选择(分支)结构 4.循环结构 无论是在机器学习还是深度学习中,Python已经成为主导性的编程语言。而且,现在许多主流的深度学习框架,例如PyTorc…...
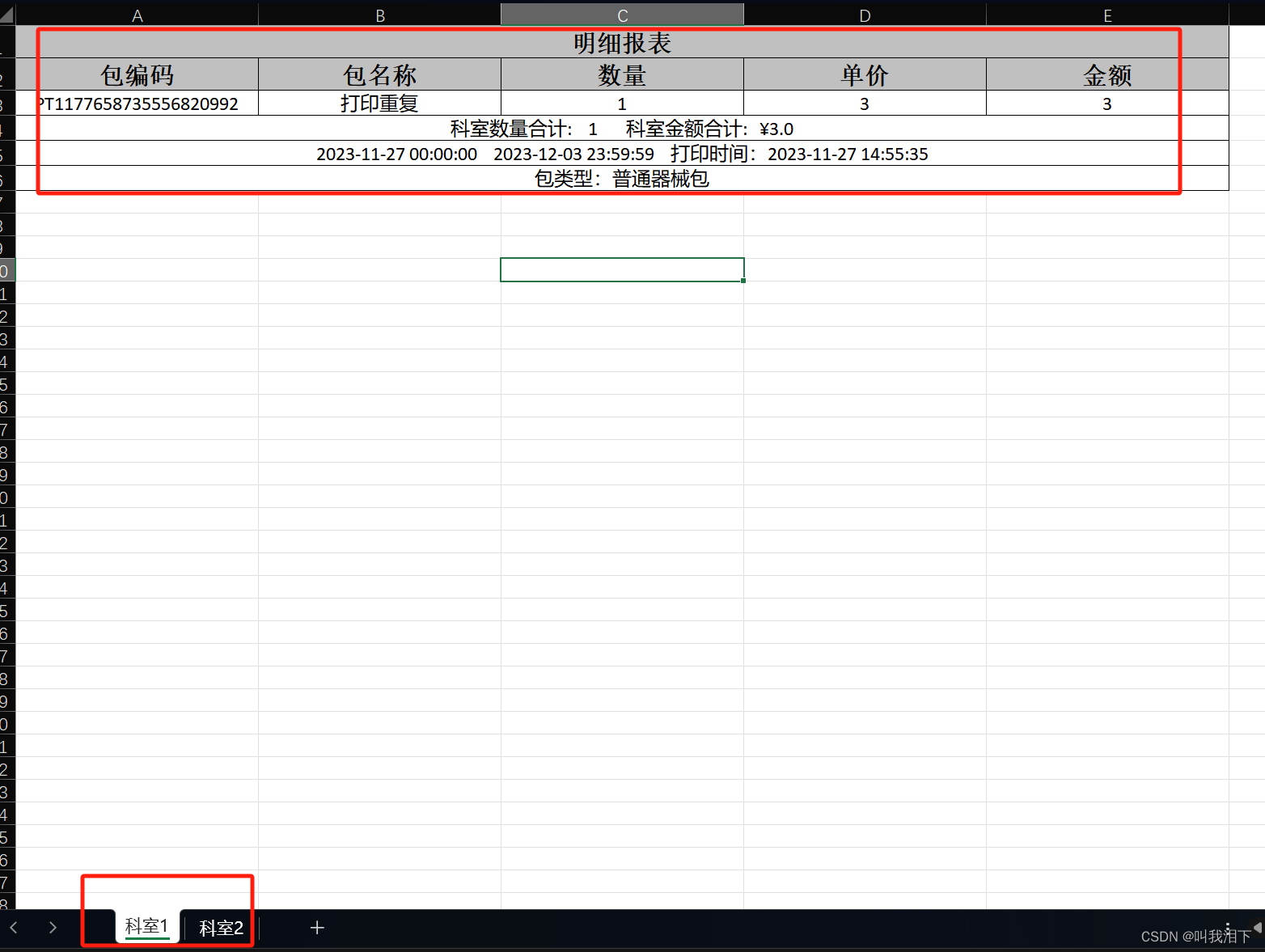
EasyExcel生成多sheet页的excel
一、controller层 ApiOperation(value "明细查询导出") PostMapping(value "/SummaryDetailExport") public void summaryDetailExport(RequestBody SearchDTO dto, HttpServletResponse response) throws IOException {reportService.deptPackagingSum…...

家用小型洗衣机哪款性价比高?内衣洗衣机品牌推荐
近日,国内著名的电子商务平台公布了“内衣洗衣机产业趋势”的研究报告。该报告指出,由于消费者对生活质量的要求越来越高,内衣洗衣机的行业也有了长足的发展,特别是在今年以来,内衣洗衣机的销售额同比上涨了830%&#…...

为何Go爬虫依然远没有Python爬虫流行
目录 一、Go与Python的比较 1、语言生态 2、易用性 3、库支持 二、Go爬虫的优势 1、性能与并发性 2、跨平台性 3、内存占用 三、Go爬虫的潜力与未来发展 1、社区支持与库完善 2、跨平台移动应用开发 3、大数据处理与实时分析 四、代码示例 五、结论 在当今的互联…...

【华为OD题库-057】MELON的难题-java
题目 MELON有一堆精美的雨花石(数量为n,重量各异),准备送给S和W。MELON希望送给俩人的雨花石重星一致,请你设计一个程序帮MELON确认是否能将雨花石平均分配。 输入描述 第1行输入为雨花石个数:n,0<n <31. 第2行输入为空格分…...
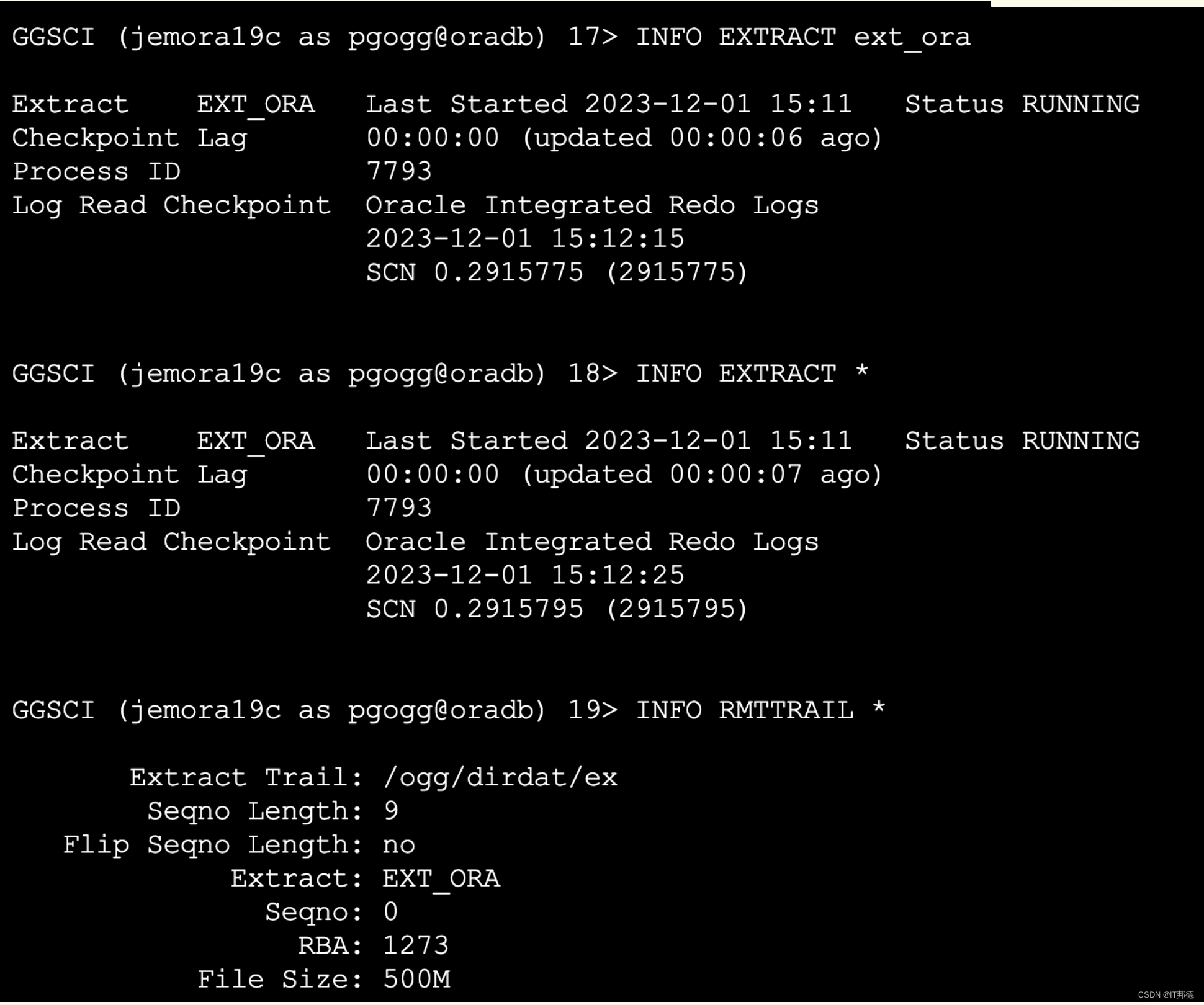
OGG实现Oracle19C到postgreSQL14的实时同步
📢📢📢📣📣📣 哈喽!大家好,我是【IT邦德】,江湖人称jeames007,10余年DBA及大数据工作经验 一位上进心十足的【大数据领域博主】!😜&am…...

iOS 26 携众系统重磅更新,但“苹果智能”仍与国行无缘
美国西海岸的夏天,再次被苹果点燃。一年一度的全球开发者大会 WWDC25 如期而至,这不仅是开发者的盛宴,更是全球数亿苹果用户翘首以盼的科技春晚。今年,苹果依旧为我们带来了全家桶式的系统更新,包括 iOS 26、iPadOS 26…...

Lombok 的 @Data 注解失效,未生成 getter/setter 方法引发的HTTP 406 错误
HTTP 状态码 406 (Not Acceptable) 和 500 (Internal Server Error) 是两类完全不同的错误,它们的含义、原因和解决方法都有显著区别。以下是详细对比: 1. HTTP 406 (Not Acceptable) 含义: 客户端请求的内容类型与服务器支持的内容类型不匹…...

在HarmonyOS ArkTS ArkUI-X 5.0及以上版本中,手势开发全攻略:
在 HarmonyOS 应用开发中,手势交互是连接用户与设备的核心纽带。ArkTS 框架提供了丰富的手势处理能力,既支持点击、长按、拖拽等基础单一手势的精细控制,也能通过多种绑定策略解决父子组件的手势竞争问题。本文将结合官方开发文档,…...

Vue3 + Element Plus + TypeScript中el-transfer穿梭框组件使用详解及示例
使用详解 Element Plus 的 el-transfer 组件是一个强大的穿梭框组件,常用于在两个集合之间进行数据转移,如权限分配、数据选择等场景。下面我将详细介绍其用法并提供一个完整示例。 核心特性与用法 基本属性 v-model:绑定右侧列表的值&…...

【HarmonyOS 5.0】DevEco Testing:鸿蒙应用质量保障的终极武器
——全方位测试解决方案与代码实战 一、工具定位与核心能力 DevEco Testing是HarmonyOS官方推出的一体化测试平台,覆盖应用全生命周期测试需求,主要提供五大核心能力: 测试类型检测目标关键指标功能体验基…...

UDP(Echoserver)
网络命令 Ping 命令 检测网络是否连通 使用方法: ping -c 次数 网址ping -c 3 www.baidu.comnetstat 命令 netstat 是一个用来查看网络状态的重要工具. 语法:netstat [选项] 功能:查看网络状态 常用选项: n 拒绝显示别名&#…...

什么是EULA和DPA
文章目录 EULA(End User License Agreement)DPA(Data Protection Agreement)一、定义与背景二、核心内容三、法律效力与责任四、实际应用与意义 EULA(End User License Agreement) 定义: EULA即…...
)
【RockeMQ】第2节|RocketMQ快速实战以及核⼼概念详解(二)
升级Dledger高可用集群 一、主从架构的不足与Dledger的定位 主从架构缺陷 数据备份依赖Slave节点,但无自动故障转移能力,Master宕机后需人工切换,期间消息可能无法读取。Slave仅存储数据,无法主动升级为Master响应请求ÿ…...

在鸿蒙HarmonyOS 5中使用DevEco Studio实现录音机应用
1. 项目配置与权限设置 1.1 配置module.json5 {"module": {"requestPermissions": [{"name": "ohos.permission.MICROPHONE","reason": "录音需要麦克风权限"},{"name": "ohos.permission.WRITE…...

如何在最短时间内提升打ctf(web)的水平?
刚刚刷完2遍 bugku 的 web 题,前来答题。 每个人对刷题理解是不同,有的人是看了writeup就等于刷了,有的人是收藏了writeup就等于刷了,有的人是跟着writeup做了一遍就等于刷了,还有的人是独立思考做了一遍就等于刷了。…...