改造python3中的http.server为简单的文件上传下载服务
改造
修改python3中的http.server.SimpleHTTPRequestHandler,实现简单的文件上传下载服务
simple_http_file_server.py:
# !/usr/bin/env python3import datetime
import email
import html
import http.server
import io
import mimetypes
import os
import posixpath
import re
import shutil
import sys
import urllib.error
import urllib.parse
import urllib.request
import socket
from http import HTTPStatus
import threading
import contextlib__version__ = "0.1"
__all__ = ["MySimpleHTTPRequestHandler"]class MySimpleHTTPRequestHandler(http.server.BaseHTTPRequestHandler):server_version = "SimpleHTTP/" + __version__extensions_map = _encodings_map_default = {'.gz': 'application/gzip','.Z': 'application/octet-stream','.bz2': 'application/x-bzip2','.xz': 'application/x-xz',}def __init__(self, *args, directory=None, **kwargs):if directory is None:directory = os.getcwd()self.directory = os.fspath(directory)super().__init__(*args, **kwargs)def do_GET(self):f = self.send_head()if f:try:self.copyfile(f, self.wfile)finally:f.close()def do_HEAD(self):f = self.send_head()if f:f.close()def send_head(self):path = self.translate_path(self.path)f = Noneif os.path.isdir(path):parts = urllib.parse.urlsplit(self.path)if not parts.path.endswith('/'):# redirect browser - doing basically what apache doesself.send_response(HTTPStatus.MOVED_PERMANENTLY)new_parts = (parts[0], parts[1], parts[2] + '/',parts[3], parts[4])new_url = urllib.parse.urlunsplit(new_parts)self.send_header("Location", new_url)self.end_headers()return Nonefor index in "index.html", "index.htm":index = os.path.join(path, index)if os.path.exists(index):path = indexbreakelse:return self.list_directory(path)ctype = self.guess_type(path)if path.endswith("/"):self.send_error(HTTPStatus.NOT_FOUND, "File not found")return Nonetry:f = open(path, 'rb')except OSError:self.send_error(HTTPStatus.NOT_FOUND, "File not found")return Nonetry:fs = os.fstat(f.fileno())# Use browser cache if possibleif ("If-Modified-Since" in self.headersand "If-None-Match" not in self.headers):# compare If-Modified-Since and time of last file modificationtry:ims = email.utils.parsedate_to_datetime(self.headers["If-Modified-Since"])except (TypeError, IndexError, OverflowError, ValueError):# ignore ill-formed valuespasselse:if ims.tzinfo is None:# obsolete format with no timezone, cf.# https://tools.ietf.org/html/rfc7231#section-7.1.1.1ims = ims.replace(tzinfo=datetime.timezone.utc)if ims.tzinfo is datetime.timezone.utc:# compare to UTC datetime of last modificationlast_modif = datetime.datetime.fromtimestamp(fs.st_mtime, datetime.timezone.utc)# remove microseconds, like in If-Modified-Sincelast_modif = last_modif.replace(microsecond=0)if last_modif <= ims:self.send_response(HTTPStatus.NOT_MODIFIED)self.end_headers()f.close()return Noneself.send_response(HTTPStatus.OK)self.send_header("Content-type", ctype)self.send_header("Content-Length", str(fs[6]))self.send_header("Last-Modified",self.date_time_string(fs.st_mtime))self.end_headers()return fexcept:f.close()raisedef list_directory(self, path):try:list_dir = os.listdir(path)except OSError:self.send_error(HTTPStatus.NOT_FOUND, "No permission to list_dir directory")return Nonelist_dir.sort(key=lambda a: a.lower())r = []try:display_path = urllib.parse.unquote(self.path, errors='surrogatepass')except UnicodeDecodeError:display_path = urllib.parse.unquote(path)display_path = html.escape(display_path, quote=False)enc = sys.getfilesystemencoding()form = """<h1>文件上传</h1>\n<form ENCTYPE="multipart/form-data" method="post">\n<input name="file" type="file"/>\n<input type="submit" value="upload"/>\n</form>\n"""title = 'Directory listing for %s' % display_pathr.append('<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" ''"http://www.w3.org/TR/html4/strict.dtd">')r.append('<html>\n<head>')r.append('<meta http-equiv="Content-Type" ''content="text/html; charset=%s">' % enc)r.append('<title>%s</title>\n</head>' % title)r.append('<body>%s\n<h1>%s</h1>' % (form, title))r.append('<hr>\n<ul>')for name in list_dir:fullname = os.path.join(path, name)displayname = linkname = name# Append / for directories or @ for symbolic linksif os.path.isdir(fullname):displayname = name + "/"linkname = name + "/"if os.path.islink(fullname):displayname = name + "@"# Note: a link to a directory displays with @ and links with /r.append('<li><a href="%s">%s</a></li>' % (urllib.parse.quote(linkname, errors='surrogatepass'),html.escape(displayname, quote=False)))r.append('</ul>\n<hr>\n</body>\n</html>\n')encoded = '\n'.join(r).encode(enc, 'surrogate escape')f = io.BytesIO()f.write(encoded)f.seek(0)self.send_response(HTTPStatus.OK)self.send_header("Content-type", "text/html; charset=%s" % enc)self.send_header("Content-Length", str(len(encoded)))self.end_headers()return fdef translate_path(self, path):# abandon query parameterspath = path.split('?', 1)[0]path = path.split('#', 1)[0]# Don't forget explicit trailing slash when normalizing. Issue17324trailing_slash = path.rstrip().endswith('/')try:path = urllib.parse.unquote(path, errors='surrogatepass')except UnicodeDecodeError:path = urllib.parse.unquote(path)path = posixpath.normpath(path)words = path.split('/')words = filter(None, words)path = self.directoryfor word in words:if os.path.dirname(word) or word in (os.curdir, os.pardir):# Ignore components that are not a simple file/directory namecontinuepath = os.path.join(path, word)if trailing_slash:path += '/'return pathdef copyfile(self, source, outputfile):shutil.copyfileobj(source, outputfile)def guess_type(self, path):base, ext = posixpath.splitext(path)if ext in self.extensions_map:return self.extensions_map[ext]ext = ext.lower()if ext in self.extensions_map:return self.extensions_map[ext]guess, _ = mimetypes.guess_type(path)if guess:return guessreturn 'application/octet-stream'def do_POST(self):r, info = self.deal_post_data()self.log_message('%s, %s => %s' % (r, info, self.client_address))enc = sys.getfilesystemencoding()res = ['<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" ''"http://www.w3.org/TR/html4/strict.dtd">','<html>\n<head>','<meta http-equiv="Content-Type" content="text/html; charset=%s">' % enc,'<title>%s</title>\n</head>' % "Upload Result Page",'<body><h1>%s</h1>\n' % "Upload Result"]if r:res.append('<p>SUCCESS: %s</p>\n' % info)else:res.append('<p>FAILURE: %s</p>' % info)res.append('<a href=\"%s\">back</a>' % self.headers['referer'])res.append('</body></html>')encoded = '\n'.join(res).encode(enc, 'surrogate escape')f = io.BytesIO()f.write(encoded)length = f.tell()f.seek(0)self.send_response(200)self.send_header("Content-type", "text/html")self.send_header("Content-Length", str(length))self.end_headers()if f:self.copyfile(f, self.wfile)f.close()def deal_post_data(self):content_type = self.headers['content-type']if not content_type:return False, "Content-Type header doesn't contain boundary"boundary = content_type.split("=")[1].encode()remain_bytes = int(self.headers['content-length'])line = self.rfile.readline()remain_bytes -= len(line)if boundary not in line:return False, "Content NOT begin with boundary"line = self.rfile.readline()remain_bytes -= len(line)fn = re.findall(r'Content-Disposition.*name="file"; filename="(.*)"', line.decode())if not fn:return False, "Can't find out file name..."path = self.translate_path(self.path)fn = os.path.join(path, fn[0])line = self.rfile.readline()remain_bytes -= len(line)line = self.rfile.readline()remain_bytes -= len(line)try:out = open(fn, 'wb')except IOError:return False, "Can't create file to write, do you have permission to write?"preline = self.rfile.readline()remain_bytes -= len(preline)while remain_bytes > 0:line = self.rfile.readline()remain_bytes -= len(line)if boundary in line:preline = preline[0:-1]if preline.endswith(b'\r'):preline = preline[0:-1]out.write(preline)out.close()return True, "File '%s' upload success!" % fnelse:out.write(preline)preline = linereturn False, "Unexpect Ends of data."def _get_best_family(*address):infos = socket.getaddrinfo(*address,type=socket.SOCK_STREAM,flags=socket.AI_PASSIVE,)family, type, proto, canonname, sockaddr = next(iter(infos))return family, sockaddrdef serve_forever(port=8000, bind=None, directory="."):"""This runs an HTTP server on port 8000 (or the port argument)."""# ensure dual-stack is not disabled; ref #38907class DualStackServer(http.server.ThreadingHTTPServer):def server_bind(self):# suppress exception when protocol is IPv4with contextlib.suppress(Exception):self.socket.setsockopt(socket.IPPROTO_IPV6, socket.IPV6_V6ONLY, 0)return super().server_bind()def finish_request(self, request, client_address):self.RequestHandlerClass(request, client_address, self,directory=directory)HandlerClass=MySimpleHTTPRequestHandlerServerClass=DualStackServerprotocol="HTTP/1.0"ServerClass.address_family, addr = _get_best_family(bind, port)HandlerClass.protocol_version = protocolwith ServerClass(addr, HandlerClass) as httpd:host, port = httpd.socket.getsockname()[:2]url_host = f'[{host}]' if ':' in host else hostprint(f"Serving HTTP on {host} port {port} "f"(http://{url_host}:{port}/) ...")try:httpd.serve_forever()except KeyboardInterrupt:print("\nKeyboard interrupt received, exiting.")sys.exit(0)if __name__ == '__main__':import argparseparser = argparse.ArgumentParser()parser.add_argument('--bind', '-b', metavar='ADDRESS',help='specify alternate bind address ''(default: all interfaces)')parser.add_argument('--directory', '-d', default=os.getcwd(),help='specify alternate directory ''(default: current directory)')parser.add_argument('port', action='store', default=8000, type=int,nargs='?',help='specify alternate port (default: 8000)')args = parser.parse_args()# 在主线程中执行# serve_forever(# port=args.port,# bind=args.bind,# directory = args.directory# )# 在子线程中执行,这样主线程可以执行异步工作thread1 = threading.Thread(name='t1',target= serve_forever,kwargs={"port" : args.port,"bind" : args.bind,"directory" : args.directory})thread1.start()# thread1.join()使用帮助:
>python3 simple_http_file_server.py --help
usage: simple_http_file_server.py [-h] [--cgi] [--bind ADDRESS] [--directory DIRECTORY] [port]positional arguments:
port specify alternate port (default: 8000)optional arguments:
-h, --help show this help message and exit
--cgi run as CGI server
--bind ADDRESS, -b ADDRESS
specify alternate bind address (default: all interfaces)
--directory DIRECTORY, -d DIRECTORY
specify alternate directory (default: current directory)
使用示例:
>python3 simple_http_file_server.py -d ~ 12345
Serving HTTP on :: port 12345 (http://[::]:12345/) ...
::ffff:127.0.0.1 - - [30/Nov/2023 09:35:06] "GET / HTTP/1.1" 200 -。。。
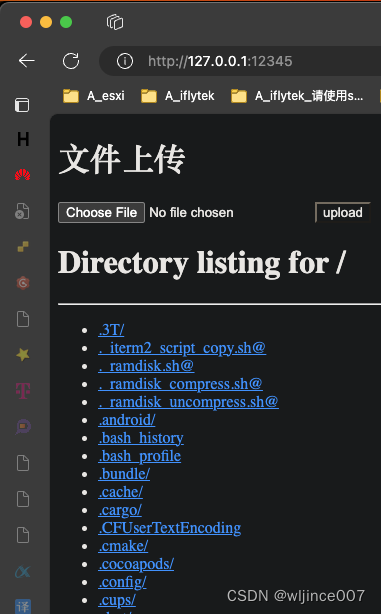
访问:
浏览器中访问:http://127.0.0.1:12345/
参考:
Python3 实现简单HTTP服务器(附带文件上传)_python3 -m http.server-CSDN博客
相关文章:
改造python3中的http.server为简单的文件上传下载服务
改造 修改python3中的http.server.SimpleHTTPRequestHandler,实现简单的文件上传下载服务 simple_http_file_server.py: # !/usr/bin/env python3import datetime import email import html import http.server import io import mimetypes import os …...

Fiddler抓包工具之fiddler的composer可以简单发送http协议的请求
一,composer的详解 右侧Composer区域,是测试接口的界面: 相关说明: 1.请求方式:点开可以勾选请求协议是get、post等 2.url地址栏:输入请求的url地址 3.请求头:第三块区域可以输入请求头信息…...

14、pytest像用参数一样使用fixture
官方实例 # content of test_fruit.py import pytestclass Fruit:def __init__(self, name):self.name nameself.cubed Falsedef cube(self):self.cubed Trueclass FruitSalad:def __init__(self, *fruit_bowl):self.fruit fruit_bowlself._cube_fruit()def _cube_fruit(s…...

C++ Primer Plus第十三章笔记
目录 基类 构造函数:访问权限的考虑 1.2 派生类和基类之间的特殊关系 继承:is-a关系 多态公有继承 静态联编和动态联编 指针和引用类型的兼容性 虚成员函数和动态联编 虚函数的注意事项 构造函数 析构函数 友元 没有重新定义 重新定义将隐…...

【JavaEE】单例模式
作者主页:paper jie_博客 本文作者:大家好,我是paper jie,感谢你阅读本文,欢迎一建三连哦。 本文于《JavaEE》专栏,本专栏是针对于大学生,编程小白精心打造的。笔者用重金(时间和精力)打造&…...
)
第十五届蓝桥杯模拟赛(第二期 C++)
俺自己做的噢,还未核实答案,若有差错,望斧正。 第一题 小蓝要在屏幕上放置一行文字,每个字的宽度相同。小蓝发现,如果每个字的宽为 36 像素,一行正好放下 30 个字,字符之间和前后都没有任何空隙…...
关于Unity中字典在Inspector的显示
字典在Inspector的显示 方法一:实现ISerializationCallbackReceiver接口 《unity3D游戏开发第二版》记录 在编辑面板中可以利用序列化监听接口特性对字典进行序列化。 主要继承ISerializationCallbackReceiver接口 实现OnAfterDeserialize() OnBeforeSerialize() …...
使用Plex结合cpolar搭建本地私人媒体站并实现远程访问
文章目录 1.前言2. Plex网站搭建2.1 Plex下载和安装2.2 Plex网页测试2.3 cpolar的安装和注册 3. 本地网页发布3.1 Cpolar云端设置3.2 Cpolar本地设置 4. 公网访问测试5. 结语 1.前言 用手机或者平板电脑看视频,已经算是生活中稀松平常的场景了,特别是各…...
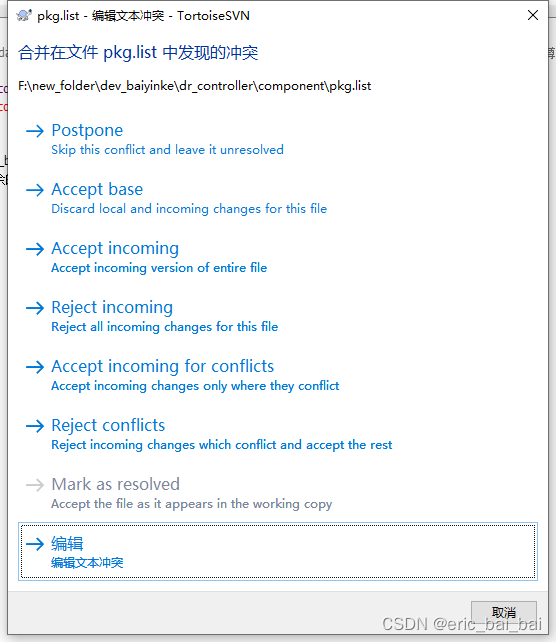
svn合并冲突时每个选项的含义
合并冲突时每个选项的含义 - 这个图片是 TortoiseSVN(一个Subversion(SVN)客户端)的合并冲突解决对话框。当你尝试合并两个版本的文件并且出现差异时,你需要解决这些差异。这个对话框提供了几个选项来处理合并冲突&…...

指针、数组与函数例题3
1、字符串复制 题目描述 设计函数实现字符串复制功能,每个字符串长度不超过100,不要使用系统提供的strcpy函数 输入要求 从键盘读入一个字符串到数组b中,以换行符结束 输出要求 将内容复制到另一个数组a中,并分别输出数组a和…...

ThreeJs样例 webgl_shadow_contact 分析
webgl_shadow_contact 官方样例中,对阴影的渲染比较特殊,很值得借鉴,学习渲染阴影的思路;这个例子中对阴影的渲染,并没有使用任何光源,没有用shadowmap的常规方式 渲染阴影;而是使用了深度材质T…...
)
Nginx(缓冲区)
先来思考一个问题,接入Nginx的项目一般请求流程为:“客户端→Nginx→服务端”,在这个过程中存在两个连接:“客户端→Nginx、Nginx→服务端”,那么两个不同的连接速度不一致,就会影响用户的体验(…...

MQTT协议理解并实践
MQTT是一个轻量的发布订阅模式消息传输协议,专门针对低带宽和不稳定网络环境的物联网应用设计 MQTT协议根据主题来分发消息进行通信,支持通配符匹配,可以低开销的使用数百万Topic进行一对一,一对多双向通信。 协议特点 1. 开放…...
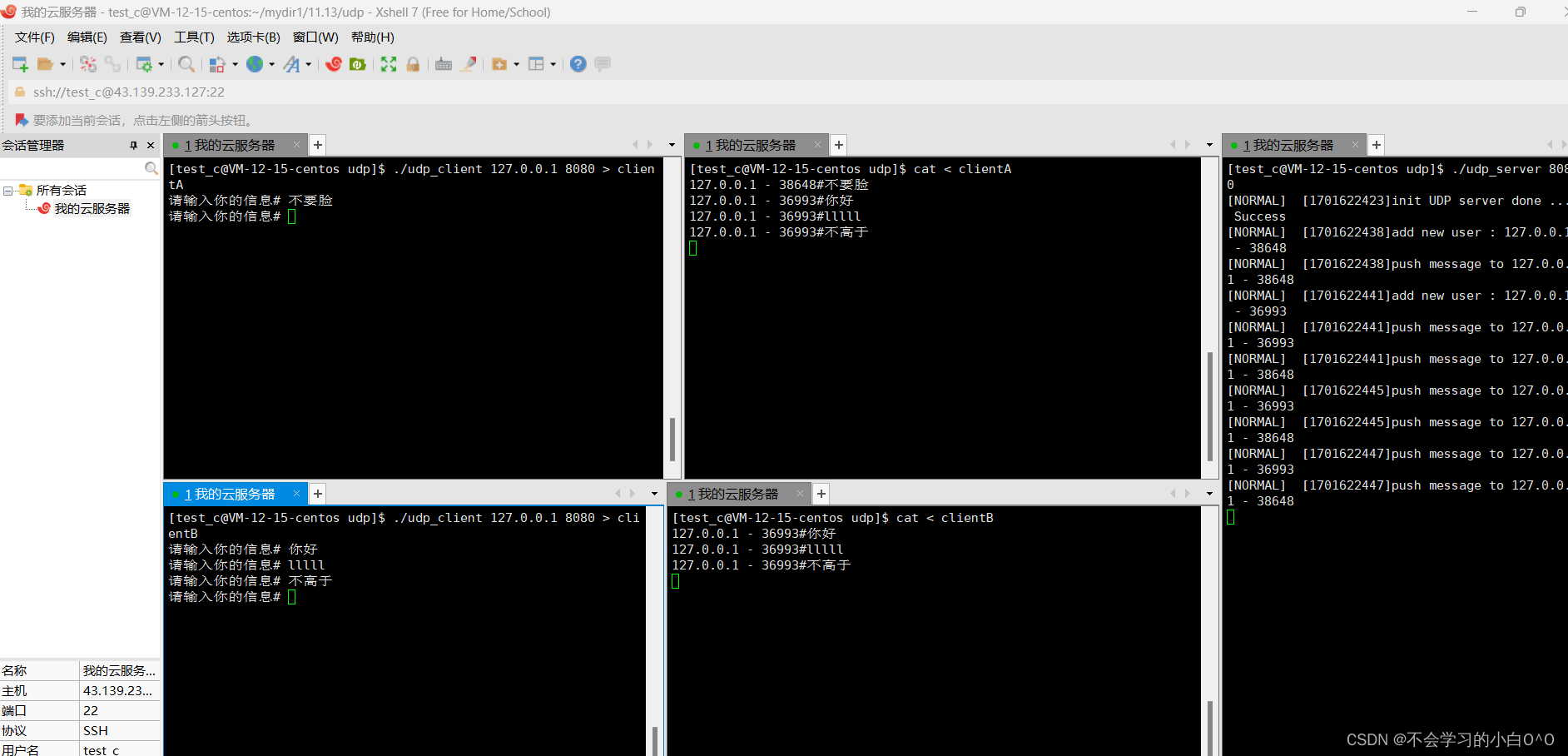
实现一个简单的网络通信下(udp)
时间过去好久了,先回忆一下上一篇博客的代码!! 目前来看,我们客户端发一条消息,我服务器收到这一条消息之后呢,服务器也知道了是谁给我发来的消息,紧接这就把这条消息放进buffer当中,…...

Linux中office环境LibreOffice_7.6.2下载
阿里云盘:LibreOffice_7.6.2 使用:下载的文件为exe文件,双击exe文件即可获取到文件 LibreOffice_7.6.2安装: 解压:tar -zxvf LibreOffice_7.6.2_Linux_x86-64_rpm.tar.gz 移动到RPMS目录:cd LibreOffice_7…...

Linux快捷控制
Linux快捷控制 工具安装 yum -y install lrzsz wget curl net-tools git防火墙 systemctl status firewalld.service systemctl stop firewalld.service systemctl disable firewalld.service宝塔 yum install -y wget && wget -O install.sh https://download.bt.…...

免费插件集-illustrator插件-Ai插件-重复复制-单一对象页面排版
文章目录 1.介绍2.安装3.通过窗口>扩展>知了插件>重复复制4.总结 1.介绍 本文介绍一款免费插件,加强illustrator使用人员工作效率,进行制卡专用分层分色。首先从下载网址下载这款插件 https://download.csdn.net/download/m0_67316550/8789050…...

GO基础之变量与常量
标识符与关键字 标识符 在编程语言中标识符就是程序员定义的具有特殊意义的词,比如变量名、常量名、函数名等等。 Go语言中标识符由字母数字和_(下划线)组成,并且只能以字母和_开头。 举几个例子:abc, _, _123, a123。 关键字 关键…...
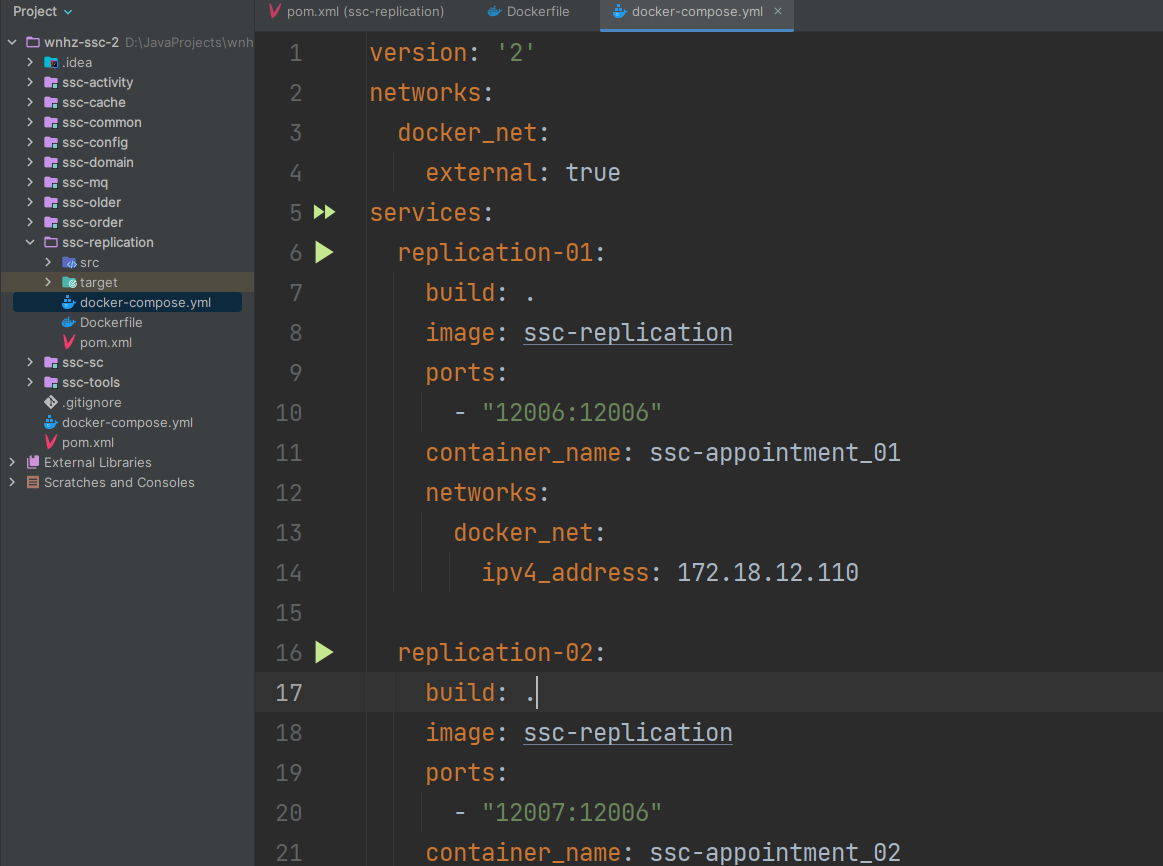
Docker Compose简单入门
Docker Compose 简介 Docker Compose 是一个编排多容器发布式部署的工具,提供命令集管理容器化应用的完整开发周期,包括服务构建,启动和停止。 Docker Compose 真正的作用是在一个文件(docker-compose.yml)中定义并运…...

使用 PHPMailer 实现邮件的实时发送
💂 个人网站:【 海拥】【神级代码资源网站】【办公神器】🤟 基于Web端打造的:👉轻量化工具创作平台💅 想寻找共同学习交流的小伙伴,请点击【全栈技术交流群】 今天我们利用GitHub上20K星星的项目 PHPMailer…...

智慧校园软件怎么选?看懂这 5 个核心功能再决定不迟
✅作者简介:合肥自友科技 📌核心产品:智慧校园软件(包括教工管理、学工管理、教务管理、考务管理、后勤管理、德育管理、资产管理、公寓管理、实习管理、就业管理、离校管理、科研平台、档案管理、学生平台等26个子平台) 。公司所有人员均有多…...

龙迅LT9211D芯片解析:如何实现MIPI与双端口LVDS的高效转换
1. 龙迅LT9211D芯片的核心价值 第一次接触龙迅LT9211D芯片是在一个车载显示项目上,当时客户要求实现4K视频从主控芯片到双屏显示的无损传输。这个看似简单的需求背后,其实隐藏着MIPI和LVDS两种信号标准的转换难题。LT9211D的出现完美解决了这个问题&…...

华泰证券2027届校招启动|提前批+国际管培+金融科技,三个专场一次说清
导读很多同学还在等“春招后半场捡漏”,但现实已经变了。头部企业的优质岗位,正在通过提前批 专项项目提前锁定人选。如果你现在才开始准备,很可能连入场资格都拿不到。这次华泰证券的校招,就是一个非常典型的信号:提…...

AI率80%+送去降AI工具处理,3款结果对比
这篇文章记录的是一个横向测试:找了几篇AI率都在80%以上的论文,分别送去嘎嘎降AI、比话降AI、率零处理,然后统一在知网检测,看最终结果。 测试设计 测试论文(4篇): 编号专业字数知网AI率&…...

从零搭建WebRTC SFU服务器:基于Mediasoup的1080P视频会议部署教程
从零搭建WebRTC SFU服务器:基于Mediasoup的1080P视频会议部署教程 视频会议已成为现代远程协作的核心工具,而WebRTC技术让浏览器间的实时音视频通信变得触手可及。但当你需要支持10人以上的高清会议时,单纯的P2P连接就会暴露出带宽和性能瓶颈…...

毕业党速看:这款 AI 论文神器太疯狂,输入标题直接生成万字长文
赶 due 党、论文特困生直接狂喜!谁懂啊家人们,以前写论文从选题到憋出万字初稿,至少得熬半个月,现在输入一个论文标题,短短 20 分钟就能自动生成结构完整、逻辑通顺、带真实参考文献的万字长文,从摘要、引言…...

iOS/Android 集成游戏盾审核被拒?权限与合规配置修复
iOS/Android 集成游戏盾审核被拒?权限与合规配置修复做手游安全的开发者基本都碰到过:集成游戏盾 SDK 后,App Store 或 Google Play / 国内安卓渠道突然审核被拒。多数不是功能 bug,而是权限声明、隐私合规、SDK 行为踩了平台红线…...

告别手动敲命令:用Rancher 2.9.2的Web界面,5分钟搞定K8S 1.26集群的Nginx部署
告别手动敲命令:用Rancher 2.9.2的Web界面,5分钟搞定K8S 1.26集群的Nginx部署 在Kubernetes的世界里,部署一个简单的Nginx服务往往需要编写复杂的YAML文件,记忆各种kubectl命令参数,这对于刚接触K8S的开发者或小型运维…...

JVM排查工具单
jstack是jdk自带的线程堆栈分析工具,使用该命令可以查看或导出 Java 应用程序中线程堆栈信息。线程快照是当前虚拟机内每一条线程上在执行的方法堆栈的集合,生成线程快照的主要目的是定位线程出现长时间停顿的原因,如线程间死锁、死循环、 请…...

如何永久备份微信聊天记录?WeChatMsg完整指南让数据真正属于你
如何永久备份微信聊天记录?WeChatMsg完整指南让数据真正属于你 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/…...