常见代码优化案例记录
1. 使用StringBuilder优化字符串拼接:
// 不优化的写法
String result = "";
for (int i = 0; i < 1000; i++) {result += i;
}// 优化的写法
StringBuilder resultBuilder = new StringBuilder();
for (int i = 0; i < 1000; i++) {resultBuilder.append(i);
}
String result = resultBuilder.toString();
2. 避免在循环中重复计算数组长度:
// 不优化的写法
for (int i = 0; i < array.length; i++) {// 访问数组元素
}// 优化的写法
int length = array.length;
for (int i = 0; i < length; i++) {// 访问数组元素
}
3. 使用局部变量替代重复调用方法:类似2
// 不优化的写法
for (int i = 0; i < list.size(); i++) {// 多次调用list.get(i)
}// 优化的写法
int size = list.size();
for (int i = 0; i < size; i++) {// 多次使用size// 使用list.get(i)
}
4. 选择合适的集合类:
// 使用ArrayList而不是LinkedList,发明LinkedList都不用LinkedList,可想而知
List<String> arrayList = new ArrayList<>();// 使用HashSet而不是TreeSet,TreeSet排序消耗性能,但大多数情况下都没必要排序
Set<String> hashSet = new HashSet<>();
5. 合理使用缓存:
// 缓存计算结果
Map<Integer, Integer> cache = new HashMap<>();
int result = cache.computeIfAbsent(input, key -> computeExpensiveOperation(key));
6. 避免过度同步:
// 避免过度同步(锁粒度要尽量最小)
private static final Object lock = new Object();synchronized (lock) {// 一些同步操作
}
7. 使用适当的算法和数据结构:
// 使用Arrays.sort()进行排序
int[] array = {3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5};
Arrays.sort(array);
Arrays.sort() 使用了一种高效的排序算法(通常是基于快速排序的变体),在大多数情况下,它能够以较高的性能对数组进行排序。
8. 减少对象创建:
// 减少对象创建
StringBuilder resultBuilder = new StringBuilder();
for (int i = 0; i < 1000; i++) {resultBuilder.append(i);
}
String result = resultBuilder.toString();
9. 使用快速失败机制:
// 使用Iterator并快速失败机制
List<String> list = new ArrayList<>();
Iterator<String> iterator = list.iterator();
while (iterator.hasNext()) {String element = iterator.next();// 对element进行操作
}
如果在遍历集合的过程中,其他线程对集合进行了结构性的修改(比如添加或删除元素),快速失败机制会立即抛出ConcurrentModificationException,以通知集合已经被修改,避免在不一致的状态下继续操作。
10. 使用多线程:
// 使用多线程
ExecutorService executor = Executors.newFixedThreadPool(5);
executor.submit(() -> {// 在线程中执行的代码
});
executor.shutdown();
11. 避免不必要的IO操作:
// 避免不必要的IO操作
try (BufferedReader reader = new BufferedReader(new FileReader("file.txt"))) {// 读取文件内容
} catch (IOException e) {e.printStackTrace();
}
12. 使用位运算代替乘除法:
// 使用位运算代替乘法
int result = 5 << 2; // 相当于 5 * 2^2 = 20
13. 避免不必要的装箱和拆箱:
// 不优化的写法
Integer sum = 0;
for (int i = 0; i < 1000; i++) {sum += i; // 自动装箱和拆箱
}// 优化的写法
int sum = 0;
for (int i = 0; i < 1000; i++) {sum += i;
}
14. 使用静态工厂方法创建对象:
// 不优化的写法
Date now = new Date();// 优化的写法
Date now = Date.from(Instant.now());
15. 合理使用try-with-resources:
// 不优化的写法
BufferedReader reader = null;
try {reader = new BufferedReader(new FileReader("file.txt"));// 读取文件内容
} catch (IOException e) {e.printStackTrace();
} finally {if (reader != null) {try {reader.close();} catch (IOException e) {e.printStackTrace();}}
}// 优化的写法
try (BufferedReader reader = new BufferedReader(new FileReader("file.txt"))) {// 读取文件内容
} catch (IOException e) {e.printStackTrace();
}
16. 使用Lambda表达式简化代码:
// 不优化的写法
List<String> names = Arrays.asList("Alice", "Bob", "Charlie");
for (String name : names) {System.out.println(name);
}// 优化的写法
List<String> names = Arrays.asList("Alice", "Bob", "Charlie");
names.forEach(System.out::println);
17. 使用并发集合提高多线程性能:
// 不优化的写法
List<String> list = new ArrayList<>();
// 在多线程环境下可能会有并发问题// 优化的写法
List<String> synchronizedList = Collections.synchronizedList(new ArrayList<>());
// 或者使用并发集合类
List<String> concurrentList = new CopyOnWriteArrayList<>();
18. 使用Stream API进行集合操作:
// 不优化的写法
List<String> names = Arrays.asList("Alice", "Bob", "Charlie");
List<String> uppercaseNames = new ArrayList<>();
for (String name : names) {uppercaseNames.add(name.toUpperCase());
}// 优化的写法
List<String> names = Arrays.asList("Alice", "Bob", "Charlie");
List<String> uppercaseNames = names.stream().map(String::toUpperCase).collect(Collectors.toList());
19. 使用局部变量替代字段访问:
// 不优化的写法
class MyClass {private int myField;public int calculate() {return myField * 2;}
}// 优化的写法
class MyClass {private int myField;public int calculate() {int localVar = myField;return localVar * 2;}
}
使用局部变量替代直接访问字段的做法,是为了在方法内部使用字段的值时,提供更好的可读性和安全性。
20. 使用ConcurrentHashMap代替同步Map:
// 不优化的写法
Map<String, Integer> map = new HashMap<>();
// 在多线程环境下需要额外的同步机制// 优化的写法
Map<String, Integer> concurrentMap = new ConcurrentHashMap<>();
21. 避免在循环中创建对象:
// 不优化的写法
List<String> myList = new ArrayList<>();
for (int i = 0; i < 1000; i++) {myList.add(new String("Element" + i));
}// 优化的写法
List<String> myList = new ArrayList<>();
String elementPrefix = "Element";
for (int i = 0; i < 1000; i++) {myList.add(elementPrefix + i);
}
22. 使用接口代替继承:
// 不优化的写法
class MyList extends ArrayList<String> {// ...
}// 优化的写法
List<String> myList = new ArrayList<>();
使用接口代替继承的原则是基于面向接口编程的设计理念,有几个原因支持这种优化方式:
- 松耦合(Loose Coupling): 使用接口使得类之间的关系更加灵活,降低了各个类之间的耦合度。在不使用具体实现类的情况下,通过接口可以更容易地替换具体的实现,使系统更加灵活和可维护。
- 多态性(Polymorphism): 通过使用接口,可以实现多态性。即一个类可以以多种形式存在,不同类的对象可以使用相同的接口进行引用,提高代码的灵活性。
- 遵循“合成优于继承”原则: 继承通常引入了额外的复杂性和依赖关系,而使用接口更加简单。合成是指通过组合现有的类和接口来创建新的类,而不是通过继承已有的类。这有助于更好地组织和维护代码。
23. 使用正则表达式进行字符串操作:
// 不优化的写法
String result = "Hello, World!".replace("Hello", "Hi");// 优化的写法
Pattern pattern = Pattern.compile("Hello");
Matcher matcher = pattern.matcher("Hello, World!");
String result = matcher.replaceFirst("Hi");
通过使用正则表达式的方式,可以更好地应对一些更为复杂的字符串操作需求。然而,对于简单的字符串替换操作,直接使用 replace 方法可能更加简洁和易读。
24. 合理使用断言:
// 不优化的写法
if (condition) {throw new IllegalStateException("Condition not met");
}// 优化的写法
assert condition : "Condition not met";
25. 合理使用enum代替常量:
// 不优化的写法
public static final int STATUS_PENDING = 1;
public static final int STATUS_PROCESSING = 2;
public static final int STATUS_COMPLETED = 3;// 优化的写法
public enum Status {PENDING, PROCESSING, COMPLETED;
}
26. 使用连接池:
// 不优化的写法
Connection connection = DriverManager.getConnection(url, username, password);
// 每次都创建新的数据库连接// 优化的写法
DataSource dataSource = // 初始化数据源(比如 HikariCP)
try (Connection connection = dataSource.getConnection()) {// 使用连接
}
27. 使用并行流进行并行计算:
// 不优化的写法
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
int sum = numbers.stream().mapToInt(Integer::intValue).sum();// 优化的写法
int sum = numbers.parallelStream().mapToInt(Integer::intValue).sum();
优势:
- 并行性: 使用并行流可以在多个线程上并行执行操作,加速对大型数据集的处理,特别是在现代多核处理器上。
- 简化并行计算: 并行流能够将并行计算的复杂性封装在底层框架中,使得无需手动管理线程。
- 适用于某些操作: 并行流在某些类型的操作(如大量数据的过滤、映射、聚合等)上表现得更好。
28. 使用异步编程提高并发性能:
// 不优化的写法
Future<Integer> future = executorService.submit(() -> {// 执行耗时操作return result;
});// 优化的写法
CompletableFuture<Integer> future = CompletableFuture.supplyAsync(() -> {// 执行耗时操作return result;
}, executorService);
29. 使用单例模式减少对象创建:
// 不优化的写法
class NonSingleton {// ...
}NonSingleton instance = new NonSingleton();// 优化的写法
class Singleton {private static final Singleton INSTANCE = new Singleton();private Singleton() {// 私有构造函数}public static Singleton getInstance() {return INSTANCE;}
}Singleton instance = Singleton.getInstance();
30. 使用String.contains检查字符串中是否包含子串:
// 不优化的写法
String text = "Hello, World!";
if (text.indexOf("World") != -1) {// 处理逻辑
}// 优化的写法
String text = "Hello, World!";
if (text.contains("World")) {// 处理逻辑
}
31. 使用接口和抽象类进行代码设计:
// 不优化的写法
class Dog {void bark() {// 狗的吠叫逻辑}
}class Cat {void meow() {// 猫的喵叫逻辑}
}// 优化的写法
interface Animal {void makeSound();
}class Dog implements Animal {@Overridepublic void makeSound() {// 狗的吠叫逻辑}
}class Cat implements Animal {@Overridepublic void makeSound() {// 猫的喵叫逻辑}
32. 使用lambda表达式简化匿名类:
// 不优化的写法
Runnable runnable = new Runnable() {@Overridepublic void run() {System.out.println("Running");}
};// 优化的写法
Runnable runnable = () -> System.out.println("Running");
33. 避免在循环中进行数据库查询:
// 不优化的写法
List<String> ids = // 获取一堆ID
for (String id : ids) {User user = userRepository.findById(id);// 处理用户对象
}// 优化的写法
List<String> ids = // 获取一堆ID
List<User> users = userRepository.findAllById(ids);
for (User user : users) {// 处理用户对象
}
34. 使用适当的日志级别:
// 不优化的写法
if (logger.isDebugEnabled()) {logger.debug("Some debug information: " + expensiveOperation());
}// 优化的写法
logger.debug("Some debug information: {}", expensiveOperation());
35. 减小方法的长度:
将大的方法拆分为小的方法,有助于提高代码的可读性和维护性。
拿阿里巴巴的开发手册来说,并没有明确规定一个方法的具体行数上限,而是提倡按照 Single Responsibility Principle(单一职责原则)和合理拆分的原则来组织代码。然而,根据阿里巴巴的《Java 开发手册》中的一些建议,可以总结一些编码规范和最佳实践,其中也包括关于方法长度的一些建议:
- Single Responsibility Principle: 一个方法应该只做一件事情。如果一个方法的功能变得复杂,可以考虑将其拆分为多个小方法,每个小方法负责一个明确的子任务。
- 规范注释: 阿里巴巴建议在方法前使用规范注释,明确方法的功能、输入参数、输出结果等信息。如果一个方法的功能需要过多的注释来解释,可能需要考虑拆分。
- 控制复杂度: 阿里巴巴建议控制单个方法的复杂度,尽量避免过多的嵌套结构和冗长的代码。这也暗示了一个方法不应该过长。
36. 使用延迟初始化:
// 不优化的写法
class MyClass {private ExpensiveObject expensiveObject = new ExpensiveObject();public ExpensiveObject getExpensiveObject() {return expensiveObject;}
}// 优化的写法
class MyClass {private ExpensiveObject expensiveObject;public ExpensiveObject getExpensiveObject() {if (expensiveObject == null) {expensiveObject = new ExpensiveObject();}return expensiveObject;}
}
37. 使用异步IO:
// 不优化的写法
InputStream inputStream = new FileInputStream("file.txt");
// 读取文件操作,可能会阻塞线程// 优化的写法
AsynchronousFileChannel channel = AsynchronousFileChannel.open(Paths.get("file.txt"));
ByteBuffer buffer = ByteBuffer.allocate(1024);
channel.read(buffer, 0, buffer, new CompletionHandler<Integer, ByteBuffer>() {@Overridepublic void completed(Integer result, ByteBuffer attachment) {// 异步读取完成后的处理逻辑}@Overridepublic void failed(Throwable exc, ByteBuffer attachment) {// 处理读取失败的逻辑}
});
38. 使用位集(BitSet)进行位操作:
// 不优化的写法
Set<Integer> set = new HashSet<>();
set.add(1);
set.add(2);// 优化的写法
BitSet bitSet = new BitSet();
bitSet.set(1);
bitSet.set(2);
39. 使用List.contains检查集合中是否存在元素:
// 不优化的写法
List<String> myList = Arrays.asList("Apple", "Banana", "Orange");
if (myList.indexOf("Banana") != -1) {// 处理逻辑
}// 优化的写法
List<String> myList = Arrays.asList("Apple", "Banana", "Orange");
if (myList.contains("Banana")) {// 处理逻辑
}
40. 使用Files.exists检查文件是否存在:
// 不优化的写法
File file = new File("lfsun.txt");
if (file.exists()) {// 处理逻辑
}// 优化的写法
Path path = Paths.get("lfsun.txt");
if (Files.exists(path)) {// 处理逻辑
}
41. 使用Math.min和Math.max获取两个数的最小和最大值:
// 不优化的写法
int a = 5;
int b = 10;
int minValue = (a < b) ? a : b;
int maxValue = (a > b) ? a : b;// 优化的写法
int a = 5;
int b = 10;
int minValue = Math.min(a, b);
int maxValue = Math.max(a, b);
42. 使用File.separator构建跨平台的文件路径:
// 不优化的写法
String path = "dir\file.txt";// 优化的写法
String path = "dir" + File.separator + "file.txt";
43. 使用String.trim去除字符串两端的空格:
// 不优化的写法
String text = " Hello, World! ";
String trimmedText = text.replaceAll("^\s+|\s+$", "");// 优化的写法
String text = " Hello, World! ";
String trimmedText = text.trim();
44. 使用String.startsWith和String.endsWith检查字符串前缀和后缀:
// 不优化的写法
String text = "Hello, World!";
if (text.indexOf("Hello") == 0) {// 处理逻辑
}// 优化的写法
String text = "Hello, World!";
if (text.startsWith("Hello")) {// 处理逻辑
}
45. 使用LocalDateTime和DateTimeFormatter进行日期时间格式化:
// 不优化的写法
Date currentDate = new Date();
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String formattedDate = sdf.format(currentDate);// 优化的写法
LocalDateTime currentDateTime = LocalDateTime.now();
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
String formattedDateTime = currentDateTime.format(formatter);
46. 使用String.substring截取子字符串:
// 不优化的写法
String text = "Hello, World";
String substring = text.substring(7, 12);// 优化的写法
String text = "Hello, World";
String substring = text.substring(7);
47. 使用ThreadLocal减少线程间共享变量:
// 不优化的写法
class SharedResource {private int value;// ...
}// 优化的写法
class SharedResource {private static ThreadLocal<Integer> threadLocal = new ThreadLocal<>();// ...
}
48. 使用可变参数改善方法的灵活性:
// 不优化的写法
void process(int arg1, int arg2, int arg3) {// 处理逻辑
}// 优化的写法
void process(int... args) {// 处理逻辑
}
49. 使用条件运算符(三元运算符)简化代码:
// 不优化的写法
int result;
if (condition) {result = 1;
} else {result = 2;
}// 优化的写法
int result = condition ? 1 : 2;
50. 使用内部类减少包级别的类可见性:
// 不优化的写法
package com.lfsun;class InternalClass {// 内部类
}// 优化的写法
package com.lfsun;public class OuterClass {private class InternalClass {// 内部类}
}
51. 使用Arrays.fill填充数组元素:
// 不优化的写法
int[] array = new int[5];
for (int i = 0; i < array.length; i++) {array[i] = 42;
}// 优化的写法
int[] array = new int[5];
Arrays.fill(array, 42);
52. 使用System.arraycopy复制数组:
// 不优化的写法
int[] sourceArray = {1, 2, 3, 4, 5};
int[] targetArray = new int[sourceArray.length];
for (int i = 0; i < sourceArray.length; i++) {targetArray[i] = sourceArray[i];
}// 优化的写法
int[] sourceArray = {1, 2, 3, 4, 5};
int[] targetArray = new int[sourceArray.length];
System.arraycopy(sourceArray, 0, targetArray, 0, sourceArray.length);
使用 System.arraycopy 复制数组是一种更为高效的方式,相较于手动使用循环遍历的方式,它具有以下优势:
- 性能优化:
System.arraycopy是由底层系统实现的本地方法,通常比手动的循环更为高效。这是因为底层系统可以针对具体的平台和硬件进行优化。 - 原子性:
System.arraycopy是原子性的操作,意味着在数组复制的整个过程中,不会被其他线程中断,确保了复制的一致性。 - 简洁性: 使用
System.arraycopy代码更为简洁,不需要手动编写循环,提高了代码的可读性和可维护性。
53. 使用List.subList获取子列表:
// 不优化的写法
List<String> list = Arrays.asList("A", "B", "C", "D", "E");
List<String> sublist = new ArrayList<>(list.subList(1, 4));// 优化的写法
List<String> list = Arrays.asList("A", "B", "C", "D", "E");
List<String> sublist = list.subList(1, 4);
54. 使用Optional类避免空指针异常:
// 不优化的写法
String name = // 获取可能为null的值
if (name != null) {System.out.println(name.length());
}// 优化的写法
Optional<String> optionalName = Optional.ofNullable(name);
optionalName.ifPresent(n -> System.out.println(n.length()));
55. 使用ConcurrentHashMap提高并发性能:
// 不优化的写法
Map<String, Integer> myMap = new HashMap<>();
myMap.put("one", 1);// 优化的写法
Map<String, Integer> myMap = new ConcurrentHashMap<>();
myMap.put("one", 1);
56. 使用Optional.orElseThrow替代自定义异常处理:
// 不优化的写法
Optional<String> value = Optional.ofNullable(getValue());
if (value.isPresent()) {return value.get();
} else {throw new CustomException("Value not found");
}// 优化的写法
return Optional.ofNullable(getValue()).orElseThrow(() -> new CustomException("Value not found"));
57. 使用方法引用简化代码:
// 不优化的写法
list.forEach(item -> System.out.println(item));// 优化的写法
list.forEach(System.out::println);
58. 使用ThreadLocalRandom获取随机数:
// 不优化的写法
Random random = new Random();
int randomNumber = random.nextInt(100);// 优化的写法
int randomNumber = ThreadLocalRandom.current().nextInt(100);
59. 使用Set接口的contains方法进行集合成员检查:
// 不优化的写法
List<String> list = Arrays.asList("Apple", "Banana", "Orange");
if (list.contains("Banana")) {// 处理逻辑
}// 优化的写法
Set<String> set = new HashSet<>(Arrays.asList("Apple", "Banana", "Orange"));
if (set.contains("Banana")) {// 处理逻辑
}
60. 使用反射和动态代理提高代码灵活性:
// 不优化的写法
if (obj instanceof MyClass) {((MyClass) obj).doSomething();
}// 优化的写法
Method method = obj.getClass().getMethod("doSomething");
method.invoke(obj);
61. 使用默认方法接口提供默认实现
// 不优化的写法
interface MyInterface {void doSomething();
}class MyClass implements MyInterface {@Overridepublic void doSomething() {// 具体实现}
}// 优化的写法
interface MyInterface {void doSomething();default void doSomethingElse() {// 默认实现}
}class MyClass implements MyInterface {@Overridepublic void doSomething() {// 具体实现}
}
62. 使用新的日期和时间API:
// 不优化的写法
Date date = new Date();
Calendar calendar = Calendar.getInstance();
calendar.setTime(date);
int year = calendar.get(Calendar.YEAR);// 优化的写法
LocalDate currentDate = LocalDate.now();
int year = currentDate.getYear();
63. 使用Lambda表达式简化事件处理:
// 不优化的写法
button.addActionListener(new ActionListener() {@Overridepublic void actionPerformed(ActionEvent e) {// 处理事件}
});// 优化的写法
button.addActionListener(e -> {// 处理事件
});
64. 使用Files.newBufferedWriter写入文本文件:
// 不优化的写法
try (PrintWriter writer = new PrintWriter(new FileWriter("file.txt"))) {writer.println("Hello, World!");
} catch (IOException e) {e.printStackTrace();
}// 优化的写法
try (BufferedWriter writer = Files.newBufferedWriter(Paths.get("file.txt"))) {writer.write("Hello, World!");
} catch (IOException e) {e.printStackTrace();
}
65. 使用静态工厂方法代替构造函数:
// 不优化的写法
MyObject obj = new MyObject();// 优化的写法
MyObject obj = MyObject.create();
66. 避免在循环中创建匿名内部类:
// 不优化的写法
List<String> names = Arrays.asList("Alice", "Bob", "Charlie");
names.forEach(new Consumer<String>() {@Overridepublic void accept(String name) {// 处理逻辑}
});// 优化的写法
List<String> names = Arrays.asList("Alice", "Bob", "Charlie");
names.forEach(name -> {// 处理逻辑
});
67. 使用局部变量类型推断(var):
// 不优化的写法
Map<String, List<String>> myMap = new HashMap<String, List<String>>();// 优化的写法
var myMap = new HashMap<String, List<String>>();
68. 使用线程池提高线程利用率:
// 不优化的写法
Thread thread = new Thread(() -> {// 线程执行的任务
});
thread.start();// 优化的写法
ExecutorService executor = Executors.newFixedThreadPool(5);
executor.submit(() -> {// 线程执行的任务
});
69. 使用ClassLoader延迟加载类:
// 不优化的写法
Class<?> myClass = Class.forName("com.lfsun.MyClass");
MyClass instance = (MyClass) myClass.newInstance();// 优化的写法
Class<?> myClass = ClassLoader.getSystemClassLoader().loadClass("com.lfsun.MyClass");
MyClass instance = (MyClass) myClass.getDeclaredConstructor().new
70. 使用Stream.distinct去除重复元素:
// 不优化的写法
List<String> myList = Arrays.asList("Apple", "Banana", "Apple", "Orange");
List<String> distinctList = new ArrayList<>(new HashSet<>(myList));// 优化的写法
List<String> myList = Arrays.asList("Apple", "Banana", "Apple", "Orange");
List<String> distinctList = myList.stream().distinct().collect(Collectors.toList());
71. 使用String.format代替字符串连接:
// 不优化的写法
String result = "Hello, " + name + "!";// 优化的写法
String result = String.format("Hello, %s!", name);
72. 使用IntStream和DoubleStream代替传统的循环:
// 不优化的写法
int sum = 0;
for (int i = 1; i <= 100; i++) {sum += i;
}// 优化的写法
int sum = IntStream.rangeClosed(1, 100).sum();
73. 使用Atomic类提高原子性操作:
// 不优化的写法
int counter = 0;
counter++;// 优化的写法
AtomicInteger counter = new AtomicInteger(0);
counter.incrementAndGet();
74. 使用StringJoiner拼接字符串:
// 不优化的写法
String result = "";
for (String s : list) {result += s + ", ";
}
result = result.substring(0, result.length() - 2);// 优化的写法
StringJoiner joiner = new StringJoiner(", ");
for (String s : list) {joiner.add(s);
}
String result = joiner.toString();
75. 使用Arrays.copyOfRange代替手动数组复制:
// 不优化的写法
int[] source = {1, 2, 3, 4, 5};
int[] destination = new int[source.length];
System.arraycopy(source, 0, destination, 0, source.length);// 优化的写法
int[] source = {1, 2, 3, 4, 5};
int[] destination = Arrays.copyOfRange(source, 0, source.length);
76. 使用Thread.join等待线程结束:
// 不优化的写法
Thread thread = new Thread(() -> {// 线程执行逻辑
});
thread.start();
// 等待线程结束
try {thread.join();
} catch (InterruptedException e) {e.printStackTrace();
}// 优化的写法
Thread thread = new Thread(() -> {// 线程执行逻辑
});
thread.start();
// 等待线程结束
thread.join();
77. 使用Files.lines读取文件内容:
// 不优化的写法
try (BufferedReader reader = new BufferedReader(new FileReader("file.txt"))) {String line;while ((line = reader.readLine()) != null) {// 处理每行内容}
} catch (IOException e) {e.printStackTrace();
}// 优化的写法
try {Files.lines(Paths.get("file.txt")).forEach(line -> {// 处理每行内容});
} catch (IOException e) {e.printStackTrace();
}
78. 使用ReentrantLock进行显式的锁定:
// 不优化的写法
synchronized (myObject) {// 临界区
}// 优化的写法
ReentrantLock lock = new ReentrantLock();
try {lock.lock();// 临界区
} finally {lock.unlock();
}
79. 使用Map.compute方法简化Map操作:
// 不优化的写法
Map<String, Integer> map = new HashMap<>();
String key = "myKey";
if (map.containsKey(key)) {map.put(key, map.get(key) + 1);
} else {map.put(key, 1);
}// 优化的写法
map.compute(key, (k, v) -> (v == null) ? 1 : v + 1);
80. 使用Objects.requireNonNull检查参数合法性:
// 不优化的写法
public void process(String data) {if (data == null) {throw new IllegalArgumentException("Data cannot be null");}// 处理逻辑
}// 优化的写法
public void process(String data) {Objects.requireNonNull(data, "Data cannot be null");// 处理逻辑
}
81. 使用Files.walk遍历文件目录:
// 不优化的写法
File folder = new File("/folder");
for (File file : folder.listFiles()) {// 处理文件
}// 优化的写法
Path folder = Paths.get("/folder");
try (Stream<Path> paths = Files.walk(folder)) {paths.forEach(path -> {// 处理文件});
} catch (IOException e) {e.printStackTrace();
}
82. 使用List的replaceAll方法更新所有元素:
// 不优化的写法
List<String> list = Arrays.asList("apple", "banana", "orange");
for (int i = 0; i < list.size(); i++) {list.set(i, list.get(i).toUpperCase());
}// 优化的写法
List<String> list = Arrays.asList("apple", "banana", "orange");
list.replaceAll(String::toUpperCase);
83. 使用CopyOnWriteArrayList提高并发性能:
// 不优化的写法
List<String> myList = new ArrayList<>();
myList.add("Apple");
myList.add("Banana");
myList.add("Orange");// 优化的写法
List<String> myList = new CopyOnWriteArrayList<>();
myList.add("Apple");
myList.add("Banana");
myList.add("Orange");
84. 使用Map.merge简化Map操作:
// 不优化的写法
Map<String, Integer> map = new HashMap<>();
String key = "myKey";
if (map.containsKey(key)) {map.put(key, map.get(key) + 1);
} else {map.put(key, 1);
}// 优化的写法
map.merge(key, 1, Integer::sum);
85. 使用Lambda表达式和Collectors进行集合操作:
// 不优化的写法
List<String> names = Arrays.asList("Alice", "Bob", "Charlie");
List<String> uppercaseNames = new ArrayList<>();
for (String name : names) {uppercaseNames.add(name.toUpperCase());
}// 优化的写法
List<String> names = Arrays.asList("Alice", "Bob", "Charlie");
List<String> uppercaseNames = names.stream().map(String::toUpperCase).collect(Collectors.toList());
86. 使用Optional解决嵌套的null检查:
// 不优化的写法
if (user != null) {Address address = user.getAddress();if (address != null) {String city = address.getCity();if (city != null) {// 处理城市信息}}
}// 优化的写法
Optional.ofNullable(user).map(User::getAddress).map(Address::getCity).ifPresent(city -> {// 处理城市信息});
87. 使用java.time.Duration和Instant计算时间差:
// 不优化的写法
long startTime = System.currentTimeMillis();
// 执行一些操作
long endTime = System.currentTimeMillis();
long elapsedTime = endTime - startTime;// 优化的写法
Instant start = Instant.now();
// 执行一些操作
Instant end = Instant.now();
Duration elapsedTime = Duration.between(start, end);
88. 使用java.nio.file.Path代替字符串操作路径:
// 不优化的写法
String filePath = "/file.txt";
File file = new File(filePath);// 优化的写法
Path filePath = Paths.get("/file.txt");
89. 使用String.isBlank判断字符串是否为空或只包含空白字符:
// 不优化的写法
if (str != null && !str.trim().isEmpty()) {// 处理非空字符串逻辑
}// 优化的写法
if (str != null && !str.isBlank()) {// 处理非空字符串逻辑
}
90. 使用Map.computeIfAbsent进行延迟初始化:
// 不优化的写法
Map<String, List<String>> map = new HashMap<>();
if (!map.containsKey("key")) {map.put("key", new ArrayList<>());
}
map.get("key").add("value");// 优化的写法
Map<String, List<String>> map = new HashMap<>();
map.computeIfAbsent("key", k -> new ArrayList<>()).add("value");
91. 使用Objects.equals避免空指针异常:
// 不优化的写法
boolean isEqual = (obj1 != null) ? obj1.equals(obj2) : (obj2 == null);// 优化的写法
boolean isEqual = Objects.equals(obj1, obj2);
92. 使用Math.floorDiv和Math.floorMod代替传统除法和取模运算:
// 不优化的写法
int quotient = a / b;
int remainder = a % b;// 优化的写法
int quotient = Math.floorDiv(a, b);
int remainder = Math.floorMod(a, b);
93. 使用ClassLoader.getSystemResourceAsStream加载类路径下的资源文件:
// 不优化的写法
InputStream stream = getClass().getClassLoader().getResourceAsStream("config.properties");// 优化的写法
InputStream stream = ClassLoader.getSystemResourceAsStream("config.properties");
使用 ClassLoader.getSystemResourceAsStream 加载类路径下的资源文件是一种更为推荐的做法,相较于 getClass().getClassLoader().getResourceAsStream,它具有以下优势:
- 更简洁:
ClassLoader.getSystemResourceAsStream的调用更为简洁,不需要通过获取类加载器再获取资源流。 - 避免空指针异常:
ClassLoader.getSystemResourceAsStream不会返回null,而是会抛出NullPointerException,这有助于在资源不存在时更早地发现问题。 - 全局资源访问:
ClassLoader.getSystemResourceAsStream使用系统类加载器,可以用于访问应用程序类路径下的资源,而不仅限于当前类的类路径。
94. 使用String.repeat重复字符串:
// 不优化的写法
String repeated = "";
for (int i = 0; i < n; i++) {repeated += "abc";
}// 优化的写法
String repeated = "abc".repeat(n);
95. 使用List.copyOf创建不可变集合:
// 不优化的写法
List<String> originalList = Arrays.asList("a", "b", "c");
List<String> immutableList = Collections.unmodifiableList(new ArrayList<>(originalList));// 优化的写法
List<String> immutableList = List.copyOf(originalList);
96. 使用Stream的anyMatch和noneMatch简化集合元素匹配:
// 不优化的写法
boolean contains = false;
for (String element : list) {if (element.equals("target")) {contains = true;break;}
}// 优化的写法
boolean contains = list.stream().anyMatch(element -> element.equals("target"));
97. 使用File.toPath将File对象转换为Path对象:
// 不优化的写法
File file = new File("lfsun.txt");
Path path = file.toPath();// 优化的写法
Path path = Paths.get("lfsun.txt");
98. 使用FileSystems.getDefault获取默认文件系统:
// 不优化的写法
Path path = Paths.get("lfsun.txt");// 优化的写法
Path path = FileSystems.getDefault().getPath("lfsun.txt");
使用 FileSystems.getDefault().getPath 获取默认文件系统的路径是一种更为推荐的做法,相较于 Paths.get,它具有以下优势:
- 更灵活:
FileSystems.getDefault().getPath可以提供更多的灵活性,允许在获取路径时指定文件系统的一些属性。例如,可以使用不同的文件系统,提供自定义的文件系统属性等。 - 统一风格: 使用
FileSystems.getDefault().getPath统一了获取路径的方式,使得代码更具一致性。这有助于提高代码的可读性和可维护性。
99. 使用Collections.newSetFromMap创建基于Map的Set:
// 不优化的写法
Map<String, Boolean> map = new ConcurrentHashMap<>();
Set<String> set = map.keySet();// 优化的写法
Set<String> set = Collections.newSetFromMap(new ConcurrentHashMap<>());
使用 Collections.newSetFromMap 创建基于 Map 的 Set 是一种更为推荐的做法,相较于直接使用 map.keySet(),它具有以下优势:
- 线程安全性: 使用
Collections.newSetFromMap创建的Set是线程安全的,底层使用的是传入的ConcurrentMap,因此适用于多线程环境。 - 不可变性: 通过
Collections.newSetFromMap创建的Set是不可变的,不能通过add、remove等方法修改其内容。这有助于确保数据的一致性。 - 灵活性: 可以通过传入不同类型的
Map实现,以创建不同类型的Set。例如,可以传入HashMap、TreeMap等。
100. 使用List.sort进行列表排序:
// 不优化的写法
List<String> list = Arrays.asList("c", "a", "b");
Collections.sort(list);// 优化的写法
List<String> list = Arrays.asList("c", "a", "b");
list.sort(Comparator.naturalOrder());
使用 List.sort 进行列表排序是一种更为推荐的做法,相较于 Collections.sort,它具有以下优势:
- 更直接:
list.sort()方法是List接口的默认方法,使得排序操作更加直接和一致。不需要通过Collections类来调用排序方法。 - 更灵活:
list.sort()方法可以接受一个Comparator参数,使得排序更加灵活。通过Comparator,可以实现自定义的排序规则,而不仅限于自然排序。 - 支持流式操作:
list.sort()方法可以很方便地与流式操作一起使用,如使用Comparator和thenComparing进行复杂排序。
101. 使用Path.resolve解析路径:
// 不优化的写法
Path path1 = Paths.get("");
Path path2 = Paths.get("file.txt");
Path fullPath = Paths.get(path1.toString(), path2.toString());// 优化的写法
Path path1 = Paths.get("");
Path path2 = Paths.get("file.txt");
Path fullPath = path1.resolve(path2);
102. 使用Stream.collect(Collectors.joining)拼接字符串:
// 不优化的写法
List<String> words = Arrays.asList("Hello", "World", "Java");
String result = words.stream().reduce("", (s1, s2) -> s1 + s2);// 优化的写法
List<String> words = Arrays.asList("Hello", "World", "Java");
String result = words.stream().collect(Collectors.joining());
103. 使用Pattern和Matcher进行正则表达式匹配:
// 不优化的写法
String text = "The quick brown fox";
boolean containsFox = text.matches(".*fox.*");// 优化的写法
Pattern pattern = Pattern.compile(".*fox.*");
Matcher matcher = pattern.matcher("The quick brown fox");
boolean containsFox = matcher.matches();
104. 使用Files.isRegularFile检查文件是否为普通文件:
// 不优化的写法
Path path = Paths.get("file.txt");
if (Files.exists(path) && Files.isRegularFile(path)) {// 处理文件逻辑
}// 优化的写法
Path path = Paths.get("file.txt");
if (Files.isRegularFile(path)) {// 处理文件逻辑
}
105. 使用Optional避免空指针异常:
// 不优化的写法
String result = null;
if (value != null) {result = value.toString();
}// 优化的写法
String result = Optional.ofNullable(value).map(Object::toString).orElse(null);
106. 使用Lambda表达式简化Comparator的创建:
// 不优化的写法
List<String> names = Arrays.asList("Alice", "Bob", "Charlie");
names.sort(new Comparator<String>() {@Overridepublic int compare(String name1, String name2) {return name1.compareTo(name2);}
});// 优化的写法
List<String> names = Arrays.asList("Alice", "Bob", "Charlie");
names.sort((name1, name2) -> name1.compareTo(name2));
107. 使用Optional.map和Optional.filter链式操作:
// 不优化的写法
Optional<String> result = Optional.ofNullable(getValue());
if (result.isPresent()) {String uppercased = result.get().toUpperCase();if (uppercased.length() > 5) {System.out.println(uppercased);}
}// 优化的写法
Optional.ofNullable(getValue()).map(String::toUpperCase).filter(s -> s.length() > 5).ifPresent(System.out::println);
108. 使用Collectors.joining拼接字符串:
// 不优化的写法
List<String> list = Arrays.asList("Apple", "Banana", "Orange");
String result = "";
for (String item : list) {result += item + ", ";
}
result = result.isEmpty() ? result : result.substring(0, result.length() - 2);// 优化的写法
List<String> list = Arrays.asList("Apple", "Banana", "Orange");
String result = list.stream().collect(Collectors.joining(", "));
109. 使用Arrays.asList创建不可变集合:
// 不优化的写法
List<String> myList = new ArrayList<>();
myList.add("Apple");
myList.add("Banana");
myList.add("Orange");
myList = Collections.unmodifiableList(myList);// 优化的写法
List<String> myList = Arrays.asList("Apple", "Banana", "Orange");
110. 使用Comparator.comparing简化比较器的创建:
// 不优化的写法
List<Person> people = Arrays.asList(new Person("Alice", 25), new Person("Bob", 30));
people.sort(new Comparator<Person>() {@Overridepublic int compare(Person person1, Person person2) {return Integer.compare(person1.getAge(), person2.getAge());}
});// 优化的写法
List<Person> people = Arrays.asList(new Person("Alice", 25), new Person("Bob", 30));
people.sort(Comparator.comparing(Person::getAge));
111. 使用StringTokenizer代替String的split方法:
// 不优化的写法
String[] tokens = "apple,orange,banana".split(",");// 优化的写法
StringTokenizer tokenizer = new StringTokenizer("apple,orange,banana", ",");
while (tokenizer.hasMoreTokens()) {String token = tokenizer.nextToken();// 处理每个token
}
使用 StringTokenizer 代替 String 的 split 方法是一种优化的方式,尤其是在需要逐个处理分隔符分割的字符串时。StringTokenizer 提供了更多的灵活性和控制,相较于 split 方法,它具有以下优势:
- 逐个处理:
StringTokenizer允许逐个处理每个分隔符分割的字符串。这对于在处理每个 token 时执行特定操作的情况非常有用。 - 更多控制选项:
StringTokenizer允许你指定多个分隔符,并且提供了更多的控制选项,例如是否返回分隔符。 - 不使用正则表达式:
StringTokenizer不依赖于正则表达式,因此在某些情况下可能比split更快。
112. 使用Runtime.getRuntime().availableProcessors()获取处理器核心数:
int processors = Runtime.getRuntime().availableProcessors();
113. 使用Arrays.copyOf代替手动数组复制:
// 不优化的写法
int[] source = {1, 2, 3, 4, 5};
int[] destination = new int[source.length];
System.arraycopy(source, 0, destination, 0, source.length);// 优化的写法
int[] source = {1, 2, 3, 4, 5};
int[] destination = Arrays.copyOf(source, source.length);
114. 使用LinkedHashMap保持插入顺序:
// 不优化的写法
Map<String, Integer> map = new HashMap<>();
map.put("one", 1);
map.put("three", 3);
map.put("two", 2);// 优化的写法
Map<String, Integer> map = new LinkedHashMap<>();
map.put("one", 1);
map.put("three", 3);
map.put("two", 2);
115. 使用System.arraycopy进行数组复制:
// 不优化的写法
int[] source = {1, 2, 3, 4, 5};
int[] destination = new int[source.length];
for (int i = 0; i < source.length; i++) {destination[i] = source[i];
}// 优化的写法
int[] source = {1, 2, 3, 4, 5};
int[] destination = new int[source.length];
System.arraycopy(source, 0, destination, 0, source.length);
116. 使用Files.newInputStream和Files.newOutputStream操作文件流:
// 不优化的写法
InputStream inputStream = new FileInputStream("input.txt");
OutputStream outputStream = new FileOutputStream("output.txt");// 优化的写法
InputStream inputStream = Files.newInputStream(Paths.get("input.txt"));
OutputStream outputStream = Files.newOutputStream(Paths.get("output.txt"));
使用 Files.newInputStream 和 Files.newOutputStream 操作文件流是一种更为现代、灵活且推荐的方式,相较于传统的 FileInputStream 和 FileOutputStream,它具有以下优势:
- 更直观的路径处理: 使用
Paths.get("input.txt")来构建路径更为直观和灵活,可以处理相对路径和绝对路径。 - 更丰富的异常处理:
Files.newInputStream和Files.newOutputStream可以抛出更丰富的异常,使得对文件操作的错误更容易排查。 - 更灵活的配置选项:
Files.newInputStream和Files.newOutputStream支持一些配置选项,例如StandardOpenOption,可以更灵活地配置文件的打开方式。
117. 使用Files.exists判断文件是否存在:
// 不优化的写法
File file = new File("lfsun.txt");
if (file.exists()) {// 文件存在逻辑
}// 优化的写法
if (Files.exists(Paths.get("lfsun.txt"))) {// 文件存在逻辑
}
118. 使用Files.createFile创建文件:
// 不优化的写法
File file = new File("lfsun.txt");
if (!file.exists()) {file.createNewFile();
}// 优化的写法
Files.createFile(Paths.get("lfsun.txt"));
使用 Files.createFile 创建文件是一种更为现代和推荐的方式,相较于传统的 File 类的方式,它具有以下优势:
- 更直观的路径处理: 使用
Paths.get("lfsun.txt")来构建路径更为直观和灵活,可以处理相对路径和绝对路径。 - 更丰富的异常处理:
Files.createFile可以抛出更丰富的异常,使得对文件创建的错误更容易排查。 - 原子性操作:
Files.createFile是一个原子性的操作,如果文件已经存在,则会抛出FileAlreadyExistsException,避免了在检查文件存在性和创建文件之间的竞态条件。
119. 使用Files.delete删除文件:
// 不优化的写法
File file = new File("lfsun.txt");
if (file.exists()) {file.delete();
}// 优化的写法
Files.deleteIfExists(Paths.get("lfsun.txt"));
120. 使用Files.walkFileTree遍历文件树:
// 不优化的写法
FileVisitor<Path> fileVisitor = new SimpleFileVisitor<Path>() {@Overridepublic FileVisitResult visitFile(Path file, BasicFileAttributes attrs) throws IOException {// 处理文件逻辑return FileVisitResult.CONTINUE;}
};Files.walkFileTree(Paths.get("/directory"), fileVisitor);// 优化的写法
Files.walkFileTree(Paths.get("/directory"), new SimpleFileVisitor<Path>() {@Overridepublic FileVisitResult visitFile(Path file, BasicFileAttributes attrs) throws IOException {// 处理文件逻辑return FileVisitResult.CONTINUE;}
});
121. 使用Files.createDirectory创建单级目录:
// 不优化的写法
File file = new File("/directory");
if (!file.exists()) {file.mkdirs();
}// 优化的写法
Files.createDirectory(Paths.get("/directory"));
122. 使用Files.createDirectories创建多级目录:
// 不优化的写法
File file = new File("/multiple/levels");
if (!file.exists()) {file.mkdirs();
}// 优化的写法
Files.createDirectories(Paths.get("/multiple/levels"));
123. 使用Files.copy复制文件:
// 不优化的写法
Path source = Paths.get("source.txt");
Path target = Paths.get("target.txt");
Files.write(target, Files.readAllBytes(source));// 优化的写法
Path source = Paths.get("source.txt");
Path target = Paths.get("target.txt");
Files.copy(source, target, StandardCopyOption.REPLACE_EXISTING);
124. 使用Files.isSameFile检查两个文件是否相同:
// 不优化的写法
Path file1 = Paths.get("file1.txt");
Path file2 = Paths.get("file2.txt");
if (Files.exists(file1) && Files.exists(file2) && Files.isRegularFile(file1) && Files.isRegularFile(file2)) {boolean areSame = Files.isSameFile(file1, file2);// 处理相同文件逻辑
}// 优化的写法
Path file1 = Paths.get("file1.txt");
Path file2 = Paths.get("file2.txt");
if (Files.isRegularFile(file1) && Files.isRegularFile(file2)) {boolean areSame = Files.isSameFile(file1, file2);// 处理相同文件逻辑
}
125. 使用Files.getLastModifiedTime获取文件最后修改时间:
Path filePath = Paths.get("file.txt");
if (Files.exists(filePath)) {long lastModifiedTime = Files.getLastModifiedTime(filePath).toMillis();// 处理最后修改时间逻辑
}
126. 使用Files.size获取文件大小:
Path filePath = Paths.get("file.txt");
if (Files.exists(filePath)) {long fileSize = Files.size(filePath);// 处理文件大小逻辑
}
127. 使用Files.readAttributes获取文件属性:
Path filePath = Paths.get("file.txt");
if (Files.exists(filePath)) {BasicFileAttributes attributes = Files.readAttributes(filePath, BasicFileAttributes.class);FileTime creationTime = attributes.creationTime();// 处理文件属性逻辑
}
128. 使用Files.probeContentType获取文件内容类型:
Path filePath = Paths.get("file.txt");
String contentType = Files.probeContentType(filePath);
129. 使用Files.isSymbolicLink检查文件是否为符号链接:
// 不优化的写法
Path filePath = Paths.get("file.txt");
if (Files.exists(filePath) && Files.isSymbolicLink(filePath)) {// 处理符号链接逻辑
}// 优化的写法
Path filePath = Paths.get("file.txt");
if (Files.isSymbolicLink(filePath)) {// 处理符号链接逻辑
}
130. 使用Files.isReadable检查文件是否可读:
// 不优化的写法
Path filePath = Paths.get("file.txt");
if (Files.exists(filePath) && Files.isReadable(filePath)) {// 处理可读文件逻辑
}// 优化的写法
Path filePath = Paths.get("file.txt");
if (Files.isReadable(filePath)) {// 处理可读文件逻辑
}
131. 使用Files.isWritable检查文件是否可写:
// 不优化的写法
Path filePath = Paths.get("file.txt");
if (Files.exists(filePath) && Files.isWritable(filePath)) {// 处理可写文件逻辑
}// 优化的写法
Path filePath = Paths.get("file.txt");
if (Files.isWritable(filePath)) {// 处理可写文件逻辑
}
132. 使用Files.getAttribute获取文件属性:
Path filePath = Paths.get("file.txt");
if (Files.exists(filePath)) {Object attribute = Files.getAttribute(filePath, "basic:creationTime");// 处理文件属性逻辑
}
133. 使用Files.setAttribute设置文件属性:
Path filePath = Paths.get("file.txt");
if (Files.exists(filePath)) {Files.setAttribute(filePath, "basic:creationTime", FileTime.from(Instant.now()));
}
134. 使用Files.isExecutable检查文件是否可执行:
// 不优化的写法
Path filePath = Paths.get("script.sh");
if (Files.exists(filePath) && Files.isExecutable(filePath)) {// 处理可执行文件逻辑
}// 优化的写法
Path filePath = Paths.get("script.sh");
if (Files.isExecutable(filePath)) {// 处理可执行文件逻辑
}
135. 使用Files.newBufferedReader读取文本文件:
try (BufferedReader reader = Files.newBufferedReader(Paths.get("file.txt"))) {String line;while ((line = reader.readLine()) != null) {// 处理每行内容}
} catch (IOException e) {e.printStackTrace();
}
136.使用DateTimeFormatter替代SimpleDateFormat:
// 不优化的写法
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String formattedDate = sdf.format(new Date());// 优化的写法
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
String formattedDate = LocalDateTime.now().format(formatter);
137. 使用LocalDate和LocalTime代替Date和Calendar:
// 不优化的写法
Date currentDate = new Date();
Calendar calendar = Calendar.getInstance();
int year = calendar.get(Calendar.YEAR);// 优化的写法
LocalDate currentDate = LocalDate.now();
int year = currentDate.getYear();
138. 使用Optional的map和flatMap进行链式操作:
// 不优化的写法
Optional<String> result = Optional.of("Hello");
if (result.isPresent()) {String uppercased = result.get().toUpperCase();Optional<String> finalResult = Optional.of(uppercased);
}// 优化的写法
Optional<String> result = Optional.of("Hello");
Optional<String> finalResult = result.map(String::toUpperCase);
相关文章:

常见代码优化案例记录
1. 使用StringBuilder优化字符串拼接: // 不优化的写法 String result ""; for (int i 0; i < 1000; i) {result i; }// 优化的写法 StringBuilder resultBuilder new StringBuilder(); for (int i 0; i < 1000; i) {resultBuilder.append(i)…...

【android开发-04】android中activity的生命周期介绍
1,返回栈 android中使用任务task来管理activity,一个任务就是一组存放在栈里的活动的集合,这个栈被称为返回栈。栈是一种先进先出的数据结构。当我们启动一个新的活动,他会在返回栈中人栈,并处以栈顶的位置࿰…...
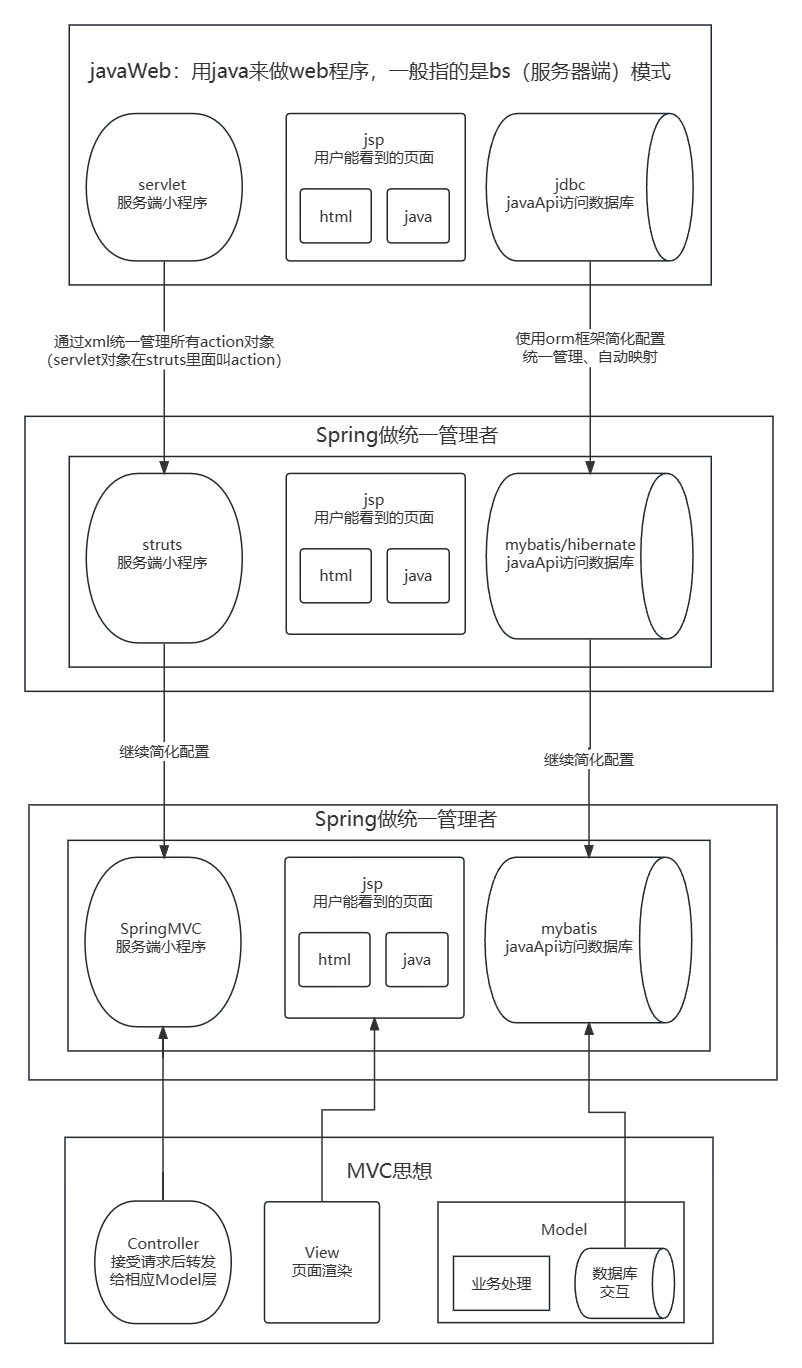
java后端技术演变杂谈(未完结)
1.0版本javaWeb:原始servletjspjsbc 早期的jsp:htmljava,页面先在后端被解析,里面的java代码动态渲染完成后,成为纯html,再通过服务器发送给浏览器显示。 缺点: 服务器压力很大,因为…...
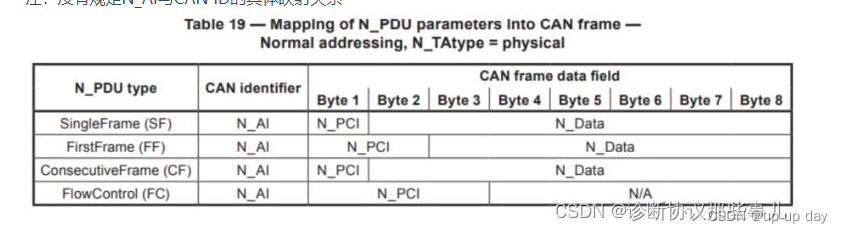
UDS 诊断报文格式
文章目录 网络层目的N_PDU 格式诊断报文的分类:单帧、多帧 网络层目的 N_PDU(network protocol data unit),即网络层协议数据单元 网络层最重要的目的就是把数据转换成符合标准的单一数据帧(符合can总线规范的),从而…...

kafka的详细安装部署
introduce Kafka是一个分布式流处理平台,主要用于处理高吞吐量的实时数据流。Kafka最初由LinkedIn公司开发,现在由Apache Software Foundation维护和开发。 Kafka的核心是一个分布式发布-订阅消息系统,它可以处理大量的消息流,并…...

【数据分享】2015-2023年我国区县逐月二手房房价数据(Excel/Shp格式)
房价是一个城市发展程度的重要体现,一个城市的房价越高通常代表这个城市越发达,对于人口的吸引力越大!因此,房价数据是我们在各项城市研究中都非常常用的数据!之前我们分享过2015-2023年我国地级市逐月房价数据&#x…...
)
PTA 7-226 sdut-C语言实验-矩阵输出(数组移位)
输入N个整数,输出由这些整数组成的n行矩阵。 输入格式: 第一行输入一个正整数N(N<20),表示后面要输入的整数个数。 下面依次输入N个整数。 输出格式: 以输入的整数为基础,输出有规律的N行数据。 输入样例: 在…...

Android 各平台推送通知栏点击处理方案
示例代码如下: RongPushClient.setPushEventListener( new PushEventListener() { Override public boolean preNotificationMessageArrived( Context context, PushType pushType, PushNotificationMessage notificationMessage) { //透传通知时,调用。…...

什么是网络安全 ?
网络安全已成为我们生活的数字时代最重要的话题之一。随着连接设备数量的增加、互联网的普及和在线数据的指数级增长,网络攻击的风险呈指数级增长。 但网络安全是什么意思? 简而言之,网络安全是一组旨在保护网络、设备和数据免受网络攻击、…...
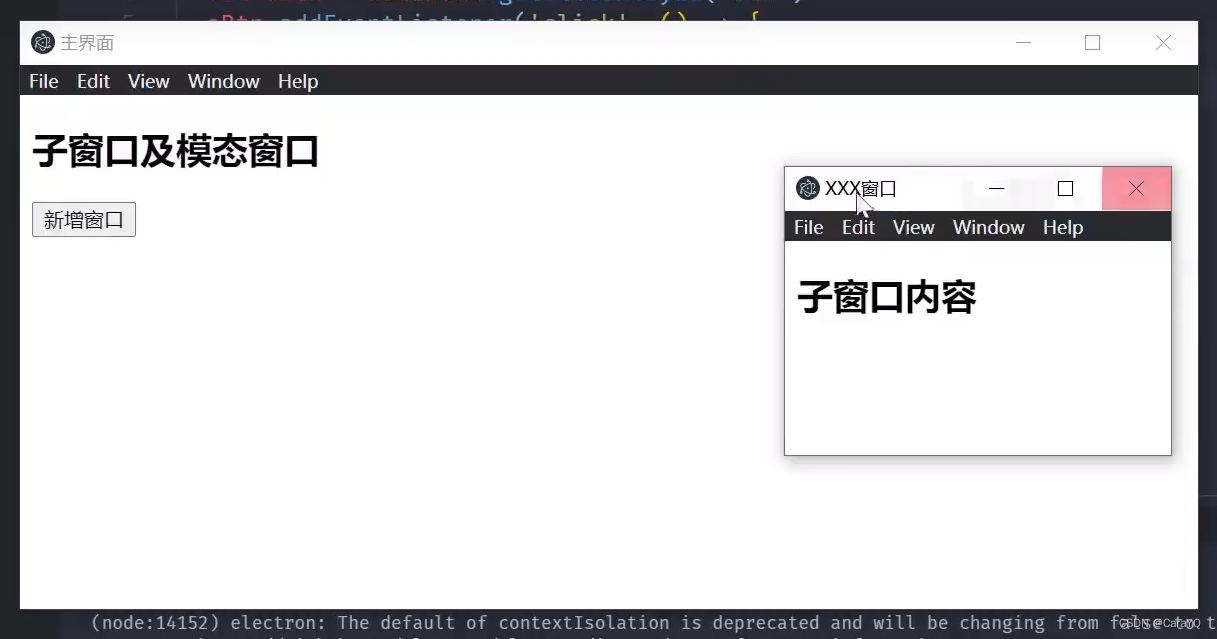
【前端】-【electron】
文章目录 介绍electron工作流程环境搭建 electron生命周期(app的生命周期)窗口尺寸窗口标题自定义窗口的实现阻止窗口关闭父子及模态窗口自定义菜单 介绍 electron技术架构:chromium、node.js、native.apis electron工作流程 桌面应用就是…...

Python中的类(Class)和对象(Object)
目录 一、引言 二、类(Class) 1、类的定义 2、类的实例化 三、对象(Object) 1、对象的属性 2、对象的方法 四、类和对象的继承和多态性 1、继承 2、多态性 五、类与对象的封装性 1、封装的概念 2、Python中的封装实现…...

dp-拦截导弹2
所有代码均来自于acwing中的算法基础课和算法提高课 Description 某国为了防御敌国的导弹袭击,发展出一种导弹拦截系统。但是这种导弹拦截系统有一个缺陷:虽然它的第一发炮弹能够到达任意的高度, 但是以后每一发炮弹都不能高于前一发的高度。…...
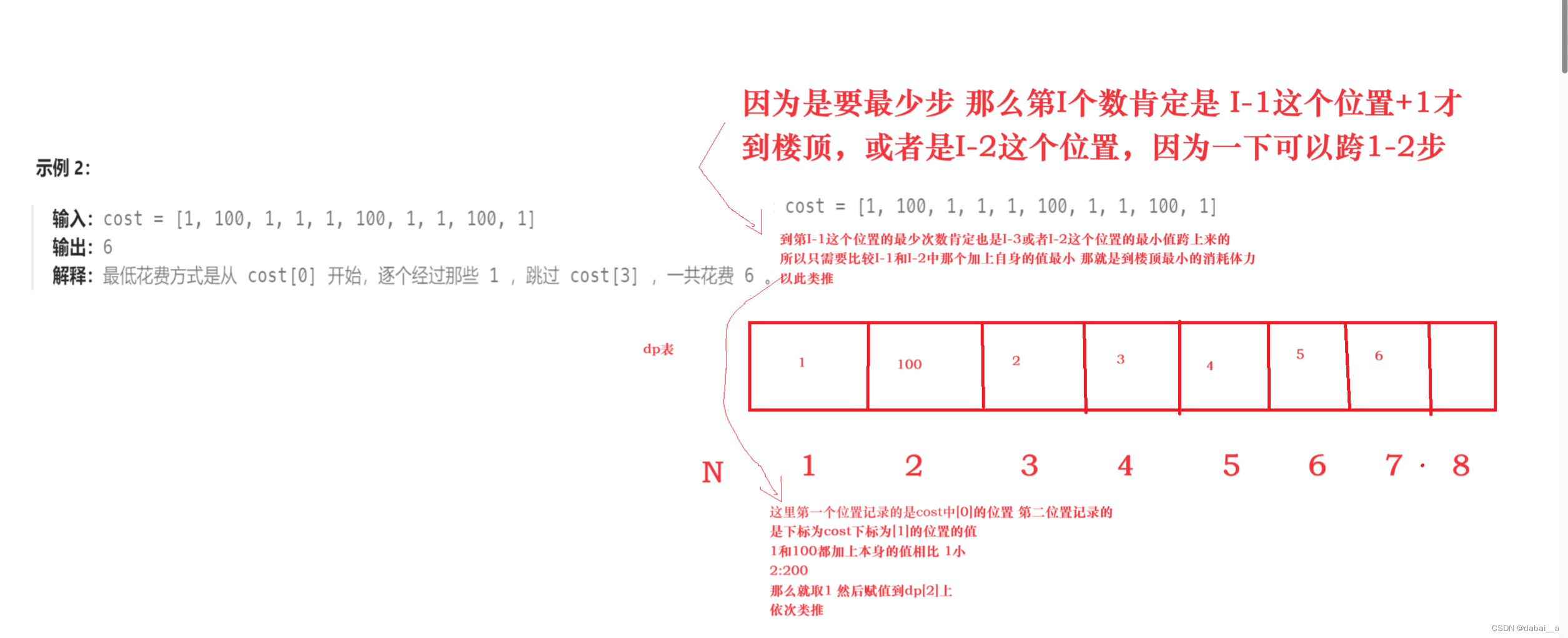
初识动态规划算法(题目加解析)
文章目录 什么是动态规划正文力扣题第 N 个泰波那契数三步问题使用最小花费爬楼梯 总结 什么是动态规划 线性动态规划:是可以用一个dp表来存储内容,并且找到规律存储,按照规律存储。让第i个位置的值等于题目要求的答案 >dp表:dp表就是用一…...
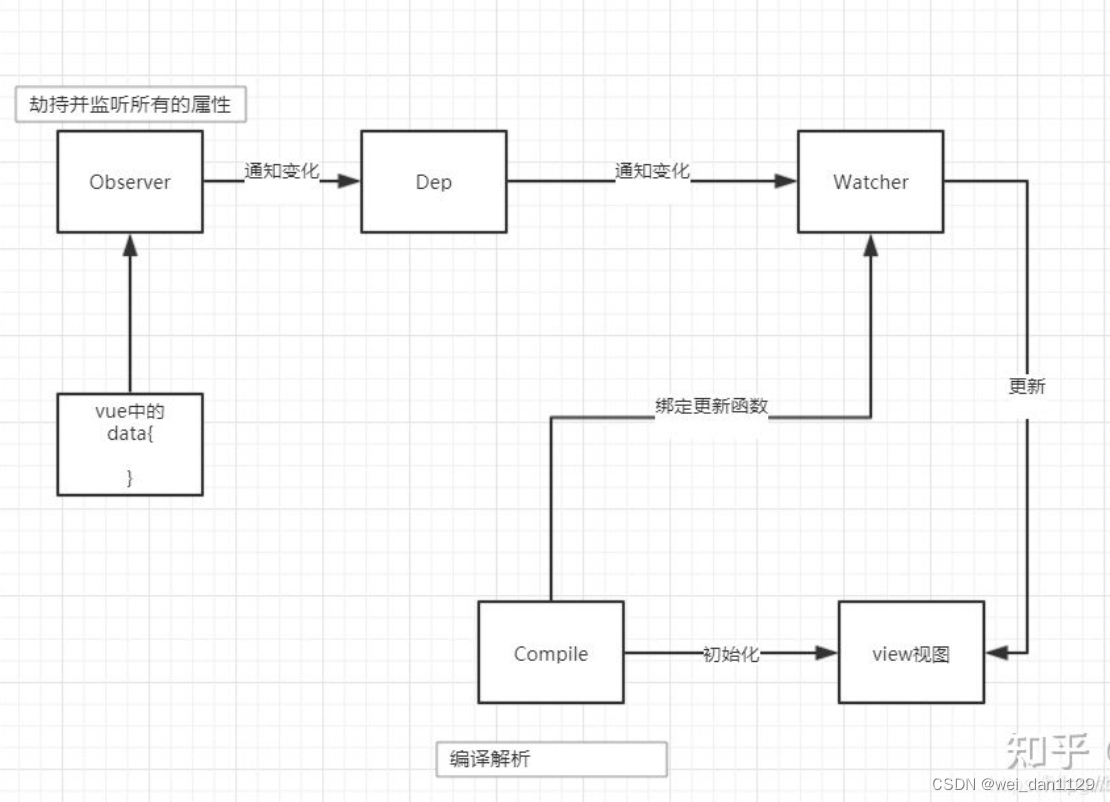
Vue2.0与Vue3.0的区别
一、Vue2和Vue3的数据双向绑定原理发生了改变 Vue2的双向数据绑定是利用ES5的一个API,Object.definePropert()对数据进行劫持 结合 发布 订阅模式的方式来实现的。通过Object.defineProperty来劫持数据的setter,getter,在数据变动时发布消息…...

探索人工智能领域——每日20个名词详解【day6】
目录 前言 正文 总结 🌈嗨!我是Filotimo__🌈。很高兴与大家相识,希望我的博客能对你有所帮助。 💡本文由Filotimo__✍️原创,首发于CSDN📚。 📣如需转载,请事先与我联系以…...
C++初阶 | [七] string类(上)
摘要:标准库中的string类的常用函数 C语言中,字符串是以\0结尾的一些字符的集合,为了操作方便,C标准库中提供了一些str系列的库函数, 但是这些库函数与字符串是分离开的,不太符合OOP(面向对象)的思想&#…...
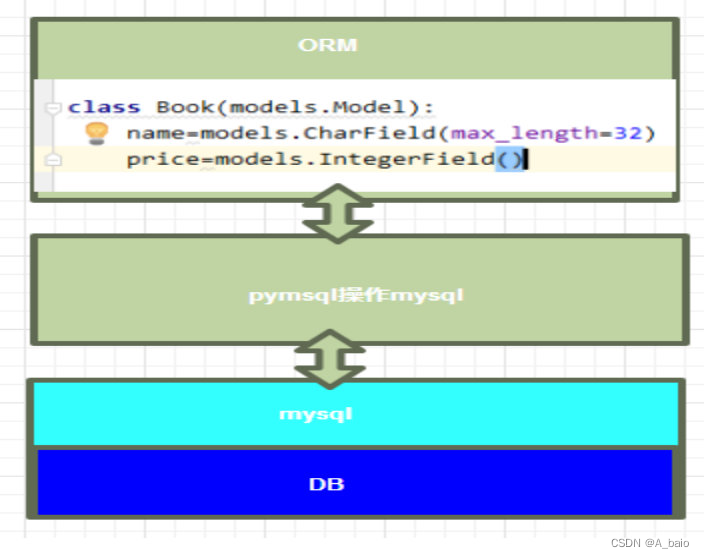
Django总结
文章目录 一、Web应用Web应用程序的优点Web应用程序的缺点应用程序有两种模式C/S、B/S C/S 客户端/服务端局域网连接其他电脑的MySQL数据库1.先用其他电脑再cmd命令行ping本机ip2.开放MySQL的访问 B/S 浏览器/服务端基于socket编写一个Web应用 二、Http协议1.http协议是什么2.h…...

【qml入门系列教程】:qml QtObject用法介绍
作者:令狐掌门 技术交流QQ群:675120140 博客地址:https://mingshiqiang.blog.csdn.net/ 文章目录 QtObject 是 Qt/QML 中的一个基础类型,通常用作创建一个没有 UI 的(不渲染任何东西的)纯逻辑对象。可以使用它来组织代码、存储状态或者作为属性和方法的容器。 以下是如何…...
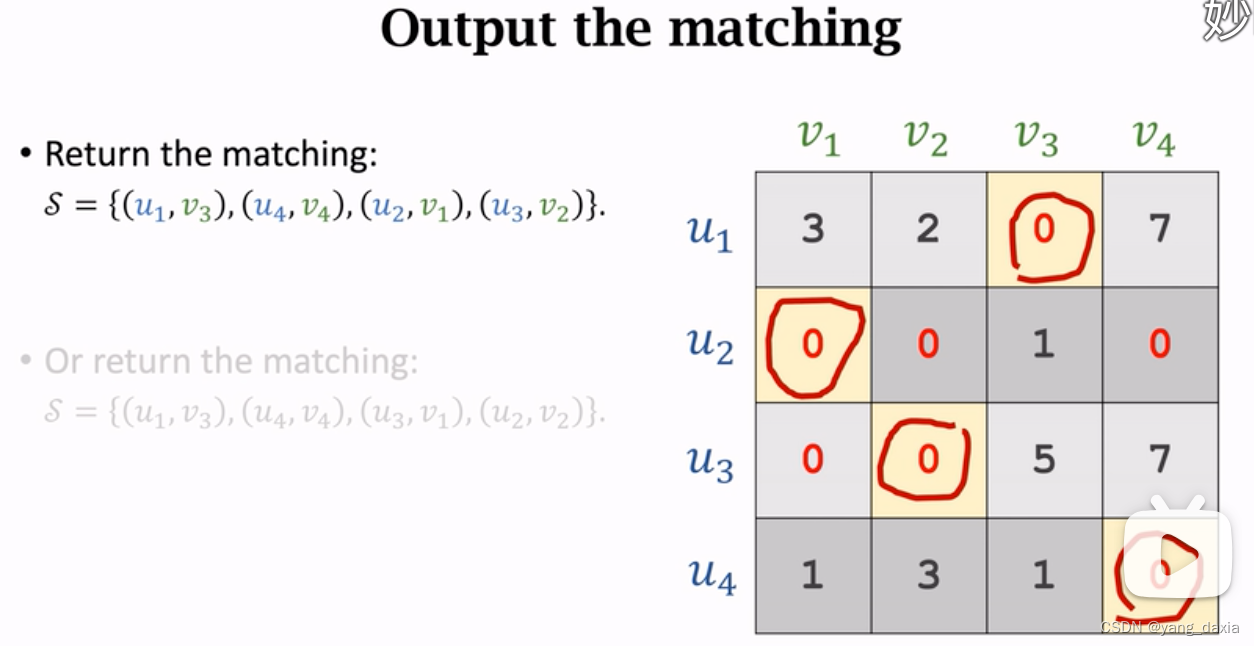
2分图匹配算法
定义 节点u直接无边,v之间无边,边只存在uv之间。判断方法:BFS染色法,全部染色后,相邻边不同色 无权二部图中的最大匹配 最大匹配即每一个都匹配上min(u, v)。贪心算法可能导致&…...
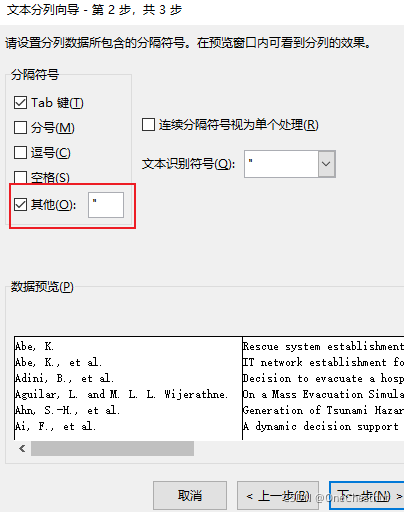
[EndNote学习笔记] 导出库中文献的作者、标题、年份到Excel
菜单栏Edit中,选择 Output Styles 在默认的 Annotated上进行修改,在Bibliography栏下的Templates中修改想要导出的格式 其中,每个粗体标题表示,针对不同的文献类型,设置相应的导出格式。一般为Journal Article&…...

LBE-LEX系列工业语音播放器|预警播报器|喇叭蜂鸣器的上位机配置操作说明
LBE-LEX系列工业语音播放器|预警播报器|喇叭蜂鸣器专为工业环境精心打造,完美适配AGV和无人叉车。同时,集成以太网与语音合成技术,为各类高级系统(如MES、调度系统、库位管理、立库等)提供高效便捷的语音交互体验。 L…...

测试微信模版消息推送
进入“开发接口管理”--“公众平台测试账号”,无需申请公众账号、可在测试账号中体验并测试微信公众平台所有高级接口。 获取access_token: 自定义模版消息: 关注测试号:扫二维码关注测试号。 发送模版消息: import requests da…...

8k长序列建模,蛋白质语言模型Prot42仅利用目标蛋白序列即可生成高亲和力结合剂
蛋白质结合剂(如抗体、抑制肽)在疾病诊断、成像分析及靶向药物递送等关键场景中发挥着不可替代的作用。传统上,高特异性蛋白质结合剂的开发高度依赖噬菌体展示、定向进化等实验技术,但这类方法普遍面临资源消耗巨大、研发周期冗长…...

Java - Mysql数据类型对应
Mysql数据类型java数据类型备注整型INT/INTEGERint / java.lang.Integer–BIGINTlong/java.lang.Long–––浮点型FLOATfloat/java.lang.FloatDOUBLEdouble/java.lang.Double–DECIMAL/NUMERICjava.math.BigDecimal字符串型CHARjava.lang.String固定长度字符串VARCHARjava.lang…...

第一篇:Agent2Agent (A2A) 协议——协作式人工智能的黎明
AI 领域的快速发展正在催生一个新时代,智能代理(agents)不再是孤立的个体,而是能够像一个数字团队一样协作。然而,当前 AI 生态系统的碎片化阻碍了这一愿景的实现,导致了“AI 巴别塔问题”——不同代理之间…...

自然语言处理——循环神经网络
自然语言处理——循环神经网络 循环神经网络应用到基于机器学习的自然语言处理任务序列到类别同步的序列到序列模式异步的序列到序列模式 参数学习和长程依赖问题基于门控的循环神经网络门控循环单元(GRU)长短期记忆神经网络(LSTM)…...
 自用)
css3笔记 (1) 自用
outline: none 用于移除元素获得焦点时默认的轮廓线 broder:0 用于移除边框 font-size:0 用于设置字体不显示 list-style: none 消除<li> 标签默认样式 margin: xx auto 版心居中 width:100% 通栏 vertical-align 作用于行内元素 / 表格单元格ÿ…...

视频行为标注工具BehaviLabel(源码+使用介绍+Windows.Exe版本)
前言: 最近在做行为检测相关的模型,用的是时空图卷积网络(STGCN),但原有kinetic-400数据集数据质量较低,需要进行细粒度的标注,同时粗略搜了下已有开源工具基本都集中于图像分割这块,…...

Vue ③-生命周期 || 脚手架
生命周期 思考:什么时候可以发送初始化渲染请求?(越早越好) 什么时候可以开始操作dom?(至少dom得渲染出来) Vue生命周期: 一个Vue实例从 创建 到 销毁 的整个过程。 生命周期四个…...

Pydantic + Function Calling的结合
1、Pydantic Pydantic 是一个 Python 库,用于数据验证和设置管理,通过 Python 类型注解强制执行数据类型。它广泛用于 API 开发(如 FastAPI)、配置管理和数据解析,核心功能包括: 数据验证:通过…...