卷积神经网络(CNN):乳腺癌识别.ipynb
文章目录
- 一、前言
- 一、设置GPU
- 二、导入数据
- 1. 导入数据
- 2. 检查数据
- 3. 配置数据集
- 4. 数据可视化
- 三、构建模型
- 四、编译
- 五、训练模型
- 六、评估模型
- 1. Accuracy与Loss图
- 2. 混淆矩阵
- 3. 各项指标评估
一、前言
我的环境:
- 语言环境:Python3.6.5
- 编译器:jupyter notebook
- 深度学习环境:TensorFlow2.4.1
往期精彩内容:
- 卷积神经网络(CNN)实现mnist手写数字识别
- 卷积神经网络(CNN)多种图片分类的实现
- 卷积神经网络(CNN)衣服图像分类的实现
- 卷积神经网络(CNN)鲜花识别
- 卷积神经网络(CNN)天气识别
- 卷积神经网络(VGG-16)识别海贼王草帽一伙
- 卷积神经网络(ResNet-50)鸟类识别
- 卷积神经网络(AlexNet)鸟类识别
- 卷积神经网络(CNN)识别验证码
来自专栏:机器学习与深度学习算法推荐
一、设置GPU
import tensorflow as tf
gpus = tf.config.list_physical_devices("GPU")if gpus:gpu0 = gpus[0] #如果有多个GPU,仅使用第0个GPUtf.config.experimental.set_memory_growth(gpu0, True) #设置GPU显存用量按需使用tf.config.set_visible_devices([gpu0],"GPU")import matplotlib.pyplot as plt
import os,PIL,pathlib
import numpy as np
import pandas as pd
import warnings
from tensorflow import keraswarnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
二、导入数据
1. 导入数据
import pathlibdata_dir = "./32-data"
data_dir = pathlib.Path(data_dir)
image_count = len(list(data_dir.glob('*/*')))
print("图片总数为:",image_count)
图片总数为: 13403
batch_size = 16
img_height = 50
img_width = 50
train_ds = tf.keras.preprocessing.image_dataset_from_directory(data_dir,validation_split=0.2,subset="training",seed=12,image_size=(img_height, img_width),batch_size=batch_size)
Found 13403 files belonging to 2 classes.
Using 10723 files for training.
val_ds = tf.keras.preprocessing.image_dataset_from_directory(data_dir,validation_split=0.2,subset="validation",seed=12,image_size=(img_height, img_width),batch_size=batch_size)
Found 13403 files belonging to 2 classes.
Using 2680 files for validation.
class_names = train_ds.class_names
print(class_names)
['0', '1']
2. 检查数据
for image_batch, labels_batch in train_ds:print(image_batch.shape)print(labels_batch.shape)break
(16, 50, 50, 3)
(16,)
3. 配置数据集
AUTOTUNE = tf.data.AUTOTUNEdef train_preprocessing(image,label):return (image/255.0,label)train_ds = (train_ds.cache().shuffle(1000).map(train_preprocessing) # 这里可以设置预处理函数
# .batch(batch_size) # 在image_dataset_from_directory处已经设置了batch_size.prefetch(buffer_size=AUTOTUNE)
)val_ds = (val_ds.cache().shuffle(1000).map(train_preprocessing) # 这里可以设置预处理函数
# .batch(batch_size) # 在image_dataset_from_directory处已经设置了batch_size.prefetch(buffer_size=AUTOTUNE)
)
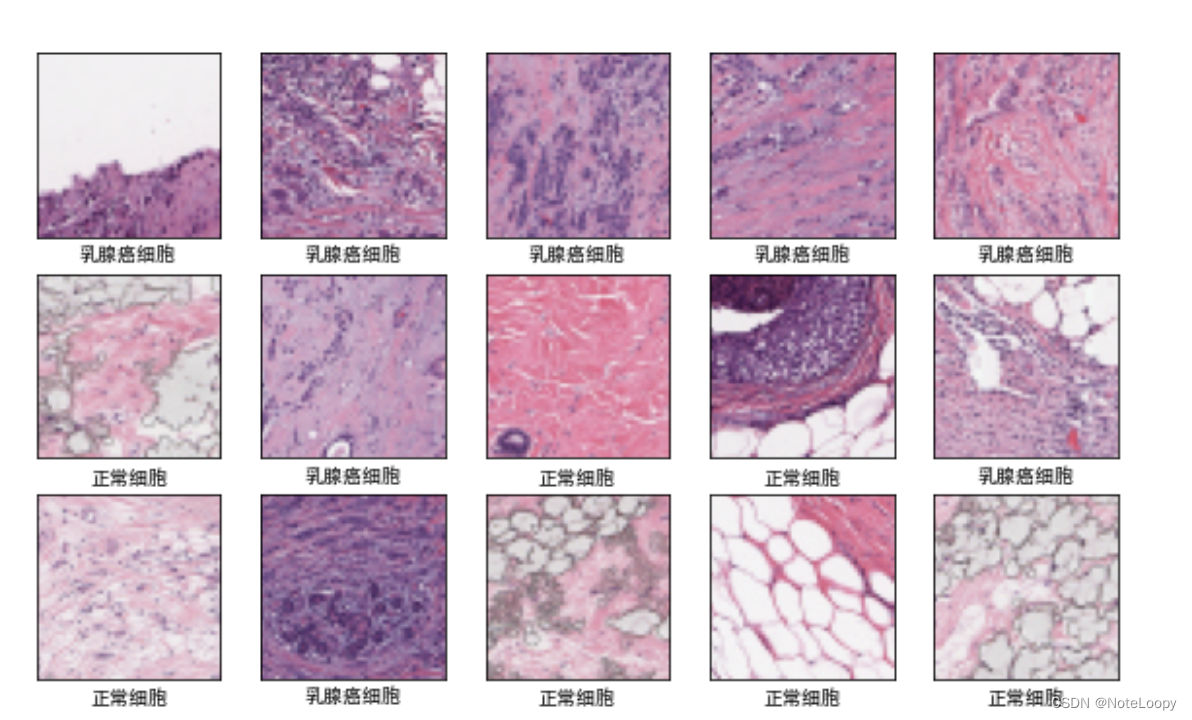
4. 数据可视化
plt.figure(figsize=(10, 8)) # 图形的宽为10高为5
plt.suptitle("数据展示")class_names = ["乳腺癌细胞","正常细胞"]for images, labels in train_ds.take(1):for i in range(15):plt.subplot(4, 5, i + 1)plt.xticks([])plt.yticks([])plt.grid(False)# 显示图片plt.imshow(images[i])# 显示标签plt.xlabel(class_names[labels[i]-1])plt.show()
三、构建模型
import tensorflow as tfmodel = tf.keras.Sequential([tf.keras.layers.Conv2D(filters=16,kernel_size=(3,3),padding="same",activation="relu",input_shape=[img_width, img_height, 3]),tf.keras.layers.Conv2D(filters=16,kernel_size=(3,3),padding="same",activation="relu"),tf.keras.layers.MaxPooling2D((2,2)),tf.keras.layers.Dropout(0.5),tf.keras.layers.Conv2D(filters=16,kernel_size=(3,3),padding="same",activation="relu"),tf.keras.layers.MaxPooling2D((2,2)),tf.keras.layers.Conv2D(filters=16,kernel_size=(3,3),padding="same",activation="relu"),tf.keras.layers.MaxPooling2D((2,2)),tf.keras.layers.Flatten(),tf.keras.layers.Dense(2, activation="softmax")
])
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 50, 50, 16) 448
_________________________________________________________________
conv2d_1 (Conv2D) (None, 50, 50, 16) 2320
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 25, 25, 16) 0
_________________________________________________________________
dropout (Dropout) (None, 25, 25, 16) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 25, 25, 16) 2320
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 12, 12, 16) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 12, 12, 16) 2320
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 6, 6, 16) 0
_________________________________________________________________
flatten (Flatten) (None, 576) 0
_________________________________________________________________
dense (Dense) (None, 2) 1154
=================================================================
Total params: 8,562
Trainable params: 8,562
Non-trainable params: 0
_________________________________________________________________
四、编译
model.compile(optimizer="adam",loss='sparse_categorical_crossentropy',metrics=['accuracy'])
五、训练模型
from tensorflow.keras.callbacks import ModelCheckpoint, Callback, EarlyStopping, ReduceLROnPlateau, LearningRateSchedulerNO_EPOCHS = 100
PATIENCE = 5
VERBOSE = 1# 设置动态学习率
annealer = LearningRateScheduler(lambda x: 1e-3 * 0.99 ** (x+NO_EPOCHS))# 设置早停
earlystopper = EarlyStopping(monitor='loss', patience=PATIENCE, verbose=VERBOSE)#
checkpointer = ModelCheckpoint('best_model.h5',monitor='val_accuracy',verbose=VERBOSE,save_best_only=True,save_weights_only=True)
train_model = model.fit(train_ds,epochs=NO_EPOCHS,verbose=1,validation_data=val_ds,callbacks=[earlystopper, checkpointer, annealer])
六、评估模型
1. Accuracy与Loss图
acc = train_model.history['accuracy']
val_acc = train_model.history['val_accuracy']loss = train_model.history['loss']
val_loss = train_model.history['val_loss']epochs_range = range(len(acc))plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
2. 混淆矩阵
from sklearn.metrics import confusion_matrix
import seaborn as sns
import pandas as pd# 定义一个绘制混淆矩阵图的函数
def plot_cm(labels, predictions):# 生成混淆矩阵conf_numpy = confusion_matrix(labels, predictions)# 将矩阵转化为 DataFrameconf_df = pd.DataFrame(conf_numpy, index=class_names ,columns=class_names) plt.figure(figsize=(8,7))sns.heatmap(conf_df, annot=True, fmt="d", cmap="BuPu")plt.title('混淆矩阵',fontsize=15)plt.ylabel('真实值',fontsize=14)plt.xlabel('预测值',fontsize=14)
val_pre = []
val_label = []for images, labels in val_ds:#这里可以取部分验证数据(.take(1))生成混淆矩阵for image, label in zip(images, labels):# 需要给图片增加一个维度img_array = tf.expand_dims(image, 0) # 使用模型预测图片中的人物prediction = model.predict(img_array)val_pre.append(class_names[np.argmax(prediction)])val_label.append(class_names[label])
plot_cm(val_label, val_pre)
3. 各项指标评估
from sklearn import metricsdef test_accuracy_report(model):print(metrics.classification_report(val_label, val_pre, target_names=class_names)) score = model.evaluate(val_ds, verbose=0)print('Loss function: %s, accuracy:' % score[0], score[1])test_accuracy_report(model)
precision recall f1-score support乳腺癌细胞 0.92 0.90 0.91 1339正常细胞 0.91 0.92 0.91 1341accuracy 0.91 2680macro avg 0.91 0.91 0.91 2680
weighted avg 0.91 0.91 0.91 2680Loss function: 0.22688131034374237, accuracy: 0.9138059616088867
pport
乳腺癌细胞 0.92 0.90 0.91 1339正常细胞 0.91 0.92 0.91 1341accuracy 0.91 2680
macro avg 0.91 0.91 0.91 2680
weighted avg 0.91 0.91 0.91 2680
Loss function: 0.22688131034374237, accuracy: 0.9138059616088867
相关文章:
卷积神经网络(CNN):乳腺癌识别.ipynb
文章目录 一、前言一、设置GPU二、导入数据1. 导入数据2. 检查数据3. 配置数据集4. 数据可视化 三、构建模型四、编译五、训练模型六、评估模型1. Accuracy与Loss图2. 混淆矩阵3. 各项指标评估 一、前言 我的环境: 语言环境:Python3.6.5编译器…...
有文件实体的后门无文件实体的后门rootkit后门
有文件实体后门和无文件实体后门&RootKit后门 什么是有文件的实体后门: 在传统的webshell当中,后门代码都是可以精确定位到某一个文件上去的,你可以rm删除它,可以鼠标右键操作它,它是有一个文件实体对象存在的。…...

GPT实战系列-大模型训练和预测,如何加速、降低显存
GPT实战系列-大模型训练和预测,如何加速、降低显存 不做特别处理,深度学习默认参数精度为浮点32位精度(FP32)。大模型参数庞大,10-1000B级别,如果不注意优化,既耗费大量的显卡资源,…...

SQL Sever 基础知识 - 数据排序
SQL Sever 基础知识 - 二 、数据排序 二 、对数据进行排序第1节 ORDER BY 子句简介第2节 ORDER BY 子句示例2.1 按一列升序对结果集进行排序2.2 按一列降序对结果集进行排序2.3 按多列对结果集排序2.4 按多列对结果集不同排序2.5 按不在选择列表中的列对结果集进行排序2.6 按表…...

vscode配置使用 cpplint
标题安装clang-format和cpplint sudo apt-get install clang-format sudo pip3 install cpplint标题以下settings.json文件放置xxx/Code/User目录 settings.json {"sync.forceDownload": false,"workbench.sideBar.location": "right","…...
C++ 系列 第四篇 C++ 数据类型上篇—基本类型
系列文章 C 系列 前篇 为什么学习C 及学习计划-CSDN博客 C 系列 第一篇 开发环境搭建(WSL 方向)-CSDN博客 C 系列 第二篇 你真的了解C吗?本篇带你走进C的世界-CSDN博客 C 系列 第三篇 C程序的基本结构-CSDN博客 前言 面向对象编程(OOP)的…...
C++ 指针详解
目录 一、指针概述 指针的定义 指针的大小 指针的解引用 野指针 指针未初始化 指针越界访问 指针运算 二级指针 指针与数组 二、字符指针 三、指针数组 四、数组指针 函数指针 函数指针数组 指向函数指针数组的指针 回调函数 指针与数组 一维数组 字符数组…...

.locked、locked1勒索病毒的最新威胁:如何恢复您的数据?
导言: 网络安全问题变得愈加严峻。.locked、locked1勒索病毒是近期备受关注的一种恶意软件,给用户的数据带来了巨大威胁。本文将深入探讨.locked、locked1勒索病毒的特征,探讨如何有效恢复被其加密的数据,并提供一些建议…...
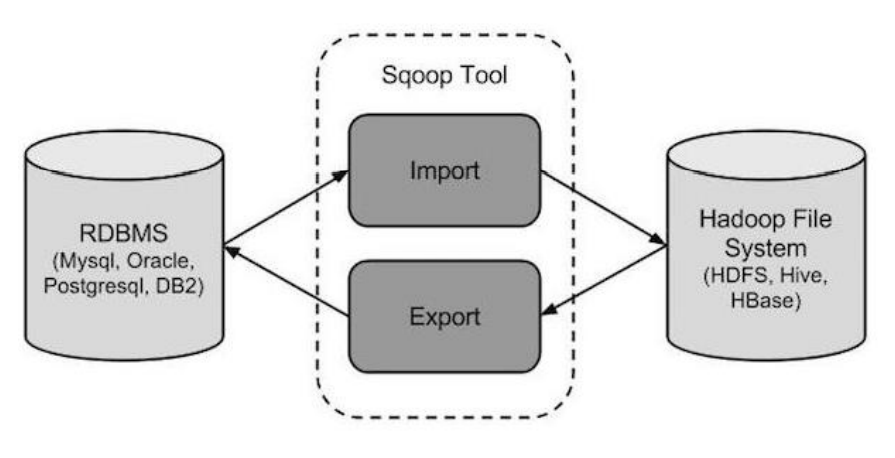
Apache Sqoop使用
1. Sqoop介绍 Apache Sqoop 是在 Hadoop 生态体系和 RDBMS 体系之间传送数据的一种工具。 Sqoop 工作机制是将导入或导出命令翻译成 mapreduce 程序来实现。在翻译出的 mapreduce 中主要是对 inputformat 和 outputformat 进行定制。 Hadoop 生态系统包括:HDFS、Hi…...

【UGUI】实现UGUI背包系统的六个主要交互功能
在这篇教程中,我们将详细介绍如何在Unity中实现一个背包系统的六个主要功能:添加物品、删除物品、查看物品信息、排序物品、搜索物品和使用物品。让我们开始吧! 一、添加物品 首先,我们需要创建一个方法来添加新的物品到背包中。…...
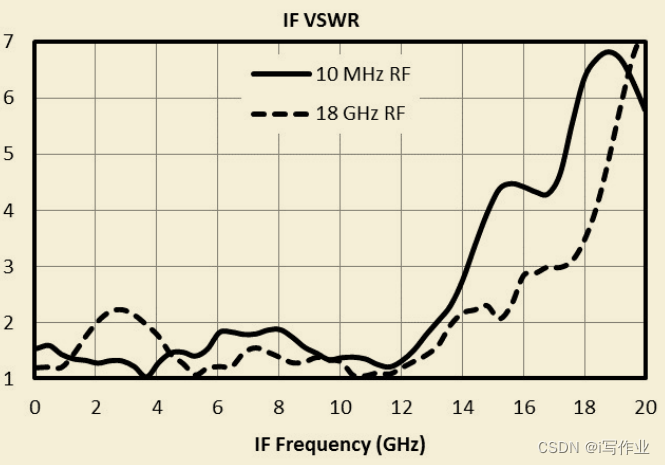
电压驻波比
电压驻波比 关于IF端口的电压驻波比 一个信号变频后,从中频端口输出,它的输出跟输入是互异的。这个电压柱波比反映了它输出的能量有多少可以真正的输送到后端连接的器件或者设备。...

Open3D 最小二乘拟合二维直线(直接求解法)
目录 一、算法原理二、代码实现三、结果展示本文由CSDN点云侠原创,原文链接。爬虫网站自重。 一、算法原理 平面直线的表达式为: y = k x + b...
)
面试题目总结(二)
1. IoC 和 AOP 的区别 控制反转(Ioc) 和面向切面编程(AOP) 是两个不同的概念,它们在软件设计中有着不同的应用和目的。 IoC 是一种基于对象组合的编程模式,通过将对象的创建、依赖关系和生命周期等管理权交给外部容器或框架来实现程序间的解耦。IoC 的…...

TrustZone概述
目录 一、概述 1.1 在开始之前 二、什么是TrustZone? 2.1 Armv8-M的TrustZone 2.2 Armv9-A Realm Management Ext...

[go 面试] Go Kit中读取原始HTTP请求体的方法
关注公众号【爱发白日梦的后端】分享技术干货、读书笔记、开源项目、实战经验、高效开发工具等,您的关注将是我的更新动力! 在Go Kit中,如果你想读取未序列化的HTTP请求体,可以使用标准的net/http包来实现。以下是一个示例,演示了如何完成这个任务: package mainimport …...

小程序如何刷新当前页面?
在小程序中,刷新当前页面通常有两种方法: 使用 wx.navigateBack 方法: wx.navigateBack({delta: 1 }) 这将返回上一页,并刷新页面。你可以通过调整 delta 参数来控制返回的页面数。例如,如果你想要返回到两页之前的页…...

ChatGPT使用路径:从新手到专家的指南
原文&精华文章&转载注明:ChatGPT与日本首相交流核废水事件-精准Prompt... hello,我是小索奇,有任何问题或者需要帮助的都可以在这里找到我或者留言哈 一、初识ChatGPT 什么是ChatGPT? ChatGPT是一种大型语言模型&…...
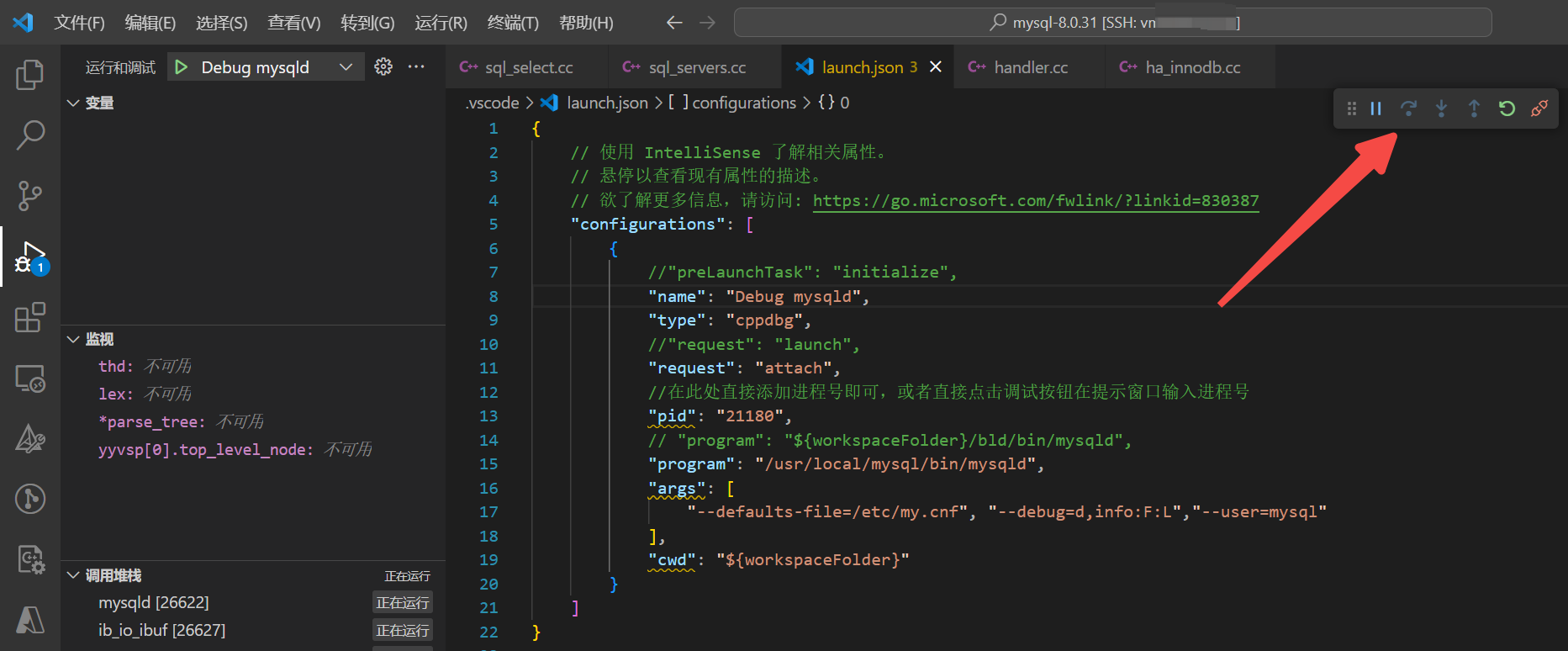
VsCode 调试 MySQL 源码
1. 启动 MySQL 2. 查看 MySQL 进程号 [root ~]# ps -ef | grep mysqld root 21479 1 0 Nov01 ? 00:00:00 /bin/sh /usr/local/mysql/bin/mysqld_safe --datadir/usr/local/mysql/data --pid-file/usr/local/mysql/data/mysqld.pid root 26622 21479 0 …...

Mysql中的正经行锁、间隙锁和临键锁
行锁、间隙锁和临键锁是数据库中的三种不同类型的锁,三者都属于行锁,第一个一般叫他正经的行锁(《Mysql是怎样运行的》一书中的说法)。 行锁(Row Lock):行锁是指对数据表中的某一行进行的锁定操…...

最强AI之风袭来,你爱了吗?
2017年,柯洁同阿尔法狗人机大战,AlphaGo以3比0大获全胜,一代英才泪洒当场...... 2019年,换脸哥视频“杨幂换朱茵”轰动全网,时至今日AI换脸仍热度只增不减; 2022年,ChatGPT一经发布便轰动全球&a…...

如何实现毫秒级手机电脑无缝协同?QtScrcpy全场景应用指南
如何实现毫秒级手机电脑无缝协同?QtScrcpy全场景应用指南 【免费下载链接】QtScrcpy QtScrcpy 可以通过 USB / 网络连接Android设备,并进行显示和控制。无需root权限。 项目地址: https://gitcode.com/GitHub_Trending/qt/QtScrcpy 30秒核心价值速…...
——CAD)
小带轮(同步带)——CAD
小带轮作为同步带传动系统的核心组件,其设计精度直接影响动力传递的效率与稳定性。在机械传动领域,同步带传动凭借无滑移、传动比精准的特性,广泛应用于数控机床、自动化设备及精密仪器中。小带轮通过与同步带齿槽的精确啮合,将旋…...

代码随想录算法营第五十四天|108. 多余的边、109. 多余的边II
KamaCoder 108. 多余的边 #include <iostream> #include <vector>using namespace std;int n; vector<int> father(1001, 0);int find(int u){if (u father[u]) return u;else father[u] find(father[u]);return father[u]; }void join(int u, int v){u …...

突破8大平台壁垒:Online-disk-direct-link-download-assistant的高效下载解决方案
突破8大平台壁垒:Online-disk-direct-link-download-assistant的高效下载解决方案 【免费下载链接】Online-disk-direct-link-download-assistant 可以获取网盘文件真实下载地址。基于【网盘直链下载助手】修改(改自6.1.4版本) ,自…...

从蔚来NOMI到小鹏全场景语音:盘点那些让你‘开口即来’的智能车机系统
从“听懂”到“懂你”:深度解析智能座舱语音交互的进化与实战选型 不知道你有没有过这样的体验:开车时想调低空调温度,手刚离开方向盘,导航提示音就响了;想切首歌,眼睛得在中控屏上找半天图标;副…...

最新9款支持论文目录智能生成的工具,附带实时更新功能全面评测
工具对比速览 工具名称 核心功能 处理速度 适用场景 特色优势 aibiye AI降重目录生成 20分钟 学术论文 知网/维普/格子达适配 aicheck AI检测目录优化 实时 初稿检查 多平台规则预判 askpaper 学术规范处理 15-30分钟 期刊投稿 保留专业术语 秒篇 一键式处…...

QQ空间数字记忆归档方案:使用GetQzonehistory实现个人动态全量备份
QQ空间数字记忆归档方案:使用GetQzonehistory实现个人动态全量备份 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory 理解个人数字资产保护的核心价值 在数字化时代ÿ…...

低代码赋能数字化运营:破解管理痛点,激活增长动能
在数字化浪潮席卷各行各业的当下,企业运营早已告别“粗放式管理”的时代,数字化、精细化、全链路成为核心竞争力的关键。对于多数企业而言,如何打破运营壁垒、盘活数据资产、降低管理成本,实现高效增长,成为亟待解决的…...

Hadoop 2.7.3 集群部署、配置与环境变量调优全流程总结
本次完成了基于 master/slave1/slave2 三节点的 Hadoop 分布式集群部署,核心涵盖集群基础配置、环境变量调优、问题排查与验证,最终实现集群全功能可用,以下是完整总结:一、核心部署与配置流程1. 基础环境准备(前置步骤…...

UG NX 移除参数
在UG NX中,“移除参数”(也称为“消参”)是一个用于断开模型与其特征历史关联的关键操作。执行后,模型的建模步骤将被清除,变成一个没有参数的“体”。 简单来说,参数化模型像一个记录了所有“施工步骤”的…...