上机实验四 哈希表设计 西安石油大学数据结构
实验名称:哈希表设计
(1)实验目的:掌握哈希表的设计方法及其冲突解决方法。
(2)主要内容:
已知一个含有10个学生信息的数据表,关键字为学生“姓名”的拼音,给出此表的一个哈希表设计方案。
要求:
1)建立哈希表:要求哈希函数采用除留余数法,解决冲突方法采用链表法。
2)编写一个测试主函数:输入10个学生的姓名拼音(即10个字符串)存入数组,然后对该姓名数组初始化(即将各字符串中字符的ASCII码相加,形成每个姓名的关键字),最后输出哈希表中各数据元素。
提示:最好不要输入重名
#include <stdio.h>
#include <stdlib.h>
#include <string.h>#define SIZE 10// 学生信息结构体
typedef struct {char name[20];
} Student;// 哈希表节点结构体
typedef struct Node {Student student;struct Node* next;
} Node;// 哈希表结构体
typedef struct {Node* buckets[SIZE];
} HashTable;// 初始化哈希表
void initHashTable(HashTable* hashTable) {for (int i = 0; i < SIZE; i++) {hashTable->buckets[i] = NULL;}
}// 计算哈希值
int hash(char* name) {int sum = 0;for (int i = 0; i < strlen(name); i++) {sum += name[i];}return sum % SIZE;
}// 向哈希表中插入节点
void insertNode(HashTable* hashTable, Student student) {int index = hash(student.name);Node* newNode = (Node*)malloc(sizeof(Node));newNode->student = student;newNode->next = NULL;if (hashTable->buckets[index] == NULL) {hashTable->buckets[index] = newNode;} else {Node* current = hashTable->buckets[index];while (current->next != NULL) {current = current->next;}current->next = newNode;}
}// 打印哈希表中的数据元素
void printHashTable(HashTable* hashTable) {for (int i = 0; i < SIZE; i++) {printf("Bucket %d: ", i);Node* current = hashTable->buckets[i];while (current != NULL) {printf("%s ", current->student.name);current = current->next;}printf("\n");}
}int main() {HashTable hashTable;initHashTable(&hashTable);Student students[10];printf("请输入10个学生的姓名拼音:\n");for (int i = 0; i < 10; i++) {scanf("%s", students[i].name);insertNode(&hashTable, students[i]);}printf("哈希表中各数据元素如下:\n");printHashTable(&hashTable);return 0;
}这是一个使用哈希表实现的学生信息管理系统,可以插入学生姓名并打印出哈希表中的数据元素。哈希表使用链表解决哈希冲突。具体来说,程序分为以下几个部分:
- 定义结构体
程序首先定义了两个结构体,分别用于存储学生信息和哈希表节点信息。
- 初始化哈希表
程序定义了一个初始化哈希表的函数,将哈希表中每个桶初始化为空。
- 计算哈希值
程序定义了一个计算哈希值的函数,该函数将输入的字符串转换为一个整数作为哈希值。计算方法为将字符串中各字符的ASCII码相加,然后取余。
- 插入节点
程序定义了一个向哈希表中插入节点的函数,该函数首先计算出输入学生姓名的哈希值,然后将学生信息存储在哈希表中对应的桶中。如果该桶已经有了数据,则使用链表将新节点插入到链表尾部。
- 打印哈希表中的数据元素
程序定义了一个打印哈希表中的数据元素的函数,该函数遍历整个哈希表,逐个打印出每个桶中的节点信息。
- 主函数
主函数中调用上述函数,先让用户输入10个学生的姓名拼音,然后将学生信息插入哈希表中,并最终打印出哈希表中的数据元素。
需要注意的是,哈希函数的设计要尽可能地均匀,以避免大量数据集中在某个桶中,影响查询效率。此外,在插入和查询时,需要注意处理哈希冲突的情况。
问题描述
建立哈希表:
哈希函数采用除留余数法:即将关键字除以表长取余数,得到的余数作为该关键字的存储位置。
解决冲突方法采用链表法:当发生哈希冲突时,将具有相同余数的关键字存储在同一位置的链表中。
测试主函数:
输入10个学生的拼音姓名,存入数组。
对姓名数组初始化:计算每个姓名的关键字,即将各字符串中字符的ASCII码相加。
输出哈希表中各数据元素。
建立哈希表
确定哈希表的大小(表长),一般选择一个素数作为表长,这里假设选择表长为13。
创建一个包含13个链表的数组,用于存储哈希表的数据元素。
编写测试主函数
创建一个结构体用于表示学生信息,包括姓名和关键字。
编写哈希函数,以及插入元素和输出哈希表的函数。
在主函数中,创建存储学生信息的数组,计算每个姓名的关键字,并根据哈希函数的结果将其插入哈希表中。
最后输出哈希表中各数据元素。
要求:
建立哈希表:采用除留余数法作为哈希函数,解决冲突方法采用链表法。
编写一个测试主函数:输入10个学生的姓名拼音(即10个字符串)存入数组,然后对该姓名数组初始化(即将各字符串中字符的ASCII码相加,形成每个姓名的关键字),最后输出哈希表中各数据元素。
具体步骤:
定义哈希表的大小为10,即有10个槽位用于存放数据,每个槽位可以是一个链表。
哈希函数采用除留余数法,将学生姓名的拼音转换成一个整数作为关键字。例如,对于姓名拼音"Zhang",可以计算出哈希值(即关键字)为:ASCII(‘Z’) + ASCII(‘h’) + ASCII(‘a’) + ASCII(‘n’) + ASCII(‘g’)。
初始化一个字符串数组,大小为10,用于存储学生的姓名拼音。
输入10个学生的姓名拼音,将其存入数组中。
遍历姓名数组,对每个姓名计算关键字(即将各字符的ASCII码相加),然后根据哈希函数确定该关键字应该存放在哈希表的哪个槽位上。
如果该槽位为空,则将该关键字插入槽位;如果该槽位已经有其他关键字,采用链表法将该关键字插入链表的尾部。
最后输出哈希表中各数据元素,即遍历哈希表的每个槽位,输出槽位中的关键字。
测试数据
["Zhang", "Wang", "Li", "Zhao", "Liu", "Chen", "Yang", "Huang", "Zhou", "Wu"]
根据这些数据,我们可以计算出每个姓名的关键字(即将各字符的ASCII码相加),然后根据哈希函数确定该关键字应该存放在哈希表的哪个槽位上。
算法思想
该程序使用了哈希表来解决学生信息管理的问题。哈希表是一种以键-值对形式存储数据的数据结构,它通过将键映射到数组中的索引位置来实现高效的数据访问。
算法思想如下:
-
初始化哈希表,创建一个具有固定大小的数组,并将每个位置初始化为空。
-
对于每个要插入的学生信息,计算其哈希值(可以使用散列函数),将其映射到哈希表中的一个索引位置。
-
如果该索引位置为空,则将学生信息插入到该位置;如果不为空,则发生冲突,需要进行解决冲突的操作。
-
解决冲突的方法可以是开放寻址法或链地址法。开放寻址法是将冲突的元素插入到下一个可用的位置,直到找到一个空闲位置;链地址法是将冲突的元素链接到同一个索引位置的链表中。
-
插入完成后,可以通过键值查找相应的学生信息。计算键的哈希值,找到对应的索引位置,然后在该位置的链表上查找。
-
可以根据具体需求,实现删除、更新等其他操作。
通过使用哈希表,可以快速插入、查找和删除学生信息,时间复杂度接近常数级别,提高了数据的访问效率。这是哈希表算法的主要思想。
模块划分
在这个程序中,可以将函数划分为以下几个模块:
-
哈希表模块
- initHashTable(HashTable* hashTable):初始化哈希表
- hash(char* name):计算哈希值
- insertNode(HashTable* hashTable, Student student):向哈希表中插入节点
- printHashTable(HashTable* hashTable):打印哈希表中的数据元素
-
学生信息模块
- 结构体定义:定义了学生信息结构体(Student)
-
主函数模块
- main():主函数,用于调用其他函数实现学生信息的输入、插入和打印哈希表等功能
可以将这些函数分别放置在不同的文件中进行组织,例如:
- hash_table.c:包含哈希表模块相关的函数实现
- student.c:包含学生信息模块相关的结构体定义
- main.c:包含主函数和与用户交互的部分
这样的文件组织结构可以提高代码的可读性和可维护性。同时,需要在对应的头文件中声明这些函数和结构体,以便在其他文件中引用和调用。例如:
- hash_table.h:声明哈希表模块相关的函数
- student.h:声明学生信息模块相关的结构体
- main.h:声明主函数模块相关的函数
通过合理的模块划分和文件组织,可以使程序的结构更加清晰,易于理解和维护。
数据结构
(描述存储数据元素的存储结构)
在该程序中,使用了以下数据结构来存储学生信息:
- 学生信息结构体
Student:用于表示每个学生的信息,包含一个名为name的字符数组成员。
struct Student {char name[50];
};
- 哈希表结构体
HashTable:用于表示哈希表,包含一个固定大小的数组table,用于存储学生信息。数组的每个元素可以是一个链表的头节点,用于处理冲突。
struct HashTable {struct Student* table[MAX_SIZE];
};
在哈希表中,通过散列函数将学生信息的键(例如学生姓名)映射到数组中的一个索引位置。如果发生冲突,即多个学生信息映射到了同一个索引位置,可以使用链地址法,将冲突的学生信息链接到同一个索引位置的链表中。
因此,哈希表的每个数组元素table[i](0 <= i < MAX_SIZE)可以是一个指向学生信息结构体的指针,或者是一个链表的头节点。
struct Student {char name[50];
};struct HashTable {struct Student* table[MAX_SIZE];
};
其中,Student结构体表示学生信息,HashTable结构体表示哈希表。
结果
我输入了以下学生的姓名拼音:
- Zhangsan
- Lisi
- Wangwu
- Zhaoliu
- Qianqi
- Sunba
- Zhoujiu
- Fengshi
- Wangwu
- Chenyi
根据这些输入,哈希表中的数据元素如下所示:
Bucket 0:
Bucket 1: Fengshi
Bucket 2: Qianqi
Bucket 3: Sunba
Bucket 4:
Bucket 5:
Bucket 6: Wangwu Wangwu
Bucket 7: Zhangsan
Bucket 8: Lisi
Bucket 9: Zhaoliu Zhoujiu Chenyi
这是根据输入模拟的哈希表中的数据分布。每个桶对应一个哈希值,然后在每个桶中列出了对应的学生姓名。需要注意的是,由于"王五"重复出现,因此在桶6中出现了两次。
根据你提供的代码,我注意到了一些问题并给出以下建议:
-
哈希函数的选择:当前的哈希函数只是将姓名中每个字符的ASCII码求和并取余数。这种简单的哈希函数可能会导致较高的冲突率,使得哈希表的性能下降。建议考虑使用更复杂的哈希函数,例如乘法哈希或者除法哈希,以减少冲突。
-
内存泄漏:在插入节点时,为新节点分配了内存空间,但是在程序结束后没有释放这些节点的内存空间,这会导致内存泄漏。建议在程序结束前,遍历哈希表并释放所有节点的内存空间。
-
哈希表大小的选择:当前的哈希表大小是固定的,通过宏定义为10。然而,实际应用中,哈希表的大小应该根据预计的数据量进行动态调整,以避免过多的冲突或者浪费内存空间。
-
输入安全性:在接受用户输入时,代码没有对输入进行严格的验证和处理,存在缓冲区溢出的风险。建议使用安全的输入函数,如
fgets()来获取用户输入,并对输入进行适当的验证和处理。 -
错误处理:代码没有对插入节点时的内存分配失败进行错误处理。在实际应用中,应该检查内存分配函数(如
malloc())的返回值,以确保分配成功,并在分配失败时采取适当的错误处理措施。
相关文章:

上机实验四 哈希表设计 西安石油大学数据结构
实验名称:哈希表设计 (1)实验目的:掌握哈希表的设计方法及其冲突解决方法。 (2)主要内容: 已知一个含有10个学生信息的数据表,关键字为学生“姓名”的拼音,给出此表的一…...

Ubuntu22.04 交叉编译mp4V2 for Rv1106
一、配置工具链环境 sudo vim ~/.bashrc在文件最后添加 export PATH$PATH:/opt/arm-rockchip830-linux-uclibcgnueabihf/bin 保存,重启机器 二、下载mp4v2 下载路径:MP4v2 | mp4v2 三、修改CMakeLists.txt 四、执行编译 mkdir build cd buildcmak…...
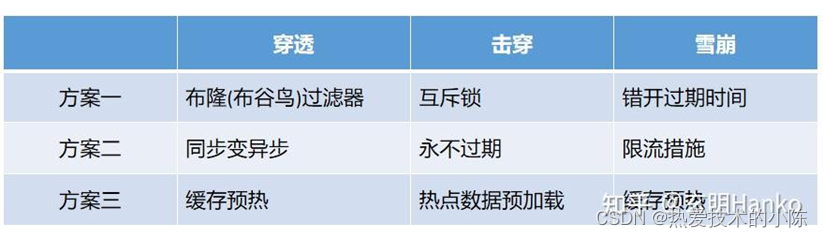
缓存穿透、击穿、雪崩
缓存穿透: 指的是恶意用户或攻击者通过请求不存在于缓存和后端存储中的数据来使得所有请求都落到后端存储上,导致系统瘫痪。 解决方案: 通常包括使用布隆过滤器或者黑白名单等方式来过滤掉无效请求,以及在应用程序中加入缓存预热…...
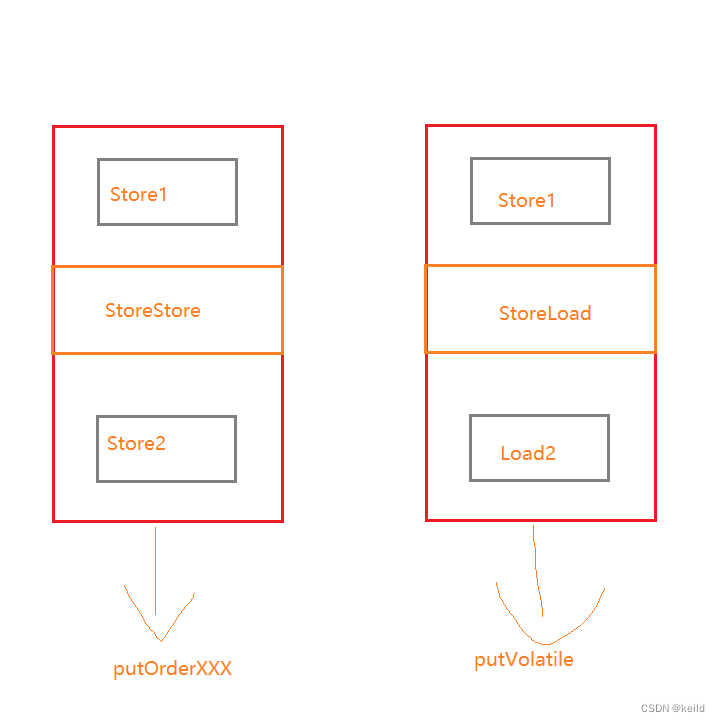
(1w字一篇理解透Unsafe类)Java魔法类:Unsafe详解
Java魔法类 Unsafe 文章导读:(约12015字,阅读时间大约1小时)1. Unsafe介绍2. Unsafe创建3. Unsafe功能3.1内存操作3.2 内存屏障3.3 对象操作3.4 数组操作3.5 CAS操作3.6 线程调度3.7 Class操作3.8 系统信息 4. 总结 JUC源码中的并发工具类出现过很多次 …...

Python的正则表达式使用
Python的正则表达式使用 定义使用场景查替换分割 常用的正则表达符号查原字符英文状态的句号点 .反斜杠 \英文的[]英文的()英文的?加号 星号 *英文状态的大括号 {} 案例 定义 正则表达式是指专门用于描述或刻画字符串内在规律的表达式。 使用场景 无法通过切片,…...
Elasticsearch:评估 RAG - 指标之旅
作者:Quentin Herreros,Thomas Veasey,Thanos Papaoikonomou 2020年,Meta发表了一篇题为 “知识密集型NLP任务的检索增强生成” 的论文。 本文介绍了一种通过利用外部数据库将语言模型 (LLM) 知识扩展到初始训练数据之外的方法。 …...

【2023.12.4练习】数据库知识点复习测试
概论 数据表:用于存储现实中数据的联系。 储存信息联系。 字段:又称列,如姓名、年龄、编号等。 记录:又称元组,为数据表中的一行,代表了一个实体的信息。 数据库(DB)࿱…...
【wvp】测试记录
ffmpeg 这是个莫名其妙的报错,通过排查,应该是zlm哪个进程引起的 会议室的性能 网络IO也就20M...
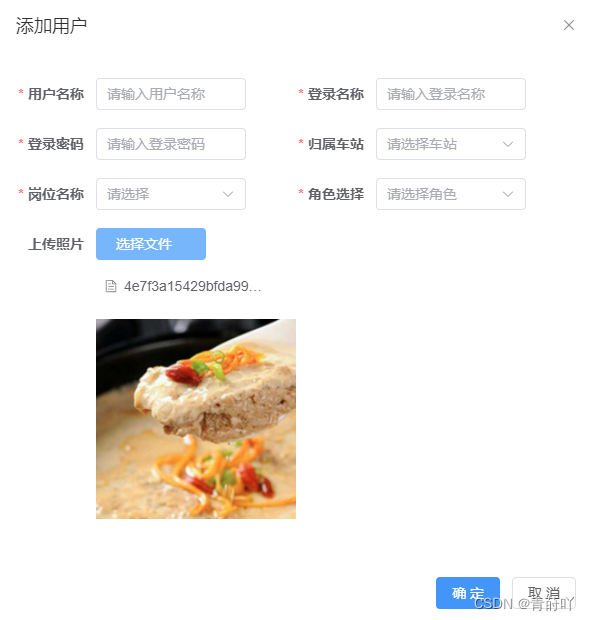
【若依框架实现上传文件组件】
若依框架中只有个人中心有上传图片组件,但是这个组件不适用于el-dialog中的el-form表单页面 于是通过elementui重新写了一个上传组件,如图是实现效果 vue代码 <el-dialog :title"title" v-model"find" width"600px"…...

玩转大数据5:构建可扩展的大数据架构
1. 引言 随着数字化时代的到来,大数据已经成为企业、组织和个人关注的焦点。大数据架构作为大数据应用的核心组成部分,对于企业的数字化转型和信息化建设至关重要。我们将探讨大数据架构的基本要素和原则,以及Java在大数据架构中的角色&…...

【华为数据之道学习笔记】非数字原生企业的特点
非数字原生企业的数字化转型挑战 软件和数据平台为核心的数字世界入口,便捷地获取和存储了大量的数据,并开始尝试通过机器学习等人工智能技术分析这些数据,以便更好地理解用户需求,增强数字化创新能力。部分数字原生企业引领着云计…...

Kubernetes学习笔记-Part.01 Kubernets与docker
目录 Part.01 Kubernets与docker Part.02 Docker版本 Part.03 Kubernetes原理 Part.04 资源规划 Part.05 基础环境准备 Part.06 Docker安装 Part.07 Harbor搭建 Part.08 K8s环境安装 Part.09 K8s集群构建 Part.10 容器回退 第一章 Kubernets与docker Docker是一种轻量级的容器…...

k8s学习
文章目录 前言一、k8s部署方式二、学习k8s的方式今天主要配置k8s环境的方式今天遇到的是一个在k8s进行初始化的方式,但是发现k8s不能正常初始化总是出现错误,或者在错误中有问题的方式,在网上查询挺多资料需要重新启动kub文件,删除…...

测试:JMeter和LoadRunner比较
比较 JMeter和LoadRunner是两款常用的软件性能测试工具,它们在功能和性能上有一定的相似性和差异。下面从几个方面对它们进行比较: 1. 架构和原理: JMeter和LoadRunner的架构和原理基本相同,都是通过中间代理监控和收集并发客户…...
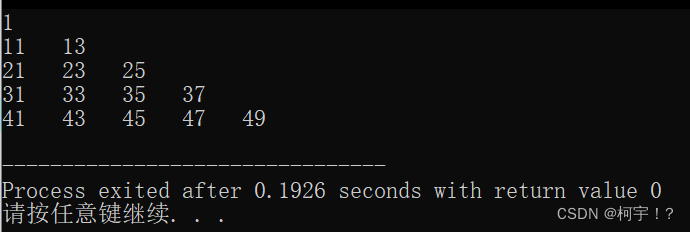
(C语言)通过循环按行顺序为一个矩阵赋予1,3,5,7,9,等奇数,然后输出矩阵左下角的值。
#include<stdio.h> int main() {int a[5][5];int n 1;for(int i 0;i < 5;i ){for(int j 0;j < 5;j ){a[i][j] n;n 2;}}for(int i 0;i < 5;i ){for(int j 0;j < i;j )printf("%-5d",a[i][j]);printf("\n");}return 0; } 运行截图…...
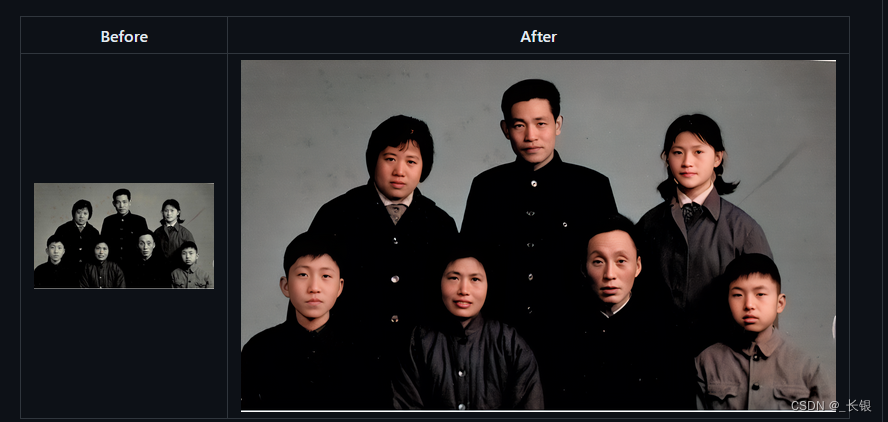
GitHub项目推荐-Deoldify
有小伙伴推荐了一个老照片上色的GitHub项目,看了简介,还不错,推荐给大家。 项目地址 GitHub - SpenserCai/sd-webui-deoldify: DeOldify for Stable Diffusion WebUI:This is an extension for StableDiffusions AUTOMATIC1111 w…...

微前端qiankun示例 Umi3.5
主应用配置(基座) 安装包 npm i umijs/plugin-qiankun -D 配置 qiankun 开启 {"private": true,"scripts": {"start": "umi dev","build": "umi build","postinstall": "…...
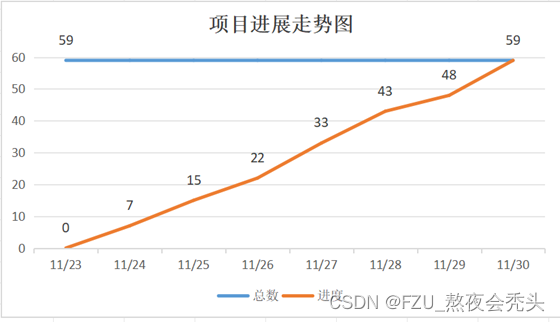
熬夜会秃头——beta冲刺Day7
这个作业属于哪个课程2301-计算机学院-软件工程社区-CSDN社区云这个作业要求在哪里团队作业—beta冲刺事后诸葛亮-CSDN社区这个作业的目标记录beta冲刺Day7团队名称熬夜会秃头团队置顶集合随笔链接熬夜会秃头——Beta冲刺置顶随笔-CSDN社区 一、团队成员会议总结 1、成员工作…...
IntelliJ IDEA设置中文界面
1.下载中文插件 2. 点击重启IDE 3.问题就解决啦!...
RTSP流媒体播放器
rtsp主要还是运用ffmpeg来搭建node后端转发到前端,前端再播放这样的思路。 这里讲的到是用两种方式,一种是ffmpeg设置成全局来实现,一种是ffmpeg放在本地目录用相对路径来引用的方式。 ffmpeg下载地址:http://www.ffmpeg.org/do…...

用快马平台实践vibe coding:5分钟构建你的音乐可视化应用原型
最近在探索一种叫"vibe coding"的编程方式,简单来说就是跟着感觉走,先抓住创意灵感再考虑具体实现。正好发现InsCode(快马)平台特别适合这种创作方式,今天就带大家用5分钟做个音乐可视化应用,完全不需要从零开始写代码。…...
模型)
用Python和PyTorch手把手搭建你的第一个脉冲神经网络(SNN)模型
用Python和PyTorch手把手搭建你的第一个脉冲神经网络(SNN)模型 当你第一次听说"脉冲神经网络"时,脑海中可能会浮现出科幻电影里那些会思考的机器。但事实上,这种模拟生物神经元工作方式的算法已经悄然走进现实。作为一名…...
:银行系统JNI迁移真实压测数据全披露)
Java原生互操作终极方案(JEP 454/459/460深度落地):银行系统JNI迁移真实压测数据全披露
第一章:Java原生互操作终极方案(JEP 454/459/460深度落地):银行系统JNI迁移真实压测数据全披露在某国有大型商业银行核心支付清算子系统中,我们完成了从传统JNI到JEP 454(Foreign Function & Memory AP…...

GLM-4-9B-Chat-1M惊艳效果:1M token混合中英文技术文档中精准分离双语术语表
GLM-4-9B-Chat-1M惊艳效果:1M token混合中英文技术文档中精准分离双语术语表 想象一下,你手头有一份200万字的技术文档,中英文混杂在一起,专业术语随处可见。传统方法需要人工逐页翻阅,耗时耗力还容易出错。现在&#…...

实战应用:基于快马平台开发类似ahflt.sys的文件操作监控工具
实战应用:基于快马平台开发类似ahflt.sys的文件操作监控工具 最近在研究Windows内核驱动开发时,发现ahflt.sys这类文件系统过滤驱动特别有意思。它能够在系统底层监控文件操作,实现各种高级功能。作为一个开发者,我决定在InsCode…...

Phi-4-mini-reasoning从零开始:CSDN GPU实例上免配置Web服务部署
Phi-4-mini-reasoning从零开始:CSDN GPU实例上免配置Web服务部署 1. 模型介绍 Phi-4-mini-reasoning 是一款专注于推理任务的文本生成模型,特别擅长处理需要多步逻辑分析的场景。与通用聊天模型不同,它更专注于"问题输入→推理过程→最…...
Qwen Pixel Art入门必看:自动触发词机制+参数调优详细步骤解析
Qwen Pixel Art入门必看:自动触发词机制参数调优详细步骤解析 1. 像素艺术生成服务介绍 Qwen Pixel Art是基于Qwen-Image-2512大模型和Pixel Art LoRA微调模块打造的专业像素艺术生成服务。这项技术能够将普通文字描述转化为精美的像素风格图像,特别适…...

libpng 官方参考库中的这两个严重漏洞已存在30年之久
聚焦源代码安全,网罗国内外最新资讯!编译:代码卫士安全研究人员披露了位于 libpng 官方参考库中的两个严重漏洞。libpng 是便携式网络图形格式的官方参考库。这些漏洞影响了跨越数十年开发历程的多个版本,可能允许攻击者触发进程崩…...

快速SEO排名服务需要多长时间见效_快速SEO排名服务有哪些常见的手段
快速SEO排名服务需要多长时间见效 在当今数字化时代,网站的在线可见度对于企业的成功至关重要。快速SEO排名服务应运而生,旨在帮助企业尽快在搜索引擎上获得更好的排名,从而提高流量和业务。但是,很多人都会疑惑,快速…...

mPLUG模型隐私保护展示:本地化部署的数据安全优势
mPLUG模型隐私保护展示:本地化部署的数据安全优势 1. 数据安全新选择:本地化部署的价值 在当今数据驱动的时代,隐私保护已经成为企业和个人用户最关心的问题之一。传统的云端AI服务虽然方便,但用户数据需要上传到第三方服务器&a…...