玩转大数据5:构建可扩展的大数据架构

1. 引言
随着数字化时代的到来,大数据已经成为企业、组织和个人关注的焦点。大数据架构作为大数据应用的核心组成部分,对于企业的数字化转型和信息化建设至关重要。我们将探讨大数据架构的基本要素和原则,以及Java在大数据架构中的角色,同时简单介绍下大数据架构在数据存储层、数据处理层和数据计算层的组件和配置以及架构的可扩展性和性能优化。
2. 大数据架构的基本要素和原则
大数据架构是指将大数据流程中的各个环节进行组合和连接,形成一个完整的大数据解决方案。它包括数据采集、数据存储、数据处理、数据计算等多个环节,每个环节都有其特定的基本要素和原则。
在构建大数据架构时,需要遵循以下原则:
1. 分布式处理:由于大数据规模巨大,单台机器无法处理所有数据,因此需要采用分布式处理方式,将数据分散到多台机器上进行处理。
2. 简单性:大数据架构应该尽可能简单,避免过于复杂的设计导致难以维护和管理。
3. 可扩展性:随着数据量的增长,架构应该能够方便地进行扩展,以满足未来的需求。
4. 可靠性:在处理大数据时,应该考虑数据的可靠性和稳定性,避免因为硬件故障或软件错误导致的数据丢失。
5. 安全性:由于大数据中可能包含敏感信息,因此需要采取措施保护数据的安全性和隐私性。
3. Java在大数据架构中的角色
Java作为一种成熟的编程语言,在大数据领域有着广泛的应用。它具有跨平台性、可移植性和丰富的开发库等优点,因此在分布式文件系统、NoSQL数据库等方面都有很好的应用。
3.1. Java在分布式文件系统中的应用
随着信息技术的不断发展,分布式文件系统在数据处理、存储和管理方面发挥着越来越重要的作用。Java作为一种通用的编程语言,在分布式文件系统中也得到了广泛的应用。
3.1.1. Java在分布式文件系统中的实现方面具有很好的优势
Java具有跨平台性,可以在不同的操作系统和硬件平台上运行。这使得Java可以轻松地与各种不同的硬件和软件环境集成,实现分布式文件系统的构建和部署。
3.1.2. Java提供了许多用于分布式文件系统的API和框架。
例如,Java NIO(New I/O)库提供了非阻塞I/O操作,可以大大提高分布式文件系统的性能和并发性。此外,Java RMI(Remote Method Invocation)框架可以实现远程过程调用,使得不同的Java虚拟机之间可以进行通信和协作。
3.1.3. 在分布式文件系统中,Java还具有很好的可扩展性和灵活性
通过使用Java的反射机制和动态代理技术,我们可以轻松地实现模块化和可扩展的系统架构。这使得我们可以根据实际需求灵活地添加或删除功能模块,以满足不断变化的应用需求。
3.1.4. Java在分布式文件系统中的安全性方面也具有很好的表现
Java提供了强大的安全机制,包括代码签名、加密、认证等,可以有效地保护分布式文件系统中的数据安全和完整性。
Java在分布式文件系统中具有广泛的应用前景。通过充分发挥Java的跨平台性、API和框架支持、可扩展性和灵活性以及安全性等方面的优势,我们可以构建出更加高效、可靠、安全的分布式文件系统,为各种应用提供更好的数据存储和管理服务。
3.2. Java在NoSQL数据库中的应用
随着大数据时代的到来,NoSQL数据库在各个行业中得到了广泛应用。由于Java语言具有跨平台性、面向对象、简单易学等特点,Java在NoSQL数据库应用中也发挥了重要作用。
3.2.1. Java与NoSQL数据库的结合
Java语言提供了多种与NoSQL数据库交互的方式,包括使用JDBC、JPA、Hibernate等标准Java API,以及使用Spring Data、Apache CXF等开源框架。这些工具使得Java应用程序能够轻松地与NoSQL数据库进行集成,实现数据的存储、查询、更新等操作。
3.2.2. Java在NoSQL数据库应用中的优势
1. 跨平台性:Java语言具有跨平台性,可以在不同的操作系统和硬件平台上运行。这使得Java在NoSQL数据库应用中具有更好的可移植性,可以轻松地适应不同的环境和需求。
2. 面向对象:Java是一种面向对象的编程语言,具有封装、继承、多态等特性,可以更好地模拟现实世界中的对象和关系。这使得Java在处理复杂的数据结构时更加灵活和高效。
3. 简单易学:Java语言相对简单易学,具有较为完善的开发环境和文档资料,便于开发人员快速上手。这为Java在NoSQL数据库应用中的推广和应用提供了便利。
4. 丰富的开源框架:Java拥有众多的开源框架和库,可以方便地实现各种复杂的功能和业务逻辑。这些框架和库也为Java在NoSQL数据库应用中提供了强大的支持。
3.2.3. Java在NoSQL数据库应用中的劣势
1. 性能问题:相比于关系型数据库,NoSQL数据库在某些方面的性能可能存在一定的差距。例如,在处理复杂查询和事务处理方面,NoSQL数据库的性能可能不如传统关系型数据库。因此,Java在NoSQL数据库应用中需要权衡性能需求和数据模型之间的关系。
2. 功能限制:NoSQL数据库在某些功能上可能存在限制,例如支持的查询语言和数据类型有限。这可能导致Java应用程序在处理某些特定数据和查询时需要额外的工作和调整。
3. 数据一致性:NoSQL数据库在数据一致性方面存在挑战。由于NoSQL数据库采用分布式架构,数据在不同节点之间的复制和同步可能存在延迟和不一致的情况。这需要Java应用程序在设计和实现中考虑数据一致性的问题,并采取相应的措施进行解决。
4. 维护和管理:相比于关系型数据库,NoSQL数据库的维护和管理可能更加复杂。例如,在集群部署和故障恢复方面,NoSQL数据库可能需要更多的配置和管理工作。因此,Java应用程序在使用NoSQL数据库时需要考虑如何进行有效的维护和管理。
3.2.4. 小结
综上所述,Java在NoSQL数据库应用中具有广泛的应用前景。通过使用标准的Java API和开源框架,Java应用程序可以轻松地与NoSQL数据库进行集成,实现数据的存储、查询、更新等操作。然而,Java在NoSQL数据库应用中也存在一些劣势和挑战,需要在实际应用中进行权衡和解决。未来随着技术的发展和应用的深入,Java在NoSQL数据库应用中的表现将更加出色。

4. 数据存储层
数据存储层是现代计算环境中不可或缺的一部分,它负责存储和管理企业的所有数据。在数据存储层中,分布式文件系统和NoSQL数据库扮演着重要的角色。本文将探讨分布式文件系统的选择与配置以及NoSQL数据库的使用和Java驱动。
4.1. 分布式文件系统的选择与配置
分布式文件系统是一种能够将数据存储在多个节点上的文件系统,它具有高可用性、可扩展性和容错性等优点。
在选择分布式文件系统时,需要考虑以下因素:
1. 性能:分布式文件系统需要能够提供高吞吐量和低延迟的性能,以满足大规模数据处理的需求。
2. 可扩展性:随着数据量的增长,分布式文件系统需要能够方便地扩展存储容量和性能。
3. 可靠性:分布式文件系统需要具有高可靠性和容错性,以确保数据的完整性和可靠性。
4. 成本:在选择分布式文件系统时,需要考虑其成本效益,包括硬件、软件、维护和管理等方面的成本。
在配置分布式文件系统时,需要考虑以下方面:
1. 节点选择:选择具有高性能、高可用性和良好网络连接的节点来构建分布式文件系统。
2. 存储容量规划:根据数据量的大小和增长速度,规划存储容量,并确保有足够的冗余空间。
3. 访问控制:设置访问控制策略,确保只有授权用户可以访问和修改数据。
4. 数据备份和恢复:制定数据备份和恢复策略,以防止数据丢失和灾难性事件的发生。
4.2. NoSQL数据库的使用
NoSQL数据库是一种非关系型数据库,它具有高性能、可扩展性和灵活性等优点。在选择NoSQL数据库时,需要考虑以下因素:
1. 数据模型:NoSQL数据库采用灵活的数据模型,可以轻松地存储和管理半结构化和非结构化数据。
2. 性能:NoSQL数据库具有高性能和低延迟的特点,可以满足大规模数据处理的需求。
3. 可扩展性:NoSQL数据库具有可扩展性,可以轻松地扩展存储容量和性能。
4. 可靠性:NoSQL数据库具有高可靠性和容错性,以确保数据的完整性和可靠性。
5. 成本:在选择NoSQL数据库时,需要考虑其成本效益,包括硬件、软件、维护和管理等方面的成本。
4.3. 小结
在数据存储层中,分布式文件系统和NoSQL数据库是两个重要的组件。通过选择合适的分布式文件系统和NoSQL数据库,并进行合理的配置和使用,可以满足现代计算环境中对数据存储和处理的需求。同时,使用Java驱动程序可以方便地进行连接管理、数据访问和事务管理等操作,从而提高数据处理效率和质量。
5. 数据处理层
在大数据处理过程中,数据处理层是一个至关重要的环节。这一环节主要涉及到批处理框架和流式处理框架的选择与配置。对于许多企业和组织来说,如何在这一环节做出正确的决策,以便能够高效、准确地处理海量数据,成为了一个亟待解决的问题。
5.1. 批处理框架的选择与配置
在大数据处理的早期,批处理框架因其能够处理大规模数据而受到广泛关注。其中,Hadoop MapReduce是最为著名的批处理框架之一。Hadoop MapReduce具有简单易用、可扩展性强以及容错性高等优点,被广泛应用于大数据处理的各个领域。
在选择与配置Hadoop MapReduce时,需要考虑到以下几点:
5.1.1. 数据规模
对于大规模的数据处理,使用分布式集群能够提高处理效率。例如,当处理的数据量较大时,单节点的处理能力往往有限,无法满足需求,此时需要借助分布式集群的力量。通过将数据分发到不同的节点上并行处理,可以显著提高处理速度。
5.1.2. 处理复杂度
对于简单的数据处理任务,可以直接使用MapReduce原生的编程模型进行处理。例如,对数据进行排序、过滤等操作都可以通过MapReduce的编程模型实现。然而,对于复杂的处理任务,如机器学习、图像处理等,使用原生MapReduce编程模型可能会比较困难。此时,可以借助一些高级库或框架进行简化。例如,使用Spark等高级框架可以更方便地处理复杂的数据处理任务。
5.1.3. 数据质量
在处理数据时,需要考虑到数据的质量和完整性。因此,需要配置合适的输入输出格式和数据清洗机制。例如,对于一些脏数据或异常数据,需要进行清洗和处理,以保证数据的质量和准确性。此外,对于不同的数据源和数据格式,也需要选择合适的输入输出格式,以保证数据的正确性和完整性。
除了以上几点,选择与配置批处理框架还需要考虑其他因素。例如,对于需要实时处理的数据,使用批处理框架可能不是最佳选择;而对于需要长时间运行的处理任务,使用批处理框架则更为合适。此外,还需要考虑批处理框架的社区支持、可维护性等因素。
5.1.4. 小结
在选择与配置批处理框架时需要考虑多方面的因素。需要根据实际需求进行选择和配置,以确保大数据处理的高效性和准确性。
5.2. 流式处理框架的选择与配置
随着大数据技术的日益成熟,流式处理框架逐渐崭露头角,成为了数据处理领域的新焦点。其中,Apache Flink以其高性能、高吞吐量和低延迟等特点,备受瞩目。在选择与配置Apache Flink时,需要注意以下几点:
5.2.1. 考虑数据流的规模
大规模的数据流处理需要分布式集群来提高处理效率。例如,对于拥有数百万条记录每秒的大规模数据流,我们需要配置具有高吞吐量和分布式特性的环境。同时,还需要根据集群的规模和数据处理需求来选择合适的节点和资源分配策略。
5.2.2. 实时性要求是流式处理框架的重要指标
Apache Flink支持实时流式处理,能够满足不同应用场景的实时性要求。为了更好地发挥其特点,我们需要根据实际应用的需求来配置合适的延迟处理机制。例如,对于需要实时反馈结果的应用,我们可以选择低延迟的配置;而对于不需要实时反馈结果的应用,我们可以适当调整延迟处理机制以优化处理效率。
此外,容错性是确保系统稳定运行的关键因素。Apache Flink具有与Hadoop MapReduce类似的容错性高的优点。在配置Apache Flink时,我们需要充分考虑如何利用这一优点来提高系统的可靠性。例如,通过配置备份节点和故障转移机制来确保数据流的稳定传输和处理。
5.2.3. 可扩展性是流式处理框架的重要特性
Apache Flink具有优秀的可扩展性,可以轻松地支持大规模的数据流处理任务。为了充分发挥这一优点,我们需要根据实际应用场景来配置合适的系统规模和资源利用策略。例如,通过增加节点数、优化资源分配和提高并行度等措施来提高系统的处理能力。
5.2.4. 关注开发成本
虽然Apache Flink具有许多优点,但其开发成本相对较高。在选择Apache Flink作为流式处理框架时,我们需要充分考虑开发成本与处理效率之间的平衡。如果处理需求不高或开发资源有限,我们也可以考虑其他更为经济实惠的流式处理框架。
5.2.5. 小结
在选择与配置批处理框架和流式处理框架时,我们需要根据实际的应用场景和数据处理需求进行综合考虑。同时,还需要注意框架之间的兼容性问题以及系统的可维护性和可扩展性等方面。只有这样,我们才能构建出高效、可靠的大数据处理系统,为各种业务场景提供强大的支持。

6. 数据计算层
6.1. 分布式计算框架的选择与配置
在当今的大数据时代,数据计算层的重要性日益凸显。计算框架的选择与配置
在大数据时代,数据计算层的重要性日益凸显。在这个层面,分布式计算框架的选择与配置尤为关键。它是整个数据处理流程的核心,直接影响着数据处理的速度、效率和准确性。而在数据计算层中,分布式计算框架的选择与配置又是关键的一环。本文将以Apache Spark为例,阐述分布式计算框架在数据计算层中的核心作用。
6.2. 分布式计算框架的基本概念
6.2.1. 分布式计算框架概述
分布式计算框架是一种能够在多台计算机上协同工作的计算框架,它可以有效地将大规模数据处理任务分配到不同的计算机上进行处理,从而提高数据处理的速度和效率。分布式计算框架是一种软件系统,它可以将大规模数据处理任务分配到多个计算节点上,实现数据的并行处理。目前,比较流行的分布式计算框架有Apache Spark、Hadoop等。在这个过程中,每个节点都可以独立地处理数据,并通过通信协议协调工作,最终得到处理结果。这些框架各有优劣,需要根据实际需求进行选择。
6.2.2. 分布式计算框架的选择
在分布式计算框架的选择上,我们需要考虑以下几个因素:
1. 计算能力:选择分布式计算框架时,首先要考虑的是其计算能力。这包括框架的运算速度、并发处理能力、容错机制等。Apache Spark是一个优秀的选择,因为它采用了高效的内存管理和并行计算机制,能够快速处理PB级别的数据。例如,Apache Spark采用了内存存储和内存计算的技术,使得数据处理速度得到了大幅提升。
2. 易用性:分布式计算框架应该易于使用,方便开发人员编写和维护代码。
2. 生态系统:优秀的分布式计算框架应该有一个健全的生态系统,包括各种工具、库、接口等。Apache Spark提供了丰富的API和开发工具,使得开发人员可以更加便捷地进行数据处理和分析。这可以方便开发者进行数据处理、数据分析、数据挖掘等工作。例如,Hadoop生态系统中的Hive、HBase等组件就为开发者提供了丰富的工具。
3. 稳定性:分布式计算框架需要具备高可用性和稳定性,能够保证数据处理任务的正常运行。Apache Spark具有高度可扩展性和容错性,可以应对各种异常情况。
4. 可扩展性:随着数据量的不断增加,分布式计算框架的可扩展性变得越来越重要。选择一个易于扩展的框架可以避免后期升级带来的麻烦。Apache Spark拥有丰富的生态系统,支持多种数据源和数据输出格式,同时提供了强大的可视化工具。例如,Spark采用了集群管理器(Cluster Manager)和任务调度器(Job Scheduler),使得集群的扩展性得到了很好的保障。
6.2.3. 分布式计算框架的配置
在配置分布式计算框架时,我们需要关注以下几个方面:
1. 硬件配置:分布式计算框架的硬件配置主要包括计算机的数量、内存大小、硬盘容量等。我们需要考虑节点的硬件配置、网络拓扑结构、存储系统等因素,以确保集群的性能和稳定性。这些硬件配置需要根据实际需求进行选择,以确保数据处理的速度和效率。
2. 软件配置:分布式计算框架的软件配置主要包括操作系统、网络环境、编程语言等。
3. 资源管理:在集群环境中,我们需要合理地分配资源,使得各个任务能够公平地共享资源,避免资源的浪费。这些软件配置需要与框架的版本和需求相匹配,以确保框架的稳定性和安全性。Apache Spark提供了灵活的资源调度机制,支持多种资源分配策略。
4. 安全与可靠性:在数据处理过程中,我们需要保证数据的安全性和可靠性。
5. 集群管理:分布式计算框架的集群管理主要包括节点的管理、任务的管理、数据的管理等。这些管理需要由专业的集群管理员进行维护,以确保集群的稳定性和安全性。Apache Spark提供了丰富的安全机制,包括身份认证、访问控制、数据加密等,以确保数据的安全性和可靠性。
6. 安全配置:分布式计算框架的安全配置主要包括用户认证、权限管理、数据加密等。
7. 监控与调试:我们需要实时监控分布式计算框架的运行状态,及时发现和解决问题。这些安全配置需要由专业的安全管理员进行设置,以确保数据的安全性和保密性。Apache Spark提供了丰富的监控工具和日志分析功能,可以帮助开发人员快速定位问题。
6.2.4. 小结
在大数据时代,分布式计算框架在数据计算层中扮演着至关重要的角色。通过选择合适的分布式计算框架并对其进行合理的配置,可以有效地提高数据处理的速度和效率,为大数据时代的各种应用提供强有力的支持。通过选择合适的分布式计算框架并正确配置,我们可以有效地提高数据处理效率和质量,为大数据分析提供强有力的支持。未来,随着技术的不断发展,分布式计算框架将会更加成熟和完善,为数据处理领域带来更多的创新和突破。Apache Spark作为一个优秀的分布式计算框架,将会在未来继续发挥其重要作用。
7. 架构的可扩展性和性能优化
在当今的大数据时代,随着数据量的不断增长,系统架构的可扩展性和性能优化变得越来越重要。本文将继续探讨数据分区和负载均衡、并行计算和任务调度等关键技术,以实现架构的可扩展性和性能优化。
7.1. 数据分区和负载均衡
数据分区和负载均衡是分布式系统中常见的策略,旨在提高系统的整体性能和稳定性。数据分区将数据按照一定的规则分布在不同的节点上,从而减轻单个节点的负载压力,避免因节点过载导致系统性能下降。负载均衡则是将任务分配到不同的节点上,以充分利用各个节点的资源,避免出现“瓶颈”现象,提高系统的吞吐量和响应速度。
在进行数据分区和负载均衡时,需要考虑以下几个因素:
1. 数据的一致性和复制:为了保证数据的一致性,通常需要进行数据复制。复制数据可以保证在节点故障时数据的高可用性,但也会带来一些问题,如数据同步和更新冲突等。因此,需要设计合适的数据复制策略,如采用主从复制、分布式锁等机制,以避免这些问题。
2. 节点的负载均衡:负载均衡不仅需要考虑任务分配的均衡性,还需要考虑各个节点的负载情况。如果某个节点的负载过高,会导致整个系统的性能下降。因此,需要设计合适的负载均衡算法,如采用轮询、随机、哈希等算法,以避免出现这种情况。
3. 任务的优先级和调度:在进行任务分配时,需要考虑任务的优先级和调度。对于一些重要的任务,需要优先分配到高性能的节点上,以保证任务的及时完成。同时,还需要考虑任务的调度策略,如采用先来先服务、短作业优先等算法,以保证任务的合理分配和系统的公平性。
此外,数据分区和负载均衡还需要考虑以下几个方面:
1. 系统的可扩展性和灵活性:数据分区和负载均衡应该能够灵活地适应系统的变化和扩展。例如,当节点数量增加或减少时,应该能够自动调整数据分区和任务分配策略,以保证系统的稳定性和性能。
2. 系统的安全性和可靠性:在进行数据分区和负载均衡时,需要考虑系统的安全性和可靠性。例如,应该采取措施防止恶意攻击、数据泄露等安全问题。同时,还需要考虑如何保证任务的可靠执行和数据的完整性。
3. 系统的优化和管理:数据分区和负载均衡需要进行系统的优化和管理。例如,应该根据系统的实际情况调整数据分区的大小和数量、优化负载均衡算法等。同时,还需要对系统进行监控和管理,及时发现和解决问题。
7.1.1. 小结
数据分区和负载均衡是分布式系统中重要的技术手段,可以提高系统的整体性能和稳定性。在进行数据分区和负载均衡时需要考虑多个因素,包括数据的一致性和复制、节点的负载均衡、任务的优先级和调度等。同时还需要考虑系统的可扩展性和灵活性、安全性和可靠性以及优化和管理等方面的问题。
7.2. 并行计算和任务调度
并行计算是指同时执行多个计算任务,以加速完成时间和提高系统的整体性能。它是解决大规模计算问题的关键技术之一,广泛应用于科学计算、工程设计、大数据分析等领域。在进行并行计算时,任务调度是一个重要的环节,它负责将任务分配到不同的计算节点上,以充分利用各个节点的计算资源。
本文将探讨在进行并行计算和任务调度时需要考虑的几个关键因素。
首先,任务的分割和通信开销是影响并行计算性能的重要因素之一。在进行并行计算时,需要将任务分割成多个子任务,并分配到不同的计算节点上。同时,各个子任务之间需要进行数据交换和通信,以避免出现“通信瓶颈”现象。因此,在进行任务分割时,需要考虑各个子任务之间的依赖关系和通信开销,以避免由于通信延迟导致整个系统的性能下降。
其次,节点的可用性和性能也是影响并行计算性能的重要因素之一。在进行任务调度时,需要考虑各个节点的可用性和性能。如果某个节点已经被其他任务占用,或者其计算能力不足,会影响整个系统的性能。因此,需要设计合适的任务调度算法,以避免出现这种情况。例如,可以采用负载均衡算法来平衡各个节点的负载,以保证整个系统的性能稳定。
最后,任务的优先级和同步也是影响并行计算性能的重要因素之一。在进行任务调度时,需要考虑任务的优先级和同步。对于一些重要的任务,需要优先分配到高性能的节点上,以保证任务的及时完成。同时,需要考虑各个子任务之间的同步问题,以保证整个系统的数据一致性。例如,可以采用锁机制来保证各个子任务之间的同步,以避免出现数据竞争和不一致的问题。
综上所述,在进行并行计算和任务调度时需要考虑多个因素。只有综合考虑这些因素并设计合适的算法和机制,才能充分发挥并行计算的潜力,提高整个系统的性能和效率。
7.3. 小结
数据分区和负载均衡、并行计算和任务调度等方面探讨了架构的可扩展性和性能优化技术。这些技术对于提高系统的整体性能和扩展性具有重要意义。但是,这些技术也面临着一些挑战和问题,如数据一致性、负载均衡算法的设计、任务调度算法的设计等。未来研究可以进一步深入这些问题的解决方案和创新实践案例的探索。
8.总结
大数据架构作为大数据应用的核心组成部分,对于企业的数字化转型和信息化建设至关重要。在构建大数据架构时,需要综合考虑各个方面的因素,确保架构的稳定性、可扩展性和高性能。同时,Java作为一种优秀的编程语言,在大数据架构中发挥着不可替代的作用。使用Java开发的大数据应用可以更好地满足企业的实际需求,提高企业的运营效率和竞争力。
相关文章:
玩转大数据5:构建可扩展的大数据架构
1. 引言 随着数字化时代的到来,大数据已经成为企业、组织和个人关注的焦点。大数据架构作为大数据应用的核心组成部分,对于企业的数字化转型和信息化建设至关重要。我们将探讨大数据架构的基本要素和原则,以及Java在大数据架构中的角色&…...

【华为数据之道学习笔记】非数字原生企业的特点
非数字原生企业的数字化转型挑战 软件和数据平台为核心的数字世界入口,便捷地获取和存储了大量的数据,并开始尝试通过机器学习等人工智能技术分析这些数据,以便更好地理解用户需求,增强数字化创新能力。部分数字原生企业引领着云计…...

Kubernetes学习笔记-Part.01 Kubernets与docker
目录 Part.01 Kubernets与docker Part.02 Docker版本 Part.03 Kubernetes原理 Part.04 资源规划 Part.05 基础环境准备 Part.06 Docker安装 Part.07 Harbor搭建 Part.08 K8s环境安装 Part.09 K8s集群构建 Part.10 容器回退 第一章 Kubernets与docker Docker是一种轻量级的容器…...

k8s学习
文章目录 前言一、k8s部署方式二、学习k8s的方式今天主要配置k8s环境的方式今天遇到的是一个在k8s进行初始化的方式,但是发现k8s不能正常初始化总是出现错误,或者在错误中有问题的方式,在网上查询挺多资料需要重新启动kub文件,删除…...

测试:JMeter和LoadRunner比较
比较 JMeter和LoadRunner是两款常用的软件性能测试工具,它们在功能和性能上有一定的相似性和差异。下面从几个方面对它们进行比较: 1. 架构和原理: JMeter和LoadRunner的架构和原理基本相同,都是通过中间代理监控和收集并发客户…...
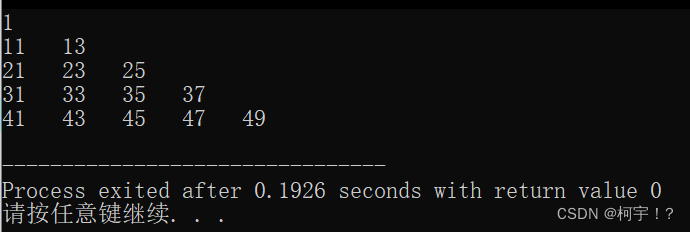
(C语言)通过循环按行顺序为一个矩阵赋予1,3,5,7,9,等奇数,然后输出矩阵左下角的值。
#include<stdio.h> int main() {int a[5][5];int n 1;for(int i 0;i < 5;i ){for(int j 0;j < 5;j ){a[i][j] n;n 2;}}for(int i 0;i < 5;i ){for(int j 0;j < i;j )printf("%-5d",a[i][j]);printf("\n");}return 0; } 运行截图…...
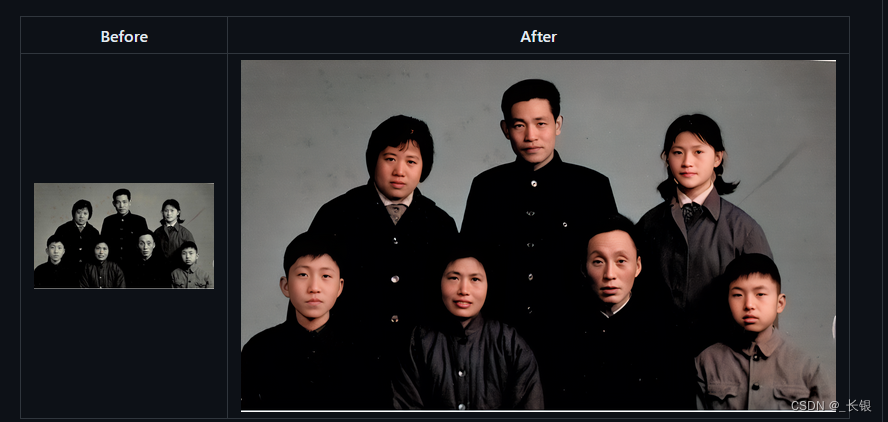
GitHub项目推荐-Deoldify
有小伙伴推荐了一个老照片上色的GitHub项目,看了简介,还不错,推荐给大家。 项目地址 GitHub - SpenserCai/sd-webui-deoldify: DeOldify for Stable Diffusion WebUI:This is an extension for StableDiffusions AUTOMATIC1111 w…...

微前端qiankun示例 Umi3.5
主应用配置(基座) 安装包 npm i umijs/plugin-qiankun -D 配置 qiankun 开启 {"private": true,"scripts": {"start": "umi dev","build": "umi build","postinstall": "…...
熬夜会秃头——beta冲刺Day7
这个作业属于哪个课程2301-计算机学院-软件工程社区-CSDN社区云这个作业要求在哪里团队作业—beta冲刺事后诸葛亮-CSDN社区这个作业的目标记录beta冲刺Day7团队名称熬夜会秃头团队置顶集合随笔链接熬夜会秃头——Beta冲刺置顶随笔-CSDN社区 一、团队成员会议总结 1、成员工作…...
IntelliJ IDEA设置中文界面
1.下载中文插件 2. 点击重启IDE 3.问题就解决啦!...
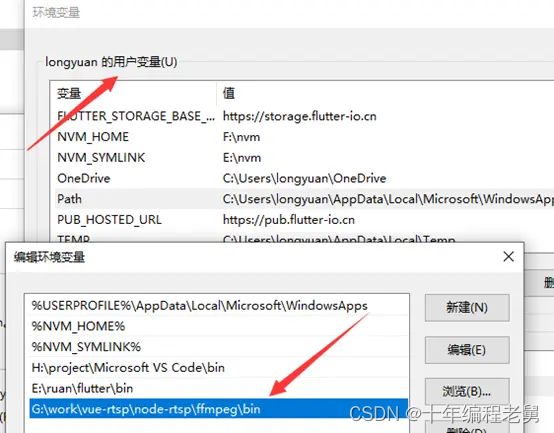
RTSP流媒体播放器
rtsp主要还是运用ffmpeg来搭建node后端转发到前端,前端再播放这样的思路。 这里讲的到是用两种方式,一种是ffmpeg设置成全局来实现,一种是ffmpeg放在本地目录用相对路径来引用的方式。 ffmpeg下载地址:http://www.ffmpeg.org/do…...

使用正则表达式时-可能会导致性能下降的情况
目录 前言 正则表达式引擎 NFA自动机的回溯 解决方案 前言 正则表达式是一个用正则符号写出的公式,程序对这个公式进行语法分析,建立一个语法分析树,再根据这个分析树结合正则表达式的引擎生成执行程序(这个执行程序我们把它称作状态机&a…...
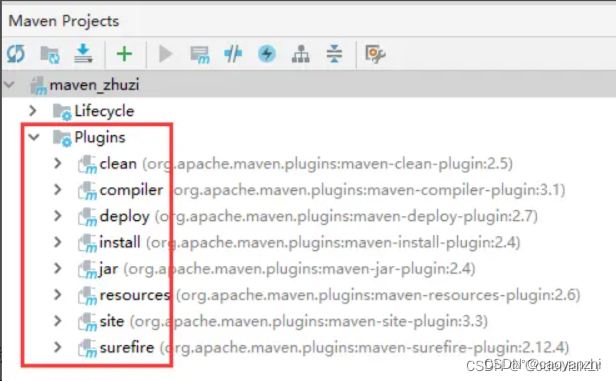
Maven生命周期
Maven生命周期 通过IDEA工具的辅助,能很轻易看见Maven的九种生命周期命令,如下: 双击其中任何一个,都会执行相应的Maven构建动作,为啥IDEA能实现这个功能呢?道理很简单,因为IDEA封装了Maven提供…...

深度学习(五):pytorch迁移学习之resnet50
1.迁移学习 迁移学习是一种机器学习方法,它通过将已经在一个任务上学习到的知识应用到另一个相关任务上,来改善模型的性能。迁移学习可以解决数据不足或标注困难的问题,同时可以加快模型的训练速度。 迁移学习的核心思想是将源领域的知识迁…...

面试官:说说synchronized与ReentrantLock的区别
程序员的公众号:源1024,获取更多资料,无加密无套路! 最近整理了一波电子书籍资料,包含《Effective Java中文版 第2版》《深入JAVA虚拟机》,《重构改善既有代码设计》,《MySQL高性能-第3版》&…...
数据结构学习笔记——广义表
目录 一、广义表的定义二、广义表的表头和表尾三、广义表的深度和长度四、广义表与二叉树(一)广义表表示二叉树(二)广义表表示二叉树的代码实现 一、广义表的定义 广义表是线性表的进一步推广,是由n(n≥0&…...
)
为什么每次optimizer.zero_grad()
当你训练一个神经网络时,每一次的传播和参数更新过程可以被分解为以下步骤: 1前向传播:网络对输入数据进行操作,最终生成输出。这个过程会基于当前的参数(权重和偏差)计算出一个或多个损失函数的值。 2计…...

一个页面从输入 URL 到页面加载显示完成,这个过程中都发生了什么
一个页面从输入URL到加载显示完成经历了以下过程: DNS解析:浏览器会解析URL中的域名,将其转换为对应的IP地址。如果浏览器缓存中存在该域名的IP地址,则跳过DNS解析步骤。 建立TCP连接:通过解析得到的IP地址࿰…...

iOS ------ UICollectionView
一,UICollectionView的简介 UICollectionView是iOS6之后引入的一个新的UI控件,它和UITableView有着诸多的相似之处,其中许多代理方法都十分类似。简单来说,UICollectionView是比UITbleView更加强大的一个UI控件,有如下…...
ElasticSearch知识体系详解
1.介绍 ElasticSearch是基于Lucene的开源搜索及分析引擎,使用Java语言开发的搜索引擎库类,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。 它可以被下面这样准确的形容: 一个分布式的实时文档存储…...

【stm32简单外设篇】- 震动传感器
一、适用场景 适用场景:防盗/防移动报警(机箱/设备被碰撞报警)、机械振动监测(异常振幅提示)、敲击触发(敲击开关)、跌落检测、简单冲击计数、测试台/生产线故障检测、嵌入式中断与 ADC 采样练习…...

OpenCore配置管理新范式:OCAuxiliaryTools提升多系统引导效率的全攻略
OpenCore配置管理新范式:OCAuxiliaryTools提升多系统引导效率的全攻略 【免费下载链接】OCAuxiliaryTools Cross-platform GUI management tools for OpenCore(OCAT) 项目地址: https://gitcode.com/gh_mirrors/oc/OCAuxiliaryTools 在…...

零基础上手PasteMD:本地AI助手,会议纪要秒变结构化文档
零基础上手PasteMD:本地AI助手,会议纪要秒变结构化文档 1. 为什么需要PasteMD这样的工具 在日常工作中,我们经常遇到这样的场景:会议结束后面对杂乱无章的笔记,需要花费大量时间整理成正式文档;从不同来源…...

CosyVoice在AI社区的应用:为CSDN技术博客添加“听文章”功能
CosyVoice在AI社区的应用:为CSDN技术博客添加“听文章”功能 你有没有过这样的经历?眼睛盯着屏幕看一篇技术文章,密密麻麻的代码和公式,看久了眼睛发酸,注意力也开始涣散。或者,你正在通勤路上,…...

TCL空调红外协议逆向与8051学习遥控器实现
1. 项目概述本项目实现一款基于8051内核单片机的通用型红外学习式空调遥控器模块,核心目标是完成对TCL品牌空调遥控协议的完整捕获、解析与复现。区别于市面常见的NEC协议学习遥控器,该设计针对TCL空调特有的14位PPM(脉冲位置调制)…...

Ubuntu 22.04新建用户,并赋予管理权限
在Ubuntu系统中,有一种特殊的用户:超级用户(root)。 root用户,权限太大,可以对系统进行任意操作。例如:删除系统文件等危险操作。为了避免误操作导致系统崩溃或数据丢失,我们一般不使…...

计算机网络————IP地址分类以及网络地址的计算[通俗易懂]
大家好,又见面了,我是你们的朋友全栈君。 一,IP地址分类 1.二进制与十进制的关系 2,IP地址的地址结构及分类 IP地址结构:网络号主机号 网络号:中主机中指明中的所在物理网络的编号 主机号:…...

Archery数据库连接池性能优化终极指南:如何提升300%并发处理能力
Archery数据库连接池性能优化终极指南:如何提升300%并发处理能力 【免费下载链接】Archery hhyo/Archery: 这是一个用于辅助MySQL数据库管理和开发的Web工具。适合用于需要管理和开发MySQL数据库的场景。特点:易于使用,具有多种数据库管理功能…...

Freerdp实战指南:解锁开源远程桌面的高效连接
1. 为什么你需要一个靠谱的远程桌面工具? 如果你和我一样,经常需要连接公司的服务器、家里的NAS,或者帮朋友远程处理电脑问题,那你肯定对“远程桌面”这四个字不陌生。市面上远程工具五花八门,有商业的,也有…...
)
RTKLIB实战:从零搭建无人机高精度定位系统(附避坑指南)
RTKLIB实战:从零搭建无人机高精度定位系统(附避坑指南) 去年夏天,我带着一台自己组装的四旋翼无人机去山区做地形测绘。当时手头只有普通的消费级GPS模块,飞了几次,发现生成的点云图总是对不上,…...