【C++】开散列实现unordered_map与unordered_set的封装
本文主要介绍unordered_map与unordered_set的封装,此次封装主要用上文所说到的开散列,通过开散列的一些改造来实现unordered_map与unordered_set的封装
文章目录
- 一、模板参数
- 二、string的特化
- 三、正向迭代器
- 四、构造与析构
- 五、[]的实现
- 六、unordered_map的实现
- 七、unordered_set的实现
- 八、哈希表代码
一、模板参数
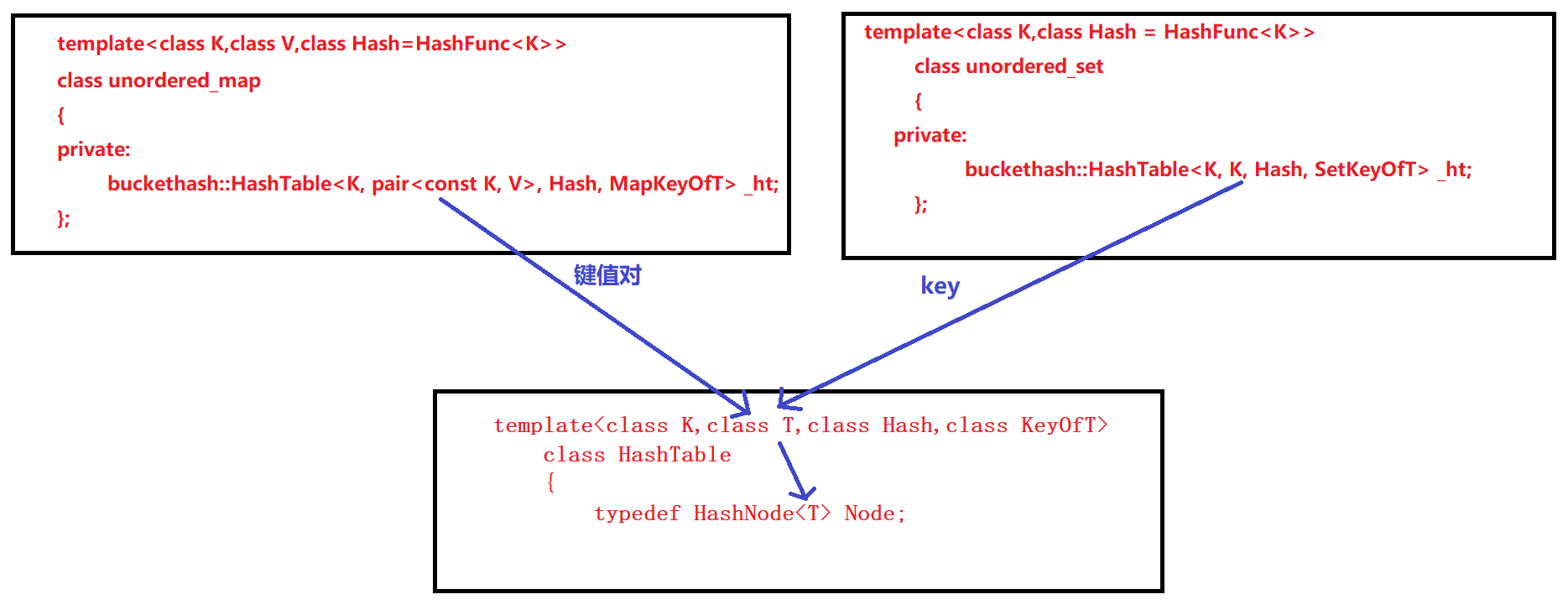
由于unordered_set 是 K 模型的容器,而 unordered_map 是 KV 模型的容器,所以需要对结点的参数进行改造,unordered_set可以使用,unordered_map也可以使用,改为T _data即可
template<class T>struct HashNode{T _data;HashNode<T>* _next;HashNode(const T& data):_data(data), _next(nullptr){}};
T模板参数可能是键值Key,也可能是Key和Value构成的键值对。如果是unordered_map容器,那么它传入底层哈希表的模板参数就是Key和Key和Value构成的键值对,如果是unordered_set容器,那么它传入底层哈希表的模板参数就是Key和Key
template<class K,class V,class Hash=HashFunc<K>>class unordered_map{private:buckethash::HashTable<K, pair<const K, V>, Hash, MapKeyOfT> _ht;};
template<class K,class Hash = HashFunc<K>>class unordered_set{private: buckethash::HashTable<K, K, Hash, SetKeyOfT> _ht;};
如此就可以实现泛型了,如果是unordered_set,结点当中存储的是键值Key;如果是unordered_map,结点当中存储的就是<Key, Value>键值对:
哈希表仿函数的支持:KeyOfT👇
我们通过哈希计算出对应的哈希地址:但是插入的时候就不能直接用data去进行比较了
对于unordered_set:data是key是可以比较的,对于unordered_map:data是键值对,我们需要取出键值对的first。而data既可以是unordered_set的,也可以是unordered_map的,所以我们需要仿函数来实现不同容器所对应的需求,然后传入:
unordered_map返回kv.first
template<class K,class V,class Hash=HashFunc<K>>class unordered_map{struct MapKeyOfT{const K& operator()(const pair<const K, V>& kv){return kv.first;}};}private:buckethash::HashTable<K, pair<const K, V>, Hash, MapKeyOfT> _ht;};
unordered_set返回key:
template<class K,class Hash = HashFunc<K>>class unordered_set{struct SetKeyOfT{const K& operator()(const K& key){return key;}};private: buckethash::HashTable<K, K, Hash, SetKeyOfT> _ht;};
这也就是Hashtable需要KeyOfT的原因所在。
二、string的特化
字符串无法取模,在这里重新写一遍,字符串无法取模的问题写库的大神们早就想到了

预留一个模板参数,无论上层容器是unordered_set还是unordered_map,我们都能够通过上层容器提供的仿函数获取到元素的键值
template<class K>
struct HashFunc
{size_t operator()(const K& key){return (size_t)key;}
};
//特化
template<>
struct HashFunc<string>
{size_t operator()(const string& key){size_t hash = 0;for (auto ch : key){hash *= 131;//顺序?abc,cbahash += ch;}return hash;}
};
string的特化:符合string类型的优先走string类型
template<class K,class V,class Hash=HashFunc<K>>
class unordered_map
template<class K,class Hash = HashFunc<K>>
class unordered_set
三、正向迭代器
哈希表的正向迭代器对哈希表指针和结点指针进行了封装,++运算符重载,可以访问下一个非空的桶,所以每个正向迭代器里面存的是哈希表地址。
template<class K, class T, class Hash, class KeyOfT>
class HashTable;template<class K,class T,class Hash,class KeyOfT>struct __HTIterator{typedef HashNode<T> Node;typedef __HTIterator<K, T, Hash, KeyOfT> Self;typedef HashTable<K, T, Hash, KeyOfT> HT;Node* _node;HT* _ht;}
所以我们构造迭代器的时候需要知道节点的地址和哈希表的地址
__HTIterator(Node*node,HT*ht):_node(node),_ht(ht){}
++运算符重载的实现:如果当前的桶还有节点,那么++就是当前桶下一个节点,如果当前元素是所在的桶的最后一个元素,那么++就是下一个非空的桶了
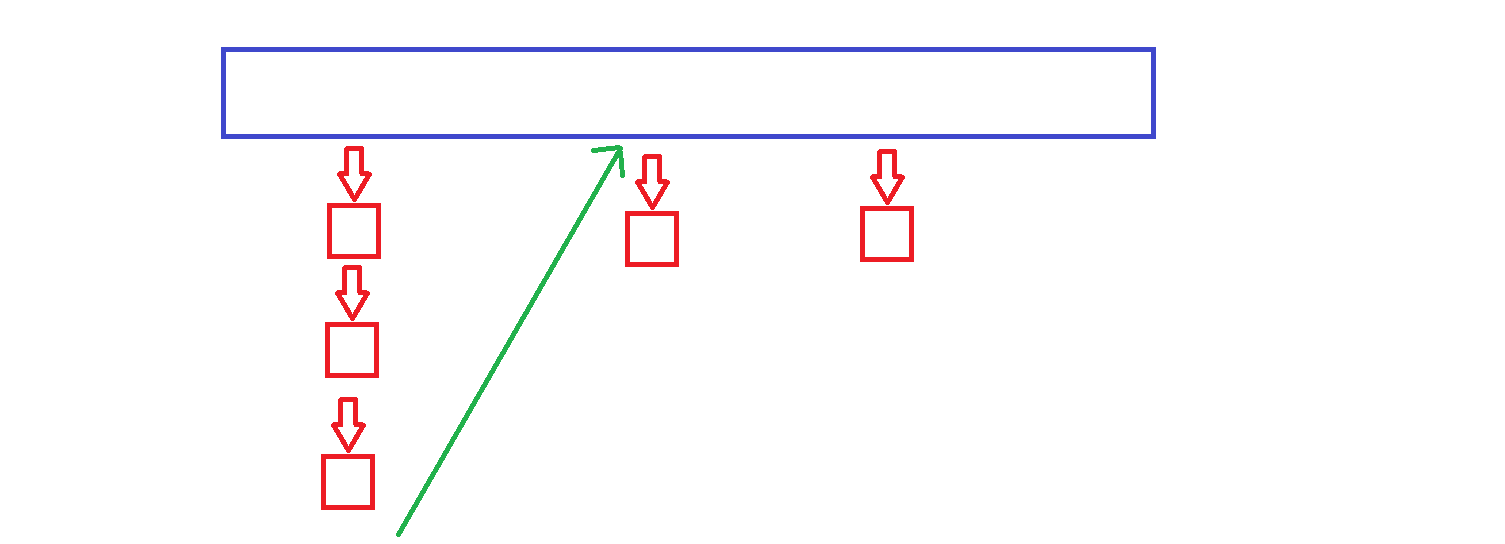
如何去找下一个非空桶:其实很简单,通过当前节点的值算出当前桶的hashi,然后++hashi就是下一个桶了,找到下一个非空桶即可
T& operator*(){return _node->_data;}T* operator->(){return &_node->_data;}bool operator !=(const Self& s) const{return _node != s._node;}Self& operator++(){if (_node->_next)//当前桶还有节点{_node = _node->_next;}//找下一个非空的桶else{KeyOfT kot;Hash hash;size_t hashi = hash(kot(_node->_data)) % _ht->_tables.size();//当前桶的哈希地址++hashi;while (hashi < _ht->_tables.size()){if (_ht->_tables[hashi])//非空桶{_node = _ht->_tables[hashi];break;}else{++hashi;}}if (hashi == _ht->_tables.size()){_node = nullptr;}}return *this;}};
–问题:哈希表中的迭代器是单向迭代器,并没有反向迭代器,所以没有实现–-运算符的重载,若是想让哈希表支持双向遍历,可以考虑将哈希桶中存储的单链表结构换为双链表结构。
存在的小细节:👇
template<class K,class T,class Hash,class KeyOfT>class HashTable{typedef HashNode<T> Node;template<class K,class T,class Hash,class KeyOfT>friend struct __HTIterator;public:typedef __HTIterator<K, T, Hash, KeyOfT> iterator;iterator begin(){for (size_t i = 0; i < _tables.size(); i++){if (_tables[i]){return iterator(_tables[i], this);}}return iterator(nullptr, this);}iterator end(){return iterator(nullptr, this);}private:vector<Node*> _tables;size_t _n = 0;};
++运算符重载去寻找下一个结点时,会访问_tables,而_tables是哈希表中的私有成员,所以我们需要把迭代器__HTIterator声明为哈希表的友元
正向迭代器__HTIterator的typedef放在了public,这是为了外部能够使用我们的typedef之后的正向迭代器
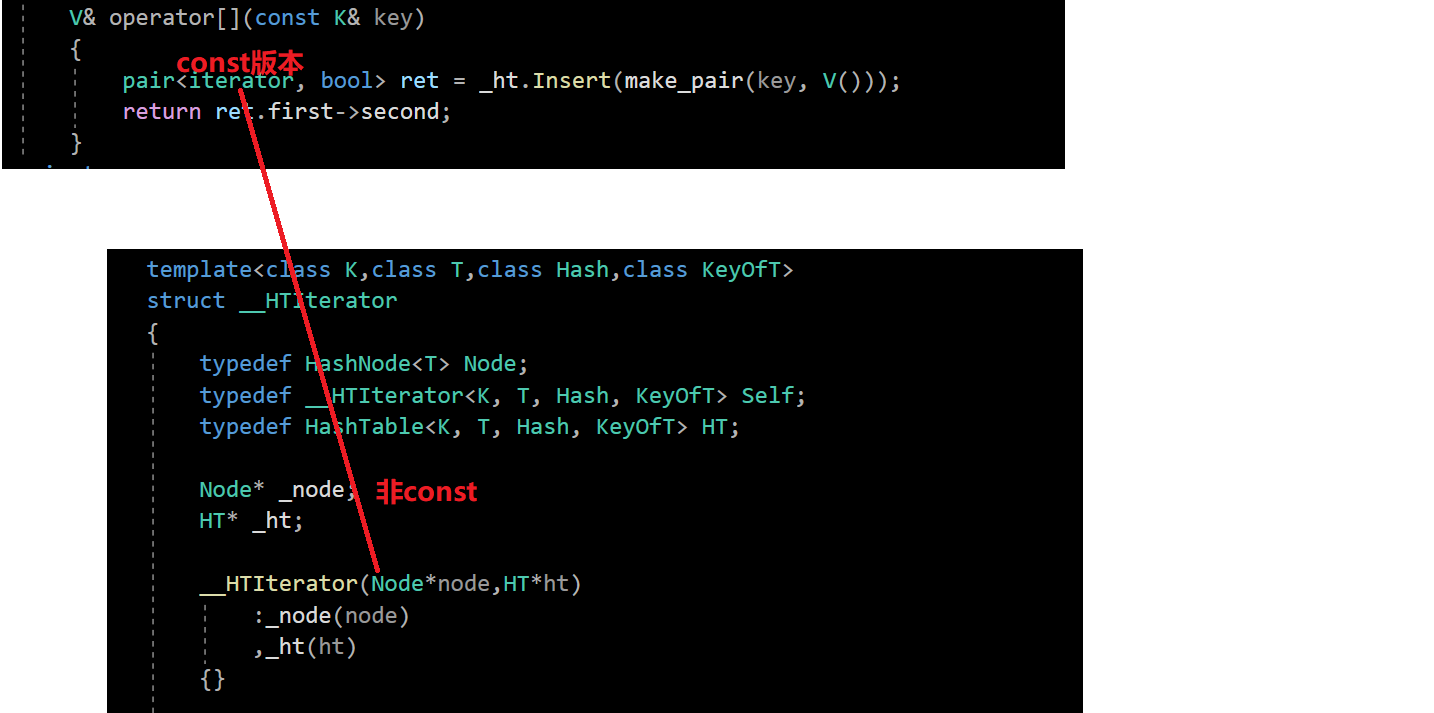
还需要注意的是,哈希表的 const 迭代器不能复用普通迭代器的代码,我们查看源码:

这与我们之前所复用的不同,上面stl源码中可以看到并没有用以前的复用:
这是因为如果使用const版本,那么_tables使用[]返回的就是const版本,那么Node*就相当于是const Node*,就会导致权限放大,无法构造;如果改成const HT* _ht; const Node* _node;,又会导致[]不能修改的问题:
四、构造与析构
默认构造
HashTable():_n(0){_tables.resize(__stl_next_prime(0));}
析构函数
哈希表当中存储的结点都是new出来的,所以哈希表被析构时必须delete。在析构哈希表时我们只需要遍历取出非空的哈希桶,遍历哈希桶当中的结点并进行释放即可👇
~HashTable(){for (size_t i = 0; i < _tables.size(); ++i){// 释放桶Node* cur = _tables[i];while (cur){Node* next = cur->_next;delete cur;cur = next;}_tables[i] = nullptr;}}
五、[]的实现
要想实现[],我们需要先把Insert的返回值修改成pair<iterator,bool>,最后的返回值也要一起修改
如果有重复的元素就返回这个找到it迭代器
没有重复的就返回newnode迭代器
pair<iterator, bool> Insert(const T&data){KeyOfT kot;iterator it = Find(kot(data));if (it != end()){return make_pair(it, false);}if (_tables.size() == _n){vector<Node*> newTables;newTables.resize(__stl_next_prime(_tables.size()), nullptr);for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){Node* next = cur->_next;size_t hashi = Hash()(kot(cur->_data))% newTables.size();cur->_next = newTables[hashi];newTables[hashi] = cur;cur = next;}_tables[i] = nullptr;}_tables.swap(newTables);}size_t hashi = Hash()(kot(data)) % _tables.size();Node* newnode = new Node(data);newnode->_next = _tables[hashi];_tables[hashi] = newnode;++_n;return make_pair(iterator(newnode,this),true);}
六、unordered_map的实现
#pragma once#include "HashTable.h"
namespace hwc
{template<class K,class V,class Hash=HashFunc<K>>class unordered_map{struct MapKeyOfT{const K& operator()(const pair<const K, V>& kv){return kv.first;}};public:typedef typename buckethash::HashTable<K, pair<const K, V>, Hash, MapKeyOfT>::iterator iterator;iterator begin(){return _ht.begin();}iterator end(){return _ht.end();}pair<iterator, bool> insert(const pair<K, V> data){return _ht.Insert(data);}V& operator[](const K& key){pair<iterator, bool> ret = _ht.Insert(make_pair(key, V()));return ret.first->second;}private:buckethash::HashTable<K, pair<const K, V>, Hash, MapKeyOfT> _ht;};void test_unordered_map(){string arr[] = { "苹果","香蕉","苹果","西瓜","哈密瓜"};unordered_map<string, int> countMap;for (auto& e : arr){countMap[e]++;}for (const auto& kv : countMap){cout << kv.first << ":" << kv.second << endl;}}
}
七、unordered_set的实现
#pragma once#include "HashTable.h"namespace hwc
{template<class K,class Hash = HashFunc<K>>class unordered_set{struct SetKeyOfT{const K& operator()(const K& key){return key;}};public:typedef typename buckethash::HashTable<K, K, Hash, SetKeyOfT>::iterator iterator;iterator begin(){return _ht.begin();}iterator end(){return _ht.end();}pair<iterator, bool> insert(const K& key){return _ht.Insert(key);}private: buckethash::HashTable<K, K, Hash, SetKeyOfT> _ht;};void test_unordered_set(){unordered_set<int> us;us.insert(13);us.insert(3);us.insert(23);us.insert(5);us.insert(5);us.insert(6);us.insert(15);us.insert(223342);us.insert(22);unordered_set<int>::iterator it = us.begin();while (it != us.end()){cout << *it << " ";++it;}cout << endl;for (auto e : us){cout << e << " ";}cout << endl;}
}
八、哈希表代码
#pragma once
#pragma once#include <iostream>
#include <string>
#include <vector>
using namespace std;
template<class K>
struct HashFunc
{size_t operator()(const K& key){return (size_t)key;}
};
//特化
template<>
struct HashFunc<string>
{size_t operator()(const string& key){size_t hash = 0;for (auto ch : key){hash *= 131;//顺序?abc,cbahash += ch;}return hash;}
};//开散列
namespace buckethash
{template<class T>struct HashNode{T _data;HashNode<T>* _next;HashNode(const T& data):_data(data), _next(nullptr){}};template<class K, class T, class Hash, class KeyOfT>class HashTable;template<class K,class T,class Hash,class KeyOfT>struct __HTIterator{typedef HashNode<T> Node;typedef __HTIterator<K, T, Hash, KeyOfT> Self;typedef HashTable<K, T, Hash, KeyOfT> HT;Node* _node;HT* _ht;__HTIterator(Node*node,HT*ht):_node(node),_ht(ht){}T& operator*(){return _node->_data;}T* operator->(){return &_node->_data;}bool operator !=(const Self& s) const{return _node != s._node;}Self& operator++(){if (_node->_next){_node = _node->_next;}else{KeyOfT kot;Hash hash;size_t hashi = hash(kot(_node->_data)) % _ht->_tables.size();++hashi;while (hashi < _ht->_tables.size()){if (_ht->_tables[hashi]){_node = _ht->_tables[hashi];break;}else{++hashi;}}if (hashi == _ht->_tables.size()){_node = nullptr;}}return *this;}};template<class K,class T,class Hash,class KeyOfT>class HashTable{typedef HashNode<T> Node;template<class K,class T,class Hash,class KeyOfT>friend struct __HTIterator;public:typedef __HTIterator<K, T, Hash, KeyOfT> iterator;iterator begin(){for (size_t i = 0; i < _tables.size(); i++){if (_tables[i]){return iterator(_tables[i], this);}}return iterator(nullptr, this);}iterator end(){return iterator(nullptr, this);}HashTable():_n(0){_tables.resize(__stl_next_prime(0));}~HashTable(){for (size_t i = 0; i < _tables.size(); ++i){// 释放桶Node* cur = _tables[i];while (cur){Node* next = cur->_next;delete cur;cur = next;}_tables[i] = nullptr;}}pair<iterator, bool> Insert(const T&data){KeyOfT kot;iterator it = Find(kot(data));if (it != end()){return make_pair(it, false);}if (_tables.size() == _n){vector<Node*> newTables;newTables.resize(__stl_next_prime(_tables.size()), nullptr);for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){Node* next = cur->_next;size_t hashi = Hash()(kot(cur->_data))% newTables.size();cur->_next = newTables[hashi];newTables[hashi] = cur;cur = next;}_tables[i] = nullptr;}_tables.swap(newTables);}size_t hashi = Hash()(kot(data)) % _tables.size();Node* newnode = new Node(data);newnode->_next = _tables[hashi];_tables[hashi] = newnode;++_n;return make_pair(iterator(newnode,this),true);}iterator Find(const K& key){KeyOfT kot;size_t hashi = Hash()(key) % _tables.size();Node* cur = _tables[hashi];while (cur){if (kot(cur->_data) == key){return iterator(cur, this);}else{cur = cur->_next;}}return end();}bool Erase(const K& key){size_t hashi = Hash()(key) % _tables.size();Node* prev = nullptr;Node* cur = _tables[hashi];while (cur){if (cur->_kv.first == key){if (cur == _tables[hashi]){_tables[hashi] = cur->_next;}else{prev->_next = cur->_next;}delete cur;--_n;return true;}else{prev = cur;cur = cur->_next;}}return false;}inline unsigned long __stl_next_prime(unsigned long n){static const int __stl_num_primes = 28;static const unsigned long __stl_prime_list[__stl_num_primes] ={53, 97, 193, 389, 769,1543, 3079, 6151, 12289, 24593,49157, 98317, 196613, 393241, 786433,1572869, 3145739, 6291469, 12582917, 25165843,50331653, 100663319, 201326611, 402653189, 805306457,1610612741, 3221225473, 4294967291};for (int i = 0; i < __stl_num_primes; ++i){if (__stl_prime_list[i] > n){return __stl_prime_list[i];}}return __stl_prime_list[__stl_num_primes - 1];}private:vector<Node*> _tables;size_t _n = 0;};
}
本篇到此结束…
相关文章:
【C++】开散列实现unordered_map与unordered_set的封装
本文主要介绍unordered_map与unordered_set的封装,此次封装主要用上文所说到的开散列,通过开散列的一些改造来实现unordered_map与unordered_set的封装 文章目录一、模板参数二、string的特化三、正向迭代器四、构造与析构五、[]的实现六、unordered_map的实现七、u…...
)
华为OD机试真题Python实现【删除指定目录】真题+解题思路+代码(20222023)
删除指定目录 题目 某文件系统中有 N 个目录, 每个目录都一个独一无二的 ID。 每个目录只有一个付目录, 但每个目录下可以有零个或多个子目录, 目录结构呈树状结构。 假设 根目录的 ID 为0,且根目录没有父目录 ID 用唯一的正整数表示,并统一编号 现给定目录 ID 和其付目…...
)
CSS选择器大全(上)
基础选择器: id选择器:#id{} 类选择器: .class{} 标签选择器: h1{} 复合选择器: 交集选择器:作用:选中同时符合多个条件的元素 语法:选择器1选择器2选择器3选择器n{} 注意ÿ…...

JavaScript 俄罗斯方块 - setTimeout和rAF
本节内容需要有些基础知识,如进程和线程,队列数据结构 一、setTimeout和setInterval 只要使用过JavaScript的朋友,对setTimeout和setInterval应该不会默生,如果光说怎样去使用这个API,并不难,无非就是隔多少毫秒再执行某个函数,把变化的内容封装在函数中,就可以制作出动…...
LeetCode:构造最大二叉树;使用中序和后序数组构造二叉树;使用前序和中序数组遍历二叉树。
构造二叉树最好都是使用前序遍历;中左右的顺序。 654. 最大二叉树 中等 636 给定一个不重复的整数数组 nums 。 最大二叉树 可以用下面的算法从 nums 递归地构建: 创建一个根节点,其值为 nums 中的最大值。递归地在最大值 左边 的 子数组前缀上 构建…...

nodejs实现jwt
jwt是json web token的简称,本文介绍它的原理,最后后端用nodejs自己实现如何为客户端生成令牌token和校验token 1.为什么需要会话管理 我们用nodejs为前端或者其他服务提供resful接口时,http协议他是一个无状态的协议,有时候我们…...

结构体占用内存大小如何确定?-->结构体字节对齐 | C语言
目录 一、什么是结构体 二、为什么需要结构体 三、结构体的字节对齐 3.1、示例1 3.2、示例2 3.3、示例3 3.4、示例4 3.5、示例5 四、结构体字节对齐总结 一、什么是结构体 结构体是将不同类型的数据按照一定的功能需 求进行整体封装,封装的数据类型与大小均…...

Vue和Uniapp:优缺点比较
Vue和Uniapp是两个流行的前端框架,都是用于开发跨平台应用程序的工具。虽然两者都有很多相似之处,但它们也有一些不同之处,这些不同之处可以影响你的选择。下面将对Vue和Uniapp的优缺点进行比较和分析,以帮助你做出更明智的决策。…...
AXI的序,保序与乱序)
AMBA-AXI(二)AXI的序,保序与乱序
💡Note:本文是根据AXI协议IHI0022F_b_amba_axi_protocol_spec.pdf(issue F)整理的。主要是分享AXI3.0和4.0部分。如果内容有问题请大家在评论区中指出,有补充或者疑问也可以发在评论区,互相学习ὤ…...
)
APIs and Open Interface--非工单领、发料(含调拨)
表名 MTL_TRANSACTIONS_INTERFACEMTL_TRANSACTION_LOTS_INTERFACE序列 MTL_MATERIAL_TRANSACTIONS_S.NEXTVALAPIs INV_TXN_MANAGER_PUB.PROCESS_TRANSACTIONS案例 杂发/杂收(代码)Declare v_user_id number : fnd_global.user_id; v_login_id number …...
互联网医院系统软件开发|互联网医院管理系统开发的好处
互联网医院一直是现在的热门行业,很多的医院已经开发了互联网医院,并且已经在良好的运行中,而有一些医院和企业正在开发中,或者打算开发互联网医院系统,其实这些企业和医院还是很有远见的,因为他们知道并了…...

2.单例模式
基本概念 单例模式:保证一个类只有一个实例,并提供一个访问该实例的全局访问点 常见应用场景 读取配置文件的类一般设计为单例模式网站计数器应用程序的日志应用,因为共享日志文件一直处于打开状态,只能有一个实例去操作Spring…...
【保姆级】Java后端查询数据库结果导出xlsx文件+打印xlsx表格
目录前言一、需求一:数据库查询的数据导出成Excel表格1.1 Vue前端实现导出按钮点击事件1.2 后端根据数据库查询结果生成xlsx文件二、需求二:对生成的xlsx文件调用打印机打印2.1 Vue前端实现按钮事件2.2 后端实现打印前言 最近在弄一个需求,需…...

Java数据库部分(MySQL+JDBC)(二、JDBC超详细学习笔记)
文章目录1 JDBC(Java Database Connectivity)1.1 什么是 JDBC?1.2 JDBC 核心思想2 JDBC开发步骤【重点】2.0 环境准备2.1 注册数据库驱动2.2 获取数据库的连接2.3 获取数据库操作对象Statement2.4 通过Statement对象执行SQL语句2.5 处理返回结…...

vue3生命周期
一、Vue3中的生命周期 1、setup() : 开始创建组件之前,在 beforeCreate 和 created 之前执行,创建的是 data 和 method 2、onBeforeMount() : 组件挂载到节点上之前执行的函数; 3、onMounted() : 组件挂载完成后执行的函数; 4、…...

Python学习笔记10:开箱即用
开箱即用 模块 python系统路径 import sys, pprint pprint.pprint(sys.path) [,D:\\Program Files\\Python\\Lib\\idlelib,D:\\Program Files\\Python\\python310.zip,D:\\Program Files\\Python\\DLLs,D:\\Program Files\\Python\\lib,D:\\Program Files\\Python,D:\\Progr…...

详解JAVA反射
目录 1.概述 2.获取Class对象 3.API 3.1.实例化对象 3.2.方法 3.3.属性 1.概述 反射,JAVA提供的一种在运行时获取类的信息并动态操作类的能力。JAVA反射允许我们在运行时获取类的属性、方法、构造函数等信息,并能够动态地操作它们。 2.获取Class…...

在nestjs中进行typeorm cli迁移(migration)的配置
在nestjs中进行typeorm cli迁移(migration)的配置 在学习nestjs过程中发现typeorm的迁移配置十分麻烦,似乎许多方法都是旧版本的配置,无法直接使用. 花了挺长时间总算解决了这个配置问题. db.config.ts 先创建db.config.ts, 该文件export了两个对象,其…...

前端工程构建问题汇总
1.less less-loader安装失败问题 npm install less-loader --save --legacy-peer-deps 加上–legacy-peer-deps就可以了 在NPM v7中,现在默认安装peerDependencies,这会导致版本冲突,从而中断安装过程。 –legacy-peer-deps标志是在v7中引…...
某马程序员NodeJS速学笔记
文章目录前言一、什么是Node.js?二、fs文件系统模块三、Http模块四、模块化五、开发属于自己的包模块加载机制六、Express1.初识ExpressGET/POSTnodemon2.路由模块化3.中间件中间件分类自定义中间件4. 跨域问题七、Mysql模块安装与配置基本使用Web开发模式Session认证JWT八、m…...
)
别再只会用Sniper了!Burp Suite Intruder四种攻击模式实战拆解(附DVWA靶场演示)
别再只会用Sniper了!Burp Suite Intruder四种攻击模式实战拆解(附DVWA靶场演示) 在Web安全测试中,暴力破解是最基础却最考验技巧的环节。很多初学者拿到Burp Suite Intruder模块时,往往只会机械地使用默认的Sniper模式…...

艾尔登法环终极调试工具:从入门到精通完全指南
艾尔登法环终极调试工具:从入门到精通完全指南 【免费下载链接】Elden-Ring-Debug-Tool Debug tool for Elden Ring modding 项目地址: https://gitcode.com/gh_mirrors/el/Elden-Ring-Debug-Tool Elden Ring Debug Tool是一款专为《艾尔登法环》玩家和模组开…...

SteamAutoCrack终极指南:如何轻松实现Steam游戏自动破解
SteamAutoCrack终极指南:如何轻松实现Steam游戏自动破解 【免费下载链接】Steam-auto-crack Steam Game Automatic Cracker 项目地址: https://gitcode.com/gh_mirrors/st/Steam-auto-crack SteamAutoCrack是一个功能强大的自动化工具,专门用于St…...

ComfyUI-Impact-Pack终极指南:如何用AI图像增强插件打造专业级工作流
ComfyUI-Impact-Pack终极指南:如何用AI图像增强插件打造专业级工作流 【免费下载链接】ComfyUI-Impact-Pack Custom nodes pack for ComfyUI This custom node helps to conveniently enhance images through Detector, Detailer, Upscaler, Pipe, and more. 项目…...

Skilo:AI Agent技能分享的革命性工具,链接即安装
1. 项目概述:Skilo,一个为AI Agent技能分享而生的“链接”如果你和我一样,日常在Claude Code、Cursor、Codex这些AI编程工具里折腾,肯定遇到过这样的场景:同事在群里丢过来一个超好用的“代码审查”技能,你…...

本地大模型联网搜索实战:LLocalSearch架构解析与部署指南
1. 项目概述:一个能“联网”的本地大模型搜索工具 如果你和我一样,经常折腾本地部署的大语言模型(LLM),比如 Llama、Qwen 或者 ChatGLM,那你肯定遇到过这个痛点:模型的知识是“静态”的。它只能…...

从晶体管到代码:聊聊Verilog里‘’、‘|’、‘~’这些符号背后的硬件故事
从晶体管到代码:Verilog逻辑运算符背后的硬件密码 在数字电路的世界里,每一行Verilog代码都是对物理世界的精确描述。当我们写下&、|、~这些看似简单的符号时,背后隐藏的是数十亿个晶体管在硅片上的精妙舞蹈。本文将带您穿越抽象的逻辑层…...

Webhook桥接器:解决内外网通信与格式转换的轻量级解决方案
1. 项目概述:一个轻量级的Webhook转发桥梁如果你在开发微服务、自动化流程,或者正在折腾各种SaaS工具之间的联动,那你一定对Webhook不陌生。简单来说,Webhook就是一个“回调通知”,当A服务发生了某件事(比如…...

从文本到代码:arrowgram 双向转换工具的设计原理与实战应用
1. 项目概述:从“箭头图”到代码生成最近在梳理一些遗留系统的架构文档时,我又一次被那些错综复杂、信息不全的流程图和时序图给“折磨”了。相信很多开发者和架构师都有同感:我们花费大量时间用绘图工具(无论是 Visio、Draw.io 还…...

保姆级教程:用Python脚本将JD9365A初始化代码一键转为RK3568设备树格式
Python脚本自动化转换:将JD9365A初始化代码高效转为RK3568设备树格式 在嵌入式Linux驱动开发中,屏幕初始化代码的转换工作常常让工程师们头疼不已。面对供应商提供的长达数百行的寄存器配置数组,手动转换为设备树格式不仅耗时费力,…...