【Linux】基础IO--重定向理解Linux下一切皆文件缓冲区
文章目录
- 一、重定向
- 1.什么是重定向
- 2.dup2 系统调用
- 3.理解输入重定向、输出重定向和追加重定向
- 4.简易shell完整实现
- 二、理解linux下一切皆文件
- 三、缓冲区
- 1.为什么要有缓冲区
- 2.缓冲区的刷新策略
- 3.缓冲区的位置
- 4.实现一个简易的C语言缓冲区
- 5.内核缓冲区
一、重定向
1.什么是重定向
在上面的代码中,当我们把0号文件描述符关闭之后,会出现下面的状况:
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#include <sys/types.h>
#include <fcntl.h>int main()
{//关闭标准输出umask(0);int fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);if(fd < 0){perror("open failed");return 1;}printf("open fd:%d\n",fd);fprintf(stdout,"open fd:%d\n",fd);fflush(stdout);close(fd);return 0;
}

我们可以看到,本来应该打印到显示器上的数据却最终输出到了 log.txt 文件中,原因如下:
我们在调用 open 打开 log.txt 之前关闭了标准输出,那么其对应的1号 fd 就闲置了出来,而 fd 的分配规则是从小到大依次寻找未被使用的最小值,所以 log.txt 对应的 fd 就为1;
同时,我们调用的 printf、fprintf 是C语言封装的输出函数,其底层调用系统调用,效果是向标准输出文件中写入数据,而标准输出 fd 默认为 1,但是 printf 与 fprintf 并不知道 1 号 fd 指向了另一个文件 log.txt,所以原本应该写入到显示器上的数据会写入到 log.txt 中。

注:由于向文件中写数据的缓冲区刷新策略不同,所以这里我们需要在关闭文件之前进行缓冲区刷新,否则 log.txt 中没有数据,具体细节在后文。
像这样,本来应该往一个文件中写入数据,但是却写入到另一个文件中去了,这种特性就叫做重定向;而重定向的本质是上层使用的 fd 不变,在内核中更改 fd 指向的 file 对象,即更改文件描述符表数组中 fd 下标中的内容,让其变为另一个 file 对象的地址。(同一个 fd 指向不同的 file 对象)
2.dup2 系统调用
我们可以使用上面 close(1) 的方式实现重定向,但是我们发现先关闭、再打开这种方式非常麻烦,并且如果 0 和 1 号 fd 都被关闭时,我们还需要先创建一个无用的临时文件占用掉 0 号 fd 之后才能使新文件的 fd 为 1。为了解决这种尴尬的情况,操作系统提供了一个系统调用接口 dup2 来让我们直接进行重定向。
函数功能
dup2() makes newfd be the copy of oldfd, closing newfd first if necessary – dup2 函数会让 newfd 成为 oldfd 的一份拷贝,并且在必要时关闭 newfd。

函数参数
int dup2(int oldfd, int newfd);
# 头文件:<unistd.h>
# oldfd:旧的文件描述符
# newfd:新的文件描述符
# int:函数返回值,成功返回 newfd,失败返回-1
函数使用
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>int main()
{int fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);if(fd < 0){perror("open failed");return 1;}int n = dup2(fd,1);if(n < 0){perror("dup2");return 2;}printf("open fd:%d\n",fd);fprintf(stdout,"open fd:%d\n",fd);fflush(stdout);close(fd);return 0;
}

printf和fprintf是C库当中的IO函数,一般往 stdout 中输出,但是stdout底层访问文件的时候,找的还是fd:1, 但此时,fd:1下标所表示内容,已经变成了log.txt的地址,不再是显示器文件的地址,所以,输出的任何消息都会往文件中写入,进而完成输出重定向。
注意:dup2 系统调用让 newfd 成为 oldfd 的一份拷贝,其本质是将 oldfd 下标里面存放的 file 对象的地址拷贝到 newfd 下标的空间中,即拷贝的是 fd 对应空间中的数据,而并不是两个 fd 数字之间进行拷贝,这样也没有意义;并且拷贝完成后只会留下 oldfd。
3.理解输入重定向、输出重定向和追加重定向
Linux 中主要有三种主要的重定向 – 输入重定向、输出重定向和追加重定向;在 Linux 命令行中它们分别使用 <、>、>> 表示,演示如下:

输出重定向
输入重定向我们上面已经实现了,就是通过 dup2(fd, 1) 系统调用将目标文件 fd 中的内容拷贝到 1 号 fd 中,从而将本该写入到显示器中的数据写入到目标文件中。
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>#define FILE_NAME "log.txt"int main()
{int fd = open(FILE_NAME, O_WRONLY | O_CREAT | O_TRUNC, 0666);if (fd < 0){perror("open failed");return 1;}int n = dup2(fd, 1);if (n < 0){perror("dup2");return 2;}char buffer[64];int cnt = 5;while (cnt){sprintf(buffer, "%s:%d\n", "hello world", cnt--);write(1, buffer, strlen(buffer));}// fflush(stdout);close(fd);return 0;
}

追加重定向
理解了输出重定向之后,追加重定向就变得非常简单了,只需要在打开文件时去掉 O_TRUNC 选项,加上 O_APPEND 选项即可。
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#define FILE_NAME "log.txt"int main()
{int fd = open(FILE_NAME, O_WRONLY | O_CREAT | O_APPEND, 0666);if (fd < 0){perror("open failed");return 1;}int n = dup2(fd, 1);if (n < 0){perror("dup2");return 2;}printf("fd:%d\n", fd);fprintf(stdout, "fd:%d\n", fd);char* msg = "hello redirect\n";write(1, msg, strlen(msg));fflush(stdout);close(fd);return 0;
}

输入重定向
输入重定向就是通过 dup2(fd, 0) 系统调用将目标文件 fd 中的内容拷贝到 0 号 fd 中,从而将本该从标准输入 (键盘) 读入的数据转换为从目标文件中读入。
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>#define FILE_NAME "log.txt"int main()
{int fd = open(FILE_NAME, O_RDONLY, 0666);if (fd < 0){perror("open failed");return 1;}int n = dup2(fd, 0);if (n < 0){perror("dup2");return 2;}char buffer[64];while(fgets(buffer,sizeof (buffer) - 1,stdin)!=NULL){buffer[strlen(buffer)] = '\0';printf("%s",buffer);}close(fd);return 0;
}

4.简易shell完整实现
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/wait.h>
#include <fcntl.h>
#include <string.h>
#include <assert.h>
#include <errno.h>
#include <ctype.h> //isspace
#include <stdlib.h>#define NUM 1024
#define OPT_NUM 64char commandline[NUM]; // 指令数组
char *myargv[OPT_NUM]; // 指针数组,用来保存切割后的字符
int lastsig = 0; // 退出信号
int lastcode = 0; // 退出码// 定义重定向相关的宏
#define NONE_REDIR 0
#define INPUT_REDIR 1
#define OUTPUT_REDIR 2
#define APPEND_REDIR 3#define trimspace(start) \do \{ \while (isspace(*start)) \++start; \} while (0)int redirtype = NONE_REDIR; // 重定向的类型默认为无重定向
char *redirfile = NULL; // 重定向的文件的起始位置// "ls -a -l -i > myfile.txt" -> "ls -a -l -i" "myfile.txt" ->
void commandcheck(char *command)
{assert(command);char *start = command;char *end = start + strlen(command);while (start < end){if (*start == '>'){*start = '\0';start++;if (*start == '>'){// "ls -a >> file.log"redirtype = APPEND_REDIR;start++;}else{// "ls -a > file.log"redirtype = OUTPUT_REDIR;}trimspace(start);redirfile = start;break;}else if (*start == '<'){//"cat < file.txt"*start = '\0';start++;trimspace(start);redirtype = INPUT_REDIR;redirfile = start;break;}else{start++;}}
}int main()
{while (1){redirtype = NONE_REDIR;redirfile = NULL;errno = 0;// 输出提示符printf("用户名@主机名 当前路径#");fflush(stdout);// 获取用户输入, 输入的时候,输入\nchar *s = fgets(commandline, sizeof(commandline) - 1, stdin);assert(s != NULL);(void)s;// 清除最后一个\n , abcd\ncommandline[strlen(s) - 1] = 0;// "ls -a -l -i" -> "ls" "-a" "-l" "-i" -> 1->n// "ls -a -l -i > myfile.txt" -> "ls -a -l -i" "myfile.txt" ->// "ls -a -l -i >> myfile.txt" -> "ls -a -l -i" "myfile.txt" ->// "cat < myfile.txt" -> "cat" "myfile.txt" ->commandcheck(commandline);myargv[0] = strtok(commandline, " ");int i = 1;if (myargv[0] != NULL && strcmp(myargv[0], "ls") == 0){myargv[i++] = (char *)"--color=auto";}// 如果没有子串了,strtok->NULL, myargv[end] = NULLwhile (myargv[i++] = strtok(NULL, " "));// 如果是cd命令,不需要创建子进程,让shell自己执行对应的命令,本质就是执行系统接口// 像这种不需要让我们的子进程来执行,而是让shell自己执行的命令 --- 内建/内置命令if (myargv[0] != NULL && strcmp(myargv[0], "cd") == 0){if (myargv[1] != NULL){chdir(myargv[1]);}continue;}if (myargv[0] != NULL && myargv[1] != NULL && strcmp(myargv[0], "echo") == 0){if (strcmp(myargv[1], "$?") == 0){printf("%d,%d\n", lastcode, lastsig);}else{printf("%s\n", myargv[1]);}continue;}// 执行命令pid_t id = fork();assert(id != -1);if (id == 0){// 因为命令是子进程执行的,真正重定向的工作一定要是子进程来完成// 如何重定向,是父进程要给子进程提供信息的// 这里重定向会影响父进程吗?不会,进程具有独立性switch (redirtype){case NONE_REDIR:// 什么都不做break;case INPUT_REDIR:{int fd = open(redirfile, O_RDONLY);if (fd < 0){perror("open failed");exit(errno);}// 重定向的文件已经成功打开了dup2(fd, 0);}break;case OUTPUT_REDIR:case APPEND_REDIR:{umask(0);int flags = O_WRONLY | O_CREAT;if (redirtype == APPEND_REDIR)flags |= O_APPEND;elseflags |= O_TRUNC;int fd = open(redirfile, flags, 0666);if (fd < 0){perror("open");exit(errno);}dup2(fd, 1);}break;default:printf("bug?\n");break;}execvp(myargv[0], myargv); // 执行程序替换的时候,会不会影响曾经进程打开的重定向的文件?不会exit(1);}int status = 0;pid_t ret = waitpid(id, &status, 0);assert(ret > 0);(void)ret;lastcode = ((status >> 8) & 0xFF);lastsig = (status & 0x7F);}
}
二、理解linux下一切皆文件
操作系统是一款管理软件,它通过向下管理好各种软硬件资源 (手段),来向上提供良好 (安全、稳定、高效) 的运行环境 (目的);也就是说,键盘、显示器、磁盘、网卡等硬件也是由操作系统来管理的。而操作系统管理软硬件的方法是 先描述、再组织,即先将这些设备的各种属性抽象出来组成一个结构体,然后为每一个设备都创建一个结构体对象,再用某种数据结构将这些对象组织起来;这也就是我们上面学习到的 文件内核数据结构 file;
同时,每种硬件的访问方法都是不一样的,比如,向磁盘中读写数据与向网卡中读写数据是有明显差异的,所以操作系统需要为每一种硬件都单独提供对应的 Read、Write 方法,这些方法位于驱动层。
但是,内核数据结构是位于操作系统层的,它如何与对应的读写方法联系起来呢?-- 通过函数指针,即在 struct file 结构体中创建函数指针变量,用于指向具体的 Write 和 Read 方法函数,这样每一个硬件都可以通过自己 file 对象中的 writep 和 readp 函数指针变量来找到位于驱动层的 Write 和 Read 方法,如下:
struct file
{//文件的各种属性int types; //文件的类型int status; //文件的状态int (*writep)(...); //函数指针,指向读函数int (*readp)(...); //函数指针,指向写函数struct file* next; //下一个file对象的地址//...
}

如图,站在操作系统内核数据结构上层来看,所有的软硬件设备和文件统一都是 file 对象,即 Linux 下一切皆文件。
注:对于键盘来说,我们只能从其中读入数据,而并不能向其写入数据;同样的,对于显示器来说,我们只能向其写入数据,而并不能从它读入数据;所以,键盘的 Write 方法和显示器的显示器的 Read 方法我们都设为 NULL。
其实 Linux 一切皆文件的特性就是面向对象语言多态的特性,file 结构体相当于基类,驱动层的各种方法和结构就相当于子类。(Linux 在编写时C++等面向对象的语言还并没有出现,所以这里是用C语言模拟实现C++面向对象)
同时,struct file 是操作系统当中虚拟出来的一层文件对象,在 Linux 中,我们一般将这一层称为 虚拟文件系统 vfs,通过它,我们就可以摒弃掉底层设备的差别,统一使用文件接口的方式来进行文件操作。
三、缓冲区
1.为什么要有缓冲区
缓冲区本质上就是一段内存,那么缓冲区是由谁申请的?缓冲区属于谁?以及为什么要有缓冲区呢?
我们以一个快递的例子进行说明:
你有一个很好的朋友他在北京,而你在重庆,你俩经常给对方送东西,那么这里有2种选择,第一你骑着车或者坐车去北京送给他,二是通过顺丰发送快递到你朋友那里。我相信大多数人更愿意选择第二种方案。
顺丰快递不是你送到快递点就立马把你的包裹寄出去,而是达到一定的数量之后一起送出去
在现实生活中,快递行业的的意义是什么呢,节省了发送者的时间。
在上面的案例中,重庆就相当于内存,北京就相当于磁盘,发送的包裹相当于数据,但由于磁盘属于外设,进程直接向磁盘文件中写数据的效率非常低,所以有了缓冲区,进程可以将自己的数据拷贝到缓冲区中,再由缓冲区将数据写入到磁盘文件中去;不过,和现实生活中一样,顺丰快递不会为了你一个人的一件快递就运输一趟,而是快递积累到一定数量时统一运输,缓冲区也不会一有数据就立马刷新,而是会采取一定的刷新策略。
所以,在现实生活中,快递行业的意义是节省发送者的时间;而在计算机中,缓冲区的意义是节省进程进行数据 IO 的时间。
与其理解 fwrite 是将数据写入到文件的函数,不如理解 fwrite 是进行数据拷贝的函数,因为 fwrite 函数只是将数据从进程拷贝到缓冲区中,并没有真正将数据写入到磁盘文件中。
2.缓冲区的刷新策略
于缓冲区中的一块数据,一次写入到外设的效率是要高于少量多批次写入到外设的,因为缓冲区等待磁盘就绪的时间要远多于写入数据的时间。(比如缓冲区写入一次数据一共要花费 1s,那么可能其中 990ms 都在等待外设就绪,只有 10ms 左右的时间在进行数据写入)
所以,为了提高效率,缓冲区一定会结合具体的设备定制自己的刷新策略,Linux 中缓冲区一共存在三种刷新策略和两种特殊情况;
三种刷新策略:
1.立即刷新 (无缓冲):缓冲区中一出现数据就立马刷新,这种很少出现;
2.行刷新 (行缓冲):每拷贝一行数据就刷新一次,显示器采用的就是这种刷新策略,因为显示器是给人看了,而按行刷新符合人的阅读习惯,同时刷新效率也不会太低;
3.缓冲区满 (全缓冲):待数据把缓冲区填满后再刷新,这种刷新方式效率最高,一般应用于磁盘文件。
两种特殊情况:
1.用户使用 fflush 等函数强制进行缓冲区刷新;
2.进程退出时一般都要进行缓冲区刷新;
3.缓冲区的位置
要知道缓冲区的位置,我们先来观察下面几个现象:
#include <stdio.h>
#include <unistd.h>
#include <string.h>
int main()
{printf("hello printf\n");fprintf(stdout, "hello fprintf\n");const char* fputsString = "hello fputs\n";fputs(fputsString, stdout);const char* msg = "hello write\n";write(1, msg, strlen(msg));return 0;
}现象1:

现象2:

#include <stdio.h>
#include <unistd.h>
#include <string.h>
int main()
{printf("hello printf\n");fprintf(stdout, "hello fprintf\n");const char* fputsString = "hello fputs\n";fputs(fputsString, stdout);const char* msg = "hello write\n";write(1, msg, strlen(msg));fork();return 0;
}
现象3:

现象4:

我们发现 printf 和 fwrite (库函数)都输出了2次,而 write 只输出了一次(系统调用)。为什么呢?肯定和
fork有关!并且这个现象一定和缓冲区有关,并且缓冲区一定不在内存中,如果缓冲区在内存中,那么write也一定会打印2次。
一般C库函数写入文件时是全缓冲的,而写入显示器是行缓冲。
printf fwrite 库函数会自带缓冲区(进度条例子就可以说明),当发生重定向到普通文件时,数据的缓冲方式由行缓冲变成了全缓冲。而我们放在缓冲区中的数据,就不会被立即刷新,甚至fork之后但是进程退出之后,会统一刷新,写入文件当中。但是fork的时候,父子数据会发生写时拷贝,所以当你父进程准备刷新的时候,子进程也就有了同样的一份数据,随即产生两份数据。write 没有变化,说明没有所谓的缓冲
我们之前谈论的所有缓冲区都不在操作系统内核中,而是位于用户级语言层面;实际上,对于C语言来说,缓冲区位于 FILE 结构体中,Linux 下,我们可以在 /usr/include/libio.h 中找到缓冲区的相关信息:


综上:printf、fwrite、fputs 等库函数会自带缓冲区,而 write 系统调用没有带缓冲区;同时,我们这里所说的缓冲区,都是用户级缓冲区。那这个缓冲区谁提供呢? printf、fwrite、fputs 是库函数, write 是系统调用,库函数在系统调用的 “上层”, 是对系统调用的 “封装”,但是 write 没有缓冲区,而 printf、fwrite、fputs 有,足以说明该缓冲区是二次加上的,又因为是C库函数,所以是由C标准库提供的。
代码结束之前,进行创建子进程
1.如果我们没有进行>,看到了4条消息stdout 默认使用的是行刷新,在进程fork之前,三条C函数已经将数据进行打印输出到显示器上(外设)你的FILE内部,进程内部不存在对应的数据啦
2.如果我们进行了>, 写入文件不再是显示器,而是普通文件,采用的刷新策略是全缓冲,之前的3条c显示函数,虽然带了\n,但是不足以stdout缓冲区写满!数据并没有被刷新!!!执行fork的时候,stdout属于父进程,创建子进程时, 紧接着就是进程退出!谁先退出,一定要进行缓冲区刷新(就是修改)写时拷贝!!数据最终会显示两份
3.write为什么没有呢?上面的过程都和wirte无关,wirte没有FILE,而用的是fd,就没有C提供的缓冲区
现在我们就可以解释上面的四种现象了:
现象1:printf、fprintf、fputs 三种C语言接口函数都是向标准输出即显示器中打印数据,而显示器采用的是行缓冲区,同时,我们每条打印语句后面都带有换行符,所以 printf、fprintf、fputs 语句执行后立即刷新缓冲区;而 write 是系统调用,不存在缓冲区,所以也是语句执行后立即刷新;所以输出结果是四条语句顺序打印。
现象2:我们通过输入重定向指令 > 将本该写入到显示器文件中的数据写入到了磁盘文件中,由于磁盘文件采用全缓冲刷新策略,所以 printf、fprintf、fputs 三条语句执行完毕后数据并不会刷新,因为缓冲区并没有被写满,而是等到进程退出这种特殊情况才会将三条语句刷新到磁盘文件中,但此时,write 语句也已经执行完毕,而 write 系统调用没有缓冲区,执行立即写入;所以输出结果是 write 在最前面。
现象3:显示器采用行缓冲,所以在 fork 之前 printf、fprintf、fputs 三条语句的数据均已刷新到显示器上了,而对于进程数据来说,如果数据位于缓冲区内,那么该数据属于进程,此时 fork 子进程也会指向该数据;但如果该数据已经写入到磁盘文件了,那么数据就不属于进程了,此时 fork 子进程也不在指向该数据了;所以,这里 fork 子进程不会做任何事情,结果和现象1一样。
现象4:我们使用重定向指令将本该写入显示器文件的数据写入到磁盘文件中,而磁盘文件采用全缓冲,所以 fork 子进程时 printf、fprintf、fputs 的数据还存在于缓冲区中 (缓冲区没满,同时父进程还没有退出,所以缓冲区没有刷新),也就是说,此时数据还属于父进程,那么 fork 之后子进程也会指向该数据;而 fork 之后紧接着就是进程退出,父子进程某一方先退出时会刷新缓冲区,由于刷新缓冲区会清空缓冲区中的数据,为了保持进程独立性,先退出的一方会发生 写时拷贝,然后向磁盘文件中写入 printf、fprintf、fputs 三条数据;然后,后退出的一方也会进行缓冲区的刷新;所以,最终 printf、fprintf、fputs 的数据会写入两份 (父子进程各写入一份),且 write 由于属于系统调用没有缓冲区,所以只写入一份数据且最先写入。
4.实现一个简易的C语言缓冲区
在理解了缓冲区的各种原理之后,我们可以手动的实现一个简易的C语言缓冲区,即实现一个简易的 FILE 结构体以及 fopen、fwrite、fclose、fflush 等C语言文件操作的相关函数,来使得我们对缓冲区的理解能够更加深刻。
mystdio.h
#pragma once #include <stdio.h>
#include <string.h>
#include <assert.h>
#include <errno.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
#include <fcntl.h>#define SIZE 1024
#define SYNC_NOW 1
#define SYNC_LINE 2
#define SYNC_FULL 4typedef struct EILE_
{int _fileno;//文件描述符int _flags;//刷新方式char buffer[SIZE];int _capacity;int _size;
}_FILE;_FILE* fopen_(const char* path_name,const char* mode);
void fwrite_(const void* ptr,size_t size,_FILE* fp);
void fclose_(_FILE* fp);
void fflush_(_FILE* fp);
mystdio.c
#include "mystdio.h"_FILE *fopen_(const char *path_name, const char *mode)
{int flags = 0;int defaultmode = 0666; // 文件的权限if (strcmp(mode, "r") == 0){flags |= O_RDONLY;}else if (strcmp(mode, "w") == 0){flags |= (O_WRONLY | O_CREAT | O_TRUNC);}else if (strcmp(mode, "a") == 0){flags |= (O_WRONLY | O_CREAT | O_APPEND);}else{// TODO}int fd = 0;if (flags & O_RDONLY)fd = open(path_name, flags);elsefd = open(path_name, flags, defaultmode);if (fd < 0){const char *err = strerror(errno);write(2, err, strlen(err));return NULL; // 为什么C语言文件打开失败返回NULL的原因}_FILE *fp = (_FILE *)malloc(sizeof(_FILE));assert(fp);fp->_fileno = fd;fp->_size = 0;fp->_capacity = SIZE;fp->_flags = SYNC_LINE; // 默认为行刷新memset(fp->buffer, 0, SIZE);return fp; // 为什么打开一个文件,就会返回一个FILE *指针
}void fwrite_(const void *ptr, size_t size, _FILE *fp)
{// 1. 写入到缓冲区中memcpy(fp->buffer + fp->_size, ptr, size); // 这里我们不考虑缓冲区溢出的问题fp->_size += size;// 2. 判断是否刷新// 1.立即刷新,直接写入if (fp->_flags & SYNC_NOW){write(fp->_fileno, fp->buffer, fp->_size);fp->_size = 0;}// 2.行刷新,判断最后的字符为'\0'else if (fp->_flags & SYNC_LINE){if (fp->buffer[fp->_size - 1] == '\0'){write(fp->_fileno, fp->buffer, fp->_size);fp->_size = 0;}}// 3.全刷新,判断缓冲区是否写满else if (fp->_flags & SYNC_FULL){if (fp->_size == fp->_capacity){write(fp->_fileno, fp->buffer, fp->_size);fp->_size = 0;}}else{}
}
void fclose_(_FILE *fp)
{fflush_(fp);close(fp->_fileno);
}
void fflush_(_FILE *fp)
{if (fp->_size > 0)write(fp->_fileno, fp->buffer, fp->_size);fsync(fp->_fileno); // 将数据,强制要求OS进行外设刷新!fp->_size = 0;
}
test.c
#include "mystdio.h"#define FILE_NAME "log.txt"int main()
{_FILE *fp = fopen_(FILE_NAME, "w");if (fp == NULL){perror("open failed");return 1;}int cnt = 5;char buffer[64];while (cnt){sprintf(buffer, "%s:%d\n", "hello world", cnt--);fwrite_(buffer, strlen(buffer), fp);}fclose_(fp);return 0;
}
5.内核缓冲区
我们之前理解的通过C语言文件接口向磁盘文件写入数据的过程是这样的:进程先通过 fprintf、fwrite、fputs 等函数将数据拷贝到缓冲区中,然后再由缓冲区以某种刷新方式刷新 (写入) 到磁盘文件中;
但实际上缓冲区并不是直接将数据写入到磁盘文件中的,而是先将数据拷贝到 内核缓冲区 – 位于内核数据结构 file 结构体中的一块内存空间 中,最后再由操作系统自主决定以什么样的刷新策略将数据写入到外设中,而这个写入的过程和用户毫无关系。
也就是说,我们向外设中写入数据其实一共分为三个步骤 – 先通过 fwrite 等语言层面的文件操作接口将进程数据拷贝到语言层面的缓冲区中,然后再根据缓冲区的刷新策略 (无、行、全) 通过 write 系统调用将数据拷贝到 file 结构体中的内核缓冲区中,最后再由操作系统自主将数据真正的写入到外设中。(所以 fwrite 和 write 其实叫做拷贝函数更合适)
注:这里操作系统的刷新策略比我们应用层 FILE 中的缓冲区的刷新策略要复杂的多,因为操作系统要根据不同的整体内存使用情况来选择不同的刷新策略,而不仅仅是死板的分为分行缓冲、全缓冲、无缓冲这么简单。
这里还存在一种特殊情况,既然进程数据被拷贝到内核缓冲区中,再由操作系统自主刷新,那么如果操作系统崩溃了就势必会出现数据丢失;这样对于像银行这种对数据丢失0容忍的机构来说就存在一定的风险,所以操作系统提供了一个系统调用函数 fsync,其作用就是将内核缓冲区中的数据立刻直接同步到外设中,而不再采用操作系统的刷新策略。

我们可以使用 fsync 接口将我们实现的简易C语言缓冲区设置为在内核缓冲区中采用无缓冲:
fwrite 等C语言库函数具有缓冲区,该缓冲区位于 FILE 结构体中,我们通过这些接口向外设写入数据时需要先将数据拷贝到缓冲区中,然后再由缓冲区根据特定的刷新策略将数据写入到外设中;而 write 等系统调用没有缓冲区,进程数据将直接写入到外设中
相关文章:
【Linux】基础IO--重定向理解Linux下一切皆文件缓冲区
文章目录 一、重定向1.什么是重定向2.dup2 系统调用3.理解输入重定向、输出重定向和追加重定向4.简易shell完整实现 二、理解linux下一切皆文件三、缓冲区1.为什么要有缓冲区2.缓冲区的刷新策略3.缓冲区的位置4.实现一个简易的C语言缓冲区5.内核缓冲区 一、重定向 1.什么是重定…...

RINEX介绍
一、RINEX是什么 Receiver Independent Exchange Format (RINEX) 是一种用于存储、交换和处理全球定位系统 (GPS) 接收机观测数据的标准化文件格式。RINEX 格式由国际电信联盟 (ITU) 和国际GPS服务 (IGS) 组织共同开发和维护。它提供了一种通用的数据格式,使得不同…...

ROS-ROS通信机制-服务通信
文章目录 一、服务通信基本知识二、自定义srv三、C实现四、Python实现 一、服务通信基本知识 服务通信也是ROS中一种极其常用的通信模式,服务通信是基于请求响应模式的,是一种应答机制。也即: 一个节点A向另一个节点B发送请求,B接收处理请求…...
chown和chmod
chown和chmod都是在Linux和Unix系统中用于设置文件和文件夹权限的命令,但它们的功能和用途有所不同。 功能:chown主要用于修改文件或文件夹的所有者和所属组,而chmod则主要用于修改文件或文件夹的读写执行权限。用途:如果想要授权…...

【GPU】linux 安装、卸载 nvidia 显卡驱动、cuda 的官方文档、推荐方式(runfile)
文章目录 1. 显卡驱动1.1. 各版本下载地址1.2. 各版本文档地址1.3. 安装、卸载方式 2. CUDA2.1. 各版本下载地址2.2. 各版本文档地址2.3. 安装、卸载方式2.4. 多版本 CUDA 切换方式 1. 显卡驱动 1.1. 各版本下载地址 https://www.nvidia.com/Download/Find.aspx?langzh-cn 1…...
6页手写笔记总结信号与系统常考知识大题知识点
题型一 判断系统特性题型二 求系统卷积题型三 求三大变换正反变换题型四 求全响应题型五 已知微分方程求系统传递函数题型六 已知系统的传递函数求微分方程题型七 画出系统的零极点图,并判断系统的因果性和稳定性 (笔记适合快速复习,可能会有…...

Qt-QSplitter正确设置比例
简短版本: splitter->setSizes({1000, 2000}); // 这个值至少跟像素值设置的一样大,或者更大,例如x10倍详细版本: setSizes 官方介绍如下: Sets the child widgets’ respective sizes to the values given in the…...

一篇吃透大厂面试题,2024找工作一帆风顺。
🏆作者简介,普修罗双战士,一直追求不断学习和成长,在技术的道路上持续探索和实践。 🏆多年互联网行业从业经验,历任核心研发工程师,项目技术负责人。 🎉欢迎 👍点赞✍评论…...

【1day】用友 U8 Cloud系统TaskTreeQuery接口SQL注入漏洞学习
注:该文章来自作者日常学习笔记,请勿利用文章内的相关技术从事非法测试,如因此产生的一切不良后果与作者无关。 目录 一、漏洞描述 二、影响版本 三、资产测绘 四、漏洞复现...

华为快应用中自定义Slider效果
文章目录 一、前言二、实现代码三、参考链接 一、前言 在华为快应用中官方提供了<slider>控件,但是这个控件的限制比较多,比如滑块无法自定义,所以这里进行下自定义,自己修改样式。 二、实现代码 整体效果如下: 源码如下…...
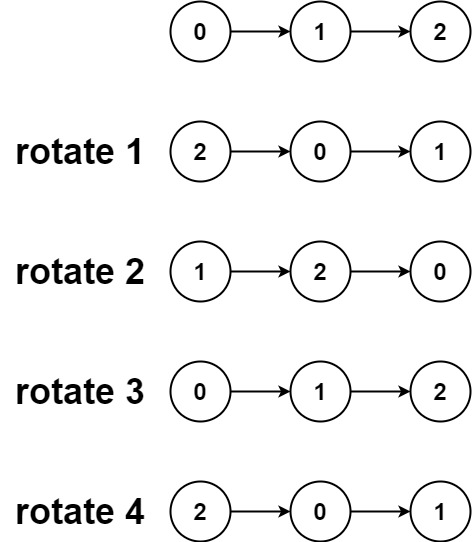
C语言每日一题(43)旋转链表
力扣 61 旋转链表 题目描述 给你一个链表的头节点 head ,旋转链表,将链表每个节点向右移动 k 个位置。 示例 1: 输入:head [1,2,3,4,5], k 2 输出:[4,5,1,2,3]示例 2: 输入:head [0,1,2], …...

CCF计算机软件能力认证考试—202209-1如此编码
题目背景 某次测验后,顿顿老师在黑板上留下了一串数字 23333 便飘然而去。凝望着这个神秘数字,小 P 同学不禁陷入了沉思…… 题目描述 已知某次测验包含 � 道单项选择题,其中第 � 题(1≤�≤&…...
Ubuntu18.04安装Ipopt-3.12.8流程
本文主要介绍在Ubuntu18.04中安装Ipopt库的流程,及过程报错的解决方法,已经有很多关于Ipopt安装的博客,但经过我的测试,很多都失效了,经过探索,找到可流畅的安装Ipopt的方法,总结成本篇博客。 …...
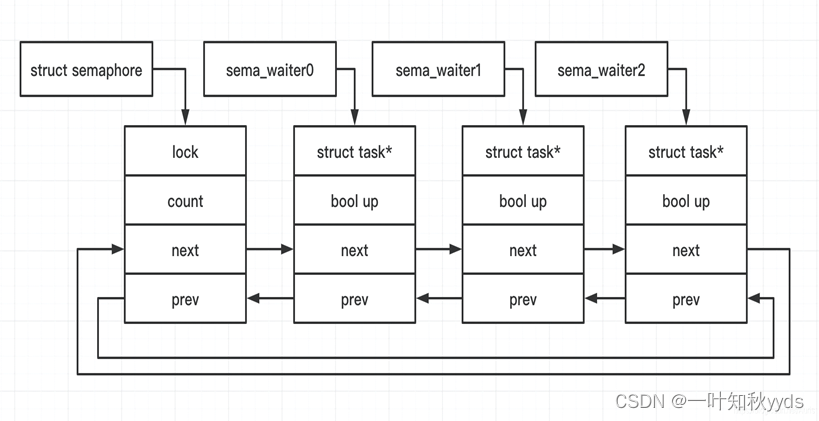
linux 内核同步互斥技术之信号量
信号量 信号量允许多个进程同时进入临界区,大多数情况下只允许一个进程进入临界区,把信号量的计数值设置为 1,即二值信号量,这种信号量称为互斥信号量。可允许多个锁持有者。 和自旋锁相比,信号量适合保护比较长的临界…...

交通强国添力量 无人机巡航为何备受期待?
在高速建设交通强国的过程中,交通运输部海事局计划完善“陆海空天”一体化水上交通运输安全保障体系。无人机巡航系统将在提升海事船舶监管和水上搜救能力方面发挥关键作用,以构建更为全面的监管体系。尽管已初步建立了海事监管体系,但仍存在…...

【PID学习笔记 6 】控制系统的性能指标之二
写在前面 上文介绍了控制系统的稳态与动态、过渡过程、阶跃响应以及阶跃信号作用下过渡过程的四种形式。本文紧接上文,首先总结过渡过程的分类,然后介绍控制系统的性能评价,最后重点介绍控制系统性能指标中的单项指标。 一、过渡过程的分类…...
ZLMediakit-method ANNOUNCE failed: 401 Unauthorized(ffmpeg、obs推流rtmp到ZLM发现的问题)
错误截图 解决办法:能推流成功,但是不能写入到wvp数据库中 修改配置文件config.ini 改成0 修改之后 重启服务 systemctl restart zlm*推流成功 解决办法:能推流,能写入数据库中 替换zlm版本,可以用我文章中提供的编译…...

聊聊logback的ThrowableProxyConverter
序 本文主要研究一下logback的ThrowableProxyConverter ThrowableHandlingConverter ch/qos/logback/classic/pattern/ThrowableHandlingConverter.java /*** Converter which handle throwables should be derived from this class.**/ public abstract class ThrowableHa…...

Kubernetes(k8s)访问不了Pod服务
在k8s集群部署java web应用的服务时,浏览器访问不了pod服务或linux终端curl http://192.168.138.112:30000即curl http://ip地址:端口号失败,如下图: 在网上找了很久的答案,最后还是没解决,后来突然想起来一直是在k8…...

python-学生管理|汉罗塔
1.编写程序,实现学生信息管理系统。 运行程序,在控制台输入“1”之后的结果如下所示: 学生管理系统 1.添加学生信息 2.删除学生信息 3.修改学生信息 4.显示所有学生信息 0.退出系统 请选择功能:1 请输入新学生的姓名:小红 请输入…...
GPU利用率提升50%:BF16数值稳定性实证)
千问图像生成16Bit(Qwen-Turbo-BF16)GPU利用率提升50%:BF16数值稳定性实证
千问图像生成16Bit(Qwen-Turbo-BF16)GPU利用率提升50%:BF16数值稳定性实证 基于 Qwen-Image-2512 底座与 Wuli-Art Turbo LoRA 构建的高性能、极速图像生成 Web 系统。 在AI图像生成领域,精度选择一直是性能与质量之间的关键权衡。…...
)
2.4 Java的基础概念(数据类型)
一、什么是数据类型?在 Java 中,数据类型决定了三件事:存什么:变量能存储的数据种类(是整数、小数还是文字?)。占多大:在内存中占用多少空间(字节数)。怎么算…...

实战Wireshark抓包分析与Python爬虫技术入门
1. Wireshark抓包实战:从零开始分析网络通信 第一次接触Wireshark时,我被这个能"偷看"网络流量的工具震撼到了。想象一下,你家的Wi-Fi就像一条繁忙的高速公路,而Wireshark就是路边的监控摄像头,能记录每一辆…...

为什么你的ranges::filter_view在C++27中突然崩溃?——深度逆向Clang 18.1.8 ABI变更引发的迭代器失效链
第一章:C27范围库扩展演进与ABI稳定性危机C27正以前所未有的力度重构范围(Ranges)库,引入std::ranges::zip_view的标准化、std::ranges::cartesian_product视图、以及支持异构比较的std::ranges::sort重载。这些增强显著提升了表达…...

保姆级教程:用llama.cpp把魔塔社区的safetensors模型转成Ollama能用的GGUF格式
从魔塔社区到Ollama:零基础完成safetensors到GGUF的华丽转身 刚接触开源大模型的新手们,往往会在魔塔社区发现令人心动的模型——比如最近热门的DeepSeek-R1系列。但下载后却面临一个尴尬局面:这些模型通常是safetensors格式,而Ol…...

告别低效查询!用SAP SE16H的‘公式’和‘分组统计’功能,5分钟搞定复杂报表数据准备
SAP SE16H高效数据加工:用内置公式与分组统计替代Excel计算 每次月底结账前,财务部的王敏总要熬夜处理几十张采购订单的统计报表。从SAP导出原始数据到Excel,用VLOOKUP匹配供应商信息,写SUMIFS公式按物料组汇总金额,最…...
Pixel Aurora Engine 赋能内容运营:社交媒体图文批量创作方案
Pixel Aurora Engine 赋能内容运营:社交媒体图文批量创作方案 1. 新媒体运营的配图痛点 每天打开电脑,新媒体运营小李都要面对同样的挑战:今天发什么图?从封面到内文配图,再到各种节日节气海报,原创设计根…...

OpenClaw社区贡献指南:为Qwen3-14b_int4_awq开发并分享自定义技能
OpenClaw社区贡献指南:为Qwen3-14b_int4_awq开发并分享自定义技能 1. 为什么我们需要更多社区技能 上周我尝试用OpenClaw自动整理电脑里堆积如山的PDF论文时,发现现有的文件处理技能无法识别某些特殊格式的学术文献。这个痛点让我意识到:Op…...

基于U-Net的肺部CT结节检测系统设计与实现
摘要:肺癌是当前威胁人类健康的重要疾病之一,肺结节作为肺癌早期筛查和诊断的重要影像学表现,其准确检测具有重要意义。CT影像因具有较高的空间分辨率,被广泛应用于肺部疾病检查。然而,传统人工阅片方式存在工作量大、…...

Flutter鸿蒙化适配中遇到的问题
Flutter 环境搭建避坑指南Flutter 作为跨平台开发的热门框架,凭借一套代码多端运行的优势,深受开发者喜爱,但环境搭建与适配却是新手入门的第一道拦路虎。我在初次配置 Flutter 开发环境时,接连踩中环境变量、模拟器版本、第三方工…...