面试就是这么简单,offer拿到手软(三)—— 常见中间件框架面试题,es,redis,dubbo,zookeeper kafka 等

面试就是这么简单,offer拿到手软(一)—— 常见非技术问题回答思路
面试就是这么简单,offer拿到手软(二)—— 常见65道非技术面试问题
面试就是这么简单,offer拿到手软(三)—— 常见中间件框架面试题,es,redis,dubbo,zookeeper kafka 等
面试就是这么简单,offer拿到手软(四)—— 常见java152道基础面试题
文章目录
- 一、消息队列
- 1.1 常见消息队列优缺点
- 1.2如何保证消息队列高可用?
- 1.2.1 使用kafka使用集群模式
- 1.2.2 确保不重复消费
- 1.2.3 确保消息可靠性传输
- 1.2.4 如何保证保证消息顺序性
- 1.2.5 如何设计消息中间件
- 二、分布式搜索引擎
- 2.1. es分布式架构原理
- 2.2. es读写流程原理
- 2.3. es优化
- 三、分布式缓存redis
- 3.1 为什么要用分布式缓存?
- 3.2 常见问题
- 3.3 redis介绍以及与memcached的区别
- 3.3.1. redis是单线程工作模型
- 3.3.2. redis和memcached 区别
- 3.3.3. redis高可用原因
- 3.3.4. redis数据:
- 3.3.5 .redis过期策略
- 3.3.6. redis高并发高可用的保证
- 3.3.7 .redis持久化
- 3.3.8. redis横向扩容
- 3.3.9 一致性hash算法(有虚拟节点,为解决热点数据)
- 3.3.10 redis cluster,hash slot算法
- 3.3.11 缓存雪崩、穿透
- 3.3.12 数据库双写不一致
- 3.3.13 redis并发竞争
- 四、dubbo:
- 4.1 dubbo工作原理
- 4.2. 支持协议
- 4.3.dubbo负载均衡策略
- 4.4.集群容错
- 4.5.动态代理策略
- 4.6 自设计rpc框架
- 五、zookeeper
- 5.1. 适用场景
- 5.2.分布式锁
- 六、分布式session
- 七、分布式事务
- 八、设计一个高并发的系统架构
- 九、分库分表
- 十、读写分离、主从复制、同步延时问题
- 10.1. 读写分离
- 10.2.主从复制
- 10.3.主从同步机制
- 10.4.同步延时问题
一、消息队列
1.1 常见消息队列优缺点
常见消息队列:activemq、rabbitmq、rocketmq、kafka
消息队列的优点: 解耦、异步、削峰
消息队列的优点: 系统可用性降低、系统复杂性提高、一致性问题
1.2如何保证消息队列高可用?
1.2.1 使用kafka使用集群模式
1.2.2 确保不重复消费
- 使用offset序号(zk实现)
- 保证幂等性(使用数据库表主键)
1.2.3 确保消息可靠性传输
- 如何解决消费端弄丢问题?
关闭自动提交offset,改为手动提交offset - 如何解决kafka本身弄丢的问题?
leader宕掉
topic设置replication.factor值大于1,要求partition必须至少2个副本
kafka服务端设置min.insync.replicas值大于1,要求leader至少感知到有至少一个follower跟自己保持联系
producer(生产者)端设置acks=all,每条数据必须是写入所有replica后,才认为写入成功
producer端设置retries=MAX,一旦写入失败,无限重试,卡在这里
1.2.4 如何保证保证消息顺序性
- kafka保证写入一个partition中的数据是一定有顺序的,生产者指定的一个key的数据一定会写入到一个partition中
- 消费者从partition中取出数据也是一定有顺序的
- 多线程处理时可能会顺序出错,设定内存队列,hash分发时,同一key分到同一队列
1.2.5 如何设计消息中间件
- 支持扩容
- 数据落磁盘
- 可用性
- 数据可靠性
二、分布式搜索引擎
elasticsearch 即 es
2.1. es分布式架构原理
es存储数据的基本单位是索引index
index -> type -> mapping -> document -> field
1个index能被分成多个shard,分布在不同的机器上,shard类比kafka,有主从性(备份)
写只能主,读可以主从
2.2. es读写流程原理
写入内存buffer和translog
- buffer快满了或一定时间后,将buffer中数据refresh到一个新的segment file中(先进入到os cache,一般1s执行一次)
- refresh持续执行后,当translog达到一定体量时,触发commit操作(buffer中现有数据全部refresh到os cache中,清空buffer,将一个commit point写入磁盘文件,标识对应的segment file,将os cache中数据fsync到磁盘)
- 可以调用api手动执行flush操作(整个commit过程即flush)
- translog也是先进入到os cache中,默认5s持久化操作一次
- 删除操作,标识del标记,逻辑删除,非物理删除
- 更新操作,即先标记原有数据del,重新写入一条数据
- 定期执行merge操作,当segment file多到一定程度的时候,es就会自动触发merge操作,将多个segment file给merge成一个segment file
2.3. es优化
- 加大分配给es的内存(数据量的体量最好小于或等于分配给es的内存)
- 数据预热,对于大量搜索的数据,定时的查询一次,将数据存入到es内存中
- 优化存入filesystem cache的数据,只存入用于搜索的数据
- 冷热分离,尽可能的将热数据放到一个索引,冷数据放到另一个索引中去,防止热数据被冷数据从cache中冲掉
三、分布式缓存redis
3.1 为什么要用分布式缓存?
为了高性能和高并发使用缓存(使用场景:数据字典)
3.2 常见问题
1)缓存与数据库双写不一致
2)缓存雪崩
3)缓存穿透
4)缓存并发竞争
3.3 redis介绍以及与memcached的区别
3.3.1. redis是单线程工作模型
3.3.2. redis和memcached 区别
1)Redis支持服务器端的数据操作:Redis相比Memcached拥有更多的数据结构和并支持更丰富的数据操作,通常在Memcached里,你需要将数据拿到客户端来进行类似的修改再set回去。这大大增加了网络IO的次数和数据体积。在Redis中,这些复杂的操作通常和一般的GET/SET一样高效。2)集群模式:memcached没有原生的集群模式,需要依靠客户端来实现往集群中分片写入数据;但是redis目前是原生支持cluster模式的
3.3.3. redis高可用原因
- 非阻塞IO多路复用模型
- 纯内存操作
- 避免了多线程的频繁上下文切换问题
3.3.4. redis数据:
String、Hash、list、set、zset
3.3.5 .redis过期策略
- 定期删除+惰性删除
- 内存淘汰
1)noeviction:当内存不足以容纳新写入数据时,新写入操作会报错
2)allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key(这个是最常用的)
3)allkeys-random:当内存不足以容纳新写入数据时,在键空间中,随机移除某个key
4)volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的key(这个一般不太合适)
5)volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个key
6)volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的key优先移除
3.3.6. redis高并发高可用的保证
主从架构、读写分离、水平扩容哨兵sentinel机制redis集群数据丢失问题:1)异步复制2)集群脑裂min-slaves-to-write 1min-slaves-max-log 10选举:slaves priority优先级 -> replica offset -> run id
3.3.7 .redis持久化
用于故障恢复持久化方案:AOF:每条数据写入一个AOF文件内,适合做热备当AOF文件膨胀到一定体量时,会触发rewrite操作,基于现有redis数据生成一份新的AOF文件,并将原有AOF文件清除一般AOF会每隔1秒,通过一个后台线程执行一次fsync操作,最多丢失1秒钟的数据AOF日志文件以append-only模式写入,所以没有任何磁盘寻址的开销,写入性能非常高,而且文件不容易破损,即使文件尾部破损,也很容易修复但:AOF日志文件通常比RDB数据快照文件更大AOF开启后,支持的写QPS会比RDB支持的写QPS低做数据恢复的时候,会比较慢RDB:每隔一定时间,生成一个快照,适合做冷备RDB对redis对外提供的读写服务,影响非常小,可以让redis保持高性能,因为redis主进程只需要fork一个子进程,让子进程执行磁盘IO操作来进行RDB持久化即可但:时间间隔问题,数据不全
3.3.8. redis横向扩容
redis cluster支撑N个redis master node,每个master都可挂载多个slave node
3.3.9 一致性hash算法(有虚拟节点,为解决热点数据)
3.3.10 redis cluster,hash slot算法
cluster有固定的16384个hash slot,对每个key计算CRC16值,然后对16384取模,可以获取key对应的hash slotredis cluster中每个master都会持有部分slot,增加一个master,就将其他master的hash slot移动部分过去,减少一个master,就将它的hash slot移动到其他master上去移动hash slot的成本是非常低的,客户端的api,可以对指定的数据,让他们走同一个hash slot,通过hash tag来实现
3.3.11 缓存雪崩、穿透
3.3.12 数据库双写不一致
3.3.13 redis并发竞争
分布式锁+时间戳
四、dubbo:
4.1 dubbo工作原理
第一层:service层,接口层,给服务提供者和消费者来实现的第二层:config层,配置层,主要是对dubbo进行各种配置的第三层:proxy层,服务代理层,透明生成客户端的stub和服务单的skeleton第四层:registry层,服务注册层,负责服务的注册与发现第五层:cluster层,集群层,封装多个服务提供者的路由以及负载均衡,将多个实例组合成一个服务第六层:monitor层,监控层,对rpc接口的调用次数和调用时间进行监控第七层:protocol层,远程调用层,封装rpc调用第八层:exchange层,信息交换层,封装请求响应模式,同步转异步第九层:transport层,网络传输层,抽象mina和netty为统一接口第十层:serialize层,数据序列化层工作流程:1)第一步,provider向注册中心去注册2)第二步,consumer从注册中心订阅服务,注册中心会通知consumer注册好的服务3)第三步,consumer调用provider4)第四步,consumer和provider都异步的通知监控中心
4.2. 支持协议
1)dubbo协议单一长连接,NIO异步通信,基于hessian作为序列化协议;适用的场景就是:传输数据量很小(每次请求在100kb以内),但是并发量很高2)rmi协议走java二进制序列化,多个短连接,适合消费者和提供者数量差不多,适用于文件的传输3)hessian协议走hessian序列化协议,多个短连接,适用于提供者数量比消费者数量还多,适用于文件的传输4)http协议走json序列化5)webservice走SOAP文本序列化
4.3.dubbo负载均衡策略
1)random loadbalance 权重2)roundrobin loadbalance 轮询3)leastactive loadbalance 自动感知4)consistanthash loadbalance 一致性hash算法
4.4.集群容错
1)failover cluster模式失败自动切换,自动重试其他机器,默认就是这个,常见于读操作2)failfast cluster模式一次调用失败就立即失败,常见于写操作3)failsafe cluster模式出现异常时忽略掉,常用于不重要的接口调用,比如记录日志4)failbackc cluster模式失败了后台自动记录请求,然后定时重发,比较适合于写消息队列这种5)forking cluster并行调用多个provider,只要一个成功就立即返回6)broadcacst cluster逐个调用所有的provider
4.5.动态代理策略
默认使用javassist动态字节码生成,创建代理类,但是可以通过spi扩展机制配置自己的动态代理策略
4.6 自设计rpc框架
注册中心 -> 动态代理 -> 负载均衡 -> 网络通信
五、zookeeper
5.1. 适用场景
1)分布式协调2)分布式锁3)元数据/配置信息管理4)HA高可用性
5.2.分布式锁
redis实现 -> 叫做RedLock算法,是redis官方支持的分布式锁算法互斥(只能有一个客户端获取锁),不能死锁,容错(大部分redis节点存活这个锁就可以加可以释放)1)第一个最普通的实现方式,如果就是在redis里创建一个key算加锁创建锁 SET my:lock 随机值 NX PX 30000释放锁 一般可以用lua脚本删除,判断value一样才删除2)RedLock算法使用redis cluster集群,为避免上一方法redis宕机问题zookeeper实现zookeeper保证只有一个人获取到锁(创建临时节点),某一线程获取到一个锁后执行一定的操作后释放锁,其他线程如果没有获取到这个锁就对这个锁注册一个监听器,感知到锁被释放后再次重新尝试取锁
六、分布式session
1.tomcat + redis在tomcat配置文件配RedisSessionManager属性
2.spring session + redisspring-session-data-redis.jarjedis.jar
七、分布式事务
1.两阶段提交方案(XA方案)有一个事务管理器,先询问后执行
2.tcc方案(try、confirm、cancel)1)Try阶段:对各个服务的资源做检测以及对资源进行锁定或者预留2)Confirm阶段:在各个服务中执行实际的操作3)Cancel阶段:业务方法执行出错,那么这里就需要进行补偿,执行已经执行成功的业务逻辑的回滚操作
3.本地消息表通过zookeeper、mq和数据库来做,数据库中有个业务表和一个消息表
4.可靠消息最终一致性基于mq实现,阿里的rocketMQ1)A系统先发送一个prepared消息到mq,如果这个prepared消息发送失败那么就直接取消操作不执行2)如果这个消息发送成功,那么接着执行本地事务,如果成功,向mq发送确认消息,如果失败就告诉mq回滚消息3)如果发送了确认消息,那么此时B系统会接收到确认消息,然后执行本地的事务4)mq会自动定时轮询所有prepared消息回调你的接口5)如果系统B的事务失败了,自动不断重试直到成功
5.最大努力通知1)系统A本地事务执行完之后,发送个消息到MQ2)这里会有个专门消费MQ的最大努力通知服务,这个服务会消费MQ然后写入数据库中记录下来,或者是放入个内存队列也可以,接着调用系统B的接口3)要是系统B执行成功就ok了;要是系统B执行失败了,那么最大努力通知服务就定时尝试重新调用系统B,反复N次,最后还是不行就放弃
八、设计一个高并发的系统架构
1.系统拆分
2.使用缓存
3.使用mq
4.分库分表
5.读写分离
6.es
九、分库分表
分库分表中间件: cobar、TDDL、atlas、sharding-jdbc、mycat
range分法(按时间分) 扩容快,但是大部分的请求,都是访问最新的数据
哈希分法(以某一字段取模分) 可以平均分配给库的数据量和请求压力,但扩容麻烦
垂直拆分:把一个有很多字段的表给拆分成多个表,或者是多个库上去
水平拆分:一个表的数据给弄到多个库的多个表里去,但是每个库的表结构都一样,只不过每个库表放的数据是不同的,所有库表的数据加起来就是全部数据
不停机迁移分库分表:双写迁移方案
十、读写分离、主从复制、同步延时问题
10.1. 读写分离
基于主从复制架构,简单来说,就搞一个主库,挂多个从库,然后我们就单单只是写主库,然后主库会自动把数据给同步到从库上去。
10.2.主从复制
主库将变更写binlog日志,然后从库连接到主库之后,从库有一个IO线程,将主库的binlog日志拷贝到自己本地,写入一个中继日志中。接着从库中有一个SQL线程会从中继日志读取binlog,然后执行binlog日志中的内容,也就是在自己本地再次执行一遍SQL。
10.3.主从同步机制
mysql实际上在这一块有两个机制,一个是半同步复制,用来解决主库数据丢失问题;一个是并行复制,用来解决主从同步延时问题。
10.4.同步延时问题
1)分库,将一个主库拆分为4个主库,每个主库的写并发就500/s,此时主从延迟可以忽略不计2)打开mysql支持的并行复制,多个库并行复制,如果说某个库的写入并发就是特别高,单库写并发达到了2000/s,并行复制还是没意义3)重写代码,插入数据之后,直接就更新,不要查询4)如果确实是存在必须先插入,立马要求就查询到,然后立马就要反过来执行一些操作,对这个查询设置直连主库。不推荐这种方法,你这么搞导致读写分离的意义就丧失了
相关文章:
面试就是这么简单,offer拿到手软(三)—— 常见中间件框架面试题,es,redis,dubbo,zookeeper kafka 等
面试就是这么简单,offer拿到手软(一)—— 常见非技术问题回答思路 面试就是这么简单,offer拿到手软(二)—— 常见65道非技术面试问题 面试就是这么简单,offer拿到手软(三ÿ…...

【Spring系列】DeferredResult异步处理
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...
使用晶振遇到的两个问题
并联电阻的问题 在一些方案中,晶振并联1MΩ电阻时,程序运行正常,而在没有1MΩ电阻的情况下,程序运行有滞后及无法运行现象发生。 原因分析: 在无源晶振应用方案中,两个外接电容能够微调晶振产生的时钟频率…...
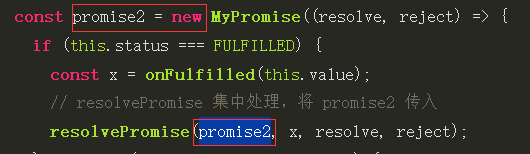
手写promise A+、catch、finally、all、allsettled、any、race
目录 手写promise 同步版 1.Promise的构造方法接收一个executor(),在new Promise()时就立刻执行executor回调 2.executor()内部的异步任务被放入宏/微任务队列,等待执行 3.状态与结果的管理 状态只能变更一次 4.then()调用成功/失败回调 catch是…...
【原神游戏开发日志1】缘起
【原神游戏开发日志1】缘起 版权声明 本文为“优梦创客”原创文章,您可以自由转载,但必须加入完整的版权声明 文章内容不得删减、修改、演绎 相关学习资源见文末 大家好,最近看到原神在TGA上频频获奖,作为一个14年经验的游戏开…...

leetcode5 最长公共前缀三种python解法
14. 最长公共前缀 编写一个函数来查找字符串数组中的最长公共前缀。 如果不存在公共前缀,返回空字符串 ""。 示例 1: 输入:strs ["flower","flow","flight"] 输出:"fl"示…...

对小程序的初了解
WXML和HTML的区别 标签名称不同 HTML:div、a、span、img WXML:view、text、image、navigator 属性节点不同 <a href"#">超链接</a> <navigator url"/pages/home/home"></navigator> 提供了类似vue的…...

QLineEdit 的 InputMask掩码
QLineEdit 的 InputMask掩码 A:只能输入字母,且不可省略 a:只能输入字母,可以省略 N:只能输入 字母和数字,且不可省略 n:只能输入 字母和数字,可以省略 X:可以输入任意字…...
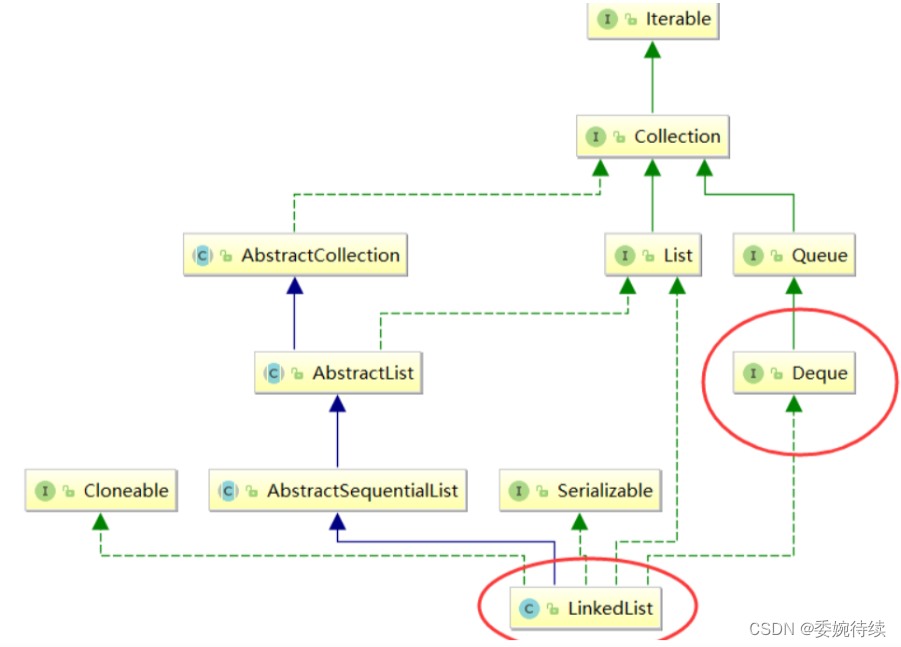
关于队列的简单理解
1.队列(Queue) 1.1 关于队列 队列 :只允许在一端进行插入数据操作,在另一端进行删除数据操作的特殊线性表, 队列具有先进先出 FIFO(First In First Out)的操作特性(队列是个接口); 入队列&#x…...

加密市场进入牛初阶段?一场新的造富效应即将拉开帷幕!
周一(12月4日),比特币一度上涨至42000美元,创下自2022年4月以来的最高水平。从目前比特币的走势来看,加密市场无疑已然进入到牛初阶段。 在牛市初期,确实存在人们不相信牛市到来的情况。由于在熊市中亏损的心理阻碍和对市场进一步…...
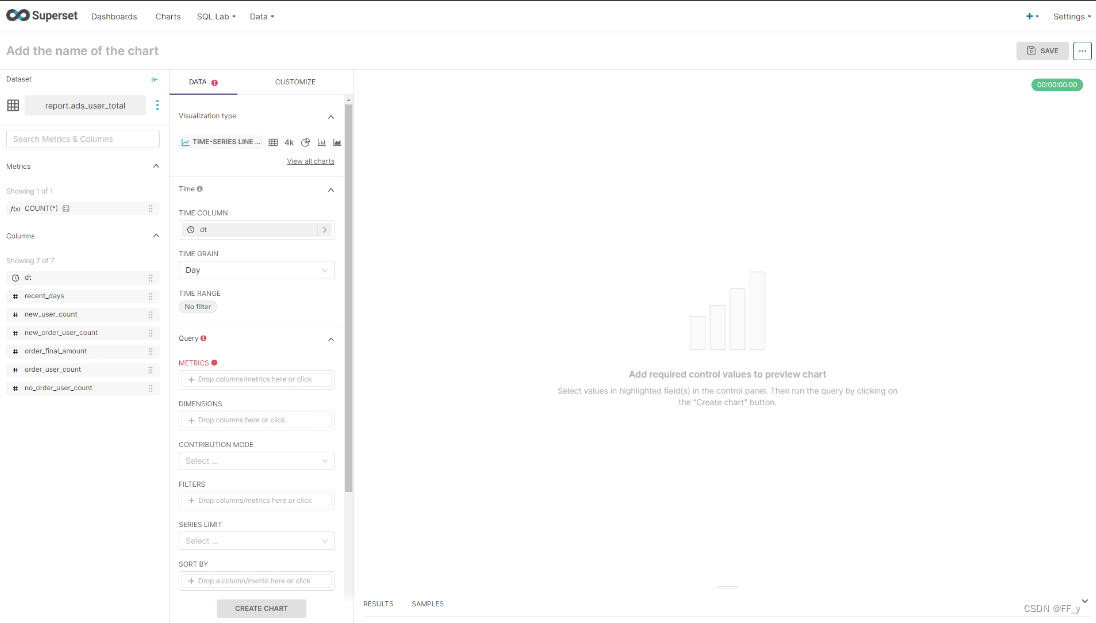
Superset基础入门
1 Superset概述 Apache Superset 是一个现代的数据探索和可视化平台。它功能强大且十分易用,可对接 各种数据源,包括很多现代的大数据分析引擎,拥有丰富的图表展示形式,并且支持自定义 仪表盘。 2 Superset安装 Superset 是由 P…...
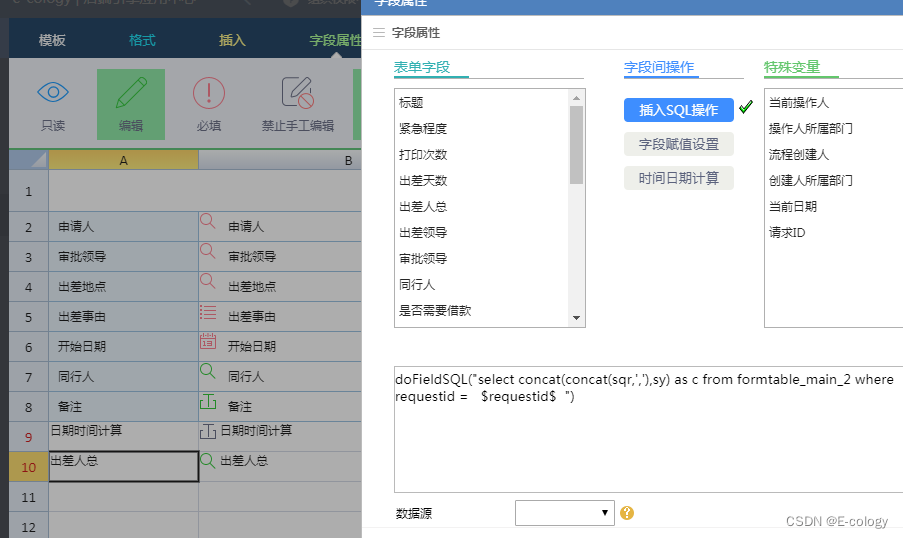
【泛微ecology】将多个字段的数据合并到一个字段
doFieldSQL("select concat(concat(sqr,,),sy) as c from formtable_main_2 where requestid $requestid$ ")...

WebSocket入门介绍及编程实战
HTTP的限制 全双工和半双工: 全双工:全双工(Full Duplex)是允许数据在两个方向上同时传输。 半双工:半双工(Half Duplex)是允许数据在两个方向上传输,但是同一个时间段内只允许一个…...
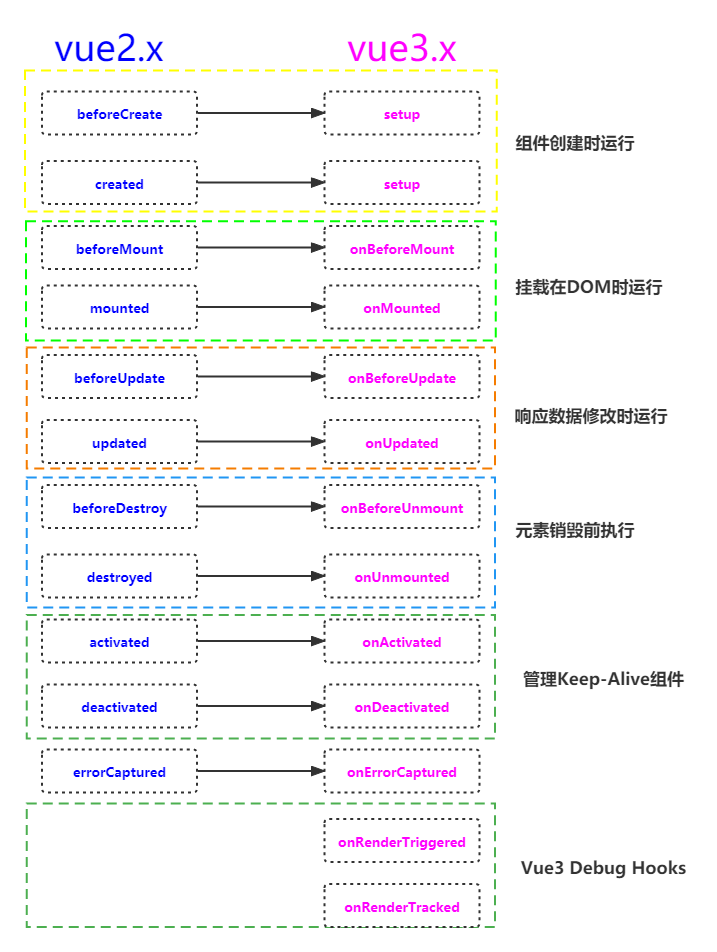
vue3里面生命周期的使用
前言: vue2里面的生命周期和vue3生命周期是非常的相似的,我们通过访问生命周期钩子来处理不同场景之间的应用。 生命周期钩子的函数定义:每一个Vue组件实例在创建时都需要经历一系列的初始化步骤,比如数据侦听,编译模…...

在python的Scikit-learn库中,可以使用train_test_split函数来划分训练集和测试集。
文章目录 一、在Scikit-learn库中,可以使用train_test_split函数来划分训练集和测试集总结 一、在Scikit-learn库中,可以使用train_test_split函数来划分训练集和测试集 在Scikit-learn库中,可以使用train_test_split函数来划分训练集和测试…...

外包干了2个月,技术明显退步了...
先说一下自己的情况,大专生,19年通过校招进入广州某软件公司,干了接近5年的功能测试,今年11月份,感觉自己不能够在这样下去了,长时间呆在一个舒适的环境会让一个人堕落!而我已经在一个企业干了四年的功能测…...

数据结构:链表应用:第9关:删除链表中满足区间值的结点
任务描述编程要求 输入输出测试说明来源 任务描述 本关任务:利用单链表表示一个递增的整数序列,删除链表中值大于等于mink且小于等于maxk的所有元素(mink和maxk是给定的两个参数,其值可以和表中的元素相同,也可以不同…...
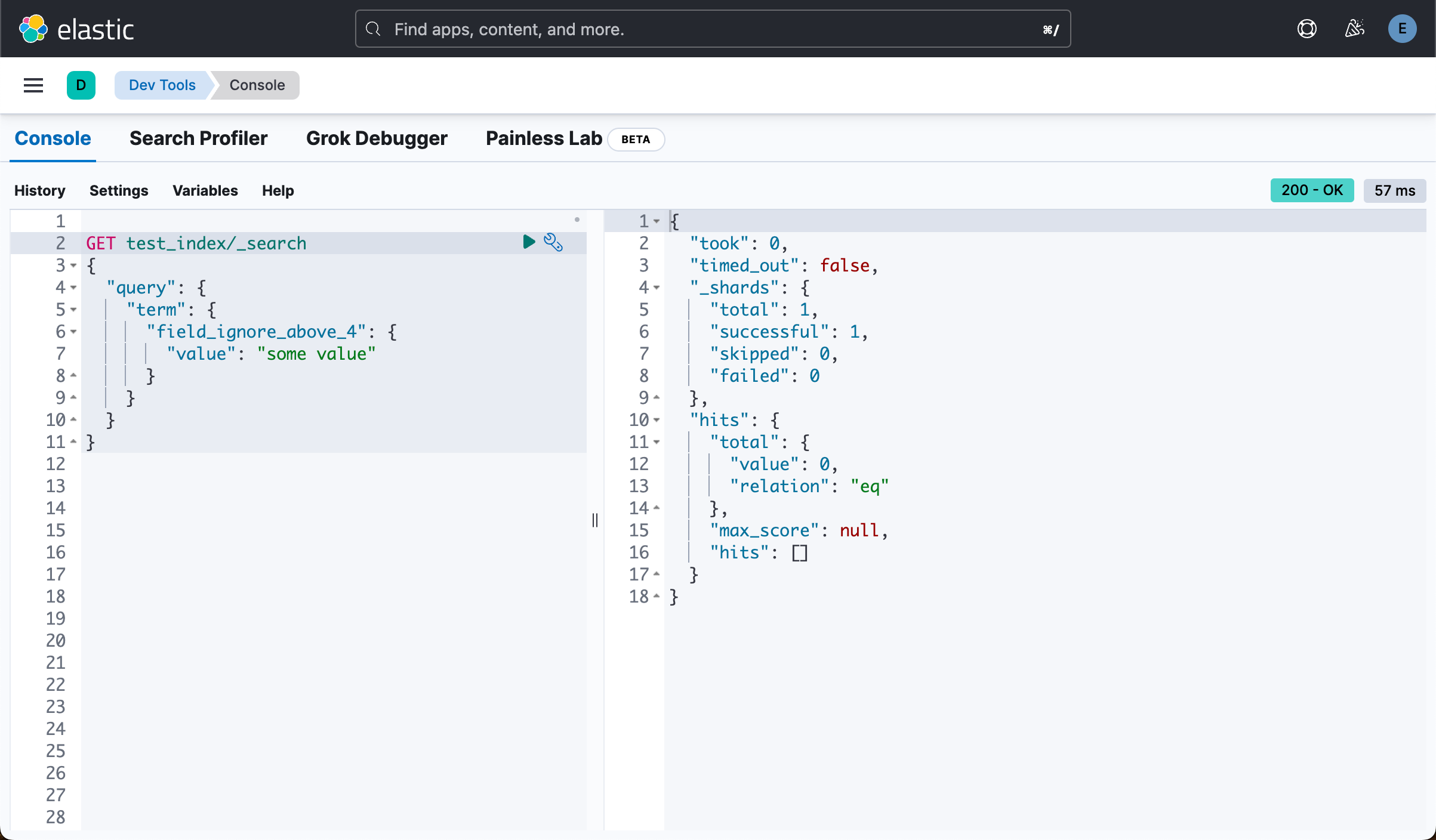
了解 ignore_above 参数对 Elasticsearch 中磁盘使用的影响
在 Elasticsearch 中,ignore_above 参数允许你忽略(而不是索引)长于指定长度的字符串。 这对于限制字段的大小以避免性能问题很有用。 在本文中,我们将探讨 “ignore_above” 参数如何影响 Elasticsearch 中字段的大小,…...

C#中的async/await异步编程模型
前言 当谈到异步编程时,C#中的async/await是一个强大且方便的工具。它使得编写并发和异步操作变得更加简单和可读,同时提供良好的可维护性。本文将详细解释async/await的使用,以及如何在C#中有效地利用它来实现异步操作。 目录 前言1. async…...
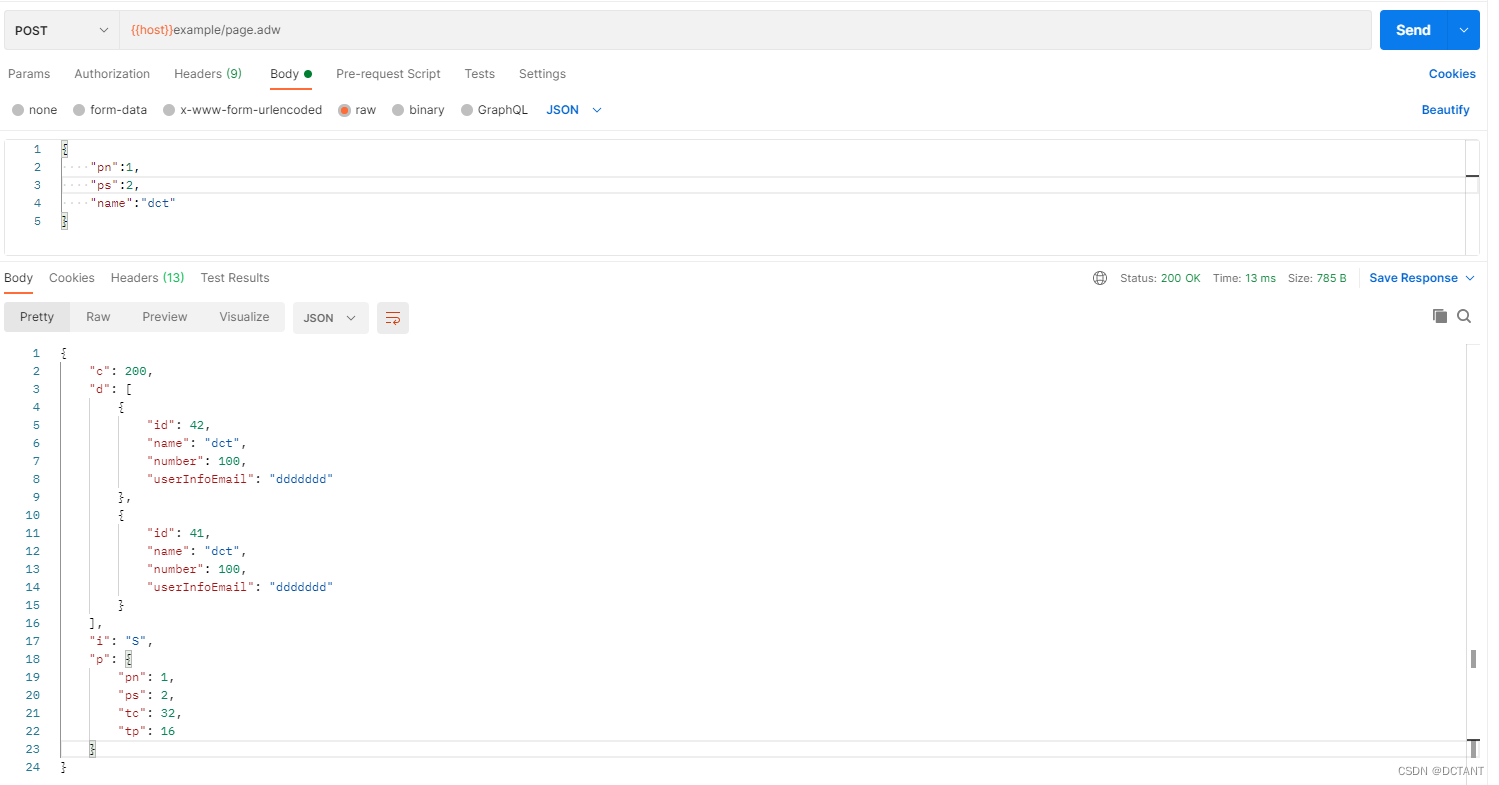
【原创】提升MybatisPlus分页便捷性,制作一个属于自己的分页插件,让代码更加优雅
前言 MybatisPlus的分页插件有一点非常不好,就是要传入一个IPage,别看这个IPage没什么大不了的,最多多写一两行代码,可这带来一个问题,即使用xml的查询没法直接取对象里面变量的值了,得Param指定xml中的变…...

告别锚框烦恼!用DiffDet4SAR在SAR图像里找飞机,实测mAP提升6%
DiffDet4SAR:用扩散模型重构SAR图像目标检测的技术革命 当你在处理SAR图像中的飞机目标检测时,是否也曾被那些繁琐的锚框设计、复杂的超参数调优折磨得焦头烂额?传统方法就像在杂乱的房间里寻找一枚特定的硬币,而DiffDet4SAR带来…...

N7 arm汇编
一、复习C语言变量类型:1.确定分配内存的大小;2.确定使用方法。数组:同类元素的集合---内存连续数组名是数组的首地址,可以当指针使用,但值不能改变数组定义:大小(数组大小不可变)初始化:数组部…...

Java Web 美术馆管理系统系统源码-SpringBoot2+Vue3+MyBatis-Plus+MySQL8.0【含文档】
💡实话实说:有自己的项目库存,不需要找别人拿货再加价,所以能给到超低价格。摘要 美术馆作为文化艺术传播的重要载体,其管理效率直接影响观众的参观体验和艺术资源的有效利用。传统美术馆管理多依赖人工操作࿰…...

uNode++:嵌入式C++轻量级事件驱动框架
1. 项目概述uNode 是一个面向嵌入式设备的轻量级 C 运行时框架,其核心目标是将 Node.js 风格的异步编程模型(事件驱动、非阻塞 I/O、单线程事件循环)无缝移植到资源受限的微控制器平台,特别是 Arduino Uno(ATmega328P&…...

基于NXP S32k1与Simulink的MBD工程实践——从Git仓库克隆到协同建模
1. 从Git仓库克隆Simulink工程到本地 第一次接触基于NXP S32K1的MBD开发时,最让我头疼的就是团队协作问题。不同工程师电脑上的Matlab版本、工具箱配置、工程路径稍有差异,就会导致模型无法正常打开。后来我们发现,用Git管理Simulink工程是解…...
Lite-Avatar创新应用:虚拟展会导览系统开发
Lite-Avatar创新应用:虚拟展会导览系统开发 1. 引言 展会现场人山人海,找不到想看的展台?语言不通看不懂展品介绍?传统的展会导览往往需要大量人力,而且很难满足个性化需求。现在,通过Lite-Avatar技术&am…...

Nanbeige 4.1-3B部署教程:适配RTX 3060/4090的显存优化参数详解
Nanbeige 4.1-3B部署教程:适配RTX 3060/4090的显存优化参数详解 1. 环境准备与快速部署 在开始部署Nanbeige 4.1-3B模型前,我们需要确保硬件和软件环境满足基本要求。 1.1 硬件要求 显卡:NVIDIA RTX 3060(12GB)或RTX 4090(24GB)显存&…...

手把手教你理解Llama2的GQA:从理论到实践的性能提升
手把手教你理解Llama2的GQA:从理论到实践的性能提升 在当今大模型技术快速迭代的背景下,如何平衡模型性能与计算效率成为工程师面临的核心挑战。Llama2作为Meta推出的开源大语言模型,其采用的Group Query Attention(GQA࿰…...
)
Cogito-v1-preview-llama-3B效果展示:多语言API文档生成(中/英/西)
Cogito-v1-preview-llama-3B效果展示:多语言API文档生成(中/英/西) 想探索更多AI镜像和应用场景?访问 CSDN星图镜像广场,提供丰富的预置镜像,覆盖大模型推理、图像生成、视频生成、模型微调等多个领域&…...

电子科技大学计算机复试面试:如何用一份‘挖坑式’简历引导老师提问?
电子科技大学计算机复试面试:如何用一份‘挖坑式’简历引导老师提问? 面试的本质是一场精心设计的对话博弈。对于电子科技大学计算机专业的复试考生而言,简历不仅是经历的罗列,更是引导面试走向的战略地图。本文将揭示如何通过&qu…...