Redis部署-主从模式
目录
单点问题
主从模式
解析主从模式
配置redis主从模式
info replication命令查看复制相关的状态
断开复制关系
安全性
只读
传输延迟
拓扑结构
数据同步psync
replicationid
offset
psync运行流程
全量复制流程
无硬盘模式
部分复制流程
积压缓冲区
实时复制
主从复制的弊端
主节点无法正常启动的原因
单点问题
如果某个服务器程序,只有一个节点(只有一个物理服务器来部署这个服务器程序),那么会引发两个严重的问题:可用性问题:如果这个服务器宕机,意味着整个服务就终端了;性能问题:一台服务器往往支持的并发量和性能是非常有限的.
引入分布式系统,主要就是为了解决上述的单点问题.
在分布式系统中,往往希望有多个服务器来部署redis服务,从而构成一个redis集群,此时就可以让这个集群给整个分布式系统中的其他服务,提供更加稳定和高效的数据存储功能.
在分布式系统中,redis的部署方式主要有:主从模式,主从+哨兵模式和集群模式.
主从模式
解析主从模式
在若干个redis节点中,有的是主节点有的是从节点.
假设现在有三个物理服务器(称为是三个节点)分别部署了一个redis-server进程,此时就可以把其中的一个节点作为主节点,另外的两个节点作为从节点.
从节点就要听取主节点的(从节点上的数据跟随主节点变化,从节点的数据要和主节点上的数据保持一致).
本来,在主节点上保存了一堆数据,引入从节点之后,就要把主节点上的数据,复制出来,放到从节点上,后续主节点上对于数据有任何的修改,都会把这样的修改给同步到从节点上.
所以,从节点就相当于是主节点的副本.
需要注意的是,在redis的主从模式中,从节点上的数据,是不允许修改的,从节点只能进行读取数据的操作!!!
之前只是单个redis服务节点,此时这个机器挂了,整个redis就挂了,但当我们引入主从模式之后,整个系统的可用性就大大提高了.因为上述的主从结构,不太可能出现这些redis机器同时宕机的情况.考虑到更高的可用性,我们也可以把这些机器放到不同的机房中.(异地多活)
由于从节点的数据都是和主节点保持一致的,因此客户从主节点读取数据和从从节点读取数据时没有区别的.所以后续如果有客户来读取数据,就可以从上述节点中随机挑选一个节点给这个客户端来提供读取数据的服务.这样,就能大大提高支持的并发量.
准确来说,主从模式,主要是针对读操作进行并发量和可用性的提高,对于写操作,无论是可用性还是并发性,都是非常依赖主节点的,但是主节点就只有一个.(如果主节点搞多个,那么数据的同步会非常麻烦)
在实际的业务场景中,读操作是比写操作要频繁的多的.
配置redis主从模式
配置redis主从模式,首先要启动多个redis服务器,正常来说,每个redis服务器是应该在一个单独的主机上(这才是真正的分布式),但是由于当前学习资源有限,就在同一个云服务器上来运行多个redis-server进程.
在一台机器上运行多个redis-server进程时,要保证这些进程的端口是不可以冲突的.
指定redis-server的端口有两种方式,一种是在启动程序的时候,通过命令行来指定端口号,--port选项;一种是在配置文件中来设定端口.
我们在这里将创建一个主节点和两个从节点.主节点的配置文件不用改变,只需要修改从节点的配置文件即可.

创建一个新目录,将redis的配置文件复制两份到此目录下.
将这两个配置文件中的port改为6380和6381,并且设定damenize为yes(按照后台进程的方式来执行).


配置完成之后,通过命令行的形式来启动这两个redis.
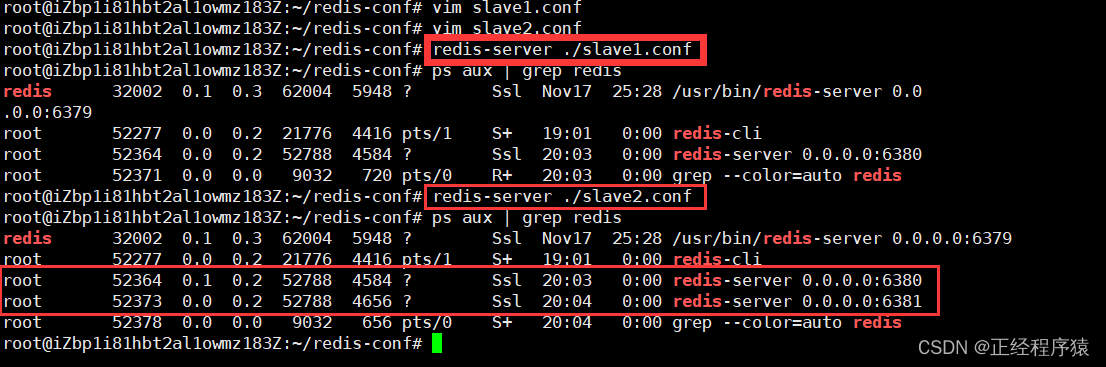
到这里,当前这几个节点并没有构成主从结构,而是各自为政,要想真正成为主从结构,还需要进一步的进行配置.
要想配置成为主从结构,就需要使用slaveof.
1.在配置⽂件中加⼊ slaveof {masterHost} {masterPort} 随 Redis 启动⽣效。
2. 在 redis-server 启动命令时加⼊ --slaveof {masterHost} {masterPort} ⽣效。
3. 直接使⽤ redis 命令:slaveof {masterHost} {masterPort} ⽣效
这里推荐使用修改配置文件的方式,会一直持久生效.
我们配置以6379为主节点,6380和6381为从节点.
在从节点的配置文件中加入slaveof配置项.

修改完配置文件之后,需要重新启动才能生效.
我们要使用kill -9的方式来停止这两个redis-server,这个停止方式是和我们直接运行redis的时候的命令是搭配的.
而如果是使用service redis-server start的方式启动,则必须使用service redis-server stop来进行停止.此时如果使用kill -9的方式停止,这个redis-server进程会自动启动.
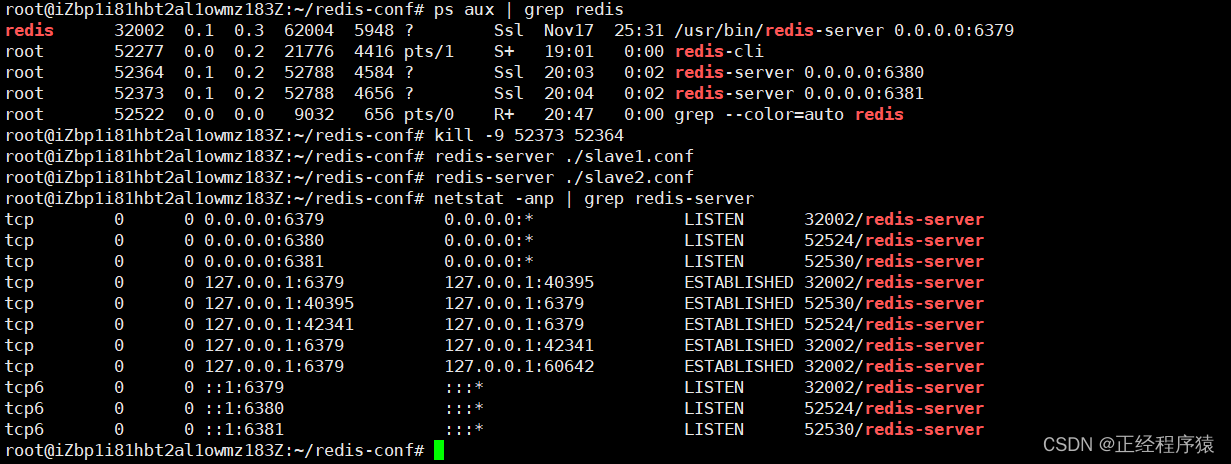
当重新启动后,从节点和主节点之间就建立了tcp连接.
主节点这边数据产生的修改,从节点就能立即感知到,就是上述这些tcp连接起到的效果.

此时在从节点中写入数据就会报错!!!
info replication命令查看复制相关的状态
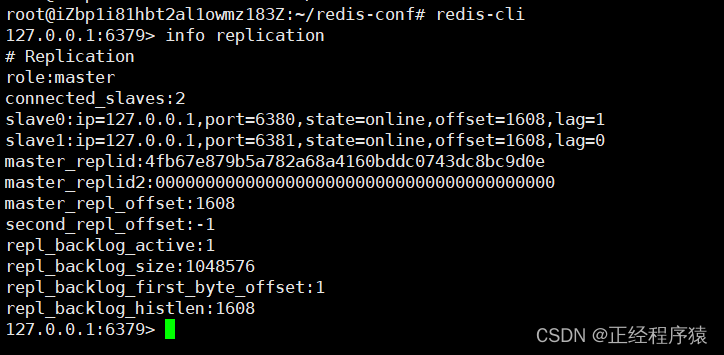
主节点的复制状态信息
从节点的复制状态信息(6380)

offset就表示从节点和主节点之间同步数据的进度.(从节点和主节点之间的数据同步不是瞬间完成的,靠网络传输,所以有延迟)
replid可以认为是主节点的身份标识.
断开复制关系
slaveof命令不仅可以建立复制,还可以在从节点上执行slaveof no one命令来断开与主节点之间的复制关系.
断开复制关系流程包括两步:
1.断开与主节点之间的复制关系.
2.从节点晋升为主节点.
从节点断开复制后并不会抛弃原有的数据,只是无法在获取主节点上的数据变化.
通过slaveof命令还可以实现切换主节点的操作,,将当前从节点的数据源切换到另⼀个主节点。执⾏
slaveof {newMasterIp} {newMasterPort} 命令即可。
切主操作的主要流程:
- 断开与旧主节点的复制关系.
- 与新主节点建立复制关系
- 删除从节点上当前的所有数据
- 与新主节点进行复制操作
安全性
对于数据⽐较重要的节点,主节点会通过设置 requirepass 参数进⾏密码验证,这时所有的客⼾
端访问必须使⽤ auth 命令实⾏校验。从节点与主节点的复制连接是通过⼀个特殊标识的客⼾端来完成,因此需要配置从节点的masterauth 参数与主节点密码保持⼀致,这样从节点才可以正确地连接到主节点并发起复制流程。
只读
默认情况下,从节点使⽤ slave-read-only=yes 配置为只读模式。由于复制只能从主节点到从节
点,对于从节点的任何修改主节点都⽆法感知,修改从节点会造成主从数据不⼀致。所以建议线上不要修改从节点的只读模式。
传输延迟
主从节点⼀般部署在不同机器上,复制时的⽹络延迟就成为需要考虑的问题,Redis 为我们提供
了 repl-disable-tcp-nodelay 参数⽤于控制是否关闭 TCP_NODELAY,默认为 no,即开启 tcp_nodelay 功能,说明如下:
• 当关闭时,主节点产⽣的命令数据⽆论⼤⼩都会及时地发送给从节点,这样主从之间延迟会变⼩,但增加了⽹络带宽的消耗。适⽤于主从之间的⽹络环境良好的场景,如同机房部署。
• 当开启时,主节点会合并较⼩的 TCP 数据包从⽽节省带宽。默认发送时间间隔取决于 Linux 的内
核,⼀般默认为 40 毫秒。这种配置节省了带宽但增⼤主从之间的延迟。适⽤于主从⽹络环境复杂
的场景,如跨机房部署.
拓扑结构
主从模式的拓扑结构描述了若干个节点之间,是按照什么样的方式来进行组织连接的.
常见的拓扑结构有:一主一从拓扑,一主多从拓扑和树形拓扑.
一主一从
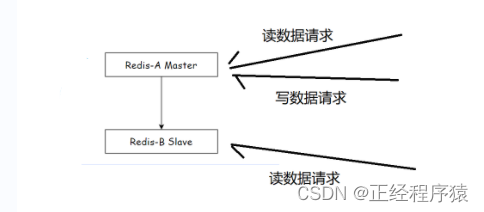
如果写数据的请求太多,此时也会给主节点造成很大压力,可以通过关闭主节点的AOF来缓解主节点的压力,只在从节点这里开启aof.
但是这种设定方式,有一个严重缺陷:主节点一旦宕机,不能让它自动重启,如果自动重启,此时没有aof文件,就会丢失数据,进一步的主从同步会把从节点的数据也给删除.
所以,当主节点挂了之后,就需要让主节点从从节点这里获取到aof的文件,在启动.
一主多从

扁平化结构,此结构一旦从节点个数增加很多,那么主节点同步一条数据就需要传输多次,可能会消耗大量的网络带宽.
树形结构

主节点同步数据不会消耗那么多的网络带宽了,但是一旦数据进行同步,同步的延迟是比较长的,因为要要进行多次网络传输.
复制过程
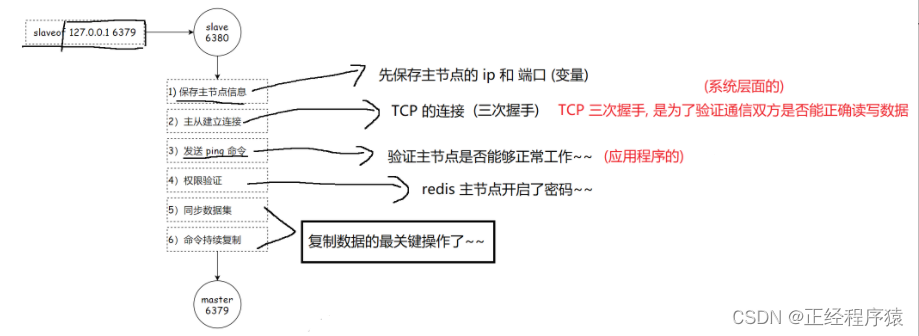
注意的是其中同步数据集这步操作,对于首次建立复制的场景,主节点会把当前所持有的所有数据全部发送给从节点,这步的操作耗时最长,所以又划分为两种情况:全量复制和部分复制.
数据同步psync
redis使用psync命令完成主从数据同步,同步过程分为:全量复制和部分复制.
psync不需要我们手动执行,redis服务器会在建立好主从复制关系之后,自动执行psync.
从节点负责执行psync,从节点从主节点这边拉取数据.
psync的命令格式:PSYNC replicationid offset.
如果replicationid设为?,offset设为-1,此时就是在尝试进行全量复制.
如果replicationid和offset设置了具体的值,则是尝试进行部分复制.
replicationid
replication是复制的意思,这个就表示是一个复制id.
replicationid是由主节点生成的,主节点启动的时候就会生成,从节点晋升为主节点的时候,也会生成.
(即使是同一个主节点,每次重启的时候,生成的replicationid都是不同的).
从节点和主节点建立了复制关系,从节点就会从主节点这里获取到replicationid.

一般replid2用不上.假设此时有一个主节点A和一个从节点B.A负责生成replid,B负责获取A的replid.
如果A和B在通信过程中出现了网络抖动,B可能会认为A挂了,此时B就会自己成为主节点,(给自己也生成一个replid),但是B也会保存之前旧的replid,这个旧的replid就会保存在replid2中,方便后续网络稳定之后,B重新与A建立复制关系.在主从模式下,上述过程需要手动干预,而哨兵模式下可以自动完成.
offset
表示偏移量.主节点和从节点上都会维护偏移量(整数).
主节点的偏移量会根据收到的修改命令占据的字节数来将offset进行累加.
从节点的偏移量就描述了,当前从节点数据同步的进度.
如果主节点的offset和从节点的offset一样,就说明从节点的数据和主节点的数据一致了.
从节点每秒钟会上报自身的复制偏移量给主节点.
综上,replicationid和offset就描述出一个数据集,就可以表示从节点从哪里复制的数据,复制到哪里了!!!!
psync运行流程

- 从节点发送psync命令给主节点,replid和offset的默认值分别是?和-1.
- 主节点根据psync的参数和自身的情况决定响应结果.
- 如果回复+FULLRESYNC replid offset,则从节点需要进行全量复制流程
- 如果回复+CONTINUE,从节点进行部分复制流程
- 如果回复-ERR,说明redis主节点版本过低,不支持psync命令.此时从节点可以使用sync命令进行全量复制.
注意:psync一般不需要进行手动执行,redis会在主从模式下自动调用执行.
sync命令(1.0.0版本就有),会阻塞redis-server处理其他的请求,而psync命令则不会.
全量复制流程
何时进行全量复制:首次和主节点进行数据同步或者主节点不方便进行部分复制的时候.
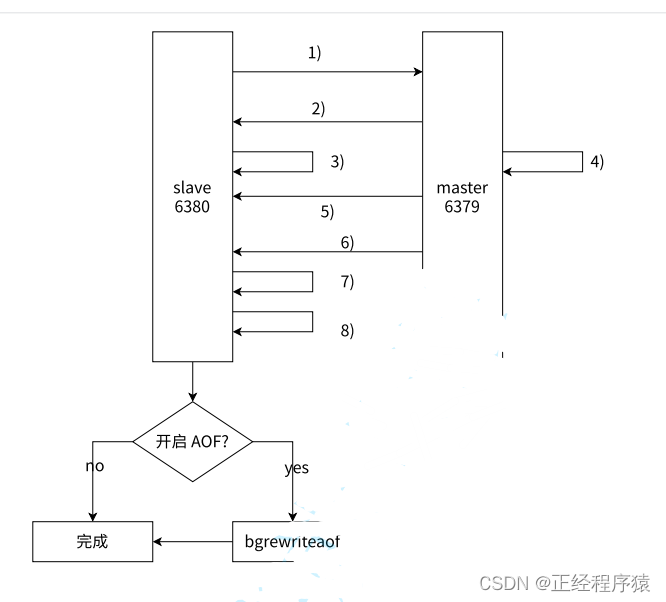
无硬盘模式
部分复制流程
全量复制虽然稳妥,但是比较低效,开销比较大.
有些时候,从节点本身已经持有了主节点的绝大部分数据,就不需要再进行全量复制了.
比如出现网络抖动,主节点最近修改的数据无法同步给从节点,进一步可能从节点已经感知不到主节点了.但是网络抖动一般是暂时的,网络恢复之后,此时就可以让从节点和主节点重新建立连接.重建连接之后,再进行数据的同步,具体是全量复制还是部分部分复制还是要看具体的交互流程.
psync带有具体的参数值,主节点就要根据参数和当前自身情况进行判定,当前这次是按照全量复制合适还是部分复制合适.

积压缓冲区
积压缓冲区是保存在主节点上的⼀个固定⻓度的队列,默认⼤⼩为 1MB,当主节点有连接的从节 点(slave)时被创建,这时主节点(master)响应写命令时,不但会把命令发送给从节点,还会写⼊复制积压缓冲区.由于缓冲区本质上是先进先出的定⻓队列,所以能实现保存最近已复制数据的功能,⽤于部分复制和复制命令丢失的数据补救.
积压缓冲区的信息可以在主节点的info replication中查看.
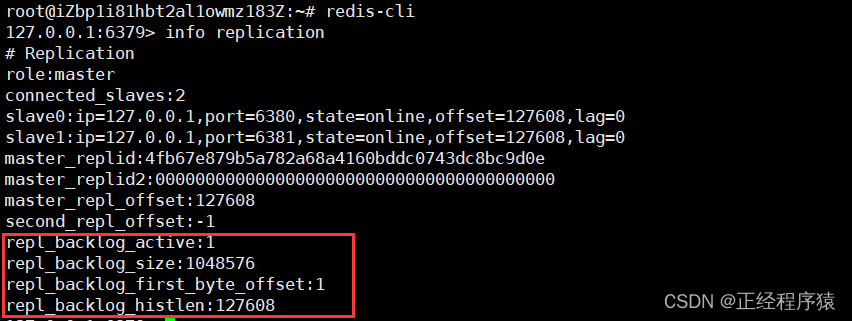
图中四项分别表示:开启复制缓冲区,缓冲区最大长度,起始偏移量(可用于计算当前缓冲区可用范围),已保存数据的有效长度.
实时复制
当从节点和主节点执行完全量复制或者部分复制之后,这一时刻从节点和主节点的数据就一致了.但是之后,主节点还会收到源源不断的新的修改数据的请求,主节点上的数据也会随之改变,此时就需要能将这些数据也同步给主节点.
所以从节点和主节点之间会建立tcp长连接,然后主节点会把自己收到的修改数据的请求,通过tcp连接发给从节点,从节点会根据收到这些修改请求来修改内存中的数据,来保持和主节点的数据一致.
在进行实时复制的时候,需要保证连接处于可用状态,在此处使用心跳包机制来实现.
主节点:默认每隔10s给从节点发送一个ping命令,从节点收到返回pong.
从节点:默认每隔1s就给主节点发起一个特定的请求,就会上报当前从节点复制的进度(offset).
这里的数值都可以可以配置.
主从复制的弊端
从节点和主节点之间断开连接,有两种情况:
1.从节点主动和主节点之间断开连接.从节点执行slaveof no one.此时从节点能够自动晋升为主节点.
2.主节点崩溃.这个时候,从节点不会自动晋升为主节点,必须通过人工干预的方式,恢复主节点.
当主节点挂了之后,从节点无法感知到主节点,就迷茫了.虽然能够提供读操作,但是此时从节点不能自动升级成为主节点,此时就只能程序员/运维来手工恢复主节点.这一过程是非常繁琐的!!!
Redis哨兵就实现了对挂了的主节点自动进行替换的功能,省去了人工手动恢复的过程.
主节点无法正常启动的原因

在现在三个节点在同一主机上的场景下,如果尝试重新启动主节点,会重启失败!!!
原因就在于这个aof文件是属于root用户的,其他用户对这个文件就只有可读权限.
从节点是通过手动启动的方式,此时root用户下启动redis服务器,于是生成的aof文件也是root用户的文件.
而通过service redis-server start的方式启动redis服务器,是通过一个redis用户来启动,那么生成的文件所属就是redis用户.
redis server需要按照可读可写的方式来打开这个aof文件,而此时这个文件对于root之外的用户就只是可读权限,因此主节点重启时就无法打开这个文件,就启动失败了.
本质的原因就是我们把三个节点的工作目录都放在了一起.
解决方案:可以将三个节点的工作目录区分开,修改配置文件中的dir选项.
步骤
1.停止之前的redis服务器.
2.删除之前工作目录下的aof文件或者可以通过chown命令修改aof文件的所属用户.
chown redis:redis appendonly.aof
将用户修改为redis,组别也修改为redis.
3.给从节点创建新的目录来作为其工作目录,并且修改从节点的配置文件,设定新的目录为其工作目录.
4.启动redis服务器.
相关文章:
Redis部署-主从模式
目录 单点问题 主从模式 解析主从模式 配置redis主从模式 info replication命令查看复制相关的状态 断开复制关系 安全性 只读 传输延迟 拓扑结构 数据同步psync replicationid offset psync运行流程 全量复制流程 无硬盘模式 部分复制流程 积压缓冲区 实时复…...

全栈冲刺 之 一天速成MySQL
一、为什么使用数据库 数据储存在哪里? 硬盘、网盘、U盘、光盘、内存(临时存储) 数据持久化 使用文件来进行存储,数据库也是一种文件,像excel ,xml 这些都可以进行数据的存储,但大量数据操作…...

服务器运行train.py报错解决
在服务器配置完虚拟环境以及安装完各种所需库后,发现报错Traceback (most recent call last): File "/root/yolov5-master/yolov5-master/train.py", line 48, in <module> import val as validate # for end-of-epoch mAP File "/root/yolov5…...

Flutter开发type ‘Future<int>‘ is not a subtype of type ‘int‘ in type cast错误
文章目录 问题描述错误源码 问题分析解决方法修改后的代码 问题描述 今天有个同事调试flutter程序时报错,问我怎么解决,程序运行时报如下错误: type ‘Future’ is not a subtype of type ‘int’ in type cast 错误源码 int order Databas…...
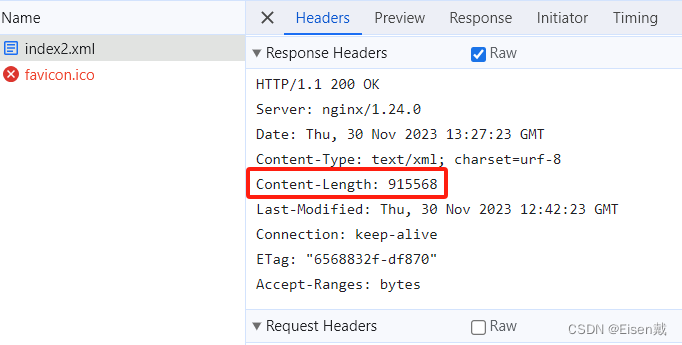
Nginx(十二) gzip gzip_static sendfile directio aio 组合使用测试(2)
测试10:开启gzip、sendfile、aio、directio1m,关闭gzip_static,请求/index.js {"time_iso8601":"2023-11-30T17:20:5508:00","request_uri":"/index.js","status":"200","…...

hls实现播放m3u8视频将视频流进行切片 HLS.js简介
github官网GitHub - video-dev/hls.js: HLS.js is a JavaScript library that plays HLS in browsers with support for MSE.HLS.js is a JavaScript library that plays HLS in browsers with support for MSE. - GitHub - video-dev/hls.js: HLS.js is a JavaScript library …...
Ubuntu20.04部署TVM流程及编译优化模型示例
前言:记录自己安装TVM的流程,以及一个简单的利用TVM编译模型并执行的示例。 1,官网下载TVM源码 git clone --recursive https://github.com/apache/tvmgit submodule init git submodule update顺便完成准备工作,比如升级cmake版本…...
)
华为OD机试真题-两个字符串间的最短路径问题-2023年OD统一考试(C卷)
题目描述: 给定两个字符串,分别为字符串A与字符串B。例如A字符串为ABCABBA,B字符串为CBABAC可以得到下图m*n的二维数组,定义原点为(0, 0),终点为(m, n),水平与垂直的每一条边距离为1,映射成坐标系如下图。 从原点(0, 0)到(0, A)为水平边,距离为1,从(0, A)到(A, C)为垂…...

python try-except
相比于直接raise ValueError,使用try-except可以使程序在发生异常后仍然能够运行。 在try的部分中,当遇到第一个Error,就跳转到except中寻找对应类型的error,后续代码不再执行,如果try中有多个Error,注意顺…...

flutter开发实战-ValueListenableBuilder实现局部刷新功能
flutter开发实战-ValueListenableBuilder实现局部刷新功能 在创建的新工程中,点击按钮更新counter后,通过setState可以出发本类的build方法进行更新。当我们只需要更新一小部分控件的时候,通过setState就不太合适了,这就需要进行…...
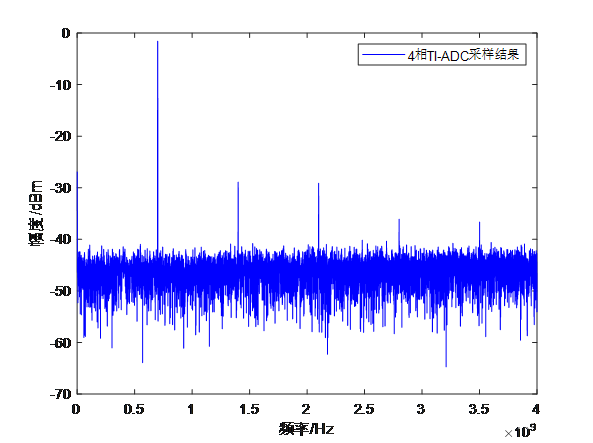
通过时间交织技术扩展ADC采样速率的简要原理
前言 数据采集是将自然界中存在的模拟信号通过模数转换器(ADC)转换成数字信号,再对该数字信号进行相应的接收和处理。数据采集系统作为数据采集的手段,在移动通信、图向采集、无线电等领域有重要作用。随着电子信息技术的飞速发展…...

FluxMQ—2.0.8版本更新内容
FluxMQ—2.0.8版本更新内容 前言 FLuxMQ是一款基于java开发,支持无限设备连接的云原生分布式物联网接入平台。FluxMQ基于Netty开发,底层采用Reactor3反应堆模型,具备低延迟,高吞吐量,千万、亿级别设备连接࿱…...
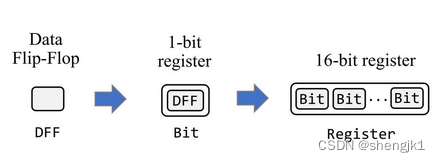
计算机寄存器是如何实现的
冯诺依曼体系 冯诺依曼体系为现代计算机的设计和发展奠定了基础,它的核心思想和原则在当今计算机体系结构中仍然被广泛采用和应用。所以只要谈论计算机的组成就离不开冯诺依曼体系 作为核心组成部分的CPU除了由运算器和控制器组成之外,还有一些寄存器…...

两数之和 三数之和 哈希方法
两数之和 package com; import java.util.*; public class Test5 { //两数之和 public static void main(String[] args) { int[] arr {1,2,3,4,5,6,7,94,42,35}; int target99; Arrays.sort(arr);//快速排序 for(int i0;i<arr.length;i) { int wtarget-arr[i]; int indexA…...

Object Detection in 20 Years: A Survey(2019.5)
文章目录 Abstract1. Introduction1.1. Difference from other related reviews1.2. Difficulties and Challenges in Object Detection 2. OBJECT DETECTION IN 20 YEARS2.1. 目标检测路线图2.1.1. 里程碑:传统探测器(粗略了解)2.1.2. 里程碑:基于CNN的…...

Springboot 设置时区与日期格式
1.配置文件修改(范围修改) spring:jackson:# 东8 北京时区time-zone: GMT8# 日期格式date-format: yyyy-MM-dd HH:mm:ss 2.Java代码修改(范围修改) 2.1 时区 import org.springframework.context.annotation.Bean; import org.…...

从零开始学Go web——第一天
文章目录 从零开始学Go web——第一天一、Go与web应用简介1.1 Go的可扩展性1.2 Go的模块化1.3 Go的可维护1.4 Go的高性能 二、web应用2.1 工作原理2.2 各个组成部分2.2.1 处理器2.2.2 模板引擎 三、HTTP简介四、HTTP请求4.1 请求的文本数据4.2 请求方法4.2.1 请求方法类型4.2.2…...
6.Eclipse里下载Subclipse插件
方法一:从Eclipse Marketplace里面下载 具体操作:打开Eclipse --> Help --> Eclipse Marketplace --> 在Find中输入subclipse搜索 --> 找到subclipse点击install 方法二:从Install New Software里下载 具体操作:打开…...

家用洗地机哪个品牌最好最实用?热门洗地机测评
随着社会的不断进步,我们逐渐意识到日常生活中的许多任务需要消耗大量的时间和体力。一个典型的例子是卫生清洁工作,尤其是在大面积地区,如大型建筑物、商场或工厂。这些任务不仅繁琐,还可能影响生活质量和工作效率。为了应对这一…...

【C语言:自定义类型(结构体、位段、共用体、枚举)】
文章目录 1.结构体1.1什么是结构体1.2结构体类型声明1.3结构体变量的定义和初始化1.4结构体的访问 2.结构体对齐2.1如何对齐2.2为什么存在内存对齐? 3.结构体实现位段3.1什么是位段3.2位段的内存分配3.3位段的跨平台问题3.4位段的应用3.5位段使用注意事项 4.联合体4…...

iPhone密码忘记了办?iPhoneUnlocker,iPhone解锁工具Aiseesoft iPhone Unlocker 高级注册版分享
平时用 iPhone 的时候,难免会碰到解锁的麻烦事。比如密码忘了、人脸识别 / 指纹识别突然不灵,或者买了二手 iPhone 却被原来的 iCloud 账号锁住,这时候就需要靠谱的解锁工具来帮忙了。Aiseesoft iPhone Unlocker 就是专门解决这些问题的软件&…...

连锁超市冷库节能解决方案:如何实现超市降本增效
在连锁超市冷库运营中,高能耗、设备损耗快、人工管理低效等问题长期困扰企业。御控冷库节能解决方案通过智能控制化霜、按需化霜、实时监控、故障诊断、自动预警、远程控制开关六大核心技术,实现年省电费15%-60%,且不改动原有装备、安装快捷、…...

基础测试工具使用经验
背景 vtune,perf, nsight system等基础测试工具,都是用过的,但是没有记录,都逐渐忘了。所以写这篇博客总结记录一下,只要以后发现新的用法,就记得来编辑补充一下 perf 比较基础的用法: 先改这…...
:滤镜命令)
ffmpeg(四):滤镜命令
FFmpeg 的滤镜命令是用于音视频处理中的强大工具,可以完成剪裁、缩放、加水印、调色、合成、旋转、模糊、叠加字幕等复杂的操作。其核心语法格式一般如下: ffmpeg -i input.mp4 -vf "滤镜参数" output.mp4或者带音频滤镜: ffmpeg…...

Spring Boot面试题精选汇总
🤟致敬读者 🟩感谢阅读🟦笑口常开🟪生日快乐⬛早点睡觉 📘博主相关 🟧博主信息🟨博客首页🟫专栏推荐🟥活动信息 文章目录 Spring Boot面试题精选汇总⚙️ **一、核心概…...

Axios请求超时重发机制
Axios 超时重新请求实现方案 在 Axios 中实现超时重新请求可以通过以下几种方式: 1. 使用拦截器实现自动重试 import axios from axios;// 创建axios实例 const instance axios.create();// 设置超时时间 instance.defaults.timeout 5000;// 最大重试次数 cons…...

自然语言处理——Transformer
自然语言处理——Transformer 自注意力机制多头注意力机制Transformer 虽然循环神经网络可以对具有序列特性的数据非常有效,它能挖掘数据中的时序信息以及语义信息,但是它有一个很大的缺陷——很难并行化。 我们可以考虑用CNN来替代RNN,但是…...

Rapidio门铃消息FIFO溢出机制
关于RapidIO门铃消息FIFO的溢出机制及其与中断抖动的关系,以下是深入解析: 门铃FIFO溢出的本质 在RapidIO系统中,门铃消息FIFO是硬件控制器内部的缓冲区,用于临时存储接收到的门铃消息(Doorbell Message)。…...

用机器学习破解新能源领域的“弃风”难题
音乐发烧友深有体会,玩音乐的本质就是玩电网。火电声音偏暖,水电偏冷,风电偏空旷。至于太阳能发的电,则略显朦胧和单薄。 不知你是否有感觉,近两年家里的音响声音越来越冷,听起来越来越单薄? —…...

JVM虚拟机:内存结构、垃圾回收、性能优化
1、JVM虚拟机的简介 Java 虚拟机(Java Virtual Machine 简称:JVM)是运行所有 Java 程序的抽象计算机,是 Java 语言的运行环境,实现了 Java 程序的跨平台特性。JVM 屏蔽了与具体操作系统平台相关的信息,使得 Java 程序只需生成在 JVM 上运行的目标代码(字节码),就可以…...