10折交叉验证(10-fold Cross Validation)与留一法(Leave-One-Out)
概念:
交叉验证法,就是把一个大的数据集分为 k个小数据集,其中 k − 1 个作为训练集,剩下的 1 个作为测试集,在训练和测试的时候依次选择训练集和它对应的测试集。这种方法也被叫做 k 折交叉验证法(k-fold cross validation)。最终的结果是这 k 次验证的均值。
十折交叉验证是将训练集分割成10个子样本,一个单独的子样本被保留作为验证模型的数据,其他9个样本用来训练。交叉验证重复10次,每个子样本验证一次,平均10次的结果或者使用其它结合方式,最终得到一个单一估测。这个方法的优势在于,同时重复运用随机产生的子样本进行训练和验证,每次的结果验证一次,10次交叉验证是最常用的。
此外,还有一种交叉验证方法就是 留一法(Leave-One-Out,简称LOO),顾名思义,就是使 k 等于数据集中数据的个数,每次只使用一个作为测试集,剩下的全部作为训练集,这种方法得出的结果与训练整个测试集的期望值最为接近,但是成本过于庞大。
在机器学习领域,n折交叉验证(n是数据集中样本的数目)被称为留一法。我们已经提到,留一法的一个优点是每次迭代中都使用了最大可能数目的样本来训练。另一个优点是该方法具有确定性。
我们用SKlearn库来实现一下LOO:
from sklearn.model_selection import LeaveOneOut# 一维示例数据
data_dim1 = [1, 2, 3, 4, 5]# 二维示例数据
data_dim2 = [[1, 1, 1, 1],[2, 2, 2, 2],[3, 3, 3, 3],[4, 4, 4, 4],[5, 5, 5, 5]]loo = LeaveOneOut() # 实例化LOO对象# 取LOO训练、测试集数据索引
for train_idx, test_idx in loo.split(data_dim1):# train_idx 是指训练数据在总数据集上的索引位置# test_idx 是指测试数据在总数据集上的索引位置print("train_index: %s, test_index %s" % (train_idx, test_idx))# 取LOO训练、测试集数据值
for train_idx, test_idx in loo.split(data_dim1):# train_idx 是指训练数据在总数据集上的索引位置# test_idx 是指测试数据在总数据集上的索引位置train_data = [data_dim1[i] for i in train_idx]test_data = [data_dim1[i] for i in test_idx]print("train_data: %s, test_data %s" % (train_data, test_data))
data_dim1的输出:
train_index: [1 2 3 4], test_index [0]
train_index: [0 2 3 4], test_index [1]
train_index: [0 1 3 4], test_index [2]
train_index: [0 1 2 4], test_index [3]
train_index: [0 1 2 3], test_index [4]train_data: [2, 3, 4, 5], test_data [1]
train_data: [1, 3, 4, 5], test_data [2]
train_data: [1, 2, 4, 5], test_data [3]
train_data: [1, 2, 3, 5], test_data [4]
train_data: [1, 2, 3, 4], test_data [5]
data_dim2的输出:
train_index: [1 2 3 4], test_index [0]
train_index: [0 2 3 4], test_index [1]
train_index: [0 1 3 4], test_index [2]
train_index: [0 1 2 4], test_index [3]
train_index: [0 1 2 3], test_index [4]train_data: [[2, 2, 2, 2], [3, 3, 3, 3], [4, 4, 4, 4], [5, 5, 5, 5]], test_data [[1, 1, 1, 1]]
train_data: [[1, 1, 1, 1], [3, 3, 3, 3], [4, 4, 4, 4], [5, 5, 5, 5]], test_data [[2, 2, 2, 2]]
train_data: [[1, 1, 1, 1], [2, 2, 2, 2], [4, 4, 4, 4], [5, 5, 5, 5]], test_data [[3, 3, 3, 3]]
train_data: [[1, 1, 1, 1], [2, 2, 2, 2], [3, 3, 3, 3], [5, 5, 5, 5]], test_data [[4, 4, 4, 4]]
train_data: [[1, 1, 1, 1], [2, 2, 2, 2], [3, 3, 3, 3], [4, 4, 4, 4]], test_data [[5, 5, 5, 5]]
使用sklearn库的KFold模块进行随机森林十折交叉验证:
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score, KFold
from sklearn.datasets import load_iris# 加载数据集(以鸢尾花数据集为例)
iris = load_iris()
X = iris.data
y = iris.target# 创建随机森林分类器
rf_classifier = RandomForestClassifier(n_estimators=100)# 创建十折交叉验证对象
kfold = KFold(n_splits=10)# 执行十折交叉验证
scores = cross_val_score(rf_classifier, X, y, cv=kfold)# 输出每折的准确率
for i, score in enumerate(scores):print("Fold {}: {:.4f}".format(i+1, score))# 输出平均准确率
print("Average Accuracy: {:.4f}".format(scores.mean()))
代码解释
在上述代码中
首先,导入了RandomForestClassifier(随机森林分类器)、cross_val_score(交叉验证函数)、KFold(交叉验证生成器)和load_iris(加载鸢尾花数据集)等必要的模块和函数。
然后,我们加载了鸢尾花数据集,并将特征数据赋值给X,目标变量赋值给y。
接下来,我们创建了一个随机森林分类器对象rf_classifier,并指定了树的数量为100。
然后,我们创建了一个KFold对象kfold,其中n_splits参数指定了将数据集分成几个折(这里是十折)。
最后,我们使用cross_val_score函数进行十折交叉验证,传入随机森林分类器对象、特征数据X和目标变量y,并指定交叉验证对象为kfold。函数将返回每个折的准确率。
最后,我们遍历输出每折的准确率,并计算并输出平均准确率。
请注意,以上代码只是一个示例,并假设您已经安装了scikit-learn库。您可以根据自己的数据集和需求进行适当的修改。
错误分析
在实验中遇到了结果为负数的情况,分析了原因如下。
Fold 1: -276.8099
Fold 2: -273.9000
Fold 3: -352.8485
Fold 4: -341.5226
Fold 5: -303.3925
Fold 6: -121.9296
Fold 7: -119.7461
Fold 8: -232.8983
Fold 9: -366.5070
Fold 10: -300.5332
Average Accuracy: -269.0088
根据以上结果,准确率的值为负数,这在一般情况下是不可能的,因为准确率的范围通常是0到1之间。负数的准确率可能是由于以下原因之一导致的:
评估指标选择错误:可能是您在计算准确率时选择了错误的评估指标。在cross_val_score函数中,默认情况下使用了分类问题的准确率评估指标,但如果您的问题是回归问题,那么准确率评估指标不适用。请确保您选择了适当的评估指标。
数据标签处理错误:检查一下您的目标变量y的标签是否被正确处理。如果目标变量的标签是连续值而不是分类值,并且您错误地将其用作分类变量进行训练和评估,那么会导致不正常的结果。确保目标变量是分类变量,并且其标签被正确地映射到类别。
数据集划分错误:在执行交叉验证时,确保数据集的划分是正确的。可能存在数据泄漏或未正确随机化数据的问题。使用KFold对象进行交叉验证时,确保数据的划分是随机且平衡的。
数据预处理错误:在应用随机森林算法之前,对数据进行预处理是很重要的。请确保数据被正确地缩放、编码或进行其他必要的预处理步骤。特别是对于包含连续值特征的数据,可能需要进行标准化或归一化处理。
请检查上述可能导致不正常结果的因素,并确保数据处理和代码逻辑的正确性。如果问题仍然存在,请提供更多的代码和数据细节,以便更好地理解问题并提供帮助。
根据以上结果,准确率的值看起来非常不正常。这个问题可能是由于数据处理或代码逻辑上的错误导致的。下面是一些可能导致此问题的原因:
数据处理错误:请确保您的特征数据X和目标变量y被正确加载和处理。检查数据的维度、数据类型和缺失值等问题。确保特征数据和目标变量的数量和顺序匹配。
参数设置错误:在随机森林分类器的初始化中,可能存在一些参数设置错误。例如,n_estimators参数指定了树的数量,确保它设置为一个合理的值。还要注意其他与随机森林相关的参数,如max_depth、min_samples_split等,以确保它们适合您的数据集。
交叉验证错误:在创建KFold对象时,确保n_splits参数设置为一个合理的值,通常使用10作为常见选择。还要注意交叉验证的策略,例如随机性的控制和数据是否被正确划分。
代码逻辑错误:请确保您的代码逻辑正确,特别是在执行交叉验证和计算准确率时。确认代码中没有引入额外的错误。
建议您仔细检查代码和数据处理的每个步骤,并根据需要进行调试和修改。确保数据加载正确、模型参数设置合理,并正确执行交叉验证和准确率计算。如果问题仍然存在,提供更多的代码和数据细节可能有助于进一步的排查。
相关文章:
与留一法(Leave-One-Out))
10折交叉验证(10-fold Cross Validation)与留一法(Leave-One-Out)
概念: 交叉验证法,就是把一个大的数据集分为 k个小数据集,其中 k − 1 个作为训练集,剩下的 1 个作为测试集,在训练和测试的时候依次选择训练集和它对应的测试集。这种方法也被叫做 k 折交叉验证法(k-fold…...
中小企业:理解CRM与ERP系统的区别与联系,提升业务效能
许多中小型企业正面临着客户递增,市场营销,货存流通等递增数据整合的困扰。这个时候需要根据自身企业的实际情况去选择适合自己的系统。那么,中小企业使用CRM系统和erp系统的区别是什么? 一、含义和目标区别 CRM系统旨在帮助企业…...
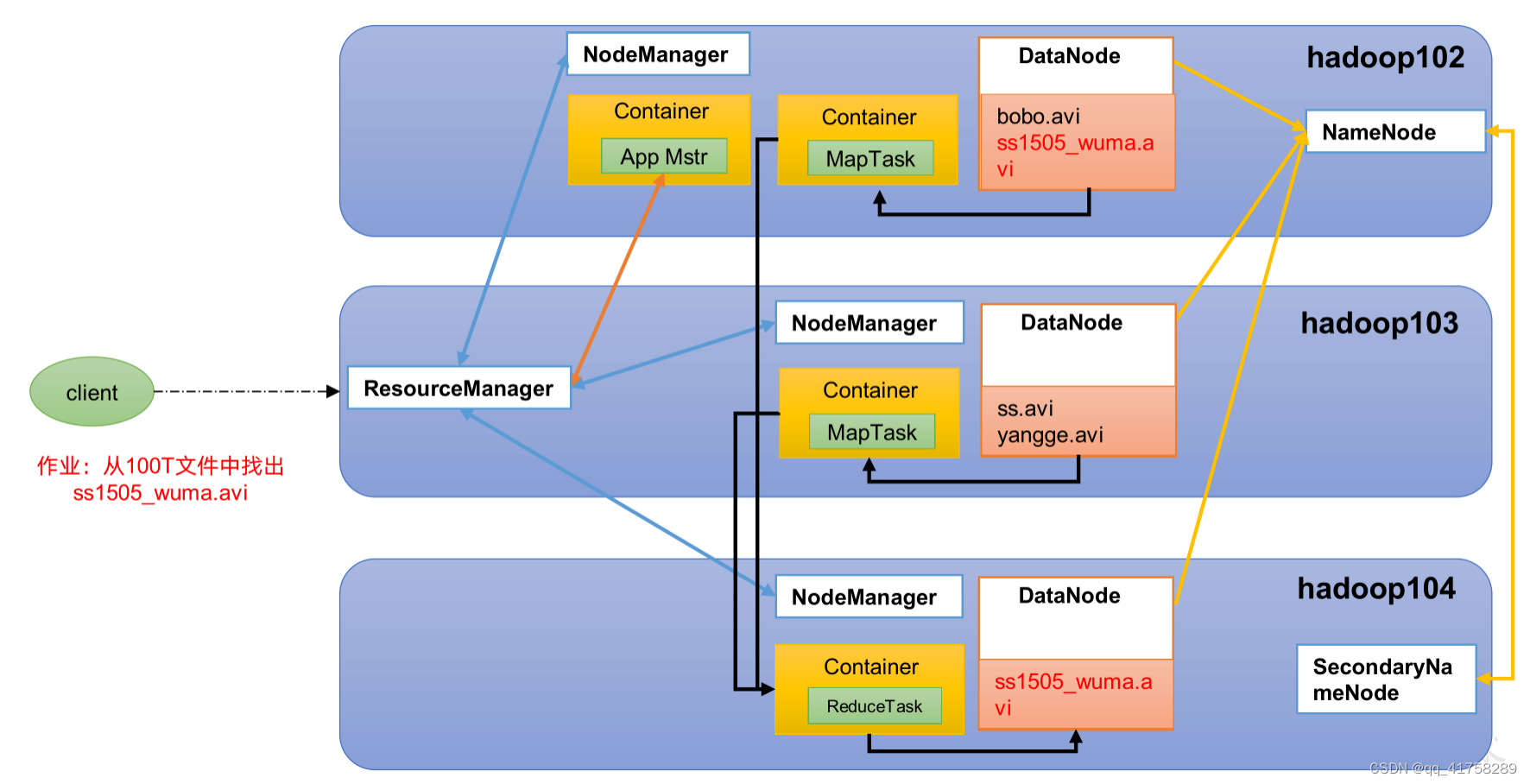
01数仓平台 Hadoop介绍与安装
Hadoop概述 Hadoop 是数仓平台的核心组件。 在 Hadoop1.x 时代,Hadoop 中的 MapReduce 同时处理业务逻辑运算和资源调度,耦合性较大。在 Hadoop2.x 时代,增加了 Yarn。Yarn 只负责资源的调度,MapReduce 只负责运算。Hadoop3.x 在…...

网络编程HTTP协议进化史
一、Http报文格式 具有约定格式的数据块 请求报文 request 状态行:本次请求的请求方式(post get)资源路径url http 协议的版本号,中间用空格划分 本次请求的请求方式(post get)资源路径url http 协议…...

第17章 匿名函数
第17.1节 匿名函数的基本语法 [捕获列表](参数列表) mutable(可选) 异常属性 -> 返回类型 { // 函数体 }语法规则:lambda表达式可以看成是一般函数的函数名被略去,返回值使用了一个 -> 的形式表示。唯一与普通函数不同的是增加了“捕获列表”。 …...

JVM虚拟机:JVM参数之标配参数
本文重点 本文我们将学习JVM中的标配参数 标配参数 从jdk刚开始就有的参数,比如: -version -help -showversion...

UEC++ 探索虚幻5笔记(捡金币案例) day12
吃金币案例 创建金币逻辑 之前的MyActor_One.cpp,直接添加几个资源拿着就用 //静态网格UPROPERTY(VisibleAnywhere, BlueprintReadOnly)class UStaticMeshComponent* StaticMesh;//球形碰撞体UPROPERTY(VisibleAnywhere, BlueprintReadWrite)class USphereCompone…...

Docker 安装 Redis 挂载配置
1. 创建挂载文件目录 mkdir -p /home/redis/config mkdir -p /home/redis/data # 创建配置文件:docker容器中默认不包含配置文件 touch /home/redis/config/redis.conf2. 书写配置文件 # Redis 服务器配置# 绑定的 IP 地址,默认为本地回环地址 127.0.0…...
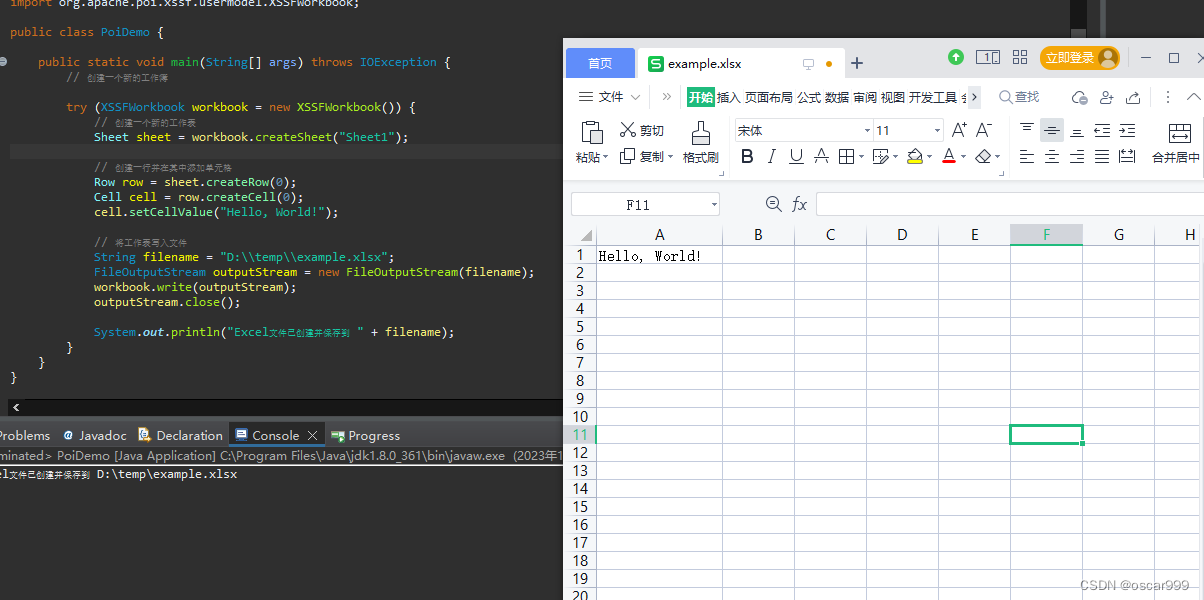
Java操作Excel之 POI介绍和入门
POI是Apache 提供的一个开源的Java API,用于操作Microsoft文档格式,如Excel、Word和PowerPoint等。POI是Java中处理Microsoft文档最受欢迎的库。 截至2023/12, 最新版本时 POI 5.2.5。 JDK版本兼容 POI版本JDK版本4.0及之上版本> 1.83.…...

麒麟v10 数据盘初始化 gpt分区
麒麟v10 数据盘初始化 gpt分区 1、查看磁盘 lsblk2 、分区 parted2.1、 设置磁盘分区形式2.2、 设置磁盘的计量单位为磁柱2.3、 分区2.4、 查看分区 3、分区格式化4、 挂载磁盘4.1、新建挂载目录4.2、挂载磁盘4.3、查看挂载结果 5、设置开机自动挂载磁盘分区5.1、 查询磁盘分区…...

php时间和centos时间不一致
PHP 时间和 CentOS 操作系统时间不一致的问题通常是由于时区设置不同造成的。解决这个问题可以通过以下几个步骤: 检查 CentOS 系统时间: 你可以通过在终端运行命令 date 来查看当前的系统时间和时区。 配置 CentOS 的时区: 如果系统时间不正…...

软件工程 复习笔记
目录 概述 软件的定义,特点和分类 软件的定义 软件的特点 软件的分类 软件危机的定义和表现形式 软件危机 表现形式 软件危机的产生原因及解决途径 产生软件危机的原因 软件工程 概念 软件工程的研究内容和基本原理 内容 软件工程的基本原理 软件过程…...
SpringBoot_02
Web后端开发_07 SpringBoot_02 SpringBoot原理 1.配置优先级 1.1配置 SpringBoot中支持三种格式的配置文件: application.propertiesapplication.ymlapplication.yaml properties、yaml、yml三种配置文件,优先级最高的是properties 配置文件优先级…...

实验报告-实验四(时序系统实验)
软件模拟电路图 说明 SW:开关,共六个Q1~Q3:输出Y0~Y3:输出 74LS194 首先,要给S1和S0高电位,将A~D的数据存入寄存器中(如果开始没有存入数据,那么就是0000在里面移位,不…...

PHP+ajax+layui实现双重列表的动态绑定
需求:商户下面有若干个门店,每个门店都需要绑定上收款账户 方案一:每个门店下面添加页面,可以选择账户去绑定。(难度:简单) 方案二:从商户进入,可以自由选择门店&#…...
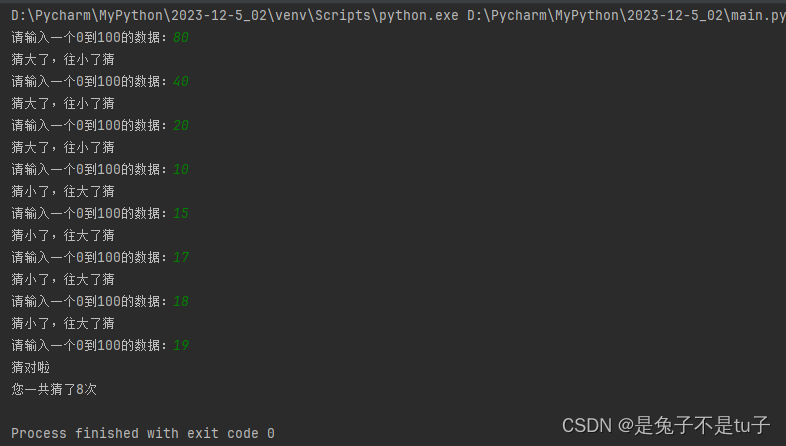
菜鸟学习日记(python)——条件控制
Python 中的条件语句是通过一条或多条语句的执行结果(True 或者 False)来决定执行的代码块。 它的一般格式为:if...elif...else if condition1: #条件1CodeBlock1 #代码块1 elif condition2:CodeBlock2 else:CodeBlock3 如果con…...

RabbitMQ 笔记
Message durability 确保消息在server 出现问题或者recovery能恢复: declare it as durable in the producer and consumer code. boolean durable true; channel.queueDeclare("hello", durable, false, false, null);Queue 指定 //使用指定的queue&…...
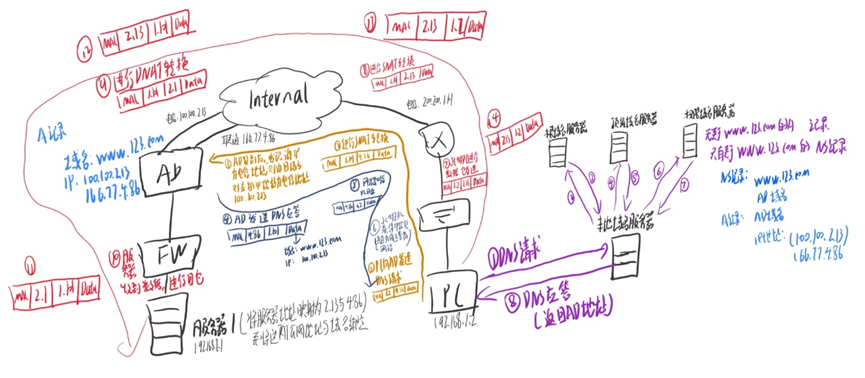
DNS协议(DNS规范、DNS报文、DNS智能选路)
目录 DNS协议基本概念 DNS相关规范 DNS服务器的记录 DNS报文 DNS域名查询的两种方式 DNS工作过程 DNS智能选路 DNS协议基本概念 DNS的背景 我们知道主机通信需要依靠IP地址,但是每次通过输入对方的IP地址和对端通信不够方便,IP地址不好记忆 因此提…...

Python基础知识-变量、数据类型(整型、浮点型、字符类型、布尔类型)详解
1、基本的输出和计算表达式: prinit(12-3) printf(12*3) printf(12/3) prinit(12-3) printf(12*3) printf(12/3) 形如12-3称为表达式 这个表达式的运算结果称为 表达式的返回值 1 2 3 这样的数字,叫做 字面值常量 - * /称为 运算符或者操作符 在C和j…...
信息化,数字化,智能化是3种不同概念吗?与机械化,自动化矛盾吗?
先说结论: 1、信息化、数字化、智能化确实是3种不同的概念! 2、这3种概念与机械化、自动化并不矛盾,它们是制造业中不同发展阶段和不同层次的概念。 机械化:是指在生产过程中使用机械技术来辅助人工完成一些重复性、单一性、劳…...

利用最小二乘法找圆心和半径
#include <iostream> #include <vector> #include <cmath> #include <Eigen/Dense> // 需安装Eigen库用于矩阵运算 // 定义点结构 struct Point { double x, y; Point(double x_, double y_) : x(x_), y(y_) {} }; // 最小二乘法求圆心和半径 …...

Android Wi-Fi 连接失败日志分析
1. Android wifi 关键日志总结 (1) Wi-Fi 断开 (CTRL-EVENT-DISCONNECTED reason3) 日志相关部分: 06-05 10:48:40.987 943 943 I wpa_supplicant: wlan0: CTRL-EVENT-DISCONNECTED bssid44:9b:c1:57:a8:90 reason3 locally_generated1解析: CTR…...

stm32G473的flash模式是单bank还是双bank?
今天突然有人stm32G473的flash模式是单bank还是双bank?由于时间太久,我真忘记了。搜搜发现,还真有人和我一样。见下面的链接:https://shequ.stmicroelectronics.cn/forum.php?modviewthread&tid644563 根据STM32G4系列参考手…...

反向工程与模型迁移:打造未来商品详情API的可持续创新体系
在电商行业蓬勃发展的当下,商品详情API作为连接电商平台与开发者、商家及用户的关键纽带,其重要性日益凸显。传统商品详情API主要聚焦于商品基本信息(如名称、价格、库存等)的获取与展示,已难以满足市场对个性化、智能…...

[10-3]软件I2C读写MPU6050 江协科技学习笔记(16个知识点)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16...

Module Federation 和 Native Federation 的比较
前言 Module Federation 是 Webpack 5 引入的微前端架构方案,允许不同独立构建的应用在运行时动态共享模块。 Native Federation 是 Angular 官方基于 Module Federation 理念实现的专为 Angular 优化的微前端方案。 概念解析 Module Federation (模块联邦) Modul…...

Redis数据倾斜问题解决
Redis 数据倾斜问题解析与解决方案 什么是 Redis 数据倾斜 Redis 数据倾斜指的是在 Redis 集群中,部分节点存储的数据量或访问量远高于其他节点,导致这些节点负载过高,影响整体性能。 数据倾斜的主要表现 部分节点内存使用率远高于其他节…...

优选算法第十二讲:队列 + 宽搜 优先级队列
优选算法第十二讲:队列 宽搜 && 优先级队列 1.N叉树的层序遍历2.二叉树的锯齿型层序遍历3.二叉树最大宽度4.在每个树行中找最大值5.优先级队列 -- 最后一块石头的重量6.数据流中的第K大元素7.前K个高频单词8.数据流的中位数 1.N叉树的层序遍历 2.二叉树的锯…...

【JVM】Java虚拟机(二)——垃圾回收
目录 一、如何判断对象可以回收 (一)引用计数法 (二)可达性分析算法 二、垃圾回收算法 (一)标记清除 (二)标记整理 (三)复制 (四ÿ…...

代码规范和架构【立芯理论一】(2025.06.08)
1、代码规范的目标 代码简洁精炼、美观,可持续性好高效率高复用,可移植性好高内聚,低耦合没有冗余规范性,代码有规可循,可以看出自己当时的思考过程特殊排版,特殊语法,特殊指令,必须…...