NPU、CPU、GPU算力及算力计算方式
NVIDIA在9月20日发布的NVIDIA DRIVE Thor 新一代集中式车载计算平台,可在单个安全、可靠的系统上运行高级驾驶员辅助应用和车载信息娱乐应用。提供 2000 万亿次浮点运算性能(2000 万亿次8位浮点运算)。NVIDIA当代产品是Orin,算力是256 TOPS。再后面是已发布的Altan,算力是1000TFLOPS,这次的Thor算力是2000 TOPS强大的着实让人震惊(但是芯片2025才出来,是时间好像有些远的PPT产品)。
产生一个疑问,这个算力是什么算力?如何计算/标定?
先看三个名词解释:
TFLOPS(teraFLOPS)等于每秒一万亿(=10^12)次的浮点运算。FLOPS(Floating-point operations per second的缩写),即每秒浮点运算次数。
TOPS(Tera Operations Per Second的缩写),1TOPS代表处理器每秒钟可进行一万亿次(10^12)操作。
DMIPS:Dhrystone Million Instructions executed Per Second,每秒执行百万条指令,用来计算同一秒内系统的处理能力,即每秒执行了多少百万条指令。
鉴于NVIDIA的Thor还是个PPT,还没有确切产品资料情况下,我们先看下现有芯片的此种算力。特斯拉FSD(自动驾驶的芯片/区别于智能座舱SOC)。
===============================================
NPU算力
NPU算力。TOPS仅指处理器每秒万亿次操作,需要结合具体数据类型精度才可以于FLOPS转换。8位精度下的MAC(乘积累加运算,MAC/ Multiply Accumulate)数量在FP16(半浮点数/16位浮点数)精度下等于减少了一半。 PS:NVIDIA、Intel和Arm携手合作,共同撰写FP8 Formats for Deep Learning白皮书。目前业界已由32位元降至16位元,如今甚至已转向8位元(FP8精度: 8 位元浮点运算规格),这也是NVIDIA使用FP8来表征算力的原因。NVIDIA上面Thor 2000TOPS也说的是这个东东。
在NPU中,芯片都用MAC阵列(乘积累加运算,MAC/ Multiply Accumulate)作为NPU给神经网络加速,许多运算(如卷积运算、点积运算、矩阵运算、数字滤波器运算、乃至多项式的求值运算)都可以分解为数个MAC指令,因此可以提高上述运算的效率。MAC矩阵是AI芯片的核心,是很成熟的架构。英伟达也在示例中使用3维的立方体计算单元完成矩阵乘加运算。TOPS是MAC在1秒内操作的数,计算公式为:
TOPS = MAC矩阵行 * MAC矩阵列 * 2 * 主频;
PS:公式中的 2 可理解为一个MACC(乘加运算)为一次乘法和一次加法为2次运算操作。下面以特斯拉自动驾驶FSD芯片为例。
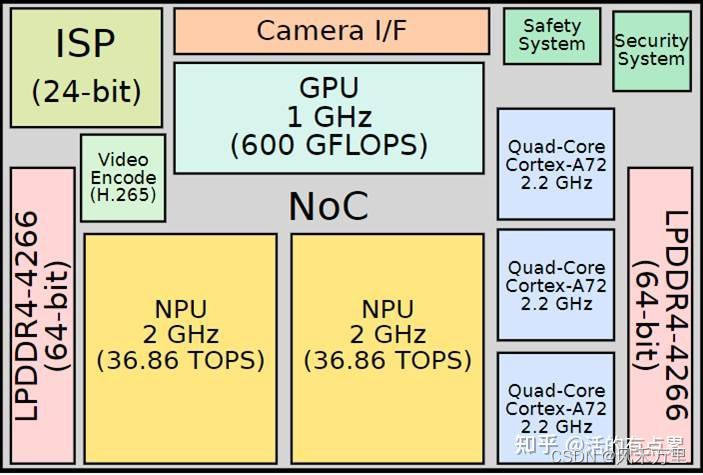
特斯拉资料中,该芯片的目标是自主4级和5级。FSD芯片采用三星(德克萨斯州奥斯汀的工厂)的14纳米工艺技术制造,集成了3个四核Cortex-A72集群,共有12个CPU,工作频率为2.2GHz,1个(ARM的)Mali G71 MP12 GPU,2个NPU工作频率为2GHz,还有其他各种硬件加速器。FSD最多支持128位LPDDR4-4266内存。
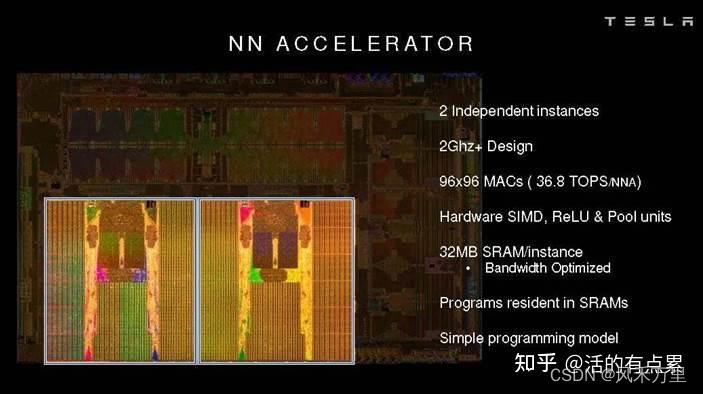
上图右侧第三行清楚的描述到:“ 96*96 MACs(单核)(36.8 TOPS/NNA)”,我们根据最上面计算公式:
TOPS = MAC矩阵行 * MAC矩阵列 * 2 * 主频 = 96 * 96 * 2 * 2G = 36.864 TOPS(单核)
上面结果和如上图片中算力数字匹配,是NPU单核算力。特斯拉FSD(Full Self-Driving) IC 中有2个NPU:每个周期,从SRAM读取256byte字节的激活数据和另外128byte的权重数据到MAC阵列中。每个NPU拥有96x96 MAC,另外在精度方面,乘法为8x8bit,加法为32bit,两种数据类型的选择很大程度上取决于他们降功耗的努力(例如32bitFP加法器的功耗大约是32bit整数加法器的9倍)。如上图,在2GHz的工作频率下,每个NPU的算力为36.86TOPS,FSD芯片峰值算力为73.7TOPS(两个单核NPU算力的累加)。
=====================================================
CPU的算力(ARM内核)
移远通信推出SA8155P平台的SIP模块AG855G,移远官网介绍中描述“AG855G的 AI 综合算力能够达到 8 TOPS”。那CPU算力呢?
高通官网及产品摘要中没有找到对其产品CPU算力的直接数字描述,但是在移远通信描述SA8155P “八核 64 位处理器,1+3+4三丛集架构,算力高达100K DMIPS”(有其他新闻媒体描述其算力为 95 KDMIPS)。加之之前找到的SA8155P 数据如下:
高通2019年发布的智能座舱芯片SA8155P,7nm工艺。CPU架构是Kryo 435(高通自己的命名)8个64位核心,3个丛集(Gold代表大核心,Silver代表小核心)
第1丛集:1×Kryo 435 Gold@2.419GHz
第2丛集:3×Kryo 435 Gold@2.131GHz
第3丛集:4×Kryo 435 Silver@1.785GHz
PS:前两个丛集是基于ARM Cortex-A76架构定制的,第三个丛集是Cortex-A55核心定制。
Graphics: Adreno 640 700MHz
Memory:4x16,2092.8MHz,LPDDR4X with ECC
NPU:NPU130 with ECC 908 MHz
Compute DSP:Q6 V66G (4 threads/2 clusters, 1024KB L2, 4x HVX) with ECC 1.4592 GHz
……
算力数据描述:
GPU计算性能:1.1 TFLOPS
AI(NPU)算力:8 TOPS(每秒运算8万亿次)
CPU算力:100K DMIPS (也有说95K DMIPS的)
这个CPU算力是怎么来的,如下正题:CPU算力计算方式描述(DMIPS:主要测整数计算能力)
以ARM核为主查询,ARM官网中描述,在“The Cortex-M3 RTL is delivered to licensees together with an "example" system testbench for simulation of a simple Cortex-M3 system, and a number of test programs including a Dhrystone test called "dhry". ”描述了DMIPS/MHz的计算方式:
DMIPS/MHz = 10^6 / (1757 * Number of processor clock cycles per Dhrystone loop)
ARM官网中有Cortex-M3和M4的数据(如下截图)

ARM官网网页资料截图
我们可以计算Cortex-M3在Wait-states 0中的DMIPS/MHz是:
DMIPS/MHz = 10^6 / (1757 * 460.2)= 1.2367 ≈ 1.24 DMIPS/MHz
上面计算结果和图片数据对应。在ARM官网未查到有Cortex-A76的DMIPS/MHz数值描述,但查询到在发布Cortex-A76时,ARM首席架构师Filippo强调Cortex-A76架构较上一代(A75)性能至少提升35%,在一些数学运行任务上,新架构处理器可以有 50%—70% 的提升。
网上资料基本都是到Cortex-A75就完了,查询到如下架构的DMIPS/MHz如下:
Arm Cortex-A75 5.2 DMIPS/MHz
Arm Cortex-A73 4.8 DMIPS/MHz
Arm Cortex-A72 4.7 DMIPS/MHz
Arm Cortex-A57 4.1 DMIPS/MHz
Arm Cortex-A55 2.7 DMIPS/MHz
Arm Cortex-A53 2.3 DMIPS/MHz
虽然高通官网及产品摘要中没有找到对其产品CPU算力的直接数字描述,但是结合如上各网络资料,我们视图计算下高通这个SA8155P的真实CPU算力。
SA8155P的CPU算力计算如下(按照A75性能提升50%来计算,即 5.2 * 1.5 = 7.8 DMIPS/MHz )
SA8155P算力 = 2.419GHz * 1核 * 7.8 DMIPS/MHz + 2.131GHz * 3核 * 7.8 DMIPS/MHz + 1.785GHz * 4核 * 2.7 DMIPS/MHz = 18868.2 + 49865.4 + 19278 = 88011.6 DMIPS ≈ 88 KDMIPS
此数值和移远通信公布的100 KDMIPS算力有约12%的误差,但这其实是用ARM的方法计算了下三星的处理器。三星将ARM Cortex-A76内核优化后叫Kryo内核,还有硬件加速器等,猜想是三星对A76的性能优化已超50%性能提升,已到达ARM架构师Filippo(上面说的)所描述的50%-70%性能提升的中位数。另外,存储器读写速度、硬件加速引擎等也都可能直接影响CPU算力表现。
当然,也有可能是如上某些数据、信息或计算还不确切。大家有资料或深入研究的也请指出。
=================================================
GPU算力
…………..后面再写了,下面把NVIDIA的Thor发布的芯片构成信息整理:
在自动驾驶领域,提高驾驶安全性,传感器在数量和分辨率上都面临同步增长。同时也引入了更复杂的AI模型(NVIDIA大致每2年的产品都会有一个质的提升)。安全性是机器人开发的首要准则,要求传感器和算法具备多样性和冗余性。这些都需要更高的数据处理能力。
NVIDIA为实现这个应用了Grace、Hopper和Ada Lovelace。
1. Hopper有令人惊叹的Transformer引擎以及Vision Transformer的快速变革。
2. 在Ada中多实例GPU的发明有助于车载计算资源的集中化,同时也降低了成本。
3. Grace是NVIDIA数据中心处理器。通常所有的并行处理算法都是由GPU卸载和加速的,因此其余的工作负载往往收到单线程的限制,而Grace正好拥有出色的单线程性能。
Thor内部Arm Poseidon AE内核(汽车增强版本)。Thor支持通过NVLink-C2C芯片互联技术连接两个芯片运行单个操作系统(现有很多兴能源汽车厂家将2~4颗Orin处理器集合起来应用来满足算力需求)。
Thor可以配置为多种模式,Thor可以将其 2000 TOPS和 2000 TFLOPs全部用于自动驾驶工作流中,也可以将其配置为一部分用于驾驶舱AI和信息娱乐,一部分用于辅助驾驶。Thor有多计算域隔离,允许并发、对时间敏感的多进程无中断运行。可以在一台计算机上同时运行Linux、QNX和Android。Thor集中了众多计算资源,不仅降低了成本和功耗,同时功能也实现了质的飞跃。

NVIDIA Thor PCBA板卡
提前3年发布,也真是难为NVIDIA了,给一众跟随的 IC 厂商指明了前进的方向。
相关文章:
NPU、CPU、GPU算力及算力计算方式
NVIDIA在9月20日发布的NVIDIA DRIVE Thor 新一代集中式车载计算平台,可在单个安全、可靠的系统上运行高级驾驶员辅助应用和车载信息娱乐应用。提供 2000 万亿次浮点运算性能(2000 万亿次8位浮点运算)。NVIDIA当代产品是Orin,算力是…...
华清远见嵌入式学习——C++——作业6
作业要求: 代码: #include <iostream>using namespace std;class Animal { public:virtual void perform() 0;};class Lion:public Animal { private:string foods;string feature; public:Lion(){}Lion(string foods,string feature):foods(foo…...

k8s安装学习环境
目录 环境准备 配置hosts 关闭防火墙 关闭交换分区 调整swappiness参数 关闭setlinux Ipv4转发 时钟同步 安装Docker 配置Yum源 安装 配置 启动 日志 安装k8s 配置Yum源 Master节点 安装 初始化 配置kubectl 部署CNI网络插件 Node节点 检查 环境准备 准…...

RepidJson将内容写入文件简单代码示例
以下是使用RapidJSON将内容写入文件的示例代码: #include <rapidjson/document.h> #include <rapidjson/writer.h> #include <rapidjson/stringbuffer.h> #include <iostream> #include <fstream>using namespace rapidjson;int mai…...

golang构建docker镜像的几种方式
目前docker支持以下几种方式指定上下文来构建镜像 本地项目路径(如:/tmp/xxx)本地压缩包路径(如:/tmp/xxx.tar)docekrfile文本链接(如:https://x.com/xxx/dockerfile)压…...

golang使用sip协议 用户名和密码注册到vos3000
在Go语言中,要使用SIP协议进行注册,您可以使用第三方库,如github.com/cloudwebrtc/sip。以下是一个简单的示例代码,演示如何使用Go语言中的该库进行基本的SIP注册: 首先,您需要安装该库: go ge…...

第4章 互联网
文章目录 4.1 计算机网络基础 94 4.1.1 计算机网络的基本概念 94 4.1.2 局域网的基本原理 96 4.1.3 局域网协议与应用 98 4.2 Internet 100 4.2.1 TCP/IP 101 4.2.2 TCP/IP应用 106 4.2.3 网络操作系统的功能 112 4.2.4 网络安全的概念 116 4.3 计算机软件编程基础 …...

【JavaWeb】前端工程化(VUE3)
前端工程化(VUE3) 文章目录 前端工程化(VUE3)一、概述二、ECMA6Script2.1 es6的变量和模板字符串2.2 es6的解构表达式2.3 es6的箭头函数2.4 rest和spread2.5 es6的对象创建和拷贝2.6 es6的模块化处理 三、前端工程化环境搭建3.1 N…...

JAVA基础知识:异常处理
异常处理是Java编程中至关重要的一部分,它允许程序在出现错误或异常情况时进行适当的处理,以保证程序的稳定性和可靠性。本文将详细介绍Java中的异常处理机制,并提供相关示例代码,帮助读者更好地理解和应用异常处理的概念和技巧。…...

PostGIS学习教程十:空间索引
PostGIS学习教程十:空间索引 回想一下,空间索引是空间数据库的三个关键特性之一。空间索引使得使用空间数据库存储大型数据集成为可能。在没有空间索引的情况下,对要素的任何搜索都需要对数据库中的每条记录进行"顺序扫描"。索引通…...

LeetCode 13 罗马数字转整数
题目描述 罗马数字转整数 罗马数字包含以下七种字符: I, V, X, L,C,D 和 M。 字符 数值 I 1 V 5 X 10 L 50 C 100 D 500 M …...

【动态规划】LeetCode2111:使数组 K 递增的最少操作次数
作者推荐 [二分查找]LeetCode2040:两个有序数组的第 K 小乘积 本文涉及的基础知识点 二分查找算法合集 分组 动态规划 题目 给你一个下标从 0 开始包含 n 个正整数的数组 arr ,和一个正整数 k 。 如果对于每个满足 k < i < n-1 的下标 i ,都有…...

SpringCloud面试题——Nacos
一:什么是Nacos? 二:服务心跳与服务注册原理? 在spring容器启动的时候,nacos客户端会进行两步操作。 向nacos服务端发送心跳向nacos服务端注册当前服务 服务心跳 客户端在启动的时候,会开启一个心跳线程…...

leetcode:统计感冒序列的数目【数学题:组合数含逆元模版】
1. 题目截图 2.题目分析 需要把其分为多个段进行填充 长为k的段,从两端往中间填充的方案数有2 ** (k - 1)种 组合数就是选哪几个数填哪几个段即可 3.组合数含逆元模版 MOD 1_000_000_007 MX 100_000# 组合数模板 fac [0] * MX fac[0] 1 for i in range(1, MX…...

外贸建站平台工具推荐?做海洋建站的平台?
外贸建站平台用哪个比较好?独立站建站系统如何选择? 随着全球市场的竞争日益激烈,如何通过互联网渠道展示企业形象、吸引客户成为外贸企业亟待解决的问题。海洋建站将为大家介绍几款优秀的外贸建站平台工具,助力企业在数字化时代…...
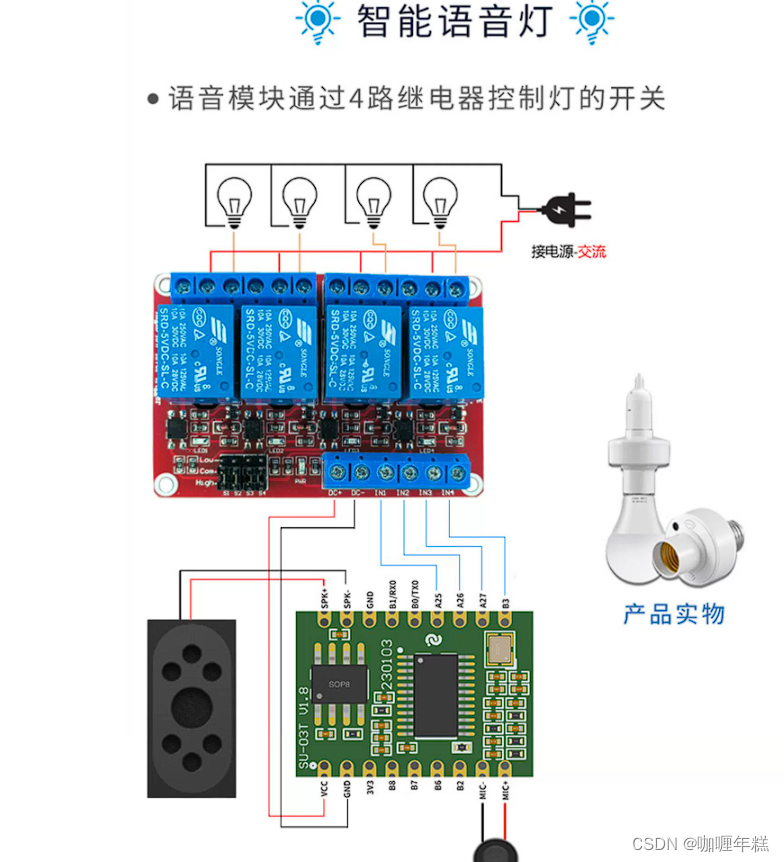
【智能家居】三、添加语音识别模块的串口读取功能点
语音识别模块SU-03T 串口通信线程控制代码 inputCommand.h(输入控制指令)voiceControl.c(语音控制模块指令)main.c(主函数)编译运行结果 语音识别模块SU-03T AI智能语音识别模块离线语音控制模块语音识别…...
物联网开发(一)新版Onenet 基础配置
onenet新创建的账号,没有了多协议接入,只有新的物联网开放平台 第一讲,先给大家讲一下:新版Onenet 基础配置 创建产品 产品开发-->创建产品 产品的品类选择个:大致符合你项目的即可,没有影响 选择智…...

qt/c/c++文件操作总结
1. 读取文件 1.1 Qt以二进制方式读取大文件返回char* 在Qt中以二进制模式读取一个大文件(以500MB为例)并将其内容存储到char*数组中,需要谨慎处理内存分配。以下是实现这一功能的步骤和示例代码: 1. 打开文件 使用QFile类以二进制模式打开文件。 2. 检查文件大小 使用…...

表示你的shell未被正确配置以使用conda activate--换成清华源anaconda
1 CommandNotFoundError: Your shell has not been properly configured to use conda activate. If using conda activate from a batch script, change your invocation to CALL conda.bat activate.To initialize your shell, run$ conda init <SHELL_NAME>这个错误提…...

VT-MRPA1-151-1X/V0/0控制2FRE16模块式模拟放大器
适用于控制带有电气位置反馈的直动式比例减压阀(DBETR- 1X 类型)或带有电气位置反馈的比例流量控制阀(2FRE... 类型);控制值输入 1 0 V(差动输入); 可分别调节“上/下”斜坡时间的斜…...

Linux应用开发之网络套接字编程(实例篇)
服务端与客户端单连接 服务端代码 #include <sys/socket.h> #include <sys/types.h> #include <netinet/in.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <arpa/inet.h> #include <pthread.h> …...

简易版抽奖活动的设计技术方案
1.前言 本技术方案旨在设计一套完整且可靠的抽奖活动逻辑,确保抽奖活动能够公平、公正、公开地进行,同时满足高并发访问、数据安全存储与高效处理等需求,为用户提供流畅的抽奖体验,助力业务顺利开展。本方案将涵盖抽奖活动的整体架构设计、核心流程逻辑、关键功能实现以及…...

23-Oracle 23 ai 区块链表(Blockchain Table)
小伙伴有没有在金融强合规的领域中遇见,必须要保持数据不可变,管理员都无法修改和留痕的要求。比如医疗的电子病历中,影像检查检验结果不可篡改行的,药品追溯过程中数据只可插入无法删除的特性需求;登录日志、修改日志…...

ESP32读取DHT11温湿度数据
芯片:ESP32 环境:Arduino 一、安装DHT11传感器库 红框的库,别安装错了 二、代码 注意,DATA口要连接在D15上 #include "DHT.h" // 包含DHT库#define DHTPIN 15 // 定义DHT11数据引脚连接到ESP32的GPIO15 #define D…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个医院查看报告小程序
一、开发环境准备 工具安装: 下载安装DevEco Studio 4.0(支持HarmonyOS 5)配置HarmonyOS SDK 5.0确保Node.js版本≥14 项目初始化: ohpm init harmony/hospital-report-app 二、核心功能模块实现 1. 报告列表…...

2025盘古石杯决赛【手机取证】
前言 第三届盘古石杯国际电子数据取证大赛决赛 最后一题没有解出来,实在找不到,希望有大佬教一下我。 还有就会议时间,我感觉不是图片时间,因为在电脑看到是其他时间用老会议系统开的会。 手机取证 1、分析鸿蒙手机检材&#x…...

【JavaSE】绘图与事件入门学习笔记
-Java绘图坐标体系 坐标体系-介绍 坐标原点位于左上角,以像素为单位。 在Java坐标系中,第一个是x坐标,表示当前位置为水平方向,距离坐标原点x个像素;第二个是y坐标,表示当前位置为垂直方向,距离坐标原点y个像素。 坐标体系-像素 …...

爬虫基础学习day2
# 爬虫设计领域 工商:企查查、天眼查短视频:抖音、快手、西瓜 ---> 飞瓜电商:京东、淘宝、聚美优品、亚马逊 ---> 分析店铺经营决策标题、排名航空:抓取所有航空公司价格 ---> 去哪儿自媒体:采集自媒体数据进…...
Mobile ALOHA全身模仿学习
一、题目 Mobile ALOHA:通过低成本全身远程操作学习双手移动操作 传统模仿学习(Imitation Learning)缺点:聚焦与桌面操作,缺乏通用任务所需的移动性和灵活性 本论文优点:(1)在ALOHA…...

LLMs 系列实操科普(1)
写在前面: 本期内容我们继续 Andrej Karpathy 的《How I use LLMs》讲座内容,原视频时长 ~130 分钟,以实操演示主流的一些 LLMs 的使用,由于涉及到实操,实际上并不适合以文字整理,但还是决定尽量整理一份笔…...