使用Pytorch从零开始实现BERT
生成式建模知识回顾:
[1] 生成式建模概述
[2] Transformer I,Transformer II
[3] 变分自编码器
[4] 生成对抗网络,高级生成对抗网络 I,高级生成对抗网络 II
[5] 自回归模型
[6] 归一化流模型
[7] 基于能量的模型
[8] 扩散模型 I, 扩散模型 II
本博文是尝试创建一个关于如何使用 PyTorch 构建 BERT 架构的完整教程。本教程的完整代码可在pytorch_bert获取。
引言
BERT 代表 Transformers 的双向编码器表示。BERT的原始论文:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding,实际上解释了您需要了解的有关 BERT 的所有内容。
老实说,互联网上有很多更好的文章解释 BERT 是什么,例如BERT Expanded: State of the art language model for NLP。读完本文后,你可能对注意力机制有一些疑问;这篇文章: Illustrated: Self-Attention 解释了注意力。
在本段中我只是想回顾一下 BERT 的思想,并更多地关注实际实现。BERT 同时解决两个任务:
- 下一句预测(NSP);
- 掩码语言模型(MLM)。

下一句话预测 (NSP)
NSP 是一个二元分类任务。输入两个句子,我们的模型应该能够预测第二个句子是否是第一个句子的真实延续。
比如有一段:
I have a cat named Tom. Tom likes to play with birds sitting on the window. They like this game not. I also have a dog. We walk together everyday.
潜在的数据集看起来像:
| 句子 | NSP类别 |
|---|---|
| I have a cat named Tom. Tom likes to play with birds sitting on the window | is next |
| I have a cat named Tom. We walk together everyday | is not next |
掩码语言模型 (MLM)
掩码语言模型是预测句子中隐藏单词的任务。
例如有一句话:
Tom likes to [MASK] with birds [MASK] on the window.
该模型应该预测屏蔽词是 play 和 sitting。
构建 BERT
为了构建 BERT,我们需要制定三个步骤:
- 准备数据集;
- 建立一个模型;
- 建立一个训练器 (Trainer)。

准备数据集
对于 BERT,应该以特定的某种方式来准备数据集。我大概花了 30% 的时间和脑力来构建 BERT 模型的数据集。因此,值得用一个段落来进行讨论。
原始 BERT 使用 BooksCorpus(8 亿字)和英语维基百科(2,500M 字)进行预训练。我们使用大约 72k 字的 IMDB reviews data 数据集。
从Kaggle: IMDB Dataset of 50K Movie Reviews下载数据集,并将其放在data/ 项目根目录下。
接下来,对于pytorch 的数据集和数据加载器,我们必须创建继承 torch.utils.data.Dataset 类的数据集。
class IMDBBertDataset(Dataset):# Define Special tokens as attributes of classCLS = '[CLS]'PAD = '[PAD]'SEP = '[SEP]'MASK = '[MASK]'UNK = '[UNK]'MASK_PERCENTAGE = 0.15 # How much words to maskMASKED_INDICES_COLUMN = 'masked_indices'TARGET_COLUMN = 'indices'NSP_TARGET_COLUMN = 'is_next'TOKEN_MASK_COLUMN = 'token_mask'OPTIMAL_LENGTH_PERCENTILE = 70def __init__(self, path, ds_from=None, ds_to=None, should_include_text=False):self.ds: pd.Series = pd.read_csv(path)['review']if ds_from is not None or ds_to is not None:self.ds = self.ds[ds_from:ds_to]self.tokenizer = get_tokenizer('basic_english')self.counter = Counter()self.vocab = Noneself.optimal_sentence_length = Noneself.should_include_text = should_include_textif should_include_text:self.columns = ['masked_sentence', self.MASKED_INDICES_COLUMN, 'sentence', self.TARGET_COLUMN,self.TOKEN_MASK_COLUMN,self.NSP_TARGET_COLUMN]else:self.columns = [self.MASKED_INDICES_COLUMN, self.TARGET_COLUMN, self.TOKEN_MASK_COLUMN,self.NSP_TARGET_COLUMN]self.df = self.prepare_dataset()def __len__(self):return len(self.df)def __getitem__(self, idx):...def prepare_dataset() -> pd.DataFrame:...
__init__中有点奇怪的部分如下:
...
if should_include_text:self.columns = ['masked_sentence', self.MASKED_INDICES_COLUMN, 'sentence', self.TARGET_COLUMN,self.TOKEN_MASK_COLUMN,self.NSP_TARGET_COLUMN]
else:self.columns = [self.MASKED_INDICES_COLUMN, self.TARGET_COLUMN, self.TOKEN_MASK_COLUMN,self.NSP_TARGET_COLUMN]
...
我们定义上面的列来创建self.df. 用should_include_text=True在数据框中包含所创建句子的文本表示。了解我们的预处理算法到底创建了什么是很有用的。
因此,should_include_text=True仅出于调试目的才需要设置。
大部分工作将在该prepare_dataset方法中完成。在该__getitem__方法中,我们准备一个训练项张量。
为了准备数据集,我们接下来要做:
- 按句子分割数据集
- 为 word-token 对创建词汇表 例如,{‘go’: 45}
- 创建训练数据集
- 在句子中添加特殊标记
- 屏蔽句子中 15% 的单词
- 将句子填充到预定义的长度
- 用两个句子创建 NSP 项
我们来逐步回顾一下prepare_dataset方法的代码。
按句子分割数据集并填充词汇表
检索句子是我们在prepare_dataset方法中执行的第一个(也是最简单的)操作。这对于填充词汇表是必要的。
sentences = []
nsp = []
sentence_lens = []# Split dataset on sentences
for review in self.ds:review_sentences = review.split('. ')sentences += review_sentencesself._update_length(review_sentences, sentence_lens)
self.optimal_sentence_length = self._find_optimal_sentence_length(sentence_lens)
请注意,我们按 . 来分割文本。但正如[devlin et al, 2018]中所述,一个句子可以有任意数量的连续文本;您可以根据需要拆分它。
如果打印sentences[:2]你会看到以下结果:
['One of the other reviewers has mentioned that after watching just 1 Oz '"episode you'll be hooked",'They are right, as this is exactly what happened with me.<br /><br />The ''first thing that struck me about Oz was its brutality and unflinching scenes ''of violence, which set in right from the word GO']
有趣的部分在于我们如何定义句子长度:
def _find_optimal_sentence_length(self, lengths: typing.List[int]): arr = np.array(lengths) return int(np.percentile(arr, self.OPTIMAL_LENGTH_PERCENTILE))
我们不是硬编码最大长度,而是将所有句子长度存储在列表中并计算 sentence_lens的70%。对于 50k IMDB,最佳句子长度值为 27。这意味着 70% 的句子长度小于或等于 27。
然后,我们将这些句子输入词汇表。我们对每个句子进行标记(tokenize),并用句子标记(单词)更新计数器 。
print("Create vocabulary")
for sentence in tqdm(sentences): s = self.tokenizer(sentence) self.counter.update(s) self._fill_vocab()
tokenization后的句子是其单词列表:
"My cat is Tom" -> ['my', 'cat', 'is', 'tom']
这是打印后您应该看到的输出self.counter:
Counter({'the': 6929,',': 5753,'and': 3409,'a': 3385,'of': 3073,'to': 2774,"'": 2692,'.': 2184,'is': 2123,...
请注意,在本教程中,我们省略了数据集清理的重要步骤。这就是为什么最受欢迎的tokens是the、,、and、a等的原因。
最后,我们准备好建立我们的词汇表了。该操作被移至_fill_vocab方法:
def _fill_vocab(self): # specials= argument is only in 0.12.0 version # specials=[self.CLS, self.PAD, self.MASK, self.SEP, self.UNK]self.vocab = vocab(self.counter, min_freq=2) # 0.11.0 uses this approach to insert specials self.vocab.insert_token(self.CLS, 0) self.vocab.insert_token(self.PAD, 1) self.vocab.insert_token(self.MASK, 2) self.vocab.insert_token(self.SEP, 3) self.vocab.insert_token(self.UNK, 4) self.vocab.set_default_index(4)
在本教程中,我们将仅将在数据集中出现 2 次或多次的单词添加到词汇表中。创建词汇表后,我们向词汇表添加特殊标记并将[UNK]标记设置为默认标记。
工作完成了一半🎉我们已经建立了词汇表。我们来测试一下:
self.vocab.lookup_indices(["[CLS]", "this", "works", "[MASK]", "well"])
输出:
[0, 29, 1555, 2, 152]
创建训练数据集
对每个具有多句子的review,我们创建真正的 NSP 项(当第二个句子是reviewer中的下一个句子时)和错误的 NSP 项(当第二个句子是来自 sentences 的任何随机句子时)。
print("Preprocessing dataset")
for review in tqdm(self.ds): review_sentences = review.split('. ') if len(review_sentences) > 1: for i in range(len(review_sentences) - 1): # True NSP item first, second = self.tokenizer(review_sentences[i]), self.tokenizer(review_sentences[i + 1]) nsp.append(self._create_item(first, second, 1)) # False NSP item first, second = self._select_false_nsp_sentences(sentences) first, second = self.tokenizer(first), self.tokenizer(second) nsp.append(self._create_item(first, second, 0))
df = pd.DataFrame(nsp, columns=self.columns)
_create_item方法完成了 99% 的工作。下面的代码比词汇创建更棘手。因此,请毫不犹豫地在调试模式下运行代码。让我们一步步看一下每次转换后句子对会发生什么。self._create_item方法的完整实现在Github代码仓中。
我们应该做的第一件事是在句子中添加特殊标记([CLS], [PAD], )[MASK]
def _create_item(self, first: typing.List[str], second: typing.List[str], target: int = 1): # Create masked sentence item updated_first, first_mask = self._preprocess_sentence(first.copy()) updated_second, second_mask = self._preprocess_sentence(second.copy())nsp_sentence = updated_first + [self.SEP] + updated_second nsp_indices = self.vocab.lookup_indices(nsp_sentence) inverse_token_mask = first_mask + [True] + second_mask
步骤1. 对句子进行掩码
同样重要的是,了解我们如何对句子的标记进行掩码:
def _mask_sentence(self, sentence: typing.List[str]): len_s = len(sentence) inverse_token_mask = [True for _ in range(max(len_s, self.optimal_sentence_length))] mask_amount = round(len_s * self.MASK_PERCENTAGE) for _ in range(mask_amount): i = random.randint(0, len_s - 1) if random.random() < 0.8: sentence[i] = self.MASK else:sentence[i] = self.vocab.lookup_token(j) inverse_token_mask[i] = False return sentence, inverse_token_mask
我们更新句子中随机 15% 的标记。请注意,对于 80% 的情况,我们设置[MASK]标记,否则我们从词汇表中设置随机单词。
上面代码中不清楚的部分是inverse_token_mask。当句子中的标记被屏蔽时,该列表有 True 值。例如,我们举一个句子:
my cat tom likes to sleep and does not like little mice jerry
对句子掩码后,inverse token mask看起来像:
sentence: My cat mice likes to sleep and does not like [MASK] mice jerry
inverse token mask: [False, False, True, False, False, False, False, False, False, False, True, False, False]
稍后当我们训练我们的模型时,我们将再次回到inverse token mask。
除了对句子掩码之外,我们还存储原始的未屏蔽句子,稍后将其用作 MLM 训练目标:
# Create sentence item without masking random words
first, _ = self._preprocess_sentence(first.copy(), should_mask=False)
second, _ = self._preprocess_sentence(second.copy(), should_mask=False)
original_nsp_sentence = first + [self.SEP] + second
original_nsp_indices = self.vocab.lookup_indices(original_nsp_sentence)
步骤2. 预处理:[CLS]和[PAD]
现在我们需要在每个句子的开头添加[CLS]。然后,我们在每个句子的末尾添加[PAD]标记,使它们具有相等的长度。假设我们应该将所有句子对齐到长度值13。
转换后我们有下面的句子:
[CLS] My cat mice likes to sleep and does not like [MASK] mice jerry
[SEP]
[CLS] jerry is treated as my pet too [PAD] [PAD] [PAD] [PAD] [PAD] [PAD]
_pad_sentence方法负责这种转换:
def _pad_sentence(self, sentence: typing.List[str], inverse_token_mask: typing.List[bool] = None): len_s = len(sentence) if len_s >= self.optimal_sentence_length: s = sentence[:self.optimal_sentence_length] else: s = sentence + [self.PAD] * (self.optimal_sentence_length - len_s) # inverse token mask should be padded as well if inverse_token_mask: len_m = len(inverse_token_mask) if len_m >= self.optimal_sentence_length: inverse_token_mask = inverse_token_mask[:self.optimal_sentence_length] else: inverse_token_mask = inverse_token_mask + [True] * (self.optimal_sentence_length - len_m) return s, inverse_token_mask
请注意,inverse token mask必须与句子具有相同的长度,因此你也应该填充它。
步骤3. 将句子中的单词转换为整数tokens
使用我们预先训练的词汇,我们现在将句子转换成tokens。通过两行代码完成:
...
nsp_sentence = updated_first + [self.SEP] + updated_second
nsp_indices = self.vocab.lookup_indices(nsp_sentence)
...
首先,我们通过[SEP]标记连接两个句子,然后转换为整数列表。将dataset.py模块作为脚本运行后,你应该看到预处理的数据集:
masked_sentence ... is_next
0 [[CLS], [MASK], of, the, other, reviewers, has... ... 1
1 [[CLS], once, fifteen, arrived, in, the, ameri... ... 0
2 [[CLS], they, [MASK], [MASK], ,, as, this, is,... ... 1
3 [[CLS], just, a, [MASK], of, [MASK], young, ma... ... 0
4 [[CLS], trust, me, [MASK], this, is, [MASK], a... ... 1... ... ...
8873 [[CLS], freshness, crystal, is, here, to, sell... ... 0
8874 [[CLS], pixar, have, proved, that, they, ', re... ... 1
8875 [[CLS], [MASK], abandons, her, slapstick, [MAS... ... 0
8876 [[CLS], they, raise, the, bar, [MASK], ,, and,... ... 1
8877 [[CLS], he, is, an, amazing, [MASK], artist, ,... ... 0
[8878 rows x 6 columns]
打印数据框中的第一项print(self.df.iloc[0]), 我们看到:
masked_sentence [[CLS], one, of, the, other, [MASK], has, ment...
masked_indices [0, 5, 6, 7, 8, 2, 10, 11, 4825, 13, 2, 15, 16...
sentence [[CLS], one, of, the, other, reviewers, has, m...
indices [0, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,...
token_mask [True, True, True, True, False, True, True, Fa...
is_next 1
Name: 0, dtype: object
现在,我们准备编写__getitem__方法了。
item = self.df.iloc[idx]inp = torch.Tensor(item[self.MASKED_INDICES_COLUMN]).long()
token_mask = torch.Tensor(item[self.TOKEN_MASK_COLUMN]).bool()attention_mask = (inp == self.vocab[self.PAD]).unsqueeze(0)
首先,我们从数据框中选择项目并创建将用于模型训练的张量。
当输入标记为 [PAD]时, attention_mask 值为True。我们在训练过程中使用它来消除[PAD]标记的嵌入。
我们有模型的输入,但我们也应该有训练的目标。
NSP目标
NSP 是一个二元分类问题。
if item[self.NSP_TARGET_COLUMN] == 0: t = [1, 0]
else: t = [0, 1] nsp_target = torch.Tensor(t)
我们将 NSP 目标创建为两项的张量。它只能有两种状态,指定是否是下一句。
[1, 0] is NOT next
[0, 1] is next
为了训练 NSP 模型,我们使用BCEWithLogitsLoss类。它期望目标类采用上述格式。
MLM目标
我们希望我们的模型仅预测masked tokens:
mask_target = torch.Tensor(item[self.TARGET_COLUMN]).long()
mask_target = mask_target.masked_fill_(token_mask, 0)
我们直接将目标中的所有非掩码整数设置为0。展望未来,我们将对模型输出执行相同的操作。
构建 pyTorch 模型
工程在bert package下,完整的神经网络模型位于model.py文件中。首先,我想向你展示该模型的对象图。然后我们将逐步浏览代码。

让我们一步步回顾一下。
联合嵌入(JointEmbedding)
我们从嵌入开始模型描述。BERT 有三个嵌入层:
- Token embedding
- Segment embedding
- Position embedding

Token embedding用于对word token进行编码。Segment embedding编码属于第一个或第二个句子。我们按以下方式预处理输入序列:如果标记属于第一个句子,则设为0,否则设为1。例如,
Input tokens: [0, 6, 24, 565, 67, 0, 443, 123, 5, 6, 5, 12, 1, 1, 1]
Input Segments: [0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1]
Position embedding对句子中单词的位置进行编码。可以选择使用嵌入层对序列中token的位置信息进行编码。在模块的代码中,它是在numeric_position方法中完成的。它所做的只是排列整数位置。
Input tokens: [0, 6, 24, 565, 67, 0, 443, 123, 5, 6, 5, 12, 1, 1, 1]
Input position: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14]
然而,我们使用周期函数来编码位置,而不是可学习的位置嵌入(如[vaswani 等人,2017]所述 )。


所以,pos变量是sin曲线上的具体值。i是用来选择pos具体sin曲线。因此,对于i = 0,我们可以得到一条周期曲线来获取pos值。i = 4,我们还有另一个周期曲线。
我们将所有嵌入保留在一个JoinEmbedding模块中。下面该模块的完整代码。
class JointEmbedding(nn.Module):def __init__(self, vocab_size, size):super(JointEmbedding, self).__init__()self.size = sizeself.token_emb = nn.Embedding(vocab_size, size)self.segment_emb = nn.Embedding(vocab_size, size)self.norm = nn.LayerNorm(size)def forward(self, input_tensor):sentence_size = input_tensor.size(-1)pos_tensor = self.attention_position(self.size, input_tensor)segment_tensor = torch.zeros_like(input_tensor).to(device)segment_tensor[:, sentence_size // 2 + 1:] = 1output = self.token_emb(input_tensor) + self.segment_emb(segment_tensor) + pos_tensorreturn self.norm(output)def attention_position(self, dim, input_tensor):batch_size = input_tensor.size(0)sentence_size = input_tensor.size(-1)pos = torch.arange(sentence_size, dtype=torch.long).to(device)d = torch.arange(dim, dtype=torch.long).to(device)d = (2 * d / dim)pos = pos.unsqueeze(1)pos = pos / (1e4 ** d)pos[:, ::2] = torch.sin(pos[:, ::2])pos[:, 1::2] = torch.cos(pos[:, 1::2])return pos.expand(batch_size, *pos.size())def numeric_position(self, dim, input_tensor):pos_tensor = torch.arange(dim, dtype=torch.long).to(device)return pos_tensor.expand_as(input_tensor)
正如您所看到的,从代码中我们创建了两个嵌入层:
self.token_emb = nn.Embedding(vocab_size, size)
self.segment_emb = nn.Embedding(vocab_size, size)
然后在forward方法中我们计算位置编码张量并准备用于segment Embedding的张量:
pos_tensor = self.attention_position(self.size, input_tensor)segment_tensor = torch.zeros_like(input_tensor).to(device)
segment_tensor[:, sentence_size // 2 + 1:] = 1
然后我们将它们相加并将得到的张量传递给LayerNorm。
output = self.token_emb(input_tensor) + self.segment_emb(segment_tensor) + pos_tensor
return self.norm(output)
注意力头
注意力是 Transformer 的核心。这正是Transformer如此出色的原因。BERT 使用自注意力机制。这篇文章 Illustrated: Self-Attention.对此进行了很好的描述。以下是来自该资源的引用:
“自注意力模块接受n 个输入并返回n 个输出。该模块中会发生什么?通俗地说,自注意力机制允许输入相互交互(“自我”)并找出应该更加关注谁(“注意力”)。输出是这些交互和注意力分数的聚合。”
可以使用多种类型的注意力。我们使用[vaswani et al, 2017]中的定义。

其中Q是查询,K是键,V是值。
对于它们中的每一个,我们创建具有可训练权重的线性层。因此,我们将教网络“注意”。在下面的图片中,您可能会看到注意力倍增的可视化。这正是我们在代码中所做的。

class AttentionHead(nn.Module): def __init__(self, dim_inp, dim_out): super(AttentionHead, self).__init__() self.dim_inp = dim_inp self.q = nn.Linear(dim_inp, dim_out) self.k = nn.Linear(dim_inp, dim_out) self.v = nn.Linear(dim_inp, dim_out) def forward(self, input_tensor: torch.Tensor, attention_mask: torch.Tensor = None): query, key, value = self.q(input_tensor), self.k(input_tensor), self.v(input_tensor) scale = query.size(1) ** 0.5 scores = torch.bmm(query, key.transpose(1, 2)) / scale scores = scores.masked_fill_(attention_mask, -1e9) attn = f.softmax(scores, dim=-1) context = torch.bmm(attn, value) return context
正如您在 中看到的__init__,我们为查询、键和值创建线性模块。为了简单起见,在本教程中它们都具有相同的形状。
我们继续上面的例子。dim_inp是嵌入的大小,等于 4。我们将隐藏注意力大小dim_out设为 6。
让我们按照forward方法一步一步来。我们不会打印张量的值,而是只打印它们的大小(形状)。
# input tensor is the output of JointEmbedding module
# attention mask is the vector that masks [PAD] tokens
def forward(self, input_tensor: size (2 x 5 x 4), attention_mask: size (2 x 1 x 5)):我们要做的第一件事是计算查询、键、值张量
query, key, value = size (2 x 5 x 6), size (2 x 5 x 6), size (2 x 5 x 6)
此外,我们计算查询和键的缩放乘法。
scale = query.size(1) ** 0.5
scores = torch.bmm(query, key.transpose(1, 2)) / scale = size (2 x 5 x 5)
torch.bmm是批量矩阵乘法函数。这将批量中的每个矩阵相乘,跳过第一个轴。transpose方法将张量转置为 2 个特定维度。
我们根本不希望我们的模型“关注”[PAD] tokens。这就是我们有注意力掩模向量的原因。使用这个向量,我们可以隐藏[PAD] tokens的分数。
scores = scores.masked_fill_(attention_mask, -1e9) = size (2 x 5 x 5)
现在,我们计算注意力上下文本身。
attn = f.softmax(scores, dim=-1) = size (2 x 5 x 5)
context = torch.bmm(attn, value) = size (2 x 5 x 6)
因此,每个输入值都由注意力张量加权。
多头注意力机制
单个注意力层(头)仅限于学习来自一个特定子空间的信息。多头注意力是一组并行注意力头,它学习从不同的表示中检索信息。您可以将它们视为卷积神经网络中的filters。

您可能会在下面的图片中看到它如何在双头注意力的可视化上发挥作用。我们打印单词it的attentions。第一个注意力(橙色)对单词animal的得分最多,而第二个注意力(绿色)对单词tired的得分最多。

让我们回到我们的代码。和往常一样,这里是模块的完整代码,然后我们一步一步地看一遍:
class MultiHeadAttention(nn.Module): def __init__(self, num_heads, dim_inp, dim_out): super(MultiHeadAttention, self).__init__() self.heads = nn.ModuleList([ AttentionHead(dim_inp, dim_out) for _ in range(num_heads) ]) self.linear = nn.Linear(dim_out * num_heads, dim_inp) self.norm = nn.LayerNorm(dim_inp) def forward(self, input_tensor: torch.Tensor, attention_mask: torch.Tensor): s = [head(input_tensor, attention_mask) for head in self.heads] scores = torch.cat(s, dim=-1) scores = self.linear(scores) return self.norm(scores)
dim_inp 和 dim_out具有与AttentionHead段落中相同的值:dim_inp等于 4,dim_out等于 6。num_heads是 3。为了简单起见,我们使用与嵌入大小相同的线性层的输出大小。
self.linear = nn.Linear(dim_out * num_heads, dim_inp) = nn.Linear(4 * 3, 4)
因此,线性层的输入大小为 12,输出为 4。
该forward方法具有与AttentionHead相同的参数。
def forward(self, input_tensor: size (2 x 5 x 4), attention_mask: size (2 x 1 x 5)):
在第一个操作中,我们计算注意力列表s。
s = [head(input_tensor, attention_mask) for head in self.heads]
s = [tensor(2 x 5 x 6),tensor(2 x 5 x 6),tensor(2 x 5 x 6),
]
此外,我们通过最后一个轴连接张量。
scores = torch.cat(s, dim=-1) = tensor(2 x 5 x 18)
通过scores线性层并归一化。
scores = self.linear(scores) = tensor(2 x 5 x 4)
return self.norm(scores)
编码器
编码器由多头注意力和前馈神经网络组成。在最初的《Attention Is All You Need》中,使用了相同编码器层的堆叠。为了简单起见,我们在本教程中只使用了一个。

class Encoder(nn.Module): def __init__(self, dim_inp, dim_out, attention_heads=4, dropout=0.1): super(Encoder, self).__init__() self.attention = MultiHeadAttention(attention_heads, dim_inp, dim_out) self.feed_forward = nn.Sequential( nn.Linear(dim_inp, dim_out), nn.Dropout(dropout), nn.GELU(), nn.Linear(dim_out, dim_inp), nn.Dropout(dropout) )self.norm = nn.LayerNorm(dim_inp) def forward(self, input_tensor: torch.Tensor, attention_mask: torch.Tensor): context = self.attention(input_tensor, attention_mask) res = self.feed_forward(context) return self.norm(res)
应该对前馈网络进行解释,因为它与你在《Attention Is All You Need》中可能看到的网络略有不同。
self.feed_forward = nn.Sequential( nn.Linear(dim_inp, dim_out), nn.Dropout(dropout), nn.GELU(),nn.Linear(dim_out, dim_inp),nn.Dropout(dropout)
)原始编码器具有RelU激活功能。我们使用GelU(参见 高斯误差线性单位(Gelus))。

我们的前馈网络用如下公式表示:

此外,我们在每个线性之后添加 dropout 层。
我们为什么使用GelU?只是因为它能带来更好的结果。您可以关注论文《Searching for Activation Functions》以获取更多详细信息。
该forward方法做起来很简单:
- 计算注意力上下文
- 通过前馈网络传递上下文
- 归一化
def forward(self, input_tensor: torch.Tensor, attention_mask: torch.Tensor): context = self.attention(input_tensor, attention_mask) res = self.feed_forward(context) return self.norm(res)
BERT
BERT 模块是一个容器,它将所有模块组合在一起并返回输出。
class BERT(nn.Module): def __init__(self, vocab_size, dim_inp, dim_out, attention_heads=4): super(BERT, self).__init__() self.embedding = JointEmbedding(vocab_size, dim_inp) self.encoder = Encoder(dim_inp, dim_out, attention_heads) self.token_prediction_layer = nn.Linear(dim_inp, vocab_size) self.softmax = nn.LogSoftmax(dim=-1) self.classification_layer = nn.Linear(dim_inp, 2) def forward(self, input_tensor: torch.Tensor, attention_mask: torch.Tensor): embedded = self.embedding(input_tensor) encoded = self.encoder(embedded, attention_mask) token_predictions = self.token_prediction_layer(encoded) first_word = encoded[:, 0, :] return self.softmax(token_predictions), self.classification_layer(first_word)
我们使用线性层(和softmax),其输出等于token预测任务的词汇量大小。
self.token_prediction_layer = nn.Linear(dim_inp, vocab_size)
self.softmax = nn.LogSoftmax(dim=-1)
下一个句子预测任务的输出为 2 的线性层
self.classification_layer = nn.Linear(dim_inp, 2)
网络的输出:
argmax(NSP output) = [1, 0] is NOT next sentence
argmax(NSP output) = [0, 1] is next sentence
forward过程的一切都很简单。首先我们计算嵌入,然后将嵌入传递给我们的编码器。
embedded = self.embedding(input_tensor)
encoded = self.encoder(embedded, attention_mask)
其次,我们计算模型的输出。
token_predictions = self.token_prediction_layer(encoded) first_word = encoded[:, 0, :]
return self.softmax(token_predictions), self.classification_layer(first_word)
还提供完整的模型图。要构建图表,请运行脚本graph.py。它将图形保存到data/logs目录中。运行tensorBoard
tensorboard --logdir data/logs
在浏览器中打开http://localhost:6006,转到“Graph”选项卡。您应该看到我们的 BERT 模型的图表。

训练模型
所有训练操作均在BertTrainer类的bert.trainer上进行。让我们看一下类构造函数。
class BertTrainer: def __init__(self, model: BERT, dataset: IMDBBertDataset, log_dir: Path, checkpoint_dir: Path = None, print_progress_every: int = 10, print_accuracy_every: int = 50, batch_size: int = 24, learning_rate: float = 0.005, epochs: int = 5, ): self.model = model self.dataset = dataset self.batch_size = batch_size self.epochs = epochs self.current_epoch = 0 self.loader = DataLoader(self.dataset, batch_size=self.batch_size, shuffle=True) self.writer = SummaryWriter(str(log_dir)) self.checkpoint_dir = checkpoint_dir self.criterion = nn.BCEWithLogitsLoss().to(device) self.ml_criterion = nn.NLLLoss(ignore_index=0).to(device) self.optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate, weight_decay=0.015)
如你所见,我们定义了要训练的模型、要使用的数据加载器和日志编写器。我们用来TensorBoard记录训练进度。阅读使用 Tensorboard 可视化模型、数据和训练,了解如何将 Tensorboard 与 pyTorch 结合使用。
构造函数中最重要的部分是损失和优化器定义。
self.criterion = nn.BCEWithLogitsLoss().to(device)
self.ml_criterion = nn.NLLLoss(ignore_index=0).to(device)
为了训练NSP任务,我们使用Sigmoid 二元交叉熵损失。为了训练MLM,我们使用负对数似然。我们使用 Adam 优化器。
训练过程发生在train方法中。
def train(self, epoch: int): print(f"Begin epoch {epoch}") prev = time.time() average_nsp_loss = 0 average_mlm_loss = 0 for i, value in enumerate(self.loader): index = i + 1 inp, mask, inverse_token_mask, token_target, nsp_target = value self.optimizer.zero_grad() token, nsp = self.model(inp, mask) tm = inverse_token_mask.unsqueeze(-1).expand_as(token) token = token.masked_fill(tm, 0) loss_token = self.ml_criterion(token.transpose(1, 2), token_target)loss_nsp = self.criterion(nsp, nsp_target) loss = loss_token + loss_nsp average_nsp_loss += loss_nsp average_mlm_loss += loss_token loss.backward() self.optimizer.step() if index % self._print_every == 0: elapsed = time.gmtime(time.time() - prev) s = self.training_summary(elapsed, index, average_nsp_loss, average_mlm_loss) if index % self._accuracy_every == 0: s += self.accuracy_summary(index, token, nsp, token_target, nsp_target) print(s) average_nsp_loss = 0 average_mlm_loss = 0 return loss
让我们回顾一下训练步骤。
inp, mask, inverse_token_mask, token_target, nsp_target = value
self.optimizer.zero_grad()
我们要做的第一件事是从加载器中检索批次数据。然后我们将梯度设置为0。
计算前向步数。
token, nsp = self.model(inp, mask)
然后我们在模型输出中隐藏除[MASK]标记之外的其他token。原因是我们训练模型仅预测[MASK]标记。
tm = inverse_token_mask.unsqueeze(-1).expand_as(token)
token = token.masked_fill(tm, 0)
此外,我们计算标准并对损失求和。
loss_token = self.ml_criterion(token.transpose(1, 2), token_target)
loss_nsp = self.criterion(nsp, nsp_target) loss = loss_token + loss_nsp
average_nsp_loss += loss_nsp
average_mlm_loss += loss_token
后向一步并更新权重。
loss.backward()
self.optimizer.step()
我们不时地计算模型的准确性
if index % self._accuracy_every == 0: s += self.accuracy_summary(index, token, nsp, token_target, nsp_target)
它计算 MLM 和 NSP 精度
nsp_acc = nsp_accuracy(nsp, nsp_target)
token_acc = token_accuracy(token, token_target, inverse_token_mask)
对于 NSP,我们计算一批中有多少张量被正确预测。
def nsp_accuracy(result: torch.Tensor, target: torch.Tensor):s = (result.argmax(1) == target.argmax(1)).sum() return round(float(s / result.size(0)), 2)
对于 MLM,我们应该做一些操作——对模型输出和目标应用屏蔽。或者就像我们在代码中所做的那样,只需选择屏蔽标记并进行比较。
def token_accuracy(result: torch.Tensor, target: torch.Tensor, inverse_token_mask: torch.Tensor):r = result.argmax(-1).masked_select(~inverse_token_mask) t = target.masked_select(~inverse_token_mask) s = (r == t).sum() return round(float(s / (result.size(0) * result.size(1))), 2)
训练结果及总结
最后,我们准备好运行模型的训练。长话短说,打开main.py脚本文件,检查学习参数并运行。
我在 nVidia GeForce 1050ti GPU 上训练了模型。如果支持cuda,模型将默认在 GPU 上进行训练。使用模型的下一个参数:
EMB_SIZE = 64
HIDDEN_SIZE = 36
EPOCHS = 4
BATCH_SIZE = 12
NUM_HEADS = 4
嵌入大小为 64,隐藏注意力上下文大小为 36,批量大小为 12,注意力头数量为 4,编码器数量为 1。学习率为 7e-5。
我们使用 TensorBoard 来跟踪训练过程。
运行训练脚本后,您应该会看到它如何准备 IMDB 数据集
Prepare dataset
Create vocabulary
100%|██████████| 491161/491161 [00:05<00:00, 93957.36it/s]
Preprocessing dataset
100%|██████████| 50000/50000 [00:35<00:00, 1407.99it/s]
然后训练器打印模型摘要:
Model Summary===================================
Device: cuda
Training dataset len: 882322
Max / Optimal sentence len: 27
Vocab size: 71942
Batch size: 12
Batched dataset len: 73526
===================================
训练开始了
Begin epoch 0
00:00:02 | Epoch 1 | 20 / 73526 (0.03%) | NSP loss 0.72 | MLM loss 11.25
00:00:04 | Epoch 1 | 40 / 73526 (0.05%) | NSP loss 0.70 | MLM loss 11.22
00:00:06 | Epoch 1 | 60 / 73526 (0.08%) | NSP loss 0.70 | MLM loss 11.13
00:00:08 | Epoch 1 | 80 / 73526 (0.11%) | NSP loss 0.71 | MLM loss 11.13
00:00:11 | Epoch 1 | 100 / 73526 (0.14%) | NSP loss 0.69 | MLM loss 11.05
00:00:13 | Epoch 1 | 120 / 73526 (0.16%) | NSP loss 0.70 | MLM loss 10.98
00:00:15 | Epoch 1 | 140 / 73526 (0.19%) | NSP loss 0.69 | MLM loss 10.95
00:00:18 | Epoch 1 | 160 / 73526 (0.22%) | NSP loss 0.70 | MLM loss 10.90
00:00:20 | Epoch 1 | 180 / 73526 (0.24%) | NSP loss 0.71 | MLM loss 10.89
00:00:22 | Epoch 1 | 200 / 73526 (0.27%) | NSP loss 0.72 | MLM loss 10.83 | NSP accuracy 0.25 | Token accuracy 0.01BERT模型甚至我们过于简化的BERT模型收敛速度很慢,需要大量的计算资源。我只能训练一个epoch。花了两个多小时:
02:20:49 | Epoch 1 | 73440 / 73526 (99.88%) | NSP loss 0.69 | MLM loss 4.49
02:20:52 | Epoch 1 | 73460 / 73526 (99.91%) | NSP loss 0.69 | MLM loss 4.37
02:20:54 | Epoch 1 | 73480 / 73526 (99.94%) | NSP loss 0.69 | MLM loss 4.24
02:20:56 | Epoch 1 | 73500 / 73526 (99.96%) | NSP loss 0.69 | MLM loss 4.38
02:20:59 | Epoch 1 | 73520 / 73526 (99.99%) | NSP loss 0.70 | MLM loss 4.37让我们看看损失值在一段时间内是如何变化的

您可能会看到我们的 BERT 模型的损失确实收敛到某个最小值,但这个过程非常慢。例如,这是有关已处理数据 44% 的日志消息
01:03:01 | Epoch 1 | 32880 / 73526 (44.72%) | NSP loss 0.69 | MLM loss 4.78
以及有关已处理100%数据 的消息:
02:20:59 | Epoch 1 | 73520 / 73526 (99.99%) | NSP loss 0.70 | MLM loss 4.37
在一个小时的训练中,NSP 损失仅减少了大约十分之一。

从上图可以看出,NSP 损失没有收敛而是发散。它收敛,但比MLM还要慢。如果我们对此图表的值应用平滑,我们可以看到这一点:

我想说我们之所以能得到这样的结果是因为我们的数据集。我们使用 IMDB 评论进行训练,并按.符号对句子进行文本分割。现在,我请你看看这些句子是什么。注意到了吗?因此,模型很难很好地捕捉数据来解决这个任务。最初的 BERT 使用英语维基百科和图书语料库,句子好、长、信息丰富。
让我们看看训练精度随时间的变化情况。


准确率实际上与损失相关。当MLM损失稍微减少时,MLM准确度稍微提高。NSP 的准确度甚至更加不稳定,在第一个 epoch 后平均略高于 0.5。结论是我们肯定需要尝试不同的数据集。但无论如何,对于教程来说这仍然是很好的结果:)
本教程中构建的模型并不是完整的 BERT。用最好的话说,它只是 BERT 的简化版本,只需了解其架构和工作原理即可。HuggingFace构建了许多预训练的 BERT(及其变体)模型。现在,您应该了解如何使用pytorch从头开始构建 BERT。此外,您可以尝试使用不同的数据集和模型参数,看看它是否能提供更好的任务结果,特别是 NSP 任务的收敛性。
本博文译自 Ivan Verkalets 的博客。
相关文章:
使用Pytorch从零开始实现BERT
生成式建模知识回顾: [1] 生成式建模概述 [2] Transformer I,Transformer II [3] 变分自编码器 [4] 生成对抗网络,高级生成对抗网络 I,高级生成对抗网络 II [5] 自回归模型 [6] 归一化流模型 [7] 基于能量的模型 [8] 扩散模型 I, 扩散模型 II…...
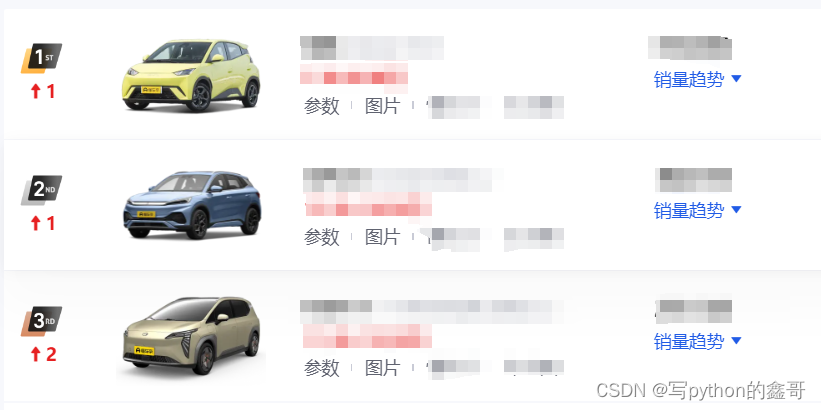
Python爬虫-新能源汽车销量榜
前言 本文是该专栏的第11篇,后面会持续分享python爬虫案例干货,记得关注。 本文以懂车平台的新能源汽车销量榜单为例,获取各车型的销量排行榜单数据。具体实现思路和详细逻辑,笔者将在正文结合完整代码进行详细介绍。 废话不多说,跟着笔者直接往下看正文详细内容。(附带…...

外包干了8个月,技术退步明显.......
先说一下自己的情况,大专生,18年通过校招进入武汉某软件公司,干了接近4年的功能测试,今年年初,感觉自己不能够在这样下去了,长时间呆在一个舒适的环境会让一个人堕落! 而我已经在一个企业干了四年的功能测…...
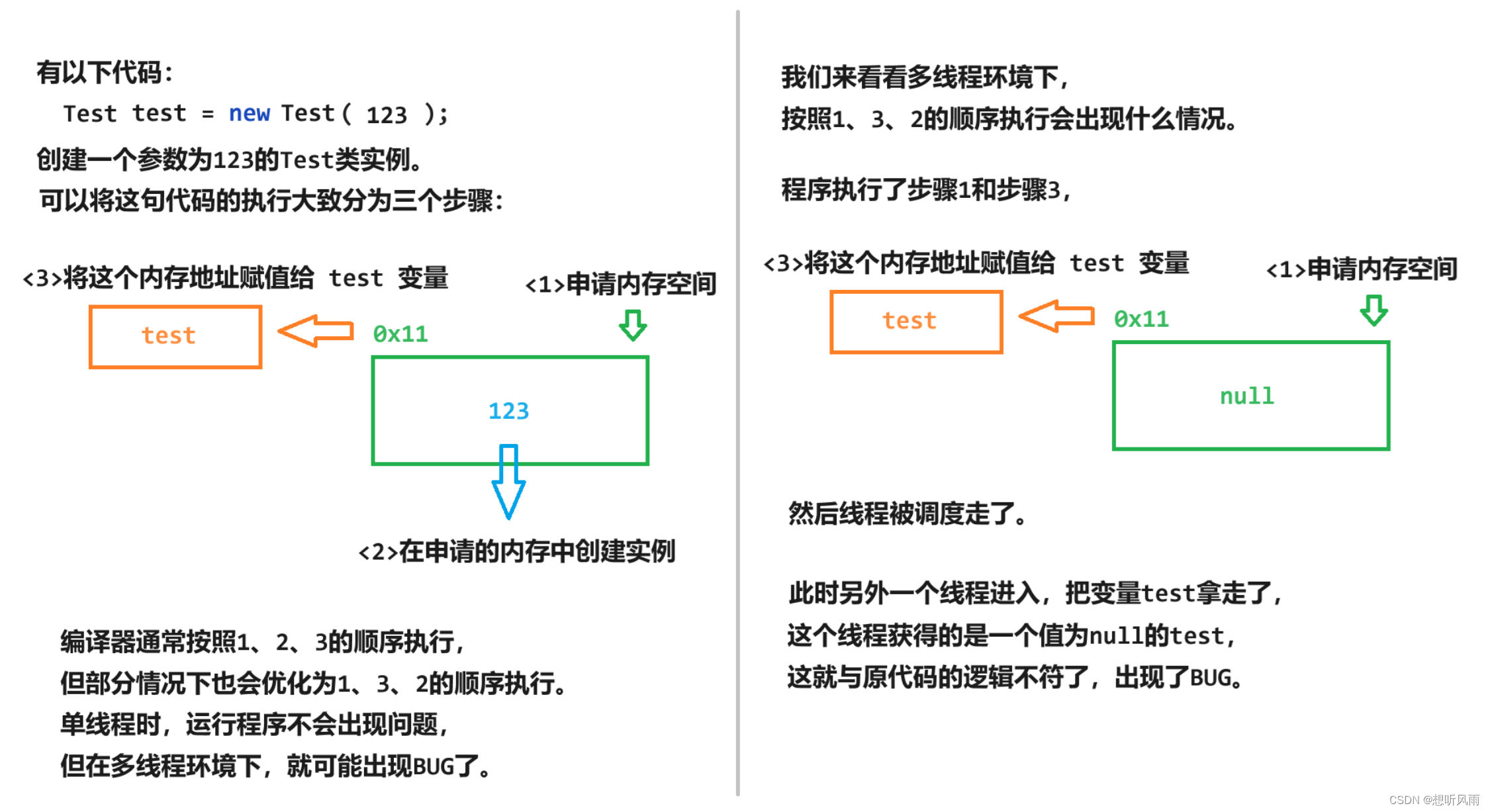
<JavaEE> volatile关键字 -- 保证内存可见性、禁止指令重排序
目录 一、内存可见性 1.1 Java内存模型(JMM) 1.2 内存可见性演示 二、指令重排序 三、关键字 volatile 一、内存可见性 1.1 Java内存模型(JMM) 1)什么是Java内存模型(JMM)?Java内存模型即Java Memory Model,简…...

docker安装mysql8
docker安装mysql8 docker search mysql:8 #搜索可以使用的msyql8的镜像 docker pull mysql:8.0.27 #拉去mysql8的镜像 创建挂载的宿主机目录 mkdir -p /data/mysql/mysql8/conf # 配置文件目录 mkdir -p /data/mysql/mysql8/data # 数据目录 touch /data/mysql/mysql8/conf/my.…...

消息丢失排查方法?
遇到丢消息问题,如果是单聊,群聊,聊天室,系统消息可以在开发者后台北极星自助查询一下消息是否发送成功。根据您实际发送的相关信息(发送者、接收者、时间、消息 ID ……)看是否可以查到消息 如果消息查不到…...
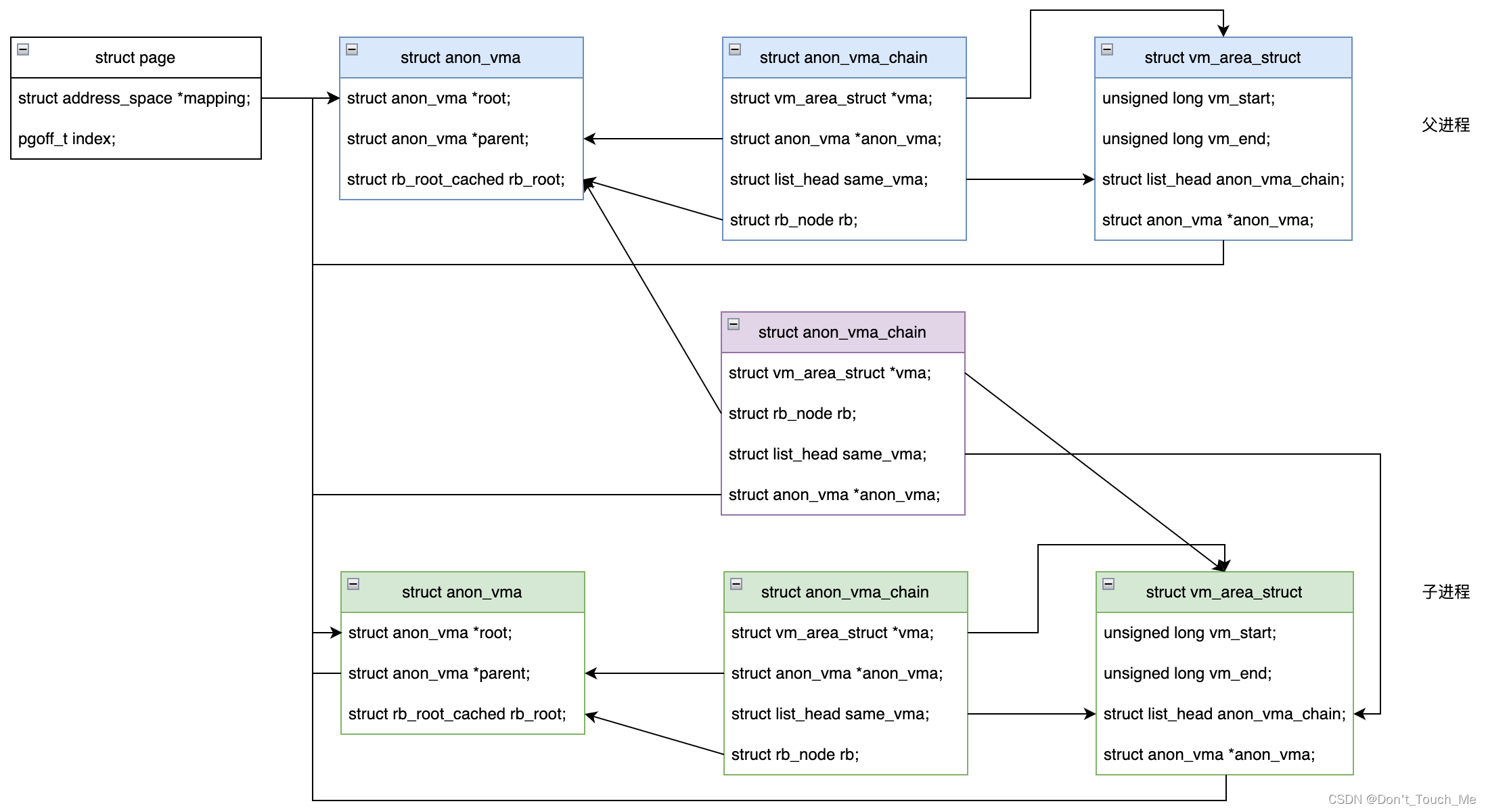
Linux 匿名页反向映射
1. 何为反向映射 正向映射: 用户进程在申请内存时,内核并不会立刻给其分配物理内存,而是先为其分配一段虚拟地址空间,当进程访问该虚拟地址空间时,触发page fault异常,异常处理流程中会为其分配物理页面&am…...

国内首个农业开源鸿蒙操作系统联合华为正式发布
2023年11月29日,在中国国际供应链促进博览会上,中信农业科技股份有限公司(简称“中信农业”)与深圳开鸿数字产业发展有限公司(简称“深开鸿”)以及华为技术有限公司(简称“华为”)联…...

python HTML文件标题解析问题的挑战
引言 在网络爬虫中,HTML文件标题解析扮演着至关重要的角色。正确地解析HTML文件标题可以帮助爬虫准确地获取所需信息,但是在实际操作中,我们常常会面临一些挑战和问题。本文将探讨在Scrapy中解析HTML文件标题时可能遇到的问题,并…...

AIM: Symmetric Primitive for Shorter Signatures with Stronger Security
目录 笔记后续的研究方向摘要引言贡献 AIM: Symmetric Primitive for Shorter Signatures with Stronger Security CCS 2023 笔记 后续的研究方向 摘要 基于头部MPC(MPCitH)范式的后量子签名方案最近引起了人们的极大关注,因为它们的安全性…...

【 Go语言使用xorm框架操作数据库】
Go语言使用xorm框架操作数据库 Xorm 是一个简单而强大的Go语言ORM(对象关系映射)库。它支持自动将结构体映射到数据库表,并提供了一系列便捷的API来执行CRUD(创建、读取、更新和删除)操作。 安装 Xorm 首先…...
DouyinAPI接口系列丨Douyin商品详情数据接口丨Douyin视频详情数据接口
抖音商品详情API是抖音开放平台提供的一套API接口,用于获取商品详情信息。通过该API,开发者可以获取到商品的详细信息,包括商品ID、名称、描述、价格、销量、评价等信息。 在使用抖音商品详情API之前,需要先注册并登录抖音开放平…...
旺店通对接中国南方电网,打破跨系统连接,让数据轻易互通成为现实
接入系统:旺店通企业版 旺店通是北京掌上先机网络科技有限公司旗下品牌,国内的零售云服务提供商,基于云计算SaaS服务模式,以体系化解决方案,助力零售企业数字化智能化管理升级。为零售电商企业的订单管理及仓储管理提供…...

简介Kadane算法及相关的普通动态规划
简介Kadane算法及相关的普通动态规划 本文详细论述Kadane算法的经典题目,并通过“首先列出动态规划解法,再改为Kadane算法解法”的方式,讲解二者的不同。最后给出一道Kadane算法变体的题目,解法极为简洁优美。 Kadane算法也是一…...
校园教务管理系统
学年论文(课程设计) 题目: 信息管理系统 校园教务管理系统 摘要:数据库技术是现代信息科学与技术的重要组成部分,是计算机数据处理与信息管理系统的核心,随着计算机技术的发展,数据库技…...

【LeetCode热题100】【双指针】接雨水
给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。 示例 1: 输入:height [0,1,0,2,1,0,1,3,2,1,2,1] 输出:6 解释:上面是由数组 [0,1,0,2,1,0,1,3,2,1,2,1] …...
)
软件工程-(可行性分析、需求分析)
目录 一.可行性研究 1.1定义 1.2项目背景 1.3三方面研究目标系统的可行性 1.3.1技术可行性分析 1.3.2 经济可行性分析 1.3.3 市场可行性分析 1.4. 数据流图 数据字典(DD) 1.5风险评估 1.6结论与建议 二、需求分析 引言 项目概述 利益相关者分析…...
HuggingFace学习笔记--BitFit高效微调
1--BitFit高效微调 BitFit,全称是 bias-term fine-tuning,其高效微调只去微调带有 bias 的参数,其余参数全部固定; 2--实例代码 from datasets import load_from_disk from transformers import AutoTokenizer, AutoModelForCaus…...

阅读笔记|A Survey of Large Language Models
阅读笔记 模型选择:是否一定要选择参数量巨大的模型?如果需要更好的泛化能力,用于处理非单一的任务,例如对话,则可用选更大的模型;而对于单一明确的任务,则不一定越大越好,参数小一…...
JSP 设置静态文件资源访问路径
这里 我们先在 WEB目录webapp 下创建一个包 叫 static 就用它来存静态资源 然后 我们扔一张图片进去 我们直接这样写 如下图 找到父级目录 然后寻找下面的 static 下的 img.png 运行代码 很明显 它没有找到 这边 我们直接找到 webapp目录下的 WEB-INF目录下的 web.xml 加入…...

变量 varablie 声明- Rust 变量 let mut 声明与 C/C++ 变量声明对比分析
一、变量声明设计:let 与 mut 的哲学解析 Rust 采用 let 声明变量并通过 mut 显式标记可变性,这种设计体现了语言的核心哲学。以下是深度解析: 1.1 设计理念剖析 安全优先原则:默认不可变强制开发者明确声明意图 let x 5; …...

地震勘探——干扰波识别、井中地震时距曲线特点
目录 干扰波识别反射波地震勘探的干扰波 井中地震时距曲线特点 干扰波识别 有效波:可以用来解决所提出的地质任务的波;干扰波:所有妨碍辨认、追踪有效波的其他波。 地震勘探中,有效波和干扰波是相对的。例如,在反射波…...

蓝牙 BLE 扫描面试题大全(2):进阶面试题与实战演练
前文覆盖了 BLE 扫描的基础概念与经典问题蓝牙 BLE 扫描面试题大全(1):从基础到实战的深度解析-CSDN博客,但实际面试中,企业更关注候选人对复杂场景的应对能力(如多设备并发扫描、低功耗与高发现率的平衡)和前沿技术的…...
:滤镜命令)
ffmpeg(四):滤镜命令
FFmpeg 的滤镜命令是用于音视频处理中的强大工具,可以完成剪裁、缩放、加水印、调色、合成、旋转、模糊、叠加字幕等复杂的操作。其核心语法格式一般如下: ffmpeg -i input.mp4 -vf "滤镜参数" output.mp4或者带音频滤镜: ffmpeg…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个生活电费的缴纳和查询小程序
一、项目初始化与配置 1. 创建项目 ohpm init harmony/utility-payment-app 2. 配置权限 // module.json5 {"requestPermissions": [{"name": "ohos.permission.INTERNET"},{"name": "ohos.permission.GET_NETWORK_INFO"…...

JUC笔记(上)-复习 涉及死锁 volatile synchronized CAS 原子操作
一、上下文切换 即使单核CPU也可以进行多线程执行代码,CPU会给每个线程分配CPU时间片来实现这个机制。时间片非常短,所以CPU会不断地切换线程执行,从而让我们感觉多个线程是同时执行的。时间片一般是十几毫秒(ms)。通过时间片分配算法执行。…...
集成 Mybatis-Plus 和 Mybatis-Plus-Join)
纯 Java 项目(非 SpringBoot)集成 Mybatis-Plus 和 Mybatis-Plus-Join
纯 Java 项目(非 SpringBoot)集成 Mybatis-Plus 和 Mybatis-Plus-Join 1、依赖1.1、依赖版本1.2、pom.xml 2、代码2.1、SqlSession 构造器2.2、MybatisPlus代码生成器2.3、获取 config.yml 配置2.3.1、config.yml2.3.2、项目配置类 2.4、ftl 模板2.4.1、…...

Java求职者面试指南:计算机基础与源码原理深度解析
Java求职者面试指南:计算机基础与源码原理深度解析 第一轮提问:基础概念问题 1. 请解释什么是进程和线程的区别? 面试官:进程是程序的一次执行过程,是系统进行资源分配和调度的基本单位;而线程是进程中的…...

【FTP】ftp文件传输会丢包吗?批量几百个文件传输,有一些文件没有传输完整,如何解决?
FTP(File Transfer Protocol)本身是一个基于 TCP 的协议,理论上不会丢包。但 FTP 文件传输过程中仍可能出现文件不完整、丢失或损坏的情况,主要原因包括: ✅ 一、FTP传输可能“丢包”或文件不完整的原因 原因描述网络…...

游戏开发中常见的战斗数值英文缩写对照表
游戏开发中常见的战斗数值英文缩写对照表 基础属性(Basic Attributes) 缩写英文全称中文释义常见使用场景HPHit Points / Health Points生命值角色生存状态MPMana Points / Magic Points魔法值技能释放资源SPStamina Points体力值动作消耗资源APAction…...