动手学习深度学习-跟李沐学AI-自学笔记(3)
一、深度学习硬件-CPU和GPU
芯片:Intel or AMD
内存:DDR4
显卡:nVidia
芯片可以和GPU与内存通信
GPU不能和内存通信
1. CPU
能算出每一秒能运算的浮点运算数(大概0.15左右)
1.1 提升CPU利用率
1.1.1 提升缓存
- 再计算a+b之前,需要准备数据(CPU可能计算的快,但是内存很慢)
- 主内存->L3->L2->L1->寄存器(进入寄存器才能开始运算,和主频一样,速度最快)
- L1访问延时:0.5ns
- L2访问延时:7ns
- 主内存访问延时:100ns
- 提升空间和时间的内存本地性(缓存效率更高)
- 时间:重用数据使得保持它们在缓存里
- 空间:按序读写数据使得可以预读取
1.1.2 提升并行
超线程:将一个CPU物理核分给两个超线程,但是对计算密集型的没用
- 高端CPU有几十个核
- 并行来利用所有核:超线程不一定提升性能,因为它们共享寄存器
例子:

2. GPU
能看到一个:xx TFLOPS(比CPU高很多)
显存会低一点点
2.1 提升GPU利用率
对于GPU来讲,一个大核包含很多小核,一个小核包含很多计算单元,一个计算单元可以开一个线程。虽然每个计算单元的计算速度可能比CPU慢,但是并行很强,总体看快。
- 并行
- 使用数千个线程(向量至少1000维)
- 内存本地性
- 缓存更小,架构更简单
- 少用控制语句
- 支持有限
- 同步开销很大
3. CPU vs GPU
本质区别:核的个数&带宽(限制峰值,每一次需要从主存里读东西),GPU的代价就是内存不能很大(太贵),控制流很弱(跳转)

3.1 CPU/GPU带宽

任务本质上还是在CPU上做的,CPU到GPU带宽不高,而且经常需要同步
因此开销很大,不要频繁在CPU核GPU之间传数据(一次传完):带宽限制,同步开销
3.2 更多的CPUs和GPUs
- CPU:AMD,ARM
- GPU:AMD,Intel,ARM,Qualcomm
3.3 CPU/GPU高性能计算编程
- CPU:C++或者任何高性能语言
- 编译器成熟
- GPU:
- Nvidia上用CUDA:编译器和驱动很成熟
- 其他用OpenCL:质量取决于硬件厂商
总结:
- CPU:可以处理通用计算,性能优化考虑数据读写效率和多线程
- GPU:使用更多的小核和更好的内存带宽,适合能大规模并行的计算任务
补充:
第31节QA
二、TPU和其他
第32节
三、单机多卡并行
第33节
四、多GPU训练实现
第34节
五、分布式训练
第35节
六、数据增广
1. 一般专注于图片
- 在已有的数据集上,增加数据多样性。
- 一般是在线生成。
- 常见:翻转(建筑物就不用反转了)、切割(在图像中切割一块(可以是随机高宽比、随机大小、随机位置),然后变形到固定形状(卷积神经网络的输入形状一般都是一样的))、颜色(改变色调、饱和度、明亮度(一般取0.5~1.5,即增加或减少50%))。
- 提供了多种数据增强方法:https://github.com/aleju/imgaug
- 从部署数据集可能有什么数据反推使用什么方法。
总结:
- 增加模型泛化性。
2. 代码实现

-
aug:图像增广的方法,有很多随机色温、色调、等等!
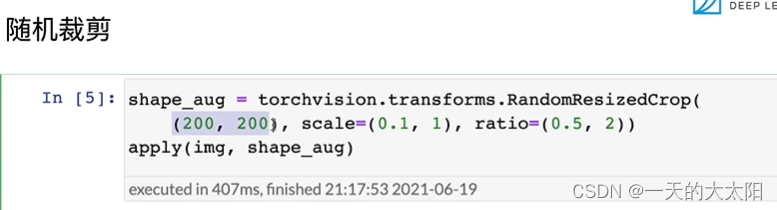
-
可以很多一起用:

-
scale:将图片扩大或缩小
-
就是将图像增广的方法执行多次(num_rows行num_cols列)
-
图片增广最后一般都会接一个totensor。
-
应用:
图片进行增广是一件不便宜的事,最好多开几个num_workers。
- 一般都可以防止过拟合!测试集的精度会更高~
- 训练时只有load时加上拟合函数:
补充:
- 数据足够多可以不再增广,但是泛化性不强还是得增广。一般正确增广都是有效的。
- CPU几个核决定了num_worker大小。CPU不能太弱,要不数据处理可能跟不上,起码得是8核以上。可以测试来确定。
- 异常检测,都可以进行重采样、数据增广。
- 测试一般不做数据增广。(也可以,例如图像大小,按比例保留短边切掉长边,变为想要的大小。一般只留中间的,也可以再取点别的地方的)实际应用不用,竞赛可以使用,因为预测成本增加了。
- 实验可以固定随即种子,gap一般都不会减少,总是会过拟合的。
- 因为是随机的,因此数据分布是不变的,只是多样性增加了(均值不变,方差变大了)。
- 图神经网络,训练难,但是强大。
- 增广是可以拼接图片的,但是label也需要拼接。
- 特定场景,需要针对特定场景单独采集数据,重新打标训练;也可以将不行的(分类错误)数据,重新label加入训练集再来训练。(可能叫主动学习~持续学习)
- 增广就是为了让训练集长得更像测试集。
- mix-up确实有用~具体为什么不知道(label叠加)
- torchvision和albumentation都可以
七、微调(迁移学习的一种)
- 可以说是对计算机视觉,深度学习最重要的技术。
- 首先标注一个数据集很贵!我们没有那么多的数据,想要训练好模型,可以先在大数据集上训练好,对于小数据集,简单学学就会了。
1. 网络架构
- 一个神经网络一般可以分成两块:
- 特征抽取:将原始像素变成容易线性分割的特征。
- 线性分类器:(softmax回归)来做分类。
- 微调:就是在源数据集(一般比较大)上已经训练好了一个模型,那么可以认为特征抽取那一块对于我们的目标数据集也可以使用(但是必须要和预训练好模型的是一样的架构,直接copy来权重即可),起码比随机好一点,但是线性分类器就不能直接使用了(随机初始化,反正这一层在最上面,loss直接就过来了,这样训练是比较快的)因为标号可能变了。然后根据自己的数据集稍微训练一下即可。使用在大数据集上预训练好的模型来初始化模型权重,完成精度的提升。预训练模型的质量很重要,需要在很大的模型上训练过。通常数度更快,精度更高。
2. 训练
-
是一个目标数据集上的正常训练任务,但是使用更强的正则化:
- 因为我们通常会使用更小的学习率(已经和最优解比较接近了,不需要特别长的学习率。微调对学习率不敏感,直接使用一个比较小的学习率就行了)。
- 使用更少的数据迭代(需要训练的epoch没有那么多了,训练太过很可能over fit)。
-
源数据集远复杂于目标数据(类别、数量、样本个数要百倍大于目标数据集),通常微调效果更好。没有特别优于目标数据集的不如自己从头开始训练。
3. 重用分类器权重
- 源数据集可能也有目标数据集中的部分标号。
- 这样线性分类器就可以使用预训练好的模型分类器中对应标号对应的向量(也可以重用其中的好几个类,还能再加上自己新建的类,但是只有重复的类能重用,而且只能手动提取权重。其余的无关标号的权重直接删除!)来做初始化。(实际用的不多)
- 没有的标号只能随机。
4. 固定一些层
- 神经网络通常学习有层次的特征表示:
- 低层次的特征更加通用(与底层细节相关,理解数据,我们认为这是通用的)
- 高层次的特征则更跟数据及相关(更加语义化一些,与标号更相关)
- 可以固定底部一些层的参数,不参与更新(这样模型复杂度降低),可以认为是一种更强的正则。对于数据集很小时很有用。但是怎么样最好是需要调的,最极端的是其余固定住,只训练最后一个全连接层,另一个极端就是全部的层一起动。
5. 代码实现
(训练集测试集)进行了数据增广,注意如果预训练模型做了norm,微调前也需要做同样的norm。模型输入大小要一样。要是有数据增强也是需要一样的。
-
下模型:(下载时,下列参数为true,说明不仅下模型定义下下来,还有训练好的parameter也一起拿下来)下一行代码是拿出最后一层。

-
更改输出层:并对最后一层的weight随机初始化

-
如果param_group为true:将非最后一层的参数取出,其他层lr小,fc层lr大。

-
不适用预训练:从零开始训练。

补充:
- 数据不平衡(也可以理解成标号不平衡)问题对特征提取的影响相对较小,对越往上层的影响越大,尤其是分类器。
- 要找预训练模型在和所使用的数据集相似的源数据集(可以更大,种类更多,但是要相似,当然不是源数据集必须包含目标数据集哦)上训练的,要不相差太大可能还不如从头开始训练。
- 标号要找对应的字符串(label的名称字符串,还要注意语义匹配不同,数据集上叫的名字可能不同),因为标号肯定是按照顺序来的,没什么意义。
- 微调中的归一化很重要,可以认为是网络中的一块,是可以换成batchnoralize就不需要这个了,但是我们copy时是没有copy这一块的,因此需要我们手动弄过去,但是如果预训练模型中有,那就不需要我们代码中自己搞的normalize了(源数据集的训练结构也做了归一化)。
- normalize参数是从源数据集上算出来的,finetune需要更改normalization的参数为自己数据集的均值和方差。
- auto-gluon会加入微调的(使用微调一般不会让模型变差,可能不会变好,但是一般不会变差)。
- 常用的CV预训练模型有imagenet上预训练的resnet系列。
- 微调是需要重新搞一下label和对应标号关系的,可以看课后习题有讲解。
- 自己预训练一个分类模型是有用的,因为可以用到其他图像技术上,反正都需要抽取特征的。
八、竞赛-树叶分类结果
第38节,略
九、实战-图像分类kaggle比赛
o-gluon会加入微调的(使用微调一般不会让模型变差,可能不会变好,但是一般不会变差)。
- 常用的CV预训练模型有imagenet上预训练的resnet系列。
- 微调是需要重新搞一下label和对应标号关系的,可以看课后习题有讲解。
- 自己预训练一个分类模型是有用的,因为可以用到其他图像技术上,反正都需要抽取特征的。
八、竞赛-树叶分类结果
第38节,略
九、实战-图像分类kaggle比赛
第39节40节,略
相关文章:
动手学习深度学习-跟李沐学AI-自学笔记(3)
一、深度学习硬件-CPU和GPU 芯片:Intel or AMD 内存:DDR4 显卡:nVidia 芯片可以和GPU与内存通信 GPU不能和内存通信 1. CPU 能算出每一秒能运算的浮点运算数(大概0.15左右) 1.1 提升CPU利用率 1.1.1 提升缓存…...

3.2 Puppet 和 Chef 的比较与应用
Puppet 和 Chef 的比较与应用 文章目录 Puppet 和 Chef 的比较与应用Puppet 和 Chef 简介工作原理对比**模块化的重要性**: Puppet 和 Chef 简介 介绍 Puppet 和 Chef 这两个流行的配置管理工具的背景和用途。强调它们的共同目标:实现自动化的系统配置和…...

promise使用示例
下面是一个 Promise 使用示例,通过 Promise 实现异步操作的链式调用: const getUser (userId) > {return new Promise((resolve, reject) > {// 模拟异步请求setTimeout(() > {const users [{ id: 1, name: Alice },{ id: 2, name: Bob },{ …...

一起学docker系列之十四Dockerfile微服务实践
目录 1 前言2 创建微服务模块2.1 **创建项目模块**2.2 **编写业务代码** 3 编写 Dockerfile4 构建 Docker 镜像5 运行 Docker 容器6 测试微服务7 总结8 参考地址 1 前言 微服务架构已经成为现代软件开发中的一种重要方式。而 Docker 提供了一种轻量级、便携式的容器化解决方案…...
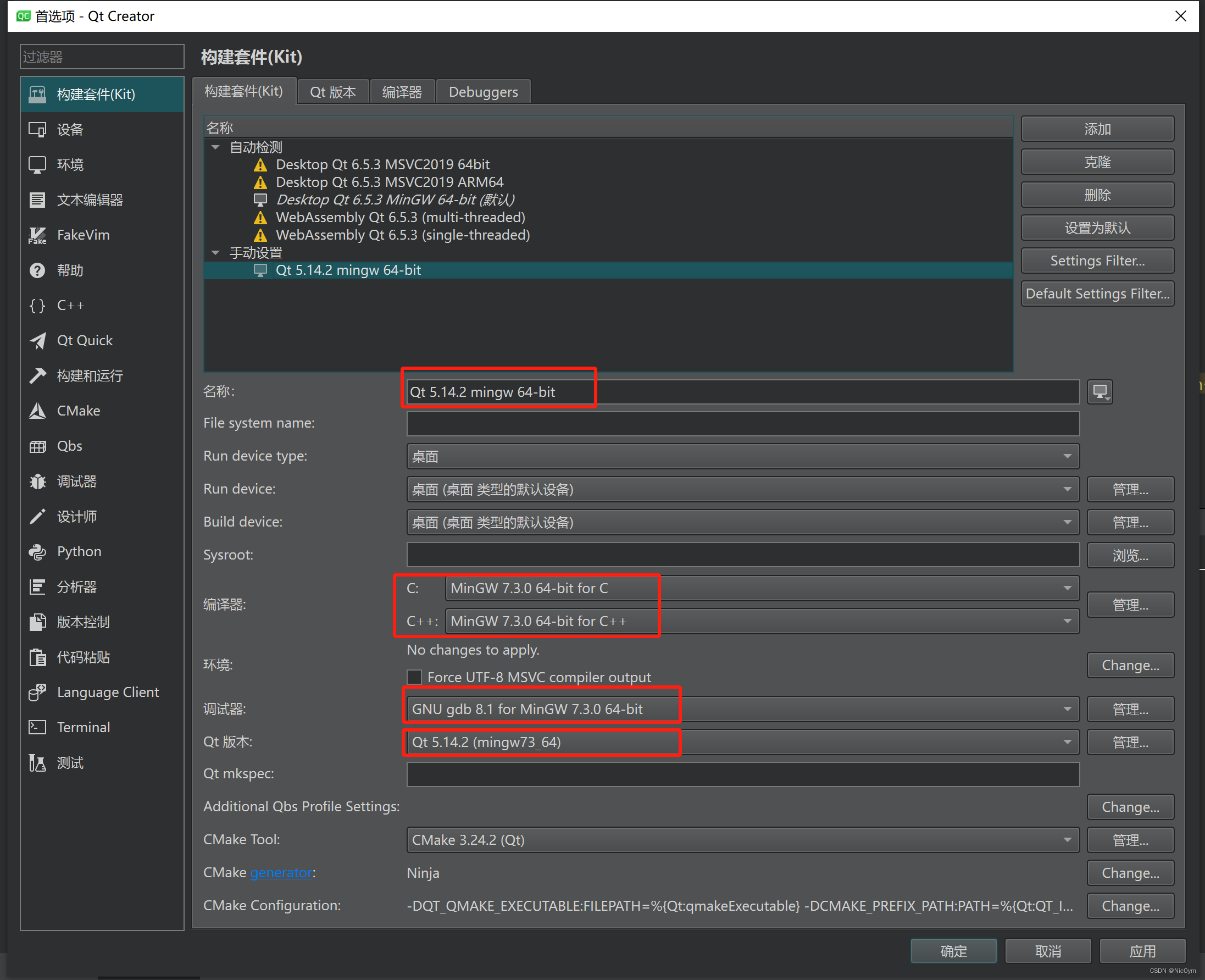
Qt Creator 11.0.3同时使用Qt6.5和Qt5.14.2
Qt Creator 11.0.3同时使用Qt6.5和Qt5.14.2 概要方法1.打开Qt Creator中的Kit,这里我直接附上几张截图,不同的版本打开位置可能有所不同,总之最终目的是要打开构建套件(Kit)2.可以看到构建套件里面有包含了“构建套件K…...

Python中字符串列表的相互转换详解
更多资料获取 📚 个人网站:ipengtao.com 在Python编程中,经常会遇到需要将字符串列表相互转换的情况。这涉及到将逗号分隔的字符串转换为列表,或者将列表中的元素连接成一个字符串。本文将深入讨论这些情景,并提供丰富…...

09、pytest多种调用方式
官方用例 # content of myivoke.py import sys import pytestclass MyPlugin:def pytest_sessionfinish(self):print("*** test run reporting finishing")if __name__ "__main__":sys.exit(pytest.main(["-qq"],plugins[MyPlugin()]))# conte…...
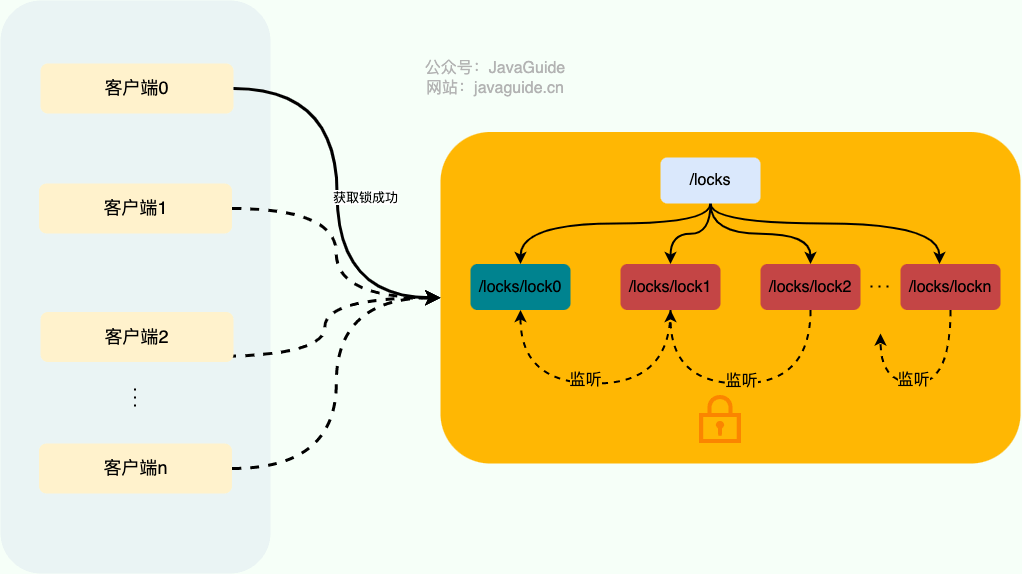
分布式锁常见实现方案
分布式锁常见实现方案 基于 Redis 实现分布式锁 如何基于 Redis 实现一个最简易的分布式锁? 不论是本地锁还是分布式锁,核心都在于“互斥”。 在 Redis 中, SETNX 命令是可以帮助我们实现互斥。SETNX 即 SET if Not eXists (对应 Java 中…...

26、pytest使用allure解读
官方实例 # content of pytest_quick_start_test.py import allurepytestmark [allure.epic("My first epic"), allure.feature("Quick start feature")]allure.id(1) allure.story("Simple story") allure.title("test_allure_simple_te…...

Uncle Maker: (Time)Stamping Out The Competition in Ethereum
目录 笔记后续的研究方向摘要引言贡献攻击的简要概述 Uncle Maker: (Time)Stamping Out The Competition in Ethereum CCS 2023 笔记 本文对以太坊 1 的共识机制进行了攻击,该机制允许矿工获得比诚实同行更高的挖矿奖励。这种名为“Uncle Maker”的攻击操纵区块时间…...

浅谈可重入与线程安全
文章目录 可重入与线程安全的关系 可重入 若一个程序或子程序可以“在任意时刻被中断然后操作系统调度执行另一段代码,这段代码又使用了该副程序不会出错”,则称其为可重入(reentrant 或 re-entrant)的。即当该副程序正在运作时&…...

深入理解TDD(测试驱动开发):提升代码质量的利器
在日常的软件开发工作中,我们常常会遇到这样的问题:如何在繁忙的项目进度中,保证我们的代码质量?如何在不断的迭代更新中,避免引入新的错误?对此,有一种有效的开发方式能帮助我们解决这些问题&a…...

pyqt5使用pyqtgraph实现动态热力图
pyqt5使用pyqtgraph实现动态热力图 一、效果图 二、流程 1、打开Designer创建一个UI界面 2、把UI转成py 3、创建一个main.py文件 4、在main文件中渲染画布、创建初始数据、画热力图、创建更新数据线程、绑定按钮触发事件三、UI界面 其中h_map.py代码如下: # -*- coding: ut…...

【android开发-16】android中文件和sharedpreferences数据存储详解
1,文件读写方式的数据存储 下面是一个简单的示例,演示如何在Android中使用内部存储来保存和读取文件: 保存文件: try { String data "这是要保存的数据"; FileOutputStream fos openFileOutput("myFile"…...
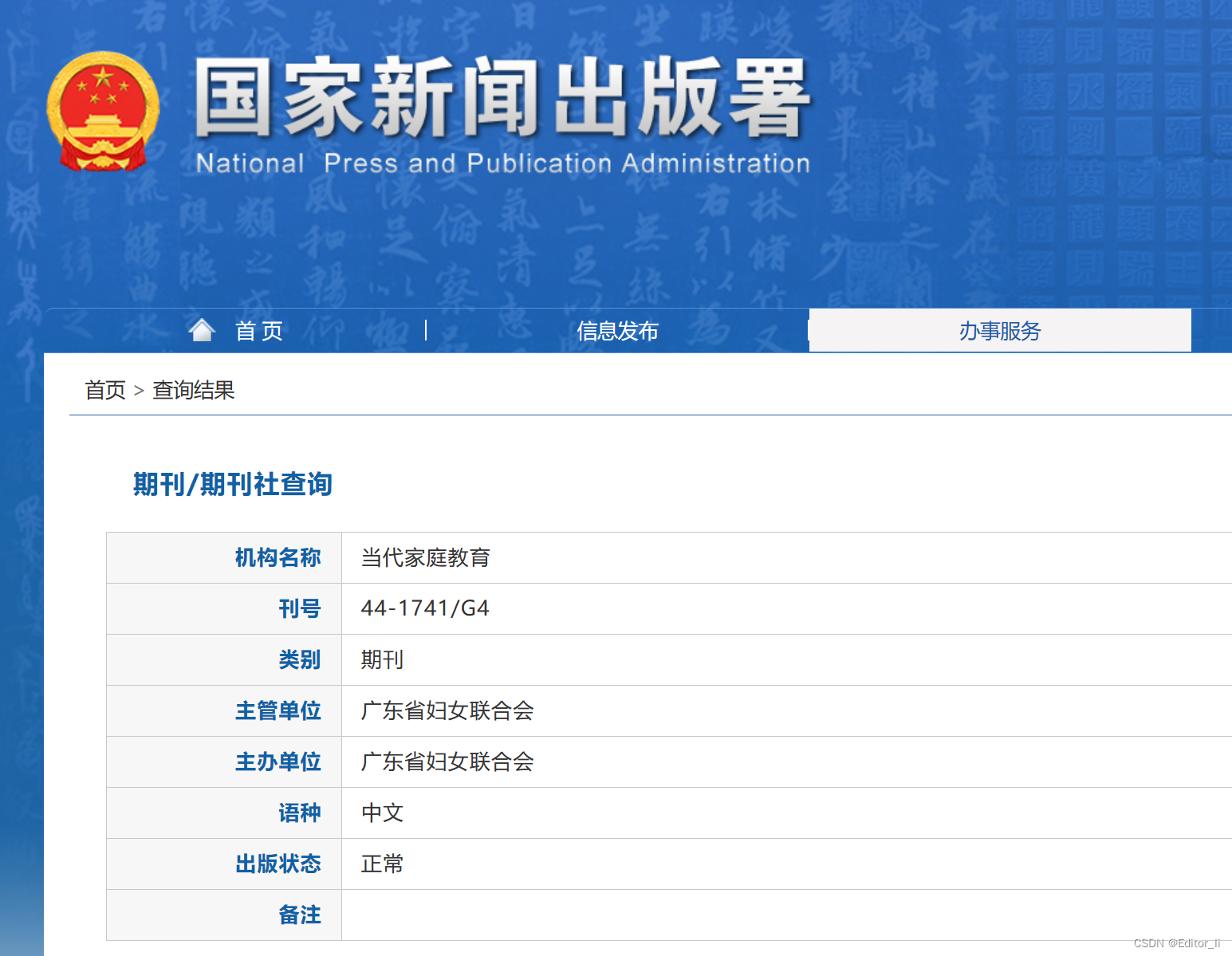
《当代家庭教育》期刊论文投稿发表简介
《当代家庭教育》杂志是家庭的参谋和助手,社会的桥梁和纽带,人生的伴侣和知音,事业的良师益友。 国家新闻出版总署批准的正规省级教育类G4期刊,知网、维普期刊网收录。安排基础教育相关稿件,适用于评职称时的论文发表…...

【操作教程】如何将外省医保转入广州市区(医保转移接续手续办理)?
登录(可以用微信扫码采用粤省事账号登录,没有粤省事小程序账号的可以自主申请很方便)广东政务服务网https://www.gdzwfw.gov.cn/ 这里不得不吐槽官网开发者,太拉胯了,居然有undefined,多刷新几次就好了&…...
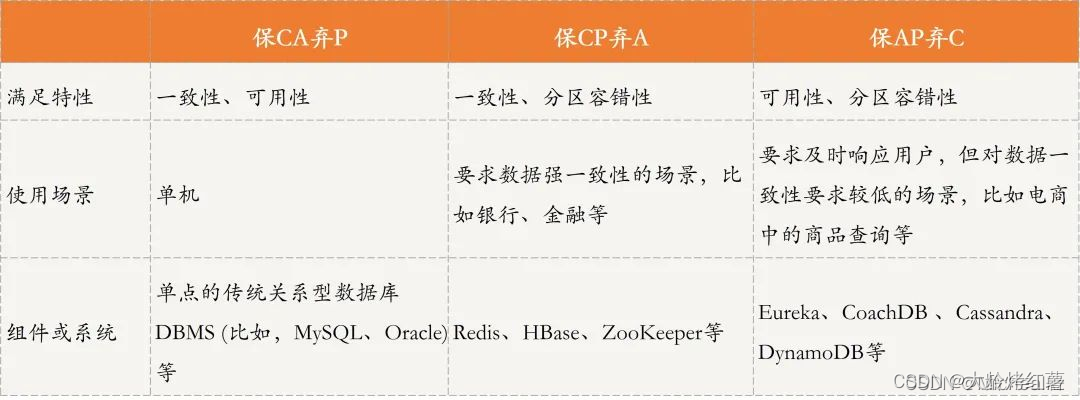
【分布式系统学习】CAP原理详解
CAP原理详解 前言CAP一张图 一、概念1.1 关键词解读1.2 关于CAP(拆分解读)1.3 CAP原理精髓 二、CAP模拟场景举例理解三、CAP原理证明为什么不能同时满足(下面举例说明)3.1 必须满足分区容错性P下的处理方式3.2 不是必须满足分区容…...

【聚类】K-modes和K-prototypes——适合离散数据的聚类方法
应用场景: 假设一批数据,每一个样本中,有唯一标识(id)、品类(cate_id)、受众(users, 小孩、老人、中年等)等属性,希望从其中找出一些样本,使得这…...

Python-炸弹人【附完整源码】
炸弹人 炸弹人是童年的一款经典电子游戏,玩家控制一个类似"炸弹人"的角色,这个角色可以放置炸弹,并在指定的时间内引爆它们消灭敌人以达到目标,此游戏共设有两节关卡,代码如下: 运行效果&#x…...

[英语学习][5][Word Power Made Easy]的精读与翻译优化
[序言] 今日完成第18页的阅读, 发现大量的翻译错误以及不准确. 需要分两篇文章进行讲解. [英文学习的目标] 提升自身的英语水平, 对日后编程技能的提升有很大帮助. 希望大家这次能学到东西, 同时加入我的社区讨论与交流英语相关的内容. [原著英文与翻译版对照][第18页] Wh…...

如何删除论文脚注横线的方法——视图-草稿-引用——显示备注——删除脚注分隔符-即可。
如何删除论文脚注横线的方法——视图-草稿-引用——显示备注——删除脚注分隔符-即可。 Word中脚注线不会删?这里有妙招!,教育,职业教育,好看视频...

2026年HR招聘偏好白皮书:这5项附加技能出现频率暴涨
2026 年的招聘市场,正在从“看你会什么岗位技能”,转向“看你能不能把岗位做得更智能”。HR筛简历时,越来越关注候选人的AI应用能力、数据化思维和业务落地能力。人社部近年发布的新职业中,已经出现生成式人工智能系统应用员、人工…...

AArch64内存管理:MAIR_EL3寄存器详解与应用
1. AArch64内存管理基础与MAIR_EL3寄存器定位 在Armv8-A/v9-A架构中,内存管理单元(MMU)通过多级页表实现虚拟地址到物理地址的转换。当处理器执行内存访问时,MMU会遍历页表条目(Translation Table Entry),其中包含两个关键信息:目…...

告别手写UI!用NXP GUI Guider拖拽设计LVGL界面,5分钟搞定音乐播放器Demo
嵌入式UI开发革命:5分钟用GUI Guider构建LVGL音乐播放器在嵌入式系统开发中,用户界面(UI)设计曾长期是工程师的痛点——既要考虑资源受限的硬件环境,又要实现流畅美观的交互体验。传统手动编写UI代码的方式不仅效率低下,调试过程更…...

【UniApp小程序开发】解决无法使用Vue自定义指令的完美替代方案:权限组件封装
在 UniApp 开发中,你是否遇到过这样的困惑:明明在 Vue Web 项目中用得顺手的 v-permission 自定义指令,一到小程序端就完全失效?本文将深入剖析其原因,并提供一套可直接复用的组件化解决方案,让你在小程序中…...

Veo 2胶片质感生成器失效?——深度解析Color Science v2.3内核中被屏蔽的Cinematic Grain Injection层
更多请点击: https://kaifayun.com 第一章:Veo 2胶片质感生成器失效现象全景透视 近期大量用户反馈,Veo 2 胶片质感生成器在调用 generate_film_effect() 接口后返回空纹理、纯灰帧或 HTTP 503 Service Unavailable 错误,且该问题…...
)
Unity事件系统实战:用事件驱动重构你的金币拾取逻辑(告别硬编码)
Unity事件系统实战:用事件驱动重构你的金币拾取逻辑(告别硬编码)在游戏开发中,我们经常会遇到这样的场景:玩家拾取金币后,需要更新UI、播放音效、解锁成就、保存数据……如果把这些逻辑全部写在金币拾取的代…...

企业内统一API网关与Taotoken聚合平台对接方案
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业内统一API网关与Taotoken聚合平台对接方案 在推进AI应用落地的过程中,许多中大型企业面临一个共同挑战:…...
)
CentOS 8.5最小化安装后,这5个必做的安全与效率优化设置(附一键脚本)
CentOS 8.5最小化安装后的5个必做安全与效率优化刚完成CentOS 8.5最小化安装的系统就像一张白纸——干净但缺乏生产力。作为运维老手,我见过太多人跳过基础优化直接部署应用,结果在后续使用中频繁遇到权限混乱、软件安装慢、SSH爆破等问题。本文将分享我…...

对比不同模型在创意生成任务中的效果与token消耗差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比不同模型在创意生成任务中的效果与token消耗差异 在为一场创意大赛准备素材时,我们面临一个常见的选择:…...