Elasticsearch:对时间序列数据流进行降采样(downsampling)
降采样提供了一种通过以降低的粒度存储时间序列数据来减少时间序列数据占用的方法。
指标(metrics)解决方案收集大量随时间增长的时间序列数据。 随着数据老化,它与系统当前状态的相关性越来越小。 降采样过程将固定时间间隔内的文档汇总为单个摘要文档。 每个摘要文档都包含原始数据的统计表示:每个指标的最小值(min)、最大值 (max)、总和 (sum)、值计数 (value_count) 和平均值 (average)。 数据流时间序列维度存储不变。
实际上,降采样可以让你用数据分辨率和精度来换取存储大小。 你可以将其包含在索引生命周期管理 (ILM) 策略中,以自动管理指标数据的数量和相关成本。
它是如何工作的?
时间序列是特定实体随时间推移的一系列观察结果。 观察到的样本可以表示为连续函数,其中时间序列维度保持不变,时间序列指标随时间变化。
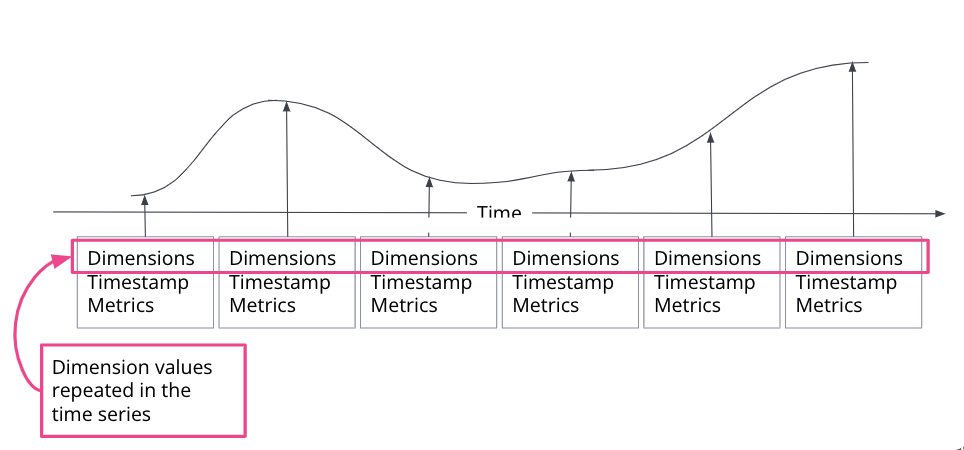
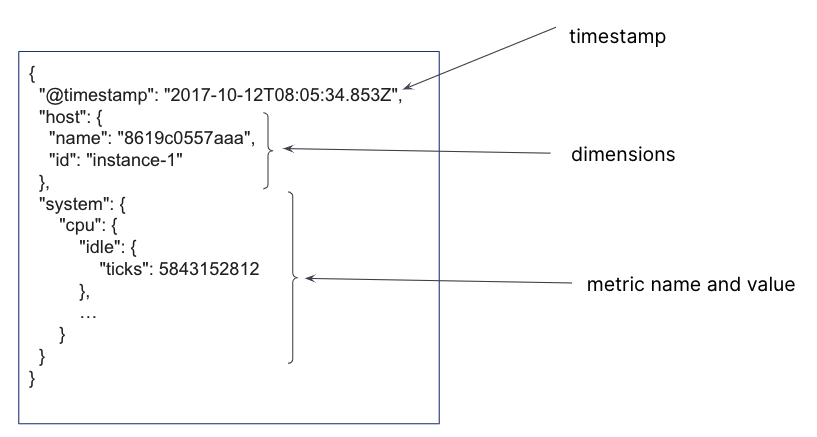
在 Elasticsearch 索引中,会为每个时间戳创建一个文档,其中包含不可变的时间序列维度以及指标名称和变化的指标值。 对于单个时间戳,可以存储多个时间序列维度和指标。
对于最新的相关数据,指标系列通常具有较低的采样时间间隔,因此它针对需要高数据分辨率的查询进行了优化。

降采样通过用更高采样间隔的数据流和该数据的统计表示替换原始时间序列来处理较旧的、访问频率较低的数据。 在原始指标样本可能已采集的情况下,例如每十秒采集一次,随着数据老化,你可以选择将样本粒度减少到每小时或每天。 你可以选择将冷归档数据的粒度减少到每月或更小。
对时间序列数据运行降采样
要对时间序列索引进行降采样,请使用 Downsample API 并将 fixed_interval 设置为你想要的粒度级别:
POST /my-time-series-index/_downsample/my-downsampled-time-series-index
{"fixed_interval": "1d"
}要将时间序列数据降采样作为 ILM 的一部分,请在 ILM 策略中包含降采样操作,并将 fixed_interval 设置为你想要的粒度级别:
PUT _ilm/policy/my_policy
{"policy": {"phases": {"warm": {"actions": {"downsample" : {"fixed_interval": "1h"}}}}}
}查询降采样索引
你可以使用 _search 和 _async_search 端点来查询降采样索引。 可以在单个请求中查询多个原始数据和降采样索引,并且单个请求可以包括不同粒度(不同桶时间跨度)的降采样索引。 也就是说,你可以查询包含具有多个降采样间隔(例如15m、1h、1d)的降采样索引的数据流。
基于时间的直方图聚合的结果采用统一的桶大小,并且每个降采样索引返回忽略降采样时间间隔的数据。 例如,如果你对已按每小时分辨率 ( "fixed_interval": "1h") 降采样的降采样索引运行带有 "fixed_interval": "1m" 的 date_histogram 聚合,则查询将返回一个存储桶,其中包含位于 第 0 分钟,然后是 59 个空桶,然后是下一小时内再次有数据的桶。
关于降采样查询的注意事项
查询降采样索引有几点需要注意:
- 当你在 Kibana 中并通过 Elastic 解决方案运行查询时,会返回正常响应,而不会通知某些查询索引已被降采样。
- 对于日期直方图聚合,仅支持 fixed_intervals(而不支持日历感知间隔)。
- 仅支持协调世界时 (UTC) 日期时间。
限制和局限
以下限制和局限适用于降采样:
- 仅支持时间序列数据流中的索引。
- 仅根据时间维度对数据进行降采样。 所有其他维度都将复制到新索引而不进行任何修改。
- 在数据流内,降采样索引替换原始索引,并且原始索引被删除。 给定时间段内只能存在一个索引。
- 源索引必须处于只读模式才能成功进行降采样过程。 有关详细信息,请查看如下的手动运行降采样示例。
- 支持对同一时段的数据进行多次降采样(降采样索引的降采样)。 降采样间隔必须是降采样索引间隔的倍数。
- 降采样作为 ILM 操作提供。 请参阅降采样。
- 新的降采样索引是在原始索引的数据层上创建的,并继承其设置(例如,分片和副本的数量)。
- 支持 gauge 和 counter 指标类型。
- 降采样配置是从时间序列数据流索引映射中提取的。 唯一需要的额外设置是降采样固定间隔。
手动运行降采样
对时间序列数据流 (TSDS) 进行降采样的推荐方法是通过索引生命周期管理 (ILM)。我们将在下面进行详述。 但是,如果你不使用 ILM,则可以手动对 TSDS 进行降采样。 本指南向你展示如何使用典型的 Kubernetes 集群监控数据。
前提条件
- 请参阅 TSDS 先决条件。
- 集群权限:manage_ilm 和 manage_index_templates。
- 索引权限:你创建或转换的任何 TSDS 的 create_doc 和 create_index。 要滚动 TSDS,你必须具有 manage 权限。
- 不可能直接对数据流进行降采样,也不可能一次对多个索引进行降采样。 只能对一个时间序列索引(TSDS 后备索引)进行降采样。
- 为了对索引进行降采样,它需要是只读的。 对于 TSDS 写入索引,这意味着需要先滚动并使其变为只读。
- 降采样使用 UTC 时间戳。
- 降采样需要时间序列索引中至少存在一个指标字段。
创建时间序列数据流
首先,你将创建 TSDS。 为了简单起见,在时间序列映射中,所有 time_series_metric 参数都设置为 gauge 类型,但也可以使用其他值,例如 counter 和 histogram。 time_series_metric 值确定降采样期间使用的统计表示的类型。
索引模板包含一组静态时间序列维度:主机 (host)、命名空间 (namespace)、节点 (node) 和 Pod。 时间序列维度不会因降采样过程而改变。
PUT _index_template/my-data-stream-template
{"index_patterns": ["my-data-stream*"],"data_stream": {},"template": {"settings": {"index": {"mode": "time_series","routing_path": ["kubernetes.namespace","kubernetes.host","kubernetes.node","kubernetes.pod"],"number_of_replicas": 0,"number_of_shards": 2}},"mappings": {"properties": {"@timestamp": {"type": "date"},"kubernetes": {"properties": {"container": {"properties": {"cpu": {"properties": {"usage": {"properties": {"core": {"properties": {"ns": {"type": "long"}}},"limit": {"properties": {"pct": {"type": "float"}}},"nanocores": {"type": "long","time_series_metric": "gauge"},"node": {"properties": {"pct": {"type": "float"}}}}}}},"memory": {"properties": {"available": {"properties": {"bytes": {"type": "long","time_series_metric": "gauge"}}},"majorpagefaults": {"type": "long"},"pagefaults": {"type": "long","time_series_metric": "gauge"},"rss": {"properties": {"bytes": {"type": "long","time_series_metric": "gauge"}}},"usage": {"properties": {"bytes": {"type": "long","time_series_metric": "gauge"},"limit": {"properties": {"pct": {"type": "float"}}},"node": {"properties": {"pct": {"type": "float"}}}}},"workingset": {"properties": {"bytes": {"type": "long","time_series_metric": "gauge"}}}}},"name": {"type": "keyword"},"start_time": {"type": "date"}}},"host": {"type": "keyword","time_series_dimension": true},"namespace": {"type": "keyword","time_series_dimension": true},"node": {"type": "keyword","time_series_dimension": true},"pod": {"type": "keyword","time_series_dimension": true}}}}}}
}摄取时间序列数据
由于时间序列数据流被设计为仅接受最近的数据,因此在本例中,你将使用摄取管道在数据被索引时对数据进行时移。 因此,索引数据将具有最近 15 分钟的 @timestamp。
使用此请求创建管道:
PUT _ingest/pipeline/my-timestamp-pipeline
{"description": "Shifts the @timestamp to the last 15 minutes","processors": [{"set": {"field": "ingest_time","value": "{{_ingest.timestamp}}"}},{"script": {"lang": "painless","source": """def delta = ChronoUnit.SECONDS.between(ZonedDateTime.parse("2022-06-21T15:49:00Z"),ZonedDateTime.parse(ctx["ingest_time"]));ctx["@timestamp"] = ZonedDateTime.parse(ctx["@timestamp"]).plus(delta,ChronoUnit.SECONDS).toString();"""}}]
}接下来,使用批量 API 请求自动创建 TSDS 并为一组 10 个文档编制索引:
PUT /my-data-stream/_bulk?refresh&pipeline=my-timestamp-pipeline
{"create": {}}
{"@timestamp":"2022-06-21T15:49:00Z","kubernetes":{"host":"gke-apps-0","node":"gke-apps-0-0","pod":"gke-apps-0-0-0","container":{"cpu":{"usage":{"nanocores":91153,"core":{"ns":12828317850},"node":{"pct":2.77905e-05},"limit":{"pct":2.77905e-05}}},"memory":{"available":{"bytes":463314616},"usage":{"bytes":307007078,"node":{"pct":0.01770037710617187},"limit":{"pct":9.923134671484496e-05}},"workingset":{"bytes":585236},"rss":{"bytes":102728},"pagefaults":120901,"majorpagefaults":0},"start_time":"2021-03-30T07:59:06Z","name":"container-name-44"},"namespace":"namespace26"}}
{"create": {}}
{"@timestamp":"2022-06-21T15:45:50Z","kubernetes":{"host":"gke-apps-0","node":"gke-apps-0-0","pod":"gke-apps-0-0-0","container":{"cpu":{"usage":{"nanocores":124501,"core":{"ns":12828317850},"node":{"pct":2.77905e-05},"limit":{"pct":2.77905e-05}}},"memory":{"available":{"bytes":982546514},"usage":{"bytes":360035574,"node":{"pct":0.01770037710617187},"limit":{"pct":9.923134671484496e-05}},"workingset":{"bytes":1339884},"rss":{"bytes":381174},"pagefaults":178473,"majorpagefaults":0},"start_time":"2021-03-30T07:59:06Z","name":"container-name-44"},"namespace":"namespace26"}}
{"create": {}}
{"@timestamp":"2022-06-21T15:44:50Z","kubernetes":{"host":"gke-apps-0","node":"gke-apps-0-0","pod":"gke-apps-0-0-0","container":{"cpu":{"usage":{"nanocores":38907,"core":{"ns":12828317850},"node":{"pct":2.77905e-05},"limit":{"pct":2.77905e-05}}},"memory":{"available":{"bytes":862723768},"usage":{"bytes":379572388,"node":{"pct":0.01770037710617187},"limit":{"pct":9.923134671484496e-05}},"workingset":{"bytes":431227},"rss":{"bytes":386580},"pagefaults":233166,"majorpagefaults":0},"start_time":"2021-03-30T07:59:06Z","name":"container-name-44"},"namespace":"namespace26"}}
{"create": {}}
{"@timestamp":"2022-06-21T15:44:40Z","kubernetes":{"host":"gke-apps-0","node":"gke-apps-0-0","pod":"gke-apps-0-0-0","container":{"cpu":{"usage":{"nanocores":86706,"core":{"ns":12828317850},"node":{"pct":2.77905e-05},"limit":{"pct":2.77905e-05}}},"memory":{"available":{"bytes":567160996},"usage":{"bytes":103266017,"node":{"pct":0.01770037710617187},"limit":{"pct":9.923134671484496e-05}},"workingset":{"bytes":1724908},"rss":{"bytes":105431},"pagefaults":233166,"majorpagefaults":0},"start_time":"2021-03-30T07:59:06Z","name":"container-name-44"},"namespace":"namespace26"}}
{"create": {}}
{"@timestamp":"2022-06-21T15:44:00Z","kubernetes":{"host":"gke-apps-0","node":"gke-apps-0-0","pod":"gke-apps-0-0-0","container":{"cpu":{"usage":{"nanocores":150069,"core":{"ns":12828317850},"node":{"pct":2.77905e-05},"limit":{"pct":2.77905e-05}}},"memory":{"available":{"bytes":639054643},"usage":{"bytes":265142477,"node":{"pct":0.01770037710617187},"limit":{"pct":9.923134671484496e-05}},"workingset":{"bytes":1786511},"rss":{"bytes":189235},"pagefaults":138172,"majorpagefaults":0},"start_time":"2021-03-30T07:59:06Z","name":"container-name-44"},"namespace":"namespace26"}}
{"create": {}}
{"@timestamp":"2022-06-21T15:42:40Z","kubernetes":{"host":"gke-apps-0","node":"gke-apps-0-0","pod":"gke-apps-0-0-0","container":{"cpu":{"usage":{"nanocores":82260,"core":{"ns":12828317850},"node":{"pct":2.77905e-05},"limit":{"pct":2.77905e-05}}},"memory":{"available":{"bytes":854735585},"usage":{"bytes":309798052,"node":{"pct":0.01770037710617187},"limit":{"pct":9.923134671484496e-05}},"workingset":{"bytes":924058},"rss":{"bytes":110838},"pagefaults":259073,"majorpagefaults":0},"start_time":"2021-03-30T07:59:06Z","name":"container-name-44"},"namespace":"namespace26"}}
{"create": {}}
{"@timestamp":"2022-06-21T15:42:10Z","kubernetes":{"host":"gke-apps-0","node":"gke-apps-0-0","pod":"gke-apps-0-0-0","container":{"cpu":{"usage":{"nanocores":153404,"core":{"ns":12828317850},"node":{"pct":2.77905e-05},"limit":{"pct":2.77905e-05}}},"memory":{"available":{"bytes":279586406},"usage":{"bytes":214904955,"node":{"pct":0.01770037710617187},"limit":{"pct":9.923134671484496e-05}},"workingset":{"bytes":1047265},"rss":{"bytes":91914},"pagefaults":302252,"majorpagefaults":0},"start_time":"2021-03-30T07:59:06Z","name":"container-name-44"},"namespace":"namespace26"}}
{"create": {}}
{"@timestamp":"2022-06-21T15:40:20Z","kubernetes":{"host":"gke-apps-0","node":"gke-apps-0-0","pod":"gke-apps-0-0-0","container":{"cpu":{"usage":{"nanocores":125613,"core":{"ns":12828317850},"node":{"pct":2.77905e-05},"limit":{"pct":2.77905e-05}}},"memory":{"available":{"bytes":822782853},"usage":{"bytes":100475044,"node":{"pct":0.01770037710617187},"limit":{"pct":9.923134671484496e-05}},"workingset":{"bytes":2109932},"rss":{"bytes":278446},"pagefaults":74843,"majorpagefaults":0},"start_time":"2021-03-30T07:59:06Z","name":"container-name-44"},"namespace":"namespace26"}}
{"create": {}}
{"@timestamp":"2022-06-21T15:40:10Z","kubernetes":{"host":"gke-apps-0","node":"gke-apps-0-0","pod":"gke-apps-0-0-0","container":{"cpu":{"usage":{"nanocores":100046,"core":{"ns":12828317850},"node":{"pct":2.77905e-05},"limit":{"pct":2.77905e-05}}},"memory":{"available":{"bytes":567160996},"usage":{"bytes":362826547,"node":{"pct":0.01770037710617187},"limit":{"pct":9.923134671484496e-05}},"workingset":{"bytes":1986724},"rss":{"bytes":402801},"pagefaults":296495,"majorpagefaults":0},"start_time":"2021-03-30T07:59:06Z","name":"container-name-44"},"namespace":"namespace26"}}
{"create": {}}
{"@timestamp":"2022-06-21T15:38:30Z","kubernetes":{"host":"gke-apps-0","node":"gke-apps-0-0","pod":"gke-apps-0-0-0","container":{"cpu":{"usage":{"nanocores":40018,"core":{"ns":12828317850},"node":{"pct":2.77905e-05},"limit":{"pct":2.77905e-05}}},"memory":{"available":{"bytes":1062428344},"usage":{"bytes":265142477,"node":{"pct":0.01770037710617187},"limit":{"pct":9.923134671484496e-05}},"workingset":{"bytes":2294743},"rss":{"bytes":340623},"pagefaults":224530,"majorpagefaults":0},"start_time":"2021-03-30T07:59:06Z","name":"container-name-44"},"namespace":"namespace26"}}你可以使用搜索 API 检查文档是否已正确索引:
GET /my-data-stream/_search
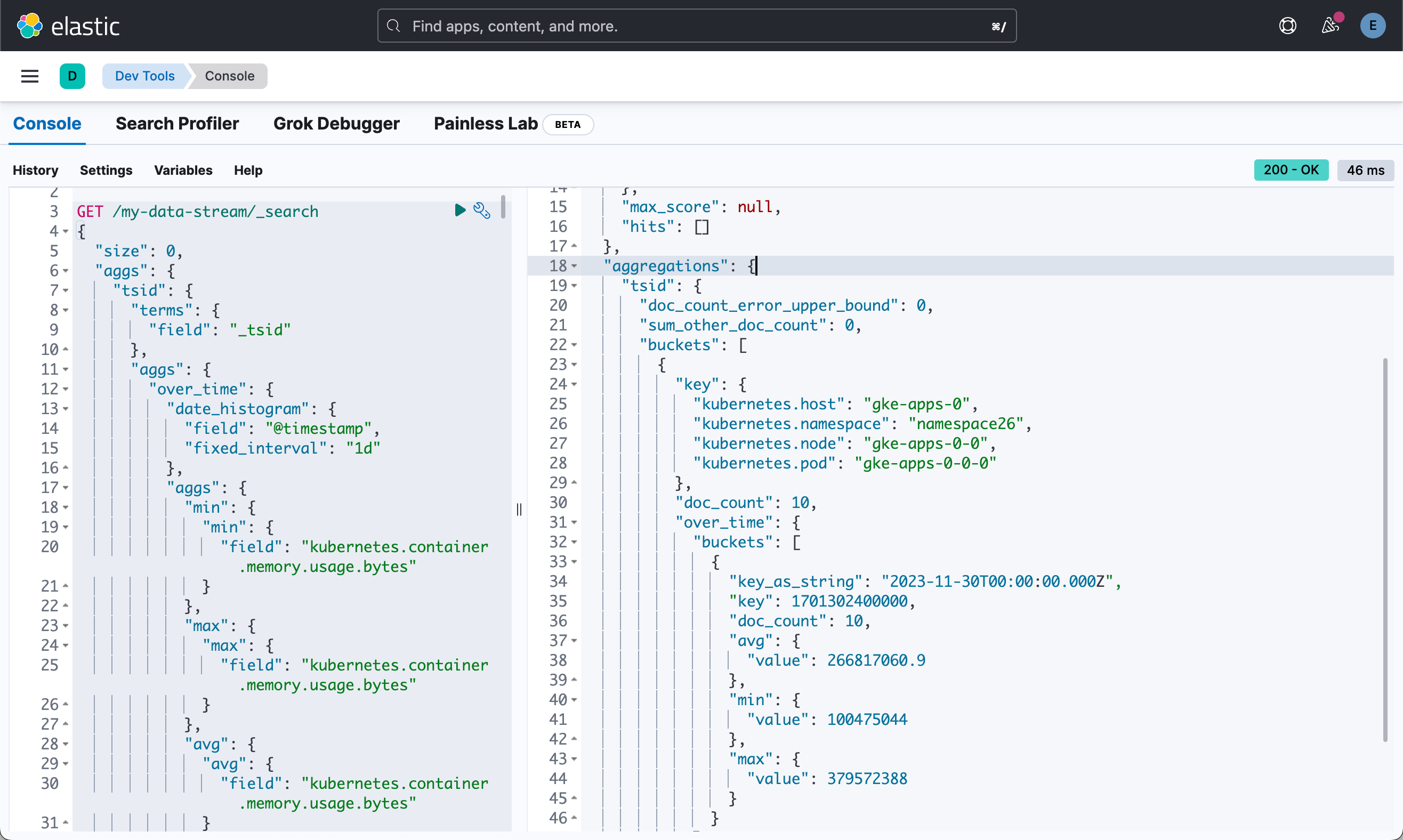
对数据运行以下聚合以计算一些有趣的统计数据:
GET /my-data-stream/_search
{"size": 0,"aggs": {"tsid": {"terms": {"field": "_tsid"},"aggs": {"over_time": {"date_histogram": {"field": "@timestamp","fixed_interval": "1d"},"aggs": {"min": {"min": {"field": "kubernetes.container.memory.usage.bytes"}},"max": {"max": {"field": "kubernetes.container.memory.usage.bytes"}},"avg": {"avg": {"field": "kubernetes.container.memory.usage.bytes"}}}}}}}
}
对 TSDS 进行降采样
TSDS 无法直接降采样。 你需要对其后备索引进行降采样。 你可以通过运行以下命令查看数据流的后备索引:
GET /_data_stream/my-data-stream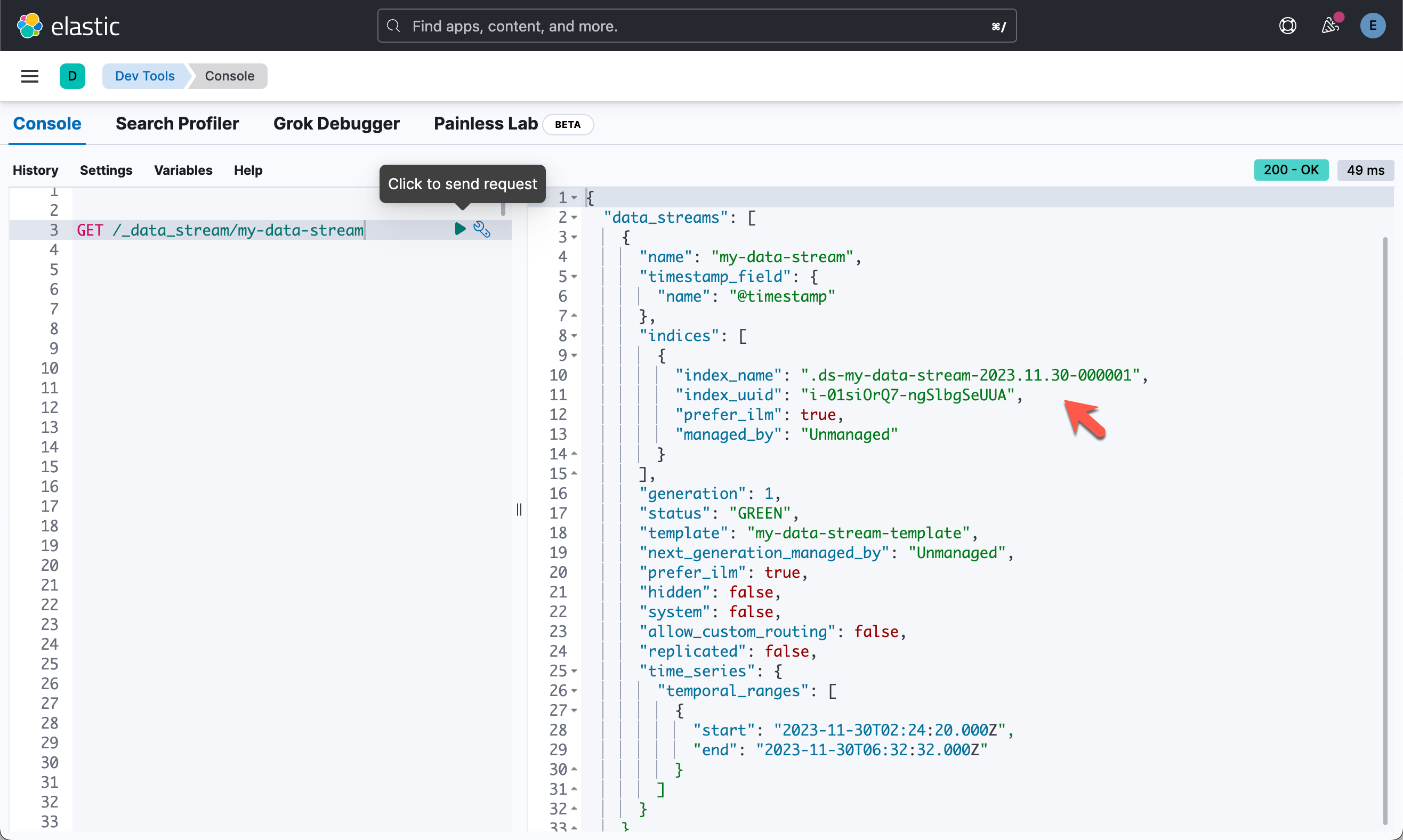
在对支持索引进行降采样之前,需要滚动 TSDS,并且需要将旧索引设为只读。
使用 rollver API 滚动 TSDS:
POST /my-data-stream/_rollover/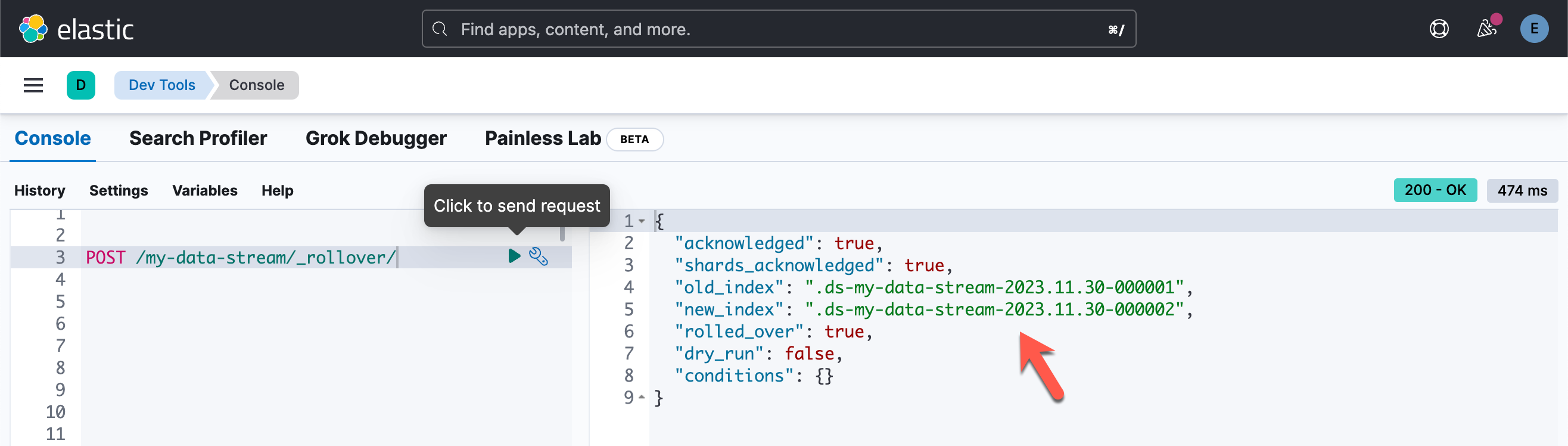
从响应中复制 old_index 的名称。 在以下步骤中,将索引名称替换为你的 old_index 的名称。
旧索引需要设置为只读模式。 运行以下请求:
PUT /.ds-my-data-stream-2023.11.30-000001/_block/write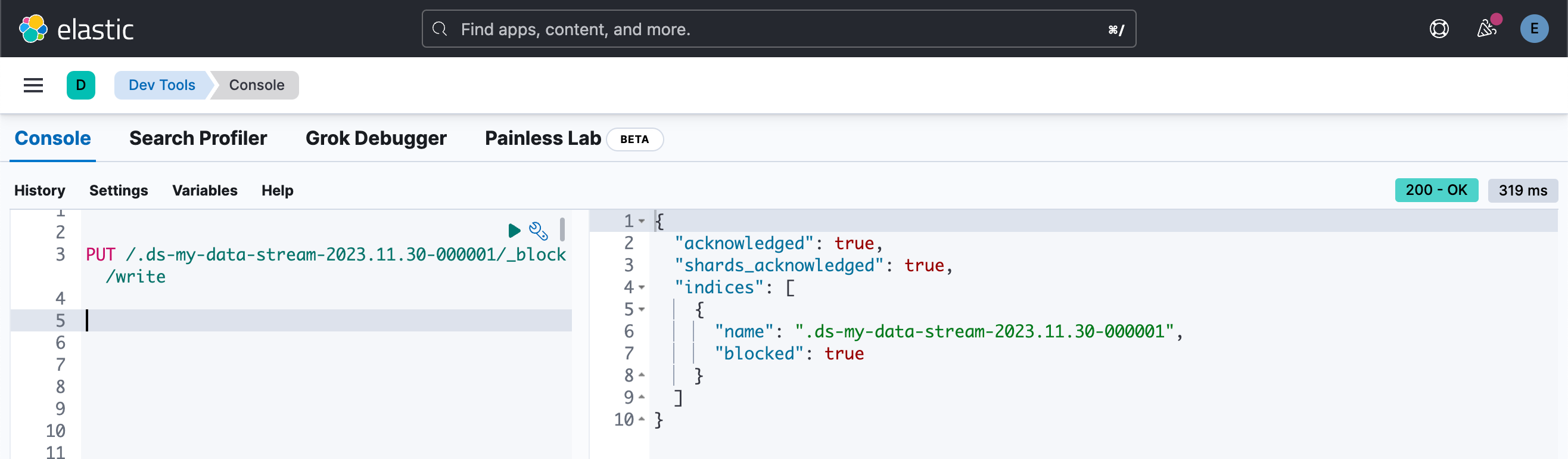
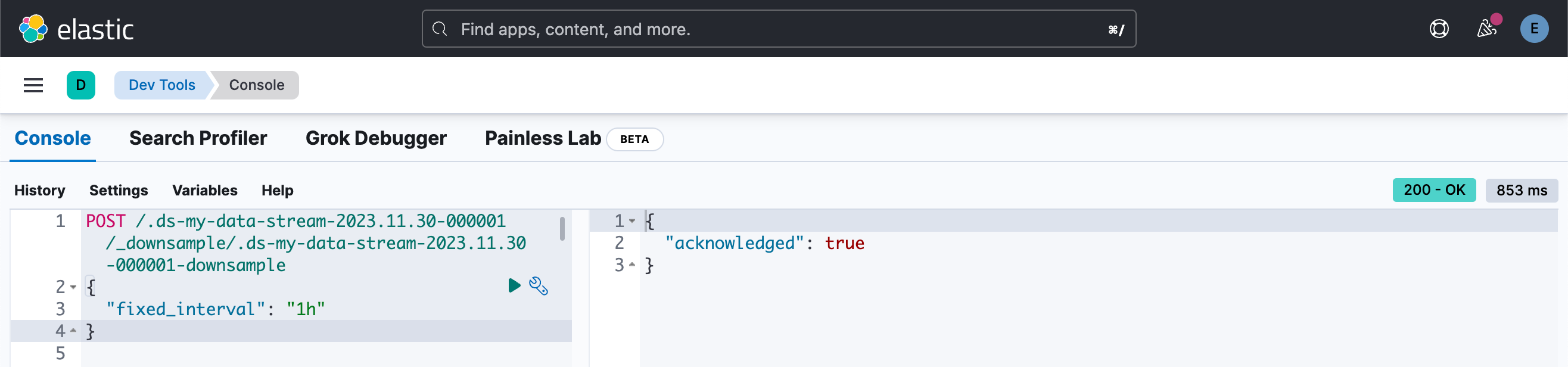
接下来,使用 downsample API 对索引进行降采样,将时间序列间隔设置为一小时:
POST /.ds-my-data-stream-2023.11.30-000001/_downsample/.ds-my-data-stream-2023.11.30-000001-downsample
{"fixed_interval": "1h"
}
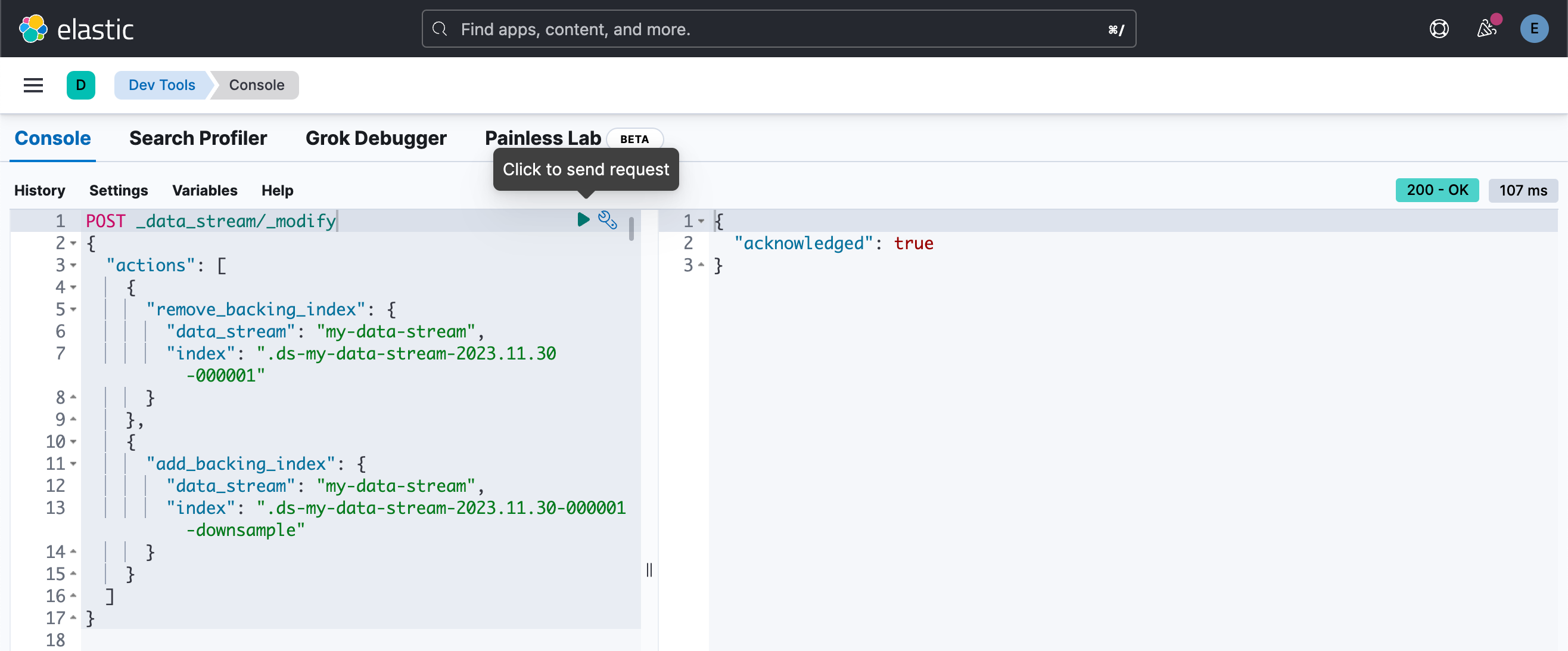
现在你可以修改数据流,并将原始索引替换为降采样后的索引:
POST _data_stream/_modify
{"actions": [{"remove_backing_index": {"data_stream": "my-data-stream","index": ".ds-my-data-stream-2023.11.30-000001"}},{"add_backing_index": {"data_stream": "my-data-stream","index": ".ds-my-data-stream-2023.11.30-000001-downsample"}}]
}
你现在可以删除旧的后备索引。 但请注意,这会删除原始数据。 如果将来可能需要原始数据,请不要删除索引。
查看结果
重新运行之前的搜索查询(请注意,在查询降采样索引时,需要注意一些细微差别):
GET /my-data-stream/_search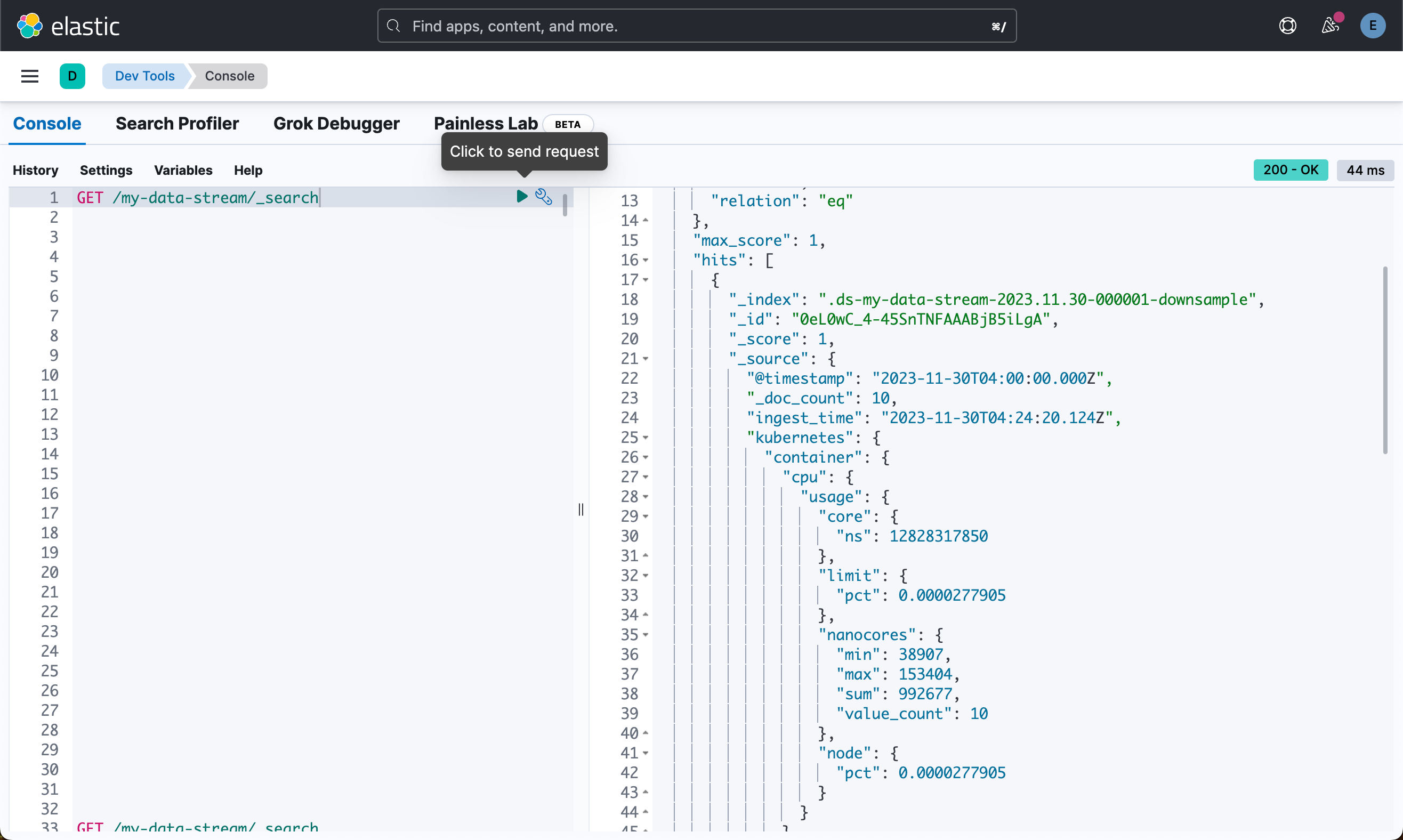
具有新的降采样后备索引的 TSDS 仅包含一份文档。 对于计数器,该文档仅具有最后的值。 对于 gauge,字段类型现在为 aggregate_metric_double。 你会看到基于原始采样指标的 min、max、sum 和 value_count 统计信息:
{"took": 3,"timed_out": false,"_shards": {"total": 4,"successful": 4,"skipped": 0,"failed": 0},"hits": {"total": {"value": 1,"relation": "eq"},"max_score": 1,"hits": [{"_index": ".ds-my-data-stream-2023.11.30-000001-downsample","_id": "0eL0wC_4-45SnTNFAAABjB5iLgA","_score": 1,"_source": {"@timestamp": "2023-11-30T04:00:00.000Z","_doc_count": 10,"ingest_time": "2023-11-30T04:24:20.124Z","kubernetes": {"container": {"cpu": {"usage": {"core": {"ns": 12828317850},"limit": {"pct": 0.0000277905},"nanocores": {"min": 38907,"max": 153404,"sum": 992677,"value_count": 10},"node": {"pct": 0.0000277905}}},"memory": {"available": {"bytes": {"min": 279586406,"max": 1062428344,"sum": 7101494721,"value_count": 10}},"majorpagefaults": 0,"pagefaults": {"min": 74843,"max": 302252,"sum": 2061071,"value_count": 10},"rss": {"bytes": {"min": 91914,"max": 402801,"sum": 2389770,"value_count": 10}},"usage": {"bytes": {"min": 100475044,"max": 379572388,"sum": 2668170609,"value_count": 10},"limit": {"pct": 0.00009923134},"node": {"pct": 0.017700378}},"workingset": {"bytes": {"min": 431227,"max": 2294743,"sum": 14230488,"value_count": 10}}},"name": "container-name-44","start_time": "2021-03-30T07:59:06.000Z"},"host": "gke-apps-0","namespace": "namespace26","node": "gke-apps-0-0","pod": "gke-apps-0-0-0"}}}]}
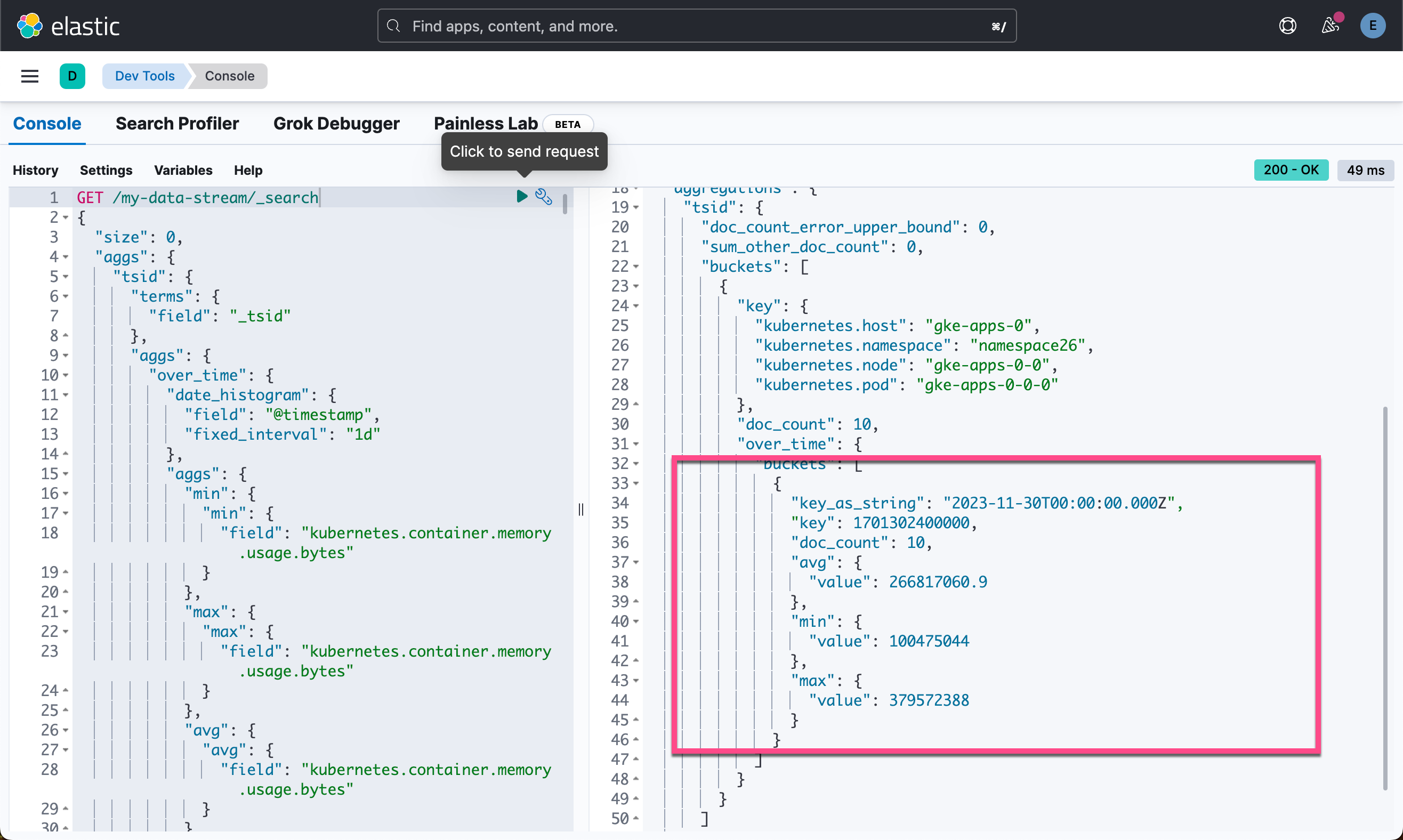
}重新运行之前的聚合。 即使聚合在仅包含 1 个文档的降采样 TSDS 上运行,它也会返回与原始 TSDS 上的早期聚合相同的结果。
GET /my-data-stream/_search
{"size": 0,"aggs": {"tsid": {"terms": {"field": "_tsid"},"aggs": {"over_time": {"date_histogram": {"field": "@timestamp","fixed_interval": "1d"},"aggs": {"min": {"min": {"field": "kubernetes.container.memory.usage.bytes"}},"max": {"max": {"field": "kubernetes.container.memory.usage.bytes"}},"avg": {"avg": {"field": "kubernetes.container.memory.usage.bytes"}}}}}}}
}
此示例演示了降采样如何在你选择的任何时间范围内显着减少为时间序列数据存储的文档数量。 随着时间序列数据的老化和数据分辨率变得不那么重要,还可以对已经降采样的数据执行降采样,以进一步减少存储和相关成本。
对 TSDS 进行降采样的推荐方法是使用 ILM。 要了解更多信息,请尝试使用 ILM 运行降采样示例。这个将在我们的下面一篇文章中进行介绍。
相关文章:
Elasticsearch:对时间序列数据流进行降采样(downsampling)
降采样提供了一种通过以降低的粒度存储时间序列数据来减少时间序列数据占用的方法。 指标(metrics)解决方案收集大量随时间增长的时间序列数据。 随着数据老化,它与系统当前状态的相关性越来越小。 降采样过程将固定时间间隔内的文档汇总为单…...

python自动化测试框架:unittest测试用例编写及执行
本文将介绍 unittest 自动化测试用例编写及执行的相关内容,包括测试用例编写、测试用例执行、测试报告等内容。 官方文档: https://docs.python.org/zh-cn/3/library/unittest.mock.html 1. 测试用例编写 在 unittest 中,一个测试用例通常…...
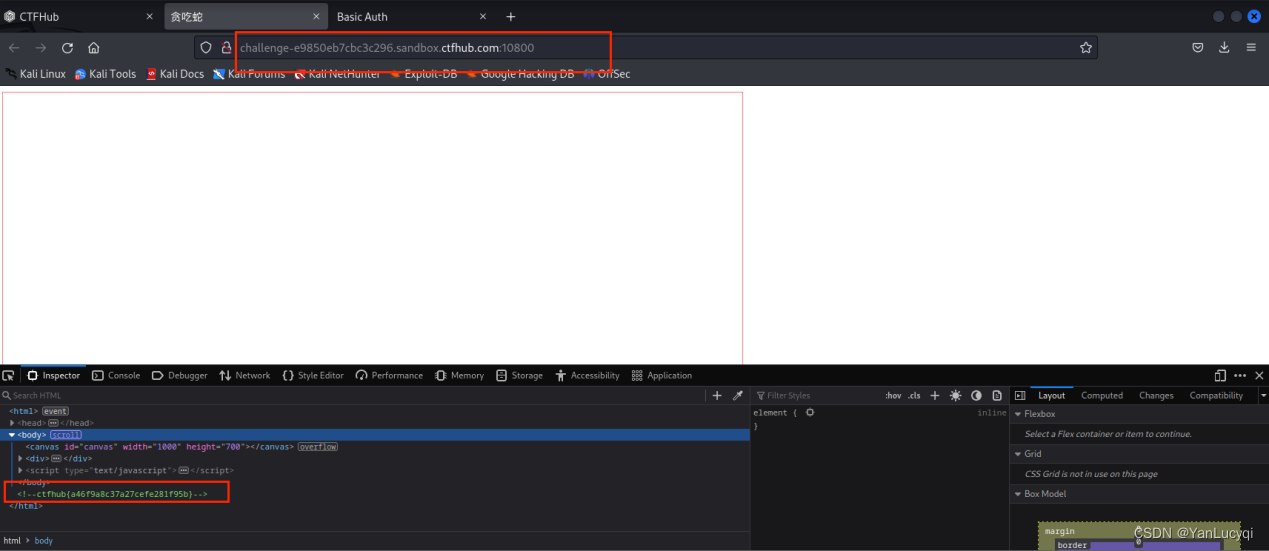
ctfhub技能树_web_web前置技能_HTTP
目录 一、HTTP协议 1.1、请求方式 1.2、302跳转 1.3、Cookie 1.4、基础认证 1.5、响应包源代码 一、HTTP协议 1.1、请求方式 注:HTTP协议中定义了八种请求方法。这八种都有:1、OPTIONS :返回服务器针对特定资源所支持的HTTP请求方法…...
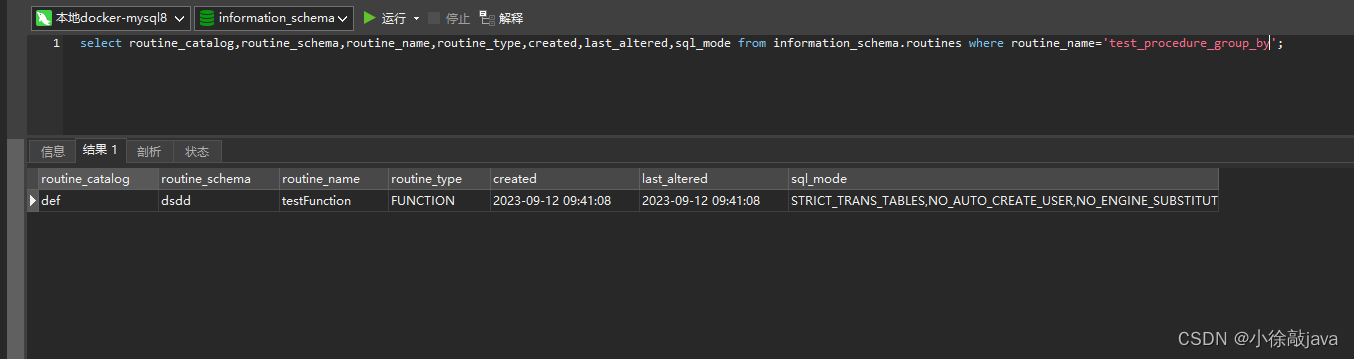
mysql8报sql_mode=only_full_group_by(存储过程一直报)
1:修改数据库配置(重启失效) select global.sql_mode;会打印如下信息 ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ENGINE_SUBSTITUTION里面包含 ONLY_FULL_GROUP_BY,那么就重新设置,在数据库中输入以下代码,去掉ONLY_FULL_GROU…...
Vue2中v-html引发的安全问题
前言:v-html指令 1.作用:向指定节点中渲染包含html结构的内容。 2.与插值语法的区别: (1).v-html会替换掉节点中所有的内容,{{xx}}则不会。 (2).v-html可以识别html结构。 3.严重注意:v-html有安全性问题࿰…...

java内部类详解
文章目录 一、介绍二、为什么要使用内部类三、非静态内部类四、静态内部类五、局部内部类六、匿名内部类七、lambda表达式内部类八、成员重名九、序列化十、如何选择内部类 一、介绍 在java中,我们被允许在编写一个类(外部类OuterClass)时,在其内部再嵌…...

Python 潮流周刊#29:Rust 会比 Python 慢?!
△请给“Python猫”加星标 ,以免错过文章推送 你好,我是猫哥。这里每周分享优质的 Python、AI 及通用技术内容,大部分为英文。本周刊开源,欢迎投稿[1]。另有电报频道[2]作为副刊,补充发布更加丰富的资讯。 ὃ…...

吴恩达《机器学习》11-1-11-2:首先要做什么、误差分析
一、首先要做什么 选择特征向量的关键决策 以垃圾邮件分类器算法为例,首先需要决定如何选择和表达特征向量 𝑥。视频提到的一个示例是构建一个由 100 个最常出现在垃圾邮件中的词构成的列表,根据这些词是否在邮件中出现来创建特征向量&…...

Pandas在Excel同一个sheet里插入多个Dataframe和行
Pandas默认的to_excel是直接把完成的Datafrme写入一个sheet里,这并不能满足我们在一个sheet里插入多个Dataframe或多行的需求。为了实现插入多行或多Dataframe的目的,我们需要新建一个ExcelWriter对象,然后依次插入数据。 这里我们以插入2个Dataframe和三行单元格为例。 新…...
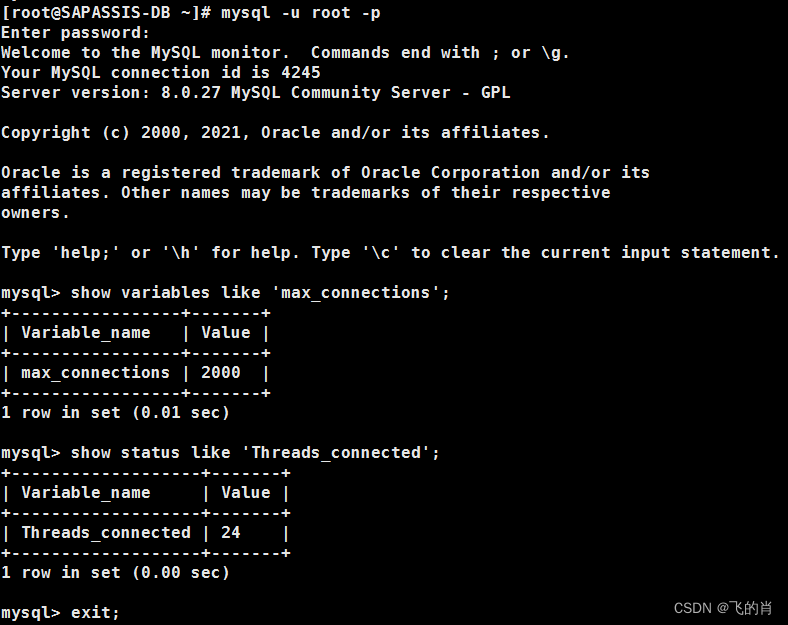
查看mysql 或SQL server 的连接数,mysql超时、最大连接数配置
1、mysql 的连接数 1.1、最大可连接数 show variables like max_connections; 1.2、运行中连接数 show status like Threads_connected; 1.3、配置最大连接数, mysql版本不同可配置的最大连接数不同,mysql8.0的版本默认151个连接数,…...
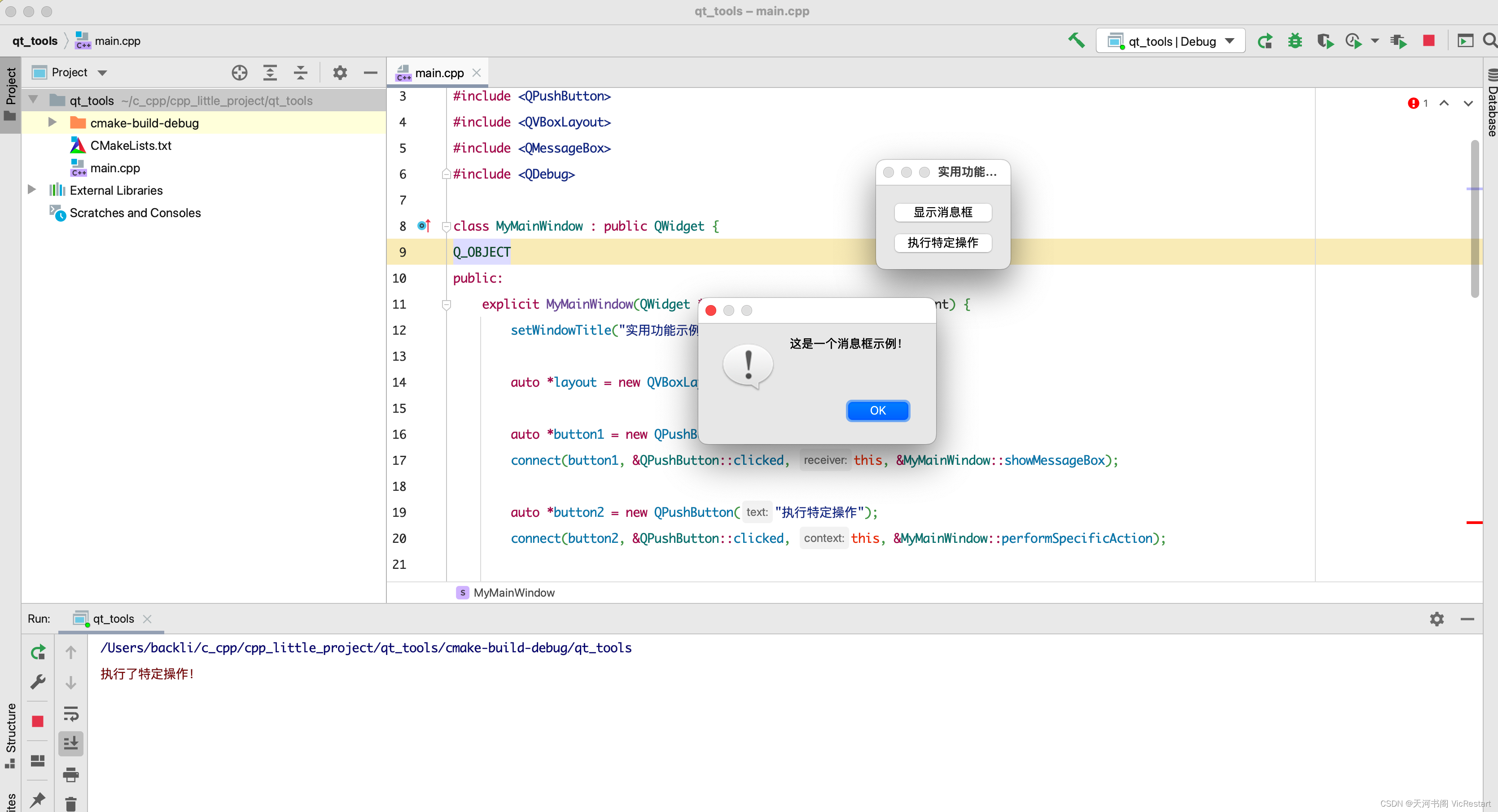
C++学习之路(七)C++ 实现简单的Qt界面(消息弹框、按钮点击事件监听)- 示例代码拆分讲解
这个示例创建了一个主窗口,其中包含两个按钮。第一个按钮点击时会显示一个简单的消息框,第二个按钮点击时会执行一个特定的操作(在这个例子中,仅打印一条调试信息)。 功能描述: 创建窗口和布局:…...

python实现一个计算器
实现一个计算器首先熟悉一下这个阅读器的属性import subprocess subprocess.run(["espeak", "-v", "enf3", "This is a Calculator"])class Calculator:def speaker(self,word):subprocess.run(["espeak", "-v", …...

C++ 共享内存ShellCode跨进程传输
在计算机安全领域,ShellCode是一段用于利用系统漏洞或执行特定任务的机器码。为了增加攻击的难度,研究人员经常探索新的传递ShellCode的方式。本文介绍了一种使用共享内存的方法,通过该方法,两个本地进程可以相互传递ShellCode&am…...
)
如何快速移植(从STM32F103到STM32F407)
最近用到F4的地方比较多,网上代码还是F1多一些,便需要移植代码,如何快速移植代码呢? 看下面这篇文章 外设 首先就是STM32的外设了。 STM32F407ZGT6的基本外设 STM32F407ZGT6 作为 MCU,该芯片是 STM32F407 里面配置…...
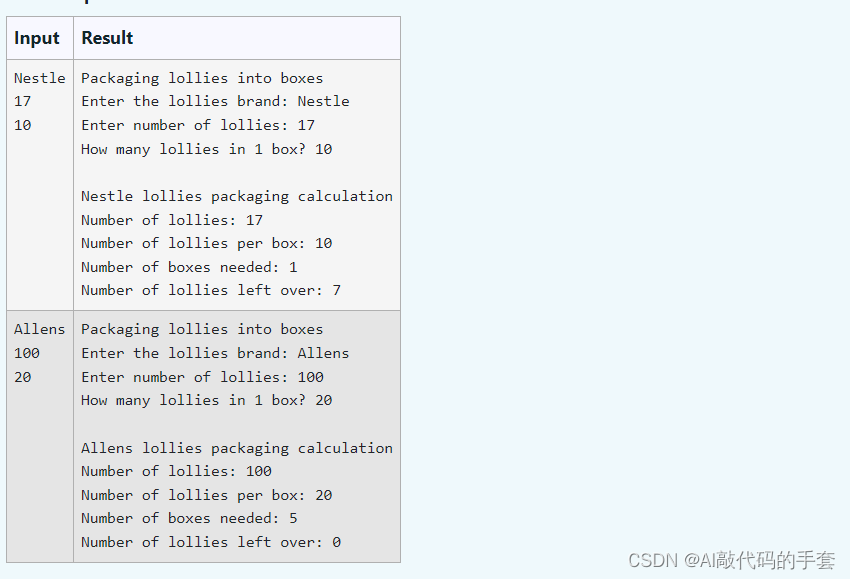
python高级练习题库实验1(B)部分
文章目录 题目1代码实验结果题目2代码实验结果题目3代码实验结果题目4代码实验结果题目5代码实验结果题目总结题目1 打包糖果小游戏,用户输入糖果品牌与个数,还有一个盒子里面可以装多少个糖果,输出一些打印信息,如下图所示: 代码 print("Packaging lollies into…...
)
Qt Rsa 加解密方法使用(pkcs1, pkcs8, 以及文件存储和内存存储密钥)
Qt RSA 加解密 完整使用 密钥格式: pkcs#1pkcs#8 如何区分密钥对是PKCS1还是PKCS8? 通常PKCS1密钥对的开始部分为:-----BEGIN RSA PRIVATE KEY-----或 -----BEGIN RSA PUBLIC KEY-----。而PKCS8密钥对的开始部分为:-----BEGIN…...

区分物理端口与软件端口概念:以交换机端口和Linux系统中的端口为例
文章目录 交换机端口和Linux系统中的端口有什么区别?1. 交换机的端口2. Linux系统中的端口因此,尽管两者都被称为"端口",但它们代表的含义和用途是完全不同的。 交换机端口和Linux系统中的端口有什么区别? 虽然都被称为…...
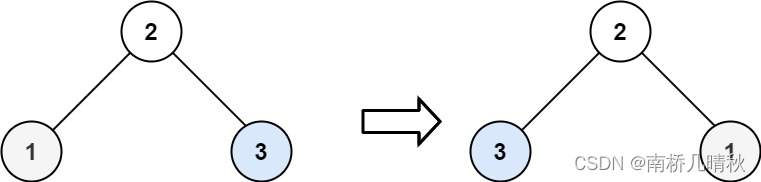
力扣226:翻转二叉树
力扣226:翻转二叉树 给你一棵二叉树的根节点 root ,翻转这棵二叉树,并返回其根节点。 示例 1: 输入:root [4,2,7,1,3,6,9] 输出:[4,7,2,9,6,3,1] 示例 2: 输入:root [2,1,3]…...

亚马逊鲲鹏系统智能自动注册与AI角色养号,探索数字化新境界
在数字化时代,亚马逊鲲鹏系统以其强大的自动化功能,为用户提供了前所未有的购物体验。如果你想利用鲲鹏系统进行自动化注册,那么准备好邮箱、IP、手机号等关键信息后,你将轻松实现自动注册,为购物之旅开启智能化新篇章…...

AOP操作日志记录
AOP操作日志记录 1.创建注解 Retention(RetentionPolicy.RUNTIME) Target(ElementType.METHOD) public interface PassportLog {String operatePage();String operateType();ClassTypEnum classType();}2.创建切面 对于字典,可以通过注解属性去转换,枚举…...

Vue3 + Element Plus + TypeScript中el-transfer穿梭框组件使用详解及示例
使用详解 Element Plus 的 el-transfer 组件是一个强大的穿梭框组件,常用于在两个集合之间进行数据转移,如权限分配、数据选择等场景。下面我将详细介绍其用法并提供一个完整示例。 核心特性与用法 基本属性 v-model:绑定右侧列表的值&…...

WordPress插件:AI多语言写作与智能配图、免费AI模型、SEO文章生成
厌倦手动写WordPress文章?AI自动生成,效率提升10倍! 支持多语言、自动配图、定时发布,让内容创作更轻松! AI内容生成 → 不想每天写文章?AI一键生成高质量内容!多语言支持 → 跨境电商必备&am…...

爬虫基础学习day2
# 爬虫设计领域 工商:企查查、天眼查短视频:抖音、快手、西瓜 ---> 飞瓜电商:京东、淘宝、聚美优品、亚马逊 ---> 分析店铺经营决策标题、排名航空:抓取所有航空公司价格 ---> 去哪儿自媒体:采集自媒体数据进…...

【JavaWeb】Docker项目部署
引言 之前学习了Linux操作系统的常见命令,在Linux上安装软件,以及如何在Linux上部署一个单体项目,大多数同学都会有相同的感受,那就是麻烦。 核心体现在三点: 命令太多了,记不住 软件安装包名字复杂&…...

Redis数据倾斜问题解决
Redis 数据倾斜问题解析与解决方案 什么是 Redis 数据倾斜 Redis 数据倾斜指的是在 Redis 集群中,部分节点存储的数据量或访问量远高于其他节点,导致这些节点负载过高,影响整体性能。 数据倾斜的主要表现 部分节点内存使用率远高于其他节…...

日常一水C
多态 言简意赅:就是一个对象面对同一事件时做出的不同反应 而之前的继承中说过,当子类和父类的函数名相同时,会隐藏父类的同名函数转而调用子类的同名函数,如果要调用父类的同名函数,那么就需要对父类进行引用&#…...
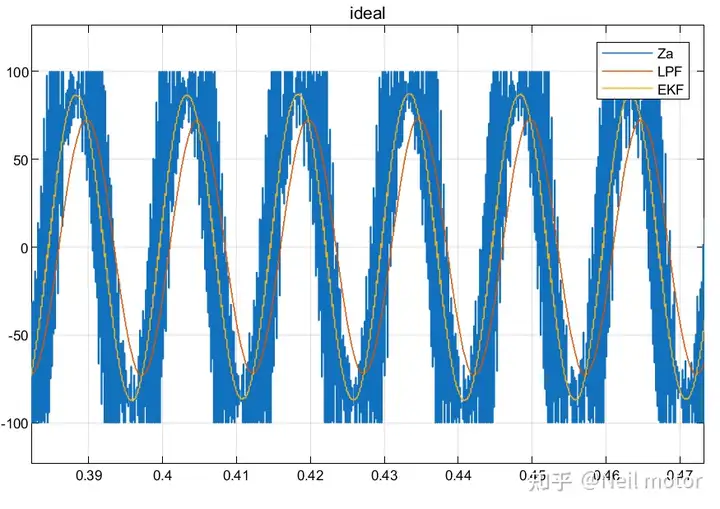
永磁同步电机无速度算法--基于卡尔曼滤波器的滑模观测器
一、原理介绍 传统滑模观测器采用如下结构: 传统SMO中LPF会带来相位延迟和幅值衰减,并且需要额外的相位补偿。 采用扩展卡尔曼滤波器代替常用低通滤波器(LPF),可以去除高次谐波,并且不用相位补偿就可以获得一个误差较小的转子位…...

智能职业发展系统:AI驱动的职业规划平台技术解析
智能职业发展系统:AI驱动的职业规划平台技术解析 引言:数字时代的职业革命 在当今瞬息万变的就业市场中,传统的职业规划方法已无法满足个人和企业的需求。据统计,全球每年有超过2亿人面临职业转型困境,而企业也因此遭…...
react菜单,动态绑定点击事件,菜单分离出去单独的js文件,Ant框架
1、菜单文件treeTop.js // 顶部菜单 import { AppstoreOutlined, SettingOutlined } from ant-design/icons; // 定义菜单项数据 const treeTop [{label: Docker管理,key: 1,icon: <AppstoreOutlined />,url:"/docker/index"},{label: 权限管理,key: 2,icon:…...

Selenium 查找页面元素的方式
Selenium 查找页面元素的方式 Selenium 提供了多种方法来查找网页中的元素,以下是主要的定位方式: 基本定位方式 通过ID定位 driver.find_element(By.ID, "element_id")通过Name定位 driver.find_element(By.NAME, "element_name"…...