Kafka使用指南
- Kafka简介
- 架构设计
- Kafka的架构设计关键概念
- Kafka的架构设计关键机制
- Partition介绍
- Partition工作机制
- 应用场景
- ACK机制介绍
- ACK机制原理
- ACK机制对性能的影响
- ACK控制粒度
- Kafka分区数对集群性能影响
- 调整分区优化集群性能
- 拓展
- Kafka数据全局有序
Kafka简介
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。它是一种高吞吐量的分布式发布订阅消息系统,可以处理消费者在网站中的所有动作流数据。这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。对于像Hadoop一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消息。
Kafka中的消息被归类为不同的主题,每个主题有若干个分区。当有新消息时,它们会以追加的形式写入分区。由于主题可能有多个分区,因此在整个主题范围内,无法保证消息的顺序。分区可以分布在不同的服务器上,实现数据冗余和伸缩。消费者可以订阅一个或多个主题,并保存消息以进行处理。
Kafka在处理大型数据流方面表现出色,它可以存储和持续处理大型的数据流。它类似于消息中间件,但与传统的消息中间件有很大的差异。传统的消息中间件只会传递数据,而Kafka的流处理能力可以让我们高效地处理数据。
Kafka是一个强大的开源流处理平台,可以用于处理大规模的数据流,并支持实时数据处理。它在现代网络中的许多社会功能中发挥着关键作用。

架构设计

Kafka的架构设计关键概念
- 生产者(Producer) :负责创建消息,然后投递到Kafka集群中。生产者需要指定消息所属的主题,同时确定好发往哪个分区。
- 消费者(Consumer) :根据它所订阅的主题以及所属的消费组,决定从哪些分区中拉取消息。
- Broker :消息服务器,可水平扩展,负责分区管理、消息的持久化、故障自动转移等。一个集群由多个Broker组成,一个Broker可以容纳多个主题。
- 分区(Partition) :为了实现扩展性,一个非常大的主题可以分布到多个Broker上,每个Partition是一个有序的队列。
- 消费组(Consumer Group) :这是Kafka用来实现一个Topic消息的广播(发给所有的Consumer)和单播(发给任意一个Consumer)的手段。一个Topic可以有多个Consumer Group。
- Zookeeper :负责集群的元数据管理等功能,比如集群中有哪些broker节点以及Topic,每个Topic又有哪些Partition等。
- 主题(Topic) :Topic是Kafka中的一个核心概念,它代表了一类消息,可以被认为是消息被发送到的地方。在Kafka中,每个Topic都由多个Partition组成,Partition是不可修改的有序消息序列,也可以说是消息日志。每个Partition都有自己专属的Partition号,通常是从0开始的,用户对Partition唯一的操作就是在消息序列尾部追加写入消息。Partition上的每条消息都会被分配一个唯一的序列号,该序列号被称为位移(offset)。通常可以使用Topic来区分实际业务,Kafka中的Topic通常会被多个消费者订阅,因此出于性能考虑,kafka并不是Topic-meaaage的两极结构,而是采用了Topic-partition-message的三级结构来分散负载。
- 主节点(Leader) : 在Kafka中,每个Topic的Partition都有一个Leader和一个或多个Follower。Leader是处理所有读写请求的Partition,而Follower则复制Leader的数据以保持与Leader的同步。每个Partition都有一个Leader,负责处理该Partition的所有读写请求。Kafka通过选举机制来确定每个Partition的Leader。在Kafka集群中,每个Broker都会参与Leader选举过程。当一个Broker出现故障时,Kafka会自动进行Leader选举以确保数据的高可用性。选举过程中,Kafka会选择一个可用的Broker作为新的Leader,以确保集群的正常运行。需要注意的是,在Kafka中,每个Partition只能有一个Leader,但可以有多个Follower。这种设计确保了数据的一致性和可靠性,因为所有的读写请求都必须通过Leader来处理。同时,Follower可以复制Leader的数据,并在Leader出现故障时接管其角色,从而确保数据的高可用性。
- 从节点(Follower) : Follower Partition是Kafka中的一种特殊类型的Partition,它与Leader Partition一起构成了Kafka的分布式存储系统。在Kafka中,每个Partition都有一个Leader和若干个Follower。Leader是处理所有读写请求的Partition,而Follower则实时从Leader中同步数据,保持和Leader数据的同步。当Leader发生故障时,某个Follower会成为新的Leader。Follower Partition的主要作用是备份数据和扩展集群规模。在正常状态下,Follower Partition会从Leader Partition中同步数据,并保持与Leader Partition的数据一致性。当Leader Partition发生故障时,Follower Partition会成为新的Leader,继续为消费者提供服务。此外,当集群规模需要扩展时,可以增加Follower Partition的数量来提高集群的存储能力和吞吐量。
Kafka的架构设计关键机制
- 消息持久化 :Kafka支持消息持久化,消费端为拉模型来拉取数据,消费状态和订阅关系有客户端负责维护,消息消费完后,不会立即删除,会保留历史消息。
- 分布式机制 :Kafka的分布式机制包括生产者、消费者和代理三部分。生产者可以发送消息至Kafka集群,以供后续的消费者进行消费。消费者可以从Kafka集群中读取数据并对其进行响应的操作。代理是Kafka集群的关键组件之一,它主要负责消息的存储和转发,并通过分布式机制保障Kafka集群的故障恢复能力和高可用性。
- 高度可扩展的架构设计 :Kafka基于高度可扩展的架构设计,支持任意数量的生产者和消费者,可以针对不同领域的数据模型、处理技术等进行选择和组合。
- 消息流处理 :Kafka提供了一个流处理平台,允许应用程序充当流处理器(stream processor),从一个或者多个主题获取输入流,并生产一个输出流到一个或多个主题,能够有效的变化输入流为输出流。
- 连接器API :Kafka提供了连接器API,允许构建和运行可重用的生产者或者消费者,能够把kafka主题连接到现有的应用程序或数据系统。例如:一个连接到关系数据库的连接器可能会获取每个表的变化。
Kafka的架构设计涵盖了多个关键部分,这些部分协同工作,使得Kafka成为一个高效、可扩展、可靠的分布式消息系统。
Partition介绍
Kafka的Partition是一个逻辑概念,是消息在Kafka中的存储单位,也是消息被分发的单位。每个Topic被分成多个Partition,分布在不同的Broker服务器上。
Partition有几个重要的特性:
- Partition中的消息是有序的,同一个Partition内的消息会按照发送的顺序进行存储。
- Partition是Kafka中消息存储的最小单位,掌握着一个Topic的部分数据。每个Partition都是一个单独的log文件,每条记录都以追加的形式写入。
- Kafka集群中的每个Partition都有且只有一个Leader和零个或多个Follower。在正常状态下,Producer和Consumer只与Leader交互,所有的读写请求都必须通过Leader来处理。当Leader发生故障时,某个Follower会成为新的Leader。
- Kafka的负载均衡和扩展性很大程度上取决于Partition的数量和分布。为了实现负载均衡,建议将Partition的数量设置为Broker的倍数。
- Kafka Producer会将消息发送到指定的Topic的Partition,而Consumer则会从指定的Partition中消费消息。
Partition工作机制
Kafka的Partition是Kafka中消息存储和分发的单位,主要负责消息的存储和管理。以下是Partition在Kafka中的工作方式:
- 创建Partition :在创建Topic时,可以指定Partition的数量。一般来说,Partition的数量通常设为Broker节点数的整数倍,这样可以保证分区数据均匀地分配到集群中,并最大化的提升并行读写效率。
- 生产者写入Partition :生产者在向某个Topic发送消息时,会根据分配策略将消息发送到对应的Partition。分配策略可以是基于Partition key值进行哈希决定写入哪个Partition,也可以是采用轮询的方式均匀地写入到各个Partition。需要注意的是,如果指定了Partition key值,可能会出现热点数据问题。
- 消费者消费Partition :消费者订阅消费一个Topic时,会从该Topic的所有Partition中消费消息。每个Partition的消费组只能由一个消费者组中的一个消费者进行消费,因此可以说Partition是消费并行度的基本单位。从消费者的角度来看,订阅消费了一个Topic,也就订阅了该Topic的所有Partition。
- Partition的复制和故障转移 :Kafka的每个Partition都有一个Leader和零个或多个Follower。在正常状态下,Producer和Consumer只与Leader交互,所有的读写请求都必须通过Leader来处理。当Leader发生故障时,某个Follower会成为新的Leader。
Kafka的Partition是Kafka中实现负载均衡、扩展性和可靠性的关键组件之一。通过合理的设置和调整Partition的数量和分布,可以提高Kafka集群的性能和可靠性。
应用场景
- 实时数据流处理 :Kafka可以作为数据流处理的中间件,用于接收和传输大量的实时数据。它可以接收来自不同数据源的数据,并将其传输到不同的数据处理系统,如Apache Storm、Apache Flink等。通过使用Kafka,可以实现高吞吐量和低延迟的实时数据处理。
- 日志收集与分析 :Kafka可以用于集中式的日志收集和分析。许多应用程序和系统会生成大量的日志数据,使用Kafka可以将这些日志数据集中存储,并提供给日志分析工具进行实时或离线的分析。通过将日志数据发送到Kafka主题中,可以实现高效的日志收集和处理。
- 消息系统 :Kafka可以作为消息系统的一种替代方案。它具有更好的吞吐量、内置分区、副本和故障转移等特性,有利于处理大规模的消息。与传统的消息系统(如ActiveMQ或RabbitMQ)相比,Kafka在处理低延迟、高吞吐量的场景下更具优势。
- 网站活动追踪 :Kafka原本的使用场景之一是用户的活动追踪。网站的活动(如网页浏览、搜索或其他用户操作信息)可以发布到不同的主题中心,这些消息可实时处理、实时监测,也可加载到Hadoop或离线处理数据仓库。每个用户页面视图都会产生非常高的数据量,Kafka能够高效地处理这些数据。
- 指标监测 :Kafka也常用于监测数据。分布式应用程序生成的统计数据可以在Kafka中进行集中聚合,以便实时监测和分析。
- 日志聚合 :Kafka可以作为日志聚合的解决方案。通过将日志数据发送到Kafka主题中,可以实现高效的日志收集和处理。
- 事件采集 :Kafka可以用于事件采集,将各种事件数据(如用户行为事件、系统事件等)采集到Kafka主题中,以便后续处理和分析。
Kafka的应用场景非常广泛,包括但不限于实时数据处理、日志收集与分析、消息系统、网站活动追踪、指标监测、日志聚合和事件采集等。
ACK机制介绍
在Kafka中,ACK(acknowledgment)机制用于确认生产者发送的消息是否成功被Kafka服务器接收并存储。这是确保消息可靠性的重要机制。
Kafka提供了三种不同级别的消息确认机制,可以根据需求进行选择:
ACK 级别 0:生产者发送消息后,不会等待任何服务器的确认,直接认为消息发送成功。这种方式下,可能会出现消息丢失的情况。ACK 级别 1:生产者发送消息后,会等待 leader 副本(partition 的 leader)确认消息后,认为消息发送成功。这种方式下,如果 leader 副本在确认消息前宕机,可能会导致消息丢失。ACK 级别 -1 或 all:生产者发送消息后,会等待所有的副本(包括 leader 和 follower)都确认消息后,认为消息发送成功。这种方式下,消息的可靠性最高,但是会对性能产生一定的影响。
选择合适的 ACK 级别取决于对消息可靠性和性能的要求。如果对消息的可靠性要求较高,可以选择 -1 或 all 级别,但需要考虑性能损耗。如果对消息的可靠性要求不高,可以选择 1 或 0 级别,以提高性能。
总的来说,ACK机制的优点是可以确保消息的可靠性,通过等待确认,生产者可以知道消息是否成功处理,从而保证数据的一致性。然而,ACK机制也存在一些缺点,例如延迟和服务器负载问题。需要根据具体的应用场景和需求来选择合适的ACK级别。
除了ACK级别外,Kafka还通过以下方式保证ACK机制的可靠性:
- 数据复制 :Kafka通过将数据复制到多个副本(partition)中,确保数据的安全性和可靠性。即使某个副本出现问题,其他副本仍然可以正常工作。
- 消息持久化 :Kafka将消息持久化到磁盘上,确保即使在服务器崩溃的情况下,消息也不会丢失。
- 数据校验 :Kafka在存储和传输数据时使用校验和(checksum)等技术来检测数据完整性,确保数据的正确性和一致性。
- 事务支持 :Kafka支持事务,可以在生产者发送消息时保证消息的可靠性。事务可以确保在写入数据之前进行验证和提交,避免因未提交的事务导致的数据不一致问题。
- 参数配置 :Kafka提供了许多参数来配置ACK机制的可靠性,例如min.insync.replicas、unclean.leader.election.enable等参数。这些参数可以用来控制消息的确认机制和副本同步等行为,以确保数据的可靠性和一致性。
Kafka通过多种机制和参数配置来保证ACK机制的可靠性。在实际应用中,需要根据具体的应用场景和需求来选择合适的ACK级别和配置参数,以实现可靠的消息传递。
ACK机制原理
在Kafka中,ACK机制的原理是确认生产者发送的消息是否成功被Kafka服务器接收并存储。当生产者发送消息后,会向Kafka的代理服务器发送一个ACK(Acknowledgement)确认消息已经被发送。Kafka代理服务器在收到ACK后,会将该消息标记为已接收,然后从分区中删除。如果Kafka代理服务器在一定时间内没有收到ACK确认消息,则会将该消息重新发送给其他生产者,以确保消息的可靠性传递。
ACK机制的可靠性取决于选择的ACK级别。ACK级别为0时,生产者认为消息发送成功,无需等待服务器的确认,可能会出现消息丢失的情况。ACK级别为1时,生产者需要等待leader副本的确认,如果leader副本在确认消息前宕机,可能会导致消息丢失。ACK级别为-1或all时,生产者需要等待所有的副本(包括leader和follower)都确认消息后,才认为消息发送成功,消息的可靠性最高,但会对性能产生一定的影响。
Kafka中的ACK机制原理是生产者发送消息后向Kafka代理服务器发送ACK确认消息已经被发送,代理服务器收到ACK后将消息标记为已接收并删除。通过选择合适的ACK级别和配置参数,可以确保消息的可靠性和一致性。
ACK机制对性能的影响
首先,ACK机制影响吞吐量。ACK级别越高,吞吐量可能越低。这是因为当生产者发送消息并等待确认时,必须等待所有相关副本(包括leader和follower)都确认消息,这会增加延迟。相反,如果ACK级别较低,生产者可能不必等待所有副本的确认,从而提高了吞吐量。
其次,ACK机制影响消息的可靠性。较高的ACK级别可以提高消息的可靠性,因为消息被更多的副本确认。然而,这也可能增加复制延迟和降低吞吐量。相反,较低的ACK级别可能会导致较低的可靠性和较高的消息丢失风险。
因此,在选择ACK级别时需要权衡吞吐量和可靠性。对于需要高吞吐量的应用,可以选择较低的ACK级别;对于需要高可靠性的应用,可以选择较高的ACK级别。
此外,Kafka的ACK机制还影响集群的延迟和持久性。例如,ACK=0时,提供了最低的延迟,但持久性最弱,当服务器发生故障时很可能发生数据丢失。ACK=1时,提供了较低的延迟以及较好的持久性,但是如果leader死亡,而follower尚未复制数据,数据就会丢失。ACK=-1时,leader收到所有消息,且follower同步完数据,才发送下一条数据,这提供了最高的可靠性,但也可能增加延迟。
因此,在选择ACK策略时,需要根据应用的需求和集群的特性进行权衡。
ACK机制对Kafka集群性能的影响主要涉及以下几个方面:
-
延迟:ACK机制会增加消息传递的延迟。当生产者发送消息后,必须等待确认才能继续发送下一条消息。等待确认的时间取决于网络延迟、副本数量和ACK级别等因素。如果延迟较高,可能会影响生产者的发送速率和消费者的消费速率,从而降低集群的整体性能。 -
吞吐量:ACK机制会影响Kafka集群的吞吐量。吞吐量是指集群在单位时间内处理的消息数量。当ACK级别较高时,生产者必须等待更多的确认,这会降低生产者的发送速率,从而影响集群的吞吐量。此外,如果集群中的副本数量较多,也会增加确认的延迟,进一步影响吞吐量。 -
CPU和内存使用:ACK机制需要额外的CPU和内存资源来处理确认消息。当集群中的消息数量较多时,处理确认消息的开销也会相应增加。这可能会影响其他任务的性能,例如消费者消费消息的速度。 -
数据一致性:ACK机制是确保数据一致性的重要手段。当生产者发送消息后,如果某个副本未能成功接收消息,可能会导致数据不一致。通过等待所有相关副本的确认,可以确保数据的一致性。但是,这也可能增加延迟和降低吞吐量。 -
可靠性:ACK机制可以提高消息的可靠性。当生产者发送消息并收到确认时,可以认为消息已经被成功接收并存储。这可以避免消息丢失的情况,提高系统的可靠性。
需要注意的是,在选择ACK策略时需要综合考虑应用的需求和集群的特性,权衡延迟、吞吐量、CPU和内存使用、数据一致性和可靠性等因素。
ACK控制粒度
Kafka中的ACK控制粒度是指生产者在发送消息时需要等待确认的副本数量。Kafka提供了三种不同的ACK控制粒度:
- ACK_roj(原子性确认) :这种控制粒度要求消息被所有的副本都接收后才能发送下一条消息,可以保证原子性操作。但是这种控制粒度会增加延迟,降低吞吐量,适用于对数据一致性要求较高的场景。
- ACK_one(领导者确认) :这种控制粒度要求消息被领导者副本接收后就可以发送下一条消息,可以减少延迟,提高吞吐量。但是这种控制粒度不能保证数据一致性,适用于对数据一致性要求不高的场景。
- ACK_all(全部副本确认):这种控制粒度要求消息被所有的副本都接收后才能发送下一条消息,可以保证数据一致性。但是这种控制粒度会增加延迟,降低吞吐量,适用于对数据一致性要求较高的场景。
Kafka客户端可以根据需要选择不同的ACK控制粒度。需要注意的是,不同的ACK控制粒度会对集群的性能和可靠性产生不同的影响,因此需要根据应用的需求和集群的特性进行选择。
Kafka分区数对集群性能影响
Kafka中的分区数对集群性能有显著影响,主要表现在以下几个方面:
-
吞吐量 :增加分区数可以增加Kafka集群的吞吐量。每个分区可以并行处理消息,因此更多的分区意味着更高的并行度,从而提高吞吐量。但是,过多的分区数也可能导致资源竞争和开销增加,从而降低性能。
-
延迟 :分区数对消息传递的延迟也有影响。较少的分区数可能会导致消息在某个分区上积压,从而增加延迟。增加分区数可以分散消息负载,减少单个分区的压力,降低延迟。但是,过多的分区数也会增加消息在多个分区之间的传播延迟。
-
负载均衡 :分区数会影响Kafka集群的负载均衡。如果分区数过少,某些broker可能会成为瓶颈,导致负载不均衡。适当增加分区数可以平衡负载,使消息更均匀地分布在各个broker上。但是,过多的分区数也可能导致过于复杂的负载均衡策略,增加管理和维护的难度。
-
存储和I/O :每个分区都需要在磁盘上存储数据日志和索引文件。因此,分区数会增加存储需求和I/O操作。过多的分区数可能会导致磁盘空间不足和I/O性能下降,从而影响集群的整体性能。
-
资源消耗 :每个分区都需要在内存中维护缓存和其他相关数据结构。因此,随着分区数的增加,内存消耗也会相应增加。这可能会对集群的资源产生压力,降低性能。
综上所述,选择合适的分区数对于优化Kafka集群的性能至关重要。需要根据应用的需求、集群的规模和硬件资源等因素进行综合考虑和调整。
调整分区优化集群性能
要调整Kafka集群的分区数以优化性能,可以采取以下措施:
-
了解业务需求:首先需要了解业务需求和数据量。考虑主题的数据量、消息生产者和消费者的数量,以及消息处理的延迟等因素,以确定合适的分区数。
-
调整副本数:副本数是Kafka保证数据可靠性和容错性的重要手段。可以根据需要调整副本数,以提高数据可靠性和容错性。但是,过多的副本数会增加存储和网络开销,因此需要根据实际情况进行权衡。
-
调整批处理大小:批处理是Kafka提高消息处理效率的重要手段。可以调整批处理的大小,以适应不同的业务需求和硬件资源。较大的批处理可以减少网络传输次数,提高处理效率,但可能会增加内存消耗和延迟。
-
调整主题和分区策略:在设计Kafka主题和分区时,需要考虑主题的数据量、消息生产者和消费者的数量,以及消息处理的延迟等因素,以制定合适的策略。例如,可以将经常被一起消费的消息放在同一个分区,以减少跨分区的消息处理延迟。
-
使用SSD存储:使用SSD存储可以显著提高Kafka的性能,因为SSD存储比传统的机械硬盘更快,能够更快地读写数据。使用SSD可以减少磁盘I/O瓶颈,提高Kafka集群的整体性能。
-
使用网络加速器:使用网络加速器可以减少网络延迟,提高数据传输的速度和可靠性,从而提高Kafka的性能和可靠性。例如,使用InfiniBand等高速网络技术可以显著提高Kafka集群的性能。
-
定期清理过期数据:定期清理过期数据可以减少磁盘空间的占用,从而提高Kafka的性能和可靠性。可以根据业务需求定期清理过期数据,释放磁盘空间,提高Kafka集群的整体性能。
调整Kafka集群的分区数需要综合考虑业务需求、硬件资源、网络环境等因素,并进行测试和优化。通过合理的分区数配置,可以提高Kafka集群的性能和可靠性,满足业务需求。
拓展
Kafka数据全局有序
Kafka的数据不是全局有序的,它只能保证单个Partition内的数据有序。因为Kafka的设计中允许多个生产者并行地向同一个主题写入消息,所以无法保证全局有序性。
如果需要全局有序,可以将所有消息发送到同一个Partition,或者使用一些外部的手段进行排序。但是这样会降低并行度和吞吐量,需要根据实际需求进行权衡。

相关文章:
Kafka使用指南
Kafka简介架构设计Kafka的架构设计关键概念Kafka的架构设计关键机制 Partition介绍Partition工作机制 应用场景ACK机制介绍ACK机制原理ACK机制对性能的影响ACK控制粒度Kafka分区数对集群性能影响调整分区优化集群性能拓展Kafka数据全局有序 Kafka简介 Kafka是由Apache软件基金…...
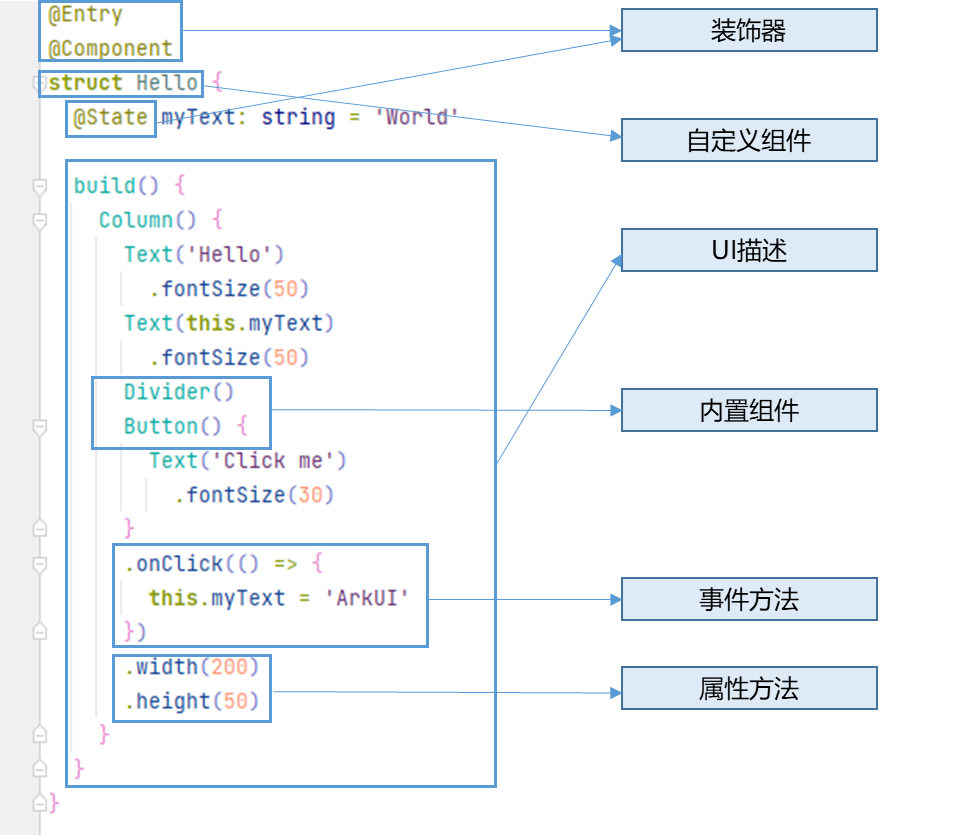
HarmonyOS4.0从零开始的开发教程03初识ArkTS开发语言(中)
HarmonyOS(二)初识ArkTS开发语言(中)之TypeScript入门 浅析ArkTS的起源和演进 1 引言 Mozilla创造了JS,Microsoft创建了TS,Huawei进一步推出了ArkTS。 从最初的基础的逻辑交互能力,到具备类…...

西工大计算机学院计算机系统基础实验一(函数编写1~10)
还是那句话,千万不要慌,千万不要着急,耐下性子慢慢来,一步一个脚印,把基础打的牢牢的,一样不比那些人差。回到实验本身,自从按照西工大计算机学院计算机系统基础实验一(…...

VMware 虚拟机 电脑重启后 NAT 模式连不上网络问题修复
问题描述: 昨天 VMware 安装centos7虚拟机,网络模式配置的是NAT模式,配置好后,当时能连上外网,今天电脑重启后,发现连不上外网了 检查下各个配置,都没变动,突然就连不上了 网上查了…...
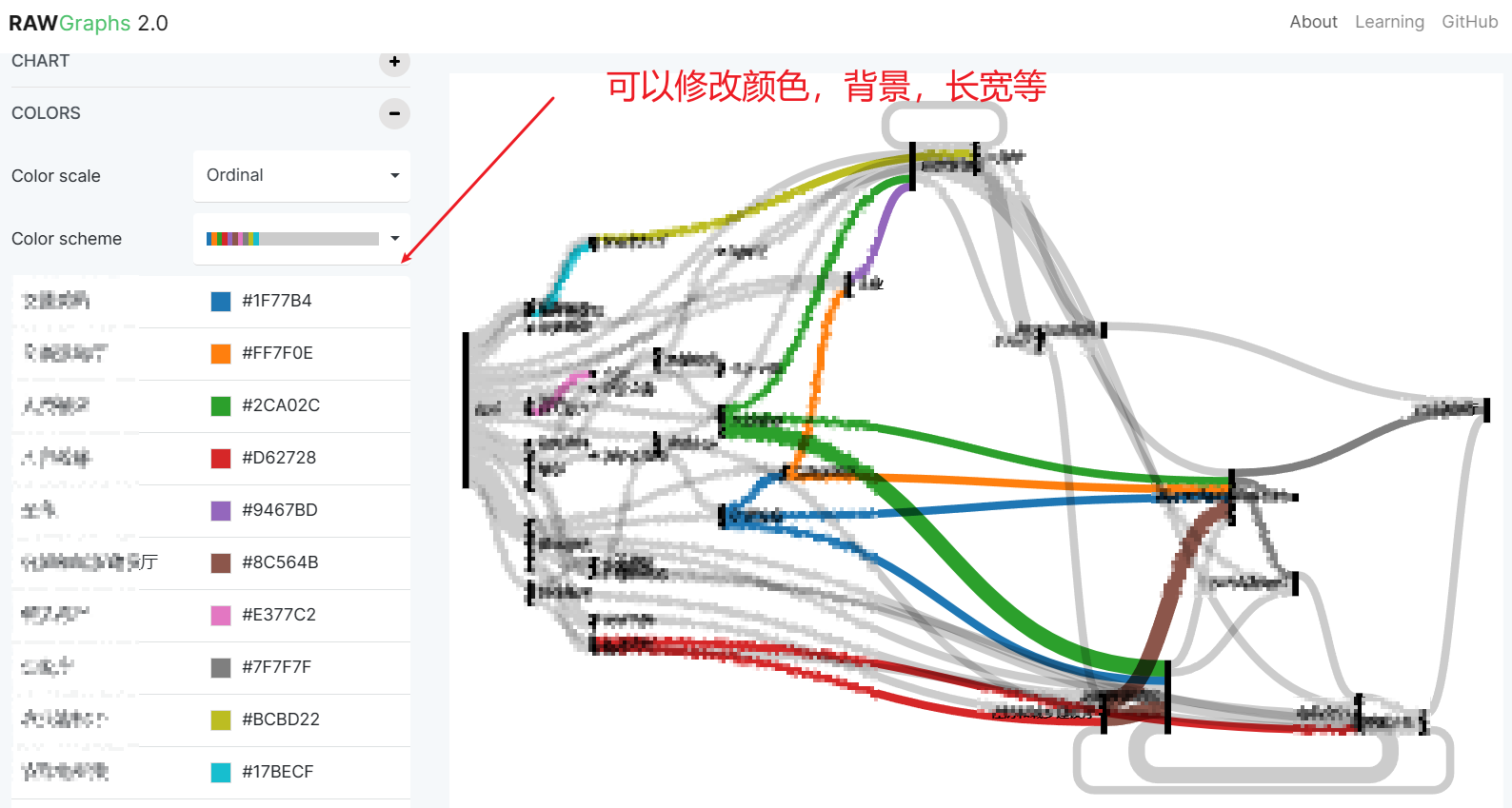
【桑基图】绘制桑基图
绘制桑基图 一、绘制桑基图(1)方法一:去在线网站直接绘制(2)方法二:写html之后在vscode上运行 二、遇到的问题(1)当导入一些excel的时候,无法绘制出桑基图 一、绘制桑基图…...
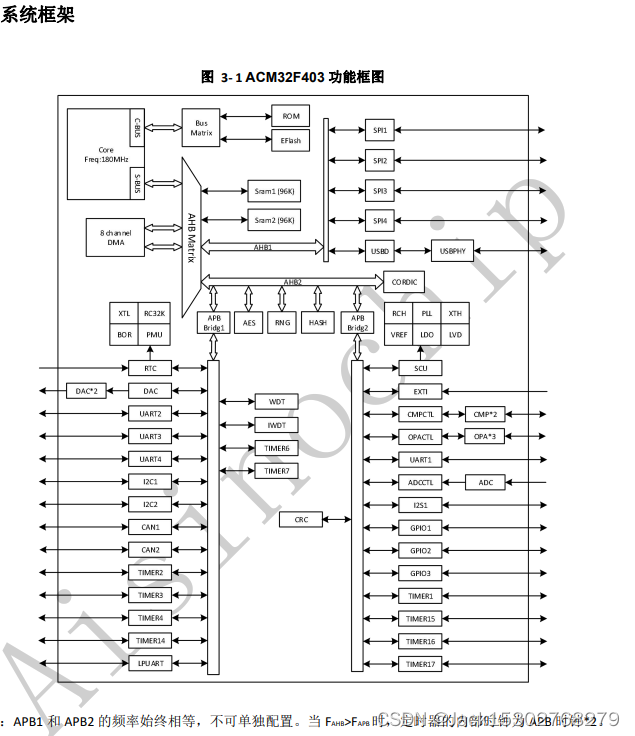
ACM32F403/F433 12 位多通道,支持 MPU 存储保护功能,应用于工业控制,智能家居等产品中
ACM32F403/F433 芯片的内核基于 ARMv8-M 架构,支持 Cortex-M33 和 Cortex-M4F 指令集。芯片内核 支持一整套DSP指令用于数字信号处理,支持单精度FPU处理浮点数据,同时还支持Memory Protection Unit (MPU)用于提升应用的…...
7. 从零用Rust编写正反向代理, HTTP及TCP内网穿透原理及运行篇
wmproxy wmproxy是由Rust编写,已实现http/https代理,socks5代理, 反向代理,静态文件服务器,内网穿透,配置热更新等, 后续将实现websocket代理等,同时会将实现过程分享出来ÿ…...
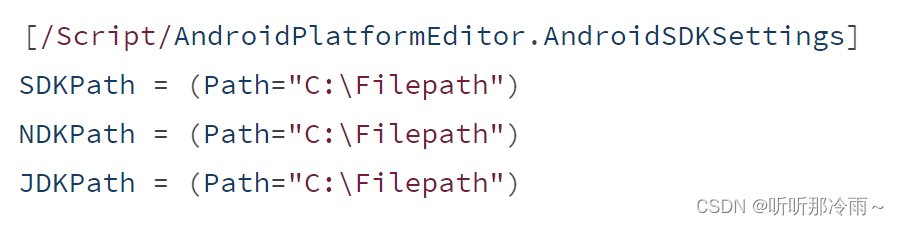
UE4.27-UE5.1设置打包Android环境
打包Android配置文件 1. 配置打包Android的SDK需求文件位于下面文件中: 2. 指定了对应的SDK环境变量名字以及NDK需求等: UE4.27-UE5.1--脚本自动配置 安装前提 1. 务必关闭虚幻编辑器和Epic Games Launcher,以确保NDK组件的安装或引擎环境…...

MySQL授权密码
mysql> crate databases school charcter set utf8; Query OK, 1 row affected, 1 warning (0.00 sec) 2.在school数据库中创建Student和Score表 mysql> use school Database changed mysql> create table student-> -> (id int(10) primary key auto_incremen…...
0X05
打开题目 点击完登录和注册都没有什么反应,所以先扫一下看看 在出现admin.php后就截止了,访问看看,进入后台。。 尝试一下弱口令 admin/12345 或者是demo/demo 设计中-自定义->右上角导出主题 找到一个导出的点,下载了一个1.zip压缩包…...

Doris优化总结
1 查看QueryProfile 利用查询执行的统计结果,可以更好的帮助我们了解Doris的执行情况,并有针对性的进行相应Debug与调优工作。 FE将查询计划拆分成为Fragment下发到BE进行任务执行。BE在执行Fragment时记录了运行状态时的统计值,并将Fragment执行的统计信息输出到日志之中。…...
案例059:基于微信小程序的在线投稿系统
文末获取源码 开发语言:Java 框架:SSM JDK版本:JDK1.8 数据库:mysql 5.7 开发软件:eclipse/myeclipse/idea Maven包:Maven3.5.4 小程序框架:uniapp 小程序开发软件:HBuilder X 小程序…...

利用STM32内置Bootloader实现USB DFU固件升级
本文将介绍如何利用STM32内置的Bootloader来实现USB DFU(Device Firmware Upgrade)固件升级功能。首先,我们会介绍USB DFU的原理和工作流程。然后,我们将详细讲解如何配置STM32芯片以支持USB DFU,并提供相应的代码示例…...

Centos7如何安装MySQL
目录 一、卸载mysql 二、安装mysql 注:本文主要是看了这位大佬安装MySQL,才想着写一篇记录一下。 一、卸载mysql 安装mysql之前一定要将之前安装的mysql相关文件删除干净,防止出现错误。 (1)关闭mysql 开启了mysql就…...

VR远程带看,助力线下门店线上化转型“自救”
VR远程带看,因自身高效的沉浸式在线沟通功能,逐渐走进了大众的视野。身临其境的线上漫游体验以及实时同屏互联的新型交互模式,提升了商家同用户之间的沟通效率,进一步实现了远程线上一对一、一对多的同屏带看,用户足不…...
算法通关村第十七关-白银挑战贪心算法高频题目
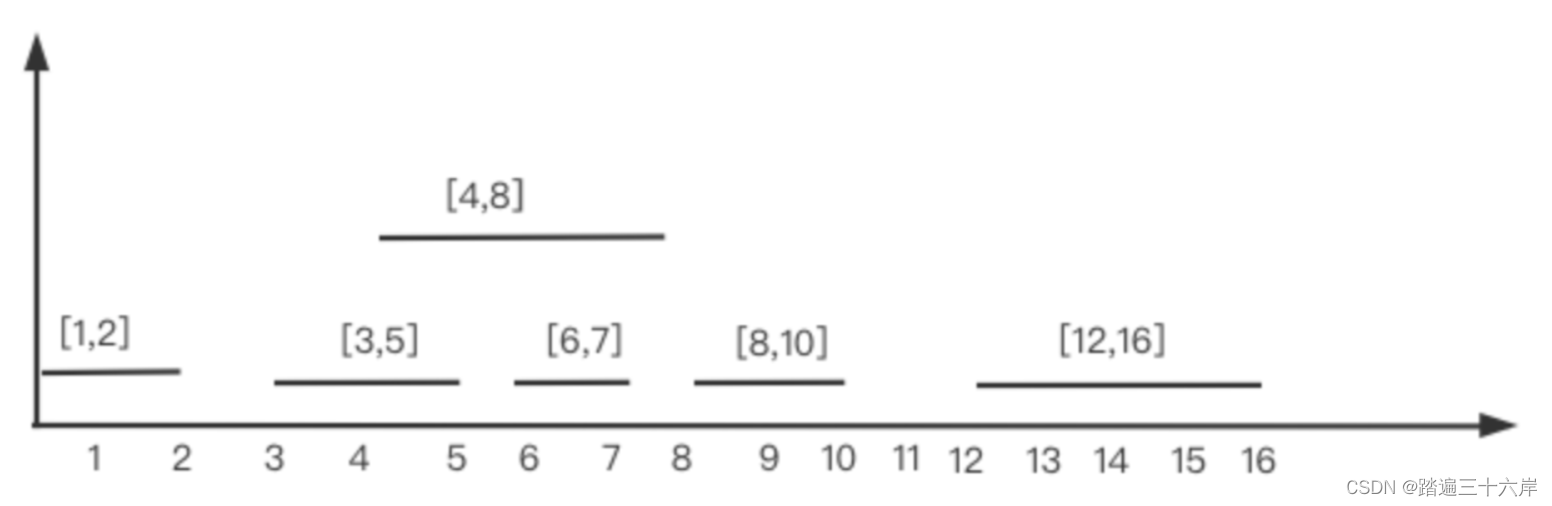
大家好我是苏麟 , 今天说说贪心算法的高频题目 . 大纲 区间问题判断区间是否重叠合并区间插入区间 区间问题 判断区间是否重叠 描述 : 给定一个会议时间安排的数组 intervals ,每个会议时间都会包括开始和结束的时间intervalsl[i] [start, end] ,请你…...
【数据结构】动态规划(Dynamic Programming)
一.动态规划(DP)的定义: 求解决策过程(decision process)最优化的数学方法。 将多阶段决策过程转化为一系列单阶段问题,利用各阶段之间的关系,逐个求解。 二.动态规划的基本思想: …...
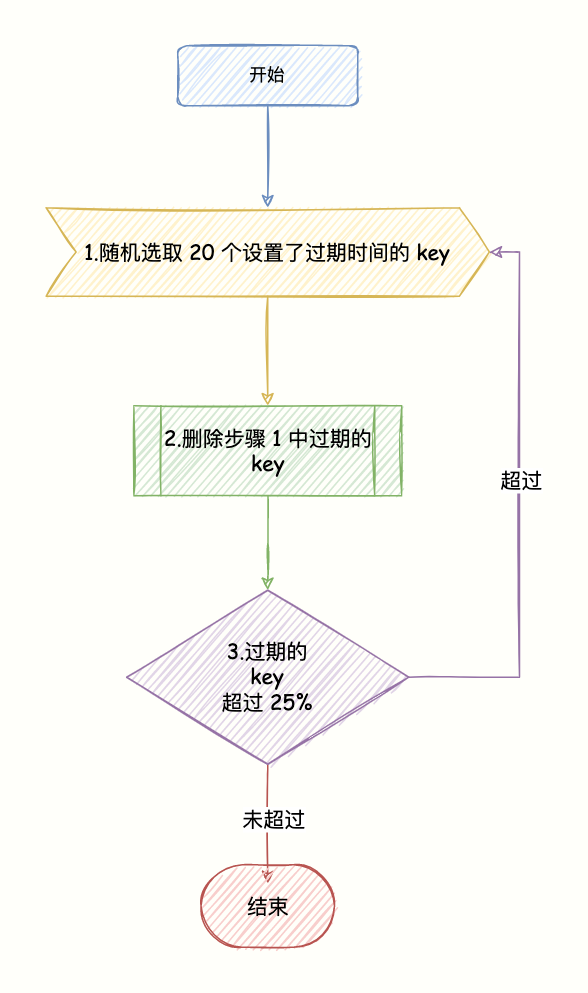
Redis key过期删除机制实现分析
文章目录 前言Redis key过期淘汰机制惰性删除机制定时扫描删除机制 前言 当我们创建Redis key时,可以通过expire命令指定key的过期时间(TTL),当超过指定的TTL时间后,key将会失效。 那么当key失效后,Redis会立刻将其删除么&#…...

ElasticSearch 谈谈分词与倒排索引的原理
ElasticSearch是一个基于Lucene的搜索服务器。Lucene是Java的一个全文检索工具包,而ElasticSearch则是一个分布式搜索和分析引擎。下面,我们将详细讨论ElasticSearch中的分词和倒排索引的原理。 分词: 在ElasticSearch中,分词是…...

【Java】Java8重要特性——Lambda函数式编程以及Stream流对集合数据的操作
【Java】Java8重要特性——Lambda函数式编程以及Stream流对集合数据的操作 前言Lambda函数式编程Stream流对集合数据操作(一)创建Stream流(二)中间操作之filter(三)中间操作之map(四)…...

2026届必备的五大AI辅助写作方案推荐榜单
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 在人工智能技术参与进来之后,学术论文写作在效率方面有了明显的大幅提升…...

OpenClaw个性化设置:Qwen3.5-9B模型参数调优实战
OpenClaw个性化设置:Qwen3.5-9B模型参数调优实战 1. 为什么需要调整模型参数? 上周我在用OpenClaw自动处理一批技术文档时,遇到了一个奇怪的现象:同样的任务指令,有时候AI能完美执行,有时候却会输出一堆无…...

数据自主权:WeChatMsg让微信聊天记录回归用户掌控
数据自主权:WeChatMsg让微信聊天记录回归用户掌控 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/WeChatMsg…...

SecGPT-14B开源大模型部署:CSDN平台内开箱即用,省去HuggingFace下载环节
SecGPT-14B开源大模型部署:CSDN平台内开箱即用,省去HuggingFace下载环节 想快速体验一个专注于网络安全问答的14B大模型,但又不想经历从HuggingFace下载几十GB模型文件的漫长等待和复杂配置?现在,在CSDN星图平台上&am…...

PWM技术原理与工程实践全解析
1. PWM技术基础解析脉冲宽度调制(PWM)作为现代电子电力控制的核心技术,其本质是通过调节脉冲信号的导通时间比例来实现对功率的有效控制。我第一次接触这个概念是在调试直流电机调速项目时,当时被其精妙的设计思想所震撼。1.1 关键…...

抑制素A抗体如何提升妊娠中期唐氏综合征筛查的效能?
一、为何抑制素A成为妊娠期的重要生物标志物?抑制素A是一种由α和βA亚基通过二硫键连接形成的异源二聚体糖蛋白。在非妊娠期,它主要由卵巢颗粒细胞分泌,作为反馈调节因子,选择性地抑制垂体前叶分泌卵泡刺激素。进入妊娠状态后&am…...

DFRobot URM07超声波传感器UART通信与温度补偿详解
1. DFRobot URM07超声波测距传感器技术深度解析1.1 产品定位与工程价值DFRobot URM07(SKU: SEN0153)是一款面向嵌入式系统设计的工业级超声波距离传感器模块,其核心价值在于将高精度测距、环境温度补偿、超低功耗与UART标准化接口四者深度融合…...

2.2.2.3 Spark实战:词频统计
本次实战涵盖了Spark词频统计(WordCount)的两种主流实现方式。首先,利用Scala在spark-shell中完成从读取文件、flatMap分词、map映射到reduceByKey聚合的完整流程,并实现结果的降序排序。其次,针对Spark 3.3.2版本的需…...

3步实现跨平台日历同步:从需求到落地
3步实现跨平台日历同步:从需求到落地 【免费下载链接】ics iCalendar (ics) file generator for node.js 项目地址: https://gitcode.com/gh_mirrors/ic/ics 场景需求:现代日程管理的痛点与解决方案 在数字化办公环境中,日程管理面临…...

Fiji图像处理软件更新故障排查指南:当科学工具遇到“升级烦恼“
Fiji图像处理软件更新故障排查指南:当科学工具遇到"升级烦恼" 【免费下载链接】fiji A "batteries-included" distribution of ImageJ :battery: 项目地址: https://gitcode.com/gh_mirrors/fi/fiji Fiji作为生物图像分析领域的瑞士军刀…...