字节开源的netPoll底层LinkBuffer设计与实现
字节开源的netPoll底层LinkBuffer设计与实现
- 为什么需要LinkBuffer
- 介绍
- 设计思路
- 数据结构
- LinkBufferNode
- API
- LinkBuffer
- 读 API
- 写 API
- book / bookAck api
- 小结
本文基于字节开源的NetPoll版本进行讲解,对应官方文档链接为: Netpoll对应官方文档链接
netPoll底层有一个非常核心的数据结构叫LinkBuffer , 本文作为netPoll正式源码分析的前导篇 , 主要来看看netPoll底层使用到的LinkBuffer的源码实现。
为什么需要LinkBuffer
我们先来看一段官方对NetPoll的定义:
- Netpoll 是由 字节跳动 开发的高性能 NIO(Non-blocking I/O)网络库,专注于 RPC 场景。
- RPC 通常有较重的处理逻辑,因此无法串行处理 I/O。而 Go 的标准库 net 设计了 BIO(Blocking I/O) 模式的 API,使得 RPC 框架设计上只能为每个连接都分配一个 goroutine。 这在高并发下,会产生大量的 goroutine,大幅增加调度开销。此外,net.Conn 没有提供检查连接活性的 API,因此 RPC 框架很难设计出高效的连接池,池中的失效连接无法及时清理。
NetPoll对标的其实就是java中的Netty框架 , 而对于这一类多路IO复用框架来说,他们底层实现都依赖于epoll,kqueue等底层操作系统向上提供的多路复用API ; 在多路复用模型设计中,底层epoll等API的事件触发方式会影响I/O和buffer的设计,这也是netpoll推出LinkBuffer的原因。
Linux提供的epoll有两种触发方式:
- 水平触发(LT) : 由于I/O就绪事件会持续触发,直到无数据可读可写 , 所以需要同步的在事件触发后主动完成I/O , 并向上层代码直接提供buffer
- 边沿触发(ET) : 由于I/O就绪事件只会通知一次,所以可选择只负责处理事件通知转发,由上层代码完成I/O并管理Buffer
go原生网络库采用边沿触发(ET)模式,而netpoll采用水平触发(LT)模式,LT模式实效性更好,主动I/O可以集中内存使用和管理,并且还可以像netpoll这样提供nocpoy操作同时还能减少GC 。
目前一些热门开源网络库同样也是采用的LT模式,如easygo,evio和gnet等
这里主动IO是指由netpoll提供一个缓冲区,当监听到fd上的读事件时,就主动将数据读取到该缓冲区中,至于什么时候从netpoll提供的缓冲区读出数据,则是用户的事情了。
主动I/O需要网络库自身提供一个数据缓冲区,这会引入上层代码并发操作buffer的问题,同时网络库自身也需要对该缓冲区进行I/O读写,因此为了保证数据正确性,同时又避免加锁带来的低性能,目前开源的网络库通常都会采取同步处理buffer (easygo , evio) 或将 buffer copy (gent) 一份提供给上层代码的方式来实现。
已有的实现方式不适合大流量环境下的业务处理或存在copy开销,同时,常见的bytes , bufio , ringbuffer 等 buffer 库 ,均存在扩容需要拷贝原数组数据,以及只能扩容无法缩容导致占用大量内存等问题。因此,LinkBuffer的提出就是为了解决上面提出的两个问题!
介绍
相比于常见的Buffer库,LinkBuffer的优势有以下几点:
- 读写并行无锁,支持零拷贝的流式读写
- 链式buffer,存在读写两个指针,实现读写并行效果
- 高效扩缩容
- 由于采用链式buffer实现,扩容时直接在尾部添加新的Node节点即可,缩容时借助头指针直接释放掉那些多余的Node节点占用的空间,同时给每个节点建立一个单独的引用计数,确保只在Node节点上的引用计数为0时,才会回收其占用的内存
- 灵活切片和拼接buffer
- 支持读取LinkBuffer中任意段数据,上层代码可以nocopy地并行处理数据流分段,无需关心生命周期,通过引用计数GC
- 支持任意拼接(nocopy) , 写buffer借助追加Node到链表尾部实现,无需copy,同时保证数据只会写一次
- nocpy buffer 池化,减少GC
- 将每个字节数组看作Node节点,构建对象池维护空闲Node节点,用于实现Node对象的复用,减少内存占用和GC
设计思路
LinkBuffer 的设计思路如下图所示:
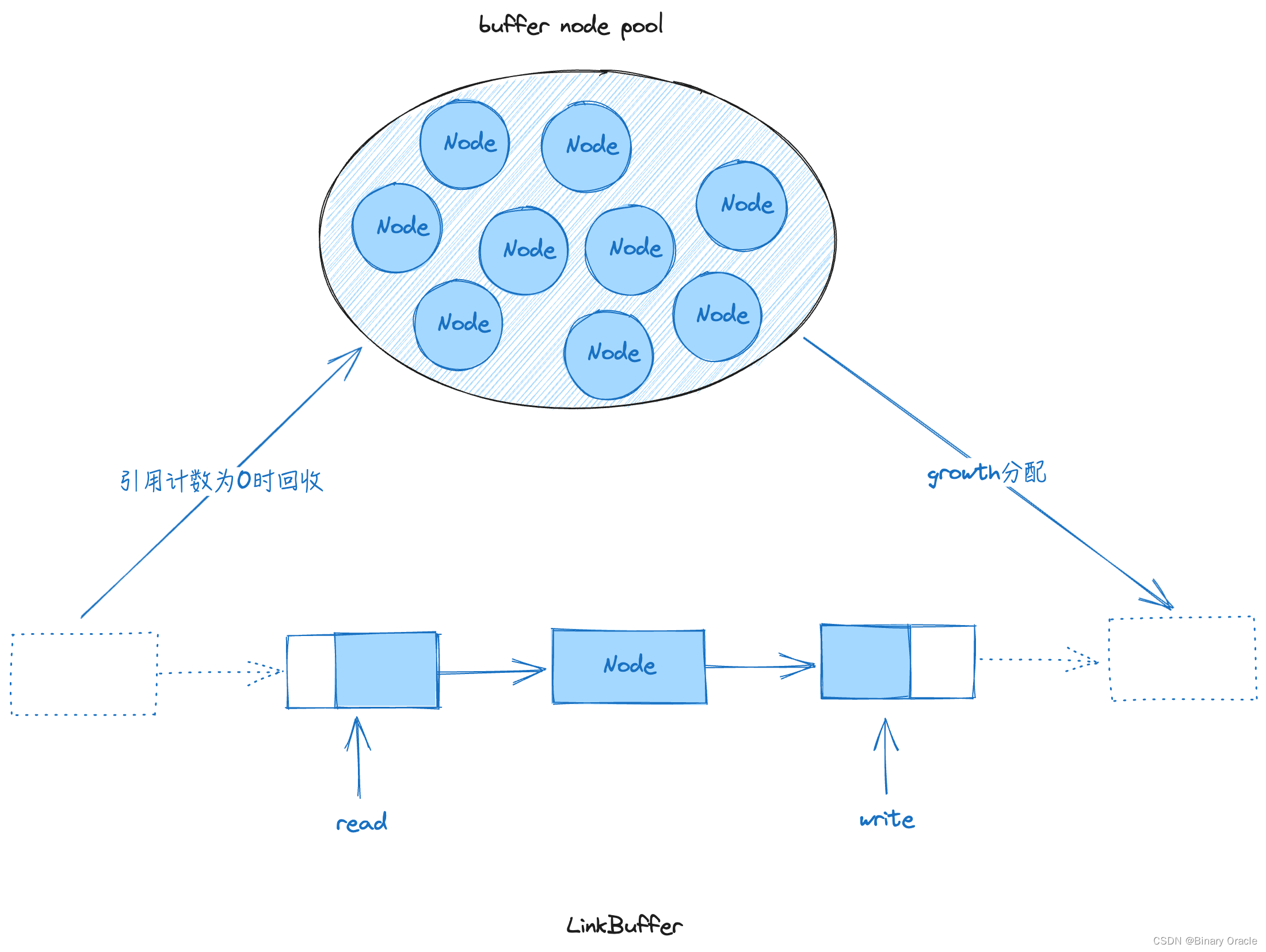
- LinkBuffer 通过将 node 串接成链表的形式,实现逻辑上的整体 buffer 。其中 node 是大小固定的内存块 (默认 4k) 。
- LinkBuffer 拥有读写两个游标 , 从链表头部读数据,链表尾部写数据,由此实现读写并行无锁。
- 对于读操作,由于切片特性,可以灵活读取一个LinkBuffer切片
(如: arr[1:10]), 同时对每个Node都有引用计数(切片多少次就标记多少次) , 当所有的切片均使用完释放后,用完的Node会自动回收到Node内存池。 - 对于写操作,可以直接在链表尾部添加新的Node实现零拷贝扩容,同时支持多个LinkBuffer按顺序拼接,实现zerocopy的buffer写操作
(把一个链表挂接到另一个链表的末尾) - node pool 为预先开辟的node池,为全局所有的LinkBuffer提供node并回收用完的node,减少了分配新内存和系统GC的开销
数据结构
LinkBufferNode
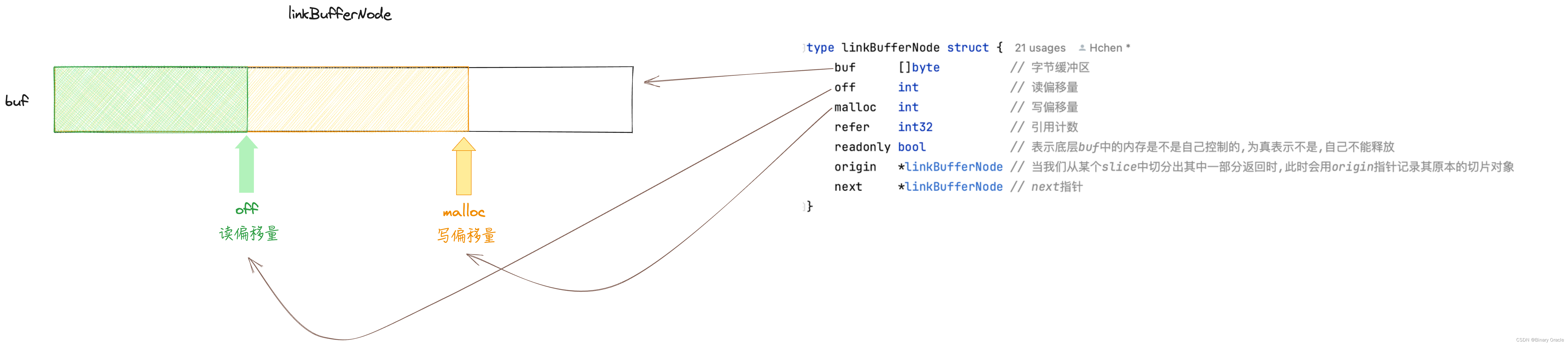
LinkBuffer 中的 LinkBufferNode 节点结构如下:
type linkBufferNode struct {buf []byte // 字节缓冲区off int // 读偏移量malloc int // 写偏移量refer int32 // 引用计数readonly bool // 只读节点,表示底层buf中的内存是不是自己控制的,为真表示不是,自己不能释放origin *linkBufferNode // 当我们从某个slice中切分出其中一部分返回时,此时会用origin指针记录其原本的切片对象next *linkBufferNode // next指针
}
LinkBufferNode的构造函数如下:
var linkedPool = sync.Pool{New: func() interface{} {return &linkBufferNode{refer: 1, // 自带 1 引用}},
}func newLinkBufferNode(size int) *linkBufferNode {// 从缓冲池中拿到一个空闲的node节点var node = linkedPool.Get().(*linkBufferNode)// 重置节点的读写偏移量,引用计数和只读属性node.off, node.malloc, node.refer, node.readonly = 0, 0, 1, false// 节点大小小于等于0,表示为只读节点if size <= 0 {node.readonly = truereturn node}// LinkBufferCap表示每个node节点的最小的大小if size < LinkBufferCap {size = LinkBufferCap}// 分配len(slice)=0 , len(cap)=size大小的切片node.buf = malloc(0, size)return node
}// malloc 底层调用的是字节开源的mache库
func malloc(size, capacity int) []byte {if capacity > mallocMax {return make([]byte, size, capacity)}return mcache.Malloc(size, capacity)
}
LinkBufferNode 中最重要的属性便是buf了,buf 是整个网络读写最终的存储变量,这段内存是单独管理的,且大小不固定,与buf相关的操作有如下几种:
- 创建时,申请了一块内存后,buf := buf[:0] 来保存内存的引用,此时 len(buf)= 0
- Malloc 时,从buf中申请了一段切片 buf[:malloc] , 此处申请的是切片引用,而不是底层实际内存,此时 len(buf) == 0 ,malloc - len(buf) = writeable ;调用方法需要做长度检查,以在Node Malloc时底层数据访问不越界
- Flush 时 , buf = buf[:malloc] ,len(buf) == malloc ,由于底层内存是重用的,且放回时并不会reset底层数组,所以严格依赖 buf = buf[:malloc] 来确保底层内存中的内容的确时我们已经写入到的
- LinkBufferNode 中哪部分数据对外可见也是依赖于len(buf)属性大小的,因为读取数据的时候都是读取buf[:len(buf)]区间范围内的数据
buf 内存分配有以下三种情况:
- 分配至mcache,需要手动free
- 当分配内存大于mallocMax时,直接make创建,被runtime自动管理
- 外部直接赋值,由外部进行管理
buf可读数据范围: readable = buf[off:len(buf)] (off 读指针)
buf可写数据范围: writeable = buf[len(buf):malloc]
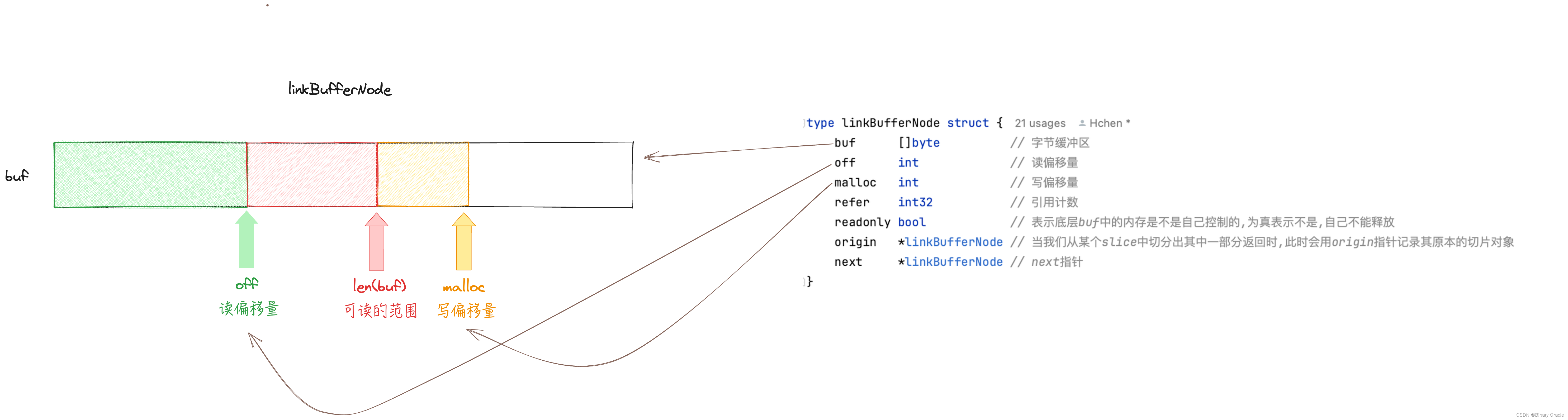
如果node的readonly属性为true,表示底层buf中的内存不是自己控制的,不能去主动释放;Node对象readonly属性为true,有以下两种情况:
- 外部bytes直接写入: WriteBinary
- 该Node属于引用类型 ,有origin节点
API
这里简单看看LinkBufferNode提供的一些常用的API实现:
- Len : 返回剩余可读数据量
// Len 剩余可读数据量
func (node *linkBufferNode) Len() (l int) {return len(node.buf) - node.off
}
- IsEmpty : 返回当前节点可读数据量是否为空
// IsEmpty 当前节点可读数据量是否为空
func (node *linkBufferNode) IsEmpty() (ok bool) {return node.off == len(node.buf)
}
- Reset : 重置节点状态
// Reset 重置节点状态
func (node *linkBufferNode) Reset() {// 如果当前节点拥有的切片是个子切片或者当前切片的引用计数不等于1,说明当前节点不能重置if node.origin != nil || atomic.LoadInt32(&node.refer) != 1 {return}// 重置读写指针node.off, node.malloc = 0, 0// 重置缓冲区len大小,cap不变node.buf = node.buf[:0]return
}
- Next: 往后读取n个字节数据,并移动读指针
// Next 往后读取n个字节数据,并移动读指针
// 调用方需要检查传入的长度n,确保其不超过malloc-off ,如果超过了,可能会读到buf重用产生的脏数据
func (node *linkBufferNode) Next(n int) (p []byte) {off := node.offnode.off += nreturn node.buf[off:node.off]
}
- Peek: 不移动读指针,只是预览数据
// Peek 不移动读指针,只是预览数据
func (node *linkBufferNode) Peek(n int) (p []byte) {return node.buf[node.off : node.off+n]
}
- Malloc: 申请一段内存来写入数据,在没有flush(buf:=buf[:malloc])前,不会读到这段内存
// Malloc 申请一段内存来写入数据,在没有flush(buf:=buf[:malloc])前,不会读到这段内存
// 注意,Node上的Malloc不会真正去申请内存,Node的内存在buf创建时就已经申请好了
func (node *linkBufferNode) Malloc(n int) (buf []byte) {malloc := node.mallocnode.malloc += nreturn node.buf[malloc:node.malloc]
}
- Refer: 返回一个新的Node对象,并设置origin父对象,此处指向的origin是根origin
// Refer 返回一个新的Node对象,并设置origin父对象,此处指向的origin是根origin --> linkBufferNode为两级结构
// 将 [read,read+n]范围的切片切分出来,由一个新的node节点引用,同时增加当前节点的引用计数
func (node *linkBufferNode) Refer(n int) (p *linkBufferNode) {// 创建一个只读节点p = newLinkBufferNode(0)// 当前节点p指向[read,read+n]范围的切片p.buf = node.Next(n)// 如果当前节点本身指向的也是一个子切片,这边不会形成一个树状结构,而是指向根节点if node.origin != nil {p.origin = node.origin} else {p.origin = node}// 增加根节点的引用计数atomic.AddInt32(&p.origin.refer, 1)return p
}
- Release: 如果当前节点不存在其他引用了,重置node各属性,放回节点池等待重用
// Release 如果有原始节点,先释放原始节点
// 如果当前节点不存在其他引用了,重置node各属性,放回节点池等待重用
func (node *linkBufferNode) Release() (err error) {// 如果当前节点指向的是子切片,先释放父切片if node.origin != nil {node.origin.Release()}// release self// 递减根节点引用计数 (计数只会在根节点上递增,所以这里只关心根节点上的递减即可)if atomic.AddInt32(&node.refer, -1) == 0 {// readonly nodes cannot recycle node.buf, other node.buf are recycled to mcache.// 释放根节点占用的buf空间if !node.readonly {free(node.buf)}// 将相关属性设置为nullnode.buf, node.origin, node.next = nil, nil, nil// 将node重新放回节点池中linkedPool.Put(node)}return nil
}
LinkBuffer
LinkBuffer 抽象来看属于一个二维切片,如果使用传统的read/write系统调用,仅支持传入一维切片,需要反复调用才能处理完整个二维切片的数据,所以LinkBuffer这里对外提供readv/writev系统调用,用来一次性传输多个数组的数据:
// writev 包装 writev 系统调用
// writev以顺序iov[0]、iov[1]至iov[iovcnt-1]从各缓冲区中聚集输出数据到fd
func writev(fd int, bs [][]byte, ivs []syscall.Iovec) (n int, err error) {// 将ivs[i].base 指向 bs[i] , 也就是将bs作为写缓冲区数据来源iovLen := iovecs(bs, ivs)if iovLen == 0 {return 0, nil}// 执行writev系统调用,将ivs[i].base指针指向的缓冲区数据写入fd代表的文件中r, _, e := syscall.RawSyscall(syscall.SYS_WRITEV, uintptr(fd), uintptr(unsafe.Pointer(&ivs[0])), uintptr(iovLen))// 清空ivs和bs缓冲区数据resetIovecs(bs, ivs[:iovLen])if e != 0 {return int(r), syscall.Errno(e)}// 返回成功写入的字节数量return int(r), nil
}// readv 包装readv系统调用 , 返回 0 或 nil 表示数据读完了
// readv则将从fd读入的数据按同样的顺序散布到各缓冲区中,readv总是先填满一个缓冲区,然后再填下一个
func readv(fd int, bs [][]byte, ivs []syscall.Iovec) (n int, err error) {// 将ivs[i].base 指向 bs[i] , 也就是将bs作为最终接收数据的缓冲区iovLen := iovecs(bs, ivs)if iovLen == 0 {return 0, nil}// 执行readv系统调用,将数据读取到ivs[i].base指针指向的缓冲区中r, _, e := syscall.RawSyscall(syscall.SYS_READV, uintptr(fd), uintptr(unsafe.Pointer(&ivs[0])), uintptr(iovLen))// 官方代码此时又执行一遍清空缓冲区操作,笔者认为这里有点小问题,也提出了相应的pr// resetIovecs(bs, ivs[:iovLen])if e != 0 {return int(r), syscall.Errno(e)}// 返回成功读取到的字节数量return int(r), nil
}
此处使用到了Linux相关的IO系统调用: Unix/Linux编程:分散输入和集中输出------readv() 、 writev()
关于readv函数实现bug的pr链接:
- fix: 修复执行syscall.SYS_READV系统调用包装函数readv时,读完数据后,又清空缓冲区的bug #297
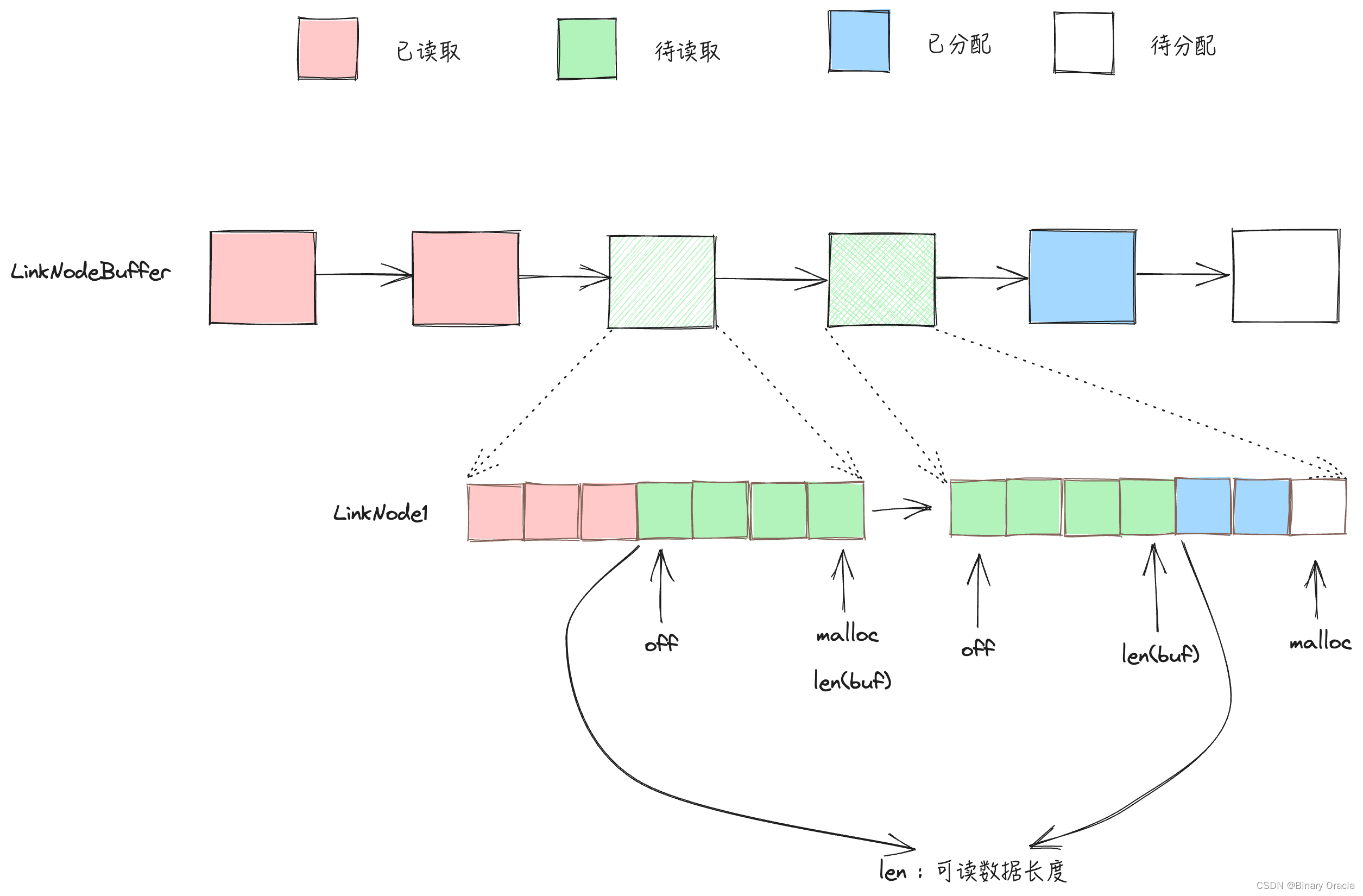
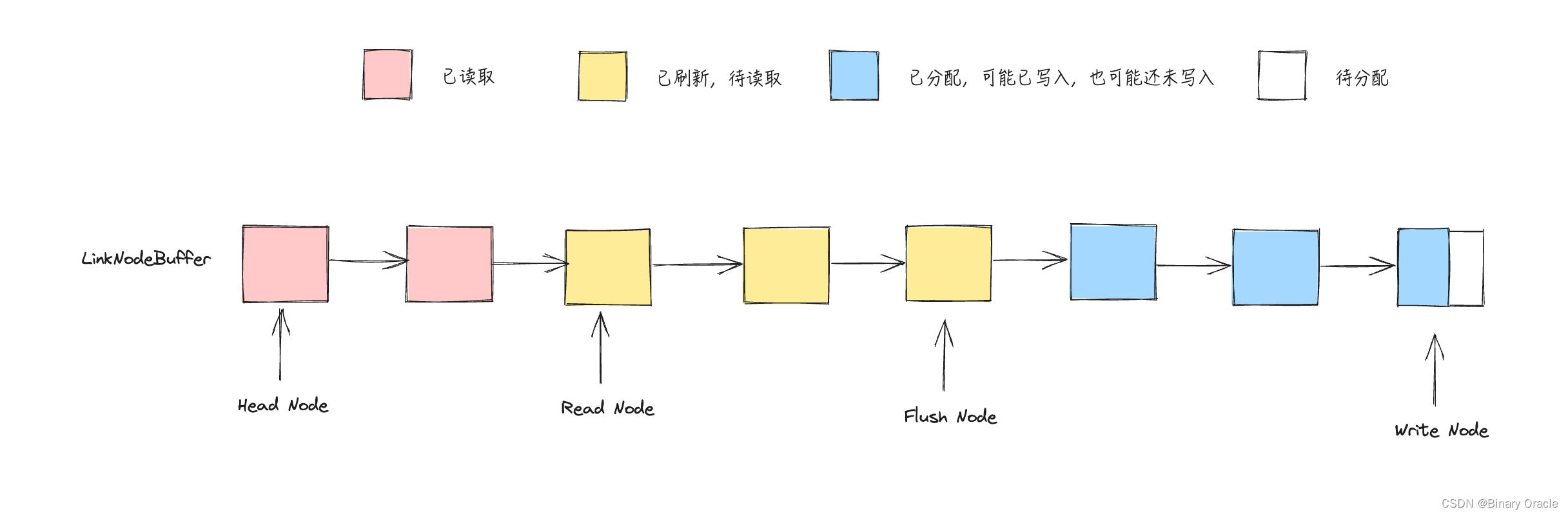
LinkBuffer 具体的数据结构如下所示:
// LinkBuffer implements ReadWriter.
type LinkBuffer struct {length int64 // 可读数据量mallocSize int // 已写数据量head *linkBufferNode // release head 头结点read *linkBufferNode // read head 读指针flush *linkBufferNode // malloc head 写开始指针write *linkBufferNode // malloc tail 写结束指针caches [][]byte // buf allocated by Next when cross-package, which should be freed when release
}
- head -> read 这一段表示可以释放的Node节点范围,因为该范围内的Node节点持有的数据都已经被读取了
- read -> flush 这一段表示已经写入但是还没有读取的Node节点范围
- flush -> write 这一段表示已经创建但是未真正写入的可写空间,因为在没有调用Flush前,这段空间内的数据是不可读的,因此这段空间内buf中的数据是可能出现无效数据的,因为用户可能分配了空间,但是还没有往里面写入数据。
读 API
这里只对Next和Slice方法展开进行讲解,其他读API,大家自行阅读源码学习即可,实现思路大同小异。
Next 函数存在两种实现场景:
- 单节点读取数据,采用的是zero-copy实现
- 跨节点读取数据,会copy出一个一维切片返回,所以不是zero-copy的实现
// Next implements Reader.
func (b *LinkBuffer) Next(n int) (p []byte, err error) {... // 递减总的可读数据量b.recalLen(-n)// 是否需要跨节点读取if b.isSingleNode(n) {// 读取当前read指向节点的可读数据,同时推进当前节点上的read指针return b.read.Next(n), nil}// 跨节点读取var pIdx intif block1k < n && n <= mallocMax {// 要在release的时候释放p = malloc(n, n)b.caches = append(b.caches, p)} else {p = make([]byte, n)}var l intfor ack := n; ack > 0; ack = ack - l {l = b.read.Len()if l >= ack {pIdx += copy(p[pIdx:], b.read.Next(ack))break} else if l > 0 {pIdx += copy(p[pIdx:], b.read.Next(l))}b.read = b.read.next}_ = pIdxreturn p, nil
}const mallocMax = block8k * block1kfunc malloc(size, capacity int) []byte {if capacity > mallocMax {return make([]byte, size, capacity)}return mcache.Malloc(size, capacity)
}// 增加或减少b.length大小
func (b *LinkBuffer) recalLen(delta int) (length int) {return int(atomic.AddInt64(&b.length, int64(delta)))
}
此处必须返回一维切片是因为协议层反序列化时需要组装出定义的结构体字段。
如果都是小读取,那只有小概率会触发到跨节点读取,对于大读取,还是优先考虑Slice;与Next的区别是,Slice会返回一个新的LinkBuffer,无论大小都是zero-copy,缺点是用户需要手动管理Buffer :
func (b *LinkBuffer) Slice(n int) (r Reader, err error) {// 递减剩余可读取数据量b.recalLen(-n)// 创建一个新的LinkBufferp := &LinkBuffer{length: int64(n),}defer func() {p.flush = p.flush.nextp.write = p.flush}()// 如果是单节点读取,那正好zero-copyif b.isSingleNode(n) {// 从 Slice() 返回的 LinkBuffer 是只读的node := b.read.Refer(n)p.head, p.read, p.flush = node, node, nodereturn p, nil}// 如果是跨节点读取// 先基于当前读节点给新 LinkBuffer 赋予第一个头节点var l = b.read.Len()node := b.read.Refer(l)// 读指针前进一个节点b.read = b.read.nextp.head, p.read, p.flush = node, node, nodefor ack := n - l; ack > 0; ack = ack - l {l = b.read.Len()// 表示是新 LinkBuffer 的最后一个 Node// 从当前读节点引用出一个需要长度的 Nodeif l >= ack {p.flush.next = b.read.Refer(ack)p.flush = p.flush.nextbreak} else if l > 0 {// 表示需要创建一个完整大小的 Node,flush 指针前进p.flush.next = b.read.Refer(l)p.flush = p.flush.next}b.read = b.read.next}// b.Release() 只会 release 已读的内容,即返回的 slice 的内容// 由于有引用计数的存在,所以底部内存并不会被回收return p, b.Release()
}
写 API
- Malloc: 预先分配一块内存,这块内存不可读,直到我们调用了Flush
// Malloc 预先分配一块内存,这块内存不可读,直到我们调用了Flush
func (b *LinkBuffer) Malloc(n int) (buf []byte, err error) {if n <= 0 {return}// 累加写入数据量计数b.mallocSize += n// 如果当前节点剩余空间不足,则进行扩容,也就是创建一个新节点挂载到链表尾部b.growth(n)// 分配n大小的切片空间返回return b.write.Malloc(n), nil
}
- MallocAck: 缩容操作,保留malloc api预分配的前n个字节数据,丢弃剩余的数据
// MallocAck 缩容操作,保留malloc api预分配的前n个字节数据,丢弃剩余的数据
func (b *LinkBuffer) MallocAck(n int) (err error) {if n < 0 {return fmt.Errorf("link buffer malloc ack[%d] invalid", n)}// 将已分配数量缩小到nb.mallocSize = n// 从flush节点开始定位n个byte,丢弃剩余byteb.write = b.flushvar l int // l 代表当前节点剩余的已分配数据量for ack := n; ack > 0; ack = ack - l {// 计算当前节点已分配数据量// len(b.write.buf) 表示当前node已经flush的数据量大小l = b.write.malloc - len(b.write.buf)// 如果当前节点已经分配出去的数据量比当前ack大,则丢弃分配的多余空间if l >= ack {b.write.malloc = ack + len(b.write.buf)break}b.write = b.write.next}// 将多分配的空间全部回收for node := b.write.next; node != nil; node = node.next {node.off, node.malloc, node.refer, node.buf = 0, 0, 1, node.buf[:0]}return nil
}
- Flush: 默认认为当前malloc的内容都为有效数据 , 调用该函数前,用户需要确保已经写入了Malloc的所有数据
// Flush 默认认为当前malloc的内容都为有效数据 , 调用该函数前,用户需要确保已经写入了Malloc的所有数据
func (b *LinkBuffer) Flush() (err error) {b.mallocSize = 0// FIXME: The tail node must not be larger than 8KB to prevent Out Of Memory.if cap(b.write.buf) > pagesize {b.write.next = newLinkBufferNode(0)b.write = b.write.next}var n int// 从flush指针指向的节点遍历到write指针指向的节点for node := b.flush; node != b.write.next; node = node.next {// 计算当前节点已分配数据量delta := node.malloc - len(node.buf)if delta > 0 {// 累加已分配数据量计数n += delta// 更新buf的len大小,[0,len]区间代表当前node节点上已经flush的数据范围node.buf = node.buf[:node.malloc]}}// 移动flush指针到当前write指针指向的节点b.flush = b.write// n 代表总的已经malloc出去的数据量,此处让所有数据都对外可见b.recalLen(n)return nil
}
book / bookAck api
- book: 申请最少min大小内存,并存放在p切片内
func (b *LinkBuffer) book(bookSize, maxSize int) (p []byte) {// 计算当前写入节点剩余空间还有多少l := cap(b.write.buf) - b.write.malloc// 没有空间了,那么新创建一个LinkBufferNode , 挂载到链表尾部if l == 0 {l = maxSizeb.write.next = newLinkBufferNode(maxSize)b.write = b.write.next}// 当前节点,剩余空间比当前需要的空间还大if l > bookSize {l = bookSize}// 分配l大小的空间return b.write.Malloc(l)
}
与malloc区别: book 用来支持 readv/writev 这类二维切片参数的API , 此外与Malloc相比也不存在内存浪费的情况。
- bookAck : 确认写入,移动写指针malloc
// bookAck 保留book预留的前n个字符,丢弃多余的book空间
func (b *LinkBuffer) bookAck(n int) (length int, err error) {// 缩小malloc大小b.write.malloc = n + len(b.write.buf)// 更新len(buf) = malloc --> 更新后,数据将可以被读取到// 和mallocAck不同的一点在于,bookAck会更新len(buf)大小,相当于调用了一次flushb.write.buf = b.write.buf[:b.write.malloc]b.flush = b.write// 增加可读数量length = b.recalLen(n)return length, nil
}
小结
本文带领大家详细研究了一下netpoll底层使用的LinkBuffer实现,其中还有诸多细节由于时间关系不能一一到来,这些内容大家可以自行阅读源码进行学习。
LinkBuffer 底层还使用到了字节开源的Mcache和GoPool实现,感兴趣的同学可以去了解一下;如果本篇文章有讲的错误之处,也欢迎在评论区指出或私信与我讨论。
相关文章:
字节开源的netPoll底层LinkBuffer设计与实现
字节开源的netPoll底层LinkBuffer设计与实现 为什么需要LinkBuffer介绍设计思路数据结构LinkBufferNodeAPI LinkBuffer读 API写 APIbook / bookAck api 小结 本文基于字节开源的NetPoll版本进行讲解,对应官方文档链接为: Netpoll对应官方文档链接 netPoll底层有一个…...

《点云进阶》专栏文章目录
目录 一、PCL进阶篇* 二、Open3D进阶篇 一、PCL进阶篇 * PCL 最小二乘拟合二维直线PCL 最小二乘拟合空间直线PCL 计算点云的倒角距离(Chamfer Distance)PCL 点云配准精度评价——点到面的均方根误差PCL 可视化八叉树PCL 计算Hausdorff距离PCL 从变换矩…...
)
二分查找算法-查找最接近的元素Python实现(题目来源dotcpp: 2926)
题目描述 在一个非降序列中,查找与给定值最接近的元素。 输入格式 第一行包含一个整数n,为非降序列长度。1 < n < 100000。 第二行包含n个整数,为非降序列各元素。所有元素的大小均在0-1,000,000,000之间。 第三行包含一个整数m&#x…...

debian11,debian 如何删除虚拟内存,交换分区
1.以管理员身份登录系统 2.输入以下命令以删除虚拟内存,该命令将关闭当前正在使用的虚拟内存。 sudo swapoff -a 3.输入以下命令以永久删除虚拟内存(硬盘内存文件): sudo rm /swapfile 4.重启系统 总结:以上步骤将删除 Debian 11 中的虚拟内存。请注意…...

智能优化算法应用:基于人工大猩猩部队算法无线传感器网络(WSN)覆盖优化 - 附代码
智能优化算法应用:基于人工大猩猩部队算法无线传感器网络(WSN)覆盖优化 - 附代码 文章目录 智能优化算法应用:基于人工大猩猩部队算法无线传感器网络(WSN)覆盖优化 - 附代码1.无线传感网络节点模型2.覆盖数学模型及分析3.人工大猩猩部队算法4.实验参数设…...

鼎捷受邀出席“中国制造业产品创新数字化国际峰会”,共话工业软件创新发展
11月30日, 由e-works数字化企业网、四川省智能制造创新中心、重庆制信信息技术服务有限公司主办的第十九届中国制造业产品创新数字化国际峰会在四川成都盛大开幕。 作为制造业研发信息化领域规模、影响力兼具的专业论坛,本届峰会以“构建基于数字底座的…...
大话数据结构-查找-多路查找树
注:本文同步发布于稀土掘金。 7 多路查找树 多路查找树(multi-way search tree),其每个结点的孩子可以多于两个,且每一个结点处可以存储多个元素。由于它是查找树,所有元素之间存在某种特定的排序关系。 …...
unity 2d 入门 飞翔小鸟 飞翔脚本(五)
新建c#脚本 using System.Collections; using System.Collections.Generic; using UnityEngine;public class Fly : MonoBehaviour {//获取小鸟(刚体)private Rigidbody2D bird;//速度public float speed;// Start is called before the first frame up…...
Linux系统调试课:I2C tools调试工具
文章目录 一、如何使用I2C tools测试I2C外设1、I2C tools概述: 2、下载I2C tools源码:3、编译I2C tools源码: 4、i2cdetect 5、i2cget 6、i2cdump...
uniapp中解决swiper高度自适应内容高度
起因:uniapp中swiper组件swiper 标签存在默认高度是 height: 150px ;高度无法实现由内容撑开,在默认情况下,swiper盒子高度显示总是 150px 解决办法思路: 动态设置swiper盒子的高度,故需要获取swiper-item盒…...
Contrast and Generation Make BART a Good Dialogue Emotion Recognizer
摘要 在对话系统中,具有相似语义的话语在不同的语境下可能具有不同的情感。因此,用说话者依赖来建模长期情境情绪关系在对话情绪识别中起着至关重要的作用。同时,区分不同的情绪类别也不是很简单的,因为它们通常具有语义上相似的…...
图的深度优先搜索(数据结构实训)
题目: 图的深度优先搜索 描述: 图的深度优先搜索类似于树的先根遍历,是树的先根遍历的推广。即从某个结点开始,先访问该结点,然后深度访问该结点的第一棵子树,依次为第二顶子树。如此进行下去,直…...

VUEX使用总结
1、Store 使用 文件内容大概就是这三个。通俗来讲actions负责向后端获取数据的,内部执行异步操作分发 Action,调用commit提交一个 mutation。 mutations通过Action提交commit的数据进行提交荷载,使state有数据。 vuex的数据是共享的…...

指定分隔符对字符串进行分割 numpy.char.split()
【小白从小学Python、C、Java】 【计算机等考500强证书考研】 【Python-数据分析】 指定分隔符对字符串进行分割 numpy.char.split() 选择题 请问下列程序运行的的结果是: import numpy as np print("【执行】np.char.split(I.Love.China, sep .)") p…...
Android12蓝牙框架
参考: https://evilpan.com/2021/07/11/android-bt/ https://source.android.com/docs/core/connect/bluetooth?hlzh-cn https://developer.android.com/guide/topics/connectivity/bluetooth?hlzh-cn https://developer.android.com/guide/components/intents-fi…...

python文件docx转pdf
centos部署的django项目,使用libreoffice做文件转换,官网给环境安装好libreoffice后,可使用命令行来进行转化 还可转换其他的各种格式,本文只做了pdf转换 import subprocess import os def convert_to_pdf(input_file, o…...

9.基于SpringBoot3+I18N实现国际化
1. 新建资源文件 在resources目录下新建目录i18n, 然后 新建messages_en.properties文件 user.login.erroraccount or password error!新建messages_zh_CN.properties文件 user.login.error帐户或密码错误!2. 新建LocaleConfig.java文件 Configurati…...
27. 深度学习进阶 - 为什么RNN
文章目录 一个柯基的例子为什么RNN or CNN Hi,你好。我是茶桁。 这节课开始,我们将会讲一个比较重要的一种神经网络,它对应了咱们整个生活中很多类型的一种问题结构,它就是咱们的RNN网络。 咱们首先回忆一下,上节课咱…...

谈一谈柔性数组
文章目录 什么是柔性数组柔性数组有什么用 什么是柔性数组 柔性数组是一种动态可变的数组,也许你从来没有听说过这个概念,但是它确实是存在的,是在C99标准底下支持的一种语法。想要使用柔性数组需要满足3个条件: 柔性数组只能存在…...
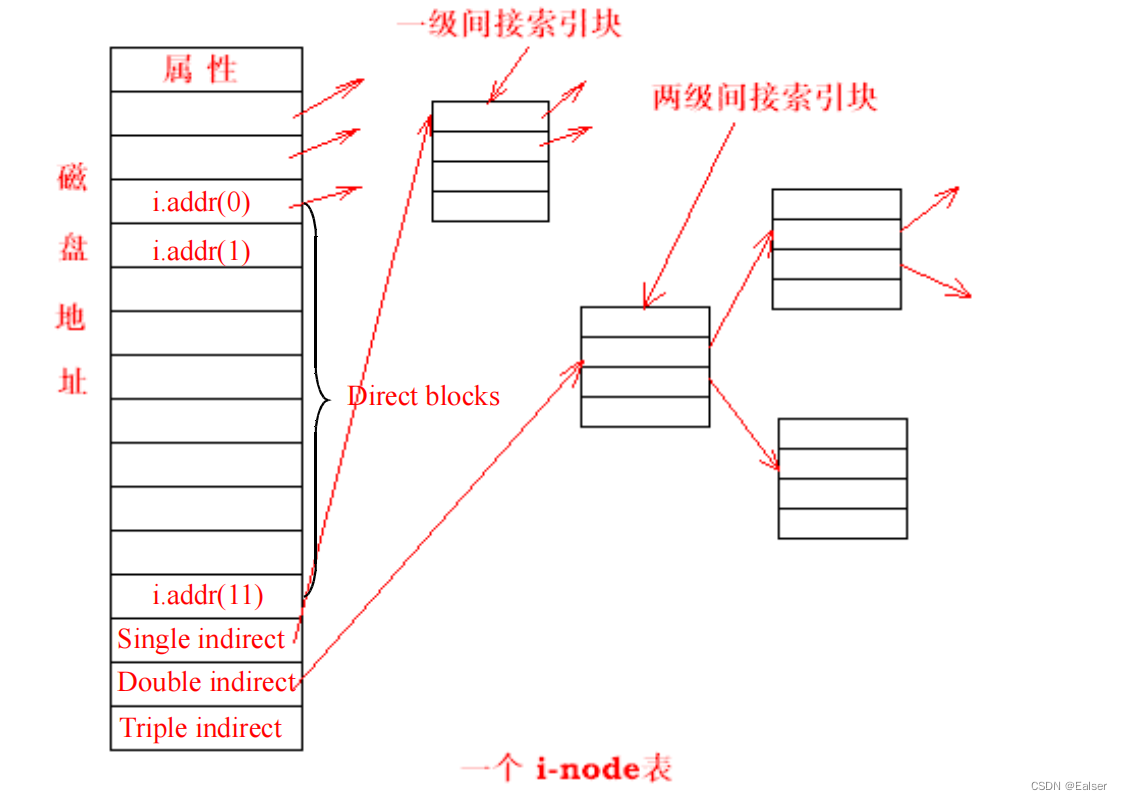
<Linux>(极简关键、省时省力)《Linux操作系统原理分析之Linux文件管理(1)》(25)
《Linux操作系统原理分析之Linux文件管理(1)》(25) 8 Linux文件管理8.1 Linux 文件系统概述8.2 EXT2 文件系统8.2.1 EXT2 文件系统的构造8.2.2 EXT2 超级块(super block)8.2.3 组描述符8.2.4 块位图 8.3 EX…...

XML Group端口详解
在XML数据映射过程中,经常需要对数据进行分组聚合操作。例如,当处理包含多个物料明细的XML文件时,可能需要将相同物料号的明细归为一组,或对相同物料号的数量进行求和计算。传统实现方式通常需要编写脚本代码,增加了开…...

【大模型RAG】拍照搜题技术架构速览:三层管道、两级检索、兜底大模型
摘要 拍照搜题系统采用“三层管道(多模态 OCR → 语义检索 → 答案渲染)、两级检索(倒排 BM25 向量 HNSW)并以大语言模型兜底”的整体框架: 多模态 OCR 层 将题目图片经过超分、去噪、倾斜校正后,分别用…...

挑战杯推荐项目
“人工智能”创意赛 - 智能艺术创作助手:借助大模型技术,开发能根据用户输入的主题、风格等要求,生成绘画、音乐、文学作品等多种形式艺术创作灵感或初稿的应用,帮助艺术家和创意爱好者激发创意、提高创作效率。 - 个性化梦境…...

理解 MCP 工作流:使用 Ollama 和 LangChain 构建本地 MCP 客户端
🌟 什么是 MCP? 模型控制协议 (MCP) 是一种创新的协议,旨在无缝连接 AI 模型与应用程序。 MCP 是一个开源协议,它标准化了我们的 LLM 应用程序连接所需工具和数据源并与之协作的方式。 可以把它想象成你的 AI 模型 和想要使用它…...

Python爬虫实战:研究feedparser库相关技术
1. 引言 1.1 研究背景与意义 在当今信息爆炸的时代,互联网上存在着海量的信息资源。RSS(Really Simple Syndication)作为一种标准化的信息聚合技术,被广泛用于网站内容的发布和订阅。通过 RSS,用户可以方便地获取网站更新的内容,而无需频繁访问各个网站。 然而,互联网…...

最新SpringBoot+SpringCloud+Nacos微服务框架分享
文章目录 前言一、服务规划二、架构核心1.cloud的pom2.gateway的异常handler3.gateway的filter4、admin的pom5、admin的登录核心 三、code-helper分享总结 前言 最近有个活蛮赶的,根据Excel列的需求预估的工时直接打骨折,不要问我为什么,主要…...

成都鼎讯硬核科技!雷达目标与干扰模拟器,以卓越性能制胜电磁频谱战
在现代战争中,电磁频谱已成为继陆、海、空、天之后的 “第五维战场”,雷达作为电磁频谱领域的关键装备,其干扰与抗干扰能力的较量,直接影响着战争的胜负走向。由成都鼎讯科技匠心打造的雷达目标与干扰模拟器,凭借数字射…...

rnn判断string中第一次出现a的下标
# coding:utf8 import torch import torch.nn as nn import numpy as np import random import json""" 基于pytorch的网络编写 实现一个RNN网络完成多分类任务 判断字符 a 第一次出现在字符串中的位置 """class TorchModel(nn.Module):def __in…...

Web后端基础(基础知识)
BS架构:Browser/Server,浏览器/服务器架构模式。客户端只需要浏览器,应用程序的逻辑和数据都存储在服务端。 优点:维护方便缺点:体验一般 CS架构:Client/Server,客户端/服务器架构模式。需要单独…...

c++第七天 继承与派生2
这一篇文章主要内容是 派生类构造函数与析构函数 在派生类中重写基类成员 以及多继承 第一部分:派生类构造函数与析构函数 当创建一个派生类对象时,基类成员是如何初始化的? 1.当派生类对象创建的时候,基类成员的初始化顺序 …...