ruoyi+Hadoop+hbase实现大数据存储查询
前言
有个现实的需求,数据量可能在100亿条左右。现有的数据库是SQL Server,随着采集的数据不断的填充,查询的效率越来越慢(现有的SQL Server查询已经需要数十秒钟的时间),看看有没有优化的方案。
考虑过SQL Server加索引、分区表、分库分表等方案,但数据量增长太快,还是很快就会遇到瓶颈,因此需要更优化的技术。在众多的NOSQL和大数据技术之下,针对此场景,主要考虑了两种方案:
-
MongoDB:json文档型数据库,可以通过集群拓展。但更适合列比较复杂的场景快速查询。
-
Hadoop:大数据领域的瑞士军刀,周边有很多相配套的工具可以使用,后期拓展性较强。
因为此需求只是简单的根据编码找到对应的卷号,因此最终选择Hadoop实现。
部署Hadoop
直接去官方下载,https://hadoop.apache.org/。
要注意版本的问题,版本不匹配会带来很多麻烦。我这里选择的是hadoop 3.3.4的版本。
步骤:
- 找到hadoop对应版本的winutils.exe、hadoop.dll文件
复制hadoop 3.3.4版本对应的winutils.exe和hadoop.dll文件到hadoop的bin文件夹下面。同步复制这两个文件,到C:\Windows\System32下面。
这两个文件可以去github上面搜索,一定要注意跟你的hadoop版本一致,否则不通过。
- 文件配置(下面的配置文件都在 hadoop 3.3.4/etc/hadoop 文件夹内)
a). hadoop-env.cmd文件配置
set JAVA_HOME=C:\Users\Administrator\.jdks\corretto-11.0.21
注意:这里的JAVA_HOME是指向的openjdk(开源)的版本,oracle的jdk用不起来。必须要安装openjdk。
b). core-site.xml
<configuration><property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property>
</configuration>
c). hdfs-site.xml
<configuration><property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/hadoop-3.3.4/data/namenode</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/hadoop-3.3.4/data/datanode</value> </property>
</configuration>
d). yarn-site.xml
<configuration><property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.auservices.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property>
</configuration>
- 配置环境变量

再添加到Path,%HADOOP_HOME%\bin
可以在控制台输入:hadoop version,验证是否安装配置正确

最后在控制台输入:start-all.cmd ,启动Hadoop。没有错误信息,表示Hadoop启动成功。

部署Hbase
安装Hbase可以到官网下载:https://hbase.apache.org/。
同样要非常关注版本的问题,因为我上面选择的Hadoop是3.3.4,与之配套的Hbase的版本是2.5.5。
步骤:
-
将之前下载的winutils.exe和hadoop.dll文件拷贝到 hbase的bin目录下,比如我的:E:\hbase-2.5.5\bin。
-
文件配置
在hbase的conf目录下,打开hbase-site.xml文件,添加如下内容:
<configuration><property><name>hbase.rootdir</name><value>file:///E:/hbase-2.5.5/root</value></property><property><name>hbase.cluster.distributed</name><value>false</value></property><property><name>hbase.zookeeper.quorum</name><value>127.0.0.1</value></property><property><name>hbase.tmp.dir</name><value>./tmp</value></property><property><name>hbase.unsafe.stream.capability.enforce</name><value>false</value></property>
</configuration>
按照上述的配置说明,在hbase目录下,添加root和tmp文件夹。
3.配置环境变量(此处省略,参考上面的hadoop的截图)
找到hbase的bin目录下的start-hbase.cmd文件,双击启动。
hbase启动完成后的界面:

基于若依进行二次开发
直接引用ruoyi的项目,在里面添加功能,当然首先需要导入相应的jar包(这些jar包在hadoop和hbase里面都有,直接引用即可)。

当然下面还有引用的jar包,这里就不截图了,供参考。

该项目基于SpringBoot框架,实现了基于HDFS、hbase的基础功能。
控制器代码如下:
package com.ruoyi.web.controller.roll;import com.ruoyi.common.core.controller.BaseController;
import com.ruoyi.common.core.domain.R;
import com.ruoyi.common.core.domain.entity.SysRole;
import com.ruoyi.common.core.page.TableDataInfo;
import com.ruoyi.common.roll.RollEntity;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.client.coprocessor.AggregationClient;
import org.apache.hadoop.hbase.client.coprocessor.LongColumnInterpreter;
import org.apache.hadoop.hbase.filter.*;
import org.apache.shiro.authz.annotation.RequiresPermissions;
import org.springframework.stereotype.Controller;
import org.springframework.util.StopWatch;
import org.springframework.web.bind.annotation.*;import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.ByteArrayOutputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.FsUrlStreamHandlerFactory;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.CompareOperator;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.MasterNotRunningException;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.ZooKeeperConnectionException;
import org.apache.hadoop.hbase.exceptions.DeserializationException;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.mapreduce.Job;@Controller
@RequestMapping("/roll")
public class RollController extends BaseController {private String prefix = "/roll";/*** 新增角色*/@GetMapping("/add")public String add() {
// long count = rowCountByCoprocessor("mytb");
// System.out.println("总记录数->>>"+count + "");return prefix + "/add";}@PostMapping("/list")@ResponseBodypublic TableDataInfo list(String inputEPC) {
// startPage();
// List<SysRole> list = roleService.selectRoleList(role);//String epc = "E280117020000333BF040B34";//String epc = "E280119120006618A51D032D"; //查询的EPCString epc = inputEPC;String tableName = "mytb";String columnFamily = "mycf";// create(tableName, columnFamily);
// insert(tableName,columnFamily);long startTime = System.currentTimeMillis();//E280119120006BEEA4E5032String reVal = query(tableName, columnFamily, epc);long endTime = System.currentTimeMillis();System.out.println("卷号查询时间为:" + (endTime - startTime) + "ms");RollEntity model = new RollEntity();model.epc = epc;model.rollName = reVal;model.searchTime = (endTime - startTime) + "ms";List<RollEntity> list = new ArrayList<>();list.add(model);return getDataTable(list);}// 创建表public static void create(String tableName, String columnFamily) {Configuration conf = HBaseConfiguration.create();conf.set("hbase.rootdir", "hdfs://localhost:9000/hbase");conf.set("hbase.zookeeper.quorum", "localhost");try {Connection conn = ConnectionFactory.createConnection(conf);if (conn.getAdmin().tableExists(TableName.valueOf(tableName))) {System.err.println("Table exists!");} else {HTableDescriptor tableDesc = new HTableDescriptor(TableName.valueOf(tableName));try {tableDesc.addFamily(new HColumnDescriptor(columnFamily));conn.getAdmin().createTable(tableDesc);System.err.println("Create Table SUCCESS!");} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();}}} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();}}// 插入数据public static void insert(String tableName, String columnFamily) {Configuration conf = HBaseConfiguration.create();conf.set("hbase.rootdir", "hdfs://localhost:9000/hbase");conf.set("hbase.zookeeper.quorum", "localhost");try {Connection conn = ConnectionFactory.createConnection(conf);TableName tn = TableName.valueOf(tableName);Table table = conn.getTable(tn);try {// for (int i = 17742000; i <= 100000000; i++) {
// Put put = new Put(Bytes.toBytes("row" + i));
// put.addColumn(Bytes.toBytes(columnFamily), Bytes.toBytes("code"),
// Bytes.toBytes("E280119120006BEEA4E5032" + i));
// table.put(put);
// }// Put put = new Put(Bytes.toBytes("E280119120006618A51D032D"));
// put.addColumn(Bytes.toBytes(columnFamily), Bytes.toBytes("code"),
// Bytes.toBytes("CQ-230308009"));
// table.put(put);Put put = new Put(Bytes.toBytes("E280117020000333BF040B34"));put.addColumn(Bytes.toBytes(columnFamily), Bytes.toBytes("code"),Bytes.toBytes("CQ-230309002"));table.put(put);table.close();// 释放资源System.err.println("record insert SUCCESS!");} catch (Exception e) {// TODO Auto-generated catch blocke.printStackTrace();}} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();}}// 查询public static String query(String tableName, String columnFamily, String rowName) {String reVal = "";Configuration conf = HBaseConfiguration.create();conf.set("hbase.rootdir", "hdfs://localhost:9000/hbase");conf.set("hbase.zookeeper.quorum", "localhost");try {Connection conn = ConnectionFactory.createConnection(conf);TableName tn = TableName.valueOf(tableName);Table table = conn.getTable(tn);try {Get get = new Get(rowName.getBytes());Result r = table.get(get);for (Cell cell : r.rawCells()) {String family = new String(CellUtil.cloneFamily(cell));String qualifier = new String(CellUtil.cloneQualifier(cell));String value = new String(CellUtil.cloneValue(cell));System.out.println("列:" + family + ":" + qualifier + " 值:" + value);reVal = value;break;}} catch (Exception e) {// TODO Auto-generated catch blocke.printStackTrace();} finally {conn.close();}} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();}return reVal;}//过滤查询public static void queryFilter(String tableName, String columnFamily, String rowName, String value) {Configuration conf = HBaseConfiguration.create();conf.set("hbase.rootdir", "hdfs://localhost:9000/hbase");conf.set("hbase.zookeeper.quorum", "localhost");try {Connection conn = ConnectionFactory.createConnection(conf);TableName tn = TableName.valueOf(tableName);Table table = conn.getTable(tn);try {Scan scan = new Scan();Filter filter = new ValueFilter(CompareOperator.EQUAL, new BinaryComparator(Bytes.toBytes(value)));scan.setFilter(filter);ResultScanner rs = table.getScanner(scan);for (Result res : rs) {System.out.println(res);}} catch (Exception e) {// TODO Auto-generated catch blocke.printStackTrace();}} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();}}//读取HDFS文件private static void readHDFSFileContents() {InputStream is = null;OutputStream os = null;BufferedInputStream bufferInput = null;BufferedOutputStream bufferOutput = null;try {is = new URL("hdfs://127.0.0.1:9000/myHadoop/1.txt").openStream();bufferInput = new BufferedInputStream(is);// IOUtils.copyBytes(is, os, 4096,false);byte[] contents = new byte[1024];int bytesRead = 0;String strFileContents = "";while ((bytesRead = is.read(contents)) != -1) {strFileContents += new String(contents, 0, bytesRead);}System.out.println(strFileContents);} catch (MalformedURLException e) {// TODO Auto-generated catch blocke.printStackTrace();} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();} finally {// IOUtils.closeStream(is);}}//创建HDFS目录private static void createHDFSDirectory() {// TODO Auto-generated method stubtry {Configuration conf = new Configuration();conf.set("fs.defaultFS", "hdfs://127.0.0.1:9000");FileSystem fs = FileSystem.get(conf);boolean result = fs.mkdirs(new Path("/myHadoop"));System.out.println(result);} catch (Exception e) {e.printStackTrace();}}//查询Hbase有多少条记录public long rowCountByCoprocessor(String tablename){long count = 0;try {Configuration conf = HBaseConfiguration.create();conf.set("hbase.rootdir", "hdfs://localhost:9000/hbase");conf.set("hbase.zookeeper.quorum", "localhost");Connection connection = ConnectionFactory.createConnection(conf);//提前创建connection和confAdmin admin = connection.getAdmin();//admin.enableTable(TableName.valueOf("mytb"));TableName name=TableName.valueOf(tablename);//先disable表,添加协处理器后再enable表//admin.disableTable(name);HTableDescriptor descriptor = new HTableDescriptor(name); //admin.getTableDescriptor(name);//descriptor.setReadOnly(false);String coprocessorClass = "org.apache.hadoop.hbase.coprocessor.AggregateImplementation";if (! descriptor.hasCoprocessor(coprocessorClass)) {descriptor.addCoprocessor(coprocessorClass);}//admin.modifyTable(name, descriptor);//admin.enableTable(name);//计时StopWatch stopWatch = new StopWatch();stopWatch.start();Scan scan = new Scan();AggregationClient aggregationClient = new AggregationClient(conf);//System.out.println("RowCount: " + aggregationClient.rowCount(name, new LongColumnInterpreter(), scan));count = aggregationClient.rowCount(name, new LongColumnInterpreter(), scan);stopWatch.stop();System.out.println("统计耗时:" +stopWatch.getTotalTimeMillis());connection.close();} catch (Throwable e) {e.printStackTrace();}return count;}
}
最终效果

相关文章:
ruoyi+Hadoop+hbase实现大数据存储查询
前言 有个现实的需求,数据量可能在100亿条左右。现有的数据库是SQL Server,随着采集的数据不断的填充,查询的效率越来越慢(现有的SQL Server查询已经需要数十秒钟的时间),看看有没有优化的方案。 考虑过S…...
Word 在页眉或页脚中设置背景颜色
目录预览 一、问题描述二、解决方案三、参考链接 一、问题描述 如何在word的页眉页脚中设置背景色? 二、解决方案 打开 Word 文档并进入页眉或页脚视图。在 Word 2016 及更高版本中,你可以通过在“插入”选项卡中单击“页眉”或“页脚”按钮来进入或者…...

python获取js data.now同款时间戳
import requestsimport time from datetime import datetimecu_t datetime.now() se cu_t.timestamp()*1000 se int(se) print(se)#cur_time time.time()*1000 #seconds int(cur_time) #print(seconds)...
线上超市小程序可以做什么活动_提升用户参与度与购物体验
标题:线上超市小程序:精心策划活动,提升用户参与度与购物体验 一、引言 随着移动互联网的普及,线上购物已经成为人们日常生活的一部分。线上超市作为线上购物的重要组成部分,以其便捷、快速、丰富的商品种类和个性化…...
旺店通:API无代码开发的集成解决方案,连接电商平台、CRM和客服系统
集成电商生态:旺店通的核心优势 在数字化转型的浪潮中,旺店通旗舰版奇门以其无代码开发的集成解决方案,正成为电商领域的关键变革者。商家们通过旺店通可以轻松实现与电商平台、CRM系统和客服系统的连接,无需深入了解复杂的API开…...
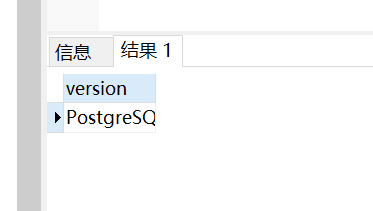
命令查询pg 数据库版本,并且分析结果行各代表什么意思
目录 1 问题2 实现 1 问题 命令查询pg 数据库版本,并且分析结果行各代表什么意思 2 实现 SELECT version(); PostgreSQL 11.7 (Debian 11.7-2.pgdg1001) on x86_64-pc-linux-gnu, compiled by gcc (Debian 8.3.0-6) 8.3.0, 64-bit这是一条关于 PostgreSQL 数据库…...
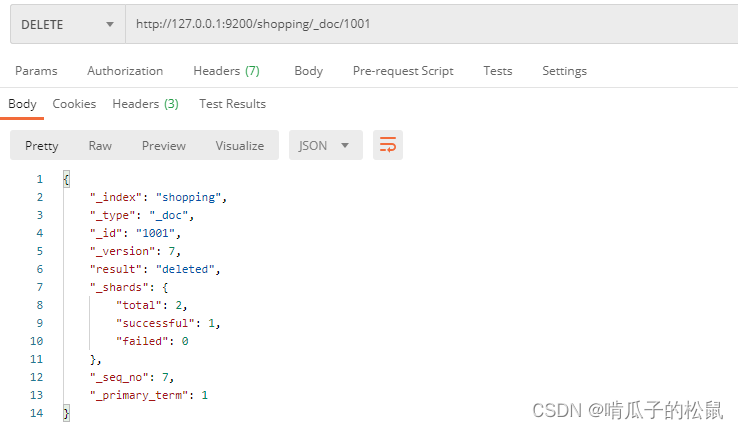
Elaticsearch 学习笔记
文章目录 Elaticsearch 学习笔记一、什么是 Elaticsearch ?二、Elaticsearch 安装1 es 安装2 问题解决3 数据格式 三、索引操作1 PUT 请求:在postman中,向 ES 服务器发 PUT 请求(PUT请求相当于创建的意思)2 GET 请求&a…...
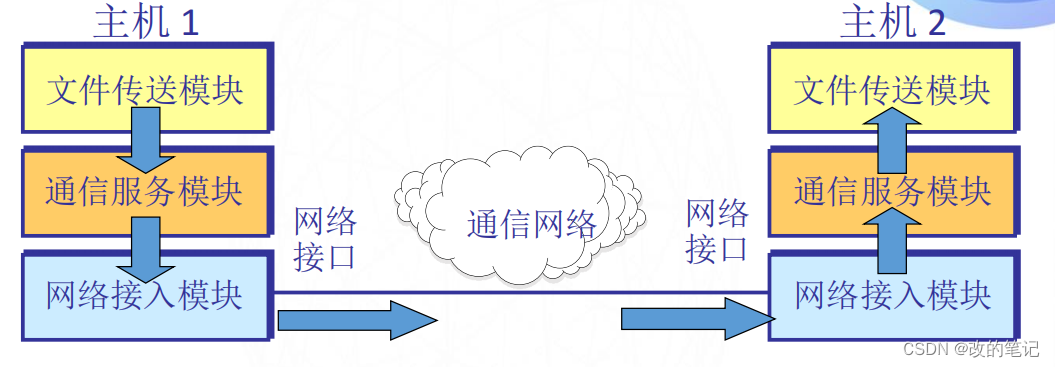
计算机网络体系的形成
目录 1、开放系统互连参考模型OSI/RM 2、两种国际标准 3、协议与划分层次 4、网络协议的三要素 5、划分层次 (1)文件发送模块使两个主机交换文件 (2)通信服务模块 (3)接入网络模块 6、分层带来的好…...
:Pytorch 基础)
PyTorch 基础篇(1):Pytorch 基础
Pytorch 学习开始 入门的材料来自两个地方: 第一个是官网教程:WELCOME TO PYTORCH TUTORIALS,特别是官网的六十分钟入门教程 DEEP LEARNING WITH PYTORCH: A 60 MINUTE BLITZ。 第二个是韩国大神 Yunjey Choi 的 Repo:pytorch-t…...

掌握Selenium4:详解各种定位方式
Selenium4中有多种元素定位方式,主要包括以下几种: 通过ID属性定位:根据元素的id属性进行定位。通过name属性定位:当元素没有id属性而有name属性时,可以使用name属性进行元素定位。通过class name定位:可以…...

go-fastfds部署心得
我是windows系统安装 Docker Desktop部署 docker run --name go-fastdfs(任意的一个名称) --privilegedtrue -t -p 3666:8080 -v /data/fasttdfs_data:/data -e GO_FASTDFS_DIR/data sjqzhang/go-fastdfs:lastest docker run:该命令用于运…...
Python第三次练习
Python 一、如何判断一个字符串是否是另一个字符串的子串二、如何验证一个字符串中的每一个字符均在另一个字符串中出现三、如何判定一个字符串中既有数字又有字母四、做一个注册登录系统 一、如何判断一个字符串是否是另一个字符串的子串 实现代码: string1 inp…...

从Java8升级到Java17,特色优化点
从Java8升级到Java17,特色优化点 一、局部变量类型推断二、switch表达式三、文本块四、Records五、模式匹配instanceof六、密封类七、NullPointerException 从Java 8 到 Java 20,Java 已经走过了漫长的道路,自 Java 8 以来,Java 生…...

js实现富文本
当涉及到使用 JavaScript 实现富文本时,一种常见的方法是使用一些现成的富文本编辑器库,比如: Quill:一个功能强大、易于集成的富文本编辑器,支持自定义样式和格式,提供丰富的插件和API。 TinyMCE…...

每日OJ题_算法_双指针②_力扣1089. 复写零
目录 力扣1089. 复写零 解析代码 力扣1089. 复写零 1089. 复写零 - 力扣(LeetCode) 难度 简单 给你一个长度固定的整数数组 arr ,请你将该数组中出现的每个零都复写一遍,并将其余的元素向右平移。 注意:请不要在…...
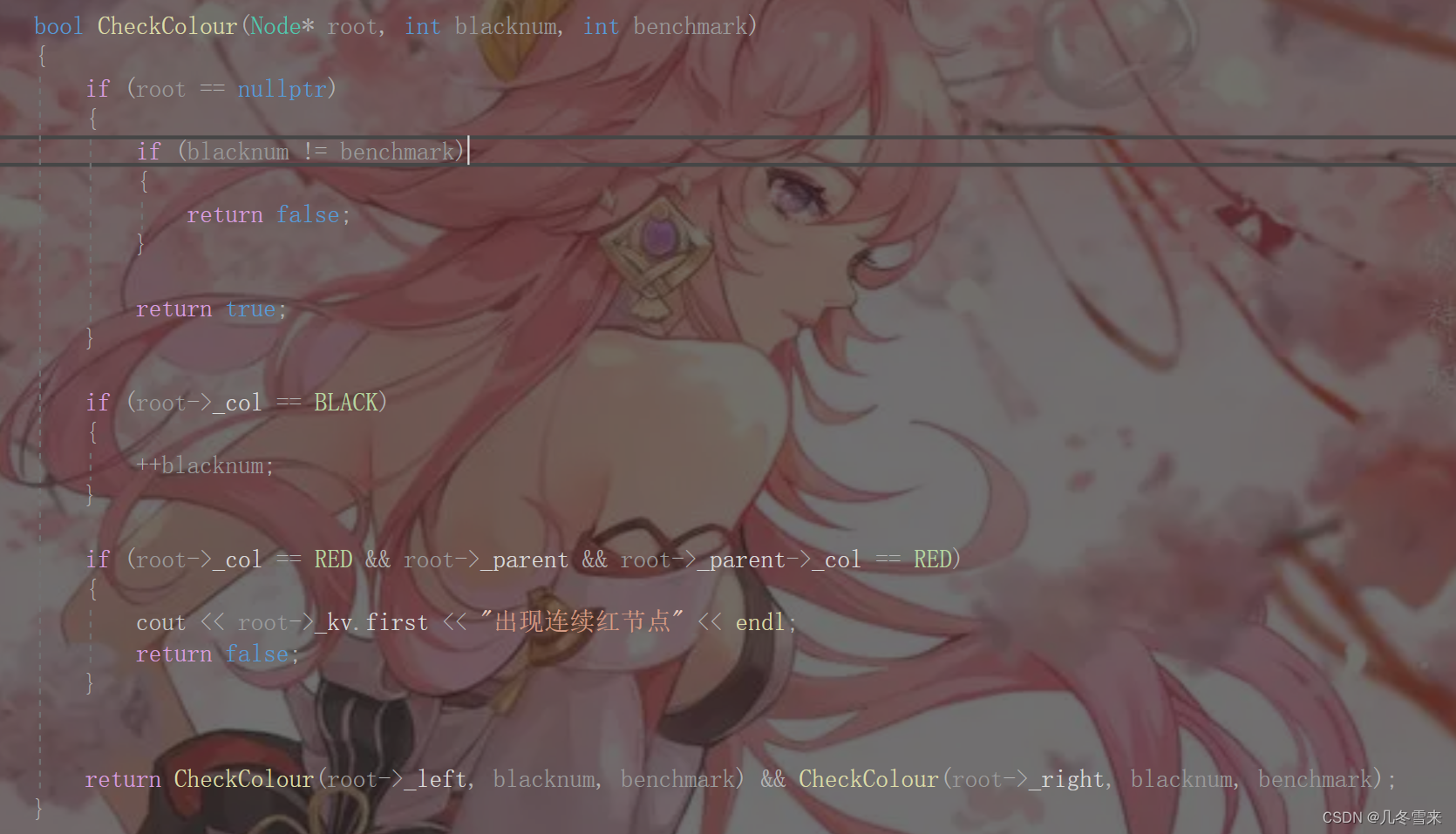
C++——红黑树
作者:几冬雪来 时间:2023年12月7日 内容:C——红黑树讲解 目录 前言: 红黑树的概念: 红黑树的性质: 红黑树的路径计算: 最长路径和最短路径: AVL树与红黑树的区别ÿ…...

【神化世界】asp网页500内部服务器错误的解决方法
问题解决方案记录 一、问题 在asp网页调试的时候,不小心改错了,好好的页面突然出现如下错误信息了: 二、解决方法 终于找到了问题所在,是sql语句出错造成的,特别记录一下。 正确的写法 sql"select * from mem…...

java面试题6
1.什么是Java中的泛型(Generic)? 答案:泛型是一种参数化类型的机制,在编译时提供类型安全性检查和重用代码的能力。使用泛型可以在编译时检测类型错误,并减少类型转换的需要。 2.Java中的反射(…...

(03)vite 处理 css
文章目录 系列全集vite 处理css流程vite如何解决协同开发,样式重复覆盖的问题?使用less通过配置,更改vite的css默认行为vite 利用postcss样式兼容低版本浏览器 系列全集 (01)vite 从启动服务器开始 (02&am…...
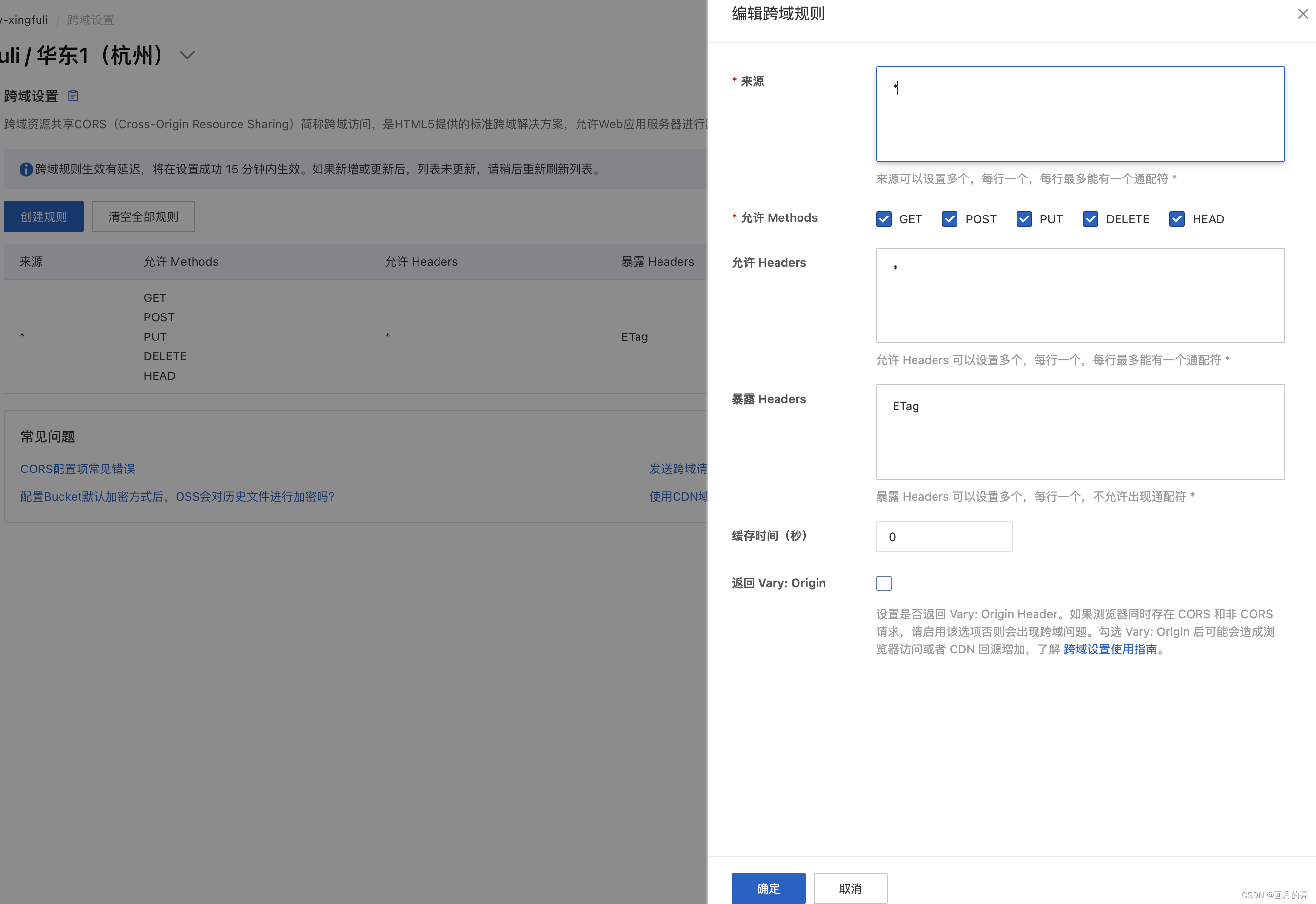
阿里云上传文件出现的问题解决(跨域设置)
跨域设置引起的问题 起因:开通对象存储服务后,上传文件限制在5M 大小,无法上传大文件。 1.查看报错信息 2.分析阿里云服务端响应内容 <?xml version"1.0" encoding"UTF-8"?> <Error><Code>Invali…...

攻防世界 crypto题GFSJ0527-【easy_RSA】
1.工具:thonny2.解题:打开附件,看到如下在一次RSA密钥对生成中,假设p473398607161,q4511491,e17 求解出d*RSA加密算法:①算法原理:RSA是一种非对称加密算法;②CTF中的常见…...

IISc Edge AI Arduino库:面向MCU的TinyML推理实践框架
1. IISc Edge AI Arduino 库概述IISc Edge AI Arduino 库是印度科学研究所(Indian Institute of Science, IISc)为“边缘人工智能”(Edge AI)课程开发的专用嵌入式软件栈,面向资源受限的微控制器平台,聚焦于…...

Local SDXL-Turbo用户体验:设计师眼中的灵感激发工具
Local SDXL-Turbo用户体验:设计师眼中的灵感激发工具 一句话总结:这是一个让你"打字即出图"的实时AI绘画工具,键盘敲下的每个词都会瞬间变成画面,特别适合设计师快速捕捉灵感和测试创意。 1. 为什么设计师需要这个工具 …...

Qwen3-8B应用解析:从零搭建一个支持长文档的个性化教育辅导机器人
Qwen3-8B应用解析:从零搭建一个支持长文档的个性化教育辅导机器人 1. 教育AI的新机遇与挑战 在数字化教育快速发展的今天,个性化辅导已成为提升学习效率的关键。传统教育面临三大痛点: 资源不均:优质教师资源有限,难…...

我的第一个多智能体项目踩坑实录:LangGraph连接Dify时,流式响应和错误处理怎么做?
我的第一个多智能体项目踩坑实录:LangGraph连接Dify时,流式响应和错误处理怎么做? 去年夏天,当我第一次尝试将Dify平台的多个智能体通过LangGraph串联成工作流时,原本以为只需要简单调用API就能完成的任务,…...
Pixel Dimension Fissioner实战教程:结合LangChain构建带记忆的像素裂变Agent
Pixel Dimension Fissioner实战教程:结合LangChain构建带记忆的像素裂变Agent 1. 工具介绍与核心能力 Pixel Dimension Fissioner是一款基于MT5-Zero-Shot-Augment核心引擎构建的文本增强工具,它将传统AI工具的文本处理能力与16-bit像素冒险游戏的视觉…...

无需写代码!Llama Factory让大模型微调像搭积木一样简单
无需写代码!Llama Factory让大模型微调像搭积木一样简单 1. 大模型微调的新时代 传统的大语言模型微调往往需要编写大量代码,从数据预处理到训练脚本,再到效果评估,整个过程对非专业开发者来说门槛极高。而Llama Factory的出现彻…...

一文读懂2026年大模型背后的关键技术
2026年,大模型(Large Model / Frontier Model)已不再是单纯的参数规模竞赛,而是进入**“效率认知执行”**三维并进的时代。单纯堆参数的路径边际效益大幅下降,行业共识转向:谁能在单位算力下输出更高“智能…...

Z-Image-GGUF网络优化配置:保障内网高速访问与模型加载
Z-Image-GGUF网络优化配置:保障内网高速访问与模型加载 如果你在企业内部部署了Z-Image-GGUF这类大模型服务,可能遇到过这样的烦恼:开发同事在办公室访问飞快,但其他楼层的同事或者远程办公的伙伴,加载模型时却慢如蜗…...

OpenClaw学习助手:Qwen3-32B自动生成练习题与错题本
OpenClaw学习助手:Qwen3-32B自动生成练习题与错题本 1. 为什么需要AI学习助手? 去年备考PMP认证时,我每天要花2小时手动整理错题本。某天深夜盯着满桌子的荧光笔标记,突然意识到:如果连知识管理这种结构化工作都要消…...