Sharding-Jdbc(3):Sharding-Jdbc分表
1 分表分库
LogicTable
数据分片的逻辑表,对于水平拆分的数据库(表),同一类表的总称。
订单信息表拆分为2张表,分别是t_order_0、t_order_1,他们的逻辑表名为t_order。
ActualTable
在分片的数据库中真实存在的物理表。即上个示例中的t_order_0、t_order_1。
DataNode
数据分片的最小单元。由数据源名称和数据表组成,例:test_msg0.t_order_0。配置时默认各个分片数据库的表结构均相同,直接配置逻辑表和真实表对应关系即可。
ShardingColumn
分片字段。用于将数据库(表)水平拆分的关键字段。SQL中如果无分片字段,将执行全路由,性能较差。Sharding-JDBC支持多分片字段。
ShardingAlgorithm
分片算法。Sharding-JDBC通过分片算法将数据分片,支持通过等号、BETWEEN和IN分片。分片算法目前需要业务方开发者自行实现,可实现的灵活度非常高。未来Sharding-JDBC也将会实现常用分片算法,如range,hash和tag等。
2 自定义分片模式
2.1 数据库表结构
创建ds_0数据库,新建表如下:
CREATE TABLE `t_order_0` (`order_id` bigint(20) NOT NULL,`user_id` bigint(20) NOT NULL,PRIMARY KEY (`order_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin;CREATE TABLE `t_order_1` (`order_id` bigint(20) NOT NULL,`user_id` bigint(20) NOT NULL,PRIMARY KEY (`order_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin;3 新建maven项目
<parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.0.3.RELEASE</version><relativePath /> <!-- lookup parent from repository --></parent><properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding><java.version>1.8</java.version></properties><dependencies><!-- jpa --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-jpa</artifactId></dependency><dependency><groupId>org.mybatis.spring.boot</groupId><artifactId>mybatis-spring-boot-starter</artifactId><version>1.3.2</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><scope>runtime</scope></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><!-- 引入shardingjdbc依赖信息 --><dependency><groupId>io.shardingjdbc</groupId><artifactId>sharding-jdbc-core</artifactId><version>2.0.3</version></dependency><dependency><groupId>com.dangdang</groupId><artifactId>sharding-jdbc-self-id-generator</artifactId><version>1.4.2</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId></dependency><dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId><version>1.0.12</version></dependency></dependencies><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId></plugin></plugins></build>
4 application配置
###数据库访问连接
spring:jdbc:db0:password: 123456className: com.mysql.jdbc.Driverurl: jdbc:mysql://192.168.222.157:3306/%s?characterEncoding=utf-8username: rootjpa:database: mysqlshow-sql: truehibernate:## 自己建表ddl-auto: noneapplication:name: sharding-jdbc-first5 配置分表算法
5.1 配置数据库连接
package com.example.demo.config;import com.alibaba.druid.pool.DruidDataSource;
import com.dangdang.ddframe.rdb.sharding.api.ShardingDataSourceFactory;
import com.dangdang.ddframe.rdb.sharding.api.rule.DataSourceRule;
import com.dangdang.ddframe.rdb.sharding.api.rule.ShardingRule;
import com.dangdang.ddframe.rdb.sharding.api.rule.TableRule;
import com.dangdang.ddframe.rdb.sharding.api.strategy.table.TableShardingStrategy;
import com.dangdang.ddframe.rdb.sharding.id.generator.IdGenerator;
import com.dangdang.ddframe.rdb.sharding.id.generator.self.CommonSelfIdGenerator;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;import javax.sql.DataSource;
import java.util.Arrays;
import java.util.HashMap;
import java.util.Map;// 数据源相关配置信息
@Configuration
public class DataSourceConfig {@Value("${spring.jdbc.db0.className}")private String className;@Value("${spring.jdbc.db0.url}")private String url;@Value("${spring.jdbc.db0.username}")private String username;@Value("${spring.jdbc.db0.password}")private String password;@Beanpublic IdGenerator getIdGenerator() {return new CommonSelfIdGenerator();}@Beanpublic DataSource getDataSource() {return buildDataSource();}private DataSource buildDataSource() {// 1.设置分库映射Map<String, DataSource> dataSourceMap = new HashMap<>(2);dataSourceMap.put("ds_0", createDataSource("ds_0"));// dataSourceMap.put("ds_1", createDataSource("ds_1"));// 设置默认db为ds_0,也就是为那些没有配置分库分表策略的指定的默认库// 如果只有一个库,也就是不需要分库的话,map里只放一个映射就行了,只有一个库时不需要指定默认库,// 但2个及以上时必须指定默认库,否则那些没有配置策略的表将无法操作数据DataSourceRule rule = new DataSourceRule(dataSourceMap, "ds_0");// 2.设置分表映射,将t_order_0和t_order_1两个实际的表映射到t_order逻辑表TableRule orderTableRule = TableRule.builder("t_order").actualTables(Arrays.asList("t_order_0", "t_order_1")).dataSourceRule(rule).build();// 3.具体的分库分表策略ShardingRule shardingRule = ShardingRule.builder().dataSourceRule(rule).tableRules(Arrays.asList(orderTableRule))// 根据userid分片字段.tableShardingStrategy(new TableShardingStrategy("user_id", new TableShardingAlgorithm())).build();// 创建数据源DataSource dataSource = ShardingDataSourceFactory.createDataSource(shardingRule);return dataSource;}private DataSource createDataSource(String dataSourceName) {// 使用druid连接数据库DruidDataSource druidDataSource = new DruidDataSource();druidDataSource.setDriverClassName(className);druidDataSource.setUrl(String.format(url, dataSourceName));druidDataSource.setUsername(username);druidDataSource.setPassword(password);return druidDataSource;}
}
5.2 配置分表策略
分表算法类需要实现SingleKeyTableShardingAlgorithm<T>接口
package com.example.demo.config;import com.dangdang.ddframe.rdb.sharding.api.ShardingValue;
import com.dangdang.ddframe.rdb.sharding.api.strategy.table.SingleKeyTableShardingAlgorithm;import java.util.Collection;// 表分片算法
public class TableShardingAlgorithm implements SingleKeyTableShardingAlgorithm<Long> {// sql 中关键字 匹配符为 =的时候,表的路由函数public String doEqualSharding(Collection<String> availableTargetNames, ShardingValue<Long> shardingValue) {for (String tableName : availableTargetNames) {if (tableName.endsWith(shardingValue.getValue() % 2 + "")) {return tableName;}}throw new IllegalArgumentException();}@Overridepublic Collection<String> doInSharding(Collection<String> availableTargetNames, ShardingValue<Long> shardingValue) {return null;}@Overridepublic Collection<String> doBetweenSharding(Collection<String> availableTargetNames,ShardingValue<Long> shardingValue) {return null;}}
6 新建实体类
package com.example.demo.entity;import lombok.Data;import javax.persistence.Entity;
import javax.persistence.Id;
import javax.persistence.Table;@Data
@Entity
@Table(name = "t_order")
public class OrderEntity {@Idprivate Long orderId;private Long userId;}7 OrderRepository
package com.example.demo.repository;import com.example.demo.entity.OrderEntity;
import org.springframework.data.jpa.repository.Query;
import org.springframework.data.repository.CrudRepository;import java.util.List;public interface OrderRepository extends CrudRepository<OrderEntity, Long> {@Query(value = "SELECT order_id ,user_id FROM t_order where order_id in (?1);", nativeQuery = true)public List<OrderEntity> findExpiredOrderState(List<String> bpIds);
}8 OrderController
package com.example.demo.controller;import com.example.demo.entity.OrderEntity;
import com.example.demo.repository.OrderRepository;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;import java.util.ArrayList;
import java.util.List;@RestController
public class OrderController {@Autowiredprivate OrderRepository orderRepository;// 查询所有的订单信息@RequestMapping("/getOrderAll")public List<OrderEntity> getOrderAll() {return (List<OrderEntity>) orderRepository.findAll();}// 使用in条件查询@RequestMapping("/inOrder")public List<OrderEntity> inOrder() {List<String> ids = new ArrayList<>();ids.add("2");ids.add("3");ids.add("4");ids.add("5");return orderRepository.findExpiredOrderState(ids);}// 增加@RequestMapping("/inserOrder")public String inserOrder(OrderEntity orderEntity) {for (int i = 0; i < 10; i++) {OrderEntity order = new OrderEntity();order.setOrderId((long) i);order.setUserId((long) i);orderRepository.save(order);}return "success";}}
9 新建启动类
package com.example.demo;import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.data.jpa.repository.config.EnableJpaRepositories;@SpringBootApplication
@EnableJpaRepositories(basePackages = "com.example.demo.repository")
public class AppSharding {public static void main(String[] args) {SpringApplication.run(AppSharding.class, args);}
}
10 启动项目
访问http://localhost:8080/inserOrder

查看数据库
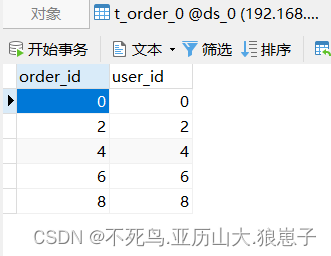

分表测试成功
相关文章:
Sharding-Jdbc(3):Sharding-Jdbc分表
1 分表分库 LogicTable 数据分片的逻辑表,对于水平拆分的数据库(表),同一类表的总称。 订单信息表拆分为2张表,分别是t_order_0、t_order_1,他们的逻辑表名为t_order。 ActualTable 在分片的数据库中真实存在的物理表。即上个示例中的t_…...
zookeeper集群 +kafka集群
1.zookeeper kafka3.0之前依赖于zookeeper zookeeper是一个开源,分布式的架构,提供协调服务(Apache项目) 基于观察者模式涉及的分布式服务管理架构 存储和管理数据,分布式节点上的服务接受观察者的注册,…...

2022年全国大学生数据分析大赛医药电商销售数据分析求解全过程论文及程序
2022年全国大学生数据分析大赛 医药电商销售数据分析 原题再现: 问题背景 20 世纪 90 年代是电子数据交换时代,中国电子商务开始起步并初见雏形,随后 Web 技术爆炸式成长使电子商务处于蓬勃发展阶段,目前互联网信息碎片化以…...
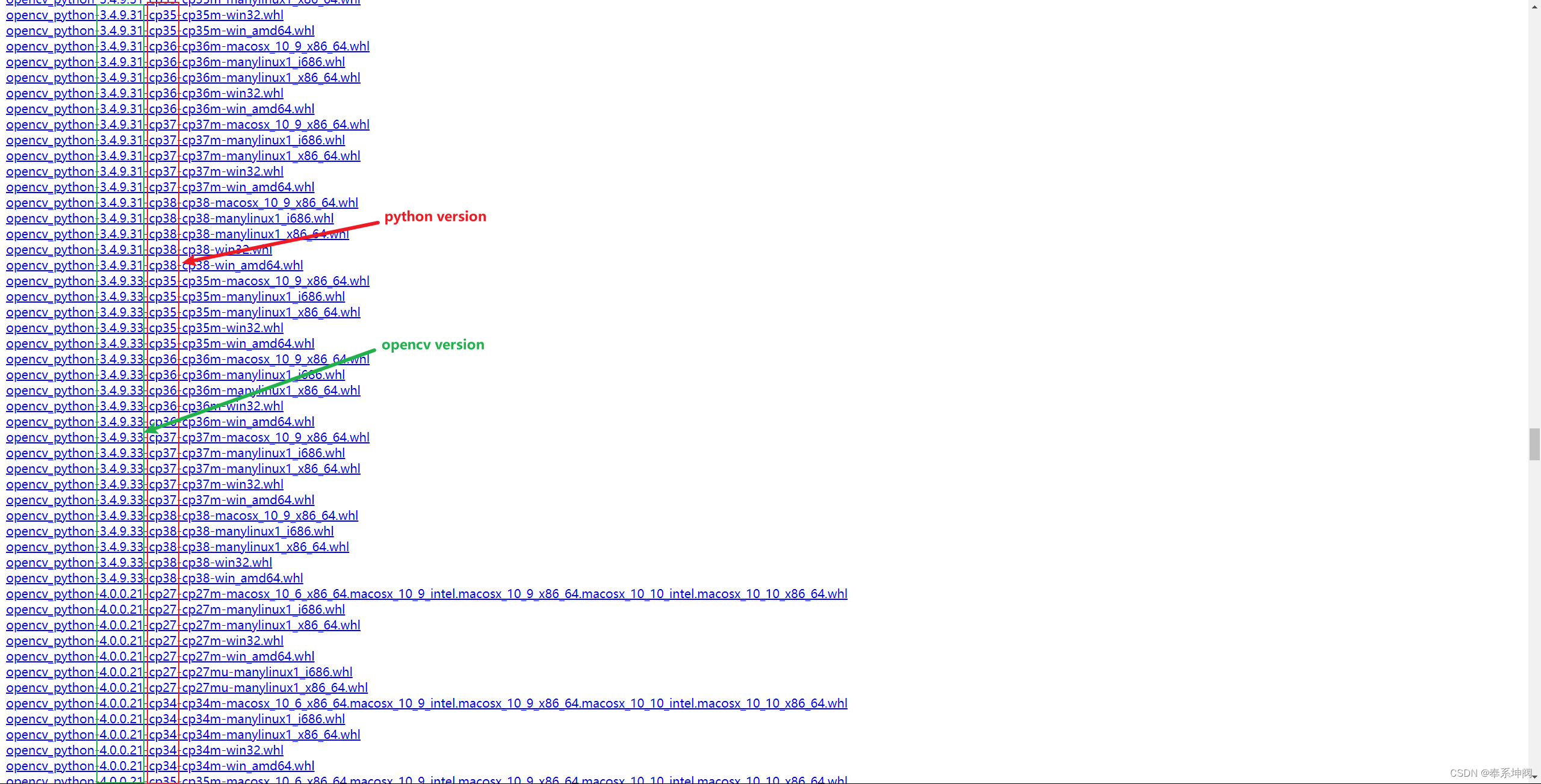
Python版本与opencv版本的对应关系
python版本要和opencv版本相对应,否则安装的时候会报错。 可以到Links for opencv-python上面查看python版本和opencv版本的对应关系,如图,红框内是python版本,绿框内是opencv版本。 查看自己的python版本后,使用下面…...

【开源视频联动物联网平台】LiteFlow
LiteFlow是一个轻量且强大的国产规则引擎框架,可用于复杂的组件化业务的编排领域。它基于规则文件来编排流程,支持xml、json、yml三种规则文件写法方式,再复杂的逻辑过程都能轻易实现。LiteFlow于2020年正式开源,2021年获得开源中…...

家用智能门锁——智能指纹锁方案
智能指纹锁产品功能: 1:指纹识别技术:光学传感器、半导体传感器或超声波传感器等。 2:指纹容量:智能指纹锁可以存储的指纹数量,通常在几十到几百个指纹之间。 3:解锁时间:指纹识别和…...

Qt6 QRibbon 一键美化Qt界面
强烈推荐一个 github 项目: https://github.com/gnibuoz/QRibbon 作用: 在几乎不修改任何你自己代码的情况下,一键美化你的 UI 界面。 代码环境:使用 VS2019 编译 Qt6 GUI 程序,继承 QMainWindow 窗口类 一、使用方法 …...
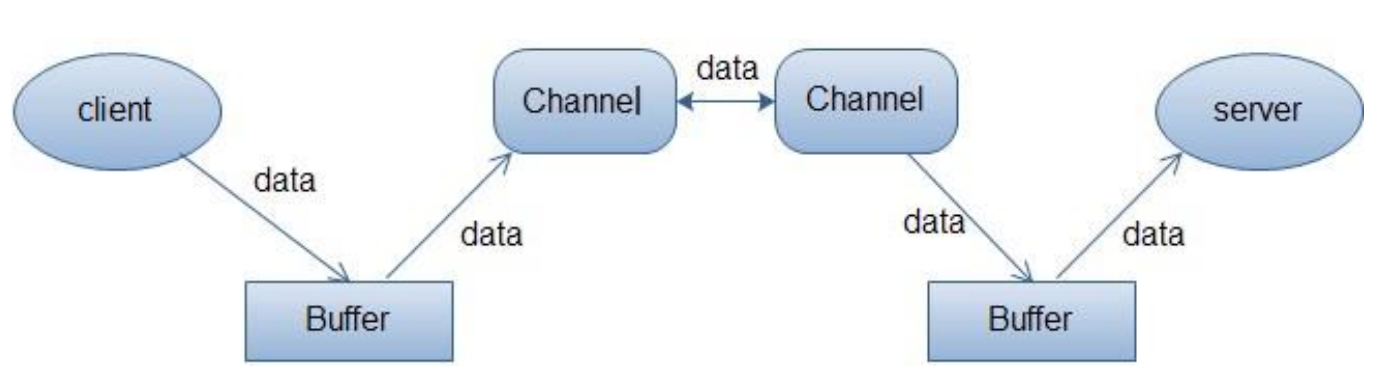
JAVA IO:NIO
1.阻塞 IO 模型 最传统的一种 IO 模型,即在读写数据过程中会发生阻塞现象。当用户线程发出 IO 请求之后,内核会去查看数据是否就绪,如果没有就绪就会等待数据就绪,而用户线程就会处于阻塞状态,用户线程交出 CPU。当…...

Python 在控制台打印带颜色的信息
#格式: 设置颜色开始 :\033[显示方式;前景色;背景色m #说明: 前景色 背景色 颜色 --------------------------------------- 30 40 黑色 31 41 红色 32 …...
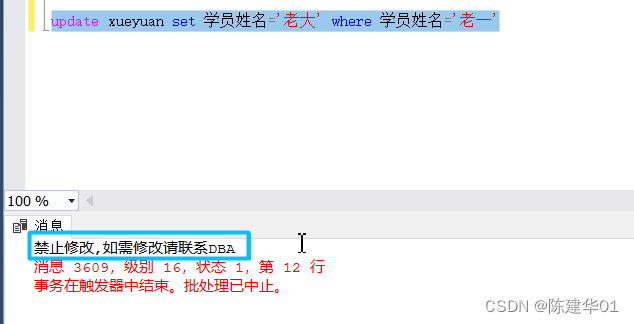
SQL Server 数据库,创建触发器避免数据被更改
5.4触发器 触发器是一种特殊类型的存储过程,当表中的数据发生更新时将自动调用,以响应INSERT、 UPDATE 或DELETE 语句。 5.4.1什么是触发器 1.触发器的概念 触发器是在对表进行插入、更新或删除操作时自动执行的存储过程,触发器通常用于强…...
C语言实现植物大战僵尸(完整版)
实现这个游戏需要Easy_X 这个在我前面一篇C之番外篇爱心代码有程序教你怎么下载,大家可自行查看 然后就是需要植物大战僵尸的素材和音乐,需要的可以在评论区 首先是main.cpp //开发日志 //1导入素材 //2实现最开始的游戏场景 //3实现游戏顶部的工具栏…...

基于YOLOv8深度学习的火焰烟雾检测系统【python源码+Pyqt5界面+数据集+训练代码】目标检测、深度学习实战
《博主简介》 小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。 ✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~ 👍感谢小伙伴们点赞、关注! 《------往期经典推…...

【C++】手撕string思路梳理
目录 基本思路 代码实现 1.构建框架: 2.构建函数重载 3.迭代器: 4.遍历string 5.resetve 开空间,insert任意位置插入push_back,append,(按顺序依次实现) 6.erase删除,clear清除,resize缩容 7.流插入࿰…...

【数据结构和算法】确定两个字符串是否接近
其他系列文章导航 Java基础合集数据结构与算法合集 设计模式合集 多线程合集 分布式合集 ES合集 文章目录 其他系列文章导航 文章目录 前言 一、题目描述 二、题解 2.1操作 1 的本质:字符可以任意排列 2.2操作 2 的本质:出现次数是可以交换的 2.…...
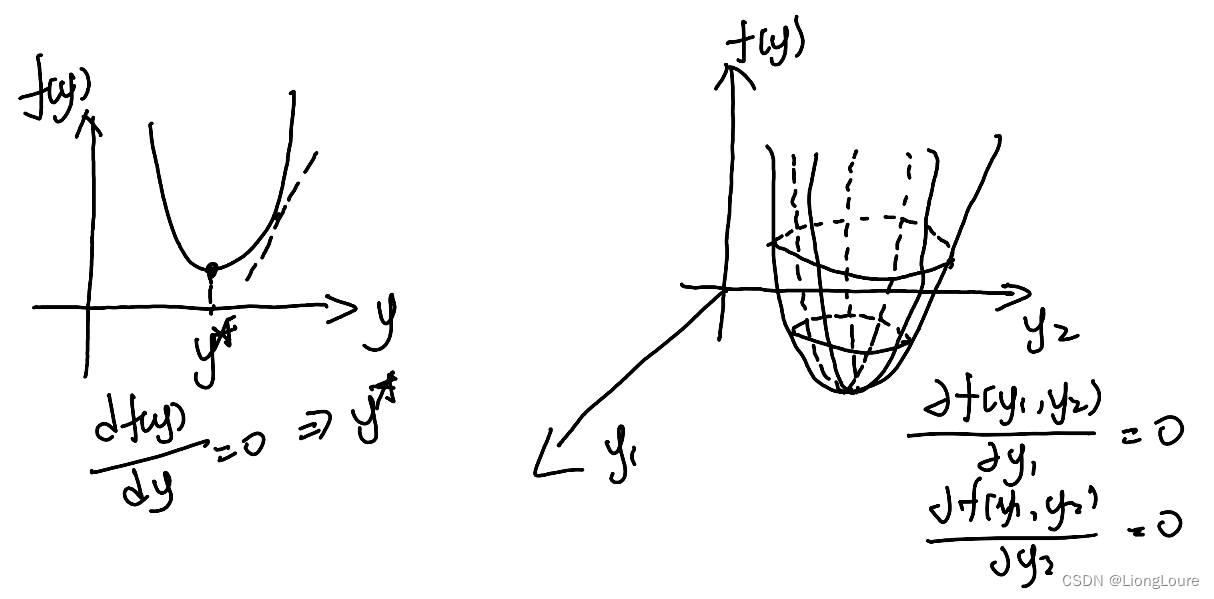
[足式机器人]Part2 Dr. CAN学习笔记-Ch0-1矩阵的导数运算
本文仅供学习使用 本文参考: B站:DR_CAN Dr. CAN学习笔记-Ch0-1矩阵的导数运算 1. 标量向量方程对向量求导,分母布局,分子布局1.1 标量方程对向量的导数1.2 向量方程对向量的导数 2. 案例分析,线性回归3. 矩阵求导的链…...
如何让软文更具画面感,媒介盒子分享
写软文这种带有销售性质的文案时,总说要有画面感,要有想象空间。只有针对目标用户的感受的设计,要了解用户想的是什么,要用可视化的描述来影响用户的感受,今天媒介盒子就和大家分享:如何让软文更具画面感。…...

Hadoop学习笔记(HDP)-Part.19 安装Kafka
目录 Part.01 关于HDP Part.02 核心组件原理 Part.03 资源规划 Part.04 基础环境配置 Part.05 Yum源配置 Part.06 安装OracleJDK Part.07 安装MySQL Part.08 部署Ambari集群 Part.09 安装OpenLDAP Part.10 创建集群 Part.11 安装Kerberos Part.12 安装HDFS Part.13 安装Ranger …...

Arrays类练习 - Java
案例:自定义Book类,里面包含name和price,按price排序(从大到小)。要求使用两种方式排序,有一个 Book[] books 4本书对象。 使用前面学习过的传递实现Comparator接口匿名内部类,也称为定制排序。可以按照price (1)从大到…...

Java多线程:代码不只是在‘Hello World‘
Java线程好书推荐 概述01 多线程对于Java的意义02 为什么Java工程师必须掌握多线程03 Java多线程使用方式04 如何学好Java多线程写在末尾: 主页传送门:📀 传送 概述 摘要:互联网的每一个角落,无论是大型电商平台的秒杀…...

使用PCSS实现的实时阴影效果
PCSS的技术可以使得阴影呈现出近硬远软的效果,并且能够实时实现。 其核心理念是通过模拟光源的面积来产生更自然、更柔和的阴影边缘。 具体步骤: 1、生成shadowmap 2、在进行阴影的比较时候进行平均,并非之前的shadow map 或者之后完全的阴影…...

树莓派超全系列教程文档--(61)树莓派摄像头高级使用方法
树莓派摄像头高级使用方法 配置通过调谐文件来调整相机行为 使用多个摄像头安装 libcam 和 rpicam-apps依赖关系开发包 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 配置 大多数用例自动工作,无需更改相机配置。但是,一…...

解决Ubuntu22.04 VMware失败的问题 ubuntu入门之二十八
现象1 打开VMware失败 Ubuntu升级之后打开VMware上报需要安装vmmon和vmnet,点击确认后如下提示 最终上报fail 解决方法 内核升级导致,需要在新内核下重新下载编译安装 查看版本 $ vmware -v VMware Workstation 17.5.1 build-23298084$ lsb_release…...

BCS 2025|百度副总裁陈洋:智能体在安全领域的应用实践
6月5日,2025全球数字经济大会数字安全主论坛暨北京网络安全大会在国家会议中心隆重开幕。百度副总裁陈洋受邀出席,并作《智能体在安全领域的应用实践》主题演讲,分享了在智能体在安全领域的突破性实践。他指出,百度通过将安全能力…...

【Go语言基础【13】】函数、闭包、方法
文章目录 零、概述一、函数基础1、函数基础概念2、参数传递机制3、返回值特性3.1. 多返回值3.2. 命名返回值3.3. 错误处理 二、函数类型与高阶函数1. 函数类型定义2. 高阶函数(函数作为参数、返回值) 三、匿名函数与闭包1. 匿名函数(Lambda函…...

CRMEB 中 PHP 短信扩展开发:涵盖一号通、阿里云、腾讯云、创蓝
目前已有一号通短信、阿里云短信、腾讯云短信扩展 扩展入口文件 文件目录 crmeb\services\sms\Sms.php 默认驱动类型为:一号通 namespace crmeb\services\sms;use crmeb\basic\BaseManager; use crmeb\services\AccessTokenServeService; use crmeb\services\sms\…...
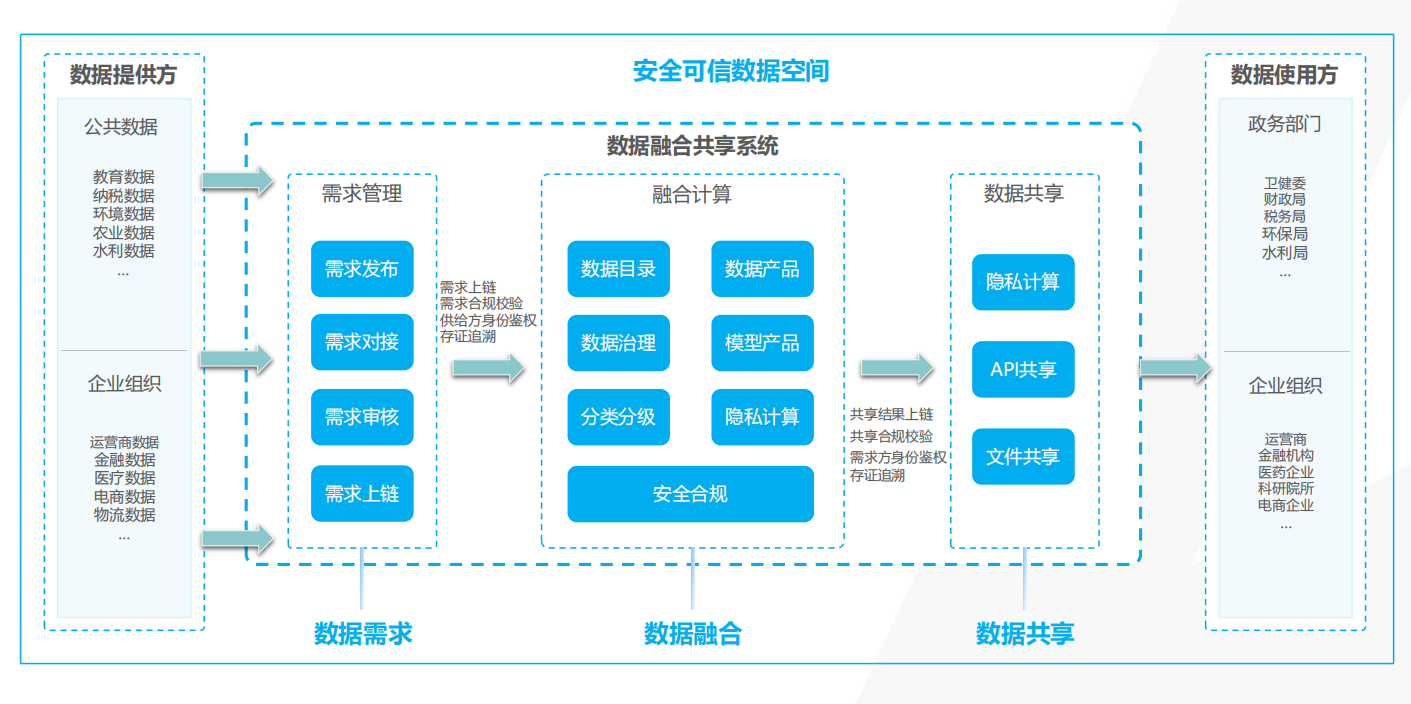
热烈祝贺埃文科技正式加入可信数据空间发展联盟
2025年4月29日,在福州举办的第八届数字中国建设峰会“可信数据空间分论坛”上,可信数据空间发展联盟正式宣告成立。国家数据局党组书记、局长刘烈宏出席并致辞,强调该联盟是推进全国一体化数据市场建设的关键抓手。 郑州埃文科技有限公司&am…...

使用 uv 工具快速部署并管理 vLLM 推理环境
uv:现代 Python 项目管理的高效助手 uv:Rust 驱动的 Python 包管理新时代 在部署大语言模型(LLM)推理服务时,vLLM 是一个备受关注的方案,具备高吞吐、低延迟和对 OpenAI API 的良好兼容性。为了提高部署效…...

(12)-Fiddler抓包-Fiddler设置IOS手机抓包
1.简介 Fiddler不但能截获各种浏览器发出的 HTTP 请求,也可以截获各种智能手机发出的HTTP/ HTTPS 请求。 Fiddler 能捕获Android 和 Windows Phone 等设备发出的 HTTP/HTTPS 请求。同理也可以截获iOS设备发出的请求,比如 iPhone、iPad 和 MacBook 等苹…...

7种分类数据编码技术详解:从原理到实战
在数据分析和机器学习领域,分类数据(Categorical Data)的处理是一个基础但至关重要的环节。分类数据指的是由有限数量的离散值组成的数据类型,如性别(男/女)、颜色(红/绿/蓝)或产品类…...

信息系统分析与设计复习
2024试卷 单选题(20) 1、在一个聊天系统(类似ChatGPT)中,属于控制类的是()。 A. 话语者类 B.聊天文字输入界面类 C. 聊天主题辨别类 D. 聊天历史类 解析 B-C-E备选架构中分析类分为边界类、控制类和实体类。 边界…...