Kafka部署与SpringBoot集成
Kafka与ZooKeeper
Apache ZooKeeper是一个基于观察者模式的分布式服务管理框架,即服务注册中心。同时ZooKeeper还具有存储数据的能力。Kafka的每台服务器作为一个broker注册到ZooKeeper,多个broker借助ZooKeeper形成了Kafka集群。同时ZooKeeper会保存一些信息,例如消息消费的进度Offset等。另外ZooKeeper还负责Kafka集群中Leader的选举。
使用
下载
从官方下载最新版Kafka:
https://kafka.apache.org/downloads.html
当前最新版本为kafka_2.13-3.4.0。
下载后解压。注意解压路径不能有空格及其他特殊字符。
Kafka中默认自带了ZooKeeper,因此不需要单独下载ZooKeeper。
当然也可不使用Kafka自带的ZooKeeper,注意配置文件保持一致即可。
配置文件
进入Kafka根目录,新建一个 tmp 文件夹,然后在其下创建 zookeeper 和 kafka-logs 文件夹,分别用于存放ZooKeeper的数据和Kafka的日志。
打开 /config/zookeeper.properties ,找到 dataDir=/tmp/zookeeper ,将其修改为新创建的 zookeeper 文件夹。然后在最后添加配置audit.enable=true。
打开 /config/server.properties ,找到 log.dirs=/tmp/kafka-logs ,将其修改为新创建的 kafka-logs 文件夹。
注意路径必须使用/,不能使用\。
若不修改上述目录,则会在磁盘的根目录下自动创建 zookeeper 和 kafka-logs 文件夹。
配置的一致性
ZooKeeper默认的端口为2181,Kafka默认的端口为9092。
若要更改Kafka的端口,则将listeners=PLAINTEXT://:9092配置开放,修改其端口值,同时要加上hostname,即改为:listeners=PLAINTEXT://localhost:9092。
Kafka配置中默认指定zookeeper.connect=localhost:2181,若使用非默认配置,需修改该属性。若有多个ZooKeeper地址可使用,隔开。
运行和关闭
运行
Kafka的运行基于ZooKeeper,因此需要在ZooKeeper服务启动后再运行Kafka。
进入Kafka根目录。
首先要启动ZooKeeper。在根目录下打开cmd命令行,输入:
.\bin\windows\zookeeper-server-start.bat .\config\zookeeper.properties
然后启动Kafka。在根目录下打开cmd命令行,输入:
.\bin\windows\kafka-server-start.bat .\config\server.properties
Kafka运行后会在根目录下生成 logs 文件夹。
命令行
进入Kafka根目录,打开cmd命令行。
topic
新建:
.\bin\windows\kafka-topics.bat --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic topic1
查看topic列表:
.\bin\windows\kafka-topics.bat --list --bootstrap-server localhost:9092
查看单个topic详情:
.\bin\windows\kafka-topics.bat --describe --bootstrap-server localhost:9092 --topic topic1
删除topic:
.\bin\windows\kafka-topics.bat --delete --bootstrap-server localhost:9092 -topic topic1
group
查看group列表:
.\bin\windows\kafka-consumer-groups.bat --list --bootstrap-server localhost:9092
查看group详情:
.\bin\windows\kafka-consumer-groups.bat --describe --bootstrap-server localhost:9092 --group test-consumer-group
ZooKeeper命令行
若运行的是Kafka自带的ZooKeeper,则要进入其命令行:
- 进入Kafka根目录,打开cmd命令行。
- 输入命令:
.\bin\windows\zookeeper-shell.bat localhost:2181。
注意地址和端口要正确,否则会提示JLine support is disabled。
执行后会打印:
Connecting to localhost:2181
Welcome to ZooKeeper!
JLine support is disabledWATCHER::WatchedEvent state:SyncConnected type:None path:null
此时即可输入ZooKeeper命令:
# 查看服务
ls /# 查看0号broker
get /brokers/ids/0
关闭
关闭时,要先关闭Kafka,再关闭ZooKeeper。
关闭Kafka时不能直接关闭命令行窗口,这样可能会导致Kafka无法完成对日志文件的解锁,于是下次启动Kafka时就会因为日志文件被锁而无法启动成功。正确的关闭方式是运行 /bin/windows/kafka-server-stop.bat 。
关闭ZooKeeper时同样要运行 /bin/windows/zookeeper-server-stop.bat 。
暴力关闭导致异常
如果暴力关闭了Kafka,再次启动时遇到提示:
ERROR Fatal error during KafkaServer startup. Prepare to shutdown
此时删除根目录下的 logs 文件夹即可。
Spring Boot集成
首先要启动ZooKeeper和Kafka服务。
依赖
<dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId>
</dependency>
配置文件
spring:kafka:bootstrap-servers: localhost:9092 #Kafka的地址producer: # 生产者key-serializer: org.apache.kafka.common.serialization.StringSerializervalue-serializer: org.apache.kafka.common.serialization.StringSerializerconsumer: # 消费者key-deserializer: org.apache.kafka.common.serialization.StringDeserializervalue-deserializer: org.apache.kafka.common.serialization.StringDeserializergroup-id: test-consumer-group #在Kafka的/config/consumer.properties中查看和修改
以上为最基础的配置。可以根据具体需求进行更加详细的配置。
生产者和消费者
对于Kafka,必须设置生产者和消费者。
- 生产者: 生产者负责将消息发送给Kafka。有异步和同步两种方式。
- 消费者: 消费者使用监听的方式接收Kafka的消息。当存在消息时会被及时消费。
生产者调用命令push来发送数据,而消费者调用命令pull来拉取数据。注意消费者的数据不是Kafka主动推送的。
生产者
为了方便测试,定义一个Controller来接收触发信号并将信息发送给Kafka。
@RequestMapping("/producer")
@RestController
public class ProducerController {@AutowiredKafkaTemplate<String, String> kafkaTemplate;// 异步发送@RequestMapping("/register")public String register(User user) {String message = JSON.toJSONString(user);System.out.println("接收到用户信息:" + message);kafkaTemplate.send("register", message);return "OK";}// 同步发送@RequestMapping("/register/sync")public String registerSync(User user) throws Exception {String message = JSON.toJSONString(user);System.out.println("接收到用户信息:" + message);ListenableFuture<SendResult<String, String>> future = kafkaTemplate.send("register", message);// 设置等待时间,超出后,不再等待返回SendResult<String, String> result = future.get(3, TimeUnit.SECONDS);return result.getProducerRecord().value();}
}
使用 KafkaTemplate<K, V> 来发送消息。其中send()方法第一个参数指定了topics的名称。
若要使用同步发送,可对kafkaTemplate.send()的返回结果调用get()方法,并在其中设置等待时间。
对于异步发送,发送后会立即收到返回结果;对于同步发送,会一直等待发送结果并返回,直到设置的等待时间耗尽。
对于异步发送,若想得知发送的最终结果,则需要注册一个监听器KafkaTemplate.setProducerListener()来等待回调:
@Configuration
public class KafkaListener {private final static Logger logger = LoggerFactory.getLogger(KafkaListener.class);@AutowiredKafkaTemplate kafkaTemplate;// 配置监听@PostConstructprivate void listener() {kafkaTemplate.setProducerListener(new ProducerListener<String, Object>() {@Overridepublic void onSuccess(ProducerRecord<String, Object> producerRecord, RecordMetadata recordMetadata) {logger.info("ok,message={}", producerRecord.value());}@Overridepublic void onError(ProducerRecord<String, Object> producerRecord, Exception exception) {logger.error("error!message={}", producerRecord.value());}});}
}
消费者
对于消费者,需设置一个监听器来监听指定的topics:
@Component
public class Consumer {@KafkaListener(topics = "register")public void consume(String message) {System.out.println("收到消息:" + message);User user = JSON.parseObject(message, User.class);System.out.println("为 " + user.getName() + " 进行账号注册");}
}
当Kafka收到消息后,监听者的回调方法被触发。
指定分区
Producer发送时指定分区和key值:
// 发送时指定0号分区,key为test
@RequestMapping("/register")
public String register(User user) {String message = JSON.toJSONString(user);System.out.println("收到用户信息:" + message);kafkaTemplate.send("register", 0, "test", message);return "OK";
}
Consumer接收时指定分区:
@KafkaListener(topics = {"register"}, topicPattern = "0")
public void onMessage(ConsumerRecord<?, ?> consumerRecord) {Optional<?> optional = Optional.ofNullable(consumerRecord.value());if (optional.isPresent()) {String message = (String)optional.get();User user = JSON.parseObject(message, User.class);System.out.println("为 " + user.getName() + " 进行账号注册");}
}
编码器和解码器
在yml中配置了编码器和解码器:
spring:kafka:...producer: # 生产者key-serializer: org.apache.kafka.common.serialization.StringSerializervalue-serializer: org.apache.kafka.common.serialization.StringSerializerconsumer: # 消费者key-deserializer: org.apache.kafka.common.serialization.StringDeserializervalue-deserializer: org.apache.kafka.common.serialization.StringDeserializer...
其中:
- key-serializer: 生产者key的编码器。
- value-serializer: 生产者value的编码器。
- key-deserializer: 消费者key的解码器。
- value-deserializer: 消费者value的解码器。
编码器和解码器统称序列化,其作用是生产者将消息编码为字节流发送,消费者接收到字节流再进行解码。
这里使用的是Kafka提供的字符串编码器StringSerializer和字符串解码器StringDeserializer。
Kafka提供了多种编码器,包含: StringSerializer、JsonSerializer、BytesSerializer、IntegerSerializer、LongSerializer、ListSerializer、StringOrBytesSerializer等等。对应地也提供了多种解码器,包含StringDeserializer、JsonDeserializer、BytesDeserializer、IntegerDeserializer、LongDeserializer、ListDeserializer、StringOrBytesDeserializer等等。
Kafka默认提供的序列化类可满足绝大多数场景。用户也可自定义编码器和解码器。
编码器
编码器需要从Serializer类派生,并实现serialize()方法。
以下为StringSerializer源码:
package org.apache.kafka.common.serialization;public class StringSerializer implements Serializer<String> {private String encoding = StandardCharsets.UTF_8.name();@Overridepublic void configure(Map<String, ?> configs, boolean isKey) {String propertyName = isKey ? "key.serializer.encoding" : "value.serializer.encoding";Object encodingValue = configs.get(propertyName);if (encodingValue == null)encodingValue = configs.get("serializer.encoding");if (encodingValue instanceof String)encoding = (String) encodingValue;}@Overridepublic byte[] serialize(String topic, String data) {try {if (data == null)return null;elsereturn data.getBytes(encoding);} catch (UnsupportedEncodingException e) {throw new SerializationException("Error when serializing string to byte[] due to unsupported encoding " + encoding);}}
}
解码器
编码器需要从Deserializer类派生,并实现deserialize()方法。
以下为StringDeserializer源码:
package org.apache.kafka.common.serialization;public class StringDeserializer implements Deserializer<String> {private String encoding = StandardCharsets.UTF_8.name();@Overridepublic void configure(Map<String, ?> configs, boolean isKey) {String propertyName = isKey ? "key.deserializer.encoding" : "value.deserializer.encoding";Object encodingValue = configs.get(propertyName);if (encodingValue == null)encodingValue = configs.get("deserializer.encoding");if (encodingValue instanceof String)encoding = (String) encodingValue;}@Overridepublic String deserialize(String topic, byte[] data) {try {if (data == null)return null;elsereturn new String(data, encoding);} catch (UnsupportedEncodingException e) {throw new SerializationException("Error when deserializing byte[] to string due to unsupported encoding " + encoding);}}
}
自定义编码器和解码器
现在希望,生产者和消费者以Object类型来处理消息:
// 编码器类
public class TestSerializer implements Serializer {@Overridepublic byte[] serialize(String topic, Object data) {String json = JSON.toJSONString(data);return json.getBytes();}
}// 解码器类
public class TestDeserializer implements Deserializer {@Overridepublic Object deserialize(String topic, byte[] data) {try {String json = new String(data,"utf-8");return JSON.parse(json);} catch (UnsupportedEncodingException e) {e.printStackTrace();}return null;}}
然后在yml中为value配置自定义的编码器和解码器:
spring:kafka:...producer: # 生产者key-serializer: org.apache.kafka.common.serialization.StringSerializervalue-serializer: com.example.test.component.TestSerializerconsumer: # 消费者key-deserializer: org.apache.kafka.common.serialization.StringDeserializervalue-deserializer: com.example.test.component.TestDeserializer...
这样就可以使用自定义解码器了。
topic内分区
每一个topic实际是分成多个区(partition)的,这些topic都存储在Kafka内。无论是生产者将消息发送到Kafka还是消费者从Kafka中获取消息,都需要明确告知Kafka分区信息是什么。
生产者发送消息时,消息要发往哪个分区是根据条件来确定的:
- 若指定分区号,则消息直接发到Kafka的指定分区。
- 若未指定分区号,但给定了数据key值,则消息可对key值取Hashcode,自动计算分区。
- 若未指定分区号,且未给定数据key值,则直接轮循分区。(默认方案)
- 自定义分区策略。
使用指定分区号及Key值的方式,只需要在调用KafkaTemplate.send()时传入对应的参数即可。
自定义分区策略
自定义分区策略,即生产者在将消息发给Kafka前,先经过自定义的分区器进行分区计算,计算出目标分区后再发给Kafka。故而自定义分区器应添加在生产者工程中。
使用自定义分区的流程为:
- 从
Partitioner派生,重载其partition()方法。在这里自定义分区逻辑。 - 添加一个
@Configuration类,在其中更新KafkaTemplate的属性,将自定义的分区器设置进来。 - 正常发送消息。
自定义分区器:
public class MyPartitioner implements Partitioner {@Overridepublic int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {// 自定义分区策略。若key以0开头,则放入分区0;其他放入分区1String keyStr = String.valueOf(key);return keyStr.startsWith("0") ? 0 : 1;}@Overridepublic void close() {}@Overridepublic void configure(Map<String, ?> map) {}
}
添加一个配置类来更新KafkaTemplate的属性:
@Configuration
public class KafkaProducerConfig {@Value("${spring.kafka.bootstrap-servers}")private String bootstrapServers;KafkaTemplate kafkaTemplate;@PostConstructpublic void setKafkaTemplate() {Map<String, Object> props = new HashMap<>();props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);// 将自定义的分区器设置进来props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, MyPartitioner.class);this.kafkaTemplate = new KafkaTemplate<String, String>(new DefaultKafkaProducerFactory<>(props));}public KafkaTemplate getKafkaTemplate(){return kafkaTemplate;}
}
然后正常发送消息即可。
SpringBoot手动提交offset
offset默认是自动计算自动提交的。若要对offset进行手动提交,流程为:
- 修改配置,关闭自动提交。
- consumer在处理结束时手动提交。
在application.yml中配置了offset自动提交:
enable-auto-commit: true # 是否自动提交offset
auto-commit-interval: 100 # 提交offset延时(接收到消息后多久提交offset,默认单位为ms)
现在添加一个配置类来覆盖yml中的配置:
@Configuration
public class KafkaConsumerConfig {@Value("${spring.kafka.bootstrap-servers}")private String bootstrapServers;@Beanpublic KafkaListenerContainerFactory<?> manualKafkaListenerContainerFactory() {Map<String, Object> configProps = new HashMap<>();configProps.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);configProps.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);configProps.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);// 关闭自动提交configProps.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);ConcurrentKafkaListenerContainerFactory<String, String> factory =new ConcurrentKafkaListenerContainerFactory<>();factory.setConsumerFactory(new DefaultKafkaConsumerFactory<>(configProps));/*** AckMode 在ENABLE_AUTO_COMMIT_CONFIG = false时生效。所有取值为:* RECORD: 每处理一条commit一次* BATCH(默认): 每次poll的时候批量提交一次,频率取决于每次poll的调用频率* TIME: 每次间隔ackTime的时间去commit* COUNT: 累积达到ackCount次的ack去commit* COUNT_TIME: ackTime或ackCount哪个条件先满足,就commit* MANUAL: listener负责ack,但是背后也是批量上去* MANUAL_IMMEDIATE: listner负责ack,每调用一次,就立即commit*/factory.getContainerProperties().setAckMode(ContainerProperties.AckMode.MANUAL_IMMEDIATE);return factory;}
}
然后在consumer的监听方法中调用Consumer.commitSync()来手动提交offset:
/**
* 消费者1
*/
@KafkaListener(topics = {"register"})
public void consumer1(@Payload String message, ConsumerRecord record, Consumer consumer) {System.out.println("consumer1收到消息并消费:" + message);// 消息消费结束,同步提交偏移量,默认为offset+1consumer.commitSync();System.out.println("consumer1提交位移");}/**
* 消费者2
*/
@KafkaListener(topics = {"register"})
public void consumer2(@Payload String message, ConsumerRecord record, Consumer consumer) {System.out.println("consumer2收到消息并消费:" + message);// 消息消费结束,同步提交偏移量,手动更改为offset+2Map<org.apache.kafka.common.TopicPartition, OffsetAndMetadata> currentOffset = new HashMap<>();currentOffset.put(new org.apache.kafka.common.TopicPartition(record.topic(), record.partition()),new OffsetAndMetadata(record.offset() + 2));consumer.commitSync(currentOffset);System.out.println("consumer2提交位移");}
注意消费者2中手动更改偏移量使用的类为org.apache.kafka.common.TopicPartition。该类这里直接手动引入而没有放在import中,是因为该类与注解@TopicPartition的类org.springframework.kafka.annotation.TopicPartition同名。如果放在import中则会造成冲突。
上述消费者2为了说明手动更改偏移量的操作而令offset+2,这样会导致偏移量与实际不符,实际开发应按实际情况处理。
如果关闭了偏移量自动提交,且在消费者逻辑中没有提交偏移量,则会导致偏移量始终不变,于是每次消费者拉取的消息都是同一条,从而造成消息重复消费。
相关文章:

Kafka部署与SpringBoot集成
Kafka与ZooKeeper Apache ZooKeeper是一个基于观察者模式的分布式服务管理框架,即服务注册中心。同时ZooKeeper还具有存储数据的能力。Kafka的每台服务器作为一个broker注册到ZooKeeper,多个broker借助ZooKeeper形成了Kafka集群。同时ZooKeeper会保存一…...
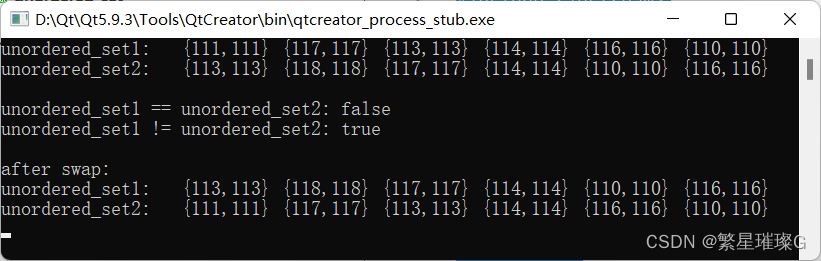
c++11 标准模板(STL)(std::unordered_set)(十三)
定义于头文件 <unordered_set> template< class Key, class Hash std::hash<Key>, class KeyEqual std::equal_to<Key>, class Allocator std::allocator<Key> > class unordered_set;(1)(C11 起)namespace pmr { templ…...

【2023】DevOps、SRE、运维开发面试宝典之ELKStack相关面试题
文章目录 1、elasticsearch的应用场景2、elasticsearch的特点3、Elasticsearch集群三种状态分别是什么?代表什么?4、Elasticsearch集群的优化方面5、Elasticsearch集群防止脑裂的配置参数?6、ELK日志采集平台架构组件介绍?7、Logstash组件的作用?8、收集Kubernetes集群程序…...

Hive中的高阶函数(二)
1、UDTF之explode函数 explode(array)将array列表里的每个元素生成一行; explode(map)将map里的每一对元素作为一行,其中key为一列,value为一列; 一般情况下,explode函数可以直接使用即可,也可以根据需要结…...

Java集合知识点总结
ArrayListLinkedListLinkedHashSetHashSetTreeSetHashTableHashMapTreeMap是否有序有序有序有序无序自然排序(Comparator)进行排序,默认升序使用的是重写comparTo方法无序无序自动排序元素是否为空可为null可为null不允许可为null不允许键允许…...
培训班出身的同学简历怎么做?面试要注意哪些?来自资深大厂HR的忠告
目录 1 不少培训班候选人的简历中,缺乏足够的商业项目年限 2 直接描述培训班学习经历会带来的负面影响 3 大龄转行Vs年轻的初级程序员,公司一般会如何选择? 4 经过培训班突击后,可以先面试小公司 5 面试官怎么面试有培训班经历…...
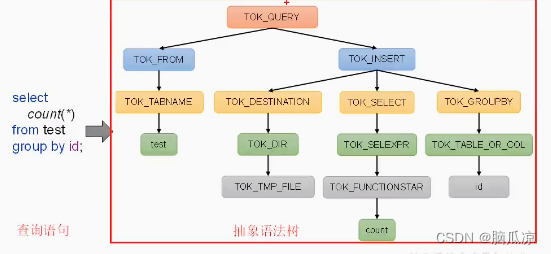
Hive3.1.3安装部署_最小化部署_元数据MySQL部署_Hiveserver2部署_metastore部署---大数据之Hive工作笔记0012
hbase 实时分析 hive 离线分析 这里是新版本的hive3.1.3的安装 关于hive的原理之前的博客已经详细说了 可以看到上面是hive运行的原理图 词法分析 语法分析...
 含义)
javascript:void(0) 含义
我们经常会使用到 javascript:void(0) 这样的代码,那么在 JavaScript 中 javascript:void(0) 代表的是什么意思呢?javascript:void(0) 中最关键的是 void 关键字, void 是 JavaScript 中非常重要的关键字,该操作符指定要计算一个表…...

不用机器学习不用大数据,给你讲通ChatGPT的深层原理
ChatGPT现在看来已经异常火爆了,很多人已经熟知,并且开始练习使用或者开始利用他开始实践了。但仍然有很多人在观望,在疑惑,今天狗哥不用那些高端大气的机器学习亦或是大数据还给你讲通ChatGPT深层到底是个啥逻辑。 目录 1. 聊家…...

JavaScript中的循环类型
JavaScript 中有三种主要的循环类型: for、while 和 do...while。 for: 循环指定次数。 例如: for (let i 0; i < 5; i) {console.log(i); } while: 当条件为真时循环。 例如: let i 0; while (i < 5) {console.log(i);i; } do...while: 先执…...

Spring Boot+Vue前后端分离项目练习02之网盘项目利用token进行登陆验证
1.添加依赖 首先需要添加jwt对应的依赖。 <dependency><groupId>io.jsonwebtoken</groupId><artifactId>jjwt</artifactId><version>0.9.1</version></dependency>2.添加配置 JWT由三部分构成,分别是 header, pa…...
)
springcloud常见面试题(2023最新)
目录前言一.微服务1.微服务是什么?2.你知道哪些RPC框架3.springCloud和Dubbo有什么区别4. SpringCloud由什么组成二.Spring Cloud Eureka1.Eureka包含几个组件2.Eureka的工作原理3.说一下什么是Eureka的自我保护机制4.什么是CAP原则5.都是服务注册中心,E…...

用户态驱动的两种方式-ixy学习
介绍在Linux下有两种启用用户态驱动的子系统:一个是UIO,另一个是VFIO,ixy这两种都支持。 UIO通过虚拟文件系统sysfs下的内存映射文件来暴露所有必要的接口以完成用户态的驱动。这些基于文件的系统调用接口给了我们充足的权限来获取设备资源而…...

机器学习 | 线性回归(单变量)
前文回顾:机器学习概述📚线性回归概念我们要使用一个数据集,数据集包含俄勒冈州波特兰市的住房价格。在这里,我要根据不同房屋尺寸所售出的价格,画出我的数据集。比方说,如果你朋友的房子是 1250 平方尺大小…...
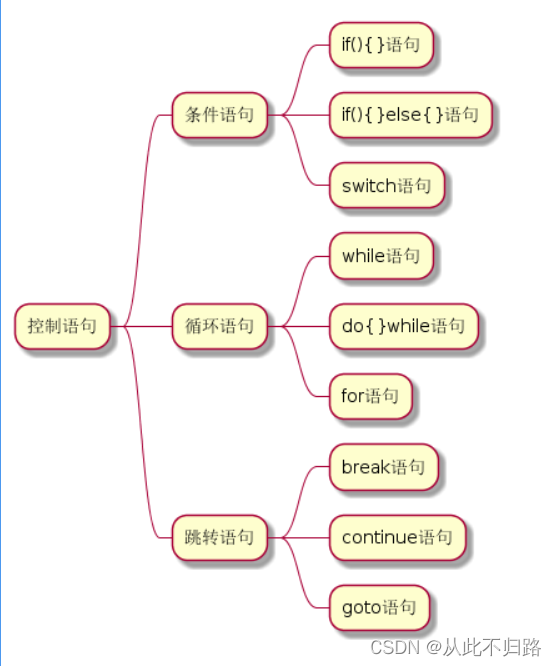
C++基础知识【3】控制语句
目录 前言 一、条件语句 1.1、if 语句 1.2、if-else 语句 1.3、switch 语句 二、循环语句 2.1、while 循环 2.2、do-while 循环 2.3、for 循环 三、跳转语句 3.1、break语句 3.2、continue语句 3.3、goto语句 四、一些新特性 4.1、if 语句和 switch 语句…...

ImportError: Can not find the shared library: libhdfs3.so解决方案
大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。喜欢通过博客创作的方式对所学的知识进行总结与归纳,不仅形成深入且独到的理…...
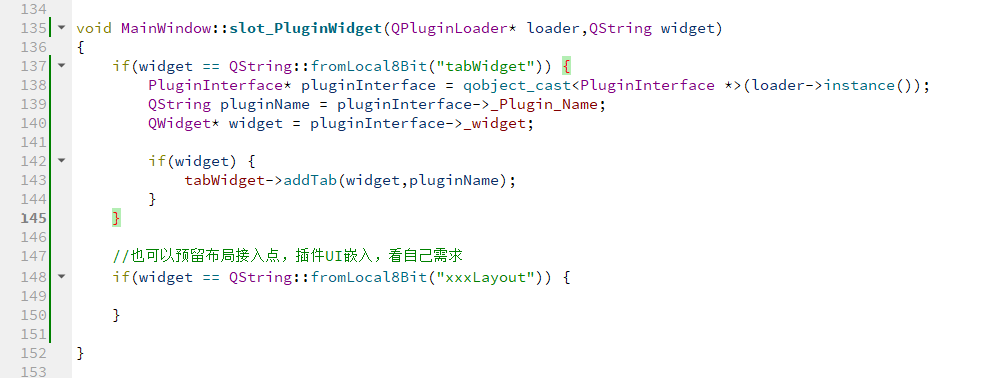
Qt插件开发总结5--主界面嵌入插件UI
文章目录一、前言二、效果展示三、嵌入插件UI1、插件接口文件添加UI指针2、插件子项目工程建立UI类3、插件类中创建UI类、使UI指针指向创建的UI类4、插件元信息中添加widget键值对,指示插件UI嵌入主界面中的位置5、主界面中预留接入点tabWidget6、插件管理器中元数据…...

一些关于linux process 和python process的记录
python mulprocess 主要用来生成另一个进程并运行 def func(i):print(helloworld)from multiprocessing import Process p Process(targetfunc,args(i, )) p.start()如果想要调用shell命令,可以采用os.popen 或者是 subprocess.run 但是前者只能执行命令并获取输…...
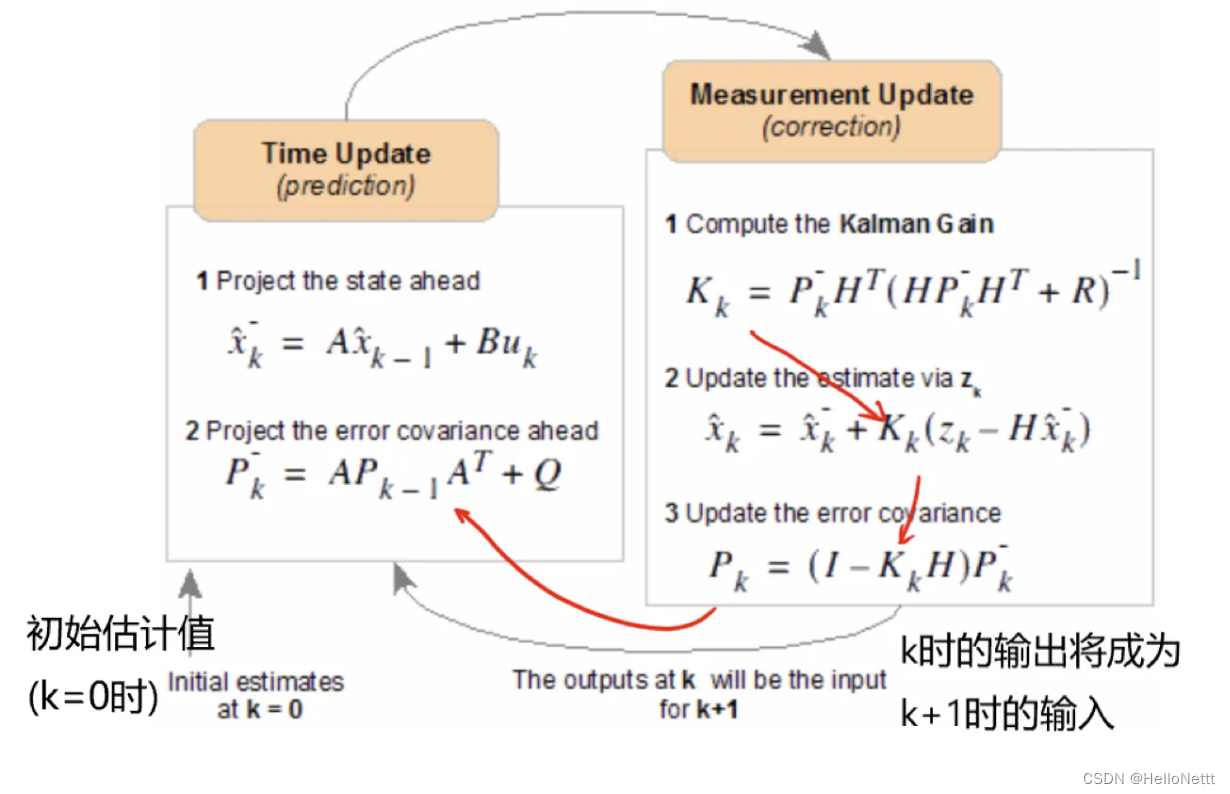
卡尔曼滤波——一种基于滤波的时序状态估计方法
文章目录1. Kalman滤波及其应用2. Kalman原理公式推导:Step 1:模型建立Step 2:开始Kalman滤波Step 3:迭代滤波本文是对 How a Kalman filter works, in pictures一文学习笔记,主要是提炼核心知识,方便作者快…...

什么是X6CrMo17-1
X6CrMo17-1X6CrMo17-1是在430的基礎上加入了鉬,提高鋼的耐點蝕、耐縫隙腐蝕性及強度等,比430鋼抗鹽溶液體性強。一、X6CrMo17-1對應牌號:1、國標GB-T標準:數字牌號:S11790、新牌號:10Cr17Mo、舊牌號&#x…...

【JavaEE】-- HTTP
1. HTTP是什么? HTTP(全称为"超文本传输协议")是一种应用非常广泛的应用层协议,HTTP是基于TCP协议的一种应用层协议。 应用层协议:是计算机网络协议栈中最高层的协议,它定义了运行在不同主机上…...

【人工智能】神经网络的优化器optimizer(二):Adagrad自适应学习率优化器
一.自适应梯度算法Adagrad概述 Adagrad(Adaptive Gradient Algorithm)是一种自适应学习率的优化算法,由Duchi等人在2011年提出。其核心思想是针对不同参数自动调整学习率,适合处理稀疏数据和不同参数梯度差异较大的场景。Adagrad通…...
)
相机Camera日志分析之三十一:高通Camx HAL十种流程基础分析关键字汇总(后续持续更新中)
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了:有对最普通的场景进行各个日志注释讲解,但相机场景太多,日志差异也巨大。后面将展示各种场景下的日志。 通过notepad++打开场景下的日志,通过下列分类关键字搜索,即可清晰的分析不同场景的相机运行流程差异…...

鱼香ros docker配置镜像报错:https://registry-1.docker.io/v2/
使用鱼香ros一件安装docker时的https://registry-1.docker.io/v2/问题 一键安装指令 wget http://fishros.com/install -O fishros && . fishros出现问题:docker pull 失败 网络不同,需要使用镜像源 按照如下步骤操作 sudo vi /etc/docker/dae…...

Rapidio门铃消息FIFO溢出机制
关于RapidIO门铃消息FIFO的溢出机制及其与中断抖动的关系,以下是深入解析: 门铃FIFO溢出的本质 在RapidIO系统中,门铃消息FIFO是硬件控制器内部的缓冲区,用于临时存储接收到的门铃消息(Doorbell Message)。…...

智能分布式爬虫的数据处理流水线优化:基于深度强化学习的数据质量控制
在数字化浪潮席卷全球的今天,数据已成为企业和研究机构的核心资产。智能分布式爬虫作为高效的数据采集工具,在大规模数据获取中发挥着关键作用。然而,传统的数据处理流水线在面对复杂多变的网络环境和海量异构数据时,常出现数据质…...

今日学习:Spring线程池|并发修改异常|链路丢失|登录续期|VIP过期策略|数值类缓存
文章目录 优雅版线程池ThreadPoolTaskExecutor和ThreadPoolTaskExecutor的装饰器并发修改异常并发修改异常简介实现机制设计原因及意义 使用线程池造成的链路丢失问题线程池导致的链路丢失问题发生原因 常见解决方法更好的解决方法设计精妙之处 登录续期登录续期常见实现方式特…...

学校时钟系统,标准考场时钟系统,AI亮相2025高考,赛思时钟系统为教育公平筑起“精准防线”
2025年#高考 将在近日拉开帷幕,#AI 监考一度冲上热搜。当AI深度融入高考,#时间同步 不再是辅助功能,而是决定AI监考系统成败的“生命线”。 AI亮相2025高考,40种异常行为0.5秒精准识别 2025年高考即将拉开帷幕,江西、…...

Java求职者面试指南:Spring、Spring Boot、MyBatis框架与计算机基础问题解析
Java求职者面试指南:Spring、Spring Boot、MyBatis框架与计算机基础问题解析 一、第一轮提问(基础概念问题) 1. 请解释Spring框架的核心容器是什么?它在Spring中起到什么作用? Spring框架的核心容器是IoC容器&#…...

怎么让Comfyui导出的图像不包含工作流信息,
为了数据安全,让Comfyui导出的图像不包含工作流信息,导出的图像就不会拖到comfyui中加载出来工作流。 ComfyUI的目录下node.py 直接移除 pnginfo(推荐) 在 save_images 方法中,删除或注释掉所有与 metadata …...