从文字到使用,一文读懂Kafka服务使用

🏆作者简介,普修罗双战士,一直追求不断学习和成长,在技术的道路上持续探索和实践。
🏆多年互联网行业从业经验,历任核心研发工程师,项目技术负责人。
🎉欢迎 👍点赞✍评论⭐收藏
Kafka知识专栏学习
| Kafka知识云集 | 访问地址 | 备注 |
|---|---|---|
| Kafka知识点(1) | https://blog.csdn.net/m0_50308467/article/details/134138971 | Kafka专栏 |
| Kafka知识点(2) | https://blog.csdn.net/m0_50308467/article/details/134733596 | Kafka专栏 |
文章目录
- 🔎 Kafka 入门学习
- 🍁01. 什么是Kafka?
- 🍁02. Kafka有什么特点,优缺点是什么?
- 🍁03. Kafka 与 Zookeeper 服务的关系?
- 🍁04. Kafka 的常见命令有哪些?
- 🍁05. Kafka 和 Zookeeper 服务如何结合?
- 🍁06. Kafka 生产者和消费者的流程图?
- 🍁6.1 生产者流程图
- 🍁6.2 消费者流程图
- 🍁07. 安装 Zookeeper 服务的详细步骤?
- 🍁08. 安装Kafka服务的详细步骤?
- 🍁09. Java项目结合Kafka服务使用。
- 🍁9.1 pom文件引入kafka服务
- 🍁9.2 创建Kafka消息发送组件
- 🍁9.3 创建Kafka消息消费组件
- 🍁9.4 Java项目使用Kafka小结

🔎 Kafka 入门学习
🍁01. 什么是Kafka?
Kafka是一个分布式流处理平台,最初由LinkedIn开发并开源。它被设计用于处理大规模的实时数据流,并能够持久化和发布数据记录。Kafka具有高吞吐量、可扩展性和容错性的特点,使得它成为构建实时流处理应用程序的理想选择。
Kafka的核心概念包括以下几个要素:
-
主题(Topic):主题是Kafka中的数据流分类,类似于消息队列中的队列。数据被发布到不同的主题中,消费者可以订阅感兴趣的主题来消费数据。
-
分区(Partition):主题可以被分为多个分区,每个分区是一个有序的日志文件,用于存储消息。分区允许数据在集群中并行处理和存储,提高了吞吐量和可扩展性。
-
副本(Replication):每个分区可以有多个副本,副本用于提供数据的冗余备份和容错性。副本分布在不同的服务器上,当某个副本不可用时,可以从其他副本中获取数据。
-
生产者(Producer):生产者是数据的发送者,负责将数据发布到Kafka的主题中。生产者可以将数据发送到指定的分区,也可以让Kafka根据一定的策略自动选择分区。
-
消费者(Consumer):消费者是数据的接收者,负责从Kafka的主题中读取数据。消费者可以以不同的方式消费数据,如按照时间顺序、按照分区等。
Kafka的应用场景非常广泛,包括日志收集、事件驱动架构、实时分析、流式处理等。它可以处理大规模的数据流,并具有高吞吐量、可靠性和可扩展性的特点,因此在处理实时数据和构建大规模数据流处理系统方面非常有价值。
🍁02. Kafka有什么特点,优缺点是什么?
Kafka具有以下特点:
-
高吞吐量:Kafka能够处理大规模的数据流,并提供很高的吞吐量。它通过将数据分区和并行处理,以及支持批量发送和接收,实现了高效的数据处理。
-
可扩展性:Kafka的分布式架构使得它可以轻松地扩展到多个服务器上,以适应不断增长的数据流量和负载。通过增加分区和副本,Kafka可以水平扩展,提高系统的容量和性能。
-
持久性:Kafka将数据持久化到磁盘中,以确保数据的可靠性和持久性。数据存储在分区中,并且可以根据需要保留一段时间,以便后续的数据分析和处理。
-
实时处理:Kafka是一个实时流处理平台,能够处理实时数据流。它支持低延迟的数据传输和处理,可以实时地将数据从生产者传递给消费者,并支持流式处理和实时分析。
-
容错性:Kafka通过将数据复制到多个副本中来提供容错性。当某个副本不可用时,可以从其他副本中获取数据,确保数据的可靠性和可用性。
-
灵活性:Kafka具有灵活的消息传递模型,可以根据需要进行消息的发布和订阅。它支持多种消息格式和协议,并提供了丰富的API和工具,使得开发者可以根据自己的需求进行定制和扩展。
Kafka的优点包括高吞吐量、可扩展性、持久性和实时处理能力,使得它成为处理大规模实时数据流的理想选择。然而,Kafka也有一些缺点:
-
复杂性:Kafka的配置和管理相对复杂,需要一定的专业知识和经验。对于初学者来说,上手可能会有一定的学习曲线。
-
存储成本:由于Kafka将数据持久化到磁盘中,需要一定的存储空间。对于大规模的数据流,存储成本可能会成为一个考虑因素。
-
延迟:尽管Kafka具有较低的延迟,但在某些场景下,特别是对于需要严格实时性的应用程序来说,延迟可能仍然是一个限制因素。
总体而言,Kafka是一个功能强大的分布式流处理平台,具有高吞吐量、可扩展性和持久性的优点,适用于处理大规模实时数据流的应用场景。然而,对于一些特定的需求,如低延迟和简单性,可能需要进行权衡和评估。
🍁03. Kafka 与 Zookeeper 服务的关系?
Kafka与Zookeeper是两个独立但密切相关的组件,它们在Kafka集群中扮演不同的角色。
Zookeeper是一个分布式的协调服务,用于管理和维护Kafka集群的元数据信息,包括主题、分区、消费者组等。Kafka使用Zookeeper来进行以下任务:
-
集群管理:Kafka集群中的每个节点都在Zookeeper中注册自己的信息,包括节点的IP地址、端口号等。Zookeeper负责监控和管理这些节点,以确保集群中的节点状态的一致性。
-
Leader选举:Kafka的每个分区都有一个分区领导者(Leader),负责处理该分区的读写请求。如果分区领导者不可用,Zookeeper会协助进行新的领导者选举,选择一个新的分区领导者。
-
消费者组协调:Kafka中的消费者可以组成消费者组,共同消费一个主题。Zookeeper负责协调消费者组的工作,包括分配分区给消费者、监控消费者的健康状态等。
-
动态扩缩容:当Kafka集群需要扩展或缩小规模时,Zookeeper可以帮助协调新节点的加入和旧节点的离开,以实现集群的动态扩缩容。
总结来说,Zookeeper在Kafka集群中扮演着重要的角色,用于管理和维护集群的元数据信息、协调分区的领导者选举以及消费者组的协调工作。Kafka依赖于Zookeeper来实现这些功能,因此在使用Kafka时需要同时启动和管理Zookeeper服务。
🍁04. Kafka 的常见命令有哪些?
Kafka的常见命令包括:
-
kafka-topics.sh:用于创建、查看和管理主题的命令。
- 创建主题:
kafka-topics.sh --create --topic my-topic --partitions 3 --replication-factor 1 --bootstrap-server localhost:9092 - 查看主题列表:
kafka-topics.sh --list --bootstrap-server localhost:9092 - 查看主题详情:
kafka-topics.sh --describe --topic my-topic --bootstrap-server localhost:9092 - 删除主题:
kafka-topics.sh --delete --topic my-topic --bootstrap-server localhost:9092
- 创建主题:
-
kafka-console-producer.sh:用于从命令行向主题发送消息的命令。
- 发送消息:
kafka-console-producer.sh --topic my-topic --bootstrap-server localhost:9092
- 发送消息:
-
kafka-console-consumer.sh:用于从命令行消费主题中的消息的命令。
- 消费消息:
kafka-console-consumer.sh --topic my-topic --bootstrap-server localhost:9092
- 消费消息:
-
kafka-consumer-groups.sh:用于管理消费者组的命令。
- 查看消费者组列表:
kafka-consumer-groups.sh --list --bootstrap-server localhost:9092 - 查看消费者组的消费情况:
kafka-consumer-groups.sh --describe --group my-group --bootstrap-server localhost:9092
- 查看消费者组列表:
-
kafka-configs.sh:用于管理Kafka配置的命令。
- 查看配置:
kafka-configs.sh --describe --entity-type topics --entity-name my-topic --bootstrap-server localhost:9092 - 修改配置:
kafka-configs.sh --alter --entity-type topics --entity-name my-topic --add-config max.message.bytes=1048576 --bootstrap-server localhost:9092
- 查看配置:
这些是Kafka的一些常见命令,用于管理和操作Kafka集群、主题、消费者组等。你可以根据需要使用这些命令来管理你的Kafka环境。
🍁05. Kafka 和 Zookeeper 服务如何结合?
Kafka和Zookeeper是紧密结合的,它们在Kafka集群中扮演不同的角色。下面是Kafka和Zookeeper服务如何结合的概述:
-
Kafka依赖Zookeeper:Kafka通过Zookeeper来管理和维护集群的元数据信息、协调分区的领导者选举以及消费者组的协调工作。Kafka集群中的每个节点都会将自己的信息注册到Zookeeper中,并通过Zookeeper来协调和同步集群中的各个节点。
-
Zookeeper保存Kafka的元数据:Kafka的主题、分区、消费者组等元数据信息都存储在Zookeeper中。Kafka通过与Zookeeper的交互来获取和更新这些元数据信息,以保持集群的一致性和可靠性。
-
Leader选举:Kafka的每个分区都有一个分区领导者(Leader),负责处理该分区的读写请求。当分区的领导者不可用时,Zookeeper会协助进行新的领导者选举,选择一个新的分区领导者。
-
消费者组协调:Kafka中的消费者可以组成消费者组,共同消费一个主题。Zookeeper负责协调消费者组的工作,包括分配分区给消费者、监控消费者的健康状态等。
总结来说,Kafka和Zookeeper通过密切的结合来实现Kafka集群的管理和协调。Kafka依赖于Zookeeper来管理集群的元数据、协调分区的领导者选举和消费者组的协调工作。因此,在使用Kafka时需要同时启动和管理Zookeeper服务,并确保Kafka集群和Zookeeper集群正常运行。
🍁06. Kafka 生产者和消费者的流程图?
🍁6.1 生产者流程图
看图识意:

🍁6.2 消费者流程图
看图识意:

🍁07. 安装 Zookeeper 服务的详细步骤?
安装Zookeeper服务的详细步骤如下:
-
下载和解压Zookeeper:从Zookeeper官方网站(https://zookeeper.apache.org)下载适合你系统的Zookeeper版本.解压下载的文件到你选择的目录中.
-
创建Zookeeper配置文件:在Zookeeper解压目录中,创建一个名为
zoo.cfg的配置文件,并添加以下内容:
tickTime=2000dataDir=/path/to/zookeeper/dataclientPort=2181
将 /path/to/zookeeper/data 替换为你希望存储Zookeeper数据的路径。
- 启动Zookeeper服务器:在Zookeeper解压目录中,执行以下命令启动Zookeeper服务器:
bin/zkServer.sh start
如果你想在后台运行Zookeeper服务器,可以使用以下命令:
bin/zkServer.sh start-foreground
- 验证Zookeeper服务器:执行以下命令验证Zookeeper服务器是否成功启动:
bin/zkCli.sh
这将打开Zookeeper的命令行客户端。在客户端中,你可以执行一些Zookeeper命令来测试服务器的正常运行。
完成了以上步骤后,你就成功安装并启动了Zookeeper服务。你可以将Zookeeper与Kafka等其他系统结合使用,以实现分布式应用程序的管理和协调。记得根据你的需求进行配置和调整,以适应你的应用场景。
🍁08. 安装Kafka服务的详细步骤?
安装Kafka服务的详细步骤如下:
-
安装Java:Kafka是用Java编写的,所以首先需要安装Java运行环境。确保你的系统上已经安装了Java,并且配置了正确的环境变量。
-
下载和解压Kafka:从Kafka官方网站(https://kafka.apache.org/downloads)下载适合你系统的Kafka版本。解压下载的文件到你选择的目录中。
-
配置Kafka:进入Kafka解压目录,编辑
config/server.properties文件来配置Kafka。你可以根据需要进行配置,例如修改监听端口、日志存储路径等。 -
启动Zookeeper:Kafka使用Zookeeper来管理集群的元数据信息。在Kafka解压目录中,执行以下命令启动Zookeeper服务器:
bin/zookeeper-server-start.sh config/zookeeper.properties
- 启动Kafka服务器:在Kafka解压目录中,执行以下命令启动Kafka服务器:
bin/kafka-server-start.sh config/server.properties
- 创建主题:使用
kafka-topics.sh命令创建一个新的主题。例如,以下命令将创建一个名为my-topic的主题:
bin/kafka-topics.sh --create --topic my-topic --partitions 3 --replication-factor 1 --bootstrap-server localhost:9092
- 测试Kafka:使用Kafka提供的命令行工具进行测试。可以使用
kafka-console-producer.sh命令向主题发送消息,并使用kafka-console-consumer.sh命令从主题消费消息。
完成了以上步骤后,你就成功安装了Kafka服务,并可以开始使用它进行数据的生产和消费。记得根据你的具体需求进行配置和调整,以适应你的应用场景。
🍁09. Java项目结合Kafka服务使用。
🍁9.1 pom文件引入kafka服务
在Java项目中使用Kafka服务,你需要在项目的pom.xml文件中添加Kafka相关的依赖项。下面是一个示例pom.xml文件,展示如何引入Kafka服务的依赖项:
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.example</groupId><artifactId>kafka-example</artifactId><version>1.0.0</version><dependencies><!-- Kafka dependencies --><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>2.8.0</version></dependency></dependencies></project>
在上述示例中,我们使用了Apache Kafka的kafka-clients依赖项。你可以根据需要选择适合的Kafka版本,并在 <dependencies> 标签中添加相应的依赖项。
完成pom.xml文件的修改后,保存并重新构建你的Java项目。这样,你的项目就可以使用Kafka相关的类和功能了。记得在代码中引入相应的Kafka包,以便使用Kafka的API进行生产和消费数据。
🍁9.2 创建Kafka消息发送组件
要在Java项目中创建Kafka消息发送组件,你可以使用Kafka提供的Java客户端API。以下是一个简单的示例,展示如何创建一个Kafka消息发送组件:
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.serialization.StringSerializer;import java.util.Properties;
import java.util.concurrent.Future;public class KafkaMessageSender {private KafkaProducer<String, String> producer;public KafkaMessageSender(String bootstrapServers) {Properties properties = new Properties();properties.put("bootstrap.servers", bootstrapServers);properties.put("key.serializer", StringSerializer.class.getName());properties.put("value.serializer", StringSerializer.class.getName());producer = new KafkaProducer<>(properties);}public void sendMessage(String topic, String message) {ProducerRecord<String, String> record = new ProducerRecord<>(topic, message);Future<RecordMetadata> future = producer.send(record);// 可以根据需要处理发送结果}public void close() {producer.close();}
}
在上述示例中,我们创建了一个 KafkaMessageSender 类,它使用KafkaProducer来发送消息。在构造函数中,我们配置了Kafka的连接信息和序列化器。 sendMessage 方法用于发送消息到指定的主题,你可以根据需要进行处理发送结果。 close 方法用于关闭KafkaProducer。
要使用这个Kafka消息发送组件,你可以在你的Java项目中创建一个实例,并调用 sendMessage 方法发送消息到Kafka主题。记得在创建组件实例时,提供正确的Kafka服务器地址(bootstrap.servers)。
public class Main {public static void main(String[] args) {KafkaMessageSender sender = new KafkaMessageSender("localhost:9092");sender.sendMessage("my-topic", "Hello Kafka!");sender.close();}
}
在上述示例中,我们创建了一个 Main 类,创建了一个 KafkaMessageSender 实例,并调用 sendMessage 方法发送消息到名为 my-topic 的Kafka主题。
🍁9.3 创建Kafka消息消费组件
要在Java项目中创建Kafka消息消费组件,你可以使用Kafka提供的Java客户端API。以下是一个简单的示例,展示如何创建一个Kafka消息消费组件:
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;import java.time.Duration;
import java.util.Collections;
import java.util.Properties;public class KafkaMessageConsumer {private KafkaConsumer<String, String> consumer;public KafkaMessageConsumer(String bootstrapServers, String groupId) {Properties properties = new Properties();properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);properties.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());consumer = new KafkaConsumer<>(properties);}public void consumeMessages(String topic) {consumer.subscribe(Collections.singletonList(topic));while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));for (ConsumerRecord<String, String> record : records) {System.out.println("Received message: " + record.value());// 可以根据需要处理接收到的消息}}}public void close() {consumer.close();}
}
在上述示例中,我们创建了一个 KafkaMessageConsumer 类,它使用KafkaConsumer来消费消息。在构造函数中,我们配置了Kafka的连接信息、消费者组ID以及序列化器。 consumeMessages 方法用于订阅指定的主题并消费消息。在消费循环中,我们使用 poll 方法来拉取消息,并遍历处理接收到的消息。你可以根据需要对消息进行处理。 close 方法用于关闭KafkaConsumer。
要使用这个Kafka消息消费组件,你可以在你的Java项目中创建一个实例,并调用 consumeMessages 方法来消费指定主题的消息。记得在创建组件实例时,提供正确的Kafka服务器地址(bootstrap.servers)和消费者组ID(group.id)。
public class Main {public static void main(String[] args) {KafkaMessageConsumer consumer = new KafkaMessageConsumer("localhost:9092", "my-group");consumer.consumeMessages("my-topic");// 在消费完成后记得调用 close 方法关闭消费者consumer.close();}
}
在上述示例中,我们创建了一个 Main 类,创建了一个 KafkaMessageConsumer 实例,并调用 consumeMessages 方法来消费名为 my-topic 的Kafka主题的消息。
🍁9.4 Java项目使用Kafka小结
使用Kafka的Java项目需要以下步骤:
-
下载和安装Kafka:从Kafka官方网站下载适合你系统的Kafka版本,并按照官方文档进行安装。
-
配置Kafka:编辑Kafka的配置文件,指定Kafka的监听地址、日志存储路径等配置项。
-
创建生产者:使用Kafka提供的Java客户端API,创建一个Kafka生产者,配置生产者的连接信息和序列化器。
-
发送消息:使用生产者发送消息到指定的Kafka主题。
-
创建消费者:使用Kafka提供的Java客户端API,创建一个Kafka消费者,配置消费者的连接信息和反序列化器。
-
订阅主题:让消费者订阅感兴趣的Kafka主题。
-
消费消息:从订阅的主题中轮询消费消息,并处理接收到的消息。
-
关闭生产者和消费者:在程序结束时,关闭生产者和消费者,释放资源。
使用Kafka的Java项目可以实现高吞吐量、可靠性和实时处理的数据流处理。Kafka提供了丰富的API和工具,使得在Java项目中使用Kafka变得简单和灵活。通过将消息发送到Kafka主题并从主题中消费消息,你可以构建实时流处理应用程序、日志收集系统、事件驱动架构等。
需要注意的是,Kafka的配置和管理可能需要一定的学习和经验。在使用Kafka时,建议参考官方文档和示例代码,以确保正确配置和使用Kafka的各项功能。

相关文章:
从文字到使用,一文读懂Kafka服务使用
🏆作者简介,普修罗双战士,一直追求不断学习和成长,在技术的道路上持续探索和实践。 🏆多年互联网行业从业经验,历任核心研发工程师,项目技术负责人。 🎉欢迎 👍点赞✍评论…...

什么是https加密协议?
前言: HTTPS(全称:Hypertext Transfer Protocol Secure) 是一个安全通信通道,它基于HTTP开发用于在客户计算机和服务器之间交换信息。它使用安全套接字层(SSL)进行信息交换,简单来说它是HTTP的安全版&…...
0012Java程序设计-ssm医院预约挂号及排队叫号系统
文章目录 **摘** **要**目 录系统实现5.2后端功能模块5.2.1管理员功能模块5.2.2医生功能模块 开发环境 摘 要 网络的广泛应用给生活带来了十分的便利。所以把医院预约挂号及排队叫号管理与现在网络相结合,利用java技术建设医院预约挂号及排队叫号系统,实…...
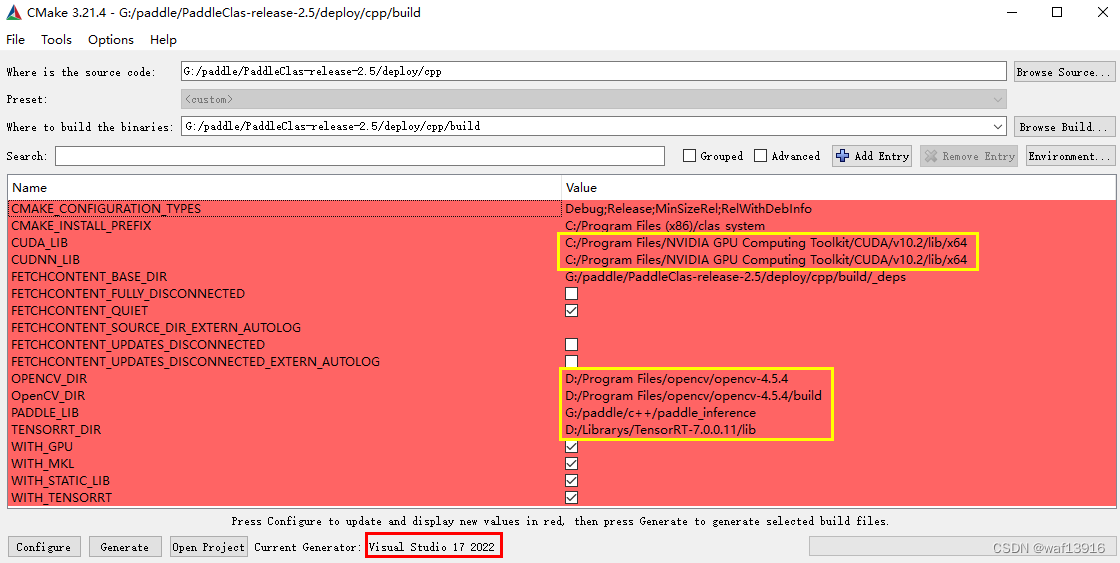
PaddleClas学习3——使用PPLCNet模型对车辆朝向进行识别(c++)
使用PPLCNet模型对车辆朝向进行识别 1 准备环境2 准备模型2.1 模型导出2.2 修改配置文件3 编译3.1 使用CMake生成项目文件3.2 编译3.3 执行3.4 添加后处理程序3.4.1 postprocess.h3.4.2 postprocess.cpp3.4.3 在cls.h中添加函数声明3.4.4 在cls.cpp中添加函数定义3.4.5 在main.…...
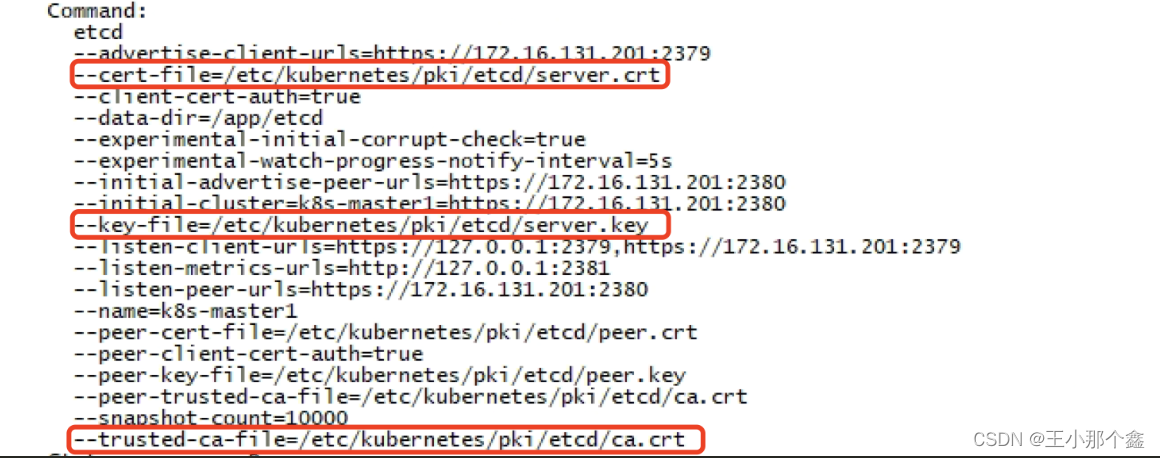
学习记录---kubernetes中备份和恢复etcd
一、简介 ETCD是kubernetes的重要组成部分,它主要用于存储kubernetes的所有元数据,我们在kubernetes中的所有资源(node、pod、deployment、service等),如果该组件出现问题,则可能会导致kubernetes无法使用、资源丢失等情况。因此…...

使用单例模式+观察者模式实现参数配置实时更新
使用vector存储观察者列表 #include <iostream> #include <vector> #include <functional> #include <algorithm>// 配置参数结构体 struct MyConfigStruct {int parameter1;std::string parameter2; };class Config { public:using Observer std::f…...

区块链实验室(28) - 拜占庭节点劫持区块链仿真
在以前的FISCO环境中仿真拜占庭节点攻击区块链网络。该环境共有100个节点,采用PBFT作为共识机制,节点编号分别为:Node0,Node,… ,Node99。这100个节点的前2010区块完全相同,自区块2011开始分叉。…...

聊聊AsyncHttpClient的ChannelPool
序 本文主要研究一下AsyncHttpClient的ChannelPool ChannelPool org/asynchttpclient/channel/ChannelPool.java public interface ChannelPool {/*** Add a channel to the pool** param channel an I/O channel* param partitionKey a key used to retrieve the cac…...
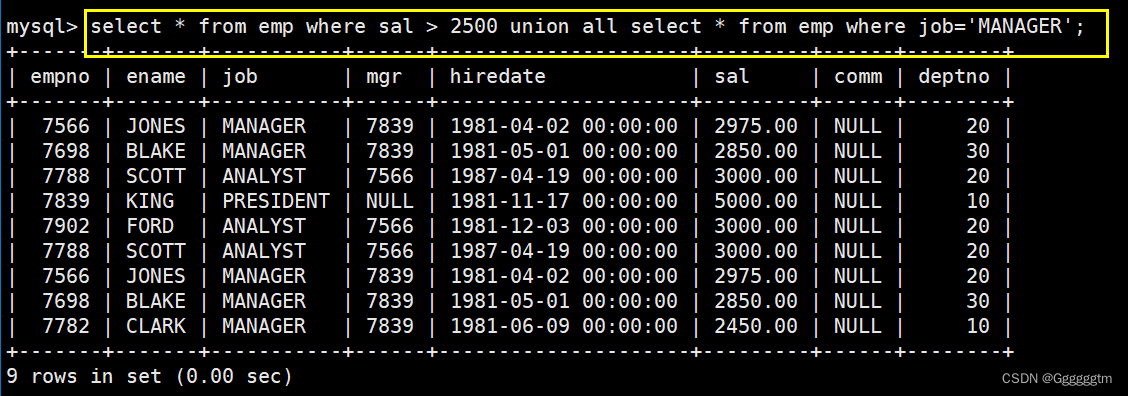
[MySQL] MySQL复合查询(多表查询、子查询)
前面我们学习了MySQL简单的单表查询。但是我们发现,在很多情况下单表查询并不能很好的满足我们的查询需求。本篇文章会重点讲解MySQL中的多表查询、子查询和一些复杂查询。希望本篇文章会对你有所帮助。 文章目录 一、基本查询回顾 二、多表查询 2、1 笛卡尔积 2、2…...

[架构之路-256]:目标系统 - 设计方法 - 软件工程 - 软件设计 - 架构设计 - 软件系统不同层次的复用与软件系统向越来越复杂的方向聚合
目录 前言: 一、CPU寄存器级的复用:CPU寄存器 二、指令级复用:二进制指令 三、过程级复用:汇编语言 四、函数级复用:C语言 五、对象级复用:C, Java, Python 六、组件级复用 七、服务级复用 八、微…...

C++初学教程三
目录 一、运算符 一、自增自减运算符 二、位运算符 三、关系运算符...

雷达点云数据.pcd格式转.bin格式
雷达点云数据.pcd格式转.bin格式 注意,方法1原则上可行,但是本人没整好pypcd的环境 方法2是绝对可以的。 方法1 1 源码如下: def pcb2bin1(): # save as bin formatimport os# import pypcdfrom pypcd import pypcdimport numpy as np…...

Fiddler抓包测试
模拟弱网测试 操作:一、Rules - Customize Rules (快捷键CtrlR)弹出编辑器 二、接着CtrlF查找m_SimulateModem标志位 三、默认上传300ms,下载150ms 四、更改后,继续Rules - Performances - Simulate Modem Speeds勾上 …...

视频处理关键知识
1 引言 视频技术发展到现在已经有100多年的历史,虽然比照相技术历史时间短,但在过去很长一段时间之内都是最重要的媒体。由于互联网在新世纪的崛起,使得传统的媒体技术有了更好的发展平台,应运而生了新的多媒体技术。而多媒体技术…...

LeetCode435. Non-overlapping Intervals
文章目录 一、题目二、题解 一、题目 Given an array of intervals intervals where intervals[i] [starti, endi], return the minimum number of intervals you need to remove to make the rest of the intervals non-overlapping. Example 1: Input: intervals [[1,2]…...

ffmpeg 实现多视频轨录制到同一个文件
引言 在视频录制中,有时会碰到这样一个需求,将不同摄像头的画面写入到一个视频文件,这个叫法很多,有的厂家叫合流模式,有的叫多画面多流模式。无论如何,它们的实质都是在一个视频文件上实现多路不同分辨率视…...

vue3中子组件调用父组件的方法
<script lang"ts" setup>前提 父组件: 子组件: const emit defineEmits([closeson]) 在子组件的方法中使用: emit(closeson)...

使用OkHttp上传本地图片及参数
下面以一个例子来讲解在项目中如何使用OKHttp来对本地图片做个最简单的上传功能,基本上无封装,只需要简单调用便可(对于OKHttp的引入不再单独做介绍)。 1:构建上传图片附带的参数(params) Map…...
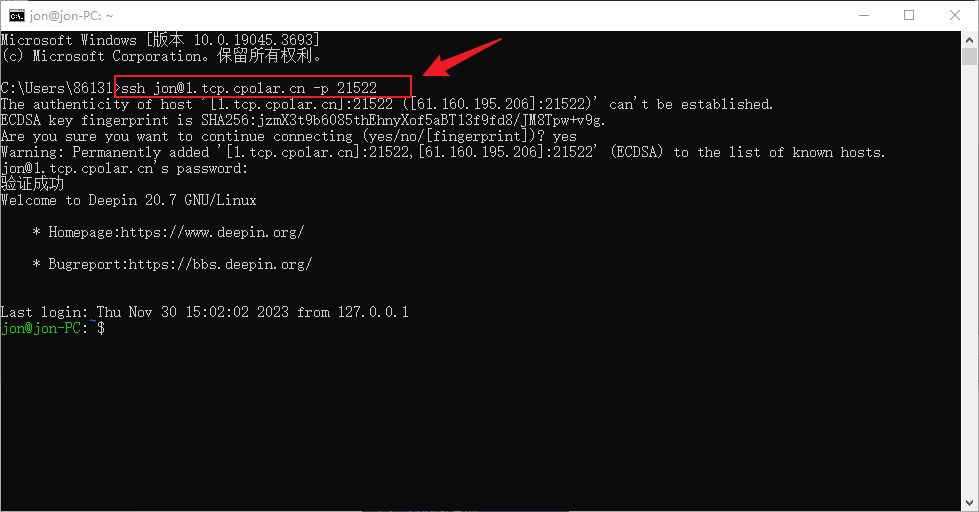
无公网IP环境如何SSH远程连接Deepin操作系统
文章目录 前言1. 开启SSH服务2. Deppin安装Cpolar3. 配置ssh公网地址4. 公网远程SSH连接5. 固定连接SSH公网地址6. SSH固定地址连接测试 前言 Deepin操作系统是一个基于Debian的Linux操作系统,专注于使用者对日常办公、学习、生活和娱乐的操作体验的极致࿰…...

不会代码(零基础)学语音开发(语音控制板载双继电器)
继电器的用途可广了,这个语音控制用处也特别广。继电器,它实际上是一种“自动开关”,用小电流去控制大电流运作,在电路中起着自动调节、安全保护、转换电路等作用。 在日常生活中,你插入汽车钥匙,车辆可以…...

KubeSphere 容器平台高可用:环境搭建与可视化操作指南
Linux_k8s篇 欢迎来到Linux的世界,看笔记好好学多敲多打,每个人都是大神! 题目:KubeSphere 容器平台高可用:环境搭建与可视化操作指南 版本号: 1.0,0 作者: 老王要学习 日期: 2025.06.05 适用环境: Ubuntu22 文档说…...

云启出海,智联未来|阿里云网络「企业出海」系列客户沙龙上海站圆满落地
借阿里云中企出海大会的东风,以**「云启出海,智联未来|打造安全可靠的出海云网络引擎」为主题的阿里云企业出海客户沙龙云网络&安全专场于5.28日下午在上海顺利举办,现场吸引了来自携程、小红书、米哈游、哔哩哔哩、波克城市、…...

Linux相关概念和易错知识点(42)(TCP的连接管理、可靠性、面临复杂网络的处理)
目录 1.TCP的连接管理机制(1)三次握手①握手过程②对握手过程的理解 (2)四次挥手(3)握手和挥手的触发(4)状态切换①挥手过程中状态的切换②握手过程中状态的切换 2.TCP的可靠性&…...

linux 下常用变更-8
1、删除普通用户 查询用户初始UID和GIDls -l /home/ ###家目录中查看UID cat /etc/group ###此文件查看GID删除用户1.编辑文件 /etc/passwd 找到对应的行,YW343:x:0:0::/home/YW343:/bin/bash 2.将标红的位置修改为用户对应初始UID和GID: YW3…...

深度学习习题2
1.如果增加神经网络的宽度,精确度会增加到一个特定阈值后,便开始降低。造成这一现象的可能原因是什么? A、即使增加卷积核的数量,只有少部分的核会被用作预测 B、当卷积核数量增加时,神经网络的预测能力会降低 C、当卷…...

【WebSocket】SpringBoot项目中使用WebSocket
1. 导入坐标 如果springboot父工程没有加入websocket的起步依赖,添加它的坐标的时候需要带上版本号。 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-websocket</artifactId> </dep…...

人工智能 - 在Dify、Coze、n8n、FastGPT和RAGFlow之间做出技术选型
在Dify、Coze、n8n、FastGPT和RAGFlow之间做出技术选型。这些平台各有侧重,适用场景差异显著。下面我将从核心功能定位、典型应用场景、真实体验痛点、选型决策关键点进行拆解,并提供具体场景下的推荐方案。 一、核心功能定位速览 平台核心定位技术栈亮…...

Spring Boot + MyBatis 集成支付宝支付流程
Spring Boot MyBatis 集成支付宝支付流程 核心流程 商户系统生成订单调用支付宝创建预支付订单用户跳转支付宝完成支付支付宝异步通知支付结果商户处理支付结果更新订单状态支付宝同步跳转回商户页面 代码实现示例(电脑网站支付) 1. 添加依赖 <!…...

CppCon 2015 学习:REFLECTION TECHNIQUES IN C++
关于 Reflection(反射) 这个概念,总结一下: Reflection(反射)是什么? 反射是对类型的自我检查能力(Introspection) 可以查看类的成员变量、成员函数等信息。反射允许枚…...

Selenium 查找页面元素的方式
Selenium 查找页面元素的方式 Selenium 提供了多种方法来查找网页中的元素,以下是主要的定位方式: 基本定位方式 通过ID定位 driver.find_element(By.ID, "element_id")通过Name定位 driver.find_element(By.NAME, "element_name"…...