大数据之HBase(二)
Master详细架构
- 位置:namenode
- 实现类:HMaster
- 组成
- 负载均衡器:通过meta了解region的分配,通过zk了解rs的启动情况,5分钟调控一次分配平衡
- 元数据表管理器:管理自己的预写日志,如果宕机,让备用节点读取日志
- 预写日志管理器WAL:32M或1小时滚动一次
RegionServer架构
- 位置:datanode
- 实现类:HRegionServer
- 读写过程
- 写过程:先把操作记录到WAL,然后记录到HDFS中的WAL预写日志中
- 读过程:一般从Block cache或Mem store中读取高频数据,否则再读取磁盘文件
- 必要服务
-
- Region拆分,合并
- mem store刷写
- wal预写日志滚动
-
HBase写流程
- 客户端向zk发送请求创建连接
- 读取zk存储meta表由哪个region server管理
- 访问103读取meta表
- 将读取的meta表作为属性保存在连接中
- 如果meta发生变化需要重新读取缓存
- 客户端发送put写操作请求
- 内存中将请求写入wal并落盘
- 内存将put请求写入mem store,此时已经返回操作成功的ack, 根据rk排序
- 等待触发刷写条件,写入对应的HDFS中的store,每次刷写会生成一个文件。
HBase读流程
- 客户端向zk发送请求创建连接
- 读取zk存储meta表由哪个region server管理
- 访问103读取meta表
- 将读取的meta表作为属性保存在连接中
- 如果meta发生变化需要重新读取缓存
- 客户端发送put读操作请求
- 读取Block cache
- 读取mem store
- 从磁盘中读取数据
- 合并这三个地方的数据,进行数据版本的合并
- HFile带有索引文件,读取rk挺快
- block cache会缓存之前读取的内容和元数据信息,如果HFile没有发生变化,则不需要再次读取
- 布隆过滤器:通过hash的方式排除掉一些肯定没有需要读取文件的位置
刷写Flush流程
- 如果一个store,即一个列族的大小超过128M,就会触发刷写
- 所有memstore的大小根据高低水位线触发,region会按照memstore的大小顺序依次刷写,知道总大小减小到一定范围
- 固定一个小时刷写一次
- 根据wal文件的数量进行刷写
文件结构
- hbase hfile查看命令参数
hbase hfile -m -p 路径/文件名:查看文件信息
storeFile合并
- 小合并:合并部分文件,减少文件的个数,加快读取效率;小合并频率高,每次刷写都会判断执行
- 文件个数3~10
- 文件大小128M之间,追求小合并快速进行
- 大合并:合并所有文件,定期清理掉过期和删除的数据;默认7天执行一次大合并
- 后期可以禁用
- 手动使用major_compact命令来控制合并时间点来进行大合并
Region拆分
- 原因:为了避免单个regioin的数据量太大
- 方式:
- 预分区(自定义分区)
- 系统分区拆分
系统拆分
实际操作:创建文件引用,不会挪动数据,两个region都由原先的regionServer管理。实际的挪动会到下次合并操作时处理。
- 拆分策略
- 按照常量大小拆分,首次拆分太晚,导致分布式效果很差
- 根据某个store的总大小,然后根据换算公式计算,大小根据分区个数的指数性增长
- 首次256M拆分,后续10G拆分
预分区(自定义分区)
根据实际数量、集群的规模等确定分区数。
建表时就创建好分区,防止表中数据被划分到不同分区。如果不指定,默认一个分区,随着表的变大,系统会自动拆分。
create 'staff1','info', SPLITS => ['1000','2000','3000','4000']
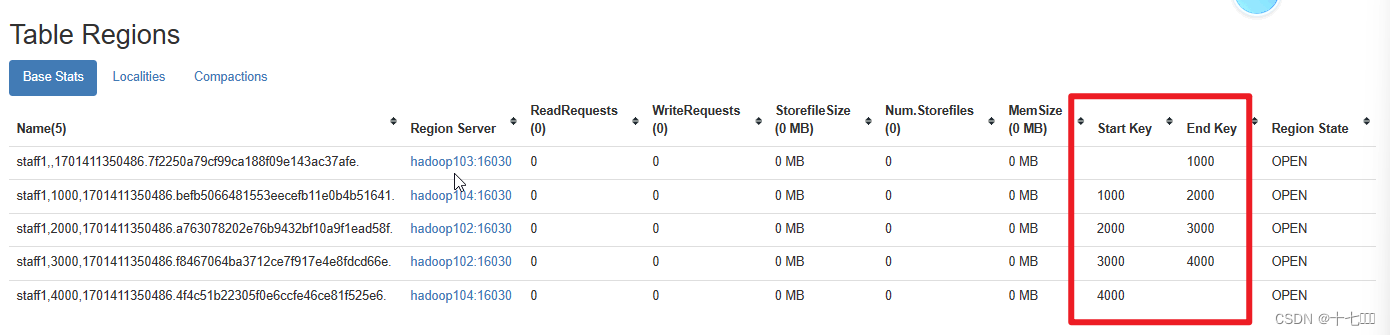
HBase优化
RowKey设计
由于rowkey是单调递增的,如果不做设计的话,后续分区时,虽然有多个分区,数据仍然只会往最后一个分区插入,这个就是热点分区问题。
设计原则
- 唯一性:每条数据的rowkey必须是唯一的
- 散列性:将需求的不变量放到rowkey的前面,变量放到后面。
- 长度:rowkey是冗余存储的,rowkey越长,冗余数据越多
HBase经验
- Block cahce负责读
- mem store负责写
HBase API
删除
public static void testDeleteData(String namespaceName, String tableName,String rk,String cf, String cl) throws IOException {//获取Table对象TableName tn = TableName.valueOf(namespaceName, tableName);Table table = connection.getTable(tn);Delete delete = new Delete(Bytes.toBytes(rk));
// delete.addColumn(Bytes.toBytes(cf),Bytes.toBytes(cl));
// delete.addColumns(Bytes.toBytes(cf),Bytes.toBytes(cl));//删除某个列族DeleteFamilydelete.addFamily(Bytes.toBytes(cf));//删除某个列DeleteColumns
// delete.addColumns(Bytes.toBytes(cf),Bytes.toBytes(cl));table.delete(delete);System.out.println("删除成功");table.close();}
查询
- get
Result result = table.get(get);
List<Cell> cells = result.listCells();
for(Cell cell : cells){//处理每个Kv的数据//获取rowkeyBytes.toString(CellUtil.cloneRow(cell));//获取列族名Bytes.toString(CellUtil.cloneFamily(cell));//获取列名Bytes.toString(CellUtil.cloneQualifier(cell));//获取数据值Bytes.toString(CellUtil.cloneRValue(cell));
}
- scan: 注意要添加起始rowkey和结束rowkey, 传入字符串类型参数即可,使用时使用Bytes.toBytes()转换为byte类型。
Scan scan = new Scan();
scan.withStartRow(Bytes.toBytes(startRow))
.withStopRow(Bytes.toBytes(endRow));
table.getScanner(scan);
相关文章:
大数据之HBase(二)
Master详细架构 位置:namenode实现类:HMaster组成 负载均衡器:通过meta了解region的分配,通过zk了解rs的启动情况,5分钟调控一次分配平衡元数据表管理器:管理自己的预写日志,如果宕机ÿ…...

前后端数据传输格式(下)
作者简介:大家好,我是smart哥,前中兴通讯、美团架构师,现某互联网公司CTO 联系qq:184480602,加我进群,大家一起学习,一起进步,一起对抗互联网寒冬 上篇主要复习了HTTP以及…...

mysql pxc高可用离线部署(三)
pxc学习流程 mysql pxc高可用 单主机 多主机部署(一) mysql pxc 高可用多主机离线部署(二) mysql pxc高可用离线部署(三) mysql pxc高可用 跨主机部署pxc 本文使用docker进行安装,主机间通过…...

XXL-JOB 日志表和日志文件自动清理
🚀 作者主页: 有来技术 🔥 开源项目: youlai-mall 🍃 vue3-element-admin 🍃 youlai-boot 🌺 仓库主页: Gitee 💫 Github 💫 GitCode 💖 欢迎点赞…...

常用sql记录
备份一张表 PostgreSQL CREATE TABLE new_table AS SELECT * FROM old_table;-- 下面这个比上面好,这个复制表结构时,会把默认值、约束、注释都复制 CREATE TABLE new_table (LIKE old_table INCLUDING ALL) WITHOUT OIDS; INSERT INTO new_table SELE…...
设备温度和振动综合监测:温振一体式传感器的优点和应用
随着工业设备的复杂性和自动化程度的提高,对设备状态监测的需求也日益增加。温振一体式传感器作为一种集振动和温度监测于一体的传感器,具备多项优势,因此在工业设备状态监测领域得到广泛应用。 温振一体式传感器基于振动传感器和温度传感器的…...
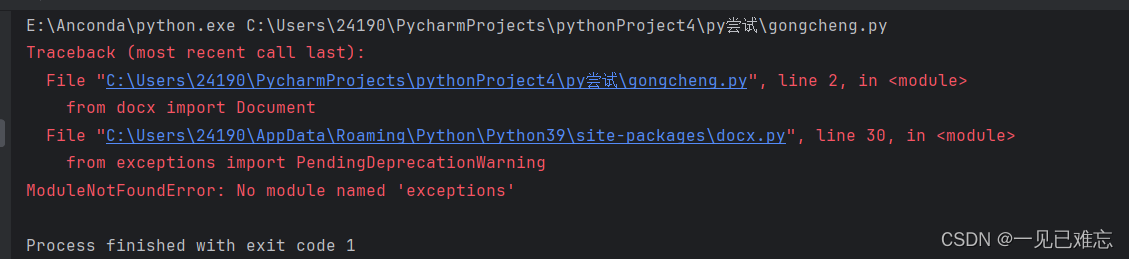
彻底解决ModuleNotFoundError: No module named ‘exceptions‘【Bug完美解决】
文章目录 项目场景:问题描述原因分析:解决方案:此Bug解决方案总结心得项目场景: 根据本文可找到bug原因并彻底解决**ModuleNotFoundError: No module named ‘exceptions‘**Bug 报错: E:\Anconda\python.exe c:\Users\24190\PycharmProjects\pythonProject4py尝试 gong…...

yarn和npm的区别
2023-12-8 yarn和npm的区别 是常用的包管理工具,用于node.js项目中安装、管理、和更新依赖项 有以下几个区别: 性能和速度:在包的安装和下载方面,yarn比npm更快速,yarn通过并行下载和缓存等优化策略,可以…...

设计图中时序图
设计图中的时序图通常用于展示两个或多个对象之间的交互和消息传递的顺序。它是一种用于描述软件或系统中的并发性和时序行为的工具。 以下是一个简单的时序图的示例: 首先,在时序图中创建两个对象,例如"对象A"和"对象B&quo…...
反射实现tomcat
获取类信息的方法 1.通过类对象 x.getClass() 2.通过class.forname方法 Class.forname(className);这里className是存储类名的字符串 3.通过类名.class 类名.class 通过类名创建对象 类名.newInstance(); 反射可以看到类的一切信息࿱…...

Ubuntu 安装 CUDA 和 cuDNN 详细步骤
我的Linux系统背景: 系统和驱动都已安装。 系统是centos 8。查看自己操作系统的版本信息:cat /etc/issue或者是 cat /etc/lsb-release 用nvidia-smi可以看到显卡驱动和可支持的最高cuda版本,我的是12.2。驱动版本是535.129.03 首先&#…...
ArkTS快速入门
一、概述 ArkTS是鸿蒙生态的应用开发语言。它在保持TypeScript(简称TS)基本语法风格的基础上,对TS的动态类型特性施加更严格的约束,引入静态类型。同时,提供了声明式UI、状态管理等相应的能力,让开发者可以…...

HTTP不同场景下的通信过程和用户上网认证过程分析
目录 HTTP不同场景的通信过程 HTTP正常交互过程 HTTP透明加速传输过程 HTTP代理服务器场景下交互过程 通过AC对上网用户不同场景的认证过程 AC上网认证正常交互过程 通过Cookie实现免认证交互过程 代理服务器场景下HTTP密码认证交互过程 HTTP不同场景的通信过程 HTTP、…...

VR 实现 Splash Screen 效果
文章目录 背景官方实现逆向分析 背景 手机 App 在实现 Splash Screen 的时候,目前都有成熟的方案可以参考,但是在做 VR 开发时,要如何实现一个 App 自己的 Splash Screen ,下面是我们基于 PICO & OCULUS 进行业务开发时经过探…...
HarmonyOS学习--TypeScript语言学习(一)
注意:这只是我学习的笔记!!! 注意:这只是我学习的笔记!!! 注意:这只是我学习的笔记!!! 本章目录如下: 一、TypeScript语言…...

【C语言】函数递归详解(一)
目录 1.什么是递归: 1.1递归的思想: 1.2递归的限制条件: 2.递归举例: 2.1举例1:求n的阶乘: 2.1.1 分析和代码实现: 2.1.2图示递归过程: 2.2举例2:顺序打印一个整数的…...

WT588F02B-8S语音芯片助力破壁机:智能声音播放提示IC引领健康生活新潮流
在追求健康饮食的时代潮流中,破壁机作为榨汁、搅拌的重要厨房电器,融入智能技术的趋势不断加强。唯创知音的WT588F02B-8S语音芯片作为声音播放提示IC,为破壁机注入了更智能、便捷的声音提示功能,引领用户迈入健康生活的新潮流。 …...

NXP iMX8M Plus Qt5 双屏显示
By Toradex胡珊逢 简介 双屏显示在显示设备中有着广泛的应用,可以面向不同群体展示特定内容。文章接下来将使用 Verdin iMX8M Plus 的 Arm 计算机模块演示如何方便地在 Toradex 的 Linux BSP 上实现在两个屏幕上显示独立的 Qt 应用。 硬件介绍 Verdin iMX8M Plu…...

RepidJson中Writer类、FilewriteStream类、 PrettyWriter类的区别
rapidjson是一个C的JSON解析库,可以用于解析和序列化JSON数据。 Writer是rapidjson中一种基本的输出流,用于将JSON数据输出到字符串或文件中。 FileWriteStream是一个Writer的子类,它专门用于将JSON数据输出到文件中。相比于普通的Writer&a…...

IntelliJ idea卡顿解决,我遇到的比较管用的方案
Setttings> Build, Execution,Deployment>Debugger> Data Views> Java 取消 Enable "toString()" object view; Speed up debugging in IntelliJ Yesterday, I observed painfully slow debugging in IntelliJ. Every step over or step in took almost…...

设计模式和设计原则回顾
设计模式和设计原则回顾 23种设计模式是设计原则的完美体现,设计原则设计原则是设计模式的理论基石, 设计模式 在经典的设计模式分类中(如《设计模式:可复用面向对象软件的基础》一书中),总共有23种设计模式,分为三大类: 一、创建型模式(5种) 1. 单例模式(Sing…...

SciencePlots——绘制论文中的图片
文章目录 安装一、风格二、1 资源 安装 # 安装最新版 pip install githttps://github.com/garrettj403/SciencePlots.git# 安装稳定版 pip install SciencePlots一、风格 简单好用的深度学习论文绘图专用工具包–Science Plot 二、 1 资源 论文绘图神器来了:一行…...

质量体系的重要
质量体系是为确保产品、服务或过程质量满足规定要求,由相互关联的要素构成的有机整体。其核心内容可归纳为以下五个方面: 🏛️ 一、组织架构与职责 质量体系明确组织内各部门、岗位的职责与权限,形成层级清晰的管理网络…...

跨链模式:多链互操作架构与性能扩展方案
跨链模式:多链互操作架构与性能扩展方案 ——构建下一代区块链互联网的技术基石 一、跨链架构的核心范式演进 1. 分层协议栈:模块化解耦设计 现代跨链系统采用分层协议栈实现灵活扩展(H2Cross架构): 适配层…...

现代密码学 | 椭圆曲线密码学—附py代码
Elliptic Curve Cryptography 椭圆曲线密码学(ECC)是一种基于有限域上椭圆曲线数学特性的公钥加密技术。其核心原理涉及椭圆曲线的代数性质、离散对数问题以及有限域上的运算。 椭圆曲线密码学是多种数字签名算法的基础,例如椭圆曲线数字签…...

JDK 17 新特性
#JDK 17 新特性 /**************** 文本块 *****************/ python/scala中早就支持,不稀奇 String json “”" { “name”: “Java”, “version”: 17 } “”"; /**************** Switch 语句 -> 表达式 *****************/ 挺好的ÿ…...

MySQL中【正则表达式】用法
MySQL 中正则表达式通过 REGEXP 或 RLIKE 操作符实现(两者等价),用于在 WHERE 子句中进行复杂的字符串模式匹配。以下是核心用法和示例: 一、基础语法 SELECT column_name FROM table_name WHERE column_name REGEXP pattern; …...

Aspose.PDF 限制绕过方案:Java 字节码技术实战分享(仅供学习)
Aspose.PDF 限制绕过方案:Java 字节码技术实战分享(仅供学习) 一、Aspose.PDF 简介二、说明(⚠️仅供学习与研究使用)三、技术流程总览四、准备工作1. 下载 Jar 包2. Maven 项目依赖配置 五、字节码修改实现代码&#…...

MFC 抛体运动模拟:常见问题解决与界面美化
在 MFC 中开发抛体运动模拟程序时,我们常遇到 轨迹残留、无效刷新、视觉单调、物理逻辑瑕疵 等问题。本文将针对这些痛点,详细解析原因并提供解决方案,同时兼顾界面美化,让模拟效果更专业、更高效。 问题一:历史轨迹与小球残影残留 现象 小球运动后,历史位置的 “残影”…...

三分算法与DeepSeek辅助证明是单峰函数
前置 单峰函数有唯一的最大值,最大值左侧的数值严格单调递增,最大值右侧的数值严格单调递减。 单谷函数有唯一的最小值,最小值左侧的数值严格单调递减,最小值右侧的数值严格单调递增。 三分的本质 三分和二分一样都是通过不断缩…...