当参数调优无法解决kafka消息积压时可以这么做
今天的议题是:如何快速处理kafka的消息积压
通常的做法有以下几种:
- 增加消费者数
- 增加 topic 的分区数,从而进一步增加消费者数
- 调整消费者参数,如
max.poll.records - 增加硬件资源
常规手段不是本文的讨论重点或者当上面的手段已经使用过依然存在很严重的消息积压时该怎么办?本文给出一种增加消费者消费速率的方案。我们知道消息积压往往是因为生产速率远大于消费速率,本文的重点就是通过提高消费速率来解决消息积压。
经验判断,消费速率低下的主要原因往往都是数据处理时间长,业务逻辑复杂最终导致一次 poll 的时间被无限拉长,如果可以通过增加数据处理的线程数来降低一次 poll 的时间那么问题就解决了。但是需要注意一下几点:
- 业务逻辑对乱序数据不敏感,因为并行一定会导致乱序问题
- kafka 的消费者是线程不安全的
- 如何提交 offset
基于上述几点,思路就是消费者 poll 下来一批数据,交给多个线程去并行处理,消费者等待所有线程执行完后提交。为了减少线程的创建与销毁则维护一个线程池。代码如下:
第一步:创建一个MultipleConsumer类用于封装消费者和线程池
public class MultipleConsumer {private final KafkaConsumer<String, String> consumer;private final int threadNum;private final ExecutorService threadPool;private boolean isRunning = true;public MultipleConsumer(Properties properties, List<String> topics, int threadNum) {// 实例化消费者consumer = new KafkaConsumer<>(properties);// 订阅主题consumer.subscribe(topics);this.threadNum = threadNum;this.threadPool = Executors.newFixedThreadPool(threadNum);}
}
理论上相较于传统的消费速率可以提升 threadNum 倍。
第二步:因为需要并行处理一批 poll 数据,因此需要对数据进行切分,切分逻辑如下
private Map<Integer, List<ConsumerRecord<String, String>>> splitTask(ConsumerRecords<String, String> consumerRecords) {HashMap<Integer, List<ConsumerRecord<String, String>>> tasks = new HashMap<>();for (int i = 0; i < threadNum; i++) {tasks.put(i, new ArrayList<>());}int recordIndex = 0;for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {tasks.get(recordIndex % threadNum).add(consumerRecord);recordIndex++;}return tasks;}
这里采用轮训的方式且切分的个数与 threadNum 一致,尽可能保证每个线程处理的数据数量相差不大
第三步:定义一个静态内部类用来处理数据,并处理同步逻辑(因为需要等待所有线程执行完再提交 offset)
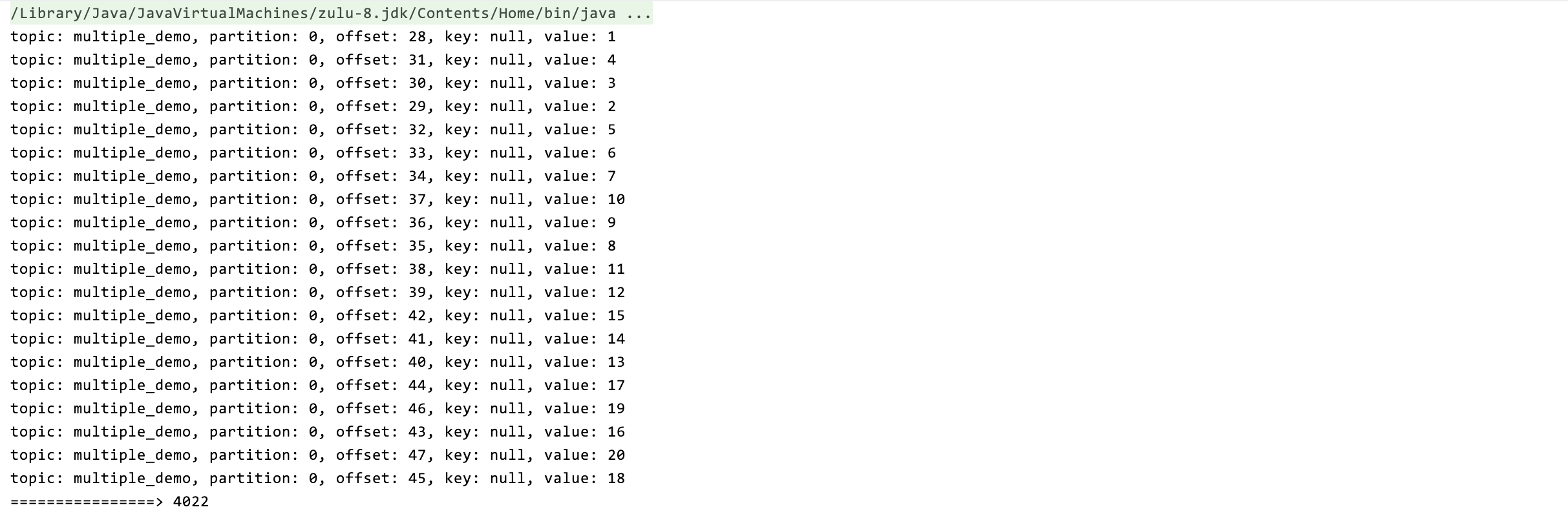
private static class InnerProcess implements Runnable {private final List<ConsumerRecord<String, String>> records;private final CountDownLatch countDownLatch;public InnerProcess(List<ConsumerRecord<String, String>> records, CountDownLatch countDownLatch) {this.records = records;this.countDownLatch = countDownLatch;}@Overridepublic void run() {try {// 处理消息for (ConsumerRecord<String, String> record : records) {System.out.println("topic: " + record.topic() + ", partition: " + record.partition() + ", offset: " + record.offset() + ", key: " + record.key() + ", value: " + record.value());TimeUnit.SECONDS.sleep(1);}} catch (InterruptedException e) {e.printStackTrace();} finally {countDownLatch.countDown();}}}
使用 CountDownLatch 实现线程同步逻辑,假设每条数据的业务处理时间为 1 s
第四步:消费者 poll 逻辑
public void start() {while (isRunning) {ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofSeconds(5));if (!consumerRecords.isEmpty()) {// 分割任务Map<Integer, List<ConsumerRecord<String, String>>> splitTask = splitTask(consumerRecords);CountDownLatch countDownLatch = new CountDownLatch(threadNum);// 提交任务for (int i = 0; i < threadNum; i++) {threadPool.submit(new InnerProcess(splitTask.get(i), countDownLatch));}// 等待任务执行结束try {countDownLatch.await();} catch (InterruptedException e) {throw new RuntimeException(e);}// 提交偏移量consumer.commitAsync((map, e) -> {if (e != null) {System.out.println("提交偏移量失败");}});}}}
完整代码如下:
import org.apache.kafka.clients.consumer.*;import java.time.Duration;
import java.time.temporal.ChronoUnit;
import java.util.*;
import java.util.concurrent.*;/*** @author wjun* @date 2023/3/1 14:50* @email wjunjobs@outlook.com* @describe*/
public class MultipleConsumer {private final KafkaConsumer<String, String> consumer;private final int threadNum;private final ExecutorService threadPool;private boolean isRunning = true;public MultipleConsumer(Properties properties, List<String> topics, int threadNum) {// 实例化消费者consumer = new KafkaConsumer<>(properties);// 订阅主题consumer.subscribe(topics);this.threadNum = threadNum;this.threadPool = Executors.newFixedThreadPool(threadNum);}public void start() {while (isRunning) {ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofSeconds(5));if (!consumerRecords.isEmpty()) {// 分割任务Map<Integer, List<ConsumerRecord<String, String>>> splitTask = splitTask(consumerRecords);CountDownLatch countDownLatch = new CountDownLatch(threadNum);// 提交任务for (int i = 0; i < threadNum; i++) {threadPool.submit(new InnerProcess(splitTask.get(i), countDownLatch));}// 等待任务执行结束try {countDownLatch.await();} catch (InterruptedException e) {throw new RuntimeException(e);}// 提交偏移量consumer.commitAsync((map, e) -> {if (e != null) {System.out.println("提交偏移量失败");}});}}}private Map<Integer, List<ConsumerRecord<String, String>>> splitTask(ConsumerRecords<String, String> consumerRecords) {HashMap<Integer, List<ConsumerRecord<String, String>>> tasks = new HashMap<>();for (int i = 0; i < threadNum; i++) {tasks.put(i, new ArrayList<>());}int recordIndex = 0;for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {tasks.get(recordIndex % threadNum).add(consumerRecord);recordIndex++;}return tasks;}public void stop() {isRunning = false;threadPool.shutdown();}private static class InnerProcess implements Runnable {private final List<ConsumerRecord<String, String>> records;private final CountDownLatch countDownLatch;public InnerProcess(List<ConsumerRecord<String, String>> records, CountDownLatch countDownLatch) {this.records = records;this.countDownLatch = countDownLatch;}@Overridepublic void run() {try {// 处理消息for (ConsumerRecord<String, String> record : records) {System.out.println("topic: " + record.topic() + ", partition: " + record.partition() + ", offset: " + record.offset() + ", key: " + record.key() + ", value: " + record.value());TimeUnit.SECONDS.sleep(1);}} catch (InterruptedException e) {e.printStackTrace();} finally {countDownLatch.countDown();}}}
}
测试一下:
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.Test;import java.util.ArrayList;
import java.util.List;
import java.util.Properties;/*** @author wjun* @date 2023/3/1 16:03* @email wjunjobs@outlook.com* @describe*/
public class MultipleConsumerTest {private static final Properties properties = new Properties();private static final List<String> topics = new ArrayList<>();public static void before() {properties.put("bootstrap.servers", "localhost:9092");properties.put("group.id", "test");properties.put("enable.auto.commit", "false");properties.put("auto.commit.interval.ms", "1000");properties.put("session.timeout.ms", "30000");properties.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");properties.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");topics.add("multiple_demo");}public static void main(String[] args) {new MultipleConsumer(properties, topics, 5).start();}
}
20 条数据的处理事件只需要 4s(threadNume = 5,即缩短 5 倍)
但是此方法的缺点:
- 只适用于业务逻辑复杂导致的处理时间长的场景
- 对数据乱序不敏感的业务场景
相关文章:
当参数调优无法解决kafka消息积压时可以这么做
今天的议题是:如何快速处理kafka的消息积压 通常的做法有以下几种: 增加消费者数增加 topic 的分区数,从而进一步增加消费者数调整消费者参数,如max.poll.records增加硬件资源 常规手段不是本文的讨论重点或者当上面的手段已经使…...
Java线程池源码分析
Java 线程池的使用,是面试必问的。下面我们来从使用到源码整理一下。 1、构造线程池 通过Executors来构造线程池 1、构造一个固定线程数目的线程池,配置的corePoolSize与maximumPoolSize大小相同, 同时使用了一个无界LinkedBlockingQueue存…...
手撕八大排序(下)
目录 交换排序 冒泡排序: 快速排序 Hoare法 挖坑法 前后指针法【了解即可】 优化 再次优化(插入排序) 迭代法 其他排序 归并排序 计数排序 排序总结 结束了上半章四个较为简单的排序,接下来的难度将会大幅度上升&…...
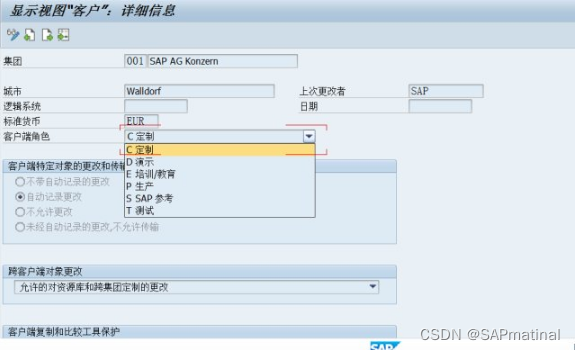
SAP 详细解析SCC4
事务代码:SCC4,选择一个客户端,点击进入,如图: 一、客户端角色 客户控制:客户的角色(生产性,测试,...) 此属性表示 R/3 系统中的客户端角色。其中可能包括…...
java异常分类和finally代码块中return语句的影响
首先看一下java中异常相关类的继承关系: 引用 1、分类 异常可以分为受查异常和非受查异常,Error和RuntimeException及其所有的子类都是非受查异常,其他的是受查异常。 两者的区别主要在: 受检的异常是由编译器(编译…...

【链表OJ题(二)】链表的中间节点
📝个人主页:Sherry的成长之路 🏠学习社区:Sherry的成长之路(个人社区) 📖专栏链接:数据结构 🎯长路漫漫浩浩,万事皆有期待 文章目录链表OJ题(二)1. 链表…...
【强烈建议收藏:MySQL面试必问系列之并发事务锁专题】
一.知识回顾 上节课我们一起学习了MySQL面试必问系列之事务,没有学习的同学可以看一下上一篇文章,肯定对你会有帮助,学习过的同学肯定知道,上节课我们留了一个小尾巴,这个小尾巴是什么呢?就是没有详细展开…...
Linux下使用Makefile实现条件编译
在Linux系统下Makefile和C/C语言都有提供条件选择编译的语法,就是在编译源码的时候,可以选择性地编译指定的代码。这种条件选择编译的使用场合有好多,例如我们开发一个兼容标准版本与定制版本兼容的项目,那么,一些与需…...
java 应用cpu飙升(超过100%)故障排查
前言害。。。昨天刚写完一份关于jvm问题排查相关的博客,今天线上项目就遇到了一个突发问题。现象是用户反映系统非常卡,无法操作。然后登录服务器查看发现cpu 一直100%以上。具体排查步骤:1,首先top命令查看服务器cpu等情况&#…...
光学设计软件Ansys的Lumerical 2023版本下载与安装使用
文章目录前言一、许可管理工具安装二、许可管理器配置三、Lumerical安装四、工具使用配置总结前言 Lumerical是一款功能强大的软件,用于设计和分析从组件到系统阶段的光子学和电磁学。这个版本的Lumerical改进了电子和光子学设计工具,用于复杂光子学&am…...
Java 异常
文章目录1. 异常概述2. JVM 的默认处理方案3. 异常处理之 try...catch4. Throwable 的成员方法5. 编译异常和运行异常的区别6. 异常处理之 throws7. 自定义异常8. throws 和 throw 的区别1. 异常概述 异常就是程序出现了不正常的情况。 ① Error:严重问题ÿ…...
JavaSE学习笔记day17
零、 复习昨日 File: 通过路径代表一个文件或目录 方法: 创建型,查找类,判断类,其他 IO 输入& 输出字节&字符 try-catch代码 一、作业 给定路径删除该文件夹 public static void main(String[] args) {deleteDir(new File("E:\\A"));}// 删除文件夹public s…...
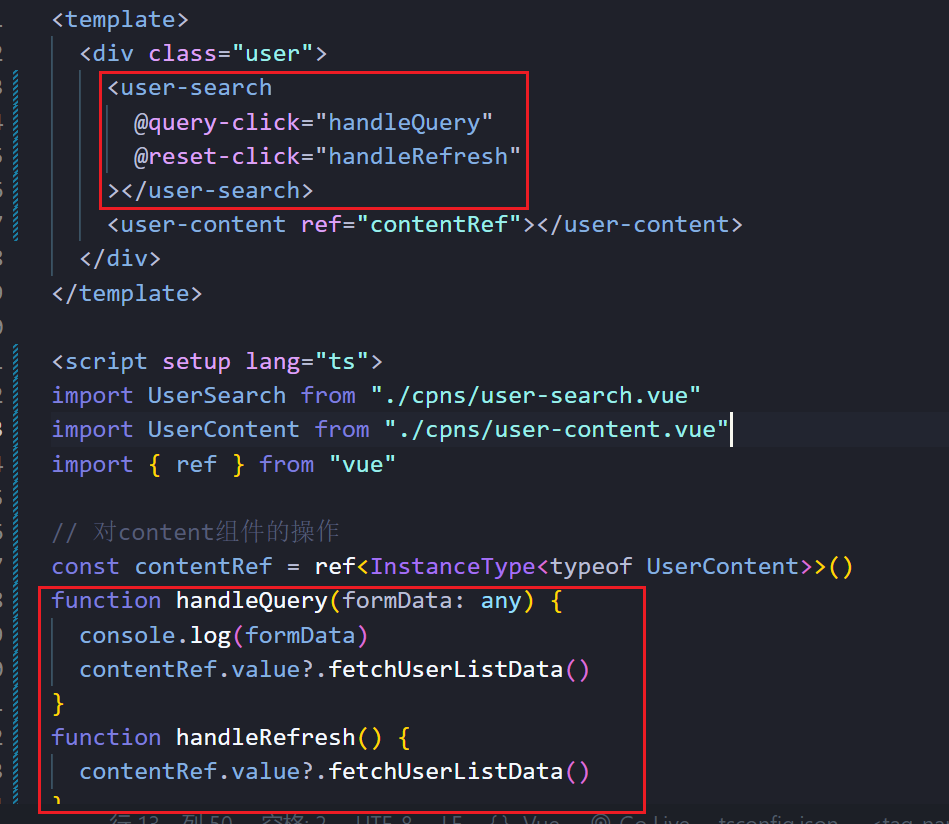
【项目】Vue3+TS 动态路由 面包屑 查询重置 列表
💭💭 ✨:【项目】Vue3TS 动态路由 面包屑 查询重置 列表 💟:东非不开森的主页 💜: 热烈的不是青春,而是我们💜💜 🌸: 如有错误或不足之处࿰…...

前脚背完这些接口自动化测试面试题,后脚就进了字节测试岗
1、请结合你熟悉的项目,介绍一下你是怎么做测试的? -首先要自己熟悉项目,熟悉项目的需求、项目组织架构、项目研发接口等 -功能 接口 自动化 性能 是怎么处理的? -第一步: 进行需求分析,需求评审&#…...

termux 安装centos
相关链接 centos官网rootfs制作其他人提供的安装脚本centos镜像列表其他人提供的安装脚本的说明 如果想使用老版本的centos7跟着上面链接5走就行 如果想用新系统比如centos9 stream,就跟我来 Q:为什么要装新系统? A:旧系统太多软件已过时,升级费时费…...
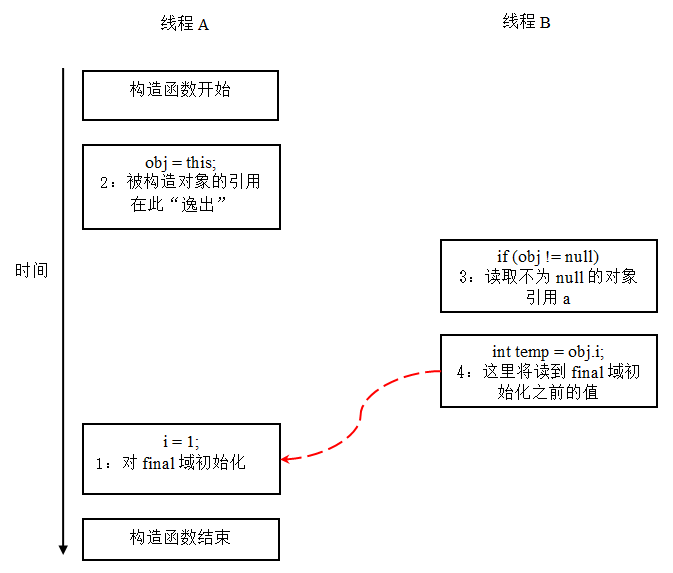
从菜鸟程序员到高级架构师,竟然是因为这个字final
final实现原理 简介 final关键字,实际的含义就一句话,不可改变。什么是不可改变?就是初始化完成之后就不能再做任何的修改,修饰成员变量的时候,成员变量变成一个常数;修饰方法的时候,方法不允…...
【vulhub漏洞复现】CVE-2018-2894 Weblogic任意文件上传漏洞
一、漏洞详情影响版本weblogic 10.3.6.0、weblogic 12.1.3.0、weblogic 12.2.1.2、weblogic 12.2.1.3WebLogic是美国Oracle公司出品的一个application server,确切的说是一个基于JAVAEE架构的中间件,WebLogic是用于开发、集成、部署和管理大型分布式Web应…...
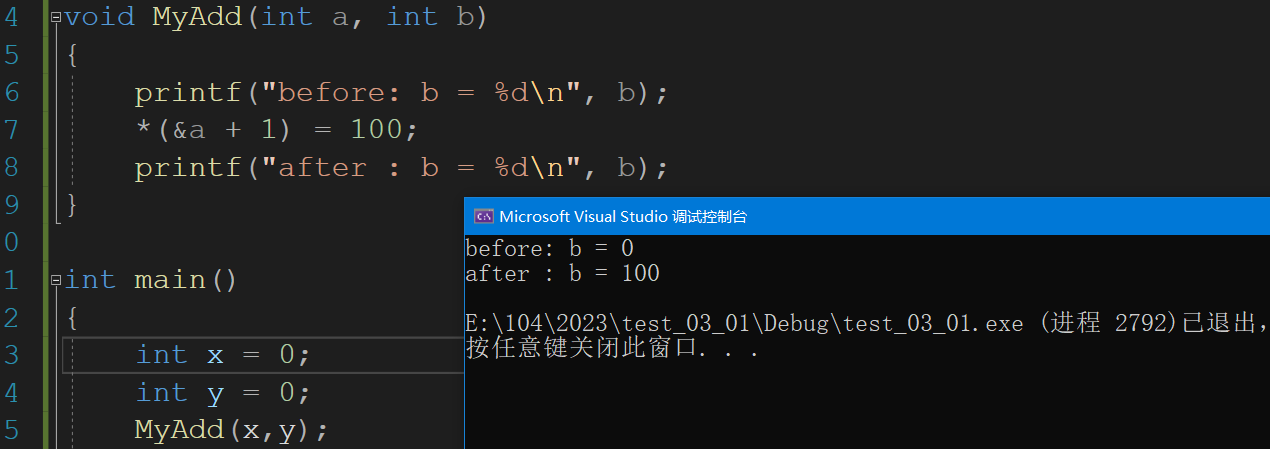
函数栈帧详解
写在前面 这个模块临近C语言的边界,学起来需要一定的时间,不过当我们知道这些知识后,在C语言函数这块我们看到的不仅仅是表象了,可以真正了解函数是怎么调用的。不过我的能力有限,下面的的知识若是不当,还…...
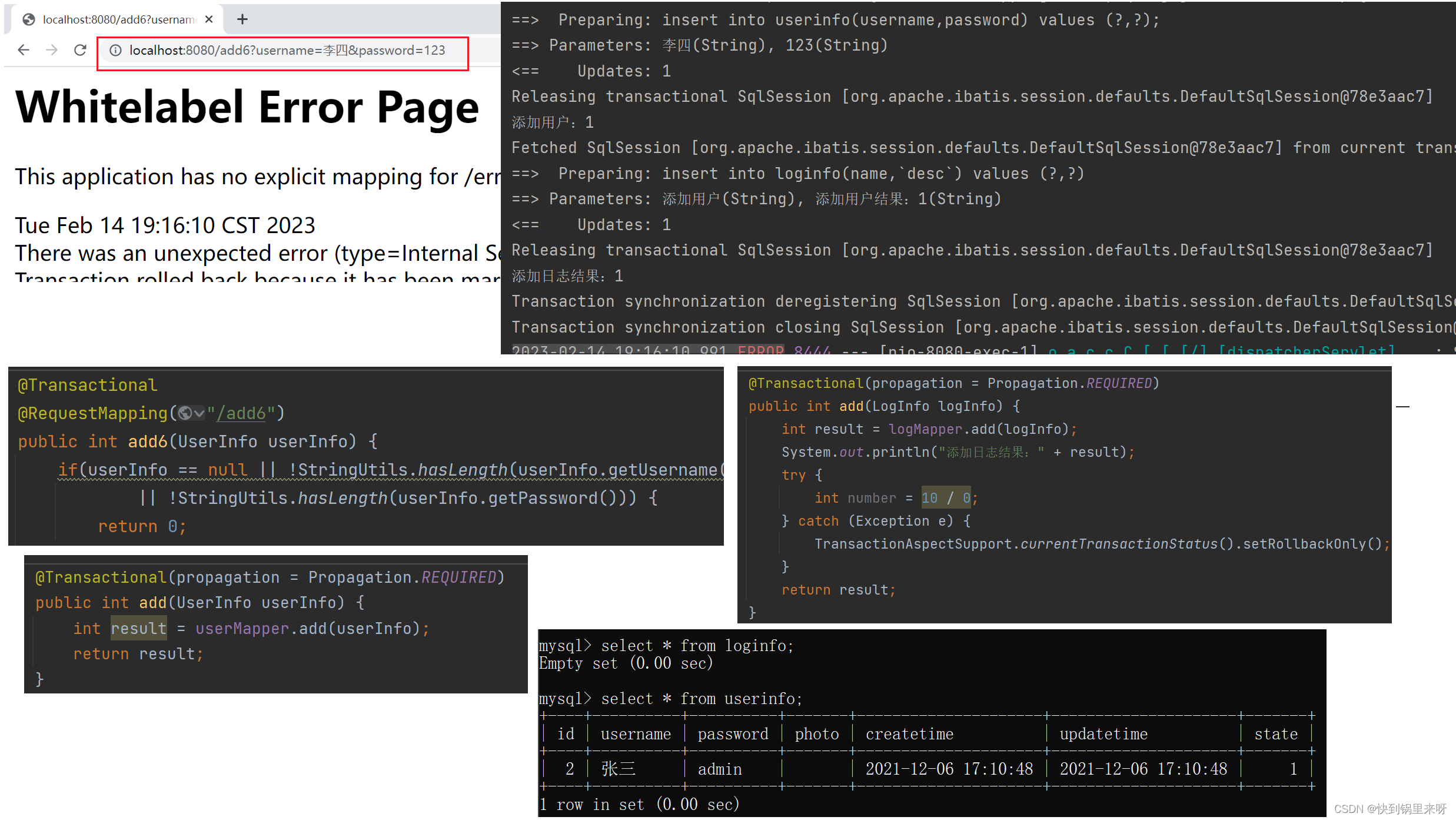
Spring 事务(编程式事务、声明式事务@Transactional、事务隔离级别、事务传播机制)
文章目录1. 事务的定义2. Spring 中事务的实现2.1 MySQL 中使用事务2.2 Spring 中编程式事务的实现2.3 Spring 中声明式事务2.3.1 声明式事务的实现 Transactional2.3.2 Transactional 作用域2.3.3Transactional 参数设置2.3.4 Transactional 异常情况2.3.5 Transactional 工作…...

车载技术——Window Display之surface的绘制过程与原理
一、Surface 概述 OpenGL ES/Skia定义了一组绘制接口的规范,为什么能够跨平台? 本质上需要与对应平台上的本地窗口建立连接。也就是说OpenGL ES负责输入了绘制的命令,但是需要一个 “画布” 来承载输出结果,最终展示到屏幕。这个…...

【UniApp小程序开发】解决无法使用Vue自定义指令的完美替代方案:权限组件封装
在 UniApp 开发中,你是否遇到过这样的困惑:明明在 Vue Web 项目中用得顺手的 v-permission 自定义指令,一到小程序端就完全失效?本文将深入剖析其原因,并提供一套可直接复用的组件化解决方案,让你在小程序中…...

3分钟上手:NBTExplorer终极指南 - 可视化编辑Minecraft游戏数据的免费神器
3分钟上手:NBTExplorer终极指南 - 可视化编辑Minecraft游戏数据的免费神器 【免费下载链接】NBTExplorer A graphical NBT editor for all Minecraft NBT data sources 项目地址: https://gitcode.com/gh_mirrors/nb/NBTExplorer 你是否曾经想要修改Minecraf…...

Fiddler手机断网真相:TLS握手与证书固定的协议级拦截
1. 为什么Fiddler一开,手机就断网?这不是配置问题,是协议层的“信任危机”Fiddler抓包手机流量,本该是移动开发、测试、安全分析中最基础的操作之一。但几乎每个刚上手的人,都会在第二天早上发现:手机Wi-Fi…...

Mysql?基础语法!!!
作为程序员、数据分析从业者,甚至是产品运营,SQL都是必须掌握的核心技能。不管是后端开发对数据库增删改查,还是数据分析提取业务数据,本质都是在写SQL语句。很多新手觉得SQL难,其实是没有理清逻辑。SQL的核心逻辑非常…...

Windows热键冲突终极指南:3分钟找出偷走你快捷键的“小偷“
Windows热键冲突终极指南:3分钟找出偷走你快捷键的"小偷" 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective …...

深入解析AlienFX Tools:从硬件直连到个性化灯光控制的完整技术方案
深入解析AlienFX Tools:从硬件直连到个性化灯光控制的完整技术方案 【免费下载链接】alienfx-tools Alienware systems lights, fans, and power control tools and apps 项目地址: https://gitcode.com/gh_mirrors/al/alienfx-tools 在Alienware设备生态中&…...

集团型企业的知识产权管理:多主体架构与数据隔离
对于拥有多家子公司、分公司或关联企业的集团型公司而言,知识产权管理面临一个特有的挑战:如何在集团层面统一管理所有主体的专利商标资产,同时确保各子公司之间的数据相互独立、不被交叉访问?这一问题在传统Excel管理模式或单公司…...

保姆级教程:用UE4/UE5的WebUI插件,把Web页面嵌入数字孪生项目
虚幻引擎WebUI插件实战:数字孪生项目中无缝嵌入Web页面的完整指南在数字孪生项目的开发过程中,将实时数据可视化的Web页面嵌入到虚幻引擎场景中已成为提升用户体验的关键技术。本文将以UE4/UE5的WebUI插件为核心工具,手把手演示如何将Web前端…...

解锁iOS设备无限可能:2026最新越狱技术深度解析与实战指南
解锁iOS设备无限可能:2026最新越狱技术深度解析与实战指南 【免费下载链接】Jailbreak iOS 26.4 - 26, 17 - 17.7.5 & iOS 18 - 18.7.3 Jailbreak Tools, Cydia/Sileo/Zebra Tweaks & Jailbreak News Updates || AI Jailbreak Finder 👇 项目地…...

腾讯元宝生成的很多公式,复制到WORD中会乱码,我应该怎么做?
从“公式乱码”到“无损流转”:企业级AI导出工程的架构实践与反思 当AI生成的专业内容在复制粘贴中“死”于格式鸿沟,我们需要的不只是工具,而是一套结构化数据流转范式。 一、痛点复盘:一个架构师眼中的“乱码危机” 在AI辅助研…...